Nuevo sistema multiclasificador jerárquico Posibilidades de aplicación
83
0
0
Texto completo
(2) Agradecimientos. Agradecimientos. A Isis, por todo el tiempo y el apoyo que me ha dado, y por hacer estos momentos tan felices A Grau, por ser un tutor, un guía, un amigo A mis padres, por apoyarme y creer en mi esfuerzo A mis hermanos, por estar a mi lado a pesar de la distancia A tío por seguir creyendo en mí A mis amigos, por hacer lucir este tiempo como si fueran un par de semanas A todos los que han apoyado este trabajo de una forma u otra.
(3) Resumen. Resumen En este trabajo se diseña e implementa un sistema multiclasificador basado en una secuencia de clasificadores que se especializan en las regiones de la base de entrenamiento donde se han concentrado los errores de los homólogos ya entrenados. Para ello se usa un conjunto de clasificadores jueces construidos jerárquicamente para separar dichas regiones y determinar la aptitud de cada clasificador para responder adecuadamente ante un nuevo caso. Para combinar las salidas de los clasificadores se usan dos variantes. La primera, basada en la selección de un único experto; y la segunda por medio de una votación pesada. Se validaron los dos modelos con diferentes clasificadores base, usando 37 bases de casos entre las cuales se encuentran 11 de carácter biomédico o bioinformático. Se realizó una comparación estadística de estos modelos con los multiclasificadores más usados: Bagging y Boosting, obteniendo resultados significativamente superiores con el multiclasificador jerárquico usando Multilayer Perceptron como clasificador base y una combinación por selección. Esto demostró la eficacia del modelo propuesto, así como su aplicabilidad en bases de carácter general.
(4) Abstract. Abstract In this thesis we designed and implemented a new ensemble of classifiers based on a sequence of classifiers which were specialized in regions of the training dataset where errors of its trained homologous are concentrated. In order to separate this regions, and to determine the aptitude of each classifier to properly respond to a new case, it was used another set of classifiers built hierarchically. We explored two variants to combine the base classifiers. The first one was based on the selection of only one expert; and for the second one we used a weighted vote. We validated both models with different base classifiers using 37 training datasets, 11 of them have biomedical or bioinformatics character. It was carried out a statistical comparison of these models with the well known Bagging and Boosting, obtaining significantly superior results with the hierarchical ensemble using Multilayer Perceptron as base classifier and selection to combine the outputs. Therefore, we demonstrated the efficacy of the proposed ensemble, as well as its applicability to general problems..
(5) Índice. Índice Introducción ........................................................................................................................ 1 Capítulo I. Técnicas de aprendizaje automatizado para la clasificación. Sistemas multiclasificadores. ............................................................................................................. 4 I.1. Árboles de decisión .................................................................................................. 5 I.2. Redes Neuronales ..................................................................................................... 9 I.3. Support Vector Machine......................................................................................... 11 I.4. Multiclasificadores ................................................................................................. 12 I.4.1. Diversidad de los clasificadores de base ......................................................... 13 I.4.2. Selección de clasificadores.............................................................................. 15 I.4.2.1. Selección basada en el rendimiento local ................................................. 15 I.4.2.2. Selección basada en el rendimiento de varios clasificadores ................... 15 I.4.2.3. Selección por agrupamiento ..................................................................... 15 I.4.3. Fusión de clasificadores................................................................................... 16 I.4.3.1. Voto mayoritario....................................................................................... 16 I.4.3.2. Voto mayoritario pesado .......................................................................... 17 I.4.3.3. Espacio de comportamiento del conocimiento......................................... 18 I.4.3.4. Conteo de Borda ....................................................................................... 19 I.4.3.5. Funciones algebraicas............................................................................... 20 I.4.3.6. Plantillas de decisión ................................................................................ 21 I.4.4. Modelos clásicos.............................................................................................. 22 I.4.4.1. Bagging..................................................................................................... 22 I.4.4.2. Boosting .................................................................................................... 24 I.4.4.3. Stacking .................................................................................................... 25 I.5. Validación de las técnicas de clasificación............................................................. 26 I.5.1. Clasificación sensible al costo......................................................................... 27 I.6. Consideraciones finales del capítulo ...................................................................... 31 Capítulo II. Diseño e implementación de un sistema multiclasificador para problemas de Bioinformática .................................................................................................................. 33 II.1. Diseño de un multiclasificador jerárquico ............................................................ 33 II.1.1. Diversidad de los clasificadores base............................................................. 34 II.1.2. Combinación de las salidas de los clasificadores........................................... 37 II.1.3. Algoritmos de entrenamiento y clasificación del clasificador jerárquico ...... 38 II.2. Implementación del modelo .................................................................................. 40 II.2.1. Selección del Weka para implementar el modelo .......................................... 40 II.2.2. Incorporación de un nuevo clasificador en el sistema Weka ......................... 41 II.2.3. Clases HierarchicMulticlassifier y HierarchicMulticlassifierByClassifier... 42 II.2.4. Posibilidades de extensión ............................................................................. 45 II.3. Uso de la herramienta............................................................................................ 46 II.4. Conclusiones parciales del capítulo ...................................................................... 50 Capítulo III. Validación .................................................................................................... 51 III.1. Bases de casos...................................................................................................... 51 III.2. Esquema de la validación..................................................................................... 52 III.2.1. Comparación estadística de poblaciones ...................................................... 53. i.
(6) Índice III.2.2. Selección de los clasificadores base ............................................................. 54 III.2.3. Resultados obtenidos en las bases................................................................. 59 III.2.3.1. Análisis estadístico de la exactitud ........................................................ 61 III.2.3.2. Análisis estadístico del área bajo la curva ROC .................................... 66 III.3. Conclusiones parciales del capítulo ..................................................................... 71 Conclusiones ..................................................................................................................... 72 Recomendaciones ............................................................................................................. 73 Referencias Bibliográficas ................................................................................................ 74. ii.
(7) Introducción. Introducción El campo de la Bioinformática ha obtenido un gran auge en nuestros días. En ella se abordan problemas biológicos con ayuda de las técnicas informáticas. En la Universidad Central “Martha Abreu” de Las Villas (UCLV) el grupo de Bioinformática ha obtenido resultados muy importantes. Sin embargo existen problemas, especialmente problemas de clasificación, que se han abordado ya con diversas técnicas y no se han logrado los resultados esperados. Los problemas de clasificación en Bioinformática se caracterizan por tener grandes conjuntos de entrenamiento. Por lo general es difícil que algún modelo logre generalizar todo el conocimiento contenido en una base tan grande. Además, por las características propias de los problemas que se tratan, muchas veces no se cuenta con toda la información descriptiva necesaria para poder usar los métodos conocidos. Muchas veces no se conoce el significado de los rasgos completamente y no se conoce aún por completo la naturaleza del problema. Pequeños cambios pueden producir propiedades completamente diferentes. El conocimiento del genoma de cualquier especie puede abrir incalculables oportunidades. Pero este conocimiento va desde la secuenciación del ADN, hasta el conocimiento funcional de cada porción del mismo. Para este conocimiento juega un papel muy importante, por ejemplo, el reconocimiento de sitios de splicing. En el mundo se investiga fuertemente en la clasificación de estos sitios. Se ha abordado este problema con innumerables técnicas de clasificación, haciendo extracción de rasgos, buscando nuevas funciones de similitud que incorporen mejor el conocimiento biológico que se tiene en la actualidad, pero a pesar de todo esto no se ha logrado superar los índices de clasificaciones correctas, en toda la medida que se espera. Otro problema que se ha abordado en el grupo es la predicción de la resistencia de la proteína proteasa a ciertos fármacos ya conocidos. Igualmente se ha investigado mucho en este problema y se ha mejorado considerablemente los resultados, pero aún se sigue trabajando en la superación de los mismos. Se ha empezado a pensar. -1-.
(8) Introducción que con los modelos de clasificación que se tienen hasta el momento va a ser difícil mejorar estos resultados. Precisamente para problemas en los que se necesite mayor confianza en la clasificación que la obtenida con los modelos conocidos, han surgido técnicas que basan su funcionamiento en combinar múltiples modelos de clasificación en un. único. sistema.. Estos. modelos. son. conocidos. como. sistemas. multiclasificadores, y en el campo de la Estadística, y sobre todo la Inteligencia Artificial, se ha avanzado bastante en este campo, pero aún hay mucho que mejorar en el mismo. Los sistemas conocidos tampoco son capaces de resolver cualquier problema, de hecho no son capaces de mejorar todo lo necesario los problemas en los que trabaja hoy el grupo de Bioinformática. Los dos problemas bioinformáticas mencionados como ejemplo son demasiado complejos para ser utilizados como prueba en el intento de diseño de nuevos modelos clasificadores pero se pueden utilizar otras bases biomédicas o bioinformática de características. similares,. pero. más. simples,. para. aproximarnos. a. un. multiclasificador que presumiblemente tenga resultados buenos en problemas bien complejos como los mencionados. La idea del nuevo multiclasificador parte de la necesidad de especializar clasificadores en distintos sectores de la base de entrenamiento para lograr un aumento de su eficacia. El problema radica en cómo separar estos sectores, lo que es una tarea difícil teniendo en cuenta la gran cantidad de rasgos que caracterizan a estos problemas habitualmente, y la poca información que se tiene de ellos. Es por ello que se hace necesario construir estas regiones en la base de entrenamiento a partir de lo que sí conocemos, el desempeño mostrado por los clasificadores ante los casos de entrenamiento y prueba. Por lo que se ha expuesto anteriormente es que se ha planteado el siguiente Objetivo general: Diseñar. e. implementar. un. nuevo. modelo. multiclasificador. con. posibilidades de aplicación general y en particular en Bioinformática logrando especializar clasificadores base en regiones concretas del problema construidas a partir del rendimiento de estos últimos.. -2-.
(9) Introducción El objetivo general se puede separar en los siguientes objetivos específicos: •. Análisis de varios modelos de aprendizaje automático para la clasificación que existen reportados y que puedan utilizarse como clasificadores básicos, así como de los modelos multiclasificadores existentes.. •. Diseñar e implementar un sistema multiclasificador con posibilidades de aplicación a problemas de Bioinformática.. •. Validar los resultados obtenidos en bases de datos generales donde pueden aplicarse otros multiclasificadores y en especial, con algunos problemas. concretos. de. clasificación. de. carácter. biomédico. o. bioinformático. Después de haber realizado el marco teórico se planteó la siguiente Hipótesis de investigación: Un sistema multiclasificador basado en la especialización de los clasificadores en regiones del problema definidas a partir del rendimiento de éstos, puede mejorar considerablemente los resultados obtenidos en problemas. de. aprendizaje. supervisado. de. clasificación. y. tiene. posibilidades generales de aplicación y en particular en Bioinformática.. El trabajo que se presenta a continuación se estructura en tres capítulos. El primer capítulo mostrará algunos modelos de clasificación que puedan ser usados como clasificadores base, o puedan servir como fuente de inspiración para modelos más complejos; además se realizará un estudio de los aspectos generales de los sistemas multiclasificadores hasta ahora existentes. En el segundo capítulo se mostrará el nuevo modelo, así como el diseño e implementación de una herramienta donde pueda probarse el mismo. En el tercer capítulo se mostrará la validación de este nuevo modelo en problemas generales de clasificación y en particular en algunos de carácter biomédico o bioinformático.. -3-.
(10) Capítulo I. Capítulo I. Técnicas de aprendizaje automatizado para la clasificación. Sistemas multiclasificadores. Cuando surgió la primera computadora, nadie pensó jamás que jugaría un papel tan importante en nuestras vidas. Más tarde, un hombre con mucha visión, pensó en hacer popular este descubrimiento, y ante esta idea surgió la pregunta que hoy nos parecería simpática: ¿para qué las personas querrían un ordenador en sus casas? El hecho es que hoy hemos llevado la tecnología a cada esfera de nuestras vidas, ya no es admisible en ninguna, contabilizar lo que en ella sucede sin hacer uso de un ordenador. Y con esto hemos logrado un desarrollo mucho más veloz de lo que nos hubiera permitido el ya obsoleto método mencionado. Pero nuestras expectativas crecen constantemente, y con los problemas de la ciencia hemos necesitado que las computadoras nos ayuden, no sólo a llevar cuentas, sino a usar el conocimiento acumulado sobre alguna materia concreta para descubrir más. Hoy la tecnología nos permite captar y almacenar gran cantidad de datos. Encontrar patrones, tendencias y anomalías en estos conjuntos de datos y resumirlos a simples modelos cuantitativos es uno de los grandes retos de la era de la información. La introducción de las computadoras en esta área abriría muchos campos de aplicación para las mismas, y nuevos niveles de capacidad y adaptabilidad. Una comprensión detallada de los algoritmos de procesamiento de información para el aprendizaje automatizado puede llevar además, a un mejor entendimiento de las habilidades (y discapacidades) humanas para el aprendizaje. Aún no sabemos cómo hacer que las computadoras aprendan ni remotamente como las personas lo hacen. Sin embargo, se han dados pasos de avance, han surgido algoritmos efectivos para ciertas tareas de aprendizaje, y ha comenzado a surgir un entendimiento teórico de este aprendizaje (Mitchell, 1997). Pero antes de seguir mencionando el tema de aprendizaje automático deberíamos revisar la definición dada por (Mitchell, 1997) de aprendizaje a partir de un conocimiento. Se dice que un programa aprende de una experiencia E respecto a alguna clase de tareas T y medida de rendimiento P, si su -4-.
(11) Capítulo I rendimiento en la tarea T, medido por P, mejora según E. Concretamente, con el aprendizaje automático buscamos una hipótesis, en un espacio de hipótesis finito, que se ajuste lo mejor posible a los datos mediante los cuales estamos aprendiendo (experiencia). Aprendemos conceptos por medio de ejemplos, que es la forma usada por los seres humanos durante su vida para aprender. Éstos deben ser tales, que logren generalizar, más que a reconocer los objetos que han sido mostrados durante el entrenamiento, para que puedan ser usados en situaciones nuevas, frente a objetos no conocidos. Existen varias técnicas de aprendizaje que pueden ser separadas en cuatro esquemas: clasificación, regresión o predicción numérica, asociación y agrupamiento. La clasificación, se refiere a las técnicas mediante las cuales se aprende sobre un objetivo discreto y conocido durante el entrenamiento. La regresión o predicción numérica agrupa esquemas en una situación similar a la anterior pero donde el objetivo es continuo. En el aprendizaje por asociación no se busca ya cómo clasificar un objeto basándose en sus rasgos característicos, sino cualquier relación existente entre los rasgos del mismo; no se define en el aprendizaje un objetivo, puede ser cualquiera de los rasgos del objeto. Y en el agrupamiento como su nombre lo indica, el objetivo es agrupar los objetos similares. En este trabajo nos vamos a concentrar en la clasificación. A continuación se hará un análisis de algunas técnicas específicas de clasificación, así como las diversas formas de validar cuán certera ha sido el empleo de las mismas para el aprendizaje.. I.1. Árboles de decisión Los árboles de decisión son una técnica muy usada en la actualidad. El conocimiento queda representado en forma de un árbol, que puede ser convertido en un conjunto de reglas “Si-Entonces” para ganar en claridad. Su funcionamiento se basa en crear ramas para separar los distintos tipos de casos. De modo que cada nodo, al finalizar el entrenamiento, representa una división. -5-.
(12) Capítulo I de los casos basada en algunos de los rasgos 1. En los nodos hojas no se hace ninguna división, sino que se le asigna la clase correspondiente a los casos que están agrupadas en el camino hasta esta hoja. Una vez construido el árbol, si se desea clasificar un nuevo caso, bastará con empezar en la raíz de éste haciendo la pregunta almacenada en el nodo acerca del rasgo indicado, y movernos al nodo hijo según el resultado de ésta. Estos pasos se seguirán hasta alcanzar un nodo hoja, en el cual estará almacenada la clase para el caso que estemos clasificando. Esta técnica tiene infinidad de variantes, cada una de ellas con diferentes requerimientos y facilidades, en general los árboles de decisión generalmente deben usarse en problemas con las siguientes características (Mitchell, 1997): •. Casos. representados. por. pares. atributo-valor:. Los. casos. son. representados por un conjunto fijo de atributos y sus valores. La situación más sencilla para este aprendizaje se alcanza en problemas con rasgos con pocos valores posibles, aunque algunos algoritmos permiten trabajar con rasgos continuos. •. Función objetivo discreta: Esta técnica sólo permite valores objetivos discretos.. •. Necesidad de una representación disjunta: Como se vio anteriormente, estos árboles representan el conocimiento como conjuntos disjuntos.. •. Presencia de errores en la base de entrenamiento: Los árboles de decisión son robustos frente a problemas donde existan errores en la base de entrenamiento, tanto en el rasgo objetivo, como en los rasgos que caracterizan a los casos.. •. El conjunto de entrenamiento puede contener casos con valores ausentes en los rasgos.. El algoritmo básico para construir árboles de decisión es el ID3. Empieza cuestionándose qué atributo debe ser mejor para ser probado en el nodo raíz. Para responder a esta pregunta, se evalúa cada atributo usando una prueba 1. Al menos esta es la idea original y esencial de los árboles de decisión. Hoy en día existen árboles de decisión cuyos nodos terminales no son exactamente casos sino métodos, por ejemplo, ecuaciones de regresión, pero de hecho, esto ya es un multiclasificador y la idea de arborear se mantiene esencialmente.. -6-.
(13) Capítulo I estadística para saber cuán bien clasifica él solo los casos de aprendizaje. Una vez seleccionado el atributo, se crea una rama para cada uno de sus posibles valores o combinaciones de estos. A continuación se reordenan los casos, dividiéndolas según el criterio que acaba de formularse para el nodo anterior. Este proceso se repite entonces para los nodos descendientes, con los conjuntos de casos correspondientes a cada uno de ellos hasta cumplir un cierto criterio de parada. De esta manera se construye un árbol de forma ambiciosa, no se vuelve atrás en ningún momento a reconsiderar las decisiones ya tomadas. El problema en el algoritmo anterior reside en seleccionar el atributo que mejor clasifica los casos por sí solo. A continuación se presenta una medida estadística tomada de la Teoría de la Información (Shannon, 1948), la ganancia de información, que mide cuán bien separa los casos en clases un atributo dado. Para ello nos detendremos antes en una medida de la pureza de la información contenida en una colección arbitraria de ejemplos conocida como la entropía. Dada una colección S, con ejemplos positivos y negativos de algún concepto objetivo, la entropía de S, correspondiente a esta clasificación binaria se calcula como: p(+) E (S ) = − log ⎡ p (+ ) 2⎢ ⎣. p ( −). p(−). ⎤ = − p (+ ) log ( p (+ )) − p (− ) log ( p (− )) 2 2 ⎥⎦. (1.1). Para cálculos de entropía se define: 0 log 2 (0 ) = 0 Aquí la función p representa la proporción de casos (positivos o negativos) en S. De hecho, la fórmula trata de un logaritmo de potencias de probabilidades. El logaritmo se utiliza para hacer sensibles las medidas menores que 1 y el signo negativo para convertir E(S) en un valor positivo. Nótese que la entropía alcanza el valor de 1 cuando la mitad de la muestra es de casos positivos, y la otra mitad de casos negativos; para otros valores se reduce su valor exponencialmente a medida que se pierde balance entre las dos clases. En general, para más de dos clases, digamos, C clases, o sea para variables discretas no binarias, la entropía de una colección S se calcula como:. -7-.
(14) Capítulo I. E (S ) = ∑ i =1 − p i log 2 ( p i ) C. (1.2). La entropía es una medida del “desorden”, de la “arbitrariedad”, de la “desinformación”. Por eso es máxima cuando hay una cantidad igual de casos en cada clase. Por esta misma razón puede ser vista además como una medida de la pureza de una colección de casos de entrenamiento. Se puede definir entonces a la ganancia de información como la disminución de la entropía esperada por dividir la muestra por el atributo en cuestión, o sea la ganancia G en una colección S de un atributo A, se calcula como:. G (S , A ) = E (S ) − ∑ valores ( A ). {. Sv S. E (S v ). (1. 3). }. Siendo: S v = s ∈ S A(s ) = v. donde la función valores(A) representa a los posibles valores de A. Nótese que la ganancia de la información es precisamente la diferencia entre la entropía existente en la colección S y la suma de las entropías de los conjuntos Sν formados, conociendo el valor ν del atributo A y pesadas por la fracción que representa el cardinal de cada uno de los conjuntos formados por los valores de A del total de S (Mitchell, 1997). Se ha definido la forma de construir un árbol de decisión, pero demos hablar de un “criterio de parada”, esto es de cuando terminar el desglose del mismo. Intuitivamente pudiéramos pensar en no detenernos hasta lograr conjuntos de casos en los que no hayan elementos de dos clases diferentes. Pero debemos tener cuidado con este planteamiento, ya que puede ser peligroso en el caso de que hayan ruidos en la base de entrenamiento. Por otra parte nos arriesgamos a provocar un ajuste excesivo a los casos de entrenamiento, con ello podríamos clasificar lo mejor posible los casos con las que se aprendió. Pero, ¿qué sucederá si los datos con los que se está aprendiendo son demasiado pocos como para ser representativos del conjunto completo? Pudiéramos no obtener nuestra meta final, que es poder clasificar satisfactoriamente nuevos casos. Este problema es conocido como sobre entrenamiento o sobre aprendizaje -8-.
(15) Capítulo I (overfitting), y Mitchell lo define como: Dado un espacio de hipótesis H, se dice que la hipótesis h de H ha sobre aprendido los datos de entrenamiento si existe alguna hipótesis alternativa h’ en H, tal que el error de h sobre la base de entrenamiento es menor que el de h’, pero el error de h’ sobre el conjunto entero es menor (Mitchell, 1997). Para evitar este fenómeno, existe una gran variedad de técnicas, las cuales esencialmente se agrupan en dos: las que evitan el crecimiento del árbol antes de que éste clasifique perfectamente el conjunto de entrenamiento; y las que lo dejan llegar a ese punto, y luego podan el árbol. Aunque el primer grupo se vea más tentador, en la práctica son más efectivas las técnicas del segundo grupo, dado que es muy difícil saber a priori el momento perfecto para parar. Por último necesitamos saber, ya sea para parar de forma prematura, o para podar el árbol una vez construido, el tamaño óptimo del mismo. Existen diversas técnicas para esto también, la más popular es dividir el conjunto en dos, uno de entrenamiento y otro de validación, entonces empezar a construir el árbol con el conjunto de entrenamiento, e ir probándolo con el conjunto de validación hasta obtener un tamaño óptimo. Otras formas de obtener el mismo resultado son usar medidas estadísticas para saber si el resultado de expandir cada nodo mejorará el aprendizaje del clasificador sobre la base de entrenamiento, o sobre la del conjunto entero de casos (Mitchell, 1997, Quinlan, 1986).. I.2. Redes Neuronales Las redes neuronales artificiales proveen un método muy práctico para predecir valores discretos, continuos o vectores a partir de un conjunto de datos, siendo uno de los clasificadores más efectivos conocidos en la actualidad. Las. redes. neuronales. están. inspiradas. en. los. sistemas. biológicos,. específicamente en el sistema nervioso. Este sistema en un organismo superior está formado por una red de neuronas interconectadas que son capaces de transmitirse estímulos eléctricos. El conocimiento que pueda guardar nuestro cerebro está representado por los enlaces creados a lo largo de nuestras vidas en este complejo sistema. Las redes neuronales intentan simular este proceso. Constan de una serie de unidades básicas (que representan las neuronas -9-.
(16) Capítulo I reales) conocidas como neuronas artificiales interconectadas entre sí. Estas unidades son capaces de, dado un vector de valores reales como entrada (que pueden ser las salidas de otras neuronas), producir una salida real (que puede convertirse en la entrada de otras tantas neuronas). Vale la pena decir que el fundamento biológico es solamente una inspiración, existen sobradas diferencias para hacer ver que este modelo dista mucho de su fuente inspiradora (Zornetzer et al., 1994). Las neuronas se unen entre ellas por enlaces pesados (ponderados), el objetivo del entrenamiento es asignar los pesos adecuados a estos enlaces. Además se agrupan en capas, que pueden ser de entrada, que son aquellas que reciben directamente los rasgos de entrada; ocultas, que son aquellas cuyas salidas serán únicamente usadas por la red; y las de salida, que son aquellas que se usarán finalmente para saber cuál es el valor de salida de la red. La red queda finalmente representada por grafos que pueden tener distintos tipos de estructura (cíclicos o no, dirigidos, o no dirigidos) (Hilera and V., 1995). Las redes neuronales artificiales funcionan muy bien en problemas con datos con mucho ruido, o con datos extraídos con sensores complejos como cámaras o micrófonos. Pueden ser usadas en problemas con representaciones más simbólicas, donde se usen clasificadores como los árboles de decisión. En estos casos la eficacia de la red generalmente es similar a la de estos otros clasificadores (Weiss and Kapouleas, 1989, Hammer and Villmann, 2003). Existen una gran variedad de redes neuronales usadas para la clasificación, la más sencilla es el perceptron simple. Pero esta red puede ser usada en problemas con clases linealmente separables, en problemas más complejos debemos usar redes multicapas. La red más popular usada para la clasificación es el multilayer perceptron, y es conocido como uno de los clasificadores más efectivos en la actualidad. Este modelo se ha usado en aplicaciones de interpretación visual de escenas, reconocimiento del habla, y estrategias de control para la robótica. Generalmente es apropiado para problemas con las siguientes propiedades (Rumelhart et al., 1986):. - 10 -.
(17) Capítulo I •. Casos representados por varios pares atributo-valor: La función objetivo que se aprenderá se define sobre casos que se pueden describir como un vector de rasgos predefinidos. Estos atributos pueden estar o no altamente correlacionados y pueden ser cualquier tipo de valor real.. •. La función objetivo puede tener salida discreta, continua, o vectorial: El resultado de cada neurona de salida puede ser un valor continuo o discreto. Y se pueden tener varias neuronas de salida, formando así un vector de componentes con distintos niveles de medición.. •. El conjunto de entrenamiento puede contener errores: Esta técnica conserva muy bien la eficacia en bases de entrenamiento con errores.. •. Debe esperarse un tiempo de entrenamiento largo: El tiempo de entrenamiento de este clasificador es generalmente más largo que, digamos, el de los árboles de decisión. En general depende de la cantidad de pesos que haya que ajustar, de la cantidad de casos que haya para generalizar, y de otros parámetros típicos de estos algoritmos.. •. Se espera una rápida evaluación del conocimiento adquirido: Aunque es cierto que toma un largo tiempo entrenar a este clasificador, también es cierto que es muy corto el tiempo que hay que emplear para probarlo.. •. El entendimiento humano de la función aprendida no es importante: Interpretar los pesos que han sido aprendidos no es fácil para un humano.. Existen otros modelos que no han sido muy usados para la clasificación como las redes recurrentes, pero incluso estas han sido aplicadas a ciertos problemas de esta naturaleza obteniendo muy buenos resultados (Bonet, 2005).. I.3. Support Vector Machine Support Vector Machine Optimization (SMO) es una técnica dentro del campo de aprendizaje automatizado supervisado, que evolucionó rápidamente y ha sido ampliamente usado en varias ramas. Este método se desarrolló en 1995 por Vladimir Vapnik y co-workers en “AT&T Bell Laboratorios”. Tuvo sus orígenes en la teoría de aprendizaje estadístico y está basado en el principio de minimización de riesgo estructural. Es usado tanto para clasificación como para regresión. - 11 -.
(18) Capítulo I (2005). En el caso de la clasificación su funcionamiento se basa en construir hiperplanos para separar las clases (Vapnik, 1995). Su algoritmo busca esencialmente. optimización los parámetros de los hiperplanos para hacer. máxima la distancia entre las clases. Este clasificador permite cambiar el método de separación de los casos por medio del kernel empleado. Así por ejemplo, para casos linealmente separables se puede usar un kernel lineal. Este último crea un hiperplano y lo ajusta según los casos de entrenamiento de tal manera que, dicho hiperplano separa a los casos de clases diferentes, pero haciendo que las distancias de los casos más cercanos sea máxima. La superficie de separación puede ser no lineal, digamos por ejemplo, hiperesferas, hipercónicas en general, hiperexponenciales,…y entonces se logran resultados más eficaces con kernels no lineales.. I.4. Multiclasificadores Debido a la importancia que tienen las decisiones financieras, médicas, sociales,…, siempre buscamos una segunda opinión antes de decidirnos; en ocasiones incluso una tercera, o cuantas nos sean posibles. Luego, “pesamos” las opiniones recaudadas, y de alguna forma tomamos la nuestra, que presumimos sea mejor que la que pudimos haber logrado solos o con ayuda de una sola opinión. Es nuestra naturaleza consultar expertos en cada tema antes de tomar una decisión importante. Sin embargo, aún no se explota este recurso al máximo en la toma automatizada de decisiones. Existen un conjunto de razones por las que podemos preferir usar un conjunto de clasificadores y no un experto único: En muchas ocasiones el rendimiento de los clasificadores depende de ciertas condiciones iniciales que pueden hacerlo generalizar el conocimiento de una mejor forma, o no; al usar varios criterios estamos reduciendo el riesgo de haber escogido mal estas condiciones iniciales. Ante volúmenes de datos muy grandes, puede ser conveniente especializar a cada clasificador en un área de los datos, y así, no obligarlo a generalizar tanto volumen de información. O en la situación opuesta, se ha demostrado que los conjuntos de clasificadores proveen mejores resultados que los clasificadores individuales ante situaciones en las que, por la escasez de datos, se deben - 12 -.
(19) Capítulo I generar nuevos casos. En situaciones en las que se debe generalizar una función objetivo muy compleja, o en situaciones en las que la información ha sido obtenida de diversas fuentes y se tienen diferencias notables en los rasgos de los casos, se puede seguir la conocida política “divide y vencerás” (Polikar, 2006). Uno de los primeros trabajos referidos a este tema es el expuesto por Dasarathy y Sheela en 1997. En este trabajo se expone como dividir los rasgos para usar dos clasificadores (Dasarathy and Sheela, 1979). En 1990, Hansen y Salamon mostraron que el poder de generalización de una red neuronal puede ser aumentado usando varias instancias de ésta y haciendo variaciones en sus parámetros (Hansen and Salamon, 1990). En ese mismo año, Schapire probó como lograr un clasificador fuerte a partir de clasificadores débiles surgiendo así la técnica boosting (Schapire, 1990), que daría origen después a los muy conocidos algoritmos AdaBoost. A partir de este momento, se empiezan a extender mucho más estos sistemas, y empiezan a aparecer en la literatura con mayor frecuencia (Xu et al., 1992, Jacobs et al., 1991, Jordan and Jacobs, 1994, Wolpert, 1992, Benediktsson and Swain, 1992, Ho et al., 1994, Rogova, 1994, Lam and Suen, 1995, Woods et al., 1997b, Kuncheva, 1993, Bloch, 1996, Cho and Kim, 1995, Kuncheva et al., 2001, Drucker et al., 1994, Battiti and Colla, 1994, Kuncheva, 2004, Smieja, 1996, Ghosh, 2002). Los paradigmas de estos enfoques difieren generalmente en los algoritmos para generar los clasificadores individuales, y la estrategia empleada para combinar a dichos clasificadores. En general hay dos formas de combinación: selección y fusión de clasificadores (Woods et al., 1997a, Kuncheva, 2005). Como se ha visto, es muy importante la forma en que se generarán los clasificadores base y como se combinarán luego. A continuación se hará una descripción de las principales formas de lograr esto (Polikar, 2006, Dietterich, 2000, Ghosh, 2002, Opitz and Maclin, 2000).. I.4.1. Diversidad de los clasificadores de base La estrategia a seguir en los casos en los que se use un sistema de clasificadores múltiples es crear varios clasificadores, y combinar sus salidas de - 13 -.
(20) Capítulo I alguna forma. Pero es necesario que los clasificadores cometan los errores en casos diferentes. Lo que se intenta es mejorar los resultados de clasificadores individuales escogiendo una estrategia de combinación adecuada, pero ninguna de éstas es capaz de salvarnos de casos mal clasificadas por todos los clasificadores. Por lo tanto, debemos obtener una combinación de clasificadores diversos, para minimizar los errores del sistema (Kuncheva and Whitaker, 2003). Existen varias formas de obtener una mejor diversidad de los clasificadores. El método más popular es usar diferentes bases de entrenamiento para cada uno de ellos. Estas bases son obtenidas usualmente por medio de métodos como el bootstrapping donde los ejemplos de la base son cambiados de forma aleatoria, usualmente por medio de la eliminación y repetición de algunos de ellos. Además, y aunque parezca paradójico, es necesario usar métodos poco estables, independientemente de reconformar las bases de entrenamiento, para que con los cambios hechos, aunque sean muy simples, se obtengan instancias significativamente diferentes a partir del mismo modelo. Otra forma de lograr diversidad en los clasificadores, es usar el mismo modelo pero con distintos parámetros. Por ejemplo, usar varias redes neuronales, pero con distintas cantidades de capas y de neuronas por capa, inicializando de diversas formas los pesos de las conexiones, etc. En la práctica, este último método no es tan usado como el mencionado anteriormente basado en la diversidad en las bases de entrenamiento. Finalmente, vale la pena mencionar el método de subespacios aleatorios (random subspace method) (Ho, 1998). Este método construye distintos clasificadores, entrenando cada uno de ellos en bases con distintos subconjuntos de rasgos. Esta técnica se ha popularizado bastante, y se ha usado satisfactoriamente en una gran cantidad de problemas (Polikar, 2006, Brown et al., 2005). Una vez lograda la diversidad de los clasificadores que se usarán como base, debemos concentrar nuestros esfuerzos en la estrategia a usar para combinar las decisiones de los clasificadores. Las salidas se pueden combinar siguiendo varias estrategias, en particular, las de selección o fusión.. - 14 -.
(21) Capítulo I. I.4.2. Selección de clasificadores Para la selección, se entrena cada clasificador como un experto en un área determinada. La decisión final del sistema entonces será aportada por los clasificadores expertos en los conjuntos a los que más se asemeja el caso que se desee clasificar (Jacobs et al., 1991, Woods et al., 1997a).. I.4.2.1. Selección basada en el rendimiento local Un primer método para seleccionar qué clasificador será el designado para un caso dado, es partir del rendimiento local. Dado un caso, para cada clasificador Ci del sistema, debemos encontrar los k casos más cercanos (se recomienda k=10) a los cuales Ci asigne la misma clase. Luego, de estos k casos, se calcula la proporción a los que Ci asignó la clase verdadera, y se asume como el rendimiento local de este clasificador. Después debemos seleccionar el clasificador con mayor rendimiento local para la clasificación del sistema; en caso de empate se puede apoyar la decisión con el clasificador restante con mayor rendimiento local (Woods et al., 1997a).. I.4.2.2. Selección basada en el rendimiento de varios clasificadores Este esquema es muy similar al anterior con dos pequeñas diferencias. Primero, k es variable y segundo, un clasificador es elegido si y solo si la diferencia de su rendimiento es significativamente mayor al de los demás clasificadores. Comienza entonces escogiendo a los k vecinos más cercanos, de ellos solo escogeremos a los que tengan una similitud superior a un umbral. Calculamos el rendimiento local de cada clasificador bajo estas condiciones y entonces si el clasificador ganador es sustancialmente superior a los demás, es escogido para aportar la respuesta final del sistema; en otro caso se hace una votación con todos los clasificadores (Giacinto and Roli, 2001).. I.4.2.3. Selección por agrupamiento Al finalizar el proceso de entrenamiento de los clasificadores, los casos son agrupados usando el método de las k medias de agrupamiento, o cualquier otro algoritmo de clustering. Entonces se estima el rendimiento de cada clasificador en cada grupo, y se asigna a cada uno de ellos el clasificador con mayor. - 15 -.
(22) Capítulo I desempeño. Para clasificar un nuevo caso se buscan las distancias a los centros de los grupos. En caso que la distancia al centro más cercano muestre diferencias significativas con respecto a las demás, entonces el clasificador asignado será el seleccionado para obtener la clasificación final del sistema; en otro caso se empleará alguna técnica de fusión con todos los clasificadores teniendo en cuenta las distancias calculadas. Para saber si las diferencias en las distancias son significativas, se puede emplear alguna técnica estadística para ello como por ejemplo una prueba clásica de Student para muestras apareadas (Kuncheva, 2002a), o tal vez mejor, una de sus alternativas no paramétricas (Siegel, 1970, Grau, 1994).. I.4.3. Fusión de clasificadores En la fusión de clasificadores, se busca aumentar el rendimiento de un experto a partir de la combinación de varios clasificadores individuales entrenados en el conjunto de casos de aprendizaje completo. Existen un gran número de estrategias de fusión: lineales, no lineales, basados en estadísticas, y un cuarto grupo integrado por aquellos que usan técnicas inteligentes para ello: integración difusa, redes neuronales, algoritmos genéticos, etc. (Canuto et al., 2007).. I.4.3.1. Voto mayoritario Hemos titulado el epígrafe con el término voto mayoritario, pero en realidad existen tres tipos del mismo. El primero exige que todos los clasificadores coincidan en una clase, voto unánime (unanimous vote). El segundo exige que al menos la mitad más uno coincidan en una clase, mayoría simple (simple majority). Y un tercero, donde simplemente se escoge la clase que más votos a favor reciba, pluralidad o mayoría (plurality voting, majority voting). Para este último se puede describir la decisión como sigue: se escoge la clase J si:. ∑. C. d = max ∑ t =1 d t , j t =1 t , J. T. T. j =1. d t , j ∈ {0,1}. (1.4). donde d t , j es la decisión del clasificador t sobre la clase j (T es el número de clasificadores y C el número de clases). Este último método es el más eficiente. - 16 -.
(23) Capítulo I para situaciones en los que se tiene un número impar de clasificadores, con dos clases, y clasificadores independientes (Boland, 1989, Shapley and Grofman, 1984, Kuncheva, 2005). Para el caso con las condiciones anteriores, la exactitud del sistema ( Psis ) compuesto de T clasificadores con probabilidad de acierto p puede ser representada por la función binomial ya que lo que se necesita es que se obtengan al menos la mitad de los votos correctos más uno:. ⎛T ⎞ T Psis = ∑ k =[T / 2 ]+1 ⎜⎜ ⎟⎟ p k (1 − p ) T − k ⎝k⎠. (1.5). Aquí [T/2] denota la parte entera de la mitad de T. La probabilidad Psis se aproxima a 1 a medida que T crece si p es menor que 0.5, y se aproxima a 0 si p es mayor que 0.5 (Boland, 1989, Shapley and Grofman, 1984).. I.4.3.2. Voto mayoritario pesado Supongamos ahora, que dentro de los votos, tenemos evidencia para asegurar que ciertos expertos están más capacitados que otros para tomar la decisión. Si pesamos con mayor fuerza las decisiones de estos expertos, entonces debemos obtener mejores resultados. Siguiendo esta idea surge el voto mayoritario pesado (weighted majority voting), en el que la expresión 1.4 es modificada añadiendo los pesos de cada clasificador. En este caso se escoge la clase J si se cumple que:. ∑. T t =1. C. wt d t , J = max ∑ t =1 wt d t , j T. (1.6). j =1. Para ganar en interpretabilidad, se suele normalizar los pesos para que sumen la unidad, pero en realidad esto no afecta en nada el resultado final. Frente a esta elección del método, surge la pregunta de cómo hacer para asignar los pesos. En caso de tener información sobre cuáles son los clasificadores más eficientes o eficaces (dependiendo de las potencias de cálculo), podemos simplemente reforzar estos clasificadores, o incluso eliminar a los demás (asignarles peso cero). Pero, ¿qué debemos hacer si esta información no está disponible? La forma más sencilla de asignar los pesos es por el porciento de clasificación de cada clasificador sobre una base de prueba, o en su defecto, sobre la propia base de entrenamiento. Sin embargo, se ha - 17 -.
(24) Capítulo I demostrado que los mejores resultados se obtienen haciendo que los pesos de cada clasificador sean proporcionales a la expresión 1.7 donde pi representa la exactitud del clasificador i (Kuncheva, 2005, Littlestone and Warmuth, 1994).. ⎛ pi log ⎜⎜ ⎝ 1 − pi. ⎞ ⎟⎟ ⎠. (1.7). El cociente pi /(1- pi) representa el “riesgo relativo” de una buena clasificación y su logaritmo garantiza magnitudes apreciables cuando este cociente es pequeño (Grau, 1994).. I.4.3.3. Espacio de comportamiento del conocimiento Otra forma muy usada para la combinación de clasificadores es mediante el espacio de comportamiento del conocimiento (behavior knowledge space) propuesto por Huang y Suen (Huang and Suen, 1993, Huang and Suen, 1995). En ese método se lleva un registro de la frecuencia de aciertos de cada clase para cada posible combinación de las salidas de los clasificadores y para ello se construye una tabla que recoge esta información. De esta forma, en el momento de clasificar un nuevo caso, se busca en la combinación adecuada, cuál fue la clase verdadera más frecuente, y esa será la clase final del sistema.. Figura 1.1: Espacio de comportamiento del conocimiento. - 18 -.
(25) Capítulo I Supongamos que se tienen tres clasificadores C1, C2 y C3 para un problema de tres clases. Existen veintisiete posibles combinaciones de salidas de los clasificadores. Durante el entrenamiento debemos registrar con qué frecuencia ocurre cada una de estas combinaciones, y con qué frecuencia resultó ser correcta cada una de las clases. En la figura 1.1 se muestra un ejemplo hipotético de esta situación, en ella se han circulado los máximos en cada combinación. Así por ejemplo, en esta situación, la combinación ω1ω2ω1 ocurre un total de veintiocho veces, de ellas resultó ser la clase correcta ω1 diez veces, ω2 quince veces y ω3 tres veces. Entonces, para clasificar un nuevo caso, cada vez que aparezca la combinación ω1ω2ω1 el sistema responderá con la clase ω2. Debe notarse que si estuviéramos usando un sistema de votación se hubiese escogido la clase ω1. Si este modelo se usa con un conjunto suficientemente denso de datos, y se normaliza adecuadamente la tabla, este método aporta resultados muy buenos.. I.4.3.4. Conteo de Borda El conteo de Borda (Borda count) se diferencia sustancialmente de los modelos anteriores en un importante aspecto, no desecha la información referente a las clases que no son las seleccionadas. Este modelo es usado cuando los clasificadores pueden ordenar las clases para los casos de entrenamiento, o sea la primera clase sería la que con más seguridad es la del caso en cuestión, la segunda la más segura del resto, y así hasta llegar hasta la última que sería la menos probable. Una vez que las C clases han sido ordenadas, cada clasificador asignará a la primera clase C-1 votos a la segunda C-2, y a la última no asignará ningún voto. Los votos asignados a cada clase por cada uno de los clasificadores son adicionados y entonces se selecciona la clase con mayor número de votos. Esta técnica fue ideada por Jean Charles de Borda en 1770, y es usada muy frecuentemente en la práctica, desde la selección del jugador más valioso en la liga de pelota en Estados Unidos, hasta la selección de la canción ganadora en el concurso de música Europeo Eurovisión.. - 19 -.
(26) Capítulo I Veamos a continuación las formas de combinar las salidas cuando los métodos individuales de aprendizaje ofrecen una clasificación blanda.. I.4.3.5. Funciones algebraicas Antes de seguir adelante detengámonos un poco en la formalización hecha por Kuncheva (Kuncheva et al., 2001) de la matriz del perfil de decisión (decision profile) sobre las salidas de los clasificadores en estos sistemas. Dado un caso x, su perfil de decisión PD(x) se compone de los elementos dt,j∈[0,1] que representa la certeza con que el clasificador t asevera que el caso pertenece a la clase j. Podemos entonces hacer notar que la fila t de esta matriz va a ser el vector que representa las probabilidades de pertenencia del clasificador t para cada una de las clases. Las funciones algebraicas constituyen un método muy sencillo de integración de clasificadores (Kittler et al., 1998, Ho et al., 1994, Kuncheva, 2002b). El vector con las probabilidades de pertenencia del caso que se esté clasificando a cada una de las clases se puede obtener como la combinación, mediante una función algebraica, de las salidas individuales de cada clasificador, de forma que la probabilidad de pertenencia (μj) de un caso a la clase ej para T clasificadores, se puede calcular por la expresión 1.8 (Polikar, 2006):. μ j ( x ) = ℜ[d1, j ( x ), d 2 , j ( x ),..., d T , j ( x )]. (1.8). Sólo nos resta definir la función ℜ ; ésta puede ser cualquier función algebraica capaz de convertir el vector con las probabilidades a una única probabilidad final ( p j ). Las siguientes son muy usadas: •. Media: la probabilidad de que el caso x sea de la clase j se obtiene promediando la columna j de PD(x). p j (x ) = •. 1 T. ∑. T t =1. d t , j (x ). (1.9). Media ponderada: esta función es muy similar a la anterior, pero permite asignar pesos a la decisión de cada clasificador. Este peso puede ser obtenido como se había discutido anteriormente en el voto mayoritario pesado:. - 20 -.
(27) Capítulo I. p j (x ) = •. 1 T. ∑. T t =1. wt d t , j ( x ). (1.10). Media equilibrada: en ocasiones puede ser que el clasificador obtenga un valor erróneo demasiado pequeño (o grande) que puede afectar en gran medida a la media. Para evitar este problema, la solución puede ser eliminar los valores extremos antes de promediarlos. Generalizando esta idea, podemos hablar, no de eliminar el valor máximo y mínimo de la muestra, sino de eliminar una cantidad preestablecida de valores en los extremos (en estadística se usa esta idea para calcular una media equilibrada o truncada eliminando el 5% de los valores extremos).. •. Mínimo, máximo, mediana: el mínimo es la función más conservadora de todas las funciones algebraicas que se han visto en este trabajo.. p j ( x ) = max {d t , j ( x )} t =1...T. p j ( x ) = min {d t , j ( x )}. (1.11). t =1...T. p j ( x ) = med iana {d t , j ( x )} t =1...T. •. Producto: esta función es muy sensible a los clasificadores pesimistas, una probabilidad cercana a cero puede descartar por completo la posibilidad de escoger esa clase. Sin embargo, si los clasificadores son realistas en su clasificación, esta función suele funcionar muy bien en la integración de clasificadores.. 1 p j (x ) = T •. T. ∏ d (x ). (1.12). t, j. t =1. Media generalizada: esta función es en realidad una generalización de las anteriormente vistas, nótese que con α→ -∞ obtenemos la función mínimo, con α→1 obtenemos la media, y con α→ ∞ el máximo.. ⎛1 p j (x, α ) = ⎜ ⎝T. ∑. α. T t =1. d t , j (x ). 1α. ⎞ ⎟ ⎠. (1.13). I.4.3.6. Plantillas de decisión Kuncheva lleva la idea de los perfiles de decisión (PD(X)) un paso más adelante para definir las plantillas de decisión (decision template) como el promedio por - 21 -.
(28) Capítulo I clase de los perfiles observados en el entrenamiento. La plantilla de decisión para la clase ωJ (PlDJ) se calcula entonces mediante la expresión:. PlD J =. 1 NJ. ∑ PD ( x. clase ( X j ) =ω j. J. ). (1.14). Frente a un nuevo caso x que deba ser clasificado, se debe calcular su perfil de decisión y seguidamente su similitud Sj a cada plantilla de decisión PlDj. Esta medida de similitud será tomada como la probabilidad de que el caso x pertenezca a la clase ωj:. p j ( x ) = S (PD ( x ), PlD j ). (1.15). La medida de similitud usualmente se toma como la distancia cuadrática Euclideana:. p j (x ) = 1 −. 1 TxC. ∑ ∑ [PD (t , k ) − d (x )] T. C. t =1. k =1. 2. j. t ,k. (1.16). donde T es el número de clasificadores, y C la cantidad de clases, PD j (t , k ) es la probabilidad dada por el clasificador t a la clase ωk en la plantilla de decisión PDj.. I.4.4. Modelos clásicos Una vez visto los aspectos para lograr la diversidad en los clasificadores base de un sistema y las técnicas empleadas para combinar sus salidas, mostraremos algunos modelos de multiclasificadores populares en la literatura.. I.4.4.1. Bagging Un primer modelo que vale la pena mencionar al hacer un estudio de este tema es el bagging. Éste es objeto de uno de los primeros trabajos reportados en este campo, al mismo tiempo es uno de los más sencillos, y sorprendentemente obtiene magníficos resultados (Breiman, 1996). Para obtener la diversidad de los clasificadores, esta técnica hace réplicas de la base de entrenamiento por el método Bootstrapping: se conforman distintos subconjuntos de forma aleatoria (por medio de reemplazos) a partir de la base original. Entonces se entrena, con cada uno de los subconjuntos, a los distintos clasificadores que participarán en. - 22 -.
(29) Capítulo I el sistema, producidos todos a partir de un mismo modelo. Estos clasificadores individuales serán entonces integrados a partir del voto mayoritario, para un caso particular, la clase dominante en las decisiones de los clasificadores será la respuesta del sistema. Para asegurar que haya suficientes casos en cada subconjunto, se escoge una porción relativamente grande del conjunto (entre un 75% y un 100%). Esto causa que los subconjuntos se superpongan significativamente, con varios casos repetidos en los distintos conjuntos, e incluso en el mismo. Para asegurar que haya verdadera diversidad bajo estas condiciones, se debe escoger un modelo con gran inestabilidad de forma tal que aseguremos diferencias reales en las decisiones de los clasificadores con estos pequeños cambios. Es por ello que las redes neuronales y los árboles de decisión, como clasificadores básicos, son modelos ampliamente utilizados en estos casos. Se han desarrollado algunas variaciones de este algoritmo. Empecemos mencionando los bosques aleatorios (random forests) (Breiman, 2001) que debe su nombre al uso de árboles de decisión. Un bosque aleatorio puede ser construido a partir de árboles individuales haciendo variar alguno de sus parámetros. Estas variaciones pueden ser, como se vio anteriormente, construir subconjuntos con los casos de entrenamiento, pero además se acostumbra construirlos con diferentes subconjuntos de los rasgos. Ver también las redes bayesianas contraídas a partir de árboles de decisión de diferentes subconjuntos de los rasgos (Grau et al., 2006). Otra variación muy conocida es el presentado por el propio Breinman en 1999 (Breiman, 1999). Este algoritmo es más bien usado en bases de entrenamiento grandes. Este gran conjunto es dividido en otros más pequeños, cada uno usado para entrenar un clasificador. En este algoritmo se hace una partición teniendo en cuenta la importancia de los casos (Chawla et al., 2002), los casos que mejoren en mayor medida la diversidad, serán considerados como los más importantes. Además, si un caso no es bien clasificado por el sistema en cierto momento del entrenamiento, entonces estará en el conjunto con el que se entrenará el próximo clasificador.. - 23 -.
(30) Capítulo I. I.4.4.2. Boosting En 1990 surge otro modelo ampliamente difundido en la actualidad considerado un gran logro en esta área, el boosting (Schapire, 1990). Schapire, su creador, plantea la forma de, a partir de aprendices débiles, clasificadores que funcionaran apenas mejor que un adivino de forma aleatoria, formar un aprendiz fuerte que fuera capaz de clasificar correctamente la base entera, a excepción de algunos casos. El funcionamiento de este esquema se basa en el mismo principio que el anterior, formar subconjuntos de entrenamiento para los clasificadores por medio del reemplazo. Sin embargo, las bases se conforman de forma tal que sean más informativas que en el caso anterior. Se conforman tres conjuntos de entrenamiento: C1, C2, C3. El primero se construye de forma aleatoria, y con él se entrena el primer clasificador. C2 se conforma de forma tal que la mitad de los casos sean de los que fueron bien clasificados por el clasificador que fue entrenado con C1, y en la otra mitad estén los casos mal clasificados por el mismo. Y el conjunto C3 se conforma de los casos en los que los dos primeros clasificadores estuvieron en desacuerdo. Luego, los tres clasificadores son integrados con un voto mayoritario. Más tarde, en 1997, Freund y Schapire introducen el AdaBoost (Freund and Schapire, 1997), recibiendo un mayor éxito, siendo ya, una versión más general de boosting. Entre los cambios más significativos hechos en esta nueva versión, está el haber incluido la posibilidad de tener más de dos valores para la función objetivo (AdaBoost.M1) e incluir la posibilidad de ser usados, no solamente para la clasificación, sino también para la regresión numérica (AdaBoost.R). En el AdaBoost no se limita a tres clasificadores, sino que se deja abierto el número a usar, y el problema de la conformación de los subjconjuntos de casos se resuelve aumentando la probabilidad de ser incluido en los próximos conjuntos al ser mal clasificado por cada clasificador. En el momento de hacer la integración, no se usa una votación mayoritaria, sino que se le da un peso a la respuesta de cada clasificador. Este peso es asignado según el rendimiento mostrado durante el entrenamiento.. - 24 -.
(31) Capítulo I. I.4.4.3. Stacking Es conocido que algunos casos de la base de entrenamiento, para un clasificador dado, están más cerca de la frontera de decisión, y esto hace que puedan ocurrir errores en el momento de la clasificación. Sin embargo, hay otras que al estar más separadas de esta frontera, pueden ser clasificadas con mayor seguridad. Pero esta frontera cambia para distintos clasificadores. Entonces, resulta interesante la idea de buscar de alguna forma, cómo reconocer qué clasificadores funcionan mejor para determinados conjuntos de casos. Wolpert obtiene un modelo en el año 1992 siguiendo este razonamiento, el conocido stacked generalization (Wolpert, 1992). En este modelo se entrenan distintos tipos de clasificadores en un primer nivel. Entonces, en un segundo nivel, se entrena otro clasificador, llamado también meta-clasificador, que recibe como entrada las salidas de los clasificadores del primer nivel, y es capaz de decidir un resultado final para el sistema. Usualmente se usa la misma técnica para obtener las bases de entrenamiento que en los modelos anteriores, se divide la base de entrenamiento en tantos subconjuntos como clasificadores haya en el primer nivel. Una vez entrenados estos clasificadores, es que se puede generar la base para el clasificador del segundo nivel y entrenarlo (Polikar, 2006). Existe un modelo, la unión de expertos (mixture of experts), muy similar al discutido anteriormente que no usa al clasificador del segundo nivel para integrar las salidas de los clasificadores en una única salida, sino que a partir del caso que se esté clasificando obtiene los pesos de cada clasificador en la decisión final. Se ha probado que para el clasificador del segundo nivel es muy eficaz el uso de modelos neuronales (Jacobs et al., 1991). En general no es sencillo establecer que una técnica pueda ser superior a las demás completamente. Para cada problema particular puede variar la eficacia de cada una de ellas. Dietterich realizó un estudio respecto a esto, y resultó que generalmente las técnicas de boosting (en particular AdaBoost) brindan muy buenos resultados (Dietterich, 2000, Opitz and Maclin, 2000). Hemos discutido varios modelos, pero aún debemos saber cuál de ellos debemos utilizar en un problema concreto para obtener los mejores resultados.. - 25 -.
(32) Capítulo I Discutamos entonces algunos aspectos relevantes de la validación de las técnicas de aprendizaje automático.. I.5. Validación de las técnicas de clasificación La clave para demostrar verdaderos adelantos en el aprendizaje automático es la evaluación. Existen una gran cantidad de técnicas para inferir conocimiento a partir de los datos, ¿pero cómo saber cuál usar en un problema en particular? Es muy usual medir la eficacia de un clasificador en términos de la razón de errores cometidos (Error Rate). O sea dado un conjunto de casos, por cada uno de ellos mal clasificados se sumará un error, mientras que por cada uno bien clasificado se contará como un éxito. Finalmente podemos obtener el índice de error (Er) como la división de la cantidad de errores (TE) sobre el total de casos (T):. Er =. TE T. (1.17). Y de forma similar se puede obtener la exactitud (Acc) del clasificador como su complemento:. Acc = 1 − Er. (1.18). Por supuesto, lo que nos interesa no es la eficacia de un clasificador en los datos de aprendizaje. Lo que realmente debe capturar nuestra atención es su desempeño en los futuros datos. Entonces la pregunta que nos debemos hacer es si la razón de error, calculado en los datos de entrenamiento, es una buena medida para estimar este error en los datos futuros. La respuesta no es definitiva. El por qué, es muy simple: el clasificador ha aprendido de estos datos, por lo tanto existe una gran semejanza entre los casos de prueba y de entrenamiento. Cualquier prueba hecha de esta forma será demasiado optimista. Para estimar el funcionamiento del clasificador en nuevos datos debemos formar dos conjuntos de casos. El primer conjunto contendrá a los casos de entrenamiento y el segundo a los de prueba, los cuales no habrán tomado parte en el proceso anterior. Estos dos conjuntos se suponen representativos de la. - 26 -.
(33) Capítulo I muestra total. A esto le llamamos “validación” para distinguirlo de “verificación” que consistiría en la prueba del método ante situaciones absolutamente nuevas. Una buena idea para la comprobación de la confiabilidad -como medida de consistencia o estabilidad de desempeño (Grau and Correa, 2004)- del desempeño es intercambiar los conjuntos, o sea usar el conjunto de entrenamiento de la primera etapa como prueba, y el de prueba como entrenamiento. Pero desgraciadamente esto exigiría que usáramos dos conjuntos (para entrenamiento y prueba) del mismo tamaño. Existe una variante estadística para lograr esto, conocida como validación cruzada (crossvalidation). Este método puede usarse unido al de estratificación para obtener resultados más confiables. El método más empleado es el de validación cruzada en diez etapas con estratificación por clases (stratified 10-fold cross-validation). Existen otras formas de separar los conjuntos para el entrenamiento y la prueba como la validación cruzada dejando uno afuera (leave-one-out cross-validation) o el método de selección con reemplazo (bootstrap (Efron, 1979)).. I.5.1. Clasificación sensible al costo En las expresiones propuestas en 1.17 y 1.18 para el cálculo de la razón de error no se han tenido en cuenta las diferencias de costos de cometer errores distintos. Imaginemos un ejemplo en el que existan solamente dos clases. Cuando un clasificador predice una clase en este problema puede acertar u ocurrir dos tipos de errores como se muestra en la tabla 1.1. Los verdaderos positivos (VP) y verdaderos negativos (VN) son las clasificaciones correctas. Un falso positivo (FP) ocurre cuando el clasificador se equivoca en su predicción clasificando la instancia como positiva, cuando ésta es realmente negativa. Mientras que un falso negativo (FN) es todo lo contrario, el clasificador predice no, cuando es sí (Kohavi and Provost, 1998). Predicción del clasificador. Valores predichos Sí. No. Valores. Sí. Verdaderos Positivos. Falsos Negativos. reales. No. Falsos Positivos. Verdaderos Negativos. - 27 -.
(34) Capítulo I Tabla 1.1 Matrices de confusión. La razón de verdaderos positivos (true positive rate, TPR) es el número de verdaderos positivos dividido por el total de positivos, esta métrica se conoce también como la sensibilidad (sensitivity). Mientras que la razón de verdaderos negativos (true negative rate, TNR), denominado también especificidad (specificity) es el número de verdaderos negativos dividido por el número total de negativos, El complemento de la especificidad (specificity) es la razón de falsos positivos (FPR) mientras que el complemento de la sensibilidad es la razón de falsos negativos (FNR). La exactitud total (Accuracy) es el número de clasificaciones correctas dividido entre el total de clasificaciones:. VP VP + FN VN Especificidad = VN + FP VP + VN Acc = VP + VN + FP + FN. Sensibilidad = TPR =. (1.19). Si se tienen más de dos clases, entonces este mismo análisis se puede hacer por clase, tomando como positivos a los casos que son de la clase encuestada, y negativas a las demás (Witten and Frank, 2005a). Si se sabe el costo de los errores representados fuera de la diagonal de la matriz de confusión, éste puede ser incorporado en el proceso de prueba. Si el error cometido en cada caso es multiplicado por el costo correspondiente, el valor obtenido finalmente puede darnos una mejor idea de cuán bueno es nuestro clasificador frente a un problema con diferencias de costos por cometer errores sobre una clase u otra. Pero lo interesante no es saber simplemente cuán bueno es, sino hacer que mejore en su etapa de entrenamiento. Una primera idea para solucionar este problema es duplicar casos. Al hacer esto estamos reforzando (en algunas técnicas) los casos duplicados, por lo tanto, si repetimos (o damos mayor peso en el caso que la técnica de clasificación lo permita) casos de las clases con mayor costo, podemos esperar que el clasificador aprenda a separar mejor estas. - 28 -.
(35) Capítulo I clases. Después podemos probarlo con un conjunto de casos sin repeticiones y esperar mejores resultados (Witten and Frank, 2005a). Denotemos con P la clase positiva, y con N el caso contrario. Supongamos que nos interese aumentar los VP de la clase P. Las técnicas de aprendizaje automático, son capaces de aprender a asignar probabilidades a las clases para casos determinados. La clasificación es hecha prediciendo la clase más probable. Sin embargo, bajo estas condiciones, puede ser que nos interese sacrificar un poco en cuanto a FP, para aumentar los VP. Por lo tanto podemos cambiar el esquema de clasificación, y no decidirnos por la clase más probable, sino decidirnos por la clase P, si su probabilidad sobrepasa un cierto punto de corte. Si hacemos variar este punto de corte entre cero y uno, podemos obtener una curva como las representadas en la figura 1.2. Estas curvas se conocen como curvas ROC (Receiver Operating Characteristic), y en realidad este análisis se puede hacer variando cualquier parámetro que produzca cambios significativos en el resultado de la clasificación. En esta figura se han representado por el eje vertical la TPR o la sensibilidad. Mientras que por el eje horizontal se han representado FPR, o el complemento de la especificidad. El punto superior izquierdo representa al clasificador perfecto, en él se obtiene un total de verdaderos positivos, y ningún falso positivo. Mientras que el extremo inferior derecho representa el peor de los casos, se obtiene un total de falsos positivos y una cantidad nula de verdaderos positivos. La eficacia respecto a la clase probada será mayor a medida que la curva se acerque a la esquina superior izquierda del cuadro representado. Cualquier segmento de curva que se encuentre por encima de otra, indica que el clasificador representado por ella es más eficiente que el perteneciente a la segunda curva (Provost and Fawcett, 1997).. - 29 -.
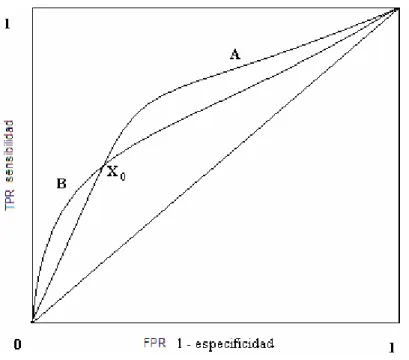
(36) Capítulo I. Figura 1.2: Curvas ROC. Esta técnica sin embargo no es suficiente para determinar si un clasificador es superior en su funcionamiento a otro o no. Consideremos la figura 1.2 nuevamente, es imposible determinar concretamente cuál de los dos clasificadores puede funcionar mejor de forma global. Podemos derivar, a partir del análisis hecho hasta aquí, y retomando la idea de que cualquier curva que esté por encima de otra, representa a un clasificador más eficiente para este segmento, que si construimos una envoltura convexa, que contenga a todas las curvas producidas por los clasificadores a prueba, entonces para que uno de estos clasificadores sea considerado óptimo, debe estar en esta envoltura. La figura 1.3 representa las curvas ROC de los clasificadores A y B. El clasificador A es óptimo para los puntos de corte inferiores a X0, mientras que el clasificador B lo es para los puntos de corte superiores a X1. Pero aún seguimos teniendo el mismo problema, dada una situación particular de diferencias de costos entre los errores referentes a falsos negativos, y falsos positivos, ¿cuál de estos dos clasificadores escoger? La respuesta a esta pregunta está dada por la razón entre cada uno de estos costos.. - 30 -.
Figure



+7




Documento similar