Implementación de una versión mejorada del sistema para la sustitución de valores nulos en una base de datos
67
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ____________________________ Firma de los autores. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _________________________ Firma de los tutores. __________________________ Firma del jefe del Seminario.
(3) Pensamiento. La confianza en sí mismo es el primer secreto del éxito. Ralph Waldo Emerson..
(4) Dedicatoria. A mi papá por su esfuerzo y dedicación en todos estos años..
(5) Agradecimientos. Les agradezco de todo corazón a todas las personas que colaboraron de forma científica, material y emocional a realizar este trabajo. A Dios porque sin él nada hubiese sido posible. A mis padres por su apoyo e incentivo. A mi compañero Chicho por su paciencia y preocupación. A mi familia que siempre estuvo presente. A mis profesores de siempre. A Anailys, Arasay y Mavelyn por soportarme y brindarme su ayuda incondicional aminorándome el estrés. A mis tutores Dr. Ramiro Pérez y Msc. Beatriz López por la asesoría prestada..
(6) Resumen. En la literatura se han reportado varias técnicas para el tratamiento de valores faltantes. Un tratamiento muy común a los datos perdidos de una base de datos es el reemplazo por un valor calculado a partir de la información que se obtiene de los valores de la tabla. Con el reemplazo de los valores faltantes se busca que al eliminar el valor perdido en su lugar quede un valor cercano al valor ausente, para lograr esto es necesario aplicar el método apropiado lo que conlleva a la necesidad de un estudio detallado de los métodos de reemplazo. Aprovechar la información contenida en los patrones de valores faltantes puede ayudar a decidir el método a utilizar y lograr un reemplazo eficiente de los valores perdidos. En este trabajo se expone las clasificaciones de los problemas de calidad de los datos que se pueden solucionar con la limpieza de datos, se plantea el concepto de valor ausente y nulo; así como la clasificación de patrones de valores nulos. Además se destaca cómo el proceso de imputación de estos valores forma parte de la limpieza de datos que es necesario llevar a cabo cuando se produce la carga de los datos operacionales en un almacén o cuando se va a hacer un proceso de minería de datos para la toma de decisiones. Se explican algunas técnicas reportadas en la literatura para solucionar los problemas ocasionados por la existencia de datos ausentes y nulos dentro de las bases de datos y se presenta una herramienta a la que se le añadió el método regresión múltiple para reemplazar valores faltante que forman parte de patrones de valores faltantes monótonos y se constató la utilidad y eficiencia de este método y de los métodos ya existentes..
(7) Abstract. In literature has been published several techniques for the treatment of missing values. A very common treatment to lost data of a data base is the replacement for a value calculated as from the information that gets from the values of a table. With the replacement of missing values, searches to eliminate the lost value and in its place leave a close value to the missing one, in order to achieve this it is necessary to apply the appropriated method which yields to the need of a detail study of replacement's methods. Making good use of the information contained in the patterns of missing values can help to decide the method to utilize and to achieve an efficient replacement of lost values. The classifications of the problems of quality of the data that can get solved with the data cleaning are exposed in this work, the concept of missing and void value is presented; as well as the kind of void values. Besides stands out how the imputation process of these values is a part of the data cleaning that is necessary to achieve in the moment of the load of operational data at a store or when a process of data mining for the decision taking do. The literature explains some techniques which solve problems caused by the existence of missing and void data within databases and offer a tool to which add the multiple regression method to replace missing values that are a part of patterns of missing monotonous values verifying its utility and efficiency as well as of the others existent methods..
(8) Índice. INTRODUCCIÓN............................................................................................................. 1 CAPÍTULO 1. LIMPIEZA DE DATOS. TRATAMIENTO DE LOS VALORES FALTANTES. ................................................................................................................... 4 1.1.Limpieza de datos. ................................................................................................... 4 1.1.2. Tipos de valores faltantes. ............................................................................... 7 1.1.3. Tipos de patrones de valores faltantes. ........................................................... 9 1.2. Tratamiento de la información faltante. ................................................................. 9 1.3. Conclusiones del capítulo..................................................................................... 18 CAPÍTULO 2. ANÁLISIS, DISEÑO E IMPLEMENTACIÓN DEL MÉTODO REGRESIÓN LINEAL MÚLTIPLE. ............................................................................ 19 2.1. Regresión lineal múltiple. ..................................................................................... 19 2.3. Modelación del sistema. ....................................................................................... 27 2.3.1. Diagrama de Casos de uso. ........................................................................... 27 2.3.2. Diagrama de Actividades............................................................................... 29 2.3.3. Diagrama de Clases....................................................................................... 32 2.3.4. Tabla de Eventos............................................................................................ 38 2.4. Modificaciones hechas al sistema......................................................................... 40 2.5. Conclusiones del capítulo..................................................................................... 42 CAPÍTULO 3. MANUAL DE USUARIO. CONSTATACIÓN DE LOS RESULTADOS DE LA HERRAMIENTA. .............................................................................................. 43 3.1. Requerimientos del software................................................................................. 43 3.2. Descripción de la herramienta y sus funcionalidades.......................................... 43 3.3. Ambiente de trabajo.............................................................................................. 43 3.3.1. Conexión con la Base de Datos. .................................................................... 43 3.3.2. Reemplazo de nulos. ...................................................................................... 47 3.4. Áreas de aplicación .............................................................................................. 49 3.5. Pruebas para constatar la eficiencia del sistema................................................. 49 3.6. Conclusiones del capítulo..................................................................................... 55 CONCLUSIONES........................................................................................................... 56 RECOMENDACIONES. ................................................................................................ 57 REFERENCIAS BIBLIOGRÁFICAS........................................................................... 58.
(9) Introducción. INTRODUCCIÓN. La existencia de valores ausentes en una base de datos puede traer problemas como la pérdida de información cuando se realizan consultas en ésta. El resultado del procesamiento de datos que contienen valores ausentes no es real, lo que provoca deterioro de la calidad de la información y que las decisiones que se tomen basadas en esta información se vean afectadas. De ahí la importancia del tratamiento de valores ausentes dentro del procesamiento de datos y la sustitución de valores nulos es uno de los aspectos fundamentales de la limpieza de datos. Existen varias técnicas para la sustitución de valores ausentes en las bases de datos. Encontrar el dato ausente es la técnica más precisa, pero a la vez, la más difícil o engorrosa de utilizar. El uso de las técnicas de sustitución está restringido por la naturaleza del valor a sustituir ya sea numérico continuo o discontinuo, cadena, fecha, booleano, u otro tipo. Anteriormente fue creado un sistema para ayudar a la sustitución de valores ausentes en una base de datos utilizando varias técnicas. El tratamiento de valores nulos mediante la regresión, casos completos, métodos estadísticos, así como la sustitución por valores existentes en la base de datos afines con los valores ausentes. Este sistema permite la conexión solamente a los siguientes gestores de base de datos SQL Server, Access y Fox Pro. En este trabajo se expone el concepto de patrón de valores faltantes monótono y patrón de valores faltantes arbitrario, valor ausente y nulo, además se muestra como el proceso de reemplazo de valores nulos es importante dentro de la limpieza de datos necesaria en la carga de datos operacionales a un almacén de datos o en la minería de datos llevada a cabo para la toma de decisiones. Se muestra el algoritmo de regresión múltiple y se presenta una nueva versión del sistema para la sustitución de valores nulos en una Base de Datos con mejoras en la interfaz y este algoritmo incluido. En la actualidad existen métodos para el reemplazo de valores nulos que aprovechan la información contenida en los patrones de valores faltantes. Esta información ayuda a que el cálculo del valor a sustituir sea más rápido y eficiente.. 1.
(10) Introducción. Planteamiento del problema La inexistencia de un método que aproveche la información contenida en los patrones de valores faltantes en la herramienta Sistema para la Sustitución de Valores Nulos en una Base de Datos provoca ineficiencia en los resultados del mismo. Este proyecto tiene como objetivo general: Obtener una versión mejorada de la herramienta Sistema para la Sustitución de Valores Nulos en una Base de Datos que incorpore nuevas facilidades y nuevos algoritmos. Y como objetivos específicos: •. Estudiar la formación de patrones para valores faltantes.. •. Estudiar la técnica de reemplazo de valores nulos por regresión múltiple.. •. Incorporar el algoritmo de regresión múltiple para reemplazar valores nulos.. •. Verificar la utilidad y la efectividad del software con bases de datos reales.. •. Mejorar el software en función de los errores encontrados.. Preguntas de Investigación: ¿Son eficientes las técnicas de sustitución de valores nulos y/o ausentes utilizadas en el Sistema para la Sustitución de Valores Nulos en una Base de Datos? ¿La formación de patrones puede ser aplicada al tratamiento de valores nulos y/o ausentes? ¿Es aplicable a todo tipo de datos, o naturaleza del dominio, el método de regresión múltiple? El Sistema para la Sustitución de Valores Nulos en una Base de Datos, fue creado con el objetivo de ayudar al reemplazo de valores nulos y/o ausentes en una base de datos, para así lograr mayor precisión en la información que se obtiene del procesamiento de los datos contenidos en la base de datos y de esta forma mejorar la toma de decisiones basada en esta información. La verificación del sistema con base de datos reales mostrará cuan eficiente es el sistema y ayudará a la mejora de este en los errores que se encuentren. Dentro de la técnica de reemplazo de valores nulos se encuentra el método de regresión múltiple el cual aprovecha la información contenida en los patrones de valores faltantes y establece la relación entre la variable que tiene el valor faltante y el resto de las variables que intervienen. Mediante esta relación se obtiene el valor por el. 2.
(11) Introducción. cual se sustituye el valor faltante, es decir, que el valor a sustituir se obtiene teniendo en cuenta los valores del resto de las variables y no el resto de los valores de la variable que tiene el valor faltante. El presente documento está estructurado de la siguiente forma: Capítulo 1. Limpieza de datos. Tratamiento de valores ausentes. Se presentan las características generales del problema, información sobre los diferentes tipos de datos ausentes y los tipos de patrones de valores faltantes, y la descripción de los métodos que se pueden emplear en el tratamiento de los mismos. Capítulo 2. Análisis y diseño de la herramienta “Sistema para la Sustitución de Valores Nulos en una Bases de Datos”. Se presenta una descripción detallada del método regresión lineal múltiple, el diseño y las características generales de la implementación del software. Capítulo 3. Manual de usuario. Constatación de los resultados de la herramienta. .Se muestra información de cómo debe ser usado el método regresión lineal múltiple y las pruebas que se le hicieron al sistema para probar su eficiencia.. 3.
(12) Capítulo 1. CAPÍTULO 1. LIMPIEZA DE DATOS. TRATAMIENTO DE LOS VALORES FALTANTES. En este capítulo se explica la importancia del proceso de limpieza de datos y los problemas de calidad de los datos que se pueden resolver con este proceso. Luego se exponen los conceptos fundamentales de valor nulo y valor ausente en una Base de Datos y la necesidad de un sistema para el reemplazo de los mismos. Después se muestra la definición de patrones de valores ausentes monótonos y arbitrarios los cuales pueden ayudar a la elección de las técnicas para el manejo de estos valores según el tipo de patrón que presentan los datos. 1.1. Limpieza de datos. Uno de los primeros y más importantes pasos en cualquier tarea de procesamiento de datos es verificar que los valores de los datos están correctos o, al menos, se ajusten a algún conjunto de reglas. Por ejemplo, una variable llamada Sexo se espera que tenga solo dos valores; una variable que representa la altura en pulgadas se espera que sea de un límite razonable (Cody, 2002). La limpieza de datos es crucial para una gran variedad de aplicaciones en muchas industrias. El proceso para mantener los datos correctos y en un estado coherente es abrumador si se tiene en cuenta que los volúmenes de datos crecen de manera explosiva. Las principales causas de los datos sucios vienen de muchos errores básicos como son la entrada de datos equivocada, campos perdidos, los errores tipográficos, etc. Aunque, los datos en general tienen alguna semántica de dependencia y estas usualmente ayuda a evitar tales errores, varias veces, estas semánticas de dependencias son ignoradas o desapercibidas durante el diseño de la base de datos (Kaewbuadee et al., 2009). La limpieza de datos es el proceso que se encarga de detectar y eliminar anomalías en los datos y la necesidad de llevarla a cabo aumenta cuando existen varias fuentes de datos que necesitan ser integradas (Galhardas, 2000). Los errores o anomalías en una Base de Datos afectan directamente la calidad de la información resultante del procesamiento de esos datos, entonces es necesario limpiar las fuentes de datos para que lleguen coherentes a los Almacenes de Datos.. 4.
(13) Capítulo 1. El Almacén de Datos es una colección de datos orientados al tema, integrados, no volátiles e historiados, organizados para el apoyo de un proceso de ayuda a la decisión (Inmon and Hakathorn, 2004). Es el lugar donde se almacena toda la información útil que proviene de sistemas de producción y fuentes externas. En los almacenes de datos, la limpieza de datos es la mayor parte del llamado proceso de ETL 1 (Rahm and Do, 2001). Los problemas de calidad de datos están presentes en simples colecciones de datos, como los archivos y bases de datos, por ejemplo, debido a la mala escritura durante la entrada de los datos, información perdida u otros datos no válidos. Cuando múltiples fuentes de datos necesitan ser integradas, por ejemplo, en los almacenes de datos, sistemas de base de datos federados o sistemas de información globales, la necesidad de la limpieza de datos aumenta significativamente. Esto es porque las fuentes contienen a menudo los datos redundantes en representaciones diferentes. Para proporcionar el acceso a los datos consistentes y exactos, la consolidación de las diferentes representaciones de los datos y la eliminación de información doble es necesaria (Rahm and Do, 2001). Los almacenes de datos requieren y proveen soporte extensivo para la depuración de los datos. Cargan y continuamente refrescan cantidades enormes de datos de una variedad de fuentes así que la probabilidad que una cierta cantidad de las fuentes contengan “datos sucios” es alta. Además, los almacenes de datos sirven para toma de decisiones, a fin de que la exactitud de sus datos sea vital para evitar conclusiones equivocadas. Por ejemplo, la información duplicada o perdida producirá estadísticas incorrectas o engañosas. Debido a la gran variedad de incongruencias posibles de los datos, la limpieza de datos es considerada uno de los problemas más grandes en el almacenamiento de datos (Rahm and Do, 2001).. 1. Siglas en inglés de Extraction Transformation Loading. 5.
(14) Capítulo 1. 1.1.1. Clasificación de los problemas de calidad de los datos. Los problemas de calidad de los datos a resolver con la limpieza de datos se pueden clasificar según su procedencia en: •. Problemas de una fuente simple de datos.. •. Problemas de fuentes múltiples de datos.. La calidad de los datos de una fuente mayormente depende del grado de control que tenga el esquema y las restricciones de integridad para controlar los valores permisibles de los datos. Las fuentes sin esquemas, como archivos, tienen pocas restricciones en cuanto a la entrada de los datos y almacenamiento, dando lugar a una probabilidad alta de errores e incongruencias. Los sistemas de base de datos, por otra parte, implementan restricciones de un modelo específico de datos así como la aplicación de restricciones de integridad específicas (Rahm and Do, 2001). En una fuente simple de datos se pueden presentar varios problemas en la calidad de los datos. Algunos de los problemas que pueden existir están relacionados con los valores de los campos. Estos problemas son los siguientes: introducir un valor fuera del rango del dominio de un campo, tener un campo con valor faltante, introducir un valor mal escrito, con abreviaturas o más de un valor en mismo campo. Otro tipo de problema es el relacionado con la dependencia entre los campos, por ejemplo no es necesario introducir en una base de datos la edad de una persona si se tiene la fecha en que nació, ya que este dato puede ser calculado a partir de esta fecha y la fecha actual. También pueden presentarse problemas de violación de la unicidad de algunos campos, por ejemplo el número de carne de identidad no puede ser el mismo para dos personas diferentes, registros duplicados, es decir, la misma información introducida más de una vez o la presencia de registros que se contradigan. Hacer referencias no definidas o definidas erróneamente es otro problema de la calidad de los datos que trata la limpieza de datos (Rahm and Do, 2001). Los problemas presentes en una fuente son agravados cuando múltiples fuentes necesitan ser integradas. Cada fuente puede contener datos sucios y los datos pueden ser representados de varias formas, pueden superponerse o contradecirse. Esto es porque las fuentes son típicamente desarrolladas, desplegadas y mantenidas independientemente. 6.
(15) Capítulo 1. para prestar servicio específicos necesarios. Esto resulta en un alto grado de heterogeneidad en sistemas de gestión de datos, modelos de datos, diseños de esquema y en los datos reales. Los problemas principales del esquema de diseño son conflictos de nombramiento y conflictos estructurales. Los conflictos de nombramiento surgen cuando el mismo nombre sirve para objetos diferentes (los homónimos) o los nombres diferentes sirven para el mismo objeto (los sinónimos). Los conflictos estructurales ocurren en muchas variaciones y se refieren a las representaciones diferentes del mismo objeto en fuentes diferentes. Un problema muy común en la integración de más de una fuente de datos en una sola fuente es la presencia de valores faltantes, debido que al integrarse los datos pueden adicionarse registros de alguna fuente en que los campos no existan o sus valores falten (Rahm and Do, 2001). 1.1.2. Tipos de valores faltantes. Un error común es la ausencia de información y por eso en la Limpieza de Datos constituye una tarea fundamental el tratamiento de los valores ausentes. Los valores nulos y los valores ausentes pueden ser consecuencias de diferentes causas: ausencia de respuesta del cliente (por ejemplo en una encuesta), fallas en la trascripción de datos, fallas en el soporte físico de los datos, mal funcionamiento de los sistemas de adquisición de datos, no aplicabilidad del valor del campo al registro de información, entre otras. La definición de estos involucra dos formas diferentes de ver la ausencia de información (Pyle, 1999): Dato ausente: es un valor que no está en nuestro conjunto de datos; pero que existe en el mundo real, sencillamente por algún error no aparece en nuestra base de datos operacional. Dato nulo(o vacío): es un valor que está fuera de la definición de cualquier dominio, el cual permite dejar el valor del atributo “latente”. En otras palabras, un valor nulo no representa el valor cero, ni una cadena vacía, estos son valores que tienen significado; implica ausencia de información porque se desconoce el valor del atributo o. 7.
(16) Capítulo 1. simplemente para ese objeto no tiene sentido. Es un dato que falta, o sea, no existe en el mundo real. Un ejemplo pudiera ser el siguiente: supongamos que controlamos en una empresa que vende sandwich la salsa que prefieren los usuarios (supongamos dos tipos de salsa: ketchup y mostaza y que son excluyentes) y además su sexo. Llega entonces un usuario que pide un sandwich sin ninguna salsa y supongamos que el operador del sistema olvida introducir al sistema el sexo del usuario. Habrá entonces dos campos sin valor: sexo y tipo de salsa, el primero existe (el usuario tiene un sexo determinado), sin embargo el segundo no existe (el usuario no quería ninguna salsa). Al cargar estos datos en el almacén se puede “sugerir” un dato para el sexo, no así para la salsa. En los sistemas de bases de datos habitualmente no se hace diferencia entre un tipo de valor y otro, sencillamente se deja vacío el campo o en el mejor de los casos se utiliza el valor NULL. En el caso de los sistemas de Bases de Datos en nuestro país es común la no utilización de la marca NULL y en su lugar se escribe 0 (si es un dato numérico) o una cadena vacía en el caso de cadenas. Esto trae una complejidad adicional en el tratamiento de nulos pues el cero y la cadena vacía pueden tener significados concretos diferentes a la ausencia de valor. Los valores ausentes son un problema común y la mejor implementación para minimizarlo es a través de una cuidadosa administración y asegurando la calidad de los datos. Cuando estos valores son menores que 1% son generalmente considerados triviales, de 1-5 % manejables, de 5-15% requiere de métodos sofisticados para manejarlos. y. más. de. un. 15%. afecta. seriamente. cualquier. clase. de. interpretación(McDermeit et al., 1999). Los valores faltantes deben ser reemplazados por varias razones. Primero, algunas técnicas de modelación no pueden lidiar con valores faltantes y desechan todos los valores de una instancia si una de las variables tiene valor faltante. Segundo, las herramientas de modelación que usan métodos de reemplazamiento por defecto pueden introducir distorsión si el método es inapropiado. Tercero, el modelador debería conocer y controlar las características de algún método de reemplazo. Cuarto, muchos métodos de reemplazo por defecto descartan la información contenida en los patrones de valores faltantes.. 8.
(17) Capítulo 1. 1.1.3. Tipos de patrones de valores faltantes. Cuando una base de datos contiene valores faltantes cada una de las filas que contienen valores ausentes forma un modelo de patrón que puede ayudar a decidir el método de imputación de valores más eficaz a utilizar. El patrón de valores faltantes indica si hay valor faltante o no en cada una de las variables analizadas. El orden de las variables es importante porque este hace que el patrón varíe. Para la clasificación de patrones se tiene en cuenta el orden en que aparecen los valores faltantes. •. Patrón de valores faltantes monótono: Para un conjunto de datos con variables Y1, Y2, Y3,…, Yp (en ese orden) se dice que el patrón de valores faltantes es monótono si la variable Yj tiene valor faltante para un caso en particular y para todos los k donde k > j Yk tiene valor faltante para ese mismo caso. Alternativamente si Yj no tiene valor faltante en un caso en particular entonces para todos los k donde k < j Yk no tiene valor faltante para ese mismo caso.. •. Patrón de valores faltantes arbitrario: Para un conjunto de datos con variables Y1, Y2, Y3,…, Yp (en ese orden) se dice que el patrón de valores faltantes es arbitrario si la variable Yj tiene valor faltante para un caso en particular y para al menos un k donde k>j Yk no tiene valor faltante para ese mismo caso. Todo patrón que no es monótono es arbitrario.. Para el caso de patrón de valores faltantes monótonos se aplica principalmente el método paramétrico de regresión lineal múltiple que asume normalidad multivariante y el método de Monte Carlo con cadena de Markov para patrones de valores faltantes arbitrarios(Yuan, 2000, Pyle, 1999). 1.2. Tratamiento de la información faltante. Varias técnicas han sido reportadas en la literatura para solucionar los problemas ocasionados por la presencia de valores ausentes en las Bases de Datos. Después de obtenida la información sobres los modelos de valores perdidos, estos pueden reemplazarse con valores apropiados. Un camino muy fácil para tratar los valores perdidos es ignorándolos, pero de esta forma se ve afectada la calidad de la Base de Datos que contiene los valores perdidos (Redman,. 9.
(18) Capítulo 1. 1992, Wand and Wang, 1996). Cuando los atributos son valores numéricos otra forma típica de manejarlos es reemplazándolos por valores promedios, sustituyéndolos por valores mínimos, valores máximos. La inferencia del valor más probable es también usada para el llenado de estos (Little and Rubin, 1987). La sustitución por el valor más probable es útil cuando los valores son nominales pues trae problemas definir el valor más probable en un conjunto de valores continuos. Los datos perdidos que no representan un gran por ciento (<5%) se pueden reemplazar usando la media (si es normal), mediana (si es sesgado) o moda (si es categórico), donde el objetivo es comparar varios grupos (las condiciones del género o tratamiento), y a menudo es deseable hacer este reemplazo dentro de cada grupo (McDermeit et al., 1999). Si el porcentaje de los valores perdidos excede el 5%, un nuevo problema surge. Reemplazar todos los registros por un solo valor disminuirá la varianza y aumentará la significación de cualquier prueba estadística basada en el mismo. Es recomendado sustituir los datos usando métodos más avanzados: imputación hot-deck, imputación múltiple (que modela la incertidumbre a los datos que faltan mientras usa los datos existentes (Rubin, 1987) o un modelo de regresión (que predice el valor que falta en función de los otros datos disponibles)). Los modelos de regresión e imputación múltiple son más elegantes, pero mucho más difíciles porque cada variable requiere una ecuación diferente y en muchos casos múltiples ecuaciones por variable debido a que algunos predictores pueden estar perdidos (McDermeit et al., 1999). Algunas de estas técnicas prometen dar más información que otras, pero son muy complejas computacionalmente. Otras son muy poderosas bajo ciertas circunstancias pero pueden introducir sesgo en otras. La complejidad computacional es un problema. Además son matemáticamente complejas y varían según el tipo de datos a los cuales serán aplicados, consumiendo también mucho tiempo para un conjunto de datos muy grande (Pyle, 1999). Analicemos ahora algunas de estas técnicas, las cuales se diferencian entre sí por su nivel de complejidad y por la calidad de los resultados:. 10.
(19) Capítulo 1. •. Análisis de Casos Completos 2 (Giménez, 2000): Esta técnica es considerada segura y conservativa, es una de las más empleadas y de hecho está fijada por defecto en muchas aplicaciones de Estadística y Minería de Datos. También es la más sencilla: simplemente se elimina todo registro que contenga algún campo con valor ausente (puede ser flexibilizado para que elimine todo registro que tenga valores ausentes en determinados campos de interés para un análisis en particular). Cualquier otra técnica alternativa de manejo de datos ausentes debe ser estudiada y evaluada en comparación con esta técnica. En algunos casos es preferible regresar al Análisis de Casos Completos y asumir sus riesgos antes que aplicar alguna otra técnica más costosa o que genere datos de baja calidad. En la implementación de esta técnica se crear una nueva tabla donde cada uno de los campos de cada uno de los registros almacena el dato correspondiente, siendo este dato extraído de la realidad (no aproximado o calculado, sino tomado directamente de la fuente de datos). Esta técnica no introduce ruido en el conjunto de datos y solo emplea observaciones “reales” ( Stone Analystics, 2003), aunque puede resultar una disminución significativa del volumen de datos a analizar, lo que resta mucha confiabilidad a los clásicos y tradicionales estudios estadísticos, en consecuencia, los resultados obtenidos pueden tener baja confiabilidad o sesgo (Little and Rubin, 1987, Rubin, 1987, Rubin, 1996).Cuando la cantidad de casos de valores ausentes en grandes bases de datos es menor que un 5% es muy común eliminar casos de la base de datos (Garson, 2005) .. •. Sustitución por medidas de tendencia central (Giménez, 2000): Esta técnica es una de las más simples y útiles; pues hace imputaciones (asignación de un valor calculado a un campo con dato ausente) y respeta completamente al subconjunto de los datos que sí están completos. La idea es bastante simple: se calcula el valor de una medida de tendencia central (media, mediana, moda y desviación estándar) para cada variable del conjunto de datos y son reemplazados los valores ausentes de esa variable por un valor que no modifique el valor de la. 2. Traducción de Complete Case Analysis, también llamado Casewise o Listwise Deletion.. 11.
(20) Capítulo 1. medida calculada. El uso de uno u otro estadígrafo depende de la naturaleza del dato. Para variables “categóricas” o “de clase” (por ejemplo, variables cuyos valores posibles sean A, B, C y D) se utiliza la moda (el valor con frecuencia más alta, es decir, el que esté presente en el conjunto de datos un número mayor de veces); para variables “enteras” u “ordinales”, se emplea la mediana (el valor que se encuentra “en medio” de la lista de datos ordenada crecientemente, es decir, el valor que cumple que la mitad de los valores de la variable son menores a él y la otra mitad son mayores que él) y para variables “reales” o “continuas” se emplea el promedio (la sumatoria de los valores de la variable divididos por su frecuencia), o la desviación estándar. Esta técnica está incluida en algunos sistemas de ayuda y soporte al proceso de Minería de Datos como un modelo de referencia; pero debe ser utilizado con cuidado pues puede introducir sesgo en el conjunto de datos. Se pretende crear un nuevo conjunto de datos que contenga exactamente el mismo número de registros que el conjunto original, sin que haya en ellos algún dato ausente. Imputa los valores ausentes en el conjunto de datos con propiedades estadísticas bien conocidas (moda, mediana y promedio) que se sabe de seguro pertenecen al espectro de valores posibles para esas variables y que tienen una buena probabilidad de aparecer. Mantiene la validez de varias pruebas estadísticas de uso común (que trabajan sobre la esperanza, el coeficiente de correlación o la covarianza). Es una buena solución cuando la ausencia es aleatoria y está distribuida normalmente ( Stone Analystics, 2003). La sustitución por las medidas de tendencia central puede generar sesgo en los datos, pues imputa un mismo valor para cada ausencia de una misma variable (es decir, que si una variable está ausente en 20 registros diferentes, habrán 20 nuevas ocurrencias de la “media” en esa variable), lo cual puede afectar los resultados de los análisis posteriores realizados sobre los datos (por ejemplo, si se aplicara una “clasificación”, la súbita aparición de más ocurrencias de los valores medios podría causar mucha “afluencia” de registros hacia una clase en particular). •. Imputación por regresión ( Stone Analystics, 2003): Predice los valores perdidos basados en la ecuación de regresión que usa las demás variables. 12.
(21) Capítulo 1. relevantes como predictoras. Para saber que tipo de regresión usar hay que tener en cuenta el tipo de la variable que tiene la información incompleta. Si el valor que ha de imputarse es número (p. ej. la edad, el salario o los valores de presión arterial) y las variables que intervienen forman un patrón de valor faltante monótono se puede emplear la regresión múltiple. En caso que sea una variable categórica, como sexo, el estatus socioeconómico o la práctica de ejercicio físico en el tiempo libre, podría emplearse la regresión logística y hacer la imputación según la probabilidad que el modelo de regresión estimado otorgue a cada categoría para el sujeto en cuestión (Cañizares et al., 2003). Este método preserva la varianza y la covarianza de las variables con valores ausentes. Además permite trabajar con una Base de Datos completa, la que puede ser analizada empleando los procedimientos y paquetes estadísticos estándares (Cañizares et al., 2003). Si los errores estándares son ignorados cuando los valores perdidos son predecidos, puede inflar el poder del modelo de predicción puesto que los valores perdidos de las variables dependientes fueron presentados perfectamente como predictores. Además esta técnica depende de un orden de acuerdo al cual las variables serán reemplazadas. •. Método probabilístico basado en la distribución de los datos no perdidos (Martina, 2005): La idea de esta técnica es estimar la distribución de los datos disponibles en la variable donde queremos restablecer los valores perdidos y entonces, generar estos de acuerdo a dicha distribución. Puede ser implementado en 4 pasos: 1. Calcular la frecuencia de los valores válidos. Para asegurar la menor acumulación de errores en el procedimiento los datos deben ser ordenados de forma ascendente de frecuencia de valores válidos. 2. Calcular porciento válido (depende de la frecuencia) y porciento acumulado. 3. Calcular el porciento de valores perdidos y el número de valores a ser reemplazados. 4. Reemplazar los nulos por el valor válido correspondiente a la frecuencia analizada. Disminuir la cantidad de los valores perdidos.. 13.
(22) Capítulo 1. Este método se repite hasta que la cantidad de valores perdidos sea cero. •. Desviación Estándar (Pyle, 1999): La forma de la variabilidad es un concepto importante en la decisión de qué valores usar para el reemplazo. La Desviación Estándar es una medida de variabilidad. Para usarla hay que calcular un nuevo valor para cada ausencia de la variable en la Base de Datos, de tal forma que mantenga la desviación estándar. El proceso del cálculo se realiza tantas veces como valores ausentes tenga la variable. La Desviación Estándar refleja más información sobre una variable que la media. Esta no solo refleja la tendencia central sino también información sobre la variabilidad con que se distribuyen las variables. Si la ausencia es múltiple hay que hacer el cálculo tantas veces como exista, requiriendo en Bases de Datos grandes de un tiempo de cómputo enorme.. •. Eliminación de Pares de Datos 3 (Giménez, 2000): Esta técnica es mayormente empleada en los casos que requieren cálculos sobre dos variables. Usa la matriz de correlación donde la correlación entre cada par de variable es calculada desde todos los casos que han validado datos para estas variables ( Stone Analystics, 2003). Esta técnica pretende ser una mejora a la técnica de Análisis de Datos Completos, ya que bajo la hipótesis MCAR, evitaría la drástica reducción del número de registros disponibles para su estudio mientras que mantendría la calidad de los datos. Por lo tanto, esta técnica no persigue la creación de un nuevo conjunto de datos que no tenga ausencias, ni aproxima o hace imputaciones en los datos, simplemente crea un nuevo conjunto de datos que será de utilidad solo para la realización de estudios sobre un par predeterminado de variables, ya que se eliminarán solo los registros donde falten los datos correspondientes a alguna de las dos variables seleccionadas, por lo que no habrá datos ausentes dentro de ese contexto (aunque en términos generales, habría datos ausentes en el conjunto de datos, aunque no sean de notar para el estudio que se ha de realizar). No introduce ruido en el conjunto de datos y solo emplea observaciones “reales”. Además es superior a la técnica Análisis de Casos Completos en cuanto a que genera un número mucho menor de eliminaciones,. 3. Traducción de Pairwise Data Deletion. 14.
(23) Capítulo 1. por lo que se dispone de un conjunto de datos de mayor significación. Las desventajas de esta técnica superan en mucho a sus ventajas, por lo que está muy desacreditada y ya casi no se emplea. Esta depende demasiado de la hipótesis MCAR, la cual es poco frecuente y difícil de demostrar. Además debido a que emplea diferentes conjuntos de datos para un mismo análisis dependiendo de qué variables se consideren, deben prepararse varios conjuntos para cada análisis (por ejemplo, se debe crear un conjunto de datos para estudiar la relación entre las variable X y Y y otro diferente para estudiar las variables X y Z) cuando lo que se desea es hacer análisis sobre un mismo conjunto de datos, los resultados obtenidos resultan sesgados y además costosos en tiempo, esfuerzo y espacio de almacenamiento. •. Imputación múltiple (Cañizares et al., 2003, Stone Analystics, 2003): Este método genera una probabilidad máxima basada en la matriz de covarianza y el vector de las medias e introduce incertidumbres estadísticas en el modelo, usando la incertidumbre para reproducir la variabilidad natural encontrada en los datos de los casos completos. Se refiere a reemplazar cada valor ausente con más de un valor imputado. Es un enfoque basado en simulaciones donde a cada valor ausente se asignan m > 1 valores extraídos de una distribución predictiva, lo que produce m bases de datos. Después, en cada base de datos se realiza el análisis estadístico que responda al propósito del estudio, desde obtener estimaciones puntuales y sus intervalos de confianza hasta modelos de regresión. En este caso se obtienen tantos resultados del análisis realizado como imputaciones se hayan hecho. La distribución predictiva se construye a partir de los valores observados; por ejemplo, usualmente se supone que el conjunto de variables sigue una distribución normal multivariada. Para construir la distribución se necesita estimar sus parámetros: vector de medias, matriz de varianzas y covarianzas. Estas estimaciones se obtienen a partir de las unidades que tienen todos los valores observados. Una vez estimados los parámetros de la distribución, se extraen muestras independientes de ella para asignar los valores en las observaciones que no están completas; según el número de muestras que se seleccione, se tendrá tantas bases de datos para analizar (Rubin, 1987). Debido a. 15.
(24) Capítulo 1. que con este método no se predice el valor ausente, sino que se modela la incertidumbre que genera la ausencia de los datos, se preservan las relaciones entre las variables cuando se realizan las imputaciones de los valores ausentes (Shafter, 1997). Requiere la construcción de 5 a 10 Bases de Datos con valores imputados, las cuales son analizadas de forma individual, haciéndolo muy intenso en cuanto a tiempo. •. Imputación Hot Deck ( Stone Analystics, 2003): Los datos ausentes son reemplazados con valores seleccionados aleatoriamente presentados en un grupo de datos completos similares; o sea, identifica los casos más similares al caso del valor. perdido. y. sustituye. el. valor. perdido. por. ese. más. similar.. El método introduce variaciones en el grupo de los datos de casos completos que producen menos tendencia hacia la media, porque la imputación se hace a partir de estos datos seleccionados aleatoriamente. Las dos áreas principales de importancia son: la selección de los conjuntos de características válidas para identificar el grupo potencial que contiene los valores con la variación razonable, y el aseguramiento de que ese conjunto de características permitirá para grandes grupos la variación razonable. Proporciona muestras exactas de población de estudio. Tiene una simplicidad conceptual. Mantiene el nivel apropiado de la medida de las variables (las variables categóricas siguen siendo categóricas y las variables continuas siguen siendo continuas) y la disponibilidad de una matriz completa de los datos en el final del proceso de la imputación que se puede analizar como cualquier matriz completa de los datos (Services, 2004). El hecho de que los valores a reemplazar son seleccionados aleatoriamente hace que sea impropio para la predicción porque los valores dependerán de factores espurios tales como el orden de casos en los conjuntos de datos o los números seudoaleatorios (Sarle, 1998). Además es difícil definir la “semejanza”, pues puede haber cualquier número de maneras de definir qué “semejanza” está en ese contexto (Services, 2004).. 16.
(25) Capítulo 1. •. Esperanza máxima (Stone Analystics, 2003): Se implementa en dos pasos iterativos donde se estiman los parámetros de un modelo comenzando por una suposición inicial. Cada iteración consiste de dos pasos: 1- Paso de esperanza: encuentra la distribución para los valores perdidos basados en los valores conocidos de las variables esperadas y la estimación actual de los parámetros. 2- Paso de maximización: sustituye los valores perdidos con el valor esperado. El método se reitera a través de estos datos hasta que sea obtenida su convergencia. La convergencia ocurre cuando el cambio de los parámetros estimados de una iteración a otra llega a ser insignificante (Services, 2004). A pesar de ser una implementación poderosa y elegante requiere de una programación especializada lo que puede llevar a que sea costoso en tiempo. No agrega ningún componente de la incertidumbre a los datos estimados. Esto significa que mientras las estimaciones del parámetro basadas en la implementación del método son confiables, los errores estándares y los test estadísticos no lo son (Services, 2004).. •. Información Completa de la Probabilidad Máxima (FIML 4 ) ( Stone Analystics, 2003): Típicamente representado como una matriz de covarianza y el vector de medias, este método usa toda la información disponible sobre los datos observados, incluyendo las medias y las varianzas basadas en los puntos de los datos disponibles para cada variable. La probabilidad es calculada para la porción observada de cada caso de datos y entonces es acumulada y maximizada. Tiene ventajas sobre la Esperanza Máxima y es que permite el cómputo directo de errores estándares apropiados y pruebas estadísticas. No requiere de la imputación (o paso esperanza) y típicamente converge rápidamente. Además de la conveniencia del uso y la facilidad del conocimiento de las propiedades estadísticas (Services, 2004). Es difícil incluir las nuevas variables para mejorar la exactitud de los parámetros estimados de los valores perdidos, pero puede no. 4. Siglas en inglés de Full Information Maximum Likelihood. 17.
(26) Capítulo 1. ser utilizado en el modelo estadístico final como predictores. Requiere también de una programación especializada lo que puede llevar a que sea costoso en tiempo. 1.3. Conclusiones del capítulo. La limpieza de datos se encarga de mejorar la calidad de la información almacenada en las base de datos. Uno de los problemas que más afecta la calidad de los datos es la ausencia de valores, es por esto que el tratamiento de valores ausentes es una parte importante dentro de la limpieza de datos. En la literatura se reportan varias técnicas para tratar la información faltante es por esto que muchas veces es difícil decidir la técnica a utilizar. El tipo de patrón de valor faltante puede ayudar a decidir la técnica a utilizar. Es recomendable utilizar el método de regresión lineal múltiple para patrones monótonos y el método de Monte Carlo con cadena de Markov para patrones arbitrarios.. 18.
(27) Capítulo 2. CAPÍTULO 2. ANÁLISIS, DISEÑO E IMPLEMENTACIÓN DEL MÉTODO REGRESIÓN LINEAL MÚLTIPLE. En este capítulo se realiza una descripción detallada del método regresión lineal múltiple y se desarrolla el análisis y diseño de la implementación de este método al ser incorporado a la herramienta “Sistema para la sustitución de nulos en Bases de Datos” que nos permitirá conocer una descripción más detallada del problema, así como las herramientas computacionales y estadísticas utilizadas para el desarrollo del mismo. 2.1. Regresión lineal múltiple. En el método de regresión lineal múltiple, un modelo de regresión es acomodado con previas variables covariantes para cada variable que tiene al menos un valor faltante. Basado en el modelo resultante, un nuevo modelo de regresión se adapta y se usa para imputar los valores faltantes para cada variable. En el conjunto de datos que tiene patrón de valor faltante monótono, el proceso es repetido secuencialmente para cada variable con valores faltantes (Yuan, 2000). El modelo que se plantea en regresión lineal múltiple es el siguiente:. Υi = β 0 + β1 Χ1i + β 2 Χ 2i + L + β k Χ ki. (1). donde Χ1 , Χ 2 ,K, Χ k son las variables independientes o explicativas. La variable respuesta depende de las variables explicativas(López, 2008). Los métodos para tratar con problemas de predicción de una variable por medio de más de una variable, son similares a los métodos que utilizan una sola variable para la predicción. Por ejemplo si se quiere predecir la variable Υ en función de dos variables Χ 1 y Χ 2 , el problema se convierte en encontrar el plano de mejor ajuste, a un diagrama. de puntos en tres dimensiones. El ajuste del modelo se puede realizar por el método de máxima verosimilitud o el método de mínimos cuadrados. En el caso de distribución normal de errores, ambos métodos coinciden. Puesto que la ecuación de un plano cualquiera se puede escribir en la forma. Υ = β 0 + β 1 Χ1 + β 2 Χ 2 , el problema se reduce a estimar los tres parámetros β0, β1 y. β2(Hoel, 1976).. 19.
(28) Capítulo 2. El criterio de mínimos cuadrados asigna a los parámetros del modelo los valores que minimizan la suma de errores al cuadrado de todas las observaciones que la llamaremos S:. S=. n. ∑e i =1. 2. i. =. n. ⎛ − ⎛⎜ ' + ' Χ + ' Χ + L + ' Χ ⎞⎟ ⎞ ⎜Y i β 0 β 1 1i β 2 2i β k ki ⎠ ⎟⎠ ∑ ⎝ i =1 ⎝. 2. Una estrategia a seguir para calcular el mínimo de S es: • Derivar S con respecto a los parámetros, • Igualar a cero cada derivada, • Resolver el sistema de ecuaciones que resulta (y en el que las incógnitas vienen dadas por los k+1 parámetros que queremos estimar) (López, 2008). Otra estrategia y la mejor en este caso por las facilidades que brinda para implementarla es aplicando métodos matemáticos en la misma forma que para la regresión lineal simple. Resulta que los valores dados por el método de mínimos cuadrados para β 0 , β1. y β 2 se obtienen resolviendo el siguiente grupo de tres ecuaciones de primer grado (Hoel, 1976).. β 0 n + β 1 ∑ Χ1 + β 2 ∑ Χ 2 = ∑ Υ β 0 ∑ Χ1 + β1 ∑ Χ12 + β 2 ∑ Χ1 Χ 2 = ∑ Υ β 0 ∑ Χ 2 + β1 ∑ Χ1 Χ 2 + β 2 ∑ Χ 22 = ∑ Χ 2 Υ Este resultado se generaliza para n variables adicionales. Así, pues, si se tienen cuatro variables por medio de las cuales de va a predecir el valor de otra, existirán cinco ecuaciones en cinco incógnitas para resolver (Hoel, 1976). Una de las ventajas del método de aproximación por mínimos cuadrados en los problemas de regresión, es la forma tan sencilla de plantear las ecuaciones necesarias para obtener las estimaciones de los parámetros de la ecuación de regresión (Hoel, 1976). Así las ecuaciones pueden plantearse efectuando las siguientes operaciones. A partir de la ecuación (1), sumar miembro a miembro las ecuaciones resultantes para obtener la primera ecuación del sistema. Luego, multiplicar por Χ 1 ambos miembros de la ecuación de regresión modificada y sumar miembro a miembro para así obtener la. 20.
(29) Capítulo 2. segunda ecuación del sistema. Finalmente multiplicar por Χ 2 ambos miembros y sumar miembro para obtener la tercera ecuación del sistema (Hoel, 1976). Si en vez de dos parámetros se hubiera necesitado determinar cinco para obtener la ecuación de regresión, se hubiera tenido que continuar este procedimiento, multiplicando por Χ 3 y sumando miembro a miembro, luego por. Χ4 y sumando y,. finalmente, por Χ 5 y sumando, para así obtener tres ecuaciones más. De esta manera, se habría obtenido un sistema de seis ecuaciones con seis incógnitas cuya solución sería las estimaciones de los seis parámetros de la línea de regresión (Hoel, 1976). Para resolver este sistema de ecuaciones utilizamos el método de Gauss, el cual explicaremos en próximo epígrafe. El error cometido en una predicción es:. (. ei = Υi − Υi´ = Υi − β 0´ + β 1´ Χ 1i + β 2´ Χ 2i + K + β k´ Χ ki donde. ). β ´ , β ´ , K , β k´ son los valores estimados del modelo. 0. 1. Notación ⎛ Υ1 ⎞ ⎜ ⎟ ⎜Υ ⎟ Υ =⎜ 2⎟ M ⎜ ⎟ ⎜Υ ⎟ ⎝ n⎠. ⎛ Υ1´ ⎞ ⎜ ⎟ ⎜ Υ 2´ ⎟ ´ Υ =⎜ ⎟ ⎜M ⎟ ⎜Υ´ ⎟ ⎝ n⎠. ⎛ β 1´ ⎞ ⎜ ⎟ ⎜ β 2´ ⎟ ´ β =⎜ ⎟ ⎜M ⎟ ⎜β´ ⎟ ⎝ n⎠. Donde Υ es el vector n dimensional de los valores observados, Υ ´ es el vector n dimensional de los valores estimados y β ´ es el vector n dimensional de los coeficientes de regresión estimados. Χ es la denominada matriz de diseño, de dimensión n x (k+1). ⎛ 1Χ 11 Χ 21 K Χ k 1 ⎞ ⎜ ⎟ ⎜ 1Χ Χ K Χ k 2 ⎟ Χ = ⎜ 12 22 .......... .. O ...... ⎟ ⎜ ⎟ ⎜ 1Χ Χ K Χ ⎟ kn ⎠ ⎝ 1n 2 n. 21.
(30) Capítulo 2. El modelo estimado puede expresarse en forma matricial:. Υ´ = Χβ ´ Υ − Υ´ = e Un estimador razonable para la varianza, σ 2 , del error aleatorio e es, en principio, la varianza de los errores de predicción (también conocidos con el nombre de residuos del modelo):. σ. ´2. 1 T 1 n 2 = e e = ∑ ei n n i =1. ( ). Sin embargo, este estimador es sesgado para σ2, lo que significa que: Ε σ ´2 ≠ σ 2 . El sesgo se define como la diferencia entre la media del estimador y el verdadero valor del parámetro que se quiere estimar. Usaremos, por tanto, la varianza residual para estimar σ2, que sí es un estimador insesgado de σ2, es decir, centrado en torno a σ2. S. ´2 r. n 1 e i2 = ∑ n − (k + 1) i =1. Ahora hablaremos de las relaciones entre las variables.. β ´ = (Χ T Χ ) Χ T Υ −1. (. Υ ´ = Χβ ´ = Χ Χ T Χ. ). −1. Χ T Υ = ΗΥ. A la matriz Η se le conoce como la matriz de proyección. Este nombre quedará justificado una vez veamos la interpretación geométrica de la estimación. Las propiedades de la matriz Η son las siguientes: •. Es idempotente: Η Η = Η. •. Es simétrica: Η T = Η. •. Tiene el mismo rango que Χ : (k+1). Es sencillo ver que el error de predicción se puede escribir en forma matricial en términos de Η :. e = Υ − Υ ´ = Υ − ΗΥ = (Ι − Η )Υ. 22.
(31) Capítulo 2. La expresión Υ ´ = ΗΥ , indica que la matriz (la cual es idempotente), transforma el vector de observaciones en el vector de valores ajustados (o predicciones) Υ ´ . Una matriz idempotente realiza una proyección, por lo que la regresión va a ser una proyección. Para entender mejor cómo es esa proyección, vamos a estudiar las relaciones existentes entre e, Υ e Υ ´ .. El vector de residuos es perpendicular al vector de valores ajustados y a la matriz de diseño(López, 2008). Veámoslo: e ⊥ Υ´ T e ⊥ Υ ´ = [(Ι − Η )Υ ] ΗΥ = Υ T (Ι − Η )ΗΥ = Υ T ΗΗΥ = 0 e⊥Χ. (. (. e T Χ ´ = [(Ι − Η )Υ ] Χ = Υ T (Ι − Η )Χ = Υ T Χ − Χ Χ T Χ T. ). −1. ). ΧT Χ = 0. Así que el modelo de regresión Υ ´ = ΗΥ proyecta el vector de observaciones sobre el subespacio vectorial de las columnas de la matriz Χ (es decir el subespacio de las variables independientes). El vector de residuos es perpendicular a cada columna Χ de y al vector de predicción Υ ´ .. Vector de observaciones Y. e Vector de residuos. Y´ Vector de valores ajustados Esp(X) Esp (Χ ) es el subespacio vectorial formado por las columnas de de Χ , es decir por los. vectores columnas de las variables explicativas.. β ´ = (Χ T Χ ) Χ T Υ = Α −1. Sabemos que el vector de observaciones Υ. se distribuye según una normal. multivariante de media Χβ y de matriz de varianzas covarianzas σ 2 Ι n. (. Υ ~ N n Χβ , σ 2 Ι n. ). 23.
(32) Capítulo 2. β ´ es una combinación lineal de las componentes del vector Υ , así que β ´ también se distribuye según una variable aleatoria normal. A continuación, calcularemos su media y matriz de varianzas y covarianzas.. ((. Ε (β ) = Ε Χ T Χ ´. ). ). −1. (. ΧT Υ = ΧT Χ. ). −1. (. Χ T Ε(Υ ) = Χ T Χ. ). −1. ΧT β = β. β ´ es un estimador centrado de β. ( ). Var β ´ = Var (ΑΥ ) = Α ⋅ Var (Υ ) ⋅ Α T. ( ) = (Χ Χ ). = ΧT Χ T. −1. (. Χ T Var (Υ )Χ Χ T Χ. −1. (. ΧT σ 2 Χ ΧT Χ. (. β ´ ~ N k +1 β , σ 2 (Χ T Χ ). −1. ). ). −1. ). −1. (. = σ 2 ΧT Χ. ). −1. β ´ ~ N (β i , σ 2 q ii ) qii es el elemento i-ésimo de la diagonal de la matriz (Χ T Χ ) (López, 2008). −1. 2.2. Método de Gauss (Álvarez et al., 2004). La mayor parte de los métodos utilizados para la solución de sistemas lineales están. concentrados en dos grandes tipos: métodos directos o exactos y métodos iterativos o de aproximaciones sucesivas. El método Gauss entra dentro de los métodos directos. Los métodos directos son aquellos en que si se pudiera evitar todos los errores de redondeo, se obtendrá la respuesta exacta en un número finitos de pasos. Aunque el método Gauss puede ser aplicado a sistemas lineales de cualquier orden, aquí sólo interesan los sistemas cuadrados, es decir, con igual número de ecuaciones e incógnitas. Se supone además, que se trata de sistemas determinados, es decir, con solución única. El método Gauss consta de dos etapas bien diferenciadas que se llaman proceso directo y proceso inverso. Proceso Directo.. El proceso directo consiste en realizar sobre el sistema de ecuaciones transformaciones elementales de dos tipos: 1. Intercambiar dos ecuaciones del sistema. 2. Sumar a una ecuación, miembro a miembro, otra ecuación (pivote) del sistema multiplicada por un número real cualquiera.. 24.
(33) Capítulo 2. Es claro que la transformación elemental de intercambiar dos ecuaciones del sistema no cambia la solución del sistema, aunque si afecta el determinante de la matriz de los coeficientes, ya que equivale a la permutación de dos de sus filas, lo cual cambia el signo del determinante. La transformación elemental de tipo 2 no altera ni la solución del sistema ni el valor del determinante. Estas transformaciones elementales se realizan con el objetivo de transformar el sistema a la forma triangular:. C11 Χ1 + C12 Χ 2 + K + C1n Χ n = d1 C 22 Χ 2 + K + C 2n Χ n = d 2 M. C nn Χ n = d n Cuando se trabaja en forma manual (y con más razón cuando se realiza un algoritmo computacional) estas transformaciones elementales se efectúan sobre los coeficientes de las ecuaciones, los cuales se escriben en forma de una matriz de orden n por n+1 que agrupa los elementos de la matriz de coeficientes y los términos independientes, y que suele llamarse matriz ampliada del sistema la cual efectuando el proceso directo, toma la forma escalonada. Para pasar de la matriz inicial a su forma escalonada, primero se efectúan n-1 transformaciones elementales de tipo 2, utilizando la fila 1 como pivote y afectando a las filas debajo de ella, de modo que se anulen todos los elementos de la primera columna que están debajo de la diagonal, después n-2 transformaciones de tipo 2 con la fila 2 como pivote, para modificar a las filas debajo de ella de manera que se anules todos los elementos de la segunda columna debajo de la diagonal; el proceso continua hasta llegara a la fila n-1 como pivote para eliminar al coeficiente de la columna n-1 debajo de la diagonal. En el paso número i del proceso directo, en el cual la fila i-esima actúa como pivote, la fila k (k>i) se cambia de acuerdo con la fórmula:. filak := filak −. a ki´ a ii´. ( filai ). con k = i +1, i+2. donde los coeficientes se han afectado con un apóstrofe para indicar que no son necesariamente los coeficientes originales. Nótese que puede suceder que el coeficiente. 25.
(34) Capítulo 2. a´ii de la fila pivote tome valor cero o muy pequeño. En ese caso se procede a permutar la fila i por alguna de las inferiores, de acuerdo con la estrategia de selección de la fila pivote que se analizará más adelante. Proceso Inverso. Una vez obtenido el sistema triangular o su forma compacta se puede calcular Xn de la última ecuación, después Xn-1 a partir de la penúltima ecuación y así sucesivamente hasta encontrar X1 de la primera ecuación. La forma de obtener la solución, de abajo hacia arriba, le da nombre a esta parte del algoritmo. Resulta: Χn =. 1 dn C nn. Χ n −1 =. 1 C n −1, n −1. (d. n −1. − C n −1, n Χ n ). M Χ1 =. 1 (d 1 − C12 Χ 2 − C13 Χ 3 − L C1n Χ n ) C11. Estrategia de pivote. La estrategia elemental de pivote es el criterio que se utiliza para seleccionar la fila que se ha de utilizar como el pivote en cada paso del proceso directo. En esta estrategia, cuando se va a realizar el paso número i del proceso directo, se utiliza la fila i-esima como pivote a menos que el elemento de la diagonal. a ii´. sea cero o menor que el. número ε muy pequeño; en ese caso, se procede a analizar las filas por debajo de la iesima, se escoge la primera que contenga el elemento de la i-esima posición distinto de cero (o modularmente mayor que ε) y esta fila se intercambia con la fila i; si todas las filas tuvieran cero en su elemento i , entonces la matriz original sería singular, contrario a lo que se ha supuesto. Esta estrategia es muy fácil de implementar pero se corre el riesgo de que el elemento. a ii´. que forma el denominador de la fórmula que cambia la. fila k en el proceso directo sea muy pequeño. En ese caso la fila i-esima puede ser multiplicada por un número muy grande y esto produce una ampliación de los errores. 26.
(35) Capítulo 2. absolutos que contiene esta fila debido a los redondeos y su propagación hasta ese momento. En sistemas un poco grandes esta acumulación y amplificación de errores puede llevar a resultados desastrosos. 2.3. Modelación del sistema. El éxito de los proyectos de desarrollo de aplicaciones o sistemas se debe a que sirve. como enlace entre quien tiene la idea y el desarrollador. El UML 5 (Lenguaje Unificado de Modelado) es una herramienta que cumple con esta función, ya que le ayuda a. capturar la idea de un sistema para comunicarla posteriormente a quien está involucrado en su proceso de desarrollo; esto se lleva a cabo mediante un conjunto de símbolos y diagramas(Schmuller, 2000). Mediante algunos de los diagramas que brinda el lenguaje UML se hizo la modelación del sistema. Estos diagramas son: •. Diagramas de Casos de Uso para modelar los procesos de negocio.. •. Diagramas de Actividad para modelar el comportamiento de los objetos en el sistema.. •. Diagramas de Clases para modelar la estructura estática de las clases en el sistema (TLDP-ES/LuCAS, 2006).. 2.3.1. Diagrama de Casos de uso. El caso de uso es una estructura que ayuda a los analistas a trabajar con los usuarios para determinar la forma en que se usara un sistema. Con una colección de casos de uso se puede hacer el bosquejo de un sistema en términos de lo que los usuarios intenten hacer con él. La idea es involucrar a los usuarios en las etapas iniciales del análisis y diseño del sistema. Esto aumenta la probabilidad de que el sistema sea de mayor provecho para la gente a la que supuestamente ayudará, en lugar de ser un manojo de expresiones de computación incomprensibles e inmanejables por los usuarios finales.. 5. Siglas en inglés de Unified Modeling Language. 27.
(36) Capítulo 2. Figura 2.1 Casos de uso para el actor Analista de Datos.. Figura 2.2 Especificación del Caso de uso Conectarse a la BD.. Figura 2.3 Especificación del Caso de uso Reemplazar Valores Nulos.. En el sistema que se propone solo hay un actor que a través de tres casos de usos interactúa con él. En la figura 2.1 se presenta este diagrama para el actor Analista de Datos, a continuación describimos los casos de uso para este actor: 1.. Conectarse a la BD (Base de Datos): este caso de uso es el encargado de realizar la conexión a la BD. El actor del sistema es el responsable de seleccionar el proveedor, introducir los datos necesarios para el proveedor seleccionado y elegir la BD a la cual desea conectarse. (Ver figura 2.2).. 2.. Reemplazar valores nulos: Después de lograda la conexión a la BD de seleccionar la tabla y el campo a tratar este caso de uso se responsabiliza de realizar el reemplazo de nulos por uno de los métodos de sustitución, ya sea por el método de. 28.
(37) Capítulo 2. casos completos ,por regresión lineal simple, por regresión lineal múltiple, por el método de sustitución por valores de otra tabla o por otros de los métodos estadísticos implementados en la herramienta (media, moda, mediana, desviación estándar.(Ver figura 2.3). 2.3.2. Diagrama de Actividades. Un diagrama de actividades ha sido diseñado para mostrar una visión simplificada de lo que ocurre durante una operación o proceso, este describe una secuencia de actividades que pueden exhibir un comportamiento en paralelo o estar sujetas a condiciones lógicas. Los diagramas de actividades de la figura 2.4, figura 2.5 muestran el conjunto de actividades que realiza un determinado objeto durante la ejecución de la aplicación. La siguiente figura muestra el diagrama de actividades para el caso de uso conectarse a la base de datos que es una de las modificaciones que se le hizo al sistema.. 29.
(38) Capítulo 2. Figura 2.4 Diagrama de Actividad para el caso de uso Conectarse a la BD.. A continuación se muestra el diagrama de actividades para el caso de uso reemplazar nulos en específico el método regresión múltiple que fue añadido al sistema.. 30.
(39) Capítulo 2. Figura 2.5 Diagrama de Actividades para el caso de uso Reemplazar valores nulos.. 31.
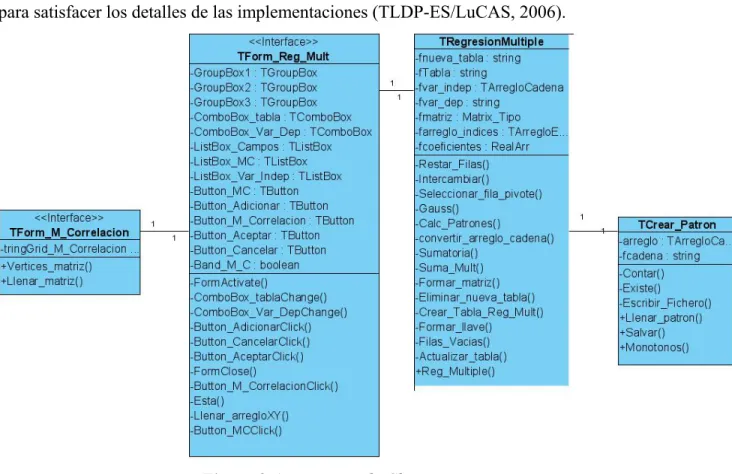
(40) Capítulo 2. 2.3.3. Diagrama de Clases. El Diagrama de Clases es el diagrama principal de diseño y análisis para un sistema. En él, la estructura de clases del sistema se especifica con relaciones entre clases y estructuras de herencia. Durante el análisis del sistema, el diagrama se desarrolla buscando una solución ideal. Durante el diseño, se usa el mismo diagrama, y se modifica para satisfacer los detalles de las implementaciones (TLDP-ES/LuCAS, 2006).. Figura 2.6 Diagrama de Clases.. Las clases desarrolladas en la inclusión del método Regresión Múltiple, juntamente con sus atributos y métodos son mostradas en la figura 2.6. El método Regresión Múltiple es aplicable solo a campos continuos. Para almacenar el contenido de los campos que intervienen en la predicción de los valores a imputar se utilizó TArregloReal, que es un arreglo de reales. También se usaron otros tipos de datos que pertenecen al conjunto de TFieldType. TipoEntero = set of TFieldType; Æ Tipo de dato integer. TipoReal = set of TFieldType; Æ Tipo de dato real. TipoCadena =set of TFieldType ; Æ Tipo de dato string.. 32.
(41) Capítulo 2. TipoFecha = set of TFieldType; Æ Tipo de dato ftDateTime, ftTime, ftDate. TipoDinero = set of TFieldType; Æ Tipo de dato ftCurrency, ftBCD, ftFMTBcd. TipoIndeterminado = set of TFieldType; Æ Tipo de dato ftUnknown, ftVariant. Matrix=array of array of string; Æ Matriz de cadena. Matrix_Tipo= array of array of real; Æ Matriz de reales. Matrix_Regresion = array of array of array of real; Æ Arreglo tridimensional de reales Matrix_Continuos = array of array of real; Æ Matriz de reales. Las clases fundamentales que se le añadieron o se le modificaron al sistema junto con sus principales atributos y métodos, se relacionan a continuación: 1.. TRegresionMultiple. Clase donde se implementa el método Regresión Múltiple, se determinan los registros donde se hará la imputación, se calcula los coeficientes de regresión, se predicen los valores a introducir en lugar de los valores nulos y se crea una nueva tabla con los valores nulos reemplazados. Los atributos de esta clase son: 3.fTabla: string; Æ En este atributo se almacena el nombre de la tabla a la que se le reemplazarán los nulos. 4. fvar_indep: TArregloCadena; Æ Este atributo almacena el nombre de los campos que representan las variables independiente. 5. fvar_dep: string; Æ Este atributo almacena el nombre del campo que representa la variable dependiente. 6. fmatriz: Matrix_Tipo; Æ Este atributo es un arreglo bidimensional que almacena los valores de las variables independientes y de la variable dependiente necesarios para hallar los coeficientes de la ecuación de regresión. 7. farreglo_indices: TArregloEntero; Æ Este atributo es un arreglo que almacena los índices de la tabla donde están los valores nulos a reemplazar. 8. fcoeficientes: RealArr; Æ Este atributo es un arreglo que almacena los coeficientes de la ecuación de regresión calculados. Los métodos de esta clase:. 33.
Figure



+7




Documento similar