Implementación del Protocolo HTTP Paralelizado en Cliente y Servidor
89
0
0
Texto completo
(2) RESUMEN. Actualmente, el empleo de las comunicaciones en Internet y el alto porcentaje de uso del Web a nivel mundial, requiere de tiempos de respuesta cortos para la visualización de la información solicitada por un usuario. Es importante reducir estos tiempos para que los usuarios logren procesar la información de manera igualmente rápida y hacer más productivas sus tareas. Con esta base, el presente trabajo muestra como se puede lograr reducir dicho tiempo de respuesta mediante ciertas modificaciones en la operación del protocolo HTTP.. Entre las principales características del Web esta el hecho de que se requieren de dos entes para el ambiente del Web: servidores web y browsers o "navegadores" como clientes. Los documentos se estructuran en forma lógica o "mark-up" cumpliendo la especificación del HyperText Mark-up Language o HTML. Para la transferencia de información en el Web se emplea al protocolo HTTP (HyperText Transport Protocol). El protocolo de red HTTP proporcionó hasta ahora un buen desempeño a los servidores al permitir la transferencia de texto, hipertexto, imágenes y otros objetos de formatos diferentes a los documentos HTML.. HTTP es un protocolo que funciona bajo el paradigma cliente-servidor y sin estado, esto es, un cliente realiza una petición de información a un servidor y espera la respuesta de tal servidor, siendo sin estado, porque no almacena información respecto a las operaciones que se han realizado con anterioridad, ya que su funcionamiento se basa en la duración de una única conexión que sólo existe durante toda la operación. Este diseño con conexión única se desea cambiar en la actualidad. Además, aún con todas las ventajas que presenta el uso del protocolo, su diseño original no tiene considerado el desempeño en los servidores, existiendo diferentes ejemplos que muestran como el protocolo tiene un desempeño bajo o nulo [3].. 1.
(3) Debido a las necesidades actuales y para mejorar el uso de anchos de banda estrechos con grandes tiempos de latencia, se requiere de un protocolo que permita llevar operaciones sin orden, control de prioridades sobre las operaciones, transmisión de datos por lotes y un manejo de bits eficientemente, por mencionar algunos. Además, se deben considerar temas como la seguridad, autenticación y autorización para permitir llevar a cabo en el Internet transacciones de tipo comercial. Con esta base, el presente trabajo propone ciertas mejoras al protocolo HTTP actual: reducir el tiempo percibido por el usuario para la visualización de los documentos solicitados a un servidor específico y mejorar el rendimiento de los servidores.. 2.
(4) CONTENIDO. IMPLEMENTACIÓN DEL PROTOCOLO HTTP PARALELIZADO EN CLIENTE Y SERVIDOR. ................................................................................................................................ 0 RESUMEN ................................................................................................................................. 1 CONTENIDO ............................................................................................................................ 3 LISTA DE FIGURAS ................................................................................................................ 5 INTRODUCCIÓN ..................................................................................................................... 6 CAPÍTULO l. DETALLES Y FUNCIONAMIENTO DEL PROTOCOLO HTTP............. 10 1.1 Funcionamiento ... ..... .. ... ...... ... ... ... .... ..... .... ... .... .... ..... ...... .. ..... .. ....... ..... .... ... .... .... ... .. l O 1.2 Parámetros del Protocolo ...... ..... .......... ..... .... .. .. .... ... .... .. .... ... .... .... ... ..... .. ........ ..... ..... 13 1.3 Mensajes HTTP . ... .... ..... ... .. ... .... ..... ...... .... .... .... .......... ... .. ..... ....... .. .. ..... ... ....... .... ..... . 15 1.4 Autenticación . ...... .... ..... ... .... .. .. .... ..... ... .... ... ..... .......... .. .. ... .. ..... ... .... ... ..... ... .. ..... ...... . 26. CAPÍTULO 2. PROPUESTAS EXISTENTES DE MODIFICACIÓN AL PROTOCOLO HTTP........................................................................................................................................ 28 2. 1 Mecanismo para Añadir Extensiones .. .. ... .... ... .. ...... .... ... .. ... ...... ... ................... ..... ..... 28 2.2 Descripción de Tamaños de Documentos por Rangos .... .. ....... ............... .. ... ......... .... . 29 2.3 Extensiones de Sesión .... ..... .. ..... .. .... ... .. ......... ..... .... .. ... .... ..... .... ... .... ........ .... .. .. ... ..... . 30 2.4 Mecanismo para la Información de Estado .... ...... .. ... .. .... ... ... ... ..... .... .... .... .. .. ... ..... .... . 31 2.5 Mejoras en la Latencia del HTTP ... .. ..... .... .... .... ... .... .. ....... ... ... ... .... .......... ... .. ... ... ... ... 32 2.6 HTTP-NG (HTTP-Next Generation) ..... ... .. .......... .. .. .. .. .... ...... ...... ..... ... .. ... .. .... .... ...... 35 2.7 SHTTP (Secure HTTP) ....... .... ..... .. ... .. .. ... ..... .... ... .... .. .. ...... ... ....... ..... ........ .. .... .. ...... .. 36 3.
(5) 2.8 HTTP Versión 1.1 .... .... ..... ... .... ........ ............................................ ......... .... .... .... ..... .. 38 CAPÍTULO 3. ARQUITECTURAS PARALELAS Y SISTEMAS DISTRIBUIDOS ......... .43. 3.1 Las Maquinas Paralelas ... ............. ...................... ... .. .... .. ........ ........ .... ......... .......... .. ... 43 3.2 Modelos ....... .. .... ........................ .. .... .. .......... ..... ......... ..... ... ....... ... .. ... .. .. .... .... .. ... ... .. .. 44 3.3 El Equipo Paralelo SPx de IBM como Ejemplo ...... .. ....... .. ....... .... ... .. .. .. ........... .... .... 47 3. 4 Sistemas Distribuidos ... .. ... .... ........ ..... .. ... ...... .. ....... ... .... .. ......... ... ............................. 48 3. 5 Principales Características de los Sistemas Distribuidos ................ .. .. ............ ...... ...... 49 3.6 Aplicación del Trabajo en un Ambiente Paralelo y Distribuido ..... ... ............. ... ....... .. 55 3.7 Herramientas de Programación de Sistemas Distribuidos y Paralelos ........... ...... ....... 56 CAPÍTULO 4. PROPUESTA PARA LA MEJORA EN RENDIMIENTO DEL PROTOCOLO HTTP.............................................................................................................. 59. 4.1 Desarrollo de la Propuesta ..... .... .... ..... ... ........ .... .... ............ ....... ..... .. ......... ... ..... .... .... 64 CAPÍTULO 5. RESULTADOS OBTENIDOS, CONCLUSIONES Y TRABAJO FUTURO . ...............................................•...............................•.........•................................................•......• 77. 5.1 Metodología de Prueba .. .... .... ........ ........ .... ... .. .. ........ ......... ........... .... ......... ....... ... ..... 77 5.2 Análisis de los Resultados ........ ... ....... ... .. ... ..... ... ............... ............ .... ... .. ................... 80 5.3 Trabajo Futuro ...... ........ .. .... .. .............. .. ..... ... ............. .... .............. ... .. .. .... .......... ..... ... 81 REFERENCIAS Y BIBLIOGRAFÍA ..................................................................................... 82 ANEXO A. JERARQUÍA DE LAS CLASES EN JAVA QUE CONFORMAN TODO EL CÓDIGO DEL CLIENTE Y DEL SERVIDOR DE HTTPF ................................................. 85 GLOSARIO ............................................................................................................................. 87. 4.
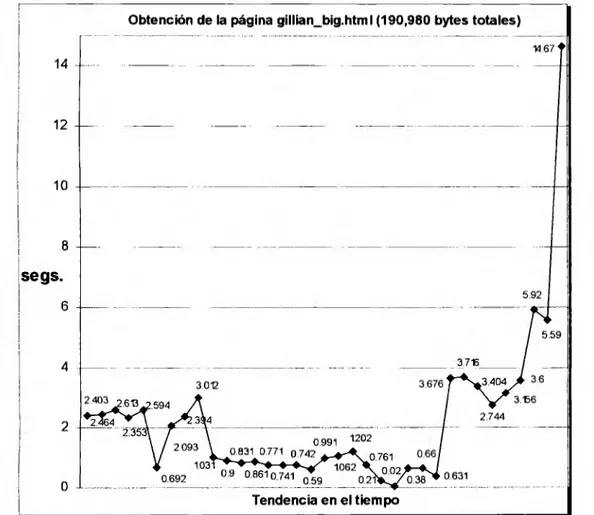
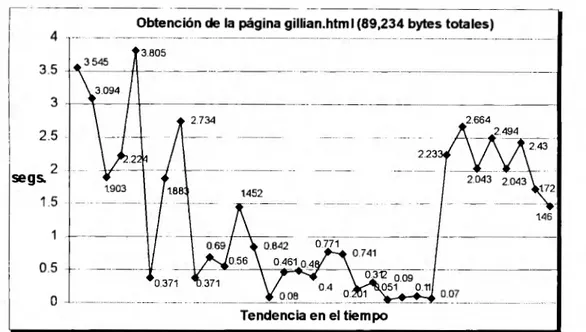
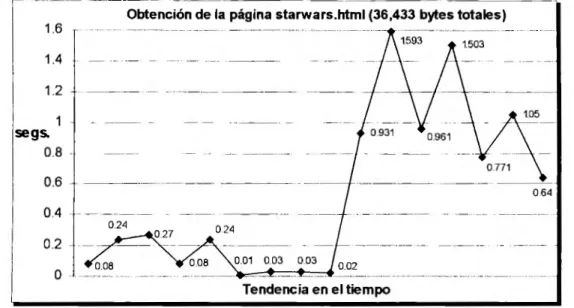
(6) LISTA DE FIGURAS. Figura 1.1.- Funcionamiento básico del protocolo HTTP ........... ... ..... .. .. ........... ....... ..... .. ..... .. .. .. 11 Figura 1.2.- Funcionamiento del protocolo HTTP con la existencia de servidores Proxy ........... . 12 Figura 4.1 .- Esquema general del trabajo propuesto .................................................................. 60 Figura 4.2 .- Detalle de la integración de los diferente SCPs de acuerdo a los protocolos por emplearse ....... ..... ........ ................. ...... ....... ........ .. ........ ........................................... ..... ........ 62 Figura 4.3.- Relación de los clientes HTTPfy el servidor distribuido y paralelo .... ......... ........... . 67 Figura 4.4.- Esquema del proceso que se realiza entre un cliente y el servidor (desarrollo inicial).. ·········· ····· ······· ·············· ·· ······················ ···· ········ ····· ········· ·· ············ ··························· ·· ··········· 71 Figura 4.5.- Esquema del proceso que se realiza entre un cliente y el servidor (versión final) ... .. 75 Figura 5.1 .- Tiempo en segundos para obtener la página gillian_big.html y su comportamiento en el tiempo ........ ...... ........ ... ........... ... ......... .... ...... ... .... ......... ..... ........ ..... ........ ...... ....... ... ......... 78 Figura 5.2 .- Tiempo en segundos para obtener la página gillian.html y su comportamiento en el tiempo . ............. ........... ... ........ ....... ......... .... ......... ..... .......... ... ................... ....... ......... ... ....... . 79 Figura 5.3 .- Tiempo en segundos para obtener la página sun.html y su comportamiento en el tiempo . ... ....... ... ........... ... ......... .... ........... .... ....................... ... ... ................. ... .. ........ ... .......... . 79 Figura 5.4 .- Tiempo en segundos para obtener la página starwars.html y su comportamiento en el tiempo ......... ... .. .......... .... ....... ....... .......... ............. ....................................... ..... .......... ... ....... 80. 5.
(7) INTRODUCCIÓN. El World-Wide-Web (WWW), también conocido como W3, se m1c10 como un proyecto para tener un lugar común en el que diferentes investigadores del CERN (Laboratorio de Partículas Físicas Europeo, ubicado en Suiza) pudieran compartir sus ideas y conocimientos con respecto a proyectos de investigación de fisica en alta energía [ 1]. En el W3 no existe una centralización de la información, y si dos proyectos tienen una relación, uno de ellos reflejará a la otra parte (mediante un enlace, que se denomina HiperTexto), dando la facilidad de que si existe una modificación en un proyecto dicho cambio no alterará al otro. Debido a esta ventaja, el proyecto ganó gran aceptación logrando su expansión hasta el Internet. Para poder acceder a la información dentro del W3, se requiere un programa cliente que se ejecuta en la computadora del usuario. Al obtener una página del W3, además de obtener texto, quizás se obtengan también imágenes, menús e hipertexto. Al hacer un clic con el 'ratón' en un hipertexto (también llamado "anchor"), visualizado como un área sobresaltada, se obtiene la información relacionada contenida en el mismo servidor o en otro servidor remoto. Las principales características del W3 son: •. La interfaz del usuario, o formato de presentación del programa cliente, es la misma para todos sin importar que servidor esté proporcionando la información, y siempre incluye la presentación de hipertexto.. •. Las ligas pueden apuntar a cualquier información disponible u objeto que se pueda visualizar.. •. Existen menús y directorios, que pueden ser también reemplazados por hipertextos que al seleccionarlos realicen las mismas acciones.. •. Hay la posibilidad de introducir nuevos formatos para multimedia y de esta forma crecer la especificación.. •. Los programas clientes del W3 pueden presentar la información transmitida (el hipertexto se transmite en forma lógica o "mark-up") de la manera que mejor se desee de acuerdo a la plataforma en donde se este ejecutando el programa cliente.. •. La información se une por medio de referencias a otra información. 6.
(8) •. El sistema de direcciones que se utiliza es el URI ( Universal Resource ldent~fier) que inician con el nombre del protocolo ("http" para las direcciones dentro del W3) seguido de la dirección Internet y nombre del recurso a obtener.. •. El protocolo de red HTTP (HyperText Transport Protocof) proporciona un buen desempeño a los servidores al permitir la transferencia de texto, hipertexto, imágenes y otros objetos de formatos diferentes a los documentos HTML.. •. El lenguaje HTML (HyperText Mark-up Language) se utiliza para transmitir textos, menús y otra información a través del W3, aunque puede usarse fuera del protocolo HTTP como lo podría ser en el correo electrónico de hipertexto.. Existen actualmente otros dos sistemas que comparten la misma arquitectura cliente-servidor y cierta funcionalidad del W3 . Estos sistemas son WAIS (Wide Area lnformation Servers), de la compañía WAIS, Inc. y Gopher, de la Universidad de Minnesota. W AIS es básicamente un sistema de búsqueda por únicamente texto. Gopher por su parte, presenta menús, texto y gráficas, siendo sus búsquedas por medio de menús. Ambos sistemas pueden producir resultados de búsquedas que incluyen gráficas, sonido y vídeo. Otra ventaja de un programa cliente W3 es que puede tener acceso a cualquier servidor WAIS, Gopher o W3. Dentro de las expectativas y desarrollos a futuro en el W3 se encuentran la implementación de un servicio de nombres mundial, en el que los documentos se obtendrán por medio del nombre y no por su ubicación; la creación de editores de hipertexto para usuarios no expertos; la integración de editores concurrentes, teleconferencias y realidad virtual; la creación de servidores para equipos no tan poderosos orientados a grupos pequeños y la implantación de servicios de lucro o comerciales dentro del Internet. El protocolo HTTP fue creado en 1990 por Tim Bemers-Lee, Roy Fielding y Henrik Nielsen, para la transferencia de cualquier objeto con información y no sólo texto, hipertexto e imágenes. Para poder lograr este objetivo, el cliente envía una lista de los posibles formatos que puede manejar, esperando del servidor la información respectiva en cualquiera de los formatos mencionados. Esto permite el crecimiento de las especificaciones iniciales del protocolo al permitir la definición de nuevos formatos. HTTP es un protocolo de petición-respuesta y sin estado. Lo primero se refiere al hecho de que un cliente realiza una petición de información a un servidor y espera la respuesta de tal servidor. La segunda implica que no almacena información respecto a las operaciones que se han realizado con anterioridad, ya que su funcionamiento se basa en la duración de una única conexión que sólo existe durante una operación. Este diseño sin conexión se desea cambiar en la actualidad como se explica en el capítulo 2.. 7.
(9) El funcionamiento del protocolo inicia con la petición del cliente, la cual incluye un comando de operación (conocido como el método) y el URI del objeto. Los URls son identificadores que hacen referencia a cierto objeto mediante diferentes sintaxis dependiendo del protocolo a emplear. Para el protocolo http se forman por: el espacio de direcciones ("http"), el nombre del servidor que contiene al objeto (ejemplo : www.cem.itesm.mx), el camino de búsqueda estructurado como subdirectorios dentro del sistema de archivos del servidor y el nombre del objeto (un ejemplo completo de URl puede ser: "http://www.cem.itesm.mx/maestrias/al245827/miobjeto.x"). Los métodos de operación comunes son "GET", "HEAD" y "POST". El método GET se emplea por todos los clientes para obtener el objeto pedido. HEAD se define para la actualización del "browser" al verificar la existencia y validez de algún URI. Y el método POST se utiliza para añadir un nuevo documento al Web, o bien, para introducir una forma de llenado. Para poder transmitir objetos cuyos formatos son binarios o de otro tipo no estándar (pero con la aceptación mutua entre cliente y servidor de emplear dichos formatos), se transfiere junto al objeto, dentro de los encabezados del mensaje, "metainformación" adicional.. Aún con todas las maravillas que presenta el uso del protocolo, su diseño original no tiene considerado el desempeño en los servidores. Existen diferentes ejemplos que muestran como el protocolo tiene un desempeño bajo o nulo [3]. Un ejemplo es: Un fabricante emite un comercial por televisión ( que muestra un cierto URL) durante la transmisión de un evento de gran cobertura, como en un Super-Bowl o en un Mundial de Fut-Bol. Éste comercial puede captar la atención de miles de personas que tratarán de obtener, durante la siguiente interrupción al evento, el recurso mostrado en el URL. Éste caso puede generar miles de peticiones durante un breve instante que degradan al servidor. Debido a todas las necesidades actuales, y orientado en el mejor uso de anchos de banda estrechos con gran tiempo de latencia, se requiere por lo tanto de un protocolo que permita llevar operaciones sin orden, control de prioridades sobre las operaciones, transmisión de datos por lotes y un manejo de bits eficientemente. Además, se deben de considerar temas como la seguridad, autenticación y autorización para permitir llevar a cabo en el Internet transacciones comerciales.. Este trabajo se enfocará en la creación de una implementación que mejore el rendimiento del protocolo HTTP en el tiempo de latencia dentro de las comunicaciones. Para lograr este objetivo, se propone la creación de dos sistemas principales: un servidor y un cliente o browser, que servirán para probar ésta tesis. 8.
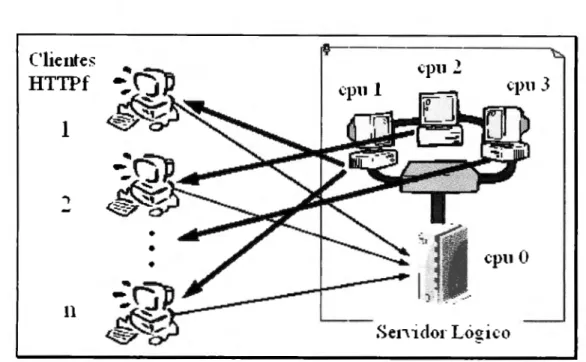
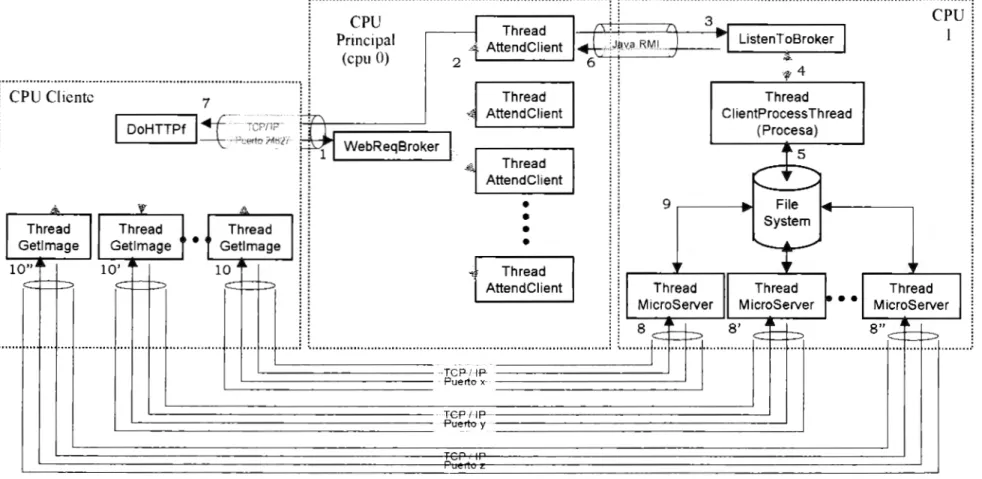
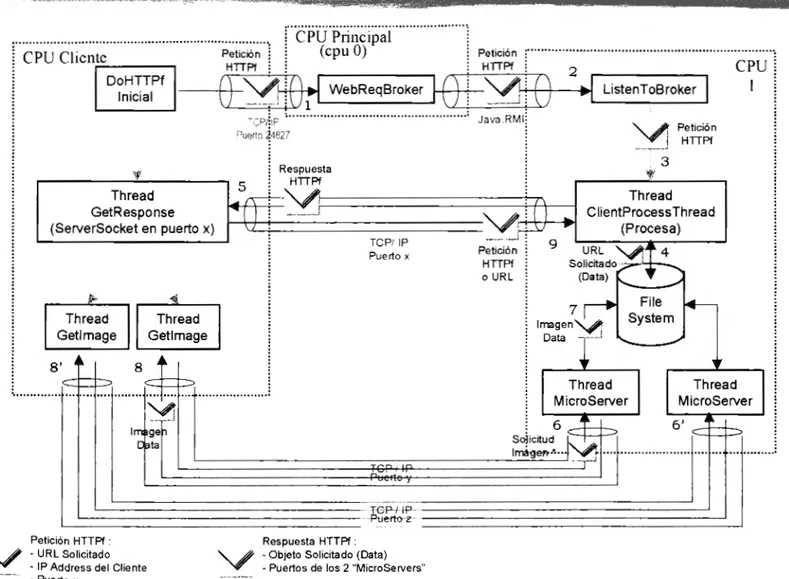
(10) Con el objetivo ya mencionado, los siguientes puntos serán considerados para la creación de los sistemas del presente trabajo: •. Soportar la versión existente del HTTP 1. O (y quizás futuras versiones de acuerdo a los documentos actuales propuestos para modificar al protocolo).. •. Paralelizar el procesamiento del servidor diseñándolo para su ejecución en una máquina de múltiples procesadores. El servidor será paralelo, esto es, sus partes o módulos de funcionamiento internos trabajarán en paralelo cuando se pueda (distribuyendo cargas en procesadores y - cuando se trate de un mismo procesador en hilos). Para el caso del cliente únicamente se realizará su diseño para el empleo de múltiples hilos o multithreading.. •. Empleo de varias conexiones (paralelizar las comunicaciones). Se analizará la posibilidad de modificar al protocolo HTTP para que maneje diferentes conexiones TCP (una conexión para la comunicación de diferentes tipos de datos: imágenes, texto, etc.); O bien, emplear UDP en lugar de TCP, con sus respectivas consideraciones.. •. Modificar el formato de los documentos en formato HTML, para proporcionar información al servidor de la cantidad de imágenes contenidas en un documento, para que de esta forma un servidor envíe todo el documento completo sin esperar a que se le pidan las partes que lo componen.. Por otra parte, se sugieren trabajos futuros que contemplen: •. Transferir las imágenes grandes por medio de otro protocolo que sea orientado a la transmisión binaria (como pudiera ser el z-modem quizás modificado).. •. Considerar la introducción del concepto de cliente Kerberizado, para emplear los sistemas en ambientes que requieran seguridad en las comunicaciones.. •. Traducir todos los valores que emplea el protocolo de HTTP a códigos numéricos, para reducir el número de caracteres a enviar en cada mensaje.. •. Introducir un mecanismo de transacciones que permita conocer si una cierta operación fue completada o no cuando haya sido abortada.. 9.
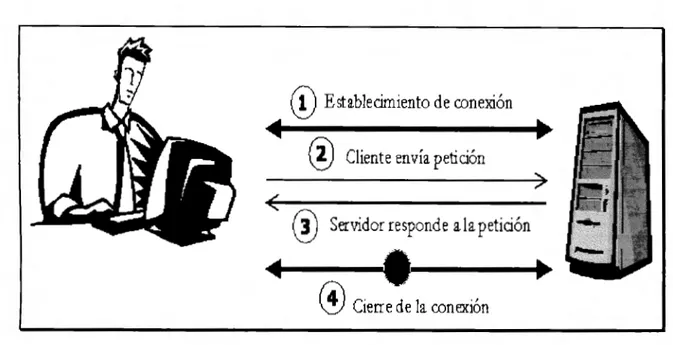
(11) CAPÍTULO 1. DETALLES Y FUNCIONAMIENTO DEL PROTOCOLO HTTP.. Con el propósito de comprender la especificación de HTTP operante actualmente en Internet, se presenta a continuación una descripción del modo de operar, las partes que componen al protocolo y los conceptos básicos de seguridad que el protocolo permite emplear.. 1.1 FUNCIONAMIENTO.. La versión 1.0 del protocolo de HTTP [2], que es la versión actualmente empleada, funciona principalmente en dos escenarios : en el primero, el cliente se conecta directamente al servidor, y en el segundo, existen uno o varios intermediarios entre el cliente y el servidor. En el escenario básico visto sin errores, la operación del HTTP se comporta de la siguiente manera: un cliente contacta a un servidor de HTTP y establece una conexión con él, enviándole una petición en la cual solicita un determinado tipo de información. El servidor recibe la petición y responde transfiriéndole al cliente la información deseada. Por último, el servidor cierra la conexión que se había establecido. La figura 1.1 muestra éste proceso.. 10.
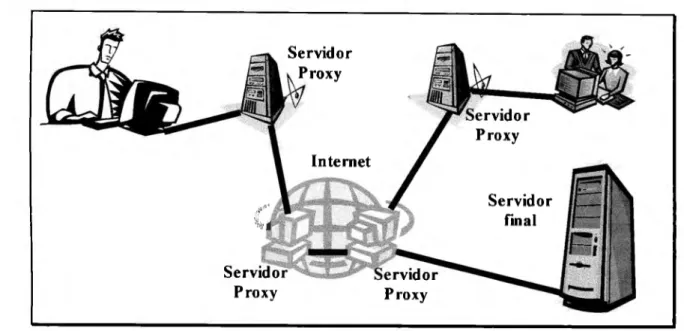
(12) (D Establecimiento de oonexión 4. ® Cliente envía petición @ Servidor responde a la petición. ~. •. @Cierre de la oonexión. .. Figura l. l.- Funcionamiento básico del protocolo HTTP.. El establecimiento de la conexión entre el cliente y el servidor emplea el protocolo de transporte TCP. La petición del cliente al servidor lleva los siguientes datos: Método de petición, URI deseado, versión del protocolo HTTP a emplear, y un mensaje tipo MIME, que contiene información del cliente y un posible cuerpo de contenido, con modificadores de petición. La respuesta del servidor al cliente consiste de una línea de estado y de un mensaje tipo MIME. La línea de estado tiene información respecto a la versión del protocolo y un código de error o de éxito. Por su parte, el mensaje tipo MIME contiene información respecto al servidor, metainformación de la entidad y el cuerpo de contenido (datos a transferir). En el segundo escenario, la forma de operar es afectada únicamente por la existencia de servidores intermediarios llamados Proxies. Estos Proxies no son mas que proveedores de un servicio de cache de recursos web, cuyo objetivo es reducir el tiempo que se toma para entregar la respuesta al cliente, para que de alguna forma se incremente el performance del protocolo de HTTP. Su funcionamiento se muestra en la figura 1.2.. 11.
(13) Proxy. Servidor final. Proxy. Proxy. Figura I .2.- Funcionamiento del protocolo HTTP con la existencia de servidores Proxy.. Los pasos que se siguen son: 1) El cliente envía una petición a un servidor final. Dicha petición pasará forzosamente por al menos un servidor Proxy. 2) El primer servidor Proxy que recibe la solicitud del cliente, analiza la petición y determina si tiene una copia fresca o reciente del recurso solicitado. En caso de tener una copia reciente del recurso, se la envía al cliente como respuesta; de esta fonna, la solicitud fue atendida sin tener que viajar por todo el Internet. Sin embargo, si el servidor Proxy no tiene el recurso, o lo tiene pero es "viejo", entonces el servidor Proxy actuará ahora como cliente y hará la petición correspondiente al servidor final (a este servidor final se le conoce origin server dentro de las referencias en idioma inglés). Es importante mencionar, que si existen varios Proxies entre el cliente y el servidor final, cada Proxy trabajará como servidor (hacia el cliente) y como cliente (hacia otro servidor). 3) Una vez que el servidor Proxy obtiene la respuesta del servidor final, guarda una copia del recurso para entregarla en futuras solicitudes. 4) Finalmente le responde al cliente como lo hubiera hecho el mismo servidor final.. Aparte de los dos escenarios descritos anteriormente, el protocolo de HTTP también define instrucciones para emplear diferentes conjuntos de caracteres (internacionalización}, mecanismos de codificación de las respuestas, envió y recepción desde y hacia el servidor de diferentes tipos de recursos (la mayoría corresponden a algún tipo de los registrados por la IANA - Internet 12.
(14) Assigned Numbers Authority), redirección para la búsqueda de algún recurso ubicado en otro servidor, autenticación simple, y comandos que se pueden aplicar a los entes intermediarios.. 1.2 PARÁMETROS DEL PROTOCOLO.. Para que el protocolo pueda desempeñar su labor, requiere de varios parámetros que le definen la forma de operar e interactuar con los diferentes entes que pueden existir en éste ambiente. Estos entes podrían ser: los diferentes navegadores que actúan como clientes, y los diferentes tipos de servidores, que se pueden subdividir en los de entrega de documentos o fuentes y los de cache. A continuación se presentan los parámetros globales establecidos en el estándar para el protocolo deHTTP:. a) Versión HTTP: versión del protocolo implementado a ser empleado.. El propósito de especificar la versión del protocolo es determinar la capacidad de las entidades a comunicarse. Esta versión se especifica con la línea: "HTTP/1.0" Para proveer compatibilidad con las versiones anteriores de HTTP, los servidores y clientes que se implementen bajo la versión 1. O deberán reconocer y manejar la versión O.9 cuando ésta se emplee. En el caso de los servidores Proxy, si éste recibe una versión inferior a la que tiene su implementación, podrá utilizar la versión mayor con el siguiente servidor y responder al cliente con la versión apropiada. Cuando reciba una petición con una versión mayor, el proxy deberá responder con un error o bien con la versión inferior.. b) Identificador Uniforme de Recursos (Uniform Resource ldentijier): Identifica un recurso de red. Pueden ser de acuerdo a la sintaxis general para URis o un URL de HTTP.. La sintaxis general para los URis se basa en las definiciones explicadas en los documentos RFC 1630, 1738 y 1808 con ciertos cambios en restricciones y adaptadas para el empleo de los proxies. Las comunicaciones bajo el protocolo HTTP utilizan la sintaxis y semántica del HTTP URL. Esta sintaxis menciona el puerto por el cual el servidor espera por este tipo de comunicaciones, y que al no mencionarse por omisión será el puerto 80.. 13.
(15) c) Formatos de fecha/tiempo (Dateí/'imeformats): Son las marcas de fecha y tiempo a emplear.. Existen tres tipos de formatos para indicar fechas y tiempos: Formato del RFC 822 (actualizado por el RFC 1123):. Sun, 06 Nov 1994 08:49:37 GMT. Formato del RFC 850 (modificado por el RFC 1036):. Sunday, 06-Nov-94 08 :49:37 GMT. Formato asctime() del lenguaje ANSI C:. Sun Nov 6 08:49 :37 1994. Todas las entidades bajo el protocolo HTTP 1.0 deberán reconocer los tres tipos de formatos, más nunca generar el formato del lenguaje ANSI C.. d) Conjuntos de caracteres codificados (Coded Character Sets): Es el nombre del conjunto de caracteres codificados que las entidades de HTTP utilizarán.. Los conjuntos de caracteres de codificación que se emplean, son los mismos que se definen para los mensajes MIME, los cuales son un método de conversión de una secuencia de octetos a una secuencia de caracteres. La conversión en la dirección opuesta no es requerida. Estos conjuntos se identifican en el protocolo de HTTP como "tokens" . El registro de Conjuntos de Caracteres IANA contiene todos los tokens, aunque para el HTTP no todos son empleados y, algunos otros recomendados para el manejo de mensajes MIME son utilizados. Entre los conjuntos válidos se encuentran los de ISO-8859 y los de US-ASCII. Además, el protocolo permite el empleo de cualquier otro tipo de conjunto definido entre las aplicaciones.. e) Mecanismo de codificación (Encoding Mechanism): Indica el tipo de codificación que estará aplicado a un recurso.. Los mecanismos de codificación son empleados para describir el tipo de procesamiento que se le dio a la información, como en el caso de una compresión o encriptación. Al especificar el mecanismo se indica más bien el programa que se requerirá para descodificar la información y poderla leer. Existen tres tipos de mecanismos definidos: "x-gzip", "x-compress" y token. Los dos primeros emplean los mecanismos de Lempel-Ziv 77 con un CRC de 32 bits (empleado en el programa "gzip") y Lempel-Ziv-Welch (empleado por el programa "compress"), respectivamente. El mecanismo dado por token permite el uso de cualquier otro mecanismo.. 14.
(16) f) Tipo de objeto (Media Type): Es el tipo de objeto del Internet que provee tipos de datos y tipos de negociación abiertos y extensibles.. Los tipos de objeto a emplearse son los descritos en el RFC 1521 o bajo IANA, aunque no necesariamente restringidos a únicamente tales tipos. Otros tipos de objetos se pueden emplear y se recomienda que sean registrados bajo IANA de acuerdo al RFC 1590. En general, los cuerpos de las entidades se deben representar en una forma canónica apropiada antes de su transmisión. La especificación de HTTP 1. O modifica la forma canónica del tipo texto al permitir a una secuencia de octetos representar un corte de línea de texto (text line break) mediante los caracteres CRLF o bien, con un simple CR o LF. Por otra parte, para el tipo texto se redefine el conjunto de caracteres de codificación empleado por omisión. Se emplea el conjunto "ISO-8859-1" en lugar del valor por omisión de "USASCII", ya que el primero es un superconjunto del segundo. Los tipos de partes múltiples que provee MIME no son de importancia para el protocolo HTTP 1. O aunque idealmente deberían de ser manejados por el agente del usuario de una forma similar a la que un agente usuario MIME realiza cuando recibe un tipo de partes múltiples.. g) Identificadores del producto (Product Tokens): Identifica una aplicación de otra cuando éstas se comunican.. Esta identificación permite el uso opcional de una descripción de versión de la aplicación y el listado de subpartes que emplee la aplicación y sus versiones.. 1.3 MENSAJES HTTP.. Los mensajes posibles a tener por el protocolo HTTP son únicamente dos: de petición y de respuesta. Para tener compatibilidad con la versión 0.9 se especifican cuatro tipos de mensajes: Simple-Request, Simple-Response, Full-Request y Full-Response, siendo los dos primeros los empleados para la versión O.9 El mensaje Simple-Request sólo permite el método "GET" y el mensaje de Simple-Response solo tiene el cuerpo de la entidad a ser transferido. En estos mensajes no se transfiere información adicional como lo hacen los mensajes Full. Un servidor de HTTP 1. O que reciba una petición simple deberá responder con una respuesta 15.
(17) simple, y solamente en este caso será válido el uso de los mensajes simples. Además, si un cliente realiza una petición Full y recibe un mensaje de respuesta que no contiene una línea de estado (Status-Line), deberá considerar al mensaje como un mensaje de respuesta simple y procesarlo. Por su parte, los mensajes Full se forman de la siguiente manera: Full-Request =. Request-Line *(General-Header I Request-Header I Entity-Header) CRLF [Entity-Body]. Full-Response =. Status-Line *(General-Header I Response-Header I Entity-Header) CRLF [Entity-Body]. De aquí se observa que cada mensaje de la versión 1.0 transfiere información adicional por medio de las líneas de petición en la petición o de estado en la respuesta, y por los encabezados. Se pueden tener varios encabezados seguidos uno de otro dados en varias líneas, separados cada uno por al menos un LWS. El orden en que se presenten los encabezados no es de importancia (aunque es preferible el orden: General-Header, Request/Response-Header y Entity-Header).. A continuación se describen todas las partes comprendidas en el esquema HTTP versión 1.0: a) Campo de Encabezado para Mensajes en General (General Message Header Field). El encabezado general se aplica en ambos tipos de mensaje: de petición y de respuesta. Sirve para describir atributos generales aplicables únicamente al mensaje a transferir. Esta versión del HTTP tiene especificados tres posibles contenidos para el encabezado general: Date, MIME-Version y Pragma. Cualquier otro encabezado o header general a utilizar deberá ser añadido mediante un cambio a la versión del protocolo.. 16.
(18) b) Mensaje de Petición (Full-Request). Como ya se mencionó en los tipos de mensajes, un mensaje de petición Full-Request está formado con los siguientes componentes: •. Request Line (Línea de petición). Formado a su vez por: Method (Método), Request-URI (URI pedido) y HTTP-Version (Versión del HTTP).. •. General Header (Encabezado General) y/o Request Headers Fields (Campos de encabezados de petición) y/o Entity-Header (Encabezado de la Entidad).. •. Entity-Body (Cuerpo de la entidad). Requerido cuando se emplea el método "POST".. b.1) Request-Line: Línea de comando de petición.. La línea de petición esta formada por el método que se aplicará al recurso URI, seguido por el URI deseado, la versión del HTTP y terminada la línea con un CRLF. A diferencia de la petición simple, esta petición permite otros métodos además del "GET".. b.2) Method: Método a ejecutar sobre el recurso dado en el URI pedido.. Los métodos especificados pueden ser "GET", "HEAD", "POST" y cualquier otro añadido como extensión al protocolo. Por medio del mensaje de respuesta se puede conocer si un método es válido, y en caso de que no se conozca o no este implementado el método indicado, se le indica al cliente mediante el código de respuesta número 501. El método "GET" indica que se desea obtener la información a la que el URI presentado apunta. Si existe un campo de encabezado If-Modified-Since dentro del mensaje de petición, el método "GET" se convierte en un GET Condicional, cuyo propósito es reducir el uso de la red al permitir a un proceso de cache el refrescar la información sin la necesidad de volverla a transferir. Por su parte, el método "HEAD" es semejante al método "GET" en el que se pide cierta información, con la diferencia de que el cuerpo de la entidad (Entity-Body) no es transferido por el servidor que dará la respuesta, esto es, con este método se obtiene un mensaje de respuesta que no contiene Entity-Body (aun cuando existan encabezados que hagan parecer que sí hay un cuerpo de entidad). Este método es útil para evaluar ligas de hipertexto. El último método descrito en la especificación de la versión 1.0 es el método "POST". "POST" permite enviarle al servidor una entidad (presentada en el campo Entity-Body dentro del mensaje Full-Request) para que éste último la maneje. El manejo de la información por el 17.
(19) servidor lo determina el URI indicado: un archivo se puede añadir a un subdirectorio, un mensaje se puede añadir a un grupo de noticias, un bloque de datos puede ser transferido para su proceso, un registro se puede añadir a una base de datos, etc. Este método requiere del campo Content-Length dentro del mensaje de petición. Si este campo no se encuentra en el mensaje, el servidor responderá con el código número 400 (los códigos de respuesta se describen posteriormente). El mensaje de respuesta del servidor permitirá conocer el resultado de la aplicación de un método "POST" por medio de los códigos de respuesta.. b.3) Request-URI: Identifica al recurso que se le aplicará la petición.. El identificador URI tiene dos opciones: absoluteURI o abs_path. El primero se emplea cuando la petición se realiza a un servidor proxy y el segundo es para cuando la petición es realizada a un servidor de origen.. b.4) Request-Header Field: Proporciona información adicional sobre la petición.. Los encabezados de petición permiten indicarle al servidor otros datos relativos a la petición y al cliente. Estos datos adicionales comprenden información de Autorización (Authorization ), Origen (From), Modificación desde cierta fecha (If-Modified-Since), Referencias (Referer) y sobre el Agente del Usuario (User-Agent), siendo estos campos los únicos existentes y permitidos por esta versión del HTTP (la descripción de todos los campos de encabezados se describe más adelante). Cualquier otro campo será definido mediante un cambio de versión al protocolo.. e) Mensaje de Respuesta (Full-Response). Cuando el servidor recibe un mensaje de petición Full-Request, contesta la petición con un mensaje de respuesta Full-Response, el cual esta formado por: •. Status Line (Línea de estado). Compuesta por: HTTP-Version, Status-Code (Código de estado) y Reason-Phrase (Frase de razón).. •. General Header (Encabezado General) y/o Response Headers Fields (Campos de encabezados de respuesta) y/o Entity-Header (Encabezado de la Entidad). 18.
(20) •. Entity-Body (Cuerpo de la entidad).. c.1) Status-Line: Línea del estado resultante de la petición realizada. La línea de estado consiste de la versión del protocolo HTTP seguido por un código numérico que junto a la frase de razón permite conocer cual fue el resultado de aplicar el mensaje de petición.. c.2) Status Codes and Reason Phrases: Da el código y la razón del mensaje de respuesta. Los códigos de razón son un número entero de 3 dígitos y la frase de razón esta dado por un texto que describe brevemente el resultado. El primer dígito del código determina la clase de la respuesta, y puede ser (para cada clase se describen los códigos y frases de razón especificados por el protocolo):. lxx: Informativo. Esta clase esta reservada para uso futuro. 2xx: Éxito. La operación ha sido exitosa. 2000K. La petición tuvo éxito y dependiendo del método dado se tiene que el mensaje de respuesta esta compuesto por: Para el método GET, se responde con una entidad correspondiente al recurso pedido. Con el método HEAD se responde con encabezados sin un cuerpo de entidad. Y para el método POST, se envía una entidad que describe el resultado de la acción. 201 Created Se ha creado un nuevo recurso (determinado por el método POST) que puede ser referenciado por el URI, el cual envía el servidor dentro del cuerpo de entidad del mensaje de respuesta. Se puede responder con 202 si la acción del POST no puede ser completada inmediatamente o dentro de cierto tiempo. 202 Accepted La petición fue aceptada pero no se ha podido procesar. El cuerpo de entidad en el 19.
(21) mensaje de respuesta debería de mencionar cuando estima el servidor completar la operación. 204 No Content. Esta respuesta es principalmente para indicar que se ha completado la petición pero sin información nueva que requiera ser enviada al cliente para su visualización (no existe un cuerpo de entidad en el mensaje de respuesta). Se emplea para la ejecución de "scripts" o casos similares. Jxx: Redirección . Se requiere(n) de otra(s) acción(es) para completar la petición. 300 Mu/tiple Choices. Este código indica que se tienen varias opciones de ubicación del recurso solicitado. Se puede regresar dentro del campo Location (de los encabezados de respuesta) la ubicación preferida por el servidor. 301 Moved Permanently. El recurso ha sido movido permanentemente a una nueva ubicación. El mensaje de respuesta proporciona, por medio del campo Location, la nueva dirección del recurso; mientras que el cuerpo de la entidad describe mediante una nota lo sucedido incluyendo un hipertexto que apunte a la nueva ubicación. Se recomienda que el cliente re-ligue sus referencias a esta nueva dirección. 302 Moved Temporarily. Parecido al código 301, éste resultado indica que el recurso se encuentra en otra localidad. El cliente no requiere cambiar sus referencias originales al recurso. 304 Not Modi.fted. Resultado de un GET condicional, éste código no regresa ningún cuerpo de entidad, aunque se deben observar los campos Date, Server y Expires como los más relevantes para los programas que hacen uso de cache. 4xx: Error del Cliente. La petición esta mal hecha o no se puede completar. Un cliente inmediatamente deberá dejar de enviar datos cuando reciba este código. 400 Bad Request. No se pudo entender la petición. El cliente deberá modificar su petición antes de repetirla.. BIBUOTECA. 20.
(22) 401 Unauthorized. No se tiene autorización para acceder al recurso solicitado. El servidor envía dentro del campo de encabezado WWW-Authenticate un reto que deberá completar el cliente, y enviar de regreso (por el cliente) su respuesta al reto en el campo de encabezado Authorization dentro de un mensaje siguiente de petición. 403 F'orbidden. Se entendió la petición pero el servidor no proporcionará el recurso ni explicará porque no desea hacerlo. 404 Not F'ound. El servidor no encontró el recurso pedido, y s1 no desea dar explicaciones puede utilizar el código 403 .. Sxx: Error del Servidor. El servidor falló al tratar de completar la petición. Un cliente inmediatamente deberá dejar de enviar datos cuando reciba este código. 500 Interna/ Server Error. Existe un error interno en el servidor que impide completar la petición. 501 Not lmplemented. Cuando el servidor no reconoce un método indicado en el mensaje de petición, regresa éste código. 502 Bad Gateway. El servidor recibió una respuesta no válida del gateway o servidor siguiente de la cadena de servidores que procesan la petición. 503 Service Unavailable. No se puede proveer el servicio por causa de una sobrecarga al servidor o por otros motivos temporales.. Además de estos códigos, se pueden emplear otros por medio de una extensión a la especificación del protocolo, aunque los mencionados aquí son los únicos que se reconocen en la práctica.. 21.
(23) c.3) Response Header Field: Proporciona información adicional a la respuesta. Esta información no puede ser transmitida por la línea de estado (Status-Line) y se relaciona con el mensaje de respuesta y el servidor (no se aplica esta información al cuerpo de la entidad). Los campos especificados por el protocolo son: Location (Ubicación), Server y WWWAuthenticate (Autenticación del WWW). Cualquier otro campo será definido mediante un cambio de versión al protocolo.. d) Entidad (Entity). Una entidad es enviada dentro de las peticiones o las respuestas cuando el tipo de mensaje lo requiere, y se compone de: •. Entity Header Fields (Campos de encabezados de la entidad).. •. Entity-Body (Cuerpo de la entidad).. d.1) Entity Header Fields: Provee metainformación opcional del Cuerpo de la entidad (EntityBody) en caso de estar presente, o del recurso identificado por la petición. Los campos válidos para los encabezados son: Allow (Permitir), Content-Encoding (Codificación del contenido), Content-Length (Longitud del contenido), Content-Type (Tipo de contenido), E,xpires (Expiración), Last-Modi.fied (Última modificación) y cualquier otro encabezado HTTP adicional añadido como extensión al protocolo sin necesidad de cambiar de versión (aunque no se garantiza que sean reconocidos por los servidores). El campo de la longitud del contenido es requerido forzosamente cuando un mensaje lleva consigo el método "POST".. d.2) Entity-Body: Contenido, si existe alguno, de la entidad. El cuerpo de la entidad es un flujo de octetos que representan cierto tipo de información de acuerdo al formato y codificación que tenga aplicada (determinada por los campos Content22.
(24) Encoding y Content-Type). Esta secuencia de octetos se puede visualizar como una estructura de dos niveles:. Entity-body = Content-Encoding ( Content-Type ( data ) ) Por omisión, no existe una codificación. Y aunque no existe un valor de omisión para el tipo de contenido, cuando este no sea especificado mediante el campo Content-Type, se debe determinar su tipo por medio de la inspección del contenido (data) o por el nombre de la extensión empleado en el URL; En caso de no poder ser determinado el tipo, se considerará como tipo "application/octet-stream". Por otra parte, dado que el cuerpo de contenido es un flujo de octetos en el que no se sabe hasta donde podría parar, se determina su tamaño por dos formas: se puede hacer uso del campo Content-Length para conocer directamente el tamaño, o bien, cuando el servidor cierre la conexión se sabrá que terminó la transmisión de información. En caso de que sea el cliente el que envía información, éste no podrá cerrar la conexión para que se determine el tamaño del cuerpo y debe enviar indiscutiblemente el tamaño mediante el encabezado provisto para este efecto (encabezado Content-Length).. e) Definiciones de los Campos de Encabezados. A continuación se describen todos los tipos de encabezados disponibles para la versión 1.0. Allow (Permitir): Lista el conjunto de métodos soportados por el "Request-URI", esto es, permite que un cliente le informe al servidor sobre los métodos que se pueden aplicar al recurso. Sin embargo, este campo no indica que métodos tiene implementados el servidor.. El campo Permitir es ignorado cuando se emplea dentro de un mensaje de petición que use el método "POST". Authorization (Autorización): El campo de autorización permite autentificar un usuario con el servidor. Se puede emplear dentro de un mensaje de petición después de haber recibido un mensaje con código de respuesta número 401.. El proceso de autenticación se describe posteriormente. Content-Encoding (Codificación del contenido): Este campo indica cual fue el mecanismo empleado para codificar al documento (y por lo tanto, el mecanismo necesario para descifrarlo), tal como se explicó en la sección "Parámetros del Protocolo - E.11coding Mechanisms". Content-Length (Longitud del contenido): Content-Length especifica el tamaño del "Entity23.
(25) Body" en bytes. Es altamente recomendado el uso de este campo para todos los mensajes. Su uso fue descrito en la sección "Entity - Entity Body" . Content-Type (Tipo de contenido): Determina el tipo de media del "Entity-Body". La sección anterior "Parámetros del protocolo - Media Type" describe mejor el significado de los tipos de media. Date (Fecha): Fecha y hora del mensaje originado (escrito bajo un cierto formato, como se describió en la sección "Parámetros del protocolo - Date/Time formats"). Este campo debe ser siempre especificado por los servidores (para ayudar al manejo de los mensajes que se encuentren en cache); se recomienda que los clientes lo especifiquen cuando empleen el método "POST". Por omisión, se determina como la fecha y hora del momento en que recibe el mensaje uno de los entes en comunicación, siendo necesaria su asignación por omisión cuando el mensaje se vaya a manejar por cache o pasar por un gateway vía otro protocolo que requiere ésta especificación.. Sólo un campo Date deberá ser insertado en cualquier tipo de mensaje. Expires (Expiración): Fecha y tiempo de expiración de la entidad. Útil para informar que un recurso probablemente cambiará (aunque no necesariamente); los proxies y clientes con cache deberán quitar de su cache este recurso después de pasada la fecha indicada en éste campo. From (De): El campo From contiene la dirección del correo electrónico del usuario o cliente, en un formato definido por el buzón del RFC 822 (actualizado por el RFC 1123). Con el uso de proxies, este campo refleja la dirección Internet del cliente original (no del proxy).. El propósito del campo From es para informar a un servidor la identidad del usuario, para que en caso necesario el servidor contacte al cliente. Se recomienda que el usuario pueda habilitar o deshabilitar el llenado de éste campo, y que no se emplee como un mecanismo de autenticación cuando de seguridad se trate. lf-Modijie,l-Since (Si-modificado-desde): Este campo es empleado junto al método "GET" para realizar una petición condicional, de tal forma que si el recurso no ha sido modificado desde la fecha indicada en este campo, se regresará un mensaje con un código de respuesta número 304 y sin Entity-Body, en caso contrario, si el recurso fue modificado después de la fecha que describe este campo, se procesará la petición como un "GET" normal . En caso de que este campo contenga una fecha inválida, se ignorará y se tratará la petición como un "GET" normal.. Éste campo tiene como propósito mejorar el uso de los caches y reducir el tráfico en la red . Last-Modified (Última-modificación): Indica la fecha y hora en que el transmisor cree que fue modificado por última vez el recurso solicitado. El tiempo de última modificación depende de la naturaleza del recurso solicitado y el concepto es diferente para un archivo, como para un objeto virtual o como para una base de datos.. 24.
(26) Si el receptor tiene una copia de este recurso con una fecha anterior a la que se presenta en este campo, el receptor deberá volver a obtener dicho recurso. Location (Ubicación): Localidad exacta del recurso dado en el campo "Request-URI", descrito en éste campo bajo un formato de URI absoluto. Sólo se permite la definición de un URI absoluto en el campo. Su uso se da en los mensajes de respuesta con códigos números 3xx. MIME-Version (Versión MIME): Versión del MIME empleado para construir el mensaje. Aún cuando la versión 1.O del HTTP no se apega al protocolo de MIME, este campo debería indicar que el mensaje es totalmente especificado como un mensaje MIME bajo la versión que aquí se presente. Por omisión, la versión que se presenta aquí es la "1. O" siendo definida su semántica por este documento y no por el del protocolo MIME. Pragma: El campo Pragma contiene directivas que deberán ser aplicadas a todos los intermediarios a través de la cadena de petición-respuesta, especialmente para los caches y proxies, sin incluir a los entes extremos (cliente y servidor origen). No existe ninguna forma de indicar una directiva a un único intermediario específico.. La única directiva descrita es la de "no-cache", la cual le indica al servidor intermedio que pase la petición al servidor de origen, con el propósito de obtener nuevamente el recurso solicitado. Otras directivas pueden ser empleadas a través de extensiones al Pragma. Referer (Referencias): Este campo permite que un cliente le indique al servidor la dirección URI de donde el recurso indicado por el campo "Request-URI" fue obtenido. Esto le permite al servidor generar listas de ligas anteriores, dar mantenimiento a ligas, etc. Este campo debe ser completado únicamente cuando el recurso fue obtenido de otro que contenga un URI y no por alguno especificado por el usuario mediante el teclado. Además, se debería permitir al usuario el habilitar o deshabilitar el llenado de este campo para no divulgar direcciones privadas. Server (Servidor): Nombra cortamente al software empleado para la creación del servidor de origen, lo cual incluye al software principal y los subproductos, con sus respectivas versiones, y posibles comentarios respecto a los mismos.. Cuando un mensaje pase por un proxy, el proxy no deberá añadir su software en este campo. Por cuestiones de seguridad, como es en el caso de la existencia de "agujeros" de seguridad en alguna implementación de un cierto servidor, este campo no debería de ser descrito (ya que revelaría la existencia de dichos "agujeros"). User-Agent (Agente usuario): Al igual que el campo Server, el campo User-Agent nombra brevemente al software principal y los subproductos, junto con sus versiones y posibles comentarios, empleados por el agente usuario (cliente o browser). Éste campo es útil para el reconocimiento de ciertos clientes en cuanto a sus capacidades y limitaciones.. No se recomienda que los proxies añadan los nombres de su software a este campo. 25.
(27) WWW-Authenticate (Autenticación del WWW): Este campo es empleado en el proceso de autenticación; siempre incluido en un mensaje con código de respuesta número 40 l. Consiste de al menos un reto que indica el (los) esquema(s) y parámetros aplicables al recurso indicado por el "Request-URI".. Pueden existir en un mensaje de respuesta varios encabezados WWW-Authenticate o bien un solo encabezado con una lista de retos separados por comas.. 1.4 AUTENTICACIÓN.. Autenticación de Acceso. El proceso de autenticación se basa en mantener una seguridad de acceso a ciertos recursos dentro de un servidor. El servidor permitirá el acceso a los recursos cuando el esquema de autenticación a seguir sea completado propiamente. Este proceso de autenticación, como ya se mencionó en la sección "Response Messages - Status Codes and Reason Phrases - Código número 401 ", consta de un mensaje enviado por un servidor el cual requiere ser completado y contestado propiamente por el cliente. El mensaje que envía el servidor nombra el (los) esquema( s) del reto a ser contestado junto a un nombre de realm y sus posibles parámetros. La versión 1. O del HTTP define un esquema de autenticación llamado "Basic", aún cuando otros esquemas y/o mecanismos pueden ser empleados. Por otra parte, el atributo de realm es necesario para todas las autenticaciones, y su valor, acompañado de la raíz canónica del URL dentro del servidor que se accesa, forma un espacio de seguridad. Estos espacios de seguridad permiten que dentro de un mismo servidor existan diferentes "zonas" que deben de ser accesadas por diferentes esquemas de acceso. Los espacios de seguridad deberán de ser siempre dentro de un solo servidor y solo podrán extenderse a otros servidores cuando el esquema lo permita. Una vez que el cliente recibe un mensaje con código de respuesta 401, recibe el reto a ser completado y podrá responder con otro mensaje de petición que incluya un campo Authorization. Este campo contendrá las credenciales necesarias que le permitan autentificarse con el servidor dentro del realm solicitado, siendo posible reutilizar las mismas credenciales, una vez que se haya realizado el primer acceso, para otras peticiones que se realicen al mismo espacio de seguridad, siempre y cuando el esquema, parámetros y/o preferencias del usuario lo permitan. En caso de que el servidor no acepte las credenciales enviadas regresará un mensaje con código de respuesta número 403 . Por su parte, los servidores prox.ies no deberán manejar en cache todos los mensajes que sean 26.
(28) parte del proceso de autenticación, debiendo dirigir tales mensajes con los encabezados sin alteración alguna. Esta versión del HTTP no define ninguna forma de autentificar un cliente con un proxy.. El esquema de autenticación "Basic". El esquema de autenticación que define la vers10n 1.0 del HTTP se denomina Basic. Este esquema es muy simple ya que consta de dos parámetros: el valor del realm dentro del encabezado WWW-Authenticate (en el mensaje de respuesta) y de una credencial simple dentro del encabezado Authorization (en el mensaje de petición). Para este esquema de autenticación, el valor de realm es igual a como se explicó en la sección anterior y no requiere de ningún otro parámetro adicional. La credencial simple de respuesta al reto consta de la unión de la identificación del usuario, el caracter de dos puntos (:) y de la contraseña asignada al usuario, contenido todo esto bajo una codificación Base64 como se describe en el RFC 1521. Este esquema básico se basa en asumir que las conexiones entre cliente y servidor son ya seguras, y se describe como un método no seguro. Para filtrar el acceso no autorizado a los recursos de un servidor de HTTP, se deben emplear mecanismos adicionales que completen la seguridad, tal como podría ser el encriptar previamente el canal de comunicación. A pesar de esto, se recomienda el empleo de este método para poder comunicarse con servidores que ya lo tengan implementado.. En base a la revisión del protocolo HTTP dada aquí, se pueden comprender mejor los detalles que en los siguientes capítulos se explican.. 27.
(29) CAPÍTUL02. PROPUESTAS EXISTENTES DE MODIFICACIÓN AL PROTOCOLO HTTP.. Debido a que la versión 1.0 actual no satisface todas las necesidades que han surgido a través del uso del protocolo en las diferentes aplicaciones expuestas en Internet, se ha visto la necesidad de modificarlo para cubrirlas. Por esta razón, se presentan a continuación los temas de mayor importancia referentes a los intentos por modificar al protocolo que han surgido desde que se liberó la versión actual. Además, muchas de estas ideas, como se podrá ver más adelante, han sido base para las nuevas caracteristicas propuestas para la futura versión del HTTP 1. 1.. 2.1 MECANISMO PARA AÑADIR EXTENSIONES. La propuesta de David M. Kristol [5] se basa en el hecho de que pueden surgir nuevas extensiones por parte de los vendedores o creadores de nuevas aplicaciones dentro del WWW, las cuales deben ser manejadas por todos los clientes. Tales extensiones serán añadidas dinámicamente y por lo tanto no habrán sido definidas para cualquier versión de la especificación del HTTP. Para esto, se propone el empleo de un mecanismo que permita añadir nuevas extensiones, "encapsular" mensajes de HTTP, uso de seguridad para las comunicaciones, el empleo de métodos de pago, la notificación para emplear la "paquetización" del mensaJe (división de un mensaje en otros) y la notificación para mantener las conexiones activas. Por otra parte, ésta propuesta trata de implantar seguridad en las comunicaciones por medio de un mecanismo llamado "wrapping', el cual encapsula un mensaje HTTP en un nuevo mensaje. El mensaje HTTP se podrá encontrar "escondido" dentro del nuevo mensaje para evitar ser visto por terceros que no tengan la autorización para hacerlo.. 28.
(30) El mecanismo para el uso de nuevas extensiones adiciona dos nuevos métodos y dos nuevos encabezados (las únicas extensiones que se pueden añadir a la definición del HTTP 1. O sin cambiar de versión son los métodos, dentro de los mensajes de petición y la de los encabezados de la entidad). Uno de los nuevos métodos, "GETEXT", permite conocer como debe responder un cliente a un servidor para ciertos recursos cuando se le aplican otros determinados métodos. "WRAPPED" es un método que indica que un mensaje de HTTP se encuentra encapsulado dentro del mensaje que se esta recibiendo; para esto, se requiere de una negociación previa entre cliente y servidor para determinar cuales son los tipos de encapsulamiento que puede soportar el solicitante (cliente) y por lo tanto, permitirle desencapsular el mensaje. Además, el encapsulamiento puede ser recursivo. Con respecto a los encabezados, los nuevos encabezados se definen como "Extension" y "Extension-Order". El primero de ellos describe todas las extensiones y sus atributos aplicables al mensaje, mientras que el segundo determina el orden o prioridad en que deben aplicarse. Para poder notificar el empleo de la "paquetización" y el mantenimiento de la conexiones, se introducen las extensiones: "HTTP/Packetize" y "HTTPIKeepConnection".. Respecto al cliente, se propone que para que éste pueda manejar las nuevas extensiones, dicho cliente se implemente de una forma modular, en la que las nuevas extensiones sean manejadas por nuevos módulos que se añadan (estilo ''plug-in") a un núcleo básico. Tales módulos serían entonces provistos por los vendedores de las nuevas aplicaciones.. 2.2 DESCRIPCIÓN DE TAMAÑOS DE DOCUMENTOS POR RANGOS. Para poder beneficiar a ciertas aplicaciones que requieren que una parte de un documento les sea provista por un servidor, describiendo a la subparte mediante un rango de bytes, Ari Luotonen [7] propone la introducción de un nuevo parámetro a ser empleado en los URLs que lo soporten, y también introduce un nuevo encabezado para los mensajes de respuesta. Ésta especificación se puede aplicar a documentos en los que tenga sentido el uso de rangos, y para aquellos que no, se tratarán como peticiones inválidas los mensajes que lo contengan. El nuevo parámetro definido se denomina "bytes", se añade al URL deseado y toma como valores un rango (en bytes por supuesto) de la subparte del documento que se desee se. 29.
(31) transmita. Se pueden incluir varios rangos dentro de la misma petición, en cuyo caso, la respuesta será un mensaje MIME multiparte. Éste parámetro debe ser construido por el browser y no por el usuario que genera las peticiones. Una vez que el servidor reciba la petición con el rango de bytes, creará la respuesta y añadirá un encabezado al mensaje de respuesta: "Range", el cual notificará al cliente cual es el rango que se esta enviando y cual es el tamaño del documento completo.. Otro de los principales factores para estandarizar esta propuesta es el uso de los proxies. Sin una estandarización, cada proxy trataría a las subpartes como un documento completo y mantendría varias copias de éste en cache. Por otra parte, con la estandarización, el proxy podría generar subpartes nuevas de Jo que tenga en cache y quizá reconstruir el documento completo si todas sus partes se encuentran allí. Por lo tanto, un servidor de origen deberá incluir el encabezado LastModified en sus mensajes de respuesta, para permitirle al cliente llevar una sincronía de todas las subpartes y volver a solicitar aquellas que se requieran actualizar, y para pennitirle también al proxy actualizar tales subpartes.. 2.3 EXTENSIONES DE SESIÓN. Dado que uno de los problemas de rendimiento que presenta el protocolo de HTTP es el de crear una nueva conexión por cada petición que se genera, Alexander Hopmann [4] propone una extensión al protocolo que le permita a los clientes mantener una conexión hacia un servidor, y realizar varias peticiones. Ésta propuesta introduce un nuevo encabezado a ser empleado en los mensajes HTTP de petición: el encabezado "Connection: mantain", el cual deberán incluir dentro del primer mensaje de petición aquellos clientes que deseen mantener la conexión que se establezca con el servidor que contacten. Si el servidor entiende este encabezado, contestará con el mismo encabezado dentro de su mensaje de respuesta. Una vez que ambos reconozcan el encabezado, el cliente podrá realizar múltiples peticiones después de la primera, respondiendo el servidor en el mismo orden en que reciba las peticiones, sin la implicación de que el cliente realice peticiones sin esperar por las respuestas previas. Respecto a los proxies, la propuesta define otro encabezado : "Connection: mantain-proxy" que empleará el cliente y el proxy en sus mensajes. Dicho encabezado tiene el propósito de mantener la conexión que se establezca entre el cliente y el proxy, dejando al proxy la libertad de negociar,. 30.
(32) si así lo desea, el mantenimiento de la conexión que requiera establecer con los servidores de ongen.. Por otra parte, para poder mejorar el rendimiento, se propone se almacenen los valores de los encabezados Accept-Charset, Accept-Language y Authent(fication durante el tiempo que perdure la conexión, de tal forma que una vez que se definan, se empleen los valores dados para los mensajes siguientes, y que sólo se vuelva a definir alguno cuando haya que cambiarlo.. Un punto que es importante es la observación que hace Hopmman [4] en cuanto a los efectos que se tendrán respecto a la seguridad. Menciona que se reduce el problema de rendimiento para el proceso de autenticación (al enviar sólo un encabezado de autenticación en la primera petición) el cual es cierto, y sin embargo, expresa el hecho de que las siguientes comunicaciones podrían ser interceptadas por un hacker para substituir a la persona original, que solo podría funcionar con los métodos de autenticación no seguros, siendo esto de menor importancia (¿estará seguro de que esto no es relevante? Habría que estudiar la situación).. 2.4 MECANISMO PARA LA INFORMACIÓN DE ESTADO. Debido al hecho de que el protocolo de HTTP es sin estado, esto es, sin estado porque un servidor de origen no necesita recordar o almacenar información respecto a las peticiones previas para poder atender una nueva, David M. Kristol [6] propone en septiembre de 1995 un mecanismo para poder incluir información del estado en que se encuentran las sesiones de un cliente con un servidor y permitir a las aplicaciones que así lo requieran, como en los programas CGI, conocer la historia de las acciones del cliente. Éste mecanismo propuesto es muy simple, se introduce un nuevo encabezado para todos los mensajes: "State-Info", que será el que contenga la información de estado y que será transmitido del servidor al cliente y viceversa. Con el nuevo encabezado se elimina la necesidad de que si un servidor requiere tener información de estado la almacene localmente. La información que contenga el encabezado "State-Info" es arbitraria y depende solamente de las aplicaciones y el significado que tenga tal información hacia ellas. Además de la introducción del nuevo encabezado, se describe el comportamiento que deben de seguir los clientes, servidores y proxies con respecto a este nuevo campo.. 31.
(33) 2.5 MEJORAS EN LA LATENCIA DEL HTTP. Uno de los primeros estudios realizados para determinar los problemas que presenta el uso del protocolo de HTTP en cuanto a rendimiento, fue el análisis realizado por Simon E. Spero [ 11]. Este documento muestra a través de un ejemplo, el de una transacción de petición-respuesta mediante el uso del HTTP, la existencia de varios factores que influyen en el tiempo de respuesta. Entre las observaciones más importantes, del resultado de su trabajo, se pueden mencionar: •. Los accesos que se realizan con el HTTP se comportan de acuerdo a un patrón: el cliente solicita un documento y solicita después las imágenes o iconos presentes en el documento; cuando obtiene todo el documento e imágenes, existe una gran probabilidad de que el usuario utilice una liga de hipertexto presente, en cuyo caso, en la mayoría de los casos existe dentro del mismo servidor el documento referenciado.. •. Parece que HTTP se toma más tiempo en esperar que en transferir los datos.. •. El establecimiento de la conexión por el TCP requiere un tiempo de un mínimo de 2 RTTs (Round Trip Time), ya que su proceso es por medio de un acuerdo (handshake) de 3 pasos: el cliente envía una solicitud de conexión, el servidor responde y el cliente reconoce (acknowledges) la respuesta del servidor (aunque en éste último paso el cliente también podría enviar datos).. •. El proceso de Arranque Lento (S/ow Start) que ejecuta el TCP cuando se crean las conexiones, que además son de vida corta con el empleo del HTTP, afecta el rendimiento de todo el proceso, al introducir más RTTs bajo condiciones en que se emplean bajos valores de MSS (Maximum Segment Size) y documentos de mayor tamaño al MSS.. •. En las redes futuras se puede minimizar relativamente el efecto que tiene el ancho de banda en las comunicaciones, quedándose la latencia como un factor dominante sobre el rendimiento de las mismas.. •. El tiempo total al utilizar una conexión de TCP ya abierta, en una red con un ancho de banda de 1. 15 Mbps, se calcula para una nueva petición aproximadamente 4 veces menor (comparada con el tiempo total que se toma el crear nuevas conexiones). Aún en el caso de emplear una conexión ya abierta se puede incurrir en la adición de RTTs adicionales ( debido a cada par petición/respuesta). Si además se considera la transmisión de varios documentos, que los encabezados repetidos de los mensajes 32.
Figure
+7
Documento similar
El desarrollo de la presente Tesis, se ha basado en el diseño e implementación de una aplicación cliente-servidor que permitiera al cliente gestionar de forma dinámica la reserva
Se indica, para cada flujo y sentido (cliente-servidor y servidor-cliente para los juegos, sólo este último para el streaming, punto a punto para VoIP), tanto el tamaño medio de
Para poder hacer referencia al servidor desde el cliente, obtenemos una referencia al proxy del objeto remoto mediante una llamada al método GetObject() de la
• Permitir al servidor enviar video usando un protocolo de transmisión diferente para cada cliente al mismo tiempo (no se conoce aplicación comercial que sea capaz hacerlo). Para
La implementación del sistema se basa en un esquema cliente-servidor mediante un flujo de operaciones que completan el siguiente proceso: en el cliente se recopilan todos los datos
abstracción de recursos, donde cada petición HTTP contiene toda la información necesaria para responder a la petición, sin necesidad de que el cliente ni el servidor
El diagrama de despliegue para este sistema incluye la representación de una PC que realiza la función de servidor y una o más PCs Cliente conectadas al Servidor por medio
El servidor de peticiones retorna la unidad de tra- bajo creada para el cliente (ver caso de uso Atender Tarea Asignada por el Servidor Central. Sección Crear una Unidad de
