Manejo de Ontologías en Sistemas Multiagentes por medio de un
Agente de Ontologías aplicado a JITIK
Title Manejo de Ontologías en Sistemas Multiagentes por medio de un Agente de Ontologías aplicado a JITIK
Authors Ceballos Cancino, Héctor G. Issue Date 2003-05
multiagentes. Dichas arquitecturas tienen como elementos principales a un agente de ontologías y un componente cliente. El agente de ontologías se encarga de cargar la ontología global del sistema y de resolver las preguntas acerca de ella que le envían los demás agentes. Estos Últimos cuentan con el componente cliente para codificar sus preguntas, enviarlas al agente de ontologías y
decodificar las respuestas obtenidas. Previo a la definición de los modelos, se presenta un estudio de los elementos que intervienen en la solución. Se incluye un resumen de los puntos a considerar y de las tecnologías que pueden utilizarse en cada uno de ellos. En los modelos propuestos se recomienda el uso de un formato de ontología de Semantic Web, DAML+OIL. La alta compatibilidad entre los elementos de este formato y la definición de la
ontología de la plataforma de desarrollo de agentes JADE permitió la fusión de ambos formatos por medio del
Toolkit Jena. Al final se obtuvo una arquitectura híbrida de administración de la ontología donde el agente cliente posee una parte de la ontología y además puede acceder al resto de ella por medio de preguntas al agente de
ontologías. El prototipo desarrollado incluye una implementación del agente de ontologías con la
funcionalidad indicada, así como una librería en Java que ofrece los servicios propios del componente cliente. Dicha librería permite almacenar una porción de la ontología en el agente cliente y hacer consultas locales (resueltas por un motor de consultas portátil) o remotas (enviadas a el agente de ontologías). Esto Último se hace utilizando un lenguaje de consulta que permite realizar preguntas complejas acerca de los esquemás e instancias definidos en DAML+OIL.
Discipline Ciencias / Sciences
Additional Links http://homepages.mty.itesm.mx/ceballos/docs/MIT_Ceball os.pdf
Item type Tesis ???pdf.cover.sheet
.thesis.degree.nam e???
Programas de Posgrado en Electrónica, Computación, Información y Comunicaciones
???pdf.cover.sheet .dc.contributor.adv isor???
pline???
???pdf.cover.sheet .thesis.degree.prog ram???
Campus Monterrey
Rights Open Access
Downloaded 19-Jan-2017 14:23:02
Multiagentes por medio de un Agente de
Ontolog´ıas aplicado a JITIK
T E S I S
Maestr´ıa en Ciencias en Sistemas Inteligentes
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Por
Ing. H´
ector Gibr´
an Ceballos Cancino
Multiagentes por medio de un Agente de
Ontolog´ıas aplicado a JITIK
TESIS
Maestr´ıa en Ciencias en
Sistemas Inteligentes
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Por
Ing. H´
ector Gibr´
an Ceballos Cancino
Monterrey
Divisi´
on de Graduados en Electr´
onica, Computaci´
on, Informaci´
on
y Comunicaciones
Direcci´on de Programas de Posgrado en Electr´onica, Computaci´on, Informaci´on y Comunicaciones
Los miembros del comit´e de tesis recomendamos que la presente tesis de H´ector Gibr´an Ceballos Cancino sea aceptada como requisito parcial para obtener el grado acad´emico de
Maestro en Ciencias en:
Sistemas Inteligentes
Comit´
e de tesis:
Dr. Ram´on Brena Pinero
Asesor de la tesis
Dr. Jose Luis Aguirre Cervantes
Sinodal
Dr. Francisco J. Cant´u Ort´ız
Sinodal
Dr. David Garza Salazar, PhD.
Director del Programa de Graduados en Electr´onica, Computaci´on, Informaci´on y Comunicaciones
Multiagentes por medio de un Agente de
Ontolog´ıas aplicado a JITIK
Por
Ing. H´
ector Gibr´
an Ceballos Cancino
TESIS
Presentada a la Divisi´on de Electr´onica, Computaci´on, Informaci´on y Comunicaciones
Este trabajo es requisito parcial para obtener el grado acad´emico de Maestro en Ciencias
en Sistemas Inteligentes
Instituto Tecnol´
ogico y de Estudios Superiores de Monterrey
Campus Monterrey
Agradezco a mi asesor, el Dr. Brena, por su gu´ıa y apoyo en la realizaci´on de esta tesis. Agradezco a mis sinodales, el Dr. Aguirre y el Dr. Cant´u, por sus cr´ıticas constructivas y enriquecedoras.
Igualmente, agradezco a todos aquellos con quien conviv´ı y trabaj´e en el Centro de IA, ahora CSI, por su amistad y compa˜nerismo.
A mis compa˜neros de la maestr´ıa, en especial a Germ´an, Charly, Novelo y Arj´an, mi amistad por siempre.
Agradezco tambi´en la hospitalidad de mi primo Hugo y a Do˜na Martha por su cocina.
H´
ector Gibr´
an Ceballos Cancino
Instituto Tecnol´ogico y de Estudios Superiores de Monterrey
Mayo 2003
Multiagentes por medio de un Agente de
Ontolog´ıas aplicado a JITIK
H´ector Gibr´an Ceballos Cancino, M.C.
Instituto Tecnol´ogico y de Estudios Superiores de Monterrey, 2003
Asesor de la tesis: Dr. Ram´on Brena Pinero
El presente trabajo muestra el desarrollo de varios modelos o arquitecturas para el manejo de ontolog´ıas en un sistema multiagentes. Dichas arquitecturas tienen como elementos principales a un agente de ontolog´ıas y un componente cliente. El agente de ontolog´ıas se encarga de cargar la ontolog´ıa globaldel sistema y de resolver las preguntas acerca de ella que le env´ıan los dem´as agentes. Estos ´ultimos cuentan con el componente cliente para codificar sus preguntas, enviarlas al agente de ontolog´ıas y decodificar las respuestas obtenidas.
Previo a la definici´on de los modelos, se presenta un estudio de los elementos que intervienen en la soluci´on. Se incluye un resumen de los puntos a considerar y de las tecnolog´ıas que pueden utilizarse en cada uno de ellos.
En los modelos propuestos se recomienda el uso de un formato de ontolog´ıa de Semantic Web, DAML+OIL. La alta compatibilidad entre los elementos de este formato y la definici´on de la ontolog´ıa de la plataforma de desarrollo de agentes JADE permiti´o la fusi´on de ambos formatos por medio del Toolkit Jena.
Reconocimientos I
Resumen II
1. Introducci´on 1
1.1. JITIK . . . 1
1.2. Planteamiento del Problema . . . 2
1.3. Hip´otesis . . . 3
1.4. Enfoque . . . 3
1.5. Alcance y Limitaciones . . . 3
2. Marco Te´orico 5 2.1. Agentes . . . 5
2.2. Sistemas Multiagentes . . . 5
2.3. Plataformas de Desarrollo para Sistemas Multiagentes . . . 6
2.3.1. JADE . . . 7
2.4. Ontolog´ıas . . . 9
2.5. Formato de Representaci´on de Ontolog´ıas . . . 9
2.5.1. XML . . . 10
2.5.2. RDF . . . 12
2.5.3. RDFS . . . 17
2.5.4. OIL . . . 19
2.5.5. DAML . . . 20
2.5.6. DAML+OIL . . . 21
2.6. Interpretaci´on de Ontolog´ıas . . . 23
2.6.1. Toolkit Jena . . . 23
2.6.2. RDFSuite de ICS-FORTH . . . 24
2.7. Lenguajes de Consulta . . . 26
2.7.1. RDF Query Language (RQL) . . . 26
2.7.2. Soporte JADE para ontolog´ıas . . . 28
3. Soluci´on Propuesta 31 3.1. Escenario de Agentes . . . 32
3.1.1. Agente de Ontolog´ıas . . . 32
3.1.2. Agente Cliente . . . 33
3.2. Adaptaciones al Soporte JADE para Ontolog´ıas . . . 33
3.3. Formato de Ontolog´ıa . . . 35
3.3.1. Metaontolog´ıa . . . 35
3.3.2. Representaci´on . . . 36
3.3.3. Almacenamiento . . . 36
3.4. Mecanismo de Consulta . . . 37
3.4.1. Lenguaje de Consulta . . . 37
3.4.2. Motor de Consultas . . . 38
3.4.3. Formato de Respuesta . . . 38
3.5. Intepretaci´on de Resultados . . . 39
3.5.1. Mapeo de la Ontolog´ıa en el Agente Cliente . . . 39
3.6. Componente cliente . . . 39
3.7. Modelos propuestos . . . 40
3.7.1. Primer Modelo . . . 40
3.7.2. Segundo Modelo . . . 43
3.7.3. Tercer Modelo . . . 46
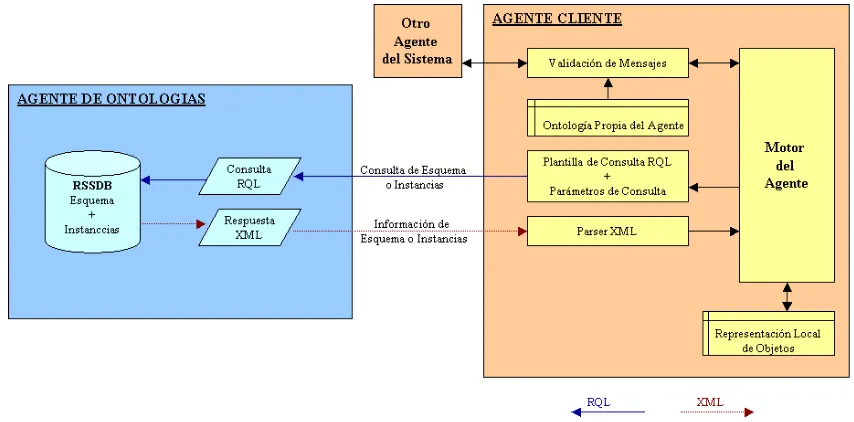
3.8. Prototipo . . . 50
3.8.1. Arquitectura . . . 50
3.8.2. Escenario de Agentes . . . 51
3.8.3. Formato de Ontolog´ıa . . . 52
3.8.4. Componente Cliente . . . 53
3.8.5. Agente de Ontolog´ıas . . . 53
3.8.6. Mecanismo de Consulta . . . 53
3.8.7. Interpretaci´on de Resultados . . . 56
3.8.8. Ventajas y Desventajas . . . 56
4. Experimentaci´on y Resultados 59 4.1. Experimentos . . . 59
4.1.1. M´etodo de Experimentaci´on . . . 60
4.1.2. Selecci´on de Consultas . . . 60
4.1.3. Rondas de Experimentos . . . 61
4.2. Ontologia de Prueba . . . 64
4.3. Corrida de Experimentos . . . 64
4.3.1. Primera Ronda . . . 64
4.3.2. Segunda Ronda . . . 67
4.3.3. Tercera Ronda . . . 70
4.3.4. Cuarta Ronda . . . 74
4.3.5. Quinta Ronda . . . 82
4.4. Resultados . . . 87
4.5. Trabajos relacionados . . . 87
4.5.1. RDFSuite de ICSForth . . . 89
4.5.2. Ontobroker . . . 89
5. Conclusiones 91
5.1. Limitaciones . . . 93
5.2. Trabajos Futuros . . . 93
A. Lenguaje de Consulta 95 A.1. Metaontolog´ıa . . . 95
A.2. Operadores de Consulta . . . 96
A.3. Contenedores de Resultados . . . 97
A.4. Gram´atica para Consultas . . . 97
A.5. Caracterizaci´on de Consultas . . . 99
A.5.1. Secci´on de Operadores . . . 99
A.5.2. Secci´on de Descripciones . . . 100
B. Ontolog´ıa de Prueba 103 B.1. Archivos DAML . . . 103
B.1.1. Archivo itesmcore.daml . . . 103
B.1.2. Archivo personal.daml . . . 114
B.2. Vista con dumpont . . . 118
1.1. Modelo Conceptual de JITIK[11] . . . 4
2.1. Interfaz de JADE . . . 8
2.2. Diagrama de nodo y arcos simple . . . 14
3.1. Diagrama de Colaboraci´on de JITIK para el Agente de Ontolog´ıas . . . 32
3.2. Arquitectura del Primer Modelo de Soluci´on . . . 41
3.3. Arquitectura del Segundo Modelo de Soluci´on . . . 43
3.4. Arquitectura del Tercer Modelo de Soluci´on . . . 47
3.5. Arquitectura del Prototipo . . . 50
3.6. ´Arbol gramatical del ejemplo de consulta . . . 55
4.1. Representaci´on Gr´afica de la Secci´on de Operadores de la Gram´atica Simpli-ficada . . . 61
4.2. Distribuci´on de Consultas en Rondas de Experimentos . . . 63
4.3. ´Arbol Gramatical del experimento 1.1 . . . 65
4.4. ´Arbol Gramatical del experimento 1.2 . . . 66
4.5. ´Arbol Gramatical del experimento 1.3 . . . 68
4.6. ´Arbol Gramatical del experimento 2.1 . . . 69
4.7. ´Arbol Gramatical del experimento 2.2 . . . 70
4.8. ´Arbol Gramatical del experimento 2.3 . . . 71
4.9. ´Arbol Gramatical del experimento 3.1 . . . 72
4.10. ´Arbol Gramatical del experimento 3.2 . . . 74
4.11. ´Arbol Gramatical del experimento 3.3 . . . 75
4.12. ´Arbol Gramatical del experimento 4.1 . . . 77
4.13. ´Arbol Gramatical del experimento 4.2 . . . 79
4.14. ´Arbol Gramatical del experimento 4.3 . . . 81
4.15. ´Arbol Gramatical del experimento 5.1 . . . 83
4.16. ´Arbol Gramatical del experimento 5.2 . . . 85
4.17. ´Arbol Gramatical del experimento 5.3 . . . 88
A.1. Representaci´on Gr´afica de la Secci´on de Operadores de la Gram´atica . . . . 99
A.2. Representaci´on Gr´afica del elemento <Description>de la Gram´atica . . . . 100
A.3. Representaci´on Gr´afica del elemento <Class> de la Gram´atica . . . 100
A.4. Representaci´on Gr´afica del elemento <Property> de la Gram´atica . . . 101
A.5. Representaci´on Gr´afica del elemento <Instance> de la Gram´atica . . . 101
2.1. Caracter´ısticas de Agentes Multiagentes . . . 7
2.2. Partes de una Sentencia B´asica . . . 14
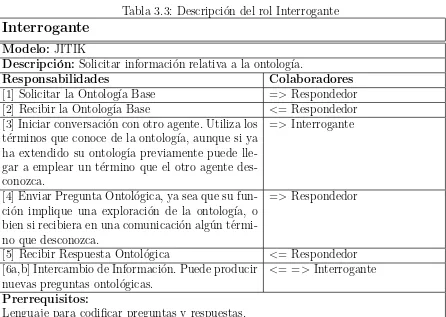
3.1. Resumen de Interacci´on entre los roles Interrogante y Respondedor . . . 33
3.2. Descripci´on del rol Respondedor . . . 34
3.3. Descripci´on del rol Interrogante . . . 34
3.4. Caracter´ısticas de los Conceptos Principales de la Metaontolog´ıa . . . 36
Introducci´
on
De la misma forma como la informaci´on fluye a trav´es de las sociedades, las unidades organizacionales demandan una mejor administraci´on de la misma para obtener resultados en los tiempos que exige la modernidad. Las organizaciones cada vez son m´as grandes y se encuentran m´as distribuidas, trayendo esto como consecuencia que la informaci´on tarde m´as en llegar de una persona a otra o que, en el peor de los casos, dicha informaci´on no llegue a las personas a las que les puede servir para realizar mejor su trabajo.
Se tiene no s´olo informaci´on distribuida, sino tambi´en usuarios distribuidos que encuen-tran cada vez m´as dificultad para generar conocimiento a partir de la informaci´on individual que poseen.
La definici´on de un marco de entendimiento com´un, as´ı como de una plataforma de comunicaci´on que mantenga la consistencia en la informaci´on poseida por cada miembro de la organizaci´on son el punto de partida para que se de la comunicaci´on y colaboraci´on entre ellos. Una herramienta utilizada para dicho fin son lasontolog´ıas, que permiten definir conceptos en forma clara y precisa evitando as´ı ambig¨uedades o fallas en la comunicaci´on.
1.1.
JITIK
Pensando en este tipo de problemas, el grupo de investigaci´on en Inteligencia Artificial del Centro de Sistemas Inteligentes del Tecnol´ogico de Monterrey, Campus Monterrey, esta llevando a cabo un proyecto que tiene como objetivo proporcionar herramientas para favore-cer la colaboraci´on entre miembros de organizaciones distribuidas, a trav´es de la aplicaci´on de tecnolog´ıas de IA. Dicho proyecto, inici´o en 1998 con el nombre CORREA[13] (CooRdi-naci´on de Recursos de Educaci´on e investigaci´on mediante Agentes) y a partir del 2000, se nombr´o RICA (Redes de Informaci´on y Conocimiento mediante Agentes), para enfatizar el objetivo de apoyar la distribuci´on de conocimiento en organizaciones. Al mismo tiempo se contextualiz´o RICA dentro de una perspectiva de Administraci´on del Conocimiento (KM, por sus siglas en ingl´es), poniendo de manifiesto su posible contribuci´on a la creaci´on de valor al dar soporte principalmente al flujo de conocimiento oportuno en las organizaciones. El proyecto est´a entrando en una tercera fase en la que se le ha nombrado ”Just-in-time Information and Knowledge”(JITIK), y que tiene como punto de partida la agentificaci´on de todos los elementos del sistema[11].
La principal funci´on de JITIK es hacer llegar oportunamente informaci´on valiosa a los miembros de la organizaci´on. Las t´ecnicas de Inteligencia Artificial que incorpora le permi-tan extraer informaci´on de diferentes fuentes, generar nuevo conocimiento y difundir dicha informaci´on y conocimiento entre los clientes del sistema. Un ejemplo de estas t´ecnicas son la Miner´ıa de Datos (Data Mining) y el Razonamiento Basado en Casos (CBR).
La naturaleza distribuida del problema dio paso a la generaci´on de un Sistema Multi-agentes en el que intervienen diferentes actores o Multi-agentes con una funci´on espec´ıfica. La cooperaci´on entre dichos agentes permite atender la problem´atica general desde diferentes ´angulos.
1.2.
Planteamiento del Problema
La comunicaci´on es la que permite coordinar los esfuerzos de los agentes que tienen una meta individual en el sistema a la vez que persiguen una meta global. Un entendimiento com´un es fundamental para lograr la consecuci´on de dicha meta.
Para lograr dicho entendimiento se requiere una definici´on clara y precisa de los t´erminos que manejan los agentes. Esto se logra a trav´es del uso de Ontolog´ıas, cuya capacidad expre-siva permite definir conceptos que sirven tanto para representar la informaci´on del sistema como las operaciones que pueden realizar.
Entre los conceptos definidos en la ontolog´ıa de cada agente se encuentran aquellos que usan para comunicarse con los dem´as agentes, as´ı como los que usan para su funcionamiento interno, teniendo as´ı una ontolog´ıa propia y diferente en cada agente.
Mantener la consistencia entre las ontolog´ıas que manejan los agentes puede ser un prob-lema si no se lleva un control adecuado. Dicho control puede ser centralizado o bien estar distribuido entre los agentes.
Un control centralizado permitir´ıa llevar un riguroso control de cambios que mantenga la integridad del sistema. Este control deber´ıa ser lo suficientemente flexible y ´agil para permitir que los desarrolladores de agentes integren todo aquello que necesiten en la ontolog´ıa. Adem´as plantea la necesidad de distribuir la ontolog´ıa entre los agentes del sistema durante la ejecuci´on.
El tener una ontolog´ıa distribuida permitir´ıa que los desarrolladores pudieran agregar los conceptos necesarios para el correcto funcionamiento de sus agentes. Sin embargo, podr´ıa darse el caso de que utilizaran nombres que provoquen ambig¨uedad durante la comunicaci´on. Problemas de este tipo dificultar´ıan el proceso de integraci´on del sistema.
Adem´as existe cierta informaci´on del sistema, codificada en t´erminos comunes a todos los agentes, que debe estar disponible para todos ellos a trav´es de un repositorio central.
1.3.
Hip´
otesis
El manejo del contenido de la ontolog´ıa del sistema puede hacerse por medio un agente in-teligente que administre un repositorio de ontolog´ıas que contenga las definiciones requeridas por cada uno de los agentes del sistema.
Dicha administraci´on debe garantizar que todos los agentes del sistema conozcan al menos un conjunto m´ınimo de informaci´on de la ontolog´ıa que sea suficiente para comunicarse entre s´ı.
Asimismo, un adecuado mecanismo de acceso a la ontolog´ıa permitir´a que los agentes obtengan las definiciones que requieran para su propio funcionamiento as´ı como la informa-ci´on contenida en la misma.
1.4.
Enfoque
La soluci´on propuesta va orientada al uso de un Agente de Ontolog´ıas que administre la ontolog´ıa del sistema. Este agente se encargar´a de distribuir entre los agentes la definici´on de conceptos que requieran, as´ı como informaci´on general del sistema, proveniente de un repositorio de ontolog´ıas.
Por otra parte, se dise˜nar´a un soporte para que los agentes del sistema accedan a la porci´on de la ontolog´ıa que requieran. Dicho soporte servir´a de interfaz con el Agente de Ontolog´ıas para solicitar y recibir informaci´on.
As´ı se tendr´a una arquitectura del sistema en la que el Agente de Ontolog´ıas posea un repositorio y distribuya entre los agentes la informaci´on que requieran, tal como se puede apreciar en la Figura 1.1.
1.5.
Alcance y Limitaciones
Se propondr´a una arquitectura de sistemas multiagentes para resolver el problema planteado. Esta arquitectura deber´a incorporar est´andares para formatos de ontolog´ıa y plataformas de desarrollo de sistemas multiagentes vigentes y estables.
Se implementar´a un prototipo funcional que muestre el manejo de la ontolog´ıa a trav´es de un Agente de Ontolog´ıas, as´ı como un componente que los desarrolladores de agentes puedan emplear para incorporar el acceso al repositorio de ontolog´ıas.
El componente acceder´a a la ontolog´ıa por medio de preguntas y respuestas dirigidas al Agente de Ontolog´ıas.
Marco Te´
orico
En esta secci´on se extender´an un poco los conceptos que envuelven el presente trabajo, comenzando con el concepto de agente, las caracter´ısticas de los sistemas multiagentes, otras definiciones de ontolog´ıa, as´ı como formatos de representaci´on de la misma. Se incluye una breve rese˜na de la plataforma de desarrollo de agentes JADE y su soporte para manejo de contenidos. A modo de introducci´on, se describen los formatos empleados para construir una ontolog´ıa de Semantic Web: XML, RDF y DAML+OIL. Asimismo, se presentan algunos lenguajes de consulta y herramientas para interpretar y explotar ontolog´ıas en estos formatos.
2.1.
Agentes
Desde un punto de vista general, se puede definir a un agente como “... todo aquello que puede considerarse que percibe su ambiente mediante sensores y que responde y act´ua en tal ambiente por medio de efectores” [7]. Otra definici´on que podemos dar para agente es “... un sistema computacional que est´a situado en alg´un ambiente, y que es capaz de acci´on aut´onoma en este ambiente para alcanzar sus objetivos de dise˜no” [10].
Adem´as de cumplir con la descripci´on anterior, un agente inteligente debe cumplir con ciertos requisitos extra, como la reactividad (que el agente pueda responder a los est´ımulos a tiempo para dar una respuesta efectiva), proactividad (el agente presenta comportamiento dirigido a metas y toma la iniciativa para lograr sus objetivos), y sociabilidad (los agentes inteligentes son capaces de interactuar con otros agentes para satisfacer sus objetivos).
2.2.
Sistemas Multiagentes
A pesar de que una soluci´on centralizada es la mayor´ıa de las veces m´as eficiente que una distribuida, la computaci´on distribuida es a veces m´as f´acil de entender y desarrollar, especialmente cuando el problema a resolver es distribuido por s´ı mismo. En ocasiones una soluci´on centralizada es imposible porque los datos y los sistemas pertenecen a organizaciones independientes que quieren mantener su informaci´on privada y a salvo.
La informaci´on involucrada es necesariamente distribuida en estos casos, y residen en sistemas de informaci´on que son grandes y complejos en varios sentidos: (1) pueden estar
ogr´aficamente distribuidos, (2) pueden tener muchos componentes, (3) pueden tener grandes cantidades de contenido, tanto en conceptos como en datos, y (4) pueden tener un ´ambito am-plio. Tambi´en, los componentes de los sistemas son t´ıpicamente distribuidos y heterog´eneos. La topolog´ıa de estos sistemas es din´amica y su contenido cambia tan r´apidamente que es dif´ıcil para un usuario o un programa de aplicaci´on obtener informaci´on correcta, o para la empresa mantener la informaci´on consistente.
Hay cuatro t´ecnicas principales para tratar con sistemas de este tama˜no y complejidad: modularidad, distribuci´on, abstracci´on e inteligencia[10]. El uso de m´odulos distribuidos inteligentes combina las cuatro t´ecnicas, proporcionando un acercamiento a Inteligencia Ar-tificial Distribuida.
De acuerdo con este acercamiento, los agentes computacionales necesitan estar distribui-dos e integradistribui-dos a trav´es de la empresa. Los agentes pueden funcionar como programas de aplicaci´on inteligentes, recursos de informaci´on activos,wrappers que envuelven y almacenan componentes convencionales, y servicios de red en l´ınea. Los agentes deben conocer los re-cursos de informaci´on que son locales a ellos y cooperan para proveer acceso global, y mejor administraci´on de la informaci´on. Por razones pr´acticas en sistemas que son muy grandes y din´amicos para formular e implementar soluciones globales, los agentes deben ejecutarse aut´onomamente y desarrollarse independientemente.
La raz´on de interconectar agentes y sistemas expertos es la de permitirles cooperar en la soluci´on de problemas, compartir experiencias, trabajar en paralelo en problemas comunes, desarrollar e implementar modularidad, tolerar las fallas a pesar de la redundancia, repre-sentar m´ultiples puntos de vista y el conocimientos de m´ultiples expertos, y ser reusable. Podemos decir pues, que los sistemas multiagentes son aquellos en que los procesos inter-act´uan para lograr sus objetivos.
Los sistemas multiagentes son la mejor forma de tipificar o dise˜nar sistemas computa-cionales distribuidos. El procesamiento de informaci´on es ubicuo.
Los ambientes multiagentes proveen una infraestructura especificando protocolos de co-municaci´on e interacci´on. Asimismo contienen agentes que son aut´onomos y distribuidos, y pueden ser ego´ıstas o cooperativos.
Un ambiente multiagentes tiene ciertas caracter´ısticas que los agentes deben conocer para poder interactuar en ´el. Tales caracter´ısticas, como implementaci´on de autonom´ıa, infraestructura de comunicaci´on y protocolo de mensajes, se enlistan en la Tabla 2.1 con los posibles valores que pueden tener[10].
2.3.
Plataformas de Desarrollo para Sistemas
Multia-gentes
Propiedad Rango de Valores Dise˜no de Autonom´ıa Plataforma
Protocolo de Interacci´on Lenguaje
Arquitectura Interna Infraestructura de
Comuni-caci´on
Memoria compartida o basado en mensajes Conectados o Desconectados (correo elect.) Punto a Punto, Multicast o Broadcast Push o Pull
S´ıncrono o As´ıncrono
Servicio de Directorio P´aginas Blancas, P´aginas Amarillas Protocolo de Mensajes KQLM, FIPA ACL
HTTP y HTML
OLE, CORBA, DSOM
[image:26.612.80.529.71.308.2]Servicios de mediaci´on Basado en Ontolog´ıa o por Transacciones Servicios de Seguridad Por fecha y hora / Autentificaci´on
Tabla 2.1: Caracter´ısticas de Agentes Multiagentes
multiagentes. A continuaci´on se describe una plataforma de este tipo que ha sido empleada para implementar la fase inicial del proyecto JITIK.
2.3.1.
JADE
JADE (Java Agent DEvelopment Framework)[15] es un infraestructura o esqueleto de software totalmente implementado en Java. Su meta es simplificar el desarrollo de sistemas multiagentes mientras asegura la compatibilidad con los est´andares a trav´es de un conjunto de servicios de sistemas y agentes compatibles con la especificaci´on FIPA: servicio de nom-bres y p´aginas amarillas, transporte de mensajes y servicio de traducci´on, y una librer´ıa de protocolos de interacci´on de FIPA listos para usarse.
La plataforma de agentes FIPA cumple con las especificaciones FIPA e incluye todos los componentes b´asicos para administrar la plataforma, esto es el ACC, el AMS y el DF. Toda la comunicaci´on de agentes es realizada a trav´es de la traducci´on de mensajes, donde FIPA ACL es el lenguaje para representar mensajes. La plataforma de agentes puede distribuirse en varios hosts. S´olo una aplicaci´on Java, y por lo tanto al M´aquina Virtual de Java, es ejecutada en cada host. Cada m´aquina virtual es b´asicamente un contenedor de agentes que provee un entorno de ejecuci´on para la ejecuci´on de agentes y permite a varios agentes concurrentemente ejecutarse en el mismo host.
La arquitectura de comunicaci´on ofrece un servicio de mensajes flexible y eficiente, donde JADE crea y administra una cola de mensajes ACL, privada para cada agente; los agentes pueden acceder su cola a trav´es de una combinaci´on de varios modos:blocking,polling,timeout
finalmente, protocolos de transporte.
B´asicamente, los agentes son implementados con un hilo por agente, pues los agentes frecuentemente necesitan ejecutar tareas paralelas. Adem´as de la soluci´on multihilo de Java, JADE soporta tambi´en la programaci´on de comportamientos cooperativos, donde JADE or-ganiza esas tareas en una forma ligera y eficiente. Entre otras cosas, JADE permite completa integraci´on con JESS, donde JADE provee el cascar´on del agente y garantiza compatibili-dad con FIPA, mientras que JESS es el motor del agente que realiza todo el razonamiento necesario.
[image:27.612.94.474.255.507.2]La plataforma de agentes provee una interfaz gr´afica para administraci´on remota, moni-toreo y control del status de los agentes, permitiendo, por ejemplo, detener y rearrancar los agentes. La interfaz, mostrada en la Figura 2.1, tambi´en permite crear e iniciar la ejecuci´on de un agente en un host remoto, siempre que el contenedor est´a andando.
Figura 2.1: Interfaz de JADE
Se puede usar la interfaz para el Facilitador de Directorios (DF) e interactuar con ´el: viendo la descripci´on de los agentes registrados, registrando y desregistrando agentes, modi-ficando la descripci´on de agentes, y buscando agentes por su descripci´on. La interfaz permite tambi´en unir el DF con otros DFs y crear una compleja red de dominios y subdominios de p´aginas amarillas.
El agente Sniffer permite rastrear los mensajes intercambiados en la plataforma JADE. Cuando el usuario decide monitorear un agente, o un grupo de agentes, cada mensaje dirigido a o proveniente de ese agente, o grupo, es registrado y mostrado en una ventana.
El agente Introspector permite monitorear y controlar el ciclo de vida de un agente en ejecuci´on y sus mensajes intercambiados, tanto la cola de mensajes enviados como de recibidos.
2.4.
Ontolog´ıas
Sowa[22], ubica a las ontolog´ıas en el estudio de las categor´ıas de las cosas que existen o pueden existir en alg´un dominio, y las define como cat´alogos de tipos de cosas que se asume existen en un dominio de inter´es D desde la perspectiva de una persona que usa un lenguaje L con el prop´osito de hablar de D. Una ontolog´ıa proporciona estructuras para definir conceptos y relaciones.
Otra definici´on de Ontolog´ıa la podemos encontrar en [9] como “... el entendimiento compartido de alg´un dominio de inter´es que puede ser usado como un esquema unificador para resolver problemas...”.
Las ontolog´ıas se pueden ocupar para reducir o eliminar confusi´on conceptual o termi-nol´ogica y lograr un entendimiento compartido[9]. De ah´ı que sirven de base para:
Comunicaci´on entre personas con diferentes necesidades y puntos de vista provenientes de sus diferentes contextos.
Interoperabilidad entre sistemas gracias a la traducci´on entre diferentes m´etodos de modelaci´on, paradigmas, lenguajes y herramientas de software.
Beneficiar la Ingenier´ıa de Sistemas, proporcionando reutilizaci´on, confiabilidad y una correcta especificaci´on del sistema.
Sowa plantea la necesidad de compartir conocimiento e identifica algunos problemas: “Diferentes sistemas pueden usar diferentes nombres para el mismo tipo de entidades; a´un peor, pueden usar los mismos nombres para diferentes cosas. Algunas veces dos entidades con diferentes definiciones son consideradas la misma, pero la tarea de probar que en realidad son la misma puede ser dif´ıcil, si no es que imposible.”[22]
Las representaciones de ontolog´ıas procesables por m´aquinas ser´an cruciales en aplica-ciones como: M´aquinas de b´usqueda, Comercio electr´onico y Administraci´on de conocimien-to.
2.5.
Formato de Representaci´
on de Ontolog´ıas
2.5.1.
XML
XML son las siglas de EXtensible Markup Language (Lenguaje Extendible de Marcaci´on) el cual es un lenguaje muy similar a HTML, pero a diferencia de HTML que fue dise˜nado s´olo para presentar datos, XML fue dise˜nado para describir datos. Las etiquetas o tags no est´an predefinidos, sino por el contrario, deben ser definidos o creados por quien las usa. Adicionalmente se puede validar un archivo XML con una Definici´on de Tipo de Documento (DTD) o con un Esquema XML (XML Schema).
La especificaci´on de XML fu´e creada por el World Wide Web Consortium (W3C)[19], una corporaci´on internacional creada para desarrollar tecnolog´ıas interoperables (especificaciones, gu´ıas, software y herramientas) que eleven al Web a su m´aximo potencial como un foro de informaci´on, comercio, comunicaci´on y entendimiento colectivo.
La forma de trabajo de W3C es por medio de comit´es o grupos de trabajos en ´areas espec´ıficas que se encargan de publicar Recomendaciones que son el resultado del trabajo de consenso en la W3C y que tienen el sello de aprobaci´on del Director.
La primera recomendaci´on de XML es la versi´on 1.0, publicada en Febrero de 1998 por la W3C y junto con la recomendaci´on de Namespaces[28] (´ambitos XML) publicada en Enero de 1999, constituye la especificaci´on base de XML. Actualmente ya se puede encontrar una segunda edici´on de la versi´on 1.0 de XML[27].
XML puede separar datos de HTML, de forma que la informaci´on que deseemos desplegar en HMTL provenga de archivos XML independientes, o inclusive, se encuentre en la misma p´agina HTML como una “isla de datos”.
Son varios los usos que se pueden dar al formato XML, entre los cuales tenemos:
Intercambio de Datos entre sistemas incompatibles.
En B2B, como lenguaje para el intercambio de informaci´on financiera entre negocios a trav´es de Internet.
Es una forma independiente de Hardware y Software para compartir datos.
Para almacenar datos en simple texto, sin la formalidad de un manejador de base de datos.
Para crear nuevos lenguajes.
Un ejemplo
El siguiente ejemplo muestra la forma en la que se podr´ıa representar una nota. En esta nota Pepe le recuerda a Juan que lleve el bal´on al partido.
1 <?xml version="1.0"?> 2 <nota fecha="07/01/2002"> 3 <para>Juan</para>
4 <de>Pepe</de>
En este ejemplo podemos observar los elementos de un archivo XML. La primera l´ınea define la versi´on de XML del documento. La siguiente l´ınea describe el elemento ra´ız del documento (nota), que tiene como atributo la fecha de la nota. Las siguientes cuatro l´ıneas describen los elementos hijos del ra´ız. La ´ultima l´ınea contiene la etiqueta de cierre del elemento ra´ız.
Sintaxis
Las reglas sint´acticas de XML son muy simples y muy estrictas. A continuaci´on se men-cionan dichas reglas:
Todos los elementos XML deben tener una etiqueta de cierre.
Las etiquetas XML son sensibles a may´usculas y min´usculas.
Todos los elementos deben estar apropiadamente anidados.
Todos los documentos deben tener una etiqueta ra´ız.
Los valores de los atributos deben siempre estar entre comillas.
Los espacios en blanco se conservan en XML, a diferencia de HTML donde se eliminan.
Elementos
Se dice que un documento XML es extensible pues se le pueden agregar elementos sin provocar que una aplicaci´on que lo utilice termine abruptamente, siempre y cuando los elementos que utilizaba originalmente sigan presentes en el documento.
Las relaciones que se pueden dar entre los elementos de un documento XML son de tres tipos: padre, hijo o hermano. Una etiqueta que agrupa a otras se dice que es padre de ´estas, mientras que las etiquetas anidadas se dice que son hijas de la etiqueta que las agrupa; a su vez, las etiquetas anidadas son hermanas entre si.
Todo aquello agrupado entre las etiquetas de inicio y cierre de un elemento XML se conoce como contenido, y puede ser de varios tipos. El contenido puede ser otros elementos, simple (solo texto), mixto (texto y otros elementos) o vac´ıo. Los elementos tambi´en pueden tener atributos.
Los nombres de los elementos pueden tener letras, n´umeros o signos de puntuaci´on pero tienen que empezar con letra, y no deben contener al inicio la palabra xml ni espacios en medio.
Validaci´on
Se dice que un documento XML est´a bien formado cuando est´a sint´acticamente bien escrito. Adem´as podemos decir que un documento XML es v´alido si est´a escrito conforme a un DTD (Document Type Definition).
El prop´osito de un DTD es definir los bloques de construcci´on legales de un documento XML. Define la estructura con una lista de elementos legales.
La W3C soporta una alternativa a DTD llamada XML Schema, que aunque se creo con el mismo prop´osito, tiene entre otras ventajas la de estar escrito en XML, con los beneficios que ello implica.
´
Ambitos o Referencias
Con el prop´osito de evitar conflictos de nombres en los documentos XML, se crearon los ´ambitos XML (XML Namespaces). Estos ´ambitos funcionan agregando un prefijo a las etiquetas de los documentos.
Por ejemplo, en el texto a continuaci´on, se ha agregado el prefijo “h” a todas las etiquetas, con lo cual se puede identificar que elementotabley todos sus hijos pertenecen a dicho ´ambito.
<h:table xmlns:h="http://www.w3.org/TR/html4/"> <h:tr>
<h:td>Apples</h:td> <h:td>Bananas</h:td> </h:tr>
</h:table>
El atributo del ´ambito (xmlns) se agrega en el elemento inicial del elemento. Su sintaxis es:
xmlns:prefijo="nombre_´ambito"
El nombre del ´ambito puede ser cualquier texto ´unico, sin embargo, se utiliza por lo general una direcci´on web (URL) donde se pueda encontrar informaci´on del ´ambito referido. Tambi´en se puede definir un ´ambito por omisi´on, lo cual nos ahorra el tener que poner prefijos a todos los elementos hijos. Su sintaxis es:
<element xmlns="nombre_´ambito">
2.5.2.
RDF
RDF proporciona interoperabilidad entre aplicaciones que intercambian informaci´on le-gible por m´aquina en la Web. RDF destaca por la facilidad para habilitar el procesamiento automatizado de los recursos Web. RDF puede utilizarse en distintas ´areas de aplicaci´on; por ejemplo: en recuperaci´on de recursos para proporcionar mejores prestaciones a los mo-tores de b´usqueda, en catalogaci´on para describir el contenido y las relaciones de contenido disponibles en un sitio Web, una p´agina Web, o una biblioteca digital particular, por los agentes de software inteligentes para facilitar el intercambio y para compartir conocimiento; en la calificaci´on de contenido, en la descripci´on de colecciones de p´aginas que representan un “documento”l´ogico individual, para describir los derechos de propiedad intelectual de las p´aginas web, y para expresar las preferencias de privacidad de un usuario, as´ı como las pol´ıticas de privacidad de un sitio Web. RDF junto con las firmas digitales ser´a la clave para construir el ”Web de confianza”para el comercio electr´onico, la cooperaci´on y otras aplicaciones.
RDF es una recomendaci´on de W3C y se describe en dos documentos: La Especificaci´on de Sintaxis y Modelo[20], y la Especificaci´on del Esquema[21]. El primer documento se centra en aspectos sint´acticos mientras que el segundo se encamina a la necesidad de un vocabulario (esquema).
El modelo RDF
La base de RDF es un modelo para representar nombres de propiedades y valores de propiedades. Se puede pensar en propiedades RDF como atributos de recursos y en este sentido corresponde al tradicional par atributo-valor. El modelo de datos b´asico consiste de tres tipos de objetos:
Recursos Todas las cosas descritas por expresiones RDF son llamadas recursos. Un recurso puede ser una p´agina web, una parte de ella o un elemento espec´ıfico en el documento fuente, entre otros. Un recurso puede ser tambi´en un objeto que no est´e accesible en el Web. Los recursos se designan siempre por URIs mas identificadores de anclas opcionales. Cualquier cosa puede tener un URI; la extensibilidad de URIs permite la introducci´on de
identificadores para cualquier entidad imaginable.
Propiedades Una propiedad es un aspecto espec´ıfico, caracter´ıstica, atributo, o relaci´on utilizado para describir un recurso. Cada propiedad tiene un significado espec´ıfico, define sus valores permitidos, los tipos de recursos que puede describir, y sus relaciones con otras propiedades.
Sujeto (Recurso) http://www.w3.org/Home/Lassila Predicado (Propiedad) Creador
Objeto (literal) “Ora Lassila”
Tabla 2.2: Partes de una Sentencia B´asica
Un Ejemplo
Consid´erese como ejemplo simple la siguiente sentencia (cuyos elementos se desglosan en la Tabla 2.2):
Ora Lassila es el creador del recurso http://www.w3.org/Home/Lassila.
En este documento podr´ıamos representar gr´aficamente una sentencia RDF usando gr´afi-cos etiquetados (tambi´en denominados “diagramas de nodos y argr´afi-cos”). En estos gr´afigr´afi-cos, los nodos (dibujados como ´ovalos) representan recursos y los arcos representan propiedades. Los nodos que representan cadenas de literales pueden dibujarse como rect´angulos. La sentencia citada anteriormente se representar´ıa gr´aficamente como se muestra en la Figura 2.2:
Figura 2.2: Diagrama de nodo y arcos simple
Sintaxis
La especificaci´on de RDF utiliza XML como su sintaxis de intercambio. RDF necesita tambi´en de los namespaces XML para asociar con precisi´on cada propiedad con el esquema que define dicha propiedad.
Esta especificaci´on define dos sintaxis XML para codificar una instancia (objeto espec´ıfico de una categor´ıa) de modelo de datos. La sintaxis serializada expresa las capacidades totales del modelo de datos de una forma muy regular. La sintaxis abreviada incluye t´erminos adicionales que proporcionan una forma m´as compacta para representar un subconjunto del modelo de datos. Los int´erpretes de RDF se han anticipado a implementar ambas sintaxis, la serializada completa y la abreviada.
[1] RDF ::= [’<rdf:RDF>’] description* [’</rdf:RDF>’]
[2] description ::= ’<rdf:Description’ idAboutAttr? ’>’ propertyElt* ’</rdf:Description>’
[3] idAboutAttr ::= idAttr | aboutAttr
[4] aboutAttr ::= ’about="’ URI-reference ’"’ [5] idAttr ::= ’ID="’ IDsymbol ’"’
[6] propertyElt ::= ’<’ propName ’>’ value ’</’ propName ’>’ | ’<’ propName resourceAttr ’/>’
[7] propName ::= Qname
[8] value ::= description | string
[9] resourceAttr ::= ’resource="’ URI-reference ’"’ [10] Qname ::= [ NSprefix ’:’ ] name
[11] URI-reference ::= string, interpreted per [URI] [12] IDsymbol ::= (any legal XML name symbol) [13] name ::= (any legal XML name symbol) [14] NSprefix ::= (any legal XML namespace prefix)
[15] string ::= (any XML text, with "<", ">", and "&" escaped)
El ejemplo presentado se traduce en RDF/XML como:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila"> <s:Creator>Ora Lassila</s:Creator>
</rdf:Description> </rdf:RDF>
Aqu´ı el prefijo del namespace s se refiere a un prefijo espec´ıfico elegido por el autor de esta expresi´on RDF y est´a definido en una declaraci´on XML del namespace como ´esta:
xmlns:s="http://description.org/schema/"
El documento XML completo que contiene la descripci´on citada anteriormente, podr´ıa ser:
<?xml version="1.0"?> <rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:s="http://description.org/schema/">
<rdf:Description about="http://www.w3.org/Home/Lassila"> <s:Creator>Ora Lassila</s:Creator>
</rdf:Description> </rdf:RDF>
[2a] description ::= ’<rdf:Description’ idAboutAttr? propAttr* ’/>’ | ’<rdf:Description’ idAboutAttr? propAttr* ’>’
propertyElt* ’</rdf:Description>’ | typedNode
[6a] propertyElt ::= ’<’ propName ’>’ value ’</’ propName ’>’ | ’<’ propName resourceAttr? propAttr* ’/>’ [16] propAttr ::= propName ’="’ string ’"’
(with embedded quotes escaped)
[17] typedNode ::= ’<’ typeName idAboutAttr? propAttr* ’/>’ | ’<’ typeName idAboutAttr? propAttr* ’>’
property* ’</’ typeName ’>’
Otro ejemplo para representar en RDF podr´ıa ser la frase:
El individuo al que se refiere el identificador de empleado id 85740 se llama Ora Lassila y tiene la direcci´on de correo lassila@w3.org. Ese individuo cre´o el recurso http://www.w3.org/Home/Lassila
se escribe en RDF/XML utilizando la sintaxis serializada completamente como:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:s="http://description.org/schema/">
<rdf:Description about="http://www.w3.org/Home/Lassila"> <s:Creator>
<rdf:Description about="http://www.w3.org/staffId/85740"> <rdf:type resource="http://description.org/schema/Person"/> <v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email> </rdf:Description>
</s:Creator> </rdf:Description> </rdf:RDF>
y utilizando la forma abreviada, as´ı:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila"> <s:Creator>
<s:Person about="http://www.w3.org/staffId/85740"> <v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email> </s:Person>
Contenedores
RDF define tres tipos de objetos contenedores: Bag (lista no ordenada de recursos o literales),Sequence (lista ordenada de recursos o literales) yalternative (una lista de recursos o literales que representan alternativas para el valor de una propiedad). La sintaxis de los contenedores RDF toma la siguiente forma:
[18] container ::= sequence | bag | alternative
[19] sequence ::= ’<rdf:Seq’ idAttr? ’>’ member* ’</rdf:Seq>’ [20] bag ::= ’<rdf:Bag’ idAttr? ’>’ member* ’</rdf:Bag>’ [21] alternative ::= ’<rdf:Alt’ idAttr? ’>’ member+ ’</rdf:Alt>’ [22] member ::= referencedItem | inlineItem
[23] referencedItem ::= ’<rdf:li’ resourceAttr ’/>’ [24] inlineItem ::= ’<rdf:li>’ value ’</rdf:li>’
Los contenedores pueden ser usados donde sea que una descripci´on (Description) sea permitida:
[1a] RDF ::= ’<rdf:RDF>’ obj* ’</rdf:RDF>’
[8a] value ::= obj | string
[25] obj ::= description | container
RDF utiliza el atributoaboutEach para hacer referencia acerca de cada uno de los miem-bros de un objeto contenedor:
[3a] idAboutAttr ::= idAttr | aboutAttr | aboutEachAttr [26] aboutEachAttr ::= ’aboutEach="’ URI-reference ’"’
Por ejemplo, en el siguiente c´odigo se dice que “Ora Lassila”es el Creador (Creator) de cada una de los objetos del contenedorpages:
<rdf:Bag ID="pages">
<rdf:li resource="http://foo.org/foo.html" /> <rdf:li resource="http://bar.org/bar.html" /> </rdf:Bag>
<rdf:Description aboutEach="#pages"> <s:Creator>Ora Lassila</s:Creator> </rdf:Description>
2.5.3.
RDFS
Compa˜n´ıas, etc.). En la especificaci´on de RDFS se especifican los mecanismos requeridos para definir elementos descriptivos de un vocabulario, para nombrar las clases de recursos con los que pueden ser usados, para restringir posibles combinaciones de clases y relaciones, y para ayudar a detectar violaciones de esas restricciones. Es decir, se trata de un lenguaje de descripci´on de vocabulario.
Es decir, el mecanismo de Esquemas RDF provee un sistema b´asico de tipos para usarse en modelos RDF. Define recursos y propiedades tales comordfs:Class yrdfs:subClassOf que son usados al especificar esquemas espec´ıficos de aplicaciones.
El lenguaje de especificaci´on de esquema es un lenguaje de representaci´on declarativa influenciado por ideas de representaci´on de conocimiento (por ejemplo, redes sem´anticas, marcos o frames, l´ogica de predicados) as´ı como de lenguajes de especificaci´on de esquemas en bases de datos (por ejemplo, NIAM) y modelos de datos en grafos. El lenguaje de especi-ficaci´on de esquema RDF es menos expresivo, pero mucho m´as simple de implementar, que los lenguajes de c´alculo de predicados completos tales como Cycl y KIF.
Elementos de RDFS
Los principales clases que contiene RDFS son:
rdfs:Resource Todas las cosas descritas por RDF, denominadasrecursos.
rdf:Property Representa una propiedad.
rdfs:Class Corresponde al concepto gen´erico de Tipo o Categor´ıa, similar a la noci´on de
Clase en lenguajes de programaci´on orientados a objetos. Las clases RDF pueden ser representadas para definir casi cualquier cosa, tal como p´aginas web, personas, tipos de documentos, bases de datos o conceptos abstractos.
Todo modelo RDF que use el mecanismo de esquemas (impl´ıcitamente) incluye las sigu-ientes propiedades principales. Estas son instancias de la clase rdf:Property y proveen un mecanismo para expresar relaciones entre clases y sus instancias de superclases.
rdf:type Indica que un recurso es miembro de una clase, y por esto, tiene todas las carac-ter´ısticas esperadas en un miembro de esa clase. Cuando un recurso tiene una propiedad rdf:type cuyo valor es de una clase espec´ıfica, decimos que el recurso es unainstancia
de la clase especificada. Un recurso puede ser una instancia de m´as de una clase.
rdf:rdfs:subClassOf Esta propiedad especifica una relaci´on de subconjunto/superconjunto entre clases. Es transitiva, esto es, si A es subclase de B y B es subclase de C, entonces A tambi´en es impl´ıcitamente subclase de C. Consecuentemente, recursos que son ins-tancias de A tambi´en ser´an insins-tancias de C, dado que A es un subconjunto tanto de B como de C. Una clase puede ser subclase de m´as de una clase.
P2 con un valor B, esto implica que el recurso A tambi´en tiene una propiedad P1 con el valor B.
Un esquema RDF puede declarar restricciones asociadas con clases y propiedades. En par-ticular, los conceptos de dominio y rango son usados en esquemas RDF para hacer sentencias acerca del contexto en el cual ciertas propiedades “tienen sentido”. Un modelo RDF que viole cualquiera de las restricciones de consistencia se dice que es un modelo inconsistente. Las principales restricciones son:
rdfs:ConstraintResource Este recurso define una subclase de rdfs:Resource cuyas instan-cias son construcciones de esquemas RDF envueltas en la expresi´on de restricciones. El prop´osito de esta clase es proveer un mecanismo que permita a los procesadores de RDF evaluar sus habilidades para verificar el modelo de consistencia de un modelo RDF.
rdfs:ConstraintProperty Este recurso define una subclase de rdf:Property; todas sus ins-tancias son propiedades usadas para especificar restricciones.
rdfs:range Es una instancia de rdfs:ConstraintProperty que es usada para restringir los valores de una restricci´on. El valor de una propiedad de rango es siempre una clase. El valor de una propiedad cuyo rango es A est´a restringida a ser una instancia de la clase A. Una propiedad puede tener a lo m´as una propiedad range. Es posible que no tenga rango, en cuyo caso la clase del valor de la propiedad no est´a restringida.
rdfs:domain Una instancia de rdfs:ConstraintProperty que es usada para especificar una clase en la cual una propiedad puede ser usada. Una propiedad puede tener cero, una o m´as clases como dominio. Si no se define una propiedad dominio, se puede usar con cualquier recurso. Si hay exactamente una propiedad dominio, s´olo puede ser usado en instancias de esa clase. Si hay m´as de una propiedad dominio, la propiedad restringida puede ser usada con instancias de cualquiera de esas clases (que son valores de las propiedades domain).
RDFS permite agregar documentaci´on multiling¨ue de los esquemas a nivel sint´actico a trav´es del uso de la facilidad xml:lang. Con rdfs:comment se puede agregar una descripci´on del recurso, mientras que con rdfs:label se incluye una versi´on legible del nombre del recurso.
2.5.4.
OIL
OIL (Ontology Interchange Language), sintetiza el trabajo de tres diferentes comunidades con el prop´osito de proveer un lenguaje de prop´osito general basado basado en etiquetas. Usa sistemas basados en marcos, l´ogica descriptiva y est´andares Web (XML y RDF)[6].
Por parte de los lenguajes basados en marcos, tiene como primitivas centrales de mod-elaci´on clases (conocidas como frames) con propiedades (conocidas como slots). Gracias a esto se pueden modelar clases y subclases utilizando propiedades definidas como pares de valores para especificar restricciones adicionales o instancias de una nueva clase.
cual permite el razonamiento con descripciones de conceptos y la derivaci´on autom´atica de taxonom´ıas de clasificaci´on. OIL hereda de la l´ogica descriptiva ambas caracter´ısticas.
OIL tiene una sintaxis bien definida en XML basada en definiciones de tipos de docu-mentos (DTD) y una definici´on de esquema XML. Adem´as, OIL est´a definido como una extensi´on de RDF (Resource Description Framework)[16] y su lenguaje de definici´on de es-quemas RDFS. RDFS provee dos contribuciones importantes: un conjunto de primitivas de modelaci´on tales como las relaciones instance-of (instancia-de) y subclass-of (subclase-de), y una sintaxis estandarizada para escribir jerarqu´ıas de clases. Tanto XML como RDF son est´andares definidos por W3C.
2.5.5.
DAML
El programa DARPA Agent Markup Language (DAML)[14] es un esfuerzo del gobier-no de EUA para proveer una base para la pr´oxima evoluci´on Web, la Web sem´antica. Su objetivo es crear lenguajes, herramientas y t´ecnicas que hagan el contenido m´as entendible por m´aquinas. Participan investigadores acad´emicos, agencias de gobierno, compa˜n´ıas de software, y organizaciones comerciales como el World Wide Web Consortium.
DARPA inici´o trabajos en el verano del 2000 y siguen trabajando en ello. Planean entregar el lenguaje en dos porciones: un lenguaje de ontolog´ıas (DAML-ONT) y posteriormente DAML-Logic. El lenguaje de ontolog´ıa ha ido evolucionando y ha sido sometido a revisiones, dando como resultado que a la fecha la versi´on m´as reciente sea DAML+OIL en su versi´on de diciembre del 2000.
DAML hereda muchos aspectos de OIL y las capacidades de ambos lenguajes son relati-vamente similares. Ambos:
soportan jerarqu´ıas de clases y propiedades basadas en subclases y relaciones de sub-propiedades;
permiten construir clases a partir de otras clases usando combinaciones arbitrarias de intersecci´on (AND), uni´on (OR), y complemento (NOT);
permiten restringir el dominio, rango y cardinalidad.
soportan propiedades transitivas e inversas; y
soportan tipos de datos concretos (enteros, cadenas y m´as).
2.5.6.
DAML+OIL
DAML+OIL[29] es un lenguaje de marcaci´on sem´antica para recursos web. Est´a con-struido sobre est´andares anteriores de la W3C tales como RDF y RDF Esquema, y extiende estos lenguajes con primitivas de modelado m´as ricas. DAML+OIL provee primitivas de modelado com´unmente encontradas en lenguajes basados en marcos oframes. La versi´on de DAML+OIL de Marzo del 2001 extiende a la versi´on de Diciembre del 2000 con valores de tipos de datos de XML Esquema (XML Schema). Fue construido a partir del lenguaje de ontolog´ıas DAML (DAML-ONT) en un esfuerzo para combinar muchos de los componentes del lenguaje OIL. El lenguaje tiene una clara y bien definida sem´antica.
DAML+OIL incluye una secci´on de encabezado (header) con informaci´on de la versi´on y referencias a otras ontolog´ıas DAML+OIL que contienen t´erminos usados en esta ontolog´ıa. DAML+OIL divide el universo en dos partes disjuntas. Una parte consiste en los valores que pertenecen a los tipos de datos de XML Esquema. Esta parte es llamadadominio de tipos de datos. La otra parte consiste en objetos (individuos) que son considerados miembros de las clases descritas en DAML+OIL (o RDF). Esta parte es llamadadominio de objetos.
Clases
El elemento de clase, daml:Class, contiene (parte de) la declaraci´on de un objeto clase. Un elemento clase se identifica por un nombre de clase (un URI) y puede contener:
Cero o m´as elementos rdfs:subClassOf, indicando que la clase definida es subclase de la expresi´on de clase en el elemento daml:subClassOf.
Cero o m´as elementos daml:disjointWith, indicando que la clase es disjunta con la expresi´on de clase en el elemento.
Cero o m´as elementos daml:disjointUnionOf, indicando que la clase tiene las mismas instancias que la uni´on disjunta de los elementos de expresiones de clase.
Cero o m´as elementosdaml:sameClassAs odaml:equivalentTo, que indican que la clase es equivalente a la expresi´on de clase que aparece en el elemento.
Cero o m´as combinaciones boleanas de expresiones de clase. La clase debe ser equiva-lente a la clase definida por las expresiones boleanas.
Cero o m´as enumeraciones. Cada elemento de la enumeraci´on indica que la clase con-tiene exactamente las instancias enumeradas en el elemento (ni m´as, ni menos).
Unaexpresi´on de clase puede ser: el nombre de una clase (un URI), una enumeraci´on (entre tags<daml:Class>...</daml:Class>), una restricci´on de propiedad, o una
combi-naci´on booleana de expresiones de clases (entre tags <rdfs:Class>...</rdfs:Class>).
Una restricci´on de propiedad es un tipo especial de expresi´on de clase. Impl´ıcitamente define una clase an´onima, que identifica la clase de todos los objetos que satisfacen la re-stricci´on. Hay dos tipos de restricciones: ObjectRestriction, que trabaja sobre propiedades de objetos, y DatatypeRestriction, que trabaja sobre propiedades de tipos de datos. Am-bas usan la misma sintaxis. En el elemento daml:Restriction se puede especificar que la propiedad tenga un tipo de valor determinado: una clase (daml:toClass), o un tipo de dato (daml:hasValue). Tambi´en se puede especificar la cardinalidad de la propiedad: exactamente N valores distintos (daml:cardinality), a lo m´as N valores distintos (daml:maxCardinality), y a lo menos N valores distintos (daml:minCardinality).
Las combinaciones boleanas de expresiones de clase pueden construirse con elementos: daml:intersectionOf, para indicar que la clase consiste de exactamente todos los objetos que son comunes a todas las expresiones de una lista (conjunci´on l´ogica); daml:unionOf, para indicar que la clase consiste de exactamente todos los objetos que pertenecen al menos una de las expresiones de una lista (disyunci´on l´ogica); y daml:complementOf, que indica que la clase consiste exactamente de todos los objetos que no pertenecen a la expresi´on de clase (negaci´on l´ogica, pero restringida a objetos ´unicamente).
Propiedades
Una propiedad, definida con rdf:Property, puede estar relacionada con objetos (instancias de ObjectProperty) o con tipos de datos (instancias de DatatypeProperty). Una propiedad contiene:
Cero o m´as elementos rdfs:subPropertyOf, para indicar que la propiedad P es una subpropiedad de otra propiedad Q.
Cero o m´as elementosrdfs:domain, que indican que la propiedad P s´olo puede aplicarse a instancias de la clase C.
Cero o m´as elementosrdfs:range, que indica que P s´olo toma valores que son instancias de la expresi´on de clase se˜nalada.
Cero o m´as elementos daml:samePropertyAs o equivalentTo, para indicar que P es equivalente a otra propiedad.
Cero o m´as elementosdaml:inverseOf, para indicar que P es la relaci´on inversa de otra propiedad Q.
Tambi´en se pueden codificar informaci´on adicional de propiedades tal como: que la propiedad sea transitiva (daml:TransitiveProperty), que no puede haber dos instancias con el mismo valor en la propiedad (daml:UniqueProperty), o que no puede haber dos propiedades en la misma instancia con el mismo valor (daml:UnambigousProperty).
Instancias
<continent rdf:ID="Asia"/>
<rdf:Description rdf:ID="Asia"> <rdf:type>
<rdfs:Class rdf:about="#continent"/> </rdf:type>
</rdf:Description>
<rdf:Description rdf:ID="India"> <is_part_of rdf:resource="#Asia"/> </rdf:Description>
Valores de Tipos de Datos
Los valores especificados con un tipo de datos, o valores tipados, se escriben con una sem´antica especial en DAML+OIL. Usualmente se escribe el valor en una representaci´on de texto, junto con el tipo de dato correspondiente en XML Schema para as´ı poder hacer la transformaci´on al momento de interpretarlo. El tipo de dato XML Schema es el rdf:type del valor, y la representaci´on l´exica es el rdf:value del valor. As´ı, el valor decimal 10.5 pudr´ıa ser escrito como<xsd:decimal rdf:value=”10.5”>suponiendo que xsd fue definido como el URI
de la especificaci´on de Tipos de datos de XML Schema.
2.6.
Interpretaci´
on de Ontolog´ıas
Existen varias herramientas para administrar y explotar ontolog´ıas en los diferentes for-matos de los que se ha hablado hasta ahora. Hay diferentes alcances en cada una de ellas, desde las que simplemente interpretan un archivo RDF, hasta las que extraen las clases e instancias de un URL espec´ıfico y las almacenan en una base de datos objeto-relacional. A continuaci´on se presentan algunas herramientas que se consideran de utilidad para construir sobre ellas alg´un mecanismo de interpretaci´on de las ontolog´ıas.
2.6.1.
Toolkit Jena
Jena[30] es una librer´ıa Java para manipular modelos RDF. Comprende un n´umero de m´odulos entre con los cuales soporta varios formatos de traducci´on e impresi´on de datos RDF, m´etodos convenientes para manipular e interrogar datos RDF y facilitar la persistencia de dato RDF en una variedad de bases de datos. Incluye una librer´ıa para manipular ontolog´ıas DAML expresadas sobre RDF.
La librer´ıa RDF es el n´ucleo de Jena para manipular colecciones de sentencias RDF. Con-tiene m´etodos para manipular modelos RDF como conjuntos de sentencias o como recursos con propiedades. Incluye llamados a m´etodos en cascada y soporte para contenedores RDF. Tambi´en tiene soporte para leer y escribir en RDF/XML, N3[34] y NTriple[35].
independiente. Checa que los datos cumplan con est´andares y recomendaciones, incluyendo etiquetas de idioma y URIs internacionales.
RDQL[30] es una implementaci´on de un lenguaje de consulta similar a SQL pero para RDF. Trata RDF como datos y provee consultas con patrones de sentencias y restricciones sobre un modelo RDF. Se dise˜n´o para ser usado en scripts y para experimentaci´on en lengua-jes de modelaci´on de informaci´on. El lenguaje est´a derivado de SquishQL.
El m´odulo de Jena para DAML est´a construido sobre la API RDF y agrega soporte para procesar documentos DAML+OIL. Incluye m´etodos para acceder propiedades conocidas de clases y propiedades DAML+OIL. Asimismo, reconoce m´ultiples vocabularios (incluidas las versiones DAML+OIL de Diciembre del 2000 y Marzo del 2003, maneja relaciones de subclases y subpropiedades en consultas b´asicas, registra traductores para mapear entre tipos concretos en tipos de datos XSD y objetos de Java, procesa autom´aticamente las referencias a otras ontolog´ıas, y reconoce propiedades transitivas e inversas.
2.6.2.
RDFSuite de ICS-FORTH
El Institute of Computer Science (ICS), un instituto de investigaci´on de Foundation for Research and Technology - Hellas (FORTH) en Grecia, desarroll´o una suite de herramientas escalables y de alto nivel para validar, almacenar y consultar esquemas RDF y descripciones de recursos[23]. SuiteRDF se enfoca en la necesidad de administraci´on efectiva y eficiente de grandes vol´umenes de metadatos RDF tal como son requeridos por aplicaciones reales de Semantic Web. El desarrollo de RDFSuite ha sido apoyado en parte por proyectos de la uni´on europea como C-Web y MesMuses y est´a disponible bajo una licencia de de software de c´odigo libre[24].
El dise˜no de RDFSuite comprende: un parser para validar RDF (VRP), una base de datos espec´ıfica para esquemas (RSSDB) y un int´erprete para el lenguaje de consulta RDF (RQL).
Validating RDF Parser (VRP)
VRP[23] es una herramienta para analizar, validar y procesar esquemas RDF y descrip-ciones de recursos. El parser analiza sint´acticamente los enunciados de un archivo RDF o XML de acuerdo a la especificaci´on de Sintaxis y de Modelo de RDF. El Validador checa si los enunciados contenidos tanto en los esquemas RDF como en las descripciones de recur-sos satisfacen las restricciones sem´anticas derivados de RDFS. A diferencia de otros parsers RDF, VRP est´a basado en herramientas para generar compiladores en Java, llamadas CUP y JFlex, similares a LEX y YACC, permiti´endole esto parsear grandes vol´umenes de de-scripciones RDF r´apidamente. El m´odulo de validaci´on de VRP tiene una representaci´on de objetos que separa esquemas de sus instancias.
RDF Schema-Specific Data Base (RSSDB)
RSSDB[23] es un almacenamiento persistente de RDF que permite cargar descripciones de recursos en ´el, en un DBMS objeto-relacional (que cumpla con un SQL-3 ORDBMS[38]), explotando el conocimiento de esquemas RDF disponibles. Preserva la flexibilidad de RDF al refinar esquemas y enriquecer descripciones en cualquier momento, mientras que puede al-macenar descripciones de recursos creados de acuerdo a uno o m´as esquemas RDF asociados. La meta principal de dise˜no de RSSDB es la separaci´on del esquema RDF de la informaci´on, as´ı como la distinci´on entre relaciones unarias y binarias presentes entre las instancias de clases y propiedades, respectivamente.
RSSDB est´a implementado sobre un manejador ORDBMS PostgreSQL (v7.1.3). Com-prende un m´odulo de Carga y uno de Actualizaci´on, ambos implementados en Java usando un conjunto de primitivas (API) para insertar, borrar y modificar enunciados RDF. El acceso al ORDBMS se hace a trav´es de una interfaz JDBC[37] (v2.0) para interoperar con varios ORDBMS de dominio p´ublico o comercial. La caracter´ıstica m´as distintiva de RSSDB es la personalizaci´on de la representaci´on en la base de datos de acuerdo a los meta esque-mas empleados (RDF/S, DAML+OIL), las peculiaridades de los esqueesque-mas RDF y las bases descriptivas as´ı como la funcionalidad de las consultas previstas. Adem´as, el cargador RSSS-DB soporta la carga incremental de namespaces distribuidos al detectar autom´aticamente cambios en esquemas RDF o datos ya almacenados.
RDF Query Language Interpreter (RQL)
RQL[23] es un lenguaje de tipos que sigue un modelo funcional (como en ODMG OQL o W3C XQuery). RQL descansa en un modelo de grafos formal (opuesto a otros lenguajes de consulta RDF basados en sentencias), que captura las primitivas de modelado RDF y permite la interpretaci´on de descripciones de recursos superpuestos por medio de uno o m´as esquemas en una variedad de contextos de aplicaci´on. La novedad de RQL consiste en su habilidad para combinar perfectamente consultas de esquemas y datos.
2.7.
Lenguajes de Consulta
Existen varios lenguajes de consulta para formatos de Semantic Web. La mayor´ıa de estos lenguajes que podr´ıan servir de referencia trabajan sobre estructuras de RDF y la codificaci´on de las consultas requiere por lo tanto tener nociones de dicho est´andar. A continuaci´on se presentan algunos lenguajes de consulta con sus elementos y sintaxis caracter´ısticos. Al final se describe con mayor detalle el soporte de JADE (ver secci´on 2.3.1) para manejo de ontolog´ıas.
2.7.1.
RDF Query Language (RQL)
RQL[31] es un lenguaje tipado, que siguiendo un enfoque funcional, define un conjunto de consultas b´asicas e iteradores. A continuaci´on se presentan los elementos m´as importantes del lenguaje, as´ı como algunos ejemplos de consultas.
Funciones
RQL define algunas funciones que le sirven para obtener resultados b´asicos de la on-tolog´ıa, al mismo tiempo que auxilian en la construcci´on de consultas m´as complejas. Dichas funciones pueden ejecutarse independientemente. A continuaci´on se presentan algunas de las m´as representativas:
subClassOf(c) Devuelve todas las subclases transitivas de c.
subClassOf ˆ(c) Devuelve todas las subclases directas de c.
superClassOf(c) Devuelve todas las superclases transitivas de c.
superClassOf ˆ(c) Devuelve todas las superclases directas de c.
subPropertyOf(p) Devuelve todas las subpropiedades transitivas de c.
subPropertyOf ˆ(p) Devuelve todas las subpropiedades directas de c.
superPropertyOf(p) Devuelve todas las superpropiedades transitivas de c.
superPropertyOf ˆ(p) Devuelve todas las superpropiedades directas de c.
subClassOf(c,n) Devuelve todas las subclases transitivas de c hasta el nivel n. Esta sintaxis aplica tambi´en para superClassOf, subPropertyOf y superPropertyOf.
topclass Devuelve el nodo ra´ız de la jerarqu´ıa de clases.
leafclass Devuelve los nodos hoja de la jerarqu´ıa de clases.
topproperty Devuelve el nodo ra´ız de la jerarqu´ıa de clases.
domain(p) Devuelve las clases del dominio de la propiedad p.
range(p) Devuelve las clases del rango de la propiedad p.
namespace(o) Devuelve el namespace del esquema o.
Class Devuelve todas las clases definidas.
Property Devuelve todas las propiedades definidas.
Consultas de Esquema
Siguiendo una sintaxis similar a la de SQL se pueden construir consultas como la siguiente:
SELECT $C1, $C2
FROM {$C1}creates{$C2}
que pregunta por el dominio y el rango de la propiedadcreates. El prefijo $ en el nombre de las variables denota variables de clases en el esquema. El resultado obtenido ser´ıa el producto cruz de las clases que pertenecen al dominio contra las que pertenecen al rango.
Si se desea conocer las propiedades definidas en la clase Painter, se hace una consulta como la siguiente:
SELECT @P
FROM {;Painter}@P
@P denota una variable de Propiedad.
Ahora bien, si se pregunta por los rangos de la propiedad exhibited que pueden ser alcanzados desde una clase en el rango de la propiedadcreates, se tendr´ıa:
SELECT $X, $Z
FROM creates{$X}, {$Y}exhibited{$Z} WHERE $X = $Y
Consultas de Descripciones o Instancias
Se puede preguntar por las instancias de la clase Artist con la siguiente pregunta:
SELECT X
FROM Artist{X}
Tambi´en se puede preguntar por las instancias que est´en relacionadas a trav´es del pred-icadocreates:
SELECT X, Y
FROM {X}creates{Y}
![Figura 1.1: Modelo Conceptual de JITIK[11]](https://thumb-us.123doks.com/thumbv2/123dok_es/4542090.39461/23.612.126.470.256.490/figura-modelo-conceptual-de-jitik.webp)