Análisis de trayectorias vehiculares GPS para evaluar su calidad de agrupamiento utilizando algoritmos clustering de minería de datos
149
0
0
Texto completo
(2) REPOSITORIO NACIONAL EN CIENCIA Y TECNOLOGÍA FICHA DE REGISTRO DE TESIS TÍTULO: “Análisis de trayectorias vehiculares GPS para evaluar su calidad de agrupamiento utilizando algoritmos clustering de Minería de datos” AUTOR:. REVISOR:. Vera LLaque Yajaira Jenniffer INSTITUCIÓN:. Ing. Cesar Espin Riofrio, MSc. FACULTAD:. Facultad de Ciencias Matemáticas y Físicas Universidad de Guayaquil Carrera: Ingeniería en Sistemas Computacional FECHA DE PUBLICACIÓN:. No. DE PÁGINAS:. 149. ÁREAS TEMÁTICAS: BASE DE DATOS & BIG DATA PALABRAS CLAVES /KEYWORDS:. Métrica, silhouette, k-means, DBscan, clustering, GPS, trayectorias.. RESUMEN/ABSTRACT: El gran volumen de datos espaciales generados por diversos dispositivos: Smartphone, GPS y sensores etc. engloban patrones atractivos en datos, convirtiéndose en un tema interesante para investigadores motivados a encontrar la mejor técnica clustering al tratar datos de trayectoria GPS, ya que en existencia se observan inconvenientes en las grandes ciudades como el tráfico vehicular. Por eso, se obtienen Bases de datos científicas que contienen recorridos vehiculares en diferentes lugares: California, China y Beijing. En esta investigación se evalúa la calidad de agrupamiento de los algoritmos identificados: Kmeans y DBscan. Aquellos utilizan datos de la tabla California para determinar, bajo ciertas condiciones, cuál de los dos algoritmos obtiene mejor agrupación de clúster. En la implementación se hicieron cambios para que el algoritmo de Kmeans consiguiera analizar los datos de trayectoria del GPS usando la medición de similitud de Hausdorff. Para Medir la calidad de agrupamiento de los algoritmos, se utiliza la métrica de Silhouette. Como resultado, el algoritmo DBscan es el de mejor calidad de agrupamiento, sin embargo, el algoritmo Kmeans obtiene resultados que están dentro de lo admitido por la métrica y facilita la identificación de las rutas de congestión. ADJUNTO PDF: SI NO X CONTACTO CON AUTOR: Vera LLaque Yajaira Jenniffer CONTACTO CON LA NSTITUCIÓN:. Teléfono: E-mail: 0960664710 [email protected] Nombre: Ab. Juan Chávez Atocha, Esp. Teléfono: 2307729 E-mail: [email protected]. II.
(3) APROBACIÓN DEL TUTOR. En mi calidad de Tutor del trabajo de investigación, “ANÁLISIS DE TRAYECTORIAS VEHICULARES GPS PARA EVALUAR SU CALIDAD DE AGRUPAMIENTO MINERÍA. DE. UTILIZANDO DATOS”. ALGORITMOS elaborado. CLUSTERING por. el. DE Srta.. YAJAIRA JENNIFFER VERA LLAQUE, Alumno no titulado de la Carrera de Ingeniería. en. Sistemas. Computacionales,. Facultad. de. Ciencias. Matemáticas y Físicas de la Universidad de Guayaquil, previo a la obtención del Título de Ingeniero en Sistemas Computacionales, me permito declarar que luego de haber orientado, estudiado y revisado, la Apruebo en todas sus partes.. Atentamente. ______________________________ Tutor: Lsi. Veloz Rodríguez Angel, MSc.. III.
(4) DEDICATORIA. Le dedico este proyecto de tesis a mis padres por ser un soporte fundamental a lo largo de este camino y a mis tutores por la guía ofrecida de su parte durante este proceso.. Yajaira. IV.
(5) AGRADECIMIENTO. Le agradezco a Dios por acompañarme y haberme. permitido. llegar. hasta. esta. instancia, por ser mi fortaleza para logar unas de mis metas propuesta, a mis padres por el apoyo constante y a mis compañeros de clase que han permanecido a mi lado aportando grandes conocimientos en el transcurso de estos años. Gracias por ser parte de esta meta cumplida.. V.
(6) TRIBUNAL PROYECTO DE TITULACIÓN. Ing. Eduardo Santos Baquerizo, MSc. DECANO DE LA FACULTAD CIENCIAS MATEMÁTICAS Y FÍSICAS. Lsi. Veloz Rodríguez Ángel, MSc. PROFESOR TUTOR DEL PROYECTO DE TITULACIÓN. Ing. Abel Alarcón Salvatierra, Mgs. DIRECTOR DE LA CARRERA DE INGENIERIA EN SISTEMAS COMPUTACIONALES. Ing. Espín Riofrio Cesar, MSc. PROFESOR REVISOR DEL PROYECTO DE TITULACIÓN. Ab. Juan Chávez SECRETARIO. VI.
(7) DECLARACIÓN EXPRESA. “La responsabilidad del contenido de este Proyecto. de. Titulación,. me. corresponden. exclusivamente; y el patrimonio intelectual de la misma a la UNIVERSIDAD DE GUAYAQUIL”. Yajaira Jenniffer Vera LLaque. AUTOR DEL PROYECTO DE TITULACIÓN. VII.
(8) UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS CARRERA DE INGENIERIA EN SISTEMAS COMPUTACIONALES. “ANÁLISIS DE TRAYECTORIAS VEHICULARES GPS PARA EVALUAR SU CALIDAD DE AGRUPAMIENTO UTILIZANDO ALGORITMOS CLUSTERING DE MINERÍA DE DATOS”. Proyecto de Titulación que se presenta como requisito para optar por el título de INGENIERO EN SISTEMAS COMPUTACIONALES. Autor: Yajaira Jenniffer Vera LLaque C.I. 0927011148 Tutor: Lsi. Ángel Veloz Rodríguez, MSc.. Guayaquil, Septiembre de 2018. VIII.
(9) CERTIFICADO DE ACEPTACIÓN DEL TUTOR. En mi calidad de Tutor del proyecto de titulación, nombrado por el Consejo Directivo de la Facultad de Ciencias Matemáticas y Físicas de la Universidad de Guayaquil.. CERTIFICO: Que he analizado el Proyecto de Titulación presentado por el/la estudiante YAJAIRA JENNIFFER VERA LLAQUE, como requisito previo para optar por el título de Ingeniero en Sistemas Computacionales cuyo título es: “ANÁLISIS DE TRAYECTORIAS VEHICULARES GPS PARA EVALUAR SU CALIDAD DE AGRUPAMIENTO UTILIZANDO ALGORITMOS CLUSTERING DE MINERÍA DE DATOS”. Considero aprobado el trabajo en su totalidad.. Presentado por:. Vera LLaque Yajaira Jenniffer. C.I. 0927011148. Tutor: Lsi. Ángel Veloz Rodríguez, MSc.. Guayaquil, Septiembre de 2018. IX.
(10) UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS CARRERA DE INGENIERÍA EN NETWORKING Y TELECOMUNICACIONES AUTORIZACIÓN PARA PUBLICACIÓN DE PROYECTO DE TITULACIÓN EN FORMATO DIGITAL 1. Identificación del Proyecto de Titulación Nombre Alumno: Vera LLaque Yajaira Jennifer Dirección: Bastión popular Bloque 4 mz.700 sl.8 Teléfono: 0960664710. E-mail: [email protected]. Facultad: Ciencias Matemáticas y Físicas Carrera: Ingeniería en Sistemas Computacionales Título al que opta: Ingeniero en Sistemas Computacionales Profesor guía: LSI. Veloz Rodríguez Ángel, MSc.. Título del Proyecto de titulación: ANÁLISIS DE TRAYECTORIAS VEHICULARES GPS PARA EVALUAR SU CALIDAD DE AGRUPAMIENTO UTILIZANDO ALGORITMOS CLUSTERING DE MINERÍA DE DATOS. 2. Autorización de Publicación de Versión Electrónica del Proyecto de Titulación. Tema del Proyecto de Titulación: Algoritmo, K-Means, DBscan, Clustering, trayectorias GPS, Métricas Silhouette. A través de este medio autorizo a la Biblioteca de la Universidad de Guayaquil y a la Facultad de Ciencias Matemáticas y Físicas a publicar la versión electrónica de este Proyecto de titulación. Publicación electrónica: Inmediata X. Después de 1 año. Firma Alumno:. ________________________________ Vera LLaque Yajaira Jenniffer C.I. 0927011148. X.
(11) 1. Forma de envío: El texto del proyecto de titulación debe ser enviado en formato Word, como archivo .Doc. O .RTF y. Puf para PC. Las imágenes que la acompañen pueden ser: .gif, .jpg o .TIFF.. DVSROM. CDROM. X. XI.
(12) ÍNDICE GENERAL APROBACIÓN DEL TUTOR ................................................................................ III DEDICATORIA ...................................................................................................IV AGRADECIMIENTO ............................................................................................V CERTIFICADO DE ACEPTACIÓN DEL TUTOR.................................................IX ÍNDICE GENERAL ............................................................................................XII ABREVIATURA ............................................................................................... XVI SIMBOLOGÍA ................................................................................................. XVII ÍNDICE DE CUADROS .................................................................................. XVIII ÍNDICE DE GRÁFICOS ................................................................................... XIX RESUMEN....................................................................................................... XXI ABSTRACT .................................................................................................... XXII INTRODUCCIÓN ................................................................................................. 1 CAPÍTULO I......................................................................................................... 4 EL PROBLEMA ................................................................................................... 4 Planteamiento del problema ....................................................................................... 4 Ubicación del problema en un contexto................................................................ 4 Situación de conflicto nudos críticos ..................................................................... 6 Causas y consecuencia del problema .................................................................. 8 Delimitación del problema....................................................................................... 9 Formulación del problema ...................................................................................... 9 Evaluación del problema ....................................................................................... 10 Objetivos ...................................................................................................................... 12 Objetivos generales ............................................................................................... 12 Objetivos específicos ............................................................................................. 12 Alcances del problema .............................................................................................. 12 XII.
(13) Justificación e importancia ........................................................................................ 13 Metodología del proyecto .......................................................................................... 15 CAPÍTULO II...................................................................................................... 17 MARCO TEORICO ............................................................................................ 17 Antecedentes del capitulo ......................................................................................... 17 Fundamentación Teórica .......................................................................................... 19 Minería de datos ..................................................................................................... 19 . Taxonomía de técnicas de minería de datos ............................................. 21. Clustering................................................................................................................. 22 . Taxonomía de clustering ............................................................................... 23. Algoritmos clustering ............................................................................................. 26 . Algoritmos k-means ....................................................................................... 26. . Mejora de Kmeans con Hausdorff ............................................................... 29. . Algoritmos DBscan......................................................................................... 30. Métrica en algoritmos ............................................................................................ 32 . Coeficiente silhouette(sc) .............................................................................. 32. Test estadísticos para validar resultados silhouette ......................................... 34 . Shapiro-Wilk .................................................................................................... 34. . Mann-whitney .................................................................................................. 36. . Blox plot ........................................................................................................... 36. Herramientas de software ..................................................................................... 37 . Q GIS ............................................................................................................... 37. . PostgreSQL ..................................................................................................... 37. . Lenguaje R ...................................................................................................... 37. Fundamentación legal ............................................................................................... 39. XIII.
(14) Artículo de la loes ................................................................................................... 40 Principio de igualdad y principio de calidad ....................................................... 41 Principios ................................................................................................................. 42 Código Orgánico Integral Penal ........................................................................... 43 Hipótesis del proyecto ............................................................................................... 45 Hipótesis 1:.............................................................................................................. 45 Hipótesis 2:.............................................................................................................. 45 Variables de la investigación .................................................................................... 46 Variable dependiente: ............................................................................................ 46 Variable independiente:......................................................................................... 46 Definiciones conceptuales ........................................................................................ 47 CAPÍTULO III..................................................................................................... 50 METODOLOGÍA DE LA INVESTIGACIÓN ........................................................ 50 Diseño de la investigación ........................................................................................ 50 Modalidad de la Investigación .............................................................................. 50 Tipo de investigación ................................................................................................. 51 De acuerdo a la abstracción: ................................................................................ 51 De acuerdo al lugar ................................................................................................ 51 De acuerdo al alcance ........................................................................................... 51 Población y muestra .................................................................................................. 52 Población: ................................................................................................................ 52 Muestra: ................................................................................................................... 58 Operacionalización de variables .............................................................................. 61 Procesamiento y análisis de datos ...................................................................... 62 Instrumentos de la investigación ............................................................................. 65 Análisis de datos ........................................................................................................ 66. XIV.
(15) . Experimentación Inicial ................................................................................. 67. . Experimento uno: ........................................................................................... 68. Distribución estadística ............................................................................................. 83 Contrastes de hipótesis ......................................................................................... 83 Estadísticos descriptivos: ...................................................................................... 84 . Algoritmos Kmeans ........................................................................................ 84. . Algoritmos DBscan......................................................................................... 87. . Test no paramétrico ....................................................................................... 90. CAPÍTULO IV .................................................................................................... 96 RESULTADOS CONCLUSIONES Y RECOMENDACIONES ............................ 96 Resultados .................................................................................................................. 96 Conclusiones............................................................................................................... 97 Recomendaciones ..................................................................................................... 98 Bibliografía ................................................................................................................ 100 ANEXOS ......................................................................................................... 102 Anexo 1. Carta de validación.............................................................................. 103 Anexo 2 Cronograma de actividades ................................................................ 104 Anexo 3. Matriz de autores..................................................................................... 106 Anexo 4. Pruebas del experimento ......................................................................... 107 2 clúster-Kmeans..................................................................................................... 107 3 clúster-Kmeans..................................................................................................... 112 2 clúster-DBscan...................................................................................................... 117 3 clúster-DBscan...................................................................................................... 122. XV.
(16) ABREVIATURA KDD. Descubrimiento de Conocimiento en Base de datos. UG. Universidad de Guayaquil. FTP. Archivos de Transferencia. ej.. Por ejemplo. HTML. Lenguaje de Marca de salida de Hyper Texto. Http. Protocolo de transferencia de Hyper Texto. Ing.. Ingeniero. CC.MM.FF. Facultad de Ciencias Matemáticas y Físicas. URL. Localizador de Fuente Uniforme. WWW. World Wide Web (red mundial). XVI.
(17) SIMBOLOGÍA e. Error. m. tamaño de la población. n. tamaño de la muestra. S. silhouette. b(i). distancia promedio intra clúster. a(i). distancia promedio inter clúster. max. valor máximo. N. número total de observaciones. x. valor de la muestra. ̅ 𝒙. media. s. Estimador de la desviación estándar. 𝒔𝟐. varianza. B. diferencias de los recorridos. W. Shapiro-Wilk. XVII.
(18) ÍNDICE DE CUADROS CUADRO N. 1 CAUSAS Y CONSECUENCIAS DEL PROBLEMA ...................... 8 CUADRO N. 2 DELIMITACIÓN DEL PROBLEMA ............................................... 9 CUADRO N. 3 CUADRO COMPARATIVO DE LAS VENTAJAS Y LIMITACIONES DE LOS ALGORITMOS K-MEANS Y DBSCAN ................................................. 31 CUADRO N. 4 VARIANZA DE RESULTADOS SILHOUETTE ........................... 33 CUADRO N. 5 COLUMNA DE DATOS DE TRAYECTORIAS DE VEHÍCULOS DE PLT .................................................................................................................... 53 CUADRO N. 6 COLUMNA DE DATOS DE TRAYECTORIAS DE VEHÍCULOS DE P_DRIVE ........................................................................................................... 54 CUADRO N. 7 COLUMNA DE DATOS DE TRAYECTORIAS DE VEHÍCULOS DE CALIFORNIA ..................................................................................................... 55 CUADRO N. 8 NÚMERO DE MUESTRA DE CALIFORNIA ............................... 60 CUADRO N. 9 MATRIZ DE OPERACIONALIZACIÓN DE VARIABLE............... 61 CUADRO N. 10 DATOS DEL ADMINISTRADOR EN POSTGRESQL .............. 62 CUADRO N. 11 TABULACIÓN PARA EL EXPERIMENTO 1............................. 68 CUADRO N. 12 TABULACIÓN DE LA OBSERVACIÓN 1 ................................. 71 CUADRO N. 13 TABULACIÓN DE LA OBSERVACIÓN 1 ................................. 74 CUADRO N. 14 RESULTADO DE SILHOUETTE EN KMEANS ........................ 74 CUADRO N. 15 TABULACIÓN DE LA OBSERVACIÓN 1 ................................. 78 CUADRO N. 16 TABULACIÓN DE LA OBSERVACIÓN 1 ................................. 81 CUADRO N. 17 RESULTADO DE SILHOUETTE EN DBSCAN ........................ 81 CUADRO N. 18 DATOS DE KMEANS EN SHAPIRO-WILK .............................. 84 CUADRO N. 19 RESULTADOS DE KMEANS CON DOS CLUSTER EN SHAPIRO-WILK................................................................................................. 84 CUADRO N. 20 RESULTADOS DE KMEANS CON TRES CLUSTER EN SHAPIRO-WILK................................................................................................. 86 CUADRO N. 21 DATOS DE DBSCAN EN SHAPIRO-WILK .............................. 87 CUADRO N. 22 RESULTADOS DATOS DE DBSCAN EN SHAPIRO-WILK ..... 87 CUADRO N. 23 RESULTADOS DATOS DE DBSCAN EN SHAPIRO-WILK ..... 88 CUADRO N. 24 DATOS DE KMEANS Y DBSCAN EN MANN _WHITNEY ....... 90 CUADRO N. 25 DATOS DE KMEANS Y DBSCAN EN MANN _WHITNEY ....... 90 CUADRO N. 26 DATOS DE KMEANS Y DBSCAN EN MANN _WHITNEY ....... 91. XVIII.
(19) CUADRO N. 27 RESULTADOS DE KMEANS CON DOS CLUSTER EN MANNWHITNEY .......................................................................................................... 91 CUADRO N. 28 PRUEBA DE MANN-WHITNEY / PRUEBA BILATERAL (TRES CLUSTERS): ..................................................................................................... 92 CUADRO N. 29 PRUEBA DE MANN-WHITNEY / PRUEBA BILATERAL VALORP : ...................................................................................................................... 93 CUADRO N. 29 VALORES PARA GRAFICAR BOX PLOT: .............................. 94. ÍNDICE DE GRÁFICOS GRÁFICO N. 1 Representación de las etapas de la metologia experimental ..... 16 GRÁFICO N. 2 Procesos de KDD ...................................................................... 20 GRÁFICO N. 3 Taxonomía de técnicas de minería de datos ............................. 21 GRÁFICO N. 4 Taxonomía de clustering ........................................................... 24 GRÁFICO N. 5 Representación graficas de técnicas clustering: A) jerárquico, b) densidad y c) particional .................................................................................... 25 GRÁFICO N. 6 Diagrama de flujo funcionamiento de k-means .......................... 28 GRÁFICO N. 7 Representación de Bloxplot....................................................... 36 GRÁFICO N. 8 Representación de las trayectorias en R ................................... 39 GRÁFICO N. 9 Tabla de la base PLT ................................................................ 53 GRÁFICO N. 10 Tabla de la base T_drive ......................................................... 54 GRÁFICO N. 11 Las tres bases de datos en Qgis ............................................. 56 GRÁFICO N. 11 Datos de trayectorias de vehículos utilizados en experimentos. .......................................................................................................................... 57 GRÁFICO N. 13 Visualización de pgAdmin III ................................................... 62 GRÁFICO N. 14 tablas cargadas en PostgreSQL .............................................. 63 GRÁFICO N. 15 Ventana inicio de lenguaje R ................................................... 64 GRÁFICO N. 16 Muestra de función de algoritmo en R ..................................... 65 GRÁFICO N. 17 Representación de las agrupaciones realizadas por cada algoritmo ............................................................................................................ 67 GRÁFICO N. 18 Representación de las agrupaciones realizadas por dos clúster de Kmeans Observación 1 ................................................................................ 69. XIX.
(20) GRÁFICO N. 19 Representación de las agrupaciones realizadas por tres clúster de Kmeans Observación 1 ................................................................................ 70 GRÁFICO N. 20 Representación de las agrupaciones realizadas por dos clúster de Kmeans Observación 2 ................................................................................ 72 GRÁFICO N. 21 Representación de las agrupaciones realizadas por tres clúster de Kmeans Observación 2 ................................................................................ 73 GRÁFICO N. 22 Representación de las agrupaciones realizadas por dos clúster de DBscan Observación 1 ................................................................................ 76 GRÁFICO N. 23 Representación de las agrupaciones realizadas por tres clúster de DBscan Observación 1 ................................................................................ 77 GRÁFICO N. 24 Representación de las agrupaciones realizadas por dos clúster de DBscan Observación 2 ................................................................................ 79 GRÁFICO N. 25 Representación de las agrupaciones realizadas por tres clúster de DBscan Observación 2 ................................................................................ 80 GRÁFICO N. 26 Gráficos P-P (distribución normal de dos clúster) .................... 85 GRÁFICO N. 27 Gráficos P-P (distribución normal de tres clústeres) ................ 86 GRÁFICO N. 28 Gráficos P-P (distribución normal de dos cluster) .................... 88 GRÁFICO N. 29 Gráficos P-P (distribución normal de tres cluster) .................... 89 GRÁFICO N. 30 Gráficos P-P ( no paramétrica) ................................................ 93 GRÁFICO N. 31 Gráficos Box plot ..................................................................... 95. XX.
(21) UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS CARRERA DE INGENIERÍA EN NETWORKING Y TELECOMUNICACIONES “ANÁLISIS DE TRAYECTORIAS VEHICULARES GPS PARA EVALUAR SU CALIDAD DE AGRUPAMIENTO UTILIZANDO ALGORITMOS CLUSTERING DE MINERÍA DE DATOS”. Autor: Yajaira Vera LLaque Tutor: Ángel Veloz Rodríguez. RESUMEN El gran volumen de datos espaciales generados por diversos dispositivos: Smartphone, GPS y sensores etc. engloban patrones atractivos en datos, convirtiéndose en un tema interesante para investigadores motivados a encontrar la mejor técnica clustering al tratar datos de trayectoria GPS, ya que en existencia se observan inconvenientes en las grandes ciudades como el tráfico vehicular. Por eso, se obtienen Bases de datos científicas que contienen recorridos vehiculares en diferentes lugares: California, China y Beijing. En esta investigación se evalúa la calidad de agrupamiento de los algoritmos identificados: Kmeans y DBscan. Aquellos utilizan datos de la tabla California para determinar, bajo ciertas condiciones, cuál de los dos algoritmos obtiene mejor agrupación de clúster. En la implementación se hicieron cambios para que el algoritmo de Kmeans consiguiera analizar los datos de trayectoria del GPS usando la medición de similitud de Hausdorff. Para Medir la calidad de agrupamiento de los algoritmos, se utiliza la métrica de Silhouette. Como resultado, el algoritmo DBscan es el de mejor calidad de agrupamiento, sin embargo, el algoritmo Kmeans obtiene resultados que están dentro de lo admitido por la métrica y facilita la identificación de las rutas de congestión.. Palabras clave: métrica silhouette, k-means, DBscan, clustering, GPS, trayectorias.. XXI.
(22) UNIVERSIDAD DE GUAYAQUIL FACULTAD DE CIENCIAS MATEMÁTICAS Y FÍSICAS CARRERA DE INGENIERÍA EN NETWORKING Y TELECOMUNICACIONES. “ANALYSIS OF GPS VEHICLE TRAJECTORIES TO EVALUATE THEIR GROUPING QUALITY USING ALGORITHMS DATA MINING CLUSTERING". Autor: Yajaira Vera LLaque Tutor: Ángel Veloz Rodríguez. ABSTRACT The large volume of spatial data generated by various devices: Smartphone, GPS and sensors etc. encompass attractive patterns in data, becoming an interesting topic for researchers motivated to find the best clustering technique when processing GPS trajectory data, since in existence there are drawbacks in large cities such as vehicular traffic. For this reason, scientific databases are obtained that contain vehicle routes in different places: California, China and Beijing. This research evaluates the quality of grouping of the identified algorithms: Kmeans and DBscan. They use data from the California table to determine, under certain conditions, which of the two algorithms gets the best cluster grouping. In the implementation changes were made so that the Kmeans algorithm could analyze the GPS trajectory data using the similarity measurement from Hausdorff. The Silhouette metric is used to measure the grouping quality of the algorithms. As a result, the DBscan algorithm is the best grouping quality, however, the Kmeans algorithm obtains results that are within metric support and facilitates the identification of congestion paths.. Keywords: Silhouette metric, Kmeans, DBscan, clustering, GPS, trayectories. XXII.
(23) INTRODUCCIÓN En el presente estudio se comprende tomar las diferentes estructuras ubicadas en áreas de la computación como análisis, planteamientos, evaluación, pruebas y resultados que directamente son aplicados para objetos intangibles que resultan ser productos finales de las actividades que realizan diariamente los seres humanos en todo el mundo, estos mismos conjuntos de caracteres denominados datos suelen crecer exponencialmente a medida que transcurre el tiempo. Estos datos se los retienen en diferentes espacios de almacenamientos del cual, al no tener conocimiento de un proceso que ayude a darle valor a esta materia bruta presentada de manera digital, provoca grandes dificultades en la extracción de información relevantes de acuerdo a las necesidades que se originen a futuro.. Por ese motivo en los distintos factores se presenta un tratamiento en los datos con el objetivo de sacar el máximo potencial de ellos, aquí hace su primera asistencia la minería de datos jugando un papel muy importante en la extracción de la información, aunque no es reconocida ni muy utilizada, las entidades no se dan cuenta del gran uso que pueden ganar ya que en la actualidad que trabajan muy bien con la tecnológica como optimizar recursos, tiempo, y sobre todo dinero.. En este sentido se enfatiza en usar la práctica de minería de datos, en función de identificar puntos claves que tendrán un valor significativo al tratar caracteres digitales a gran escala. Por medio de las técnicas que ofrece estos mismos procesos, se descubre cómo se es útil darles un buen uso a estos conocimientos, donde sus diferentes tácticas de seguimiento están inmersas en la extracción de información ya que los métodos se basan en mejores opciones hacia el avance del aspecto empresarial o social que busca patrones ocultos en los datos.. Así, el análisis en las unidades GPS se generan constantemente debido al posicionamiento de un objeto en movimiento puede usarse para resolver varios. 1.
(24) problemas en tráfico de vehículos, incluida la congestión masiva, la falta de vías de acceso y señalización deficiente, entre otros. El aumento de objetos que circulan en un espacio físico, conduce a una mayor demanda en el flujo de vehículos. Aquí nace la necesidad en descubrir la eficiencia de gestionar el tráfico. Al dar seguimiento a este gran volumen de información requiere de un gran esfuerzo de supervisar estos subprocesos, por el cual, dentro de las variedades que obtiene la minería de dato.. Entre los métodos que se pueden usar para solucionar inconvenientes de la congestión del tráfico se usa clustering porque se puede automatizar los procesos de manera no supervisada y pertenece a la técnica de descriptiva, ya que clustering identifica de forma automática los elementos de acuerdo a las características en común y crea cúmulo de objetos, llamados clústeres que se agrupan: por similitud (propiedad de compacidad) y por diferencias (propiedad de separación). En la variedad de clustering esta los algoritmos. En esta investigación, proponemos evaluar la calidad de agrupación de los algoritmos y se identifica dos, Kmeans como parte de la agrupación de particiones técnicas y algoritmo DBscan como parte de las técnicas de agrupamiento de densidad usando datos de trayectoria GPS. Este análisis se basa en la optimización de error cuadrático para dividir una base de datos en k grupos para obtener resultados esperados con éxito de los datos vehicular con el fin de entender las relaciones que existe entre los cúmulos de trayectoria GPS.. Con la finalidad de realizar una experimentación y de resultados estudiar la comparación de los algoritmos ya mencionados. Para la evaluación de resultados se necesita medir la distancia entre las agrupaciones y dentro de la misma agrupación, mediante métricas silhouette. Esta métrica permite evaluar las agrupaciones de trayectorias GPS para determinar la complejidad de la información en el comportamiento de mayor significado, predecir estrategias antes un escenario y mediante test estadístico saber que tratamiento fue más eficiente. El argumento de cada capítulo se presenta a continuación:. 2.
(25) Capitulo I. En esta sección se detalla el problema del porque surge la problemática del proyecto, como afecta al entorno que se encuentra, las causas y consecuencias que son provocados por necesidades a través de grandes volúmenes de datos, fijar objetivo para definir el alcance siendo la limitante de proyecto que se debe cumplir, la formulación del problema y dar una solución del mismo mediante la metodología. Capitulo II. Esta parte trata del marco teórico, que comprende todas definiciones del estudio, los antecedentes, fundamentación teórica, fundamentación legal, hipótesis, variables del proyecto, Capitulo III. Se trata de cómo se llevará la propuesta del desarrollo, es decir, que será la guía del proyecto siguiendo las etapas de la metodología. El análisis de la sección de algoritmos describe los algoritmos juntos con las modificaciones realizadas, la métrica seleccionada para evaluar la calidad del agrupamiento y test estadísticos. Capitulo IV. En la sección de resultados y discusión se describe los experimentos realizado para determinar mediante los resultados de test estadísticos cuál de los dos algoritmos presenta la mejor calidad de agrupamiento utilizando trayectorias de GPS. Las conclusiones y la sección de trabajo futuro establecen los resultados de la investigación y describe las acciones futuras que se llevarán a cabo.. 3.
(26) CAPÍTULO I EL PROBLEMA Planteamiento del problema Ubicación del problema en un contexto. Hay varias técnicas para el agrupamiento de trayectorias vehiculares, pero no existe un adecuado tratamiento que permita analizar la masiva reproducción de datos en bruto que se generan por los Sistemas de Posicionamiento Geográfico (GPS), dispositivos inteligentes y dispositivos de teledetección dentro de las limitantes en ciudades grandes, relacionándose con las actividades del ser humano, que inicia desde cuando uno sube al bus hasta llegar al destino deseado, en el trascurso del viaje pueden ocurrir sucesos inesperados, donde las personas pueden ocasionar o vivir casos como afluencias vehiculares, accidente automovilístico, comportamiento imprudente de los conductores etc.. Sin embargo, el problema en trayectorias vehiculares destaca uno de los principales inconvenientes, que es el congestionamiento de los transportes públicos y privados debido a ciertos tiempos en el día conocidas como las horas picos, producto de esto se originan el cruce de horarios cotidianos cuando las personas adultas, jóvenes y niños entran o salen de sus jornadas laborales y establecimiento educativos en dirección a un lugar en específico, estas circunstancias ocasionan la reducción del flujo normal de los peatones que seleccionan vías de mayor frecuencia basando su decisión por costumbre o por ruta únicas más factible de llegar a su destino.. 4.
(27) Si nos proponemos identificar intersecciones de las rutas en sectores de la ciudad por medio de herramientas tecnológica es difícil visualizar a simple vista la existencia de tráfico vehicular, donde los datos que son recopilados y almacenados en una base de datos nacen de la necesidad de saber dónde inicia o se origina el flujo anormal de los vehículos. Esto crea incertidumbre entre la sociedad de como predecir estos sucesos mediante cálculos matemáticos y probabilidades estadísticas que ayuden a tratar los datos vehiculares para encontrar rutas viables y rápidas dentro de las ciudades.. Por otro lado, el ser humano está acostumbrado a clasificar elementos en pequeños grupos ya sea por varios criterios o por intuición cuando se trata de cantidades mínimas, debido al nivel de experiencia al realizar consecutivamente un mismo trabajo, pero al hablar de una colección de millones de datos se vuelve muy extensa poder procesarlos, ya que estas crecen exponencialmente a través del tiempo provocando afectación innegable.. Además, el tiempo requerido es muy excedente para el tratamiento de agrupaciones de datos, se necesita separar estos conglomerados de una manera coherente y ordenada. Por esta razón el extraer los datos recopilados se da la necesidad de aplicar técnicas de minerías de datos en clustering. Estos métodos separan en grupos las trayectorias para realizar un análisis exhaustivo del comportamiento en la relación del conjunto y complementar con aportes de mejoras o avances en este estudio.. En la actualidad el interés de los investigadores crece y se han propuesto varios métodos de agrupación específicos en trayectorias GPS, pero hasta el momento no existe un tratamiento adecuados para estas clases de datos. Por lo tanto, afecta al resultado final que se los considera como nuevo conocimiento que pueden llegar a aportar y a resolver los diversos problemas mencionados en este estudio.. 5.
(28) Al no saber que tratamiento sea el adecuado para los datos de trayectoria GPS, se puede cometer grandes errores que pueden causar daños irremediables a gran escala como perdidas monetarias, recursos y tiempo en las entidades, por que varían sus resultados provocando error estadístico y mala relación en las agrupaciones de las trayectorias que deben pasar por varias fases de Kdd (Descubrimiento de Conocimiento en Base de datos). Aquí surge la opción de usar más de un método en la base de datos y así comparar los valores de las trayectorias vehiculares con los que se verifica mediante la evaluación de la calidad de estos resultados para prevenir estos acontecimientos.. Situación de conflicto nudos críticos. Actualmente, al tener variedades de escenarios enfocados en el tránsito vehicular y el aplicar diferentes técnicas relacionadas al tratamiento de datos, se complica el no poder identificar una buena alternativa para tener un agrupamiento de calidad en los recorridos, por consiguiente,. acarrea muchos problemas por. ejemplo el congestionamiento vehicular que se manifiestan en las ciudades grandes, estas registran un sin número trayectorias diariamente y el uso de un gran volumen de datos que se presentan en la recopilación de información de las entidades por cada actividad realizadas, estas se almacenan en un lugar específico con la ayuda de las herramientas que permitan un aprendizaje autónomo.. En consecuencia, el proceso correcto en las bases de datos ayuda a darle el buen uso de los mismo, volviéndose necesario minar los datos para extraer esa información que se incrementado exponencialmente en los últimos años. Las técnicas de minería de datos a pesar de sus increíbles características. En la solución de muchos problemas de la actualidad, no son reconocidas ni explotadas por las organizaciones gubernamentales y privadas, que pueden ser de gran ayuda en la solución de problemas, ya que existe discordancia en las opiniones sobre el beneficio que trae consigo la minería de dato.. 6.
(29) Este estudio pretende indagar sobre el análisis los datos en la distribución de los patrones de las trayectorias GPS, para ello se requiere un claro entendimiento y la compresión que conlleva el algoritmo de clustering (k-means y dbscan), entre ellas se deberá elegir la mejor técnica para trayectoria GPS, evitando así errores en la relación de los grupos. Esté análisis evidentemente será de carácter empírico, ya que determinar qué técnica es la correcta se necesita probar cada una ellas; por tanto, la obtención de resultados podría tomar un tiempo considerable. Las interrogantes que se arrojen como resultado de las pruebas, necesitarán una experimentación para resolverlas, mediante el uso de métricas se evalúa la calidad de los mismo y se Determinara que tratamiento se aproxima a un resultado certero.. 7.
(30) Causas y consecuencia del problema. Las causas y consecuencias se detallan a continuación en el siguiente cuadro:. CUADRO N. 1 CAUSAS Y CONSECUENCIAS DEL PROBLEMA CAUSAS. CONSECUENCIAS. Técnicas de minería de Las entidades que contienen grandes datos no son reconocidas volúmenes de información no saben qué por. ser. tecnología tratamiento utilizar en sus datos y ni. emergente. No. existe. como darle uso a los mismo. una. técnica Errores estadísticos y mala relación en. exacta para tratar los datos las agrupaciones de las trayectorias de trayectoria GPS.. GPS.. La mala agrupación de las trayectorias. GPS. se Mala interpretación en los resultados. originan por no seleccionar obtenidos de los algoritmos. el tratamiento correcto. No se evalúa la calidad de Análisis erróneos e incluso pérdida de agrupamientos. en. las dinero ,recursos y tiempo. trayectorias vehiculares.. en las. organizaciones.. Elaborado: Yajaira Vera Fuente: Yajaira Vera. 8.
(31) Delimitación del problema CUADRO N. 2 DELIMITACIÓN DEL PROBLEMA CAMPO:. Soberanía, derechos y tecnologías en el ordenamiento territorial y ambiente de la construcción.. ÁREA:. ASPECTO:. TEMA:. Base de datos & big data Propuesta de investigación con una experimental para el ámbito trayectoria vehicular Análisis de las técnicas de minería de datos de clustering utilizando trayectoria GPS. Elaborado: Yajaira Vera Fuente: Yajaira Vera. Formulación del problema. ¿Cuál es la incidencia de las técnicas de la minería de datos de clustering en la evaluación de la calidad de agrupamiento en las trayectorias vehiculares? La incidencia de las técnicas de minería de datos en la evaluación de la calidad de agrupamiento en las trayectorias vehiculares es que en la actualidad existen carencias de identificar la mejor técnica de la minería de datos de clustering para mejorar la calidad de agrupamiento de clúster.. 9.
(32) Evaluación del problema Los aspectos que se evaluaran en el proyecto son:. Delimitado:. Las trayectorias vehiculares dentro de las ciudades con una gran movilidad de vehículos definen las rutas en las que son usados con frecuencia por personas, debido a la recurrencia de estas mismas vías y no optar por otras rutas, ocasionan un retraso en el flujo vehicular, el cual posiblemente obstruye caminos para cualquier emergencia, sin embargo, estos inconvenientes se engloban y se presentan en un conglomerado de datos que son productos del reclutamiento de estudios hechos por personas relacionadas al tránsito vehicular en una ciudad.. Claro:. Analizar y evaluar los datos demanda tiempo, pero los procesos automáticos en los grandes volúmenes de datos aplicando minería de datos en entidades optimiza el manejo de los datos de una manera eficiente para la segmentación de los grupos.. Evidente:. Los algoritmos son frecuentemente usados para analizar los datos de gran escala como en los recorridos de las trayectorias vehiculares. El mal uso de datos en procesos de minería de datos inclina a cometer caos en los resultados, por lo tanto, al no tener conocimiento de estas herramientas pueden provocar errores en las similitudes y diferencias de las agrupaciones del clúster.. 10.
(33) Concreto:. La comparación entre dos algoritmos clustering de técnicas de minería deben ser evaluados, si no se evalúa los resultados se obtendrá unas predicciones incorrectas y lógicamente una mala toma de decisiones.. Relevante:. En la actualidad el interés de los investigadores crece y se han propuesto varios métodos de agrupación específicos en trayectorias vehiculares para resolver diversos problemas como puede ser el tránsito vehicular, pero hasta el momento no existe un tratamiento adecuados para estas clases de datos que aporte al conocimiento hacia toma de decisión.. Factible:. En esta investigación, se puede prevenir cometer grandes errores que pueden causar daños irremediables a gran escala como perdidas monetarias, recursos y tiempo en las entidades, por que varían sus resultados provocando error estadístico y mala relación en las agrupaciones de las trayectorias que deben pasar por varias fases de Kdd. Este estudio ayuda en el procesamiento de la información y aproxima a que el resultado sea muy certero para la toma de decisión.. 11.
(34) Objetivos. Objetivos generales. Analizar los recorridos vehiculares GPS para valorar su calidad de agrupamiento usando algoritmos Clustering de Minería de datos.. Objetivos específicos. . Analizar las técnicas de minería de datos de clustering que se consideran relevantes.. . Analizar las diferentes características presentes en una trayectoria GPS.. . Identificar la métrica que esté orientada a medir la calidad de agrupamiento en trayectoria GPS.. . Realizar experimentos que permitan evaluar los resultados con respecto a la calidad del agrupamiento utilizando herramienta R.. Alcances del problema. El alcance de la investigación es el estudio del arte que comprende las siguientes actividades: . Identificar dos algoritmos de clustering: k-means y DBscan.. . Identificar las métricas para evaluar la calidad de estos algoritmos: métrica silhouette.. . Experimento para evaluar los dos algoritmos de la calidad 1.Instalar las herramientas de trabajo indispensable para este estudio como Qgis, PostgreSQL y R. 2.Visulaizar las tres bases de datos en Qgis. 12.
(35) 3.Subir y seleccionar la base de datos más significativa para el estudio en PostgreSQL: California. 4.Programar los dos algoritmos en lenguaje r teniendo en consideración las limitan de cada algoritmo. 5.Realizar la Aplicación de los algoritmos para la muestra del análisis de acuerdo a los test de la métrica identificada. . Validar esos resultados obtenidos con silhouette.. Como resultados, Analizar la información y determinar cuál es la técnica que mejor se acople a las trayectorias GPS de datos vehicular mediante la comparación entre los dos algoritmos evaluados con la métrica mencionada.. Justificación e importancia. Esta investigación permite conocer los intereses por el cual el análisis de las técnicas de minería de datos están inmersos en el agrupamiento de información referente a las trayectorias GPS; este mismo conjunto de datos son almacenados diariamente en. repositorios digitales convirtiéndose en un gran volumen de. información, difícil de tratar para un ser humano pero mediante un aprendizaje no supervisado se puede optar por una solución al problema de la gran ola de datos que está inundando a diferentes sectores laborales.. Dada la gran importancia en la necesidad de manipular y visualizar grandes cantidades de datos espaciales y que en su contenido albergan un factor clave que es de utilidad como la tendencias o patrones, surge la interrogante de cómo se debe tratar esta información, por motivo que no existe una técnica adecuada para las trayectorias, en espera de identificar el tratamiento que mejor se acople a ellos y esto aporta a resolver la temática de este proyecto.. 13.
(36) Esta investigación pone en práctica dos algoritmos de técnicas no supervisada para encontrar relaciones entre grupos y llegar a la experimentación aplicando métrica a los resultados dados de cada algoritmo. Con la finalidad de resaltar la utilidad de evaluar la calidad de los resultados y también la importancia de utilizar métrica para predecir nuevos conocimientos más acertados en las trayectorias GPS.. Sin embrago, es de suma importancia, tener un conocimiento sobre la correcta utilización de los algoritmos dados, que otorgan una opción para resolver diversos problemas en cualquier área de trayectorias GPS, por lo tanto, centrándose en la reproducción de datos vehiculares ya existentes que dan. mucho énfasis al. conflicto de tránsito vehicular agregando eventos en lo que ocasionan la reducción del flujo normal de los peatones que seleccionan vías de mayor frecuencia basando su decisión por costumbre o por ruta únicas más factible de llegar a su destino.. Por esa razón, se necesita extraer la información mediante técnicas de minería de datos siendo sus tratamientos esenciales en este proyecto. “La tarea de encontrar patrones ocultos dentro del gran conjunto de datos a fin de transferir la información recuperada en conocimiento útil” (Giraldo Juan, 2017). En la actualidad, se presencia variedades de técnicas en minería y se enfatiza a los métodos no supervisados en dirección a la identificación de patrones que ayuden a explicar o reducir los clústeres en los datos vehiculares.. Clustering. es. de. suma. importancia. para. este. estudio. convirtiéndose. principalmente en el tratamiento para las agrupaciones de las trayectorias vehiculares. De acuerdo a lo mencionado por (Aggarwal, 2015) se refiere: “clustering es una técnica no supervisada en tarea de crear agrupaciones de clúster de acuerdo a la relación de su semejanzas o diferencia que existen entre los grupos” (p60).. 14.
(37) Además, el agrupamiento de trayectoria manifiesta en los últimos años un interés progresivo en los investigadores y empresarios que han propuesto varios métodos de agrupación específicamente en trayectorias GPS. En usar los algoritmos referenciado en este estudio puede llegar a solucionar diversos conflictos en existencia. Uno de ellos es popular con un funcionamiento simple y la otra es eficiente, por lo cual, la orientación en el análisis de las agrupaciones es la comparación entre los dos algoritmos y observar la posible variación en los resultados y evaluarlos con test de métrica que más adelante se mencionara.. Metodología del proyecto. En el presente estudio, se usa la metodología de investigación experimental por motivo, que se ajusta a los parámetros de alcances y objetivos planteados en este estudio, la investigación experimental consiste en una serie de pasos o fases consecutivas para el desarrollo, integrada por un conjunto de actividades sistemáticas y procesos que suelen recaudar información necesaria sobre el tema a investigar.. La opinión del autor (Ana Mondragón, 2016) define lo siguiente diciendo cual es el objetivo de la investigación experimental: “El objetivo se centra en controlar el fenómeno a estudiar, emplea el razonamiento hipotético-deductivo. Emplea muestras representativas, diseño experimental como estrategia de control y metodología cuantitativa para analizar los datos”.. Es decir, necesita de otras técnicas para poder realizar un buen trabajo experimental. Lo primero es encontrar la información teórica del proyecto para fundamentar la temática a examinar, ya sea en artículos científicos, articulo de congresos, revistas y libro, con el fin de describir de qué modo o por qué causa se produce este tema y su efecto en las conductas observadas, sabiendo que se. 15.
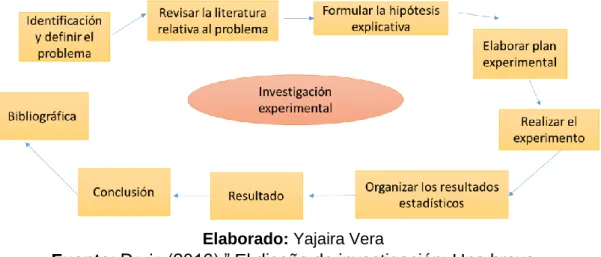
(38) maneja deliberadamente la variable experimental, luego observar lo que ocurre en condiciones controladas con la necesidad de la repetición voluntaria de los fenómenos para verificar su hipótesis empíricamente. GRÁFICO N. 1 Representación de las etapas de la metologia experimental. Elaborado: Yajaira Vera. Fuente: Doris,(2016),” El diseño de investigación: Una breve revisión metodológica” Por este medio, la fase de la metodología aportará necesariamente a conseguir resultados y con el objetivo de finalizar con el test de evaluaciones para determinar el tratamiento que funcione mejor en datos espaciales de trayectorias GPS para observar el comportamiento o relaciones que se crea entre cada técnica implementada en este estudio.. 16.
(39) CAPÍTULO II MARCO TEORICO Antecedentes del capitulo. Los algoritmos relevantes a este estudio son dos, uno de ellos es k-means propuesto por Mac Queen en 1967 y DBscan propuesto por Martin Ester en 1996. Ambos son algoritmos clustering o llamado agrupamiento de aprendizaje no supervisado, según lo mencionado por los autores afirman. “Los algoritmos clustering son una herramienta eficaz para extraer información de datos en bruto” (Pagola Miguel, 2015). Entonces este autor nos quiere decir que facilita el trabajo con datos de gran dimensión como los recorridos vehiculares.. Además, otro autor confirma como deberían ser las agrupaciones con datos GPS según su criterio. La idea básica de los algoritmos de agrupamiento es marcar un lugar y su radio. Los puntos de datos GPS dentro de este radio se reconocen como el mismo PDI (involucrar lugares de interés) y el punto central, cual es nuevo, representa la media de estos puntos de datos GPS. Este proceso se repite hasta que todos los puntos dentro de este radio ya no cambien. Nosotros notamos que los PDI son diferentes de los puntos de permanencia. Un punto de permanencia es el punto de agrupamiento de una trayectoria, mientras que los PDI son lugares clave de interés (Wu Ruizhi, 2018).. La finalidad de este autor es tener los recorridos más destacados y localización de mayor aglomeración en el área de estudio para obtener un análisis en los resultados, en ellos se busca caminos viables y rápidas de diversos puntos, todo esto realizado empíricamente mediante la comprobación con métrica silhouette que miden las distancias entre y dentro de los grupos de clúster.. 17.
(40) Si, se emplea en ecuador esta investigación aportará para resolver diferentes índoles de cualquier sector. Si hablamos de salud ej. identificar la cantidad de enfermedades en un sector, en la agricultura ej. identificar la cantidad de productos de las cosechas en cada hectárea. Ahora si hablamos de datos de trayectorias vehicular podemos identificar las rutas de cogestión. Además, la redactora (Paola, 2017) del diario del comercio publica que: De acuerdo con el Anuario de Transportes 2015 del Instituto Nacional de Estadística y Censos (INEC), el número de vehículos se incrementó un 57% entre el 2010 y el 2015 en el país. En el 2015 se matricularon 1’925.368 vehículos motorizados, frente a los 1’226.349 registrados hasta finales del 2010. Las estadísticas indican que Pichincha es la provincia del país con el mayor parque automotor. Entre enero y diciembre del 2015 registró 492 568 matriculaciones, seguida de Guayas (362 857) y de Manabí (152 231). La presencia de más autos, precisamente, incrementa el tiempo de permanencia de los ciudadanos dentro de los buses o automóviles. La situación se vuelve más crítica cuando hay lluvia. Hoy, por ejemplo, Zambrano demoró 45 minutos en movilizar a un estudiante de la Universidad Católica - desde la avenida 12 de octubre y Vicente Ramón Roca- hasta el estadio Olímpico Atahualpa. Cumplir con esa ruta, en días normales, le toma usualmente 15 minutos.. En conclusión, es evidente que, si se sigue incrementando vehículos en un sector, al momento de recorrer las carencias aumentan dando paso la congestión vehicular en Ecuador.. 18.
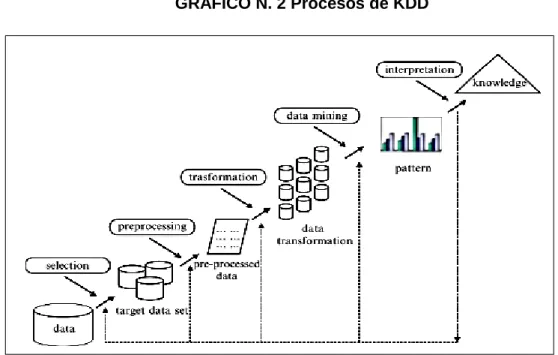
(41) Fundamentación Teórica. Por muchos años las empresas han generado datos que se almacenan en repositorios digitales, dando como resultados grandes volúmenes de datos que no son relevantes, ni de utilidad para estas empresas. De ahí la importancia de utilizar componentes inteligentes de aprendizaje no supervisado para descubrir nuevos conocimientos al procesar información de gran escala.. Al referirnos a volúmenes inmensos de datos se toma en consideración lo que dice este autor. “Los datos de alta dimensión son inherentemente difíciles de analizar y computacionalmente intensiva para diversos algoritmos de aprendizaje en tareas de procesamiento de datos multidimensionales”(Houari, Bounceur, Kechadi, Tari, & Euler, 2016).. Las técnicas clustering de datos espaciales o trayectorias GPS se denomina como clustering de trayectorias son parte de aprendizajes en minería de datos, con el fin de validar estos modelos mediante métrica silhouette.. Minería de datos Al hablar de Data mining o minería de datos debemos saber primero que es un kdd(Descubrimiento de Conocimiento en Base de datos), este término hace referencia a todo el proceso de identificación de modelos interpretativos potencialmente útiles con el fin de generar conocimiento. El autor (Federico, 2013) corrobora esta teoría según como lo explica en el GRÁFICO1 de su libro “Customer Relationship Management in the Financial Industry”, en resumen, generar conocimiento útil es de suma importancia para las empresas donde los datos son procesados a través varias etapas.. 19.
(42) GRÁFICO N. 2 Procesos de KDD. Elaborado: Federico Rajola Fuente: Federico, (2013) “Customer Relationship Management in the Financial Industry” Una vez pasada por la selección, eliminación hasta llegar a la transformación de los datos entra como variable a la fase de minería de datos, es aquí donde se origina la siguiente pregunta ¿qué es la Data mining?, esto se refiere a la aplicación de algoritmos para extraer modelos o reglas de comportamiento de los datos y corregir la interpretación de los resultados. En conclusión, la minería de datos aporta a este proyecto para la extracción de grandes volúmenes de datos como lo es las trayectorias GPS, pero para su respectivo análisis existe la necesidad de aplicar las técnicas de data mining.. El autor (Guruvayur, 2017) según su conocimiento afirma que: “Las herramientas de minería de datos usan cálculos científicos y estrategias de inteligencia de máquina. La prominencia de tales estrategias en la disección de los problemas de negocios se ha mejorado con la llegada de gran cantidad de información”.. Lo que se puede decir es que las predictivas estiman variables desconocidas de entrada mientras que la descriptiva no necesita de eso, a razón, las técnicas no 20.
(43) supervisada cumplen un papel fundamental en este proyecto. En este GRÁFICO2 demuestra la clasificación de las técnicas de minería de datos según el autor se manifiestan de la siguiente manera.. . Taxonomía de técnicas de minería de datos. Estas técnicas se dividen en dos, popularmente conocidas como supervisada y no supervisada, o también como predictiva o descriptiva, según el autor Francisco José García González define las diferencias entre estos métodos: “Las Descriptivas identifican patrones que explican o resumen los datos y las predictivas permiten estimar valores futuros o desconocidos de variables de interés,. a. partir. de. otras. variables. de. la. Base. de. datos”. (Francisco José García González, 2013).. Lo que se puede decir es que las predictivas estiman variables desconocidas de entrada mientras que la descriptiva no necesita de eso, a razón, las técnicas no supervisada cumplen un papel fundamental en este proyecto. En este GRÁFICO 3 demuestra la clasificación de las técnicas de minería de datos según el autor se manifiestan de la siguiente manera. GRÁFICO N. 3 Taxonomía de técnicas de minería de datos. Elaborado: Yajaira Vera Fuente: Anabella De Battista, P. C. (2016). Mineria de Datos Aplicada a Datos Masivos.. 21.
(44) A razón, utilizar una técnica o llamadas también algoritmos de minería de datos las recomendable seria clustering para el agrupamiento y análisis de datos en trayectorias vehiculares.. Clustering. “Clustering es un método para crear grupos de objetos, llamados clústeres, sí los objetos en un clúster son muy similares (se compactan) y los objetos en diferentes clústeres (se separan). Los criterios involucrados en el proceso de agrupamiento generalmente se basan en una medida de similitud entre los objetos” (Ceri, 2013) & (Shikha Agrawal, 2015). Este autor se refiere a la separación de cúmulos cuando la información existente en la base de datos sea similar, se agrupan los puntos y si se aíslan de los otros grupos la razón es porque no existe ninguna relación en la información que se encuentran en las bases de datos.. En la actualidad el análisis de clustering en minería de datos ha jugado un rol muy importante en una amplia variedad de áreas tales como: reconocimiento de patrones, análisis de datos espaciales, procesamiento de imágenes, cómputo y multimedia, análisis médico, economía, bioinformática y biometría principalmente. (Ochoa leticia, 2017). . Datos. Diariamente, se producen grandes volúmenes de datos de diversos tipos como de textos, espaciales o geográficos, imágenes, audio, videos, literalmente son originados en la web, GPS, redes sociales, sensores y como en áreas más específicas Marketing, Biología, Psicología e incluso en diagnostico médicos etc.. 22.
(45) Aquí aparece, la terminología la minería de datos espaciales es cuando se aplica los métodos de data mining y se usa datos espaciales o geográficos para hallar patrones o tendencias en las trayectorias GPS. SDM posee las mismas características a minería de datos y se comprueba por el medio del autor que dice:. SDM tiene como objetivo mejorar la capacidad humana para extraer conocimiento y conocimientos de grandes y complejas colecciones de datos digitales. Extrae de manera eficiente conocimiento previamente desconocido, potencialmente útil y, en última instancia, comprensible de estos enormes conjuntos de datos para una tarea determinada con restricciones. (Deren Li, 2015) . Trayectoria GPS. Las trayectorias GPS nacen por los puntos de objetos en movimientos como los recorridos vehiculares o conocida por muchos investigadores trayectorias espaciales. Las características principales de una trayectoria es la formación de puntos continuos. Este tema es de gran atención porque genera nuevas oportunidades y desafíos en la extracción de conocimiento sobre objetos en movimiento ya que, por medio de la aplicación de las técnicas clustering, se puede agrupar los recorridos más frecuentes o identificar los puntos clave del tránsito vehicular.. . Taxonomía de clustering. Dentro de la taxonomía de clustering podremos saber que técnicas se puede utilizar para esta clase datos, además según el autor Oyelade existe una variedad de técnicas de agrupamiento propuesta en su artículo científico, se considera entre toda la división a las técnicas básicamente tradicionales como los más destacados a jerárquico, partición y densidad.. 23.
(46) GRÁFICO N. 4 Taxonomía de clustering. Elaborado: Yajaira Vera Fuente: Oyelade, J. (2016). Clustering Algorithms: Their Application to Gene Expression Data. Bioinformatics and Biology Insights.. En el GRÁFICO No.4 menciona a clustering Jerárquico, se refiere básicamente a la aglomeración de manera jerárquica, se debe a que no tiene variable de entrada por lo cual hace sus agrupaciones respetando las asociaciones de la información símil que estén en la base de datos, también es muy sensible a los ruidos que provoca que los clústeres hagan una mala asociación entre los grupos haciéndolo uno solo conjunto difícil de identificar los clúster, entre ellas existe dos técnicas donde las AGNES empiezan aglomerando con un clúster independiente y luego hacen combinaciones de dos puntos semejantes hasta convertirlo en un solo conjunto, por otro lado CURE para las divisivas empieza con un cumulo global y luego busca puntos asociados hasta formar los grupos.. En cambio, Las técnicas Particional son las más populares entre clustering, este método necesita iniciar fijando un número de clúster para saber en cuantos grupos se quiere formar, una relación satisfactoria es lo que se espera de estos algoritmos como k-means utiliza la media fijando el centroide de cada clúster para hacer las agrupaciones basados en la similitud de los puntos dentro del clúster y separando los puntos diferentes de otros grupos mediante la medición de distancia con la. 24.
(47) formula euclidiana. También Pam es un algoritmo de partición robusto cuando minimiza la distancia de entre grupos y tiene un grado de complicación al tratar con volúmenes de datos.. Y por otro lado las técnicas de Densidad se basan en hallar clúster en las extensas bases de datos espaciales con ruido de alta dimensionalidad donde la densidad de los puntos puede ser alta o baja. DBscan pertenece a esta clase de algoritmo muy utilizado en datos geográficos, siendo dependiente de la densidad de los datos para poder agruparlos arbitrariamente y aislar los ruidos para una mayor compacidad en los grupos. Denclue básicamente utiliza dos fases para procesar los datos, la primera un mapa con los datos más relevantes, la segunda identifica los a motores de densidad y los puntos atraídos por densidad convenientemente. GRÁFICO N. 5 Representación graficas de técnicas clustering: A) jerárquico, b) densidad y c) particional a) Clustering jerárquico (no se fija k). b) Clustering basado en densidad. (B,C)NUCLEO (A) BORDE. Hasta que forma un solo clúster. (N) RUIDO. c) Clustering particional (suele fijarse k). Elaborado: Yajaira Vera Fuente: Datos de la investigación. En el cuadro no. 5 tenemos de ejemplos la representación gráfica de cómo se separan los datos y se van formando las agrupaciones según las técnicas clustering aplicada.. 25.
(48) Algoritmos clustering. Algoritmos Clustering prácticamente son técnicas de agrupamientos de aprendizajes automáticos no supervisados con la característica principal de encontrar patrones ocultos dentro del gran volumen de datos para generar cocimiento útil de aporte a la toma de decisión en las empresarias. En tarea de monitorear los patrones ocultos y saber la distribución dichos datos como el autor menciona en su siguiente artículo:. El objetivo de los algoritmos de clustering es dividir los datos en clústeres o grupos. Básicamente obtener los clústeres de un conjunto de datos no etiquetados X = {x(1),...,x(m)} es particionar X en C subgrupos {1 < C < m) , de tal que forma que cada uno de ellos represente una subestructura de X. (Miguel Pagola, 2015). En conclusión, los algoritmos de agrupamiento se utilizan para organizar, categorizar y analizar datos de gran escala. En este estudio, se aplica algoritmos clustering sabiendo las útiles que proporciona cada técnica en el procedimiento de agrupar los datos. De acuerdo a un criterio determinado se selecciona dos métodos, a saber, la técnica que mejor se acople a las trayectorias de datos vehiculares, lo cual se consideran a k-means y DBscan, a razón, comparar su eficiencia, velocidad y veracidad en los resultados.. . Algoritmos k-means. “K-Means es un método para particionar un conjunto dado de N puntos de datos en K grupos (llamados clústeres) en el espacio euclidiano D-dimensional. La partición en el espacio se basa en ciertas métricas de similitud que generalmente es la distancia euclidiana” (kaul, 2017).. 26.
(49) Se construyó basado en la clasificación no supervisada para agrupar (clustering) por particiones. Es necesario conocer de antemano el valor de su parámetro de entrada k, el cual define la cantidad de grupos o clústeres se formarán. Los clústeres están representados por su centroide los cuales pueden ser puntos reales o no, en cada iteración los centroides se recalculan.. Procedimiento:. 1. Seleccione aleatoriamente puntos K que forman los grupos K iniciales (número de clústeres k).. 2. Reasigna los puntos en el clúster para cada punto x, calcularla distancia de puntos de objeto a la clase más divisibles. (euclidiana).. 3.Calcular el centroide de cada clase, que pasan a ser los nuevos valores iniciales.. 4. Si no existe un criterio de convergencia, aunque el algoritmo siempre termina, no se garantiza que se obtenga la solución óptima. (ej. Si en dos iteraciones no cambian las clasificaciones de los puntos), volver a la opción 2 o 3.. 27.
(50) GRÁFICO N. 6 Diagrama de flujo funcionamiento de k-means. Elaborado: Yajaira Vera Fuente: Datos de la investigación. Mediante el presente GRÁFICO no. 6 podemos observar en el diagrama de flujo el funcionamiento de K-means, donde la determinación del centroides consiste en calcular los centroides, determinación de distancia de los puntos al centroides se refiere a calcular la distancia en los grupos de manera entre clúster y dentro del clúster para saber la distancia mínima en ellos. Mientras mayor es el número de iteraciones mejora el centroide del clúster. Una de la manera de medir las distancias es la euclidiana. Así, como el siguiente autor menciona:. Dentro de cada agrupación, la variación se identifica mediante la suma de la distancia euclidiana para cada dos puntos de datos dividida por el número de puntos de datos en cada grupo donde se define como el número. 28.
Figure


+7





Documento similar