Introducción
La codificación clínica permite seleccionar la in-formación relevante contenida en los documentos clínicos en lenguaje natural y traducirla a un len-guaje normalizado1. Constituye una etapa esencial para el posterior análisis de dicha información. Pa-ra codificar la información clínica contenida en las historias de salud digitales de urgencias es necesa-rio buscar alternativas a la codificación que suele llevarse a cabo mediante el personal documentalis-ta, dada la dificultad que representa el alto volu-men de episodios generados en este ámbito.
El término procesamiento del lenguaje natural (PLN) hace referencia a aquellas técnicas compu-tacionales que nos permiten interpretar el
lengua-je natural hablado o escrito para realizar posterior-mente determinadas tareas2. Estas técnicas ya han demostrado su utilidad en el ámbito sanitario (sis-temas de ayuda a la decisión clínica, de alerta sa-nitaria, programas de cribado, etc.)3 y reciente-mente vienen empleándose para la codificación automática de los textos clínicos recogidos en las historias de salud digitales4. En nuestro entorno, dichas técnicas se enfrentan a las dificultades pro-pias del lenguaje clínico como el uso de jerga, si-nónimos, acrónimos y abreviaturas5-8.
Existen dos tipos de codificadores automáti-cos: los normativos y los probabilísticos. Los pri-meros utilizan métodos basados en reglas y dic-cionarios para extraer los segmentos codificables de un texto9. Como afirman Crowston et al.10, “se
ORIGINAL
Desarrollo de un sistema de codificación automática
para recuperar y analizar textos diagnósticos
de los registros de servicios de urgencias hospitalarios
JUANANTONIOGOICOECHEA SALAZAR1, MARÍAADORACIÓNNIETO GARCÍA2,
ANTONIOLAGUNA TÉLLEZ1, VICENTEDAVIDCANTO CASASOLA1,
JULIANARODRÍGUEZ HERRERA1, FRANCISCOMURILLO CABEZAS3
1Servicio de Producto Sanitario, Servicio Andaluz de Salud, Sevilla, España. 2Departamento de Medicina
Preventiva y Salud Pública, Facultad de Medicina de la Universidad de Sevilla, España. 3Departamento de Medicina, Facultad de Medicina de la Universidad de Sevilla, España.
Objetivos:Desarrollar un codificador automático para recuperar información de los re-gistros de urgencias hospitalarios y evaluar su desempeño.
Método:Se utilizaron los textos diagnósticos de los urgenciólogosde 27 hospitales du-rante 2010 y 2011: los textos de 3.042.695 registros de 2010 para desarrollar el codifi-cador automático y los de 3.072.861 registros de 2011 para comprobar su funciona-miento. Para su evaluación, se seleccionó una muestra aleatoria de los registros de 2011 que fue doblemente codificada por el codificador automático y por un experto en codificación clínica. Se calcularon la precisión, el recall y la F-score del codificador.
Resultados: Contenían información potencialmente codificable 2.936.842 registros de 2011 (95,6% del total). En ellos, el codificador automático identificó 3.516.384 textos diferentes (1,2 por registro) de los que codificó 3.087.243 (87,8%) y proporcionó códi-gos a 2.639.427 (89,9% de 2.936.842). La precisión fue 0,976 (CI 95% = 0,957-0.990), su recall 0,878 (CI 95% = 0,844-0,910) y su F-score 0,925 (CI 95% = 0,903-0,943).
Conclusiones:Este codificador se adapta eficientemente al entorno de urgencias y per-mite la codificación de millones de registros en pocas horas, haciendo operativa la in-formación diagnóstica que contienen. El codificador podría mejorar su recall si incorpo-rara un motor probabilístico. [Emergencias 2013;25:430-436]
Palabras clave: Servicios de urgencia. Codificación clínica. Procesamiento del lenguaje natural. CIE-9-MC. Almacenamiento y recuperación de información.
CORRESPONDENCIA:
Juan Antonio Goicoechea Salazar Servicio Andaluz de Salud Avenida de la Constitución, 18 41071 Sevilla, España E-mail: jantonio.goicoechea@ juntadeandalucia.es
FECHA DE RECEPCIÓN: 21-1-2013
FECHA DE ACEPTACIÓN: 11-5-2013
basan en el conocimiento y analizan los fenóme-nos lingüísticos que aparecen en el texto, utili-zando su información sintáctica, semántica y dis-cursiva”. Los segundos utilizan métodos estadísticos (regresión logística, campos aleatorios condicionales, clasificadores Naive Bayes, mode-los ocultos de Markov, etc.)8 para inferir patrones de conocimiento a partir de un cuerpo de entre-namiento formado por textos diagnósticos ya co-dificados.
Al enfrentarse a un nuevo texto, estos codifica-dores probabilísticos proponen distintos códigos con sus índices de confianza asociados, asignán-dole el código con mayor índice si éste supera un umbral prefijado. La elección del umbral influye, por tanto, en el resultado final de la codificación. El rendimiento de estas herramientas depende en gran medida del volumen y calidad del cuerpo de entrenamiento10. Ambas aproximaciones, normati-va y probabilística, resultan complementarias.
En los últimos años han tenido lugar distintas iniciativas para codificar automáticamente los tex-tos clínicos en español de las altas de los servicios de urgencias y de las consultas, aunque su aplica-ción es todavía limitada. En 2000, la Conselleria de Sanitat de la Generalitat Valenciana11 desarrolló un codificador automático para urgencias hospitala-rias utilizando una aproximación normativa, como hizo también el Hospital Italiano de Buenos Aires con su servidor de terminología en español (STHI-BA)12, que fue utilizado en 2007 por Megasalud de Chile para codificar los textos libres escritos por los médicos de su red ambulatoria13.
Sin embargo, la mayoría de los codificadores automáticos que trabajan con textos en español utilizan motores probabilísticos o mixtos. La em-presa ASHO proporciona servicios de codificación automática para los servicios de urgencias hospita-larias14y SIGESA de codificación semiautomática15. Desde 2008 la Fundación Puigvert codifica sus epi-sodios urgentes mediante Ontology de Thera®16 y el Hospital Clínic de Barcelona utiliza CodingSuite de W4KIT17. El Hospital Reina Sofía de Murcia18 dis-pone de un codificador cuya operativa desconoce-mos y Osakidetza, el Servicio Vasco de Salud, utili-za un sistema automático (Kodifika) para codificar los diagnósticos de consultas externas19,20.
Los codificadores automáticos son difíciles de adaptar a contextos distintos para los que fueron creados4,21-23 y para maximizar su capacidad de co-dificación es esencial adecuarlos al lenguaje clínico del área donde vayan a implantarse. Por ello, de-cidimos iniciar un proyecto de investigación para desarrollar un sistema de codificación automática con el objetivo de recuperar la información de los
registros de los servicios de urgencias de 27 hos-pitales del Servicio Andaluz de Salud (SAS), que proporcionan asistencia sanitaria a 5.896.646 per-sonas, así como evaluar su rendimiento (Tabla 1).
Método
Se consideraron los textos diagnósticos escritos por facultativos en 6.115.556 episodios de urgencias de 27 hospitales del SAS durante 2010 y 2011, reco-gidos en la historia de salud digital Diraya. Se utiliza-ron 3.042.695 registros de 2010 para desarrollar el sistema automático de codificación y 3.072.861 re-gistros de 2011 para comprobar su funcionamiento. También se utilizaron los tesauros generados en al-gunos hospitales para facilitar la codificación.
El codificador utiliza una metodología normati-va. Dispone de dos elementos básicos: un módulo de PLN que modifica, en su caso, los textos origi-nales escritos por los médicos y un archivo con expresiones (palabras o grupos de palabras) aso-Tabla 1.Registros de episodios de urgencias en 2011 por hospital: total, no codificables, potencialmente codificables y codificados
Hospitales Registros Registros Registros Registros de clasificados clasificados codificados
urgencias como como (%) (d)
(a) no-codificables potencialmente (%) (b) codificables
(%) (c)
H. 1 25.415 3,3 96,7 90,9
H. 2 28.876 1,9 98,1 92,6
H. 3 41.084 1,7 98,3 88,0
H. 4 41.787 1,7 98,3 87,9
H. 5 52.545 1,9 98,1 92,1
H. 6 53.652 3,8 96,2 90,8
H. 7 56.046 7,4 92,6 89,2
H. 8 56.576 3,6 96,4 87,6
H. 9 60.779 3,5 96,5 90,3
H. 10 68.189 3,3 96,6 91,6
H. 11 74.623 1,9 98,1 89,5
H. 12 78.808 2,3 97,7 88,6
H. 13 80.473 2,0 98,0 89,5
H. 14 85.498 8,0 92,0 88,1
H. 15 118.614 5,5 94,4 89,2
H. 16 128.752 6,3 93,6 87,2
H. 17 130.229 3,4 96,6 89,9
H. 18 142.665 4,3 95,7 90,1
H. 19 142.754 3,2 96,8 89,7
H. 20 144.352 3,6 96,4 88,7
H. 21 150.891 12,0 88,0 88,1
H. 22 154.946 1,7 98,3 91,4
H. 23 177.675 7,1 92,9 90,5
H. 24 194.572 2,2 97,8 91,4
H. 25 217.736 4,5 95,5 90,2
H. 26 241.988 3,8 96,2 91,7
H. 27 323.336 5,0 95,0 89,5
Total 3.072.861 4,4 95,6 89,9
ciadas a uno o más códigos diagnósticos de la Clasificación Internacional de Enfermedades, 9ª edición, Modificación Clínica (CIE-9-MC) (fichero de expresiones codificadas-FEC).
Las expresiones del FEC provienen de textos de los tesauros hospitalarios y de los registros de 2010 transformados mediante PLN. Su codifica-ción con CIE-9-MC se desarrolló en tres etapas: en la primera, 15 documentalistas expertos de 14 hospitales las codificaron; en la segunda, dos ex-pertos de los Servicios Centrales del SAS revisaron dicha codificación, y propusieron algunas modifi-caciones y, en la tercera, un grupo de consenso de 5 expertos en documentación discutió, aprobó y validó la codificación final (6.882 códigos).
Antes de tratar un texto clínico, el codificador comprueba si éste se encuentra en una lista de textos no codificables, en cuyo caso lo ignora. En caso contrario, el módulo PLN le aplica, cuando sea necesario, un conjunto de reglas que permi-ten dividir textos compuestos, eliminar palabras que no aportan información y textos duplicados e identificar textos que requieren códigos de causas externas (códigos E).
Como muestra la Figura 1, el proceso comple-to se lleva a cabo en varias etapas y se apoyan en diccionarios auxiliares que aumentan su sensibili-dad. Tras cada etapa, el texto obtenido se
compa-ra con las expresiones del FEC y, si coincide con alguna, se le asignan los correspondientes códigos CIE-9-MC. En caso contrario, se continúa con la siguiente etapa. Las etapas son:
1. Tratamiento básico del texto original: todas las letras pasan a mayúsculas; se eliminan los sig-nos de puntuación excepto "/" y "+"; se eliminan los espacios redundantes entre palabras así como los del inicio y final del texto; y se eliminan las le-tras repetidas contiguas de una palabra dejando un máximo de dos.
2. Se divide el texto si contiene los términos o signos "Vs", "Versus", "/", "+".
3. Se busca cada palabra del texto en un dic-cionario de sinónimos. Si se encuentra se reem-plaza por otra palabra o expresión alternativa (si-nónimo, abreviatura expandida, revisión ortográfica, etc.).
4. Se identifican y eliminan palabras que no contienen información, tras buscarlas en un “fi-chero de palabras vacías” y otro de “excepciones a las palabras vacías”.
5. Se buscan grupos de palabras contenidos en el texto en un “diccionario de grupos de palabras sinónimos”. Si un grupo se encuentra se reempla-za por su correspondiente sinónimo.
6. Se identifican y eliminan expresiones que no contienen información, tras buscarlas en un “fi-Figura 1.Diagrama de flujo operativo del codificador automático. CIE: Clasificación Internacional de
Enfermedades.
Literal
Literal 1
Literal 2 sí
no
no
no
no
no
no
no sí Literal tratado (mayúsculas, signos, números, espacios, repeticiones,...)
ASIGNA CÓDIGO/S CIE
ASIGNA TAMBIÉN CÓDIGO E
NO ASIGNA CÓDIGO CIE
Nueva expresión tras análisis individual de palabras: corrector ortográfico, sustitución por
sinónimos y eliminación de palabras vacías
Nueva expresión tras buscar cadenas de códigos E
Nueva expresión tras eliminar palabras vacías condicionadas a otras palabras del literal
Nueva expresión tras alterar el orden de las palabras
Fichero de expresiones
Fichero de expresiones
Fichero de expresiones
Fichero de expresiones
Fichero de expresiones
Fichero de expresiones
encuentra +, /, versus, vs
encuentra
encuentra
encuentra
encuentra
encuentra Nueva expresión tras analizar grupos de
chero de expresiones vacías” y otro de “excepcio-nes a las expresio“excepcio-nes vacías”.
7. Si el texto tiene 4 palabras o menos, se reordenan generando textos alternativos.
8. Se comprueba si el comienzo o el final del texto coincide con alguna palabra o expresión in-cluida en un “diccionario de causas externas”, en cuyo caso, estas palabras o expresiones se extraen del texto reservándose su correspondiente código E. Si tras procesar el texto restante, éste coincide con alguna expresión del FEC se le asignan los co-rrespondientes códigos CIE-9-MC y el código E re-servado.
9. Si tras completar el proceso, el texto no coincide con ninguna de las expresiones del FEC, se almacena para su posterior revisión.
Tras obtener los códigos CIE-9-MC de cada re-gistro, el codificador automático los ordena. Los códigos procedentes de textos médicos incluidos en el informe de alta se colocan delante, como también se hace con los códigos más específicos.
Finalmente, los registros se clasifican atendiendo a su primer código CIE-9-MC y se agrupan siguien-do al software de clasificación clínica “CCS”, des-arrollado por el Health Care and Utilization Project24 de la Agency for Healthcare Research and Quality.
Para evaluar el rendimiento del codificador, se seleccionó una muestra aleatoria entre los 3.072.861 registros de 2011. Para calcular su tama-ño se asumió p = 0,5, error alfa = 0,05 y precisión = 0,05. Los 385 registros de la muestra fueron co-dificados por una experta, ignorando los códigos previos asignados por el codificador. Dado que tan-to el codificador autan-tomático como la experta podí-an asignar varios códigos a un registro, la evalua-ción valoró si el código del diagnóstico principal asignado por la experta coincidía exactamente con alguno de los asignados por el codificador automá-tico. Cada registro en la muestra se clasificó como:
− Verdadero positivo: el código del diagnóstico principal asignado por la experta se encontraba entre los asignados por el codificador.
− Falso positivo: el codificador automático asignaba códigos a un registro que no contenía información suficiente para ser codificado según la experta.
− Verdadero negativo: el codificador no asigna-ba códigos a un registro que no contenía infor-mación suficiente para ser codificado según la ex-perta.
− Falso negativo: la experta asignaba un códi-go de diagnóstico principal y el codificador auto-mático asignaba otro o ninguno.
Se utilizaron los estadísticos habituales para evaluar el desempeño de estos instrumentos23,25-27:
− Precisión: proporción entre los registros cuyo diagnóstico principal se había codificado correcta-mente y el total de registros codificados por el co-dificador automático.
− Recall: proporción de registros cuyo diagnós-tico principal se había codificado correctamente y el total de registros con suficiente información pa-ra ser codificados.
− F-score o media armónica de la precisión y el Recall que mide el rendimiento global del sistema. F-score = (2 * Precisión * Recall) / (Precisión + Recall).
Para el cálculo de estos estadísticos se utiliza-ron las denominadas “micromedias”26,27 que per-miten evaluar el comportamiento global del codi-ficador sin magnificar la influencia de los códigos menos frecuentes. Los intervalos de confianza de la precision, recall y F-score se obtuvieron siguien-do a Goutte y Gaussier28.
Resultados
El codificador automático descartó los textos del 4,4% de los 3.072.861 registros de urgencias de 2011 por reconocerlos como no codificables (rango hospitalario entre 1,7% y 12,0%). En el 95,6% de los registros restantes el codificador identificó 3.516.384 textos diferentes (1,20 por registro) y codificó 3.087.243 de ellos (87,8%), proporcionando códigos al 89,9% de estos regis-tros (rango hospitalario entre 87,2% y el 92,6%). Globalmente logró codificar el 85,9% del total de registros de urgencias.
Los textos que el codificador automático des-cartó con más frecuencia como no codificables te-nían un contenido administrativo: “alta”, “alta ad-ministrativa”, “admisión hospitalaria”, etc.; o carecían de significado clínico: “.”, “vacío”, “otros”, etc. (Tabla 2).
Al 84,7% de los registros codificados se les asignó un solo código diagnóstico. Asimismo, al 20,7% de los registros codificados se les propor-cionó algún código E (Tabla 3).
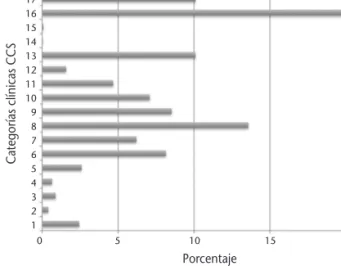
Al clasificar los registros utilizando la categoría CCS del código CIE-9-MC que ocupó la primera posición en el registro, se comprobó que las "lesio-nes e intoxicacio"lesio-nes", las "enfermedades del apara-to respiraapara-torio" y las "enfermedades del sis-tema osteomuscular y tejido conectivo" constituían el 43,7% de las urgencias codificadas. El 10,1% de los registros fueron clasificados dentro de los "sín-tomas, signos, condiciones mal definidas y factores que influyen en el estado de salud" (Figura 2).
evaluación del codificador. De acuerdo al criterio de la documentalista experta, el codificador auto-mático no asignó código a ningún registro no co-dificable. En 45 registros el codificador automáti-co discrepó de la experta, asignó un código erróneo en 8 casos y dejó sin codificar 37.
La precisión del codificador automático fue 0,976 con un intervalo de confianza al 95% (IC95%) entre 0,957 y 0,990. El Recall fue 0,878 (IC95%: 0,844-0,910) y el F-Score 0,925 (IC95%: 0,903-0,943).
Discusión
Aunque Diraya permite a los médicos asignar directamente códigos CIE-9-MC a los textos diag-nósticos, tan sólo un 7,8% de los registros de ur-gencias contenían algún código asignado por los facultativos. Frente a ello, el codificador automáti-co logró automáti-codificar el 85,9% del total de los regis-tros, porcentaje que asciende al 89,9% tras des-cartar los que contenían textos no codificables.
Estas cifras se comparan favorablemente con otros resultados publicados. En 2000, el objetivo a
priori de la Conselleria de Sanitat de la Generalitat
Valenciana era lograr codificar el 50% de sus
re-gistros de urgencias11. En 2009, el Hospital Reina
Sofía de Murcia codificó el 74,3% de sus episo-dios18. En 2011, el Hospital Clínic de Barcelona
al-canzó el 80%, con un umbral de confianza míni-mo del 66%17,29. ASHO asegura que su software
logra codificar el 85% de los registros de urgen-cias14. No hemos podido compararnos con los Tabla 2.Textos diagnósticos (o ausencia de texto)
no-codificables más frecuentes en los registros de urgencias
Textos escritos Número de % sobre % sobre
(o ausencia de texto) registros el total de el total de
registros registros de
no codificables urgencias
Alta, alta administrativa,
alta informática 15.302 11,2 0,5
Admisión, admisión
hospitalaria 5.874 4,3 0,2
. 5.349 3,9 0,2
Consulta 4.976 3,7 0,2
Ver informe, ver informe
en papel 3.907 2,9 0,1
Prodromos 3.694 2,7 0,1
3.216 2,4 0,1
Otros 1.073 0,8 0,0
Tabla 3.Número de códigos diagnósticos y códigos E en los registros de urgencias
Número de códigos Número Número Porcentaje
de episodios de códigos de registros
de urgencias
Códigos diagnósticos
1 2.236.308 2.236.308 84,7
2 336.892 673.784 12,8
3 51.661 154.983 2,0
ⱖ4 14.566 63.973 0,5
Códigos E
1 534.518 534.518 97,8
2 11.651 23.302 2,1
ⱖ3 213 643 0,0
Figura 2.Distribución en Categorías Clínicas CCS (%) de los episodios de urgencias codificados. 1 = Enfermedades infeccio-sas y parasitarias, 2 = Neoplasias, 3 = Enfermedades endocri-nas, nutricionales y metabólicas y trastornos de inmunidad, 4 = Enfermedades de la sangre y órganos hematopoyéticos, 5 = Enfermedades mentales, 6 = Enfermedades del sistema nervio-so y órganos de los sentidos, 7 = Enfermedades del aparato circulatorio, 8 = Enfermedades del aparato respiratorio, 9 = En-fermedades del aparato digestivo, 10 = EnEn-fermedades del siste-ma genitourinario, 11 = Complicaciones del embarazo, parto y puerperio,12 = Enfermedades de la piel y tejido subcutáneo, 13 = Enfermedades del sistema osteomuscular y tejido conecti-vo, 14 = Anomalías congénitas, 15 = Determinadas afecciones que se originan en el periodo perinatal, 16 = Lesiones e intoxi-caciones, 17 = Síntomas, signos, condiciones mal definidas y factores que influyen en el estado de salud, 18 = Códigos resi-duales, no clasificados y todos los códigos E 259 y 260.
Porcentaje
0 5 10 15 20
Categorías clínicas CCS
18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1
Tabla 4.Codificación doble de una muestra aleatoria de episodios de urgencias
Codificación por Codificación automática
documentalista experto
Asigna código Asigna el mismo código CIE-9-MC a 370 que el documentalista registros a 325 registros
Ausente el código Asigna un código asignado por el distinto al del documentalista documentalista en 45 registros a 8 registros
No asigna código a 37 registros No asigna código No asigna código a
rendimientos de Ontology de Thera®en español y del Autocoder de SIGESA.
En otro contexto, Megasalud, en Chile, codifi-có el 77,4% de más de 14 millones de textos es-critos por los médicos en su red ambulatoria13, y Kodifika, el codificador de Osakidetza, codificó el 86% de los diagnósticos de 4 millones de consul-tas ambulatorias especializadas y asignó códigos probables al 14% restante19,20. Incluso en el ámbi-to ambulaámbi-torio, nuestro codificador resultó muy eficaz y en un estudio piloto realizado en febrero de 2012 (datos no publicados) codificó el 89,0% de una muestra compuesta por 1.532.473 regis-tros de consultas de atención primaria de Andalu-cía. No hemos encontrado datos publicados que evalúen los mencionados codificadores en espa-ñol, por lo que sólo nos hemos comparado con su capacidad para codificar.
Tras una revisión sistemática de 113 sistemas de codificación automática, Stanfill et al.23 pusie-ron de relieve la dificultad de comparar sus rendi-mientos, dada la variedad y complejidad de tareas que realizan, los distintos resultados esperados y los diversos estándares y métodos utilizados en su evaluación. Uno de los codificadores automáticos más sobresalientes, el descrito por Pakhomov et al.25, utiliza una metodología mixta basada en dic-cionarios y en el aprendizaje automático. Este co-dificador obtiene distintos rendimientos según la frecuencia con que aparecen los textos en el cuer-po de entrenamiento. Cuando un texto aparece 25 veces o más (grupo A) obtiene los mejores re-sultados (precisión = 0,967; recall= 0,968, F-score = 0,967). Cuando aparece menos de 25 veces (grupo B) los resultados empeoran (precisión = 0,866; recall = 0,937, F-score = 0,904). Los peores valores se obtienen cuando los textos no aparecen en el cuerpo de entrenamiento (grupo C) (preci-sión = 0,586, recall = 0,445 y F-score = 0,507). La precisión de nuestro codificador es mayor que la encontrada por Pakhomov25 en cualquiera de los tres grupos. Este buen comportamiento se debe a que busca coincidencias léxicas exactas y se muestra más robusto frente a los falsos positivos que los sistemas probabilísticos, que pueden ser forzados a mejorar su recall a costa de aumentar-los. El recall global de nuestro codificador auto-mático es menor que el obtenido por Pakhomov25 en los grupos A y B, pero mayor que el de C. Nuestro F-score es inferior al de su grupo A, pero mayor que el de B y C.
Los participantes en el 2007 International Cha-llenge30para crear algoritmos de inteligencia com-putacional para automatizar la asignación de códi-gos CIE-9-MC a textos clínicos obtuvieron un
F-score promedio de 0,767 (sd = 0,132) y una mediana de 0,798. El mejor F-score (0,891) lo lo-gró Szeged30. Dos de los tres mejores equipos uti-lizaron métodos de aprendizaje automático27. Aun-que en un contexto diferente, nuestro codificador alcanzó un F-score de 0,925.
MIDAS7, el codificador automático de un equi-po español fuera de competición, utilizó un soft-ware de aprendizaje automático (Weka) e imple-mentó un algoritmo de árbol de decisión obtuvo un F-score = 0,800.
Nuestro codificador se probó en un alto núme-ro de episodios de urgencias pnúme-rocedentes de 27 hospitales de diferente tamaño (de 100 a 1.100 camas) y complejidad (de comarcales a regiona-les), y proporcionó resultados robustos y fiables, aunque también presentó algunas limitaciones. En primer lugar, en su evaluación encontramos una tasa de falsos negativos del 12,2% (IC 95% 9,0-15,6): 10,0% (IC 95% 7,1-13,2) no habían sido codificados y 2,2% (IC 95% 0,9-3,8) contenían códigos erróneos. Este porcentaje podría reducirse al analizar los textos residuales y complementar el codificador con métodos probabilísticos que au-mentaran su recall. En segundo lugar, un 10,1% de los registros se codificaron en el grupo 17 de la clasificación CCS, que reúne “síntomas, signos, condiciones mal definidas y factores que influyen en el estado de salud”, si bien esto podría ser re-flejo del carácter sintomático de muchas urgencias y el poco detalle de los textos clínicos. La retroali-mentación a los clínicos ayudaría a reducir este porcentaje. Por último, nuestro codificador tiene una capacidad limitada para ordenar los códigos generados, y aunque sitúa primero los incluidos en el informe de alta y los más específicos, la or-denación mejoraría si los médicos pudieran identi-ficar el texto que contiene el diagnóstico princi-pal. No obstante, el número medio de códigos por episodio actual, 1,20 en 2011, minimiza el impacto de esta limitación.
Bibliografía
1 Díaz A, Fornieles Y, editoras. Codificación en CIE-9-MC. Edición 2010. Normas Generales. Consejería de Salud. Granada: Junta de Andalucía; 2009. pp. 119.
2 Chowdhury G. Natural language processing. ARIST. 2003;37:51-89. 3 Demner-Fushman D, Chapman W, McDonald C. What can Natural
Language Processing do for Clinical Decision Support? J Biomed In-form. 2009;42:760-72.
4 Meystre SM, Savova GK, Kipper-Schuler KC, Hurdle JF. Extracting in-formation from textual documents in the electronic health record: a review of recent research. Yearb Med Inform. 2008;128-44. 5 Friedman C, Hripcsak G. Natural language processing and its future
in medicine. Academic Medicine. 1999;74:890-5.
6 Morales LP, Carrillo J, Cuadrado A, Frutos JC. Sistemas de Acceso In-teligente a la Información Biomédica: una revisión. Revista Interna-cional de Ciencias Podológicas. 2010;4:7-15.
Information-Extrac-tion Approach to Medical Text ClassificaInformation-Extrac-tion. Procesamiento del len-guaje Natural. 2008;41:97-104.
8 Nadkarni PM, Ohno-Machado L, Chapman WW. Natural language processing: an introduction. J Am Med Inform Assoc. 2011;18:544-51. 9 Krauthammer M, Nenadic G. Term identification in the biomedical
literature. Journal of Biomedical Informatics. 2004;37:512-26. 10 Crowston K, Liu X, Allen EE. Machine learning and rule-based
auto-mated coding of qualitative data. Proceedings of the American So-ciety for Information Science and Technology. 2010;47:1-2. 11 Bolonl A, Bosch S, Gosálbez E, Morín M, Ortega JB, Sempere J, et al.
Manual de uso del codificador automático de urgencias hospitalarias. Valencia: Conselleria de Sanitat. Generalitat Valenciana; 2000. pp. 151. 12 López-Osornio A, Gambarte ML, Otero C, Gómez A, Martínez M, Soriano E, et al. Desarrollo de un servidor de terminología clínico. Octavo Simposio de Informática en Salud. 34 JAIIO. 2005. Santa Fe, Argentina: Sociedad Argenti-na de Informática e Investigación Operativa (SADIO); 2005. pp. 29-43. 13 Torres C, Navas H, Benítez S. Implementación de servicios
terminoló-gicos en una red de atención ambulatoria. RevistaeSalud.com [Inter-net]. 2009. (Consultado 20 Marzo 2013). Disponible en: http://archi-vo.revistaesalud.com/index.php/revistaesalud/article/view/306. 14 ASHO. Codificación en CIE-9-MC / CIE-10-MC de urgencias médicas
[Internet]. 2011. (Consultado 20 Marzo 2013). Disponible en: http://www.asho.net/?page_id=12.
15 SIGESA. Análisis de la Casuística «Sistemas de Gestión Sanitaria [In-ternet]. 2012. (Consultado 20 Marzo 2013). Disponible en: http://www.sigesa.com/consulting/analisis-casuistica/.
16 Danés C, López L, Muñoz JA, Campos T, López P, Castellón E, et al. Implantación de un sistema de codificación automático para episo-dios de urgencia y lista de espera. Papeles Médicos. 2010;19:1. 17 Conesa A, Lozano R, Casado X, Farreres R, Castellón E, Pastor X.
Im-plantación de un sistema de codificación automática de diagnósticos en Urgencias. Libro de Ponencias y Comunicaciones. XII Congreso Nacional de Documentación Médica [Internet]. Sociedad Española de Documentación Médica; 2011. 196- 202. (Consultado 13 Enero 2013). Disponible en: http://sedom.es/congresos/.
18 De San Eustaquio F. La información de la Atención en Urgencias Hospitalarias. Hospital General Universitario Reina Sofía. Servicio Murciano de Salud. 4o Foro sobre el sistema de información del Sis-tema Nacional de Salud. Ministerio de Sanidad Política Social e Igualdad. [Internet]. Madrid; 2010. (Consultado 13 Enero 2013). Disponible en: http://www.msssi.gob.es/estadEstudios/estadisticas/si-sInfSanSNS/4ForoSISNS/main.htm.
19 Osakidetza. El programa Kodifika, Premio Barea 2012 [Internet]. 2012. (Consultado 13 Enero 2013). Disponible en: http://www.osaki- detza.euskadi.net/r85-gkhgal01/es/contenidos/informacion/hgal_pre-mio_barea_2012/es_hgal/hospital_galdakao.html.
20 Yetano J, Ladrón de Guevara JM, López G, Salvador J, Rodríguez S, Ogueta M, et al. Desarrollo del Conjunto de Datos Básicos de la Asis-tencia Ambulatoria Especializada (CDB-AAE) de Osakidetza. Experiencia piloto en tres hospitales. Investigación Comisionada. Vitoria-Gasteiz. Departamento de Sanidad, Gobierno Vasco, 2011. Informe no: Osteba D-11-05. [Internet]. (Consultado 25 Marzo 2013). Disponible en http://www9.euskadi.net/sanidad/osteba/datos/d_11_05_conj_bas_dat. pdf
21 Zeng QT, Goryachev S, Weiss S, Sordo M, Murphy SN, Lazarus R. Extracting principal diagnosis, co-morbidity and smoking status for asthma research: evaluation of a natural language processing system. BMC Med Inform Decis Mak. 2006;6:30.
22 Turchin A, Kolatkar NS, Grant RW, Makhni EC, Pendergrass ML, Ein-binder JS. Using Regular Expressions to Abstract Blood Pressure and Treatment Intensification Information from the Text of Physician No-tes. J Am Med Inform Assoc. 2006;13:691-5.
23 Stanfill MH, Williams M, Fenton SH, Jenders RA, Hersh WR. A syste-matic literature review of automated clinical coding and classification systems. J Am Med Inform Assoc. 2010;17:646-51.
24 HCUP-US Tools & Software Page [Internet]. (Consultado 13 Enero 2013). Disponible en: http://www.hcup-us.ahrq.gov/toolssoftware/ccs/ccs.jsp. 25 Pakhomov SV, Buntrock JD, Chute CG. Automating the Assignment
of Diagnosis Codes to Patient Encounters Using Example-based and Machine Learning Techniques. JAMIA. 2006;13:516-25.
26 Yang Y, Liu X. A re-examination of text categorization methods. Pro-ceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval [Internet]. New York, NY, USA: ACM; 1999. (Consultado 13 Enero 2013). Disponible en: http://doi.acm.org/10.1145/312624.312647.
27 Pestian J, Brew C, Matykiewicz P, Hovermale DJ, Jonson N, Cohen KB, et al. A Shared Task Involving Multi-label Classifcation of Clinical Free Text. BioNLP ’07 Proceedings of the Workshop on BioNLP 2007: Biological, Translational, and Clinical Language Processing. 2007;97-104.
28 Goutte C, Gaussier E. A probabilistic interpretation of precision, re-call and F-score, with implication for evaluation. in: Proceedings of the 27th European Conference on Information. Retrieval. 2005;345-59.
29 Conesa A. Implantació d’un sistema de codificació automàtica de diagnòstics a urgències [Internet]. 2011. (Consultado 15 Enero 2013). Disponible en: http://www.slideshare.net/ForumCIS/implanta-ci-dun-sistema-de-codificaci-automtica-de-diagnstics-a-urgncies. 30 Computational Medicine Center. 2007 International Challenge:
Classif-ying Clinical Free Text Using Natural Language Processing | Computatio-nal Medicine Center [Internet]. 2007. (Consultado 13 Enero 2013). Dis-ponible en: http://computationalmedicine.org/challenge/previous#results.
Development of an automated coding system to retrieve and analyze diagnostic information stored in hospital emergency department records
Goicoechea Salazar JA, Nieto García MA, Laguna Téllez A, Canto Casasola VD, Rodríguez Herrera J, Murillo Cabezas F
Objectives:To develop an automated coding system to retrieve information from hospital emergency department (ED) records and to evaluate the performance of the system.
Methods:Diagnostic reports written by ED physicians in 27 hospitals of the Andalusian public health service in 2010 and 2011 were used. The automated coder was developed based on texts from 3 042 695 records for 2010; the coding system’s performance was tested in texts from 3 072 861 records for 2011. For evaluation, a set of randomly selected records from 2011 were coded by the automated system and by an expert clinical coder. The system’s precision, recall, and F-score were calculated.
Results:A total of 2 936 842 records for 2011 contained potentially codifiable information (95.6% of the records). The automated coder identified 3 516 384 different diagnostic texts (1.2 per record) and coded 3 087 243 (87.8%) of them; codes were entered for 2 639 427 records (89.9% of the 2 936 842 with potentially codifiable information). The system’s precision was 0.9760 (95% CI, 0.957-0.990), recall was 0.8784 (95% CI, 0.84-0.910), and the F-score was 0.925 (95% CI, 0.903–0.943).
Conclusions:This system adapts efficiently to the ED setting, coding millions of records in a few hours and making the diagnostic information available for use. Incorporating probabilistic methods would improve the system’s recall. [Emergencias 2013;25:430-436]