Carta de Erlang B implementada como red neuronal artificial
88
0
0
Texto completo
(2) CARTA DE ERLANG B IMPLEMENTADA COMO RED NEURONAL ARTIFICIAL. JOHAN JULIAN MOLINA MOSQUERA CODIGO: 20161027020. TESIS DE GRADO. DIRECTOR: PhD, PAULO CESAR CORONADO CODIRECTOR: PhD(c), OSCAR JULIAN PERDOMO CHARRY. UNIVERSIDAD DISTRITAL FRANCISCO JOSE DE CALDAS MAESTRIA EN TELECOMUNICACIONES MÓVILES FACULTAD DE INGENIERÍA, PROGRAMA DE ELECTRÓNICA BOGOTÁ 2017.
(3) Nota de Aceptación: ______________________________ ______________________________ ______________________________ ______________________________ ______________________________ ______________________________. ______________________________ Firma del presidente del jurado. ______________________________ Firma del jurado. ______________________________ Firma del jurado. Bogotá (14, 11,2017).
(4) Dedico este trabajo final de maestría a mi familia, quienes han mostrado de forma significativa su apoyo incondicional..
(5) Agradezco las asesorías técnicas ofrecidas por parte de los docentes de la Maestría en Telecomunicaciones Móviles (Universidad Distrital Francisco José de Caldas), PhD(c). Oscar Julián Perdomo Charry, PhD. Paulo Cesar Coronado y PhD(c). Jóse Ignacio Palacios Osma..
(6) CONTENIDO Pág. INTRODUCCIÓN .................................................................................................... 9 1.. PLANTEAMIENTO DEL PROBLEMA ........................................................... 12. 2.. JUSTIFICACIÓN ............................................................................................ 13. 3.. OBJETIVOS................................................................................................... 14 3.1 Objetivo General .......................................................................................... 14 3.2 Objetivos Específicos................................................................................... 14. 4.. MARCO TEÓRICO ........................................................................................ 15 4.1 MODELO DE ERLANG-B ............................................................................ 15 4.2 REDES NEURONALES ARTIFICIALES ...................................................... 16 4.3 SISTEMA OPERATIVO ANDROID .............................................................. 17 4.3.1 ARQUITECTURA .................................................................................. 18 4.3.2 DESARROLLO DE APLICACIONES EN ANDROID ............................. 18 4.3.3 VISTAS, ACTIVIDADES, SERVICIOS E INTENTOS EN ANDROID .... 20 4.3.4 LENGUAJE DE PROGRAMACIÓN XML .............................................. 21 4.3.5 LENGUAJE DE PROGRAMACIÓN JAVA ............................................. 22 4.3.6 Kit de Desarrollo de Java JDK (Java Development Kit) ........................ 23 4.3.7 Microcontroladores ................................................................................ 23 4.4 Diferencias entre aplicativos ........................................................................ 24. 5.. METODOLOGIA ............................................................................................ 26 5.1 DISEÑO DE RED NEURONAL MULTICAPA .............................................. 26 5.2 ENTRENAMIENTO RNA ............................................................................. 44 5.3 MODELO VISTA CONTROLADOR DE APLICACIÓN MÓVIL .................... 54 5.3.1 Modelo MVC de aplicación nativa ......................................................... 54 5.3.2 Algoritmo del modelo RNA de Erlang B ................................................ 55 5.3.3 Funcionalidad de aplicación móvil ......................................................... 57 5.4 VALIDACIÓN DE DATOS ............................................................................ 62. 6. APORTES DE INVESTIGACIÓN ...................................................................... 70 TRABAJOS FUTUROS ........................................................................................ 75 CONCLUSIONES ................................................................................................. 76 REFERENCIAS ..................................................................................................... 77.
(7) LISTA DE FIGURAS Figura 1. Diagrama de bloques general ................................................................ 10 Figura 2.Neurona .................................................................................................. 16 Figura 3.Red Neuronal Artificial multicapa ............................................................ 17 Figura 4. Ciclo de vida de una actividad ................................................................ 21 Figura 5. Esquema de bloques general de un microcontrolador ........................... 23 Figura 6. Gráfica de las funciones 𝑓𝑋 = 3𝑋 y 𝑓𝑋 = 5𝑋 ........................................ 27 Figura 7. RNA multicapa de función lineal Y=aX ................................................... 28 Figura 8. Diagrama de flujo de modelo RNA para función lineal f(X)=3X .............. 29 Figura 9. Funciones de activación Logsig y Purelin .............................................. 30 Figura 10. Carta de Erlang B en dispersión y discriminación a 5 y 6 canales ....... 31 Figura 11. Carta de Erlang B extendida a 120 Canales ........................................ 32 Figura 12. Guide de ecuación Erlang B ................................................................. 33 Figura 13. Diagrama de Nassi Schneiderman para algoritmo de función Erlang B34 Figura 14. RNA multicapa de función Erlang B ..................................................... 37 Figura 15. Diagrama de Flujo del proceso matemático RNA de la Función Erlang B por cada par de canales ........................................................................................ 40 Figura 16. Diagrama de Flujo de Función Canal ................................................... 41 Figura 17. Diagrama de flujo de función de activación Logsig .............................. 42 Figura 18. Diagrama de flujo de función para 5 canales ....................................... 42 Figura 19. Diagrama de flujo de función para 10 canales ..................................... 43 Figura 20. Diagrama de flujo del algoritmo de entrenamiento RNA ...................... 44 Figura 21. Diagrama de flujo de función Levenberg Marquardt............................. 45 Figura 22. RNA multicapa para función lineal ....................................................... 45 Figura 23. Estado de entrenamiento hasta 1000 épocas ...................................... 46 Figura 24. Rendimiento del entrenamiento. .......................................................... 46 Figura 25. Ajuste en los datos de salida ................................................................ 47 Figura 26. Diagrama de flujo del algoritmo de entrenamiento RNA ...................... 48 Figura 27. Diagrama de flujo de función Levenberg Marquardt............................. 49 Figura 28. RNA multicapa para función No lineal Erlang B ................................... 49 Figura 29. Estado de entrenamiento hasta 1000 épocas ...................................... 50 Figura 30. Rendimiento del entrenamiento. .......................................................... 51 Figura 31. Ajuste en los datos de salida ............................................................... 52 Figura 32. Modelo MVC app nativa Android .......................................................... 54 Figura 33. Dirección del Proyecto Android ............................................................ 57 Figura 34. Icono de acceso ................................................................................... 57 Figura 35. Comparativo entre Carta Erlang B y App ............................................. 58 Figura 36. Gráfica de tiempo 7:14 a.m vs probabilidad de bloqueo 13.2% .......... 59 Figura 37. Gráfica de tiempo 7:15 a.m vs probabilidad de bloqueo 36.7% .......... 59 Figura 38. Gráfica de tiempo 7:16 a.m vs probabilidad de bloqueo 57.1% .......... 60 Figura 39. Gráfica de tiempo de 7:03 a.m a 7:36 a.m vs probabilidad de bloqueo .............................................................................................................................. 60 Figura 40. Función RNA Erlang B en Sistema embebido ...................................... 61 Figura 41. Carta de Erlang B ................................................................................. 62 Figura 42.Resultados ejecución de App para 1ra. Actividad ................................. 64.
(8) Figura 43. Resultados de HTML5 para 1ra.Actividad ............................................ 65 Figura 44. Resultados de App Android para 1ra.Actividad .................................... 65 Figura 45. Resultados ejecución de App para 2da. Actividad ............................... 66 Figura 46. Resultados ejecución de App para 3ra. Actividad ................................ 67 Figura 47. Resultados comparativos entre Matlab y Excel .................................... 68 Figura 48. Modelo RNA de función Erlang B ......................................................... 70 Figura 49. Modelamiento matemático de la RNA .................................................. 70 Figura 50. Carta de Erlang B ................................................................................. 71 Figura 51. Modelo MVC app Nativa ...................................................................... 74.
(9) LISTA DE TABLAS Tabla 1. Comparativo entre aplicaciones .............................................................. 24 Tabla 2.Datos de Función 𝑓(𝑋) = 3𝑋 .................................................................... 26 Tabla 3.Datos de Función 𝑓(𝑋) = 5𝑋 .................................................................... 26 Tabla 4. Datos de Función no lineal Erlang B de 5 a 12 canales .......................... 35 Tabla 5. Datos de Función no lineal Erlang B de 13 a 20 canales ........................ 36 Tabla 6. Configuración RNA de función Erlang B .................................................. 38 Tabla 7. Resultados de la Intensidad de Tráfico A ................................................ 63 Tabla 8. Resultados de la cantidad de usuarios .................................................... 64 Tabla 9. Resultados de entrenamiento RNA por cada par de canales. ................. 71 Tabla 10. Software de entrenamiento e Implementación de ecuaciones RNA ...... 73.
(10) INTRODUCCIÓN Las tecnologías buscan nuevas posibilidades para el futuro de las comunicaciones móviles, las empresas proveedoras presentan un portafolio con las más recientes soluciones de red, evidenciando capacidad en la misma, diseñadas para aumentar la experiencia del usuario a medida que el tráfico de datos móviles crece de forma exponencial, optimizar la calidad de los servicios demanda la ampliación de los canales y disminución de la probabilidad de bloqueo (grado de servicio), conociendo que la carta de Erlang B proporciona la lectura de un límite máximo de 100 canales y 10% en la probabilidad de bloqueo. Por lo anterior, el inconveniente que presenta la función de Erlang B es que no siempre es práctica en aplicaciones reales, debido a la complejidad computacional que requiere al momento de utilizar altas tasas de intensidad de tráfico [1] y número de canales, por esa razón es conveniente utilizar modelos aproximados y diseños de redes neuronales artificiales las cuales responden mejor a las no linealidades de la función; en este trabajo de investigación el objetivo es implementar la carta de Erlang B como Red Neuronal Artificial y aplicación para Smartphone. Desde el comienzo del siglo XX, ha habido un rápido crecimiento de la popularidad de los sistemas de telecomunicaciones. Al aumentar el número de abonados que utilizan los sistemas de telecomunicaciones, se incrementa la capacidad en la cantidad de llamadas realizadas. Los sistemas de telecomunicaciones se conforman de dispositivos de hardware costosos, tales como conmutadores, con la función de llevar el tráfico de las llamadas telefónicas. El tráfico generado por las llamadas telefónicas es aleatorio porque el número de llamadas generadas dentro de un período de tiempo y la duración de cada llamada son impredecibles. En el diseño de sistemas de telecomunicaciones, sobre el dimensionamiento de los requisitos de capacidad dará lugar a un problema económico debido a los altos costos. Por otra parte, en virtud del dimensionamiento, se disminuirá la calidad de servicio (QoS) por la degradación de la señal. Por lo tanto, la estimación del tráfico esperado generado es tarea crucial en el diseño y dimensionamiento de los sistemas de telecomunicaciones [2]. Algunos casos de estudio e investigaciones relacionadas con el modelo de Erlang B son los siguientes: En una aproximación simple para la fórmula de Erlang B [3]. Se ha investigado la exactitud de la fórmula aproximada producida. En varios problemas de comunicaciones a menudo se requiere calcular la fórmula de Erlang B inversa. Utilizando la aproximación ofrecida se han ofrecido expresiones explícitas para la estimación de la función de pérdidas de Erlang inversa. En el proyecto de un modelo de rendimiento para los flujos IP [4], se investiga el bloqueo como un parámetro genérico de rendimiento que ayuda a modelar el rendimiento de las redes basadas en flujo. Se presentan los resultados de la simulación, subrayando la observación de que existe una relación entre los parámetros tradicionales de rendimiento de IP y el bloqueo de flujo. 9.
(11) El trabajo de estimación del número de órganos usando las fórmulas de Erlang B y Erlang C [5], recapitula el trabajo realizado para estudiar el modelo de distribución de Poisson, el modelo de distribución de Erlang y las restricciones de dimensionamiento de una red relacionada con estos modelos. Este documento también describe la herramienta de planificación de una red basada en los modelos considerados. Introduciendo el comportamiento de la aplicación, utilizado para el embalaje de recursos Erlang. Los recursos pueden variar de bibliotecas a clústeres de procesos y pueden configurarse para ejecutarse en un solo procesador o distribuirse en un conjunto de nodos. Estos estudios han permitido desarrollar una herramienta para la planificación de la red, que también subrayó los límites del uso de la regla de Rigault. En el proyecto de Dimensionamiento de redes de conmutación de circuitos utilizando el código de simulación basado en la fórmula de Erlang B [6], se presenta una aproximación a la dimensión de las redes de conmutación de circuitos y encuentra la relación entre los parámetros de las redes de circuitos conmutados en la condición de probabilidad específica de bloqueo de llamadas. Se crea un código de simulación basado en fórmula de Erlang (B) para dibujar gráficos que muestran dos curvas; Uno de simulación y el otro como calculado. Estas curvas representan las relaciones entre el número medio de llamadas y la duración media de la llamada con la probabilidad de bloqueo de llamadas. Este código de simulación facilita la selección de parámetros apropiados para las redes de conmutación de circuitos. La propuesta de Estimación de probabilidad de pérdida de paquetes utilizando el modelo Erlang B en redes VoIP modernas [7], se basa en el modelo simple de Erlang B que es ampliamente utilizado para el dimensionamiento clásico de las redes de telecomunicación. Analizando su potencial aplicable a las modernas redes convergentes IP. Introduciendo un procedimiento para determinar los valores adecuados de las variables de entrada para el modelo Erlang B original basado en las características del codec y el enlace de red en uso. Por último, se prueba el resultado del modelo y la aplicabilidad con los resultados de simulación utilizando el software NS2. En el trabajo sobre la fórmula de Erlang B y la extensión del método ERT [8], el resultado clave fue el teorema sobre la división del tráfico y la extensión del método ERT para la estimación del rendimiento de los esquemas con división del tráfico. La excelente precisión (error relativo menor de 1%) se muestra en el ejemplo numérico. El documento también contiene el nuevo algoritmo de la fórmula de Erlang-B para el número entero de canales basados en la aproximación parabólica. A diferencia de las anteriores referencias, la propuesta de investigación se desarrolla como lo indica el diagrama de bloques general: Figura 1. Diagrama de bloques general. Fuente 1. Autor. 10.
(12) En este diagrama de bloques (figura 1), se ordenan las etapas de la siguiente Manera: - Carta de Erlang B con las variables de Intensidad de tráfico, cantidad de canales, cantidad de usuarios y grado de servicio. - Diseño y entrenamiento de red neuronal artificial multicapa con datos tabulados. - Implementación del modelo vista controlador de aplicación móvil. - Comparación con otros aplicativos y validación de resultados. Se agrega a los casos de estudio mencionados, que no tienen una metodología de diseño de RNA multicapa para la función de Erlang B que pueda ser implementada en sistemas abiertos como Smartphone y sistemas cerrados como microcontroladores PIC. A continuación se mencionan las tres secciones en que se estructura el documento: en la sección uno (cuatro capítulos), se define la introducción, el problema, la justificación y los objetivos generales y específicos. En la sección dos (dos capítulos), se incluye el marco referencial con los componentes teóricos, conceptuales, científicos y tecnológicos, y se plantea el diseño metodológico con análisis de datos, entrenamiento RNA multicapa, modelos y algoritmos. Finalmente, en la sección tres (dos capítulos), se realiza la validación, análisis de resultados y conclusiones.. 11.
(13) 1. PLANTEAMIENTO DEL PROBLEMA 1.1 DEFINICIÓN Uno de los principales problemas de la conmutación es determinar el número de componentes (circuitos, multi grabadoras, suscriptores, servidores) que deben estar instalados para hacer frente al determinado tráfico ofrecido y así no afectar la calidad del servicio QoS [9]. Se observa que en cada momento en que se presenta el número de llamadas o el número de paquetes en una red de datos, se usan las fórmulas Erlang B o Erlang C para determinar el número de órganos. Como el uso de la fórmula Erlang B no siempre es práctica. A veces, en aplicaciones reales, es más conveniente utilizar aproximaciones. Por ejemplo, una aproximación puede reducir la complejidad computacional. Una expresión simple puede describir claramente el comportamiento de la función, mientras que la interpretación de la solución exacta es difícil [1]. También sucede, que el tráfico generado por las llamadas telefónicas es aleatorio porque el número de llamadas generadas dentro de un período de tiempo y la duración de cada llamada son impredecibles. De las aplicaciones para Smartphone disponibles en la tienda en línea “Play Store”, no existe una aplicación intuitiva y eficiente que incluya las variables de entradas y salidas del modelo de Erlang B, previo entrenamiento de datos en MATLAB para obtener pesos y bias, los cuales serían la base para la implementación de red neuronal artificial en dispositivos Smartphone. Por los motivos anteriormente expuestos, la pregunta que surgiría seria la siguiente: ¿Cuál sería la metodología para implementar una aplicación móvil a partir de las variables presentes en la carta de Erlang B y el entrenamiento de red neuronal artificial?. 12.
(14) 2. JUSTIFICACIÓN. Es importante aplicar la inteligencia computacional a las redes y los sistemas de telecomunicaciones en especial para determinar la intensidad de tráfico, grado de servicio, duración de llamada y demás características impredecibles que son determinantes para mejorar la calidad del servicio QoS [5]. En estas últimas décadas se ha masificado el uso de smartphone, lo que precisa desarrollar una aplicación móvil básica e intuitiva, que se caracterice por manejar las variables presentes en la carta de Erlang B dependiendo del entrenamiento de la RNA multicapa. En el proyecto, se destaca la implementación de redes neuronales artificiales multicapa para funciones lineales y no lineales en sistemas abiertos como Smartphone y sistemas cerrados como microcontroladores PIC, adoptando los modelos, algoritmos y ecuaciones planteadas de acuerdo al dimensionamiento RNA. Esta metodología de diseño de Redes Neuronales Artificiales Multicapa, entrenamiento, tratamiento algorítmico y matemático, permitirá avanzar en el desarrollo de nuevos productos de inteligencia computacional a nivel de aplicaciones móviles. Con estas técnicas de machine learning, se permitirá predecir comportamientos de parámetros (intensidad de tráfico/usuario, número de usuarios) no lineales presentes en las telecomunicaciones móviles, logrando así, optimizar el uso de recursos (canales, ranuras de tiempo y radiocanales). La aplicación desarrollada cumple con los requerimientos de dimensionamiento celular, en donde se menciona que el grado de servicio (GoS) en los sistemas de radiotelefonía móvil pública (PMT) suele ser del 1% al 2% y el tráfico por terminal (móvil) es de 17 a 25 mErlang y los grupos de canales grandes son más sensibles a un porcentaje de sobrecarga a diferencia de los grupos de canales pequeños.. 13.
(15) 3. OBJETIVOS. 3.1 Objetivo General Implementar la carta de Erlang B como Red Neuronal Artificial y aplicación para Smartphone 3.2 Objetivos Específicos -. Diseñar el modelo de red neuronal artificial multicapa con las variables presentes en la carta de Erlang B. Entrenar la red neuronal artificial (RNA) multicapa para obtener pesos y bias de la misma. Implementar el modelo vista controlador (MVC) de la aplicación nativa para el dispositivo móvil o smartphone. Validar los datos obtenidos de la aplicación móvil. Efectuar la comparación entre las dos aplicaciones existentes en la web y la propuesta en el proyecto.. 14.
(16) 4. MARCO TEÓRICO. 4.1 MODELO DE ERLANG-B El modelo de Erlang-B se basa en los siguientes supuestos [10]: - Las llamadas entrantes (llegadas de llamadas) se generan aleatoriamente y se asume que son distribuciones de Poisson. - Los tiempos de retención de llamadas son aleatorias y distribuidas exponencialmente. - Existe una capacidad finita del enlace. - Las llamadas bloqueadas se borrarán, ya que no hay cola de espera. Cualquier usuario bloqueado no volverá a intentar la misma solicitud de inmediato. La calidad de servicio QoS para Erlang (B) puede medirse por el valor de probabilidad de bloqueo de llamadas. El bloqueo de llamadas es una función de dos parámetros de variables, la carga de tráfico ofrecida en erlangs (A) y el número de troncales (N). La fórmula de Erlang (B) se puede expresar como la siguiente1: P𝐵 (C, A) =. AC ) C!. (. ∑C K=0. AK K!. (1). Donde: P𝐵 (C, A): Probabilidad de bloqueo de llamadas. A: Intensidad de tráfico (carga de tráfico en Erlangs). N: Número total de canales utilizados en el sistema. Si la tasa de llamadas por unidad de tiempo (ʎ), el número medio de solicitudes servidas por la misma unidad de tiempo (ᶙ ) así que el tiempo promedio de duración de la llamada (tiempo de espera) es 1/ᶙ .Entonces la carga de tráfico se puede calcular fácilmente como el siguiente: A= ʎ /ᶙ (2) Si se sustituye la ecuación (2) en la ecuación (1) se tendrá lo siguiente: P𝐵 (C, A) =. (ʎ /ᶙ)C ) C!. (. ∑C K=0. (ʎ /ᶙ)K K!. (3). Hoy en día, la tecnología de Voz sobre IP (VoIP) es cada vez más importante, pero el problema de la capacidad básica sólo se modifica ligeramente al rendimiento de los datos disponibles de la conexión. Por lo tanto, el modelo Erlang B puede utilizarse también en este caso. El modelo original de Erlang B puede extenderse [11] y la nueva variable es el factor de recuperación “r”. Denota la probabilidad de que un abonado bloqueado intente llamar de nuevo inmediatamente. La carga de tráfico hacia el sistema de telecomunicaciones consta de dos partes: las primeras tentativas y repetidas llamadas [12]: 𝐴 = 𝐴0 + 𝑅 = 𝐴0 + 𝐴. 𝑃𝐵 (𝐶, 𝐴). 𝑟 (4). 15.
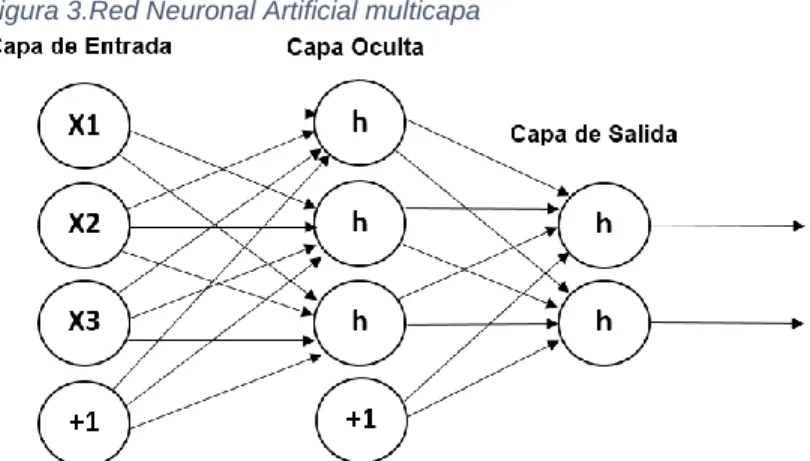
(17) Donde 𝐴0 es la carga de tráfico generada por los intentos iniciales (en Erlang), “R” representa la carga de llamadas repetidas y 𝑃𝐵 es la probabilidad de bloqueo utilizando el modelo original de Erlang B (1). La ecuación (4) se puede transformar fácilmente a la forma: 𝐴0 = (𝐴 − 𝐴. 𝑃𝐵 (𝐶, 𝐴). 𝑟) 𝐴0 = 𝐴(1 − 𝑃𝐵 (𝐶, 𝐴). 𝑟) (5) Mediante el uso de métodos numéricos iterativos se puede encontrar la carga de tráfico original 𝐴0 del sistema de comunicación. 4.2 REDES NEURONALES ARTIFICIALES Las redes neuronales artificiales representan un tipo de computación que se basa en la forma en que el cerebro realiza cálculos. En las redes de comunicación inalámbrica, existe una relación no lineal entre las características de las células y los patrones de desconexión. Las redes neuronales son buenas en el ajuste de funciones no lineales [13]. Por lo tanto, se puede aprovechar la RNA en este escenario. Como se muestra en la Figura 2, el elemento básico de una red neuronal artificial es la neurona que es una unidad computacional que toma como entrada 𝑋 = (𝑋1 , 𝑋2 , 𝑋3 , 𝑏)𝑇 , donde b es la unidad de oscilación (+1), el vector de peso es 𝑊 = (𝑤1 , 𝑤2 , 𝑤3 , 𝑤4 )𝑇 , la función de activación determinada por el diseñador de la red es 𝑔(.), para obtener a la salida de la neurona artificial la función: 3 𝑇. ℎ𝑊,𝑏 (𝑥) = 𝑔(𝑊 𝑥) = 𝑔 (∑ 𝑤𝑖 𝑥𝑖 + 𝑏) 𝑖=1. Figura 2.Neurona. Fuente 2.M. T. Hagan, H. B. Demuth. Una RNA consiste en una capa de entrada de neuronas, una o más capas ocultas de neuronas, y una capa final de neuronas de salida. La capa de entrada y la capa oculta están conectadas por enlaces sinápticos llamados pesos y la capa oculta y la capa de salida están conectadas de la misma manera. En la Figura 3 se muestra una red neural feedforward de tres capas. Los círculos etiquetados como "+1" son unidades de bias que corresponden al término de interceptación. Se tiene en cuenta que las unidades de polarización no tienen entradas o conexiones en ellas, ya que siempre producen el valor "+1" [13].. 16.
(18) Figura 3.Red Neuronal Artificial multicapa. Fuente 3.M. T. Hagan, H. B. Demuth. Los pesos de la red se obtienen por entrenamiento. Para esto es necesario utilizar algoritmos que se generan desde la plataforma de simulación. El algoritmo de aprendizaje “backpropagation” es uno de los utilizados [14] en las redes neuronales artificiales. 4.3 SISTEMA OPERATIVO ANDROID Android es un Sistema Operativo móvil basado en una versión modificada del Sistema Operativo LINUX. Es una plataforma móvil gratuita, abierta, completa y confiable, diseñada principalmente para dispositivos móviles con pantalla táctil como teléfonos inteligentes y tabletas, dándoles la posibilidad de navegar por Internet, instalar aplicaciones, videojuegos, escuchar música, enviar mensajes de texto, realizar llamadas, entre otras funciones. Fue originalmente diseñado por la empresa Android Inc. como parte de una estrategia para incursionar en el campo de la telefonía móvil, hasta que fue adquirida en el año 2005 por Google. La ventaja principal de Android es que su codificación es abierta y gratuita, así qué, quien utilicé el sistema operativo para realizar aplicaciones, puede descargar su código fuente. Ofrece un enfoque unificado al desarrollo de aplicaciones. Dichas aplicaciones pueden funcionar en diferentes dispositivos mientras éstos funcionen con el sistema operativo Android. El código abierto permite a los fabricantes de dispositivos móviles crear interfaces de usuario (UI) y añadir características propias a ciertos dispositivos.. 17.
(19) 4.3.1 ARQUITECTURA El sistema operativo Android está aproximadamente dividido en 5 partes: -. -. -. -. Kernel Linux: es el núcleo de Android. Esta capa contiene todos los drivers de menor nivel para los diversos componentes de hardware de un dispositivo Android. Librerías: contienen los códigos que proveen las principales características del sistema operativo. Entorno de ejecución (Runtime) Android: en la misma capa que las librerías, el entorno de ejecución de Android provee un núcleo de librerías que permite a los desarrolladores programar aplicaciones en Android usando el lenguaje de programación Java. Framework de aplicaciones: expone las diversas capacidades del sistema operativo Android para que los desarrolladores de aplicaciones puedan hacer uso de ellas. Aplicaciones: en esta capa superior se encuentran las aplicaciones que trae por defecto un dispositivo Android (Teléfono, Contactos, Navegador web, etc) y aquellas que pueden ser descargadas e instaladas o adquiridas desde Google Play. Cualquier aplicación que se programe estará en esta capa.. 4.3.2 DESARROLLO DE APLICACIONES EN ANDROID Android es una plataforma móvil de desarrollo, diseñada para encarar un mercado gratuito y abierto, en el que todos los usuarios de dispositivos móviles puedan tanto obtener aplicaciones como desarrollarlas. El Kit de Desarrollo de Software (SDK) de Android provee una extensa variedad de interfaces de programación de aplicaciones o APIs. Estas APIs sirven de gran ayuda como herramienta para el desarrollo de aplicaciones eficientes. La Máquina Virtual Dalvik (DalvikVM): Las aplicaciones en Android son escritas en su mayoría usando lenguaje de programación Java, y son ejecutadas utilizando una máquina virtual (VM) personalizada llamada Dalvik en vez de la tradicional máquina virtual de Java (JVM). Cada aplicación de Android funciona en un proceso separado dentro de su propia instancia en Dalvik, dejando toda la responsabilidad de manejo de memoria y de procesos al entorno de ejecución. La VM Dalvik y el entorno de ejecución se asientan por encima de un núcleo Linux que se encarga del manejo de interacciones de hardware de bajo nivel. Las aplicaciones también son en parte programadas utilizando el lenguaje de programación XML. 18.
(20) Framework de Aplicaciones: El marco de trabajo o Framework de aplicaciones de Android provee todo lo necesario para desarrollar una aplicación móvil. Una aplicación posee un ciclo de vida que involucra los siguientes componentes: - Actividades: son funciones que la aplicación realiza. - Vistas: definen la apariencia de la aplicación. - Intentos: informan al sistema acerca de lo que realiza una aplicación. - Servicios: permiten procesamientos en segundo plano sin intervención del usuario. - Notificaciones: alertan al usuario sobre acontecimientos [15]. Kit de Desarrollo de Software SDK (Software Development Kit): El SDK de Android está compuesto por una extensa sección de herramientas, documentación, tutoriales y ejemplos para el desarrollo de aplicaciones. También se incluyen librerías para Java, que contienen las APIs del framework de aplicaciones. Los principales sistemas operativos se pueden usar como ambientes de desarrollo. Las características principales del SDK son: - El depurador de las aplicaciones que estén funcionando en un dispositivo o en un emulador. - Un perfil de memoria y desempeño para encontrar fallas de memoria. - Un emulador de dispositivos preciso para simular diferentes plataformas de hardware. - Herramientas para el despliegue de aplicaciones. El SDK puede ser integrado a Eclipse, un Ambiente de Desarrollo Integrado (IDE) especial para Java. La integración se lleva a cabo mediante el plugin de Herramientas de Desarrollo de Android (ADT), que añade nuevas capacidades al IDE Eclipse con el fin de crear proyectos, ejecutarlos, depurar aplicaciones en el emulador o en un dispositivo, y empaquetar aplicaciones para su despliegue en Google Play. Emulador de Android: El SDK de Android incluye un emulador de dispositivos móviles que permite desarrollar aplicaciones de prueba sin necesidad de usar un dispositivo físico. Gestor de Dispositivos Virtuales de Android (AVD Manager): El gestor AVD provee una interfaz gráfica en la cual se pueden crear y gestionar Dispositivos Virtuales de Android, requeridos por el emulador de Android.. 19.
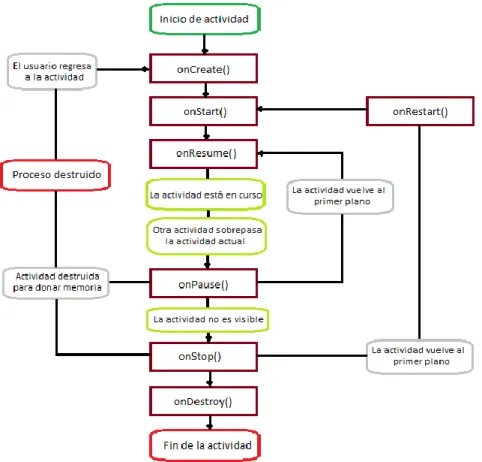
(21) 4.3.3 VISTAS, ACTIVIDADES, SERVICIOS E INTENTOS EN ANDROID Vistas: La mayoría de aplicaciones en Android necesitan una interfaz de usuario. El SDK de Android cuenta con numerosos elementos disponibles para realizar esta interfaz, empaquetados en un archivo de Java llamado android.view. Una vista es una Interfaz de Usuario que representa un área rectangular de la pantalla del dispositivo móvil, que contiene los controles, objetos gráficos, y la disposición espacial de los mismos de una aplicación. Para que una vista sea realmente funcional, debe ir ligada a una actividad. Actividades: Una actividad constituye la clase2 base que encierra una vista. Contiene la codificación de los componentes visuales e interactivos de una aplicación. Es la encargada de disponer las acciones que realice y de sus recursos, de elaborar los métodos, identificar objetos de programación y de realizar las tareas en segundo plano. Cada vista de una aplicación es una extensión de su actividad. Las actividades utilizan las vistas para formar Interfaces de Usuario gráficas que muestran información y responden a comandos del usuario. Ciclo de vida de una actividad: Las aplicaciones en Android pueden tener múltiples procesos, mientras que el mismo sistema operativo permite que varias aplicaciones corran simultáneamente, proveen memoria y energía necesarias. Sin embargo, sólo puede haber una aplicación visible al tiempo y específicamente, sólo una actividad. La actividad define una serie de eventos que gobiernan su ciclo de vida, que se muestran a continuación. onCreate(): Llamado cuando la actividad es creada por primera vez. onRestart():Llamado cuando la actividad ha sido detenida, antes de ser iniciada de nuevo. onStart(): Llamado cuando la actividad se hace visible al usuario. onResume(): Llamado cuando la actividad empieza a interactuar con el usuario. onPause(): Llamado cuando la actividad actual es pausada y una anterior es continuada. onStop(): Llamado cuando la actividad no es visible ya para el usuario. onDestroy(): Llamado cuando la actividad ha sido destruida por el sistema, ya sea manualmente o para que el sistema conserve memoria).. 2. Háblese de clase refiriéndose a la estructura principal de un programa en el lenguaje de programación Java. 20.
(22) Figura 4. Ciclo de vida de una actividad. Fuente 4.Android Application Development for Dummies, DonnFelker, pág 119, Editorial Wiley.. Intentos: Un intento constituye un mecanismo de comunicación asíncrono entre una tarea específica y una actividad. Está compuesto por una acción para ser realizada y un dato con el cual operar. Cuando una aplicación contiene más de una actividad, se utilizan intentos para navegar entre ellas. Servicios: Son líneas de código que funcionan en un segundo plano de la aplicación y no necesitan una Interfaz de Usuario. Se encargan de ejecutar las acciones que se realicen en una vista, desde su actividad respectiva. 4.3.4 LENGUAJE DE PROGRAMACIÓN XML XML proviene de Extensible Markup Language (“Lenguaje de Marcado Extensible”). Se trata de metalenguaje extensible de etiquetas que fue desarrollado por el Word Wide Web Consortium (W3C), un consorcio internacional que elabora recomendaciones para la World Wide Web.. 21.
(23) El XML es una adaptación del SGML (Standard Generalized Markup Language), un lenguaje que permite la organización y el etiquetado de documentos. Esto quiere decir que el XML no es un lenguaje en sí mismo, sino un sistema que permite definir lenguajes de acuerdo a las necesidades. Las bases de datos, los documentos de texto, las hojas de cálculo y las páginas web son algunos de los campos de aplicación del XML. El metalenguaje aparece como un estándar que estructura el intercambio de información entre las diferentes plataformas. Los expertos nombran varias ventajas que derivan de la utilización del XML. Es extensible (se pueden añadir nuevas etiquetas tras el diseño del documento), su analizador es estándar y facilita el análisis y procesamiento de los documentos XML creados por terceros. Entre los lenguajes creados con XML, se destacan el XSL (Extensible Style Sheet Language) y el XLINK (que intenta trascender las limitaciones de los enlaces de hipertexto en HTML). La validez de los documentos (es decir, que su estructura sintáctica se encuentre desarrollada correctamente) depende la relación especificada entre los distintos elementos a partir de una definición o documento externo [15]. 4.3.5 LENGUAJE DE PROGRAMACIÓN JAVA Java es un lenguaje de programación de alto nivel orientado a objetos. Fue creado por la empresa Sun Microsystems y publicado en 1995. Los programas en Java se hacen con clases, a partir de una definición de clase se puede crear una cantidad de objetos, que también se conocen como instancias de una clase. Los objetos agrupan en estructuras encapsuladas tanto sus datos como los métodos (o funciones) que manipulan esos datos. Una de las principales características es que es un lenguaje independiente de la plataforma. Eso quiere decir que si se realiza un programa en Java podrá funcionar en cualquier ordenador del mercado, trayendo una ventaja significativa para los desarrolladores de software. Esto lo consigue porque se ha creado una Máquina de Java para cada sistema que hace de puente entre el sistema operativo y el programa de Java y posibilita que este último se entienda perfectamente. Los programas en Java suelen estar en una de las siguientes categorías: -. Applets: Los applets son pequeños programas que se incorporan en una página Web y que por lo tanto, necesitan de un Navegador Web compatible con Java para poder ejecutarse. A menudo los applets se descargan junto con una página HTML desde un Servidor Web y se ejecutan en la máquina 22.
(24) -. -. cliente. Aplicaciones: Las aplicaciones son programas independientes de propósito general que normalmente se ejecutan desde la línea de comandos del sistema operativo. Con Java se puede realizar cualquier programa que normalmente se crearía con algún otro lenguaje de programación. Servlets: Los servlets al contrario de los applets son programas que están pensados para trabajar en el lado del servidor y desarrollar aplicaciones Web que interactúen con los clientes [16].. 4.3.6 Kit de Desarrollo de Java JDK (Java Development Kit) Es un software que provee herramientas de desarrollo para la creación de programas en Java. Puede instalarse en un computador local o en una unidad de red. Es necesario tener el JDK instalado en el computador para poder programar aplicaciones para Android. 4.3.7 Microcontroladores La arquitectura de los PIC [17] responde al esquema de bloques de la figura 5. Todos están basados en la arquitectura Harvard, con memorias de programa y datos separados. Como en la mayoría de los microcontroladores, la memoria de programa es mucho mayor que la de datos. La memoria de programa está organizada en palabras de 12,14 o 16 bits mientras que la memoria de datos está compuesta por registros de 8 bits. El acceso a los diversos dispositivos de entrada y salida se realiza a través de algunos registros de la memoria de datos, denominados registros de funciones especiales SFR (Special Function Registers). Muchos microcontroladores PIC cuentan con una cierta cantidad de memoria EEPROM para el almacenamiento no volátil de datos. Figura 5. Esquema de bloques general de un microcontrolador. Fuente 5. Texto - Microcontroladores: Fundamentos y Aplicaciones con PIC. 23.
(25) 4.4 Diferencias entre aplicativos La aplicación móvil nativa propuesta realiza cálculos matemáticos con formato de doble precisión, gestión a bases de datos, graficación y adaptabilidad al análisis de tráfico de los sistemas de telefonía fija y móvil, en la siguiente tabla se describe la comparación entre aplicativos por factores de precisión, conectividad, tipo de aplicación, variables de función Erlang B, entre otras. Tabla 1. Comparativo entre aplicaciones. Ítem. 1 2 3 4. 5. 6. 7. 8. 9. FACTOR. Precisión. APP ERLANG B/C –Play Store. APLICACIÓN HTML5. APP ERLANG B PROPUESTA. https://play.google.com/sto re/apps/details?id=dim.erl angbccalculator&hl=es. http://www.erlang.com/calcul ator/erlb/. https://play.google.com/sto re/apps/details?id=com.pe rsonal.erlangbrna&hl=es. 4 decimales. 3 decimales. Más de 4 decimales Conexión No requiere Requiere acceso a No requiere acceso a internet internet acceso a internet Tipo de Nativa Web Nativa aplicación Integración No No Si RNA multicapa Variable Si Si Si intensidad de tráfico del Sistema troncal Variable Si Si Si Número de canales Variable Si Si Si Probabilidad de Bloqueo Variable No No Si intensidad de tráfico/usuar io. Variable No No Si número de llamadas bloqueadas 24.
(26) Ítem. 10. 11. FACTOR. Gestión a base de datos Graficación GOS y Número de usuarios vs tiempo. APP ERLANG B/C –Play Store. APLICACIÓN HTML5. APP ERLANG B PROPUESTA. https://play.google.com/sto re/apps/details?id=dim.erl angbccalculator&hl=es. http://www.erlang.com/calcul ator/erlb/. https://play.google.com/sto re/apps/details?id=com.pe rsonal.erlangbrna&hl=es. No. Si. Si. No. No. Si. 25.
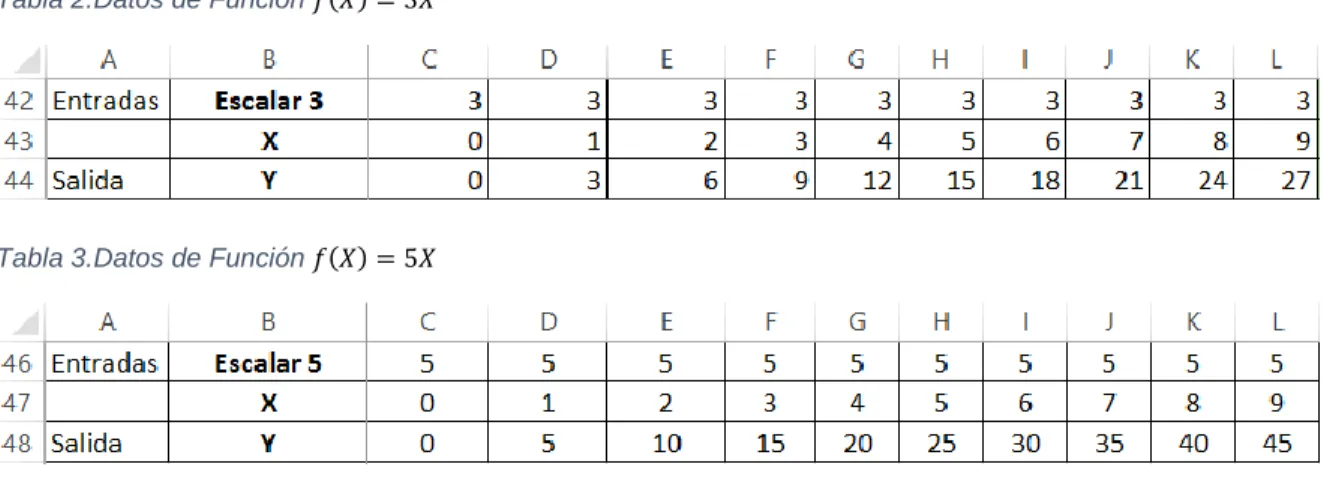
(27) 5. METODOLOGIA 5.1 DISEÑO DE RED NEURONAL MULTICAPA Con los resultados obtenidos de la ecuación 1 y con la guía de la carta de Erlang B, se construye la tabla de datos tomando como variables de entrada, el número de canales “C” y la intensidad de tráfico “A” (Erlangs), y como variable de salida, la probabilidad de bloqueo (GOS).. Pbloqueo =. AC ) C!. (. ∑C K=0. AK K!. = GOS (1). Ecuación 1. Ecuación de Erlang B. La ecuación de Erlang B como función no lineal, no responde al principio de superposición. Recordando que una función lineal sí cumple con las propiedades de adición y homogeneidad, la linealidad está asociada al concepto de espacio vectorial, conjunto en los que se definen dos operaciones, una interna (suma de vectores 𝑋 + 𝑌) y otra externa (multiplicación por un escalar 𝑎𝑋, en la que “𝑎” pertenece a un conjunto externo). Para comprobar la linealidad de una función 𝑓(𝑋) no es necesario realizar la comprobación de las propiedades de homogeneidad y aditividad por separado, con mostrar que 𝑓(𝑎𝑋 + 𝑏𝑌) = 𝑎𝑓(𝑋) + 𝑏𝑓(𝑌) la linealidad queda demostrada [18]. En este orden de ideas, para poder diseñar con precisión la RNA de la ecuación de Erlang B, fue preciso diseñar la tabla de datos y la red neuronal multicapa para una función lineal básica como 𝑓(𝑋) = 𝑎𝑋 Las siguientes tablas representan las funciones lineales 𝑓(𝑋) = 3𝑋 y 𝑓(𝑋) = 5𝑋, donde 3 y 5 son los escalares, la variable independiente 𝑋 es la entrada y la variable dependiente 𝑓(𝑋) = 𝑌 es la salida de cada respectiva función: Tabla 2.Datos de Función 𝑓(𝑋) = 3𝑋. Tabla 3.Datos de Función 𝑓(𝑋) = 5𝑋. 26.
(28) La representación gráfica de las funciones lineales 𝑓(𝑋) = 3𝑋 y 𝑓(𝑋) = 5𝑋 se muestran en la figura 6 en el plano de dos dimensiones, el eje independiente 𝑋 vs el eje dependiente 𝑓(𝑋) = 𝑌 Figura 6. Gráfica de las funciones 𝑓(𝑋) = 3𝑋 y 𝑓(𝑋) = 5𝑋. Fuente 6. Autor. El diseño RNA de la figura 7 es la que mejor responde a estos sistemas lineales, esta se compone de una capa de entrada (2 neuronas con función de activación logsig), una capa oculta (2 neuronas con función de activación purelin) y una capa de salida (una neurona con función de activación purelin), permitiendo que con esta última función de activación, se presenten valores oscilantes entre 0 y mayores a 1.. 27.
(29) Figura 7. RNA multicapa de función lineal Y=aX. Fuente 7. Autor. El modelo RNA multicapa de función lineal 𝑓(𝑋) = 𝑎𝑋 actuará en total con diez pesos y 5 bias (cada bias/neurona). En el diagrama de flujo de la figura 8, se efectúan las operaciones aritméticas presentes en cada neurona con propagación hacia adelante, iniciando desde la capa 1 y finalizando en la capa 3; los valores de los pesos “W 1-10”y unidades de oscilación “B1-5” de esta RNA, se obtienen del entrenamiento y utilización del algoritmo de aprendizaje Levenberg Marquardt.. 28.
(30) Figura 8. Diagrama de flujo de modelo RNA para función lineal f(X)=3X. Fuente 8. Autor. 29.
(31) Las funciones de activación se muestran a continuación: Figura 9. Funciones de activación Logsig y Purelin. Fuente 9. https://www.researchgate.net/figure/38320164_fig1_Figura-1-Funciones-de-activacion-a-Funcionlogistica-o-LogSig-b-Funcion-Gaussiana-o. Este previo desarrollo metodológico de estudiar el comportamiento de red neuronal artificial en funciones lineales, permitió establecer para la función no lineal de Erlang B, unos criterios para rediseñar la RNA, analizar y tabular los datos de acuerdo a las variables presentes de intensidad de tráfico y probabilidad de bloqueo por número de canales.. 30.
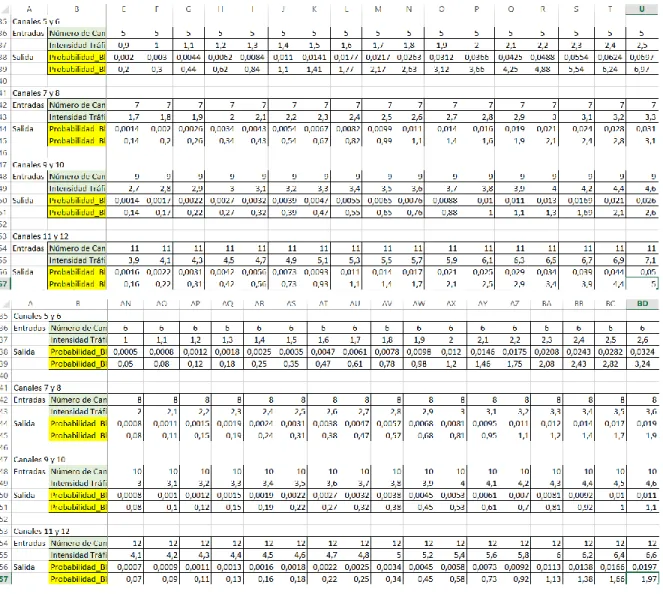
(32) Para este proceso, se siguieron los siguientes pasos: 1. Graficar el comportamiento por canal: Con la utilización de la fórmula Erlang B, se calcula y tabulan los datos de las variables Canales, Intensidad de Tráfico y Probabilidad de bloqueo. Logrando obtener el gráfico en dispersión de los diferentes tramos no lineales que se muestran en la figura 10. Figura 10. Carta de Erlang B en dispersión y discriminación a 5 y 6 canales. Fuente 10. Autor. 31.
(33) Como ejemplo de la no linealidad, se tiene que la intensidad de tráfico varía entre 0.7 y 2.7 Erlangs para 5 canales y de 1 a 3.5 Erlangs para 6 canales. Esto sucede de forma progresiva para los demás canales. En la gráfica 10 se observa la extensión a 120 Canales de la carta Erlang B. Figura 11. Carta de Erlang B extendida a 120 Canales. Fuente 11. Autor. Este criterio “no lineal” determina la necesidad de utilizar una red neuronal artificial de mayor magnitud y complejidad matemática. 2. Tabular los datos por cada par de canales: Para ser precisos en el registro de los datos, fue necesario desarrollar en Matlab los script y guide de la ecuación Erlang B. En el siguiente diagrama de bloques se muestra el proceso de registro y pruebas para seleccionar la arquitectura de red neuronal artificial: Ecuación Erlang B (Script, Guide Matlab y algoritmo). Tabulación de datos por cada par de canales (Excel). 32. Pruebas de configuración RNA (Algoritmo trainlm).
(34) A continuación se muestra el guide, script de matlab (ver anexo), algoritmo en diagrama Nassi Schneiderman y algunas tablas con datos registrados: Figura 12. Guide de ecuación Erlang B. Fuente 12. Autor. 33.
(35) En el diagrama de Nassi Schneiderman de la figura 13 se muestra la forma original del algoritmo de la ecuación de Erlang B: Pbloqueo =. AC ) C!. (. ∑C K=0. AK K!. = GOS (1). Ecuación 1. Erlang B. Este diagrama permite entender el desglose de la ecuación como algoritmo, el cual contiene diferentes ciclos repetitivos finitos de sumatoria y factorial. En el caso del numerador, se eleva la intensidad de tráfico “𝐴” al número de canales “𝐶” y ese resultado se divide por el ciclo del factorial de “𝐶”. Para la parte del denominador, se establece el ciclo de sumatoria que inicia en “𝑘 = 0” y finaliza en “𝑘 = 𝐶”, dentro de este ciclo se realiza la operación de “𝐴” elevado a “𝑘” sobre el ciclo anidado del factorial “𝑘”. La probabilidad de bloqueo o GOS resultara de dividir el valor obtenido del numerador entre el valor obtenido del denominador. Figura 13. Diagrama de Nassi Schneiderman para algoritmo de función Erlang B. Fuente 13. Elaborado por el autor con herramienta PseInt. 34.
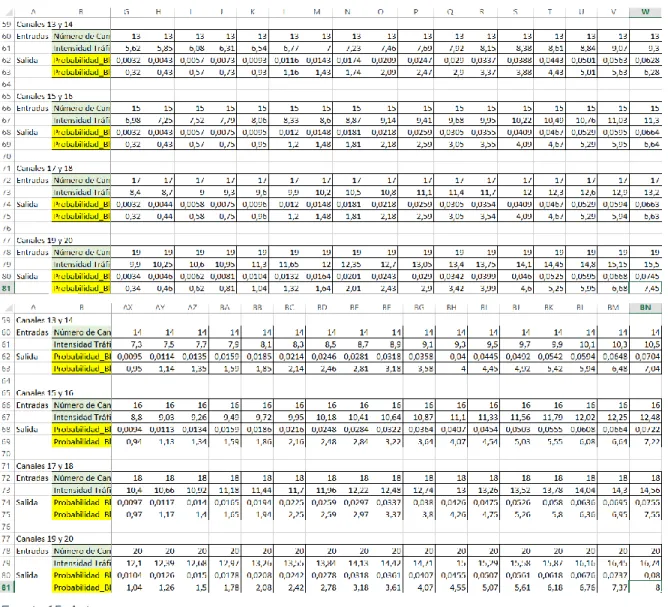
(36) Tabla 4. Datos de Función no lineal Erlang B de 5 a 12 canales. Fuente 14. Autor. 35.
(37) Tabla 5. Datos de Función no lineal Erlang B de 13 a 20 canales. Fuente 15. Autor. Así mismo, se tabulan los datos para los demás canales. Se determina organizar la tabulación por cada par de canales con el objetivo de mejorar los ajustes al momento de aplicar el algoritmo de aprendizaje levenberg Marquardt de matlab.. 36.
(38) 3. Diseño de RNA multicapa para la función Erlang B: Al realizar las diferentes pruebas de configuraciones de red neuronal artificial y entrenamientos con el algoritmo “trainlm”, el modelo de RNA multicapa de la figura 14, es el que mejor representa a la función Erlang B ya que ajusta de forma óptima los datos obtenidos de salida por cada par de canales seleccionados. Figura 14. RNA multicapa de función Erlang B. Fuente 16. Autor. 37.
(39) El número de neuronas con sus respectivas funciones de activación por capa, se muestran en la siguiente tabla: Tabla 6. Configuración RNA de función Erlang B. Número de Capa. Número de neuronas/Capa. Función de activación/capa. 1 (Entrada). 2. Logsig. 2 (Oculta). 6. Logsig. 3 (Oculta). 5. Purelin. 4 (Salida). 1. Purelin. Fuente 17. Autor. 4. Ecuaciones de RNA multicapa para función Erlang B: Por cada neurona se genera una ecuación. Desde la capa uno de entrada están ingresando a cada neurona los valores de intensidad de tráfico “𝐴” y número de canales “𝐶”. Cada una de estas ecuaciones realiza la operación de sumatoria, entre la multiplicación de cada entrada por su respectivo peso “𝑊𝑛” obtenido del entrenamiento, adicionando el bias “𝑏𝑛” también obtenido del entrenamiento, y luego, a ese resultado se le aplica la función de activación que para la red, es la Logsig o Purelin. De forma progresiva y con propagación hacia adelante, se producen los demás cálculos matemáticos hasta llegar a la última neurona de la capa cuatro de salida, siendo la que muestra el valor de la probabilidad de bloqueo “𝑃𝑟”. (𝐶 − 𝐶𝑎𝑛𝑎𝑙𝑒𝑠, 𝐴 − 𝐼𝑛𝑡𝑒𝑛𝑠𝑖𝑑𝑎𝑑 𝑑𝑒 𝑇𝑟á𝑓𝑖𝑐𝑜 "Erlangs", 𝑊𝑛 − 𝑃𝑒𝑠𝑜𝑠, 𝑏𝑛 − 𝑏𝑖𝑎𝑠, 𝑃𝑟 − 𝑃𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑑𝑎𝑑 𝑑𝑒 𝑏𝑙𝑜𝑞𝑢𝑒𝑜 𝑜 𝑔𝑟𝑎𝑑𝑜 𝑑𝑒 𝑠𝑒𝑟𝑣𝑖𝑐𝑖𝑜) Neurona 1 𝐴1 = (𝑪 ∗ 𝑊1) + (𝑨 ∗ 𝑊2) + 𝑏1 𝑁1 = 1/(1 + 𝑒 −𝐴1 ) Neurona 2 𝐴2 = (𝑪 ∗ 𝑊3) + (𝑨 ∗ 𝑊4) + 𝑏2 𝑁2 = 1/(1 + 𝑒 −𝐴2 ) Neurona 3 𝐴3 = (𝑁1 ∗ 𝑊5) + (𝑁2 ∗ 𝑊6) + 𝑏3 𝑁3 = 1/(1 + 𝑒 −𝐴3 ) Neurona 4 𝐴4 = (𝑁1 ∗ 𝑊7) + (𝑁2 ∗ 𝑊8) + 𝑏4 𝑁4 = 1/(1 + 𝑒 −𝐴4 ) Neurona 5 𝐴5 = (𝑁1 ∗ 𝑊9) + (𝑁2 ∗ 𝑊10) + 𝑏5 𝑁5 = 1/(1 + 𝑒 −𝐴5 ) Neurona 6 𝐴6 = (𝑁1 ∗ 𝑊11) + (𝑁2 ∗ 𝑊12) + 𝑏6 38.
(40) 𝑁6 = 1/(1 + 𝑒 −𝐴6 ) Neurona 7 𝐴7 = (𝑁1 ∗ 𝑊13) + (𝑁2 ∗ 𝑊14) + 𝑏7 𝑁7 = 1/(1 + 𝑒 −𝐴7 ) Neurona 8 𝐴8 = (𝑁1 ∗ 𝑊15) + (𝑁2 ∗ 𝑊16) + 𝑏8 𝑁8 = 1/(1 + 𝑒 −𝐴8 ) Neurona 9 𝐴9 = (𝑁3 ∗ 𝑊17) + (𝑁4 ∗ 𝑊18) + (𝑁5 ∗ 𝑊19) + (𝑁6 ∗ 𝑊20) + (𝑁7 ∗ 𝑊21) + (𝑁8 ∗ 𝑊22) + 𝑏9. 𝑁9 = 𝐴9 Neurona 10 𝐴10 = (𝑁3 ∗ 𝑊23) + (𝑁4 ∗ 𝑊24) + (𝑁5 ∗ 𝑊25) + (𝑁6 ∗ 𝑊26) + (𝑁7 ∗ 𝑊27) + (𝑁8 ∗ 𝑊28) + 𝑏10. 𝑁10 = 𝐴10 Neurona 11 𝐴11 = (𝑁3 ∗ 𝑊29) + (𝑁4 ∗ 𝑊30) + (𝑁5 ∗ 𝑊31) + (𝑁6 ∗ 𝑊32) + (𝑁7 ∗ 𝑊33) + (𝑁8 ∗ 𝑊34) + 𝑏11. 𝑁11 = 𝐴11 Neurona 12 𝐴12 = (𝑁3 ∗ 𝑊35) + (𝑁4 ∗ 𝑊36) + (𝑁5 ∗ 𝑊37) + (𝑁6 ∗ 𝑊38) + (𝑁7 ∗ 𝑊39) + (𝑁8 ∗ 𝑊40) + 𝑏12. 𝑁12 = 𝐴12 Neurona 13 𝐴13 = (𝑁3 ∗ 𝑊41) + (𝑁4 ∗ 𝑊42) + (𝑁5 ∗ 𝑊43) + (𝑁6 ∗ 𝑊44) + (𝑁7 ∗ 𝑊45) + (𝑁8 ∗ 𝑊46) + 𝑏13. 𝑁13 = 𝐴13 Neurona 14 𝐴14 = (𝑁9 ∗ 𝑊47) + (𝑁10 ∗ 𝑊48) + (𝑁11 ∗ 𝑊49) + (𝑁12 ∗ 𝑊50) + (𝑁13 ∗ 𝑊51) + 𝑏14. 𝑷𝒓 = 𝑁14 = 𝐴14 5. Algoritmo y funciones características del modelo RNA multicapa En el diagrama de flujo de la figura 15 se observa el proceso matemático de la red neuronal artificial de la función Erlang B por cada par de canales:. 39.
(41) Figura 15. Diagrama de Flujo del proceso matemático RNA de la Función Erlang B por cada par de canales. Fuente 18. Autor. En los siguientes pseudocódigos y diagramas de flujo, se efectúan las diferentes funciones y subrutinas de las operaciones aritméticas básicas que deben presentarse en cada neurona, iniciando desde la capa 1 y finalizando en la capa 4. Se precisa que en el pseudocódigo, se toman los valores de pesos y bias, como ejemplos de constantes que ingresan a una neurona y de forma progresiva con propagación hacia adelante, se realizan los diferentes cálculos. 40.
(42) En la figura 16 se muestra el diagrama de flujo de la función del algoritmo principal, en el que se determina la decisión para que se ejecute la función dependiendo del canal ingresado: Algoritmo llamarfunciones Escribir 'Ingresar el canal' Leer C Si C==5 Entonces c5 SiNo Si C==10 Entonces c10 SiNo Escribir 'No existe entrenamiento neuronal' Fin Si Fin Si FinAlgoritmo Figura 16. Diagrama de Flujo de Función Canal. Fuente 19. Autor. La función con retorno, sirve para calcular la probabilidad de bloqueo después de realizarse el cálculo matemático con los respectivos argumentos: En la figura 17 se muestra el diagrama de flujo para la función de activación de la RNA (Ecuación con función de activación Logsig). 41.
(43) Funcion funeurona <- calc(w1,w2,b1,A,c) k <- (A*w1)+(C*w2)+b1 funlogsig <- 1/(1+exp(-k)) Escribir 'LA PROBABILIDAD DE BLOQUEO ES' funeurona <- funlogsig Fin Funcion Figura 17. Diagrama de flujo de función de activación Logsig. Fuente 20. Autor. En la figura 18 se muestra el diagrama de flujo de la función de 5 canales, donde se almacena en variables los valores de intensidad de tráfico, pesos y bias; estas variables son enviadas como parámetros a la función general para que así, se pueda realizar el cálculo final de probabilidad de bloqueo. Función para 5 Canales en neurona Funcion c5 Escribir 'Ingresar Intensidad de Tráfico' Leer A c<-5 w1<-1 w2<-1 b1<-1 Escribir calc(w1,w2,b1,A,c) Fin Funcion Figura 18. Diagrama de flujo de función para 5 canales. 42. Fuente 21. Autor.
(44) En la figura 19 se muestra el diagrama de flujo de la función para 10 Canales en neurona. Funcion c10 Escribir 'Ingresar Intensidad de Tráfico' Leer A c<-10 w1<-2 w2<-2 b1<-2 Escribir calc(w1,w2,b1,A,c) Fin Funcion Figura 19. Diagrama de flujo de función para 10 canales. Fuente 22. Autor. 43.
(45) 5.2 ENTRENAMIENTO RNA Para el caso lineal, de la tabla 7 que tiene 30 datos (20 datos de entrada y 10 datos de salida), para optimizar el ajuste y asegurar una predicción de precisión, se tomaron el 90% para entrenamiento (18 datos de entrada y 9 datos de salida) y el 10% son utilizados para validación (dos datos de entrada y un dato de salida). Con la herramienta de simulación Matlab y las funciones establecidas para el entrenamiento de las redes neuronales artificiales multicapa, se configuran las capas, el número de neuronas/capa y las respectivas funciones de activación/neurona. La función lineal 𝑓(𝑋) = 𝑎𝑋, si el escalar 𝑎 = 5. Tabla 7. f(X)=5X. Fuente 23. Autor. El algoritmo para el entrenamiento RNA es el de Levenberg-Marquardt y se observa en los diagramas de flujo de las figuras 20 y 21: Figura 20. Diagrama de flujo del algoritmo de entrenamiento RNA. Fuente 24. Autor. 44.
(46) Figura 21. Diagrama de flujo de función Levenberg Marquardt. Fuente 25. Autor. Las gráficas obtenidas del entrenamiento, rendimiento y ajuste a través de las épocas, se muestran a continuación: En la figura 15 se muestra el diseño RNA de 3 capas con funciones de activación logsig, en la que una capa de entrada se constituye de 2 neuronas, la segunda capa oculta de 2 neuronas y la tercera capa (salida) de una neurona. En esta ventana también se visualiza el tipo de entrenamiento con el número de iteraciones del gradiente descendente necesarios para el mejor ajuste de la función de costo o error medio cuadrático. Son dos entradas para la primera capa, la primera entrada es el valor del escalar "𝑎 = 5" y la segunda entrada son los valores de la variable independiente “𝑋” en el rango de 0 a 9. Para la capa de salida, se obtiene el resultado de 𝑓(𝑋) = 𝑌. Figura 22. RNA multicapa para función lineal. Fuente 26. Herramienta nntraintool de Matlab. 45.
(47) En la figura 16 se observa cómo se modifica el gradiente descendente y el valor adaptativo mu a cada iteración hasta llegar a la configuración de 1000 iteraciones con cero fallas de validación, y así lograr el óptimo ajuste (menor función de costo) y mejor entrenamiento con las constantes de pesos y bias de la RNA: Figura 23. Estado de entrenamiento hasta 1000 épocas. Fuente 27. Herramienta plottrainstate de Matlab. En la figura 17, a la primera iteración la función de costo es máxima y a medida que se ejecutan las demás iteraciones, se modifica también el gradiente descendente, hasta alcanzar el objetivo de entrenamiento con el mejor ajuste a las 1000 épocas y el mínimo error medio cuadrático de 3.8224e-06: Figura 24. Rendimiento del entrenamiento.. 𝐹𝑢𝑛𝑐𝑖ó𝑛 𝑑𝑒 𝐶𝑜𝑠𝑡𝑜: 𝐽(𝜃0 , 𝜃1 ). Fuente 28. Herramienta plotperform de Matlab. 46.
(48) En la figura 18 se observa el ajuste óptimo de todos los datos de salida presentes en el entrenamiento, con la función de regresión: 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 𝑇𝑎𝑟𝑔𝑒𝑡 + 0.00018 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 20 + 0.00018 𝑂𝑢𝑡𝑝𝑢𝑡 = 20 + 0.00018 𝑂𝑢𝑡𝑝𝑢𝑡 = 20.00018 Ecuación 2. Regresión. La línea de color azul muestra cómo se pueden predecir los datos de salida que no se encuentran definidos en los puntos, ejemplo: si se tiene un target de 22.5, a qué valor equivale el Output? 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 𝑇𝑎𝑟𝑔𝑒𝑡 + 0.00018 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 22.5 + 0.00018 𝑂𝑢𝑡𝑝𝑢𝑡 = 22.5 + 0.00018 𝑂𝑢𝑡𝑝𝑢𝑡 = 22.50018 Ecuación 2. Regresión. Es decir que se predice con precisión el resultado de 22.5, obtenido de: 𝑓(𝑋) = 5𝑋 𝑓(𝑋) = 5 ∗ 4.5 𝑓(𝑋) = 22.5 ≈ 22.50018 Ecuación 3. Función Lineal. La predicción no será precisa cuando se toma datos muy alejados de la tabla de entrenamiento, esto se observa en el extremo de la tabla 7 en las celdas de colores verde, amarillo y rojo. Siendo las celdas de color verde, los datos de predicción precisa y las celdas de color rojo, los datos de predicción imprecisa. Figura 25. Ajuste en los datos de salida. Fuente 29. Herramienta Training de Matlab. 47.
(49) En el siguiente caso No Lineal, en donde se modela la RNA de la función de Erlang B. La recopilación de datos por cada tabla (par de canales), para obtener el mejor ajuste con valores de pesos y bias de la RNA, se tomaron 243 datos (162 datos de entrada y 81 datos de salida), de los cuales el 92.6% son utilizados para entrenamiento (150 datos de entrada y 75 datos de salida) y el 7.4% son utilizados para validación (12 datos de entrada y 6 datos de salida). Para el desarrollo algorítmico básico, se toma de referencia la tabla 4 con los datos de la función Erlang B establecida para 5 y 6 canales. El algoritmo para el entrenamiento RNA es el de Levenberg-Marquardt y se observa en los diagramas de flujo de las figuras 26 y 27: Figura 26. Diagrama de flujo del algoritmo de entrenamiento RNA. Fuente 30. Autor. 48.
(50) Figura 27. Diagrama de flujo de función Levenberg Marquardt. Fuente 31. Autor. Las gráficas obtenidas del entrenamiento, rendimiento y ajuste a través de las épocas, se muestran a continuación: En la figura 19 se muestra el diseño RNA de 4 capas con funciones de activación Logsig y purelin, en la que una capa de entrada se constituye de 2 neuronas, la segunda capa (oculta) de 6 neuronas, la tercera capa (oculta) de 5 neuronas y la cuarta capa (salida) de una neurona. En esta ventana también se visualiza el tipo de entrenamiento con el número de iteraciones del gradiente descendente necesarios para el mejor ajuste de la función de costo o error medio cuadrático. Son dos entradas para la primera capa, la primera entrada es el valor del número de canales "𝐶" y la segunda entrada es el valor de la intensidad de tráfico del sistema troncal “𝐴”. Para la capa de salida, se obtiene el resultado de la probabilidad de bloqueo "𝑃𝑏". Figura 28. RNA multicapa para función No lineal Erlang B. 49 Fuente 32. Herramienta nntraintool de Matlab.
(51) En la figura 20 se observa cómo se modifica el gradiente descendente y el valor adaptativo mu a cada iteración hasta llegar a la configuración de 1000 iteraciones con cero fallas de validación, y así lograr el óptimo ajuste (menor función de costo) y mejor entrenamiento con las constantes de pesos y bias de la RNA: Los parámetros de la hipótesis3 y la función de costo se modifican al aplicar la formulación del gradiente descendente 𝜃𝑗 para (𝑗 = 0 𝑦 𝑗 = 1): 𝜕 𝐽(𝜃0 , 𝜃1 ) 𝜕𝜃0. 𝜃0 ≔ 𝜃0 − 𝛼. Ecuación 4. Gradiente descendente 𝑗. 𝜃1 : = 𝜃1 − 𝛼. =0. 𝜕 𝐽(𝜃0 , 𝜃1 ) 𝜕𝜃0. Ecuación 5. Gradiente descendente 𝑗. =1. Donde 𝛼 es el índice de aprendizaje y 𝜃0 , 𝜃1 son los parámetros de la hipótesis. Figura 29. Estado de entrenamiento hasta 1000 épocas. Fuente 33. Herramienta plottrainstate de Matlab. En la figura 21, a la primera iteración la función de costo es máxima y a medida que se ejecutan las demás iteraciones, se modifica también el gradiente descendente, hasta alcanzar el objetivo de entrenamiento con el mejor ajuste a las 1000 épocas y el mínimo del error medio cuadrático es de 0.000326. La ecuación de esta función de costo 𝐽(𝜃0 , 𝜃1 ) es: 𝑚. 1 𝐽(𝜃0 , 𝜃1 ) = ∑(ℎ𝜃 (𝑥 (𝑖) ) + 𝑦 (𝑖) )2 2𝑚 𝑖=1. 3. https://www.coursera.org/learn/machine-learning/home/week/5. 50.
(52) Ecuación 4. Función de costo Figura 30. Rendimiento del entrenamiento.. 𝐹𝑢𝑛𝑐𝑖ó𝑛 𝑑𝑒 𝐶𝑜𝑠𝑡𝑜: 𝐽(𝜃0 , 𝜃1 ). Fuente 34. Herramienta plotperform de Matlab. La función hipótesis4 ℎ𝜃 (𝑥) obtenida: ℎ𝜃 (𝑥) = 𝜃 𝑇 𝑥 = 𝜃0 + 𝜃1 𝑥 Ecuación 4. Hipótesis. En la figura 22 se observa el ajuste óptimo de todos los datos de salida presentes en el entrenamiento, con la función de regresión: 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 𝑇𝑎𝑟𝑔𝑒𝑡 + 5.5 𝑒 − 05 Ecuación 2. Regresión. Para un target de 5.54% que sería la probabilidad de bloqueo “objetivo”, se obtendría un output o “salida”: 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 5.54 + 0.000055 𝑂𝑢𝑡𝑝𝑢𝑡 = 5.540055 Ecuación 2. Regresión. El output o probabilidad de bloqueo de 5,540055% correspondería a las entradas de 5 canales y 2,3 Erlangs de intensidad de tráfico troncal mostradas en la tabla 4. La línea de color azul muestra cómo se pueden predecir los datos de salida que no se encuentran definidos en los puntos, ejemplo: si se tiene un target de 10.57%, a qué valor equivale el Output? 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 𝑇𝑎𝑟𝑔𝑒𝑡 + 0.000055 𝑂𝑢𝑡𝑝𝑢𝑡 = 1 ∗ 10.57 + 0.000055 𝑂𝑢𝑡𝑝𝑢𝑡 = 10.57 + 0.000055 𝑂𝑢𝑡𝑝𝑢𝑡 = 10.570055 Ecuación 2. Regresión. 4. https://www.coursera.org/learn/machine-learning/home/week/5. 51.
(53) Es decir que se predice con precisión el resultado de la probabilidad de bloqueo del 10.570055%, obtenido con las entradas de 5 canales y 2.95 Erlangs de intensidad de tráfico troncal: Figura 31. Ajuste en los datos de salida. Fuente 35. Herramienta Training de Matlab. Estos son los pesos y bias que se obtienen del mejor rendimiento y entrenamiento de la RNA cuando se utilizan cinco y seis canales de la función Erlang B: Pesos y bias de la capa 1 (2 neuronas, 4 pesos y 2 bias) nete.iw{1,1} -1.1812. 1.2860. 1.2886 -1.7049 nete.b{1,1} 1.1535 -1.0212 Pesos y bias de la capa 2 (6 neuronas, 12 pesos y 6 bias) nete.Lw{2,1} -65.0083 -69.0249 0.6256 -12.7446 242.3190 131.4527 69.6368 30.9379 1.2498 -7.6400 71.1546 31.7876. 52.
(54) nete.b{2,1} 69.6571 6.3902 -167.6786 -25.8695 5.7968 -26.5411 Pesos y bias de la capa 3 (5 neuronas, 30 pesos y 5 bias) nete.Lw{3,2} -1.0829. 0.5180 -0.8023 -0.6179 -0.1269. -1.1068. 0.1409. 0.3091. 6.7554. 0.6706. 1.0200 -5.9041. -0.2859 -0.3026 -0.5302 -1.9808 -0.6752. 0.5012. -1.0995. 0.4176 -0.5173 -5.8599 -0.0467. 6.2448. -1.1256. 0.2186 -0.5018 -2.7707 -0.5678. 3.3014. nete.b{3} 0.7035 -0.7908 0.2191 -0.1025 0.8228 Pesos y bias de la capa 4 (1 neurona, 5 pesos y un bias) nete.Lw{4,3} -0.5827. 8.7893 -1.6495 -7.8050 -3.7658. nete.b{4} 0.9651 Esos valores de pesos y bias obtenidos de forma vectorizada del mejor entrenamiento y aplicación del algoritmo de aprendizaje levenberg Marquardt de matlab, se adoptan a las ecuaciones de la RNA con propagación hacia delante de forma no vectorizada para la implementación de las funciones de retorno, escritas en lenguajes de programación como C++ y java. En el siguiente diagrama se observa el procedimiento: Forma Vectorizada Mejor ajuste de datos Obtención W n y bn Aplicación “trainlm”. Adoptar W n y bn a Ecuaciones de53 RNA. Forma No Vectorizada Funciones de retorno Lenguaje C++ y Java.
(55) 5.3 MODELO VISTA CONTROLADOR DE APLICACIÓN MÓVIL 5.3.1 Modelo MVC de aplicación nativa Para el diseño de la aplicación nativa en el entorno de desarrollo Android Studio, se tienen presentes tres partes que actúan de forma dinámica, siendo estas: el modelo, la vista y el controlador. En el modelo, se plasma el marco referente y el punto de partida del diseño, que para el proyecto sería la función y el sistema de red neuronal artificial multicapa Erlang B con todo el componente matemático de forma no vectorizada y gestión a base de datos. En la vista, se diseña la interfaz y se determina los objetos básicos del algoritmo (cajas de texto, botones, etiquetas y gráficos) para la entrada, proceso y salida de datos; que deben estar presentes de forma intuitiva para facilitar la interacción entre la persona y el dispositivo móvil. En lo que respecta al controlador, esta hace referencia al proceso de software que permite la funcionalidad de la vista diseñada en leguaje XML, el modelo Erlang B y la base de datos. En esta última parte, se incluyen las clases de java, métodos y librerías de Android. En la siguiente figura se observa el MVC de la aplicación nativa: Figura 32. Modelo MVC app nativa Android. Fuente 36. Autor. 54.
(56) 5.3.2 Algoritmo del modelo RNA de Erlang B Este es el Pseudocódigo del algoritmo para los canales 5 y 6: Algoritmo Erlang B_RNA // Declaración de Pesos y Bias para Capa 1 de Entrada (2 Neuronas) W1 <- 0.4158; W2 <- -0.3281; W3 <- -0.5319; W4 <- 0.5659 B1 <- 0.6686; B2 <- -0.1193 // Declaración de Pesos y Bias para Capa 2 Oculta (6 Neuronas) W5 <- 56.7571; W6 <- -49.0134; W7 <- 39.76; W8 <- 48.4762 W9 <- 46.4096; W10 <- 43.0829; W11 <- -15.8276; W12 <- 2.3848 W13 <- -34.8022; W14 <- -35.8864; W15 <- -17.0401; W16 <- -26.4928 B3 <- -31.1933; B4 <- -44.1764; B5 <- -47.3409; B6 <- -4.3592; B7 <- 35.7450; B8 <- 17.9714 // Declaración de Pesos y Bias para Capa 3 Oculta (5 Neuronas) W17 <- -0.9138; W18 <- 2.1482; W19 <- 0.3043; W20 <- -0.2036; W21 <- -2.2236; W22 <- 0.8460 W23 <- -1.6284; W24 <- 3.9088; W25 <- 5.6251; W26 <- 3.3621; W27 <- 6.3604; W28 <- -1.9955 W29 <- 0.4149; W30 <- 1.9551; W31 <- -2.6968; W32 <- -2.6590; W33 <- -5.5211; W34 <- 1.8229 W35 <- 2.4951; W36 <- -3.4823; W37 <- 0.0085; W38 <- -1.8867; W39 <- 2.4870; W40 <- -1.4073 W41 <- -0.0270; W42 <- 0.4426; W43 <- 3.6352; W44 <- 2.9463; W45 <- 4.7868; W46 <- -0.8626 B9 <- 2.0368; B10 <- -3.3673; B11 <- 3.8926; B12 <- -2.3079; B13 <- -2.9902 // Declaración de Pesos y Bias para Capa 4 de Salida (Una Neurona) W47 <- -2.6080; W48 <- 9.6290; W49 <- -7.0703; W50 <- 2.5824; W51 <- 6.6411 B14 <- 0.7330 Escribir 'INGRESAR EL NUMERO DE CANALES' Leer C Escribir 'INGRESAR LA INTENSIDAD DE TRAFICO DEL SISTEMA TRONCAL' Leer A // Capa 1 -Función de activación Logsig // Neurona 1 A1 <- (C*W1)+(A*W2)+B1 N1 <- 1/(1+exp(-A1)) // Neurona 2 A2 <- (C*W3)+(A*W4)+B2 N2 <- 1/(1+exp(-A2)) // Capa 2 -Función de activación Logsig // Neurona 3 A3 <- (N1*W5)+(N2*W6)+B3 N3 <- 1/(1+exp(-A3)) // Neurona 4 A4 <- (N1*W7)+(N2*W8)+B4 N4 <- 1/(1+exp(-A4)) 55.
(57) // Neurona 5 A5 <- (N1*W9)+(N2*W10)+B5 N5 <- 1/(1+exp(-A5)) // Neurona 6 A6 <- (N1*W11)+(N2*W12)+B6 N6 <- 1/(1+exp(-A6)) // Neurona 7 A7 <- (N1*W13)+(N2*W14)+B7 N7 <- 1/(1+exp(-A7)) // Neurona 8 A8 <- (N1*W15)+(N2*W16)+B8 N8 <- 1/(1+exp(-A8)) // Capa 3 -Función de activación Purelin // Neurona 9 A9 <- (N3*W17)+(N4*W18)+(N5*W19)+(N6*W20)+(N7*W21)+(N8*W22)+B9 N9 <- A9 // Neurona 10 A10 <- (N3*W23)+(N4*W24)+(N5*W25)+(N6*W26)+(N7*W27)+(N8*W28)+B10 N10 <- A10 // Neurona 11 A11 <- (N3*W29)+(N4*W30)+(N5*W31)+(N6*W32)+(N7*W33)+(N8*W34)+B11 N11 <- A11 // Neurona 12 A12 <- (N3*W35)+(N4*W36)+(N5*W37)+(N6*W38)+(N7*W39)+(N8*W40)+B12 N12 <- A12 // Neurona 13 A13 <- (N3*W41)+(N4*W42)+(N5*W43)+(N6*W44)+(N7*W45)+(N8*W46)+B13 N13 <- A13 // Capa 4 -Función de activación Purelin // Neurona 14 A14 <- (N9*W47)+(N10*W48)+(N11*W49)+(N12*W50)+(N13*W51)+B14 N14 <- A14 Escribir 'LA PROBABILIDAD DE BLOQUEO ES ',N14,'%' FinAlgoritmo. 56.
Figure

+7




Outline
Documento similar
Tomando el relevo a los antecedentes iberoamericanos en materia de autonomía local, especialmente, la Carta de Autonomía Municipal Iberoamericana aprobada por
Resumen: Un modelo de red neuronal artificial es utilizado para calcular los momentos rotacionales extremos y definitivos en una estructura para edificios de varios pisos con
El controlador (usualmente otra red neuronal) monitorea entradas y salidas de la planta y manipula la entrada de control para calcular la predicción de la salida, basado en
De acuerdo con lo anterior se determinó que el entrenamiento y aprendizaje de la Red Neuronal Artificial, así como los datos tomados para tales fines debían ir de acuerdo a
En el entrenamiento de la red neuronal se obtuvo un rango de error mínimo en el reconocimiento de de cada patrón presentado. Al observar el comportamiento del
MoU Carta de la Energía - ARIAE Objetivo común: estabilidad regulatoria Reguladores: implementación legislación nacional Carta de la Energía: inspirar la legislación nacional ARIAE
Para poder realizar la identificación de cada árbol y su posterior recuento, se presenta una Red Neuronal Celular capaz de reducir la imagen de cada uno de ellos, una vez separada de
En ella tiene lugar la fase de aprendizaje en la que se genera la matriz de pesos, así como la parte de recuperación en la que se genera el nuevo estado neuronal,
