Crides asíncrones en MPI : Millorant temps i energia
59
0
0
Texto completo
(2) 2.
(3) Agraïments A la meva família pel seu recolzament continu. Al meu consultor Ivan Rodero per la seva ajuda i dedicació. A la Universitat de Rutgers per deixar-me fer servir el clúster de computació on s’han fet totes les proves d’aquest treball.. 3.
(4) Índex de continguts 1. Introducció .................................................................................................................................. 6 1.1. Objectiu del treball ............................................................................................................. 6. 1.2. Resum................................................................................................................................... 6. 1.3. Motivació ............................................................................................................................. 7. 1.4. Finalitat del treball.............................................................................................................. 7. 1.5. Plantejament del problema ............................................................................................... 7. 1.5.1. MPI_Barrier ................................................................................................................ 7. 1.5.2. MPI_Reduce ............................................................................................................... 8. 1.6. 2. Treballs relacionats ..................................................................................................................... 8 2.1. MPI ....................................................................................................................................... 8. 2.2. Intel....................................................................................................................................... 9. 3. MPI. Mètodes col·lectius síncrons i asíncrons. ..................................................................... 9. 4. Programes .................................................................................................................................. 10 4.1. 5. Programa de multiplicació de matrius .......................................................................... 10. 4.1.1. Presentació del programa ....................................................................................... 10. 4.1.2. Modificacions fetes.................................................................................................. 11. 4.2. 4. Resum del mètode.............................................................................................................. 8. Càlcul del número π ......................................................................................................... 12. 4.2.1. Presentació del programa ....................................................................................... 12. 4.2.2. Modificacions fetes.................................................................................................. 13. Metodologia experimental ....................................................................................................... 14 5.1. Clúster de computació ..................................................................................................... 14. 5.2. Metodologia dels càlculs ................................................................................................. 14. 5.2.1. Programa de multiplicació de matrius .................................................................. 14. 5.2.2. Programa de càlcul del número π ......................................................................... 15.
(5) 6. Resultats ..................................................................................................................................... 16 6.1. Programa de multiplicació de matrius .......................................................................... 16. 6.2. Programa de càlcul del número π .................................................................................. 17. 7. Conclusions ............................................................................................................................... 18 7.1. Programa de multiplicació de matrius .......................................................................... 18. 7.2. Programa de càlcul del número π .................................................................................. 19. 7.3. Conclussions generals...................................................................................................... 19. 8. Treball futur ............................................................................................................................... 20 8.1. Optimització/ampliació dels programes de proves ................................................... 20. 8.2. Substitució en temps d’execució de les crides síncrones ........................................... 20. 8.3. Optimització automàtica dels paràmetres asíncrons .................................................. 21. 9. Taules de resultats .................................................................................................................... 22 9.1. Multiplicació de matrius .................................................................................................. 22. 9.1.1. Experiments síncrons ............................................................................................. 22. 9.1.2. Experiments asíncrons............................................................................................ 23. 9.2 9.2.1. Experiments síncrons ............................................................................................. 30. 9.2.2. Experiments asíncrons............................................................................................ 30. 10. Gràfiques de resultats .......................................................................................................... 38. 10.1. Multiplicació de matrius .................................................................................................. 38. 10.2. Càlcul del número π ......................................................................................................... 46. 11. Codi programes .................................................................................................................... 54. 11.1. Mutiplicació de matrius ................................................................................................... 54. 11.1.1. Síncron....................................................................................................................... 54. 11.1.2. Asíncron .................................................................................................................... 55. 11.2. 5. Càlcul del número π ......................................................................................................... 30. Càlcul del número π ......................................................................................................... 57. 11.2.1. Síncron....................................................................................................................... 57. 11.2.2. Asíncron .................................................................................................................... 58.
(6) 1 Introducció 1.1. Objectiu del treball. En els últims anys s’han pogut crear clústers de supercomputació, fent servir ordinadors de sobretaula o servidors corporatius interconnectats, de tal manera que l’ús de llibreries com MPI han fet que els càlculs abans restringits als supercomputadors, s’hagin socialitzat i tornat menys elitistes. Aquestes llibreries de programació, paral·lelitzen i reparteixen els càlculs entre tots els nodes d’un clúster d’ordinadors, d’una manera síncrona. Això fa que es perdi temps i energia en el temps d’espera fins que tots els fils d’execució del càlcul han acabat la seva feina. L’objectiu d’aquest treball és: demostrar que la transformació de càlculs feta de manera asíncrona, fa que disminueixi els temps de processament i el consum d’energia del clúster. Es faran dues transformacions de crides síncrones d’MPI a asíncrones (disponibles en MPI a partir de la versió 3) i es presentaran els resultats, així com la seva discussió i conclusions. 1.2. Resum. La computació d’altes prestacions, abans restringida als grans superordinadors, ha pogut sortir d’aquestes gran sales i entrar a la gran majoria de centres d’investigació del món pel fet de poder fer servir ordinador de sobretaula o servidors corporatius interconnectats en xarxa. L’ús de llibreries del tipus MPI en aquests clústers, ha fet que càlculs abans restringits a grans i costoses màquines, s’hagin socialitzat. Aquestes llibreries de programació, paral·lelitzen i reparteixen els càlculs entre tots els components d’un clúster d’ordinadors, de manera que es pot treballar alhora en una sèrie de càlculs i aprofitar tot el potencial de càlcul dels processadors del clúster. Ara bé, el fet de fer servir diferents processadors, obliga a tenir sincronitzats els càlculs,de manera que si la línia del programa s’obre en quatre per realitzar un càlcul, hem de tenir cura que tinguem tots quatre resultats abans de poder continuar amb el programa. Això ho soluciona MPI fent les operacions síncrones, és a dir, cada procés fa el seu càlcul i un cop acaba, pregunta per l’estat de la resta de processos. Fins que tots els processos no obtenen la resposta de que tots han acabat, no es continua amb la execució del programa. Aquesta sincronia fa que els processos facin treballar contínuament els processadors, ja que estan preguntant com van la resta de fils d’execució amb els càlculs. Si podem transformar aquests fils d’execució de síncron a asíncron, de manera que evitem aquesta pregunta continua sobre l’estat de la resta de fils d’execució del programa de manera que, un cop un fil a acabat entri en espera una determinada quantitat de temps abans de preguntar l’estat de la resta de fils, aconseguim una millora en el consum energètic del clúster i, fins i tot, una millora en el rendiment dels càlculs.. 6.
(7) 1.3. Motivació. Normalment, les persones que fan servir càlculs en clústers d’alt rendiment computacional, no tenen els coneixements tècnics de programació com per poder optimitzar i millorar els rendiments dels seus càlculs. Si els oferim la possibilitat de poder accedir a millores només canviant un paràmetre de la línia d’execució del seu programa, els estem facilitant el treball a aquests investigadors.. 1.4. Finalitat del treball. Demostraré que es pot optimitzar el temps de càlcul i el consum energètic canviant la filosofia síncrona de la llibreria MPI. Tornant les barreres síncrones en asíncrones, fent esperar al processadors un cop han acabat la seva part de càlcul i evitant la continua consulta d’estats a la resta de fils, aconseguim optimitzar els recursos computacionals existents.. 1.5. Plantejament del problema. S’hauran de trobar exemples de càlculs en MPI que facin servir mètodes síncrons. Un cop escollits, trobar la manera de substituir la barrera síncrona on esperen de manera activa els diferents fils de computació creats, en una barrera asíncrona, on el procés un cop acabat el càlcul continuaria endavant. Haurem de forçar a que quedi en espera (i per tant, sense consumir tanta energia) un determinat espai de temps (definit mitjançant un paràmetre en la línia d’execució) abans de preguntar per l’estat de la resta de fils d’execució del programa. Per totes les execucions es passarà un paràmetre que regularà la complexitat del càlcul del programa. A més, per les variants asíncrones, tindrem un parell de paràmetres més: un que definirà el temps d’espera abans de saber l’estat de l’execució de la resta de fils i saber així si han acabat o no per poder continuar amb l’execució del codi i un segon paràmetre que indicarà el grau de repartiment dels càlculs entre tots els fils. Així doncs, un zero indicarà un repartiment equitatiu de la complexitat dels càlculs entre tots els fils de l’execució del programa i un 100 un grau màxim de desigualtat en aquest repartiment de tasques entre els fils. La funció d’aquests paràmetres és: . 1.5.1. pel paràmetre de temps d’espera, poder determinar quin és el millor temps d’espera per maximitzar l’execució del programa en funció de temps de computació i energia consumida. pel paràmetre de desequilibri, saber si es pot millorar el temps d’execució i l’energia consumida si els fils no executen la mateixa quantitat de càlculs. Potser que tinguem més eficiència si tenim una part dels fils executant més càlculs que una altra part que ja ha fet una part de la feina i resta en espera dels primers. MPI_Barrier. Aquest mètode serveix per assegurar-nos que cap fil d’execució s’avançarà de la resta en l’execució de codi. En arribar un fil a aquest mètode, restarà aturat fins que no arribin 7.
(8) també la resta de fils d’execució del programa. Moment en el qual, tots continuaran normalment. És com una barrera física que no s’obre fins que tots els fils han arribat a ella. En aquest cas, substituïm aquest mètode per MPI_Ibarrier, que es diferencia en que en arribar un fil a aquesta barrera, continua endavant l’execució del codi sense esperar a la resta de fils. Per evitar que cada fil tingui una execució descontrolada, hem d’afegir un mètode que ens permeti de controlar l’estat de la resta de fils (MPI_Test) per poder abandonar així l’estat latent del procés. 1.5.2. MPI_Reduce. Aquest mètode realitza un càlcul amb els resultats obtinguts per cada fil, reduint-lo a un únic valor. En el nostre cas, fem una suma amb els valors reportats per tots els fils. En substituir aquest mètode pel seu equivalent asíncron MPI_Ireduce, i com en el cas anterior, per poder saber quan em de treure de l’espera al fil, fem servir el mètode MPI_Test. 1.6. Resum del mètode. Es busca un tipus de programa que realitzi un càlcul complex i susceptible de ser paral·lelitzat. Un cop el tenim es realitza la transformació en el seu funcionament, de síncron a asíncron, de tal manera que un cop un fil ha acabat la seva tasca de càlcul, entre en espera. Cada cert temps, el fil surt de l’espera per saber l’estat de la resta de fils que componen l’execució del programa. Aquest temps es pot definir mitjançant un paràmetre a la línia de comandes d’execució del programa. Un altre paràmetre ens servirà per realitzar el repartiment de tasques entre els fils de l’execució. S’automatitza mitjançant shellscript el llançament dels programes tant en la seva versió síncrona con asíncrona, modificant els paràmetres de complexitat de càlcul, temps d’espera i desequilibri i guardant els resultats de les execucions en un fitxer de text. Aquest fitxer de text amb el valors dels paràmetres, el temps d’execució i l’energia consumida, s’importen a una fulla d’excel que permetrà crear les gràfiques que ajudaran a interpretar els resultats obtinguts.. 2 Treballs relacionats 2.1. MPI. MPI-3 incorpora instruccions asíncrones o no bloquejants, que tenen l’avantatge de no carregar el sistema amb comunicacions de control entre els fils d’execució d’un procés. Amb aquesta nova versió, diversos estudis han demostrat que els temps d’execució es veuen reduïts en fer servir aquest tipus de crides en comptes dels mètodes bloquejants tradicionals. Un exemple seria: Mastering Perfomance Challenges with the New MPI-3 Standard Mikhail Brinsky, Alexander Supalov, Michael Chuvelev and Evgeny Leksikov Descàrrega 8.
(9) Hi han d’altres autors que han trobat la manera de solucionar la despesa d’energia en les crides síncrones. En arribar a una barrera bloquejant tenen dues opcions: o fer dormir al processador, o variar el seu voltatge. Tot va encaminat a disminuir el consum d’energia del sistema: Exploiting Energy Saving Opportunity of Barrier Operation in MPI Programs Wenjing Yang, Canqun Yang Second Asia International Conference on Modeling & Simulation, 2008. AICMS 08. Descàrrega Aquest treball estaria agafant part de les idees exposades en aquests articles: . agafant els avantatges de la menor càrrega de comunicacions que donen les crides asíncrones. D’aquesta manera, podem aconseguir millorar els temps d’execució en reduir càrrega de treball. En posar el fil d’execució en espera, aconseguim reduir el consum energètic del sistema computacional.. Fusionant aquestes dues idees aconseguim un millor resultat energètic i un menor temps de càlcul. Redundant en un benefici per l’investigador i pel medi ambient.. 2.2. Intel. Per una altra banda, Intel amb el seu disseny d’MPI, també aprofita les noves funcionalitats de la versió 3. Tornen a destacar els mètodes no bloquejants d’aquesta nova versió. Un altre tema interessant del qual parlen és la possibilitat de fer un ajust automàtic dels paràmetres d’execució a les aplicacions. Aquest seria un dels punts que han quedat fora de l’abast d’aquest treball, però que té un gran interès com a treball de futur. Scaling MPI –Hybrid Applications Towards Performance Michael Steyer Descàrrega Standards, Standards & Standards -MPI 3 Michael Steyer Descàrrega. 3 MPI. Mètodes col·lectius síncrons i asíncrons. Els mètodes col·lectius síncrons possibiliten la comunicació entre un grup de processos, evitant la necessitat de programar protocols de comunicació punt a punt entre processos i sent molt més eficients que aquesta comunicació punt a punt. 9.
(10) Aquest grup de processos es relacionen mitjançant un comunicador intern i tots els seus mètodes seran bloquejants a nivell local. Dintre del grup de processos tindrem un procés que més endavant anomeno “principal” i que s’encarrega d’aglutinar totes les dades del programa. També s’encarregarà de calcular i distribuir dades així com de rebre les dades calculades per tot els processos del grup definit. Aquesta sincronització dels fils del grup afegeix molts missatges de comunicació entre els fils, que poden arribar a penalitzar l’execució del programa sencer. Per tant, s’ha de fer servir amb cura i no abusar d’aquests mètodes. Els mètodes col·lectius asíncrons es caracteritzen perquè les seves crides fan retornar immediatament el fil d’execució que el crida. D’aquesta manera, si volem tenir controlada l’execució del programa, hem d’afegir mètodes de sincronització entre fils. Amb tot això, aconseguim que la comunicació entre fils sigui gairebé inexistent, quedant reduïda a la mínima expressió i alliberant recursos del sistema. A priori obtindrem un millor rendiment sense sacrificar res. La pèrdua de la sincronització automàtica dels mètodes síncrons es veu compensada per la no necessitat continua de comunicació entre fils per assegurar aquesta sincronització. Per realitzat aquest treball es fa servir la versió MPI-3 d’openMPI. Aquesta versió, estandarditzada al novembre de 2014, tot i que encara no és molt utilitzada per la comunitat, incorpora les crides asíncrones necessàries per fer aquest treball.. 4 Programes 4.1. Programa de multiplicació de matrius. 4.1.1. Presentació del programa. El primer cas del treball recau sobre el mètode de barrera MPI_Barrier. Fem realitzar a cadascun dels fils d’execució uns càlculs i el fem esperar fins que no acabin la resta de fils. En aquest cas, tots els fils realitzen el mateix tipus de càlcul i no depenen dels resultats obtinguts per altres fils. Un exemple senzill de programa on aplicar aquestes premisses seria una multiplicació de matrius. Determino a 16 el nombre de processos que farà servir el programa. El programa accepta tres paràmetres d’entrada: . 10. SIZE: que indica la mida de les matrius a multiplicar. El seu valor per defecte és 100. IMBALANCE: on podem fer que cada fil d’execució realitzi més o menys càlculs. D’aquesta manera tindrem fils d’execució que faran més càlculs que uns altres. I aquests últims es veuran forçats a esperar més temps a que acabin aquells fils amb una càrrega computacional més alta. El valor per defecte és 10. Amb aquest paràmetre, juntament amb un valor constant (IMBALANCE_BASE=50) i el número de procés adjudicat per MPI_Comm_rank, es calcula quantes multiplicacions haurà de fer cada procés. Agafarem valors entre 0 i 100. On 0 indica un repartiment equitatiu en les tasques de computació i un 100 un màxim de desigualtat en els càlculs a realitzar per cada procés.
(11) . ITERS: és el nombre de vegades que farem servir l’MPI_Barrier. D’aquesta manera podem repetir l’experiment diverses vegades i obtenir una mitjana dels resultats obtinguts. El valor per defecte és 10.. L’execució del programa aniria així: 1) MPI crea els 16 processos i comença la primera volta de càlculs. 2) Segons el rang del procés, haurà de calcular més o menys vegades la multiplicació de dos matrius quadrades de mida SIZE. El procés 0 sempre serà el que menys càlculs realitzarà (degut a l’algoritme fet servir per desequilibrar el treball entre els processos: IMBALANCE_BASE + (IMBALANCE * num_rang_proces). Per tant, en el nostre cas de 16 processos i per uns valors d’IMBALANCE de 0, 50 i 100 tindríem un repartiment de tasques com el següent: num_rang_proces 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15. Nº multiplicacions a fer amb IMBALANCE = 0 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50 50. Nº multiplicacions a fer amb IMBALANCE = 50 50 100 150 200 250 300 350 400 450 500 550 600 650 700 750 800. Nº multiplicacions a fer amb IMBALANCE = 100 50 150 250 350 450 550 650 750 850 950 1050 1150 1250 1350 1450 1550. 3) Multiplicació de matrius. Es multipliquen dues matrius quadrades de SIZExSIZE, omplertes amb números aleatoris 4) Un cop cada procés a acabat el seu nombre de multiplicacions, s’atura a l’MPI_Barrier i queda a l’espera de la finalització de la resta de processos. 5) Un cop acaben tots els processos els seus càlculs assignats, s’informa per pantalla de l’acabament i es continua amb la següent iteració. El procés s’acabarà un cop fetes les iteracions fixades pel paràmetre ITERS. 4.1.2. Modificacions fetes. Modifiquem el programa de manera que la barrera síncrona, feta servir per aturar els processos més ràpids, la transformem en una barrera asíncrona MPI_Ibarrrier. En aquest cas perd la funcionalitat de barrera, ja que el procés que hi arribi, seguirà amb la execució de la resta de codi del programa. Hem de crear una manera de fer entrar en espera latent el procés perquè no consumeixi energia ni ample de banda preguntant contínuament per 11.
(12) l’estat de la resta de fils. És per això que introduïm un nou paràmetre d’entrada (que s’afegeix als tres ja existents del procés síncron) que permet definir el temps d’espera abans de preguntar per l’estat de la resta de fils d’execució. Aquest nou paràmetre és el primer en ordre de definició i forma part d’una estructura de temps timespec. En concret indicarem els nanosegons (ns) d’espera del procés abans d’executar el mètode MPI_Test. Aquest mètode posarà a true un paràmetre de la seva crida quan la resta de fils d’execució hagin acabat els càlculs. Si el resultat de MPI_Test es false, el procés entrarà en espera els ns indicats al paràmetre d’entrada. La resta del programa es comporta i funciona de la mateixa manera que la versió síncrona. 4.2 4.2.1. Càlcul del número π Presentació del programa. La computació paral·lela pot facilitar molt el càlcul del número π. En aquest cas farem servir pel càlcul la següent equació:. Que podem interpretar com el càlcul de l’àrea sota la corba definida:. 4 3 2 1 0 0. 1. Per calcular aquesta integral, podem aplicar el teorema de Riemann, que consisteix en dibuixar un nombre finit de rectangles dintre de l’àrea de la corba a calcular. Calculant la suma de les àrees de tots els rectangles definits, aproximem el valor de l’àrea i, per tant, de la integral. Com més petits siguin aquests rectangles, és a dir, com més rectangles fem servir per realitzar el càlcul, més acurada serà la mesura. He trobat una adaptació a MPI d’aquest mètode publicat al web de la Washington University in St. Louis. Concretament al seu Center for High Performance Computing (enllaç). Donada la seva senzillesa i l’ús de la crida síncrona MPI_Reduce, decideixo fer servir aquest codi. 12.
(13) Afegeixo un únic paràmetre d’entrada: npts: per poder ajustar el grau de complexitat del càlcul de π indicant el nombre rectangles que s’hauran de fer servir al càlcul. La primera cosa que fa el programa és repartir el nombre de rectangles a fer servir entre tots els fils d’execució del programa. Després d’això, cada fil escull una coordenada x a l’atzar i càlcul l’àrea del rectangle que li correspon a aquesta coordenada. Després de repetir aquest procés tantes vegades com rectangles li hagin assignat, el fil queda blocat a la crida MPI_Reduce fins que es tenen totes les dades i es pot realitzar la suma global de tots els resultats parcials calculats pels fils d’execució. Un cop calculada la suma total, s’alliberen els processos i el fil principal mostra per pantalla el valor de π trobat i el nombre de rectangles fets servir. Per realitzar els càlculs de tots dos programes, he fet servir 16 fils d’execució. 4.2.2. Modificacions fetes. Com en l’anterior programa, he d’afegir dos paràmetres d’entrada a l’existent de la versió síncrona per donar cabuda al temps d’espera dels fils . tv_nsec, temps d’espera. Amb un valor per defecte de 5000 ns. IMBALANCE, per desequilibrar els càlculs entre fils. Amb un valor per defecte de 0 = sense desequilibri.. Una de les modificacions més imaginatives de fer per aquest programa va ser dissenyar el desequilibri de càlculs entre els fils d’execució. D’això s’encarrega el fil principal al principi de tot del programa on la resta de fils queden a l’espera en la crida MPI_Bcast a rebre el valor calculat per cadascun d’ells. La manera de fer el desequilibri és la següent: es reparteixen equitativament el nombre de rectangles a calcular entre tots els fils d’execució. Si la repartició no pot ser exacta, el sobrant se’l queda el fil principal. Desprès d’això, i anant fil per fil, restem un percentatge dels rectangles assignats. Aquest percentatge és calcula agafant a l’atzar un número entre 0 i el valor del paràmetre IMBALANCE. Aquesta quantitat restada, és sumada a un dels fils d’execució escollit aleatòriament. Un cop el fil principal té assignat el nombre de càlculs que haurà de fer cada fil, els hi comunica mitjançant la crida MPI_Bcast. En tenir cada fil d’execució els seus paràmetres de càlcul, passen a realitzar la suma parcial. Quan la tenen calculada, mitjançant la crida asíncrona MPI_Ireduce, es comunica al buffer del fil principal que s’encarrega d’emmagatzemar aquestes sumes parcials. A partir d’aquí, el funcionament és totalment idèntic al programa anterior de multiplicació de matrius asíncron. Preguntem amb MPI_Test l’estat de la resta de fils i si encara tenim fils calculant, entra en espera el temps assenyalat pel paràmetre d’entrada tv_nsec. Un cop transcorregut aquest temps d’espera, torna a preguntar per l’estat de la resta de fils. Entrarà en espera un altre cop si no han acabat o continuarà cap al final del programa si ja han acabat tots. Un cop tots els fils han acabat els seus càlculs, el fil principal indica per pantalla el valor de π trobat i el nombre de rectangles d’aproximació fets servir.. 13.
(14) 5 Metodologia experimental 5.1. Clúster de computació. Situat a la Universitat de Rutgers, als Estat Units, és un clúster d’altes prestacions compost per vuit nodes. Aquest clúster disposa d’un Raritan com a instrumentació de mesura d’energia i un Yokogawa per mesurar el voltatge i la intensitat de cada node. Gràcies a aquests aparells, s’han pogut aconseguir totes les mesures de consum d’energia obtingudes en aquest treball. Cada servidor té la següent configuració de maquinari: . . 2 x Intel Xeon E5-2690 v2 @ 3,00 Ghz. Aportant un total de 16 nuclis. 128 Gb DRAM Emmagatzematge: o 1 TB NVRAM (Fusion-IO IoDrive2) o 2 TB en discos d’estat sòlid (SSD) o 4 TB en discos durs tradicionals (HDD) Coprocessadors Intel Xeon Phi 7120P. Amb 16 GB de RAM, 61 nuclis i 244 fils d’execució. Xarxa: o Infiniband que proporciona 56 Gbps o Ethenet a 10 Gigabit.. Podem trobar les característiques completes al següent enllaç. 5.2. Metodologia dels càlculs. 5.2.1. Programa de multiplicació de matrius. L’energia gastada en el procés de càlcul es mesura mitjançant un comptador d’energia ja instal·lat i disponible als clúster de computació. Aquest programa monitoritza les PDUs (Unitats de Distribució d’Energia) i extreu els consums de cada servidor del clúster utilitzat pel programa. Mitjançant un simple script, es poden extreure els resultats de consum d’energia de cada servidor a un fitxer de text des d’on podrem extreure els resultats per revisar, sumar-los finalment i obtenir les xifres d’energia. El programa el llancem mitjançant la comanda de Linux time, que ens retornarà el temps d’execució del programa. Per poder automatitzar les execucions, donat que un experiment complet pot allargar-se més d’una hora, es creen scripts que iteren per tots els valors dels paràmetres d’entrada que considero adients en cada moment. Per la versió síncrona de la suma de matrius, faig servir els següents valors com a paràmetres d’entrada: . 14. Mida de les matrius quadrades: SIZE = 100 Nombre d’iteracions per cada conjunt de càlculs: ITERS = 60 Desequilibri entre nombre de multiplicacions de matrius per fil d’execució: IMBALANCE = (0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100).
(15) Realitzo 10 experiments diferents, 7 dels quals són complets i dels altres 3 falten algunes combinacions de valors de paràmetres d’entrada. Això va ser causat per coincidir amb d’altres experiments que s’estaven realitzant al clúster i com és lògic tenien més prioritat que les meves mesures. Un inconvenient que va impedir que en algunes ocasions no acabessin els meus experiments satisfactòriament. No he vist la necessitat de completar aquestes repeticions donada la consistència dels resultats obtinguts en les sèries completes d’experiments. En total obtinc 8 hores i 23 minuts de temps d’execució repartit entre les diferents combinacions dels paràmetres d’entrada. Per la versió asíncrona de la multiplicació de matrius, mantinc els mateixos valors dels tres paràmetres d’entrada fets servir anteriorment. D’aquesta manera puc comparar fàcilment execucions fetes amb ambdós programes. A més a més, afegeixo el paràmetre de temps d’espera: . Temps d’espera (en ns) del fil d’execució abans de preguntar per l’estat de la resta de fils: tv_nsec = (3000, 5000, 7000, 9000, 11000, 13000, 15000). En aquest cas realitzo 6 experiments: tres complets i tres amb alguns valors incomplerts pels motius exposats de manca d’exclusivitat d’ús del clúster. En total aconsegueixo 33 hores i 18 minuts de temps d’execució repartit entre les diferents combinacions dels paràmetres d’entrada. 5.2.2. Programa de càlcul del número π. La metodologia feta servir en aquest programa és igual per tots els programes. Extraiem el consum registrat per les PDUs mitjançant software i calculem el temps d’execució llançant el programa amb la comanda time de Linux. Llenço scripts d’execució per poder automatitzar la recollida de dades. El paràmetre utilitzat en el programa síncron és: npts, nombre de rectangles generats: 10.000.000.000 Pel programa asíncron hem de tenir en compte també el temps d’espera i el desequilibri: tv_nsec, amb valors: 3000, 5000, 7000, 9000, 11000, 13000, 15000 IMBALANCE: 0, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100. Com que per aquests càlculs vaig poder tenir en exclusivitat el clúster de computació, vaig realitzar una primera sèrie de 20 experiments síncrons. Veient que els resultats eren equilibrats i conseqüents, no vaig trobar la necessitat de fer més experiments. Ja disposava d’unes bones mesures de referència per poder comparar els resultats asíncrons. Pel programa asíncron sí que realitzo repeticions dels experiments. En total en faig 11. Tots complets. En total són una mica més de 6 hores de computació.. 15.
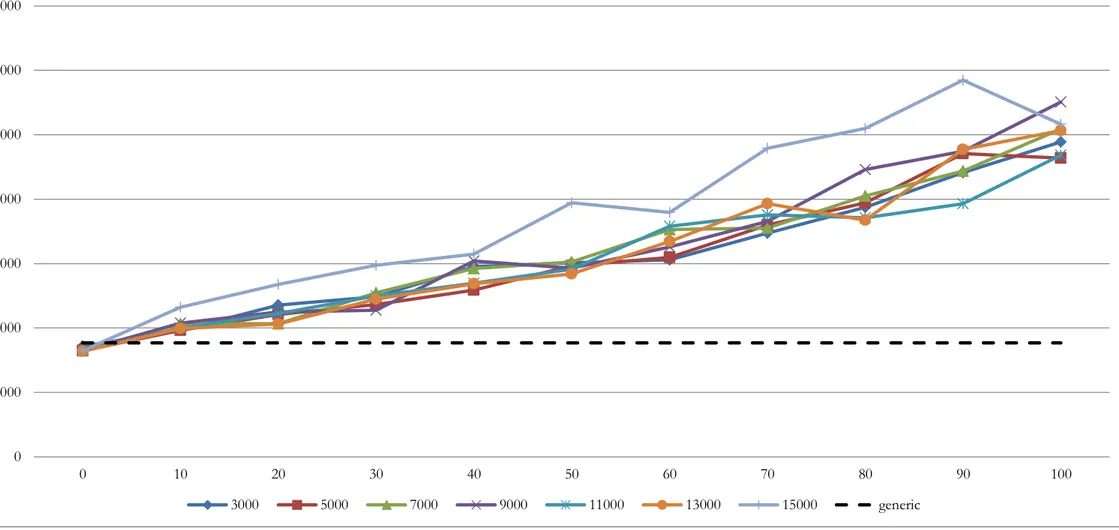
(16) 6 Resultats 6.1. Programa de multiplicació de matrius. Fent la mitjana dels resultats de l’execució síncrona, obtenim els valors de referència amb que compararem els resultats obtinguts de manera asíncrona. L’esmentada falta d’exclusivitat en l’ús del clúster fa que determinades mesures coincideixin amb altres treballs que s’executen en aquell moment, fent augmentar els valors de consum d’energia i de temps d’execució. Com que aquests valors són clarament visibles per la seva llunyania amb els obtinguts en d’altres experiments, fan que siguin fàcilment eliminats sense necessitat de fer servir cap mètode estadístic. Val a dir, que per la diferència horària existent entre els Estats Units i Catalunya, aquests problemes han estat mínims, ja que els meus horaris de treball al clúster solien coincidir amb les hores de mínima activitat d’allà. Obtenim dos tipus de resultats: energia consumida i temps d’execució. A part de les taules amb els resultats ordenats, confecciono diversos tipus de gràfiques que m’ajuden a veure com es comporten les execucions dels diferents experiments. En totes aquestes gràfiques, es mostren els valors asíncrons en línia continua i els valors síncrons (de referència) en línia discontínua. Les taules creades són: . . . . 16. Consum energètic vs. IMBALANCE (Figura 1), on es pot veure com influeix el desequilibri de càlculs entre fils d’execució en el consum energètic. A mida que augmentem el desequilibri, augmenta el consum d’energia. Excepte per valors de desequilibri igual a zero, la resta de valors queden per sobre del valor de referència síncron. Per tant, només millorem consum si no afegim desequilibri als fils d’execució. Temps d’execució vs. IMBALANCE (Figura 3), on tenim el temps d’execució dels programes en funció del grau de desequilibri introduit. Fins als valors d’IMBALANCE = 60, es pot veure que el temps d’execució és gairebé equivalent entre el programa síncron i l’asíncron. És més, els valors asíncrons sense desequilibri són millors que els trobats amb crides síncrones. Un cop més, es pot comporvar que alts nivells de desequilibri fan augmentar el temps d’execució ostensiblement. Consum energètic vs. Temps d’espera del fil d’execució (tv_nseq) (Figura 2), on podem observar el consum d’energia segons el grau de desequilibri introduït als càlculs del fil i segons el temps d’espera introduït al programa asíncron. Tornem a veure que valors grans de desequilibri fan augmentar el consum d’energia. Tots es valors queden per sobre de la seva referència síncrona excepte pels valors amb IMBALANCE = 0. Temps d’execució vs. Temps d’espera del fil d’execució (tv_nseq) (Figura 4). Aqui tenim representats els temps d’execució per temps d’espera i per sèries de desequilibri. Tormen a apreciar alts temps d’execució per aquells valors alts de desequilibri. Els millors valors de temps els trobem als experiments asíncrons amb desequilibri nul, que a més, queden per sota dels valors de referència síncrons. Consum energètic + temps d’execució vs. IMBALANCE per cada temps d’espera del fil d’execució fet servir. (Figures 5, 6, 7, 8, 9, 10 i 11). Aqui he representat per.
(17) separat cada temps d’espera fet servir en els experiments. Així, per cada valor de desequilibri tenim el temps d’execució i el consum energètic. La tònica general és que un augment del desequilibri augmenta el consum i el temps d’execució. I que els millors resultats els trobem allà on el desequilibri és igual a zero. En aquests casos, també s’arriba a millorar el valor de referència que és el temps d’execució del programa amb barreres col·lectives síncrones. 6.2. Programa de càlcul del número π. Aquesta vegada la comparació de resultats no es fa exactament igual que amb el programa de multiplicació de matrius, ja que he aplicat una part de les conclusions obtingudes del programa anterior. Veient que el desequilibri entre el grau de càlcul entre fils fa augmentar el temps d’execució en tots els casos, decideixo anar una mica més enllà i fer les comparacions de tots els resultats asíncrons únicament amb el millor resultat que es pot obtenir de manera síncrona, que és amb IMBALANCE = 0. És per això que no introdueixo el desequilibri en el càlcul síncron. Una vegada ordenats en taules els resultats asíncrons, i donat que he realitzat 11 repeticions, elimino també aquells valors que veig que se surten de la tendència general. Però no només elimino els valors afectats sinó tots els obtinguts en aquell experiment concret. D’aquesta manera m’asseguro d’obtenir els millors resultats asíncrons possibles ja que he de tenir en compte que: El temps d’execució és molt curt i, per tant, les diferències entre els temps obtinguts no seran molt grans. Pel consum energètic passarà el mateix, ja que un temps petit d’execució implicarà un consum d’energia petit, minimitzant les diferències. Realitzo també diverses gràfiques: . . . . 17. Consum energètic vs. IMBALANCE (Figura 12), on tenim el consum d’energia en funció del desequilibri imposat. Hem de tenir en compte que el valor genèric de referència no fa servir cap desequilibri en els seus càlculs. Podem observar que els valors asíncrons sense desequilibri tenen millors temps d’execució que els de referència. Temps d’execució vs. IMBALANCE (Figura 14). Tenim representat el temps d’execució en funció del desequilibri i el temps d’espera. Es pot observar un augment gradual del temps d’execució amb el desequilibri. El que no es pot assegurar es que un augment del temps d’espera augmenti sempre el temps d’execució. Es pot apreciar que els valors amb desequilibri igual a zero, són els que tenen un millor resultat, millorant la referència. Consum energètic vs. Temps d’espera del fil d’execució (tv_nseq) (Figura 13). Aquí tornem a tenir el consum d’energia de l’aplicació en funció del temps d’espera i del grau de desequilibri. Es pot veure clarament que la sèria amb desequilibri nul, és la que millor resultats obté, bastant per sota del valor de referència. Temps d’execució vs. Temps d’espera del fil d’execució (tv_nseq) (Figura 15). Hem representat el temps d’execució de l’aplicació en funció del temps d’espera i amb sèries de dades per diferents percentatges de desequilibri. Valors grans de desequilibri tenen valors grans de temps d’execució. Un altre cop, la sèrie sense desequilibri obté els millors resultats..
(18) . Consum energètic + temps d’execució vs. IMBALANCE per cada temps d’espera del fil d’execució fet servir. (Figures 16, 17, 18, 19, 20, 21 i 22). La representació separada per cada temps d’espera fa més clars els resultats obtinguts. És obvi que l’augment de desequilibri fa augmentar el temps d’execució i el consum d’energia. En tots els casos, el desequilibri nul obté els millors resultats i millora els valors de referència.. 7 Conclusions 7.1. Programa de multiplicació de matrius. En tots els casos on el desequilibri de càlculs entre fils d’execució no existeix, el mètode asíncron és més eficient en termes de consum energètic. En el cas del temps d’execució, obtenim una millora gairebé general en tots els casos plantejats. Com en el cas del consum energètic, quan no existeix desequilibri de càlculs entre fils, la millora es sempre efectiva. En el cas d’augmentar el desequilibri, fins a un valor d’IMBALANCE de 50 obtenim valors gairebé equivalents als síncrons per tots els temps d’espera. Només en els temps d’espera més alts, també obtenim igualtat de resultats amb els desequilibris més alts (90). Les conclusions que podem extreure són les següents: Si busquem millorar consum energètic, hem de distribuir equitativament els càlculs a realitzat entre tots els fils d’execució existents. L’estalvi d’energia ve donat perquè estem evitant sobrecarregar els processos en la consulta de l’estat de la resta de fils d’execució del programa. Com que estem reduint el nombre de consultes i a més, estem posant en espera els processos durant una part important de l’execució, és fàcil de trobar la millora del codi asíncron. Els percentatges de millora obtinguts van de l’11 al 22 %, sent millors els resultats obtinguts amb valors alts de temps d’espera del procés. En canvi si busquem millorar temps d’execució, hem de continuar buscant l’equilibri de càlcul entre els fils d’execució. El percentatge de millora respecte als valors síncrons és situa al voltant del 32 %. Si augmentem el desequilibri entre processos, no obtenim cap millora en els resultats. En aquest cas, l’augment del temps d’espera no s’aprecia entre els diferents temps d’espera donat que són valors molt petits: De l’ordre dels 17-18 segons. Els percentatges de millora segons el temps d’espera van del 28% al 32%. Però aquests valors no els considero fiables per la curta durada de l’experiment. Trobem millora entre els experiments asíncrons respecte els síncrons, però no tinc prou dades per assegurar com afecta en aquest cas el temps d’espera del procés. Si mirem els experiments amb més durada, sí que podem observar una millora del temps d’execució en augmentar el temps d’espera. De manera equivalent al consum energètic, podem assegurar que amb fils d’execució amb càrrega de treball equivalent i temps d’espera grans, obtenim millora de temps d’execució respecte el mètode síncron. Aquest guany en el temps d’execució el podem atribuir a la millor optimització de la comanda MPI_Test (feta servir en el procés asíncron per conèixer l’estat del càlcul pels diferents fils) respecte l’MPI_Barrier del procés síncron. MPI_Barrier és una crida bloquejant, mentre que MPI_Test no ho és pas. Això la fa més efectiva i el seu ús 18.
(19) augmenta el rendiment dels programes ja que actua de manera diferent a MPI_Barrier per aconseguir saber l’estat de la resta del fils d’execució del programa.. 7.2. Programa de càlcul del número π. Tal i com es podia preveure, els millors resultats asíncrons en terme de temps d’execució i consum energètic els trobem en tots aquells experiments que no introdueixen desequilibri entre els fils d’execució. El percentatge de millora en el temps d’execució és d’un 7% aproximadament. Pel consum energètic, els guanys van del 2,95% al 7,57%, depenent del temps d’espera fet servir. En aquest cas, els temps d’espera alts milloren més el consum energètic. Sent el valor òptim 7000 ns. Es pot observar també, que el menor temps d’espera és el que obté de llarg el pitjor resultat. Malgrat tot també millora el valor síncron. Podem veure que la nova crida asíncrona MPI_Ireduce, torna a tenir un millor rendiment que la seva equivalent síncrona. També hem de tenir en compte un detall: el càlcul del desequilibri afegeix una càrrega de càlcul al programa asíncron que no té el síncron. A més, aquest càlcul de desequilibri, incorpora una barrera síncrona. Per tant, el programa asíncron ni ho és en la seva totalitat, ni tampoc és del tot equivalent amb el seu rival síncron. Tot i això, aconsegueix millorar els resultats computacionals, donant una idea de la efectivitat de les noves crides asíncrones. 7.3. Conclussions generals. Com s’ha pogut veure, les crides asíncrones tenen un rendiment molt superior a les equivalents síncrones. Aquesta nova perspectiva en la programació, fa millorar encara més els resultats obtinguts amb els programes que fan servir MPI. La computació d’altes prestacions ha permès assolir grans èxits en la investigació mundial i el fet de millorar una llibreria tan necessària pels científics, farà possible assolir noves fites, impensables d’aconseguir a un nivell tan “amateur” mirant uns anys enrere. També s’ha pogut demostrar que desequilibrar els fils d’execució fa malbaratar recursos, ja que tenim uns processos fent càlculs mentre uns altres els tenim esperant una bona estona. Això fa que s’allarguin els temps d’execució i el consum energètic. En igualtat de condicions (desequilibri entre fils) es pot observar que el sobrecost que incorporen les barreres síncrones és molt alt. Les noves crides asíncrones retornen més ràpidament i amb menys recursos l’estat dels fils quan es crida a MPI_Test. La recomanació és ràpida: evitar les barreres síncrones. En la gran majoria dels casos, la transformació és trivial, però degut a que els programes d’investigació no són tan simples com aquests que he fet servir de test, es veu necessari anar una mica més enllà per realitzar aquestes millores de manera transparent. Ho explico en el següent apartat.. 19.
(20) 8 Treball futur A continuació detallo els treballs que seguirien a aquest treball de final de màster, però que la falta de temps m’ha impedit desenvolupar. 8.1. Optimització/ampliació dels programes de proves. Una primera millora seria transformar el programa asíncron del número π: treure la barrera síncrona MPI_Bcast per la seva equivalent asíncrona MPI_Ibcast. D’aquesta manera reduiríem els sobrecost de càlcul i comunicacions que genera el repartiment del nombre de rectangles a calcular entre tots els fils d’execució i milloraríem encara més els temps d’execució i consum energètic del programa. 8.2. Substitució en temps d’execució de les crides síncrones. Aquesta seria l’actuació que tindria una aplicació més pràctica en l’àmbit d’us dels programes MPI. El que es pretén es substituir les crides síncrones per les seves asíncrones de manera totalment transparent per l’usuari i en temps d’execució. És a dir, sense haver de tocar el codi original. Això es pot realitzar amb les anomenades llibreries de profiling (pMPI). Aquestes llibreries es fan servir per poder prendre mesures estadístiques de les funcions MPI d’un programa. Moltes presenten els resultats mitjançant gràfics permetent veure, per exemple, on triga més el programa a realitzar els càlculs i, amb aquesta informació, procedir a optimitzar aquella part de codi que resulta més ineficient. Aquestes llibreries s’enllacen al programa MPI en temps d’execució de manera que, quan el programa original ha de cridar a una operació MPI, en comptes d’anar-la a buscar a la llibreria d’MPI, crida a la operació equivalent de pMPI. Aquesta operació equivalent és la que hem desenvolupat nosaltres i, normalment afegeix una marca de temps abans de cridar a la operació original que, aquesta vegada sí, es va a buscar a les llibreries d’MPI. El seu funcionament es podria resumir de la següent manera:. Per tant, el que hauríem de fer és definir dintre de la llibreria de profiling com volem que es comporti el programa en el cas d’arribar a una determinada crida síncrona. El que voldrem és que en comptes de cridar al mètode síncron ho faci a l’asíncron. I un cop retorni aquest últim, veure les condicions de la resta de fils per començar l’espera o no. Seria un algoritme com el següent:. 20.
(21) D’aquesta manera, aconseguim alliberar de l’optimització a l’usuari del programa, que potser no té els coneixement o el temps per anar modificant els programes que fa servir, i aconseguiríem ràpida i fàcilment una millora en els resultats obtinguts. També s’hauria de donar la possibilitat a l’usuari de poder modificar els paràmetres que afecten directament al rendiment asíncron, com per exemple el temps d’espera. Jo seria partidari de posar uns paràmetres per defecte que s’han vist que funcionen amb els programes de test i fer servir els de l’usuari solament si els indiqués a l’hora de crida el programa. 8.3. Optimització automàtica dels paràmetres asíncrons. Una segona fase en l’optimització de programes MPI, seria la de que el programa sabés escollir aquells paràmetres que aportarien uns millors resultats. Alliberaríem totalment a l’usuari dels sobrecostos del funcionament d’MPI i podria centrar-se en l’optimització pura i dura dels càlculs aritmètics pròpiament dits.. 21.
(22) 9 Taules de resultats 9.1 9.1.1. 22. Multiplicació de matrius Experiments síncrons. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 4195 8050 12701 18086 23732 29214 34721 60907. 15 67 118 169 221 271 322 429. 5158 7256 12632 18290 23758 29231 35633 42222 47612. 16 67 117 169 220 271 322 374 430. 13264 3149. 102 4. 4228 8354 13149 18923 24718 30498 36144 48911 83942 111909 131982. 15 67 118 168 221 272 322 416 596 773 949. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 4545 7434 13241 18912 24813 30413 36089 49564 87325 118068 126367. 18 68 119 168 221 271 322 416 595 771 946. 4330 7348 13135 18639 24640 30382 36066 48162 88959 116570 147284. 17 67 118 170 220 271 322 417 592 773. 4332 8199 13195 18842 24747 30470 36061 49695 84235 105378 131592. 16 66 119 168 221 272 322 416 590 779 954. IMBALANCE. Consum. Temps. Consum. Temps. Consum Mitjà. Temps Mitjà. 0 10 20 30 40 50 60 70 80 90 100. 4432 15632 27542 39451 51350 63254 74913 97662 137493 179598 221406. 18 66 118 168 220 271 320 420 592 774 949. 4199 15640 27557 39464 51136 63366 75038 96966 137766 189706 222537. 17 66 117 169 219 270 321 416 591 818 957. 5302 8936 16263 23291 30393 37477 44526 60316 95313 134465 163528. 25 60 118 168 220 271 322 414 572 780 951. 16 4340 66 8298 118 13211 166 19016 220 24643 271 30465 322 36069 418 48759 593 95171 775 120023 950.
(23) 9.1.2. 23. Experiments asíncrons. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000. 0 10 20 30 40 50 60 70 80 90 100. 4006 16010 28029 39791 52060 63862 76166 112755 155979 199715 243424. 16 67 118 169 221 271 322 477 661 847 1033. 4436 15642 27568 39189 51099 63015 75158 99451 138896 179780 220625. 16 67 118 168 221 270 322 475 660 845 1153. 4297 6959 21119 29676 44908 60630 72993 211210 391293 563643 861350. 18 66 117 168 218 270 322 427 595 772 950. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000. 0 10 20 30 40 50 60 70 80 90 100. 3715 15572 27404 62704 74500 96815 136983 179230 219407. 15 66 117 270 321 417 591 773 947. 4829 17279 30178 43098 56247 69492 82169 104052 138721 181161 220805. 18 66 117 167 219 271 321 415 596 778 949. 4430 15391 27535 39219 51137 62979 74893 97529 137645 180370 251601. 18 65 117 168 218 270 321 418 591 775 1080. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000. 0 10 20 30 40 50 60 70 80 90 100. 4007 16021 28009 52044 64273 75355 111758 398987 529752 708967. 16 68 118 220 272 319 474 655 847 1030. 5296 6960 22888 33344 46554 59820 71822 209457 508351 568074 749980. 16 67 118 169 220 270 320 475 792 850 1051. 4437 15662 27335 39290 51235 63049 74984 97151 138225 181000 220736. 18 66 117 168 219 270 320 417 593 776 951.
(24) 24. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000. 0 10 20 30 40 50 60 70 80 90 100. 37607 54480 65822 66095 86335 110935 152297 200716 235857. 117 167 220 271 321 418 593 773 952. 4429 15620 27512 39401 51056 62949 74837 97455 137790 181406 221379. 18 66 117 169 219 269 321 419 591 779 951. 4441 15402 27531 39197 51138 63250 74964 97313 138915 179269 221483. 18 65 118 167 219 271 321 417 596 769 951. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000. 0 10 20 30 40 50 60 70 80 90 100. 5301 7779 13100 27179 34171 67397 199812 373392 554982 723111. 16 66 119 168 220 319 473 660 846 1036. 5256 7831 27327 41331 54603 66042 78799 220357 397786 582105 757253. 16 67 119 169 221 272 319 473 664 848 1039. 4420 15566 27438 39297 50895 62782 74633 96959 136927 178998 220445. 18 66 118 168 219 270 321 417 590 771 950. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000. 0 10 20 30 40 50 60 70 80 90 100. 4413 15324 27213 39281 50857 62722 74509 97319 137242 178962 219833. 18 66 116 169 218 270 321 419 592 773 949. 4432 15619 27284 39402 51293 63186 74837 97448 171838 180227 221476. 18 66 116 169 220 271 321 418 738 774 952. 4429 15630 27554 39227 51321 63306 75194 97480 138259 180767 222328. 18 66 117 167 220 270 322 417 593 775 954.
(25) 25. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000. 0 10 20 30 40 50 60 70 80 90 100. 3484 6877 16671 28052 37728 56388 67379 202398 553381 718180. 16 66 118 169 220 271 320 472 845 1033. 5284 6842 22761 39527 52699 54438 81789 221574 403832 582857 758292. 16 66 117 169 219 272 322 476 658 852 1034. 4415 15567 27422 39060 51177 62768 74616 97388 138339 179252 221129. 18 66 118 167 220 270 321 419 596 772 953. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000. 0 10 20 30 40 50 60 70 80 90 100. 4408 15548 27382 39219 51097 62683 74493 96578 137213 179279 220291. 19 66 117 169 219 270 321 416 592 774 950. 4427 15388 27509 39403 51056 62960 74853 97463 138094 222653. 18 65 118 168 219 270 321 418 593 953. 4434 15664 27552 39187 51379 63255 74937 96882 138693 180487 222567. 18 66 117 168 220 270 321 416 594 775 955. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000. 0 10 20 30 40 50 60 70 80 90 100. 3491 6967 19338 32583 43894 54391 68547 -. 16 68 118 170 219 271 322 -. 6955 19294 42214 56410 74965 77311 216307 -. 18 68 118 168 221 272 322 477 -. 3722 15354 27440 39098 51142 63037 74676 96722 137400 180464 219756. 15 65 118 167 220 271 321 416 592 777 947.
(26) 26. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000. 0 10 20 30 40 50 60 70 80 90 100. 4412 15315 27394 39071 51219 62951 74858 96772 138025 179045 221243. 18 65 117 168 219 270 321 415 593 770 953. 4448 15684 27627 39559 51273 63212 75144 97277 137794 179886 222686. 18 66 117 169 219 269 321 418 591 773 948. 4441 15636 27565 39459 51151 63025 74938 97372 138065 180096 220944. 18 66 117 169 219 269 321 418 591 773 948. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000. 0 10 20 30 40 50 60 70 80 90 100. 4403 7851 18452 29785 39547 53757 69394 -. 16 67 119 168 221 272 322 -. -. -. 3715 15587 27449 39270 50943 62787 74911 97005 137949 180222 221157. 15 67 117 168 219 270 322 417 594 777 954. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000. 0 10 20 30 40 50 60 70 80 90 100. 4408 15599 27149 38983 51044 62687 74525 97746 138342 180182 221733. 18 66 116 168 219 270 321 419 594 775 953. 4461 22577 42246 60821 55787 63189 80085 97872 180554 220717. 18 66 117 168 219 270 321 418 772 948. 4433 15642 27317 39470 51391 63289 74972 97629 138260 180128 -. 18 66 116 169 219 271 321 419 592 773 -.
(27) 27. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000. 0 10 20 30 40 50 60 70 80 90 100. -. -. -. -. 3487 15336 27209 39278 50931 63038 74642 97177 137384 179121 -. 14 66 116 169 218 271 321 418 592 773 -. Temps d’espera. IMBALANCE. Consum. Temps. Consum. Temps. Consum. Temps. 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000. 0 10 20 30 40 50 60 70 80 90 100. 4427 15613 27496 39080 51086 62892 74803 97097 179147 220466. 18 66 117 168 219 271 322 418 773 951. 4427 15380 27505 39159 51282 63169 75064 97438 138233 179956 222371. 19 65 117 168 219 271 322 418 594 773 956. -. -. Temps d’espera. IMBALANCE. Consum Mitjà. Temps Mitjà. 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000. 0 10 20 30 40 50 60 70 80 90 100. 4285,5 14475,5 26972,167 38194,6 51090,2 63780,333 75979,833 120302 183252,83 247316,5 336202. 17 66 117 168 219 270 322 438 616 798 1019.
(28) 28. Temps d’espera. IMBALANCE. Consum Mitjà. Temps Mitjà. 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000. 0 10 20 30 40 50 60 70 80 90 100. 4522 13933 28480,333 41142,4 52974,833 63239,333 76382,833 120678,17 245760,83 306702,83 393067. 17 66 118 168 220 271 320 437 637 799 981. Temps d’espera. IMBALANCE. Consum Mitjà. Temps Mitjà. 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000. 0 10 20 30 40 50 60 70 80 90 100. 4708,5 12958,167 24986 37619,5 48856,667 63607,6 74228,167 134895,83 225907,33 309340,17 394074,33. 17 66 118 168 220 271 321 436 640 798 980. Temps d’espera. IMBALANCE. Consum Mitjà. Temps Mitjà. 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000. 0 10 20 30 40 50 60 70 80 90 100. 4408,6667 12647,667 24882,833 37408 49189,333 60415,333 74677,833 135380,5 191234,2 335051,2 393852. 18 66 118 168 220 271 321 436 607 804 980.
(29) 29. Temps d’espera. IMBALANCE. Consum Mitjà. Temps Mitjà. 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000. 0 10 20 30 40 50 60 70 80 90 100. 4102,8 12651,833 24776,333 38664 50848,167 63596,833 74245,667 120890 137821 179872,75 221157,25. 17 66 118 169 220 270 321 429 592 773 949. Temps d’espera. IMBALANCE. Consum Mitjà. Temps Mitjà. 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000. 0 10 20 30 40 50 60 70 80 90 100. 4284 15451,2 28522,6 41665,8 49742,4 61141,8 74777,4 97563 138183,67 180271,5 221202,33. 17 66 117 168 219 271 321 418 593 774 952. Temps d’espera. IMBALANCE. Consum Mitjà. Temps Mitjà. 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000. 0 10 20 30 40 50 60 70 80 90 100. 4113,6667 15443 27403,333 39172,333 51099,667 63033 74836,333 97237,333 137808,5 179408 221418,5. 17 66 117 168 219 271 322 418 593 773 954.
(30) 9.2 9.2.1. Càlcul del número π Experiments síncrons Experiment. Consum. Temps. 1 2 3 4 5 6 7 8 9 10 11. 3040 3691 3532 3539 3695 3537 3790 3535 3537 3529 3528 3541. 12 14 13 13 14 13 25 13 13 13 13 14. Mitjana. 9.2.2. 30. Experiments asíncrons. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000. 6090 3989 3981 5394 5384 5153 7495 7492 7495 8916 11507. 25 16 16 22 22 21 31 32 31 37 48. 3292 3995 3998 3995 5409 6819 6825 8939 9645 9639 7520. 13 17 16 16 22 28 28 37 40 40 32. 3760 4004 3995 4704 6110 4700 8229 9646 6815 8001 10348. 15 17 16 19 25 19 34 40 28 33 43. 3525 3998 4702 4472 6112 6826 5414 6116 9648 7998 8937. 14 16 19 18 25 28 22 25 41 33 37.
(31) 31. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000. 3295 3996 4701 4702 5410 5407 6827 5405 9644 11771 7520. 13 16 19 19 22 22 28 22 40 49 31. 3296 3997 4707 4702 8237 4703 5410 7524 6815 8943 10827. 13 16 19 19 34 19 22 31 28 37 45. 3766 4009 5419 6127 4712 5421 5415 5417 6130 8947 8982. 15 16 22 25 19 23 22 22 25 37 37. 3307 4025 4725 6147 4732 6156 5437 5208 8275 9692 11828. 14 16 19 25 19 25 22 21 34 40 49. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum Mitjà. Temps Mitjà. 0 10 20 30 40 50 60 70 80 90 100. 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000 3000. 3067 4007 6832 4709 7533 6838 6833 7540 6843 9662 11786. 12 16 28 20 31 28 28 31 28 40 49. 3769 4005 4001 5413 4706 5415 6124 6123 6828 6828 11775. 15 16 16 22 19 22 25 25 28 28 50. 3290 3293 3997 4712 6118 8003 4709 7535 6824 6828 8240. 13 13 16 19 25 33 19 31 28 28 34. 3437 3933 4708 4968 5908 6029 6122 6945 7747 8831 9776. 14 16 19 20 24 25 25 29 32 37 41. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000. 3284 3980 3979 4685 5383 6090 6100 6101 8199 11003 9597. 13 16 16 19 22 25 25 26 34 46 40. 3295 3995 4001 3995 4708 5172 6113 7520 8226 9641 7998. 13 16 17 17 19 21 25 31 34 40 33. 3296 3995 4704 4700 5410 5405 6821 8937 7520 8933 7523. 13 17 19 19 22 22 28 37 31 37 31. 3290 4000 3996 4707 5171 8234 7524 8225 8225 7524 11759. 13 16 16 19 21 34 31 34 35 31 49.
(32) 32. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000. 3294 3995 3995 3995 4700 5413 6118 6110 11757 9635 11764. 13 17 16 16 19 22 25 25 49 40 49. 3305 3997 3997 4700 4700 5405 4705 6815 5411 11523 8936. 14 16 16 19 19 22 19 28 22 48 37. 3311 4017 4723 5198 4735 6857 6153 6626 6849 6850 9696. 13 16 19 21 19 28 25 28 28 28 40. 3309 4026 4728 6145 6145 6158 5447 8038 7570 8989 6154. 13 17 19 25 25 25 22 33 31 37 25. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum Mitjà. Temps Mitjà. 0 10 20 30 40 50 60 70 80 90 100. 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000 5000. 3298 3298 6125 4715 5430 4476 5423 6833 8245 11790 10366. 13 13 26 20 22 18 22 28 34 49 43. 6120 4005 4001 5415 5884 6125 5418 8249 8958 6125 8953. 25 16 16 22 24 25 22 34 37 25 38. 3294 4006 4001 4470 5420 6122 7529 6823 6829 8238 8951. 13 17 16 18 22 25 31 28 28 34 37. 3298 3931 4425 4731 5180 5933 6193 7203 7883 9413 9274. 13 16 18 19 21 24 25 30 33 39 38. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000. 3280 3981 4686 5401 5389 6788 7951 9131 10039 11521 13405. 13 16 19 22 22 28 27 30 33 37 45. 3291 3999 3996 4712 5406 5413 6821 6816 8231 10348 11052. 13 16 16 19 23 22 28 28 34 43 46. 3298 3995 3995 5415 7298 6110 6824 7525 8229 8225 11059. 13 16 17 22 30 25 28 31 34 34 46. 3301 3997 4001 6112 5413 5405 7527 5409 8232 9643 9639. 13 16 16 25 22 22 31 22 35 40 40.
(33) 33. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000. 3290 3995 4007 4700 5415 6117 6111 7290 7526 8234 7520. 14 16 16 19 22 25 25 30 31 34 31. 3290 3291 3996 4701 7524 7529 7528 8238 8234 10348 8225. 13 13 17 19 31 31 31 34 34 43 34. 3311 4015 4726 4726 4728 6138 6853 7565 8269 7563 9692. 13 16 19 19 19 25 28 31 35 31 40. 3309 4025 4018 5677 6149 4731 7569 5444 8995 7568 11828. 13 16 17 23 25 19 31 22 37 31 49. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum Mitjà. Temps Mitjà. 0 10 20 30 40 50 60 70 80 90 100. 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000 7000. 3303 6119 4712 4708 6124 4709 6128 6598 7701 10786 11232. 13 25 19 19 25 19 25 27 31 43 46. 3297 4003 3303 5181 5427 7541 6827 7305 8250 6135 6830. 13 16 13 21 22 31 28 30 34 25 28. 3298 4003 4005 4709 5417 6118 7531 6828 5413 7294 11535. 13 16 16 19 22 25 31 28 22 30 48. 3297 4129 4131 5095 5845 6054 7061 7104 8102 8879 10183. 13 17 17 21 24 25 28 28 33 36 41. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000. 3293 3981 3990 4687 9243 5956 7831 9729 9486 12165 15405. 13 16 16 19 31 18 24 30 34 43 42. 3294 6110 4705 4700 4704 5406 4710 7534 8225 6825 11047. 13 25 19 19 20 22 19 31 34 28 46. 3290 3995 4706 3995 6112 6110 6118 5415 10348 9416 8227. 13 16 20 16 25 25 25 22 43 39 34. 3290 3290 3999 4703 4709 4700 6824 6113 7533 8234 11053. 13 13 16 19 19 19 27 25 31 35 46.
(34) 34. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000. 3297 3995 4704 3995 5405 5405 6122 6815 9643 10119 11053. 13 16 19 16 22 22 25 28 40 42 46. 3295 3996 4002 4702 6823 8229 4700 8931 6821 7527 11766. 13 16 17 19 28 34 19 37 28 31 49. 3308 4020 6152 5444 6151 6148 4735 8277 7563 10408 10873. 13 16 25 22 25 25 19 34 32 43 45. 6152 4028 4021 4738 6150 7576 5444 5436 10521 6183 6922. 25 16 17 19 25 31 22 22 43 25 28. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum Mitjà. Temps Mitjà. 0 10 20 30 40 50 60 70 80 90 100. 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000 9000. 3295 4005 4240 4709 6900 5592 10780 7536 10358 8950 11774. 13 16 17 20 28 22 43 31 43 37 49. 3300 3999 4006 4003 4709 5174 6827 5414 10356 11774 7998. 13 17 16 16 19 21 28 22 43 49 33. 6124 4004 4705 6124 6118 6128 5413 5411 6818 7518 8933. 25 16 19 26 25 25 22 22 28 31 37. 3296 4155 4500 4549 6084 5858 6516 7307 8926 9491 11022. 13 17 18 18 24 23 25 29 36 39 43. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000. 5788 4089 6079 5387 5384 5158 11052 25189 22503 25917 34816. 15 15 25 22 22 21 40 70 60 69 93. 3295 3995 4703 5410 4707 6111 5413 6816 6580 8229 8940. 13 16 19 22 19 26 22 28 27 34 37. 6118 4000 3995 4700 6117 6119 6815 6119 8934 8226 6111. 25 16 17 19 25 25 28 25 37 34 25. 3295 3995 4701 4706 5407 6588 6148 8937 7521 6582 8945. 13 16 19 19 22 27 25 37 31 28 37.
(35) 35. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000. 6110 3999 3995 5411 6816 5178 8701 6110 10343 6816 8940. 25 17 16 22 28 21 36 25 43 28 37. 3290 3995 4005 5406 4705 6114 12461 7527 7522 6117 11520. 13 16 17 23 19 25 52 31 31 25 48. 3310 4018 4731 5201 6148 4734 5910 7573 6862 10404 9696. 13 16 19 21 25 19 24 31 29 43 40. 3314 4020 4024 4492 5443 6149 8274 10171 6859 6160 8986. 13 16 16 18 23 25 34 42 28 25 37. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum Mitjà. Temps Mitjà. 0 10 20 30 40 50 60 70 80 90 100. 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000 11000. 3298 3999 4008 4709 6126 6126 5414 6833 8240 8247 10368. 13 16 16 19 25 25 22 28 34 35 43. 3293 3998 5415 4704 5180 5415 5421 6828 8237 9645 7523. 13 16 22 19 21 22 22 28 34 40 31. 3294 3996 4003 5405 5411 5408 8228 5404 7520 7522 8934. 13 16 16 22 23 22 34 22 31 31 37. 3299 4002 4449 5004 5391 5831 7159 7511 7418 7863 9364. 13 16 18 20 22 24 29 31 31 33 39. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000. 10363 18137 13666 17021 16010 20613 25336 21962 21952 10047 8235. 27 49 36 45 42 54 66 58 57 39 34. 3290 4007 3997 6122 7531 5405 7525 5408 5409 9641 9644. 13 16 16 25 31 22 32 22 22 40 40. 3294 3995 4710 5405 4711 4700 6825 7524 7526 10348 10352. 13 16 19 23 20 19 28 31 31 43 43. 3290 4008 3998 4714 5406 6823 8936 7527 5405 -. 13 16 16 19 22 28 37 31 22 -.
(36) 36. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000. 3290 4002 3995 5417 5406 5415 6116 9641 7285 7997 11055. 13 17 16 22 22 22 25 40 30 33 46. 3292 3995 3995 4710 5405 5417 7533 6111 6589 11757 11758. 13 16 17 19 22 22 31 25 27 49 50. 3075 4022 4018 4727 5446 5442 6149 6150 11828 9687 11824. 12 16 16 19 22 22 25 25 50 40 49. 3318 4018 4027 4492 4966 6616 5443 6861 6858 8990 11816. 13 16 16 18 21 27 22 28 28 37 49. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum Mitjà. Temps Mitjà. 0 10 20 30 40 50 60 70 80 90 100. 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000 13000. 3301 4004 3770 4709 4715 5420 6831 8011 7539 9664 8244. 13 17 15 19 19 22 28 33 31 40 34. 3293 3761 4710 4706 4709 5409 5413 9643 8232 8230 7534. 13 15 20 19 19 22 22 40 34 34 31. 3289 4000 3994 4000 5404 6110 6107 11754 6813 9637 8931. 13 16 16 16 22 25 26 49 28 40 37. 3273 3981 4121 4900 5370 5676 6688 7863 7348 9550 10129. 13 16 17 20 22 23 28 32 30 40 42. IMBALANCE. Temps d’espera. Consum. Temps. Consum. Temps. Consum. Temps. Consum. Temps. 0 10 20 30 40 50 60 70 80 90 100. 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000 15000. 3296 10722 13323 14699 14785 24850 21729 20602 29647 34401. 13 31 36 40 39 66 57 54 79 90. 3290 4000 4701 4701 5407 6120 5877 8238 6827 9648 7528. 13 16 19 19 22 25 24 34 28 40 31. 3290 3997 4002 5407 5411 6113 6112 8003 7532 11764 11525. 13 16 16 22 23 25 25 33 31 49 48. -. -.
Figure




+7





Documento similar
A més, en aquest projecte l’alumnat treballa amb material i imatges del seu abast i al mateix temps amb continguts acadèmics, per tant, es pretén treballar de forma
• el retard en la lectura és d’entre un i dos anys i afecta altres àrees de l’aprenentatge escolar.. • està relacionat amb el retard en el temps en la consecució de
GUIA EN EL MEDI NATURAL I DE TEMPS LLIURE A24103.
Al llarg del temps, hem avançat amb el coneixement i abordatge dels pacient amb BBD amb malaltia cardiovascular prèvia o quan el bloqueig apareixia de forma concomitant a un
b) S'escriu amb d, darrere vocal, en les paraules planes els femenins i derivats de les quals porten una d: àcid (amb d, per àcida), òxid (per òxida).. c) S'lescnu amb d, darrere
Como ya se ha mencionado al citar las características principales de esta línea, el Tramo Reembolsable va a corresponder a un préstamo preferencial con un tipo de interés
9.La figura següent mostra els valors dels senyals E i load d’un registre de vuit bits du- rant un cert interval de temps.. tants en què el registre es carrega amb l’entrada E i
ATOMS input to most programs, overwritten with output parameters ATMOD file with the model parameters input to the program ORIENT ATOLD a collection of parameter sets, to be used
