USO DE INTELIGENCIA
ARTIFICIAL APLICANDO
ÁRBOLES DE DECISIÓN
EJECUTADOS EN R PARA LA
DETERMINACIÓN DE ZONAS
HOMOGÉNEAS FÍSICAS.
KAREN TATIANA BASTIDAS MÉNDEZ
ANGIE VICTORIA BONILLA BAUTISTA
PROYECTO DE GRADO PARA OPTAR POR EL TÍTULO DE
INGENIERAS CATASTRALES Y GEODESTAS
BAJO LA MODALIDAD INVESTIGACIÓN INNOVACIÓN
DIRIGIDO POR:
ING. MSC. EDWIN ROBERT PEREZ CARVAJAL
UNIVERSIDAD DISTRITAL FRANCISCO JOSÉ DE CALDAS
FACULTAD DE INGENIERÍA
UNIVERSIDAD DISTRITAL
FRANCISCO JOSÉ DE CALDAS
FACULTAD DE INGENIERÍA
INGENIERÍA CATASTRAL Y GEODESIA
_____________________________________________ PROYECTO DE GRADO
USO DE INTELIGENCIA ARTIFICIAL APLICANDO ÁRBOLES DE DECISIÓN EJECUTADOS EN R PARA LA DETERMINACIÓN DE
ZONAS HOMOGÉNEAS FÍSICAS.
ESTUDIO DE CASO: UPZ 63 ARBORIZADORA Y UPZ 109 CIUDAD SALITRE ORIENTAL.
______________________________________________ DIRIGIDO POR:
ING. MSC. EDWIN ROBERT PEREZ CARVAJAL
PRESENTADO POR:
KAREN TATIANA BASTIDAS MÉNDEZ 20122025098 ANGIE VICTORIA BONILLA BAUTISTA 20121025101
DEDICATORIA
A Dios, por darme la vida, por darme la oportunidad de llegar a este momento tan importante en mi vida, y en mi carrera profesional, a él por darme a mi familia, motor principal de mi vida.
A mi mamá, María del Carmen Méndez Barrios, por permitirme vivir, por formarme con delicadeza y amor, por acompañarme en cada paso de mi vida y por apoyarme en mis decisiones, por sus concejos y recomendaciones con amor, por ser la mejor mamá del mundo.
A mi hermana, Leidy Johanna Sarmiento Mendez, por ser mi mejor amiga y mi ejemplo a seguir, por todas sus palabras de aliento y apoyo, por mostrarme un ejemplo de mujer luchadora y completa .
A mi sobrino, Juan Diego Marroquin Sarmiento Mendez, por enseñarme a ser fuerte, constante y persistente, por darme fuerza y ánimo cada mañana y mostrarme su amor todos los días.
A Armando Segura y Miguel Silva, por ser una apoyo para mi y para mi familia.
Mi corazón está lleno de alegría y satisfacción por este nuevo logro y de amor y agradecimiento por cada una de las personas que me acompañan día a día.
DEDICATORIA
Dios, por darme la oportunidad de vivir y por estar conmigo en cada paso que doy, por fortalecer mi corazón e iluminar mi mente y por haber puesto en mi camino a aquellas personas que han sido mi soporte y compañía durante todo el periodo de estudio.
A mi madre Amparo Bautista Torres por darme la vida, el apoyo incondicional durante todo mi proceso de crecimiento como persona y como profesional. Por ser esa mujer llena de fortaleza y ser mí ejemplo a seguir. Gracias a ella tengo la determinación y la fortaleza para conseguir mis metas teniendo siempre presente que el actuar con transparencia siempre será bien recompensado.
Mamá todo esto es gracias a ti.
A mi padre Luis Alberto Bonilla Arias por apoyar económicamente este proceso y desde la distancia seguir mi proceso.
A mis hermanos Vanessa y Leonardo por sentirse siempre tan orgullosos de mí, a mis hermanas Lorena, Alejandra y Camila, mis sobrinas Antonella y María Paula por motivarme a ser una excelente mujer y profesional para ser su ejemplo a seguir.
AGRADECIMIENTOS
De manera especial expresamos gratitud a cada una de las personas que participaron en el desarrollo de este proyecto.
Agradecemos a Dios, a quién debemos toda nuestra fortaleza, fuerza y deter-minación en este proyecto, a cada uno de los miembros de nuestras familias, por su paciencia y amor.
A nuestra Universidad Distrital Francisco José de Caldas y al nuestro Proyec-to Curricular Ingeniería Catastral y Geodesia, por brindarnos herramientas para desarrollar el presente trabajo y adquirir conocimientos que nos servirán y complementarán nuestro camino laboral y personal.
RESUMEN
Según Marvin Minsky, Padre de la inteligencia articial, esta es la ciencia de construir máquinas que hagan cosas que cuando los humanos la realizaran requirieran inteligencia y razonamiento [8] .De la ciencia de la inteligencia articial se derivan diferentes campos, entre los que está el aprendizaje de máquina, que consiste en un conjunto de métodos que detectan patrones en los datos, los cuales se usan para hacer predicciones [9], de esos métodos este trabajo usará el árbol de clasicación, en el que por medio de reglas de deci-sión se realiza una clasicación de datos. Se hará uso de la minería de datos, la inteligencia articial y los arboles de clasicación para determinar Zonas Homogéneas Físicas en Las UPZ Ciudad Salitre Oriental y UPZ Arboriza-dora por medio de predicciones en el Software R, a manera de presentar una herramienta más para complementar el análisis de estas zonas en el catastro de la ciudad de Bogotá.
Índice
1. INTRODUCCIÓN 9
2. RESUMEN EJECUTIVO 9
2.1. ¾EN QUÉ CONSISTE EL PROYECTO? . . . 9
2.2. ¾POR QUÉ SE REALIZA EL PROYECTO? . . . 10
2.3. ¾PARA QUE SE REALIZA EL PROYECTO? . . . 10
3. DESCRIPCIÓN DEL PROBLEMA 10 4. OBJETIVOS 11 4.1. GENERAL . . . 11
4.2. ESPECÍFICOS . . . 11
5. CRONOGRAMA DE ACTIVIDADES 11 6. MARCO CONCEPTUAL 12 6.1. INTELIGENCIA ARTIFICIAL . . . 12
6.2. MINERÍA DE DATOS . . . 13
6.3. ARBOLES DE DECISIÓN Y CLASIFICACIÓN . . . 13
6.4. SOFTWARE R . . . 13
6.4.1. EL ENTORNO R . . . 14
6.4.2. TINN-R . . . 15
6.4.3. LIBRERÍAS PARA ARBOLES DE DECISIÓN . . . 15
7. MARCO ESPACIAL 19 7.1. UNIDAD DE PLANEAMIENTO ZONAL EN BOGOTÁ . . . . 19
7.2. ZONAS HOMOGÉNEAS FÍSICAS EN BOGOTÁ . . . 19
7.3. UPZ 65 ARBORIZADORA . . . 22
7.4. UPZ 109 CIUDAD SALITRE ORIENTAL . . . 23
9. METODOLOGÍA 28
9.1. METODOLOGÍA DE DIGITALIZACIÓN DE ZHF . . . 28
9.2. METODOLOGÍA DE CONSTRUCCIÓN DE CÓDIGO EN R . 30 10. ANÁLISIS DE LOS PRODUCTOS 33 10.1. UPZ CIUDAD SALITRE ORIENTAL . . . 33
10.1.1. PRE PROCESAMIENTO DE DATOS . . . 33
10.1.2. VALIDACIÓN CRUZADA . . . 36
10.1.3. MODELO FINAL . . . 37
10.1.4. DIAGNÓSTICO DE ITERACIÓN . . . 62
10.2. UPZ ARBORIZADORA . . . 69
10.2.1. PRE PROCESAMIENTO DE DATOS . . . 69
10.2.2. VALIDACIÓN CRUZADA . . . 73
10.2.3. MODELO FINAL . . . 73
10.2.4. DIAGNÓSTICO DE LA ITERACIÓN . . . 98
10.3. ANÁLISIS DE RESULTADOS . . . 104
11. EVALUACIÓN Y CUMPLIMIENTO DE OBJETIVOS 105 11.1. SALIDAS GRÁFICAS UPZ CIUDAD SALITRE ORIENTAL . 105 11.1.1. ZHF CATASTRO . . . 106
11.1.2. ZHF PREDICT . . . 107
11.1.3. ANÁLISIS DE PREDICCIÓN UPZ CIUDAD SALITRE ORIENTAL . . . 108
11.2. SALIDAS GRÁFICAS UPZ ARBORIZADORA . . . 109
11.2.1. ZHF CATASTRO . . . 109
11.2.2. ZHF PREDICT . . . 110 11.2.3. ANÁLISIS DE PREDICCIÓN UPZ ARBORIZADORA 111
1. INTRODUCCIÓN
El presente trabajo tiene como n desarrollar un algoritmo en el Software R, haciendo uso de árboles de clasicación para la determinación de zonas homogéneas físicas en dos UPZ de la ciudad de Bogotá, esto con el n de vericar efectividad y precisión de los clasicadores más adecuados para los datos que se tienen en cada UPZ. Para cumplir con cada uno de los objetivos propuestos se emplea el método de clasicación C5.0, el cual procesa inter-namente variables de tipo numérico y tipo texto, y que presentó los mejores resultados en cuanto a número de datos clasicados con el mejor ajuste. A cada conjunto de datos presentado en este trabajo, se le realizará un análisis de validación cruzada para vericar el ajuste y conabilidad de los datos en cada una de las muestras, este proceso es uno de los determinantes de selección de mejor clasicador, como se nombró anteriormente el escogido fue C5.0. Con el n de vericar la aplicación la inteligencia articial en la determinación de Zonas Homogéneas Físicas, se hizo necesario dar uso a datos proporcionados por la Unidad Administrativa Especial de Catastro Distrital (UAECD) de la ciudad de Bogotá y trabajo en campo para la recolección de información catastral.
Para el procesamiento de los datos se hizo uso del Software R y librerías relacionadas a Arboles de Clasicación, Regresión de Clasicación, Ploteo de Arboles de Clasicación, Análisis de variables Discretas, entre otras que se especicarán más adelante.
Finalmente como resultado se obtienen las Zonas Homogéneas Físicas predi-chas para cada uno de los predios de cada UPZ, y se realiza un análisis de las variables necesarias para determinar cada una de las zonas homogéneas físicas por UPZ, buscando dar importancia a los arboles de decisión como determinantes de información creíble para denir zonas homogéneas físicas. Palabras clave: Árbol de Clasicación, Inteligencia Articial, Unidad de Pla-neamiento Zonal, Zonas Homogéneas Físicas, R, C5.0, RPART, Validación Cruzada, Minería de datos.
2. RESUMEN EJECUTIVO
2.1. ¾EN QUÉ CONSISTE EL PROYECTO?
de zonas homogéneas físicas urbanas, las cuales son base para la determina-ción de los avalúos masivos. A partir de esta determinadetermina-ción realizar un análisis comparativo con respecto a las Zonas Homogéneas Físicas determinadas por la UAECD de Bogotá.
2.2. ¾POR QUÉ SE REALIZA EL PROYECTO?
Este proyecto se realiza por dos razones especícas y dependientes, la pri-mera es la comparación del proceso automático realizado por medio de la programación en R de la generación de Zonas Homogéneas Físicas con las determinadas por la UAECD y por la necesidad de reducir al mínimo la sub-jetividad del proceso así mismo los tiempos de determinación y cálculo de Zonas Homogéneas Físicas.
2.3. ¾PARA QUE SE REALIZA EL PROYECTO?
Para que los sectores en los que se produce y se usa la información de Zonas Homogéneas Físicas sean implementadas como una herramienta que contri-buya al análisis de su producto o trabajo.
En general para que se produzca una evolución en la realización del proceso de determinación y diseño de Zonas Homogéneas Físicas.
3. DESCRIPCIÓN DEL PROBLEMA
La obtención de zonas homogéneas físicas ha sido por mucho tiempo un pro-ceso ligado a la subjetividad del creador y modelador de información, sus resultados sobre una misma información en ocasiones varía, de acuerdo a diferentes aspectos no establecidos, que hacen parte de la determinación del valor de catastral de cada uno de los predios de Bogotá, de acuerdo a esta situación y a la tecnicidad del proceso, se quiere formular una metodología que ayude a la estándarización de procesos y decisiones que aun siendo sub-jetivas pueden generalizarse, y así lograr resultados poco variables y con un altísimo nivel de conabilidad.
4. OBJETIVOS
4.1. GENERAL
Determinar Zonas Homogéneas Físicas mediante arboles de clasicación, usando el algoritmo C5.0, en la consola del software R, realizando prediccio-nes buscando suministrar resultados de conabilidad para crear un insumo de información catastral pertinente y concreta.
4.2. ESPECÍFICOS
Validar el uso de árboles de decisión en la determinación de Zonas Homogéneas Físicas en una UPZ.
Implementar un algoritmo en lenguaje de R para el modelamiento y determinación de Zonas Homogéneas Físicas en una UPZ
Contrastar las Zonas Homogéneas Físicas obtenidas tradicionalmente VS las Zonas Homogéneas Físicas obtenidas mediante el uso de Inteli-gencia articial especícamente por Árboles de Decisión.
Apoyar al grupo de investigación GIGA con la elaboración de una apli-cación de arbol de clasiapli-cación en R, para la determinación Zonas Ho-mogéneas Físicas en dos UPZ, a la cual se le suministre como insumo información catastral.
5. CRONOGRAMA DE ACTIVIDADES
ACTIVIDAD INICIO DURACIÓN(Días) FINAL
Solicitud Información
Catastral a UAECD. 6 noviembre2017 5
10 noviembre
2017 Organización de la
Información Catastral. 11 noviembre2017 5
15 noviembre
2017 Depuración de la
Información Catastral. 16 noviembre2017 2
17 noviembre
2017 Complementación de la
Información Catastral. 18 noviembre2017 5
22 noviembre
2017 Código en R que cree
Zonas Homogéneas Físicas UPZ 65 Arborizadora y 109
Ciudad Salitre Oriental
13 diciembre
2017 10
22 diciembre
2017 Contraste de Información
Obtenida en el aplicativo
VS Información tradicional. 7 enero 2018 2
9 enero 2018
Cuadro 1: CRONOGRAMA DE ACTIVIDADES PROPUESTO
6. MARCO CONCEPTUAL
6.1. INTELIGENCIA ARTIFICIAL
mejores juicios y más rápidamente que el ser humano. En la medicina tiene gran utilidad al acertar el 85 % de los casos de diagnóstico.[26]
6.2. MINERÍA DE DATOS
La minería de datos se trata de extraer patrones de los datos almacenados. Estos patrones se pueden usar para obtener información sobre los aspectos de las operaciones de los datos y para predecir resultados para situaciones futuras como una ayuda para la toma de decisiones.Los patrones a menudo se reeren a las categorías a las que pertenecen las situaciones, clases o zonas.
6.3. ARBOLES DE DECISIÓN Y CLASIFICACIÓN
Los árboles de decisión permiten obtener de forma visual las reglas de de-cisión bajo las cuales operan los consumidores, a partir de datos históricos almacenados. Su principal ventaja es la facilidad de interpretación. [10] Los árboles de decisión son una técnica de minería de datos (Data Mining, DM) prepara, sondea y explora los datos para sacar la información oculta en ellos. Se aborda la solución a problemas de predicción, clasicación y segmentación.
Las técnicas de la minería de datos provienen de la Inteligencia Articial y de la Estadística. Dichas técnicas no son más que algoritmos, más o menos sosticados, que se aplican sobre un conjunto de datos para obtener unos resultados. Las técnicas más representativas son: redes neuronales, regresión lineal, árboles de decisión, modelos estadísticos, agrupamiento o clustering y reglas de asociación.
La clasicación inicial de las técnicas de minería de datos distingue entre técnicas predictivas, en las que las variables pueden clasicarse en depen-dientes e independepen-dientes; técnicas descriptivas, en las que todas las variables tienen el mismo estatus y técnicas auxiliares, en las que se realiza un análisis multidimensional de datos. [11]
6.4. SOFTWARE R
estadísticas clásicas, análisis de series de tiempo, clasicación, agrupamiento, ...) y grácos, y es altamente extensible. El lenguaje S suele ser el vehículo de elección para la investigación en metodología estadística, y R proporciona una ruta de código abierto para la participación en esa actividad.[14]
Uno de los puntos fuertes de R es la facilidad con la que se pueden producir parcelas de calidad de publicación bien diseñadas, que incluyen símbolos matemáticos y fórmulas cuando es necesario.
Para acceder a la red integral de archivos de R, se tienen disponibles una serie de links que abren todas las posibilidades de información del programa para cada país. Este se debe elegir de acuerdo a la ubicación más cercana al lugar de vivienda. Para el caso del presente trabajo se encuentran 2 links relacionados al país Colombia, cada uno de ellos creados por la Universidad ICESI.
Tras Ingresar al link se encuentra la información para descarga e instalación del software, de ahí en adelante sólo queda descargar el software e instalar las librerías para iniciar la programación.
6.4.1. EL ENTORNO R
R es un conjunto integrado de instalaciones de software para manipulación de datos, cálculo y visualización gráca que incluye
Instalación efectiva de manejo y almacenamiento de datos.
Un conjunto de operadores para cálculos en matrices, en particular matrices.
Una colección grande, coherente e integrada de herramientas interme-dias para el análisis de datos.
Instalaciones grácas para el análisis de datos y visualización en pan-talla o en copia impresa.
Un lenguaje de programación bien desarrollado, simple y efectivo que incluye condicionales, bucles, funciones recursivas denidas por el usua-rio e instalaciones de entrada y salida.
R, como S, está diseñado en torno a un verdadero lenguaje informático y per-mite a los usuarios agregar funciones adicionales deniendo nuevas funciones. Gran parte del sistema está escrito en el dialecto R de S, lo que facilita a los usuarios seguir las elecciones algorítmicas realizadas. Para tareas intensivas en cómputo, el código C, C ++ y Fortran se puede vincular y ejecutar en tiempo de ejecución. Los usuarios avanzados pueden escribir código C para manipular objetos R directamente. [15]
Finalmente se dene R como un entorno en el que se implementan técnicas estadísticas. R se puede extender fácilmente a través de paquetes. Hay alre-dedor de ocho paquetes suministrados con la distribución R y otros que están disponibles a través de la familia de sitios de Internet de CRAN que cubren una amplia gama de estadísticas modernas.
R tiene su propio formato de documentación similar a LaTeX, que se utiliza para suministrar documentación completa, tanto en línea en una variedad de formatos como en copia impresa. [14]
6.4.2. TINN-R
El proyecto comenzó a mediados de 2003, seis meses después de que el actual coordinador del proyecto (CPC) comenzara a trabajar con el medio ambiente R. En agosto de 2003, decidió adoptar R como la herramienta principal en la enseñanza de estadísticas y también análisis de datos estadísticos.
Tinn-R es un reemplazo gratuito, simple pero eciente para el editor de có-digo básico proporcionado por Rgui. El proyecto está coordinado por José Claudio Faria, es un código de fuente abierta registrado bajo licencia pública general GPL, es un editor, procesador de textos ASCII, UNICODE genérico para el sistema operativo Windows, el cual está muy bien integrado en R, y que cuenta con características de interfaz gráca de usuario (GUI). El pro-pósito de Tinn-R es facilitar el aprendizaje y el uso de toda la potencialidad del entorno R para la informática estadística.
A continuación se muestra el link autorizado de descarga por los creadores del software Tinn-R. [16]
6.4.3. LIBRERÍAS PARA ARBOLES DE DECISIÓN
La variedad de librerías para la el proceso de clasicación es extensa, por lo que el estado del arte del presente trabajo y los resultados estadísticos de los árboles de decisión indican cuales son los más acertados.
Alguna de las librerías existentes para hacer Clasicación y Regresiones de Arboles se presentan a continuación.
Dtree: Combina varios algoritmos de árbol de decisión, más métodos de regresión lineal y conjunto en un solo paquete. Permite el uso de resul-tados continuos y categóricos. Una característica opcional es cuanticar la estabilidad de los métodos del árbol de decisión, que indica cuándo se puede conar en los resultados y cuándo los métodos de conjunto pueden ser preferenciales.
Tree: Clasica información y la devuelve en un gráco de árbol de decisión.
FFTrees (Generate, Visualise, and Evaluate Fast-and-Frugal Decision Trees): Crea, visualiza y prueba árboles de decisiones rápidos y pru-dentes (FFT). Las FFT son árboles de decisión muy simples para pro-blemas de clasicación binarios, pueden ser preferibles a los algoritmos más complejos porque son fáciles de comunicar, requieren muy poca información y son resistentes contra el sobreajuste.
Rpart (Partición recursiva y árboles de clasicación): Es la implemen-tación de una partición recursiva para árboles de clasicación, regresión y supervivencia, como una implementación de la mayor parte de la fun-cionalidad del libro de Breiman, Friedman, Olshen y Stone escrito en el año 1984.
C5.0 (Árboles de decisión C5.0 y modelos basados en reglas): Árboles de decisión C5.0 y modelos basados en reglas para el reconocimiento de patrones que extienden el trabajo de Quinlan hecho en el año 1993, y actualmente es la versión mejorada del algoritmo C4.5.
6.5.3.1 RPART
la ecuación que compone la regresión para la creación del árbol de clasica-ción es la siguiente:
, y=T RU E, parms, control, cost,. . .) (6.1)
Los argumentos que pueden usarse para construir, enriquecer y alterar el modelo, son los siguientes:
Formula: Es una función genérica, la cual se devuelve en datos tipo data.frame, son variables en las cuales sólo una es variable respuesta. Data: El data.frame o marco de datos en el cual se encuentran las variables que se utilizan en la formula.
Weights: Caso opcional, para dar peso a las observaciones de una va-riable.
Subset: indica un subgrupo (si existe) de la muestra con el cual se realizará el entrenamiento del modelo.
Na.action: borra aquellas observaciones que no tienen información. Method: Existen 4 métodos denidos,sin embargo para el presente tra-bajo se especican 2, Método class para árbol de clasicación y mé-todo anova para regresión de árbol.
Control: Son parámetros opcionales para controlar el crecimiento del árbol, para número mínimo de observaciones en un nodo para determi-nar una división con minsplit y para una división que disminuya la falta total de ajuste con cp factor de complejidad del costo.
Para examinar los resultados esta librería las funciones más importantes usa-das en la práctica son, printcp para mostrar tabla cp, plotcp para trazar resultados de la validación cruzada, summary para mostrar los resultados de la clasicación o regresión. [1]
6.5.3.2 C50
El paquete C50 contiene una interfaz para poder usar el algoritmo de cla-sicación y C5.0, este algoritmo tiene dos modos de uso, el primero es un modelo básico de desición y otro basado en reglas, que al nal muestra los mismos resultados, pero imprimen diferente información.
que generalmente son más fáciles de entender si se hace un comparativo con las redes neuronales, este algoritmo es fácil de usar y no presupone ningún conocimiento especial de Estadística o aprendizaje automático.[5]
La formula para ajustar modelos de árbol de clasicación o modelos basados en reglas es la siguiente:
C5,0(x, y, trials= 1, rules=F ALSE, weights=N U LL, control=C5,0Control(), costs=N U LL, ...)
(6.2)
C5,0(f ormula, data, weights, subset, na.action=na.pass, ...) (6.3)
Los argumentos que pueden usarse para construir y enriquecer, son los si-guientes:
x: data.frame o matriz a predecir
y: mector de dos o más niveles o data.frame que contiene las otras variables.
Trials: Es un entero que especica el número de iteraciones de refuerzo por cada rama del árbol, el valor default es 1.
Rules: para indicar si se quiere predecir un modelo con reglas, esto no genera un gráco de árbol.
Weights: Vector opcional de pesos que no es tomado como variable divisora en el modelo.
Control: Es una lista de parámetros de control para el modelo, su raíz es C5,0Control()y su ecuación es la siguiente:
C5,0Control(subset=T RU E, bands= 0, winnow=F ALSE, noGlobalP runing=F ALSE, CF = 0,25, minCases= 2,
f uzzyT hreshold=F ALSE, sample= 0, seed=sample.int(4096, size= 1)−1L, earlyStopping=T RU E, label= ”outcome”)
(6.4)
Cost: una matiz que describe una penalización por cada error que co-meta el árbol de clasicación.
Data: Conjunto de datos que contiene toda la información a analizar. Subset: indica un subgrupo (si existe) de la muestra con el cual se realizará el entrenamiento del modelo.
Na.action: borra aquellas observaciones que no tienen información.
7. MARCO ESPACIAL
Con el n de probar el algoritmo que se desarrollará en el software R, se tomarán los datos de los predios de las UPZ 65 Arborizadora localizada en la localidad 19 Ciudad Bolívar y la 109 Ciudad Salitre Oriental localizada en la localidad 13 Teusaquillo, elegidas por la heterogeneidad entre si y la variabilidad de las características de los predios en cada una de ellas.
7.1. UNIDAD DE PLANEAMIENTO ZONAL EN
BO-GOTÁ
Según la secretaría de planeación de la ciudad de Bogotá, una unidad de planeamiento zonal es un área urbana más pequeña que una localidad y más grande que un barrio, sirve como unidad territorial para planicar el desarrollo urbano en el nivel zonal, también para el desarrollo de una norma urbanística en el nivel de detalle que requiere Bogotá. La planicación a esta escala, además de ser la base para la denición de la norma especíca, que se concreta en la chas normativas y decretos de cada UPZ, permite hacer una mejor inversión de los recursos, en obras realmente requeridas por la comunidad, buscando el benecio colectivo. [12]
7.2. ZONAS HOMOGÉNEAS FÍSICAS EN BOGOTÁ
Según la Unidad Administrativa Especial de Catastro Distrital una Zona Homogénea Física es un espacio geográco con características similares en cuanto a los siguientes parámetros:
Vías Topografía
Uso actual del suelo Norma de uso del suelo
Tipicación de las construcciones Áreas Homogéneas de la tierra Disponibilidad de aguas superciales
Las cuales permiten la diferenciación de espacios geográcos con caracterís-ticas físicas diferentes.[13]
Para la creación de las Zonas Homogéneas Físicas, Bogotá ha creado las UPZ con el n principal de desarrollar una norma urbanística con un buen nivel de detalle, dado que Bogotá presenta una heterogeneidad bastante notoria. Sin embargo no todas estas UPZ esta normatizadas y por el momento se encuentran reglamentadas bajo la norma general urbana como el POT o el Acuerdo 06 de 1990.
Las zonas homogéneas físicas están compuestas por 8 variables normativas que dan como resultado una codicación de 13 dígitos para cada una de las zonas presentes, estos variables son:
Clase de suelo Área de actividad
Tratamientos Urbanísticos Topografía
Servicios Públicos Vías
Actividad económica del inmueble
Tipo según actividad económica del inmueble.
Figura 2:TABLA DE ZONAS HOMOGENEAS FÍSICAS, VIGENCIA 2014 HOJA
Los primeros 3 ítems van están directamente relacionados con la norma, que para aquellas UPZ que se encuentra reglamentada están bajo la norma del Decreto 190 de 2004 POT y para las que no, el Acuerdo 06 de 1990, mientras que los códigos 4 al 8 describen la condición y el uso actual del inmueble.
7.3. UPZ 65 ARBORIZADORA
Figura 3:BARRIOS CATASTRALES UPZ 65, Fuente: Elaboración Propia
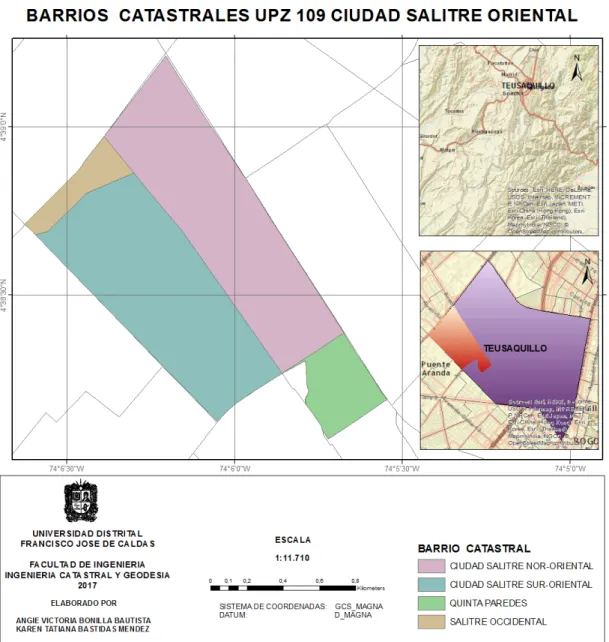
7.4. UPZ 109 CIUDAD SALITRE ORIENTAL
o no construidas, se desarrollarán usos múltiples de acuerdo con el carácter de la UPZ.[18]
8. ESTADO DEL ARTE
En la consulta de información correspondiente a la realización de Arboles de Clasicación, zonas homogéneas físicas, regresión de árbol, inteligencia articial y minería de datos, se realiza la consulta en documentos tanto na-cionales como internana-cionales, y la experiencia obtenida en este tipo de labor, en proyectos de esta índole.
I. Desarrollo de Modelos de Evaluación Usando Operadores de una Lógica Continua
_____________________________________________
http://sedici.unlp.edu.ar/bitstream/handle/10915/27208/Documento_completo.pdf?sequence=1
_____________________________________________
En este artículo se desarrollaron modelos para la evaluación de sistemas usan-do el métousan-do LSP (Logic Score of Preference) para determinar modelos para la evaluación de bienes inmobiliarios. El empleo del método LSP permite expresar aspectos en la evaluación que otras técnicas meramente aditivas no permiten, ofreciéndonos la posibilidad de construir modelos que se ajusten con una mayor precisión a las necesidades del usuario, sea este un ente recau-dador de impuestos scales, un agente inmobiliario o cualquier otro interesado en obtener una tasación de un bien inmueble.[19]
II. Propuesta Metodológica para Calcular el Avalúo Catastral de un Predio Utilizando Redes Neuronales Articiales
_____________________________________________
http://repository.udistrital.edu.co/handle/11349/4489
_____________________________________________
se emplearon para la estimación del modelo fueron obtenidos en la investiga-ción de mercado directa e indirecta realizada en el proceso de Actualizainvestiga-ción de la Formación Catastral de la zona urbana del Municipio de Fusagasugá que entró en vigencia el primero de enero de 2013. Para obtener el mejor modelo de RNA, en el que se seleccionen las variables que más contribuyen a la determinación del valor de un inmueble, se realizaron, numerosas pruebas, utilizando el algoritmo Perceptrón Multicapa de tipo supervisado MLP y el software estadístico SPSS V. 21. [20]
III. Redes Neuronales aplicadas al Avalúo Inmobiliario
_____________________________________________
http://www.rpiol.com/MyWord_0011.html
_____________________________________________
Este trabajo muestra la aplicación de la tecnología de redes neuronales en la elaboración de Avalúos Inmobiliarios. Ante el declive de los análisis de regresión múltiple frente a la dinámica del mercado inmobiliario, causado principalmente por las falencias de los paquetes estadísticos de considerar algo más que reglas y modelos matemáticos rígidos. Se comparó la habilidad predictiva de una red neuronal con modelos de regresión múltiple, obteniendo como resultado: En tareas de predicción las redes neuronales y los modelos de regresión múltiple generan similares resultados; mientras que para tareas de clasicación las redes neuronales rinden mejor.[21]
IV. El Uso de árboles de decisión como herramienta para generar un modelo de valoración territorial en Vilcabamba, Ecuador.
_____________________________________________
http://coello.ujaen.es/congresos/cicum/ponencias/Cicum2010.2.17_ReyesBueno_El_uso_de_arboles_de_decision.pdf
El objetivo de este estudio fue elaborar un modelo de valoración de tierras adaptado a las características no lineales de las variables que catastrales, y compararlo con el método tradicional de regresión lineal.
Identican el valor agregado que los árboles de decisión dan sobre las variables catastrales y determinan por medio de información propia y verídica que su resultado es mejor al determinado por medio de métodos tradicionales. [22]
V. Sistema De Valuación Catastral
_____________________________________________
http://www.reci.org.mx/index.php/reci/article/view/14
_____________________________________________
Este artículo resalta la importancia del conocimiento del valor del suelo y como a través de un sistema valuatorio se debe mantener actualizados estos valores con el n de mejorar la recaudación del impuesto predial, ya que la recaudación de este es la fuente principal de ingresos propios de los munici-pios.
El procedimiento de valoración colectiva de carácter general es el proceso mediante el que se actualizan simultáneamente los valores catastrales de to-dos los inmuebles de una misma clase de un municipio, con la nalidad de homogeneizarlos y referenciarlos uniformemente con los valores de mercado. [23]
VI. Modelos de valoración automatizada en Lituania
_____________________________________________
https://www.researchgate.net/publication/28136091_Modelos_de_valoracion_automatizada_en_Lituania
Este artículo hace un resumen de cómo inició el proceso de valuación masiva en Lituania desde 1998. Al transcurrir el tiempo ha buscado automatizar el proceso a través del uso de herramientas como ORACLE Discover,NCCS y GIS. Sin embargo existen casos especícos que no permiten la estandarización y toca generarlos manualmente. Hacia el año 2005 Lituania impone una ley sobre impuesto predial donde el factor principal de cálculo del mismo es la valuación masiva. Es así como Lituania busca estandarizar el proceso de la valuación masiva a través de herramientas tecnológicas permitiendo ampliar conocimientos sobre GIS . [24]
VII. Análisis De Efectividad Al Implementar La Técnica De Árboles De Decisión Del Enfoque De Aprendizaje De Máquina
Para La Determinación De Avalúos Masivos Para Las Upz 79 Calandaima, 65 Arborizadora Y 73 Garcés Navas
En este trabajo se presenta una herramienta más a partir de la implemen-tación del algoritmo de árboles de decisión, del enfoque del aprendizaje de máquina, a los procesos valuatorios de los bienes inmuebles, mostrando otra alternativa para emplear un proceso de esta índole en la investigación que involucra un avalúo y vericar su efectividad, este trabajo muestra su efec-tividad y su aplicabilidad en 3 UPZ de Bogotá en donde se evidencian muy buenos resultados Catastralmente hablando.[25]
9. METODOLOGÍA
A continuación se encuentra la metodología por medio de la cual se llega al resultado nal de este trabajo, la primera parte describe la determina-ción de Zonas Homogéneas Físicas y La segunda parte el desarrollo de los experimentos con los arboles de clasicación en el software R.
dada en el Decreto Distrital 619 de 2000, revisado por el Decreto Distrital 469 de 2003, y compilado por el Decreto Distrital 190 de 2004.
Los planos de las UPZ correspondientes, se obtuvieron de la página de la Secretaria Distrital de Planeación, adicionalmente con la información de las cartillas por UPZ que se encuentran en la misma página, estas con el n de contextualizar las características de la zona y el reconocimiento de campo, permitió la elaboración de las mismas.
1. Visita UPZ: se realizó una visita por cada una de las upz con el n de conocer los aspectos físicos de las mismas puesto que los últimos dígitos de la codicación corresponden a características como tal del uso actual de los inmuebles.
2. Consulta de norma: como anteriormente mencionamos, a través de la página de la SDP se obtuvieron los planos normativos de cada una de las UPZ.
3. Georreferenciación de la norma: los planos obtenidos de la pagina SDP fueron cargados al software GIS y se procedió a hacer la Georreferen-ciación de las mismas.
4. Creación de GDB por UPZ: Se creo una GDB con el n de tener orga-nizada la información de cada una de las UPZ y tener la información. 5. Creación de feature class por variable de ZHF: Se creó un feature class
por variable para luego poder realizar el cruce de información.
6. Carga de shapes necesarios: los shapes necesarios se obtuvieron dela MAPA DE REFERENCIA BOGOTÁ 2017 que se encuentra en la pá-gina web IDECA, a estos shapes se les realizaron geoprocesamientos con el software GIS para obtener información de la zona de interés, para el caso, se consideraron pertinente la información de los shapes de: lotes, malla vial, contorno de la upz y cuerpos de agua.
7. Digitalización Feature Class: con los feature class creados previamente y los planos de la norma cargados en el software GIS se procede a realizar la digitalización de cada variable.
9. Intersección con shape de lotes: se realiza la intersección con el shape de lotes, para poder determinar a que zhf pertenece cada uno de los mismos.
10. Shape listo para procesamiento en R: el resultado del anterior geoproce-samientos nos indica da el producto que se usara para el procesamiento en R.
Figura 5: PROCESO DE DETERMINACIÓN SOFTWARE GIS. Fuente: Elaboración Propia
9.2. METODOLOGÍA DE CONSTRUCCIÓN DE
CÓ-DIGO EN R
A Continuación describiremos la metodología de construcción del código en el software R para la construcción de los modelos de arboles de clasicación, este procedimiento depende de los insumos generados en el procesamiento anterior, pues el Shape, contiene la información base para realizar el proce-samiento.
Este procesamiento se realiza de la misma manera para los dos casos de estudio planteados inicialmente Para las UPZ 63 Arborizadora y UPZ 109 Salire Sur Oriental, sien embargo el análisis y resultado de los datos reejan dinámicas diferentes, que se presentarán en el Capítulo 10 de Análisis y Resultados de cada UPZ.
1. Abrir TINN-R: Esta es la ventana de código GUI que usamos para la construcción del código base.
2. Cargar Librerías necesarias para cada uno de los procedimientos, estas librerías son indispensables para que el código construído no presente ningún error, estas librerías son:
library(sp): Esta librería trabaja deniendo clases y métodos para
procesamiento de datos espaciales, es útil para el ploteo de ma-pas, selección de datos espaciales y para trabajo que requiera uso de coordenadas, puede usarse a partir de la versión 3.0.0 de R yse
complementa con librerías comoRColorBrewer, Rgdal, rgeos, gstat, maptools, deldir
.[3]
library(rgdal): Esta librería Proporciona enlaces a la Biblioteca de
abstracción de datos 'geoespaciales' GDAL y acceso a operacio-nes de Projection y Transformación desde la biblioteca PROJ.4. Las bibliotecas 'GDAL' y 'PROJ.4' son externas al paquete. Su uso está dirigido y depende del paquete sp. [4]
library(base): Esta librería contiene las funciones básicas que
per-miten que R funcione como un lenguaje: aritmética, entrada / salida, soporte de programación básica, etc. Sus contenidos están disponibles a través de la herencia de cualquier entorno. [6]
library(C50) : Librería que contiene funciones de algoritmos de
entrenamiento para determinar Árboles de decisión C5.0 y mode-los basados en reglas para el reconocimiento de patrones. [5]
library(caret): Es una Librería que contiene un conjunto de
fun-ciones que intentan simplicar el proceso para crear modelos pre-dictivos. El paquete contiene herramientas para división de datos, preprocesamiento, seleccion de características, ajuste de modelo y estimación de importancia de las variables.[7]
3. Cargar el Shape mediante la herramienta readOGR, deniendo
ante-riormente ubicación del archivo .shp y nombre del archivo .shp.
4. Convertir la información de tabla del shape en un archivo tipo da-ta.frame para simplicar los cálculos y asignación de clases en R. 5. Seleccionar variables necesarias para la creación del modelo y crear un
6. Análisis de Frecuencia de cada una de las variables que ingresan al modelo.
7. para la construcción del modelo nal se determinan 3 procedimientos para constituir el resultado nal.
Validación Cruzada: De la base de datos general se toma un alea-torio del 70 % de los datos para correr el modelo Train y el 30 % de los datos para validarlo Test
Modelo con la totalidad de los Datos
Modelo de Prueba o iterativo que hará uso de la función trials denida anteriormente en la fórmula del algoritmo C50.
Figura 6: PROCESO DE DETERMINACIÓN EN R. Fuente: Elaboración Propia
10. ANÁLISIS DE LOS PRODUCTOS
10.1. UPZ CIUDAD SALITRE ORIENTAL
10.1.1. PRE PROCESAMIENTO DE DATOSPara el preprocesamiento de los datos se carga el shape a R, y con las co-lumnas de información del shape se crea una data frame zhf_lotes_salitre.df,
luego, se eliminan las columnas de las variables que no se necesitan para el análisis de los datos creando un nuevo data frame llamadonew_zhf_lotes,luego
Figura 7: SHAPE CIUDAD SALITRE ORIENTAL
Al tener el data frame con la información objeto de estudio se verica de acuerdo al número de las los datos que pudieron haberse eliminado.
Figura 8: NÚMERO DE FOLIOS DATA FRAME new_zhf_lotes Ybase_codigos
Luego se realiza una unión de los códigos para determinar el que será el nú-mero relacionado a la Zona Homogénea Física de cada polígono del shape y se forma un nuevo data frame uniendo base_codigos y base_cod_concatenado formando
df.concatenado.
Cuadro 2: CÓDIGOS ZONA HOMOGENES FÍSICA SEGÚN MANUAL Y FRECUENCIA UPZ 109.
Código Código de ZHF Frecuencia
41 6452115153344 37
10 6212115152112 28
29 6332415153344 15
42 6713215152131 14
1 5717715152131 10
7 6211115152131 8
24 6222115152112 8
16 6212115153422 6
19 6221115153324 6
25 6222115152312 6
18 6221115153322 5
31 6332415153444 5
33 6412115152312 5
3 5717715153344 4
15 6212115153324 4
13 6212115152312 3
14 6212115153322 3
22 6221115153424 3
27 6332415152344 3
37 6412115153324 3
40 6412115153444 3
21 6221115153422 2
30 6332415153351 2
35 6412115152344 2
36 6412115153322 2
38 6412115153344 2
2 5717715152322 1
4 5717715153351 1
5 5717715153352 1
6 5717715153451 1
8 6211115152151 1
Código Código de ZHF Frecuencia
11 6212115152152 1
12 6212115152153 1
17 6212115153444 1
20 6221115153344 1
23 6221115153444 1
26 6312415153412 1
28 6332415153144 1
32 6332415153451 1
Después de haber concatenado los códigos se realiza una asignación de clase a cada código haciendo uso de reglas de decisión If-Else.
Lo anterior con el n de construir la variable respuesta para el modelo y crear la base para la predicción, nalmente se compacta toda la información y se crea un sólo data frame que será usado para la validación cruzada, modelo nal y modelo iterativo.
10.1.2. VALIDACIÓN CRUZADA
Para realizar la validación cruzada se realizó la selección de el 70 % de los aleatorios y se denominó clasicación_train, a la muestra restante se le nom-bró clasicación_test, con esto lo que se busca es Crear un modelo de árbol de clasicación tomando como datos de entrenamiento los datos de la base Train y validar su comportamiento y ajuste con los datos de la base Test.
Algoritmo 1 DATOS DE ENTRENAMIENTO PARA VALIDACIÓN CRUZADA UPZ 109
>train_idx <- sample(nrow(clasicación), 0.7*nrow(clasicación)) >clasicación_train <- clasicación[train_idx,]
>clasicación_test <- clasicación[-train_idx,]
Como ya se mostró antes la totalidad de los datos es de 205, es decir que en la base de entrenamiento serán 143 y los datos de prueba serán 62.
en cuanto a los datos predichos con respecto a los datos presentados. El resultado de la matriz de confusión se muestra en la siguiente gráca.
Figura 9: MATRIZ DE CONFUSIÓN VALIDACIÓN CRUZADA UPZ 109.
El resultado anterior nos da respuesta de un 72 % de exactitud de predicción del modelo de la validación cruzada con los datos del test, lo cual resulta ser bueno y aceptable pues en la zona, los lotes son muy grandes y son muy pocos, lo que hace que el número de zonas homogéneas físicas iniciales sean reducidas y puede que la información que está presente en el Train o el Test no resulte ser suciente para cubrir las dos bases de datos y es probable que se presenten observaciones ausentes en alguno de los dos grupos, pues según la información contenida en el cuadro 2, existen códigos con sólo una aparición dentro de todos los datos, es decir queda clasicado sólo en uno de los dos grupos.
10.1.3. MODELO FINAL
1. ÁRBOL DE CLASIFICACIÓN
Figura 10: ÁRBOL DE CLASIFICACIÓN UPZ 109
Las condiciones para interpretación de este árbol no están dadas, por lo que tomamos la decisión de dividirlo por número de nodo ascendente y determinar el número de datos que ingresaron para análisis por clase y el error de predicción.
Los árboles de decisión a veces pueden ser bastante difíciles de entender pero una característica importante de C5.0 es su capacidad para generar clasicadores llamados conjuntos de reglas que consisten en colecciones desordenadas de reglas (relativamente) simples de si-entonces, que des-criben el comportamiento de los nodos y las hojas del árbol clasicador. Los resultados de análisis para cada rama de árbol se describirán por medio de tablas, que dan información de cada nodo del árbol llamado VARIABLE y su condición en el patrón de clasicación.
La precisión de la regla se estima mediante la relación de Laplace (n-m + 1) / (n + 2) este valor se encontrará en las tablas correspondientes a cada regla y el valor de conanza de la predicción y error se encuentra en el gráco del árbol, este es un valor entre 0 y 1.
Cuadro 3: REGLA 1 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase5 5717715152131 0.917
VARIABLE CONDICIÓN
COD_1 <= 5
COD_8 <= 2
COD_11 <= 1
Para la predicción de la variable clase 5 se encontró un patrón en el cual sólo tres variables eran necesarias para la predicción de la clase, COD_1 que hace referencia a la clase de suelo que debe ser obligatoria-mente suelo protegido, el COD_8 que hace referencia a el estado de la vía y debe ser obligatoriamente malo o sin vidas y el COD_11 que hace referencia a el tipo según la actividad económica del inmueble debe ser para no edicados: urbanizable no urbanizado, para Residencial: Ti-po 1, Comercial y de servicios:Vecinal, Industrial: industria extractiva, Equipamientos: Colectivo educación, Espacio publico: espacio publico vial y para recreaciones y deportivo: Parques. El porcentaje de cona-bilidad de clasicación de los datos es de un 91 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 4: REGLA 2 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase6 6211115152131 0.818
VARIABLE CONDICIÓN
COD_2 <= 45
COD_8 <= 2
COD_11 <= 1
cual sólo tres variables eran necesarias para la predicción de la clase, COD_2 que hace referencia a el área de actividad que debe ser obliga-toriamente Residencial, Dotación y entre el área de comercio y servicios en sub-categorias como: de servicios empresariales, de servicio empre-sariales e industriales, especial de servicios, de servicios al automóvil o de comercio cualicado, el COD_8 que hace referencia a el estado de la vía y debe ser obligatoriamente malo o sin vidas y el COD_11 que hace referencia a el tipo según la actividad económica del inmueble debe ser para no edicados: urbanizable no urbanizado, para Residencial: Ti-po 1, Comercial y de servicios:Vecinal, Industrial: industria extractiva, Equipamientos: Colectivo educación, Espacio publico: espacio publico vial y para recreaciones y deportivo: Parques. El porcentaje de cona-bilidad de clasicación de los datos es de un 81 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 5: REGLA 3 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase4 6713215152131 0.938
VARIABLE CONDICIÓN
COD_1 >5
COD_2 >45
Cuadro 6: REGLA 4 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase2 6212115152112 0.309
VARIABLE CONDICIÓN
COD_8 <=2
Para la predicción de la variable clase 2 se encontró un patrón en el cual sólo una variable era necesaria para la predicción de la clase, COD_8 que hace referencia a el estado de la vía y debe ser obligatoriamente ma-lo o sin vías. El porcentaje de conabilidad de clasicación de ma-los datos es de un 30 % lo cual indica que el porcentaje de error es signicativo.
Cuadro 7: REGLA 5 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase 33 6212115152152 0.5
VARIABLE CONDICIÓN
COD_8 <= 2
COD_9 <= 1
COD_10 > 3
COD_11 > 1
un 50 % lo cual indica que el porcentaje de error es signicativo.
Cuadro 8: REGLA 6 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase7 6222115152112 0.9
VARIABLE CONDICIÓN
COD_2 > 21
COD_8 <= 2
COD_9 <= 1
COD_11 > 1
Para la predicción de la variable clase 7 se encontró un patrón en el cual sólo cuatro variables eran necesarias para la predicción de la clase, COD_2 que hace referencia a el área de actividad que debe ser obliga-toriamente Dotacionales, comercio y servicios, central, urbana integral, industrial, suelo de protección y residencial a excepción de residencial neta, el COD_8 que hace referencia a el estado de la vía y debe ser obligatoriamente malo o sin vías, el COD_9 que hace referencia a la inuencia de la vía y debe ser sin vías, COD_11 puede ser cualquier tipo según la actividad económica. El porcentaje de conabilidad de clasicación de los datos es de un 90 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 9: REGLA 7 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase16 6212115152312 0.8
VARIABLE CONDICIÓN
COD_2 <= 21
COD_8 <= 2
Para la predicción de la variable clase 16 se encontró un patrón en el cual sólo tres variables eran necesarias para la predicción de la clase, COD_2 que hace referencia a el área de actividad que debe ser obliga-toriamente Residencial Neta, el COD_8 que hace referencia a el estado de la vía y debe ser obligatoriamente malo o sin vidas y el COD_9 que hace referencia a a la inuencia de la vía debe ser vial loca, zonal o intermedia, arterial complementaria arterial básica o principal. El por-centaje de conabilidad de clasicación de los datos es de un 80 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 10: REGLA 8 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase10 6222115152312 0.875
VARIABLE CONDICIÓN
COD_2 > 21
COD_2 <= 31
COD_8 <= 2
COD_9 > 1
Cuadro 11: REGLA 9 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase13 6412115152312 0.857 VARIABLE CONDICIÓN
COD_2 > 31
COD_10 <= 1
Para la predicción de la variable clase13 se encontró un patrón en el cual sólo dos variables eran necesarias para la predicción de la clase, COD_2 que hace referencia a el Área de actividad económica que debe ser Dotacional, Comercio y Servicios, Central Urbana Integral o Industrial, en ningún caso residencial y COD_10 que hace referencia a Actividad económica de los inmuebles y debe ser obligatoriamente Residencial o No Edicado. El porcentaje de conabilidad de clasicación de los datos es de un 85 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 12: REGLA 10 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase19 6332415152344 0.8 VARIABLE CONDICIÓN
COD_2 <= 33
COD_8 <= 2
COD_9 > 1
COD_10 > 1
básica o principal, COD_10 que hace referencia a la actividad econó-mica debe ser residencial, comercial y de servicios, industrial, equipa-mientos, espacio publico y recreaciones y deportivo . El porcentaje de conabilidad de clasicación de los datos es de un 80 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 13: REGLA 11 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase27 5717715152322 0.5 VARIABLE CONDICIÓN
COD_8 <= 2
COD_10 > 1
COD_10 <= 3
COD_11 > 1
Para la predicción de la variable clase 27 se encontró un patrón en el cual sólo tres variables eran necesarias para la predicción de la clase, COD_8 que hace referencia a el estado de la vía y debe ser obligato-riamente malo o sin vías, COD_10 que hace referencia a la actividad económica que debe ser obligatoriamente residencial y el COD 11 que hace referencia a el tipo según la actividad económica del inmueble debe ser Tipo 2, tipo 3 , tipo 4, tipo 5 y tipo 6. El porcentaje de con-abilidad de clasicación de los datos es de un 50 % lo cual indica que el porcentaje de error es signicativo.
Cuadro 14: REGLA 12 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase24 6412115152344 0.750 VARIABLE CONDICIÓN
COD_2 > 33
COD_8 <= 2
COD_10 > 3
COD_2 que hace referencia a el área de actividad que debe ser comer-cio y servicomer-cios, central, urbana integral, industrial, suelo de protección, COD_8 que hace referencia a el estado de la vía y debe ser obligato-riamente malo o sin vías y COD_10 que hace referencia a la actividad económica del inmueble que debe ser obligatoriamente industrial, equi-pamientos, espacio publico, recreaciones y deportivo. El porcentaje de conabilidad de clasicación de los datos es de un 75 % lo cual indica que el porcentaje de error no es signicativo.
Figura 11: NODO 2 ÁRBOL DE DECISIÓN UPZ 109
Cuadro 15: REGLA 13 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase11 6221115153322 0.857 VARIABLE CONDICIÓN
COD_3 <= 11
COD_8 > 2
COD_9 <= 3
Para la predicción de la variable clase 11 se encontró un patrón en el cual sólo cuatro variables eran necesarias para la predicción de la cla-se, COD_3 que hace referencia a el tratamiento urbanístico que debe ser obligatoriamente de desarrollo, el COD_8 que hace referencia a el estado de la vía y debe ser obligatoriamente regular, bueno o excelen-te, el COD_9 que hace referencia a la inuencia de la vía y debe ser vial loca, zonal o intermedia, o sin vías, COD_11 que hace referencia al tipo según la actividad económica debe ser dependiendo de su ac-tividad económica alguno de los tres primeros tipos. El porcentaje de conabilidad de clasicación de los datos es de un 85 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 16: REGLA 14 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase9 6221115153324 0.875 VARIABLE CONDICIÓN
COD_3 <= 11
COD_9 <= 3
COD_10 <= 3
COD_11 > 3
Cuadro 17: REGLA 15 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase17 6212115153322 0.8 VARIABLE CONDICIÓN
COD_2 <= 31
COD_3 > 11
COD_8 > 2
COD_9 <= 3
COD_11 <= 3
Para la predicción de la variable clase 17 se encontró un patrón en el cual sólo cinco variables eran necesarias para la predicción de la clase, COD_2 que hace referencia a el área de actividad que debe ser resi-dencial o de equipamientos colectivos, COD_3 que hace referencia a el tratamiento urbanístico que debe ser cualquier tipo de tratamiendo, el COD_8 que hace referencia a el estado de la vía y debe ser regular, bueno o excelente, el COD_9 que hace referencia a la inuencia de la vía y debe ser vía zonal o intermedia, local o sin vidas y el COD_11 que hace referencia al tipo según la actividad económica debe ser de-pendiendo de su actividad económica alguno del 4 ítem en adelante. El porcentaje de conabilidad de clasicación de los datos es de un 80 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 18: REGLA 16 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase15 6212115153324 0.833 VARIABLE CONDICIÓN
COD_2 <= 31
COD_3 > 11
COD_9 <= 3
COD_11 > 3
cual sólo cuatro variables eran necesarias para la predicción de la clase, COD_2 que hace referencia a el área de actividad que debe ser resi-dencial o de equipamientos colectivos, COD_3 que hace referencia a el tratamiento urbanístico que debe ser cualquier tipo de tratamiento, el COD_9 que hace referencia a la inuencia de la vía y debe ser vía zonal o intermedia, local o sin vias y el COD_11 que hace referencia al tipo según la actividad económica debe ser dependiendo de su ac-tividad económica alguno de los tres primeros tipos. El porcentaje de conabilidad de clasicación de los datos es de un 83 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 19: REGLA 17 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase25 6412115153322 0.75 VARIABLE CONDICIÓN
COD_2 > 31
COD_8 > 2
COD_10 <= 3
COD_11 <= 3
Cuadro 20: REGLA 18 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase20 6412115153324 0.8
VARIABLE CONDICIÓN
COD_2 > 31
COD_9 <= 3
COD_10 <= 3 <= 3
COD_11 > 3
Para la predicción de la variable clase 20 se encontró un patrón en el cual sólo cuatro variables eran necesarias para la predicción de la clase, el COD_2 que hace referencia a el Área de actividad económica que debe ser Dotacional, Comercio y Servicios, Central Urbana Integral o Industrial, en ningún caso residencial, el COD_9 que hace referencia a la inuencia de la vía y debe ser vía zonal o intermedia, local o sin vías, el COD_10 que hace referencia a la actividad económica que de-be ser obligatoriamente residencial y el COD_11 que hace referencia al tipo según la actividad económica debe ser dependiendo de su ac-tividad económica alguno de los tres primeros tipos. El porcentaje de conabilidad de clasicación de los datos es de un 80 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 21: REGLA 19 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase26 6412115153344 0.6 VARIABLE CONDICIÓN
COD_2 <= 41
COD_3 <= 21
COD_8 > 2
COD_10 > 3
cla-se, el COD_2 que hace referencia a el Área de actividad económica que debe ser dotacional o residencial, COD_3 que hace referencia a el tratamiento urbanístico que puede ser de consolidación, de renovación urbana, de conservación, mejoramiento integral, suelo de protección, parques urbanos, en general todos los tratamientos urbanísticos a ex-cepción del tratamiento urbanístico de desarrollo ,el COD_8 que hace referencia a el estado de la vía y debe ser regular, bueno o excelente,y el COD_10 que hace referencia a la actividad económica que debe ser obligatoriamente industrial, equipamientos, espacio publico o recrea-ciones y deportivo. El porcentaje de conabilidad de clasicación de los datos es de un 60 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 22: REGLA 20 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase1 6452115153344 0.33 VARIABLE CONDICIÓN
COD_2 > 41
COD_3 <= 21
COD_8 > 2
COD_10 > 3
Cuadro 23: REGLA 21 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase14 5717715153344 0.857 VARIABLE CONDICIÓN
COD_1 <= 5
COD_8 > 2
COD_10 <= 4
Para la predicción de la variable clase 14 se encontró un patrón en el cual sólo tres variables eran necesarias para la predicción de la clase, COD_1 que hace referencia a la clase de suelo que debe ser obliga-toriamente suelo protegido, el COD_8 que hace referencia a el estado de la vía y debe ser obligatoriamente regular, bueno o excelente y el COD_10 q que hace referencia a la actividad económica debe ser no edicado, residencial, comercial y de servicios e industrial. El porcen-taje de conabilidad de clasicación de los datos es de un 85 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 24: REGLA 22 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase28 5717715153351 0.5 VARIABLE CONDICIÓN
COD_1 <= 5
COD_9 <= 3
COD_10 > 4
espacio publico o recreaciones y deportivo . El porcentaje de conabi-lidad de clasicación de los datos es de un 50 % lo cual indica que el porcentaje de error es signicativo.
Cuadro 25: REGLA 23 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase3 6332415153344 0.889 VARIABLE CONDICIÓN
COD_1 > 5
COD_3 > 21
COD_8 > 2
COD_9 <= 3
COD_10 <= 4
Cuadro 26: REGLA 24 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase23 6332415153351 0.750 VARIABLE CONDICIÓN
COD_1 > 5
COD_8 > 2
COD_9 <= 3
COD_10 > 4
Para la predicción de la variable clase 23 se encontró un patrón en el cual sólo tres variables eran necesarias para la predicción de la clase, COD_1 que hace referencia a la clase de suelo que debe ser obligato-riamente suelo no protegido, el COD_8 que hace referencia a el estado de la vía y debe ser regular, bueno o excelente, el COD_9 que hace referencia a la inuencia de la vía y debe ser vía zonal o intermedia, local o sin vías y el COD_10 que hace referencia a la actividad econó-mica debe ser industrial, equipamientos, espacio publico o recreaciones y deportivo. El porcentaje de conabilidad de clasicación de los datos es de un 75 % lo cual indica que el porcentaje de error es signicativo.
Cuadro 27: REGLA 25 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase30 5717715153451 0.4 VARIABLE CONDICIÓN
COD_9 > 3
COD_10 > 3
COD_11 <= 3
Para la predicción de la variable clase 30 se encontró un patrón en el cual sólo tres variables eran necesarias para la predicción de la clase, el COD_9 que hace referencia a la inuencia de la vía y debe ser vía arte-rial complementaria o artearte-rial básica, el COD_10 que hace referencia a la actividad económica debe ser industrial, equipamientos, espacio publico o recreaciones y deportivo y el COD_11 que hace referencia al tipo según la actividad económica debe ser dependiendo de su ac-tividad económica alguno de los tres primeros tipos. El porcentaje de conabilidad de clasicación de los datos es de un 40 % lo cual indica que el porcentaje de error es signicativo.
Cuadro 28: REGLA 26 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase8 6212115153422 0.875 VARIABLE CONDICIÓN
COD_2 <= 21
COD_9 > 3
COD_10 <= 3
residencial o comercial y de servicios . El porcentaje de conabilidad de clasicación de los datos es de un 87 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 29: REGLA 27 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase22 6221115153422 0.6 VARIABLE CONDICIÓN
COD_2 > 21
COD_9 > 3
COD_10 <= 3
COD_11 <= 3
Cuadro 30: REGLA 28 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase18 6221115153424 0.75 VARIABLE CONDICIÓN
COD_2 <=22
COD_9 > 3
COD_10 <= 3
COD_11 > 3
Para la predicción de la variable clase 18 se encontró un patrón en el cual sólo cuatro variables eran necesarias para la predicción de la clase, el COD_2 que hace referencia a el Área de actividad económica que debe ser residencial, dotacional, de comercio y servicios, central, urbana integral, industrial, suelo de protección, minería ,el COD_9 que hace referencia a la inuencia de la vía y debe ser vía arterial complementaria o arterial básica, el COD_10 q que hace referencia a la actividad económica debe ser no edicado, residencial o comercial y de servicios y el COD_11 que hace referencia al tipo según la actividad económica debe ser dependiendo de su actividad económica alguno de los tres primeros tipos en adelante. El porcentaje de conabilidad de clasicación de los datos es de un 75 % lo cual indica que el porcentaje de error no es signicativo.
Cuadro 31: REGLA 29 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase35 6212115153444 0.5 VARIABLE CONDICIÓN
COD_2 <= 22
COD_9 > 3
COD_10 > 3
COD_11 > 3
cual sólo cuatro variables eran necesarias para la predicción de la cla-se, el COD_2 que hace referencia a el Área de actividad económica residencial neta o residencial con zonas delimitadas de comercio y ser-vicios, el COD_9 que hace referencia a la inuencia de la vía y debe ser vía arterial complementaria o arterial básica, el COD_10 que hace referencia a la actividad económica debe ser industrial, equipamientos, espacio público o recreaciones y deportivo y el COD_11 que hace refe-rencia al tipo según la actividad económica debe ser dependiendo de su actividad económica alguno de los tres primeros tipos en adelante. El porcentaje de conabilidad de clasicación de los datos es de un 50 % lo cual indica que el porcentaje de error es signicativo.
Cuadro 32: REGLA 30 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase12 6332415153444 0.857 VARIABLE CONDICIÓN
COD_2 > 22
COD_2 <= 33
COD_9 > 3
COD_11 > 3
Cuadro 33: REGLA 31 DE CLASIFICACIÓN UPZ 109.
PREDICCIÓN CÓDIGO PRECISIÓN
clase21 6412115153444 0.875 VARIABLE CONDICIÓN
COD_2 > 33
COD_9 > 3
COD_11 > 3
Para la predicción de la variable clase 12 se encontró un patrón en el cual sólo tres variables eran necesarias para la predicción de la cla-se, COD_2 que hace referencia a el Área de actividad económica que debe ser parques, comercio y servicios, central, urbana integral, indus-trial, suelo de protección o minería ,el COD_9 que hace referencia a la inuencia de la vía y debe ser vía arterial complementaria o arterial básica y el el COD_11 que hace referencia al tipo según la actividad económica debe ser dependiendo de su actividad económica alguno de los tres primeros tipos en adelante. El porcentaje de conabilidad de clasicación de los datos es de un 50 % lo cual indica que el porcentaje de error es signicativo.
Figura 13: NODO 49 ÁRBOL DE DECISIÓN UPZ 109
Size: es el número de clases que formó el árbol clasicador: 31 Errors: 11 observaciones de 205 fueron mal clasicadas, lo cual corresponde a un 5.4 % de error en la clasicación de los datos.
Cuadro 34: HOJAS CON INFORMACIÓN DEL ÁRBOL DE DECISIÓN UPZ 109
Decision Tree Size Errors
31 11( 5.4 %)
El siguiente cuadro muestra las clasicaciones realizadas por el algorit-mo C5.0 y el número de casos ajustado a cada una, el número de falsos positivos y falsos negativos, clasicados en cada clase.
Los falsos positivos son aquellos que casos de otras clases que se clasi-can en una clase3 especíca y Los Falsos Negativos son propios de esa clase que se clasican en otra, cuando estos falsos positivos sólo constan de una observación o se presenta un sólo caso, la clase es eliminada. Así se describe a continuación, mostrando en color azul, los falsos ne-gativos únicos que causan la eliminación de la clase.
Cuadro 35: FALSOS POSITIVOS Y NEGATIVOS UPZ 109.
Clase Casos Falsos Positivos Falsos Negativos
clase1 37 0 0
clase10 6 0 0
clase11 5 0 0
clase12 5 0 0
clase13 5 0 0
clase14 4 0 0
clase15 4 0 0
clase16 3 0 0
Clase Casos Falsos Positivos Falsos Negativos
clase18 3 0 0
clase19 3 0 0
clase2 28 0 0
clase20 3 0 0
clase21 3 1 0
clase22 2 1 0
clase23 2 0 0
clase24 2 0 0
clase25 2 0 0
clase26 2 1 0
clase27 1 1 0
clase28 1 1 0
clase29 1 0 1
clase3 15 1 0
clase30 1 2 0
clase31 1 0 1
clase32 1 0 1
clase33 1 1 0
clase34 1 0 1
clase35 1 1 0
clase36 1 0 1
clase37 1 0 1
clase38 1 0 1
clase39 1 0 1
clase4 14 0 0
clase40 1 0 1
clase41 1 0 1
clase42 1 0 1
clase5 10 0 0
clase6 8 1 0
clase7 8 0 0
clase8 6 0 0
negativo para su clase verdadera y como un falso positivo para la clase predicha .
Cuadro 36: PORCENTAJE DE PARTICIPACIÓN DE VARIABLES EN LA CLASIFICACIÓN UPZ 109
VARIABLE PORCENTAJE DE PARTICIPACIÓN
COD_8 100.00
COD_9 83.90
COD_2 76.59
COD_10 75.61
COD_11 68.78
COD_3 42.44
COD_1 27.80
COD_4 0
COD_5 0
COD_6 0
COD_7 0
2. PREDICCIONES DEL ÁRBOL DE CLASIFICACIÓN
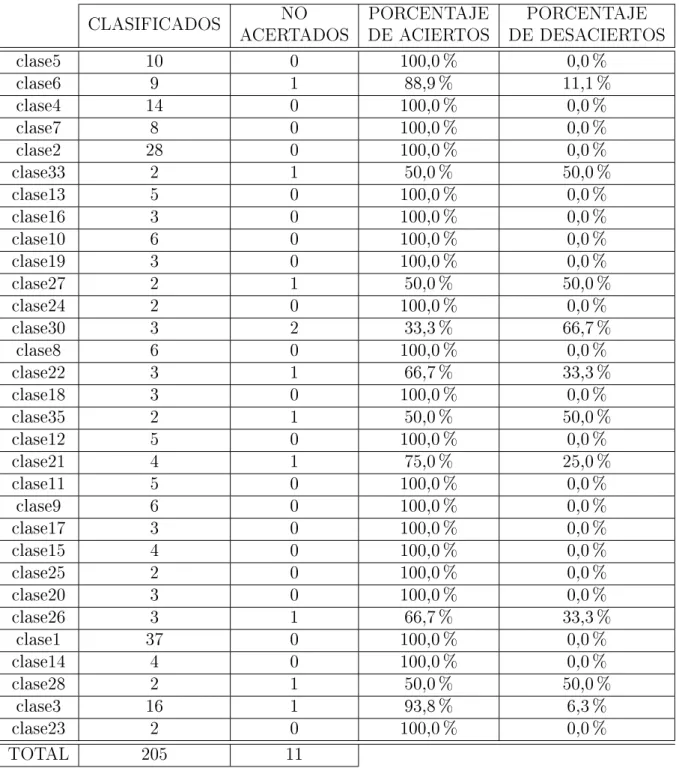
El siguiente cuadro nos muestra información de número de datos que ingresaron para la clasicación de una clase y número de datos que no fueron clasicados en esa clase, adicional a eso se muestra el porcentaje de aciertos y desaciertos de clases clasicadas.
10.1.4. DIAGNÓSTICO DE ITERACIÓN
En esta sección se hizo uso de la herramienta TRIALS nombrada anterior-mente para que el algoritmo recorriera tantas veces sea necesario cada nodo del árbol de clasicación para lograr una estimación más cercana a la reali-dad y la idea es aumentar el número de hasta que no se clasique ningún falso negativo.
Cuadro 37: ERROR DE PREDICCIÓN POR POBLACIÓN UPZ 109.
CLASIFICADOS ACERTADOS DE ACIERTOS DE DESACIERTOSNO PORCENTAJE PORCENTAJE
clase5 10 0 100,0 % 0,0 %
clase6 9 1 88,9 % 11,1 %
clase4 14 0 100,0 % 0,0 %
clase7 8 0 100,0 % 0,0 %
clase2 28 0 100,0 % 0,0 %
clase33 2 1 50,0 % 50,0 %
clase13 5 0 100,0 % 0,0 %
clase16 3 0 100,0 % 0,0 %
clase10 6 0 100,0 % 0,0 %
clase19 3 0 100,0 % 0,0 %
clase27 2 1 50,0 % 50,0 %
clase24 2 0 100,0 % 0,0 %
clase30 3 2 33,3 % 66,7 %
clase8 6 0 100,0 % 0,0 %
clase22 3 1 66,7 % 33,3 %
clase18 3 0 100,0 % 0,0 %
clase35 2 1 50,0 % 50,0 %
clase12 5 0 100,0 % 0,0 %
clase21 4 1 75,0 % 25,0 %
clase11 5 0 100,0 % 0,0 %
clase9 6 0 100,0 % 0,0 %
clase17 3 0 100,0 % 0,0 %
clase15 4 0 100,0 % 0,0 %
clase25 2 0 100,0 % 0,0 %
clase20 3 0 100,0 % 0,0 %
clase26 3 1 66,7 % 33,3 %
clase1 37 0 100,0 % 0,0 %
clase14 4 0 100,0 % 0,0 %
clase28 2 1 50,0 % 50,0 %
clase3 16 1 93,8 % 6,3 %
clase23 2 0 100,0 % 0,0 %
Figura 14: ÁRBOL DE CLASIFICACIÓN - ITERACIÓN UPZ 109
Figura 16: ÁRBOL DE CLASIFICACIÓN - ITERACIÓN NODO 26 UPZ 109
Figura 17: ÁRBOL DE CLASIFICACIÓN - ITERACIÓN NODO 49 UPZ 109
formó el clasicador es el mismo al propuesto con las zonas homogéneas físicas, el error en la clasicación de los datos es de un 22.4 % que se explica partiendo de la idea de que 46 de los 205 datos fueron mal clasicados.
Cuadro 38: HOJAS CON INFORMACIÓN DEL ÁRBOL DE DECISIÓN -ITERACIÓN UPZ 109
Decision Tree Size Errors
31 11( 5.4 %) 26 33(16.1 %) 29 37(18.0 %) 28 34(16.6 %) 30 19( 9.3 %) 32 32(15.6 %) 31 17( 8.3 %) 27 58(28.3 %) 30 20( 9.8 %) 31 32(15.6 %) 32 44(21.5 %) 31 60(29.3 %) 26 35(17.1 %) 29 43(21.0 %) 28 43(21.0 %) 28 31(15.1 %) 30 23(11.2 %) 32 22(10.7 %) 33 13( 6.3 %) 31 41(20.0 %) 30 41(20.0 %) 33 90(43.9 %) 28 23(11.2 %) 31 26(12.7 %) 27 46(22.4 %) 0( 0.0 %) <<