BIBLIOTECAS DEL TECNOLÓGICO DE MONTERREY
PUBLICACIÓN DE TRABAJOS DE GRADO
Las Bibliotecas del Sistema Tecnológico de Monterrey son depositarias de los trabajos recepcionales y de
grado que generan sus egresados. De esta manera, con el objeto de preservarlos y salvaguardarlos como
parte del acervo bibliográfico del Tecnológico de Monterrey se ha generado una copia de las tesis en
versión electrónica del tradicional formato impreso, con base en la Ley Federal del Derecho de Autor
(LFDA).
Es importante señalar que las tesis no se divulgan ni están a disposición pública con fines de
comercialización o lucro y que su control y organización únicamente se realiza en los Campus de origen.
Cabe mencionar, que la Colección de
Documentos Tec,
donde se encuentran las tesis, tesinas y
disertaciones doctorales, únicamente pueden ser consultables en pantalla por la comunidad del
Tecnológico de Monterrey a través de Biblioteca Digital, cuyo acceso requiere cuenta y clave de acceso,
para asegurar el uso restringido de dicha comunidad.
El Tecnológico de Monterrey informa a través de este medio a todos los egresados que tengan alguna
inconformidad o comentario por la publicación de su trabajo de grado en la sección Colección de
Redes Neuronales en el Pronóstico del Precio de Acciones del
Mercado de Valores Edición Única
Title
Redes Neuronales en el Pronóstico del Precio de Acciones
del Mercado de Valores Edición Única
Authors
Bertha Adriana Alarcón Cisneros
Affiliation
ITESMCampus Monterrey
Issue Date
19981201
Item type
Tesis
Rights
Open Access
Downloaded
19Jan2017 05:46:12
REDES NEURONALES EN EL PRONÓSTICO
DEL PRECIO DE ACCIONES DEL M E R C A D O DE
VALORES
T E S I S
M A E S T R Í A EN CIENCIAS
E S P E C I A L I D A D EN I N G E N I E R Í A D E S I S T E M A S C O M P U T A C I O N A L E S
I N S T I T U T O T E C N O L Ó G I C O Y D E E S T U D I O S S U P E R I O R E S DE M O N T E R R E Y
P O R
B E R T H A A D R I A N A A L A R C Ó N C I S N E R O S
REDES NEURONALES EN EL PRONÓSTICO
DEL PRECIO DE ACCIONES DEL MERCADO DE VALORES
P O R
B E R T H A A D R I A N A A L A R C Ó N CISNEROS
TESIS
Presentada a la División de Graduados e Investigación Este trabajo es Requisito Parcial
para Obtener el Grado de
Maestra en Ingeniería de Sistemas Computacionales
I N S T I T U T O T E C N O L Ó G I C O Y D E E S T U D I O S S U P E R I O R E S D E M O N T E R R E Y
I N S T I T U T O T E C N O L Ó G I C O Y D E E S T U D I O S S U P E R I O R E S D E M O N T E R R E Y
DIVISIÓN DE GRADUADOS E INVESTIGACIÓN
P R O G R A M A DE GRADUADOS EN INFORMÁTICA
Los miembros del comité de tesis recomendamos que la presente tesis de
Bertha Adriana Alarcón Cisneros sea aceptada como requisito parcial para obtener el grado académico de Maestra en Ciencias, especialidad en:
INGENIERÍA DE SISTEMAS COMPUTACIONALES
Comité de tesis:
Dr. Carlos Scheel Mayenberger
Director del Programa de Graduados en Computación, Información y Comunicaciones.
Resumen
En esta tesis se experimenta una metodología para la predicción de precios de acciones y valores. En específico se experimenta con las acciones del mercado de valores en México para pronosticar el precio de cierre y la tendencia futura del mismo. La metodología aplicada es la teoría de las redes neuronales, la cual pertenece al área de la inteligencia artificial dentro de las ciencias computacionales.
Las variables del mercado de valores se caracterizan por su no linealidad en el tiempo. De las redes neuronales existentes se experimentó con las redes de retropro pagación y LVQ. La primera red se aplicó por su capacidad de mapeo de funciones no lineales que se usó para predecir el precio futuro de la variable. Por otro lado, se experimentó con la red LVQ debido a su capacidad de clasificar patrones; el objetivo de la clasificación fue detectar la tendencia futura del precio.
El horizonte de predicción definido fue de un día y la alimentación a la red fue de las series de tiempo de los precios diarios de la acción a predecir. Se experimentó con distintos factores del aprendizaje de las redes como la de normalización de las series, la cantidad de historia necesaria para el aprendizaje y la función de transferencia entre los nodos de la red.
En la evaluación del rendimiento de las redes se establecieron criterios en base a una simulación de inversión de capital en el mercado de valores. En dicha simulación, se observaron las ganacias y el porcentaje de tendencias pronosticadas acertadamente en el período especificado, tales resultados fueron comparados contra los por el análisis técnico.
Por los resultados de la red de retropropagación se concluyó que es difícil el mapeo del precio a partir de la definición del problema. Sin embargo, para la predicción de la tendencia futura de las acciones, las redes obtuvieron buenos resultados como método de pronóstico. En comparación con los promedios móviles las redes superaron su rendimiento.
Agradecimientos
Agradezco al Consejo Nacional de Ciencia y Tecnología por su aceptación en el progra ma de apoyo financiero para la realización de estudios de postgrado; al doctor Manuel Valenzuela y a Eduardo Moreno por guiarme en el desarrollo de este trabajo final de la maestría. Gracias al Dr. Rogelio Soto Rodríguez por ser parte del comité de tesis, así como al Dr. Horacio Martínez Alfaro.
A mis amigos Mario Vera, Adolfo Garza y Víctor Zamora expreso especial agrade cimiento por su apoyo y contribuciones. Agradezco a mi familia y amigos su confianza y compańía en este logro. Deseo compartir con todos ellos la felicidad de finalizar este trabajo.
índice General
índice de Tablas vii índice de Figuras viii Capítulo 1 Introducción 1
1.1 Antecedentes 1 1.2 Objetivo de la tesis 3 1.3 Organización del documento 4
Capítulo 2 Redes neuronales 5
2.1 Posición de las redes neuronales dentro de las metodologías de solución
a problemas 5 2.2 Terminología y conceptos básicos 7
2.2.1 Estructura básica y funcionamiento de una neurona 7
2.2.2 Representación de la información 8 2.2.3 Organización de las neuronas 8 2.3 Aprendizaje en las redes neuronales 10
2.3.1 Clasificación de procesos de aprendizaje 11
2.4 Métricas de aprendizaje de la red 13
2.4.1 Convergencia 13 2.4.2 Generalización 14 2.4.3 Estabilidad 15
2.5 Resumen 16
Capítulo 3 Predicción de precios de acciones 17
3.1 Métodos de predicción de series de tiempo 17
3.1.1 Series de tiempo 18 3.1.2 Enfoque cualitativo 19 3.1.3 Enfoque cuantitativo 19
3.3 Redes neuronales como método de predicción 21
3.3.1 Revisión de trabajos anteriores 22
3.4 Resumen 25
Capítulo 4 Diseńo de experimentación 26
4.1 Descripción de experimentación 26
4.2 Datos disponibles 27 4.3 Representación de los datos 28
4.4 Modelos de redes propuestas para la predicción 28
4.5 Generación de patrones 29 4.5.1 Normalización 30 4.6 Variación de tipo de red y sus parámetros 32
4.7 Evaluación de pronósticos 33 4.7.1 Ganancia en la simulación de inversión 33
4.7.2 Porcentaje de tendencias correctas 34 4.7.3 Frecuencia de ganancia mayor a ganancia neta 35
4.7.4 Ejemplo de criterios de evaluación 35 4.8 Comparación de pronósticos de la red neuronal contra los promedios
móviles 36 4.9 Equipo de cómputo de desarrollo 37
4.10 Resumen 37
Capítulo 5 Experimentación de redes neuronales en la predicción de
precios y tendencias de variables del mercado 38
5.1 Retropropagación en la predicción del precio de cierre 38 5.2 Retropropagación y LVQ en el pronóstico de la tendencia del precio . . 39
5.2.1 Definición de la prueba 39 5.2.2 Selección de red, normalización e historia 41
5.2.3 Ciclos de entrenamiento 43 5.2.4 Interpretación de los resultados 44
5.3 LVQ en la clasificación de la tendencia del precio 45
5.3.1 Definición de la prueba 45 5.3.2 Selección de conciencia y nodos en la capa de Kohonen 45
5.3.3 Tamańo de patrones de entrada 47 5.3.4 Interpretación de los resultados 47 5.4 Evaluación del rendimiento de las redes neuronales 48
5.5 Resumen 53
Capítulo 6 Conclusiones y trabajos futuros 55
6.2 Trabajos futuros 56
Apéndice A Tablas 58
A . l Generación de patrones 58 A.2 Archivos de datos de pruebas 60
índice de Tablas
1.1 Ventajas y desventajas de los métodos de pronóstico más usados. . . . 2
2.1 Patrones de la función de OR con la salida deseada 12
3.1 Resultados del análisis de discriminación múltiple contra los de la red
neuronal de retropropagación 24
4.1 Series de tiempo disponibles del precio de cierre de variables del mercado. 28
4.2 Estructura de patrones 30 4.3 Parámetros variados de las redes de retropropagación y LVQ 32
4.4 Tabla de contingencia de pronósticos 34 4.5 Cálculo de ganancia de los pronósticos 36 4.6 Resultados de ganancias obtenidas en la simulación de inversión . . . . 36
4.7 Tabla de ganancias acumuladas 37
5.1 Archivos de entrenamiento 40 5.2 Variables fijas en la prueba 40 5.3 Ejemplo de evaluación de un entrenamiento 41
5.4 Resultados de las evaluaciones de los experimentos 42
5.5 Resultados de experimentos 43 5.6 Archivos de datos de prueba 45 5.7 Evaluaciones de variación de conciencia y nodos de Kohonen 46
5.8 Resultados de variación de número de elementos de los patrones 47 5.9 Descripción de redes para la obtención de pronósticos finales 48
5.10 Ganancia obtenida por las redes neuronales 49 5.11 Porcentajes de tendencias correctas obtenidas por LVQl y LVQ2. . . . 50
5.12 Mejores resultados de la red LVQ 50 5.13 Ganancia obtenida de los promedios móviles y las redes neuronales. . . 51
5.14 Porcentajes de tendencias correctas obtenidas por los promedios móviles. 52
5.15 Resultados globales de redes neuronales y promedios móviles 52
[image:12.612.127.548.186.664.2]índice de Figuras
2.1 Posición de las redes neuronales 6 2.2 Estructura de una neurona 8 2.3 Ejemplo de estructura de una red neuronal 9
2.4 Gráfica del aprendizaje de juego de ajedrez 11 2.5 Nodo de red con alimentación hacia atrás 13
2.6 Convergencia de la red neuronal 14 2.7 Gráfica de función de sigmoidal asimétrica 14
3.1 Serie de tiempo Telmex del 1 de marzo de 1994 al 2 de septiembre de 1997. 18 3.2 Identificación gráfica de línea de tendencia del precio de cierre de acciones. 20 3.3 Gráfica del promedio móvil del precio de cierre la acción de Telmex. . . 21
3.4 Predicción en el mercado de valores 23
4.1 Diagrama del proceso de experimentación para el cálculo de predicción
por medio de redes neuronales 27 4.2 Alimentación de la red por series de tiempo 28
4.3 Gráfica de la función tangente hiperbólica 31
4.4 Ganancia de los entrenamientos 34
4.5 Error vs. aciertos 35
5.1 Representación de primera prueba 39 5.2 Gráfica de ganancia de las redes de retropropagación y LVQ 42
5.3 Gráfica promedio y promedio menos desviación del RMS durante el en
trenamiento 44 5.4 Gráfica del error RMS durante el entrenamiento 44
5.5 Gráficas de RMS variando el factor de conciencia 46
5.6 Resultados 53
Capítulo 1
Introducción
1.1 Antecedentes
Pocas actividades han sido estudiadas tan exhaustivamente y por tantas áreas como las operaciones de las acciones del mercado de valores. Además de la complejidad del problema, al anticipar correctamente los precios es posible obtener cierta recompensa o incluso modificar el sistema.
En cuanto a la búsqueda de modelos que describan tal sistema económico, la complejidad existe por la no linealidad y el ruido inherente en las variables que influyen en tal área. Las variables que influyen en ios precios de las acciones se pueden clasificar en económicas, políticas, sociales y psicológicas.
Estas variables hacen que el cambio del precio sea no lineal debido a que su ajuste generalmente no es proporcional a la cantidad del cambio del precio del valor real de la acción. Dentro de las variables económicas se encuentran: la inflación, el valor de la moneda, el ciclo económico del país, y la liquidez de la empresa a la que pertenece la acción. Por otro lado, el cambio de gobernantes, las modificaciones en leyes de mercado, el establecimiento de reglas sobre productos o servicios de influencia en la economía del país; son variables de tipo político que afectan en el precio de las acciones. En lo que se refiere a las variables sociales, se ha observado en México, que eventos sociales de transcendencia política tienen gran influencia en el mercado de valores. Ejemplos de estos eventos han sido levantamientos armados y atentados a candidatos políticos. Por último, otra variable en el análisis de precios en el mercado de valores es la psicológica. Epstein se refiere a ella como los temores de las masas que, en un momento dado, influyen en el comportamiento del mercado accionario; particularmente en los máximos de los precios [1]. Por ejemplo, en estudios sobre la psicología del mercado, se entiende que los inversionistas y mercados sobrereaccionan a las malas noticias y subreaccionan a las buenas. Además la cantidad de participantes del mercado con objetivos, reacciones e interrelaciones distintos hacen que los precios sigan un comportamiento no lineal.
Los primeros utilizan la experiencia para realizar un análisis de las variables que puedan influir en la variable a predecir; mientras que los procedimientos cuantitativos se basan en el conocimiento y evaluación de modelos matemáticos con la información histórica. Los métodos cuantitativos de predicción asumen la existencia de ciclos en la infor mación histórica de los precios de las acciones; además suponen que es posible detectar y medir tales ciclos para anticipar precios futuros [2].
Dentro de los métodos cuantitativos más usados actualmente se encuentran los modelos de BoxJenkins (o ARIMA) del área estadística, y el análisis técnico del área económica. Ambos se encuentran clasificados como métodos extrapolativos, es decir, los pronósticos se calculan usando sólo la historia previa de la variable a predecir. Las ventajas y desventajas de estos dos métodos se presentan en la tabla 1.1.
Tabla 1.1: Ventajas y desventajas de los métodos de pronóstico más usados.
Método Ventajas Desventajas
Análisis técnico Fácil de aprender, usar y Por lo sencillo del método entender es fácil cometer errores,
especialmente a largo plazo.
Estadísticos p.e BoxJenkins
La selección de los valo res del modelo permite identificar en los datos más patrones que otros métodos no encuentran.
Difícil de entender; caro por su uso en tiempo de proce samiento
Aún con la existencia de métodos sencillos como el análisis técnico, continúa la búsqueda de métodos cada vez más precisos en la predicción de los precios del mercado. No sólo quienes están directamente involucrados en las operaciones del mercado están interesados en tal objetivo, la complejidad de la predicción también representa un reto para las áreas fuera de la economía que proponen nuevos métodos de resolver problemas.
Las redes neuronales, que pertenecen al área de la inteligencia artificial, son algo ritmos que imitan el aprendizaje del cerebro.
Brown, resume el aprendizaje del cerebro como el proceso de transformar seńales de corto plazo en códigos que después pueden ser utilizados para producir nuevas ins tancias de las percepciones [3]. Una percepción es el resultado obtenido, de los niveles concientes de la mente, de lo que toman los sentidos y asocian con la experiencia ante rior.
En su estructura y operación que imita al cerebro, las redes neuronales son sis temas que consisten en una gran cantidad de elementos simples de procesamiento in
terconectados entre sí. Las conexiones tienen asociado un valor determinado llamado peso, valores que son modificados mediante un proceso de entrenamiento. Una vez entrenada, la red es capaz de obtener una nueva respuesta para una nueva entrada. Así, estos algoritmos son sistemas de procesamiento de información capaces de inferir nuevas instancias a partir de ejemplos.
Los problemas que han abordado las redes neuronales son el procesamiento de patrones y el mapeo de funciones complejas. Ambos se caracterizan por el ruido en los datos y datos incompletos.
En el mapeo de funciones, la eficiencia de las redes es comparable con la de los modelos de regresión no lineales no paramétricos de la estadística. Una ventaja de ellas, es que con muy pocos o ningún supuesto a priori sobre la naturaleza del problema, tienen la habilidad de modelar procesos no lineales [4]. Otra ventaja de las redes neuronales es el aprendizaje incremental que son capaces de realizar, por lo que no es necesario empezar un nuevo análisis cada vez que se presenta un nuevo dato.
1.2 Objetivo de la tesis
En la predicción de los precios de acciones el punto de divergencia o separación entre el enfoque cualitativo y el cuantitativo es conocido como la teoría de camino aleatorio.
Esta teoría establece que los precios de las acciones cotizadas en el mercado de valores siguen una secuencia aleatoria en el tiempo [2]. Esto quiere decir que estadísticamente los datos históricos del precio de las acciones son independientes entre sí, y por conse cuencia, el pronóstico de los precios futuros no puede ser aproximados con referencia única a los precios anteriores.
Esta aparente aleatoriedad de los precios de las acciones incrementa el interés por buscar métodos cuantitativos para su predicción. Tomando en cuenta la hipótesis de los métodos cuantitativos que asumen la existencia de ciclos detectables en los datos históricos de los precios de las acciones, y por ello es posible medirlos, en esta tesis proponemos realizar tal pronóstico con las observaciones secuenciales o series de tiempo del precio futuro de una acción.
La aportación de esta tesis es medir el desempeńo de las redes para el pronóstico de las series de tiempo diarias del mercado de valores tomando como referencia las predicciones de los métodos más comúnmente empleados por el análisis técnico.
1.3 Organización del documento
El pronóstico de los precios de acciones ha sido descrito en el presente capítulo. De la misma forma se describieron los factores que influyen en las variables del mercado. Dichos factores hacen que las variables mencionadas siguan una trayectoria no lineal en el tiempo.
Se describieron además los métodos de solución que se han dado a la predicción. Al considerar la hipótesis de pronosticar cuantitativamente las variables del mercado, se planteó, como objetivo de la tesis, usar los algoritmos de redes neuronales cuyas características son el mapeo de funciones no lineales.
En el siguiente capítulo se posiciona a las redes neuronales como metodología de solución a problemas. Se introducen también los conceptos que se usan en el desarrollo de la tesis; se decriben las características principales de las redes y la forma general en la que se mide su aprendizaje.
En el capítulo 3 se revisan las metodologías empleadas en la predicción de variables del mercado de valores. Además se resume el avance de las redes neuronales en la experimentación de pronósticos de dichas variables.
Posteriormente, en el capítulo 4 se delimita el proceso que se implemento durante la experimentación de variables del mercado de valores de México. Por otro lado, para clasificar a las redes como un buen método de predicción, se describe la forma en la que se evaluaron los resultados de la experimentación.
El capítulo 5 muestra las especificaciones de las pruebas realizadas para encontrar la red, o redes, con mejor rendimiento al simular la inversión de capital en las acciones de prueba. Además se compara el desempeńo de las redes neuronales con el de los promedios móviles.
Capítulo 2
Redes neuronales
En el capítulo anterior se planteó el problema de la predicción de precios de acciones como un problema complejo por la no linealidad y el ruido inherente en los movimientos de los precios en el tiempo.
Como consecuencia del avance tecnológico, han sido desarrollados un gran número de métodos de solución en distintas áreas. Dentro de las ciencias computacionales, la inteligencia artificial es el grupo de métodos de solución a problemas que tratan de imitar el funcionamiento del cerebro y de los sistemas evolutivos. Hasta ahora estos métodos están formados por los sistemas expertos, las redes neuronales, los algoritmos genéticos y la lógica difusa.
En la siguiente sección clasifican los métodos de solución y se ubican los métodos de la inteligencia artificial dentro de esta clasificación. También se introducen los conceptos teóricos y las características principales de las redes neuronales.
2.1 Posición de las redes neuronales dentro de las
metodologías de solución a problemas
Las propiedades computacionales de los métodos de solución agregan un grado de li bertad extra al problema cuando tenemos que decidir si el uso de cierta tecnología es deseable para la aplicación en particular.
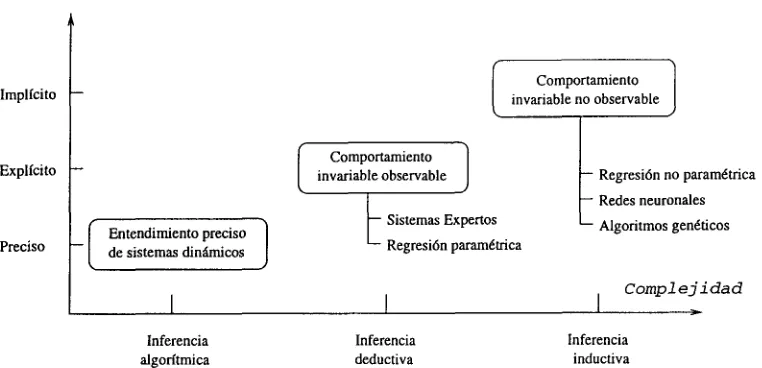
Refenes da una clasificación general de los métodos de solución por su inferencia en métodos de inferencia algorítmica, deductiva o inductiva [4]. Basados en esta clasi ficación, en la figura 2.1 se muestra la posición de las redes y de algunos métodos con los que éstas compiten actualmente. En el eje horizontal se representa la complejidad del sistema, verticalmente se representan los niveles de entendimiento del mismo.
Métodos de inferencia algorítmica Los métodos de inferencia algorítmica se ubi can en el primer nivel de complejidad de solución a problemas. Estas metodologías de solución usan modelos fuertes para extraer las características del sistema de forma que puedan expresarlo en unas cuantas ecuaciones sin parámetros de liber
Conocimiento
Implícito
Comportamiento invariable no observable
Explícito invariable observable Comportamiento — Regresión no paramétrica
— Redes neuronales
Algoritmos genéticos Preciso Entendimiento preciso de sistemas dinámicos
— Sistemas Expertos Regresión paramétrica
Complejidad
Inferencia algorítmica
Inferencia deductiva
Inferencia inductiva
Figura 2.1: Posición de las redes neuronales.
tad. Estos métodos, en los que es posible implementar un algoritmo, son la mejor alternativa de solución en problemas fáciles de modelar.
Métodos de inferencia deductiva En el segundo nivel de solución no tenemos un entendimiento exacto de la dinámica del sistema, por lo que no es posible escribir las ecuaciones que lo describan. Sin embargo, podemos observar en el tiempo que bajo condiciones similares el sistema tiene un comportamiento parecido. Esto permite especificar un conjunto explícito de reglas de forma general para describir su dinámica.
En este nivel de solución a problemas se encuentran los sistemas expertos que hacen fuertes suposiciones con algunos parámetros de libertad. Los sistemas expertos son la combinación del conjunto de reglas que describen el conocimiento de un dominio específico y la heurística definida para llegar a la solución dentro de ese dominio. Normalmente las reglas son definidas por uno o más expertos de la aplicación del sistema.
Otra metodología en esta clasificación es la regresión paramétrica. Este método hace suposiciones sobre la relación entre las variables invoulucradas en el proble ma, y deduce los coeficientes de las variables a partir de los datos observados.
La lógica difusa también está en la categoría de inferencia deductiva. Al igual que los sistemas expertos se basa en la generación de reglas de desición. La diferencia entre ellos es que la lógica difusa define el dominio del problema por rangos numéricos, en lugar de categorías binarias como lo hacen los sistemas expertos.
[image:20.612.125.506.69.253.2]de la experiencia.
Métodos de inferencia inductiva La inducción es aprender una generalización a partir de un conjunto de ejemplos. Estos métodos buscan un modelo para des cribir sistemas en los que es muy difícil observar las reglas que lo definan. En este caso se tienen que realizar dos tareas: estimar un modelo para los datos observados, y analizar las propiedades de los resultados obtenidos por el modelo.
Por lo general en estos problemas se cuenta con una gran cantidad de datos a partir de los cuales se hace una estimación del modelo mediante técnicas de inferencia estadística. Un ejemplo dentro de la estadística es la regresión no paramétrica.
Es importante el análisis de los resultados en estas metodologías para saber las propiedades del modelo estimado; una forma de hacerlo es cuantificar la sensibi lidad de una salida a cambios en cada entrada y estimar la importancia relativa de las entradas.
Los métodos de la inteligencia artificial que se encuentran en este nivel de solución a problemas son las redes neuronales y los algoritmos genéticos. Desde el punto de vista estadístico, las redes neuronales son análogas a los modelos de regresión no lineal no paramétricos (BoxJenkins). El aprendizaje de las redes imita el aprendizaje del cerebro asumiendo que este último almacena la información en las neuronas y sus conexiones, y da una respuesta dependiendo de la fuerza de las conexiones entre ellas.
Por su parte el aprendizaje de los algoritmos genéticos, se basa en los principios naturales de evolución y herencia para encontrar soluciones óptimas a problemas.
Las redes neuronales como métodos de inferencia inductiva aprenden a modelar un problema a partir de la observación de instancias del mismo. En las siguientes secciones se introducen los conceptos básicos y el funcionamiento del aprendizaje de las redes.
2.2 Terminología y conceptos básicos
Las redes neuronales son algoritmos que intentan imitar el procesamiento de informa ción del cerebro mediante elementos básicos de procesamiento o neuronas. En términos computacionales, una red neuronal es una estructura de elementos simples de procesa miento altamente interconectados [5].
2.2.1 Estructura básica y funcionamiento de una neurona
Una neurona es un núcleo celular al que entran y salen filamentos que la conectan con otros elementos del sistema nervioso. Ante un estímulo, las neuronas transmiten a otras
impulsos para generar una respuesta del cerebro. La transmisión se realiza a través de filamentos entre ellas. En las ciencias computacionales llamamos nodo y conexiones al núcleo y a los filamentos, respectivamente.
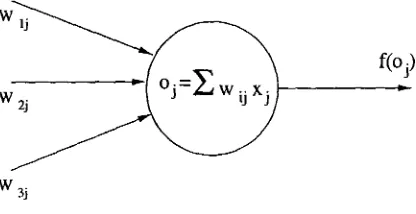
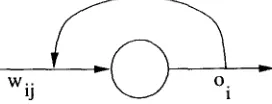
Un nodo recibe impulsos de otros nodos o de elementos periféricos del sistema por medio de las conexiones. Cada conexión tienen un peso asociado u>tJ, una vez que el
nodo recibe tales entradas se dice que ha sido activado, luego calcula su valor de salida mediante una función de transferencia f(oj) como se muestra en la figura 2.2.
W3 i
Figura 2.2: Estructura de una neurona.
La salida, f(oj), es propagada a otros nodos a través de las conexiones y el proceso de activación se repite en los nodos intermedios hasta que se llega a un nodo llamado de salida. Los pesos de las conexiones y el estado de activación de cada nodo representan el conocimiento o aprendizaje distribuidos en la red.
2.2.2 Representación de la información
Los estímulos son introducidos a la red por medio de una representación en forma de esquema que capta los elementos esenciales del problema a aprender. Cada estímulo que entra a la red, es una instancia de dicho problema y se le llama patrón o vector de aprendizaje.
En la representación, el problema se pasa a otro dominio de los datos en el que existe el problema análogo y se intenta realizar la solución, en lugar de tratar con el problema originalmente planeado. En este sentido, una representación es un dispositivo heurístico para examinar y posteriormente resolver el problema [6, 7]. La representación es llamada también normalización o preprocesamiento.
2.2.3 Organización de las neuronas
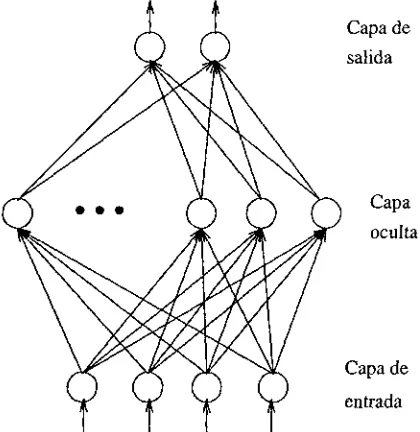
Al conjunto de nodos que participan en la respuesta ante la entrada de un estímulo le llamamos red neuronal. Dentro de la red, los nodos son organizados en grupos o en capas de forma que se establecen conexiones jerárquicas entre ellos.
[image:22.612.243.451.184.291.2]encuentran las capas de nodos en las que se itera para obtener el peso de las intercone xiones, a estas capas les llamamos ocultas o intermedias. Por último, la capa en la que se obtiene el resultado de la interconexión de los pesos y nodos es la capa de salida.
A la definición matemática formal que define la organización de una red se llama arquitectura [8]. La arquitectura de la red es importante para determinar sus carac terísticas de aprendizaje, y particularmente su habilidad de generalización, además de definir los vectores para entrenar a la red de manera que se produzcan salidas correctas. En la figura 2.3 se muestra la arquitectura de una red que consta de cuatro nodos en la capa de entrada, una sola capa oculta con un número indefinido de nodos en la capa oculta, y dos nodos en la capa de salida.
Capa de
salida
Capa
oculta
Capa de
entrada
Figura 2.3: Ejemplo de estructura de una red neuronal.
La arquitectura anterior, corresponde a la de una red de retropropagación que es una red totalmente conectada. Esto quiere decir que cada nodo de una capa i está ligado a todos los nodos de la capa superior i + 1. Además es una red con alimentación hacia adelante, esto es, los nodos de la capa i solo afectan directamente a los nodos de la capa i + 1.
[image:23.612.233.443.230.446.2]2.3 Aprendizaje en las redes neuronales
El cerebro realiza el aprendizaje por la habilidad de asociar simultáneamente circuns tancias actuales con todas las experiencias anteriores acumuladas. Filósofos, psicólogos y neurólogos están de acuerdo en que si los fenómenos psicológicos son procesos físicos en el cerebro, entonces el aprendizaje obviamente causa un cambio físico en el cerebro, aunque el lugar exacto donde ocurren los cambios es difícil de localizar [3].
El aprendizaje de una red neuronal artificial consiste en un cambio de estado de la red cuando se modifican los valores en los pesos de sus conexiones al recibir estímulos por medio de patrones. Un patrón es la representación numérica del estímulo en forma vectorial. A este proceso de aprender también se llama adaptación o entrenamiento.
Previo al proceso de aprendizaje, se inicializan los pesos de las conexiones de la red con valores arbitrarios que pueden ser aleatorios o predefinidos. El entrenamiento empieza cuando presentamos a la red un patrón en la capa de entrada que se encarga de distribuir los elementos del vector a los nodos de la siguiente capa.
A partir de la segunda capa, cada nodo evalúa una función con los pesos de las conexiones y los valores transferidos por los nodos de la capa anterior para calcular su salida. Así, la salida está determinada por una función de transferencia y es propagada como entrada de los nodos de la siguiente capa. Cuando la capa que recibe los valores propagados es la capa de salida, el resultado de la función de transferencia representa la salida o respuesta de la red para el patrón que recibió de entrada.
Una vez que se han presentado a la red un patrón o un conjunto de patrones, los pesos de las conexiones son modificados de acuerdo al algoritmo específico de la arquitectura de la red. Se espera que conforme más veces la red ha modificado sus pesos, la respuesta ante nuevos estímulos sea más cercana a una respuesta óptima o deseada en el entorno del problema aprendido. De ahí que es importante tener una gran cantidad de datos.
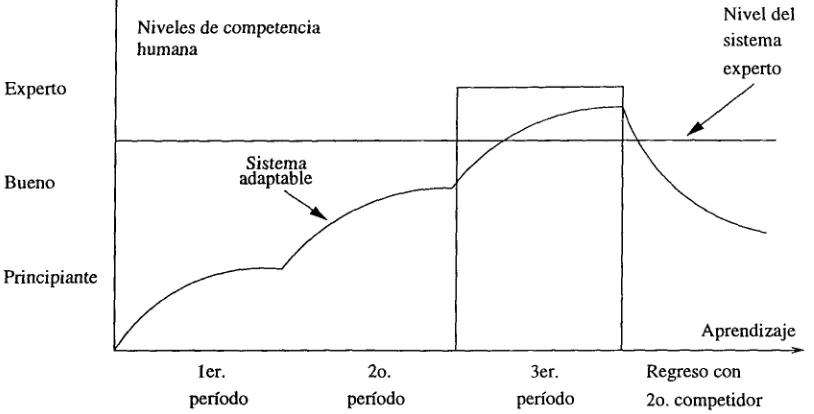
Para describir la adaptabilidad del aprendizaje de las redes, si una red aprendiera a jugar ajedrez de sus oponentes humanos, ésta iría aumentando el grado de dificultad de su estrategia conforme aprende del oponente. Por ejemplo, si se le entrena como en la figura 2.4, donde va aumentando paulatinamente el nivel de experiencia del oponente, la red irá incrementando su nivel de juego también; si después de llegar a un nivel alto, vuelve a jugar con alguien de nivel de juego más bajo, entonces la red aprende de las malas jugadas por lo que también baja su nivel de juego.
En este caso el rectángulo del tercer período de entrenamiento representa el nivel de juego al que puede llegar un competidor humano. Un sistema de conocimiento fijo como los sistemas expertos, por su parte, juega dependiendo de su propio nivel de conocimiento. Por lo tanto es muy probable que un sistema de conocimiento constante pierda con un competidor con mayor experiencia [3].
Durante el aprendizaje puede haber influencia de otros factores diferentes a los
Niveles de competencia humana
Nivel del sistema
experto Experto
Bueno
Sistema adaptable
Principiante
Aprendizaje
ler. 2o. 3er. Regreso con
2o. competidor
período período período
Figura 2.4: Gráfica del aprendizaje de juego de ajedrez.
patrones de entrada. Por ejemplo, cuando damos a la red la salida deseada se dice que es aprendizaje con retroalimentación. En la siguiente sección se dan dos clasificaciones de las redes neuronales por factores que influyen en su aprendizaje.
2.3.1 Clasificación de procesos de aprendizaje
El aprendizaje de las redes puede ser clasificado en base a dos criterios: dependiendo de la influencia de factores distintos a las entradas durante el aprendizaje, y por la dirección en la que se encuentran las conexiones.
Influencia externa en las redes neuronales Una red puede tener o no influencia o retroalimentación de factores diferentes a los patrones de entrada para realizar el aprendizaje, de tal forma que el aprendizaje puede ser supervisado, de refuerzo asociativo, o no supervisado.
En el aprendizaje supervisado, la retroalimentación es el conocimiento a priori de salida correcta de cada entrada. Se llama supervisado porque cuando intenta resolver la instancia de un problema, el resultado se compara con el resultado correcto.
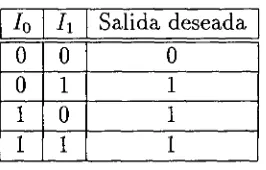
El cambio en las conexiones depende de la diferencia entre la salida de la red y la salida deseada. Es decir, el objetivo durante este aprendizaje es eliminar o disminuir la diferencia entre la salida actual y la deseada ya sea minimizando una función costo o maximizando una función objetivo. Un ejemplo de aprendi zaje supervisado se muestra en la tabla 2.1. Donde se dan los patrones para el aprendizaje de la función O R con entradas 70, h, y salida deseada.
[image:25.612.105.512.47.254.2]Tabla 2.1: Patrones de la función de OR con la salida deseada.
lo h Salida deseada
0 0 0
0 1 1
1 0 1
1 1 1
En el aprendizaje de refuerzo asociativo, también llamado aprendizaje por recom pensa, la retroalimentación del aprendizaje es una seńal escalar llamada seńal de refuerzo que es una evaluación del aprendizaje de la red. La seńal de refuerzo puede ser provista a la red ya sea por cada instancia del problema (entrada,salida) o por grupos de secuencias de instancias. Este aprendizaje de refuerzo asociativo está orientado hacia la evaluación. El objetivo de este tipo de aprendizaje es maximizar una función de la seńal de refuerzo.
En el aprendizaje no supervisado, la red no recibe ninguna retroalimentación del ambiente. Los pesos son ajustados dependiendo de las entradas y de las salidas calculadas. Este aprendizaje esta orientado hacia la auto organización. El objetivo de este tipo de aprendizaje es captar regularidades o asociaciones del conjunto de patrones de entrada.
Clasificación de las redes neuronales por el cálculo de su salida. Dependiendo de la forma en la que la red neuronal realiza el cálculo de la salida a través de las conexiones en la etapa de prueba, la red puede ser clasificada como red con alimentación hacia adelante o red con alimentación hacia atrás.
En una red con alimentación hacia adelante la salida de una neurona no puede influir en sí misma directamente ni indirectamente a través de otras neuronas, en estas redes los cálculos se realizan de una sola pasada. Cuando la última capa procesa sus salidas los cálculos terminan [5]. La red de la gráfica 2.3 es una red con alimentación hacia adelante.
La diferencia de una red con alimentación hacia atrás es que la salida de un nodo puede influir en otros nodos aunque se encuentren en capas del mismo nivel o inferiores lo que hace que exista influencia de la salida del mismo nodo. Un tipo de redes que tienen esta clase de alimentación son las redes recursivas ya que tienen nodos como el de la figura 2.5.
Es frecuente que una vez terminado el proceso de aprendizaje, la red dé buenos resultados para datos que vio durante el entrenamiento, y sin embargo dé malos resul
[image:26.612.242.375.73.158.2]w.
Figura 2.5: Nodo de red con alimentación hacia atrás.
tados ante nuevas entradas, es decir, para datos fuera del conjunto de entradas con las que se entrenó. Para evitarlo y para conocer las propiedades del método de solución, se observan las métricas de aprendizaje.
2.4 Métricas de aprendizaje de la red
En esta sección se describen los parámetros que miden el aprendizaje de las redes neuronales cuando se resuelve un problema. Estas medidas son la convergencia, la generalización y la estabilidad.
2.4.1 Convergencia
A la capacidad de un método de solución de aprender el problema definido para un conjunto de datos y bajo ciertas condiciones y requerimientos computacionales se llama convergencia [4]. En arquitecturas fijas de redes neuronales se observa la convergencia conforme los ciclos de entrenamiento tienden a infinito, y el error minimizado tiende a valores pequeńos.
Por ejemplo, la red de retropropagación usa con frecuencia la función de error RMS (root mean square) definida en la ecuación 2.1. Este error es calculado durante el entrenamiento, cada vez que un subconjunto de los N patrones de entrenamiento llamado época, se muestran a la red.
RMS = ^E ż'c ( ż j' ^ ~ y i'c ) (2.1)
Donde djiC es el valor de salida deseado de la unidad j para el vector de entrena miento c, y t/j> c es el valor de salida actual. En la figura 2.6 se observa que el error de
las dos redes converge cerca de los 80,000 ciclos de entrenamiento.
El eje horizontal de la gráfica 2.6 representa el número de ciclos de entrenamiento y el eje vertical representa el error cuadrático medio de la red.
La función sigmoidal de la ecuación 2.2 se usa algunas veces como función de transferencia de la red de retropropagación. La ventaja de esta función diferenciable es su no linealidad y que es monótona por lo que puede encontrar el conjunto de pesos de la red que minimizan la función de error.
[image:27.612.279.415.34.86.2]0.8
0 . 4
0 . 2
Red A Red B
0 2 0 0 0 0 4 0 0 0 0 6 0 0 0 0 8 0 0 0 0
Ciclos de entrenamiento
Figura 2.6: Convergencia de la red neuronal.
fM =
^ (2.2)La ecuación tiene asíntotas en 0 y 1, su gráfica se muestra en la figura 2.7.
f(oj )
1
0
Figura 2.7: Gráfica de función de sigmoidal asimétrica.
Se ha demostrado que las funciones de transformación sigmoidales simétricas pue den mejorar la velocidad de convergencia sobre las sigmoidales asimétricas por hasta 10 veces en la solución de problemas no triviales [4].
2.4.2 Generalización
La propiedad de genaralización mide la habilidad del método de solución de reconocer patrones que están fuera del conjunto de patrones con los que se hizo el aprendizaje, ésta es la principal propiedad a buscar en las redes neuronales.
problemas del ajuste de curvas son encontrar el orden del polinomio y encontrar los coeficientes del polinomio una vez que se determinó el orden. Si se escoge un orden del polinomio menor al de la curva, se hará un mal ajuste aún para los datos dentro del conjunto de datos de entrenamiento. Por el contrario, si se determina un orden mayor, puede ser que el conjunto de datos de entrenamiento obtenga buenos resultados, pero los resultados de los datos fuera de tal conjunto sean malos. De la misma forma, una red con una estructura más simple de lo necesario no puede dar buenos resultados en el conjunto de entrenamiento; y una estructura más complicada de lo necesario, puede obtener buenos resultados ante datos vistos, pero malos ante datos no vistos durante el entrenamiento.
Se cree que la selección de la función de error es importante en las características de convergencia y generalización cuando se realiza el aprendizaje supervisado. La función de error más usada es de la familia de las cuadráticas como el error cuadrático medio de la ecuación 2.3 [4].
Ł=4ż(<k
yż.e)
2(23)
ż j,c
2.4.3 Estabilidad
Paul Refenes define la estabilidad como la propiedad de producir resultados consistentes al variar los valores de los parámetros que influyen en el aprendizaje del método de solución [4]. Es decir, deben ser identificados los intervalos de los valores de las variables de control con las que se obtengan resultados estables estadísticamente.
Hay dos tipos de variables de control del aprendizaje de las redes neuronales: las variables independientes de la arquitectura de la red y las variables específicas de cada arquitectura. Las variables de control del aprendizaje de las redes neuronales comunes entre las arquitecturas pueden ser: función de transferencia, función de error, regla de aprendizaje, número de nodos en las capas y ciclos de entrenamiento.
Como parámetros de control específicos de la arquitectura, para la red de retropro pagación se pueden mencionar la velocidad de aprendizaje, la regla de aprendizaje, y el momentum. Por ejemplo, cuando se espera salir de un mínimo local, una velocidad de aprendizaje pequeńa de esta red implica cambios pequeńos en los pesos aún cuando se requiera de cambios mayores. En cambio, cuando la velocidad de aprendizaje es grande implica un cambio en los pesos más grande. Ambos casos pueden traer problemas de estabilidad al aprendizaje de la red [9].
647186
2.5 Resumen
Dentro de los métodos de solución a problemas, las redes neuronales se posicionaron como un método de inferencia inductiva. A diferencia de los métodos de inferencia algorítmica y deductiva, los de inferencia inductiva tienen la capacidad de aprender a modelar sistemas complejos en base a la observación de los datos del mismo.
Las redes neuronales intentan imitar al funcionamiento del cerebro como el proceso de transformar la información almacenada en las neuronas por medio de las conexio nes entre ellas en respuesta a un estímulo. Además, en este capítulo se introdujo la terminología de las redes usada más adelante.
Para evaluar el aprendizaje de las redes neuronales, se busca que el modelo de la red cumpla con las propiedades de convergencia, generalización y estabilidad que se decribieron en este capítulo.
En el siguiente capítulo se describen algunos métodos empleados hasta ahora para el problema de predecir variables del mercado de valores. También se revisan las refe rencias de los avances de las redes neuronales en la solución del problema propuesto en esta tesis.
Capítulo 3
Predicción de precios de acciones
Herbst dice del objetivo de los pronósticos de los precios de acciones: "No habría un propósito racional de la operación si no se tiene noción de la dirección de los precios de una acción" [2]. Operación en este caso es el hecho de realizar una compra o venta de acciones del mercado de valores.
En la búsqueda de modelos matemáticos que describan las series de tiempo de las variables económicas y financieras, se ha demostrado que son sistemas claramente no lineales, además de la existencia de ruido inherente [10, 11].
En su estudio de los datos económicos y financieros en el tiempo como procesos no lineales, James B. Ramsey lista los tres siguientes puntos importantes a considerar cuando se modelan tales sistemas. Primero, el sistema económico debe ser modelado como un sistema dinámico, por lo que debemos empezar a descubrir las ecuaciones apropiadas de movimiento. En segundo lugar, el ruido del sistema debe ser tomado en cuenta en el modelo. Por último, el fenómeno más difícil de modelar es que los sistemas económicos están sujetos a eventos que reinicializan el sistema con probabilidad de distribución no detectable [10].
En este capítulo vemos los enfoques que se han desarrollado para el análisis de series de tiempo de los precios de las acciones del mercado de valores. Describimos además el análisis técnico debido a que es la metodología más usada actualmente. En el capítulo también presentamos trabajos anteriores de redes neuronales que han abordado desde distintas persectivas la predicción de variables del mercado de valores.
3.1 Métodos de predicción de series de tiempo
Los métodos de predicción, no sólo de las series de tiempo sino en general, se clasifican en los enfoques cualitativo y cuantitativo dependiendo de si utilizan o no modelos matemáticos para obtener los valores futuros [12].
La siguiente subsección contiene una breve definición de serie de tiempo, y luego se describen los enfoques mencionados aplicados a las series de tiempo.
3.1.1 Series de tiempo
Una serie de tiempo es una secuencia de valores de una variable x tomados de intervalos periódicos en el tiempo y ordenados cronológicamente. Por ejemplo en la figura 3.1 se muestra la serie de tiempo de los precios de cierre de la acción A de Telmex.
20
10
i 1 1 1 ! ! T g L M E X
M a r 9 4 S e p 9 4 M a r 9 5 S e p 9 5 M a r 9 6 S e p 9 6 M a r 9 7 S e p 9 7 T i e m p o
Figura 3.1: Serie de tiempo Telmex del 1 de marzo de 1994 al 2 de septiembre de 1997.
En este caso la variable es el precio de cierre de una acción del mercado accionario. Dicho precio es el valor con el que se realiza la última compra o venta de dicha acción durante el día.
En el análisis univariable de la serie de tiempo {x(t)}^=1 de N observaciones de la variable x pueden presentarse dos situaciones:
1. Cuando el valor de x en el tiempo t + r es determinado por valores de la misma variable en instantes anteriores de tiempo. En este caso una relación del tipo
x(t + r) = f(x(t),x(t T), ...,x(t nr)) (3.1)
se mantiene para un entero n y una función / . Es decir, el sistema es totalmente determinístico y por lo tanto su comportamiento es predecible.
2. Cuando lo valores de x(t) son aleatorios independientes, de forma que los valores pasados de x no influyen del todo en sus valores futuros. En este caso no hay un mecanismo determinístico modelando los datos, por lo que la predicción no es posible.
En la mayoría de los casos se tiene una serie de observaciones de una variable cuya evolución en el tiempo es regida por un conjunto determinístico de ecuaciones, pero la medición es afectada por ruido. Un modelo para la serie esta dado por
x(t + r) = / ( i ( í ) , x ( í r ) , . . . , a ; ( í n r ) ) + 6 (3.2)
donde Łt es un conjunto de variables aleatorias, y la exactitud de la predicción depende
de la varianza del conjunto de las variables aleatorias { Łt} . Se dice que un sistema de
este tipo es determínistico con cierto nivel estocástico.
3.1.2 Enfoque cualitativo
El enfoque de predicción cualitativo se basa en la intuición y la experiencia de una persona o un grupo de personas que realizan el pronóstico, y proyecta hasta cierto grado de manera subjetiva el dato futuro. Analiza el conjunto de las variables relacionadas con la serie de tiempo para calcular el pronóstico.
3.1.3 Enfoque cuantitativo
El enfoque cuantitativo se basa en cifras exactas y modelos matemáticos formales. Los métodos estadísticos son ejemplo del enfoque cuantitativo. A su vez, los modelos estadísticos se clasifican en dos tipos: modelos de series de tiempo y causales. La diferencia entre ambos es que el modelo causal relaciona más de una serie de tiempo para la obtención del pronóstico.
El punto de divergencia entre ambos enfoques se describe en la teoría del camino aleatorio. Esta teoría establece que los precios cotizados en el mercado de valores sigue una secuencia aleatoria en el tiempo [2]. Es decir que estadísticamente los datos históricos del precio de las acciones son independientes entre sí, por lo que no pueden ser calculados únicamente con los precios anteriores.
A pesar de esta teoría, una gran cantidad de métodos cuantitativos se han intere sado en modelar estas series de tiempo. Entre ellos se encuentra el análisis técnico que es el método contra el que se compara el método probado en esta tesis.
3.2 Análisis Técnico
Análisis técnico es el estudio de los precios de las variables del mercado de valores; principalmente precios de acciones, volumen de transacciones e indicadores económicos por medio de la observación de la historia de la misma variable.
El análisis técnico parte de la premisa de que todas las variables financieras, mo netarias, políticas y psicológicas se encuentran reflejadas en la oferta y demanda, y por lo tanto en el precio de la acción. Para el análisis de las variables, se apoya en la interpretación de gráficas utilizando técnicas como la identificación de patrones y los promedios móviles.
3.2.1 Gráficas
En la identificación de patrones, el analista puede reconocer formaciones que se han ob servado repetidamente en las gráficas de variables del mercado de valores. Por ejemplo, en la gráfica 3.2, donde la recta es la línea de tendencia obtenida del patrón reconocido, el analista podría detectar una clara tendencia a la baja y ningún signo de cambio de tendencia en el precio de una acción aún cuando la empresa tenga buenas ganancias. En ese caso, el analista no recomendaría comprar hasta asegurarse de que hay evidencia en el cambio de la tendencia.
30
1990 1991 1992 1993 T i e m p o
Figura 3.2: Identificación gráfica de línea de tendencia del precio de cierre de acciones.
3.2.2 Promedios móviles
La segunda herramienta de apoyo que mencionamos fueron los promedios móviles que son mecanismos para el suavizamiento de curvas, con el propósito de eliminar, tanto como sea posible, fluctuaciones no deseadas en los datos.
Para el elemento t + 1 de la serie de tiempo el promedio móvil de n está definido por la ecuación 3.3.
1 ^
PMt+1 = ż VÍ (3.3)
^ i=t—n
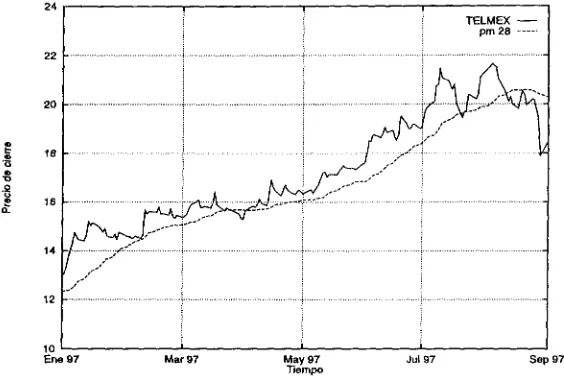
donde n es el número de días que se promedian, o tamańo del intervalo y vl son los elementos de la serie de tiempo. En la figura 3.3 se observa un promedio móvil de la serie de Telmex A.
Algunas veces el análisis técnico los usa como un método directo para comprar y vender acciones, se dice que es recomendable comprar cuando el precio tiene un cambio
por arriba del promedio, y vender cuando el movimiento es por abajo del mismo. Por su naturaleza no son muy precisos los resultados de este método, sin embargo, usados como guía general de la tendencia de los precios es muy útil [13, 14].
24
22
20
•Q A •o .9
16 o .
14
12
10
E n e 9 7 M a r 9 7 M a y 9 7 J u l 97 S e p 9 7 T i e m p o
Figura 3.3: Gráfica del promedio móvil del precio de cierre la acción de Telmex.
El problema en la construcción de los promedios móviles es escoger el período apro piado para calcular el promedio. Esta selección depende en gran parte de la naturaleza de los datos y el propósito de su aplicación.
El análisis técnico es un método relativamente fácil para determinar tendencias de precios de acciones, por lo que es el método más usado actualmente, seguido por la es tadística dentro de los métodos cuantitativos. El ruido, la aleatoriedad, la complejidad y la existencia de información parcial de las variables que influyen en las series de tiem po de las acciones han hecho que diversas áreas se interesen en buscar otros métodos para realizar sus pronósticos. Dentro de estas áreas se encuentran: la teoría de juegos [1], la teoría de caos [11], la lógica difusa [15], y las redes neuronales [16, 17, 18, 19].
3.3 Redes neuronales como método de predicción
En los últimos 10 ańos, se han realizado diversos trabajos para probar la eficiencia de los redes neuronales como método de predicción. Las áreas de estadística, computación, economía y finanzas han trabajado en conjunto para probar en específico el mapeo de las variables del mercado de valores.
HetchNielsen hace la siguiente observación de la superioridad de las redes neuro nales sobre modelos lineales estadísticos del mapeo de funciones: La ventaja principal del mapeo de las redes sobre el análisis de regresión de la estadística clásica es que las redes neuronales tienen formas funcionales más generales que la estadística puede
i
T E L M E X p m 2 8
[image:35.612.169.451.103.291.2]tratar. Las redes neuronales son libres de dependencias en superposiciones lineales y funciones ortogonales, cuyas aproximaciones deben ser usadas en la estadística. Se ha reunido suficiente evidencia experimental para establecer con cierta confianza que el mapeo de las redes son, en general, comparables a las mejores aproximaciones de regresión no lineales estadísticas.
Las redes neuronales realizan el mapeo de la función / : A C Rn —>• Rm, es decir, mapea una función desde un subconjunto finito A de n dimensiones en el es pacio Euclidiano n dimensional a un subconjunto finito f[A] de m dimensiones en ese mismo espacio. El mapeo se realiza por medio de ejemplos de entrenamiento
{xi,y1),(x2,y2),~,(xk,yk) — de la acción de mapeo, donde yk = f(xk) [8].
La siguiente subsección es una revisión de trabajos anteriores de las redes neurona les en el mapeo de series de tiempo con características no lineales, y en el pronóstico de los precios de las acciones. Los enfoques de la predicción de precios por redes neurona les son tanto por series de tiempo como por análisis de variables e incluso combinando otros métodos para el cálculo del pronóstico.
3.3.1 Revisión de trabajos anteriores
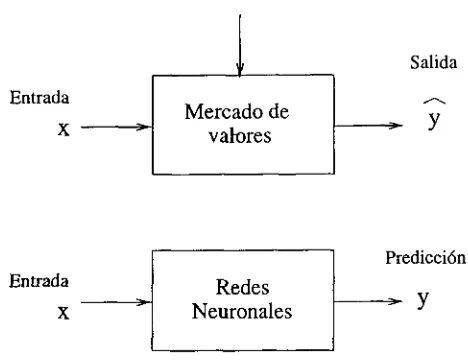
En el sistema tradicional de predicción del mercado de valores se tiene como entra das al proceso de pronóstico además del subconjunto de variables del mercado, otro subconjunto de información que influye de forma indirecta como son noticias, rumores y tendencias de los accionistas. Los modelos basados en redes neuronales realizan el pronóstico tomando en cuenta únicamente la entrada del primer subconjunto de va riables relacionadas con el mercado y el resto de la información es interpretada como ruido en el cálculo de la salida [4]. En la figura 3.4 se muestran ambas aproximaciones donde x son las variables del mercado y y es la salida del sistema.
En la experimentación se ha observado que x en la redes neuronales es de dos tipos: series de tiempo de una sola variable o series de tiempo multivaríable. Las series de tiempo han sido formadas a partir de información cuantitativa y cualitativa, por lo que se han podido comparar los resultados con ambas aproximaciones. Algunos ejemplos de las entradas de los trabajos realizados son:
• Siete indicadores del mercado de Estados Unidos en relación con otros mercados entre ellos el índice del dólar, y 14 indicadores basados en el precio y volumen del índice S&P 500 [16].
• Los factores de confianza y económico del índice Fortune 500 de Estados Unidos [18].
• Las series de tiempo e influencias externas económicas como: el índice de precios de Canadá, las tasas de intercambio de Canadá y Estados Unidos, y el índice del mercado intercambiario de Toronto [20].
Otra información
Entrada
X
1
Mercado de valores
Salida
y
Entrada
X
Redes Neuronales
Predicción
— y
Figura 3.4: Predicción en el mercado de valores.
• 16 índices técnicos del mercado de Taiwán generados a partir del precio más alto de la acción durante el día, el más bajo, el precio de cierre y el volumen de transacciones realizadas durante el mismo [17].
• Un conjunto de 15 variables relacionadas al precio de la acción, cambio promedio en el precio de la acción por día, diferencia entre el precio máximo del ańo con el precio de cierre de la acción. En el estudio de las acciones de la compańía Sumitomo Metal de Japón [21].
• Series de tiempo del porcentaje de cambio del índice económico MSCI de Estados Unidos [22].
Cuando se realiza un predicción siguiendo la serie de tiempo de una variable, se cree que el comportamiento previo de la misma y sus transformaciones son suficientes para pronosticar su comportamiento futuro. En el análisis multivariable, el precio futuro de un valor es determinado al analizar otras series económicas como índices, inflación, cambios en la moneda, y otros, reflejando y asumiendo que los cambios en estas series tienen un impacto con cierto retraso en el tiempo en la variable dependiente [22].
Respecto a la salida de la red, los trabajos anteriores se dividen en dos grupos: los que obtuvieron la tendencia de la variable a predecir, y los que definieron la salida como el valor del precio futuro o la magnitud del cambio.
En el caso del primer grupo, el pronóstico es la dirección del precio de la acción o del índice del mercado que se está observando. Se ha observado que entre más específica es la tarea por aprender de la red, más efectivos son los resultados. Dean Barr reporto en su trabajo: debido al ruido y posibles valores aleatorios inherentes al
[image:37.612.189.423.54.234.2]mercado financiero, construir una red neuronal para predecir la dirección de la tendencia del mercado, puede ser más efectivo que pronosticar ambos, la tendencia y su amplitud
[16]
En el segundo grupo la salida de la red neuronal se definió como el precio futuro de la variable. Principalmente los expertos en métodos estadísticos comparan resultados para medir la exactitud del pronóstico. Estos métodos están dentro de los métodos de ARIMA (AutoRegressive Integrated Moving Average) y entre ellos se encuentran el suavizamiento exponencial no estacionario, el modelo BoxJenkins, y el suavizamiento de Holt no estacionario [22, 23, 24].
El trabajo de Younghc y Swales [18] es un ejemplo en el que se aplica entrada multivariable con salida igual a la tendencia del precio de la acción. Cada vector representa una empresa clasificada como la empresa cuyos precios de acciones con buen resultado en el mercado o la compańía cuyo resultado en el mercado es malo. Esta clasificación se hace en base a información cualitativa consultada por los inversionistas.
Los parámetros cualitativos a los que se asignó valores para formar las series de tiempo fueron: confianza, factores económicos fuera del control de la firma, crecimien to, planes estratégicos, productos nuevos, pérdidas anticipadas, ganancias anticipadas, tendencia óptima a largo plazo y tendencia óptima a corto plazo. En la tabla 3.1 se muestan los resultados de la red neuronal y los obtenidos por el método de análisis de discriminación múltiple (ADM).
Tabla 3.1: Resultados del análisis de discriminación múltiple contra los de la red neu ronal de retropropagación.
Modelo Datos de entrenamiento Datos de prueba Grupol Grupo2 Grupol Grupo2 ~ADM 72% 76% 70% 60%
Red Neuronal 86% 96% 90% 65%
Los porcentajes representan el número de compańías que fueron clasificadas co rrectamente por ambos modelos de predicción. Se observa que tanto en los datos de entrenamiento como en los de prueba, las redes clasificaron con mayor acierto.
Hill y O'Connor, por su parte evaluaron la capacidad de las redes neuronales para modelar series de tiempo univariables comparando sus resultados con métodos tradicionales, entre ellos el BoxJenkins y el suavizamento exponencial y un método gráfico en el que el analista calcula por experiencia la tendencia del precio [23].
dades, y no lineales con discontinuidades. Se observó superioridad de las redes neronales con las series de tiempo discontinuas.
En los trabajos encontrados se experimentó con diferentes horizontes de predicción. La mayoría de ellos calcularon el pronóstico del período de tiempo consecutivo siguiente al último valor de la entrada de la red.
A pesar del número de trabajos realizados se encontró que la red de retropropa gación se utilizó en todos los experimentos de predicción de variables del mercado de valores. En dos de los trabajos se combinó la red con otros mecanismos: con un méto do de optimización y con un sistema de reglas basado en conocimiento. El primero, o sistema híbrido combina un método modificado del algoritmo de retropropagación con un método de optimización aleatoria para encontrar el mínimo global de la función total de error de la red en un número pequeńo de pasos [21]. En el segundo trabajo mencionado, se entrenaron seis redes cuya salida era la recomendación de inversión a largo o corto plazo. La salida de las redes es la entrada a un sistema de generación de reglas de forma que la salida global del sistema es la combinación de la salida de las redes [25].
El resultado de la comparación entre las evaluaciones de las redes neuronales y otros métodos tradicionales, se observó que las redes obtienen mejores pronósticos en la predicción a corto plazo tanto de la tendencia como del precio de la variable a predecir.
3.4 Resumen
Las condiciones para aplicar un método cuantitativo de pronóstico son la existencia de información histórica disponible, que puede ser cuantificable en forma de datos numéricos; y que se espere que algunos aspectos de la información continúen en el futuro. Un ejemplo de este tipo de método es el análisis técnico que usa los promedios móviles para determinar la tendencia futura de las series de tiempo de variables del mercado.
Varios estudios se han realizado para probar la eficiencia de las redes neurona les como método alternativo para la predicción de variables del mercado de valores [15, 16, 17, 18, 20, 21, 19, 25, 22]. Dentro de las referencias encontradas, diferentes entradas y enfoques se codificaron como entrada a las red de retropropagación. Los pronósticos obtenidos por las redes fueron comparados contra otros métodos estadísti cos y económicos. En todos los casos, las redes obtuvieron resultados relativamente mejores.
En el siguiente capítulo se define el proceso del aprendizaje del problema de las redes neuronales de retropropagación y LVQ. Además se definen los criterios de eva luación, que se emplean en el capítulo posterior, para la selección de la mejor red y sus parámetros.
Capítulo 4
Diseńo de experimentación
En el capítulo anterior se revisaron los enfoques y métodos en la predicción de series de tiempo del mercado de valores. También se revisó el avance de las redes neuronales en la solución a dicha predicción en trabajos anteriores.
El objetivo de este capítulo es especificar las consideraciones hechas para el desa rrollo de la experimentación con las redes de retropropagación y LVQ. Se describen las variaciones en las redes mencionadas y sus parámetros, además de la forma en la que se evalúan los mismos. Las series de tiempo que se quieren predecir son el precio de cierre de variables del mercado de valores de México.
4.1 Descripción de experimentación
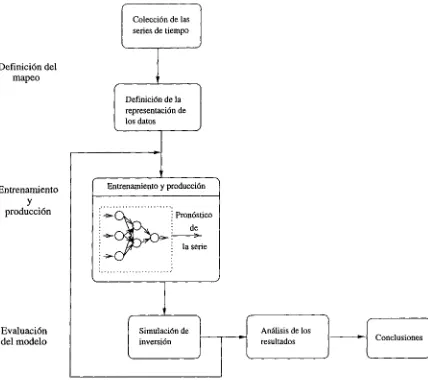
En la búsqueda del modelo de red que aprenda el mapeo de las series de tiempo men cionadas, se realizan una serie de pruebas con las redes y los valores de sus parámetros de aprendizaje. El proceso para la realización de estas pruebas se muestra en la figura 4.1.
La definición del mapeo depende de la información disponible, a partir de ésta, se implementa una representación o preprocesamiento de los datos, con el que se espera que la red aprenda las características del problema.
En el paso que aparece como entrenamiento y producción, se selecciona una confi guración de red, es decir, el tipo de red y los valores de sus parámetros de aprendizaje; la red es entrenada y se produce la salida para el archivo de datos de prueba.
Una vez obtenida la salida de la red, se realiza una simulación de inversión de capital. En la simulación se opera en la inversión dependiendo de la salida de la red; es decir, cuando la salida es positiva se compra y cuando es negativa se vende.
Se repite el proceso de entrenamiento, producción y evaluación para varias confi guraciones de redes. El objetivo es agrupar entrenamientos para analizar los resultados y obtener conclusiones de la experimentación.
En las siguientes secciones se describen a detalle la definición del mapeo para su aprendizaje, las consideraciones hechas en la selección de las redes y sus parámetros, y
Definición del mapeo
Colección de las series de tiempo
Definición de la representación de los datos
Entrenamiento
y
producción
Evaluación del modelo
Entrenamiento y producción
Pronóstico de
sa la serie
Simulación de inversión
Análisis de los
resultados Conclusiones
Figura 4.1: Diagrama del proceso de experimentación para el cálculo de predicción por medio de redes neuronales.
la forma en que se evaluaron los resultados obtenidos por los mismos.
4.2 Datos disponibles
Los datos disponibles son las series de tiempo del precio de cierre del I P C1, Cemex 2
de la bolsa mexicana de valores para los períodos que se muestran en la tabla 4.1. El precio de cierre de una acción del mercado accionario es el precio con el que se realiza la última compra o venta de dicha acción durante el día.
El IPC es el indicador de la bolsa de valores de México que representa el movi d a fuente de estos los daots del índice de precios y cotizaciones, fue la página en internet http://www.infosel.com.mx
2
Los datos de las acciones se obtuvieron de Infolatina
[image:41.612.94.522.40.429.2]