Source Language Categorization for improving a Speech into Sign Language Translation System
Texto completo
Figure
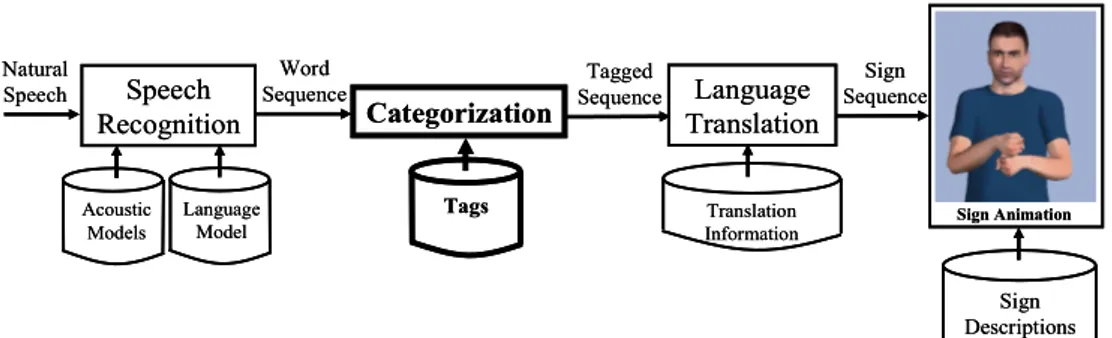
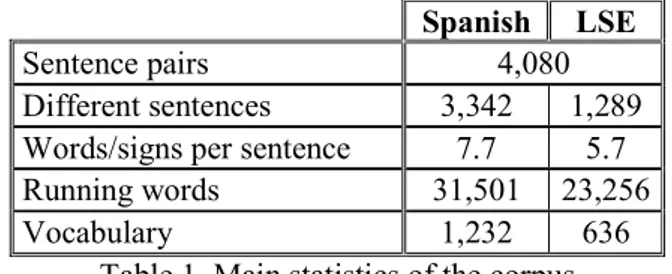

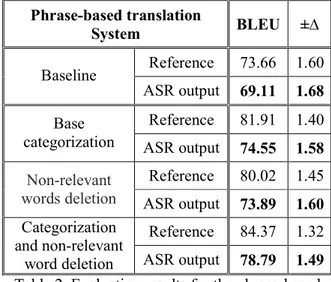
Documento similar
A survey and critique of American Sign Language natural language generation and machine translation systems.. Technical report, University of
Finally, specifications are independent of the implementation language, and they can be used for testing implementations written in different languages. In particular, the approach
There are some frameworks for model mutation, but they are specific for a language (e.g., logic formulae [5]) or domain (e.g., testing [1, 2]); moreover, mutation operators are
This view lets the home automation expert model the catalog of functional units and services that de- velopers will later use to create home automation applications.. Figure
In its original form, the system operated manually and the torque load required was achieved using motor start and stop control buttons, motor speed, applied torque load,
For all the above, HDs should be integrated into a standardized management system, that is a comprehensive system for controlling the hazards associated with the HDs handling
The general idea of the language is to “thread together,” so to speak, existing systems that parse and analyze single web pages into a navigation procedure spanning several pages of
A simpler idea is to ignore low frequency words in the scoring function, as given by their collection prior, if they appear in the relevance model with low probability, because
