Módulo para diagnosticar la necesidad de realizar la coronariografía a los pacientes del Cardiocentro Ernesto Che Guevara
79
0
0
Texto completo
(2) Declaración Jurada. Los que suscriben, Ana Maria Alvarez González y Damayanti Gutiérrez Borrás, hacemos constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería Informática, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicado sin autorización de la Universidad.. Ana Maria Alvarez González. Damayanti Gutiérrez Borrás. Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma de los Tutores. Firma del Jefe del Laboratorio.
(3) Dedicatoria A mis padres y a mi hermano por todo el amor y apoyo que me han brindado. A mi novio por estar siempre cuando lo necesito. A mi familia por estar conmigo en todo momento. Ana Maria. A mi mamá por ser lo más importante de mi vida, por su apoyo incondicional y por brindarme todo su amor. A mi papá por su preocupación en cada instante. A mi novio por su paciencia y su comprensión. A toda mi familia por su constancia y por animarme en todo momento. Damayanti.
(4) Agradecimientos A: Nuestros padres, por ser los mejores. Nuestras familias por su apoyo incondicional. Nuestras tutoras Mabel y Beyda por su apoyo y ayuda. Al profesor Dánel por asesorarnos y aclarar todas nuestras dudas. Los doctores del Departamento de Hemodinámica del Cardiocentro por brindarnos toda la información médica que necesitábamos. Nuestros compañeros de aula Héctor y Francisco por brindarnos su ayuda, conocimiento y paciencia cuando más los necesitábamos. Carlos (Chino) por su ayuda y dedicación en momentos de desesperación. Al profesor Alejandro por su asistencia. En fin, a todos los que contribuyeron a que este momento se hiciera realidad..
(5) RESUMEN La coronariografía es un proceso diagnóstico por imagen cuya función es el estudio de los vasos circulatorios del corazón que no son visibles mediante la radiología convencional. Realizar la prueba sin que verdaderamente el paciente lo requiera puede afectarlo y en algunos casos ocasionar la muerte. Además de resultar costosa por los recursos médicos que en ella se invierten. La presente investigación se desarrolla en el Departamento de Hemodinámica del Cardiocentro “Ernesto Che Guevara” de Villa Clara, cuyo objetivo es desarrollar un módulo para el software AngioDat que permita diagnosticar la necesidad de realizar la coronariografía a los pacientes utilizando métodos de Inteligencia Artificial, Se parte de una base de casos con la información relacionada de los pacientes a los que se les ha realizado coronariografía. A partir de esta información se definen los datos predictores para la confección de la base de conocimiento con la cual se trabajará posteriormente con el software Weka. Luego se determina el método de Inteligencia Artificial que mejor discrimine entre pacientes con coronariografía positiva o negativa. Con el modelo seleccionado se desarrolla un módulo para AngioDat que diagnostique la necesidad de realizar la coronariografía a pacientes candidatos a ella..
(6) ABSTRACT Coronary angiography is a diagnostic imaging process whose function is the study of the circulatory vessels of the heart that are not visible by conventional radiology. Perform the test without the patient truly requires it can affect and in some cases result in death. In addition to being costly for medical resources invested in it. This research is conducted in the Department of Cardiology Hemodynamics "Ernesto Che Guevara" of Villa Clara, which aims to develop a module for AngioDat software to diagnose the need for coronary angiography patients using artificial intelligence methods, It is part of a database with information related cases of patients who have undergone coronary angiography. From this information the data predictors for making the knowledge base which will subsequently work with the Weka software defined. Artificial Intelligence method that best discriminates between patients with positive or negative coronary angiography is then determined. With the model selected a module for AngioDat diagnose the need for coronary angiography patients candidates it develops..
(7) Índice INTRODUCCIÓN .......................................................................................................... 1 CAPÍTULO 1. MARCO TEÓRICO CONCEPTUAL SOBRE LAS TÉCNICAS, HERRAMIENTAS Y METODOLOGÍA UTILIZADAS ................................................ 4 1.1. Minería de datos................................................................................................. 4. 1.2. Tipos de modelos ............................................................................................... 6. 1.3. Aprendizaje automatizado ................................................................................. 7. 1.4. Sistemas informatizados existentes vinculados al campo de acción ................. 9. 1.5. Fundamentación de la Metodología utilizada .................................................. 10. 1.6. Herramientas para el desarrollo del software AngioDat .................................. 11. 1.7. Conclusiones parciales ..................................................................................... 14. CAPÍTULO 2. MÉTODOS DE APRENDIZAJE AUTOMATIZADO PARA LA PREDICCIÓN DE LA CORONARIOGRAFÍA ............................................................ 15 2.1. Construcción de la base de conocimiento ........................................................ 15. 2.2. Determinación de las técnicas de aprendizaje automatizado empleadas ......... 20. 2.3. Construcción y descripción de los modelos experimentales............................ 22. 2.4. Conclusiones parciales ..................................................................................... 29. CAPÍTULO 3. DESARROLLO DEL MÓDULO PARA EL SISTEMA ANGIODAT 30 3.1. Modelo del negocio.......................................................................................... 30. 3.2. Diseño e implementación del módulo.............................................................. 31. 3.3. Arquitectura del sistema .................................................................................. 36. 3.4. Conclusiones parciales ..................................................................................... 41. CAPÍTULO 4. ANÁLISIS DE FACTIBILIDAD DEL MÓDULO IMPLEMENTADO PARA EL SOFTWARE ANGIODAT ........................................................................... 42 4.1. Planificación basada en uno de los métodos de estimación ............................. 42. 4.2. Casos de prueba ............................................................................................... 48. 4.2.1 4.3. Funcionalidades a probar .......................................................................... 48. Conclusiones parciales ..................................................................................... 50. CONCLUSIONES ........................................................................................................ 51 RECOMENDACIONES .............................................................................................. 52 REFERENCIAS BIBLIOGRÁFICAS ....................................................................... 53 ANEXOS ....................................................................................................................... 55.
(8) Lista de Tablas Tabla 1.1 Matriz de confusión .......................................................................................... 9 Tabla 2.1 Atributos irrelevantes ..................................................................................... 16 Tabla 2.2 Atributo descartado ........................................................................................ 16 Tabla 2.3 Atributos seleccionados para la MD............................................................... 17 Tabla 2.4 Atributo SCA original .................................................................................... 18 Tabla 2.5 Atributo SCA modificado .............................................................................. 18 Tabla 2.6 Atributo TipoAI original ................................................................................ 18 Tabla 2.7 Atributo TipoAI modificado........................................................................... 19 Tabla 2.8 Atributo TipoAI ordinal ................................................................................. 19 Tabla 2.9 Atributo Aestable ordinal ............................................................................... 19 Tabla 2.10 Matriz de confusión del algoritmo NaiveBayes ........................................... 23 Tabla 2.11 Matriz de confusión del algoritmo Logistic ................................................. 24 Tabla 2.12 Matriz de confusión del algoritmo MultilayerPerceptron ............................ 25 Tabla 2.13 Matriz de confusión del algoritmo SMO para c = 100 ................................. 25 Tabla 2.14 Matriz de confusión del algoritmo IBk para k = 3 ....................................... 26 Tabla 2.15 Matriz de confusión del algoritmo J48 ......................................................... 27 Tabla 2.16 Matriz de confusión del algoritmo RandomForest ....................................... 28 Tabla 2.17 Metaclasificadores ........................................................................................ 28 Tabla 2.18 Matriz de confusión del algoritmo Ada Boost M1 con Random Forest....... 28 Tabla 3.1 Actores del sistema ......................................................................................... 31 Tabla 3.2 Especificación del Caso de uso Gestionar paciente ....................................... 34 Tabla 3.3 Especificación del Caso de uso Determinar coronariografía ......................... 35 Tabla 4.1 Factores de pesos de los actores ..................................................................... 43 Tabla 4.2 Factores de pesos de los casos de uso ............................................................ 43 Tabla 4.3 Factor de complejidad técnica ........................................................................ 45 Tabla 4.4 Factor de ambiente ......................................................................................... 46 Tabla 4.5 Distribución genérica del esfuerzo ................................................................. 47 Tabla 4.6 Distribución real del esfuerzo ......................................................................... 47 Tabla 4.7 Caso de prueba Insertar paciente .................................................................... 49 Tabla 4.8 Caso de prueba Determinar coronariografía................................................... 49.
(9) Lista de Figuras Figura 1.1 Tipos de conocimientos ................................................................................. 5 Figura 1.2 Etapas en un proyecto de MD ........................................................................ 5 Figura 2.1 Porciento de exactitud del algoritmo NaiveBayes ....................................... 23 Figura 2.2 Porciento de exactitud del algoritmo Logistic ............................................. 24 Figura 2.3 Porciento de exactitud del algoritmo MultilayerPerceptron ........................ 24 Figura 2.4 Porciento de exactitud del algoritmo SMO .................................................. 25 Figura 2.5 Porciento de exactitud del algoritmo IBk..................................................... 26 Figura 2.6 Porciento de exactitud del algoritmo J48 ..................................................... 27 Figura 2.7 Porciento de exactitud del algoritmo RandomForest ................................... 27 Figura 2.8 Resultados .................................................................................................... 29 Figura 3.1 Diagrama de Casos de uso del negocio ........................................................ 30 Figura 3.2 Diagrama de Casos de uso del sistema ........................................................ 33 Figura 3.3 Pantalla Gestionar paciente .......................................................................... 35 Figura 3.4 Pantalla determinar coronariografía ............................................................. 36 Figura 3.5 Diagrama de paquetes .................................................................................. 36 Figura 3.6 Diagrama de componente Determinar coronariografía ................................ 37 Figura 3.7 Diagrama de secuencia añadir paciente ....................................................... 38 Figura 3.8 Diagrama de secuencia determinar coronariografía ..................................... 39 Figura 3.9 Diagrama de clases determinar coronariografia ........................................... 40 Figura 3.10 Diagrama de despliegue ............................................................................. 41.
(10) INTRODUCCIÓN La coronariografía es un examen de diagnóstico por imagen cuya función es el estudio de los vasos circulatorios del corazón que no son visibles mediante la radiología convencional. Esta técnica se basa en la administración por vía intravascular de un contraste radiopaco. Los rayos X no pueden atravesar el compuesto por lo que se revela en la placa radiográfica la morfología del árbol arterial así como sus distintos accidentes vasculares, émbolos, trombosis, aneurismas y estenosis. Para realizar una coronariografía se introduce un catéter, generalmente en una arteria femoral o del brazo, el cual a través de la aorta va a llegar al corazón. Desde allí el catéter es dirigido hacia una de las arterias coronarias, luego a la otra, y se inyecta allí una sustancia de contraste, que resultará opaca a los rayos X, y permitirá observar los lugares en donde hay isquemia u obstrucción. La imagen radiográfica permite apreciar los posibles estrechamientos del paso de sangre o la obstrucción de la coronaria. Al realizar esta prueba el doctor determina si hacer una angioplastia (tratamiento quirúrgico) o mandar un tratamiento de medicación. Por lo que se considera una técnica invasiva para el paciente que la requiera. El Cardiocentro “Ernesto Che Guevara” de Villa Clara, es un hospital especializado en tratamientos y estudios de la especialidad de cardiología. En el departamento de Hemodinámica del Cardiocentro se realizan estudios diagnósticos simples o contrastados, coronarios y no coronarios, así como procedimientos intervencionistas coronarios, no coronarios y periféricos a pacientes de varias provincias del país. En el departamento se llevan registros en formato físico, lo cual es propenso al riesgo de sufrir daño, pérdida, etcétera. Actualmente existe un sistema desarrollado en Microsoft Office Access que maneja algunos de los conceptos que se tratan en el departamento. Dicho software está escasamente documentado, carece de patrones de diseño, presenta muy poca seguridad, y una gran limitación en cuanto a acceso a la base de datos, y posibles estudios sobre estos. En cursos anteriores se desarrolló el software AngioDat 1.0 que permite la gestión de los datos del paciente desde de su llegada al Cardiocentro. Además guarda información sobre la morfología del árbol arterial de cada paciente estudiado y tiene la ventaja de dejar a un lado el software privado (Microsoft Office Access), para migrar completamente al software libre, que brinda una serie de mejorías como por ejemplo: el 1.
(11) bajo costo de adquisición, la innovación tecnológica y la independencia del proveedor. Dicho software no permite el diagnóstico de la necesidad de realizar la coronariografía a los pacientes, por lo que se pone en peligro la vida de estos y se gastan gran cantidad de recursos médicos. Teniendo en cuenta lo antes descrito se define como problema de investigación el siguiente: El sistema informático AngioDat 1.0 necesita un módulo que permita un diagnóstico de la necesidad de efectuar una coronariografía, ya que realizarla sin que verdaderamente el paciente lo requiera puede afectarlo. Este tipo de prueba, además de resultar costosa por los recursos médicos que en ella se invierten, resulta riesgosa para el paciente. Para resolver el problema de investigación planteado se propone como objetivo general: Desarrollar un módulo para el software AngioDat que permita diagnosticar la necesidad de realizar la coronariografía a los pacientes utilizando métodos de Inteligencia Artificial. Los objetivos específicos que se definieron tienen como propósito contribuir al cumplimiento del objetivo general propuesto en la investigación, los cuales se enumeran a continuación: 1. Construir una base de casos donde estén representados pacientes a los que se les ha realizado la coronariografía. 2. Determinar el método de aprendizaje automatizado que mejor discrimine la coronariografía. 3. Desarrollar un módulo para AngioDat a partir del método seleccionado que permita valorar la necesidad de realizar el resultado la coronariografía a pacientes candidatos a ella. Preguntas de Investigación: ¿Qué técnica de Inteligencia Artificial discrimina mejor entre pacientes con coronariografía positiva o negativa? ¿El tratamiento de los valores perdidos permitirá mejorar la exactitud de la clasificación?. 2.
(12) Justificación de la Investigación: En el departamento de Hemodinámica del Cardiocentro de Villa Clara se realizan estudios diagnósticos simples o contrastados, coronarios y no coronarios, así como procedimientos intervencionistas coronarios, no coronarios y periféricos a pacientes de varias provincias del país. La coronariografía se considera una técnica invasiva para los pacientes, pues esta consiste en la introducción de un catéter en una arteria femoral o del brazo, el cual a través de la aorta va a llegar al corazón. Por lo que realizar dicha prueba sin que verdaderamente el paciente lo requiera puede afectarlo, y en algunos casos ocasionar la muerte de este. Además se invierten en ella gran cantidad de recursos médicos. Hipótesis: A partir de la aplicación de las técnicas de aprendizaje automatizado, una vez preprocesados los datos, podrá obtenerse un método de clasificación con una adecuada sensibilidad. Estructura del documento El trabajo se ha organizado en Introducción, cuatro Capítulos, Conclusiones, Recomendaciones, Bibliografía y Anexos. El primer capítulo, trata el marco teórico relacionado con los procesos de Minería de Datos y metodología utilizada. Mencionando las principales características, definiciones y diferentes tipos de problemas a los que da solución la Minería de Datos. En el segundo capítulo, se construye la base de conocimiento y se prepara para su utilización. Se determinan las técnicas de aprendizaje automatizado empleadas y se explican los experimentos realizados. Los resultados obtenidos son analizados y se elige la técnica de aprendizaje automatizado que mejor discrimina entre una coronariografía positiva o negativa. En el tercer capítulo, se exponen los requisitos funcionales y no funcionales del sistema y se detallan los actores y casos de uso, mostrando los diferentes diagramas que apoyan la solución propuesta, así como su despliegue. El capítulo cuatro, presenta un conjunto de casos de prueba realizados al sistema, así como el análisis de sus resultados, que permiten verificar y validar el software desarrollado. Además se expone la técnica de estimación empleada. 3.
(13) CAPÍTULO 1. MARCO TEÓRICO CONCEPTUAL SOBRE LAS TÉCNICAS, HERRAMIENTAS Y METODOLOGÍA UTILIZADAS El presente capítulo está dedicado a dar los fundamentos teóricos sobre la temática abordada, para lo que se hablará sobre las técnicas informáticas que se utilizan para la caracterización. Particularmente se diserta acerca de la Minería de Datos y los procesos y técnicas que la conforman.. 1.1 Minería de datos El concepto de Data Mining o Minería de datos (MD) data desde los años 60, cuando los estadísticos manejaban términos como: Data Fishing, Data Mining o Data Archaeology. La idea principal era encontrar correlaciones sin una hipótesis previa en Base de Datos (BD) con ruido. Fue a principios de la década del 80 del pasado siglo que Rakesh Agrawal, Gio Wiederhold, Robert Blum y Gregory Piatetsky-Shapiro, entre otros, empezaron a consolidar los términos de MD y Descubrimiento del Conocimiento en BD (Verónica S. Bogado 2003). La MD se define formalmente como “un conjunto de técnicas y herramientas aplicadas al proceso no trivial de extraer y presentar conocimiento implícito, previamente desconocido, potencialmente útil y humanamente comprensible, a partir de grandes conjuntos de datos, con objeto de predecir, de forma automatizada, tendencias o comportamientos y descubrir modelos previamente desconocidos” (Matheus, 1992). La MD produce cinco tipos de información: asociaciones, secuencias, clasificaciones, agrupamientos y pronósticos.. Tipos de conocimientos de la MD Antes de describir la MD, dando alguna definición al respecto, es necesario comprender e identificar los tipos de conocimientos que se pueden extraer de una BD. Se puede clasificar los tipos de conocimiento según las siguientes categorías (PangNing Tan, 2006): . Evidente: esta información se puede obtener de las BD a través de consultas SQL. 4.
(14) . Multidimensional: modela una tabla con n atributos como un espacio de n dimensiones, lo que permite detectar varias situaciones difíciles de observar. Este tipo de análisis se logra utilizando herramientas OLAP (On-Line Analytical Processing).. . Oculto: es la información no evidente, desconocida hasta el momento, pero potencialmente útil, que puede obtenerse a través de técnicas de MD. Esta información tiene un gran valor, ya que hasta el momento se desconoce, y descubrirla permite tener una nueva visión del problema y de su solución (Figura 1.1).. Figura 1.1 Tipos de conocimientos. Se estima que un 80% de la información contenida en una BD corresponde al conocimiento evidente (fácilmente recuperable). El otro 20% requiere de técnicas más complejas para su obtención. Puede que esta cifra parezca despreciable, pero la información oculta en ese pequeño porcentaje puede ser de vital importancia para el éxito de la empresa u organización.. Etapas de la Minería de Datos En un proyecto de MD se deben tener en cuenta las siguientes etapas (Figura 1.2):. Figura 1.2 Etapas en un proyecto de MD. 5.
(15) Selección de atributos Los datos pueden tener un gran volumen y contener una cantidad inmensa de información. En esta etapa se reduce considerablemente el volumen de los datos, seleccionando solo los atributos y tuplas que aporten la información que sea más influyente sobre el tema a tratar. Existen varios métodos para la selección de este subconjunto de atributos (Reyes, 2005). Preprocesamiento de Datos El formato de los datos de las distintas fuentes por lo general no suele ser apropiado. Esto dificulta que los algoritmos de minería obtengan buenos modelos trabajando sobre estos datos en bruto. El objetivo del preprocesamiento es adecuar los datos para que la aplicación a los algoritmos de minería sea óptima. Para esto hay que filtrar, eliminar datos incorrectos, no válidos, crear nuevos valores y categorías para los atributos e intentar completar o descartar los valores desconocidos e incompletos. Extracción de Conocimiento Es la aplicación de diferentes algoritmos sobre los datos ya preprocesados, para extraer patrones. Evaluación e Interpretación de Patrones Una vez obtenidos los patrones se debe comprobar su validez. Si los modelos son varios, se debe elegir el que se ajuste mejor al problema. Si ninguno de los modelos alcanza los resultados esperados, se debe volver a las etapas anteriores y modificar alguna entrada para, de esta manera, generar nuevos modelos.. 1.2 Tipos de modelos La Minería de Datos utiliza modelos predictivos y descriptivos sobre el conjunto de datos existentes, lo que permite el manejo y estructuración eficiente de la información para presentar datos visuales de gran utilidad en la toma de decisiones, generación de datos estadísticos y otras aplicaciones útiles en instituciones y empresas (Agrawal, 1996). Descripción por cada modelo: 6.
(16) . Descriptivos o no supervisados: este modelo aspira a descubrir patrones y tendencias sobre el conjunto de datos sin tener ningún tipo de conocimiento previo de la situación a la cual se quiere llegar. Descubre patrones en los datos analizados. Proporciona información sobre las relaciones entre los mismos.. . Predictivos o supervisados: crean un modelo de una situación, donde las respuestas son conocidas y luego, lo aplica en otra situación de la cual se desconoce la respuesta. Conociendo y analizando un conjunto de datos, intentan predecir el valor de un atributo (etiqueta), estableciendo relaciones entre ellos.. En la presente investigación se utilizará el modelo predictivo y la clasificación como tipo de problema de MD. La clasificación asume que hay un conjunto de objetos caracterizados por algún atributo o rasgo que pertenece a diferentes clases. La etiqueta de clase es un valor (simbólico) discreto y es conocido para cada objeto. El objetivo es construir los modelos de clasificación (a veces llamados clasificadores), que asignan la etiqueta de clase correcta a objetos no vistos antes y sin etiquetas. Los modelos de clasificación sobre todo son usados para el modelado predictivo. La clasificación es uno de los tipos de problemas más importantes de MD que están presentes en una amplia gama de aplicaciones y tiene conexiones con casi todos los otros tipos de problemas. Algunas técnicas de clasificación producen una clase comprensible o descripciones de concepto.. 1.3 Aprendizaje automatizado Entre las técnicas de clasificación se encuentran: . Métodos Bayesianos: El método Bayesiano brinda un enfoque probabilístico a la inferencia. Está basado en el presupuesto de que los valores de interés están gobernados por distribuciones de probabilidad y que pueden tomarse decisiones óptimas razonando sobre estas probabilidades junto con los datos observados. El algoritmo NaiveBayes está entre los más prácticos y efectivos métodos para muchos problemas de aprendizaje (Sánchez Tarragó, 2007).. . Funciones: Una vez adaptada para un problema particular, la red neuronal usa una función numérica para ponderar cada conexión de la red. El usuario presenta. 7.
(17) nuevos ejemplos al sistema, causando que los pesos se alteren. El estado final de los nodos de salida determina el resultado . Algoritmos basados en instancias o perezosos: Estos algoritmos clasifican una instancia comparándola con una base de datos de ejemplos preclasificados. La principal suposición que se hace es que instancias similares tendrán clasificaciones similares. Se les llama "holgazanes" porque realizan poco trabajo en la etapa de aprendizaje, en los casos más simples tan solo se almacenan los ejemplos en memoria, transfiriendo el esfuerzo al momento de clasificar una nueva instancia, cuando el sistema debe decidir cuáles de los ejemplos memorizados debe utilizar para hacer la clasificación.. . Árboles de decisión: Estos se construyen comenzando por la raíz hasta las hojas. Primeramente se escoge un atributo para discriminar y se produce un subnodo por cada valor del atributo. Si todos los ejemplos con un valor particular de atributo tienen la misma clase, el nodo se convierte en hoja, de otra forma se escoge otro atributo para seguir discriminando entre las clases. El árbol está completo cuando todos los ejemplos son representados por un nodo hoja. Para determinar cuál atributo se ramifica en cada nivel se calcula la información ganada al discriminar con cada atributo y se usa aquel que maximice la ganancia. Un árbol aprendido puede representarse también como un conjunto de reglas si-entonces, más fáciles de interpretar para un usuario.. . Metaclasificadores: Además de buscar el algoritmo que individualmente rinde mejores resultados para un problema determinado existe una vía alternativa para mejorar aún más la precisión: agrupando los clasificadores en ensambles (Dietterich, 1997), también llamados metaclasificadores. Un ensamble es un conjunto de clasificadores cuyas predicciones individuales son combinadas de alguna manera (típicamente mediante el voto) para clasificar nuevos ejemplos. Esta es una de las áreas más activas de investigación en aprendizaje supervisado ya que los ensambles son mucho más precisos que los clasificadores individuales que los componen (Dietterich, 1997, Gams M, 1994).. Evaluación de la clasificación En la evaluación de los procesos de aprendizaje, las medidas de calidad de la clasificación se construyen a partir de una matriz de confusión que registra correctamente e incorrectamente los ejemplos reconocidos de cada clase. 8.
(18) Predicciones positivas. Predicciones negativas. Clase positiva. Verdaderos positivos (VP). Falsos negativos (FN). Clase negativa. Falsos positivos (FP). Verdaderos negativos (VN). Tabla 1.1 Matriz de confusión. En la (Tabla 1.1) se pueden obtener cuatro indicadores del desempeño que miden la calidad de la clasificación para las clases positivas y negativas de forma independiente: . Tasa de verdaderos positivos TVP=VP/ (VP+FN): es el porcentaje de casos positivos correctamente clasificados como pertenecientes a la clase positiva.. . Tasa de verdaderos negativos TVN=VN/ (FP+VP): es el porcentaje de casos negativos correctamente clasificados como pertenecientes a la clase negativa.. . Tasa de falsos positivos FP=FP/ (FP+VN): es el porcentaje de casos negativos mal clasificados como pertenecientes a la clase positiva.. . Tasa de falsos negativos FN=FN/ (VP+FN): es el porcentaje de casos positivos mal clasificados como pertenecientes a la clase negativa.. 1.4 Sistemas informatizados existentes vinculados al campo de acción El proceso de gestión de los pacientes se realizaba con un software desarrollado en Microsoft Office Access que maneja algunos de los conceptos que se tratan en el Departamento de Hemodinámica. Dicha aplicación está escasamente documentada, carece de patrones de diseño, presenta muy poca seguridad y una gran limitación en cuanto a acceso a la base de datos y posibles estudios sobre estos. En cursos anteriores como parte de la Práctica Profesional surgió la necesidad de desarrollar el software AngioDat 1.0 para responder a las necesidades de los doctores, brindando soporte a las actividades que desempeñan y ofreciendo seguridad y consistencia a la información. AngioDat 1.0 permite la gestión de los datos del paciente desde de su llegada al Cardiocentro. En caso que el paciente lo requiera, también se almacena la información del tratamiento efectuado. El sistema está diseñado para ser utilizado por los propios especialistas del Cardiocentro y permite guardar información sobre la morfología del árbol arterial de cada paciente estudiado. Dicho software requiere un módulo que sea 9.
(19) capaz de hacer un diagnóstico más certero de la necesidad de efectuar una coronariografía a los pacientes.. 1.5 Fundamentación de la Metodología utilizada Rational Unified Process (RUP) o Proceso Unificado de Desarrollo de Software, constituye la metodología estándar más utilizada para el análisis, diseño, implementación y documentación de sistemas orientados a objetos. Esta metodología emplea el Unified Modeling Language (UML) o Lenguaje Unificado de Modelado para preparar todos los esquemas de un sistema de software. RUP se caracteriza por ser un proceso: . Centrado en la arquitectura: La arquitectura involucra los aspectos estáticos y dinámicos más significativos del sistema, está relacionada con la toma de decisiones que indican cómo tiene que ser construido el sistema y ayuda a determinar en qué orden.. . Dirigido por caso de usos: Se define un caso de uso como un fragmento de funcionalidad del sistema que proporciona al usuario un valor añadido. Los casos de uso representan los requisitos funcionales del sistema.. . Iterativo e incremental: El trabajo se divide en partes más pequeñas o mini proyectos. Permitiendo que el equilibrio entre casos de uso y arquitectura se vaya logrando durante cada mini proyecto, así durante todo el proceso de desarrollo cada mini proyecto se puede ver como una iteración.. RUP propone la creación del software durante cuatro fases: inicio, elaboración, construcción y transición. Durante la fase de inicio, se desarrolla una descripción del producto final a partir de una buena idea y se presenta el análisis de negocio para el producto. Durante la fase de elaboración, se especifican en detalle la mayoría de los casos de uso del producto y se diseña la arquitectura del sistema. La relación entre la arquitectura del sistema y el propio sistema es primordial. Durante la fase de construcción se crea el producto. En esta fase, la línea base de la arquitectura crece hasta convertirse en el sistema completo. La descripción evoluciona hasta convertirse en un producto preparado para ser entregado a la comunidad de usuarios. 10.
(20) La fase de transición cubre el período durante el cual el producto se convierte en versión beta. En la versión beta un número reducido de usuarios con experiencia prueba el producto e informa de defectos y deficiencias. Los desarrolladores corrigen los problemas e incorporan algunas de las mejoras sugeridas en una versión general dirigida a la totalidad de la comunidad de usuarios. La fase de transición conlleva actividades como la fabricación, formación del cliente, el proporcionar una línea de ayuda y asistencia, y la corrección de los defectos que se encuentren tras la entrega (Jacobson, 2000).. 1.6 Herramientas para el desarrollo del software AngioDat . El NetBeans IDE 7.1, se utiliza como entorno de desarrollo integrado pues es un proyecto de código abierto con una gran base de usuarios y una comunidad en constante crecimiento. La plataforma NetBeans permite que las aplicaciones sean desarrolladas a partir de un conjunto de componentes de software llamados módulos. Permite también crear aplicaciones web con PHP 5, un potente debugger integrado y además viene con soporte para Symfony un gran entorno Modelo Vista Controlador (MVC) escrito en PHP.. . Los lenguajes empleados son HTML5, CSS3, JavaScript y PHP para la implementación de las interfaces. . HyperText Markup Language (HTML) o Lenguaje de Marcado de Hipertexto, es predominante para la elaboración de páginas web. Es usado para describir la estructura y el contenido en forma de texto, así como para complementar el texto con objetos tales como imágenes. El lenguaje HTML puede ser creado y editado con cualquier editor de textos básico, como puede ser el Bloc de notas de Windows, o cualquier otro editor que admita texto sin formato como Microsoft Wordpad, Notepad++, entre otros (Mora, 2002).. . Cascading style sheets (CSS) u hojas de estilo en cascada es un lenguaje usado para definir la presentación de un documento estructurado escrito en HTML o XML. La idea del desarrollo de CSS es separar la estructura de un documento de su presentación. La información de estilo puede ser adjuntada como un documento separado o en el mismo documento HTML. Una hoja de estilos CSS consiste en una serie de reglas. Cada regla consiste en uno o más selectores y un bloque de estilos con los 11.
(21) estilos a aplicar para los elementos del documento que cumplan con el selector que les precede. Cada bloque de estilos se define entre llaves, y está formado por una o varias declaraciones de estilo. CSS3 está dividida en varios documentos separados, llamados módulos. Cada módulo añade nuevas funcionalidades a las definidas en CSS2, de manera que se preservan las anteriores para mantener la compatibilidad. . JavaScript es un lenguaje de programación interpretado que se define como orientado a objetos. Es basado en prototipos, imperativo, débilmente tipado y dinámico. Se utiliza principalmente en su forma del lado del cliente implementado como parte de un navegador web. Permite mejoras en la interfaz de usuario y páginas web dinámicas y en bases de datos locales al navegador (Flanagan, 2002).. . Personal Home Page (PHP) es un lenguaje de programación interpretado, diseñado originalmente para la creación de páginas web dinámicas. Se usa principalmente para la interpretación del lado del servidor pero actualmente puede ser utilizado desde una interfaz de línea de comandos o en la creación de otros tipos de programas incluyendo aplicaciones con interfaz gráfica. Es ventajoso trabajar con PHP ya que es un lenguaje multiplataforma completamente orientado a la web, tiene capacidad de conexión con la mayoría de los motores de base de datos que se utilizan en la actualidad destacando su conectividad con MySQL y PostgreSQL. Muestra capacidad de expandir su potencial utilizando la enorme cantidad de módulos y posee una amplia documentación en su página oficial, entre la cual se destaca que todas las funciones del sistema están explicadas y ejemplificadas en un único archivo de ayuda. Es libre, por lo que se presenta como una alternativa de fácil acceso para todos y permite aplicar técnicas de programación orientada a objetos (Thomson, 2010).. . PostgreSQL, es una herramienta de código libre que ofrece seguridad en términos generales e integridad en la base de datos por lo que se utiliza para la confección de esta. Este gestor se caracteriza por una alta concurrencia y una amplia variedad de tipos nativos, por tener llaves ajenas (foráneas) y disparadores (triggers). La herramienta de administración empleada fue el entorno de escritorio visual PgAdmin3 (PosgreSQL, 1996). 12.
(22) . Para el montaje del software se utiliza el servidor independiente de plataforma XAMPP, que consiste principalmente en la base de datos MySQL, los intérpretes para lenguajes de script: PHP y Perl. El servidor web Apache, que es flexible, rápido y eficiente, continuamente actualizado y adaptado a los nuevos protocolos y el servidor Tomcat que funciona como un contenedor de servlets e implementa las especificaciones de estos. Se caracteriza por ser multiplataforma, extensible y modular, ya que puede ser adaptado a diferentes entornos y necesidades con los diferentes módulos de apoyo que proporciona.. . CASE Visual Paradigm UML 9.0 es la herramienta utilizada para la confección de los diagramas, con la que se mejoró la calidad y la productividad del software.. . Con la herramienta Pentaho se confecciona el archivo .arff la cual se define como una plataforma de inteligencia de negocios orientada a la solución y centrado en procesos. La Suite Business Intelligence Open Source Pentaho pretende ser una alternativa a las soluciones propietarias tradicionales más completas: SAP, Cognos, Microstrategy, Microsoft, etc., incluyendo todos aquellos componentes que se encuentran en las soluciones de BI propietarias más avanzadas (Michel, 2012). Pentaho es líder mundial de los sistemas de Inteligencia de negocios Open Source. Pentaho BI Suite ofrece una amplia gama de herramientas orientadas a la integración de información y al análisis inteligente de los datos de una organización. Cuenta con potentes capacidades para la gestión de procesos de extracción, transformación y carga de datos (ETL por sus siglas en inglés), informes interactivos, análisis multidimensionales de información (OLAP) o minería de datos y cuadros de mando con indicadores y tablas. Además usa tecnologías estándar: Java, XML, JavaScript. Todos estos servicios están integrados en una plataforma web, en la que el usuario puede consultar la información de una manera fácil e intuitiva (INTRYO, 2012).. . Existe una gran variedad de softwares para el aprendizaje automático como por ejemplo YALE, Java-ML, Rapid Miner, Weka, entre otras. Weka es el más popular dentro del mundo del software libre por la gran cantidad de algoritmos y técnicas que contiene para el trabajo en diversas áreas de la Inteligencia Artificial. Debido a ello en la presente investigación se decidió. 13.
(23) utilizar esta plataforma para la utilización de los diferentes métodos con que cuenta, específicamente en la rama del aprendizaje automático. Weka es un conocido software para aprendizaje automático y minería de datos escrito en. Java.. Contiene. una. extensa. colección. de. técnicas. para. preprocesamiento de datos y modelado. Soporta varias tareas estándar de minería de datos, especialmente, preprocesamiento de datos, agrupamiento, clasificación, regresión, visualización, y selección. Todas sus técnicas se fundamentan en la asunción de que los datos están disponibles en un fichero plano o una relación, en la que cada registro de datos está descrito por un número fijo de atributos. Weka es portable porque está completamente implementado en Java y puede ejecutarse en casi cualquier plataforma, es muy fácil de utilizar por un principiante gracias a su interfaz gráfica de usuario (Kairúz, 2008).. 1.7 Conclusiones parciales En el presente capítulo se abordaron de forma teórica lo referente a MD. Se mencionan sus principales conceptos, etapas, tipos de modelos y tipos de conocimiento. Se trata además la metodología utilizada. La utilización de la MD para resolver el problema planteado sería la solución más apropiada teniendo en cuenta que lo que se persigue es obtener información relevante para la toma de decisiones. AngioDat 1.0 necesita un módulo que diagnostique la necesidad de realizar la coronariografía a los pacientes, ya que realizarla en vano equivale a una gran pérdida de recursos médicos y pone en peligro la vida de los pacientes.. 14.
(24) CAPÍTULO 2. MÉTODOS DE APRENDIZAJE AUTOMATIZADO PARA LA PREDICCIÓN DE LA CORONARIOGRAFÍA En el presente capítulo se realiza la construcción de la base de conocimiento y se prepara para su utilización. Luego se determinan las técnicas de aprendizaje automatizado a utilizar y se explican cada uno de los experimentos realizados. Por último se analizan los resultados obtenidos y se elige el modelo computacional de aprendizaje automatizado que mejor discrimina entre una coronariografía positiva o negativa.. 2.1 Construcción de la base de conocimiento En esta fase se presentan las distintas tareas realizadas, con el objetivo de construir una base de conocimientos, la cual se utilizará a la hora de determinar las técnicas de aprendizaje automatizado a utilizar.. Recolección inicial de los datos Primeramente se tomaron los datos de los pacientes, del software desarrollado en Microsoft Office Access, a los que se les había realizado la coronariografía atendidos entre los años 2013-2015. Estos tenían muchos valores perdidos y conociendo que toda la información de los pacientes, se archiva en sus historias clínicas, se trabajó directamente con estas para completar dichos valores, pasándolos a un archivo Excel.. Descripción de los atributos recolectados Se procede en esta fase, describir los atributos adquiridos en su formato original. Estos tuvieron que ser tratados para poder formar con ellos una Base de Casos (BC) coherente y consistente con la que se pudiera trabajar a lo largo del proyecto. La descripción de los estos aparece en Anexo 1.. Selección de los atributos El objetivo de esta fase es seleccionar los atributos que serán incluidos en el proceso de MD, así como las medidas que se adoptaron para tomar estas decisiones. Debido a que algunos atributos son de carácter irrelevante para la aplicación de la MD, se procedió a descartar estos de los atributos finales (Tabla 2.1). 15.
(25) Atributos irrelevantes HC Provincia Ainest TAS TAD FC Tabla 2.1 Atributos irrelevantes. Teniendo en cuenta que algunos de los atributos permanecían constantes para todos los pacientes y no aportaban información al proceso de MD, se decidió descartar el que se muestra a continuación en la (Tabla 2.2): Atributo descartado ERC Tabla 2.2 Atributo descartado. Luego del preproceso y selección quedaron finalmente 19 atributos, de los cuales 11 son de tipo numérico y 8 de tipo nominal, obteniéndose la siguiente lista a tener en cuenta para la MD (Tabla 2.3):. 16.
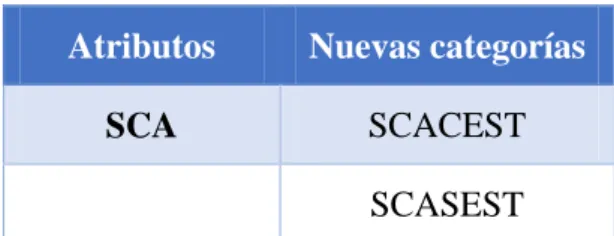
(26) Atributos Edad Sexo HTA DM Tabaco Dislipidemia SCA Topografía TipoAI Aestable Peso Talla HB Tcoag Tsang Plaq Creat Glic Clase Tabla 2.3 Atributos seleccionados para la MD. Edición de la base de conocimiento Para aumentar la calidad de los atributos del apartado anterior, se analizó la BD en busca de datos con ruido, faltantes o irrelevantes. Como resultado del análisis se detectaron atributos mal categorizados por los expertos médicos, como se muestran a continuación Atributo SCA: 17.
(27) Atributo SCA. Categorías SCACEST (Síndrome coronario agudo con elevación del ST) SCASEST (Síndrome coronario agudo sin elevación del ST) Angina Inestable AI con CE (Angina Inestable con Cambios Eléctricos) AI sin CE (Angina Inestable sin Cambios Eléctricos) BRIHH Agudo Trombosis Intrastent Angina Vasoespástica Tabla 2.4 Atributo SCA original. Finalmente se definieron solo dos categorizaciones (SCACEST y SCASEST), eliminando las tuplas que presentaran BRIHH Agudo y Trombosis Intrastent de las cuales 10 pertenecían a la clase negativa y 4 a la positiva, las demás caracterizaciones se tomaron como valores perdidos y en caso de que no hubiera ningún valor seleccionado se colocó el valor de No Presenta, como se muestra en la (Tabla 2.5): Atributos. Nuevas categorías. SCA. SCACEST SCASEST. Tabla 2.5 Atributo SCA modificado. Atributo TipoAI: Atributo TipoAI. Categorías Mixta De reciente comienzo De empeoramiento progresivo Post Infarto De reposo. Tabla 2.6 Atributo TipoAI original. 18.
(28) Según el criterio de los expertos médicos la angina Post Infarto es un tipo de angina en reposo, por lo que estos casos se convirtieron en De reposo. La angina mixta no existe por lo que se decidió que en los casos donde esta se contemplaba, 57 en total, donde 25 pertenecían a la clase negativa y 32 a la positiva, se pusieran valores perdidos y en caso de que no hubiera ningún valor seleccionado se colocó el valor de No Presenta, como se expone en la (Tabla 2.7): Atributo. Nuevas categorías De reciente comienzo. TipoAI. De empeoramiento progresivo De reposo Tabla 2.7 Atributo TipoAI modificado. En este atributo se puede establecer un orden. Por ello se decidió convertir a ordinal (Tabla 2.8): Atributo TipoAI. Nuevas categorías. Orden. No Presenta. 0. De reciente comienzo. 1. De empeoramiento progresivo 2 De reposo. 3. Tabla 2.8 Atributo TipoAI ordinal. Atributo Aestable: La angina estable es un atributo que se le puede establecer un orden (Tabla 2.9): Atributos. Categorías. Orden. Aestable. No Presenta. 0. I. 1. II. 2. III. 3. IV. 4. Tabla 2.9 Atributo Aestable ordinal. 19.
(29) Atributos peso, talla, HB, tcoag, Tsang, plaq, creat, glic: En los atributos de los datos complementarios del paciente (peso, talla, HB, tcoag, tsang, plaq, creat, glic) al existir muchos valores perdidos, se decidió sustituir con la media de esos valores, excepto en el peso por ser un atributo determinante. Atributo clase: Según el criterio de los expertos médicos, la coronariografía de un paciente es positiva, cuando al menos en una de las arterias del corazón existe una obstrucción del más del 50 por ciento o en la arteria TCI (Tronco coronario izquierdo) debe ser más de un 30 por ciento. En caso contrario esta sería negativa, por lo que la creación de la clase se basa en este criterio, teniendo dos categorizaciones: positiva o negativa. Los demás atributos que no aparecen en este apartado permanecieron con los valores originales. Finalmente la base de casos quedó representada por un total de 19 atributos sobre 845 casos, de los cuales 506 pertenecen a la clase positiva y 339 a la negativa. De estos, 11 son numéricos y 8 nominales.. 2.2 Determinación. de. las. técnicas. de. aprendizaje. automatizado empleadas Las principales tareas en los problemas de MD pueden ser divididas en dos grupos: predictivas y descriptivas. En este caso se tomó la decisión de contemplar únicamente las tareas predictivas, a partir de los objetivos principales del proyecto, relacionados con la predicción de pacientes que presentarán coronariografía positiva. El inconveniente planteado en este proyecto puede ser tratado como un problema de clasificación, en el que la clase es el resultado de la coronariografía que se le realiza a cada paciente. La forma de enunciarlo podría ser la siguiente: Se dispone de una BD con información de cada uno de los pacientes atendidos en el Departamento de Hemodinámica. La clase sería el resultado de la coronariografía que se le realiza a cada paciente, por lo que sólo admite dos posibles valores: positiva o negativa. Por tanto, el dilema que se afronta en este proyecto puede ser tratado como un problema de clasificación. 20.
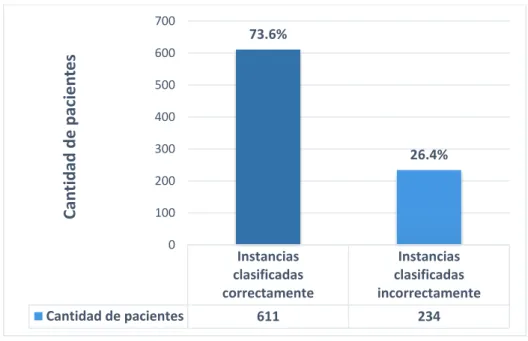
(30) Técnicas de clasificación Se seleccionaron 9 algoritmos de clasificación pertenecientes a cinco paradigmas de aprendizaje, disponibles en la herramienta de minería de datos WEKA. A continuación se explican estos clasificadores, mencionando solo las características más importantes. . NaiveBayes: Este algoritmo se basa en la hipótesis de que las variables que describen a las instancias son estadísticamente independientes. En la mayoría de las ocasiones esto no es verdadero, sin embargo, con frecuencia, esta simplificación del problema arroja resultados con una buena aproximación. A partir del conjunto de entrenamiento se calcula la probabilidad a priori de que una instancia cualquiera pertenezca a una clase, también se calcula la probabilidad condicional de que un atributo tome un valor si la instancia pertenece a una determinada clase, luego con estos datos se puede calcular utlizando la fórmula de Bayes y asumiendo independencia entre las variables, la probabilidad de que una instancia pertenezca a una clase si sus atributos toman determinados valores. La clasificación de la instancia dada será la que haga máxima esta probabilidad (Duda RO, 1973).. . Logistic. . MultilayerPerceptron: Tiene como objetivo la categorización o clasificación de forma supervisada de los datos, siendo una de las redes más utilizadas para la clasificación (Couchman, 2003).. . SMO: Está basado en redes neuronales (funcionamiento inspirado en el cerebro humano, de ahí su nombre) cuya característica más importante es su capacidad de aprender a partir de ejemplos, lo cual les permite generalizar sin tener que formalizar el conocimiento adquirido. En esta investigación se utilizó c = 1; 10; 100.. . IBk: Cuando a este algoritmo se le proporciona una nueva instancia, busca (entre las que se utilizaron durante el entrenamiento) las K instancias más parecidas, y clasifica la nueva en la clase de mayor frecuencia entre estas K instancias. Utiliza la distancia Euclideana para medir similitud entre ellas. En esta investigación se utilizó K = 1; 3; 5 (Sánchez Tarragó, 2007).. . J48: Genera árboles de decisión para atributos discretos y continuos, utiliza la razón de ganancia para seleccionar el atributo de cada nodo y aplica estrategias de poda para reducir el ruido de los datos de entrenamiento (Quinlan, 1993). 21.
(31) . RandomForest: Este algoritmo construye muchos árboles de decisión. Cada árbol se construye escogiendo, entre los atributos que describen a las instancias, un pequeño subconjunto aleatorio. Para clasificar un nuevo objeto, se le da el vector que lo describe a cada árbol, los cuales hacen su clasificación independientemente. Cada clasificación es un voto. El bosque selecciona la clasificación que más votos obtenga (Breiman, 2001).. . Bagging: La idea básica que subyace en bagging es que el error del modelo construido por un clasificador se debe en parte a la selección de un conjunto de entrenamiento específico. Por tanto, si se crean varios conjuntos de datos tomando muestras con reemplazo y se crean sendos clasificadores, se reducirá el componente de varianza del error de salida (Buhlmann P, 2002).. . AdaBoostM1: El algoritmo AdaBoost desarrollado por (Matheus, 1992) es sin duda el algoritmo del tipo Boosting más conocido y estudiado. Este utiliza por lo general los árboles de decisión como modelos de base. En la iteración m del algoritmo, siguiendo cierta distribución, se construye un árbol y se observa las predicciones de éste sobre todos los datos de la muestra. A aquellos datos mal clasificados, se les asignan un peso mayor, influyendo de esta manera sobre la distribución de los datos de la etapa m+1 y forzando al predictor correspondiente a tomarlas “más en cuenta”. El predictor que se obtiene al final resulta de un voto mayoritario ponderado o de un promedio ponderado de los predictores de las distintas etapas. Al focalizarse sobre los ejemplos mal clasificados, el error empírico disminuye rápidamente. Sin embargo, en vez de contribuir al aprendizaje sobre los datos utilizados, se prueba que el error de generalización disminuye también, lo cual hace de AdaBoost un algoritmo con un muy buen rendimiento.. 2.3 Construcción y descripción de los modelos experimentales Análisis de los datos Después de haber realizado las tareas de preprocesamiento se dispone de un fichero de datos con 19 atributos sobre 845 casos. Este fichero se importó a la herramienta WEKA y se procedió a clasificarlos con los algoritmos descritos anteriormente, dando como resultado los valores que se describen más adelante.. 22.
(32) Resultados En el estudio se usó el método de validación cruzada con 10 particiones (Kohavi, 1995), técnica que incrementa la fiabilidad de los modelos generados. Los parámetros de los algoritmos se optimizaron para obtener mejores resultados y a menos que se mencione, estos fueron los predeterminados. Los resultados de los experimentos se muestran en los siguientes gráficos así como sus matrices de confusión: NaiveBayes: 700. 72.2%. Cantidad de pacientes. 600 500 400 300. 27.8%. 200 100 0. Instancias clasificadas correctamente. Instancias clasificadas incorrectamente. 610. 235. Cantidad de pacientes. Figura 2.1 Porciento de exactitud del algoritmo NaiveBayes. a. b. Clasificados como. 389. 117. a = positiva. 118. 221. b = negativa. Tabla 2.10 Matriz de confusión del algoritmo NaiveBayes. 23.
(33) Logistic: 700. 74.4%. Cantidad de pacientes. 600 500 400 300. 25.6%. 200 100 0. Cantidad de pacientes. Instancias clasificadas correctamente. Instancias clasificadas incorrectamente. 629. 216. Figura 2.2 Porciento de exactitud del algoritmo Logistic. a. b. Clasificados como. 411. 95. a = positiva. 121. 218. b = negativa. Tabla 2.11 Matriz de confusión del algoritmo Logistic. MultilayerPerceptron: 700 72%. Cantidad de pacientes. 600 500 400 300. 28%. 200. 100 0. Cantidad de pacientes. Instancias clasificadas correctamente. Instancias clasificadas incorrectamente. 608. 237. Figura 2.3 Porciento de exactitud del algoritmo MultilayerPerceptron. 24.
(34) a. b. Clasificados como. 401. 105. a = positiva. 135. 204. b = negativa. Tabla 2.12 Matriz de confusión del algoritmo MultilayerPerceptron. SMO: Para la ejecución del algoritmo se optimizó el valor de la c, esta tomó valores de 1, 10 y 100. Para c = 1 se clasificaron correctamente 636 casos e incorrectamente 209 de los 845 valores. Para c = 10 se clasificaron adecuadamente 637 y erróneamente 208 y finalmente para c = 100, mostrando los mejores resultados con respecto a las dos corridas anteriores, se clasificaron correctamente 639 e incorrectamente 206 datos. Por ello para futuras comparaciones se tomará dicho valor (Figura 2.4). A continuación se muestra la matriz de confusión para el valor de c = 100 (Tabla 2.13). Cantidad de pacientes. 700. 75.3%. 75.6%. 75.4%. 600 500 400. Instancias clasificadas correctamente. 300. 24.7%. 24.6%. 24.4%. 200. Instancias clasificadas incorrectamente. 100 0. 1. 10. 100. Valor de c Figura 2.4 Porciento de exactitud del algoritmo SMO. a. b. Clasificados como. 431. 75. a = positiva. 131. 208. b = negativa. Tabla 2.13 Matriz de confusión del algoritmo SMO para c = 100. 25.
(35) IBk: Para la ejecución del algoritmo IBk se optimizó el valor de la k esta tomo valores de 1, 3 y 5. 700. Cantidad dee pacientes. 71.1%. 71.6%. 71%. 600 500 400 300. 28.9%. 29%. 28.4%. Instancias clasificadas correctamente Instancias clasificadas incorrectamente. 200 100 0. 1. 3. 5. Valor de K. Figura 2.5 Porciento de exactitud del algoritmo IBk. Como se muestra en la (Figura 2.5) según fue variando el valor de la k en las ejecuciones del algoritmo este fue mostrando diferentes resultados, como son: para k = 1 se clasificaron correctamente 601 e incorrectamente 244 del total de valores. Para k = 3 se clasificaron adecuadamente 605 y erróneamente 240 y para k = 5 se clasificaron correctamente 600 datos e incorrectamente 245. El mejor resultado se muestra para el valor k = 3 con 71.6% de efectividad en casos clasificados correctamente, por ello para futuras comparaciones se tomará este valor. A continuación se muestra la matriz de confusión para k = 3 (Tabla 2.14). a. b. Clasificados como. 426. 80. a = positiva. 160. 179. b = negativa. Tabla 2.14 Matriz de confusión del algoritmo IBk para k = 3. 26.
(36) J48:. Cantidad de pacientes. 700. 73.6%. 600 500 400 300. 26.4%. 200 100 0. Cantidad de pacientes. Instancias clasificadas correctamente. Instancias clasificadas incorrectamente. 611. 234. Figura 2.6 Porciento de exactitud del algoritmo J48. a. b. Clasificados como. 410. 96. a = positiva. 138. 201. b = negativa. Tabla 2.15 Matriz de confusión del algoritmo J48. RandomForest:. Cantidad de pacientes. 700. 72.3%. 600 500 400 300. 27.7%. 200 100 0. Cantidad de pacientes. Instancias clasificadas correctamente. Instancias clasificadas incorrectamente. 622. 223. Figura 2.7 Porciento de exactitud del algoritmo RandomForest. 27.
(37) a. b. Clasificados como. 414. 92. a = positiva. 131. 208. b = negativa. Tabla 2.16 Matriz de confusión del algoritmo RandomForest. Metaclasificadores: Metaclasificador. Clasificador. Instancias clasificadas correctamen te. Instancias clasificadas incorrectament e. % de instancias clasificadas correctament e. AdaBoostM1. J48. 576. 269. 68.2%. AdaBoostM1. RandomForest. 617. 228. 73%. Bagging. IBK. 596. 249. 70.5%. Bagging. J48. 615. 230. 72.8%. Tabla 2.17 Metaclasificadores. Como se observa en la (Tabla 2.17) el metaclasificador que obtuvo mejores resultados fue el Ada Boost M1 con base Random Forest con un 73% de instancias clasificadas correctamente, para futuras comparaciones se tomará este resultado. A continuación se muestra la matriz de confusión para dicho resultado (Tabla 2.18). a. b. Clasificados como. 409. 8297. a = positiva. 131. 208. b = negativa. Tabla 2.18 Matriz de confusión del algoritmo Ada Boost M1 con Random Forest. 28.
(38) % de instancias clasificadas correctamente. 76,0% 75,0% 74,0% 73,0% 72,0% 71,0% 70,0% 69,0%. 75,6% 74,4% 73,6% 72,2%. 72%. 73%. 72,3% 71,6%. Algoritmos de clasificación Figura 2.8 Resultados. Como resultado de la experimentación entre los clasificadores se observa evidentemente que el algoritmo que mayor porciento de instancias correctamente clasificó es el SMO, por lo que se decidió tomar este algoritmo para continuar con el estudio.. 2.4 Conclusiones parciales Se realizó el análisis exploratorio inicial de los atributos, con su preprocesamiento y limpieza, donde quedaron 19 atributos, sobre 845 casos de los cuales 506 pertenecen a la clase positiva y 339 a la negativa. Se aplicaron 9 algoritmos pertenecientes a 5 paradigmas de aprendizaje, disponibles en la herramienta de minería de datos WEKA. De estos, el que mayor porciento de instancias clasificadas correctamente obtuvo fue el SMO.. 29.
(39) CAPÍTULO 3. DESARROLLO DEL MÓDULO PARA EL SISTEMA ANGIODAT En el presente capítulo se exponen los requisitos funcionales y no funcionales del sistema y se detallan los actores y casos de uso que identifican las funcionalidades fundamentales del sistema. Se realiza además un estudio de la arquitectura utilizada en la estructuración del sistema y se representan los diferentes diagramas que apoyan la solución propuesta así como su despliegue.. 3.1 Modelo del negocio Atendiendo a la situación actual de los doctores del Departamento de Hemodinámica del Cardiocentro de Villa Clara, se define el caso de uso siguiente: . Realizar estudio angiográfico: Se basa esencialmente en el estudio cardiovascular que los doctores realizan a los pacientes para determinar el tratamiento a aplicar, ya sea por angioplastia (quirúrgico) o medicación.. Figura 3.1 Diagrama de Casos de uso del negocio. Definición de los requisitos En esta sección se definen los requisitos funcionales y no funcionales del sistema. Requisitos funcionales (RF) RF1: Insertar paciente RF2: Eliminar paciente RF3: Actualizar paciente RF4: Determinar coronariografía RF5: Gestionar coronariografía RF6: Gestionar angioplastia RF7: Conformar informe final 30.
(40) RF8: Gestionar usuario Requisitos no funcionales Interfaz: La interfaz debe ser sencilla y fácil de usar. Usabilidad: El sistema contará con índices que faciliten la exploración y rutas que indiquen al usuario en donde se encuentra en todo momento. Software: Se hace necesario instalar PostgresSQL 9.2, Netbeans 7.1, jdk 7, servidor GlassFish 3.1, servidor Tomcat y la biblioteca Weka 3.8.0. Rendimiento: El tiempo de respuesta no debe exceder los cinco segundos ante las solicitudes del usuario.. Actores del sistema Los actores son personas u otros sistemas que pueden interactuar directamente con el sistema a desarrollar y realizar alguna acción sobre este. El sistema propuesto tiene en cuenta dos actores, los cuales se muestran en la (Tabla 3.1). Actor del sistema Doctor. Descripción Persona encargada de atender al paciente cuando este llega a la sala y determina el tipo de tratamiento a aplicar ya sea por angioplastia (quirúrgico) o medicación. Además evalúa la necesidad de realizar la coronariografía al paciente. Administrador. Persona encargada de establecer los usuarios. del. sistema,. así. como. eliminarlos Tabla 3.1 Actores del sistema. 3.2 Diseño e implementación del módulo Según el criterio de los usuarios (doctores) se desea que luego de insertar los datos de un paciente, se pueda determinar si su coronariografía será positiva o negativa. Para esto se creó el botón Determinar coronariografía en la pantalla Gestionar Paciente.. 31.
(41) Se procede a realizar el módulo que necesita el sistema informático AngioDat 1.0. Para ello se construyó un servicio Web cuya funcionalidad es clasificar una instancia con los datos del paciente al que se le desea diagnosticar el resultado de la coronariografía, que devuelve un valor entero, indicando la clase (positiva o negativa). A continuación se muestra un fragmento de código: public ClassifierBean() { failed = false; try { smo = new SMO(); data = DataSource.read(getClass().getResourceAsStream("/resources/dataset.arff")); data.setClassIndex(data.numAttributes() - 1); smo.buildClassifier(data); } catch (Exception e) { failed = true; } } public Clazz classify(XMLInstance xmlInstance) { Clazz clazz = new Clazz(); try { if(!failed) { clazz.value = (int) smo.classifyInstance(toWekaInstance(xmlInstance)); } } catch (Exception e) {} return clazz; } Como se puede apreciar se crea un objeto que utiliza el método SMO que aparece en el paquete correspondiente en Weka. Se carga el archivo .arff y luego se construye el clasificador pasándole como parámetro la base de casos. Posteriormente se procede a la clasificación pasándole una instancia xml con los datos del paciente, retornando un valor entero: 0 si el resultado de la coronariografía es positiva, 1 si el resultado de la coronariografía es negativa y -1 si existe algún error. Posteriormente se creó una aplicación Web que consume el servicio. Esta se encarga de obtener los datos del paciente introducidos en el sistema AngioDat y convertirlos en una 32.
(42) instancia xml. Además convierte el resultado obtenido con el clasificador en un texto, colaborando a un mejor entendimiento por parte de los usuarios.. Diagrama de Casos de uso del sistema El diagrama de casos de uso del sistema muestra de forma gráfica los requisitos funcionales asociados a cada uno de los actores que pueden interactuar con el sistema. En la (Figura 3.2) se muestra una vista detallada de los casos de uso del sistema.. Figura 3.2 Diagrama de Casos de uso del sistema. Los casos de usos significativos del sistema (CUS), son: . Gestionar paciente: Es el encargado de la recogida de los datos de los pacientes desde su llegada al Cardiocentro.. . Gestionar coronariografía: Se encarga de guardar la información del paciente después de realizado el estudio.. . Gestionar angioplastia: Almacena los datos de los pacientes que se les realiza el tratamiento quirúrgico.. . Determinar coronariografía: Donde se expone la necesidad de realizar o no la coronariografía a un paciente.. 33.
(43) Descripción de los casos de uso arquitectónicamente significativos En este apartado se hace una detallada descripción de los casos de uso del sistema más significativos, con el objetivo de entender el funcionamiento de cada una de las actividades en el software. Se especificarán los siguientes casos de uso: Gestionar paciente y Determinar coronariografía. Caso de uso del sistema. Gestionar paciente. Actores. Doctor. Propósito. Insertar, actualizar, eliminar y consultar los datos de los pacientes que ingresan en la sala. Resumen. El caso de uso del sistema comienza cuando el doctor presiona el botón adicionar en la página Gestionar Paciente, donde se muestra una nueva interfaz para insertar los datos del paciente. Responsabilidades. Añadir, actualizar, eliminar y consultar los datos de los pacientes. Casos de usos asociados Requisitos especiales Precondiciones. El sistema se encuentra disponible y el doctor se encuentra autenticado en este Tabla 3.2 Especificación del Caso de uso Gestionar paciente. El caso de uso Gestionar paciente, es el encargado de insertar, actualizar, eliminar y consultar los datos del paciente que ingresan a la sala. Este caso utiliza las pantallas Paciente, SCA, Coronariografía y Angioplastia, generando un informe final que almacena los principales datos del paciente con los resultados del estudio realizado. Para más detalles consultar Anexo 2 Manual de Usuario sección Añadir un paciente.. 34.
(44) Caso de uso del sistema. Determinar coronariografía. Actores. Doctor. Propósito. Determinar la coronariografía. Resumen. El caso de uso del sistema comienza cuando el doctor selecciona un paciente insertado y presiona el botón Determinar coronariografía en la página Gestionar Paciente, donde se muestra la información de la necesidad de realizar o no la coronariografía.. Responsabilidades. Determinar coronariografía. Casos de usos asociados. Gestionar paciente. necesidad. de. realizar. o. no. una. Requisitos especiales Precondiciones. El sistema se encuentra disponible y el doctor se encuentra autenticado en este. Debe existir al menos un paciente insertado Descripción. La acción del actor comienza cuando el doctor selecciona un paciente en la tabla de la (Figura 3.3) y presiona el botón Determinar coronariografía. Realizada la acción se muestra la (Figura 3.4) con el resultado de la coronariografía del paciente seleccionado. Luego el doctor presiona el botón Atrás y se muestra nuevamente la (Figura 3.3). Para más detalles ver Anexo 2 Manual de Usuario. Tabla 3.3 Especificación del Caso de uso Determinar coronariografía. Figura 3.3 Pantalla Gestionar paciente. 35.
(45) Figura 3.4 Pantalla determinar coronariografía. 3.3 Arquitectura del sistema La programación por capas es una arquitectura cliente-servidor en el que el objetivo primordial es la separación de la lógica de negocios de la lógica de diseño. La ventaja principal de este estilo es que el desarrollo se puede llevar a cabo en varios niveles y, en caso de que sobrevenga algún cambio, solo se ataca al nivel requerido sin tener que revisar entre código mezclado. Además, permite distribuir el trabajo de creación de una aplicación por niveles; de este modo, cada grupo de trabajo está totalmente abstraído del resto de niveles, de forma que basta con conocer la API que existe entre niveles. En el diseño de sistemas informáticos actual se suelen usar las arquitecturas multinivel o programación por capas. En dichas arquitecturas a cada nivel se le confía una misión simple, lo que permite el diseño de arquitecturas escalables (que pueden ampliarse con facilidad en caso de que las necesidades aumenten). El más utilizado actualmente es el diseño en tres niveles (o en tres capas). En la (Figura 3.5) se muestra en un diagrama de paquetes la distribución arquitectónica de la aplicación desarrollada.. Figura 3.5 Diagrama de paquetes. 36.
(46) Capa Visual Incluirá la interacción con el usuario, la lógica de presentación de los datos involucrada en las interfaces gráficas de usuario. Capa Manejo de datos Proveerá a la aplicación de un conjunto centralizado de funcionalidades o servicios que podrán ser utilizadas a través de una interfaz. Capa de Datos Incorporará aquellos datos que deberán persistir y el acceso centralizado a los mismos.. Diagrama de componente. Figura 3.6 Diagrama de componente Determinar coronariografía. Diagramas de secuencia Los diagramas de secuencia se utilizan en etapas definidas de la producción de un software tales como: las fases de elaboración y construcción, así como de los flujos de análisis y diseño de una aplicación, estos resultan una herramienta de gran utilidad a la hora de mostrar cómo se realizan los casos de uso y cómo se comporta la interacción dada entre los determinados objetos o entidades del software. A continuación se muestran los diagramas de secuencia para los casos de uso, Gestionar paciente específicamente añadir un paciente y Determinar coronariografía.. 37.
Figure



+7





Documento similar