Casa
m
abierta al tiempo
Universidad Autónoma Metropolitana
Unidad lztapalapa
’División de Ciencias Básicas e Ingeniería
Departamento de Ingeniería Eléctrica
’Migración de un Sistema de Memoria Virtual Distribuida
Tesis que presenta el alumno
’Javier Bolaños Molina
95320099
Para la obtención del grado de
Licenciado en Computación
1
Asesores
Dra. Elizabeth Pérez
Corté
/
INDICE
PREFACIO
...
11. INTRODUCCI~N
...
..41.1 Sistemas Distribuidos
...
41.2 Memona vimial distribuida
...
71.2.1 Conceptos
...
.71.2.2 Diseño..
...
.91.2.2.1 Modelos de consistencia para la MVD
...
92. DESCRIPCIÓN DEL PROBLEMA
...
182.1 MVD UAMI
...
182.1.1 Interfaz ai usuario.
...
.182.2 Migración
...
.263.1 Descripción
...
.273.2 Dependencias de plataforma
...
..285. CONCLUSIONES
Y
PERSPECTIVAS...
.35.
.
2.1.2 Diseño y arquitectura...
213. Propuesta de Solución
...
274. IMPLANTACIÓN DE LAS SOLUCIONES
...
34PREFACIO
Importancia de los Sistemas
Distribuidos
Andrew S. Tanenbam define "Sistema Distribuido como
una
colección de computadoras independientes, que aparecen ante los usuarios del sistema como una única computadora".Una aplicación distribuida viene siendo cualquier aplicación compuesta por procesos que se ejecutan en varias computadoras a la vez, y que da al usuario la impresión que se ejecuta en un solo lugar.
Varios ejemplos de estas aplicaciones las vemos en la vida diaria, tales como los cajeros automáticos, las tarjetas de crédito y el ejemplo clásico Internet. Donde podemos realizar compras, ventas, visitar museos, espectáculos, oír música, etc., a partir de nuestra estación de trabajo.
Estas aplicaciones han influido de tal manera nuestro comportamiento y modo de vida que su estudio y comprensión son importantes, tanto para entender su funcionamiento como para mejorarlo y expandirlo.
Necesidad de una
MVD
en la UAMiEl Laboratorio de Sistemas Distribuidos estudia los problemas relacionados con la construcción de las aplicaciones distribuidas y explora nuevas posibilidades. Actualmente cuenta con software para desarrollo de aplicaciones distribuidas a través de envío y recepción de mensajes tales como PVM y MPI. También se desarrolló
un
sistema de memoria virtual distribuida (MVD) para explorar la construcción de aplicaciones distribuidas que utilicen memoria compartida como medio de comunicaci6n. Dicho sistema se construyó para un p p o de 4 máquinas Sparc.Posteriormente, se equip6 el laboratorio de un cúmulo de 16 computadoras personales INTEL (CL) con sistema operativo Linux. Con el objetivo de probar nuestro sistema de MVD en una plataforma mas amplia, se planteó la migración del sistema de MVD hacia el cúmulo Linux.
Una Memoria Virtual Distribuida simplifica la tarea del programador al quitarle el manejo de la comunicación entre. procesos en distintas máquinas, brindándole un esquema de desarrollo similar al de las aplicaciones centralizadas.
La migración de la MVD hacia el CL nos permitirá la comparación entre. los diferentes esquemas de construcción de las aplicaciones distribuidas así como la evaluaci6n de la portabiiidad, la escalabiíidad y
el desempeño del sistema de MVD.
Programación en una
MVD
En el modelo tradicional del modelo de Von Neumann, los eventos suceden secuencialmente, uno detrás de otro. Un programador describe los eventos que llevarán a la solución del problema y da un orden para dichos eventos.
Aigunas
veces un par de eventos pueden ocurrir en cualquier orden, o incluso concurrentemente, pero el modelo de Von Neumann requiere una secuencia ordenada, obligando al programador a proveerla...
*. .
....
.,
La detección automática de partes concurrentes, donde procedimientos complejos con varios pasos pueden ejecutarse a la vez es prácticamente imposible. El programador debe ayudar, evitando restricciones para la concurrencia donde no sea necesario y señalando explícitamente oportunidades para la concurrencia donde sea posible.
En multiprocesadores de memoria compartida, cada procesador puede leer y escribir cualquier elemento en la memoria común. Cada procesador tiene un gran cache para reducir el tráfico entre los procesadores y la memoria común.
En
los multiprocesadores de memoria distribuida, cada procesador tiene su propia memoria y los datos en la memoria de un procesador son inaccesibles a los otros procesadores. Donde losprocesadores deben compartir datos, estos explícitamente envían y reciben mensajes que contienen los datos.
Dos aspectos, no presentes en la programación secuencial, complican la programación en memoria distribuida.
Uno
es el movimiento de los datos. En el modelo deVon
Neumann, cada bit de información es siempre accesible. En la memoria distribuida, los datos vistos por un procesador, pero disponibles en otro, deben ser explícitamente enviados por el procesador que los tiene al que los necesita, y explícitamente recibidos por el último.El otro aspecto que distingue la programación en memoria distribuida de la programación secuencial es la sincronización. En el modelo de Von Neumann, donde las instrucciones son ejecutadas una detrás de la otra, la sincronización es abundante. Después de que una instrucción se ejecuta, la siguiente instrucción está segura que el trabajo de la instrucción anterior se ha realizado. En la programación concurrente, cada procesador ejecuta sus instrucciones secuencialmente, pero las instrucciones en diferentes procesadores generalmente no ocurren en un orden estricto. Con varias instrucciones requeridas antes de un cálculo en
un
procesador pueda comenzar, la sincronización es requerida para controlar el orden de los cálculos.Producir un programa correcto para un multiprocesador de memoria compartida requiere considerar los mismos aspectos acerca de sincronización que en un multiprocesador de memoria distribuida, excepto el movimiento de datos.
Objetivos
Con este trabajo se pretende migrar un sistema de memoria virtual distribuida que actualmente se encuentra en Solaris Sparc a la plataforma Linux Intel 32.
Estructura
El capítulo 1 contiene una introducción acerca de lo que son los sistemas distribuidos y la memoria virtual distribuida, el conocimiento de estos temas es esencial para el desarrollo del trabajo. En el capítulo 2 se da una descripción del sistema de memoria virtual distribuida existente en el laboratorio, tanto desde el punto de vista del usuario programador de aplicaciones como el funcionamiento interno del sistema; esto nos sirve como preámbulo a la descripción del problema que se tiene que resolver que es la migración del sistema. En el capítulo 3 se analizan los sistemas de y a donde se quiere llevar la migraci6n de la MVD, cuales son las compatibilidades, cuales son las incompatibilidades y las alternativas a éstas. Todo esto para formalizar una propuesta de migración. El capítulo 4 describe los pormenores de la
implantación, en particular se describen cuáles fueron los problemas que surgieron al momento de la implantación que no fueron visibles en la propuesta de migracibn. Por último en el capítulo 5 se dan las conclusiones respecto al trabajo realizado, cuales fueron las metas que se lograron, el trabajo que queda pendiente de realizar y posibles líneas de investigación.
n
I.
INTRODUCCI~N
Este capítulo examina las bases teóricas que sustentan el uso de los sistemas distribuidos. Se examina un sistema distribuido desde el punto de vista del programador de aplicaciones así como del diseño interno, posteriormente se introduce al caso particular del tipo de sistema distribuido que se va a usar: Sistema de memoria virtual distribuida.
1.1 Sistemas Distribuidos
En el inicio de la era de la informática las computadoras eran grandes y caras. Debido a su escasez y
coste, éstas funcionaban de forma independiente entre ellas.
A partir de los afíos 70, surgen los primeros miniordenadores, que competirían con los grandes ordenadores tanto por las prestaciones como por su precio, con lo que se extendió su uso.
L o s
grandessistemas centralizados fueron dejando paso lentamente a sistemas mucho más descentralizados, y formados por varios ordenadores o a sistemas multiprocesador. Pronto surgieron nuevas necesidades de
interconexión de los equipos, y se desarrollaron las redes de área local (LAN), como Ethernet o Token
ring.
1..
.
.."_<
I , . .
" .
.. ,
..
.
..,.,
.< .
Aunque los actuales sistemas de red solucionan parte de las necesidades actuales de comunicación entre computadoras, tienen importantes limitaciones, y no son aplicables a una gran cantidad de problemas. Por eilo surge la necesidad de crear sistemas distribuidos que sustituyan a los actuales sistemas de red o a los sistemas multipesadores.
Los sistemas distribuidos están basados en las ideas básicas de transparencia, eficiencia, flexibilidad,
escalabilidad y fiabilidad. Sin embargo estos aspectos son en parte contrarios, y por lo tanto los sistemas distribuidos han de cumplir en su diseño el compromiso de que todos los puntos anteriores sean solucionados de manera aceptable.
Transparencia
El concepto de transparencia de un sistema distribuido va ligado a la idea de que todo el sistema funcione de forma similar en todos los puntos de la red, independientemente de la posición del usuario. Queda como labor del sistema operativo o ambiente de ejecución el establecer los mecanismos que oculten la naturaleza distribuida del sistema y que permitan trabajar a los usuarios como se tratara de un único equipo.
El que el sistema disponga de varios procesadores debe lograr un mayor rendimiento del sistema, pero el sistema operativo debe controlar que tanto los usuarios como los programadores vean el núcleo del sistema distribuido como un único procesador. El paralelismo es otro punto clave que debe controlar el sistema operativo, que debe distribuir las tareas entre los distintos procesadores como en un sistema multiprocesador, pero con la dificultad añadida de que esta tarea hay que realizarla a través de varios ordenadores.
Eficiencia
I< ..
I ..
...
c ".
..
<.
*...
La idea de que un procesador vaya a realizar una tarea de forma rápida es bastante compleja, y depende de muchos aspectos concretos, como la propia velocidad del procesador, pero también la localidad del procesador, los datos, los dispositivos, etc.
Flexibilidad
Un proyecto en desarrollo como el diseño de un sistema distribuido debe estar abierto a cambios y actualizaciones que mejoren el funcionamiento del sistema.
Escalabilidad
Un sistema operativo distribuido debería funcionar tanto para una docena de ordenadores como varios millares. Igualmente, debería no ser determinante el tipo de red utilizada (LAN o WAN) ni las distancias
entre los equipos, etc.
Aunque este punto sería muy deseable, puede que las soluciones válidas para unos cuantos ordenadores no sean aplicables para varios miles. Del mismo modo el tipo de red condiciona tremendamente el rendimiento del sistema, y puede que lo que funcione para un tipo de red, para otro requiera un nuevo diseño.
La escalabilidad propone que cualquier ordenador individual ha de ser capaz de trabajar independientemente como un sistema distribuido, pero también debe poder hacerlo conectado a muchas otras máquinas.
Fiabilidad
Una de las ventajas claras que nos ofrece la idea de sistema distribuido es que el funcionamiento de todo el sistema no debe estar ligado a ciertas máquinas de la red, sino que cualquier equipo pueda suplir a otro en caso de que uno se estropee o falle.
La forma más evidente de lograr la fiabilidad de todo el sistema está en la redundancia. La información
no debe estar almacenada en un solo servidor, sino en por lo menos dos máquinas. Mediante la redundancia evitamos el caso de que el fallo de un servidor bloquee todo el sistema.
Otro tipo de redundancia más compleja se refiere a los procesos. Las tareas críticas podrían enviarse a varios procesadores independientes, de forma que el primer procesador realizaría la tarea normalmente,
pero ésta pasaría a ejecutarse en otro procesador si el primero hubiera fallado.
, . Sincronización
s". La sincronizaci6n en sistemas de un único ordenador no requiere ninguna consideración en el diseño del sistema operativo, ya que existe un reloj único que proporciona de forma reguiar y precisa el tiempo en cada momento. Sin embargo, los sistemas distribuidos tienen un reloj por cada ordenador del sistema, con lo que es fundamental una coordinación entre todos los relojes para mostrar una hora única. Los osciladores de cada ordenador son ligeramente diferentes, y como consecuencia todos los relojes sufren un desfase y deben ser sincronizados continuamente. La sincronización no es trivial, porque se realiza a través de mensajes por la red, cuyo tiempo de envío puede ser variable y depender de muchos factores,
como la distancia,la velocidad de transmisión o la propia saturación de la red, etc.
1 .
,-
.I.
El reloj
La sincronización no tiene por qué ser exacta, y bastará con que sea aproximadamente igual en todos los
-= I
-.,.,
ordenadores. Hay que tener en cuenta, eso sí, el modo de actualizar la hora de un reloj en particular. Es fundamental no retrasar nunca la hora, aunque el reloj adelante. En vez de eso, hay que alentar la actualización del reloj, frenarlo, hasta que alcance la hora aproximadamente. Existen diferentes algoritmos de actualización de la hora, tres de ellos se exponen brevemente a continuación.
Algoritmo de Lamport
Tras el intento de sincronizar todos los relojes, surge la idea de que no es necesario que todos los relojes tengan la misma hora exacta, sino que simplemente mantengan una relación estable de forma que se mantenga la relación de qué suceso ocumó antes que otro suceso cualquiera.
Este algoritmo se encarga exclusivamente de mantener el orden en que se suceden los procesos. En cada mensaje que se envía a otro ordenador se incluye la hora. Si el receptor del mensaje tiene una hora anterior a la indicada en el mensaje, utiliza la hora recibida incrementada en uno para actualizar su propia
hora.
Algoritmo de Cristian
Consiste en disponer de un servidor de tiempo, que reciba la hora exacta. El servidor se encarga de enviar a cada ordenador la hora. Cada ordenador de destino sólo tiene que sumarle el tiempo de transporte del mensaje, que se puede calcular de forma aproximada.
Algoritmo de Berkeley
La principal desventaja del algoritmo de Cnstian es que todo el sistema depende del servidor de tiempo, lo cual no es aceptable en
un
sistema distribuido fiable.El algoritmo de Berkeley usa la hora de todos los ordenadores para elaborar una media, que se reenvía
para que cada equipo actualice su propia hora relanzando el reloj o adoptando la nueva hora, según el
caso.
Otros problemas de sincronización
" . El reloj es únicamente uno de tantos problemas de sincronización que existen en los sistemas distribuidos.
A continuación planteamos otros problemas relacionados con la sincronización.
En
el momento de modificar unos datos compartidos, los procesos deben lograr la exclusión mutua que garantice que dos procesos no modifiquen los datos a la vez.Algunos algoritmos distribuidos requieren que un proceso funcione como coordinador. Es necesario establecer ciertos algoritmos de elección de estos procesos.
Es
necesario ocultar las técnicas de sincronización mediante la abstracción de las transacciones atómicas, que permitan a los programadores salvar los detalles de la programación con sincronización.Soluciones frente a bloqueos son bastante más complejas que en sistemas con un único procesador.
, .
*..
.%+
I -
1.2 Memoria virtual distribuida
1.2.1
Conceptos
Memoria virtual y paginación
Según el procesador ejecuta un programa, lee una instrucción de memoria y la decodifica.
Al
decodificarla instrucción puede necesitar el contenido de o almacenar un dato en una dirección de memoria. El procesador entonces ejecuta la instrucción y se mueve a la siguiente instrucción en el programa. De está
forma el procesador esta siempre accediendo la memoria tanto para leer o escribir datos.
En un sistema de memoria virtual todas estas direcciones son virtuales y no físicas. Estas direcciones virtuales son convertidas a direcciones físicas por el procesador, basado en información mantenida en
un
conjunto de tablas mantenidas por el sistema operativo.Para hacer esta traducción fácil, la memoria virtual y la física son divididas en porciones de tamaño manejables llamadas páginas.
Paginación
La paginación permite que la memoria de un proceso no sea contigua y que a un proceso se le asigne memoria física donde quiera que ésta esté disponible. La paginación evita el gran problema de acomodar trozos de memoria de tamaño variable en el almacenamiento auxiliar.
La memoria física se divide en bloques de tamaño fijo llamados marcos. La memoria lógica también se divide en bloques del mismo tamaño llamados páginas. Cuando un proceso se va a ejecutar, sus páginas
se cargan desde el almacenamiento auxiliar en cualesquiera de los marcos disponibles. El almacenamiento
se divide en bloques de tamaño fijo del mismo tamaiio que los marcos de memoria. Cada dirección
generada por el procesador se divide en dos partes: un número de página y un desplazamiento en la página. El número de página se utiliza como índice en U M tabla de páginas, que contiene la dirección base para cada página de la memona física. La dirección base se combina con el desplazamiento en la página para definir la dirección de memoria física que se envía a la unidad de memoria.
La paginación es una forma de relocalización dinámica. Cada dirección lógica está enlazada a la dirección física mediante el hardware de paginación.
L o s algoritmos de administración de memoria como la paginación son necesarios por un requisito básico: todo el espacio de direcciones lógicas de un proceso debe encontrarse en memoria física antes de que el proceso se pueda ejecutar. Esta restricción aunque razonable limita el tamaño de un programa al tamaño de la memoria física.
La memoria virtual es una técnica que @te la ejecución de procesos que pueden o no estar
completamente en memoria. La principal ventaja evidente de este esquema es que los programas pueden
no estar completamente en memoria.
Dos
perspedivas de la memoriaUn aspecto importante de la paginación es la clara separación entre la perspectiva del usuario y de la memoria física real. El programa de usuario cree que la memoria es un espacio contiguo que contiene un solo programa. En realidad, el programa de usuario está disperso por la memoria física, la cual también contiene otros programas. La diferencia entre la perspectiva que el usuario tiene de la memoria y la memoria física real se concilia a través del hardware de traducción de direcciones. Las direcciones lógicas se traducen a direcciones físicas. Esta correspondencia se oculta al usuario y es controlada por el sistema operativo.
Un resultado de la separación entre las direcciones lógicas y físicas es que pueden ser diferentes. El sistema operativo controla esta correspondencia y puede activarla para el usuario o desactivarla para el
sistema operativo. Puesto que éste administra la memoria física, debe estar al tanto de los detalles de la asignación de memoria física: qué marcos estáu asignados, qué marcos están libres, cuántos hay en total,
etc. Esta información casi siempre se conserva en una estructura de datos llamada tabla de marcos, la cual tiene una entrada por cada marco físico de página, que indica si el marco esta asignado y, de estar asignado, a qué página de qué proceso [Silberschatz].
Memoria Compartida Distribuida
En la actualidad existen dos tipos de sistemas con varios procesadores: multiprocesadores y multicomputadoras.
En
un multiprocesador, dos o más CPU comparten una memoria principal común.Cualquier proceso, en cualquier procesador, puede leer o escribir cualesquiera palabra en la memoria compartida, sólo moviendo datos desde o hacia la localidad deseada. El caso de las multicomputadoras es diferente, aquí cada procesador tiene su propio espacio de direcciones y éste es ajeno de los demás, no se
comparte la memoria. Nuestro trabajo se basa en el manejo de las multicomputadoras para dar al programador de aplicaciones distribuidas un sistema con memoria compartida distribuida de forma transparente.
En los primeros días de la computación distribuida, se suponía de manera implícita que los programas en las máquinas sin memoria compartida físicamente (multicomputadoras) se ejecutaban en espacios diferentes. Con este punto de vista, la comunicación se pensaba como el envío y recepción de mensajes entre procesadores conectados a través de una
red.
En 1986, Li propuso un esquema diferente, conocido como memoria compartida distribuida (DSM). La proposición que hacía era el tener un conjunto de estaciones de trabajo conectadas mediante una red compartiendo un espacio de direcciones virtuales mediante páginas. En la forma más simple de esta representación, cada página se encuentra en una estación. Una referencia a una página local utiliza toda la velocidad de transferencia de la memoria mientras que una referencia remota provocara un fallo de página en hardware entonces el sistema operativo se encargara de localizar la máquina que contiene la página para solicitarla, después de obtener la página se reiniciará el proceso y se ejecutará la instrucción detenida [Tanenbaum].La
idea de este diseño es muy similar al funcionamiento de los sistemas tradicionales de memoria virtualy paginación, la diferencia es cuando un proceso intenta acceder a una página que no se localiza en memoria y se produce un fallo de página, el sistema operativo, en lugar de buscar la página en disco para
recuperarla tiene que buscarla en las máquinas de la red.
Para el usuario de una multicomputadora de este tipo no encuentra mucha diferencia con respecto a un multiprocesador donde los procesadores pueden escribir y leer de la memoria común.
En
estos sistemasprogramador de aplicaciones no perciba dónde está trabajando realmente si en un multiprocesador o en una multicomputadora. Este esquema aunque presenta grandes ventajas al usuario presenta un serio inconveniente: el desempeño que se alcanza está muy por debajo del que se pudiera obtener de un multiprocesador esto debido a que las páginas van de un lado a otro presentando un problema conocido como ping pong, de aquí proviene la necesidad de encontrar una técnica que ofrezca un mejor
desempeño,
Un
método para optimizar este desempeño consiste en no compartir todo el espacio de direcciones sino solo aquellas variables o estructuras de datos requeridas por más de un proceso. Así este método nocomparte direcciones de memoria sino variables lo cual da un mayor nivel de abstracción
.
Una posible optimización sobre este método consiste en repetir las variables compartidas en varias máquinas.
En
este momento el problema de simular un procesador se convierte en el problema demantener consistentes las copias de las variables compartidas. Las lecturas pueden realizarse de manera local, sin ningún trafico en la red y las escrituras deben de mantener un protocolo de actualización para las copias.
Como vemos mientras más avanzamos en esta dirección obtenemos mejor desempeño, pero a cambio tenemos la desventaja de que el programador debe tener un mayor conocimiento acerca de la operación del sistema.
En
general, todos estos son contratos que se tienen que establecer entre la memoria y laforma en que el programador de aplicaciones va a utilizarla. Todos estos
aspectos
se estudiarán a fondo en la siguiente sección que trata sobre estos contratos que llamaremos modelos de consistencia.1.2.2 Diseño
Hablar del diseño de una Memoria Virtual Distribuida
(MVD),
es hablar de la consistencia que se emplea,de la forma en que se evitan las condiciones de competencia, en fin de los métodos que nos garanticen que los procesos tendrán el comportamiento que se espera de ellos según el contrato que se halla hecho entre el software y la memoria. Este comportamiento interno, deberá ser lo más transparente como sea posible para el usuario final.
En
esta sección hablaremos precisamente de dos de los tópicos más importantes, los diferentes modelos de consistencia y los principales algoritmos de exclusión mutua que existen actualmente.1.2.2.1 Modelos de consistencia para la MVD
Comenzaremos esta sección hablando de la consistencia, pero ¿qué entendemos por consistencia?
La consistencia en las bases de datos, por ejemplo, trata de que los datos tenga una lógica para el usuario, es
decir,
no basta que cumplan ciertas reglas de integridad, sino que cuadren los datos, que la información almacenada sea consistente con toda la demás información almacenada.En un Sistema Distribuido, como el nuestro, la consistencia, se define de una forma similar:
Un modelo
de
consistencia es en esencia un contrato entre el sojiware y la memoria [Adve 19901.
Estoes, si el software acuerda obedecer ciertas reglas, la memoria promete trabajar de forma correcta. Si el
software viola estas reglas, todo acaba y ya no se garantiza que la operación de memoria sea la correcta.
Existe una gran cantidad de contratos, desde contratos que imponen sólo restricciones menores en el software hasta aquellos que hacen la programación normal casi imposible. En esta sección estudiaremos varios modelos de consistencia utilizados en los sistemas MVD.
~ , ..., ...
Consktencia estricta
De los modelos que estudiaremos, el modelo de consistencia estricta, es el más estricto de todos. Se
defiie mediante la siguiente condición:
Cualquier lectura a una localidad de memoria x regresa el valor guardado por la operación de escritura
nuís reciente en
x
Para los programadores habituados a trabajar en maquinas con un solo procesador, esta definición es
natural y se espera un comportamiento de ese estilo. Por ejemplo, en el siguiente programa: a=l; a=2; print(a);
el programador esperaría que se imprima 2, cualquier otro resultado sería incorrecto [print es un
procedimiento que imprime su@) parámetro(s)].
En un sistema MVD, el asunto es más complicado. Supongamos que tenemos dos maquinas A y B, trabajando conjuntamente y supongamos que
x
es una variable que está guardada sólo en la máquina B.imagine que un proceso en la máquina
A
lee x en el momentoTI,
lo que significa que se envía un mensajea B para obtener x. Poco después, en
T,
un proceso en B realiza una escritura en x. Si hay unaconsistencia estricta, la lectura siempre debe regresar el valor anterior sin importar la posición de las máquinas y la cercanía de
T,
yT1.
Sin embargo, siTz-
T,
es, digamos, 1 nanosegundo, y las máquinas se encuentran a una distancia de 3 metros entre sí, para que la solicitud de lectura deA
aB
se obtenga antesde la escritura, la señal debe viajar a 10 veces la velocidad de la luz, algo prohibido por la teoria de la relatividad de Einstein. ¿Será razonable que los programadores demanden la consistencia estricta del sistema, aunque esto requiera violar las leyes de la física?
Para estudiar la consistencia en detalle daremos varios ejemplos. Para precisar estos ejemplos,
necesitamos una notación especial. En esta notación, se pueden mostrar varios procesos
(Pi.
PZ
etc.) a distintas alturas de la figura. Las operaciones realizadas por cada proceso se muestran en formahorizontal, de modo que el tiempo aumenta hacia la derecha. Las líneas rectas separan los procesos. Los símbolos W@)u y R(y)b significan que se han realizado una escritura a
x
con el valor a y una lecturadesde y regresando
b,
respectivamente. Supondremos que el valor inicial de todas las variables en estetipo de diagramas es O. Como ejemplo, en la figura
1.1,
PI
realiza una escritura a la localidadx,
con el valor 1. Después,P,
leex
y ve el 1. Este comportamiento es correcto para una memoria con consistencia estricta.P,: Wlxll P,: Wlxll
P,: R W l P,: R(x)O R(x)l
f
4
fb)Figura 1.1. El comportamiento de dos procesos. EL eje horizontal es el tiempo.
(a) Memoria con consistencia estricta. (b) Memoria sin consistencia estricta.
En contraste, en la figura 1.1 (b),
P2
realiza una lectura después de la escritura (posiblemente un nanosegundo después de ésta, pero aun así ocurre después de ésta), y obtiene O. Una lectura posterior da1. Este comportamiento es incorrecto para una memoria con consistencia estricta.
En
resumen, cuando la memoria tiene consistencia estricta, todas las escrituras son visibles al instante amemoria, todas las lecturas posteriores desde esa localidad ven el nuevo valor, sin importar qué tan pronto se haga la lectura después del cambio y sin importar los procesos que est& haciendo la lectura ni
la posición de éstos. De manera análoga, si se realiza una lectura, se obtiene el valor actual, sin importar
lo rápido que se realice la siguiente escritura.
En la vida diaria, exigir una consistencia tal, es prácticamente imposible y también en cierta forma innecesaria, ya que por experiencia se sabe que los programadores suelen controlar bien los modelos más débiles. Por ejemplo, en los libros de texto sobre sistemas operativos se analizan las secciones críticas y el problema de exclusión mutua. Este análisis siempre incluye la advertencia de que los programas escritos en paralelo (como el problema de los productores y los consumidores) no debe establecer hipótesis acerca
de las velocidades relativas de los procesos ni del intercalado de sus instrucciones en el tiempo, se le enseña a programar de forma tal que no importe el orden exacto de ejecución de las proposiciones (de hecho, de las referencias a memoria). Cuando sea esencial el orden de los eventos, deben utilizarse semáforos u otras operaciones de sincronización.
A continuación presentamos otros tipos de consistencia más débiles que la estricta, pero que ofrecen una consistencia bastante aceptable.
Consistencia Secuenciai
La consistencia secuencial es un modelo de memoria un poco más débil que la consistencia estricta. Fue
definida por primera vez por Lamport [Lamport], quien dijo que una memoria con consistencia secuencial es la que satisface la siguiente condición:
El resultado de cualquier ejecución es el mismo que si las operaciones de todos los procesos fueran ejecutadas en algún orden secuencial, y las operaciones de cada proceso individual aparecen en esta secuencia en el orden especificado por su programa
Lo
que significa esta definición es que cuando los procesos se ejecutan en paralelo en diferentes máquinas(o aun en seudoparalelo en un sistema de tiempo compartido), cualquier intercalado válido es un
comportamiento aceptable, pero todos los procesos deben ver la misma serie de llamadas a memoria. Una memoria donde un proceso (o procesos) ve un intercalado y otro proceso ve otro distinto no es una memoria con consistencia secuencial. Observe que no se habla del tiempo; es decir, no hay referencia
alguna al almacenamiento más reciente". Observe que en este contexto, un proceso "ve"" las escrituras de todos los procesos pero sólo sus propias lecturas.
P,: WlXU P,: WlXU
P,: RWO R(x)l P; R(x)l R(x)l
Figura 1.2. Dos resultados posibles
En la figura 1.2 se puede ver el hecho de que el tiempo no juega
ningún
papel. El comportamiento de una memoria que se muestra en la figura 1.2(a) cumple la consistencia secuencial, aunque la primera lectura realizada por P,regrese el valor inicial O en vez del valor nuevo 1.La memoria con consistencia secuencial no garantiza que una lectura regrese el valor escrito por otro
proceso un nanosegundo antes, un microsegundo antes, o incluso un minuto antes. S610 garantiza que
todos los procesos vean todas las referencias a memoria en el mismo orden. Si el programa que genera la
figura 1.2(a) se ejecuta de nuevo, podría dar el resultado de la figura 1.2(b).
L o s
resultados no sondeterministar. Una nueva ejecución de un programa podria no proporcionar el mismo resultado, a menos
que se utiiicen operaciones explícitas de sincronización.
Para comprender mejor el punto, veamos un pequeño ejemplo de un programa compuesto de tres
procesos, que se ejecutan en paralelo en tres procesadores distintos y que utilizan la misma memoria
compartida distribuida con consistencia secuencial; todos tienen acceso a las variables a, b y c. Desde el
punto de vista de referencia a la memoria, una asignación se debe ver como una escritura, y un enunciado
de impresión como una lectura simultánea de sus dos parámetros. Se supone que todos los enunciados son
at6micos.
a = 1; print ib,d b = 1; print ( a 4
print (%C)
c = 1
imprime: O01011
a = l b = l c = 1 print(b.c) pMt(a,c) pMt(a,b)
FIgnra 1.3. TICS procesos en paralelo
a = l ; b = l ; b = l ;
b = 1 c = 1; a = 1;
print ( a d print (a&) c = l ;
print i b 4 print (ac) print i b d
print (ab) print í b 4 print ib,c)
c= 1 a = 1; print (b.c)
Imprime: 101011 imprime: O10111 imprime: 111111
Las posibles variantes de ejecución para estos seis enunciados son 720 ( 6 ! ) , aunque algunas de éstas
Una memoria con consistencia secuencial se puede implantar en un sistema MVD o multiprocesador que duplique las páginas que se pueden escribir, garantizando que ninguna operación de memoria comienza hasta que las anteriores hayan concluido. Por ejemplo, en un sistema con un mecanismo de transmisión eficiente, confiable y por completo ordenado, todas las variables compartidas se podrían agrupar en una o
más páginas y se podrían transmitir las operaciones a las páginas compartidas.
No
importa el orden exactoen que se intercalen las operaciones mientras todos los procesos estén de acuerdo en el orden de todas las operaciones en la memoria compartida.
Aunque la consistencia secuencial es un modelo amigable con el programador, tiene un problema serio de desempezo. Lipton y Sandberg [Lipton 19881 demostraron que si el tiempo de lectura es r, el de
escritura es w y el tiempo mínimo de transferencia de paquete entre los nodos es t , entonces siempre
ocurre que r+w 2 t.
En
otras palabras, para cualquier memoria con consistencia secuencial, la modificación del protocolo para mejorar el desempeño de la lectura empeora el desempeño de la escritura, y viceversa. Por esta razón, los investigadores han estudiado otros modelos (más débiles).En
las siguientes secciones, analizaremos algunos de ellos.
Consistencia causal
El modelo de consistencia causal [Hutto 19901 representa un debilitamiento de la consistencia secuencial que hace una distinción entre los eventos potencialmente relacionados por causalidad y aquellos que no lo
están.
Si el evento B es causado o influido por un evento anterior,
A,
la causalidad requiere que todos vean primero aA,
y después vean aB.
Consideremos ahora un ejemplo de memoria. Suponga que el proceso
PI
escribe una variable x. DespuésPz
leex
y escribe y . Aquí la lectura dex
y la escritura de y están potencialmente relacionadas de formacausal, pues el cálculo de y podría depender del valor de
x
leido porP2
(es decir, el valor escrito porPI).
Por otro lado, si dos procesos escriben de forma espontánea y simultánea en dos variables, no estánrelacionados de forma causal. Cuando ocurre una lectura seguida por una escritura, los dos eventos están
en potencia relacionados de forma causal. De manera análoga, una lectura está relacionada de forma causal con la escritura que proporciona el dato obtenido por la lectura. Las operaciones que no están relacionadas de forma causal son concurrentes.
Para que una memoria sea consistente de forma causal, obedece las siguientes condiciones:
Las
escrituras potencialmente relacionadas deforma
causal son vistas por todos los procesos en el mismo orden.Las
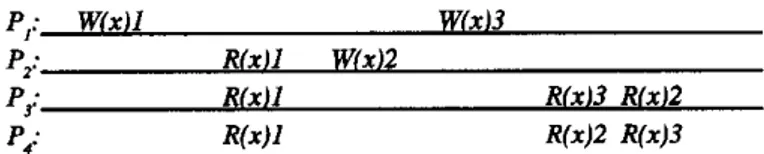
escrituras concurrentes pueden ser vistas en un orden dqerente en máquinas dqerentes.Como ejemplo de consistencia causal, considere la figura 1.5. Aquí tenemos una sucesión de eventos permitida con memoria consistente de forma causal, pero prohibida para una memoria con consistencia secuencial o con consistencia estricta. Lo que hay que observar es que las escrituras W(x)2 y W(x)3 son concurrentes, por lo que no se requiere que todos los procesos los vean en el mismo orden, Si el software
faUa cuando procesos diferentes ven eventos concurrentes en orden distinto, se ha violado el contrato de memoria ofrecido por la memoria causal.
P,: W(Xl1 WíxJ3
P,: Rlxll WíxI2
P3: RlxU Ríx13 RIx12
P,: R W R(x)2 R(x)3
Figara 1.5. Esta succsjóu está permitida para una memoria con Consistencia causal, pem no
para una memoria w n consisteucia secucncial o una memoria con consistencia estricta.
Ahora considere un segundo ejemplo. En la figura 1.6(a) tenemos que W(x)2 potencialmente depende de W(x)l, ya que 2 puede ser un resultado de un cálculo que implique al valor leído por R(x)l. Las dos escrituras están relacionadas de forma causal, de modo que todos los procesos deben verlas en el mismo orden. Por lo tanto, la figura 1.6(a) es incorrecta. Por otro lado, en la figura 1.6(b), la lectura ha sido eliminada, de modo que W(x)l y W(x)2 son ahora escrituras concurrentes. La memoria causal no necesita
ordenar de forma global las escrituras concurrentes, por lo que la figura 1.6(b) es correcta.
P,: Wlxll P,: Wlxll
P,: RlxIl WI XI2 P,: Wlx12
P,: Rlxll Ríx12 Ríxll P,: RíxlZ Rlxil
P,: R W l R(x)l R(x)2 P,: R W Wxi2
fa) íb)
Figura 1.6. (a) UM violación de la memona causal. (b) UM sucesión correcta de eventos en l a memoria causal
La implantación de la consistencia causal mantiene un registro de cuáles procesos han visto y cuáles escrituras. Esto significa de hecho que debe constnllrse y mantenerse una gráfka de dependencia con las
operaciones que dependen de otras. Hacer esto implica cierto costo.
Consistencia de liberación
Los modelos anteriores presentan una desventaja desde el punto de vista practico: si un proceso está
dentro de su región crítica, en principio los demás procesos no tienen acceso a las variables compartidas, entonces no tiene ningún sentido estar replicando las variables que se están actualizando, esto mientras el proceso este en su región crítica, pero sucede que en los modelo de consistencia anteriores no se puede
saber cuando un proceso está entrando o saliendo de una región crítica.
La mejor solución consiste en dejar que el proceso termine su sección crítica y garantizar entonces que los resultados finales se envíen a todas partes, sin preocuparse demasiado porque todos los resultados intermedios han sido propagados a todas las memorias en orden, o incluso si no fueron propagados. Esto
se lleva a cabo mediante un nuevo tipo de variable, la variable de sincronización, que se utiliza con fines de sincronización. Las operaciones en ella se utilizan para sincronizar la memoria. Cuando termina una sincronización, todas las escrituras realizadas en esa máquina se propagan hacia afuera y todas las escrituras realizadas en otras máquinas son traídas hacia la máquina en cuestión. En otras palabras, toda la
memoria (compartida) está sincronizada.
La consistencia de liberación [Gharachorloo 19901 proporciona dos tipos de estas variables. Los accesos
de adquisición indican a la memoria del sistema que está a punto de entrar a una región crítica. Los
accesos de liberación dice que acaba de salir de una región crítica. Estos accesos se implantan como
operaciones ordinarias sobre variables o como operaciones especiales.
En
cualquier caso, el programador es responsable por colocar un código explícito en el programa para indicar el momento de realizarlos;..
,.
...
, . t , .*. , ,”,..
enter-critical-region o leave-critical-region.
También es posible utilizar barreras en vez de las regiones m’ticas con la consistencia de liberación. Una barrera es un mecanismo de sincronización que evita que cualquier proceso inicie la fase n
+
1 de unprograma hasta que todos los procesos terminen la fase
n.
Cuando un proceso llega a una barrera, debe esperar que todos los demás procesos lleguen ahí también. Cuando llega el último, todas las variablescompartidas se sincronizan y continúan entonces todos los procesos. La salida de la barrera es la adquisición y la llegada es la liberación.
Además de estos accesos de sincronización, también se lee y escribe en las variables compartidas. La adquisición y liberación no tienen que aplicarse a toda la memoria, sino que protegen sólo algunas variables compartidas específicas, en cuyo caso sólo éstas se mantienen consistentes. Las variables compartidas que se mantienen consistentes son protegidas.
El contrato entre la memoria y el software dice que cuando el software realiza una adquisición, la memoria se asegurará que todas las copias locales de las variables protegidas sean actualizadas de manera consistente con las remotas, en caso necesario. Ai realizar una liberación, las variables protegidas que hayan sido modificadas se propagan hacia las demás máquinas. La realización de una adquisición no
garantiza que los cambios realizados de manera local sean enviados a las demás máquinas de inmediato. De manera análoga, la realización de una liberación no necesariamente importa las modificaciones de las demás máquinas.
P,: AcoíL) Wíxil Wíxi2 ReUL)
P,: AcdLJ Ríx) 2 RelíLJ
Figura 1.7. UM secuencia de eventos váiida para la consistencia de liberación.
P; Rí*U
La figura 1.7 muestra una secuencia de eventos válida para la consistencia de liberación. El proceso P, realiza una adquisición, modifica una variable compartida dos veces, y después realiza una liberación. El proceso Pz realiza una adquisición y lee
x.
Se garantiza que obtiene el valor de x al momento de laliberación, es decir, 2 (a menos que la adquisición de P2 se realice antes de la adquisición de PI). Si la adquisición fue realizada antes de la liberación de
PI
la adquisición tendría que retrasarse hasta que ocurrala liberación. Puesto que P, no puede realizar U M adquisición antes de leer una variable compartida, la memoria no tiene la obligación de darle el valor actual de x, de modo que se permite que regrese 1.
Para aclarar el concepto de consistencia de liberación, describiremos de forma breve una implantación simple, en el contexto de la memoria distribuida compartida (la consistencia de liberación fue ideada en realidad para el multiprocesador Dash, pero la idea es la misma, aunque la implantación no lo es). Para r e a i i i
una
adquisición, un proceso envía un mensaje a un controlador de sincronización solicitando unaadquisición sobre una cerradura particular. Si no hay competencia, se aprueba la solicitud y termina la adquisición. Después, se pueden realizar de manera local una serie arbitraria de lecturas y escrituras a los datos compartidos. Ninguno de estos se propaga a las demás máquinas.
Ai
realizar la liberación, los datos modificados se envían a las demás máquinas que los utilizan. Después de que cada máquina ha reconocido la recepción de los datos, el controlador de sincronización es informado de la liberación. De esta manera, se pueden realizar una cantidad arbitraria de lecturas y escrituras sobre las variables compartidas con un costo fijo. Las adquisiciones y liberaciones de las diversas cerraduras ocurren demanera independiente entre sí.
,
’.
Aunque el algoritmo centralizado descrito arriba puede realizar el trabajo, de ninguna manera es el Único método. En general, una memoria distribuida compartida tiene consistencia de liberación si cumple las siguientes reglas:
I . Antes de realizar un acceso ordinario a una variable comparlida, deben terminar con éxito todas las
2. Antes de permitir la realización de una liberación, deben terminar las lecturas y escrituras anteriores
3. Los accesos de adquisición y liberación deben ser consistentes con el procesador (no se pide la adquisiciones anteriores del proceso en cuestión.
del proceso.
consistencia secuencial).
Vale la pena mencionar que existe
un
poco de complejidad detrás de la palabra "realizados" aquí y en todas partes, en el contexto deMVD.
Se dice que una lectura ha sido realizada cuando ninguna escrituraposterior afecta el valor regresado. Se dice que una escritura ha sido realizada en el instante en que todas
las lecturas posteriores regresan el valor escrito por la escritura. Se dice que una sincronización ha sido realizada cuando todas las variables compartidas han sido actualizadas. También se puede distinguir entre las operaciones que se realizan de manera local o global [Dubois 19881.
Si se cumplen todas estas condiciones y los procesos utilizan la adquisición y la liberación de manera
adecuada (es decir, en pares adquisición-liberaci6n), los resultados de cualquier ejecución no serán diferentes de lo que ocurriría en una memoria con consistencia secuencial. De hecho, los bloques de acceso a las variables compartidas son atómicos debido a las primitivas de adquisición y liberación, con el
fin
de evitar el intercalado.Consistencia de liberación perezosa
Una implantación diferente de la consistencia de liberación es la consistencia de
iibemci6n
perezosa.
En la consistencia de liberación normal, Uamada consistencia de liberación fuerte, para distinguir la otra variante, al realizar una liberación, el procesador que realiza ésta expulsa todos los datos modificados hacia los demás procesadores que tienen una copia en caché y que podrian necesitarlos.No
existe formade determinar si en realidad los utilizarán, de modo que para estar seguros, todos obtienen lo moditicado.
Aunque el envio de todos los datos de esta manera es directo, por lo general no es eficiente. En la consistencia de liberación perezosa, en el momento de liberación, nada se envía, sino que cuando se realiza una adquisición, el procesador que intenta realizar ésta debe obtener los valores más recientes de las variables de la máquina o máquinas que los contienen. Se puede utilizar un protocolo con marcas de tiempo para determinar cuál de las variables debe transmitirse.
En muchos programas, una región crítica se localiza dentro de un ciclo. Con la consistencia de liberación fuerte, se realiza una liberación por cada paso por el ciclo, y todos los datos modificados deben ser
enviados a los demás procesadores que tienen copias de ellos. Este algoritmo desperdicia el ancho de banda e introduce un retraso innecesario. Con la consistencia de liberación perezosa, no se hace nada al momento de la liberación. En la siguiente adquisición, el procesador determina que ya tiene todos los datos que necesita, por lo que tampoco se generan mensajes en ese momento. El resultado neto es que, con la consistencia de liberación perezosa, no se genera tráfico alguno en la red hasta que otro procesador realiza una adquisición.
Las
parejas adquisición-liberación repetidas por un mismo procesador en1 .
ibera~ión Fuerte h s datos compartidos son
mnsistentes al salir de una región
atica
iberación Perezosa No se envía la actualización de los
datos compartidos al salir de la región narcas de tiempo, para saber cual fue el ultimo que
crítica, si no solo cuando otro p'oceso nndifico alguna variable.
la requiera
Se obtiene, para el programador, una
wnsistencia secuencial
Actualiza a la salida de la región crítica las vaxiable a
tododos los procesos, sin saber si estos los requieren o no.
Complica un poco más el algoritmo, al tener que llevar
.
I.2.
DESCRIPCIÓN DEL PROBLEMA
En
este capítulo se describe el funcionamiento del sistema de MVD existente en el laboratorio y el cual sepretende migrar.
El conocimiento del sistema nos permitirá tener una herramienta precisa para poder dehminar cual es el problema con el que nos tenemos que enfrentar.
2.1 MVD
UAMl
2.1
.l
lnterfaz al usuario
La MVD ofrece
un
comportamiento similar al que se observa en las aplicaciones desarrolladas para una sola computadora, ya sea uniprocesador 6 multiprocesador, en donde los procesos se comunican a través de variables de memoria compartida, al existir zonas compartidas se presentan condiciones de competencia que hacen necesario que se ofrezcan mecanismos para la sincronización entre procesos. La unidad de memoria que a nivel de programador nuestra MVD proporciona es la regi6n, se proporcionan también las funciones para la creación de procesos ligeros (hilos) además de candados y barreras para la sincronización entre ellos. Las funciones ofrecidas por la MVD las podemos agrupar de la siguiente manera:Destrucción Espera Creación de barreras
Adquirir candado Liberar candado
Esperar
barreraLa MVD se ejecutará en un agrupamiento de estaciones de trabajo
SUN
SPARC-5, con Solaris 1.5.1 Seofrecerá una biblioteca de funciones que el usuario enlazará a sus programas de aplicación desarrollados en lenguaje C. Para la ejecución de aplicaciones se requiere que se ejecute en una de las computadoras un servidor, que es el responsable de la administración de la memoria compartida, la asignación de candados
y barreras además del registro y localización de los sitios que se encuentran ejecutando aplicaciones; con respecto a los sitios, el servidor se encarga de asignarles un identificador numérico Único. El usuario ejecuta su aplicación en cualquiera de los sitios del agrupamiento, dicho sitio será llamado nodo maestro, se debe de proporcionar el nombre de la computadora en donde se ejecuta el servidor, de no ser así el
sistema lo solicitará y los nombres de las computadoras en donde quiere que se ejecute su aplicación, ésta
úitima información debe encontrarse
en
un archivo. Las regiones de memoria compartida creadas por cada aplicación no pueden ser accedidas por otras aplicaciones únicamente por los procesos (hilos). . .
. . .
. . .
..
._
..
..
._
-.
._
..
..
....
._
..
._
._
..
._
..
..
..
:..
. .
. .
. .
. .
. .
..
L
..
...
::.
i
..:
...?!??M?.???Pe!?Fi.W.!I?.
...
i
rb&
A: rporaaáo queseejeamm los Sitios 1.2 y 3.
B: rporaaáo que segeai*m los sitios 4 y 5.
fig. 2.1
Ejecución de aplicaciones en la
MVD
Para la ejecución de aplicaciones, en primer lugar el servidor debe de estar en ejecución en un sitio bien conocido, el ejecutable de la aplicación deb de encontrarse en cada computadora del agrupamiento, el usuario ejecuta su aplicación en cualquiera de los sitios disponibles, éste sitio llamado nodo maestro solicita registrarse ante el servidor (1) el cual recibe los datos de la localización del nodo y le envía un idenMicador de sitio único (2), enseguida el nodo maestro obtiene la información de los sitios
involucrados en la aplicación para ejecutar dicha aplicación en los sitios correspondientes (3), el nodo maestro permanece en estado de espera por los nodos hijos, cada uno de los sitios involucrados a su vez se registran ante el servidor (4) y reciben su identifkador de sitio
(9,
informan al nodo maestro que se encuentran listos (6) y se colocan en estado de espera, el nodo maestro que se encuentra en estado de espera permanece14 así hasta recibir la información de que todos los nodos hijos se encuentran listos para comenzar la ejecución de la aplicación al mismo tiempo que registra los identifkadores de los nodos hijos. (fig. 3.2).3
Fig. 2.2
Una vez que se ha completado la inicialización el nodo maestro comienza a crear los hilos de aplicación, es decir envía los mensajes correspondientes para la creación de hilos en los sitios registrados (7), enviando además la información acerca de las regiones de memoria compartida, y las variables de sincronización, desde este momento los hilos de aplicación en cada sitio interacthan a través de variables compartidas y primitivas de sincronización, el servidor únicamente realiza funciones de localización de sitios, cuando los hilos de aplicación terminan, en cada sitio se notifica al
nodo
maestro que se ha terminado (8), en el nodo maestro mientras tanto se ejecuta la misma aplicación y se espera por los la finalización de los hilos creados, hasta que todos los hilos notifican que han terminado la aplicación en elnodo
maestro puede continuar, mientras tanto los nodos hijos permanecen en un estado de espera hastaque el nodo maestro les indique que hacer, el nodo maestro al confiiar que todos los hilos creados han terminado envía a cada nodo hijo el mensaje de terminación (9), esperando por la confiación de cada
7 8
9
Fig. 2.3
2.1.2
Diseño y arquitectura
Funcionalmente la MVD está integrada por varios componentes que permiten ofrecer la funcionalidad propuesta, el manejador de hilos que implementa un esquema de nombramiento de hilos a nivel de agrupamiento de computadoras de manera que cada hilo sea identificado de manera única, ofrece una interfaz para la creación y espera por hilos de aplicación, además interactúa de una manera muy estrecha con el manejador de comunicaciones que es el que se encarga de los detalles de la comunicación entre los hilos a través de la red, atendiendo aspectos como los tipos, tamaños y formatos de los mensajes,
implementa mecanismos de temporización, retransmisiones y eliminación de duplicados así como el
mantenimiento de la información de los sitios con los que se tiene comunicación. Juntos, el manejador de
hilos y comunicaciones soportan al manejador local de
MVD,
el cual es el responsable de atender laspeticiones sobre las regiones de memoria compartida, mantenimiento de la coherencia local, localización de los datos y el soporte para el modelo de coherencia ofrecido por la memoria, a su vez éste manejador ofrece como interface primitivas de sincronización y manejo de regiones, internamente las regiones son divididas en páginas, que es la unidad manejada por la
MVD
(fig 2.4).I'
I. .
Hlos
I
~ i g . 2.4
21
Manejador de hilos
Este manejador establece un esquema de nombramiento de hilos, administración e interface para la
creación y espera por hilos de aplicación. Para el nombramiento de los hilos utilizamos el identifcador de sitio que otorga el servidor, el cual es único, para el servidor su identificador de sitio es siempre O, el
identifkador de los hilos a nivel de agrupamiento de computadoras se forma concatenando el identifkador de sitio y un índice en una tabla que registra los hilos creados en cada sitio, de ésta manera
conseguimos identificar los hilos sin ambigtiedad. (fig 2.5).
TablaCkhüoshcales TaMaCkhilCSlOCakS
r
r
Fig. 2.5
El manejador registra desde su inicialización 3 hilos que r e b á n tareas especificas para el correcto funcionamiento de la
MVD,
las entradas reservadas para estos hilos en la tabla de hilos locales son el O,1
y 2, de ésta manera, conociendo el identificador de sitio podemos dirigimos a cualquiera de los 3 hilos
, ..
r .
I .
" .
" .
,-
I *.
Fig. 2.6
El hilo que se registra en la entrada O es el hilo principal, el cual realiza las
nitinas
de iniciaiización yregistro de los sitios involucrados en las aplicaciones, crea los hilos de recepción de mensajes, el manejador local de
MVD
y los hilos de aplicación, así como las regiones y variables de sincronización, elhilo que monitorea la recepción de mensajes se registra en la entrada 1, este hilo se encarga de v d i c a r si existen mensajes recibidos por el sitio, determinar el tipo de mensaje recibido, ya sea solicitud 6 respuesta, la correcta entrega de dichos mensajes, retransmisiones y detección de duplicados
,
por Último,el hilo manejador local de MVD se registra en la entrada 2, este se encarga de atender las peticiones sobre
páginas, creación de hilos de aplicación y el mantenimiento de la coherencia local (fig. 2.6).
Con base en los 3 hilos mencionados el manejador proporciona la facilidad de crear hilos de aplicación encargáudose la
MVD
de la ubicación de los mismos. La aplicación ejecutándose en el nodo maestroinvoca a la llamada de creación de hilo, desde ese momento la
MVD
toma el control y determina ahora elsitio en el que se ejecutará el hilo a ser creado, envía el mensaje correspondiente al sitio (1), al hilo
manejador local de MVD indicándole la dirección de la función, el mensaje recibido es respondido (2)
esperando entonces por la información referente a las regiones y variables de sincronización, una vez recibida ésta información (3) el hilo de aplicación es creado en el sitio, no sin antes confimar (4) que la
información ha sido recibida (fig. 2.7).
En
el nodo maestro se tiene un registro de cuantos y que nodos son los que tomarán parte en la aplicación, de ésta manera, cuando se crea un nuevo hilo de aplicación el nodo maestro consulta el registro y obtiene el identificador del sitio en turno. Si tenemos tres nodos hijos con identificadores 7, 9 y 11 respectivamente, ésta infamación la posee elnodo
maestro, en el nodo maestro se ejecuta el c6digo que crea 5 hilos de aplicación, la manera de determinar en que sitio se creará dicho hilo se obtiene utilizando la operación módulo para obtener el índice correspondiente dentro del registro, al inicio turno presenta unvaior de -1, al ejecutar la primem llamada a crea~hilo turno toma el valor de 1 así el nodo maestro obtiene el identiíicador del
nodo
hijo ai cual se le solicitará la creación de un hilo de aplicación, en estesda j=l huta 5
f
o 1 2 3 4 5 " . M
IddeSyiD
1
-Fig. 2.8
Así como se ofrece la facilidad para crear hilos de aplicación también proporciona una forma de esperar
por dichos hilos, es decir la aplicación no puede continuar hasta que todos los hilos creados han
tenninado su ejecución
IEsDera nor h i l o s 0
1
cedergrocesador í )
1
h i l o s terminados = hilos terminados + i1
Fig. 2.9
25
En el nodo maestro la aplicación ejecuta la llamada a esperar por hilos, internamente se entra en un ciclo
en el cual se comprueba si se han recibido las notificaciones de los hilos creados acerca de su
terminación, el hilo manejador de MVD es el que recibe dichas notificaciones incrementando el contador de hilos que han terminado (fig 2.9).
Manejador de comunicaciones
Se encarga de establecer los diferentes tipos, formato y tamaño de mensajes, así como de proporcionar mecanismos de retransmisión y detección de duplicados.
2.2 Migración
Como se plantea nuestro objetivo del proyecto, es necesario realizar la migración de un sistema de memoria virtual distribuida para lo cual se debe observar especial atención en aspectos que definen el comportamiento actual del sistema en la plataforma actual (Solaris Sparc), es decir, el esfuerzo de la migración se va a concentrar en aspectos que involucrau dependencias de plataforma de la MVD tanto de
hardware como de software, esto es, Arquitectura de procesador, sistema operativo, librerías de desarrollo, interconexión de red, etc., pues es donde se va a requerir dar una alternativa viable para la nueva plataforma (Linux Intel 32).
De igual forma es importante ver la compatibilidad existente entre ambas plataformas dado que esto a su vez nos garantizará que partes de la MVD serán inmunes a la migración, dado esto, mientras más compatibilidad exista entre las plataformas, menos serán las partes que habrá que reemplazar.
Independientemente de la tarea a llevar a cabo con la migración cabe mencionar que la MVD actual no cuenta con mecanismos de sincronización como semáforos o barreras por lo cual al final de la migración no podremos tener un sistema de MVD totalmente funcional.