Algoritmo para el reconocimiento automático de matrículas utilizando la herramienta de simulación Matlab
81
0
0
Texto completo
(2) Universidad Central “Marta Abreu” de Las Villas Facultad de Ingeniería Eléctrica Departamento de Telecomunicaciones y Electrónica. Trabajo de diploma. Algoritmo para el reconocimiento automático de matrículas utilizando la herramienta de simulación Matlab.. Autor: Javier Barco Alvárez. E-mail: jbarco@uclv.edu.cu. Tutores: Ing. Reinier Alejandro Alonso Quintana. MSc. Roberto Díaz Amador.. Santa Clara. 2014. "Año 56 de la Revolución".
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería en Telecomunicaciones y Electrónica, autorizando a que el mismo sea utilizado por la institución para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del autor. Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del autor. Firma del jefe de departamento donde se defiende el trabajo. Firma del responsable de Información Científico-Técnica.
(4) PENSAMIENTO “Saber no es suficiente, debemos aplicar. Desear no es suficiente, debemos hacer”.. Johann W. Von Goethe. i.
(5) DEDICATORIA Debo agradecer a muchas personas el haber llegado hasta aquí. A todos, sin excepción, les agradezco infinitamente. No puedo, sin embargo, dejar de mencionar a aquellos, sin cuya ayuda, hubiese sido imposible este empeño. . A quienes siempre me han guiado por el camino de la verdad: Mis padres.. . A quienes amo sin medida: Mi hermana y novia.. . A quienes me dan aliento para seguir adelante: Mis Compañeros.. . A mis Tutores quienes me han hecho crecer y han ejercido gran influencia en mí como profesional y en lo personal, sin cuya guía hubiese sido muy difícil la culminación de este trabajo.. ii.
(6) AGRADECIMIENTOS La gratitud es el más legítimo pago al esfuerzo ajeno, es reconocer que todo lo que somos es la suma del sudor de los demás, es tener conciencia de que un hombre solo no vale nada y que la dependencia humana, además de obligada es hermosa: por tanto, le agradezco a todos los que hicieron posible la realización de esta investigación.. Muchas Gracias. iii.
(7) TAREA TÉCNICA . Estudio del estado del arte sobre algoritmos y aplicaciones actuales de localización y reconocimiento de matrículas vehiculares y sus principales causas de fallo.. . Creación de una base de casos de matrículas cubanas con sistemas de adquisición instalados.. . Implementación de un algoritmo para la localización de una matrícula en una imagen.. . Implementación de un algoritmo para el reconocimiento de caracteres de una matrícula.. . Discusión de los resultados obtenidos.. . Elaboración del informe final.. Firma del autor. Firma del tutor. iv.
(8) RESUMEN La identificación de la matrícula tiene un sin número de aplicaciones en interés de mantener controles y registros de acceso a zonas restringidas, mantener seguimientos policiales y controles de recorridos sobre vehículos, cobro de peajes en determinados tramos de carretera, entre otros. Debido a la importancia que reviste el control no supervisado de los automóviles para el Ministerio del Interior el objetivo general de esta investigación es desarrollar un algoritmo para el reconocimiento automático de matrículas de vehículos utilizando la herramienta de simulación Matlab. En este informe se recoge un estudio sobre el estado actual de los algoritmos de reconocimiento de matrículas vehiculares. Se incluye además un bosquejo sobre los procedimientos y técnicas de procesamiento digital de imágenes utilizadas en la etapa de pre-procesamiento para el acondicionamiento de las imágenes de entrada a los algoritmos de reconocimiento de patrones empleados, igualmente se recogen los conceptos necesarios para la comprensión y utilización de redes neuronales en la etapa de reconocimiento de los caracteres.. v.
(9) Contenido Pensamiento ...................................................................................................... i Dedicatoria ......................................................................................................... ii Agradecimientos .............................................................................................. iii Tarea técnica .................................................................................................... iv Resumen ........................................................................................................... v Introducción...................................................................................................... 1 Capítulo I: Estado del arte ............................................................................... 4 1.1 Reconocimiento automático de matrículas .......................................... 4 1.2 Aplicaciones ............................................................................................ 5 1.3 Software comerciales ............................................................................. 6 1.4 Algoritmos empleados en el reconocimiento de matrícula ................. 8 1.4.1 Programación dinámica ...................................................................... 9 1.4.2 Transformada de Hough ...................................................................... 9 1.4.3 Transformada de Gabor .................................................................... 10 1.4.4 Operaciones morfológicas ................................................................ 10 1.4.5 AdaBoost ............................................................................................ 11 1.4.6 Detección de bordes .......................................................................... 12 1.4.7 Detección por color ........................................................................... 13 1.5 Matrículas automovilísticas en Cuba .................................................. 14 1.5.1 Formato de las matrículas de vehículos .......................................... 15 Capítulo II: Materiales y métodos ................................................................. 17 2.1 Entrada de imágenes ............................................................................ 17. vi.
(10) 2.2 Pre-procesamiento de imágenes ......................................................... 18 2.2.1 Transformación en escala de grises ................................................ 19 2.2.2 Filtro de mediana ............................................................................... 20 2.2.3 Matemática morfológica .................................................................... 21 2.2.3.1 Operadores morfológicos .............................................................. 22 2.2.4 Transformación en binario ................................................................ 25 2.2.4.1 Método de Otsu ............................................................................... 26 2.3 Localización de la matrícula................................................................. 28 2.3.1 Detección de bordes por Sobel ........................................................ 28 2.3.2 Bagging ............................................................................................... 32 2.3.3 Boosting ............................................................................................. 32 2.3.4 AdaBoost ............................................................................................ 32 2.4 Segmentación de caracteres................................................................ 37 2.4.1 Función para corregir el ángulo ....................................................... 37 2.4.2 Función para separar los caracteres ................................................ 38 2.5 Reconocimiento de caracteres ............................................................ 40 Capítulo III: Discusión de resultados ........................................................... 43 3.1 Localización de las matrículas............................................................. 43 3.2 Localización de caracteres .................................................................. 47 3.3 Corrección del ángulo de inclinación de las matrículas ................... 48 3.4 Clasificadores implementados ............................................................ 52 3.5 Evaluación del rendimiento del algoritmo completo ......................... 54 Conclusiones .................................................................................................. 56 vii.
(11) Recomendaciones.......................................................................................... 57 Referencias bibliográficas ............................................................................. 58 Bibliografía consultada .................................................................................. 60 Anexos ............................................................................................................ 61 Anexo 1. Proceso empleado en la obtención de la localización de matrículas en una imagen. ......................................................................... 61 Anexo 2. Proceso empleado en el reconocimiento de los caracteres alfanuméricos de las matrículas. ............................................................... 63 Anexo 3. Función principal del algoritmo ANPR propuesto. .................. 64. viii.
(12) INTRODUCCIÓN La identificación de la matrícula es fácilmente realizable por humanos, pero en la actualidad el número creciente de vehículos y la necesidad de poder realizar el trabajo con menos recursos humanos ha llevado a la existencia de sistemas que hagan esto de manera automática. Para las máquinas, una matrícula es simplemente una mancha oscura que se encuentra dentro de una región de la imagen, con una intensidad y luminosidad determinadas. Debido a esto, es necesario diseñar un sistema matemático robusto, capaz de percibir y extraer lo que deseamos de la imagen capturada.(Pozo, 2009) En la mayoría de los casos, los vehículos están señalizados por sus números de matrícula, que permiten la identificación del auto, del propietario y otros datos de interés. En la actualidad la identificación de la matrícula tiene un sin número de aplicaciones en interés de mantener controles y registros de acceso a zonas restringidas, mantener seguimientos policiales sobre determinados vehículos y mantener controles de recorridos de vehículos, cobro de peajes en determinados tramos de carretera, entre muchos otros. El principal problema en la identificación automática es tal vez la gran variabilidad en los sistemas de adquisición de la imagen de la matrícula, que está determinada por variaciones en la iluminación, en la velocidad del vehículo, en la posición relativa del vehículo respecto a la cámara entre muchas otras. Debido a la importancia que reviste el control no supervisado de los automóviles y la gran capacidad con que cuenta el Ministerio del Interior (MININT) en cuanto a la cantidad de cámaras instaladas en todo el país, se hace necesario desarrollar herramientas capaces de captar matrículas a partir de imágenes provenientes de distintas fuentes y con distintos niveles de calidad. En este sentido las herramientas de procesamiento digital de imágenes y de redes neuronales existentes permiten elaborar estudios con el fin de mejorar los resultados que se obtienen actualmente con los software que se disponen. Teniendo en cuenta lo anteriormente planteado se determinó como problema de investigación de este trabajo, ¿Cómo desarrollar un algoritmo capaz de identificar. 1.
(13) la matrícula de automóviles en una imagen, y determinar cuáles son los caracteres en la misma? El objetivo general de esta investigación es desarrollar un algoritmo para el reconocimiento automático de matrículas de vehículos utilizando la herramienta de simulación Matlab. Para cumplir con este objetivo se proponen los siguientes objetivos específicos: . Realizar un estudio del estado del arte sobre algoritmos y aplicaciones actuales de localización y reconocimiento de matrículas vehiculares y sus principales causas de fallo.. . Implementar un algoritmo para la localización de una matrícula en una imagen.. . Implementar un algoritmo para el reconocimiento de caracteres de una matrícula.. Organización del informe El informe de la investigación se estructura en introducción, capitulario, conclusiones,. recomendaciones,. referencias. bibliográficas,. bibliografía. consultada y anexos. . Introducción: Se dedica a realizar un acercamiento a la vigencia y los objetivos del tema de la investigación realizada.. . Capitulario: En el primer capítulo se abordan los tópicos más importantes sobre el reconocimiento automático de matrículas vehiculares en el mundo. Además se hace referencia a los sistemas de reconocimiento de matrículas comerciales existentes y los resultados que presentan; y se exponen las características de las matrículas en Cuba. En el segundo capítulo se describe el algoritmo para el reconocimiento automático de matrículas de vehículos; y se exponen los métodos empleados para la realización de la investigación y se realiza una descripción matemática de estos. En el tercer capítulo se realizan varias pruebas para comprobar la eficacia del algoritmo y se discuten los resultados obtenidos.. 2.
(14) . Conclusiones: Se recogen en esta sección las conclusiones sobre los resultados obtenidos en la investigación.. . Recomendaciones: Se exponen las recomendaciones que se generan a partir de las conclusiones del trabajo.. . Referencias bibliográficas: Se realiza un listado de los documentos consultados en el desarrollo de la investigación y que aparecen citados en el texto del informe.. . Bibliografía consultada: Se incluye un listado de los documentos empleados en la investigación y que no se citan en el informe.. . Anexos: En esta sección se abordan aspectos relacionados con el tema tratado no incluidos en el informe sobre el desarrollo de la investigación. Se brindan los códigos de la función principal implementada para el diseño del algoritmo.. 3.
(15) CAPÍTULO I: ESTADO DEL ARTE 1.1 Reconocimiento automático de matrículas El reconocimiento automático de placas o mejor conocido como ANPR (Automatic Number Plate Recognition), se le atribuye a la compañía inglesa Police Development Branch en 1976. Un sistema ANPR es un equipo especial formado por un software y hardware específicos, que procesa señales gráficas de entrada como imágenes estáticas o secuencias de video, y reconocen los caracteres de una matrícula a partir de estas fuentes. La parte hardware de un sistema ANPR está formado típicamente por una cámara, una unidad de procesado de imágenes, un disparador u obturador, una unidad de transmisión y otra de almacenamiento. El disparador controla físicamente un sensor directamente instalado en un carril. Siempre que el sensor detecte un vehículo a una distancia apropiada de la cámara, este activará el mecanismo de reconocimiento. Alternativamente a esta solución, se encuentra la detección por software o el continuo procesado de una señal video muestreada. La detección por software, o el procesado continuo de video, pueden consumir mayores recursos de sistema, pero no necesitan hardware adicional, como en el caso del hardware con disparador. (Jiménes, 2012). En la figura 1 se muestra el esquema físico de un sistema ANPR.. Fig. 1:Esquema físico de un sistema ANPR. (videovigilancia, 2014). 4.
(16) Un sistema ANPR puede ser separado en seis principales pasos: 1) entrada de imágenes o video de datos con vehículos, 2) pre-procesamiento de la imagen para elevar la calidad de la misma, 3) detección y localización de la matrícula en la imagen, 4) segmentación de la matrícula, 5) reconocimiento de los caracteres de la matrícula, 6) mostrar y guardar los resultados. Los pasos 3 y 4 juegan un papel importante en el correcto reconocimiento de la matrícula. En la figura 2 se muestra un diagrama en bloque de un sistema de ANPR en el cual se ven muy bien identificados los seis pasos comentados con los que consta el algoritmo.. Fig. 2: Diagrama en bloque de un sistema ANPR. Para el desarrollo del trabajo se deberá sobrepasar diferentes dificultades producidas por el ángulo de captura, ángulo de inclinación de la cámara, la velocidad de los vehículos, la calidad y resolución de la imagen, diferentes factores de ruido en el objeto de interés como peatones, bicicletas y otros vehículos. En algunos casos, el ANPR se puede configurar para almacenar también una fotografía del conductor. Estos sistemas a menudo utilizan iluminación infrarroja para hacer posible que la cámara pueda tomar fotografías en cualquier momento del día. La tecnología ANPR tiende a ser específica para una región, debido a la variación entre matrículas de un lugar a otro.(Yu and Wen, 2012) 1.2 Aplicaciones El reconocimiento automático de matrículas mediante un sistema de visión artificial es un tema de indudable interés comercial con numerosas aplicaciones como el control de aparcamientos, acceso a instalaciones, tarificación de peajes, cálculo de la velocidad media entre puntos de una carretera, etc.. 5.
(17) En los parqueos, el reconocimiento de matrículas es usado para calcular la duración en la que el coche ha estado aparcado. Cuando un vehículo llega a la entrada del parqueo, el número de matrícula es automáticamente reconocido y almacenado en la base de datos. Cuando el vehículo más tarde sale y llega a la puerta de salida, el número de matrícula es nuevamente reconocido y comparado con el primero almacenado en la base de datos. La diferencia de tiempo es usada para calcular el coste del aparcamiento. Los sistemas de reconocimiento automático de matrículas pueden ser usados en control de accesos, por ejemplo, esta tecnología es usada en algunas compañías para conceder el acceso solo a vehículos del personal autorizado. En algunos países estos sistemas de reconocimiento están instalados a lo largo de un área de la ciudad para detectar y monitorear el tráfico de vehículos. Cada vehículo es registrado en una base de datos central y, se puede comparar con una lista negra de vehículos robados o controlar la congestión en accesos a la ciudad en las horas pico. En muchas ciudades se utiliza este tipo de sistema como por ejemplo en Londres (Reino Unido), Gotemburgo (Suecia), Trondhein (Noruega), Copenhague (Dinamarca), Bristol (Reino Unido), Edimburgo (Escocia), Roma y Génova (Italia), Helsinki (Finlandia), Hong Kong y Singapur.(Pozo, 2009) 1.3 Software comerciales A pesar de existir varios software comerciales, el reconocimiento automático de matrículas es un tema que está siendo muy investigado. Los sistemas comerciales en uso en la actualidad pueden obtener tasas de acierto superiores al 95% en entornos controlados. En entornos en los que las condiciones de iluminación no están controladas o varía el tamaño, orientación o perspectiva de la placa, la tasa de acierto se reduce hasta el 75 %.(Pozo, 2009) A continuación se describen algunas de las aplicaciones comerciales de ANPR más utilizadas en el mundo, y se exponen sus principales características y resultados que presentan.. 6.
(18) Sistema de reconocimiento de matrículas Biartic Se caracteriza por la capacidad de lecturas masivas en ángulos extremos y en cualquier situación climatológica con una velocidad de procesamiento muy elevada. La fiabilidad de lectura es de un 98.5% con una velocidad de identificación y registro de 15 matrículas por segundo. Los datos del reconocimiento se recogen en una base de datos junto con la fecha, hora, fotografía, sentido del movimiento y posición GPS con la que se puede tramitar el boletín de denuncia desde el propio vehículo patrulla. En el caso de sistemas en puntos fijos se añade información de velocidades medias. Los datos registrados son procesados en tiempo real con diferentes bases de datos (listas negras, blanca, informativas) soportando más de 40 millones de registros teniendo una respuesta inmediata mientras el sistema continúa procesando más lecturas sin perder su efectividad.(Rios, 2014) Sistema de reconocimiento de matrículas Motorola Permite leer placas y cotejarlas con la información de una base de datos instalada para una rápida verificación de identidad. Esta solución es escalable y de rápida implementación, utiliza cámaras infrarrojas resistentes que se conectan con un software de tecnología de reconocimiento óptico de caracteres de última generación, lo que le permite mantener el área vigilada independientemente de las condiciones climáticas y de iluminación. Automáticamente detecta y procesa placas de vehículos con listas de placas buscadas. Mantiene el área vigilada independientemente de las características del entorno y de las condiciones de iluminación. Ofrece una velocidad de captura relativa de 210 km/h con una precisión del 90%. (Solutions, 2014) Lector de matrículas XCI-NPR-ACR El sistema puede reconocer las matrículas de hasta 25 países europeos a una distancia entre 3 y 18 metros, e incluye Ethernet 10/100 y conector RS232. El XCINPR se ha diseñado para una instalación sencilla y de fácil mantenimiento. La carcasa dispone de acceso físico fácil. El módulo proporciona la detección y notificación de matrícula incorrecta. La cámara puede configurarse con dos 7.
(19) funciones de alarma, que le permite controlar las acciones exteriores, tales como encender una luz o elevar una barrera. Posee una fiabilidad de un 99% y funciona de día y de noche.(Sony, 2007) Lector de matrículas en Cuba (PVigChapa) PVigChapa fue concebido con el objetivo fundamental de detectar matrículas de vehículos a partir de la secuencia de video o imágenes estáticas tomadas por cámaras de video vigilancia instaladas en lugares de interés operativo para el MININT, extendidos a lo largo de todo el país. PVigChapa consta de las siguientes funcionalidades:. detección. de. matrículas,. consiste. en. la. detección. y. reconocimiento de matrículas; gestión de alertas, constituye una de las funcionalidades que más valor agregado le aporta a PVigChapa como sistema, ya que facilita el trabajo de los órganos de enfrentamiento mediante la emisión de alertas ante el paso por los puntos de vigilancia de vehículos que son de interés para el MININT; búsqueda de matrículas, esta opción le brinda a los usuarios de PVigChapa la posibilidad de realizar búsquedas sobre las informaciones almacenadas de forma local en el punto de vigilancia; y gestión de listas de vigilancia, están concebidas con el objetivo de mantener el seguimiento de vehículos de interés para el MININT, permite crear listas en las que se incluyen un grupo de matrículas de vehículos que se mantendrán bajo vigilancia y se activará una alerta cuando PVigChapa detecte el paso de uno de ellos por un punto de vigilancia. 1.4 Algoritmos empleados en el reconocimiento de matrícula El reconocimiento automático de matrículas consta de un algoritmo cuyos pasos elementales se encuentran bien diferenciados: localización de la matrícula en la imagen, realce y mejoramiento de la localización detectada y detección de los caracteres.(Dorsch et al., 2009) No se debe pasar por alto que lo que hace que un sistema sea más eficiente que otro, es la utilización de distintos métodos en cada paso del algoritmo. Se debe tener en cuenta a la hora de diseñar un sistema de ANPR, para qué clase de aplicación se desea emplear pues cada método tiene sus potencialidades y. 8.
(20) debilidades, por ejemplo si se desea que la respuesta del sistema sea obtenida en tiempo real los algoritmos empleados deben favorecer la rapidez sobre la complejidad de los cálculos, lo que puede provocar que cuando las condiciones de iluminación no son las adecuadas, o la matrícula está sucia o inclinada el sistema tiende a cometer un mayor número de errores que otros procedimientos que poseen un mayor tiempo de procesamiento pues en estos se emplean métodos de clasificación y procesamiento de imágenes más eficientes pero mucho más lento, de ahí que se deba establecer una relación de compromiso entre la eficacia del sistema y el tiempo de procesamiento. A continuación se muestra una serie de algoritmos empleados en ANPR para la localización y reconocimiento de caracteres de matrícula. 1.4.1 Programación dinámica El algoritmo basado en la programación dinámica no necesita encontrar la matrícula en la imagen pues este segmenta directamente los caracteres alfanuméricos, por lo que no requiere ninguna característica de la matrícula como son los bordes, color, o líneas, que son parámetros que son afectados con la variación de la intensidad. Para la extración de los caracteres se basa en las características de alto y ancho de los mismos, combinados con un rango de valores de umbral. La programación dinámica posee un tiempo computacional bajo por lo que es un algoritmo rápido lo que posibilita su uso en sistemas de tiempo real y posee una exactitud de hasta un 97.14%.(Kolour and Shahbahrami, 2011)(Kang, 2009) 1.4.2 Transformada de Hough Es uno de los más eficientes algoritmos para detectar líneas en imágenes binarias, aunque tiene como desventaja el tiempo de ejecución. Además requiere un tiempo computacional muy alto cuando la imagen binaria posee una alta resolución. Este algoritmo consiste en mirar por regiones de una imagen que contengan dos líneas paralelas que puedan ser consideradas como candidatos a posibles matrículas. Para lograr un buen resultado la transformada de Hough es combinada con un algoritmo de detección de bordes. Primeramente es aplicado el algoritmo de. 9.
(21) detección de bordes y luego la transformada de Hough, de forma tal que esta última encuentre dos pares de líneas paralelas que formen un paralelogramo, que es considerado como un posible candidato para matrícula. Como ahora la transformada de Hough actúa solamente sobre los contornos de los objetos de la imagen se disminuye considerablemente el tiempo de ejecución y el tiempo computacional. Este algoritmo tiene la desventaja de dar varios posibles candidatos a matrícula los cuales deben ser analizados en cuanto a su relación de alto por ancho para de esta forma seleccionar de forma correcta la matrícula de todos los demás candidatos.(Kolour and Shahbahrami, 2011) 1.4.3 Transformada de Gabor El filtro de Gabor es una herramienta de análisis de textura con el cual se logra la detección de la matrícula, esta se basa en el análisis de textura de la imagen en varias direcciones y escalas. (Kolour and Shahbahrami, 2011) En (Ktata et al., 2013) se emplea este método para la localización de la matrícula en la imagen, pues los caracteres sobre la matrícula producen un patrón de textura específico que puede ser considerado como una característica a la hora de localizar la matrícula en la imagen. En ese estudio primeramente se emplearon los filtros de Gabor, los cuales son una clase especial de filtros lineales que son orientados, y permiten resaltar las texturas y áreas homogéneas de la imagen. 1.4.4 Operaciones morfológicas Las operaciones morfológicas constituyen una herramienta de procesamiento de imagen basado en la forma. A través de un elemento estructural los operadores morfológicos se encargan de analizar las imágenes digitales. La matrícula tiene forma rectangular pero con este método pueden ser detectados varios posibles candidatos que presenten la misma forma. Este algoritmo es muy usado en disímiles estudios como es el caso de (Dehshibi and Allahverdi, 2011) en el cual primeramente se erosiona la imagen usando como elemento estrcutural un rectángulo y luego es dilatada empleando la misma estructura. En este trabajo para eliminar el problema de los posibles candidatos se empleó el AdaBoost (Adaptative Boosting) como clasificador binario empleando características Haar. 10.
(22) like, dando hasta un 98.75% de exactitud localizando correctamente las matrículas. Además son empleadas por (Kasaei et al., 2010) en el cual una vez que se tiene la imagen binaria y filtrada por un filtro de bordes de Sobel, se aplica un operador de cierre en la dirección horizontal empleando un elemento estructural con forma rectangular para la localización de la matrícula. En esta investigación para eliminar el problema de los posibles candidatos, se analizaron teniendo en cuenta el radio, la forma y las dimensiones de alto y ancho. También (Mai et al., 2011) emplean el operador morfológico de apertura combinado con una operación de sustracción para el pre-procesamiento de la imagen. Luego se emplea un filtro de bordes de Canny y se aplica un operador morfológico de cierre, uno de apertura para eliminar el ruido, y uno de dilatación para agrandar el tamaño de los posibles candidatos. Para eliminar el problema de los posibles candidatos se realiza un análisis de estos muy parecido al estudio anterior. 1.4.5 AdaBoost El AdaBoost es un algoritmo que se basa en la selección de varios clasificadores débiles para la construcción de un nuevo clasificador fuerte. Se denominan clasificadores débiles pues solamente es necesario que estos posean una probabilidad de acierto ligeramente superior al 50%. Este sistema se basa sobre el entrenamiento,. por lo que para el desarrollo de este algoritmo es necesario. entrenar una base de datos que contenga imágenes de matrículas manualmente extraídas y sea lo más grande posible. Este algoritmo es muy usado para los sistemas de ANPR; es empleado por (Dehshibi and Allahverdi, 2011) en el cual utilizan el AdaBoost como clasificador binario empleando características Haar like para clasificar varios posibles candidatos a matrículas y mantener las áreas correctas, a través de este procedimiento se obtiene una exactitud de 96.93%. Además en este estudio para el reconocimiento de caracteres se empleó un AdaBoost multiclases de tipo SAMME con una exactitud de un 94.5%. (Dlagnekov, 2004), también emplea este método para la localización de la matrícula, dando muy buenos resultados los experimentos realizados, de 158 imágenes pasadas al clasificador fuerte detectó correctamente un 95.6% .. 11.
(23) 1.4.6 Detección de bordes Este algoritmo es muy empleado en ANPR pues para la localización de la matrícula se basa en las características física que poseen las matrículas, ya que estas poseen gran cantidad de bordes verticales debido a los caracteres incluidos en la misma, en comparación a otras partes del vehículo. Este algoritmo es muy usado por varios autores como es el caso de (Dorsch et al., 2009) los cuales emplean un filtro de bordes de Sobel a una imagen binaria, para luego analizar los picos máximos en la dirección horizontal y vertical de la imagen. Este método tiene el inconveniente que estos máximos no sólo representan la ubicación de la matrícula, sino que también pueden haber picos en otras zonas de alta densidad de bordes, como carteles, fondos arbolados, rejas o alambrados; por lo que es necesario descartar aquellos que no cumplen con las condiciones típicas de la matrícula como: ancho mínimo, ancho máximo, alto mínimo, etc. En este trabajo se logran muy buenos resultados en zonas con pocos bordes verticales, se detecta un 70% de las matrículas y en zonas con muchos bordes el algoritmo detecta un 54% de las matrículas. Además este método es empleado por (Saha et al., 2009) donde se emplea el filtro de bordes de Sobel en la dirección horizontal y vertical, para luego analizar las zonas de la imagen que contengan un mayor número de bordes como posibles candidatos a matrículas. Ellos logran en los experimentos realizados una exactitud de hasta un 92%, pues a diferencia del trabajo anterior en la etapa de pre-procesamiento se emplea un filtro de mediana para remover gran parte del ruido de la imagen. (Chunyu et al., 2013), también se basa en la extracción de bordes de la imagen para la localización de la matrícula, pero con la particularidad de que se emplea un operador diferencial en la dirección horizontal y vertical. (Sarker et al., 2013) es otro de los muchos trabajos que emplea este método con la diferencia de que en este caso sólo analizan la parte inferior de la foto disminuyendo así el tiempo de procesamiento; para la detección de bordes emplean un filtro de Sobel. En este trabajo el algoritmo diseñado se equivocó en 416 imágenes de 52 000 imágenes captadas dando una efectividad de hasta un 99.2%. (Ashoori-Lalimi and Ghofrani, 2011) emplean la detección de bordes a través de un filtro de Sobel combinado con los operadores morfológicos. 12.
(24) de apertura y cierre para eliminar los pequeños detalles de la imagen y de esta manera quedarnos con los posibles candidatos a matrícula. Los posibles candidatos a matrícula son analizados en cuanto a sus radios, relación de ancho por alto, etc. En este estudio se logra una exactitud de hasta un 95.2% a la hora de localizar la matrícula en la imagen. 1.4.7 Detección por color La detección de la matrícula por el color es una técnica muy empleada en los sistemas ANPR aunque es utilizada muchas veces en combinación con otras técnicas como la detección de bordes, debido a que el color es muy afectado por la variación de la intensidad. (Yu and Wen, 2012) para realizar la localización de la matrícula emplearon la técnica de LTU (Look-Up-Table) en la cual se crea una distribución de color de la matrícula, con la cual se pueden identificar varios candidatos que posean colores muy parecidos a la matrícula. Se puede comprobar la rectangularidad o la relación de alto por ancho de los candidatos para de esta manera obtener la matrícula. En este estudio se realizó un experimento el cual en condiciones de día, de 200 matrículas, se detectaron bien 184, mientras que en condiciones de noche de 150 matrículas se detectaron bien 138. Con lo que se concluye que el sistema diseñado detecta un 92% de las matrículas correctamente en condiciones de día y de noche. (Machecha and Sepúlveda, 2008) realizan una búsqueda de posibles candidatos lo cual se divide en dos sub-bloques en paralelo, uno para localizar las matrículas de color amarillo y otro para la localización de matrículas de color blanco. Para la búsqueda de matrículas amarillas se basa en que una imagen en el plano Cb muestra los objetos amarillos o muy cercanos a esta tonalidad, por lo que a una imagen en el plano Cb se le realiza la umbralización con el objetivo de mostrar como verdaderos los píxeles de color amarillo. Para la búsqueda de matrículas blancas se realiza el mismo procedimiento con la diferencia de que la umbralización muestra como falso los píxeles correspondientes a los objetos con bajo nivel de azul. Paralelo a esto la imagen pasa por un detector de bordes verticales (filtro de Sobel) y con un proceso de dilatación se unen los bordes que están suficientemente cerca (de la placa). Combinando estos dos métodos con un filtro para eliminar las manchas 13.
(25) pequeñas en la imagen se tienen los posibles candidatos de matrícula. Luego estos son análizados teniendo en cuenta la relación de largo por ancho, umbral de color, etc. Una vez analizados los algoritmos más empleados en ANPR estos son evaluados teniendo en cuenta algunos de los parámetros más importantes en la siguiente tabla. Método. Complejidad de implementación. Sensibilidad a condiciones ambientales. Detección de bordes. Tiempo computacional. Programación dinámica. Alta. Baja. No. Baja. Hough + bordes. Media. Baja. Sí. Alta. Transformada de Gabor. Baja. Alta. Sí. Alta. Morfológicas. Baja. Alta. Sí. Alta. AdaBoost. Baja. Alta. No. Baja. Bordes + color. Media. Media. Sí. Alta. Tabla 1.1: Comparación de algoritmos basados en ANPR. (Kolour and Shahbahrami, 2011) 1.5 Matrículas automovilísticas en Cuba La chapa o matrícula antigua de los vehículos cubanos (comenzó a sustituirse en el año 2013) tiene unas dimensiones exclusivas que no se corresponden con los estándares del fabricante —la firma alemana UTSCH—, encargado de suministrar el equipamiento, las materias primas e insumos, por lo que el mantenimiento de este sistema resultaba costoso. Sólo por concepto de sustitución de matrículas en. 14.
(26) los trámites de traspasos, cambios de domicilio, deterioro, pérdida y nuevas producciones, el monto del sostenimiento era de 198 696 euros al año. La diversidad de colores tenía sus inconvenientes, pues cada color de matrícula posee un precio diferente, y la empresa suministradora exige comprar 5 000 unidades como mínimo de cada orden de producción. Este sistema tenía desventajas. relacionadas. con. la. identificación. humana. y. los. sistemas. tecnológicos, debido a la poca separación y el escaso contraste entre el color de fondo y sus caracteres, a la diversidad de colores y a otros factores que influyen en la ilegibilidad de la matrícula como, por ejemplo, las confusiones entre algunos caracteres como la O con la Q y con el cero; la B con el 8, la Z con el 2, entre otros. Por lo que se decidió realizar un nuevo proceso de reinscripción y cambio de chapa de identificación de los vehículos mediante la implementación de un nuevo sistema, más económico para su sostenimiento, más efectivo como elemento de identificación humana y técnica, y mucho más flexible para su administración. El cambio está refrendado en el artículo 224 de la Ley 109 del Código de Seguridad Vial, que le confiere al MININT la facultad para disponer las reinscripciones generales o parciales, los cambios de chapas de identificación y de licencia de circulación de los vehículos inscritos. 1.5.1 Formato de las matrículas de vehículos Se emplea un formato estándar del fabricante, donde el código alfanumérico tendrá una letra y seis dígitos, agrupados en dos grupos de tres para facilitar su identificación, en el caso de los vehículos, como autos y camiones, y una letra y cinco dígitos para las motos. De esta manera pueden obtenerse 20 millones de posibilidades de combinaciones en el caso de los primeros vehículos y 1 699 983 variantes para las motos. Los autos y camiones, tienen matrículas con 420 mm de largo por 110 mm de ancho; y las motos con 200 mm de largo por 140 mm de ancho. Todas las chapas son blancas con los caracteres en negro y tienen un folio en la parte superior derecha y una imagen de la Isla de Cuba, impresos con láser como medida de seguridad. Una banda de color azul en el extremo izquierdo con la 15.
(27) palabra CUBA en posición vertical tienen las matrículas de las personas jurídicas, elemento que la diferencia de las matrículas de las personas naturales, al desaparecer la variedad de colores de fondo, pues las chapas no identifican el sector de pertenencia del medio. La letra A identifica las matrículas oficiales, actualmente de color blanco; las letras C, D, y E, para el sector diplomático; la letra K para los extranjeros, las letras F y M para identificar FAR y MININT, respectivamente, y la T, para los vehículos rentados al turismo. El resto de las letras no tiene ningún significado. Los vehículos destinados al servicio de protocolo se identifican, además, con una pegatina con orla de color azul oscuro y el texto Protocolo. Los vehículos pertenecientes a la prensa extranjera tienen una pegatina con orla de color verde y el texto P. Ambas pegatinas se colocan en el centro de la parte superior del parabrisas delantero. No se emplean las letras I, O, Q, S, W y la Z para evitar confusiones en la identificación.(Cruz, 2013). 16.
(28) CAPÍTULO II: MATERIALES Y MÉTODOS En este capítulo se discuten los métodos empleados para la realización de la investigación y se realiza una descripción matemática de estos. En la siguiente figura se muestra un diagrama en bloque de un sistema ANPR a partir del cual se comenzará a describir sus principales bloques y las funciones que se emplean en cada segmento del algoritmo.. Fig. 3: Diagrama en bloque de un sistema ANPR. 2.1 Entrada de imágenes Las imágenes de entrada de los sistemas de ANPR son adquiridas de varias formas en dependencia de la cámara que esté captando las fotos o secuencias de video, sea digital o analógica. Las imágenes utilizadas fueron captadas mediante las cámaras de video vigilancia instaladas en la ciudad de Cienfuegos en el mes de abril de 2014 entre los horarios de 7:00 am y 7:00 pm, debido a que el entorno urbano no posee la suficiente iluminación para realizar capturas en horas de la noche; las fotografías fueron tomadas a partir de flujos de video en formato MPG4m con resolución de 704x480 píxeles, 20 imágenes por segundo y una compresión de 45%, debido a que el video es transportado sobre un enlace SHDSL con velocidad de 2 Mbit/s lo cual obliga a la limitación evidente de la calidad del mismo. Se incluyen en el estudio un total de 325 imágenes de vehículos en las cuales varía la orientación angular de la matrícula, la iluminación de la imagen y el zoom del lente de la. 17.
(29) cámara, por tanto el resultado final de los algoritmos propuestos puede mejorar si la fuente de las imágenes es adquirida a partir de un ambiente controlado. Sin embargo, la gran variabilidad presente en la base de casos conformada en un entorno de adquisición real, le confiere al trabajo una alta aplicabilidad y versatilidad. Las imágenes en formato JPG son cargadas por el Matlab en tres matrices cada una de ella con los colores primarios rojo, verde y azul (RGB) almacenados en tres matrices en un arreglo de mxnx3, donde „m‟ es el número de filas y „n‟ el número de columnas de la imagen. Debido a esto el color de cada píxel está determinado por la combinación de la intensidad de estos colores primarios en el plano donde se ubica el píxel. Es necesario realizar ciertas transformaciones a esta imagen para disminuir el tiempo de procesamiento; por lo que, en el bloque de preprocesamiento de la imagen lo primero que se realiza es la transformación de la imagen a escala de grises ya que en esta la información es almacenada en una sola matriz de mxn. Teniendo en cuenta que el presente trabajo está orientado a matrículas que tendrán en todos los casos fondo blanco con letras negras, esta transformación no debe tener mayores implicaciones en el resultado final. 2.2 Pre-procesamiento de imágenes En general las técnicas de pre-procesamiento de imágenes se pueden dividir en tres categorías, los métodos de dominio espacial, que se basan en manipular directamente los píxeles en una imagen, los métodos de dominio de frecuencia, que operan sobre la transformada de Fourier o sobre otros dominios de frecuencia de una imagen, y los métodos combinados, que procesan una imagen en el dominio de la frecuencia y el espacio. Las técnicas de pre-procesamiento de imágenes juegan un papel fundamental en los sistemas ANPR pues las imágenes captadas deben sobrepasar diferentes dificultades producidas por el ángulo de captura, ángulo de inclinación de la cámara, la velocidad de los vehículos, la calidad y resolución de la imagen, diferentes factores de ruido en el objeto de interés como peatones, bicicletas y otros vehículos.(Shih, 2010). 18.
(30) 2.2.1 Transformación en escala de grises La transformación en escala de grises tiene la intención de cambiar los niveles de gris de una imagen entera en una forma uniforme, o sea modifica los niveles de gris dentro de una ventana definida por una función de mapeo. Esta transformación usualmente realza el contraste de la imagen logrando que los detalles puedan ser más visibles. Esto se logra aplicando a todos los píxeles una función que es la que se encarga del realce de la misma. La imagen en escala de grises es representada frecuentemente por 4bits/píxeles o 8bits/píxeles, donde la cantidad de niveles de grises con que contará dicha imagen va a estar determinado por la cantidad de bits/píxeles como se muestra en la ecuación.(Shih, 2010) (1) Para la transformación de las imágenes en escalas de grises se emplea la ecuación 2. (2) Donde „R‟, „G‟ y „B‟ son los componentes de crominancia de los colores rojo, verde y azul respectivamente, mientras que „y‟ es la información de luminancia con la que serán cargados los píxeles. En la figura 4 se muestra la transformación en escalas de grises de la imagen original.. Fig. 4: Transformación en escalas de grises de una imagen. Se pueden eliminar ciertos tipos de ruidos empleando filtros lineales, pero los filtros gaussianos y filtros de mediana son los más empleados para este propósito.. 19.
(31) Por ejemplo, el filtro de mediana es muy útil removiendo el ruido impulsivo de una fotografía, de ahí que se haya empleado para la realización de la investigación. Primero se pasa un filtro de mediana con una máscara de 3x3 píxeles y en caso de no detectar ningún candidato a matrícula se le pasa entonces el mismo filtro pero variando la máscara a 5x5, 7x7 y 9x9 píxeles. 2.2.2 Filtro de mediana Este filtro se basa en reemplazar el nivel de gris de cada píxel por la mediana de los niveles de gris en un entorno de este píxel, resolución del filtro de mediana, siendo este método muy efectivo si lo que se desea preservar es la agudeza de los bordes de la imagen. En la investigación se emplea el filtro de mediana de Matlab medfilt2, lo que hace es sustituir el nivel de gris del píxel que se está analizando por el nivel de gris del píxel que corresponde con la mediana. Para determinar la mediana se ordenan los píxeles teniendo en cuenta todos los niveles de gris del píxel que se quiere transformar y todos los píxeles vecinos de forma ascendente, para luego determinar la mediana por medio de la ecuación 3. Donde „N‟ es el número de píxeles analizados. (3). En la figura 5 se muestra como se suavizan las regiones de altas frecuencias a partir de aplicarle un filtro de mediana a la imagen en escala de grises.. Fig. 5: Empleo de un filtro de mediana a una imagen en escala de grises. Una vez filtrada la imagen se crea una estructura elemental de forma rectangular de 3x12 píxeles, debido a que las matrículas de los automóviles poseen dicha 20.
(32) forma, y se emplean los operadores morfológicos de erosión y de dilatación con la estructura elemental creada para de esta manera eliminar los pequeños detalles de la imagen y separar las regiones de interés a través de la erosión y luego la ampliación de los mismos a partir de la dilatación. Para crear la estructura elemental se emplea la función de Matlab strel, y para la erosión y dilatación las funciones de Matlab imerode e imdilate respectivamente. En la figura 6 se muestra como queda la imagen filtrada luego de ser aplicados los filtros morfológicos de erosión y dilatación.. Fig. 6: Imagen filtrada luego de ser aplicados los filtros morfológicos de erosión y dilatación. 2.2.3 Matemática morfológica La matemática morfológica se basa en un análisis geométrico de formas y texturas de imágenes. Los operadores morfológicos trabajan con dos imágenes, la imagen que se quiere procesar, o imagen activa como se le suele llamar, y la estructura elemental. Cada estructura elemental tiene una forma diseñada, lo cual puede ser considerado como una sonda o un filtro que se le pasa a la imagen activa; por lo que la imagen activa puede ser modificada explorándola con diversas estructuras elementales. Las operaciones elementales en la morfología matemática son dilación y erosión, las cuales pueden estar combinadas consecutivamente para producir otras operaciones, como la apertura y el cierre.(Shih, 2010).. 21.
(33) 2.2.3.1 Operadores morfológicos Dilatación Sea „A‟ y „B‟ conjuntos de. y Ø representando al conjunto vacío, la dilatación de. „A‟ por „B‟ es denotada como. y viene dada por la ecuación 4. { | ̂. }. (4). Dicha ecuación se basa en la obtención de la reflexión de „B‟ sobre su origen y cambiar esta reflexión por „z‟, tal que ̂ y „A‟ se solapen en al menos un elemento distinto de cero. Basado en esta interpretación la ecuación 4 puede ser escrita de la forma siguiente. { |[ ̂. ]. }. (5). Comúnmente „B‟ es referido a la estructura elemental que se le pasa a la imagen „A‟ como una máscara de convolución con la diferencia que la convolución se basa en operaciones aritméticas y la dilatación lo que hace es mover a „B‟ respecto a su origen, y desplazarlo después sucesivamente de tal forma que se deslice sobre el conjunto „A‟. (yan-ying et al., 2010)(Malpartida, 2003) La dilatación toma cada píxel del objeto con valor a 1 y le pone un valor de 1 a todos aquellos píxeles pertenecientes al fondo que tengan una conectividad con el píxel del objeto, o sea, pone a 1 los píxeles del fondo vecinos a los píxeles del objeto.(Mendoza and Beltrán, 2009) Erosión Sea „A‟ y „B‟ conjuntos de. , la erosión de „A‟ por „B‟ es denotada como. y. viene dada por la ecuación 6. { |. }. (6). Dicha ecuación indica que la erosión de „A‟ por „B‟ es el conjunto de todos los puntos de „z‟ tal que „B‟, trasladado por „z‟, está contenido en „A‟. La erosión es la operación contraria a la dilatación por lo que ambas se pueden relacionar, o sea se puede aplicar la operación inversa siguiendo la ecuación 7. (yan-ying et al., 2010). 22.
(34) ̂. (7). La erosión toma cada píxel del objeto que tiene una conectividad con los píxeles del fondo y los coloca a 0, o sea pone a 0 todos los píxeles del objeto vecinos a los píxeles del fondo. (Mendoza and Beltrán, 2009) Apertura y cierre Son las combinaciones de erosión/dilatación y dilatación/erosión respectivamente, que tienen como objetivo simplificar la imagen. La apertura generalmente alisa los contornos de los objetos rompiendo estrechas uniones entre objetos de la imagen o eliminando objetos muy estrechos, y eliminando prolongaciones finas de los objetos. El cierre tiende a alisar los contornos de los objetos pero realizando la operación contraria a la apertura pues este generalmente incrementa el grosor de las estrechas uniones entre objetos y de las finas prolongaciones de estos. Además de eliminar pequeños huecos y rellenar las irregularidades de los contornos de los objetos. Apertura La apertura de „A‟ por „B‟ es denotada como. y viene dada por la ecuación. 8. (8) Cierre El cierre de „A‟ por „B‟ es denotada como. y viene dada por la ecuación 9. (9). Dilatación en escalas de grises La dilatación en escalas de grises de „f‟ por „b‟ es denotada como. y viene. dada por la ecuación 10. {. |. }. (10). 23.
(35) Donde. y. son los dominios de „f‟ y „b‟ respectivamente. La condición de que y que. ; es análoga a la definición de la dilatación. binaria en la cual los dos conjuntos tienen que ser solapados por al menos un elemento. Erosión en escalas de grises La erosión en escalas de grises de „f‟ por „b‟ es denotada como. y viene dada. por la ecuación 11. {. Donde. y. |. }. (11). son los dominios de „f‟ y „b‟ respectivamente. La condición de que y que. ; es análoga a la definición de la erosión. binaria en la cual la estructura elemental tiene que estar completamente contenida por el conjunto que está siendo erosionado. (yan-ying et al., 2010) Luego se haya una imagen resultante entre la diferencia de la imagen filtrada por el filtro de mediana y la que se obtiene una vez que se aplicaron los operadores morfológicos, para de esta manera lograr eliminar los lugares de la imagen que poseen un nivel demasiado oscuro, y así resaltar en esta, los lugares con predominio de colores claros y de mayor intensidad como es el caso de la matrícula, la cual es de color blanco y está fabricada de un material reflexivo, lo que hace que esta región sea de las más brillantes en la imagen, siendo esto una característica importante a la hora de la localización de las matrículas. Para lograr esto, se emplea la función de Matlab imsubtract que consiste en la resta de cada elemento de un arreglo „x‟ con su correspondiente elemento de un arreglo „y‟, donde los elementos de estos arreglos deben ser de la misma clase y deben poseer el mismo tamaño. En la figura 7 se muestra como queda la imagen resultante luego de ser aplicada la función imsubtract, y se puede apreciar claramente como las partes más oscuras de la imagen que no son de interés se han eliminado completamente.. 24.
(36) Fig. 7: Imagen resultante de la resta de las imágenes por medio de la función imsubtract de Matlab. Una vez que se haya la imagen resultante se realiza la transformación a binario. Esta transformación es muy importante pues al llevar la imagen a dos niveles solamente el tratamiento de estás es mucho más sencillo. Como con la operación anterior se logran eliminar las partes más oscuras de la imagen, a la hora de determinar el umbral para la división de dos clases de la imagen quedan resaltadas las zonas claras de la imagen como es la matrícula. No obstante a esto se decide que las 80 filas superiores de la imagen sean colocadas a 0 pues la matrícula casi nunca se encuentra ubicada en esta posición de la imagen, y con este paso del algoritmo se logra aumentar considerablemente el desempeño del mismo a la hora de la localización de la matrícula en la imagen. En la figura 8 se muestra un ejemplo de la transformación en binario de una imagen.. Fig. 8: Transformación en binario de una imagen. 2.2.4 Transformación en binario La binarización consiste en convertir una imagen en niveles de gris, en blanco y negro. La binarización se basa en establecer un umbral a partir del cual se van a comparar los niveles de grises de la imagen y si el valor con que se compara es 25.
(37) mayor que el umbral se pone a 1 (blanco) de lo contrario se pone a 0 (negro), como se muestra en la ecuación 12. (12). {. Para la transformación de las imágenes en binario se emplea la función de Matlab im2bw, a la cual se le tiene que pasar el nivel de umbral a partir del cual se va a separar la imagen en dos clases. Para determinar el umbral se emplea la función de Matlab graythersh la cual emplea el método de Otsu. 2.2.4.1 Método de Otsu Esta técnica calcula el valor de umbral de forma que la dispersión dentro de cada segmento sea lo más pequeña posible, pero al mismo tiempo sea lo más alta posible entre segmentos diferentes. Para ello se calcula el cociente entre ambas varianzas y se busca que este cociente sea máximo, siendo este valor el umbral buscado. En la ecuación 13 se muestra la probabilidad de ocurrencia de un nivel de gris „i‟ en la imagen. Donde „N‟ es el número de píxeles de la imagen y. el. número de píxeles con nivel de gris „i‟, donde „i‟ va desde 0 hasta 255. (13). En el caso de la umbralización en dos niveles los píxeles son divididos en dos clases:. , con niveles de gris, [1,…, t] y. , con niveles de gris, [t+1,…, L]; donde. „t‟ es la variable que buscamos y „L‟ es el último de los niveles de gris en una imagen. En las ecuaciones 14 y 15 se determinan la distribución de probabilidad de los niveles de gris para ambas clases. (14). (15) Donde. y. se determinan a través de las ecuaciones mostradas a. continuación.. 26.
(38) (16). ∑. (17) ∑. En las ecuaciones 18 y 19 se determinan las medias para ambas clases. (18). ∑. (19) ∑. En la ecuación 20 se determina la media total de la imagen. (20) A través de la ecuación 21 se determina la varianza entre clases de una imagen binarizada. (21) Para la binarización la meta es conseguir un valor de t tal que. sea máximo, es. decir, cuando la varianza entre dos clases sea máxima.(Industrial, 2005) Una vez que se tiene la imagen binarizada se emplea. la función de Matlab. bwareaopen la cual elimina las manchas en la imagen que posean una resolución menor que 40 píxeles, lo cual se puede apreciar claramente en la imagen mostrada en la figura 9.. 27.
(39) Fig. 9: Borrado de pequeñas manchas con una resolución menor que 40 píxeles. 2.3 Localización de la matrícula La localización de la matrícula en la imagen es una de las etapas más difíciles del algoritmo debido a la gran diversidad de automóviles existentes con diferentes formas y ruidos asociados con peatones, bicicletas u otros autos que pueden hacer que el algoritmo tienda a equivocarse. Además esta etapa se ve seriamente afectada cuando las condiciones de iluminación no son adecuadas (horario nocturno en entornos en los cuales no hay alumbrado artificial adecuado), las matrículas se encuentran deformadas o sucias, entre otros. El primer paso a la hora de localizar la matrícula en la imagen es la detección de bordes verticales de la imagen empleando el operador de Sobel. 2.3.1 Detección de bordes por Sobel El operador Sobel es un detector de bordes muy usado el cual emplea un par de matrices de 3x3 píxeles que son simétricamente horizontales y verticales, y que la suma de todos sus elementos es cero. Estas matrices son convolucionadas con la imagen original píxel a píxel y el máximo valor de la convolución es considerado como el valor del píxel de salida detectándose de esta manera los bordes de la imagen. Estas matrices son mostradas en la figura 10; la primera de ellas determina los bordes verticales y la segunda los bordes horizontales en la imagen.(yan-ying et al., 2010) En la figura 11 se muestra la detección de bordes de una imagen en binario a través del empleo del operador vertical de Sobel.. 28.
(40) Fig. 10: Operadores gradiente de Sobel.. Fig. 11: Operador de Sobel vertical aplicado a una imagen. Cuando se tienen los bordes de los elementos de la imagen detectados se realiza nuevamente la dilatación para aumentar el tamaño de los bordes y cerrar los contornos detectados. Una vez realizado esto se emplea la función de Matlab imfill para rellenar los huecos de los objetos detectados y se aplica nuevamente la función de Matlab bwareaopen pero esta vez con una resolución de 1500 píxeles que es aproximadamente la resolución que tienen los caracteres de las matrículas en las imágenes captadas, y así de esta manera eliminar los caracteres de la placa y solamente quedarnos con la forma de la misma. En la figura 12 se muestra como se transforma una imagen con los bordes detectados una vez que se le aplique el operador morfológico de dilatación y la función de Matlab imfill; y en la figura 13 se muestra como se eliminan las manchas en la imagen con una resolución menor que 1500 píxeles una vez que se ha empleado la función de Matlab bwareaopen.. 29.
(41) Fig. 12: Empleo del operador morfológico de dilatación y la función de Matlab imfill a una imagen con los bordes detectados.. Fig. 13: Borrado de los manchas en la imagen con una resolución menor que 1500 píxeles. Mediante la función de Matlab bwlabel se determinan los elementos conexos en la imagen para de esta manera analizar uno a uno todos los objetos captados y definir cuales cumplen con las características de una matrícula. Esta función de Matlab devuelve una imagen del mismo tamaño a la de entrada con la particularidad de que a todos los valores del fondo le asigna valor 0, mientras que al primer objeto detectado dentro de la imagen le asigna a todos sus píxeles valor 1, al segundo objeto detectado le asigna a todos sus píxeles valor 2, y así sucesivamente hasta el último objeto. Una vez empleada la función bwlabel son evaluados todos los candidatos según la relación de alto/ancho de la matrícula, de esta manera los candidatos que posean una relación menor a 0.16 o mayor a 0.32 son eliminados. Además son eliminados aquellos candidatos que posean un área mayor que 10 000 píxeles y un mayor 30.
(42) número de filas que columnas. En la figura 14 se muestra como una vez evaluados los candidatos teniendo en cuenta las características de las matrículas estos son reducidos en gran medida. En la mitad superior de la. imagen se. observa cómo se obtiene la matrícula, pero en la mitad inferior se obtienen más de un candidato, los cuales poseen características muy similares a las matrículas en cuanto a su forma.. Fig. 14: Evaluación de los candidatos a matrícula. Como se puede observar en la figura este paso del algoritmo tiene el inconveniente de poder detectar varios candidatos por lo que se decidió realizar un multiclasificador empleando el AdaBoost a partir de redes neuronales para los casos en que sean identificadas más de 2 regiones de interés, para aumentar la eficacia del algoritmo. Esta etapa es muy necesaria pues en caso de no emplear el clasificador se tendrían que evaluar cada una de las regiones y esto consumiría mucho más tiempo de procesamiento.. 31.
(43) 2.3.2 Bagging Bagging es una técnica donde los datos son tomados de un dataset original en „S‟ tiempos creándose „S‟ nuevos dataset del mismo tamaño al original. Cada dataset es construido por la selección aleatoria de datos del original con reposición; la reposición indica que en un mismo dataset pueda ser seleccionado el mismo dato más de una vez. Después de tener las „S‟ dataset construidos, se aplica el algoritmo de aprendizaje a cada uno individualmente. Cuando se quiera clasificar un nuevo dato este se le pasa a los „S‟ clasificadores y se toma como respuesta el que tenga una mayoría de voto. (Harrington, 2012) 2.3.3 Boosting El boosting es una técnica muy similar al bagging, pero en boosting los clasificadores. diferentes. son. entrenados. secuencialmente.. Cada. nuevo. clasificador es entrenado basado en su desempeño durante el entrenamiento. El boosting hace nuevos clasificadores sobre datos que son previamente clasificados por anteriores clasificadores. El boosting se diferencia al bagging porque la salida es calculada a partir de la suma de los pesos de los clasificadores. En boosting los clasificadores no tienen los mismos pesos como en bagging pues los pesos son asignados basándose en cuan exitosos fueron los clasificadores en las iteraciones previas. Existen numerosas versiones del boosting pero solo nos referiremos a la denominada AdaBoost que es una de las técnicas más empleadas en la actualidad y es la que se emplea en la realización de la investigación. 2.3.4 AdaBoost El AdaBoost es un algoritmo que se basa en la selección de varios clasificadores débiles para la construcción de un nuevo clasificador fuerte. Se denominan clasificadores débiles pues solamente es necesario que estos posean una probabilidad de acierto mayor o igual a un 51%. En Adaboost un peso es aplicado a cada ejemplo en el entrenamiento de los datos el cual es denotado por el vector D, e inicialmente todos serán iguales. Un clasificador débil es entrenado primeramente a partir de un dataset. Los errores 32.
(44) del clasificador débil son calculados y el clasificador débil es entrenado en un segundo tiempo con la misma base de datos. En este segundo tiempo los pesos del entrenamiento son ajustados considerando los ejemplos que fueron incorrectamente clasificados. El objetivo final de AdaBoost es obtener una respuesta de todos los clasificadores entrenados en cada iteración, por lo que para esto se le asigna a cada clasificador un valor de α basado en los errores cometidos por cada clasificador. En la ecuación 22 se muestra como se determina el error de los clasificadores, y en la ecuación 23 como se determina el valor de α. En la figura 15 se muestra una representación esquemática bien detallada del AdaBoost. (Harrington, 2012) (22). (23). Fig. 15: Representación esquemática del AdaBoost.(Harrington, 2012) Una vez que se ha determinado el valor de. se pueden actualizar los pesos del. vector „D‟ si la predicción del clasificador fue correcta como se muestra en la ecuación 24, en caso de que la predicción fuese incorrecta se actualizan los pesos del vector D como se muestra en la ecuación 25.. 33.
(45) (24) (25). Después de haber determinado el valor de „D‟ el AdaBoost comienza otra iteración, hasta lograr que el error en el entrenamiento sea 0 o hasta que el número de clasificadores débiles sea un valor definido por el usuario.(Harrington, 2012) Como se menciona anteriormente este algoritmo se basa en la obtención de un clasificador fuerte a partir de varios clasificadores débiles. Para la realización de este trabajo se decidió emplear como clasificadores débiles las redes neuronales, creándose 17 redes neuronales y un alfabeto para el entrenamiento de estas, formado por 150 imágenes de matrículas y 150 imágenes de errores. Las imágenes de errores se tomaron de fragmentos de los vehículos como carteles, focos, defensa, entre otras partes que suelen hacer fallar el algoritmo. En la figura 16 se muestra un fragmento de este alfabeto creado para el entrenamiento de las redes neuronales.. Fig. 16: Fragmento del alfabeto creado para el entrenamiento de las redes neuronales. En las 17 redes neuronales a la hora de pasarle la imagen ya sea para su entrenamiento o para clasificarlo una vez construida la red neuronal, las imágenes fueron modificadas a una resolución fija de 15x80 píxeles, por lo que el número de neuronas que presenta la capa de entrada es de 1200. Además fueron 34.
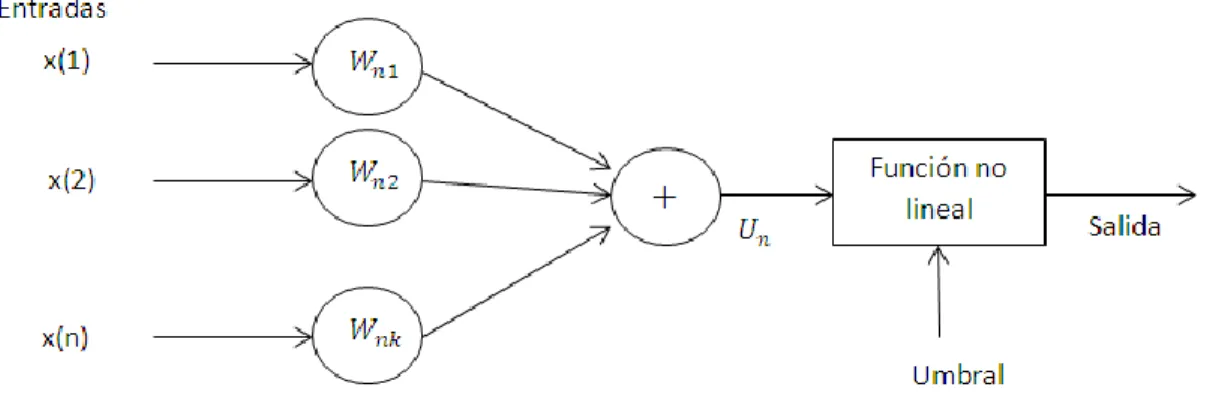
(46) empleadas 2 neuronas en la capa de salida debido a que son dos clases las que se quieren clasificar. El número de neuronas que forman las capas de entrada y salida está determinado por el problema, mientras que el número de capas ocultas y el número de neuronas en cada una de ellas no está fijado ni por el problema ni por ninguna regla teórica por lo que el diseñador es quien decide esta arquitectura en función de la aplicación. Lo lógico es pensar que la mejor solución sería implementar una red con muchas capas ocultas y un gran número de neuronas, pero esto trae consigo un aumento considerable de la carga computacional, lo que implica una mayor dificultad de implementación en tiempo real y un crecimiento en el tiempo de aprendizaje por parte de la red.(Serrano et al., 2009) Una vez planteado esto se realizaron varias pruebas variando el número de neuronas con que iba a contar la capa oculta y se decidió el empleo de 60 debido a que fue con el cual se lograron mejores resultados. 2.3.5 Redes neuronales Una red neuronal es la modelación matemática aproximada de las estructuras y funcionalidades de las redes neuronales biológicas. El modelo artificial de una neurona está compuesto por un conjunto de conexiones, estas conexiones pueden ser excitadoras (presentan signo positivo), o inhibidoras (conexiones negativas); y por pesos o sinapsis que determinan el comportamiento de la neurona. Además está formado por un sumador que se encarga de sumar todas las entradas multiplicadas por las respectivas sinapsis, una función de activación no linear para limitar la amplitud de la salida de la neurona, y un umbral exterior que determina el umbral por encima del cual la neurona se activa. En la figura 17 se muestra el esquema de un modelo neuronal en el cual se ven reflejados todos los componentes por los que está compuesto y que han sido explicados.(Serrano et al., 2009). 35.
(47) Fig. 17: Esquema de un modelo neuronal. Aunque parece un principio básico y sencillo, el verdadero potencial de este campo de la inteligencia artificial surge cuando se comienzan a interconectar varias neuronas para conformar una red. En la ecuación 26 se enuncia la expresión matemática de una neurona: (26) (∑. En la cual. es la entrada iésima,. ). es el factor de ponderación correspondiente. a cada entrada y b es el factor de polarización de la neurona o umbral y. es la. función de transferencia. Es necesario conocer que la función de transferencia es el factor que define las propiedades de la neurona y puede ser cualquier función matemática, aunque las empleadas principalmente son, las funciones paso unitario, lineal y no lineal (sigmoidea). Algoritmo de aprendizaje back propagation El algoritmo de aprendizaje back propagation es un algoritmo de descenso por gradiente que retropropaga las señales desde la capa de salida hasta la capa de entrada optimizando los valores de los pesos sinápticos mediante un proceso iterativo que se basa en la minimización de la función de coste.(Serrano et al., 2009) Lo más habitual es minimizar alguna función monótona creciente del error, como el valor absoluto del error o el error medio cuadrático, y la más utilizada es la cuadrática, que viene dado por: 36.
Figure




+7





Documento similar
"No porque las dos, que vinieron de Valencia, no merecieran ese favor, pues eran entrambas de tan grande espíritu […] La razón porque no vió Coronas para ellas, sería
entorno algoritmo.
The 'On-boarding of users to Substance, Product, Organisation and Referentials (SPOR) data services' document must be considered the reference guidance, as this document includes the
In medicinal products containing more than one manufactured item (e.g., contraceptive having different strengths and fixed dose combination as part of the same medicinal
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
Package Item (Container) Type : Vial (100000073563) Quantity Operator: equal to (100000000049) Package Item (Container) Quantity : 1 Material : Glass type I (200000003204)
