Algoritmo VMO continuo con topologías estructuradas
90
0
0
Texto completo
(2) Dictamen con derechos de autor para MFC. Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor ____________. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor ____________. Firma del jefe del Seminario____________.
(3) Pensamiento. No sientas que te falte nada salvo el corazón, recuerda que lo tienes todo si te alumbra el sol..
(4) Dedicatoria. A los que están de pie sobre la tierra y hacen de mi algo mejor, a mis muertos a los que tantas veces me encomendé en días de agonía..
(5) Agradecimientos. A tantas personas va dedicada esta página que no me aventuro a nombrarlas, por miedo a que al hurgar en la memoria se queden algunos, y para no pecar, me refugio en Machado cuando reza ¨conmigo vais mi corazón os lleva ¨..
(6) RESUMEN. Las meta-heurísticas poblacionales constituyen, en la actualidad, una poderosa herramienta para la solución de problemas complejos de optimización. Investigaciones han revelado que no existe la mejor de las meta-heurísticas para solucionar cualquier problema complejo, por lo que la búsqueda de nuevas estrategias en la exploración del espacio de búsqueda para una mejor calidad de las soluciones se ha convertido en un objetivo deseado. De manera que la presente investigación estará encaminada a implementar y validar un modelo basado en. una meta heurística poblacional, VMO, la cual será implementada siguiendo una. topología estructurada, con el objetivo de evitar estados de convergencia prematura o estancamiento. Las topologías a usar son: en un primer algoritmo, topologías con ksubpoblaciones sin solapamiento; mientras que en la segunda etapa topologías con ksubpoblaciones con solapamiento. Ambas con el objetivo de presentar un modelo más robusto. Los resultados de esta investigación son la obtención de distintas variantes VMO_TOP1 y VMO_TOP2 con mejor comportamiento que el modelo basado en VMO clásico..
(7) Resumen.
(8) Abstract. ABSTRACT Population meta-heuristics are currently a powerful tool in the solution of complex optimization problems. Some investigations have shown that there is not a best of metaheuristics for solving any complex problem. Therefore seeking for new strategies in the exploration of the search space in order to achieve a better quality in the solutions has become a desired goal. So this investigation will be focused in the implementation and validation of a model based in a population meta-heuristic, VMO, which will be implemented following a structured topology aiming to avoid premature convergence or stemming states. The used topologies are: in the first algorithm topologies with ksubpopulations without overlapping. While in a second stage we use topologies with ksubpopulations with overlapping. Both are used with the goal of presenting a more robust model. The results of this investigation allowed to obtain distinct variants VMO_TOP1 and VMO_TOP2 with a better performance than the classic VMO based model..
(9) Índice. TABLA DE CONTENIDOS INTRODUCCIÓN…………………………………………………………………………………………………………………………………..1 CAPÍTULO 1 MÉTODOS HEURÍSTICOS DE BÚSQUEDA…………………………………………………………………………..2 IMPORTANCIA DE LOS PROBLEMAS DE OPTIMIZACIÓN ........................................................................................... 3 MÉTODOS DE SOLUCIÓN DE PROBLEMAS ........................................................................................................... 4 META-HEURÍSTICAS…………………………………………………………………………………................................................8 Meta-heurísticas de trayectoria simple………………………………………………………………………………………12 Meta-heurísticas poblacionales………………………………………………………………………………………………….14 EJEMPLOS DE USO DE LAS META-HEURÍSTICAS EN PROBLEMAS REALES ................................................................... 17 Meta-heurísticas en la Logística Portuaria…………………………………………………………………………………17 Las redes de telecomunicaciones y las meta-heurísticas…………………………………………………………….18 Manejo de empresas de trasporte público de autobuses……………………………………………………………19 CONCLUSIONES PARCIALES............................................................................................................................ 19 CAPÍTULO 2 ALGORITMO VMO CON TOPOLOGÍA LOCAL……………………………………………………………………2 OPTIMIZACIÓN BASADA EN MALLAS VARIABLES ................................................................................................. 2 Descripción general de la meta heurística………………………………………………………………………………….3 Proceso de expansión…………………………………………………………………………………………………………………4 Proceso de contracción…………………………………………………………………………………………………..……….…7 TOPOLOGÍA DE VECINDAD EN PSO ................................................................................................................... 9 Modelo gbest y lbest………………………………………………………………………………………………………………….11 IMPLEMENTACIÓN DEL VMO CON TOPOLOGÍAS................................................................................................ 13 VMO local sin solapamiento………………………………………………………………………………………………………17 VMO local con solapamiento……………………………………………………………………………………………………..18 CONCLUSIONES PARCIALES............................................................................................................................ 19 CAPÍTULO 3 ANÁLISIS EXPERIMENTAL DE LOS RESULTADOS……………………………………………………………..2 ESPECIFICACIONES DEL EXPERIMENTO ............................................................................................................... 2 TÉCNICAS ESTADÍSTICAS………………………………………………………………………………………………………………………….16 Descripción de los tests estadísticos utilizados…………………………………………………………………………..17 MARCO EXPERIMENTAL………………………………………………………………………………………………………………………….18 ANÁLISIS DE LOS RESULTADOS DE LOS TEST ESTADÍSTICOS PARA LAS DISTINTAS VARIANTES DE DISEÑO .......................... 19 Dimensión 10……………………………………………………………………………………………………………………………..19 Dimensión 30……………………………………………………………………………………………………………………………..21.
(10) Índice Dimensión 50……………………………………………………………………………………………………………………………..23 CONCLUSIONES PARCIALES............................................................................................................................ 25 CONCLUSIONES…..…………………………………………………………………………………………………………………………….1 RECOMENDACIONES…………………………………………………………………………………………………………………………1 REFERENCIAS BIBLIOGRÁFICAS………………………………………………………………………………………………………….1 ANEXO A. TABLAS DE LOS VALORES OBTENIDOS PARA CADA UNA DE LAS FUNCIONES DE PRUEBA DEL CEC´2005 POR LOS MODELOS ESTUDIADOS……………………………………………………………………………………… .. 1.
(11) Índice. LISTA DE FIGURAS Figura 1.1 Clasificación de los problemas de optimización ............................................. 3 Figura 1.2 Encasillamiento de los algoritmos heurísticos en óptimos locales ................. 7 Figura 1.3 Meta-heurísticas de acuerdo a su inspiración .............................................. 11 Figura 1.4 Espacio de búsqueda ..................................................................................... 12 Figura 2.1 Esquema general de modelo VMO .................................................................. 9 Figura 2.2 (a) Topología de estrella (𝑔𝑏𝑒𝑠𝑡) (b) Topología de anillo (𝑙𝑏𝑒𝑠𝑡) .............. 11 Figura 2.3 Esquema de generación de subpoblaciones .................................................. 15 Figura 2.4 Esquema general de la topología estructurada ............................................ 16 Figura 2.5 Esquema del modelo VMO-Top1 .................................................................. 17 Figura 2.6 Proceso general de modelo VMO-Top1........................................................ 18 Figura 2.7 Esquema del modelo VMO-Top2 .................................................................. 18 Figura 2.8 Proceso general de modelo VMO-Top2........................................................ 19.
(12) Índice. LISTA DE TABLAS Tabla 1.1 Número de artículos por técnicas bio-inspiradas (Delgado, 2010) ............... 10 Tabla 3.1 Resultados para dimensión 10........................................................................ 19 Tabla 3.2 Mediana .......................................................................................................... 20 Tabla 3.3 Resultados del test de Wilcoxon para dimensión 10 ...................................... 21 Tabla 3.4 Resultados para dimensión 30........................................................................ 21 Tabla 3.5 Mediana .......................................................................................................... 23 Tabla 3.6 Resultados del test de Wilcoxon para dimensión 30 ...................................... 23 Tabla 3.7 Resultados para dimensión 50........................................................................ 24 Tabla 3.8 Mediana .......................................................................................................... 25 Tabla 3.9 Resultados del test de Wilcoxon para dimensión 50 ...................................... 25 Tabla A.1 Resultados del modelo VMO puro ................................................................... 1 Tabla A.2 Resultados del modelo VMO-Top1 .................................................................. 2 Tabla A.3 Resultados del modelo VMO-Top2 .................................................................. 3.
(13) Introducción. INTRODUCCIÓN. Los problemas de optimización continua desempeñan un papel esencial en la formulación de muchas situaciones de la vida real; partiendo de problemas clásicos hasta problemas más complejos que se abordan necesariamente desde la perspectiva de la Inteligencia Artificial. Algunos de estos problemas de optimización son relativamente fáciles de resolver como los problemas lineales (las restricciones y la función objetivo constituyen expresiones lineales) y otros no tan simples, los cuales por su propia naturaleza no pueden ser abordados mediante un procedimiento de búsqueda exhaustivo que obtenga la mejor solución tras una búsqueda por todo el dominio de posibles valores (Molina Cabrera, 2007). Debido a la gran complejidad que estos problemas han alcanzado, en la mayoría de las veces, la aplicación de un método exacto para su solución, se ha vuelto impracticable. Esto ha proporcionado el auge de los métodos heurísticos, vocablo este, que surge del griego heuriskein, que significa encontrar. Un método o procedimiento heurístico pudiera definirse entonces como (Martínez et al., 2006): “Un método heurístico es un procedimiento para resolver un problema complejo de optimización mediante una aproximación intuitiva, en la que la estructura del problema se utiliza de forma inteligente para obtener una buena solución de manera eficiente” Una de las principales desventajas de estos métodos, es que dependen en gran medida del problema para el cual fueron diseñados. Por esta razón surge un grupo de métodos bajo el nombre de meta-heurísticas, con el objetivo de obtener mejores soluciones que los heurísticos tradicionales para un mayor número de problemas con solo realizársele pequeñas modificaciones. En (Glover and Kochenberger, 2003) se definen los procedimientos meta-heurísticos como: “Los procedimientos meta heurísticos son una clase de métodos aproximados que están diseñados para resolver problemas complejos de optimización, en los que los heurísticos clásicos no son efectivos. Las metas heurísticas proporcionan un marco general para crear nuevos algoritmos híbridos combinando diferentes conceptos derivados de la inteligencia artificial, la evolución biológica y los mecanismos estadísticos”..
(14) Introducción Numerosos son los procedimientos meta-heurísticos creados, sobre todo a partir de la formulación del así denominado Teorema de No Free Lunch (Wolpert and Macready, 1997) que dio pie a una suerte de catarsis, a partir de la cual quedó definitivamente claro que un algoritmo de búsqueda u optimización se comporta en estricta concordancia con la cantidad y calidad del conocimiento específico del problema que incorpora, o sea que no existe un único algoritmo capaz de resolver con la mayor calidad todo tipo de problemas. Dentro de las tantas clasificaciones que a lo largo de los años se le ha dado a las metaheurísticas, una de las más comunes es subdividirlas en: métodos de búsqueda local o metaheurísticas de trayectoria simple y meta-heurísticas poblacionales. Los métodos de Búsqueda Local (BL), se enfocan en la explotación de las soluciones ya encontradas, o sea, realizar un proceso de búsqueda en las vecindades de una solución, denominada solución actual, que en un inicio se pudiera generar de manera aleatoria, sufriendo un proceso de transformación en el cual se obtiene una nueva solución que reemplazará a la actual si mejora a esta siguiendo algún criterio de comparación. Este proceso se repetirá hasta que se genera un número máximo de soluciones o se alcanza un óptimo local. Varios de los métodos de Búsqueda Local que se han desarrollado, podemos citar por ejemplo: los métodos de Cuasi-Newton (Luenberguer, 1989) entre los cuales encontramos L-BFGS y L-BFGS-B, la muy utilizada Búsqueda Tabú (Glover and Laguna, 1997), el Método Solis Wets (Solis and Wets, 1981), Método Simplex de Nelder y Mead (Spendley et al., 1962). Dichos métodos son muy precisos y de rápida convergencia, pudiendo caer estancados en óptimos locales y no alcanzando en ocasiones el óptimo global que es lo que realmente se pretende. Esto es conocido como el fenómeno de la convergencia prematura. Por otra parte están los algoritmos poblacionales. Estos emplean un conjunto de soluciones (población) en cada iteración del algoritmo en lugar de utilizar una única solución como las meta-heurísticas del grupo anterior, por lo que su búsqueda realiza el énfasis en el fomento de la exploración. Estas proporcionan de forma intrínseca un mecanismo de exploración paralelo al proceso de búsqueda de soluciones, y su eficacia depende en gran medida de cómo se manipule dicha población. Dentro de esta clasificación se destacan los Algoritmos Evolutivos y los algoritmos basados en Inteligencia Colectiva..
(15) Introducción Dentro de este subgrupo se puede citar entonces los Algoritmos Genéticos (AGs) (Goldberg, 1998), la Búsqueda Dispersa (Laguna and Martí, 2003), los Algoritmos Basados de Distribuciones (Estimation of Distribution Algorithms, EDA) (Lozano et al., 2006), la Optimización de Colonias de Hormigas (Ant Colony Optimization; ACO) (Dorigo and Caro, 1999) y los Sistemas de Partículas (Particle Swarm Optimization, PSO) (Kennedy and Eberhart, 1995), Agujero Negro (Hatamlou, 2013), Optimización de Mallas Variables de su inglés (Variable Mesh Optimization) (Puris et al., 2012) desarrollada por el grupo de Inteligencia Artificial de la Universidad Central “Marta Abreu” de Las Villas, entre otras. Estos métodos trabajan en cada iteración del algoritmo, con un conjunto (población) de soluciones en vez de una única solución. De esta manera los algoritmos poblacionales proveen una forma natural para explorar el espacio de búsqueda. Por lo tanto la manera en que esta población es manipulada afectará de forma directa el rendimiento. Como una alternativa para mejorar la eficiencia de las meta-heurísticas, han surgido varias propuestas que utilizan un enfoque de procesamiento estructurado de éstas. Con el uso de esta técnica se tratan de evitar los estados de convergencia prematura o estancamiento; una forma de lograr esto es preservando la diversidad en la población. Un método común para estructurar los algoritmos de inteligencia colectiva es utilizar múltiples subpoblaciones de forma tal que se mantenga el proceso de exploración de manera simultánea en varias zonas del espacio de búsqueda. Varios son los ejemplos de meta-heurística en las cuales se ha hecho uso de las topologías: el EPUS-PSO variante de PSO con topología de estrella (Hsieh et al., 2008), el DMS-PSO variante de PSO con topologías de subpoblaciones dinámicas (Zhao et al., 2008), en la optimización basada en las colonias de hormigas (Christodoulou, 2005), entre otras. Teniendo en cuenta lo expuesto anteriormente y aprovechando las ventajas que puede traer la implementación de algoritmos poblacionales siguiendo una topología estructurada, la presente investigación estará encaminada a desarrollar un modelo basado en VMO, del cual se obtendrán dos variantes estructuradas; VMO-Top1 donde crearán subpoblaciones sin solapamiento y VMO-Top2 donde dichas subpoblaciones estarán solapadas. Con el objetivo de conocer si las soluciones que se obtienen muestran una verdadera mejoría de las soluciones estadísticamente hablando, con respecto a las que obtiene la meta-heurística.
(16) Introducción VMO, sin necesidad de incrementar la complejidad temporal y espacial del algoritmo original. Por todo lo anteriormente expuesto enunciamos el siguiente problema de investigación: En el VMO clásico los nodos están totalmente comunicados, esta característica confiere una alta tasa de convergencia provocando que quede atrapado en soluciones locales. En consecuencia con dicho problema pueden plantearse las siguientes preguntas de investigación: ¿Qué debe caracterizar una versión estructurada del VMO? ¿Qué elementos de deben tener en cuenta para comparar adecuadamente el desempeño de los modelos VMO-Top1 y VMO-top2 con la versión clásica? En consecuencia con lo anterior se plantea el objetivo general de este trabajo: Diseñar e implementar una variante del algoritmo VMO continuo con topologías estructuradas, que incorpore estas estrategias en el proceso de generación de nodos. Para ganar en claridad durante el proceso investigativo, se desglosa este objetivo general en los siguientes objetivos específicos: Diseñar una nueva topología estructurada para VMO continuo, que esté inspirada en otras variantes locales poblacionales (ej. Topología de Anillo en Optimización de Enjambres de Partículas). Implementar dos alternativas distintas del modelo teniendo en cuenta la información a compartir. Diseñar un experimento estadístico que permita evaluar el desempeño del algoritmo, respecto a la variante clásica, en problemas multimodales. Luego de haber construido el marco teórico se formuló la siguiente hipótesis de investigación: En la versión estructurada de VMO aumenta el desempeño de esta meta-heurística en problemas de optimización global, en espacio de búsqueda multimodales, sin necesidad d aumentar la complejidad del modelo original. Dicha hipótesis será validada si se comprueba que las soluciones obtenidas por las versiones estructuradas presentadas, difieren, mostrando mejoría, a las del VMO clásico..
(17) Introducción Este trabajo se compone de tres capítulos. Luego de esta Introducción, en el Capítulo 1 se exponen los métodos heurísticos de búsqueda. En el Capítulo 2 se aborda de manera específica el modelo en sí y sus distintas alternativas. En el Capítulo 3 se realizan análisis estadísticos con el fin de validar los modelos propuestos. Finalmente se elaboran las Conclusiones y se listan las Referencias Bibliográficas que se utilizaron en este trabajo..
(18) Capítulo 1. Capítulo 1 Métodos heurísticos de búsqueda.
(19) Capítulo 1. CAPÍTULO 1 MÉTODOS HEURÍSTICOS DE BÚSQUEDA Los problemas de optimización continua desempeñan un papel esencial en la formulación de muchos problemas básicos de la vida real. Numerosas investigaciones aseguran este hecho, tanto en la gestión de servicios (planificación de los servicios hospitalarios (Lamiri et al., 2009), cabina de servicio (Schilde et al., 2011), los problemas de planificación de la salud (Nickel et al., 2012, Shariff et al., 2012), etc.), así como aplicaciones industriales (planificación de la producción (Clark et al., 2011), el avance ingeniería de diseño (Liao, 2010), la planificación financiera (Guillén et al., 2007), la gestión de riesgos (Papadakos et al., 2011), entre otros.. Todos ellos van desde problemas clásicos hasta problemas más complejos que se abordan necesariamente desde la perspectiva de la Inteligencia Artificial. algunos de estos problemas de optimización son relativamente fáciles de resolver como los problemas lineales (las restricciones y la función objetivo constituyen expresiones lineales) y otros no tan simples, los cuales por su propia naturaleza no pueden ser abordados mediante un procedimiento de búsqueda exhaustivo que obtenga la mejor solución tras una búsqueda por todo el dominio de posibles valores(Molina Cabrera, 2007). De una manera sencilla resolver un problema de optimización no es más que, dado un dominio de soluciones y una función objetivo, encontrar un óptimo global de dicha función o sea dada una función 𝐹: 𝐷−> 𝑅 siendo D continua en 𝑅𝑛 , encontrar un punto 𝑥0 ∈ 𝐷 tal que: 𝐹(𝑥0 ) <= 𝐹(𝑥) para todo 𝑥 ∈ 𝐷, en el caso de minimización de la función 𝐹. 𝐹(𝑥0 ) >= 𝐹(𝑥) para todo 𝑥 ∈ 𝐷, en el caso de maximización de la función 𝐹. La idea es asignar valores del dominio, permitidos por las restricciones la tal forma que la función sea optimizada. Los componentes de un problema de optimización son (Bello and Puris, 2009): Función objetivo (Fitness function)..
(20) Capítulo 1 Conjunto de parámetros (desconocidos) los cuales afectan el valor de la función objetivo. Conjunto de restricciones que limitan los valores que se pueden asignar.. Importancia de los problemas de optimización La optimización en el sentido de encontrar la mejor solución, o al menos una solución lo suficientemente buena para un problema es un campo de vital importancia en la vida real. Constantemente estamos resolviendo pequeños problemas de optimización, como el camino más corto de ir un lugar a otro, la organización de una agenda, etc. En general éstos son lo suficientemente pequeños y pueden ser resueltos sin recurrir a elementos externos a nuestro cerebro. Pero conforme se hacen más grandes y complejos, el uso de los ordenadores para su resolución es inevitable. Debido a la gran importancia de los problemas de optimización, a lo largo de la historia de la Informática se han desarrollado múltiples métodos para tratar de resolverlos (Nieto, 2006). Una clasificación muy simple de estos métodos se muestra en la Figura 1.1 Clasificación de los problemas de optimización. Inicialmente, las técnicas las podemos clasificar en exactas (o enumerativas, exhaustivas, etc.) y técnicas aproximadas. Las técnicas exactas garantizan encontrar la solución óptima para cualquier instancia de cualquier problema en un tiempo acotado. El inconveniente de estos métodos es que el tiempo necesario para llevarlos a cabo, aunque acotado, crece exponencialmente con el tamaño del problema, ya que la mayoría de éstos son NPCompletos. Esto provoca en muchos casos que el tiempo necesario para la resolución del problema sea inabordable. Por lo tanto, los algoritmos aproximados para resolver estos problemas están recibiendo una atención cada vez mayor por parte de la comunidad internacional a lo largo de los últimos años. Estos métodos sacrifican la garantía de encontrar el óptimo a cambio de encontrar una buena solución en un tiempo razonable (Nieto, 2006).. Figura 1.1 Clasificación de los problemas de optimización.
(21) Capítulo 1. Métodos de solución de problemas El uso de la computadora para dar respuesta a problemas reales tales como: ¿Cuántos caminos hay para…..? ¿Listar todas las posibles soluciones para…? ¿Hay un camino para…? usualmente requiere de una búsqueda exhaustiva dentro del conjunto de todas las soluciones potenciales, por eso los algoritmos que resuelven este tipo de problemas reciben el nombre de algoritmos exactos o de búsqueda exhaustiva. Por ejemplo, si se desean encontrar todos los caminos de un laberinto, se deben examinar todos los caminos iniciando desde la entrada. Un ejemplo es la búsqueda con retroceso o backtracking, que trabaja tratando continuamente de extender una solución parcial. En cada etapa de la búsqueda, si una extensión de la solución parcial actual no es posible, se va hacia atrás para una solución parcial corta y se trata nuevamente. El método retroceso se usa en un amplio rango de problemas de búsqueda, incluyendo el análisis gramatical (parsing), juegos, y planificación (scheduling). La segunda técnica es tamiz o criba, y es el complemento lógico de retroceso en que se tratan de eliminar las no-soluciones en lugar de tratar de encontrar la solución. El método tamiz es útil principalmente en cálculos numéricos teóricos. Se debe tener en mente, sin embargo, que retroceso y tamiz son solamente técnicas generales. Se aplicarán en algoritmos cuyos requerimientos en tiempo son prohibitivos. En general, la velocidad de los ordenadores no es práctica para una búsqueda exhaustiva de más de 100 elementos. Así, para que estas técnicas sean útiles, deben considerar solamente una estructura dentro de la cual se aproxima el problema. La estructura debe ser hecha a medida, a menudo con gran ingenio, para cuadrar con el problema particular, de modo que el algoritmo resultante será de uso práctico. Los métodos exactos de resolución de problemas se han aplicado con éxito en disímiles de problemas. Algunos ejemplos de estos métodos son los algoritmos voraces, algoritmos de divide y vencerás, algoritmos de ramificación y poda, backtraking, etc. Todos estos procedimientos resuelven problemas que pertenecen a la clase P de forma óptima y en tiempo razonable. Como se ha comentado anteriormente, existe una clase de problemas, denominada NP, con.
(22) Capítulo 1 gran interés práctico para los cuales no se conocen algoritmos exactos con tiempos de convergencia en tiempo polinómico. Es decir, aunque existe un algoritmo que encuentra la solución exacta al problema, tardaría tanto tiempo en encontrarla que lo hace completamente inaplicable. Además, un algoritmo exacto es completamente dependiente del problema (o familia de problemas) que resuelve, de forma que cuando se cambia el problema se tiene que diseñar un nuevo algoritmo exacto y demostrar su optimalidad. Para la mayoría de problemas de interés no existe un algoritmo exacto con complejidad polinómica que encuentre la solución óptima a dicho problema. Además, la cardinalidad del espacio de búsqueda de estos problemas suele ser muy grande, lo cual hace inviable el uso de algoritmos exactos ya que la cantidad de tiempo que necesitaría para encontrar una solución es inaceptable. Debido a estos dos motivos, se necesita utilizar algoritmos aproximados o heurísticos que permitan obtener una solución de calidad en un tiempo razonable(Esmorís, 2013). El término heurística proviene del vocablo griego heuriskein, que puede traducirse como encontrar, descubrir o hallar. Desde un punto de vista científico, el término heurística se debe al matemático George Polya quien lo empleó por primera vez en su libro How to solve it (Polya, 2014). Con este término, Polya englobaba las reglas con las que los humanos gestionan el conocimiento común y que, a grandes rasgos, se podían simplificar en(Esmorís, 2013): . Buscar un problema parecido que ya haya sido resuelto.. . Determinar la técnica empleada para su resolución así como la solución. obtenida. . En el caso que sea posible, utilizar la técnica y solución descrita en el punto. anterior para resolver el problema planteado. Existen dos interpretaciones posibles para el término heurística. La primera de ellas concibe las heurísticas como un procedimiento para resolver problemas. La segunda interpretación de heurística entiende que estas son una función que permite evaluar la bondad de un movimiento, estado, elemento o solución. Existen métodos heurísticos (también llamados algoritmos aproximados, procedimientos inexactos, algoritmos basados en el conocimiento o simplemente heurísticas) de diversa.
(23) Capítulo 1 naturaleza, por lo que su clasificación es bastante complicada. Se sugiere la siguiente clasificación (Esmorís, 2013): 1.. Métodos constructivos: Procedimientos que son capaces de construir una. solución a un problema dado. La forma de construir la solución depende fuertemente de la estrategia seguida. Las estrategias más comunes son: Estrategia voraz: Partiendo de una semilla, se va construyendo paso a paso una solución factible. En cada paso se añade un elemento constituyente de dicha solución, que se caracteriza por ser el que produce una mejora más elevada en la solución parcial para ese paso concreto. Este tipo de algoritmos se dice que tienen una visión “miope” ya que eligen la mejor opción actual sin que les importe qué ocurrirá en el futuro. Estrategia de descomposición: Se divide sistemáticamente el problema en subproblemas más pequeños. Este proceso se repite (generalmente de forma recursiva) hasta que se tenga un tamaño de problema en el que la solución a dicho subproblema es trivial. Después, el algoritmo combina las soluciones obtenidas hasta que se tenga la solución al problema original. Los algoritmos más representativos de los métodos de descomposición son los algoritmos de divide y vencerás tanto en su versión exacta como aproximada. Métodos de reducción: Identifican características que contienen las soluciones buenas conocidas y se asume que la solución ´optima también las tendrá. De esta forma, se puede reducir drásticamente el espacio de búsqueda. Métodos de manipulación del modelo: Consisten en simplificar el modelo del problema original para obtener una solución al problema simplificado. A partir de esta solución aproximada, se extrapola la solución al problema original. Entre estos métodos se pueden destacar: la linealización, la agrupación de variables, introducción de nuevas restricciones, etc. 2. Métodos de búsqueda: Parten de una solución factible dada y a partir de ella intentan mejorarla. Algunos son: Estrategia de búsqueda local 1: Parte de una solución factible y la mejora progresivamente. Para ello examina su vecindad y selecciona el primer movimiento que produce una mejora en la solución actual (first improvement)..
(24) Capítulo 1 Estrategia de búsqueda local 2: Parte de una solución factible y la mejora progresivamente. Para ello examina su vecindad y todos los posibles movimientos seleccionando el mejor movimiento de ellos, es decir aquél que produzca un incremento (en el caso de maximización) más elevado en la función objetivo (best improvement). Estrategia aleatorizada: Para una solución factible dada y una vecindad asociada a esa solución, se seleccionan aleatoriamente soluciones vecinas de esa vecindad. El principal problema que presentan los algoritmos heurísticos es su incapacidad para escapar de los óptimos locales. En la Figura 1.2 se muestra cómo para una vecindad dada el algoritmo heurístico basado en un método de búsqueda local se quedaría atrapado en un máximo local. En general, ninguno de los métodos constructivos descritos anteriormente tendrían por qué construir la solución óptima global.. Figura 1.2 Encasillamiento de los algoritmos heurísticos en óptimos locales Los algoritmos heurísticos no poseen ningún mecanismo que les permita escapar de los óptimos locales (Muñoz, 2007). Para solventar este problema se introducen otros algoritmos de búsqueda más elaborados que eviten en la medida de lo posible quedar atrapados. Estos algoritmos de búsqueda más inteligentes, son los denominados metaheurísticos..
(25) Capítulo 1. Meta-heurísticas El término meta-heurística fue acuñado por F. Glover en el año 1986. Con este término, pretendía definir un “procedimiento maestro de alto nivel que guía y modifica otras heurísticas para explorar soluciones más allá de la simple optimalidad local” (Glover, 1986). Actualmente, existe varios trabajos científicos publicados que abordan problemas de optimización a través de meta-heurísticas, investigaciones sobre nuevas meta-heurísticas, y extensiones o mejoras de las meta-heurísticas ya conocidas. La evolución de las meta-heurísticas durante los últimos 25 años ha tenido un comportamiento prácticamente exponencial. En el tiempo que transcurre desde las primeras reticencias (por su supuesta falta de rigor científico) hasta la actualidad, se han encontrado soluciones de muy alta calidad a problemas que hace tiempo parecían inabordable. De modo general, atendiendo los criterios de (Rodríguez Ortiz, 2010), se puede decir que las meta-heurísticas combinan ideas que provienen de cuatro campos de investigación bien distintos: . Las técnicas de diseño de algoritmos (resuelven una colección de problemas). . Algoritmos específicos (dependientes del problema que se quiere resolver).. . Fuente de inspiración (del mundo real).. . Métodos estadísticos.. Las meta-heurísticas son técnicas de inspiración biológica y física, que por medio de heurísticas emulan los procesos de optimización que se pueden observar en la naturaleza, como por ejemplo: la evolución. Los algoritmos meta-heurísticos no tienen una base matemática estricta y las funciones buscan directamente en el universo de soluciones con diversas estrategias. Por sus características, generalmente ellos proveen una respuesta en menor tiempo y de alta calidad a problemas de gran complejidad, mostrando su innegable potencial en aplicaciones del mundo real (Michalewicz, 2002, Dorigo, 2003). Los algoritmos meta-heurísticos abordan problemas que por su condición no pueden ser resueltos satisfactoriamente por los métodos derivativos y por su estructura no necesitan la información diferencial. Sin embargo, aunque resuelven problemas más variados, su.
(26) Capítulo 1 naturaleza iterativa y la ausencia de información sobre las derivadas hacen que sean susceptibles al punto (o puntos) inicial de optimización y hacen que los parámetros del algoritmo ganen gran importancia en el funcionamiento y resultado del mismo (Rao, 1996, Feoktistov, 2006). Las meta-heurísticas toman su inspiración de procesos que mejoran sus condiciones o cuyo objeto o comportamiento emergente muestre una notable mejoría en alguna característica, ya sea en la calidad final o en el refinamiento de ciertos parámetros del proceso. Por ejemplo, el temple de un material, es un proceso que mejora la calidad del material por el control de la temperatura (Jang, 1996, de Castro, 2007). Teniendo en mente los procesos, se intenta simularlos por medio de heurísticas emulando el comportamiento de mejoría (optimización) que presenta el proceso de donde nace la idea; así, estos métodos han logrado soluciones aceptables a problemas de gran dificultad en un tiempo y a unos costos razonables (Bäck, 1997). Una primera conclusión que se puede extraer de las definiciones dadas es que, en muchos casos, son reglas de sentido común que permiten hacer una búsqueda inteligente. Debido a esta característica, para bastantes meta-heurísticas no existe un marco teórico que las sustente, sino que es a través de los buenos resultados experimentales donde encuentran su justificación. A pesar de que en la actualidad existen diversas opiniones en cuanto a la clasificación de las meta-heurísticas, a continuación se presentan los siguientes criterios de clasificación (Esmorís, 2013): . Atendiendo a la inspiración: Natural: algoritmos que se basan en un símil. real, ya sea biológico, social, cultural, etc. Sin inspiración: algoritmos que se obtienen directamente de sus propiedades matemáticas. . Atendiendo al número de soluciones: Poblacionales: buscan el óptimo de. un problema a través de un conjunto de soluciones. Trayectoriales: trabajan exclusivamente con una solución que mejoran iterativamente. . Atendiendo a la función objetivo: Estáticas: no hacen ninguna. modificación sobre la función objetivo del problema. Dinámicas: modifican la función objetivo durante la búsqueda..
(27) Capítulo 1 . Atendiendo a la vecindad: Una vecindad: durante la búsqueda utilizan. exclusivamente una estructura de vecindad. Varias vecindades: durante la búsqueda modifican la estructura de la vecindad. . Atendiendo al uso de memoria: Sin memoria: se basan exclusivamente en. el estado anterior. Con memoria: utilizan una estructura de memoria para recordar la historia pasada. Generalmente, estas características (pueden incluirse más) se suelen combinar para permitir una clasificación más elaborada. En la Tabla 1.1 se presenta un resumen de las publicaciones sobre las técnicas más populares en aplicaciones, híbridos, mejoras metodológicas, comparaciones y pruebas. Se tienen en cuenta artículos, conferencias, libros, capítulos de libros de las principales publicaciones del área. Se aprecia el aumento del uso de los métodos meta-heurísticos y la mayor aceptación de algunos métodos, como Algoritmos Genéticos (AG), Recocido Simulado (SA) u Optimización de Enjambre de Partículas (PSO), mientras que otros algoritmos como Programación Evolutiva y Estrategias Evolutivas, a pesar de ser métodos más antiguos, no son tan frecuentemente aplicados. De igual manera, las meta-heurísticas consideradas en la Tabla 1.1 se limitan a las que tienen más acogida según la literatura. Tabla 1.1 Número de artículos por técnicas bio-inspiradas (Delgado, 2010) Números de artículos (metodologías y aplicaciones) Meta-heurística antes del 2001 2001 - 2005 2006 - 2010 Total Algoritmos Genéticos. 7285. 14723. 13850. 35858. Recosido Simulado. 3490. 3287. 3388. 10165. PSO. 7. 742. 5262. 6011. Colonias de Hormigas. 47. 699. 2223. 2969. Búsqueda Tabú. 465. 692. 793. 2969. Evolución diferencial. 93. 382. 1362. 1837. Algoritmos Inmunológicos. 65. 420. 1180. 1665. Programación evolutiva. 252. 382. 321. 955. Estrategias evolutivas. 168. 342. 620. 930. GRASP. 235. 298. 392. 925.
(28) Capítulo 1 Algoritmos Meméticos. 5. 141. 396. 542. Búsqueda dispersa Hooke and Jeeves Pattern search Quimiotaxis bacteriana. 21. 93. 170. 284. 113. 34. 55. 202. N.A.. 1. 22. 23. Las fuentes de inspiración de las meta-heurísticas se pueden dividir en tres grandes grupos: evolución, procesos físicos y aprendizaje (Esmorís, 2013). Los diferentes métodos desarrollados hasta la actualidad pueden ser clasificados atendiendo las características de estos grupos, ya sea dentro de una de las líneas estrictamente o en una combinación de ellas. En la Figura 1.3 Meta-heurísticas de acuerdo a su inspiraciónse observan las técnicas más representativas de las diferentes categorías.. Figura 1.3 Meta-heurísticas de acuerdo a su inspiración1. 1. Tomado de PÉREZ LEÓN, S. R. 2013. Implementación de un algoritmo basado en Colonias de Hormigas para la optimización de funciones con datos mezclados. Universidad Central "Marta Abreu" de las Villas..
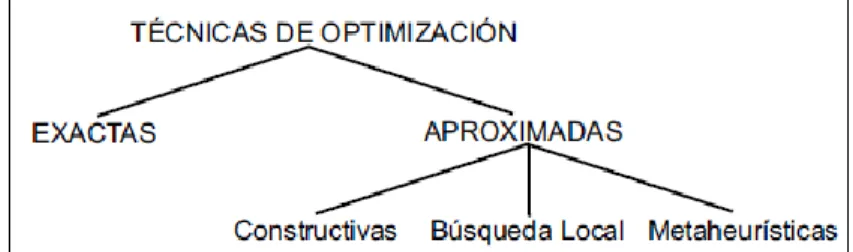
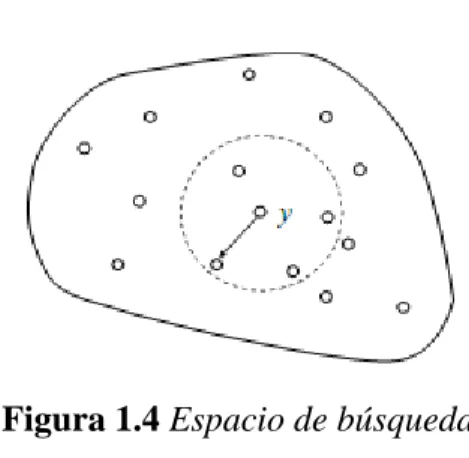
(29) Capítulo 1. Meta-heurísticas de trayectoria simple. Los métodos de Búsqueda Local BL o meta-heurísticas de trayectoria simple, definen un proceso de transformación que parte de una solución inicial generada de forma aleatoria o mediante algún otro algoritmo la cual constituye la solución actual. A esta solución se le aplican dicho método para obtener un conjunto de soluciones en un entorno cercano. O sea mediante un proceso iterativo dada una solución actual buscan una mejor solución en su vecindario Figura 1.4 Espacio de búsqueda, dicha mejor solución pasa a ser la solución actual y se repite el proceso hasta que se generan un número máximo de soluciones o se alcanza un óptimo local. Lo dicho puede expresarse de la siguiente forma: Encontrar una solución 𝑥 tal que 𝑓(𝑥) = 𝑚𝑖𝑛𝑓(𝑦) para todo 𝑦 ∈ 𝑣𝑒𝑐𝑖𝑛𝑑𝑎𝑟𝑖𝑜(𝑥).. Figura 1.4 Espacio de búsqueda A su vez existen dentro de las propias estrategias de búsqueda local dos subgrupos bien definidos: por un lado los métodos de BL deterministas y por otro los estocásticos. A continuación mostramos algunos representantes de ambos grupos: Métodos de Búsqueda Local Deterministas: Métodos de Cuasi-Newton (Luenberguer, 1989): Difieren del método de Newton puro en que no utilizan la matriz Hessiana en sus iteraciones sino que una aproximación de esta. Existen diversas variantes de métodos cuasi newton, por ejemplo los métodos L-BFGS y L-BFGS-B que hacen un uso limitado de la memoria (usa mucha menos memoria que otros algoritmos para el mismo problema); L-BFGS viene de BFGS de memoria limitada. Únicamente necesita la función y su gradiente, pero no la matriz Hessiana. L-BFGS, es capaz de.
(30) Capítulo 1 resolver funciones sin restricciones, mientras que la variante L-BFGS-B puede resolver funciones con restricciones simples (del tipo 𝑙𝑖 < 𝑥𝑖 <𝑢𝑖 , siendo 𝑥𝑖 la variable i-ésima y 𝑙𝑖 y 𝑢𝑖 los límites inferior y superior de esa variable) en sus parámetros.. Búsqueda Local Guiada: Acumula sanciones durante una búsqueda. Utiliza algoritmos de sanciones. Cuando el algoritmo de búsqueda local determinado se instala en un óptimo local, GLS modifica la función objetivo con un régimen específico. A continuación, la búsqueda local opera con una función aumentada de objetivo, que está diseñado para llevar a cabo la búsqueda del óptimo local. La clave está en la forma en que la función objetivo se modifica.. Métodos de Búsqueda Local Estocásticos: Búsqueda Tabú (Glover and Laguna, 1997): La búsqueda tabú utiliza un procedimiento de búsqueda local o por vecindades para moverse iterativamente desde una solución x hacia una solución x' en la vecindad de x, hasta satisfacer algún criterio de parada. Para poder explorar regiones del espacio de búsqueda que serían dejadas a un lado por el procedimiento de búsqueda local, la búsqueda tabú modifica la estructura de vecinos para cada solución a medida que la búsqueda progresa. Las soluciones admitidas para 𝑵 ∗ (𝒙) (vecindad reducida de 𝑥) son determinadas mediante el uso de estructuras de memoria. La búsqueda entonces progresa moviéndose iterativamente de una solución x hacia una solución x' en 𝑵 ∗ (𝒙). Quizás la estructura de memoria más importante usada para determinar las soluciones permitidas a un 𝑁 ∗ (𝑥), sea la lista tabú. En su forma más simple, una lista tabú es una memoria de corto plazo que contiene las soluciones que fueron visitadas en el pasado reciente (menos de n iteraciones atrás, donde n es el número de soluciones previas que van a ser almacenadas. La búsqueda tabú excluye las soluciones en la lista tabú de 𝑁 ∗ (𝑥)..
(31) Capítulo 1 Método Solis West (Solis and Wets, 1981): Sigue un esquema de ascensión de colinas con un tamaño de salto adaptativo. Para cada iteración partiendo de una solución actual x. Se genera un valor d mediante una distribución normal con 0 de media y ρ de desviación estándar. La nueva solución se obtiene sumando dicho valor d junto con un valor bias que mantiene un cierto grado de “inercia” sobre los movimientos anteriores.. Método Simplex de Nelder y Mead (Spendley et al., 1962): El método utiliza el concepto de un simplex, que es un polítopo de N+1 vértices en N dimensiones: un segmento de línea en una línea, un triángulo en un plano, un tetraedro en un espacio tridimensional y así sucesivamente. El método busca de modo aproximado una solución óptima local a un problema con N variables.. Un inconveniente de la BL está indicado por su propio nombre pues se orienta a alcanzar óptimos locales y no lo deseado realmente: encontrar la mejor solución en todo el espacio de búsqueda o sea el óptimo global, pues converge de forma rápida a los óptimos locales los cuales pueden ser soluciones muy alejados del óptimo global. Este comportamiento es denominado convergencia prematura.. Meta-heurísticas poblacionales Las meta-heurísticas basadas en población, o meta-heurísticas poblacionales, son aquellas que emplean un conjunto de soluciones (población) en cada iteración del algoritmo, en lugar de utilizar una única solución como las meta-heurísticas del grupo anterior. Estas proporcionan de forma intrínseca un mecanismo de exploración paralelo del espacio de soluciones, y su eficacia depende en gran medida de cómo se manipule dicha población. Dentro de esta clasificación se destacan los Algoritmos Evolutivos y los algoritmos basados en Inteligencia Colectiva. Ambos tienen en común el haber sido inspirados en algún proceso natural , en el primero de los casos en la teoría de la evolución de Darwin (Darwin, 1859), quien planteó que la evolución de las especies se produce por tres conceptos: replicación, variación y selección natural mientras que los algoritmos basados en Inteligencia Colectiva toman su inspiración.
(32) Capítulo 1 en ejemplos biológicos de comportamiento colectivo (enjambres) como es el caso de las colonias de insectos, las bandadas de aves y los cardúmenes de peces. Los Algoritmos Evolutivos son métodos de optimización y búsqueda de soluciones basados en los postulados de la evolución biológica. En ellos se mantiene un conjunto de entidades que representan posibles soluciones, las cuales se mezclan, y compiten entre sí, de tal manera que las más aptas son capaces de prevalecer a lo largo del tiempo, evolucionando hacia mejores soluciones cada vez. Numerosos han sido los modelos de AEs propuestos. A continuación mostramos algunos de los más destacados:. Algoritmos Genéticos (AGs) (Goldberg, 1998): Su principal mecanismo empleado para generar nuevos individuos es mediante un operador de recombinación (denominado cruce) que combina información de diferentes individuos para producir los nuevos individuos. Dentro de los AGs, el operador de mutación es empleado, por contra, con una probabilidad baja, simplemente como un operador capaz de aumentar la diversidad en la población. Búsqueda Dispersa (Laguna and Martí, 2003): En este modelo se mantienen dos subpoblaciones, una élite, de las mejores soluciones encontradas (para explotar las soluciones encontradas), y otra formada por individuos alejados de los individuos de la población anterior (para mantener cierta diversidad en el proceso de combinación). Además, es un modelo que considera el uso de un proceso de mejora local, para explotar más las soluciones encontradas. Evolución Diferencial (Storn and Price, 1997): Se caracteriza en que, dado que las soluciones se representan mediante vectores reales, las poblaciones de soluciones son modificadas de forma sucesiva mediante operadores de suma y resta vectorial, así como operaciones de intercambio de valores hasta que la población converge. Algoritmos Basados en estimación de Distribuciones (Estimation of Distribution Algorithms, EDA) (Lozano et al., 2006): Se caracterizan en que no utilizan ni los operadores de cruce ni los de mutación para generar nuevas soluciones.. Se genera la nueva población mediante muestreo de una.
(33) Capítulo 1 distribución de probabilidad, la cual es estimada a partir de los mejores individuos de las generaciones anteriores.. Por otra parte, la principal característica de los algoritmos basados en la Inteligencia Colectiva viene determinada por la estrecha colaboración social que presentan a través del sistema de comunicación que surge entre los individuos del grupo. Esta comunicación, a su vez, puede aparecer de forma directa o indirecta. La comunicación indirecta ocurre cuando un individuo altera el medio en que se desarrollan y los otros son capaces de captar estos cambios. La comunicación directa es aquella que ocurre a través de la obtención de la ubicación de otros individuos mediante sonido, visibilidad u otra forma directa de interacción. Entre los algoritmos más significativos y estudiados de Inteligencia Colectiva están: Sistemas de Partículas (Particle Swarm Optimization, PSO) (Kennedy and Eberhart, 1995): El PSO se caracteriza en que es un modelo inspirado en modelos naturales de movimiento como las bandadas de pájaros. En estos, la población está compuesta de una serie de partículas que representan las soluciones, y la evolución de la población se realiza debido al desplazamiento en el espacio de búsqueda de dichas partículas. Dicho desplazamiento está principalmente formado por dos direcciones: Una hacia la mejor solución global encontrada; y la otra hacia la mejor solución encontrada por dicha partícula. Optimización basada en colonia de hormigas (Ant Colony Optimization; ACO) (Dorigo and Caro, 1999). Son métodos poblacionales inspirados en el comportamiento de las hormigas naturales. Los mismos realizan un proceso constructivo y estocástico guiado por unos rastros de feromona que van depositando cada hormiga, dando una medida de cuán deseado ha sido un determinado camino, y a través de una función de visibilidad que evalúa la calidad del desplazamiento. Otro modelo poblacional que fue recientemente desarrollado por el grupo de Inteligencia Artificial del departamento de computación de la Universidad de las Villas y será la base de nuestra investigación es la llamada Optimización basada en Mallas Variables (VMO, de su nombre en inglés Variable Mesh Optimization)..
(34) Capítulo 1 Esta meta-heurística propone formas de búsqueda que combinan en un mismo proceso niveles variables de intensificación y exploración. La esencia de este modelo es crear una malla de puntos en el espacio m dimensional, donde se realiza el proceso de optimización de una función 𝐹𝑂(𝑥1 , 𝑥2 , … , 𝑥𝑚 ); la cual se mueve mediante un operador de expansión hacia otras regiones del espacio de búsqueda. Dicha malla se hace más “fina” en aquellas zonas que parecen ser más promisorias. Es variable en el sentido que la malla cambia su tamaño (cantidad de nodos) y configuración durante el proceso de búsqueda. Existe otro operador en la búsqueda desarrollada por este modelo que se denomina contracción de la malla y se encarga de seleccionar los puntos más representativos de cada zona explorada del espacio de búsqueda.. Ejemplos de uso de las meta-heurísticas en problemas reales Diversos son los problema reales en los que las meta-heurísticas han desempeñado un importante papel en la solución de los mismos. Algunas de las áreas en las cuales se ha aplicado con éxito estos algoritmos son: la logística portuaria, la planificación de frecuencias en las telecomunicaciones y la programación de la tripulación de las empresas de trasporte público de autobuses, entre otros muchos ejemplos.. Meta-heurísticas en la Logística Portuaria Las terminales portuarias de contenedores compiten por un mercado que anualmente mueve varios cientos de millones de TEUs (acrónimo del término en inglés Twenty-foot Equivalent Unit, que significa Unidad Equivalente a Veinte Pies) alrededor del mundo.. Se trata de un mercado altamente competitivo en el que las grandes operadoras escogen como base de operaciones los puertos de países política y socialmente estables, bien ubicados y con buena relación coste/calidad. Las terminales se enfrentan a amenazas constantes por parte de competidores actuales y futuros.. Entre las respuestas a estas amenazas destaca la mejora en la gestión logística de la terminal por su incidencia directa en los precios y en la calidad del servicio. En este sentido, los responsables de la terminal necesitan sistemas de gestión y control que les permitan adoptar.
(35) Capítulo 1 decisiones adecuadas con las que hacer frente a las amenazas. La gran mayoría de los problemas que surgen en una terminal portuaria de contenedores pertenecen a la clase de los problemas NP-duros, por lo que deben considerarse procedimientos heurísticos o metaheurísticos para su resolución en situaciones reales (Batista and Moreno-Vega, 2013).. Las redes de telecomunicaciones y las meta-heurísticas La industria de las telecomunicaciones ha proporcionado, y sigue proporcionando, una gran cantidad de problemas de optimización que surgen desde el propio diseño del sistema de comunicación hasta algunos aspectos de su funcionamiento. La resolución de estos problemas ha jugado, sin lugar a dudas, un papel muy destacado en el desarrollo y utilización de este tipo de sistemas. No obstante, a medida que se han ido haciendo más populares y su penetración en el mercado es mayor, el tamaño de los sistemas de telecomunicaciones ha ido creciendo y, por tanto, los problemas que plantean tienen una dimensión tan elevada que los hacen inabordables con técnicas exactas. Los algoritmos meta-heurísticos son una de las mejores opciones en este contexto, ya que son capaces de encontrar soluciones de calidad en tiempos aceptables. Algunos de los problemas abordados en esta área son la planificación de celdas, la asignación automática de frecuencias y la optimización del proceso de difusión en redes ad hoc de dispositivos móviles. Debido a las características de estos problemas, se han desarrollado meta-heurísticas avanzadas que abarcan dos ámbitos: optimización multiobjetivo y sistemas de computación grid. El primer caso está motivado por la naturaleza multiobjetivo de dos de los problemas abordados (planificación de celdas y difusión óptima), en los que existen varias funciones contrapuestas que se han de optimizar a la vez. El segundo caso viene dado por la complejidad y dimensión de los problemas planteados, por lo que se han desarrollado modelos que permiten su ejecución en sistemas de computación grid, lo que nos va a permitir, no sólo reducir el tiempo de ejecución de los algoritmos, sino también obtener modelos de búsqueda que permitan resolver estos problemas de forma más efectiva(Valero, 2008)..
(36) Capítulo 1. Manejo de empresas de trasporte público de autobuses Los problemas de programación de la tripulación son bien conocidos, y se han propuesto varias técnicas para resolverlos, en particular, utilizando la formulación puesta a cubrir un solo objetivo. Sin embargo, en la práctica, existe la necesidad de considerar múltiples objetivos, algunos de ellos en conflicto unos con otros; por ejemplo, la calidad y el costo del servicio, lo que implica también que los métodos de solución alternativa han de ser desarrollados. Lourenço en su trabajo (Lourenço et al., 2001) propone meta-heurísticas multiobjetivo basado en la búsqueda tabú y algoritmos genéticos para dar solución a este tipo de problemas. Estas meta-heurísticas también presentan algunas de las características de innovación relacionados con la estructura del problema de programación de la tripulación que guían la búsqueda de manera eficiente y les permita encontrar buenas soluciones. Algunas de estas nuevas características también se pueden aplicar para el desarrollo de la heurística para otros problemas de optimización combinatoria. En la actualidad estos métodos se han incorporado con éxito en la planificación de sistemas de transporte con GIST y están realmente utilizado por varias compañías(Lourenço et al., 2001).. Conclusiones parciales De lo expuesto anteriormente se puede concluir que los métodos exactos no son la variante más adecuada para la solución de problemas complejos de optimización. Ello es debido a que estos métodos son dependientes del problema que resuelven. Además la cardinalidad del espacio de búsqueda de problemas complejos suele ser muy grande, lo cual hace inviable el uso de algoritmos exactos, ya que la cantidad de tiempo que necesitaría para encontrar una solución es inaceptable. Por otro lado, las meta-heurísticas de trayectoria simple dependen en gran medida de punto inicial y tienden a quedar estancadas rápidamente en óptimos locales. Por tanto para la presente investigación haremos uso de meta-heurísticas poblacionales ya que estas nos proporcionan un mecanismo natural de exploración en todo el espacio de soluciones y fomentan la diversidad durante todo el proceso de búsqueda..
(37) Capítulo 1.
(38) Capítulo 2. Capítulo 2 Algoritmo VMO con topología local.
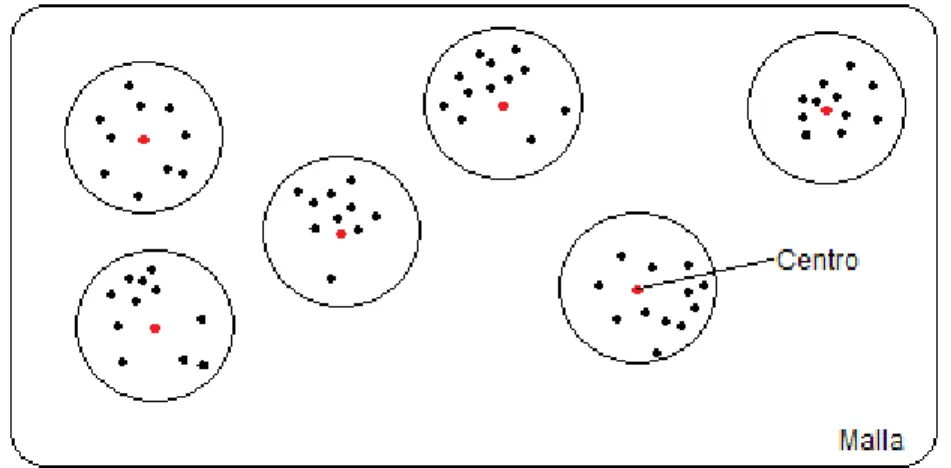
(39) Capítulo 2. CAPÍTULO 2 ALGORITMO VMO CON TOPOLOGÍA LOCAL En presente capítulo se describe la implementación del algoritmo para resolver problemas de optimización continua sin restricciones. Este tipo de problemas de optimización que clásicamente se formaliza como:. min/ max 𝑓(𝑥), 𝑥 = (𝑥1 , 𝑥2 , 𝑥3 , … , 𝑥𝑛 )𝑇 ∈ 𝑅 𝑛. (2.1). donde xi es la variable de decisión definida en el dominio Li < xi < Ui. Los términos Li y Ui son los límites inferiores y superiores, respectivamente, que son definidos a priori. En concreto, en este trabajo, nos centramos en las funciones multimodales (véase para una mejor descripción (Suganthan et al., 2005a)), que son más difíciles que los típicos unimodales. Como ha sido mencionado anteriormente, la meta heurística que utilizada en este trabajo es Optimización basada en Mallas Variables (VMO, de su nombre en inglés Variable Mesh Optimization) (Puris et al., 2012).. Optimización Basada en Mallas Variables. La Optimización Basada en Mallas Variables (Variable Mesh Optimization; VMO) es una meta heurística poblacional con características evolutivas donde un conjunto de nodos que representan soluciones potenciales a un problema de optimización, forman una malla (población) que dinámicamente crece y se desplaza por el espacio de búsqueda (evoluciona). Para ello, se realiza un proceso de expansión en cada ciclo, donde se generan nuevos nodos en dirección a los extremos locales (nodos de la malla con mejor calidad en distintas vecindades) y el extremo global (nodo obtenido de mejor calidad en todo el.
(40) Capítulo 2 proceso desarrollado); así como a partir de los nodos fronteras de la malla. Luego se realiza un proceso de contracción de la malla, donde los mejores nodos resultantes en cada iteración son seleccionados como malla inicial para la iteración siguiente. La formulación general de la meta-heurística abarca tanto los problemas de optimización continuos como los discretos, en nuestro caso realizaremos énfasis en los problemas continuos. En (Puris, 2009) se da un descripción detallada de la misma.. Descripción general de la meta heurística La esencia del método VMO es crear una malla de nodos en el espacio m-dimensional, donde se realiza el proceso de optimización de una función 𝐹𝑂(𝑥1 , 𝑥2 , … , 𝑥𝑚 ); la cual se mueve mediante un proceso de expansión hacia otras regiones del espacio de búsqueda. Dicha malla se hace más “fina” en aquellas zonas que parecen ser más promisorias. Es variable en el sentido que la malla cambia su tamaño (cantidad de nodos) y configuración durante el proceso de búsqueda. Los nodos se representan como vectores de la forma n(𝑥1 , 𝑥2 , … , 𝑥𝑚 ).. El proceso de generación de nodos en cada ciclo comprende los pasos siguientes: Generación de la malla inicial. Generación de nodos en dirección a los extremos locales. Generación de nodos en dirección al extremo global. Generación de nodos a partir de las fronteras de la malla. El método incluye los parámetros: Cantidad de nodos de la malla inicial (𝑆𝐼𝑀 ). Cantidad máxima de nodos de la malla en cada ciclo (𝑆𝑇𝑀 , donde 3∙𝑆𝐼𝑀 ≤ 𝑆𝑇𝑀 ). Tamaño de la vecindad (k). Condición de parada (M)..
(41) Capítulo 2. Proceso de expansión El algoritmo realiza un proceso de expansión mediante el cual la población se traslada a través del espacio de soluciones. Esta operación se realiza siguiendo los pasos descritos a continuación (Puris et al., 2012).. Paso 1: Generación aleatoria de la malla inicial: Para cada uno de los nodos 𝑛𝑖 de la malla inicial se valoriza aleatoriamente cada dimensión con un valor real entre el intervalo definido en cada caso.. Paso 2: Generación de nodos en dirección a los extremos locales: El primer tipo de exploración del modelo se basa en llevar a cabo un análisis de las vecindades para cada uno de los nodos de la malla. La vecindad de 𝑛𝑖 esta definida por los k vecinos más cercanos a este (teniendo en cuenta la distancia). El mejor nodo dentro de esta vecindad es seleccionado como extremo local 𝑛𝑖∗ . Únicamente es generado un nodo entre 𝑛𝑖 y 𝑛𝑖∗ si 𝑛𝑖∗ posee mejor valor de la función objetivo que 𝑛𝑖 . Para calcular los vecinos más cercanos de cada nodo de la malla se utiliza como función de distancia la euclidiana, definida por (2.1): 2. 1 2 𝐷𝑒𝑢𝑐𝑙𝑖𝑑𝑖𝑎𝑛𝑎 (𝑛1 , 𝑛2 ) = √∑𝑀 𝑖=𝑗(𝑣𝑗 − 𝑣𝑗 ). 2. (2.1). Los nuevos nodos (nz) son calculados usando la función definida por (2.2): 𝑛𝑧 = 𝐹(𝑛𝑖 , 𝑛𝑖∗ , 𝑃𝑟(𝑛𝑖 , 𝑛𝑖∗ )). (2.2). donde Pr es el factor de cercanía y representa la relación entre la aptitud del nodo actual y su extremo local. Este factor se calcula por la ecuación (2.3). Se toma un valor en el intervalo [0, 1], más grande cuando tiene una mejor calidad ni: 1. 𝑃𝑟(𝑛𝑖 , 𝑛𝑖∗ ) = 1+|𝑓𝑖𝑡𝑛𝑒𝑠𝑠(𝑛 )−𝑓𝑖𝑡𝑛𝑒𝑠𝑠(𝑛∗ )| 𝑖. (2.3). 𝑖. La función F puede ser descrita de diferentes maneras. En este trabajo la componente vzjdel nodo nzserá calculada por (2.4):.
Figure



+7




Documento similar