Sistemas de bases de datos
Texto completo
Figure
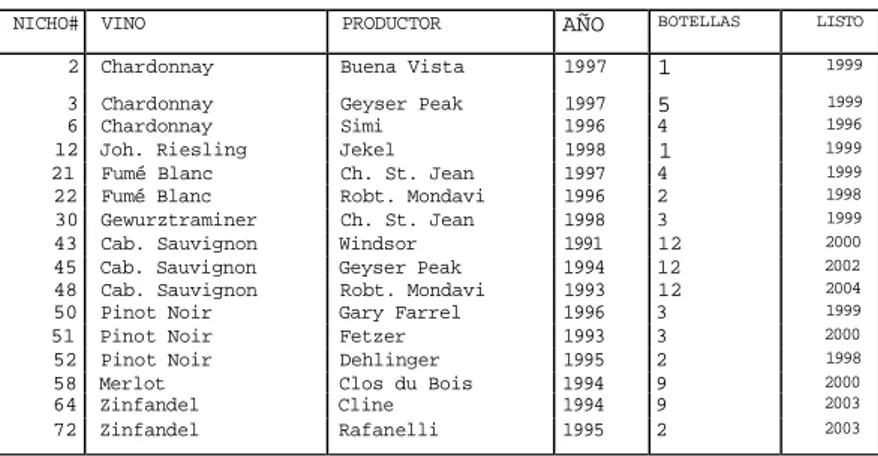
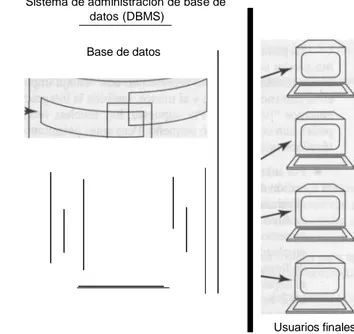
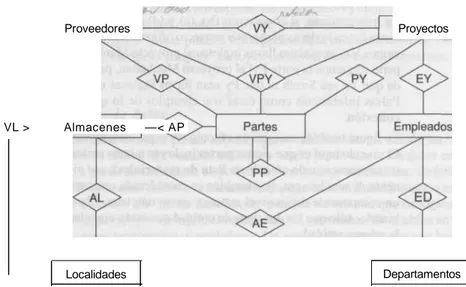
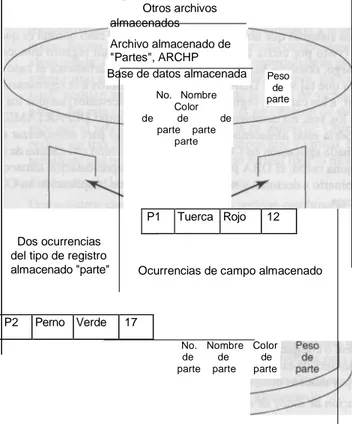
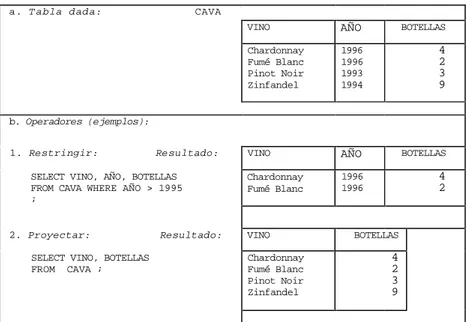
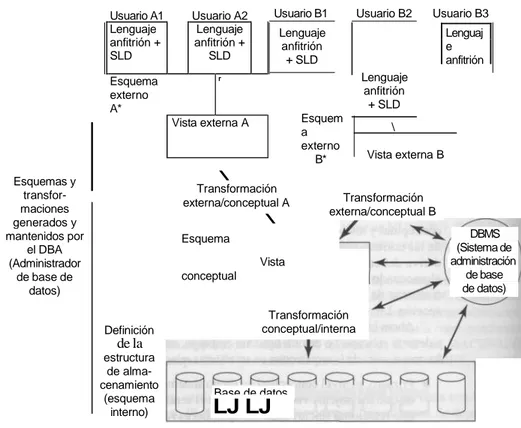
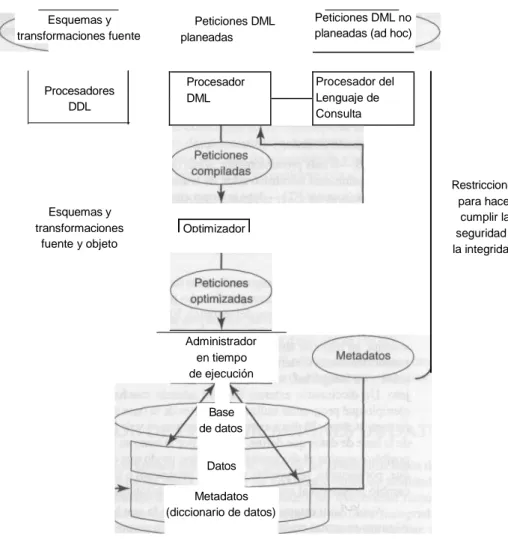
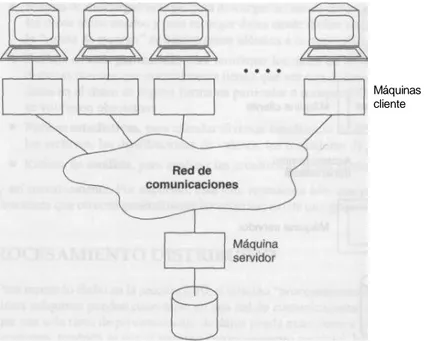
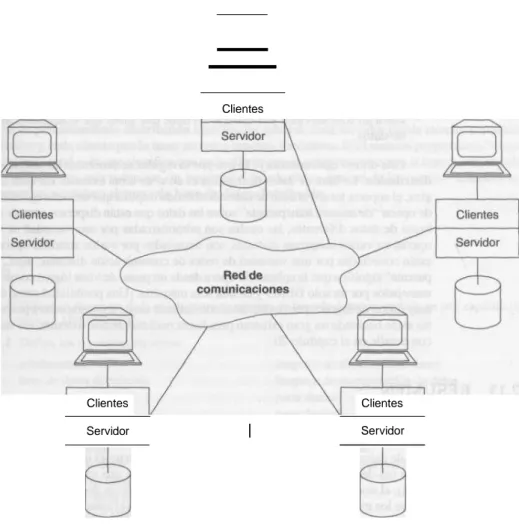
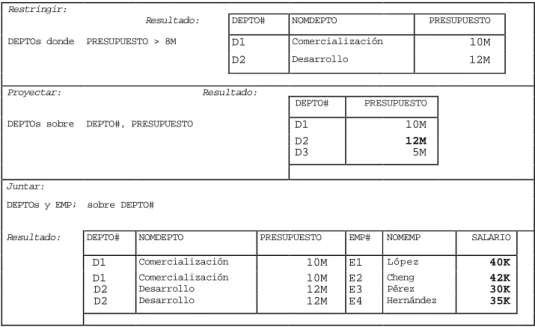
Documento similar
b) Pensar que las normas «anteriores» no pertenecen a los nuevos sistemas jurídicos del nuevo orden jurídico del nuevo orden estatal, pero que son aplicables. Si CRNA no se reformula
El desarrollo de una conciencia cáritas es esencial para identificar cuando un momento de cuidado se convierte en transpersonal, es necesaria para identificar
GS RM 9902 - Alternancia de arcillas algo yesíferas, areniscas, are- niscas de grano fino y algún nivel de caliza al sur de Villarta - Quintana (U. 15).u. GS RM 9904 - Alternancia
RM 9901 Deformación hidroplástica en las areniscas del Buntsandsteint. RM 9902 Falla entre Dogger y
La sensible mejora que supone el presente proyecto para este tramo de la carretera, así como la posibilidad de evitar entrar en la población de Roldán en el trayecto entre la autovía
Para ello, trabajaremos con una colección de cartas redactadas desde allí, impresa en Évora en 1598 y otros documentos jesuitas: el Sumario de las cosas de Japón (1583),
Entre nosotros anda un escritor de cosas de filología, paisano de Costa, que no deja de tener ingenio y garbo; pero cuyas obras tienen de todo menos de ciencia, y aun
o Si dispone en su establecimiento de alguna silla de ruedas Jazz S50 o 708D cuyo nº de serie figura en el anexo 1 de esta nota informativa, consulte la nota de aviso de la
