FACULTAD DE CIENCIAS
Escuela Profesional de Matemática
INFORME DE COMPETENCIA PROFESIONAL
PARA OPTAR EL TÍTULO PROFESIONAL DE:
LICENCIADO EN MATEMÁTICA
DISEÑO E IMPLEMENTACIÓN DE UN SISTEMA DE
CALIFICACIÓN Y SU FUNDAMENTACIÓN
MATEMÁTICA
PRESENTADO POR:
JOSÉ PARIS MIGUEL CAÑAMERO
ASESOR
Mg. WILLIAM CARLOS ECHEGARAY CASTILLO
y me apoyaron.
A l Profesor Wiiiiam Echegaraypor su apoyo, amistad y
comprensión en la revisión del trabajo así como sus sugerencias.
A l personal del Centro de Estudios Pre-Universitarios de la
Universidad Peruana Cayetano Heredia por guardar, usar y
Por su apoyo y ánimo
para alcanzar nuevas metas,
El presente informe consta de cuatro capítulos y un apéndice que contiene los códigos fuentes del sistema. Está estructurado de la siguiente manera:
En el Capitulo I se establece las necesidades por las que se requiere una calificación automatizada. En la introducción se indica las condiciones a favor y en contra y siendo esto una polémica se deja establecido que con los defectos y virtudes de un sistema
automatizado, este ha llegado para ser usado. A continuación se introduce los conceptos tanto de hardware como de software necesario para el sistema. Las estructuras de datos
toman las formas de bases de datos que en el contexto matemático se expresan mediante relaciones y son visualizadas como tablas de datos.
En el Capítulo II está dedicado al estudio de los conceptos matemáticos que se usan
para la definición de un sistema de base de datos. Se hace énfasis en las relaciones y la forma como se pueden ver las operaciones desde el punto de vista matemático. Las operaciones con relaciones son las que forman el algebra relacional de las Matemáticas y aun cuando esto es mucho más amplio se restringe a las operaciones básicas.
En el Capítulo III realiza una descripción de las estructuras de datos fundamentales describiéndolas en detalle y estableciendo las tablas que forman la base de datos general. Se indica las operaciones matemáticas que sirven para formar las diversas relaciones. Se menciona los conceptos que permiten adaptar el sistema a otros requerimientos y su adaptación a otras situaciones.
PRÓLOGO 1
CAPÍTULO I
INTRODUCCIÓN, PRUEBAS DE SELECCIÓN MÚLTIPLE, OBJETIVOS,
HARDWARE Y SOFTWARE DEL SISTEMA 2
1 .1 . - In tr o d u c c ió n 2
1.2. - Pruebas de selección múltiple 3
1.3- Objetivos 4
1.4. - Componentes de hardware del sistema 5
1.4.1. - Lectora ópticade tarjetas 5
1.4.2. - Tarjetasópticas 6
1.5. - Componentes de software: base de datos 7
1.5.1. - Importancia y ventajas de las bases de datos 8
1.5.2. - Desventajas de las bases de datos 10
1.5.3. - Arquitectura de una base de datos 11
CAPÍTULO II
BASES DE DATOS Y PRINCIPIOS MATEMATICOS 15
2.1 Relaciones 15
2.2. Dominios y atributos 16
2.3. Más sobrellaves 17
2.4. Algunos aspectos del algebrarelacional 18
2.4.1 Lenguajes de consulta 18
2.4.2. El algebra relacional 18
2.4.3. Operaciones fundamentales 19
2.4.4. Operaciones derivadas de las básicas 21
2.4.5. Operaciones adicionales 27
2.5. Operaciones extendidas del algebra relacional 30
CAPÍTULO III
SISTEMA DE CALIFICACIÓN 42
3.1. Introducción 42
3.2. El flujo de datos 43
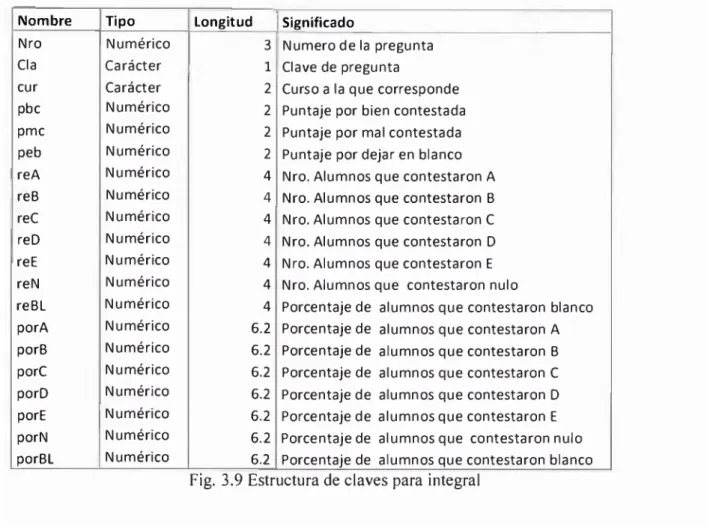
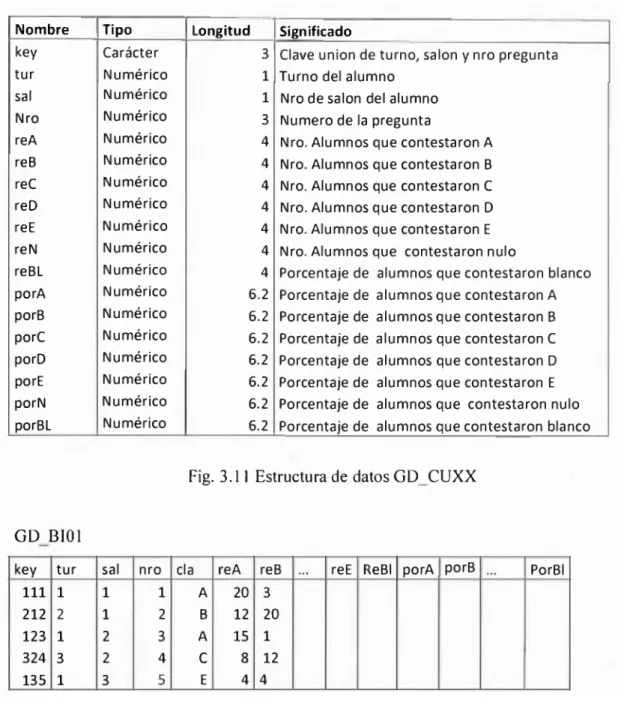
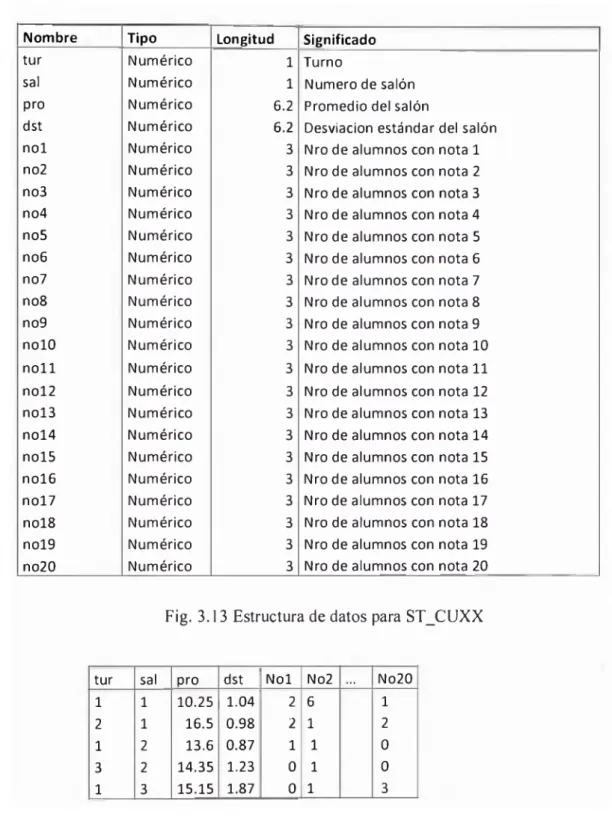
3.3 Base de datos ALUMNO 44
3.4. Lectura de datos 46
3.5. Estructuras de datos adicionales 49
3.6. Procesos de cálculo 51
3.6.1. Corrección de datos de entrada 51
3.6.2. Generación de la clave 52
3.6.3.. Calificación 53
3.7. Generación de consultas reportes 56
3.7.1. Reportes para estudio de pruebas 57
3.7.2. Reportes para informe de estudiantes 57
CAPÍTULO IV
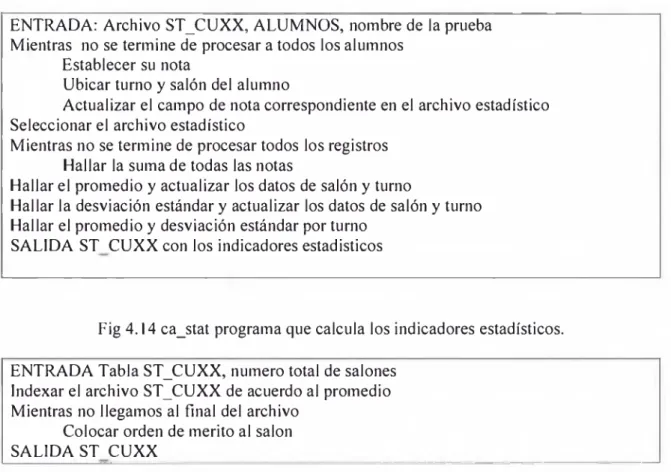
DESCOMPOSICION JERÁRQUICA DEL SISTEMA Y ALGORITMOS 59
4.1. Menú principal y secundarios. 60
4.2. Procesamiento de pruebas 61
4.2.1. Inicialización 63
4.2.2. Calificación y consistencia 64
4.2.3. Calificación final y generación de grados de dificultad 66
4.2.4 Estadísticos diversos 68
4.2.5. Reportes 69
4.2.6. Normalización 71
4.3. Procesamiento de pruebas integrales 71
4.3.1. Inicialización 73
4.3.2. Calificación y consistencia 73
4.3.3. Calificación y gradosde dificultad por turnoy salón 75
4.3.4. Generación de estadísticas diversas 76
4.3.6. Grados de dificultad y estadísticos por turno y salón 79 4.3.7. Generación de un orden de mérito de un examen integral. 79
4.4 Calificación de pruebas de hasta 50 preguntas 80
4.5 Calificación de pruebas externas 81
4.6 Reportes varios 82
A PENDICE 84
CONCLUSIONES 128
La calificación de pruebas de selección múltiple se ha convertido en el método
usual que existe en la actualidad para la asignación de notas a grupos grandes de estudiantes que intervienen en un examen de conocimientos o habilidades. Las grandes ventajas pueden pensarse en dos características esenciales: 1) la prontitud con la que se pueden obtener los resultados para poblaciones numerosas y 2) el anonimato con que se califica de modo que existe la uniformidad y un mismo criterio de calificación.
En este caso la calificación es realizada usando computadoras y periféricos
especializados. El periférico especializado es la lectora óptica de marcas, la cual está acompañado de un software especializado que permite la lectura de datos y la consiguiente conversión a información digital que luego es procesada por el sistema objeto del presente trabajo. Es posible también el aplicar pruebas de selección múltiple en línea, con lo cual la
lectora óptica no sería necesaria.
Las aplicaciones para calificación de pruebas de selección múltiple entonces dependen del fabricante de la lectora óptica de marcas. El fabricante proporciona el software que realiza la comunicación entre la lectora y el periférico. Los datos una vez convertidos en información digital son trabajados por los sistemas de calificación de acuerdo a las políticas de la institución. El sistema presentado ha sido diseñado para poder adaptarse a la mayor cantidad de posibles pruebas. También es posible adaptarlo a otras aplicaciones como procesos de encuestas.
HARDWARE Y SOFTWARE DEL SISTEMA 1.1 Introducción
La calificación de pruebas ha sido y es siempre una necesidad de parte de las instituciones educativas que ofrecen cursos y programas a un número elevado de participantes y que requiere que los resultados se den de manera casi inmediata. Esto, aunado al hecho de que
el número de preguntas a evaluar sea relativamente alto, hace que la calificación manual sea demasiado lenta y los resultados no se obtengan en forma oportuna.
La solución al problema anterior se da con el establecimiento de pruebas de selección múltiple y que puedan ser calificadas por una computadora y una lectora de marcas ópticas
o de tarjetas o en línea.
Las pruebas de selección múltiple tienen como objetivo establecer una pregunta con cuatro o cinco alternativas de las cuales solo una es la correcta y los demás son llamados
distractores. Eso hace que los instrumentos electrónicos “ lean” la posición correcta para la clave y al calificar detecten si la marca está colocada en la posición correcta.
El presente trabajo describe un sistema de calificación de diversos tipos de pruebas de selección múltiple en forma automatizada. Asimismo incluye el encontrar algunos de los indicadores de índole estadístico que permiten validar ya sea la prueba en sí o la pregunta desde un punto de vista estadístico.
El sistema se desarrolló para atender diversas necesidades, en un inicio una simple calificación de pruebas pero luego se adecuó para poder evaluar encuestas de diverso tipo. Con ligeras modificaciones y adecuaciones se logró establecer y atender esas y otras necesidades.
en este contexto las bases de datos. Estas estructuras así como los algoritmos son discutidos en los capítulo 3 y 4.
El sistema tiene como estructuras de datos a las tablas relaciónales o bases de datos. Esto debido a que el sistema de soporte de la misma (en este caso el Microsoft FoxPro) posee
un sub lenguaje de consulta y de manipulación de tablas que facilitan la programación sin necesidad que se incluyan rutinas que están incluidas en el lenguaje de consulta. También
las tablas quedan expeditas o son formadas de tal manera que puedan usarse a programas o sistemas que permitan un análisis mas profundo de los datos. Las tablas pueden en ese sentido exportarse a un paquete estadístico como SPSS ú otros como a Matlab.
1.2 Pruebas de selección múltiple
Una de las preocupaciones de toda institución es la de determinar la efectividad de las pruebas de selección múltiple en la evaluación de candidatos. Al respecto las opiniones en contra de la misma están fundamentadas por las siguientes afirmaciones aún cuando hay otras:
1. En las pruebas de selección múltiple un alumno puede adivinar o sencillamente marcar al azar y obtener la respuesta correcta.
2. El entrenamiento para pruebas de selección múltiple también incluye técnicas para deducir la respuesta correcta sin tener que resolver en si la pregunta. Esto hace que la elaboración de distractores tenga que hacerse en forma bastante cuidadosa y
amplia.
3. Dado que en las pruebas de selección múltiple se da un conjunto de por lo menos 10 a 20 preguntas para un tiempo limitado, no es posible establecer preguntas que evalúen de forma adecuada o profunda un determinado tema.
4. Al ser calificada una prueba por una máquina no ingresan factores humanos que permitirían hacer una evaluación rigurosa del trabajo del alumno. La asignación de
puntaje es estricta, obteniéndose la totalidad o nada del puntaje y de ese modo no se reconoce ningún avance parcial que pueda haber realizado el estudiante.
participantes. Cada una de las afirmaciones en contra de las pruebas de selección múltiple tiene una refutación como se enumera nuevamente:
1. Efectivamente en las pruebas de selección múltiple el alumno puede adivinar y la probabilidad de que acierte la respuesta correcta es de 1/5 si hay una respuesta correcta y 4 distractores. Esta es la razón por la que en muchas evaluaciones las opciones incorrectas disminuyen el puntaje en 1/5 de lo que vale la respuesta
correcta. Así por ejemplo, si se bonifica con 5 puntos la respuesta correcta entonces se asigna con -1 la elección de uno de los distractores.
2. Efectivamente la preparación para un examen incluye algunas técnicas legales e
ilegales que los participantes pueden usar. Sin embargo la elección de distractores adecuados y lo que se pregunta en si disminuyen las chances de que esto suceda. Es común ver que no se pide la respuesta correcta, sino algo relacionado con la misma u a obtener a partir de ella.
3. Se tiene que entender que este tipo de pruebas son de entrenamiento o se utilizan
en un proceso de selección. Las preguntas que evalúen de forma algo más profunda y con mayores criterios corresponden a cuestionarios donde se quiere evaluar la formación de la persona en los temas a evaluar. Es más parte de un proceso formativo antes que de un proceso selectivo.
4. Basándonos en el punto anterior la opción de dar puntaje parcial corresponde a criterios humanos basados más en el aspecto formativo que en el proceso selectivo.
De la discusión precedente podemos decir que la efectividad de evaluación de candidatos usando pruebas de selección tiene varios aspectos tanto a favor como en contra. El hecho
que no intervenga el aspecto humano para algunos es considerado ventajoso ya que de ese modo se elimina el aspecto subjetivo de la persona que evalúa y por otro lado la calificación de pruebas con máquinas aporta el sentido de equidad bajo la premisa que todos son calificados con el mismo criterio o en este caso con la misma clave.
1.3 Objetivos
a. Resolver el problema de calificación y prontitud de notas cuando la población de estudiantes era de un mínimo de 500 alumnos, los cuales daban pruebas diarias de
diversas materias. La calificación manual se complicaba por los errores humanos y por la cantidad de pruebas, que se comenzaba a acumulaban mas rápido de lo que
se corregían.
b. Tener un conjunto de bases de datos (tablas) que permitan conocer la historia educativa tanto de los estudiantes como de las pruebas que se llevan a cabo. Esto último se da en cuanto a pregunta.
c. Disponer de la información para la generación de diversos reportes de índole general o particular. Al estar organizados como bases de datos por año y/o
semestre el acceso a la información de un periodo determinado estaba contemplado en el sistema mismo.
d. Evitar los errores propios de una calificación manual. Los medios electrónicos al ser más seguros asegura que los errores se reduzcan a su mínima expresión.
e. Permitir la corrección de errores que producidos en forma involuntaria tales como
algunas claves incorrectas o preguntas donde pueda existir una clave doble.
f. Opción de re-calificar con prontitud cualquiera de las pruebas antes rendidas y actualizar los datos.
1.4 Componentes de hardware del sistema
El sistema de calificación consta de una parte electrónica o de hardware que apoya a la parte conceptual y al software. Aparte de un computador, que ejecuta el software tenemos
lo siguiente:
1 .4 .1 .- L e c to r a ó p tic a de ta r je ta s
Un OMR (Optical Mark Reader) es un periférico que se puede comunicar a un computador y cuyo objetivo es convertir marcas realizadas con lápiz o lapicero en información que es usada fácilmente por programas especializados del computador. Dependiendo del modelo
izquierdo. Su versatilidad da para leer códigos de barras también. La figura 1.1 muestra una lectora de marcas típica.
1.4.2 Tarjetas Ópticas
Una tarjeta óptica está constituida por una hoja con un diseño acorde al modelo de lectora que se usa. El diseño de la tarjeta se realiza con un software especial que proporcional el fabricante y se hace la adaptación a las necesidades de una institución. Dependiendo de la densidad y del diseño la información que se puede captar en una tarjeta puede variar. Para exámenes es fácil tener tarjetas hasta para más de 200 preguntas. La figura 1.2 las muestra.
Fig.l.l Lectora óptica de marcas.
4 . >L-MÜ»*I r , * ¿**h ■
MK t l *
* .*¿#
i* - - ■ i*
’ »i', »ifi #*¡ ^*H *4*1
*!• ■4*1
«MI- i| •írél *4 f|
te ^tokrtsgr^
1.5 Componentes de software: bases de datos
Las bases de datos constituyen la estructura de datos usada en el sistema de calificación. En el sistema se representara como un conjunto de tablas debido a la naturaleza del sistema de software de apoyo teniendo su fundamento teórico en las relaciones matemáticas.
Aun sin haber estudiado de manera formal, la mayor parte de las personas y a través de
muchas fuentes tienen una idea general de lo que es una base de datos. La impresión general es diagramada en la siguiente figura:
Usrates en toa
Fig. 1.3
Esta percepción nos permite hacer la siguiente definición: Una base de datos es un conjunto de información almacenada usada por programas, sistemas y usuarios de una determinada institución. En dicho sentido se asume que la institución es de un tamaño mediano a grande y que posee suficiente información que debe ser almacenada.
Una institución mantiene una gran cantidad de datos, denominada los “datos operacionales”. Los datos operacionales pueden ser alumnos, notas de alumnos, pruebas de alumnos, etc.
que no forman parte de la base de datos a menos que el sistema los incorpore. En forma similar la datos de salida se refiere a reportes y mensajes que emanan del sistema ya sea
impresos o mostrados en el terminal. Nuevamente tal reporte contiene información que es derivada de la data operacional pero no es en sí mismo parte de la base de datos.
Un ejemplo de datos operacionales se muestra a continuación:
Fig.1.4
En este ejemplo los datos son variados y se explican por ellos mismos. Es claro que
cualquier institución educativa guardará información sobre sus cursos, exámenes, alumnos y otros. En el caso del sistema en el que se esta trabajando los datos más importantes serán
los cursos, alumnos, notas, exámenes y la clave de exámenes.
El otro elemento importante en las bases de datos está constituido por las relaciones que pueden asociarse a dos o más entidades que participan del sistema. Esto es representado en el esquema mediante flechas apropiadas. Estas relaciones se han declarado como bidireccionales. Asimismo entre dos entidades se pueden dar más de una relación así como en una relación puedan intervenir más de una entidad. Por ejemplo para formar claves de exámenes deben participar el profesor, examen y curso.
1.5.1 Importancia y ventajas de las bases de datos.
La respuesta más general de por que usar bases de datos se da en el sentido de tener un control centralizado de los datos operacionales. Esto comparado con que cada aplicación tenga sus propios archivos privados, lo cual origina que los datos operacionales estén
dispersos y sea muy difícil controlarlos en forma sistemática.
a) La redundancia en los datos almacenados puede reducirse. Esto en contraste con aplicaciones que mantienen sus propios datos, lo cual origina duplicación y desperdicio de espacio en disco. El reto aquí es identificar las aplicaciones que usarán los mismos datos. Por ejemplo la data de clave será usada por la aplicación
que califica tarjetas así como por la aplicación que origina indicadores estadísticos. b) Problemas de inconsistencia en los datos almacenados pueden ser previstos (hasta
cierto punto). Esto esta relacionado con el hecho que cada dato tiene una única representación dentro de la base de datos.
c) La data almacenada puede ser compartida. Diversas aplicaciones pueden usar la misma data y aquí se enfatiza el hecho que para el uso se pongan ciertos niveles de
seguridad e incluso forma de ver los datos.
d) Reglas comunes o estándares pueden ser implementadas, de modo que todas las aplicaciones, por ejemplo, usen un mismo lenguaje o sub lenguaje para su desarrollo.
e) Problemas de integridad de los datos pueden ser solucionados. Este problema tiene
que ver con el hecho que la base de datos solo debe contener datos que son exactos. Inconsistencia entre dos entidades que representan el mismo hecho es un ejemplo de falta de integridad, lo cual es consecuencia de que exista alguna redundancia entre los elementos que están almacenados.
0 Requerimientos conflictivos pueden ser balanceados. Esto tiene que ver con los requerimientos de la institución versus los de una persona individual. Las personas que administran las bases de datos tienen la responsabilidad de encontrar soluciones a problemas de conflicto entre dos partes de una misma institución que desean tener acceso a los mismos datos y cuyas necesidades puedan afectar una a la otra.
g) Las bases de datos tienen un fundamento matemático fuerte basado en las matemáticas discretas. El énfasis está establecido en el estudio de las relaciones y
h) Se reducen los costos en cuanto a ingresos de datos y otros elementos ya que no es
en forma individual sino con fines institucionales. Los datos estarán disponibles para varias divisiones de la misma institución.
1.5.2 Desventajas de las bases de datos.
Se ha mencionado muchas ventajas en el uso de bases de datos. Sin embargo existen algunos aspectos que también necesitan algo de control y atención. Entre las desventajas tenemos:
a) Los sistemas de bases de datos son complejos y el diseño consume tiempo y tiene
sus dificultades. Dependiendo del tamaño y de los requerimientos de la organización esta tarea puede demorar un tiempo considerable. Como consecuencia de ello se tiene que tener una persona (as) altamente especializado (s) que se
constituye en el administrador de bases de datos, que es una persona o un grupo de personas.
b) Se requiere una inversión significativa en cuanto a software y hardware en muchos casos. Muchas organizaciones en la actualidad, recurren a manejadores de archivos
y con software limitado manejan sus necesidades.
c) Si existiera una folla en la base de datos, esto afectaría la mayor parte de las aplicaciones. De hecho esto puede eventualmente paralizar a la misma institución y por ello es necesario prevenir copias de respaldo que mantengan la integridad de los datos operacionales.
d) Si una institución trabaja con archivos el mudar a una estructura de bases de datos implica un costo considerable en tiempo como en recursos humanos y materiales. e) Se requiere un entrenamiento especial para acostumbrar a todos los programadores
y usuarios al nuevo sistema. Esto puede convertirse en un proceso lento y algo costoso dependiendo del nivel de experto que se tenga o requiera.
^ Si existen aplicaciones individuales se requerirá un mayor tiempo para la ejecución de esa aplicación comparado con las usuales. Esto genera ciertos conflictos con
1.5.3 Arquitectura de una base de datos
La presente nota es para indicar un marco en lo que se trabajara en relación a las bases de
datos. La mayor parte de las bases de datos son descritas de esta forma y ello se refleja en la figura que se presenta a continuación.
Esquema externo
Fig.1.5 Arquitectura simple
En esta figura observamos que la arquitectura se divide en tres niveles generales: interno o esquema físico, esquema conceptual y nivel o esquema externo. El nivel interno es el más cercano a lo que entendemos por almacenaje físico, es decir la forma como los datos son almacenados. El nivel externo es el más cercano a los usuarios, es decir la forma como los usuarios verán los datos. El nivel conceptual es el de acople entre los dos esquemas anteriores. Si el nivel externo esta dedicado a las vistas individuales el nivel conceptual
puede pensarse que es una vista de usuario comunitario. De está forma pueden existir múltiples “vistas externas”, cada cual representando más o menos algunas porciones de la
base de datos pero solo existe una vista conceptual que consiste de la representación abstracta de la base de datos en su totalidad. En ese sentido tengamos presente que la mayor parte de usuarios y aplicaciones solo usa una parte de la base de datosy no toda en su totalidad. También existirá una sola vista interna que representa a la base de datosy la forma como se almacena en forma física.
U s u a r io s
N iv e l E x t e r n o
D is e ñ o
correspondencias
■
N iv e l C o n c e p t u a l
. . . T tx x r o s p o fK itjn
A l m a c e n a m i e n t o l
■
___________________________________N i v e l I n t e r n o
Fig.l.6
Para ver algunos de los elementos de la Base de datos la figura anterior es ampliada a continuación:
Usuario Usuano Usuario Usuario
Fig.1.7
La figura muestra los tres niveles, los cuales son fácilmente reconocidos.
los usuarios terminales el sistema proveerá con un lenguaje simple y a la medida de las necesidades. Es importante notar que aun los sistemas de manejo de archivos en la actualidad proveen de un sub lenguaje de manejo de datos basado en el lenguaje dedicado
a la extracción y almacenaje de información en la base de datos.
Un usuario individual está interesado solo en una parte de la base de datos, denominada la vista externa. Esta vista es algo diferente de la forma como los datos están almacenados en forma física. Por ejemplo una persona que ve las notas de los alumnos de una determinada aula puede verla como una tabla, donde cada fila describe el nombre del alumno y las notas que tendría. Si el usuario final es el alumno el tendría acceso a sus propias notas y por tanto seria una vista restringida de la anterior. Esto indica que por ejemplo con una vista
externa estemos viendo registros adecuados a lo que deseamos ver, pero que de ningún modo constituyen la forma como son almacenadas en la base de datos. Vistas individuales pueden existir si el alumno es un usuario el base de datos. Para definir la vista externa usamos las herramientas que nos proporciona el sistema de base de datos. La vista externa consiste entonces de descripciones de lo que va a contener o será mostrada al usuario. Esto se logra con el lenguaje asociado así como con un mapeo al esquema conceptual.
El esquema o vista conceptual, al que mayormente se refieren también como el modelo conceptual ó el modelo de datos que es una representación de toda la información contenida en la base de datos y en una forma que es algo abstracta en comparación con la forma en la que la misma es almacenada físicamente. También puede ser algo diferente de la forma como ella es vista por un usuario particular. En forma amplia se pretende que sea una vista de los datos tal como son. De ese modo un registro conceptual no es necesariamente lo mismo que un registro externo o un registro almacenado. El modelo conceptual se define mediante el esquema conceptual que incluye definiciones de cada uno de los diversos tipos de registros conceptuales. Estas definiciones tienen la intención de adicionar muchas características especiales, tales como revisiones de autorizaciones,
procedimientos de validación, restricciones en datos, y otros.
El tercer nivel de la arquitectura es el nivel interno. El nivel interno es una representación a un nivel muy bajo de la base de datos en su totalidad y consiste de ocurrencias múltiples
de múltiples tipos de registros internos. Este registro es el que reside en el dispositivo de almacenamiento masivo tal como los discos duros.
que maneja todos los accesos a la base de datos. Conceptualmente sucede lo siguiente: (l) un usuario envía un requerimiento de acceso para lo que usa un sub lenguaje de datos, (2) el DBMS intercepta e interpreta el requerimiento y (3) el DBMS conjuga el esquema
externo, el mapeo externo/conceptual, el esquema conceptual, y la definición de la estructura de almacenamiento. Con ello procesa el pedido. Asimismo el DBMS procesa pedidos mucho mas complicados y ejecuta programas que pueden haber sido desarrollados en algún lenguaje compatible.
Asimismo el DBMS es responsable de aplicar revisiones de autorización y todos los procedimientos de validación que se hayan implementado. La figura 1.8 muestra la importancia dentro de las base de datos y su posición en figura 1.3.
Sistema de administacion
2.1 Relaciones
Dada una familia de conjuntos Di,D2,D3,...D n ,no necesariamente distintos, un conjunto R
de n-uplas ordenadas de la forma (di,d2,d3,...,d n ) de tal forma que di pertenece a Di, d2 pertenece a D2, ... , dn pertenece a Dn, es llamada una relación de n componentes. Los conjuntos Di,D2,D3,...D n son los dominios de R y n es el grado de la relación.
En forma matemática una relación puede considerarse como un subconjunto del producto cartesiano DixD2xD3X...xDn . Por tanto no existe un ordenamiento entre los elementos que lo constituyen.
La figura 2.1 muestra la relación llamada alumno. En esta relación de grado 7 definido con dominios Código, Ape.Paterno, Ape.materno, Nombre, Edad, Domicilio y Sexo. De
inmediato observamos que cada dominio es un subconjunto de uno más amplio. Por ejemplo el dominio de Edad no considerara todos los números enteros, así como el de Sexo considera dos instancias.
Alumno Codigo Ape-Paterno Ape-Materno Nombre Edad Domicilio Sexo
2000101 Campos Pizarro Ricardo 16 San Miguel M
2000102 Palacios Robledo Jimena 15 Jesús Maria F
2000103 Vega Paz Claudia 14 Miradores F
2000104 Garcia Calderón Luis Alfonso 17 Breña M
2000105 Oropesa Rivera Carla 17 Miradores F
2000106 Garcia Vega Cindy Rocío 16 Los Olivos F 2000107 Arévalo Rivero Eduardo 18 San Isidro M
Fig.2.1 Relación alumno
En las relaciones en muchas situaciones es frecuente que se tenga un atributo con valores que identifican en forma única a cada ocurrencia de la relación. Por ejemplo en la relación Alumno el atributo Código identifica en forma única a cada ocurrencia de la relación. En
este caso decimos que Código constituye la llave primaria de la relación. En algunos casos la llave primaria se puede formar con dos o mas atributos de modo que cada ocurrencia sea única.
Asumiendo que se tiene una llave primaria entonces la relación puede visualizarse como una función cuyo dominio es precisamente el conjunto de elementos que definen la llave
primaria y tenemos así en el ejemplo notado: Alumno: Dominio de Códigos y el rango el producto cartesiano de los dominios de los otros elementos.
En general si D| constituye la llave primaria y D2,D3,...D n los otros dominios entonces la
relación es R : D ^ D2x D 3x ....xDn que se puede considerar como una función en el sentido matemático estricto y por tanto aplicar todas las propiedades de funciones y de productos cartesianos.
2.2 Dominios y atributos
De la representación gráfica se deduce que es importante indicar las diferencias que existen entre un dominio y las columnas o atributos que son elementos del dominio. Un atributo representa un uso de un elemento de un dominio dentro de una relación. Para enfatizar esta distinción modelamos una declaración del esquema que tendría la relación alumno como se muestra en la figura 2.2.
DOMAIN COD« NUMERICA)
DOMAIN Ape-Pa CHARACTER(20)
DOMAIN Ape-Ma CHARACTER(20)
DOMAIN Nombre CHARACTER(IO)
DOMAIN Ed NUMERICA)
DOMAIN Distrito CHARACTER(20)
DOMAIN Sex CHARACTER(l)
DOMINIO NOTA NUMERICO)
RELATION ALUMNO (Código DOMAIN COD«,
(Ape-Paterno DOMAIN Ape.Pa,
Ape-Materno DOMAIN Ape.Ma,
Nombre DOMAIN Nombre,
Edad DOMAIN Ed,
Domicilio DOMAIN Distrito,
Sexo DOMAIN Sex)
Fig. 2.2 Declaraciones de un esquema
Es bueno notar también que una relación puede definirse con menos dominios que atributos. Por ejemplo la relación anterior donde cada alumno tendrá 2 ó mas exámenes y
para cada uno de ellos el dominio será NOTA.
De forma normal se trabajara con relaciones en donde cada valor en la relación o sea cada
valor de un atributo en cada instancia de la relación es atómica o no descomponible.
2.3 Mas sobre llaves.
Un aspecto importante es que no toda relación tiene un solo atributo como la llave primaria. Lo que si se tiene es que cada relación tiene alguna combinación de atributos que al tomarse en forma conjunta tendrán la propiedad de la identificación única. Una
candidato a ser llave. Por ejemplo en la relación alumno el Ape.Paterno puede constituir una llave siempre y cuando este no se repita.
Codigo Pract Nota
2000101 P01 13
2000101 P02 15
2000101 P03 12 2000102 P01 17
2000102 P03 19 2000104 P01 12
2000104 P02 15
Fig.2.3 Código y Pract forman llave única.
2.4 Algunos aspectos del algebra relaciona!. 2.4.1 Lenguajes de consulta
Un lenguaje de consulta (query language) es un lenguaje en el cual un usuario adquiere información de una base de datos. Estos lenguajes están generalmente a un nivel más alto que un lenguaje de programación estándar. Estos lenguajes pueden clasificarse como lenguajes de procedimientos y lenguajes de no procedimientos. En los lenguajes de procedimientos el usuario pide al sistema realizar una sucesión de operaciones en la base
de datos para computar el resultado final. En un lenguaje de no procedimientos el usuario describe la información deseada sin necesidad de dar un procedimiento especifico para hallar dicha información.
2.4.2 El algebra relaciona!
El algebra relacional es un lenguaje de consulta de procedimientos. Matemáticamente consiste de un conjunto de operaciones que toman una o dos relaciones como entrada y producen una nueva relación como su resultado. Por tanto las operaciones mas importantes son: selección, proyección, unión, diferencia de conjuntos, producto cartesiano y renombrar. También y en base a las operaciones básicas se deducen otras, tales como
Las operaciones fundamentales de selección, proyección y renombrar y son llamada
operaciones unarias porque operan sobre solo una relación. Las otras operaciones actúan sobre pares de relaciones y por tanto son llamadas operaciones binarias.
1. La operación selección
La operación de selección nos produce una nueva relación cuyo resultado son aquellas tupias que satisfacen una determinada condición. La nueva relación es construida tomando un subconjunto horizontal de la tabla existente, esto es todas las filas de una tabla existente que satisfacen una determinada condición. Usemos el ejemplo de la tabla 2.1 que se muestra aquí y usemos el símbolo r para denotar selección con un subíndice para el
predicado que enuncia la condición. La operación en general se denota con Tp(R) donde
p es un predicado y R la relación sobre la que actúa r .
^Dom¡c¡i¡o="M¡rafiores“(A lum no)viene a ser la relación con componentes como sigue:
2.4.3 Operaciones Fundamentales
Código Ape-Paterno Ape-Materno Nombre Edad Domicilio Sexo
2000103 Vega Paz Claudia 14 Miraflores F
2000105 Oropeza Rivera karla 17 Miraflores F
Fig. 2.4 Relación Alumnos que viven en Miraflores
En el predicado de selección se permiten comparadores tales como =, £ <,<=, >, >= en el predicado que especifica la condición. Más aun se pueden combinar diversos predicados en
uno más grande usando los símbolos de conectividad a ,v , -i .Por ejemplo para seleccionar
aquellos alumnos que viven en Miraflores y con edad mayor a 15 se usa la siguiente
expresión: r Domic¡l¡0=„Mjraflores„AEdad>15(A lum no)que nos da:
Código Ape-Paterno Ape-Materno Nombre Edad Domicilio Sexo
2000105 Oropeza Rivera karla 17 Miraflores F
La operación selección es una operación matemática sobre una relación en la que se tomen tupias como resultado. Esta operación impone una o más condiciones sobre los atributos y el dominio al que pertenecen. En muchos problemas matemáticos se usa la selección en forma natural, por ejemplo en problemas que involucran el tiempo, el dominio de la función considerara solo elementos que son mayores que cero. En la solución de
ecuaciones se consideran solo soluciones que no son extrañas al problema. También observamos que la relación que se obtiene tiene los mismos atributos que la relación original lo cual muchas veces luce como reiterativo. Esto se nota claramente en las figuras 2.4y 2.5.
2. Operación de proyección
La operación de proyección también genera una nueva relación pero forma o toma un subconjunto vertical de una tabla existente extrayendo columnas especificas y eliminando
las filas que ser repiten. El símbolo que se usa es n que se usa como n a^ i ian(R)en
donde a i ,a2,a3,....,a„ son un conjunto de nombres de atributos o dominios y R la relación de donde se extraen esos atributos. Como ejemplo y en tabla 2.1 tenemos.
n ( COd¡go,domiciiio)(Alumno) que nos da la siguiente relación.
Alumno-Domicilio Codigo Domicilio
2000101 San Miguel 2000102 Jesús María
2000103 Miraflores 2000104 Breña
2000105 Miraflores
2000106 Los Olivos 2000107 San isidro
Fig. 2.6 Resultado de una proyección
En matemáticas la función proyección proyecta sobre algunas de las componentes de su dominio. Por ejemplo P(x,y,z)=(x,z) es una función proyección de un espacio tridimencional a uno bi-dimensional. La idea es la misma y es una restricción a un
La operación de renombrar tiene como objetivo principal renombrar un atributo de una
relación o la relación misma. Utiliza el operador P y es usado como PA(B)que es la
relación B con nombre cambiado a A. También se usa como Pa,b(B)que da esencialmente
la misma relación B con el dominio o atributo b cambiado por a.
Tomando como base el ejemplo 2.1 la relación Pdistr¡t0/dom¡cii¡o (B) esta dada por:
3. Operación renombrar:
Codigo Ape-Paterno Ape-Materno Nombre Edad Distrito Sexo
2000101 Campos Pizarro Ricardo 16 San Miguel M
2000102 Palacios Robledo Jimena 15 Jesus Maria F
2000103 Vega Paz Claudia 14 Miraflores F
2000104 Garcia Calderon Luis Alfonso 17 Breña M
2000105 Oropeza Rivera karla 17 Miraflores F 2000106 Garcia Vega Cindy Rocía 16 Los Olivos F
2000107 Arevaio Rivero Eduardo 18 San isidro M
Fig.2.7 Resultado de la la operación de renombrar
En este ejemplo se observa que “Domicilio” ha cambiado por “Distrito”. En sistemas de base de datos los dominios constituyen la estructura de la base de datos y todo sistema provee con herramientas para poder cambiar la estructura.
2.4.4 Operaciones derivadas de las básicas
Las operaciones siguientes son consecuencia de las elementales o derivadas de principios matemáticos establecidos. Estas operaciones son posibles porque los resultados de las operaciones primarias, al ser también relaciones, se les puede aplicar operaciones basadas
en principios matemáticos.
I. Composición de operaciones relaciónales.
Es muy común tener consultas que resultan de la composición de una proyección con una
selección o de una selección con una proyección. Por ejemplo n ai ^ ^a (R)es una
proyección pero si R = T p(A) tenemos la composición n 3i ^a ( r p(A))que es otra
preguntar por los alumnos que tienen edad mayor o igual a 16 y del resultado solo queremos el apellido paterno y su domicilio.
^ (Ape.Paterno.domicilio) (r|Edad^i6)(Alu m n o )) = Composición nos produce la siguiente relación
Ape-Paterno Edad
Campos 16
Garcia 17
Oropeza 17
Garcia 16
Arevaio 18
Fig.2.8 Resultado de una composición
El resultado nos produce la respuesta a una pregunta o consulta que se hace a la relación misma.
2. La operación de unión
La operación de unión es un operador binario entre dos relaciones S y T y se escribe como S U T y cuyo objetivo es la relación cuyos componentes es el conjunto de todas las
combinaciones de tupias en S y T que son iguales en sus atributos comunes.
Ejemplo: En una Universidad se tiene las siguientes relaciones para alumnos y profesores.
Lo que se pide es los apellidos de todas las las personas que son ya sea alumnos o profesores. Para ello la figura
Alumno Profesor
Codigo Ape-Paterno Edad Domicilio Código Ape-Paterno Domicilio
2000101 Campos 16 San Miguel 101 Vega San Isidro
2000102 Palacios 15 Jesús Maria 102 Calderon Los Olivos
2000103 Vega 14 Miraflores 103 Vizcarra Pueblo Libre
2000104 Garcia 17 Breña 104 Garcia Pueblo Libre
2000105 Oropeza 17 Miraflores 105 Sandoval Los Olivos 2000106 Garcia 16 Los Olivos 106 Bedoya Los Olivos
2000107 Arevaio 18 San isidro 107 Palacios Miraflores
Se hace la operación n (ApePaterno)(A lu m n o )U n (ApePaterno)(Profesor) que nos produce:
Ape-Paterno
Campos
Palacios
Vega Garcia
Oropeza
Garcia Arevalo
Calderón
Vizcarra
Sandoval Bedoya
Fig. 2.10 Resultado de una unión
En este ejemplo el resultado son 11 registros aun cuando hay 7 alumnos y 7 profesores. De hecho como la relación es un conjunto, los registros repetidos no se consideran. Ello también significa que los repetidos constituyen (como Garcia) el apellido paterno tanto de un alumno como de un profesor.
3. La operación de diferencia
En forma análoga a la unión la diferencia constituye una relación donde los tupies están en una de ellas pero no en la otra. Por ejemplo y tomando las relaciones anteriores
n (Ape.Paterno|(A , u m n o ) - n Ape.Patemo|(P r o í e s o r ) constituye los apellidos paternos de
estudiantes que no son profesores. El resultado se ve en figura 2.13.
Ape-Paterno
Campos
Oropeza Arevalo
4. La operación producto cartesiano.
La operación de producto cartesiano, denotada con un X permite combinar información de
dos relaciones. Escribimos como R ,X R 2 la nueva relación que se forma y nos damos una
idea debido a que una relación por si misma es un subconjunto del producto cartesiano de sus dominios. Sin embargo en este caso el mismo nombre del atributo puede aparecer en ambas relaciones y por tanto necesitaremos un esquema de nombres para distinguir este atributo.En la práctica y cuando pueda haber confusión se adiciona el nombre del atributo a la relación. Daremos un ejemplo y para ello introducimos una versión simplificada de alumno y notas tal como se muestra en fig. 2.14
Alumno Código Ape-Paterno Notas Codigo Pract Nota
2000101 Campos 2000101 P01 13
2000102 Palacios 2000101 P02 15
2000103 Vega 2000101 P03 12
2000104 Garcia 2000102 P01 17
2000105 Oropeza 2000102 P03 19
2000106 Garcia 2000104 P01 12
2000107 Arevaio 2000104 P02 15
Fig.2.14 Relaciones Alumno y Notas
Alumno=(Código, Ape.Paterno) y Notas=(Código, Pract, Nota). Luego la relación
R = AlumnoXNotas es (Alumno.Codigo,Alumno.Ape-Paterno, Notas.codigo,
Notas.Pract, Notas.Nota). De esa forma de especificar el esquema conocemos el origen de cada atributo. Sin embargo podemos escribir la relación ignorando los nombres de atributos que no se repiten. Y asi R es (AlumnoCodigo,Ape-Paterno, Notas.codigo, .Pract, Nota) lo cual se entiende claramente y no tiene ninguna ambigüedad. La figura 2.15 muestra el resultado del producto cartesiano.
Alumno.codigo Ape-Paterno Notas.codigo Pract Nota
2000101 Campos 2000101 P01 13
2000101 Campos 2000101 P02 15
2000101 Campos 2000101 P03 12
2000101 Campos 2000102 POI 17
2000101 Campos 2000102 P03 19
2000101 Campos 2000104 POI 12
2000101 Campos 2000104 P02 15
2000102 Palacios 2000101 POI 13
2000102 Palacios 2000101 P02 15 2000102 Palacios 2000101 P03 12
2000102 Palacios 2000102 POI 17
2000102 Palacios 2000102 P03 19
2000102 Palacios 2000104 POI 12 2000102 Palacios 2000104 P02 15
2000107 Arevalo 2000101 POI 13
2000107 Arevalo 2000101 P02 15
2000107 Arevalo 2000101 P03 12
2000107 Arevalo 2000102 POI 17
2000107 Arevalo 2000102 P03 19
2000107 Arevalo 2000104 POI 12
2000107 Arevalo 2000104 P02 15
Fig.2.15 Resultado de AlumnoXNotas
En la figura 2.15 no se están exhibiendo todos los elementos pero si se da idea del total.
Es de notar que el producto cartesiano nos pueden dar muchos más elementos de los que se pueden requerir. Por ejemplo si deseamos hallar los Ape-Paterno de todos los alumnos que
han dado la práctica 2, es claro que necesitamos la información tanto de Alumno como de
Notas. Si escribimos r pract=..p02„(AlumnoXNotas) tendremos lo mostrado en la figura
2.16. En esta relación se nota que la columna Ape-Paterno puede contener algunos apellidos de personas que no han dado la práctica 02. Esto se debe a que el producto cartesiano toma todas los pares posibles sin hacer ninguna distinción.
Como la operación de producto cartesiano asocia cada fila de alumno con cada fila de
alumnoxnotas que contiene su nombre y alumno.codigo=notas.codigo. Luego, si ponemos
^Alumno.codigo=Notas.codígoí^pract=Mp02M(AlufflnoXNotdS)) obtenernos todas los registros que
han dado la practica 2 tal como se muetra en fig. 2.17.
Alumno.codigo Ape-Paterno Notas.codigo Pract Nota
2000101 Campos 2000101 P02 15
2000101 Campos 2000104 P02 15
2000102 Palacios 2000101 P02 15 2000102 Palacios 2000104 P02 15
2000103 Vega 2000101 P02 15
2000103 Vega 2000104 P02 15
2000104 Garda 2000101 P02 15
2000104 Garda 2000104 P02 15
2000105 Oropeza 2000101 P02 15
2000105 Oropeza 2000104 P02 15
2000106 Garda 2000101 P02 15
2000106 Garda 2000104 P02 15
2000107 Arevaio 2000101 P02 15 2000107 Arevaio 2000104 P02 15
Fig.2.16 Resultado de r pracU..p02..(AlumnoXNotas)
Alumno.codigo Ape-Paterno Notas.codigo Pract Nota
2000101 Campos 2000101 P02 15
2000104 Garda 2000104 P02 15
Fig.2.17 Resultado de r Alumno codlgo=Notascod¡go(r pract=„p02„(AlumnoXNotas))
La consulta inicial era por los Ape-Paterno y esto se muestra en la fig.2.18 ya que solo se
está interesado en los Ape-Paterno. Este es el resultado de la proyección siguiente:
n A p e _ p a te rn o (•^A Ium n o.cod ¡go=N ota s.cod¡go ( ^ p r a c t= " p 0 2 ” l U f f i n o X N O t a S ) ) )
Ape-Paterno
Campos
Garda
Fig.2.18 Respuesta final a Apellidos de alumnos que dieron la Pract P02
2.4.5 Operaciones Adicionales.
Una expresión general de álgebra relacional se construye de expresiones más pequeñas. Si Ei y E2 son expresiones del Algebra Relacional. Luego también las siguientes son expresiones válidas:
* E t u E j
*
• M E j
•
r p( E
) donde p es un predicado sobre atributos en E1.• n S( E ) donde S es una lista consistente de algunos de los atributos en E1.
• Px (E!) donde x es el nuevo nombre para el resultado de E1.
Las operaciones mencionadas hasta el momento permiten dar respuesta a las consultas que se realicen usando el álgebra relacional. Sin embargo si nos restringimos a únicamente las operaciones fundamentales, ciertas consultas serán muy largas de especificar. Por tanto definimos operaciones adicionales que sin agregar ninguna potencia al algebra simiplifican algunas consultas comunes. Para cada nueva operación planteamos una expresión equivalente que usa solo las operaciones fundamentales.
1. Operación de intersección de conjuntos
Supongamos que introducimos una nueva relación a nuestros ejemplos ilustrada por fig.2.19 y que muestra las notas de un examen de los alumnos que lo rindieron;
Codigo Exa
2000101 15 2000102 13 2000103 17
2000104 14
2000105 12 2000107 19
Ahora en nuestras relaciones deseamos hallar los códigos de los alumno que rindieron tanto la práctica calificada como el examen. Esto corresponderá a la siguiente operación
n cod¡go(Examen) n
n codigo
(Notas) que nos da el resultado de fig. 2.20.Codigo
2000101 2000102 2000104
Fig. 2.20 Resultado de intersección n codigo(Examen)n n codigo (Notas)
La operación de intersección se puede reemplazar con un par de operaciones de diferencias
de conjuntos como sigue r n s = r - (r- s).
2. Operación junta-natural
A menudo es deseable simplificar ciertas consultas que requieren un producto cartesiano. Usualmente una consulta que involucra un producto cartesiano incluye una operación de selección en el resultado del producto. Por ejemplo considere la consulta “Hallar los nombres de todos los alumnos conjuntamente con su código y la nota de su examen” . Para ello primero formamos el producto cartesiano de Alumno x Examen. Luego seleccionamos
aquellas tupias que tienen el mismo código, seguido por la proyección de el resultado sobre Ape_Paterno,código y Exa. La expresión relacional corresponde a:
^ A p e _Paterno,E xam en.cod ¡go,exa (^ A lu m n o .c o digo=Exam en.cod igo ( E X S f f l S n X A l U f f l n o ) )
La operación junta natural es una operación binaria que nos permite conbinar ciertas
selecciones y un producto cartesiano en una sola operación. Es denotada por el símbolo
x . La operación de Junta Natural forma un producto cartesiano de sus dos argumentos,
realiza una selección forzando la igualdad en los atributos que aparecen en los esquemas de ambas relaciones y finalmente no considera los atributos duplicados. Si consideramos la consulta anterior esta es expresada de la siguiente forma e ilustrada en la fig. 2.2 1.
Como los esquemas de Alumno y Examen tienen el atributo Codigo en común, la operación de junta natural solo considera los pares de tupies que tienen el mismo valor para código. En otras palabras combina cada par de tupies en uno solo sobre la unión de los dos esquemas. Luego realiza la operación de proyección.
Ape
Paterno Código Exa
Campos 2000101 15
Palacios 2000102 13
Vega 2000103 17
Garcia 2000104 14
Oropeza 2000105 12
Arevaio 2000107 19
Fig. 2.21 Resultado de n Ape_PaternoExamen.codigoexa(Alumno|x|Examen)
Si consideramos dos relaciones r y s con sus esquemas R y S, que son en realidad listas de
atributos. Si consideramos los esquemas como conjuntos en lugar de listas, podemos considerar que los atributos que aparecen en ambos esquemas están en R n S y los que
aparecen en R, o en ambos como R u S . Análogamente los que aparecen en S pero no en
R son S - R , y también los que están en R pero no en S R - S . Todas estas operaciones son sobre conjuntos de atributos y no sobre relaciones.
Con ello podemos dar una definición formal de la junta natural. Considerando las relaciones r(R) y s(S) la junta natural es una relación sobre el esquema R u S definida
como sigue:
r x s —
n RuS(rri
v, v, aí. Vj * *, v, . V„,tiV rx s ) donde R r \ $ = V„}3. La operación de asignación.
Esto es importante puesto que permite que esta relación pueda ser usada en operaciones
posteriores. Asi tenemos p <— r|x|s ; q ^
n cod¡go
(Examen) nn cod¡go
(Notas) comoasignaciones a nuevas variables p y q.
2.5 Operaciones extendidas del algebra relaciona)
Las operaciones básicas del Algebra Relacional han sido extendidas de diversas formas. Una extensión simple consiste en permitir operaciones aritméticas como parte de la proyección. Asimismo permitir opraciones agregadas tales como calcular la suma de los
elementos de un conjunto o su promedio.
I. Proyección generalizada.
La proyección generalizada extiende la operación de proyección usual permitiendo que funciones aritméticas puedan ser usadas en la lista de proyección. La proyección
generalizada tiene la forma n FiF2 F (E) donde E es una expresión del algebra relacional y
cada uno de Fi, F2, F3,..., Fn, es una expresión aritmética que involucra constantes y atributos del esquema de E. Como caso especial, la expresión aritmética puede ser
simplemente una constante o un atributo.
En la relación alumno (repetimos la fig.2.1) hallaremos los que son mayores de 16 años y solo queremos el código y el Ape-paterno:
Código Ape-Paterno Ape-Materno Nombre Edad Domicilio Sexo
2000101 Campos Pizarro Ricardo 16 San Miguel M
2000102 Palacios Robledo Jimena 15 Jesús Maria F
2000103 Vega Paz Claudia 14 Miraflores F
2000104 Garcia Calderon Luis Alfonso 17 Breña M
2000105 Oropeza Rivera karla 17 Miraflores F
2000106 Garcia Vega Cindy Rocía 16 Los Olivos F 2000107 Arevaio Rivero Eduardo 18 San isidro M
El resultado estará dada por la expresión
n
Ape_PaternoEdad>16(Alumno) obteniendo loApe.Paterno Edad
Campos 16
Garcia 17
Oropeza 17
Garcia 16
Arevalo 18
Fig. 2.22 Resultado de n Ape-Paterno,Edad>16(A l u m n 0 )
La figura 2.23 muestra la relación pensión y lo pagado y podemos estar interesados en la deuda lo cual hacemos como una proyección.
Codigo Ape.Paterno Ape.Materno Nombre Pensión Pagado
2000101 Campos Pizarro Ricardo 3000 2300
2000102 Palacios Robledo Jimena 2500 2000
2000103 Vega Paz Claudia 3200 1800
2000104 Garcia Calderon Luis Alfonso 2400 2100
2000105 Oropeza Rivera karla 3000 2300
2000106 Garcia Vega Cindy Roda 2800 2400
2000107 Arevalo Rivero Eduardo 2900 2600
Fig.2.23 Pagos de estudiantes
La proyección n Ape-patemo,Nombre>pens¡on-Pagado(Pago s ) nos da la deuda de cada alumno. Sin
embargo el atributo que resulta de Pension-Pagado no tiene un nombre. Podemos usar aqui la operación de rename al resultado de la proyección generalizada y decir lo siguiente
n Ape-Pa,erno,Nombre.Pension-Pagado as Deuda (P a g o s ) y el resultado se muestra en la figura
2.2.4.
Ape.Paterno Nombre Deuda
Campos Ricardo 700
Palacios Jimena 500
Vega Claudia 1400
Garcia Luis Alfonso 300
Oropeza karla 700
Garcia Cindy Roda 400
Arevalo Eduardo 300
Observe que se ha puesto de nombre Deudas a esta nueva relación. Es obvio que se puede realizar mas de una operación con los atributos de la relación. El atributo al que se hace la operación o permanece con su nombre o debe ser renombrado con objeto de tener una mayor claridad y el resultado final no se presente a segundas interpretaciones.
2. Funciones agregadas
Las funciones de agregación o agregadas toman una colección de valores y retorna un solo valor como resultado. Por ejemplo la función sum toma un conjunto de valores y retorna el valor de la suma total. Esta función aplicada a {11,19,13,13,16,12} retorna el valor de 80.
La función avg retorna el promedio de los valores. Cuando se aplica a la colección anterior retorna el valor 14. La función count nos da como resultado el total de elementos en la colección y en este caso retorna 6. Otras funciones agregadas incluyen min y max que en forma respectiva retornan el valor mínimo y el máximo de una colección. En el ejemplo que estamos estudiando nos daría 11 y 19 respectivamente.
La colección de datos sobre la que operan las funciones son llamadas multi-conjuntos debido a que pueden tener múltiples ocurrencias de un valor y el orden en que aparecen no
tiene mayor relevancia. Se les ha llamado multi-conjuntos a diferencia de los conjuntos donde solo hay una sola copia de cada elemento.
Nombre Distrito Exa-01 Exa-02
Campos Miradores 15 14
Palacios Miradores 16 13
Vega Breña 16 14
Garcia Lima 17 18
Oropeza La Molina 20 18
Garcia Lima 14 16
Arevalo Lima 13 14
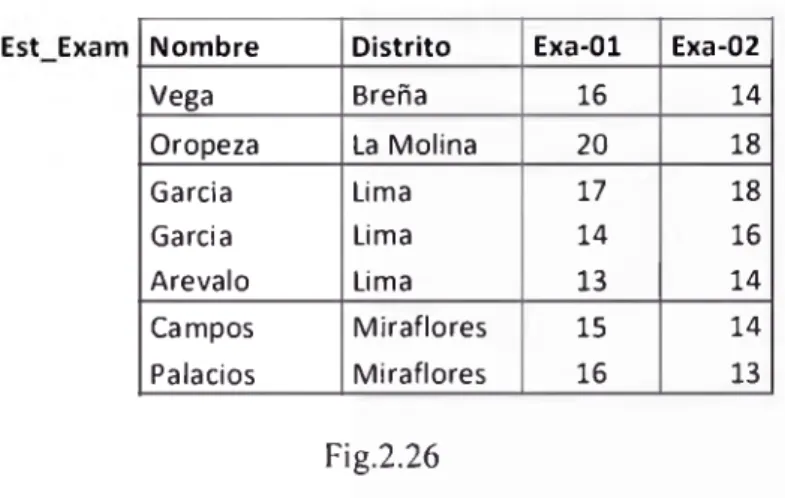
Fig. 2.25
Para ilustrar el concepto de agregación usaremos la relación Est_Exam ilustrada en fig.
2.25. La expresión n Avg(Exa_01)(Est_Exam ) nos permite hallar el promedio de las notas
como una relación con un valor numérico correspondiente al promedio de todas las notas del Exa-01.
Las funciones de agregación permiten algunas modificaciones a su uso natural. Por ejemplo podemos eliminar duplicados introduciendo el modificador distinta la función. Si hacemos ficount-d¡st¡nt(D¡str¡to) ( ^ s t _ Ex a m ) nos permite la consulta para hallar el número de
distritos donde residen los alumnos. El resultado en este caso es la relación con un único elemento que es 4.
Asumamos ahora que deseamos hallar el promedio de Ex-01 de todos los alumno pero por
distrito. La expresión D¡str¡toQ Avg(Exa_01)(Est_Exam ) '° realiza. En esta expresión el
atributo Distrito, como subíndice a la izquierda del operador f i indica que la relación de entrada sera dividida de acuerdo al numero de distritos. La figura 2.26 muestra los cuatro gurpos que se forman.
Nombre Distrito Exa-01 Exa-02
Vega Breña 16 14
Oropeza La Molina 20 18
Garcia Lima 17 18
Garcia Lima 14 16
Arevalo Lima 13 14
Campos Miradores 15 14
Palacios Miradores 16 13
Fig.2.26
La función avg(Exa-Ol) como subíndice a la derecha de Q indica que para cada grupo de tupies se tiene que hallar el promedio. El resultrado es la relación de cuatro términos mostrada en fig. 2.27.
Distrito Exa-01
Breña 16
La Molina 20
Lima 14.66
Miradores 15.5
La expresión G)iGj.... G„ ° f, (a,),f2(a2).... Fm(A„ ,(E) constituye la de la operación de agregación. E
constituye una expresión o relación, Gi,G2,...,Gn constituyen una lista de atributos sobre
cuya base se hara la agrupación, cada F¡ es una función de agregación y cada A¡ es el nombre de un atributo.
El significado de la operación es que las tupias en el resultado de la expresión E están particionados en grupos de modo que:
1. Todos los tupies en un grupo tienen los mismos valores para Gi,G2,...,Gn .
2. Tupies en diferentes grupos tienen diferentes valor para Gi,G2,...,Gn .
Por tanto los grupos pueden identificarse por los valores de los atributos Gi,G2,...,Gn y para
cada grupo (gi,g2,...,gn ) el resultado es la tupia (gi,g2,...,gn, a ,,a2,...,an ) donde por cada i, a¡ es el resultado de aplicar la función F¡ en el multi-conjunto de valores para atributo A¡ en cada grupo.
Es de notar que como un caso especial de la operación de agregación la lista de atributos Gi,G2,...,Gn puede ser vacia en cuyo caso se tiene un solo grupo que corresponde a la
operación de agregación sin agrupación.
Distrito Pro-Exa-01 Max-Ex-01
Breña 16 16
La Molina 20 20
Lima 14.66 17
Miradores 15.5 16
FÍg.2.28 Resultado de Distrito °Avg(Exa-01)as Pro-Exa-01,max(Exa-01)as Max-Ex-01 ( ^ S t—EX3ffi)
De este modo se implementan operaciones adicionales. Por ejemplo para hallar la nota promedio de exa-Ol y la máxima nota de acuerdo al distrito se puede escribir la expresión
Distrito0 Avg(Exa-oi)>max(Exa-oi)(Est_Exam). Como en las proyecciones generalizadas el
3. Ju n ta externa.
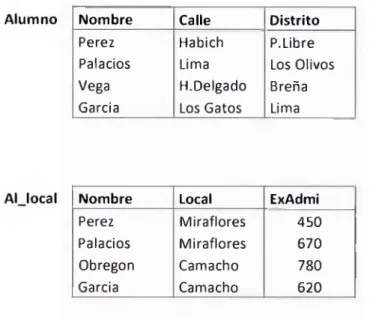
La operación de junta externa es una extensión de la operación de junta natural discutida anteriormente. Suponga las dos relaciones mostradas en figura 2.29 y nuestro objetivo es generar una sola relación con toda la información.
Nombre Calle Distrito
Perez Habich P.Libre Palacios Lima Los Olivos
Vega H.Delgado Breña
Garcia Los Gatos Lima
Nombre Local ExAdmi
Perez Miraflores 450
Palacios Miraflores 670
Obregon Camacho 780
Garcia Camacho 620
Fig.2.29 Relaciones Alumno y A ljo c al
Una posible solución podría ser el hacer la junta natural Alumno x|AI_local cuyo
resultado se muestra en fig. 2.30.
Nombre Calle Distrito Local ExAdmi
Perez Habich P.Libre Miraflores 450
Palacios Lima Los Olivos Miraflores 670
Garcia Los Gatos Lima Camacho 620
Fig. 2.30 Resultado de Alumno|x|AI_local
Nótese en esto que hemos perdido la Calle y el Distrito Breña debido a que la tupia que lo describe no figura en la relación A ljo c a l de locales; y en forma similar perdemos Local y ExAdmi de Obregon ya que la tupia que describe a Obregon esta ausente de la relación Alumno.
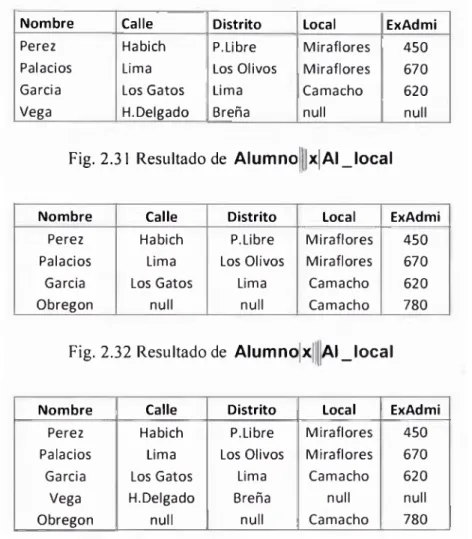
La operación Junta externa nos permite evitar esta perdida de información. Existen tres
denotada por |x|| y junta externa total denotada por ||x ||. Todas las tres formas calculan la
junta natural, y adicionan los registros extras al resultado. Los resultados de cada una de ellas es mostrado en las figuras 2.31 a 2.33.
Nombre Calle Distrito Local ExAdmi
Perez Habich P.Libre Miraflores 450
Palacios Lima Los Olivos Miraflores 670
Garcia Los Gatos Lima Camacho 620
Vega H.Delgado Breña null null
Fig.2.31 Resultado de Alumno |||x|AI_local
Nombre Calle Distrito Local ExAdmi
Perez Habich P.Libre Miraflores 450
Palacios Lima Los Olivos Miraflores 670
Garcia Los Gatos Lima Camacho 620
Obregon nuil nuil Camacho 780
Fig.2.32 Resultado de Alumnox AI_local
Nombre Calle Distrito Local ExAdmi
Perez Habich P.Libre Miraflores 450
Palacios Lima Los Olivos Miraflores 670
Garcia Los Gatos Lima Camacho 620
Vega H.Delgado Breña null null
Obregon nuil nuil Camacho 780
Fig. 2.33 Resultado de Alumno x AI_local
4. Valores nulos.
En esta sección tiene como objetivo el indicar la forma como diversas operaciones relaciónales trabajan con los valores nulos y como lo tratan. Esta aclaración es debido a que existen diversas formas de tratarlas y como resultado nuestras definiciones pueden parecer algo arbitrarias. Lo ideal es tratar de evitar las operaciones con valores nulos.
El valor especial “nuil” nos indica valor desconocido o inexistente, lo que implica que diversas operaciones como que involucren valores nulos nos puede dar “nuil” también. En forma similar si usamos comparaciones como <,>,<=, =, etc que involucren un valor nulo nos dará también nuil. Aquí se puede decir que el resultado es el nuevo valor de nuil.
Comparaciones que involucran nuil pueden ocurrir dentro de expresiones booleanas que usan las operaciones “and”, “or”, y “not” . Definamos como estas operaciones tratan con el
“nuil”.
• And: (true And desconocido) = desconocido; (false and desconocido)=false; (desconocido and desconocido)= desconocido.
• Or: ((true Or desconocido) = true; (false and desconocido)=desconocido; (desconocido or desconocido)= desconocido
• Not: (Not desconocido) = desconocido.
Se describe a continuación la manera como las operaciones relaciónales tratan con los valores nulos. Estas definiciones están en concordancia con el lenguaje SQL.
• Selección: La operación de selección evalúa el predicado P en
r p(E)
para cada tupia en E. Si el predicado retorna el valor true entonces es añadido al resultado y en caso que se retorne el valor falso o nuil no se añade al mismo.• Proyección: La operación de proyección trata al nuil en la misma forma como otro valor cuando se eliminan duplicados. Luego si dos tupias en el resultado
proyectado son exactamente las mismas y ambas tienen nuil en los mismos campos, ellos son tratados como duplicados. La decisión es algo arbitrario ya que sin conocer los valores actualizados no conocemos si las dos instancias de nuil son duplicados o no.
• Unión, Intersección, diferencia: Estas operaciones tratan a nuil como la operación de proyección. Ellos tratan tupias que tienen los mismos valores en todos los campos como duplicados aun si algunos de ellos tienen valores nulos en ambos. Este comportamiento puede parecer arbitrario, especialmente en el caso de diferencia e intersección, ya que no se conoce si los valores actuales (si existen) representados por los nuil son los mismos.
• Proyección G eneralizada: Loas tupias duplicadas que contienen valores nulos son manejadas como en la operación de proyección.
2.6. Modificación de la base de datos
El desarrollo que se ha realizado hasta el momento está concentrado en la extracción de información de una base de datos y su relación con los operadores matemáticos. Ahora veremos que podemos hacer modificaciones en base a consultas y por tanto establecerlos como operadores matemáticos.
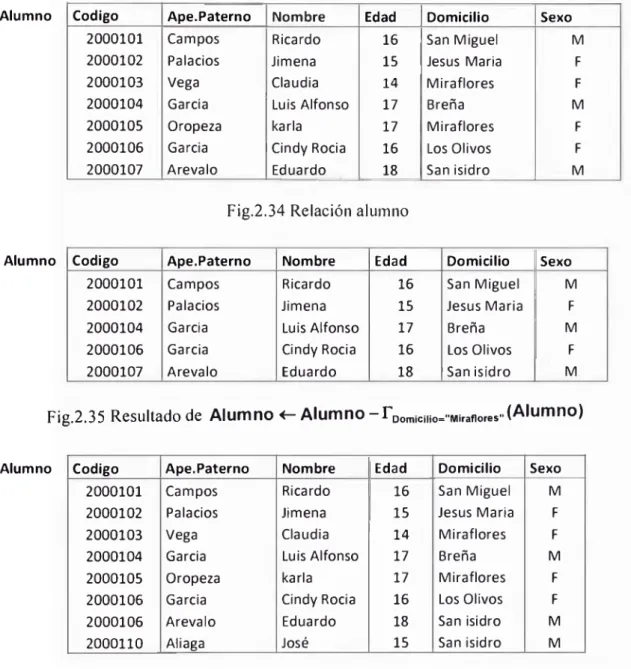
2.6.1 B orrado El objetivo fundamental es el de escoger tupias para mostrar, con la
diferencia que en lugar de ser mostrados serán borrados de la base de datos. El hecho es que se eliminan la tupia entera y no valores particulares. En el lenguaje relacional es
expresado como r ^ r - E donde r es la relación y E es una consulta en algebra relacional. Por ejemplo si deseamos eliminar todos los alumnos que viven en San Miguel los resultados son exhibidos en figuras 2.34 y 2.35.