Estudio de completitud técnica del SGBD PostgreSQL en relación con otros gestores de bases de datos
116
0
0
Texto completo
(2) Dictamen Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ______________________ Firma de la Autora. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ________________________________ Firma del Tutor. ______________________________ Firma del Jefe del Laboratorio.
(3) Dedicatoria A mis padres por estar siempre conmigo y confiar en mí todo el tiempo..
(4) Agradecimientos A mi familia por estar siempre a mi lado. A mi tutor por haberme ayudado, guiado y apoyado durante todo este tiempo. A Linet por estar siempre que la necesité, en las buenas y las malas. A Ana Francys, que aunque no esté aquí en este momento, me dio fuerzas para seguir adelante. A Javier por darme siempre apoyo y tenerme paciencia. A mis amigas y amigos que han compartido conmigo todos estos años. A todos los profesores que durante estos cinco años me educaron como profesional. A todas las personas que de una forma u otra tuvieron que ver con la realización de este Trabajo de Diploma..
(5) Resumen El presente trabajo pretende realizar un estudio de completitud de algunas de las características técnicas que un Sistema de Gestión de Bases de Datos debe tener, para su correcto uso en la creación de sistemas de información. La necesidad del mismo parte del interés nacional de crear herramientas de software –en este caso un SGBD- soberano, basado en lo mejor existente dentro de lo conocido como software libre, relacionado con esta línea, en este caso el PostgreSQL. El estudio se realizó por métodos comparativos con respecto a otros SGBD muy conocidos y utilizados en el mundo. Se tuvieron en cuenta en este trabajo características tales como las facilidades en la creación de tablas o clases, las interrelaciones y métodos de indexado, dentro del lenguaje de definición de datos; así como las facilidades visuales de creación de consultas, procedimientos almacenados y funciones, y herramientas de interfaz como formularios e informes, como parte del lenguaje de manipulación de datos de cada gestor analizado. También se estudiaron otras características típicas de este tipo de software.. Palabras Claves Bases de Datos, Sistemas de Gestión de Bases de Datos, Características Técnicas de SGBD, PostgreSQL..
(6) Abstract The present work seeks to carry out a completed study of some of the technical characteristics that a Databases Management System should have, for its correct use in the creation of information systems. The necessity of the same part of the national interest to create software tools -in this case a DBMS- sovereign, based on the best thing existent inside that known as free software, related with this line, in this case the PostgreSQL. The study was carried out for comparative methods with regard to other very well-known and used in the world DBMS. They were kept in mind in this such characteristic work as the facilities in the creation of tables or classes, the relationships and the indexing methods, inside the data definition language; as well as the visual facilities for creation of queries, stored procedures and functions, and interface tools like forms and reports, like part of the data manipulation language each analyzed DBMS. Other typical characteristics of this software type were also studied.. Key words Databases, Database Management Systems, DBMS Technical Characteristics, PostgreSQL..
(7) Tabla de Contenidos INTRODUCCION ..................................................................................................................1 CAPÍTULO 1. VISIÓN GENERAL DE CARACTERÍSTICAS TÉCNICAS DE LOS SGBD....................................................................................................................................10 1.1. Lenguajes de los SGBD..............................................................................................10 1.2. Métodos de indexado..................................................................................................12 1.3. Control de concurrencia .............................................................................................17 1.4. Control de la redundancia...........................................................................................20 1.5. Restricciones de los accesos no autorizados...............................................................20 1.6. Almacenamiento persistente de objetos y estructuras de datos de programas ...........20 1.7. Inferencias en la base de datos mediante reglas de reducción....................................21 1.8. Suministro de múltiples interfaces con los usuarios...................................................21 1.9. Cumplimiento de las restricciones de integridad........................................................22 1.10. Respaldo y Recuperación .........................................................................................23 1.11. Conclusiones Parciales .............................................................................................30 CAPÍTULO 2. ANÁLISIS DE CARACTERÍSTICAS TÉCNICAS IMPORTANTES PARA LA COMPLETITUD EN DIFERENTES SGBD. ....................................................31 2.1. Planteamiento del caso de estudio..............................................................................31 2.2. Lenguaje de Definición de Datos (DDL) ...................................................................32 2.2.1. Creación de Tablas...............................................................................................32 2.2.2. Relaciones ............................................................................................................38 2.2.3. Métodos de Indexado ...........................................................................................40 2.3. Lenguaje de Manipulación de Datos (DML)..............................................................46 2.3.1. Consultas ..............................................................................................................46 2.3.2. Procedimientos almacenados y funciones............................................................51 2.3.3. Formularios e Informes ........................................................................................55 2.4. Control de Concurrencia.............................................................................................59 2.5. Respaldo y Recuperación ...........................................................................................64 2.6. Conclusiones Parciales ...............................................................................................68 CAPÍTULO 3. CARACTERIZACIÓN COMPARATIVA DEL SGDB-OR POSTGRESQL. ....................................................................................................................69 3.1. Lenguaje de Definición de Datos del PostgreSQL.....................................................69 3.1.1. Creación de Tablas...............................................................................................69 3.1.2. Relaciones ............................................................................................................72 3.1.3. Métodos de Indexado ...........................................................................................72 3.2. Lenguaje de Manipulación de Datos de PostgreSQL.................................................73.
(8) 3.2.1. Consultas ..............................................................................................................73 3.2.2. Procedimientos Almacenados y Funciones..........................................................75 3.2.3. Formularios e Informes ........................................................................................76 3.3. Control de Concurrencia.............................................................................................76 3.4. Respaldo y Recuperación ...........................................................................................79 3.5. Conclusiones Parciales ...............................................................................................82 CONCLUSIONES ................................................................................................................85 RECOMENDACIONES.......................................................................................................86 REFERENCIAS BIBLIOGRÁFICAS .................................................................................87 BIBLIOGRAFÍA ..................................................................................................................89 ANEXOS ..............................................................................................................................93 Anexo 1. Control de redundancia......................................................................................93 Anexo 2. Restricción de los accesos no autorizados .........................................................93 Anexo 3. Almacenamiento persistente de objetos y estructuras de datos de programas...96 Anexo 4. Inferencias en la base de datos mediante reglas de deducción ..........................97 Anexo 5. Cumplimiento de las restricciones de integridad.............................................100.
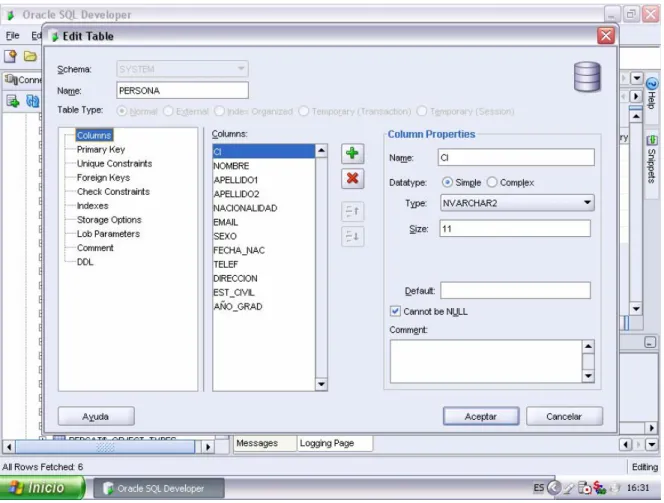
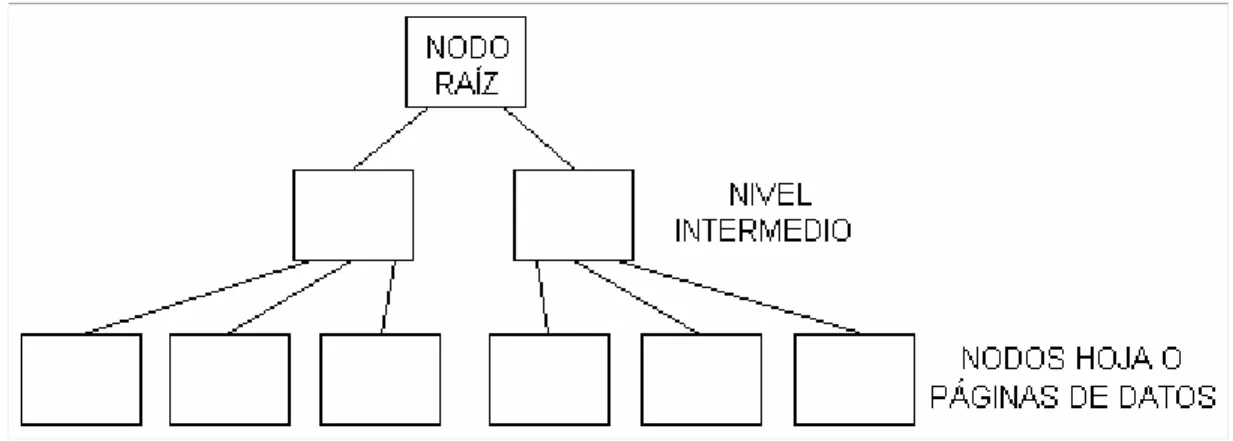
(9) Lista de Figuras 1. Figura 1. Modelo Entidad-Relación del caso de estudio “Control de Maestrías”.. 31. 2. Figura 2. Tabla Persona creada mediante la interfaz interactiva SQL*Plus.. 37. 3. Figura 3. Tabla Persona creada mediante Oracle Enterprise Manager.. 37. 4. Figura 4. Tabla Persona creada mediante Oracle SQL Developer.. 38. 5. Figura 5. Diagrama de un índice B*Tree.. 41. 6. Figura 6. Ventana de diseño de una consulta en Access.. 46. 7. Figura 7. Ventana de presentación o vista de una consulta en Access.. 47. 8. Figura 8. Ventana del SQL Query Analyzer, del SQL Server.. 48. 9. Figura 9. Ventana del View, del SQL Server.. 49. 10. Figura 10. Ventana de creación de una Vista (View), del Oracle.. 50. 11. Figura 11. Código SQL generado de una Vista del Oracle.. 50. 12. Figura 12. Creación de un Procedimiento almacenado en SQL Server.. 52. 13. Figura 13. Resultado de un Procedimiento almacenado en SQL Server.. 52. 14. Figura 14. Creación de una Función en SQL Server.. 53. 15. Figura 15. Creación de un Procedimiento almacenado en Oracle.. 54. 16. Figura 16. Formulario de Personas en Access.. 56. 17. Figura 17. Definición de un informe en vista diseño en Access.. 57. 18. Figura 18. Formulario de Personas en Oracle.. 58. 19. Figura 19. Ventana de opciones de control de concurrencia en Access.. 59. 20. Figura 20. Ventana de opciones de respaldo en SQL Server.. 66. 21. Figura 21. Constructor Gráfico de Consultas en PostgreSQL.. 74. 22. Figura 22. Código generado de la Consulta en el Editor SQL de PostgreSQL.. 74. 23. Figura 23. Función generada en PostgreSQL.. 75. 24. Figura 24. Ventana de diálogo para resguardos en PostgreSQL.. 81. 25. Figura 25. Ventana de diálogo para restaurar una base de datos en PostgreSQL.. 82.
(10) Lista de Tablas 1. Tabla 1. Características Generales de algunos SGBD. 4. 2. Tabla 2. Comparación a partir del Soporte del Sistema Operativo.. 5. 3. Tabla 3. Clasificación por Ambiente y Modelo de Datos.. 5. 4. Tabla 4. Clasificación por LDD y LMD.. 6. 5. Tabla 5. Resumen de las características técnicas de los SGBD Access, SQL. 68. Server y Oracle. 6. Tabla 6. Resumen de las características técnicas del SGBDOR PostgreSQL. 84.
(11) INTRODUCCION Planteamiento del Problema: Hasta el momento en nuestro país se utilizan diferentes sistemas gestores de bases de datos (SGBD), en ocasiones el que mejor resuelva determinado problema -según sus características-, pero a veces por ser el que conoce el implementador. Sería de mucha utilidad que existiera un sistema que incluyera lo mejor de cada sistema gestor de bases de datos y de esta forma se lograra que uno solo resolviera si no todos los problemas, si la mayoría al menos para los sistemas de información generales. Mucho mejor aún sería que ese sistema fuese de creación nacional y además basado en las tecnologías de software libre que permitan tener una independencia tecnológica de nuestro país no solo en el SGBD en sí, sino además en los sistemas de información o aplicaciones que se desarrollarían en base al mismo. Algunos de estos gestores tienen características de ser monousuarios lo que no permite desarrollar sistemas de información para redes globales e incluso trabajan con problemas en redes locales, al contrario otros gestores dan amplia posibilidades de trabajo en redes globales al incluir mejores prestaciones en el trabajo con registros sin embargo adolecen de no tener un lenguaje de manipulación de información que incluya desarrolladores de ventanas y de informes con formatos elegantes, así como otras prestaciones generales como un sistema de menú, centrándose en el diseño de la estructura de la base de datos, las interrelaciones y las consultas y procedimientos almacenados. La mayoría de estos gestores trabajan sobre el modelo relacional y aunque se conoce que existen gestores supuestamente orientados a objetos, estos no son de un amplio uso comercial. En los últimos tiempos hay algunos gestores que han tratado de combinar ambos paradigmas y también tratan de incluir otras formas de almacenamiento o de tratamiento de la información para dar respuesta a sistemas como los de toma de decisiones. Algunos de ellos han tomado la denominación de objeto-relacionales (SGBDOR).. 1.
(12) Introducción En este caso se quiere hacer una comparación de las principales características técnicas y otras sugeridas, de los más conocidos sistemas gestores de bases de datos, con las que posee el PostgreSQL, y a partir de ahí fundamentar criterios de completitud del sistema gestor de bases de datos que se está desarrollando en nuestro país, basado en aquel, para que de esta manera se satisfagan la mayoría de nuestras necesidades.. Objetivo General: Estudiar y revelar las características internas del SGBDOR PostgreSQL, para destacar sus potencialidades y debilidades en comparación con otros SGBD Relacionales y ObjetoRelacionales, que sirvan de base para fundamentar criterios de completitud de un futuro SGBD nacional sobre software libre.. Objetivos Específicos: 1.. Formalizar y fundamentar diferentes criterios de completitud de un supuesto SGBD de factura nacional basado en PostgreSQL.. 2.. Revelar en detalle algunas características de creación de tablas, índices y otros elementos de una Base de Datos implementada en Oracle, SQL Server y Access, sobre la base de una pequeña estructura de un caso de estudio, así como las características del Lenguaje de Manipulación de Datos, en especial el tipo de SQL que utiliza, las posibilidades de creación o no de interfaz de usuario, etc.. 3.. Revelar en detalle las características de creación de tablas, índices y otros elementos de una Base de Datos implementada en PostgreSQL sobre la base de una pequeña estructura del mismo caso de estudio, así como las características del Lenguaje de Manipulación de Datos, en especial el tipo de SQL que utiliza, las posibilidades de creación o no de interfaz de usuario, etc.. 4.. Comparar las características obtenidas anteriormente del PostgreSQL con respecto a las de los otros SGBD, para establecer las potencialidades y las debilidades del PostgreSQL.. Preguntas de Investigación:. 2.
(13) Introducción 1.. ¿Qué características debe tener un buen SGBD actualmente desde el punto de vista de su lenguaje de definición de datos (LDD) y su lenguaje de manipulación de datos (LMD)?. 2.. ¿Qué otras características de implementación de sistemas de información en ambiente visual y gráfico son importantes para un buen SGBD?. 3.. ¿Qué criterios de completitud deberían incluirse en ese Software a desarrollar?. 4.. ¿Qué potencialidades de carácter de desarrollo de aplicaciones de bases de datos incluye el SGBD PostgreSQL con respecto a otros gestores comerciales importantes?. 5.. ¿Qué debilidades de carácter de desarrollo de aplicaciones de bases de datos incluye el SGBD PostgreSQL con respecto a otros gestores comerciales importantes?. 6.. ¿Servirá realmente el PostgreSQL como Software Libre, de base para el desarrollo de un SGBD nacional?. Justificación de la Investigación: Al establecer esta comparación se pretende hacer más fácil la construcción del nuevo sistema gestor de bases de datos que nuestro país necesita, ya que se pondrán a la mano de sus desarrolladores parte de la información técnica necesaria, que serviría como una guía que permita tomar lo mejor de cada gestor que se utiliza actualmente nuestro país y en el mundo, y obtener un resultado mucho más rápido, completo y eficiente, lo que estaría acorde con la máxima actual de la Ingeniería del Software.. Viabilidad de la Investigación: Se tiene información muy dispersa y generalmente comercial de estos gestores, pero no se cuenta con información profunda técnicamente de lo que poseen estos y sus potencialidades para el desarrollo de aplicaciones de tipo sistemas de información. Por tanto hay que emplear mucho uso de la Bibliografía más relevante tanto clásica en libros como actualizada en Internet y Revistas especializadas para alcanzar los objetivos. Por otra parte se cuenta en el Seminario de Bases de Datos con las facilidades de equipamiento, conectividad y bibliografía en formato impreso para acometer la investigación.. Marco Teórico Preliminar:. 3.
(14) Introducción Un Sistema de Gestión de Bases de Datos es esencial para el adecuado funcionamiento y manipulación de los datos almacenados en soportes computacionales. Se puede definir como: el conjunto de programas, procedimientos, lenguajes, etc., que suministra, tanto a los usuarios no informáticos como a los analistas, programadores o al administrador, los medios necesarios para describir, recuperar y manipular los datos almacenados en la base, manteniendo su integridad, confidencialidad y seguridad.(Elmarsi and Navathe, 2007a) A continuación se muestran algunas características generales de diferentes sistemas gestores de bases de datos: Tabla 1. Características Generales de algunos SGBD. SGBD DB2 Informix Microsoft SQL Server MySQL. Oracle PostgreSQL Microsoft Access Paradox Visual FoxPro. Creador IBM Informix Software (actual IBM) Microsoft junto a Sybase MySQL AB (después Sun Microsystem, actual Oracle) Oracle Corporation. Fecha de la 1ª versión publicada 1982 1985. Última versión estable 9 10.0. 1989. 9.00.2047. Propietario. Noviembre de 1996. 5.0. GPL o Propietario. 1977. Propietario Licencia BSD. Licencia de Software Propietario Propietario. PostgreSQL Global Development Group Microsoft. Junio de 1989. 11g Release 1 8.2.3. 1990. 2010. Propietario. Ansa (después Borland, ahora Corel) Fox Software Inc. (actual Microsoft). 1985. 9. Propietario. FoxBase en 1983. 6.0. Propietario. También se puede analizar otra comparación a partir del soporte del sistema operativo.. 4.
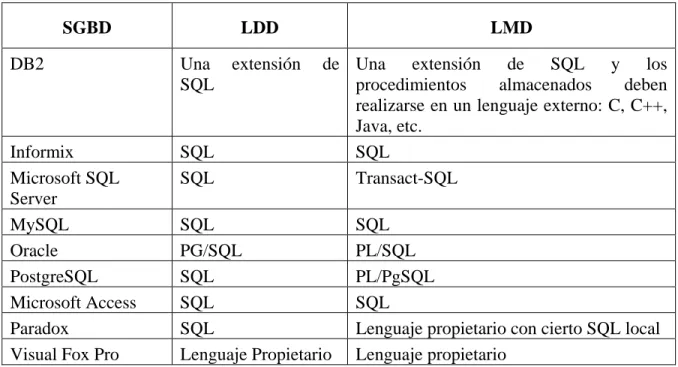
(15) Introducción. Tabla 2. Comparación a partir del Soporte del Sistema Operativo. SGBD. Windows. Mac OS X. Linux. BSD. Unix. z/OS. DB2 Informix Microsoft SQL Server MySQL Oracle PostgreSQL Microsoft Access Paradox Visual Fox Pro. 9 9 9. No 9 No. 9 9 No. No 9 No. 9 9 No. 9 No No. 9 9 9 9 9 9. 9 9 9 No No No. 9 9 9 No No No. 9 9 9 No No No. 9 9 9 No No No. 9 9 No No No No. Todos los gestores que aparecen en la tabla anterior tienen implementado la integridad referencial. En cuanto al ambiente de trabajo y al tipo o modelo de datos se pueden clasificar así: Tabla 3. Clasificación por Ambiente y Modelo de Datos. SGBD. Tipo de Base de Datos. DB2. Relacional. Informix Microsoft SQL Server MySQL Oracle PostgreSQL Microsoft Access Paradox Visual Fox Pro. Relacional Relacional Relacional Relacional* Objeto-relacional Relacional Relacional En su última versión es orientado a objeto. Ambiente Monousuario, cliente/servidor, permite bases de datos distribuidas Monousuario, cliente/servidor Cliente/servidor Cliente/servidor Cliente/servidor Cliente/servidor Monousuario, cliente/servidor Monousuario, cliente/servidor Monousuario, cliente/servidor. Otra característica interesante es determinar el tipo de lenguajes de definición de datos (LDD) y de manipulación de datos (LMD) que presentan:. 5.
(16) Introducción Tabla 4. Clasificación por LDD y LMD. SGBD. LDD. DB2. Una extensión SQL. Informix Microsoft SQL Server MySQL Oracle PostgreSQL Microsoft Access Paradox Visual Fox Pro. SQL SQL. LMD de Una extensión de SQL y los procedimientos almacenados deben realizarse en un lenguaje externo: C, C++, Java, etc. SQL Transact-SQL. SQL PG/SQL SQL SQL SQL Lenguaje Propietario. SQL PL/SQL PL/PgSQL SQL Lenguaje propietario con cierto SQL local Lenguaje propietario. A continuación una breve reseña de otras características de los principales sistemas de gestión de bases de datos que serán tratados en el presente trabajo:. Oracle Aparte de lo antes expuesto sobre este gestor se puede agregar que soporta el indexado B*Tree, con lo cual mejora el rendimiento cuando se accede a una tabla, y el bitmap. Soporta también objetos como cursores, disparadores, funciones, procedimientos y rutinas externas. Los métodos de particionamiento soportados son rango, hash, compuesto (rango+hash) y listas. El PL/SQL es propio de Oracle, la base de datos incluye un compilador de Java y una JVM (Java Virtual Machine) con la ingeniería de la base de datos. Esto permite a los desarrolladores escribir procedimientos almacenados, disparadores y funciones en el estándar de programación Java incluido en el lenguaje PL/SQL. Los desarrolladores compilan los programas Java directamente en la base de datos o leen de una clase Java utilizando la utilidad de Oracle llamada LoadJava. Oracle es utilizado por empresas como: General Motors, General Electric, Intel Corporation, HP, Philips, Nike, Banco de Crédito de Perú, Alcatel, British Gas, Andinatel. 6.
(17) Introducción Ecuador, Mercado Libre, Mastercard Internacional, Boing, Sri Ecuador, Concep, Superintendencia de Bancos de Ecuador, Toyota Casa Baca, Iess, entre otros.. PostgreSQL Soporta el indexado full-text a través de un disparador incluido en la distribución además de muchos otros. Soporta objetos como dominio, cursores, disparadores, funciones, procedimientos y rutinas externas. No permite métodos de particionamiento.. MySQL Soporta el estándar B*Tree indexing con el uso de las tablas innodb, soporta objetos como cursores, funciones, procedimientos y rutinas externas, pero no soporta dominio ni métodos de particionamiento. Está escrito en C y C++, tiene procesos multihilos (capacidad de trabajar servidores con varios procesadores), permite el desarrollo de APIs para C, C++, Eiffel, Java, Perl, PHP, Pitón, Ruby y TCL. Empresas que utilizan MySQL: Sony, Suzuki, Lycos, Yahoo, Dell, PortaOne, Nasa, UNICEF, McAffe, Aizawa Securities, Google, etc.. Microsoft SQL Server Soporta el indexado full-text aunque su indexado por defecto es B*Tree. Soporta cursores, disparadores, funciones, procedimientos y rutinas externas. También soporta el rango como método de particionamiento. Empresas que lo utilizan: AT&T Business Services, Lexis-Nexis, Chevron Canadá, Smead Manufacturing, Disco, Ragnorak Systems, Keylime Software, CS HePalth Systems, Verizon, Ticketmaster.com, entre otras.. DB2 Soporta el indexado reverso y bitmap. Soporta cursores, disparadores, funciones, procedimientos y rutinas externas. Como métodos de particionamiento soporta rango, hash, compuesto y lista. Permite a los usuarios tener acceso a una cantidad casi ilimitada de datos; ejecutar una amplia gama de tareas, desde apoyo de decisiones hasta transacciones. 7.
(18) Introducción comerciales; trabajar con distintos tipos de datos de texto, imágenes, sonido y video; administrar datos de manera rápida y sencilla; ejecutar el mismo software de una terminal a otra, de un grupo de trabajo a otro y de una empresa a otra. Utilizando este gestor un negocio minorista puede llegar al mercado global, sin el costo de adquirir y manejar nuevas franquicias, creando una aplicación para vender sus productos online.. Informix Soporta indexado tree R-/R+, hash y expresión. Los objetos soportados por él son cursores, disparadores, funciones, procedimientos y rutinas externas. Permite manejar datos alfanuméricos, contenidos digitales y multimedia (video, imágenes y audio), contenidos basados en Web, aplicaciones lógicas y datos abstractos como series financieras. Permite crear aplicaciones utilizables en la Web. La funcionalidad del SQL paralelo aumenta el desempeño y permite que todas las operaciones de bases de datos se ejecuten en paralelo, eliminando potenciales cuellos de botella.. Access Los informes y formularios pueden hacerse directamente por programación, o de forma interactiva. Puede guardar documentos con formato HTML y publicarlos en Internet/Intranet, permite unir múltiples tablas en una única vista interrelacionada, llamada página de acceso grupal, que agrupa registros que van desde categorías generales hasta detalles específicos, comprime las bases de datos conservando espacio en computadora y manipulándolas más rápido. Permite la integración de un servidor SQL para crear bases de datos empresariales.. Hipótesis de Investigación: La definición de los criterios de completitud de un buen SGBD debe servir de pauta para el desarrollo futuro de un software de este tipo de factura nacional, en base al conocido PostgreSQL considerado software libre. Entre estos criterios de completitud deben considerarse las potencialidades que demanda un SGBD en su Lenguaje de Definición de Datos (tablas, interrelaciones, atributos, tipos de dominios, formas de almacenamiento, de indexado, etc.), así como en su Lenguaje de Manipulación de Datos, en cuanto al uso de un lenguaje de consulta estándar. 8.
(19) Introducción como SQL u otro, las potencialidades de generación de forma visual de consultas, procedimientos almacenados, y funciones, y la creación de interfaces de usuario óptimas en ambiente de ventanas o en Web, tanto para la captación (formularios) como para la presentación formateada de la información resultantes (informes) y otros objetos de una IGU. También es importante revelar las potencialidades o debilidades del PostgreSQL en cuanto al Control de Concurrencia y al Respaldo y Recuperación.. Organización de la tesis Para un mejor ordenamiento de las ideas y conclusiones de este trabajo se determinó organizarlo en tres capítulos que incluyen lo siguiente: 1. Capítulo 1: Estudio del Marco Teórico relacionado con los SGBD más utilizados en la actualidad. 2. Capítulo 2: Implementación de un breve problema en diferentes gestores y estudio a partir de esto de algunas características seleccionadas de estos gestores. 3. Capítulo 3: Comparación de las posibilidades e insuficiencias del PostgreSQL en comparación con los gestores estudiados anteriormente y planteamiento de los requerimientos de completitud técnica del mismo, a fin de ser tomado en consideración como base para la creación de un SGBD de factura nacional.. 9.
(20) CAPÍTULO 1. VISIÓN GENERAL DE CARACTERÍSTICAS TÉCNICAS DE LOS SISTEMAS DE GESTIÓN DE BASES DE DATOS..
(21) CAPÍTULO 1. VISIÓN GENERAL DE CARACTERÍSTICAS TÉCNICAS DE LOS SGBD. En este capítulo se aborda el marco teórico-referencial de las principales características que se consideran importantes en un SGBD. Según el libro, SISTEMAS DE BASES DE. DATOS. Conceptos fundamentales, las características “deseables” en un SGBD son las siguientes:(Elmasri and Navathe, 1997) 1. Control de la redundancia. 2. Restricciones de los accesos no autorizados. 3. Almacenamiento persistente de objetos y estructuras de datos de programas. 4. Inferencias en la base de datos mediante reglas de deducción. 5. Suministro de múltiples interfaces con los usuarios. 6. Representación de vínculos complejos entre los datos. 7. Cumplimiento de las restricciones de integridad. 8. Respaldo y recuperación. Además de estas características consideramos importante agregar los lenguajes de los SGBD y dentro del lenguaje de definición de datos hacer énfasis en los métodos de indexado, y como otra característica importante consideramos el control de la concurrencia.. 1.1. Lenguajes de los SGBD En muchos SGBD en los que no se mantiene una separación estricta de niveles, el DBA y los diseñadores de las bases de datos utilizan un mismo lenguaje, el lenguaje de definición de datos (DDL: Data Definition Language), para definir ambos esquemas. El SGBD contará con un compilador de DDL cuya función será procesar enunciados escritos en el DDL para identificar las descripciones de los elementos de los esquemas y almacenar la descripción del esquema en el catálogo del SGBD. Cuando en los SGBD se mantenga una clara separación entre los niveles conceptual e interno, el DDL servirá solamente para especificar el esquema conceptual. Se utiliza otro lenguaje, el lenguaje de definición de almacenamiento (SDL: Storage Definition Language), para especificar el esquema interno. Las correspondencias entre los dos. 10.
(22) Capítulo 1 esquemas se pueden especificar en cualquiera de los dos lenguajes. Para una verdadera arquitectura de 3 esquemas, se necesitaría un tercer lenguaje, el lenguaje de definición de vistas (VDL: View Definition Language), para especificar las vistas del usuario y sus correspondencias con el esquema conceptual. Una vez que se han compilado los esquemas de la base de datos y que en esta se han introducido datos, los usuarios requerirán algún mecanismo para manipularla. Las operaciones de manipulación más comunes son la obtención, la inserción, la eliminación y la modificación de los datos. El SGBD ofrece un lenguaje de manipulación de datos (DML: Data Manipulation Language) para estos fines. En los SGBD actuales no se acostumbra a distinguir entre los tipos de lenguajes antes mencionados; más bien se utiliza un amplio lenguaje integrado que cuenta con elementos para definir esquemas conceptuales, definir vistas, manipular datos y definir su almacenamiento. Un ejemplo de esto es el SQL que representa una combinación de todo esto. Son dos los principales tipos de DML, los de alto nivel o no por procedimientos que se pueden utilizar de manera independiente para especificar las operaciones complejas de base de datos de forma concisa. En muchos SGBD es posible introducir interactivamente instrucciones de DML de alto nivel desde una terminal o bien incorporados en un lenguaje de programación de propósito general. En el segundo caso es preciso identificar los enunciados de DML dentro del programa para que el SGBD pueda procesarlos. Los DML de bajo nivel o por procedimientos deben estar incorporados en un lenguaje de programación de propósito general. Por lo regular, este tipo de DML obtiene registros individuales de la base de datos y los procesa por separado; por tanto, necesita utilizar elementos del lenguaje de programación, como la creación de ciclos, para obtener y procesar cada registro individual de un conjunto de registros. Por esta razón, los DML de bajo nivel se conocen también como DML de registro por registro (el dBASE era un ejemplo típico). Los DML de alto nivel, como SQL, pueden especificar y recuperar muchos registros con una sola instrucción de DML, y es por ello que se les llama DML de conjunto por conjunto u orientado a conjuntos (en esto se diferenciaba del anterior el FoxBASE). Las consultas en los DML de alto nivel suelen especificar que datos hay que obtener, y no como obtenerlos; por ello, tales lenguajes se denominan también declarativos.. 11.
(23) Capítulo 1 Siempre que las ordenes de un DML, sean de alto o de bajo nivel, se incorporen en un lenguaje de programación de propósito general, a ese lenguaje se le llamará lenguaje anfitrión, y al DML sublenguaje de datos. En los SGBD más recientes, como los orientados a objetos, el lenguaje anfitrión y el DML suelen formar un solo lenguaje integrado. Por otro lado, los DML de alto nivel empleados de manera interactiva e independiente se denominan lenguajes de consulta. En general, las órdenes tanto de obtención como de actualización de datos de un DML de alto nivel se pueden utilizar interactivamente, así que se consideran parte del lenguaje de consulta. Por lo regular, los usuarios finales esporádicos emplean un lenguaje de consulta de alto nivel para especificar sus solicitudes, en tanto que los programadores utilizan el DML en su forma incorporada. Para los usuarios simples y paramétricos casi siempre se incluyen interfaces amables con el usuario que permiten interactuar con la base de datos; estas también pueden aprovecharlas los usuarios esporádicos y otros que no deseen aprender los detalles de un lenguaje de consulta de alto nivel.. 1.2. Métodos de indexado El índice de una base de datos es una estructura de datos que mejora la velocidad de las operaciones, permitiendo un rápido acceso a los registros de una tabla. Al aumentar drásticamente la velocidad de acceso, se suelen usar sobre aquellos campos sobre los cuales se hagan frecuentes búsquedas. El índice tiene un funcionamiento similar al índice de un libro, guardando parejas de elementos: el elemento que se desea indexar y su posición en la base de datos. Para buscar un elemento que esté indexado, solo hay que buscar en el índice dicho elemento para, una vez encontrado, devolver el registro que se encuentre en la posición marcada por el índice. Los índices pueden ser creados usando una o más columnas, proporcionando la base tanto para las búsquedas rápidas al azar como de un ordenado acceso eficiente a registros. Los índices son construidos sobre árboles B, B+, B- o sobre una mezcla de ellos, funciones de cálculo u otros métodos. El espacio en disco para almacenar el índice e típicamente menor que el espacio de almacenamiento de la tabla (puesto que los índices generalmente contienen solamente los. 12.
(24) Capítulo 1 campos claves de acuerdo con los que la tabla será ordenada, y excluyen el resto de los detalles de la tabla), lo que da la posibilidad de almacenar en memoria los índices de tablas que no cabrían en ella. En una base de datos relacional un índice es una copia de parte de una tabla.(Buxton et al., 2009a) Algunas bases de datos amplían la potencia del indexado al permitir que los índices sean creados de funciones o expresiones. Otra opción a veces soportada es el uso de índices filtrados, donde las entradas del índice son creadas solamente para los registros que satisfagan una cierta expresión condicional. Un aspecto adicional de flexibilidad es permitir la indexación en funciones definidas por el usuario, también como expresiones formadas de un surtido de funciones incorporadas.(Buxton et al., 2009b) Las estructuras de acceso de índice suelen definirse con base en un solo campo del archivo, el llamado campo de indexación. Por lo regular, el índice contiene todos los valores del campo de indexación junto con una lista de apuntadores a todos los bloques que contienen registros con ese valor en ese campo. Los valores del índice están ordenados para que podamos efectuar búsquedas binarias en el índice. Como el archivo de índices es mucho más pequeño que el de datos, una búsqueda binaria en un índice es bastante eficiente.(Buxton et al., 2009c) Hay varios tipos de índices ordenados:(Sumathi and Esakkirajan, 2007a) 9 Índices primarios: es un archivo ordenado cuyos registros son de longitud fija y contienen dos campos. El primero de estos campos tiene el mismo tipo de datos que el campo clave de ordenamiento del archivo de datos, y el segundo campo es un apuntador a un bloque de disco: una dirección de bloque. El campo clave de ordenamiento se denomina clave primaria del archivo de datos. Hay una entrada de índice (o registro de índice) en el archivo de índice por cada bloque del archivo de datos. Para cada entrada del índice los valores de sus campos son el campo de clave primaria del primer registro de un bloque y un apuntador a ese bloque. 9 Índices de agrupamiento: si los registros de un archivo están ordenados físicamente según un campo no clave que no tiene un valor distinto para cada registro, dicho campo se denomina campo de agrupamiento. Podemos crear este tipo de índice para acelerar la obtención de registros que tienen el mismo valor en. 13.
(25) Capítulo 1 el campo de agrupamiento. Este tipo de índice también es un archivo ordenado con dos campos, el primero es del mismo tipo que el campo de agrupamiento del archivo de datos, y el segundo un apuntador a un bloque. Hay una entrada en el índice de agrupamiento por cada valor distinto del campo de agrupamiento, y contiene el valor y un apuntador al primer bloque del archivo de datos que tiene un registro con ese valor en el campo de agrupamiento. 9 Índices secundarios: también son archivos ordenados con dos campos. El primero es del mismo tipo que algún campo no de ordenamiento del archivo de datos, y se denomina campo de indexación del mismo. El segundo campo es un apuntador a un bloque o bien un apuntador a un registro. Puede haber muchos índices secundarios para el mismo archivo. Los índices secundarios según campos claves son índices densos: contienen una entrada por cada registro del archivo. El índice de múltiples niveles considera al archivo de índice, al que se le llama primer nivel o nivel base del índice de múltiples niveles, como un archivo ordenado con un valor distinto para cada entrada de índice. Por tanto, podemos crear un índice primario para este primer nivel; este índice del primer nivel es ahora el segundo nivel del índice de múltiples niveles. Como el segundo nivel es un índice primario podemos usar anclas de bloque para que el segundo nivel tenga una entrada por cada bloque del primer nivel. Esto proceso se repite una y otra vez. Este esquema es útil para cualquier tipo de índice, sea primario, de agrupamiento o secundario, en tanto el índice del primer nivel tenga valores distintos para las entradas de índice y sean de longitud fija.(Ramakrishnan and Gehrke, 2007a) Un árbol de búsqueda es un tipo especial de árbol que sirve para guiar la búsqueda de un registro, dado el valor de uno de sus campos. Los índices de múltiples niveles pueden considerarse como variaciones de los árboles de búsqueda. Cada nodo del índice de múltiples niveles puede tener hasta fo apuntadores y fo valores de clave, donde fo es el abanico (fan-out) del índice. Los valores del campo de índice de cada nodo nos guían al siguiente nodo, hasta llegar al bloque del archivo de datos que contiene los registros deseados. Al seguir un apuntador, restringimos nuestra búsqueda en cada nivel a un subárbol del árbol de búsqueda e ignoramos todos los nodos que no estén en dicho subárbol.(Ramakrishnan and Gehrke, 2007a). 14.
(26) Capítulo 1 El árbol B es un árbol de búsqueda con algunas restricciones adicionales. Dichas restricciones garantizan que el árbol siempre estará equilibrado y que el espacio desperdiciado por la eliminación, si lo hay, nunca será excesivo. Los algoritmos para insertar y eliminar aumentan en complejidad para mantener estas restricciones. No obstante la mayor parte de las inserciones y eliminaciones son procesos simples; se complican solo en circunstancias especiales: a saber, cuando intentamos hacer una inserción en un nodo que ya está lleno o una eliminación en un nodo que después quedará ocupado hasta menos de la mitad.(Ramakrishnan and Gehrke, 2007a) A veces se emplean árboles B como organizaciones primarias de los archivos, en cuyo caso se almacenan registros completos en los nodos del árbol B, no sólo las entradas <clave de búsqueda, apuntador a registro>. Esto funciona correctamente si el archivo tiene un número relativamente pequeño de registros y los registros son pequeños. En caso contrario, el abanico y el número de niveles se incrementan tanto que impiden un acceso eficiente.(Ramakrishnan and Gehrke, 2007a) En su mayoría, las implementaciones de índices dinámicos de múltiples niveles emplean una variación de la estructura de datos del árbol B: el árbol B+. En el árbol B todos los valores del campo de búsqueda aparecen una vez en algún nivel del árbol, junto con un apuntador de datos. En un árbol B+ los apuntadores de datos se almacenan sólo en los nodos hojas del árbol, por lo cual la estructura de los nodos hoja difiere de la de los nodos internos. Los primeros tienen una entrada por cada valor del árbol de búsqueda, junto con un apuntador de datos al registro (o al bloque que contiene el registro), si el campo de búsqueda es un campo clave. Si no lo es, el apuntador apunta a un bloque que contiene apuntadores a los registros del archivo de datos, creándose así un nivel de in dirección adicional.(Ramakrishnan and Gehrke, 2007a) Los nodos hoja del árbol B+ suelen estar enlazados para ofrecer un acceso ordenado a los registros según el campo de búsqueda. Los nodos internos del árbol B+ corresponden a los demás niveles del índice. Algunos valores del campo de búsqueda de los nodos hoja se repiten en los nodos internos del árbol B+ con el fin de guiar la búsqueda.(Sumathi and Esakkirajan, 2007b). 15.
(27) Capítulo 1 En el caso de un árbol B+ construido según un campo clave, los apuntadores de los nodos internos son apuntadores de árbol a bloques que son nodos del árbol, en tanto que los apuntadores de los nodos hoja son apuntadores de datos a los registros o bloques del archivo de datos, con la excepción del apuntador del siguiente nodo hoja. Si partimos del nodo hoja del extremo izquierdo, podremos recorrer todos los nodos hoja como si fueran una lista enlazada mediante estos apuntadores. Esto hace posible el acceso ordenado a los registros de datos según el campo de indexación.(Sumathi and Esakkirajan, 2007c) Como las entradas en los nodos internos de un árbol B+ contienen valores de búsqueda y apuntadores de árbol, pero no apuntadores de datos, es posible empaquetar más entradas en un nodo interno de este tipo de árbol que en un nodo interno de un árbol B. Esto puede reducir el número de niveles del árbol B+, mejorándose así el tiempo de búsqueda.(Ramakrishnan and Gehrke, 2007a) Todos los índices antes mencionados incluyen un apuntador físico que especifica la dirección del registro físico en el disco en forma de un número de bloque y un desplazamiento. A esto se le conoce como índice físico y tiene la desventaja de que el apuntador debe modificarse si el registro se pasa a otro lugar del disco. Para solucionar este problema podemos usar una estructura llamada índice lógico que mantiene los dos campos. Cada entrada tiene un valor para el campo de indexación secundaria apareado con el valor del campo empleado para la organización primaria del archivo. Si un programa busca el valor del campo de indexación en el índice secundario, podrá localizar el valor correspondiente del campo empleado para la organización primaria del archivo y utilizarlo para tener acceso al registro valiéndose de dicha organización. Los índices lógicos se utilizan cuando se espera que las direcciones físicas de los registros cambien con frecuencia. El costo es la búsqueda adicional que se basa en la organización primaria del archivo.(Sumathi and Esakkirajan, 2007c) En muchos sistemas el índice no es parte integral del archivo de datos, sino que puede crearse y desecharse dinámicamente; es por ello que se acostumbra a llamarlo estructura de acceso. Siempre que esperemos requerir acceso frecuente a un archivo según una condición de búsqueda que implique un campo en particular, se puede solicitar al SGBD la creación de un índice basado en ese campo. Por lo general se crea un índice secundario con el fin de. 16.
(28) Capítulo 1 evitar la ordenación física de los registros del archivo de datos.(Ramakrishnan and Gehrke, 2007a) A menudo se utilizan los índices para imponer una restricción de clave al campo de índice de un archivo. Cuando se busca en el índice el lugar donde se insertará un registro nuevo resulta sencillo verificar al mismo tiempo si algún otro registro del archivo tiene el mismo valor para el campo de indexación. Si es así, la inserción podría rechazarse.. 1.3. Control de concurrencia Existen varias técnicas de control de concurrencia que sirven para garantizar la no interferencia o el aislamiento de transacciones que se ejecutan de manera concurrente. Casi todas ellas aseguran que los planes sean establecidos en series, empleando protocolos o conjuntos de reglas que garantizan esta posibilidad. Una de las principales técnicas para controlar la ejecución concurrente de transacciones se basa en el concepto de bloquear elementos de información. Un candado es una variable asociada a un elemento de información de la base de datos y describe el estado de ese elemento respecto a las posibles operaciones que se pueden aplicar a él. En general, hay un candado por cada elemento de información en la base de datos. Usamos los candados como una forma de sincronizar el acceso a los elementos de la base de datos por parte de transacciones concurrentes.(Connolly and Begg, 2005a) Los candados pueden ser: 9 Candados binarios: pueden tener dos estados o valores, que pueden ser bloqueado o desbloqueado (1 ó 0). A cada elemento de la base de datos se asocia un candado distinto. Si el valor del candado sobre un cierto elemento es 1, ninguna operación de base de datos que solicite el elemento podrá tener acceso a él. Si el valor del candado sobre el elemento es 0, se podrá tener acceso a él cuando se solicite. Cuando se usa bloqueo binario se debe incluir en las transacciones dos operaciones, bloquear-elemento y desbloquear-elemento. 9 Candados compartidos y exclusivos: el esquema de bloqueo binario es demasiado estricto en lo general, porque como máximo una transacción puede poseer un candado sobre un elemento dado. Debemos permitir que varias transacciones tengan acceso al 17.
(29) Capítulo 1 mismo elemento si lo hacen exclusivamente para leerlo. Sin embargo, si una transacción va a escribir un elemento deberá poseer acceso exclusivo a él. Con este fin, podemos usar un tipo de candado diferente llamado candado múltiple. En este hay tres operaciones de bloqueo: bloquear-lectura, bloquear-escritura y desbloquear. Además, un candado asociado a un elemento tiene tres posibles estados: bloqueado para leer, bloqueado para escribir o desbloqueado. Un elemento bloqueado para leer posee un candado compartido porque otras transacciones no pueden leerlo; en cambio uno bloqueado para escribir posee un candado exclusivo, porque una sola transacción posee de manera exclusiva el candado del elemento. El orden de las transacciones en el plan en serie equivalente se basa en el orden en que las transacciones en ejecución bloquean los elementos que requieren. Si una transacción necesita un elemento que ya está bloqueado, puede verse obligada a esperar hasta que se libere dicho elemento. Un enfoque distinto que garantiza la ejecución en serie implica el uso de marcas de tiempo de las transacciones para ordenar la ejecución de transacciones según un plan en serie equivalente.(Connolly and Begg, 2005b) Una marca de tiempo es un identificador único que el SGBD crea para identificar una transacción. Por lo regular, los valores de marca de tiempo se asignan en el orden en que las transacciones se introducen en el sistema, por lo que una marca de tiempo puede considerarse como el tiempo de inicio de una transacción. Las técnicas para el control de concurrencia basadas en marcas de tiempo no usan bloqueos.(Connolly and Begg, 2005b) Las marcas de tiempo se pueden generar de diversas maneras. Una posibilidad consiste en usar un contador que se incrementa cada vez que su valor se asigna a una transacción. Las marcas de tiempo de las transacciones están enumeradas del 1 en adelante. Un contador de computador tiene un valor máximo finito por lo que el sistema deberá restablecer el contador a 0 cuando haya un lapso corto en el que ninguna transacción se esté ejecutando. Otra forma de implementar las marcas de tiempo consiste en emplear el valor actual del reloj del sistema y asegurar que no se generen dos valores de marca de tiempo antes que el reloj cambie.(Connolly and Begg, 2005b) Otros protocolos para controlar la concurrencia conservan los valores antiguos de un elemento de información cuando este se actualiza. Estos se conocen como técnicas de. 18.
(30) Capítulo 1 control de concurrencia de multiversión, porque se mantienen varias versiones del elemento. Cuando una transacción requiere acceso a un elemento, se elige un aversión apropiada para mantener la ejecución en serie del plan que se está llevando a cabo, si es posible. La idea consiste en que algunas operaciones de lectura que serían rechazadas si se usaran otras técnicas, se pueden aceptar leyendo una versión anterior del elemento a fin de mantener la ejecución en serie. Cuando una transacción escribe un elemento, escribe una nueva versión y se conserva la versión anterior de dicho elemento. En general, los algoritmos para el control de concurrencia de multiversión utilizan el concepto de ejecución en serie por vistas, no el de ejecución en serie por conflictos.(Elmarsi and Navathe, 2007a) Una desventaja obvia de esta técnica es que se requiere más almacenamiento para mantener múltiples versiones de los elementos de la base de datos. Sin embargo, es posible que de todos modos sea necesario mantener versiones anteriores; por ejemplo con fines de recuperación. Por añadidura, algunas aplicaciones de bases de datos requieren la conservación de versiones anteriores para mantener una historia de cómo evolucionan los valores de los elementos de información. El caso extremo es una base de datos temporal, que sigue la pista a todos los cambios y los momentos en que ocurrieron. En tales casos, no hay gasto adicional por las técnicas de multiversión, ya que de todos modos se mantienen versiones anteriores.(Elmarsi and Navathe, 2007a) En todas las técnicas anteriormente expuestas se realiza una cierta verificación antes de que pueda ejecutarse una operación de base da datos. Esta verificación representa un gasto extra durante la ejecución de las transacciones, y su efecto es hacerlas más lentas. En las técnicas de control de concurrencia optimista, también llamadas técnicas de validación o de certificación, no se efectúa verificación alguna durante la ejecución de las transacciones. Mientras se ejecuta la transacción, todas las actualizaciones se aplican a copias locales de los elementos, que se mantienen para la transacción. Al final de la ejecución, una fase de validación comprueba si cualquiera de las actualizaciones viola la serie. El sistema debe mantener cierta información que necesita para la fase de validación. Si no se viola la serie, la transacción se confirma y la base de datos se actualiza a partir de copias. locales;. en. caso. contrario,. la. transacción. se. aborta. y. se. reinicia. posteriormente.(Elmarsi and Navathe, 2007b). 19.
(31) Capítulo 1 Este protocolo de control de concurrencia comprende tres fases:(Elmarsi and Navathe, 2007c) 1.. Fase de lectura: una transacción puede leer valores de elementos de información a partir de la base de datos. Sin embargo, las actualizaciones solo se aplican a copias locales de los elementos, las que se mantienen en el espacio de trabajo de transacción.. 2.. Fase de validación: se efectúa una verificación para asegurarse de que no se violará la serie si las actualizaciones de la transacción se aplican a la base de datos.. 3.. Fase de escritura: si la fase de validación se realiza con éxito, las actualizaciones de la transacción se aplican a la base de datos; si no, las actualizaciones se desechan y la transacción se reinicia.. El control de concurrencia optimista se basa en la idea de efectuar todas las actualizaciones de una vez; así pues, la ejecución de las transacciones se efectúa con un mínimo de gasto extra hasta llegar a la fase de validación. Si hay poca interferencia entre las transacciones, casi todas se validarán sin dificultad. Sin embargo, si hay mucha interferencia, se desecharán los resultados.(Elmarsi and Navathe, 2007b). 1.4. Control de la redundancia Sobre este tema no se profundizará en los capítulos 2 y 3 para más información ver el Anexo 1.. 1.5. Restricciones de los accesos no autorizados Sobre este tema no se profundizará en los capítulos 2 y 3 para más información ver el Anexo 2.. 1.6. Almacenamiento persistente de objetos y estructuras de datos de programas Sobre este tema no se profundizará en los capítulos 2 y 3 para más información ver el Anexo 3.. 20.
(32) Capítulo 1. 1.7. Inferencias en la base de datos mediante reglas de reducción Sobre este tema no se profundizará en los capítulos 2 y 3 para más información ver el Anexo 4.. 1.8. Suministro de múltiples interfaces con los usuarios En vista de que muchos tipos de usuarios con diversos niveles de conocimiento técnicos realizan operaciones en las bases de datos, el SGBD debe ofrecer diferentes interfaces. Entre estas podemos mencionar los lenguajes de consulta para usuarios esporádicos, las interfaces de lenguaje de programación para programadores de aplicaciones, las formas y códigos de órdenes para los usuarios paramétricos y las interfaces controladas por menús y en lenguaje natural para los usuarios autónomos. Entre las interfaces con el usuario que pueden ofrecer los SGBD están las siguientes: 9. Interfaces basadas en menús: estas presentan al usuario listas de opciones, llamadas menús, que lo guían para formular solicitudes. Los menús hacen innecesario memorizar las órdenes y la sintaxis específica de un lenguaje de consulta, pues permiten construir la solicitud paso por paso eligiendo las opciones de los menús que el sistema presenta. Los menús desplegables son una técnica cada vez más utilizada en las interfaces del usuario basadas en ventanas, y a menudo se utilizan en las interfaces para hojear, que permiten al usuario examinar el contenido de una base de datos en una forma no estructurada.. 9. Interfaces gráficas: las interfaces graficas suelen presentar al usuario los esquemas en forma de diagrama, y este puede entonces especificar una consulta manipulando el diagrama. En muchos casos, estas interfaces se combinan con menús. Casi todas las interfaces graficas se valen de un dispositivo apuntador para escoger ciertas partes del diagrama de esquema que se exhibe.. 9. Interfaces basadas en formas: presentan una forma o formulario a cada usuario. Este puede entonces llenar todos los espacios de la forma para insertar datos nuevos, o bien llenar solo ciertos espacios, en este caso el SGBD obtendrá los registros que coincidan con los datos especificados. Las formas suelen diseñarse y programarse para los usuarios simples como interfaces de transacciones programadas. Muchos. 21.
(33) Capítulo 1 SGBD cuentan con lenguajes especiales, los lenguajes de especificación de formas, con los que los programadores pueden especificar dichas formas. Algunos sistemas cuentan con utilerías que definen formas al permitir que el usuario construya interactivamente una forma de muestra en la pantalla. 9. Interfaces de lenguaje natural: estas interfaces aceptan solicitudes escritas en inglés o en algún otro idioma e intentan entenderlas. Las interfaces de lenguaje natural suelen tener su propio esquema, similar al esquema conceptual de la base de datos. La interfaz consulta las palabras en su esquema, y en un conjunto de palabras estándar, para interpretar la solicitud. Si la interpretación tiene éxito, la interfaz genera una consulta de alto nivel que corresponde a la solicitud en lenguaje natural y la envía al SGBD para su procesamiento; en caso contrario, se inicia un diálogo con el usuario para esclarecer la solicitud.. 9. Interfaces para usuarios paramétricos: los usuarios paramétricos a menudo tienen un conjunto pequeño de operaciones que deben realizar repetidamente. Los analistas de sistemas y los programadores diseñan e implementan una interfaz especial para una clase conocida de usuarios simples. Casi siempre se incluye un conjunto reducido de órdenes abreviadas, con el fin de reducir al mínimo el número de digitaciones requeridas para cada solicitud.. 9. Interfaces para el DBA: generalmente los sistemas de base de datos contienen órdenes privilegiadas que solo el personal del DBA puede utilizar. Entre ellas están las órdenes para crear cuentas, establecer los parámetros del sistema, otorgar autorizaciones a las cuentas, modificar los esquemas y reorganizar la estructura de almacenamiento de una base de datos.. Para ver como se comporta este aspecto en los diferentes gestores de bases de datos, lo haremos a través del estudio de los informes y formularios dentro del lenguaje de manipulación de datos.. 1.9. Cumplimiento de las restricciones de integridad Sobre este tema no se profundizará en los capítulos 2 y 3 para más información ver el Anexo 5.. 22.
(34) Capítulo 1. 1.10. Respaldo y Recuperación Todo SGBD debe contar con recursos para recuperarse de fallos de hardware o de software. Para ello está el subsistema de respaldo y recuperación del SGBD. Por ejemplo, si el sistema falla mientras se está ejecutando un completo programa de actualización, el subsistema de recuperación se encargará de asegurarse de que la base de datos se restaure al estado en que estaba antes que comenzara la ejecución del programa. Como alternativa el subsistema de recuperación puede asegurarse de que el programa reanude su ejecución en el punto en que fue interrumpido, de modo que su efecto completo se registre en la base de datos. A menudo las técnicas de recuperación de información están imbricadas con los mecanismos de control de concurrencia. Algunas técnicas funcionan mejor con métodos específicos de control de concurrencia. Siempre que se introduce una transacción a un SGBD para ejecutarla, el sistema tiene que asegurarse de que todas las operaciones de la transacción se completen con éxito y su efecto quede asentado permanentemente en la base de datos o; la transacción no tenga efecto alguno sobre la base de datos ni sobre cualquier otra transacción. El SGBD no debe permitir que se apliquen a la base de datos algunas operaciones de una transacción pero no otras de la misma transacción. Esto puede suceder si una transacción falla después de ejecutar algunas de sus operaciones, pero antes de ejecutarlas todas.(Date, 2001a) Hay varias razones por las que una transacción puede fallar mientras se está ejecutando: 1. Un fallo de la computadora (caída): un error de hardware o software ocurre en el sistema de cómputo durante la ejecución de la transacción. Si el equipo falla, es posible que se pierda el contenido de la memoria interna de la computadora. 2. Un error de la transacción o del sistema: alguna operación de una transacción puede hacer que ésta falle, por ejemplo, un desbordamiento de enteros o una división entre 0. También puede haber un fallo de transacción debido a valores erróneos de los parámetros o a un error lógico de programación. Por añadidura, puede suceder que el usuario interrumpa a propósito la transacción durante su ejecución; por ejemplo, al emitir ctrl.+c en un entorno UNIX.. 23.
(35) Capítulo 1 3. Errores locales o condiciones de excepción detectadas por la transacción: durante la ejecución de transacciones pueden presentarse ciertas condiciones que requieran la cancelación de la transacción. Por ejemplo, es posible que no se encuentren los datos para la transacción. Una condición, como un saldo insuficiente en una cuenta en una base de datos bancaria, puede hacer que se cancele una transacción, como un retiro de fondos de esa cuenta. Esto puede hacerse con una instrucción ABORTAR programada en la misma transacción. 4. Imposición del control de concurrencia: el método de control de concurrencia puede decidir que se aborte la transacción, para reiniciarla después, porque viola la ejecución en serie o porque varias transacciones se encuentran en un estado de bloqueo mortal. 5. Fallo del disco: algunos bloques de disco pueden perder sus datos por un mal funcionamiento de lectura o escritura o por un aterrizaje de una cabeza de lectura/escritura. Esto puede suceder durante una operación de lectura o de escritura de la transacción. 6. Problemas y catástrofes físicos: esto se refiere a una interminable lista de problemas que incluyen interrupción del suministro de energía, fallo del acondicionamiento de aire, incendio, robo, sabotaje, sobre-escritura en discos o cintas por error, y que el operador haya montado la cinta equivocada, etc. Los cuatro primeros fallos son más comunes que los dos restantes. Siempre que ocurre un fallo de los cuatro primeros, el sistema debe mantener suficiente información para recuperarse del fallo. Los dos últimos no ocurren con tanta frecuencia; si se dan, la recuperación es una tarea bastante complicada. Existen técnicas que pueden servir para recuperarse de estos fallos en las transacciones. No analizaremos las técnicas de cómo un sistema especifico implanta la recuperación. Nuestra intención es describir conceptualmente varias estrategias distintas para que ocurra esta.(Date, 2001a) La recuperación de fallos en las transacciones casi siempre equivale a una restauración de la base de datos a algún estado anterior de modo que sea posible reconstruir un estado correcto a partir del estado anterior. Para lograr esto el sistema debe conservar, fuera de la. 24.
(36) Capítulo 1 base de datos, información sobre las modificaciones hechas a los elementos de información al ejecutarse las transacciones. Por lo general, esta información se guarda en la bitácora del sistema. Una estrategia de recuperación podría ser la siguiente:(Elmarsi and Navathe, 2007d) 1. Si hay daños extensos en una porción considerable de la base de datos por algún fallo catastrófico, como un aterrizaje de las cabezas del disco, el método de recuperación restaurará una copia anterior de la base de datos que se habría vaciado en almacenamiento secundario y reconstruiría un estado más actualizado, volviendo a aplicar o rehaciendo las operaciones de las transacciones confirmadas asentadas en la bitácora hasta el momento del fallo. 2. Cuando la base de datos no presenta daños físicos pero se ha vuelto inconsistente debido a fallos no catastróficos de los primeros cuatro tipos antes mencionados, la estrategia consiste en invertir los cambios que provocaron la inconsistencia, deshaciendo algunas operaciones a fin de restaurar un estado consistente de la base de datos. En este caso no necesitamos una copia completa de la base de datos, ya que durante la recuperación solo se consultan las entradas asentadas en la bitácora del sistema. Se pueden distinguir dos técnicas para recuperarse de fallos no catastróficos en las transacciones. Las técnicas de actualización diferida no actualizan en realidad la base de datos sino hasta después de que una transacción llega a su punto de confirmación; en ese momento es que se graban en la base de datos. Antes de ser confirmadas, todas las actualizaciones se asientan en el espacio de trabajo local de la transacción. Durante la confirmación, las actualizaciones se graban primero definitivamente en la bitácora y luego se escriben en la base de datos. Si una transacción falla antes de llegar a su punto de confirmación, no habrá modificado en absoluto la base de datos, por lo que no se necesita DESHACER. Puede ser necesario REHACER, a partir de la bitácora, el efecto de las operaciones de una transacción confirmada, ya que es posible que su efecto no se haya registrado todavía en la base de datos. Por esto la actualización diferida es conocida también como algoritmo de NO DESHACER/REHACER.(Elmarsi and Navathe, 2007d) Se puede expresar un protocolo de actualización diferida como el siguiente:. 25.
(37) Capítulo 1 1.. Una transacción no puede modificar la base de datos antes de llegar a su punto de confirmación.. 2.. Una transacción no llega a su punto de confirmación antes de asentar todas sus operaciones de actualización en la bitácora y forzar la escritura de la bitácora en el disco.. En las técnicas de actualización inmediata, es posible que algunas operaciones de una transacción actualicen la base de datos antes de que la transacción llegue a su punto de confirmación. Sin embargo, estas operaciones casi siempre se asientan en la bitácora en disco mediante escritura forzada antes de aplicarse a la base de datos, lo que hace posible la recuperación. Si una transacción falla después de asentar algunos cambios en la base de datos pero antes de llegar al punto de confirmación, será preciso anular el efecto de sus operaciones sobre la base de datos; esto es, la transacción deberá revertirse. En este caso es preciso DESHACER y REHACER durante la recuperación, y es por ello que se denomina algoritmo de DESHACER/REHACER. Existe una variación de este algoritmo en la que todas las actualizaciones se asientan en la base de datos antes de que la transacción se confirme por lo que solo requiere la operación DESHACER, por lo cual se le conoce a ésta variación como algoritmo de DESHACER/NO REHACER.(Elmarsi and Navathe, 2007d) El proceso de recuperación está a menudo íntimamente ligado con las funciones del sistema operativo, en particular con el almacenamiento intermedio y en memoria caché de páginas del disco en la memoria principal. Por lo regular, una o más páginas del disco que contienen el elemento de información que ha de actualizarse se colocan en un almacenamiento intermedio (caché) en la memoria principal, donde se actualizan antes de escribirse otra vez en el disco. Este almacenamiento es tradicionalmente una función del sistema operativo, pero debido a su importancia para que los procedimientos de recuperación sean eficientes, puede ser que esto lo maneje el SGBD llamando a rutinas de bajo nivel del sistema operativo. Por esto para fines de recuperación conviene suponer que cada elemento de información corresponde a una página de disco.(Sumathi and Esakkirajan, 2007d) Por lo general, un grupo de buffer dentro de la memoria, llamados caché del SGBD, está bajo el control del SGBD y sirve para almacenar elementos de la base de datos. Se utiliza. 26.
(38) Capítulo 1 un directorio del caché para seguir la pista a los elementos que están en los buffer. Este directorio puede ser una tabla de entradas <nombre del elemento, ubicación del buffer>. Cuando el SGBD necesita hacer algo con un elemento, primero examina el directorio para determinar si el elemento está en el caché. Si no es así, será preciso localizarlo en el disco y copiar las páginas de disco apropiadas en el caché. Puede ser necesario desalojar algunos de los buffer de caché para disponer de espacio para el nuevo elemento. Se puede usar alguna estrategia de reemplazo de paginas del sistema operativo, como el menos usado recientemente (LRU: Least Recently Used) o el primero que entra primero que sale (FIFO: First In, First Out) para seleccionar el almacenamiento intermedio que se desalojará.(Sumathi and Esakkirajan, 2007d) Cada elemento en el caché tiene asignado un bit de modificación que se puede incluir en la entrada del directorio y que indica si el elemento ha sido modificado o no (0, cuando se lee inicialmente y se coloca en almacenamiento intermedio, y 1, cuando se modifica dicho elemento). Cuando se desaloja un elemento, se escribirá en el disco solo si su bit de modificación es 1.(Sumathi and Esakkirajan, 2007d) Son dos las principales estrategias que se utilizan para desalojar hacia el disco un elemento de información modificado. La primera es denominada actualización en el lugar, escribe el elemento en la misma ubicación en el disco, sobrescribiendo así el valor anterior del elemento. Con ello, se mantiene una copia de cada elemento en el disco. La otra estrategia se denomina creación de sombras y escribe el nuevo elemento en un lugar diferente del disco, lo que hace posible mantener múltiples copias de un elemento de información. En general, el valor antiguo del elemento antes de la actualización se denomina BFIM (Before Image) y el nuevo valor después de la actualización se denomina AFIM (After Image). Con la creación de sombras la BFIM y la AFIM se conservan en disco; por tanto no es realmente necesario mantener una bitácora para la recuperación.(Ramakrishnan and Gehrke, 2007b) Cuando se utiliza la actualización en el lugar es necesario utilizar una bitácora para la recuperación. En este caso, el mecanismo de recuperación debe cuidar que la BFIM del elemento de información se asiente en la entrada de la bitácora apropiada, y que dicha. 27.
Figure



+7



Documento similar