LNE2NEXI: traductor de consultas del lenguaje natural a NEXI con analizador sintáctico
85
0
0
Texto completo
(2) DICTAMEN. El que suscribe. ,. hago constar que el trabajo titulado fue. realizado. en. la. Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de. , autorizando. a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio. Fecha.
(3) Pensamiento. Nunca consideres el estudio como un deber, sino como una oportunidad para penetrar en el maravilloso mundo del saber. Albert Einstein.
(4) Agradecimientos “El agradecimiento es la memoria del corazón” A mi mamá Raquel por su amor, por su comprensión, por darme la vida y estar conmigo cuando la necesito. A mi papá Ernesto por ser un padre ejemplar, por ser cariñoso, por educarme y guiarme siempre por el buen camino. A mi abuela Lucila por estar siempre pendiente de mí. A mi padrastro Osvaldo por haberme respetado y ayudado. A mi hermanita Elienys por ser tan cariñosa conmigo. A mi primo Alejandro por ser el hermano varón que nunca tuve. A mi abuelo Nito por su compresión y apoyo. A mi abuelos Miriam y Oriol por su ayuda. A mi padrino Luis por darme un gran apoyo y por tratarme como un hijo. A mis tíos por preocuparse tanto por mí. A toda la familia, a mis amigos y a todo el que de una forma u otra ha contribuido en mi formación. A mi tutor Darien. por insertarme en este trabajo que tanto ha aportado a mi formación. profesional, además por la ayuda que me ha dado. Ernesto.
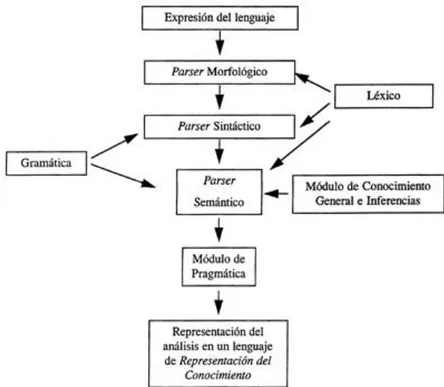
(5) Resumen RESUMEN Para interactuar con los Sistemas de Recuperación de Información sobre documentos XML, los usuarios deben expresar tanto su necesidad de contenido como las restricciones estructurales en forma de una consulta estructurada. Históricamente, estas consultas estructuradas han sido elaboradas en lenguajes formales, tales como XPath o NEXI. Desafortunadamente, los lenguajes formales de consulta son demasiado complejos para ser utilizados por los usuarios inexpertos, y están estrechamente ligados a la estructura física subyacente de la colección de documentos XML. La presente investigación se basa en la idea de especificar el contenido de los usuarios y las necesidades estructurales a través de consultas en lenguaje natural. Consecuentemente, se. desarrolló. un. traductor que transforma. consultas. formuladas en lenguaje natural a NEXI, que incluye un parser que verifica si las consultas obtenidas están correctas sintácticamente..
(6) Abstract ABSTRACT To interact with information retrieval systems on XML documents, users must express both their need for content and structural constraints in the form of a structured query. Historically, these structured queries have been developed in formal languages such as XPath or NEXI. Unfortunately, formal query languages are too complex to be used by inexperienced users, and are closely linked to the underlying physical structure of the collection of XML documents. This research is based on the idea of specifying users' content and structural needs through natural language queries. Consequently, it is developed a translator that converts natural language queries to NEXI. This translator includes a parser which checks if obtained queries are syntactically correct..
(7) Tabla de contenidos TABLA DE CONTENIDOS INTRODUCCIÓN ....................................................................................... 1 CAPÍTULO 1. INTERFAZ DE CONSULTA EN LENGUAJE NATURAL EN LOS SISTEMAS DE RECUPERACIÓN DE INFORMACIÓN SOBRE DOCUMENTOS XML ................................................................... 5 1.1 Introducción .......................................................................................... 5 1.1.1 Recuperación de información en documentos XML ...................... 7 1.1.1.1 Desafíos en la recuperación de información sobre documentos XML ................................................................................ 7 1.1.1.2 Visiones de los documentos XML ......................................... 10 1.1.1.3 Tipos de consultas en los documentos XML ......................... 10 1.2 Evento INEX ....................................................................................... 11 1.2.1 Restricciones en las consultas ..................................................... 12 1.2.2 Presentación del formato ............................................................. 13 1.3 Lenguajes de consultas para documentos XML ................................. 14 1.3.1 XPath ........................................................................................... 14 1.3.2 XQuery......................................................................................... 15 1.3.3 NEXI ............................................................................................ 17 1.4 Desventajas de los lenguajes estructurados ...................................... 18 1.4.1 Soluciones previas del NLP en la RI-XML ................................... 19 1.4.2 Soluciones previas de los traductores de LN a NEXI .................. 20 1.5 Consideraciones finales ..................................................................... 22 CAPÍTULO 2. TRANSFORMACIÓN DE LAS CONSULTAS DE LENGUAJE NATURAL A NEXI ............................................................... 23 2.1 Introducción ........................................................................................ 23 2.2 Características generales del lenguaje de consultas NEXI ................ 24 2.2.1 Consultas de tipo CO en NEXI .................................................... 24 2.2.2 Consultas de tipo CAS en NEXI .................................................. 25 2.2.2.1 Ruta de especificación ......................................................... 26 2.2.2.2 Cadena de filtrado ................................................................. 27.
(8) Tabla de contenidos 2.2.2.3 Aritmética de filtrado ............................................................. 28 2.2.2.4 Operadores lógicos ............................................................... 28 2.3 Procesamiento del lenguaje natural .................................................. 30 2.3.1 Técnicas que se aplican para el tratamiento del lenguaje natural.. ................................................................................................. 31 2.3.2 NLP y la RI.................................................................................. 35 2.4 Herramienta que realiza el proceso de traducción de LN a NEXI ...... 36 2.4.1 Análisis de la estructura ............................................................... 37 2.4.2 Clasificación de la solicitud de información.................................. 40 2.4.3 Clasificación de operadores lógicos y relacionales ..................... 40 2.4.4 Clasificador del lenguaje ............................................................ 41 2.4.5 Formulación de consultas en NEXI .............................................. 42 2.5 Módulo para realizar el análisis sintáctico de las consultas en NEXI . 43 2.6 Consideraciones finales ..................................................................... 44 CAPÍTULO 3. INTERACCIÓN CON LA HERRAMIENTA ....................... 45 3.1 Guía de usuario .................................................................................. 45 3.2 Pruebas realizadas a la herramienta .................................................. 49 3.3 Vulnerabilidades de la herramienta .................................................... 54 3.4 Consideraciones finales ..................................................................... 56 CONCLUSIONES .................................................................................... 57 RECOMENDACIONES ............................................................................ 58 BIBLIOGRAFÍA ....................................................................................... 59 ANEXOS. ................................................................................................. 62.
(9) Introducción INTRODUCCIÓN Formular una consulta en lenguaje natural y obtener una respuesta pertinente es lo que el usuario frecuente echa de menos en el proceso de recuperación de información. Además, como el lenguaje natural es la mejor manera hasta ahora para exponer nuestra necesidad de información, su uso ayudaría en gran medida a cualquier Sistema de Recuperación de Información (SRI) si la consulta se analiza correctamente. Sin embargo, en la actualidad, las técnicas de Procesamiento del Lenguaje Natural (NLP, siglas en inglés) no están lo suficientemente desarrolladas para acercarse a la percepción humana del lenguaje, y los resultados reales aún no se ajustan a los que podríamos esperar [1]. En el caso de los SRI "tradicionales", donde los documentos se consideran solo como texto (documentos planos), los motores de búsqueda clásicos necesitan una consulta compuesta por una lista de términos o palabras claves. Redactar este tipo de consultas es muy simple para el usuario ocasional, y el valor añadido por las técnicas de NLP no vale la pena debido a la complejidad de las mismas. Por otra parte, se han desarrollado muchas interfaces en lenguaje natural (NLI, siglas en inglés) para consultar documentos estructurados como bases de datos; la mayoría de ellos mediante la transformación del lenguaje natural al lenguaje de consultas SQL [2]. Los beneficios que se pueden obtener usando estas interfaces son mucho más altos que en la Recuperación de Información (RI) tradicional. De hecho, SQL (y cualquier lenguaje de consulta estructurado) es apenas usado por los usuarios inexpertos. Además, el empleo directo de estos lenguajes exige al usuario conocer la estructura de la base de datos (o de los documentos). La Recuperación de Información sobre documentos XML (RI-XML) se enmarca entre estos dos dominios pues combina características de la RI tradicional y la RI sobre bases de datos. Debido a que los documentos XML separan el contenido de su estructura, los Sistemas de Recuperación de Información sobre documentos XML (SRI-XML) son capaces de retornar como respuesta a una consulta resultados más específicos dentro de un documento y no el documento en su totalidad. Para que el usuario tome ventaja de esta posibilidad se necesita una interfaz lo suficientemente flexible que recoja tanto los requerimientos estructurales 1.
(10) Introducción como los de contenido de sus consultas. Históricamente, los SRI-XML han utilizado dos tipos de interfaces: una basada en palabras claves y otra basada en un lenguaje de consulta establecido con este fin. Los primeros son por lo general fáciles de usar, pero son incapaces de expresar las necesidades estructurales del usuario. En comparación, las interfaces basadas en algún lenguaje de consulta son capaces de expresar las necesidades estructurales de los usuarios (así como las necesidades de contenidos), pero no son prácticos para un uso operativo toda vez que son muy difíciles de utilizar, especialmente para los usuarios no expertos; además de que están atadas a la estructura física del documento [3]. El lenguaje de consultas NEXI (Narrowed Extended XPath I) [4] para la RI-XML se introdujo en el 2005 como un lenguaje derivado de XPath [5] que elimina aspectos limitantes de este e incorpora nuevas características. La diferencia más significativa con XPath es la semántica. Mientras que en XPath se define la semántica, en NEXI el motor de recuperación debe deducir la semántica a partir de la consulta. En la literatura se reportan diversos trabajos que tratan el empleo de técnicas de procesamiento del lenguaje natural para transformar consultas a lenguajes de recuperación de información ya establecidos como XPath y sus variantes, NEXI, etc. [3, 6-14]. Sin embargo estos trabajos usan como lenguaje natural al idioma inglés y algunas de las herramientas obtenidas como resultado de sus investigaciones no son de carácter público. Atendiendo a lo expuesto anteriormente se percibe como problema de investigación la necesidad de una herramienta que transforme consultas formuladas en lenguaje natural sobre el idioma español al lenguaje de consultas NEXI para ser usada en un SRI-XML. De esta forma, el objetivo general del presente trabajo es desarrollar una herramienta en el lenguaje de programación Java que transforme consultas formuladas en lenguaje natural sobre el idioma español a NEXI. Para dar cumplimiento a este objetivo se plantean los siguientes objetivos específicos: 1. Desarrollar una herramienta que transforme las consultas formuladas en lenguaje natural a NEXI haciendo uso de técnicas de procesamiento del lenguaje natural. 2.
(11) Introducción 2. Implementar un analizador sintáctico que verifique la sintaxis de las consultas escritas en NEXI y adicionarlo a la herramienta anterior. Justificación de la investigación: El. volumen. de. información. electrónica. existente. en. la. actualidad. es. extremadamente grande y crece rápidamente, por lo que cada vez son más necesarios SRI eficientes que permitan obtener en cada momento aquellos documentos que respondan a una necesidad informativa dada. Debido a la amplia aceptación del lenguaje XML como estándar para el modelado, almacenamiento e intercambio de datos estructurados, su potencialidad para mezclar información estructurada y no estructurada, así como a las ventajas que ofrece para la RI, este formato de datos constituye el más popular para representar documentos estructurados que formarán la colección documental de un SRI estructurado. Los resultados de esta investigación se podrán aplicar en múltiples escenarios con un impacto positivo desde el punto de vista social, educacional y económico, pues contribuirá a la incorporación en los Sistemas de Información existentes de un motor de búsqueda sobre documentos estructurados (XML), con una interfaz de consulta en lenguaje natural. El traductor que se obtendrá podrá ser adaptado para que tenga una aplicabilidad inmediata en diversos escenarios como en la medicina, bibliotecas o repositorios científicos; permitiéndoles a los usuarios obtener información relevante sobre una colección de documentos XML formulando una consulta en lenguaje natural. Viabilidad de la investigación: El volumen de trabajo que implica este proyecto se puede ajustar a un período de seis meses; teniendo en cuenta que existen los equipos y recursos necesarios para su desarrollo. Con el propósito de brindar una adecuada exposición de los resultados obtenidos en esta investigación el resto del documento queda estructurado de la siguiente manera: en el primer capítulo se repasan los conceptos generales de la RI a través del estudio de los SRI. Por la importancia que tiene para el desarrollo de esta investigación, se estudia de manera especial la RI-XML. Se realiza una breve descripción de los lenguajes de consulta y las ventajas del NLP para la RI-XML. Se 3.
(12) Introducción efectúa una revisión de las soluciones previas al NLP en la RI-XML, haciendo énfasis en los sistemas que traducen de lenguaje natural a NEXI. En el capítulo dos se detalla el mecanismo de traducción utilizado para transformar las consultas del lenguaje natural español a NEXI, y se describe la implementación de un analizador sintáctico para realizar el análisis sintáctico de las consultas en NEXI. Finalmente, en el tercer capítulo se describen los aspectos fundamentales a tener en cuenta para el uso de la herramienta obtenida. Se realizan pruebas al software y se analizan las vulnerabilidades que este presenta.. 4.
(13) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML CAPÍTULO 1. INTERFAZ DE CONSULTA EN LENGUAJE NATURAL EN LOS SISTEMAS DE RECUPERACIÓN DE INFORMACIÓN SOBRE DOCUMENTOS XML En este capítulo se repasan los conceptos generales de la RI a través del estudio de los SRI. Por la importancia que tiene para el desarrollo de esta investigación, se estudia de manera especial la RI-XML. Se realiza una breve descripción de los lenguajes de consultas y las ventajas del NLP para la RI-XML. Además, se efectúa una revisión de las soluciones previas al NLP en la RI-XML, haciendo énfasis en los sistemas que traducen de lenguaje natural a NEXI. 1.1 Introducción La RI es una disciplina que desde hace varios años está experimentando un renovado interés debido al aumento de la disponibilidad de documentos en formato electrónico y la necesidad de obtener en cada momento aquellos que respondan a una necesidad informativa dada. Según [15] la RI es el conjunto de acciones, métodos y procedimientos para la representación, almacenamiento, organización y recuperación de la información. El objetivo fundamental de la RI es, dada una necesidad de información y un conjunto de documentos, obtener los documentos relevantes para esa necesidad, ordenarlos en función del grado de relevancia, y presentarlos al usuario. Se define relevancia como la medida de cómo un documento se ajusta a una consulta, entendiéndose como consulta una expresión formal de la necesidad informativa del usuario. Se habla de recuperación de información automática cuando las tareas indicadas anteriormente se lleven a cabo con un ordenador, definiendo un Sistema de Recuperación de Información como el software concebido para cumplimentarlas, cuyo objetivo fundamental es brindarle a un usuario que ha articulado una consulta toda la información que la satisfaga. Los SRI son comparados frecuentemente con BD relacionales. Tradicionalmente, los SRI utilizan como fuentes de datos texto no estructurado, mientras que las BD 5.
(14) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML son diseñadas para consultar datos relacionales: registros que tienen valores para atributos predefinidos como número de empleado, título, salario, entre otros. Existen diferencias significativas entre los SRI y los Sistemas de Gestión de Bases de Datos Relacionales (SGBDR) en términos del modelo de recuperación, estructuras de datos y lenguajes de consulta. Algunos problemas que requieren consultar texto estructurado son manejados más eficazmente por una base de datos relacional, donde una consulta en lenguaje SQL puede ser suficiente para satisfacer una necesidad de información con altos niveles de precisión y exhaustividad. Sin embargo, muchas fuentes de datos estructurados que contienen texto son modeladas como documentos estructurados en lugar de datos relacionales. Estos documentos pueden representar obras literarias, artículos científicos, vídeos anotados, historiales médicos, entre otros [16]. Reflexionando brevemente sobre el concepto de documento, se pueden citar múltiples ejemplos en los que, a pesar de poder considerarse este como una unidad indivisible, resulta más natural tratarlo como un conjunto de partes: Un libro podría dividirse en capítulos, estos a su vez en secciones y las secciones incluso se podrían estructurar en párrafos. En caso de una obra de teatro tendríamos más divisiones: actos, escenas, discursos y líneas. Un artículo científico normalmente consta de resumen, una serie de secciones (cada una pudiendo dividirse en varias subsecciones y así sucesivamente), referencias bibliográficas, agradecimientos, entre otras. Historias clínicas de pacientes, donde se suele seguir una estructura rígida en cuanto a las partes que la componen y su orden [17]. A la búsqueda que se realiza sobre tales documentos se le denomina recuperación estructurada y los sistemas que la ponen en práctica Sistemas de Recuperación de Información Estructurada [16]. Actualmente,. el. estándar. más. difundido. para. representar. documentos. estructurados es el XML. En el contexto de la RI, los SRI cuya colección documental está formada por este tipo de documentos se denominan Sistemas de 6.
(15) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML Recuperación de Información sobre documentos XML y con estos, ha surgido un importante campo de investigación dentro de la RI estructurada que es la RI en documentos XML. 1.1.1 Recuperación de información en documentos XML Debido a la amplia aceptación del lenguaje XML como estándar para el modelado, almacenamiento e intercambio de datos estructurados, su potencialidad para mezclar información estructurada y no estructurada, así como a las ventajas que ofrece para la RI, este formato de datos constituye el más popular para representar documentos estructurados que formarán la colección documental de un SRI estructurada. En las secciones siguientes se presentarán los desafíos que tienen lugar en la RIXML; las diferencias entre los documentos XML orientados a los datos y orientados al contenido, sus variantes de recuperación y las formas de presentación de las consultas. 1.1.1.1 Desafíos en la recuperación de información sobre documentos XML En esta sección se abordaron los desafíos que trae consigo la recuperación de información cuando la colección documental está formada por documentos XML y se presentan nuevos retos que tienen lugar para este tipo de documento estructurado. El primer desafío que presenta la RI a partir de documentos XML es que los usuarios requieren que el sistema devuelva como resultado de sus búsquedas partes de documentos (ejemplo: elementos XML) y no documentos completos como es usual en los SRI clásicos. Un criterio para seleccionar la parte del documento más apropiada es seguir el principio de recuperación de documentos estructurados: un sistema siempre debe recuperar la parte más específica de un documento en respuesta a una consulta [18]. Este principio motiva la estrategia de recuperación que devuelve la unidad más pequeña que contiene la información buscada, y no retornar nada por debajo. 7.
(16) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML de este nivel. Sin embargo, esto puede resultar difícil de implementar algorítmicamente [16]. Paralelo al problema de cuáles partes de un documento retornar al usuario, aparece el problema de cuál parte del documento indexar o simplemente encontrar la unidad de indexación correcta. En la RI no estructurada seleccionar la unidad de indexación adecuada resulta bastante simple. En cambio, en la recuperación estructurada existen diferentes variantes para definirla. Un enfoque es agrupar los nodos en pseudo-documentos que no se solapen como se muestra en la figura 1.1. En el ejemplo, libros, capítulos y secciones se han diseñado para que constituyan unidades de indexación. La desventaja de este enfoque es que los pseudo-documentos pueden no tener sentido para el usuario porque son unidades semánticamente incoherentes.. Figura 1.1 Representación de nodos no solapados como unidades de indexación.. Otro método es usar uno de los elementos más extensos como unidad de indexación; por ejemplo, el elemento libro en una colección de libros. Se pueden postprocesar los resultados de la búsqueda para encontrar para cada libro el subelemento más relevante a la consulta. Desafortunadamente este proceso de recuperación en dos partes falla en retornar el mejor subelemento para muchas 8.
(17) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML consultas, debido a que la relevancia de un elemento en su totalidad no es frecuentemente un buen predictor de la relevancia de los subelementos que lo componen. En lugar de recuperar unidades extensas e identificar los subelementos relevantes se pueden buscar todos los nodos hojas, seleccionar los más relevantes y propagarlos a elementos más extensos. Este enfoque presenta problemas similares a los del anterior: la relevancia de los nodos hojas no es frecuentemente un buen predictor de la relevancia de los elementos en los que están contenidos. El método menos restrictivo es indexar todos los elementos. Esto tiene el inconveniente de que muchos elementos XML no tienen importancia para las búsquedas, como elementos tipográficos o números que no tienen significado sin un contexto asociado. Además, indexar todos los elementos podría inducir a que los resultados de las búsquedas sean sumamente redundantes. El anidamiento de elementos en un documento XML suele igualmente traer problemas de redundancia a la hora de presentar los resultados al usuario y para calcular la relevancia de los términos. En la mayoría de los enfoques, los resultados contienen elementos anidados. Se pueden eliminar algunos elementos en un postprocesamiento para reducir la redundancia o se pueden colapsar los elementos anidados en la lista de resultados y resaltar los términos de la consulta para enfocar la atención del usuario a los fragmentos de texto relevantes. Otro desafío relacionado con el anidamiento es que se necesita distinguir contextos diferentes de un término cuando se calculan las estadísticas del mismo para el ordenamiento, en particular la frecuencia documental inversa. Una posible solución para esto es calcular la frecuencia documental inversa para pares término/contexto [16]. En muchas ocasiones, tienen lugar esquemas XML diferentes en una misma colección, pues los documentos XML provienen de fuentes diferentes. Este fenómeno se denomina heterogeneidad o diversidad de esquemas y representa otro desafío a tener en cuenta en la RI-XML. En [16] se presenta una explicación detallada del mismo y posibles soluciones. 9.
(18) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML 1.1.1.2 Visiones de los documentos XML Atendiendo al contenido del documento XML y a su estructura interna, estos pueden clasificarse de dos formas diferentes: vista del documento centrada en los datos y vista del documento centrada en el contenido. Los documentos que se orientan siguiendo el primer enfoque se usan fundamentalmente entre aplicaciones de empresa como un formato de intercambio para datos estructurados, donde predominan valores numéricos o datos del tipo atributo-valor y el texto representa usualmente una pequeña fracción del total de datos. del. documento.. Frecuentemente. son. usados. como. una. nueva. representación del esquema relacional. Por otra parte los documentos orientados al contenido utilizan el lenguaje como el formato para representar su estructura lógica y se identifican por presentar textos extensos, como secciones de una obra literaria. La recuperación de información en los documentos orientados al contenido se caracteriza por un emparejamiento inexacto y un ordenamiento de los resultados. En cambio, en los documentos orientados a los datos, las consultas suelen imponer. condiciones. exactas. de. emparejamiento,. enfatizando. en. las. características estructurales de los mismos. Dado que los SGBDR están mejor equipados para manejar restricciones estructurales, muchos de los sistemas de recuperación de documentos XML orientados a los datos son extensiones de sistemas de bases de datos relacionales. Una visión más general de la integración de la RI-XML y las BD se presenta en [19]. 1.1.1.3 Tipos de consultas en los documentos XML Una de las ventajas que presentan los SRI estructurada es la posibilidad de incluir diferentes tipos de consultas. Un documento estructurado, específicamente en formato XML, permite refinar la consulta incluyendo algún tipo de información sobre la estructura. Por ejemplo, si se consulta una colección de artículos científicos se podría restringir la búsqueda a una cierta unidad estructural, como el. 10.
(19) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML título o el resumen. De manera general se distinguen dos tipos de consulta para documentos estructurados: Consultas de tipo “solo contenido” (CO, content only, siglas en inglés): equivalentes a las consultas clásicas de los SRI, se construyen solo con términos o palabras claves. Consultas de tipo “contenido y estructura” (CAS, content-and-structure, siglas en inglés): presentan restricciones estructurales en adición a los términos o palabras claves. Este tipo de consultas se puede tratar siguiendo dos enfoques: o SCAS (Strict content-and-structure, siglas en inglés): recuperan elementos relevantes que emparejan exactamente con la estructura especificada en la consulta. o VCAS (Vague content-and-structure, siglas en inglés): recuperan elementos relevantes que pueden no ser los mismos que los elementos de la consulta, pero son similares desde el punto de vista estructural; o recuperan elementos relevantes incluso si no cumplen con las condiciones estructurales, tratan la especificación de la estructura en la consulta como una sugerencia para la búsqueda. Frecuentemente, asociado a las consultas de tipo CAS, se presenta un lenguaje específico de consulta. Un modelo para obtener un lenguaje de consulta de contenido y estructura puede encontrarse en [20]. Otra propuesta de lenguaje de consulta, ampliamente utilizado, es el NEXI, propuesto en [4] además de ser tratado con más detalle posteriormente en este trabajo. 1.2 Evento INEX El amplio uso de XML en bibliotecas digitales, catálogos de productos, repositorios de datos científicos y en la Web ha impulsado el desarrollo de adecuados métodos de búsqueda y navegación de documentos XML. El principal punto de encuentro para la comunidad que investiga en el área de la RI-XML es el programa INEX, un esfuerzo colaborativo que ha producido colecciones de referencia, conjuntos de consultas y juicios de relevancia para la evaluación de los SRI-XML. 11.
(20) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML Esta iniciativa ofrece una oportunidad a los participantes para evaluar sus métodos de recuperación mediante procedimientos uniformes de puntuación y un foro para que las organizaciones participantes puedan comparar sus resultados. Como parte de un esfuerzo a gran escala para mejorar la eficiencia de la investigación en recuperación de datos y bibliotecas digitales, este proyecto inicia un esfuerzo internacional coordinado para promover los procedimientos de evaluación para la RI-XML. Las organizaciones participantes contribuyen a la construcción de un gran banco de pruebas de documentos XML. En el año 2002, la colección INEX estaba compuesta por 12,000 artículos de las publicaciones de la IEEE y fue expandida en el 2005. Desde el 2006 INEX usa como colección de prueba la Wikipedia en Inglés, la cual es mucho más extensa. Más información sobre este programa se puede consultar en [21, 22]. 1.2.1 Restricciones en las consultas Para obtener consultas individuales que sean útiles para fines de evaluación estas deberán cumplir los requisitos que se explican a continuación: • Cada consulta debe contener al menos un about (), cláusula que exige una interpretación de RI (no cuantitativa). Esta cláusula debe ocurrir en el filtro final. En la consulta //A[B], esta es la B. En //A[B]//C[D], es D. • No debe ser un simple proceso mecánico para resolver la ruta de acceso. Para satisfacer este requisito, toda consulta debe ser en la forma //A[B] ó //A [B] //C[D]. La forma //A[B]//C no se permite en INEX porque la resolución de C desde A[B] es un proceso mecánico. Además, al desarrollar un tema para INEX: • Se debe tener más de 5 resultados conocidos. Si esto no puede ser satisfecho, se abandona la consulta y se elije otra. • Debe ser “medio” complejo. Realizar la búsqueda y examinar los primeros 25 resultados. Si hay menos de 2 o más de 20 resultados relevantes, la consulta no es de mediana complejidad.. 12.
(21) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML • Las consultas deben reflejar una necesidad de información real. • Las consultas deben ser diversas. 1.2.2 Presentación del formato Las consultas son presentadas en el formato de consulta INEX detallado cada año en el informe anual en las directrices para el desarrollo de la consulta [23]. Se detallará aquí el formato 2003, que no ha cambiado en talleres posteriores. <?xml version="1.0" encoding="ISO-8859-1" ?> <!ELEMENT inex_topic (title, description, narrative, keywords)> <!ELEMENT title (#PCDATA)> <!ELEMENT description (#PCDATA)> <!ELEMENT narrative (#PCDATA)> <!ELEMENT keywords (#PCDATA)> <!ATTLIST inex_topic topic_id CDATA #REQUIRED query_type CDATA #REQUIRED> <inex tema tema id=""> - Suministrado por INEX una vez que todos los temas han sido recogidos. Este y otros atributos pueden estar presentes en los temas finales seleccionados por INEX. <inex type=""> tema de consulta - ya sea "CO" o "CAS". Este atributo determina si la consulta es de CO ó CAS. En consecuencia, determina el tipo de consulta utilizado en la etiqueta <title>. <title> - una consulta NEXI (CO o CAS). Debe tenerse en cuenta que el carácter codificado en XML será necesario, esto incluye la sustitución de '<' con '<'. <description> - una corta traducción en lenguaje natural (una o dos frases) del título. <narrative> - una explicación detallada de la información que necesita, incluyendo una descripción de lo que hace un resultado relevante. Debería ser posible para alguien que no sea el autor leer la narración y un resultado y determinar de forma inequívoca si el resultado es relevante o no.. 13.
(22) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML <keywords> - una lista separada por comas de términos y frases utilizadas en el tema de la formulación. Es importante que el título, descripción, narración y todos describan la misma información que necesitan. Ejemplo de una consulta INEX <inex_topic query_type="CAS"> <title> //article[.//yr = 2001 or .//yr = 2002]//sec[about (., vacaciones de verano)] </title> <description> Vacaciones de verano ya sea de 2001 o de 2002. </description> <narrative> Retornar los elementos de la sección que se trate de vacaciones de verano. Donde las secciones son descendientes del elemento artículo, y el artículo es de 2001 o 2002. </narrative> <keywords> verano, vacaciones, 2001, 2002 </keywords> </inex_topic> 1.3 Lenguajes de consultas para documentos XML Son diversos los lenguajes de consultas que existen para la RI-XML, a continuación se describen brevemente algunos de los más utilizados por la comunidad que investiga en esta área. 1.3.1 XPath XPath (XML Path Language) [5] es un lenguaje que permite construir expresiones que recorren y procesan un documento XML. La idea es parecida a las expresiones regulares para seleccionar partes de un texto sin atributos (plain text). XPath permite buscar y seleccionar teniendo en cuenta la estructura jerárquica del XML. XPath fue creado para su uso en el estándar XSLT, en el que se usa para seleccionar y examinar la estructura del documento de entrada.. 14.
(23) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML Todo el procesamiento realizado con un fichero XML está basado en la posibilidad de direccionar o acceder a cada una de las partes que lo componen, de modo que se puede tratar cada uno de los elementos de forma diferenciada. El tratamiento del fichero XML comienza por la localización del mismo a lo largo del conjunto de documentos existentes en la colección. Para llevar a cabo esta localización de forma unívoca, se utilizan los URI (Uniform Resource Identifiers), de los cuales los URL (Uniform Resource Locators) son los más conocidos. Una vez localizado el documento XML, la forma de seleccionar información dentro de él es mediante el uso de XPath. Con XPath se puede seleccionar y hacer referencia a texto, elementos, atributos y cualquier otra información contenida dentro de un fichero XML. XPath en sí es un lenguaje sofisticado y complejo, pero distinto de los lenguajes procedurales conocidos (C, C++, Basic, Java...). Además, como casi todo en el mundo de XML, aún está en estado de desarrollo, por lo que no es fácil encontrar herramientas que incorporen todas sus funcionalidades. XPath es a su vez la base sobre la que se han especificado nuevas herramientas para el tratamiento de documentos XML, herramientas tales como XPointer [24], XLink [25] y XQuery (se trata a continuación). Así, XPath sirve para decir cómo debe procesar una hoja de estilo el contenido de una página XML, pero también para poder poner enlaces o cargar en un navegador zonas determinadas de una página XML, en vez de toda la página. 1.3.2 XQuery XQuery [26, 27] es un lenguaje de consulta diseñado para consultar colecciones de datos XML. Es semánticamente similar a SQL, pero incluye algunas capacidades de programación. La versión 1.0 de XQuery fue desarrollada por el grupo de trabajo para consultar XML del W3C. El trabajo fue estrechamente coordinado con el desarrollo de XSLT 2.0 por el grupo de trabajo XSL; los dos grupos compartieron la responsabilidad. 15.
(24) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML del XPath 2.0, que es un subconjunto de XQuery 1.0. El XQuery 1.0 es una recomendación del W3C desde el 23 de enero del 2007. XQuery proporciona los medios para extraer y manipular información de documentos XML, o de cualquier fuente de datos que pueda ser representada mediante XML, como por ejemplo Bases de Datos Relacionales. XQuery utiliza expresiones XPath para acceder a determinadas partes del documento XML. Añade además unas expresiones similares a las usadas en SQL, conocidas como expresiones FLWOR. Las expresiones FLWOR toman su nombre de los 5 tipos de sentencias de las que pueden estar compuestas: FOR, LET, WHERE, ORDER BY y RETURN. También incluye la posibilidad de construir nuevos documentos XML a partir de los resultados de la consulta. Se puede usar una sintaxis similar a XML si la estructura (elementos y atributos) es conocida con antelación, o usar expresiones de construcción dinámica de nodos en caso contrario. Todos estos constructores se definen como expresiones dentro del lenguaje, y se pueden anidar arbitrariamente. El lenguaje se basa en un modelo en árbol con la información contenida en el documento XML, que consiste en siete tipos distintos de nodo: elementos, atributos, nodos de texto, comentarios, instrucciones de procesamiento, espacios de nombres y nodos de documentos. El sistema de tipos usado por el lenguaje considera todos los valores como secuencias, asumiéndose un valor simple como una secuencia de un solo elemento. Los elementos de una secuencia pueden ser valores atómicos o nodos. Los valores atómicos pueden ser números enteros, cadenas de texto, valores booleanos, etc. La lista completa de los tipos disponibles está basada en las primitivas definidas en XML Schema. XQuery 1.0 no incluye capacidad de actualizar los documentos XML. Tampoco puede realizar búsquedas textuales. Estas dos capacidades están siendo objeto de desarrollo para su posible incorporación en la siguiente versión del lenguaje.. 16.
(25) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML Ejemplos de uso de XQuery: Extraer información de una base de datos para usarla en un Servicio Web. Generar un resumen de la información almacenada en una base de datos XML. Realizar búsquedas textuales en la web y compilar los resultados de la misma, facilidad que fue incorporada en versiones superiores a la 1.0. Seleccionar y transformar datos de XML a XHTML de forma que se puedan publicar en la Web. Obtener datos desde diferentes fuentes con vistas a ser integradas por la aplicación. Dividir un documento XML que representa una serie de múltiples transacciones en varios documentos XML, uno por cada transacción. 1.3.3 NEXI El grupo INEX definió los requisitos del lenguaje de consultas para futuros eventos. Si bien no se sugirieron cambios para las consultas de CO, se sugirieron varias modificaciones para las consultas CAS [4] . El grupo de trabajo identificó muchos aspectos de XPath que se deben analizar (por ejemplo, funciones), aspectos a ser severamente limitados (por ejemplo, el único operador que se permite en un camino de etiquetas es el operador descendiente). Nuevas características se han añadido (por ejemplo, el filtro “about”). La forma de XPath se consideró apropiada, mientras que el nivel de detalle se consideró inadecuado. La lista completa de cambios se describe en el informe del grupo de trabajo [28]. Las enmiendas se consideraron suficientes para justificar un lenguaje XPath derivado. NEXI se introduce como ese lenguaje. El uso de comodines en los términos de búsqueda ha sido la diferencia más significativa con XPath. En NEXI el motor de la recuperación debe deducir la semántica de la consulta [4]. En el próximo capítulo serán abordadas las características generales de este lenguaje. 17.
(26) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML 1.4 Desventajas de los lenguajes estructurados Para interactuar con SRI-XML los usuarios deben expresar sus necesidades de información en forma de una consulta estructurada. Tradicionalmente, estas consultas estructuradas han sido expresadas usando lenguajes formales como XPath y NEXI para la RI-XML. Desafortunadamente, los lenguajes formales de consulta tienden a ser complejos y difíciles de usar por usuarios no expertos; además de que se necesita conocer la estructura de la fuente de datos. A consecuencia de esto, investigaciones recientes han concebido la idea de especificar las necesidades estructurales y de contenido implícitas en las consultas de los usuarios haciendo uso del lenguaje natural. La motivación principal de utilizar NLP es que los lenguajes formales de consulta son demasiado difíciles para que los usuarios expresen con precisión su necesidad de información. Un segundo problema con los lenguajes de consulta formales es que están demasiados atados a la estructura física de los documentos; y por consiguiente, los usuarios requieren un conocimiento íntimo de la composición de los documentos para expresar completamente sus requisitos estructurales. Entonces, para que los usuarios recuperen información de resúmenes, los cuerpos o las bibliografías, necesitarán saber los nombres reales de esas etiquetas en la colección (por ejemplo: res, bdy, y bib), esta información puede ser obtenida del DTD (Document Type Definition) o esquema [26] de un documento y hay situaciones donde el propietario de la colección no desea que los usuarios tengan acceso a esos archivos. En caso de una colección heterogénea, una misma etiqueta puede tener nombres múltiples (por ejemplo: el resumen podría ser nombrada como res, o resumen). Este es un problema identificado por los participantes en el INEX 2004 que han propuesto el uso de metaetiquetas para trazar un mapa entre colecciones y extensiones para NEXI, y manipular nombres múltiples de la etiqueta. Naturalmente, ninguna de estas soluciones es trivial. En contraste, los requisitos estructurales en la consultas realizadas en lenguaje natural están esencialmente. 18.
(27) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML expresados en un nivel conceptual más alto, dejando la estructura del documento completamente escondida del usuario [3]. No se puede esperar que un usuario sin experiencia pueda utilizar correctamente los idiomas complejos de consulta. Sin embargo, los usuarios serían capaces de intuitivamente expresar su necesidad de información en lenguaje natural [8]. 1.4.1 Soluciones previas del NLP en la RI-XML El XML es un estándar universalmente aceptado para el intercambio y almacenamiento de información, por lo que constituye una necesidad consultar estos documentos estructurados en lenguaje natural. y no en un lenguaje de. consulta estructurado. Anteriormente fueron considerados los beneficios que se pueden obtener con el empleo del LN (Lenguaje Natural) en la RI-XML, en la literatura se reportan diversos trabajos que abordan temas relacionados con el NLP en la RI-XML. En [29] se discute el lugar del NLP en la recuperación XML y se expone un método para analizar las consultas en lenguaje natural. Este artículo se centra en una técnica para traducir las consultas en lenguaje natural a un lenguaje formal de consulta. En [30] se describe una interfaz de lenguaje natural para la consulta de una base de datos XML. Esta interfaz puede aceptar una sentencia arbitraria en idioma Inglés como una consulta. Esta consulta se traduce, potencialmente después de reformularla, en una expresión XQuery. La traducción se basa en la proximidad gramatical del lenguaje natural de los tokens analizados en el árbol de análisis sintáctico de la frase de consulta, con la proximidad de los elementos correspondientes en los datos XML que se necesitan recuperar. Una evaluación experimental, a través de un estudio de usuarios, demuestra que este tipo de interfaz de lenguaje natural es lo suficientemente buena para ser utilizada, sin restricciones en el dominio de aplicación. Una clase importante de consultas en lenguaje natural pueden ser traducidas en expresiones XQuery que pueden ser evaluadas en relación con una base de datos XML. Este sistema en su forma 19.
(28) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML actual admite comparación de predicados, conjunciones, simple negación, la cuantificación y la clasificación. En el futuro, se espera añadir soporte para la disyunción, para las consultas de varias sentencias, para la negación compleja, y para la construcción de resultados compuestos. En [31] se describe una interfaz interactiva de consulta en lenguaje natural a una base de datos XML. Este sistema puede aceptar una sentencia arbitraria en idioma Inglés como entrada de la consulta, que puede incluir agregación, nidificación entre otras cosas. 1.4.2 Soluciones previas de los traductores de LN a NEXI En [7] se presenta la herramienta NLPX, un SRI-XML, que presenta una interfaz en lenguaje natural que acepta consultas en idioma inglés. NLPX utiliza plantillas para obtener los requisitos estructurales y de contenido de los usuarios, los que transforma al lenguaje formal NEXI. El sistema fue desarrollado para la participación en el INEX 2004, donde se utilizaron los mismos temas y las valoraciones de años anteriores; sin embargo, los sistemas participantes usaron una consulta de entrada en lenguaje natural, en vez de una consulta en un lenguaje formal de consultas (NEXI). Los ejemplos de ambos tipos de consultas son expresados en la figura 1.2. Puede notarse que la consulta realmente contiene dos solicitudes de información, en primer lugar, los artículos que tratan sobre la recuperación de información, y en segundo lugar, las secciones sobre la imagen y comprensión del texto. Sin embargo, el usuario sólo quiere recibir resultados que coincidan con la segunda solicitud.. Figura 1.2 Consulta en NEXI y en lenguaje natural. 20.
(29) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML En [3] se enfatiza sobre el trabajo previo de los autores presentados en INEX 2004 y 2005. Al igual que con el año anterior, la meta de los participantes en el INEX 2006 era producir una interfaz de consulta que tradujera consultas en LN Inglés a NEXI. Las consultas traducidas fueron ejecutadas por un sistema de back-end único (GPX) y el rendimiento de la recuperación de las consultas traducidas se registró como si se tratara de un sistema estándar. Los participantes en el tema de NLP compararon el rendimiento de sus sistemas en la recuperación utilizando consultas NEXI obtenidas manualmente. El proceso de traducción del NLPX consta de cuatro pasos sintácticos derivados de INEX 2006 y la información semántica de la consulta en lenguaje natural. Se produjeron varias mejoras en NLPX con respecto a la participación del año anterior. Sin embargo, el número de mejoras fue menor que en años anteriores lo que puede indicar que la investigación está llegando a una meseta. Una vez que una consulta en lenguaje natural, es fragmentada y adaptada se transforma en una consulta NEXI utilizando el actual sistema de NLPX. Se trata de un proceso de dos fases. En primer lugar, se amplía el contenido de la consulta, mediante la derivación de frases sobre la base de sus propiedades léxicas, como los sintagmas nominales que incluyen adjetivos y participios. Luego, se lleva al formato de una consulta NEXI en base a la instrucción, la estructura y valores del contenido. Se pasa la consulta NEXI al actual sistema de GPX para la transformación, como si se tratara de una consulta estándar. Los resultados del análisis del rendimiento de NLPX se dividen en dos partes. La primera parte explica cómo NLPX fue capaz de traducir consultas en lenguaje natural a NEXI. La segunda parte presenta el rendimiento de la recuperación de las consultas traducidas en comparación con las consultas originales en NEXI. Los elementos de descripción de los 125 temas INEX se han convertido al formato de NEXI por NLPX. Estas traducciones fueron la base del sistema que se utiliza manualmente formando expresiones NEXI como entrada, en comparación con la descripción de cada tema y los elementos castitle para probar su exactitud. La tasa de exactitud global entre la traducción y las descripciones fue alta (70,4 21.
(30) Capítulo 1. Interfaz de consulta en lenguaje natural en los Sistemas de Recuperación de Información sobre documentos XML %), sin embargo, la similitud entre las traducciones y los castitles originales fue mucho más baja (35,2 %). 1.5 Consideraciones finales A manera de resumen se puede afirmar que el funcionamiento de los SRI se sintetiza en: representar el problema de necesidad de información del usuario (consulta); representar y organizar el contenido de la fuente de conocimiento; comparar la consulta con los componentes del contenido y por último, presentar los resultados al usuario para que interactúe o los juzgue. La existencia de documentos estructurados, específicamente en lenguaje XML, y la necesidad de establecer mecanismos de recuperación sobre los mismos, obliga al diseño y la implementación de nuevos modelos y técnicas de RI. Las técnicas de NLP están siendo utilizadas con éxito en la RI-XML, diversos trabajos tratan el empleo de dichas técnicas para transformar consultas en lenguaje natural a lenguajes de RI ya establecidos como NEXI. Por lo que se presentan las consultas en lenguaje natural como una alternativa viable a los lenguajes formales de consulta.. 22.
(31) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI CAPÍTULO 2. TRANSFORMACIÓN DE LAS CONSULTAS DE LENGUAJE NATURAL A NEXI Para efectuar la traducción de consultas de lenguaje natural a NEXI se requirió un estudio de los lenguajes de consulta XML, de las tecnologías existentes relacionadas con la RI y de técnicas para el procesamiento del lenguaje natural. En el presente capítulo se tratan los principales aspectos de NEXI, se describe el mecanismo de traducción utilizado para transformar las consultas del lenguaje natural español a NEXI, haciendo uso de técnicas del procesamiento del lenguaje natural y se describe la implementación de un analizador sintáctico para realizar el análisis sintáctico de las consultas en NEXI. 2.1 Introducción La recuperación de información efectiva en los documentos XML requiere que el usuario tenga un buen conocimiento de la estructura del documento y del lenguaje formal de consulta. XML se utiliza ampliamente, en particular en internet, e implica que los usuarios ocasionales deben ser capaces de consultar cualquier corpus XML. Desde esa perspectiva surgen dos grandes dificultades para los usuarios ocasionales: El conocimiento de algún lenguaje estructurado de consultas (un lenguaje con fines de formalizar la semántica y la gramática, en contraposición al lenguaje natural). El pleno conocimiento de la estructura de los documentos XML y su semántica. Lenguajes de consulta para documentos XML como XPath, XQuery y NEXI son demasiado complejos para ser considerado su uso por los usuarios finales [14]. Este trabajo presenta una aproximación para la transformación de consultas realizadas en lenguaje natural a documentos XML y su traducción al lenguaje de consultas NEXI, siendo este procedimiento transparente para el usuario ocasional.. 23.
(32) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI 2.2 Características generales del lenguaje de consultas NEXI El lenguaje de consultas NEXI para la RI-XML se introdujo en el 2005 como un lenguaje derivado de Xpath que elimina aspectos limitantes de este e incorpora nuevas características. La sintaxis de NEXI es similar a XPath, sin embargo, sólo se utilizan pasos descendientes y se extiende XPath mediante la incorporación de una cláusula “about” (sobre) para proporcionar la RI a las consultas. La sintaxis de las consultas en NEXI es la siguiente: //A[about(.//B,C)] Donde A es la ruta de contexto, B es la ruta de acceso relativa y C es el contenido requerido. Es posible que una sola consulta NEXI contenga más de una solicitud de información. El objetivo de la solicitud se formula primero y, a continuación cada una de las solicitudes de apoyo es insertada mediante la búsqueda de su descendiente más cercano, siguiendo el formato NEXI [32]. 2.2.1 Consultas de tipo CO en NEXI La unidad más pequeña de búsqueda en una consulta de CO es la palabra, esta es correctamente utilizada en NEXI si se rige por la siguiente gramática: word: NUMBER | ALPHANUMERIC ALPHANUMERIC: {LETTER}{LETTERDIGITEXTRAS}* NUMBER: "-"?{DIGIT}+ LETTER: [a-zA-Z] DIGIT: [0-9] LETTERDIGIT: [a-zA-Z0-9] LETTERDIGITEXTRAS [a-zA-Z0-9’-] Los números positivos, números negativos y las secuencias de caracteres alfanuméricos precedidos por un carácter alfabético son válidos. Los guiones y los apóstrofes son permitidos sólo después del primer carácter de un alfanumérico. 24.
(33) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI Ejemplo: Para buscar solamente la palabra Apple, la consulta de CO es: Apple Interpretación libre: Se prevé que el uso de la palabra Apple ayudará a localizar documentos de relevancia. No se dice si se quiere obtener “ordenador Macintosh”, “Granny Smith”, o “El señor de Apple”, pero se encuentra lo que se quiere de todos modos [4]. Búsqueda de frases Una frase es una secuencia de doble cita de las palabras: phrase: ’"’ word_list ’"’ word_list: word word | word_list Word Una frase debe contener dos o más palabras. Una frase que contiene una sola palabra es errónea y las citas se deben quitar para hacer una consulta de una sola palabra. Ejemplo: Para buscar Charles Babbage, la consulta de CO es: “Charles Babbage” Interpretación libre: se prevé que los documentos pertinentes contienen estas dos palabras adyacentes entre sí, pero no es necesario. Pueden contener ambas palabras no adyacentes. Un documento pertinente ni siquiera puede contener una u otra palabra [4]. 2.2.2 Consultas de tipo CAS en NEXI Las consultas CAS pueden adoptar tres formas posibles en NEXI: / / A [B] devolver la etiqueta A sobre B / / A [B] / / C descendientes C de A, donde A es sobre B (utilizado en INEX'02) / / A [B] / / C [D] descendientes C de A, donde A es sobre B y C sobre D, A y C son las rutas donde B y D son los filtros, respectivamente. La sintaxis se define como:. 25.
(34) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI cas: path cas_filter | path cas_filter path | path cas_filter path cas_filter cas_filter: ’[’ filtered_clause ’]’ El uso de la forma / / A [B] / / C no es útil para la evaluación de la recuperación de información. Una vez que el resultado de / / A [B] se ha determinado, se trata de una proceso mecánico de extracción del / / C descendiente. El uso de esta forma está desfasado en INEX'03 [4]. 2.2.2.1 Ruta de especificación Los nombres de etiquetas y atributos siguen las especificaciones del código XML. XMLTAG: {XML_NAME}{XML_NAMECHAR}* XML_NAMECHAR: [-_.:a-zA-Z0-9] XML_NAME: [_:a-zA-Z] Los nodos de elementos en el árbol XML se identifican como “//tag” y los nodos de atributo como “//atributo@”. El "//*" comodín se incluye para identificar al subsiguiente o posterior descendiente (tag o atributo). node: named_node | any_node | tag_list_node NODE_QUALIFIER: "//" named_node: NODE_QUALIFIER tag attribute_node: NODE_QUALIFIER ’@’ tag any_node: NODE_QUALIFIER ’*’ En los casos que se requiera de la etiqueta A o de la etiqueta B", se escribe "// (A | B)". tag_list: tag ’|’ tag | tag_list ’|’ tag tag_list_node: NODE_QUALIFIER ’(’ tag_list ’)’ Un camino a través del árbol XML se especifica como una secuencia de nodos. La única relación entre los nodos de un camino es descendiente. 26.
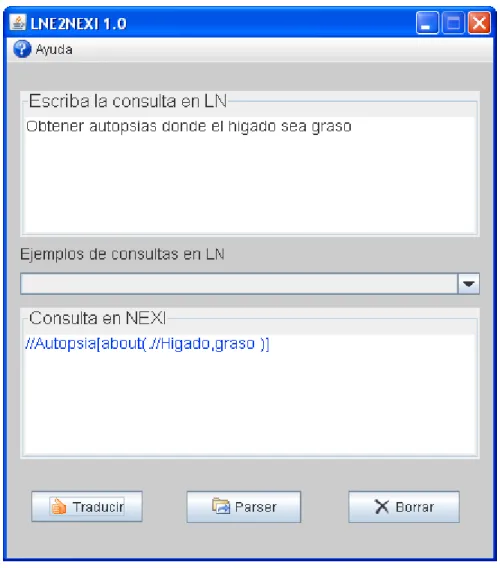
(35) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI La ruta de acceso / / T1. . . / / Tn es una secuencia ordenada de nodos en el árbol que parte en T1 y que termina en Tn tal que para todo n ∈ p, Tp+1 es un descendiente de Tp [4]. Interpretación libre: es poco probable que la información pertinente se encuentre en lugares no especificados en una consulta de usuario. Las especificaciones de ruta deben por tanto, considerarse consejos sobre dónde buscar. Filtros de ruta En la actualidad las rutas se pueden filtrar, ya sea con cadenas de búsqueda, o numéricamente. 2.2.2.2 Cadena de filtrado Los documentos pueden ser filtrados a sólo aquellos que cumplan un determinado requisito de consulta en la ruta dada (o en relación con la ruta especificada). about_clause : ABOUT ’(’ relative_path ’,’ co ’)’ relative_path: ’.’ | ’.’ path ABOUT: "about" Las rutas relativas se especifican en relación con una ruta de contexto. En / / A [B], la ruta de contexto es / / A. Para B en / / A [B] / / C [D] la ruta de contexto es / / A, para D la ruta de contexto es / / A / / C. La ruta de acceso relativa “.” se interpreta como “la ruta de contexto”. La ruta de acceso relativa “. / / p” se interpreta como “un p descendiente de la ruta de contexto” [4]. Ejemplo: //article[about(.//p, recuperación de información)] Interpretación estricta: Buscar en los artículos elementos de p sobre recuperación de información. Interpretación libre: Lo que se quiere es más probable un artículo completo que menciona la recuperación de información en una etiqueta p. Los resultados pertinentes no se limitan a esto, pero ayudan a encontrar lo que se quiere.. 27.
(36) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI 2.2.2.3 Aritmética de filtrado Los documentos también pueden ser filtrados a sólo aquellos que satisfacen una consulta numérica, con la cadena de filtrado, esta se especifica con una ruta relativa. arithmetic_clause: relative_path arithmetic_operator NUMBER arithmetic_operator: ’>’ | ’<’ | ’=’ | ’>=’ | ’<=’ Ejemplo: //article[.//pdt//yr = 2003] Interpretación estricta: Recuperar los documentos que “contengan el valor 2003 en //article//pdt//yr”. Interpretación libre: Una interpretación libre podría mirar a un intervalo de años (2002, 2003 y 2004). Esto puede ser útil si, por ejemplo, un taller celebrado en diciembre de 2003, publicó el procedimiento formal en 2004. Por otra parte, un artículo publicado electrónicamente en diciembre del 2002, finalmente podría aparecer su impresión en enero del 2004, lo que lleva a confusión sobre la fecha de publicación. El ejemplo anterior también se puede describir con cadena de filtrado: //article[about(.//pdt//yr, 2003)] Sin embargo se prefiere, la sintaxis de la aritmética. 2.2.2.4 Operadores lógicos Los filtros de ruta se pueden unir con los operadores lógicos AND y OR. filtered_clause: filter | filtered_clause AND filtered_clause | filtered_clause OR filtered_clause | ’(’ filtered_clause ’)’ AND: "AND" | "and" OR: "OR" | "or". 28.
(37) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI Ejemplos: //article[about(., apple) and about(., computadora)] //article[about(., apple) or about(., computadora)] Interpretación estricta: el primer ejemplo devolverá los artículos que traten sobre apple y computadora, por otro lado el segundo ejemplo devolverá los artículos acerca de apple o computadora. Se introduce además una diferencia en el sentido de las consultas: //article[about(.//sec, computadoras apple)] y //article[about(.//sec, apple) and about(.//sec, computadora) La primera consulta pide los artículos que tienen una sección de discusión “las computadoras de Apple”. Por su parte la segunda pide los artículos que tienen una sección de discusión “Apple” y una sección discusión “computadora” (aunque no son la misma sección). Interpretación libre: La segunda consulta contiene el operador lógico AND estrictamente como un consejo sobre cómo obtener la información que se necesita. CO, CPEA y VCAS interpretan todos los operadores lógicos libremente. Ejemplos de algunas consultas CAS se exponen a continuación, junto con una interpretación estricta. Ejemplo 1 //sec[about(.,sistemas móviles pago electrónico)] Devolver las secciones que mencionan los sistemas móviles de pago electrónico. Ejemplo 2 //*[about(.,descomposición valor singular)] El motor de la recuperación debe deducir los elementos más adecuados para devolver, que traten sobre la descomposición de valor singular. Ejemplo 3 //article[.//fm//yr>=1998]//sec[about(.//p,realidad virtual)]. 29.
(38) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI Retornar de los artículos publicados a partir del 1998, las secciones que tratan sobre realidad virtual. 2.3 Procesamiento del lenguaje natural El NLP es un área de investigación en continuo desarrollo, se aplica en la actualidad en diferentes actividades como son la traducción automática de textos, SRI, elaboración automática de resúmenes, interfaces en lenguaje natural, etc. Si bien en los últimos años se han realizado avances notables, los fundamentos teóricos del NLP se encuentran todavía en estado de desarrollo. El NLP se concibe como el reconocimiento y utilización de la información expresada en lenguaje humano a través del uso de sistemas informáticos. En su estudio intervienen diferentes disciplinas tales como lingüística, ingeniería informática, filosofía, matemáticas y psicología. Debido a las diferentes áreas del conocimiento que participan, la aproximación al lenguaje en esta perspectiva es también estudiada desde la llamada ciencia cognitiva [33]. Aún siendo evidente que los obstáculos a superar en el estudio del tratamiento del lenguaje son considerables, los resultados obtenidos y la evolución en los últimos años sitúan al NLP en posición para liderar una nueva dimensión en las aplicaciones informáticas del futuro: los medios de comunicación del usuario con el ordenador pueden ser más flexibles y el acceso a la información almacenada más eficiente. Por ejemplo, con la creación de interfaces inteligentes el usuario dispondría de la facilidad de interactuar con el ordenador en lenguaje natural. Asimismo, el uso de técnicas de NLP puede tener un alto impacto en la gestión documental y en los sistemas de traducción automática. No obstante, la complejidad implícita en el tratamiento del lenguaje implica limitaciones en los resultados y, por tanto, aplicaciones en áreas de conocimiento concretas y con un uso restringido del lenguaje.. 30.
(39) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI La carencia de un orden de la estructura oracional en algunos idiomas, y la dificultad para obtener una representación tanto sintáctica como semántica, son algunos de los problemas que se presentan. Tanto desde un enfoque computacional como lingüístico se utilizan técnicas de inteligencia artificial: modelos de representación del conocimiento y de razonamiento. algoritmos de búsqueda estructuras de datos Se investiga cómo el lenguaje natural puede ser utilizado para cumplir diferentes tareas y la manera de modelar el conocimiento. En el siguiente epígrafe se presenta una introducción a las técnicas que se aplican para el tratamiento del lenguaje natural. Generalmente la bibliografía sobre el tema se caracteriza por su estilo técnico y, dada su componente interdisciplinar, se presenta como una materia de difícil comprensión para los legos en el tema. En vista a conocer estas técnicas de representación y procesamiento, es necesario tener en cuenta una doble dimensión: se trata por una parte de un problema de representación lingüística, y por otra de un problema de tratamiento mediante recursos informáticos. 2.3.1 Técnicas que se aplican para el tratamiento del lenguaje natural El uso de técnicas computacionales procedentes especialmente de la inteligencia artificial no aportaría soluciones adecuadas sin una concepción profunda del fenómeno lingüístico. Por otra parte, las gramáticas utilizadas para el tratamiento del lenguaje han evolucionado hacia modelos más adecuados para un tratamiento computacional. El estudio del lenguaje natural se estructura normalmente en 4 niveles de análisis: léxico sintáctico semántico pragmático 31.
(40) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI Análisis léxico El nivel léxico es el conjunto de información sobre cada palabra que el sistema utiliza para el procesamiento. Las palabras que forman parte del diccionario están representadas por una entrada léxica, y en caso de que esta tenga más de un significado o diferentes categorías gramaticales, tendrá asignada diferentes entradas. En el nivel léxico se incluye la información morfológica, la categoría gramatical, irregularidades sintácticas y representación del significado. Normalmente el léxico sólo contiene la raíz de las palabras con formas regulares, siendo el analizador morfológico el que se encarga de determinar si el género, número o flexión que componen el resto de la palabra son adecuados. Análisis sintáctico Tiene como función etiquetar cada uno de los componentes sintácticos que aparecen en la oración y analizar cómo las palabras se combinan para formar construcciones gramaticalmente correctas. El resultado de este proceso consiste en generar la estructura correspondiente a las categorías sintácticas formadas por cada una de las unidades léxicas que aparecen en la oración [34]. Las gramáticas, tal como se muestra en el siguiente ejemplo, están formadas por un conjunto de reglas: O --> SN, SV SN --> Det, N SN --> Nombre Propio SV --> V, SN SV --> V SP --> Preposición, SN SN = sintagma nominal SV = sintagma verbal Det = determinante O = oración N = sustantivo 32.
(41) Capítulo 2.Transformación de las consultas de lenguaje natural a NEXI V = verbo El resultado del análisis se puede expresar en forma arbórea. Los árboles son formas gráficas utilizadas para expresar la estructura de la oración, consistentes en nodos etiquetados (O, SN, SV...) conectados por ramas.. Figura 2.1 Procesamiento del lenguaje natural. Análisis semántico En muchas aplicaciones del NLP los objetivos del análisis apuntan hacia el procesamiento del significado. En los últimos años las técnicas de procesamiento sintáctico han experimentado avances significativos, resolviendo los problemas fundamentales. Sin embargo, las técnicas de representación del significado no han obtenido los resultados deseados, y numerosos aspectos continúan sin encontrar soluciones satisfactorias. Definir qué es el significado no es una tarea sencilla, y puede dar lugar a diversas interpretaciones. A efectos funcionales, para facilitar el procesamiento, la 33.
Figure



+7




Documento similar
Después de una descripción muy rápida de la optimización así como los problemas en los sistemas de fabricación, se presenta la integración de dos herramientas existentes
Por lo tanto, en base a su perfil de eficacia y seguridad, ofatumumab debe considerarse una alternativa de tratamiento para pacientes con EMRR o EMSP con enfermedad activa
The part I assessment is coordinated involving all MSCs and led by the RMS who prepares a draft assessment report, sends the request for information (RFI) with considerations,
Proporcione esta nota de seguridad y las copias de la versión para pacientes junto con el documento Preguntas frecuentes sobre contraindicaciones y
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
Por tanto, a través de GENBOT, se podrá obtener un chatbot que se integrará en Telegram e interpretará consultas en lenguaje natural que después, serán traducidas a un
8. La coordinación, el impulso y el desarrollo del Campus de Lugo en materia de infraes- tructuras, sin perjuicio de que los actos ejecutivos derivados de su actuación correspondan
El contar con el financiamiento institucional a través de las cátedras ha significado para los grupos de profesores, el poder centrarse en estudios sobre áreas de interés
