Traductor de Español a Latín para la descripción de las especies botánicas
82
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ________________ ________________ Firma de los autores. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ______________ _______________ Firma de los tutores. __________________ Firma del jefe del Laboratorio.
(3) Pensamiento. No necesito saberlo todo, tan sólo necesito saber dónde encontrar aquello que me hace falta, cuando lo necesite. Albert Einstein. I.
(4) Dedicatoria Dedicatoria. A mí, por tanto esfuerzo y noches sin dormir. A mis padres, por su apoyo en todo momento. A toda mi familia, por su preocupación. A mis amigos, siempre presentes en momentos difíciles.. Daril Alemán Morales. II.
(5) Dedicatoria. Dedicatoria En memoria de mi abuelo Fernando que siempre confió en mí y me brindó apoyo en todo momento de su vida; y sé que está orgulloso de mí. A toda mi familia que de una forma u otra me brindaron su apoyo. Fernando D. García García. III.
(6) Agradecimientos Agradecimientos A mis padres, por su incondicional apoyo en todos los momentos de mi vida y por hacer de mí una mejor persona. A mis abuelos, por preguntarme en todo momento aun cuando no entendieran nada. A mi hermana Deyanira, por hacerme olvidar los problemas. A todos mis tíos, por estar siempre presentes. A Fernando, mi compañero de tesis, por su aporte en la realización de la misma. A Víctor, Sergito y Ruperto por su ayuda en estos 5 años. A todos los colegas que aún continuamos juntos después de tantas aventuras. A los que ya no están. A mis tutoras, por su paciencia y apoyo en estos meses difíciles. A Maikel, por su ayuda a última hora. A Dayana, por los buenos momentos, típico de ella. A Nesty, por su apoyo en la distancia. A todos los que contribuyeron en mi formación como estudiante.. Daril Alemán Morales Muchas Gracias.. IV.
(7) Agradecimientos Agradecimientos. A mi madre, por haberme dado la fuerza necesaria durante todos estos años para enfrentarme a las dificultades de la vida. A mis abuelas, mi abuelo Marcelino, mis tías y mi padre, por preocuparse tanto por mí. A mis hermanas Maité y Kemeelyt, por estar en todo momento disponibles para brindarme su ayuda y cariño. A mi novia Baby por su cariño y ayuda desinteresada. A todos mis amigos, que estuvieron junto a mí en los buenos y malos momentos. A mis compañeros de aula, especialmente a Victor Marrero, Sergito y Daril por su ayuda académica incondicional. A mis tutoras Zenaida y Susana por su inestimable ayuda. A mis profesores de clases que con tanta sabiduría me prepararon para ser un buen profesional. A mi compañero de tesis Daril, por todo su apoyo y su paciencia infinita. A mi compañero Maikel y a todas aquellas personas que de una forma u otra, ayudaron a la realización de este trabajo.. GRACIAS A DIOS Fernando D. García García. Muchas gracias.. V.
(8) Resumen Resumen Los profesionales de la botánica requieren conocer un sistema preciso y universal que les permita describir las nuevas unidades que van siendo incorporadas al sistema de su ciencia. En la Universidad Central “Marta Abreu” de las Villas (UCLV) existe un Jardín Botánico en el cual se llevan a cabo investigaciones acerca del mundo vegetal. Por solicitud de esta entidad, surgió la idea de desarrollar una aplicación computacional que dotara a sus especialistas de la herramienta básica en la práctica taxonómica. Como antecedente de este trabajo, se desarrolló una primera versión del software con el fin de automatizar el proceso taxonómico. El mismo fue desarrollado como trabajo de Diploma por parte de dos estudiantes de la carrera Ciencia de la Computación en el año 2006. Esta versión no cumplía aún con todos los requerimientos de la problemática en cuestión. Por ello se decidió dar continuidad al tema a través del presente trabajo. La aplicación se desarrolló en dos etapas. En la primera de ellas se realizó el diseño del programa que daría solución al problema planteado. Para ello se utilizó la notación del Lenguaje de Modelación Unificado. En la segunda etapa se procedió a la implementación del programa utilizando conjuntamente la programación a través de un lenguaje declarativo, como lo es Prolog, y la programación orientada a objeto, en este caso Java. De esta forma quedó desarrollado EsLatín3, Traductor de Español a Latín para la descripción de las especies botánicas, que constituye una herramienta muy útil y eficiente.. VI.
(9) Abstract Abstract The professionals of the botany need to know a precise and universal system that allows them to describe the new units that are incorporated into the system of their science. In the Central University “Marta Abreu“ of Las Villas (UCLV) exists a Botanical Garden in which researches are carried out on the vegetable world. For request of this entity, arose the idea of creating an application that will provide its specialists with the basic tool in the taxonomic practice.. As precedent of this work, the first version of the software was developed in order to automate the taxonomic process. It was developed like a Diploma Paper on the part of two students of the major of Computer Science in 2006. This version was still not fulfilling with all the requests of the issue in question. That is why it was decided to give continuity to that topic through the present work.. The application was developed in two stages. The first one was the creation of the design of the program that would answer the problem. For this, there was used the notation of the Unified Modelling Language. The second stage was the implementation of the program using jointly the programming through a declarative language, as it is Prolog, and the programming faced to the object, in this case Java. This way was developed EsLatín3, a Translator from Spanish to Latin for the description of the botanical species, which constitutes a very useful and efficient tool.. VII.
(10) Índice Contenido Dedicatoria .............................................................................................................................................. II Dedicatoria ............................................................................................................................................. III Agradecimientos .................................................................................................................................... IV Agradecimientos ..................................................................................................................................... V Resumen ................................................................................................................................................ VI Abstract ................................................................................................................................................. VII Introducción ............................................................................................................................................ 1 Planteamiento del problema .................................................................................................................... 1 Objetivo general ...................................................................................................................................... 2 Objetivos específicos .............................................................................................................................. 3 Preguntas de investigación ...................................................................................................................... 3 Justificación de la investigación ............................................................................................................. 4 CAPÍTULO 1: PROCESAMIENTO DEL LENGUAJE NATURAL EN LA INTELIGENCIA ARTIFICIAL ................. 5 1.1. Procesamiento del lenguaje natural ....................................................................................... 5. 1.1.1. Introducción .................................................................................................................... 5. 1.1.2. Historia ............................................................................................................................ 6. 1.1.3. Problemática del lenguaje natural .................................................................................. 7. 1.2. Traducción automática: métodos, problemas y potencial ..................................................... 9. 1.2.1. ¿Qué es la traducción automática? ................................................................................ 9. 1.2.2. Métodos de traducción automática ............................................................................... 9. 1.2.3. Problemas de la traducción automática ....................................................................... 12. 1.2.4. Futuro de la traducción automática ............................................................................. 13. 1.3. La programación lógica y el lenguaje natural ....................................................................... 13. 1.3.1. Las gramáticas en Prolog .............................................................................................. 14. 1.3.2. Gramáticas Libres del Contexto .................................................................................... 15. 1.3.3. Gramáticas de Cláusulas Definidas ............................................................................... 17. 1.4. Descripción de plantas mediante el Latín Botánico .............................................................. 21 VIII.
(11) Índice 1.4.1. Características del texto latino empleado en la descripción de las especies botánica. 21. 1.4.2. El texto no comparativo en la descripción de las especies botánicas. ......................... 23. 1.5. Conclusiones parciales .......................................................................................................... 25. CAPÍTULO II: IMPLEMENTACIÓN DE ESLATÍN 3, TRADUCTOR DE ESPAÑOL A LATÍN PARA LA DESCRIPCIÓN DE LAS ESPECIES BOTÁNICAS ......................................................................................... 26 2.1. Introducción .......................................................................................................................... 26. 2.2. Modelación del sistema ........................................................................................................ 26. 2.2.1. Diagrama de Casos de Uso ............................................................................................ 27. 2.2.2. Diagrama de Actividades............................................................................................... 28. 2.2.3. Diagrama de Clases ....................................................................................................... 28. 2.3. ¿Por qué se escogen los lenguajes JAVA y PROLOG? ........................................................... 33. 2.3.1. La Gramática en Prolog ................................................................................................. 33. 2.3.2. El archivo Diccionario .................................................................................................... 35. 2.3.3. Predicados auxiliares en Prolog .................................................................................... 36. 2.3.4. Enlace Java-Prolog......................................................................................................... 37. 2.3.5. Acerca del instalador del Software. .............................................................................. 40. 2.4. Conclusiones Parciales .......................................................................................................... 40. CAPÍTULO III: MANUAL DE USUARIO DE ESLATÍN 3 .............................................................................. 41 3.1. Características del software .................................................................................................. 41. 3.2. Pasos para la instalación del software .................................................................................. 42. 3.3. Trabajo con la aplicación....................................................................................................... 42. 3.4. El menú Archivo .................................................................................................................... 45. 3.5. El menú Editar ....................................................................................................................... 46. 3.6. El menú Diccionario .............................................................................................................. 47. 3.7. El menú Herramientas .......................................................................................................... 54. 3.8. El menú Ayuda ...................................................................................................................... 56. CONCLUSIONES ..................................................................................................................................... 59 Recomendaciones ................................................................................................................................. 60 Referencias bibliográficas ..................................................................................................................... 61 Anexos................................................................................................................................................... 64. IX.
(12) Introducción Introducción En la era de la comunicación y de las tecnologías, la difusión de información y de ideas no debería tener obstáculos y, por lo tanto, la diversidad de lenguas existentes no debería constituir una barrera. Sin embargo, ante la ausencia de una lengua común surge la necesidad de contar con instrumentos que permitan acceder a cualquier tipo de información, independientemente del idioma en que esté escrita o expresada.. Hoy día, los avances en la Tecnología de la Información y las Comunicaciones (TIC) se han combinado para fomentar la automatización de la traducción. La relación entre la tecnología y la traducción se remonta al período de la Guerra Fría, ya que en los años 50 la competición entre los EEUU y la Unión Soviética era tan intensa a todos los niveles, que miles de documentos tuvieron que ser traducidos del ruso al inglés y viceversa. Al mismo tiempo, toda esta gran demanda puso de manifiesto la ineficacia de los procesos de traducción, sobre todo en áreas especializadas del conocimiento, e hizo que aumentara el interés por la traducción automática. La importancia de los sistemas de traducción radica en que pueden contribuir a eliminar las barreras de comunicación entre personas de diferentes culturas. Aunque en la actualidad ya se comercializan algunos sistemas de traducción automática, la obtención de un sistema de calidad y totalmente automático está lejos de haberse conseguido. Haciendo uso de la computadora como herramienta de desarrollo ha sido posible construir aplicaciones para el procesamiento del lenguaje natural, tales como: traductores, diccionarios electrónicos, reconocedores de voz, procesadores de textos especializados, correctores ortográficos, analizadores sintácticos, bases de datos terminológicos, entre otros.. Planteamiento del problema. El latín, lengua que tuvo su origen en la región del Lacio, Península Itálica, es el idioma utilizado por los profesionales de la botánica para describir las nuevas unidades o grupos taxonómicos que van siendo incorporados al corpus que conforma el sistema de su 1.
(13) Introducción ciencia. El documento prescriptivo para la práctica de la nomenclatura botánica es el Código Internacional de Nomenclatura Botánica (ICBN, por sus siglas en inglés). Aunque en la actualidad no es obligatorio hacer estas descripciones en latín, muchos investigadores lo continúan utilizando con el objetivo de mantener un consenso general y casi universal que permita el global entendimiento acerca de este ámbito que, efectivamente, es patrimonio de toda la humanidad.. El estudio del latín en Cuba no satisface todas las demandas profesionales de esta lengua, pues sólo se imparte en el nivel universitario como parte de la carrera Licenciatura en Filología. Por esta razón se hace muy difícil la capacitación de profesionales en el área de la Botánica. Ante estos inconvenientes se decidió abrir un curso de postgrado de latín en el Jardín Botánico Nacional impartido por la Dra. Susana Carreras Gómez, profesora titular del Departamento de Lingüística y Literatura de la Facultad de Humanidades de la Universidad Central “Marta Abreu” de Las Villas. El curso pretende dotar a los especialistas de los conocimientos acerca de la lengua latina que se emplea en la nomenclatura botánica y la práctica taxonómica. Como herramienta de ayuda en la impartición de este curso se utiliza el software EsLatín versión 2, desarrollado como parte de un trabajo de diploma por los estudiantes de Ciencia de la Computación Marvin Ávila Kotliarov y Noeslen Mendoza Morales en el año 2006.. El trabajo anteriormente mencionado constituye el antecedente principal de la presente investigación. Realiza traducciones de palabras aisladas y no de frases completas. Con el objetivo de ampliar la ayuda, se decidió dar continuidad al tema por medio del presente trabajo de diploma.. Objetivo general Desarrollar un software que facilite el proceso de traducción de frases del español al latín, mejorando la capacidad de traducción y las funcionalidades de la aplicación actual en aras de sentar bases concretas en el proceso de construcción de un definitivo traductor automático de una taxonomía completa.. 2.
(14) Introducción. Objetivos específicos. 1- Analizar los referentes teóricos y metodológicos que sustentan el estudio. 2- Dominar elementos básicos del latín empleado en la botánica. 3- Determinar el universo lingüístico que se incorporará al traductor. 4- Lograr un correcto análisis morfológico y sintáctico de las palabras para mejorar el proceso de traducción. 5- Adicionar funcionalidades de modificación a la base de conocimiento. 6- Crear una interfaz visual tan cómoda y eficiente como la de la versión anterior del software.. Preguntas de investigación. 1- ¿Cuál de los métodos de traducción automática es el más adecuado para resolver el problema? 2- ¿Es Prolog el lenguaje adecuado para representar el conocimiento? 3- ¿Se podrá utilizar la base de conocimiento de la versión actual del EsLatín en la nueva aplicación? 4- ¿Cómo se tratará la ambigüedad de las palabras según el contexto en que estén escritas?. 3.
(15) Introducción Justificación de la investigación. Entre los principios de Nomenclatura Botánica expresados en El Código de Nomenclatura Botánica está el de escribir los nombres científicos en latín o latinizados, aunque sus orígenes se encuentren en otro idioma. En el Jardín Botánico de la Universidad Central “Marta Abreu” de Las Villas (UCLV), este proceso se realiza con ayuda de la aplicación EsLatín versión 2 la cual efectúa traducciones palabra a palabra. Pero la práctica taxonómica va más allá de la traducción de palabras y la creación de sintagmas nominales. Los especialistas deben expresar las características de las especies, entre las que se encuentran tamaño, color, forma, etc., y esto se realiza a través de la construcción de oraciones, lo cual no puede hacerse en una única consulta en el EsLatín. Sin dudas, un software que permita la traducción de una oración completa del español al latín ha de constituir un aporte de gran valía para los profesionales de la botánica, que ahorrarían tiempo, añadirían automatización al proceso y verían reducido el corpus de la lengua latina que ellos deben incorporar a su conocimiento. Una vez introducidos los aspectos generales del presente trabajo, se describe cómo se ha estructurado la tesis en capítulos. Capítulo I: En este capítulo se trata el tema del Procesamiento del Lenguaje Natural como una rama de la Inteligencia Artificial para el desarrollo de este tipo de aplicaciones. Se hace un análisis de los diferentes métodos de traducción automática, con el objetivo de determinar cuál de ellos es el más adecuado para la investigación. Por último se hace referencia, al uso de la programación lógica en la solución de problemas relacionados con el lenguaje natural.. Capítulo II: En el segundo capítulo se concentra toda la labor de análisis previo de los problemas y los métodos a utilizar, el diseño y organización de las clases y la explicación de la implementación del software EsLatín versión 3.. Capítulo III: El tercer y último capítulo constituye el manual de usuario donde se explican las principales funcionalidades de la aplicación.. 4.
(16) Capítulo 1 CAPÍTULO 1: PROCESAMIENTO DEL LENGUAJE NATURAL EN LA INTELIGENCIA ARTIFICIAL 1.1. Procesamiento del lenguaje natural Una meta fundamental de la Inteligencia Artificial es la manipulación del lenguaje. natural usando herramientas de computación, que les permitan a las computadoras comunicarse con un humano en su propio lenguaje (español, inglés, francés, etc.). A esta tarea se le denomina Procesamiento del Lenguaje Natural (Russell and Norvig 1995). El mismo. se. ocupa. de. la. formulación. e. investigación. de. mecanismos. eficaces. computacionalmente para la comunicación entre personas o entre personas y máquinas.. 1.1.1 Introducción. El Procesamiento del Lenguaje Natural (PLN) (Moreno, Palomar et al. 1999) es uno de los campos relacionados con la Inteligencia Artificial, “que hace uso de un conjunto de mecanismos que la computadora asimila en un lenguaje de programación definido (formal) y le permite comunicarse con el ser humano en su propio lenguaje (español, inglés, etc.)”.(Montero Martínez 2000). En sentido general se ocupa de la formulación e investigación de mecanismos eficaces computacionalmente para la comunicación entre personas o entre personas y máquinas por medio de lenguajes naturales. El PLN no trata de la comunicación por medio de lenguajes naturales de una forma abstracta, sino de diseñar mecanismos para comunicarse que sean eficaces computacionalmente, que se puedan realizar por medio de programas que ejecuten o simulen la comunicación. El lenguaje natural es inherentemente ambiguo a diferentes niveles: a nivel léxico, una misma palabra puede tener varios significados, y la selección del apropiado se debe deducir a partir del contexto oracional o conocimiento básico. Muchas investigaciones en el campo del PLN han estudiado métodos para resolver las ambigüedades léxicas mediante diccionarios, gramáticas, bases de conocimiento y correlaciones estadísticas. Desde este punto de vista, el conocimiento humano sería incomprensible para una computadora, teniendo en cuenta que una computadora puede almacenar un texto en archivos, con lo que poseería la misma 5.
(17) Capítulo 1 información que una persona, pero no podría extraer inferencias lógicas de ese texto, generalizarlo, resumirlo, o responder a preguntas sobre dicho texto, porque no lo entiende, simplemente lo conoce. Por ello surgen un conjunto de disciplinas como el procesamiento del texto, tecnologías del lenguaje, lingüística computacional, etc., entre las que se incluye igualmente el procesamiento del lenguaje natural, que pretenden proporcionar a las computadoras la habilidad de entender el texto y no sólo almacenarlo. La experiencia práctica acumulada en este campo, señala la conveniencia de orientar el reconocimiento del lenguaje natural más al análisis de frases, oraciones y textos en su conjunto, que al reconocimiento de palabras aisladas. En otras palabras, dar más prioridad al reconocimiento del sistema en su conjunto que al reconocimiento de cada una de las partes que lo conforman.. 1.1.2 Historia. Las primeras aplicaciones del procesamiento del lenguaje natural surgieron entre 1940 y 1960, teniendo como interés fundamental la traducción automática de textos entre diferentes idiomas (Hutchins 2007). Los experimentos en este ámbito se basaban fundamentalmente en la sustitución automática palabra por palabra, por lo que se obtenían traducciones muy rudimentarias, que no proporcionaban unos resultados claros. Surgió por tanto la necesidad de resolver ambigüedades sintácticas y semánticas, así como la importancia de considerar la información contextual. Los problemas más relevantes en este tiempo fueron la carencia de un orden de la estructura oracional en algunas lenguas, y la dificultad para obtener una representación tanto sintáctica como semántica; pero una vez que se empezaron a tener en cuenta, se dio paso a una concepción más realista del lenguaje en la que era necesario contemplar las transformaciones que se producen en la estructura de la frase durante el proceso de traducción. En los años sesenta los intereses se desplazaron hacia la comprensión del lenguaje. La mayor parte del trabajo realizado en este período se centró en técnicas de análisis sintáctico. Hacia los setenta la influencia de los trabajos en inteligencia artificial fue decisiva, y el interés se centró en la representación del significado. Como resultado se construyó el 6.
(18) Capítulo 1 primer sistema de preguntas-respuestas basado en lenguaje natural. En esta misma época surgió la máquina Eliza (Giannetti 1997, Dávila, Astorga et al. 2007) que reproducía las habilidades conversacionales de un psicólogo, para lo cual recogía patrones de información de las respuestas del cliente y elaboraba preguntas que simulaban una entrevista. Entre los años 70 y 80, ya superados los primeros experimentos, se hicieron intentos más serios de construir programas más fiables, por lo que aparecieron numerosas gramáticas orientadas a un tratamiento computacional, y la tendencia hacia la programación lógica experimentó un notable crecimiento. En Europa surgieron intereses en la elaboración de programas para la traducción automática, y se creó el proyecto de investigación Eurotra (Benotti 2004) que tenía como finalidad la traducción multilingüe. En Japón aparecieron equipos dedicados a la creación de productos de traducción para su distribución comercial. Los últimos años se caracterizan por la incorporación de técnicas estadísticas y el desarrollo de formalismos adecuados para el tratamiento de la información léxica. Se han introducido nuevas técnicas de representación del conocimiento muy cercanas a la inteligencia artificial, y las técnicas de procesamiento utilizadas por investigadores procedentes del área de la lingüística e informática son cada vez más próximas.. 1.1.3 Problemática del lenguaje natural. Uno de los principales problemas encontrados al tratar el texto es la ambigüedad. En el lenguaje humano es posible encontrar múltiples expresiones y palabras que pueden tener varios significados dependiendo de las circunstancias de uso. En el campo del PLN el problema de la ambigüedad puede tratarse desde distintas perspectivas. Desde la ambigüedad debido a palabras polisémicas, hasta la ambigüedad producida por las distintas interpretaciones que pueda tener una oración. Dentro del PLN, por tanto, se pueden distinguir tres tipos de ambigüedad (Vázquez Pérez 2009): Ambigüedad léxica (Kaplan, Doorn et al. 2010) Ambigüedad sintáctica o ambigüedad estructural (Fernández Reyes 2011) Ambigüedad semántica.(Gelbukh and Sidorov 2006). 7.
(19) Capítulo 1 La primera de ellas se produce cuando una misma palabra puede pertenecer a diferentes categorías gramaticales. La segunda aparece cuando debido a la forma en que se asocian los distintos constituyentes de una oración, esta se puede interpretar de varias formas. Por último, la ambigüedad semántica se refiere a los distintos significados que puede tener una palabra dependiendo del uso que se le esté dando en cada momento. Para tratar de eliminar la ambigüedad es preciso dividir el lenguaje en partes, es decir, construir modelos más pequeños donde cada uno de ellos se encarga de un determinado aspecto de la lengua. Según (Sosa 1997) el lenguaje natural se estructura normalmente en cuatro niveles de análisis: morfológico, sintáctico, semántico y pragmático. Análisis morfológico: Se ocupa de la formación y estructura de las palabras a partir de las unidades más básicas de significado denominadas morfemas. Su función consiste en detectar la relación que se establece entre las unidades mínimas que forman una palabra, como puede ser el reconocimiento de sufijos o prefijos (Pereira and Shieber 2002).. Análisis sintáctico: Este módulo se ocupa de realizar el análisis sintáctico de tal forma que selecciona la etiqueta gramatical más apropiada para cada palabra (Montero Martínez 2000). El resultado de este proceso consiste en generar la estructura correspondiente a las categorías sintácticas formadas por cada una de las unidades léxicas que aparecen en la oración.. Análisis semántico: En este caso se ocupa de asignar el sentido correspondiente a cada palabra (resolver la ambigüedad semántica). Este módulo puede funcionar en paralelo con el módulo de análisis sintáctico o posteriormente (Dagerman, Akan et al. 2013). En cualquier caso, existen diferentes técnicas aplicables para resolver la ambigüedad: lógica de predicados, redes semánticas, grafos de dependencias conceptuales, etc.. Análisis pragmático: Añade información adicional al análisis del significado de la frase en función del contexto donde aparece. Da cuenta de la información no lingüística que influye en el procesamiento e interpretación. En resumen, se ocupa de cómo las oraciones se utilizan 8.
(20) Capítulo 1 en diferentes situaciones y cómo el uso puede afectar a su interpretación. Se trata de uno de los niveles de análisis más complejos (Reyes 1990).. 1.2. Traducción automática: métodos, problemas y potencial. 1.2.1 ¿Qué es la traducción automática?. Entre las dificultades históricas de la comunicación se puede mencionar la barrera del lenguaje. Es por ello que la traducción ha cobrado gran interés aún antes del nacimiento de la informática. Los avances tecnológicos han propiciado el desarrollo de herramientas para la automatización de este proceso. La traducción automática (en adelante: TA) es sin duda un desafío científico. Sin embargo la razón por la cual despierta tanto interés no es de índole científica, sino por una necesidad netamente práctica. No existe en la bibliografía una definición formal de lo que significa TA. Según (Hernández Mercedes 2002), en sentido estricto es “el proceso por el cual una máquina traduce un texto de una lengua a otra, subdividiendo la sintaxis, identificando las partes del discurso, intentando resolver eventuales ambigüedades y, por último, traduciendo los componentes y la estructura en la lengua de destino”. El propósito de este trabajo está en capturar el potencial de las técnicas y paradigmas actualmente desarrollados en el área de la TA, para poder utilizar la mejor variante que permita resolver el problema en cuestión.. 1.2.2 Métodos de traducción automática. Enfoques basados en normas. Las estrategias basadas en normas, de acuerdo con (Hutchins 2007), se pueden dividir en tres enfoques tradicionales, a saber: el sistema de traducción directa, el sistema interlingua y el sistema de transferencia. 9.
(21) Capítulo 1 Sistema de traducción directa. El sistema de traducción directa es el enfoque más sencillo (Craciunescu and GerdingSalas 2007). Está diseñado para un par de lenguas determinado. Se traduce directamente de la lengua fuente (LF) a la lengua meta (LM), su supuesto básico es que el vocabulario y la sintaxis de los textos de la lengua fuente no necesitan ser analizados, sólo lo estrictamente necesario para la resolución de ambigüedades. Normalmente, estos sistemas consisten en un único diccionario bilingüe y un programa único para analizar el texto fuente.. Sistema interlingua. El segundo sistema básico es el sistema interlingua, que asume que es posible convertir un texto de LF en representaciones sintácticas y semánticas comunes para más de una lengua (Zapata and Benítez 2009). El texto en la LF se transforma en un lenguaje intermedio mediante el componente “Análisis” (véase Figura 1.1). El texto en la LM se obtiene a partir de la representación del texto en el lenguaje intermedio, mediante el componente “Generación”. La estructura del lenguaje intermedio, llamado “interlingua”, es independiente de la lengua fuente y de la lengua meta y está basada en una lengua artificial, como por ejemplo el esperanto. Un argumento a su favor es el efecto de economía: con un solo sistema se puede traducir a varias lenguas, aunque por otro lado, la construcción de tal interlingua es un trabajo muy complejo.. Sistema de transferencia. Este sistema establece una representación intermedia entre las lenguas origen y meta, alrededor de la cual se organiza el análisis y la síntesis. La transferencia separa el proceso de traducción en tres fases: análisis, transferencia y síntesis y, a su vez, se puede producir en varios niveles: léxico, sintáctico y semántico (Amores Carredano 2002).. 10.
(22) Capítulo 1. Figura 1.1 El diagrama de la pirámide (Hutchins and Somers 1992). Una manera sencilla para poder entender las relaciones entre los tres sistemas, es reconocer que el sistema de interlingua elimina el componente “transferencia”, y que la traducción directa traduce sin el componente “análisis” y “generación” (la traducción sólo existe a partir del componente “transferencia”).. Enfoques basados en corpus. Los enfoques basados en corpus, también llamados “enfoques empíricos”, se pueden distinguir en dos sistemas, a saber, la TA basada en ejemplos (Diéguez M. 1998) y la TA estadística (Somers 2003).. Traducción automática basada en ejemplos. La idea básica de la traducción automática basada en ejemplos es reutilizar muestras reales con sus respectivas traducciones como base de una nueva traducción (Muñoz and Ramírez 2010). Se caracteriza por encontrar traducciones correspondientes a una base de datos de traducciones reales. El proceso consiste en tres etapas: encontrar correspondencias, alinear y recombinar. En la primera etapa el sistema encontrará, mediante correspondencias con la entrada, muestras de traducciones que pueden contribuir a la traducción. La segunda etapa, la alineación, consiste en identificar las partes útiles de la traducción correspondiente. El tercer paso, llamado “recombinación”, recombina las partes correspondientes. Cuando se sabe qué partes de los ejemplos se reutilizan, es preciso intentar que las partes correspondan de manera legítima.. 11.
(23) Capítulo 1 Traducción automática estadística. En su forma auténtica, la traducción automática estadística no usa datos lingüísticos tradicionales. La esencia de este método es alinear frases, grupos de palabras y palabras individuales de textos paralelos y calcular las probabilidades de que una palabra en una frase de una lengua se corresponda con una palabra en una frase de una traducción con la que está alineada. Dado que la TA estadística genera sus traducciones a partir de métodos estadísticos basados en corpus de textos bilingües, la disponibilidad de un corpus grande de traducciones fiables es una característica esencial de este sistema. Se suele ver este método como “antilingüístico”. La idea de este sistema es modelar el proceso de traducción en términos de probabilidades estadísticas. Para mayor información sobre este método puede consultar (Tomás Gironés 2003).. 1.2.3 Problemas de la traducción automática. Actualmente, la traducción automática perfecta sin la ayuda del ser humano no existe. A pesar de ello, una tasa de precisión básica de más del 90% no es rara en los programas modernos. Lo que sigue siendo más problemático son los momentos de ambigüedad y complejidad que todos los idiomas poseen, donde tanto los análisis basados en las normas como los basados en el análisis estadístico de frases se estrellan con ambigüedades básicas como una referencia singular, una peculiaridad lingüística, algo que no tiene equivalencia lingüística directa, etc. (Ledo Mezquita 2006). Una razón que explica la dificultad que tienen los ordenadores con la traducción es simplemente el hecho de que traducir en sí es difícil, incluso para los traductores humanos. Un traductor se dedica a producir un texto “equivalente” en una lengua meta, que tenga que servir autónomamente, siendo fiel al texto fuente y comprensible en la lengua meta. El término “equivalencia” es difícil de precisar. Hay que tener en cuenta que las lenguas difieren, y, por consiguiente, que una lengua meta no siempre permite expresar el mismo contenido que una lengua fuente. Crear un texto equivalente en la lengua meta no es un trabajo sencillo. El traductor no sólo debe “inventar” traducciones para los nuevos términos que aparecen en el texto fuente, sino que también debe actuar como intermediario entre dos culturas. Queda claro que incluso para los traductores humanos el trabajo de traducir es muy 12.
(24) Capítulo 1 difícil y requiere mucha creatividad. Encontrar una nueva terminología, un neologismo, es más bien una cuestión de inventar una regla que seguir una regla. La mediación intercultural es un trabajo muy complejo: el traductor no sólo tiene que ser capaz de extraer el sentido de un texto, sino también tiene que ser capaz de prever el sentido que extraiga el lector potencial del texto meta.. 1.2.4 Futuro de la traducción automática. Si bien es cierto que la traducción perfecta no existe, hay que dejar constancia de que el sueño de conseguir mecanizar la traducción se ha realizado. La existencia de numerosos programas de ordenador capaces de traducir una gran variedad de textos de un idioma a otro es ya un hecho y no una quimera (Gutiérrez and Figueroa 2011). Sin embargo, la realidad nunca es perfecta. De hecho no existen máquinas de traducir que sean capaces de analizar textos en cualquier idioma y producir una traducción perfecta a cualquier otro idioma sin intervención humana. Esta es una aspiración para el futuro y sólo en ese futuro se podrá saber si esto es realizable. Se sigue investigando para poder crear sistemas rentables desde el punto de vista lingüístico y comercial. Algunos sistemas resultan muy útiles cuando se trata de parafrasear un texto para que lo entienda, por ejemplo, una determinada comunidad. Es decir, si se trata de un lenguaje botánico, es posible que a un especialista de esta área le resulte muy útil un sistema de TA que esté disponible en el mercado, pues no necesita una traducción de alta calidad. El camino que se está siguiendo va orientado a la creación de sistemas de TA basados en sublenguajes, como pueden ser el médico, el jurídico, el científico, etc. para poder limitar el vocabulario y la sintaxis de estos textos y hacer más fácil su traducción.. 1.3. La programación lógica y el lenguaje natural Un paradigma de programación representa un enfoque particular o filosofía para la. construcción del software. No es mejor uno que otro, sino que cada uno tiene ventajas y desventajas. También hay situaciones donde un paradigma resulta más apropiado que otro. Para el caso del tratamiento del lenguaje natural el paradigma más apropiado es el lógico 13.
(25) Capítulo 1 (Warren 1983, Bratko 1986). Este paradigma, que resultó una apasionante novedad en la década del 70, tiene como característica diferenciadora el hecho de manejarse de manera declarativa y con la aplicación de las reglas de la lógica. Esto significa que en lugar de basarse, como en el caso de los paradigmas procedurales, en el planteo del algoritmo para la resolución del problema, se basa en expresar todas las condiciones del problema y luego buscar un objetivo dentro de las declaraciones realizadas. Esta forma novedosa de tratamiento de la información llevó a pensar en un determinado momento en la revolución que significaría la existencia de “programas inteligentes” que pudieran responder, no por tener en la base de datos determinados conocimientos, sino por poder inferirlos a través de la deducción. Actualmente es utilizado en aplicaciones que tienen que ver con la Inteligencia Artificial, particularmente en dos campos: Sistemas Expertos (Lezcano 2005, Riley and Giarratano 2012) y Procesamiento de Lenguaje Natural (Rowe 1988).. En el caso del procesamiento del lenguaje natural se trata de dividir el lenguaje en partes y relaciones y tratar de comprender su significado. Para plantear los problemas en términos del paradigma lógico, es necesario en primer lugar poder plantearlos en términos de reglas lógicas. La resolución es una regla de inferencia que permite a la computadora decir qué proposiciones siguen lógicamente a otras proposiciones. El software que utiliza el principio de resolución trabaja con cláusulas lógicas. Utiliza la búsqueda a ciegas “primero en profundidad” para intentar identificar las partes derecha e izquierda de las cláusulas de una forma lógica, investigando los términos que unifican para permitir una identificación correcta.. 1.3.1 Las gramáticas en Prolog. Muchas de las investigaciones hechas hasta la fecha en la construcción eficiente de sistemas de procesamiento del lenguaje natural, han concluido que las inferencias constituyen 14.
(26) Capítulo 1 un mecanismo poderoso mediante el cual el lenguaje puede ser analizado sintácticamente y generado. La lógica de cláusulas definidas, el subconjunto de la lógica en el cual está basado Prolog, ha mostrado un amplio uso para construir analizadores sintácticos y generadores. Un lenguaje puede verse como un conjunto (normalmente infinito) de frases de longitud finita. Cada frase está compuesta de símbolos de algún alfabeto, según una combinación determinada para formar frases correctas. Para especificar cómo construir frases correctas en cualquier lenguaje se utilizan como formalismo las gramáticas, que constituyen un conjunto de reglas que definen la estructura legal en un lenguaje.. Las reglas de una gramática definen qué cadenas de palabras o símbolos son oraciones válidas de la lengua. Además, la gramática generalmente brinda algún tipo de análisis de la oración, en una estructura que hace su significado más explícito.. 1.3.2 Gramáticas Libres del Contexto Una clase fundamental de la gramática es la Gramática Libre de Contexto (GLC). Según (Pereira and Shieber 2002), “constituyen un sistema para definir las expresiones de un idioma en términos de reglas, que son las ecuaciones recursivas sobre tipos de expresiones, llamadas no terminales, y expresiones primitivas, llamadas terminales.” En las GLC, las palabras o símbolos básicos de la lengua se identifican por símbolos terminales, mientras que las categorías o frases de la lengua se identifican por símbolos no terminales (Wu 2011). Cada regla expresa una forma posible para un no terminal, como una secuencia de terminales y no terminales. El análisis de una cadena de acuerdo con una GLC es un árbol de análisis, que muestra las frases constituyentes de la cadena y sus relaciones jerárquicas. El siguiente ejemplo se expone en (Monferrer, Pacheco et al. 2001) y muestra de forma sencilla el empleo de una GLC. <oracion> <sintagma_nominal> <sintagma_verbal> <sintagma_nominal> <determinante> <nombre> <sintagma_verbal> <verbo> <sintagma_nominal> 15.
(27) Capítulo 1 <sintagma_verbal> <verbo> <determinante> el <determinante> la <nombre> hombre <nombre> manzana <verbo> come Los no terminales se escriben entre paréntesis angulados (esta notación para describir gramáticas se denomina BNF —Backus-Naur Form—). La derivación de una frase a partir del no terminal inicial de la gramática (que en el ejemplo anterior puede ser <oracion>) puede describirse mediante el siguiente árbol de derivación:. A partir de esta gramática es sencillo construir un analizador en Prolog (Bratko 1986):. oración (Z):- conc (X, Y, Z), sintagma_nominal (X), sintagma_verbal (Y). sintagma_nominal (Z):- conc (X, Y, Z), determinante (X), nombre (Y). sintagma_verbal (Z):- conc (X, Y, Z), verbo (X), sintagma_nominal (Y). sintagma_verbal (X):- verbo (X). determinante ([el]). determinante ([la]). nombre ([hombre]). 16.
(28) Capítulo 1 nombre ([manzana]). verbo ([come]).. Una de las deficiencias de las GLC es que no se pueden utilizar para describir la concordancia de número, entre el nombre y el verbo o el artículo y el nombre, ya que ignoran la interdependencia estructural de los constituyentes de la sentencia. Para superar estas deficiencias, se extienden las gramáticas libres de contexto a las gramáticas de cláusulas definidas.. 1.3.3 Gramáticas de Cláusulas Definidas Las gramáticas de cláusulas definidas (GCD) (Gurney, Claffy et al. 1989, Sterling 1994) son una clase particular de las gramáticas, usada para la construcción de sistemas del lenguaje natural; hacen un uso eficiente del poder del Prolog como un lenguaje de programación de propósito general. Son usadas de maneras específicas: ellas sirven como una descripción del lenguaje y como una descripción del proceso para analizar dicho lenguaje. Para entender completamente un lenguaje ya sea lenguaje natural o un lenguaje de programación se tiene que comprender su gramática. La estructura de un lenguaje contiene una secuencia de palabras ordenadas de acuerdo con reglas específicas. Estas reglas tienen en cuenta modo, género, número y la estructura de la oración. Estas reglas son también aplicadas a las descripciones y calificación de palabras y frases.. Las GCD son una extensión de las GLC donde se permite a los no terminales contener argumentos que representen la interdependencia de los componentes de una frase (Monferrer, Pacheco et al. 2001). Por ejemplo, se pueden añadir a los terminales del ejemplo anterior los argumentos “singular” o “plural” para asegurar la concordancia de número (los no terminales también tendrían un argumento más para definir una frase en singular o plural, etc.).. determinante ( singular, [el | S], S). determinante (plural, [los | S], S).. 17.
(29) Capítulo 1 Basado en el trabajo de (Gelbukh 2010) y (Villayandre Llamazares 2010), un formalismo conocido como las GCD expresan las reglas libres del contexto. como. declaraciones lógicas. Las GCD son más poderosas que las GLC. El problema de analizar sintácticamente una cadena de un lenguaje se convierte en el problema de probar que un teorema sigue los axiomas de cláusulas definidas del lenguaje. Una oración en GCD se define por el sintagma nominal y el sintagma verbal. Un ejemplo es el siguiente: oración --> sintagma_nominal, sintagma_verbal. Para leer una regla en una GCD se lee el símbolo “-->”, que significa puede tomar la forma y el símbolo “,”, que significa seguido por. El ejemplo anterior se puede leer como: una oración puede tomar la forma de un sintagma nominal seguido por un sintagma verbal. Esta regla anterior es equivalente a la siguiente cláusula en Prolog: oracion (S0, S):sintagma_nominal (S0, S1), sintagma_verbal (S1, S). Dicha cláusula se puede leer como: una oración extiende de S0 a S si existe un sintagma nominal de S0 a S1 y un sintagma verbal de S1 a S. Una GCD para una gramática que acepte la oración “el músico toca el violín” es de la siguiente forma: oracion --> sintagma_nominal, sintagma_verbal. sintagma_nominal --> determinante, nombre. sintagma_verbal --> verbo, sintagma_nominal. determinante --> [el]. nombre --> [músico]. nombre --> [violín]. verbo --> [toca].. 18.
(30) Capítulo 1 GCD y los Analizadores Sintácticos del Lenguaje Natural Muchos lenguajes de programación no están bien capacitados para transformar gramáticas en analizadores sintácticos del lenguaje natural ni generadores. Prolog, sin embargo, es un lenguaje particularmente conveniente para hacer esto. Los programas escritos en notación GCD son transformados a Prolog usando el predicado expand_term (T1, T2). Este predicado funciona de la siguiente forma: si T1 es un término de Prolog retorna el término inalterado en el valor para T2. Si T1 es un término en GCD, Prolog retorna el término equivalente de Prolog en T2. Esta transformación es hecha automáticamente al mismo tiempo que las reglas son leídas, pero el procedimiento puede ser útil también cuando se usa para propósitos específicos, como parte de los predicados consult y reconsult. También es usado por el intérprete en el nivel superior. En el momento en que el programa escrito en notación GCD es compilado o consultado es que se realiza la transformación descrita anteriormente. Prolog traduce cada regla escrita en GCD en una cláusula que pueda ser comprendida por su intérprete. El operador “-->” es transformado a “:“. Luego se traducen los no terminales en predicados con dos argumentos adicionales. El primer argumento añadido es la lista de palabras que se pasaron dentro del símbolo no terminal (se refiere a los token de entrada). El argumento final es la lista remanente cuando está terminado (se refiere a los token de salida). Las secuencia de token son listas, un token vacío es equivalente a una lista vacía, la lista vacía es escrita como “[ ]”. El equivalente en Prolog a una GCD que acepte la oración “el músico toca el violín” es de la siguiente forma: oracion (S0, S) :- sintagma_nominal (S0, S1), sintagma_verbal (S1, S). sintagma_nominal (S0, S) :- determinante (S0, S1), nombre (S1, S). sintagma_verbal(S0,S) :- verbo (S0,S1), sintagma_nominal (S1, S). sintagma_verbal (S0, S) :- verbo (S0, S). determinante ([el|S], S). nombre ([músico|S], S). nombre ([violín|S], S). verbo ([toca|S], S). 19.
(31) Capítulo 1 Sintaxis de las GCD La sintaxis de las GCD es similar a la sintaxis en Prolog. A continuación se muestran algunas reglas para el uso de dichas gramáticas (Corporation 1986). -. Los símbolos no terminales son escritos como cualquier átomo o estructura en Prolog que no sea una lista.. -. Los terminales son escritos como cualquier término en Prolog. Para distinguir los terminales de los no terminales, una secuencia de terminales es escrita como una lista en Prolog; una secuencia vacía es escrita como la lista vacía. Las secuencias de terminales que son listas de caracteres se ponen entre comillas.. -. La parte izquierda de la regla contiene solamente los no terminales, opcionalmente seguidos por una secuencia de terminales escritos como una lista.. -. La parte derecha de una regla puede contener terminales y no terminales.. -. Las alternativas pueden ser tratadas explícitamente en la parte derecha de la regla, usando el operador “;” o la barra vertical.. -. El símbolo de corte puede ser incluido en la parte derecha de la regla y no es necesario encerrarlo entre paréntesis.. Cómo llamar a una GCD Una vez que se tiene la GCD se puede llamar en Prolog con el predicado que representa el símbolo distinguido de la misma. Por ejemplo se puede llamar el predicado oracion de la siguiente forma: oracion ([‘el’, ‘músico’, ‘toca’, ‘el’, ‘violín’], L). Si la variable L instancia con la lista vacía “[ ]”, quiere decir que la gramática reconoce la oración. De lo contrario la oración no fue reconocida por la gramática. Cuando se escribe una gramática utilizando GCD es necesario recordar que sigue siendo Prolog y por tanto la resolución de la gramática se realizará mediante búsqueda primero en profundidad y backtracking. Hay que tener por tanto especial cuidado de no introducir recursividad infinita. Por otro lado, al utilizar backtracking la resolución puede. 20.
(32) Capítulo 1 llegar a ser muy ineficiente, por eso es bastante recomendable el uso del corte (con precaución).. 1.4. Descripción de plantas mediante el Latín Botánico El latín es una lengua indoeuropea de la rama itálica que fue hablada en la antigua. República Romana y el Imperio Romano desde el siglo IX A.C. Su nombre deriva de la existencia de una zona geográfica de la península itálica denominada "Vetus Latium" o 'antiguo llano' (hoy llamado Lacio). Ganó gran importancia con la expansión del estado romano, siendo lengua oficial del imperio en gran parte de Europa y África septentrional, junto con el griego. Hoy día, el latín sigue siendo utilizado como lengua litúrgica oficial de la Iglesia Católica de rito latino. Es la lengua oficial de la Santa Sede. Por otra parte, la nomenclatura de especies y grupos de la clasificación biológica sigue haciéndose con términos en latín o latinizados.. 1.4.1 Características del texto latino empleado en la descripción de las especies botánicas La sintaxis del texto latino empleado en la descripción de las especies botánicas no responde en sentido general a la sintaxis del latín clásico. Visto de manera integral, el texto del latín botánico, sistema lingüístico que es considerado por algunos como una lengua particular, comporta características singulares, que apuntan principalmente al rasgo de la síntesis. Existen dos tipos de texto que responden a los objetivos de dos tipos de descripción: el texto de la descripción no comparativa, que se propone exponer una especie en su integralidad fenoménica, es decir, en toda su apariencia, y que hace alusión a las características de todos sus órganos y partes visibles, y el texto de la descripción comparativa, que tiene como objetivo dar a conocer las características de una especie a partir de los rasgos que la distinguen o que la acercan a otras especies.. 21.
(33) Capítulo 1 Según (Carreras 2009) “Existen dos tipos principales de descripción: la descripción positiva y la descripción comparativa. La primera es la inicial, la del holotipo o modelo primario y paradigmático, el cual se conserva en el herbario, y describe todos los aspectos de la especie; la segunda, como su nombre lo indica, es comparativa, y se utiliza para separar el nombre de dos especies, subespecies, variedades que se pensaba hasta ese momento que formaban parte de una misma categoría taxonómica” En la simplificación del texto no comparativo se destaca la presencia de un tipo único de oración: la oración atributiva, es decir, aquella que emplea los verbos ser o estar con valor copulativo, donde además dichos verbos se omiten por quedar sobreentendidos. El texto de carácter comparativo es más complejo que el anterior: en primer lugar, ofrece una mayor libertad para el empleo de oraciones tanto atributivas como predicativas (aquellas que no emplean los verbos ser o estar como copulativos), pero, aunque la gama de oraciones es mayor, las mismas acaban repitiéndose y empleando los mismos verbos, adverbios y complementos, con igual significado. En cuanto a los elementos que componen estas estructuras, entre los que se destacan por su frecuencia de uso los adjetivos y los adverbios, se puede apreciar una práctica sostenida de composición y derivación sí presentes, pero no tan usuales en el latín clásico, lo cual reduce la complejidad estructural de la sintaxis textual. Tratándose de un sistema lingüístico para la comunicación científica dentro de una lengua específica, está claro el hecho de que el referente del texto está acotado por aspectos de la propia ciencia, de manera que los sujetos de las oraciones, que en este caso son los elementos descritos, se repiten en cada texto. Asimismo se reiteran en los adjetivos las características de las partes descritas, o sea, de los sujetos de las oraciones, que son por decreto aspectos determinantes en el discernimiento de los diferentes grupos taxonómicos. Las condiciones en que se presenta una especie: lugar, época del año, nivel de desarrollo de la planta, están expresados tanto por adverbios como por sintagmas nominales, que conforman el sistema de los complementos en las oraciones, y que asimismo suelen repetirse. Sobre la base de la consideración de Carreras, el presente trabajo se ocupa solamente de la oración que estructura el texto no comparativo, o sea, de la oración atributiva latina 22.
(34) Capítulo 1 empleada en las descripciones botánicas: “En lo que respecta a la lógica del proceso descriptivo, hay que aprender en primer lugar a desarrollar descripciones positivas, para crear el referente de la comparación. […]. En lo que respecta al conocimiento de la lengua latina que ha de permitir la práctica de la descripción comparativa, hay que partir del aprendizaje de aquella que se emplea en la descripción positiva, más simple y esquemática, aunque todavía notablemente compleja para los botánicos”.. 1.4.2 El texto no comparativo en la descripción de las especies botánicas.. El texto no comparativo en la descripción de las especies botánicas ocupa un solo párrafo para cada especie. Está compuesto por oraciones atributivas que omiten el verbo ser o estar. Dentro del párrafo se encuentran segmentos gramaticales separados por coma, punto y coma y punto y seguido, de acuerdo con la jerarquía del núcleo de cada segmento. El texto está encabezado por el nombre de la especie y algunos datos de ayuda a la labor del taxónomo. Generalmente la primera oración está compuesta por un sintagma nominal que informa acerca del porte de la planta (árbol, arbusto, hierba, enredadera); dicho sintagma es el núcleo del predicado nominal de una oración atributiva que omite el verbo copulativo y cuyo sujeto está referido en el nombre de la especie. Ejemplo: Marila biflora URB. (spec. nov.). Arbor parva v. mediocris. (Se expresa que la Marila biflora es una especie nueva, descrita por el conocido botánico Ignatius Urban y que es un árbol pequeño o mediano). Las oraciones restantes responden a una estructura que en teoría presenta seis elementos: 1. Sintagma nominal sujeto de la oración 2. Adjetivo núcleo del predicado nominal (NPN) 3. Adverbio o frase adverbial que modifica al adjetivo NPN 4. Sintagma nominal con preposición que modifica al NPN 23.
(35) Capítulo 1 5. Sintagma nominal sin preposición que modifica al NPN 6. Oración que modifica al núcleo del sujeto y que repite la estructura de los seis elementos El sujeto (elemento 1) de esta sexta oración, que es subordinada, puede estar acompañado por los cinco elementos restantes, y teóricamente estas estructuras subsistémicas pueden repetirse infinitamente, aunque generalmente no pasan de un segundo nivel; es decir, que en un sistema estructural completo no suele aparecer más de una oración 6 subordinada a otra oración 6. Los sujetos principales (elemento 1) de las oraciones que componen el texto suelen ser: ramas, hojas, flores, sépalos, pétalos, estambres, ovario, inflorescencias, frutos, semillas, entre otros menos frecuentes. Como ya se ha dicho, las características que pueden presentar estos sujetos están bien definidas dentro de la ciencia botánica, y se representan en las oraciones atributivas a través de los adjetivos (elemento 2). Las condiciones en que se presentan estas características expresadas en los adjetivos se expresan mediante los adverbios (elemento 3), los sintagmas nominales con preposición (elemento 4) y los sintagmas nominales sin preposición (elemento 5). Los elementos 4 y 5 en latín, suelen traducirse al español por un sintagma nominal con preposición, lo que en esta lengua española los convertiría a casi todos en un elemento 4. Los denominados “elementos 5” son muy usuales, pero presentan muy poca variedad: en 1111 descripciones revisadas, en las que casi siempre aparecen, no pasan de veinte elementos diferentes. En cada oración solamente puede aparecer un sujeto (elemento 1), pero el resto de los elementos puede repetirse, pues de un mismo ente pueden expresarse varias características (elemento 2), en condiciones diversas (elementos 3, 4 y 5). La oración subordinada (elemento 6) aparece solamente cuando no es suficiente un adjetivo para expresar determinada característica del sujeto; entonces es preciso crear una estructura más compleja, pero que siempre coincide con la estructura de la oración subordinante. Ejemplos de oraciones atributivas en la descripción no comparativa: 24.
(36) Capítulo 1 Rami (1), elongati (2), graciles (2), hirsuti (2). Ramas (1) alargadas (2), gráciles (2), hirsutas (2). Rami (1) teretes (2), non (3) v. vix (3) striati (2), glabri (2), internodiis 2,5-4 cm longis (6). Ramas (1) rollizas (2), no (3) o apenas (3) estriadas (2), lampiñas (2), que tienen entrenudos de 2,5 a 4 cm de largo (6). Rami (1) pallide (3) grisei (2). Ramas (1) pálidamente (3) grisáceas (2). Folia (1) inferne (3) sensim (3) in petiolum (4) angustata (2). Hojas (1) por debajo (3) notablemente (3) estrechadas (2) hacia el peciolo (4). Folia (1) alterna (2), basi (5 que pasa a 4 en español) parum (3) v. vix (3) in petiolum (4) protracta (2), apice (5 que pasa a 4 en español) acuminata (2), nervo medio supra impresso, subtus crasse prominente (6). Hojas (1) alternas (2), en la base (4) poco (3) o apenas (3) protractas (2) hacia el peciolo (4), acuminadas (2) en el ápice (4), que tienen el nervio medio impreso por encima y gruesamente prominente por debajo (6). Como puede apreciarse, la oración en español sigue la estructura del texto en latín, salvo algunos cambios de posición dentro de cada sintagma, los cuales también son previsibles, ya que se repiten sistemáticamente.. 1.5. Conclusiones parciales En este capítulo se abordaron temas del procesamiento del lenguaje natural, así como. el uso de la programación lógica y en especial de las gramáticas en Prolog en la solución de problemas que involucren el lenguaje natural. También se hace un breve análisis de los métodos de traducción automática para determinar cuál de ellos sería el más conveniente para dar solución a este trabajo. Por último, se mencionan las características del texto latino empleado en la descripción de las especies botánicas, para brindar al lector una rápida familiarización con el tema. 25.
(37) Capítulo 2 CAPÍTULO II: IMPLEMENTACIÓN DE ESLATÍN 3, TRADUCTOR DE ESPAÑOL A LATÍN PARA LA DESCRIPCIÓN DE LAS ESPECIES BOTÁNICAS 2.1. Introducción El traductor de español a latín EsLatín 3, como ya fue indicado en el capítulo I de esta. tesis tiene su versión 2 (Ávila Kotliarov and Mendoza Morales 2006) . Este nuevo software ha retomado las ideas de ese trabajo anterior, además permite realizar traducciones referentes a la descripción de plantas del idioma español al latín. También permite realizar actualizaciones al diccionario que sirve como herramienta a la aplicación. La interfaz visual se mantiene similar a la de la versión anterior para permitirle al usuario una rápida familiarización con la herramienta. En este capítulo se explica cuáles han sido las herramientas computacionales utilizadas en la implementación del software, así como los diagramas correspondientes al diseño del mismo.. 2.2. Modelación del sistema Los sistemas o aplicaciones toman forma cuando una o varias personas tienen la visión. de cómo la tecnología pueden mejorarlos. Los desarrolladores deben entender la idea mientras crean el sistema, para ello debe existir un enlace entre quien tiene la idea y el desarrollador. El UML (Lenguaje Unificado de Modelado) es una herramienta que cumple con esta función, se basa en símbolos y diagramas que permiten a los creadores generar diseños que capturen la idea de un sistema para comunicárselo de una forma fácil de comprender a quien realice el proceso de desarrollo. Existen diversas herramientas que permiten la realización de diagramas UML y la integración de los mismos en un modelo de diseño. Los más notables son Select Enterprise, Rational Rose y Visual Paradigm que es el utilizado a lo largo del presente proyecto.. 26.
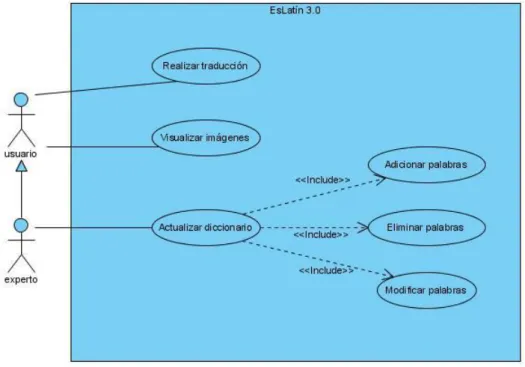
(38) Capítulo 2 2.2.1 Diagrama de Casos de Uso Un caso de uso es una descripción de las acciones de un sistema desde el punto de vista de un usuario. Se representa la interacción con el sistema a desarrollar donde se muestran los requisitos funcionales. Cada caso de uso, que representa el sistema, es una colección de situaciones y cada una de estas una secuencia de pasos. A las entidades que inician las secuencias se les conoce como actores. En el problema que se aborda se han definido dos actores, cada uno con sus respectivos casos de uso. El primero de ellos es el usuario encargado de interactuar con el sistema y realizar cualquier traducción, así como de utilizar el visor de imágenes. El segundo de ellos es el experto en el lenguaje latín, quien se encarga de actualizar el diccionario. Los casos de uso son los siguientes: Realizar traducción: Caso de uso que corresponde a las acciones de efectuar la traducción y comprobar los resultados de la solución. Visualizar imágenes: Utilizar el gestor de imágenes. Actualizar diccionario: Caso de uso que incluye adicionar, eliminar o modificar palabras del diccionario por parte del experto.. Figura 2.1 Diagrama de Casos de Uso. 27.
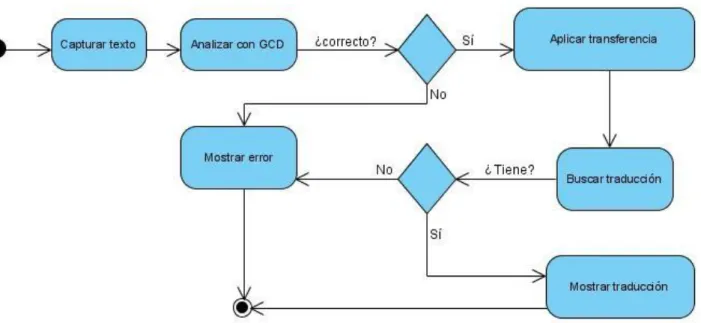
(39) Capítulo 2 2.2.2 Diagrama de Actividades Los diagramas de actividades describen cómo se desarrolla un flujo de actividades entre elementos del sistema o del dominio.. Figura 2.2 Diagrama de Actividades. 2.2.3 Diagrama de Clases. Figura 2.3 Diagrama de Clases. 28.
(40) Capítulo 2 Visual: Es la clase principal del sistema. Se encarga mayormente de la administración de los componentes gráficos del sistema. Los principales métodos implementados para efectuar esta labor son los siguientes: mostrar Diccionario( ){…} Este método es el encargado de mostrar el diccionario donde se encuentran todas las palabras con su significado. mostrarImagen(File file){…} Se encarga de mostrar el visor de imágenes que brinda utilidad para reconocer rasgos propios de las plantas, y además sirve para orientar mejor cualquier tipo de búsqueda. abrirFichero( ){…} Es el encargado de abrir un fichero previamente confeccionado por el usuario con el texto a traducir. salvarFichero( ){…} Se encarga de guardar un fichero con el texto a traducir y el resultado de la traducción. Esta clase también controla las acciones de cada botón de la aplicación.. Encriptación: Esta clase es la encargada de la seguridad del sistema. Es necesario proteger el diccionario de una incorrecta manipulación por parte de los usuarios en tiempo de ejecución del programa. Con este fin se incluye en el sistema la posibilidad de establecer una protección mediante el uso de una contraseña. Para acceder a la ventana de modificaciones del diccionario es necesario introducir la contraseña correcta. La contraseña se protege mediante un algoritmo criptográfico y luego se almacena en un fichero. Los métodos de la clase son los siguientes: encriptarMD5(String palabra){…} Este método se encarga de encriptar la contraseña utilizando el algoritmo MD5 que es uno de los más seguros y conocidos. verificarPassword(String palabra){…} 29.
Figure

+7

Documento similar
Para recibir todos los números de referencia en un solo correo electrónico, es necesario que las solicitudes estén cumplimentadas y sean todos los datos válidos, incluido el
Las actividades ilegales o criminales, sin embargo, cuando faltan víctimas, no tie- nen por qué rendir siempre forzosamente más beneficios. Más bien sucede lo contra- rio. La amenaza
La determinación molecular es esencial para continuar optimizando el abordaje del cáncer de pulmón, por lo que es necesaria su inclusión en la cartera de servicios del Sistema
Para ello, trabajaremos con una colección de cartas redactadas desde allí, impresa en Évora en 1598 y otros documentos jesuitas: el Sumario de las cosas de Japón (1583),
Habiendo organizado un movimiento revolucionario en Valencia a principios de 1929 y persistido en las reuniones conspirativo-constitucionalistas desde entonces —cierto que a aquellas
En este sentido, puede defenderse que, si la Administración está habilitada normativamente para actuar en una determinada materia mediante actuaciones formales, ejerciendo
En la parte central de la línea, entre los planes de gobierno o dirección política, en el extremo izquierdo, y los planes reguladores del uso del suelo (urbanísticos y
Non Invasive diagnosis of subclinical and mild CHD: 1) increase the prescription of a statin in hypercholesterolemic patients; 2) enhancing the adherence, and perhaps the targets
