Agente de Software que Obtiene Información Interpretando Ontologías
140
0
0
Texto completo
(2) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey División de Electrónica, Computación, Información y Comunicaciones Programa de Graduados. Tesis. Maestría en Ciencias Sistemas Inteligentes. Agente de Software que obtiene información interpretando por. Leonardo Maycotte 766818. Monterrey, N.L., Mayo de 2004.
(3) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey División de Electrónica, Computación, Información y Comunicaciones Programa de Graduados. Tesis. Maestría en Ciencias en Sistemas Inteligentes. Agente de Software que obtiene información interpretando ontologías por. Leonardo Maycotte 766818. Monterrey, N.L., Mayo de 2004.
(4) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey División de Electrónica, Computación, Información y Comunicaciones Programa de Graduados Los miembros del comité de tesis recomendamos que la presente tesis de Leonardo Maycotte sea aceptada como requisito parcial para obtener el grado académico de Maestro en. Ciencias en: Sistemas Inteligentes Comité de Tesis:. Arturo Galván R. Asesor Principal. Alejandro Parra B.. Luis Humberto González Guerra. Sinodal. Sinodal. Director del Programa de Graduados. Mayo de 2004.
(5) Agradecimientos Quiero agradecer a mis padres por su apoyo incondicional gracias al cual fue posible la realización de mis estudios de maestría. A mi asesor el Dr. Arturo Galván por su gran enseñanza académica y apoyo indispensable para la realización del presente trabajo. Así como a mis sinodales Alejandro Parra y Luis Humberto González. Al Dr. Francisco Cantú y Dr. Rogelio Soto por su apoyo en el Centro de Sistemas Inteligentes. Así como al Dr. Hugo Terashima como coordinador de la maestría y a Doris por su ayuda con trámites administrativos. Al Dr. Arturo Nolazco y a la cátedra de Técnicas avanzadas para detección de intrusos, análisis de vulnerabilidad y control de acceso en sistemas computacionales por permitirme ser parte de ella durante mi segundo año de maestría. A la cátedra Tecnologías de conocimiento distribuido y agentes inteligentes por permitirme ser parte de ella durante mi segundo semestre de maestría así como al Dr. Breña y Dr. Garrido por su enseñanza de agentes inteligentes. Al Dr. Gordillo, Uresti y Valenzuela así como a los demás profesores que son parte de la maestría en ciencias en sistemas inteligentes. A mis compañeros Victor Báñales, Héctor Gibrán y Germán Montalvo. Así como a mis amigos y familiares entre los que se encuentran Jorge, Mauricio, Nato, Haid, Arturo, Gama, Tony, Mandin y Juanito..
(6) Índice general 1. Introducción 1.1. Planteamiento del Problema 1.2. Objetivo 1.3. Justificación 1.4. Hipótesis 1.5. Agente de Semantic Web 1.6. Alcance y Limitaciones. 3 6 6 6 7 7 7. 2. Marco Teórico 2.1. Ontología 2.2. Semantic Web 2.3. XML 2.3.1. Historia 2.3.2. Reglas 2.3.3. Namespaces 2.3.4. Document Type Definitions (DTD's) y XML Schemas 2.4. XSLT 2.4.1. Ejemplo de XSLT 2.5. DOM y SAX 2.5.1. DOM 2.5.2. SAX 2.6. RDF 2.7. RDF Schemas (RDFS) 2.7.1. Elementos 2.8. OWL. 9 9 10 11 11 12 13 14 16 18 19 19 22 22 24 25 27. 3. Solución Propuesta 3.1. Metodología: 5 Pasos 3.2. Implementación 3.3. Pruebas y Resultados 3.3.1. Búsquedas por 3.3.2. Búsquedas por 3.3.3. Búsquedas por 3.3.4. Búsquedas por 3.3.5. Búsquedas por 3.3.6. Búsquedas por. 29 29 32 40 41 42 43 44 45 46. ID Nombre Segundo Nombre Apellido Nombre y Segundo Nombre Nombre y Apellido. I.
(7) 3.3.7. Búsquedas por Segundo Nombre y Apellido 3.3.8. Búsquedas por Nombre, Segundo Nombre y Apellido 3.3.9. Caso especial 1: Nombre y Segundo Nombre iguales 3.3.10. Caso especial 2: Nombre y Apellido iguales 3.3.11. Caso especial 3: Segundo Nombre y Apellido iguales 3.3.12. Caso especial 4: ID's iguales 3.4. Herramientas Utilizadas 3.4.1. 4Suite 3.4.2. VERSA 3.4.3. Protege 3.4.4. Python. 4. Conclusiones. 47 47 48 49 50 51 51 51 52 54 54. 57. 4.1. Trabajos Futuros 4.1.1. Implementación en ventas 4.1.2. Integración con bases de datos 4.1.3. Web services y RDF. 57 57 58 58. A. Navegación en un árbol de DOM. 61. B. XML a partir de una clase de Python. 63. C. 4RDF: parser de RDF. 65. D. Editando y Señalizando RDF. 67. E. RDF Schema de una organización. 73. F. Información de empleados en RDF. 77. G. Documento RDFS parseado mediante 4RDF. 89. H. Documento RDF parseado mediante 4RDF. 97. I. Aplicación web 1.1. Página principal Umbrella.html 1.2. Primer CGI: Parseo de RDFS 1.3. Segundo CGI: Búsqueda de información 1.4. Librería: enbus08.py 1.5. Librería: HTML para python 1.6. Hoja de estilo para presentación en web. II. 105 105 106 109 110 115 124.
(8) Índice de figuras 1.1. Agente de viajes. 5. 2.1. Ejemplo de XML 2.2. Documento de XML 2.3. Ejemplo de namespaces 2.4. Ejemplo de un DTD 2.5. Helio World! en XML 2.6. Stylesheet de hello.xml 2.7. Helio World! en HTML 2.8. Árbol de DOM 2.9. Un statement de RDF 2.10. Varios statement's de RDF. 11 12 13 14 18 18 19 21 23 23. 3.1. Ejemplo de una organización 3.2. Tabla de MySQL 3.3. Tabla de base de datos en Protege 3.4. Creación del esquema en Protege 3.5. Ejemplo de una instancia de la clase Technicians 3.6. Definición de información en Protege 3.7. Función getProperties 3.8. Tripletas RDF de propiedades 3.9. Opciones de búsqueda 3.10. Resultados de la búsqueda 3.11. Página principal de la aplicación web 3.12. Menú de Protege 3.13. Selección de formato para un proyecto nuevo. 29 30 30 35 35 36 37 37 39 40 41 54 55. 4.1. Agente de ontologías en ventas 4.2. Agentes en bases de datos. 58 59. III.
(9) IV.
(10) índice de cuadros 3.1. 3.2. 3.3. 3.4.. Base de datos de información departamental Base de datos de información personal Base de datos de sueldos y prestaciones Número de instancias de cada clase. V. 32 33 33 35.
(11) Resumen Este documento presenta una metodología y su implementación para definir información mediante ontologías utilizando RDF. La metodología consta de cinco pasos entre los cuales se define la información en RDF utilizando un editor de ontologías gráfico, Protege, para posteriormente ser manejada en archivos RDF. En la implementación presentada en este trabajo la información de los archivos RDF se hace disponible para consultas en web..
(12) 2.
(13) Capítulo 1 Introducción El manejo de la información es cada vez mas importante y por lo tanto surge la necesidad de establecer claramente definiciones y conceptos así como las relaciones existentes entre los datos contenidos en dicha información. Esto se conoce como definición de ontologías, es decir, dar conceptos y relaciones de los recursos de un dominio. Por ejemplo, la palabra creador utilizada dentro de una ontología bíblica se refiere a Dios, mientras que en una ontología editorial se refiere a el autor de un documento. Un ejemplo que ilustra lo anterior es el de un agente de viajes que ofrece la posibilidad de reservar paquetes completos de vacaciones, es decir, avión, tren, camión, hotel, renta de autos, excursiones, etc. Los proveedores ofrecen sus servicios en la red1 así como las compañías de tarjetas de crédito, lo cual nos permite encontrar ofertas, realizar reservaciones, garantizar fondos y realizar pagos. En este caso todos los proveedores de servicios son máquinas, como lo es el agente de viajes, los hoteles, las arrendadoras de autos, las aerolíneas, las compañías de tarjetas de crédito, etc. Y sólo el usuario del servicio de viajes, que interactúa con el agente, es humano. El agente de viajes toma las preferencias del usuario, busca ofertas, muestra las ofertas y costos obtenidos en base a las preferencias, toma el pedido, verifica fondos de la tarjeta de crédito proporcionada para la compra del paquete y cobra, realiza las reservaciones del paquete así como sus respectivos pagos, y, finalmente le envía una confirmación de compra al usuario con su itinerario de vacaciones. En este ejemplo el agente de viajes y los participantes desempeñan diferentes roles y cuentan con diferentes metas que mencionaremos a continuación: Roles Agente de Viajes: proporcionar un sistema que le brinda al usuario opciones para sus vacaciones en base a preferencias. Cobrar comisión por cada paquete vendido. Proveedores de servicios: vender sus servicios de una manera sencilla y automática por internet. Compañías de tarjetas de crédito: brindarle a sus clientes una manera segura y confiable de utilizar sus tarjetas de crédito en internet. 1. Web Services en inglés ó Servicios web en español. 3.
(14) • Usuario: reservar paquetes completos de vacaciones de una manera sencilla entre una gran variedad de ofertas. Metas • Agente de viajes: satisfacción al cliente y venta de paquetes vacacionales. • Proveedores de Servicios: vender sus servicios. • Compañías de tarjetas de crédito: realizar pagos. • Usuario: comprar la mejor combinación de servicios para sus vacaciones. Con respecto a las ontologías, todos los proveedores de servicios así como nuestro agente viajero deben de manejar conceptos en común, es decir, hablar el mismo lenguaje. Para esto, debe existir una ontología de viajes en donde se describa un conjunto de conceptos y sus relaciones entre sí. Los conceptos se deben asociar con un nombre y así se genera un vocabulario estándar que se utiliza para comunicar estos conceptos entre los participantes. Esto nos permite que el concepto de usuario conocido como conductor para la agencia de autos, cliente para la agencia de viajes, pasajero para la aerolínea, etc., sea entendido como la misma persona. Las consideraciones a tomar en este ejemplo son las siguientes: 1. Se cuenta con una ontología de viajes conocida por el agente de viajes y los proveedores de servicios. 2. Al mismo tiempo se tiene una ontología bancaria conocida por el agente de viajes y las compañías de tarjetas de crédito. 3. El agente de viajes cuenta con directorios de servicios para buscar hoteles, aerolíneas, tours, etc. 4. Los proveedores y las compañías de tarjetas de crédito ofrecen sus servicios en web. En base a estas consideraciones, se puede generar un sistema en donde el usuario dé información en base a sus preferencias de viaje. Datos como: • Fechas de salida y regreso. • Ciudades de salida y regreso. • Ciudades de visita. • Días por ciudad de visita. • Excursiones de interés: deportivas, culturales, arqueológicas, etc. • Personas que viajan. • Rango de gasto para hoteles. • Personas por habitación. • Renta de auto y ciudades de renta. 4.
(15) • Tipo de auto de renta (chico, mediano, de lujo). • Tipo de clase para viajar en avión, tren, autobús (Primera, negocios, turista). En base a estos datos, el agente codifica la información siguiendo el estándar de la ontología de viajes para enviar queries2 a cada proveedor de servicios en base a las preferencias del usuario. Posteriormente, el agente recibe de los proveedores ofertas definidas con la ontología de viajes, las cuales puede entender y mostrar al usuario. Se genera una nueva forma en web3, en base a las ofertas obtenidas por el agente, en donde las opciones brindadas se basan en los servicios que ofrece el agente de viajes así como sus proveedores. Es decir, si sólo se ofrece transporte aéreo entre dos ciudades sólo se van a mostrar vuelos y no posibilidades de viaje en autobús y/o barco. A continuación el usuario selecciona las mejores ofertas para él, generando así su paquete de viaje completo. Una vez generado el paquete de viaje, el usuario ó cliente proporciona su información de pago, en este caso, compañía de tarjeta de crédito y número de tarjeta. Debido a que es una transacción monetaria, el agente toma la información de pago y la codifica en base a la ontología bancaria. Esto se hace para verificar los fondos del cliente con la compañía de la tarjeta, y, en caso de no faltar, realizar el cobro por el paquete al cliente. Finalmente el agente reserva y paga a los proveedores de servicios que les corresponde. Y por último, el agente confirma la venta del paquete y envía el itinerario al cliente y/o usuario del sistema de reservaciones4. En la figura 1.1 se puede observar el sistema de reservaciones planteado. usuario. intarfase web. Figura 1.1: Agente de viajes Para este ejemplo se tomó como base el caso de reservación de viaje[26] desarrollado por el Web Services Architecture Working Group5. 2. Preguntas en sistemas de información ya sea a una base de datos, servicio en línea, etc. Se habla de la interfaz con el usuario 4 En este sistema se espera que los costos por cancelación o cambio de fechas dependa de los proveedores de servicios y del agente viajero 5 http://WBH.w3.org/2002/vs/arch/ 3. 5.
(16) El ejemplo anterior ilustra cómo hoy en día el mundo corporativo es llevado a adoptar el uso de ontologías en aplicaciones web, lo cual podemos observar con el mayor uso de XML (eXtensible Markup Language)[21] así como el desarrollo de diversos lenguajes para anotación semántica como Resource Description Framework (RDF)[9j, Agent Markup Language + Ontology Inference Layer (DAML + OIL)[28], y el Web Ontology Language (OWL)[12j. Las representaciones ontológicas procesables por máquinas serán cruciales en aplicaciones como: Máquinas de búsqueda, comercio electrónico y administración del conocimiento[24]. En nuestro caso nos interesa representar el conocimiento de una forma adecuada para posteriormente poder realizar búsquedas específicas sobre la información de nuestra organización.. 1.1.. Planteamiento del Problema. El manejo de información dentro de una organización puede ser complejo y difícil si no se cuenta con una estructura estándar para la definición y almacenamiento de los datos. La búsqueda y extracción de datos en archivos o bases de datos pueden consumir grandes cantidades de tiempo y probablemente se haga en muchas ocasiones de manera manual, es decir, una persona busca los datos que necesita en archivos de hojas de cálculo o de texto. Para optimizar esto, muchas empresas manejan aplicaciones de web con consultas a bases de datos mediante queries de SQL (Structured Query Language). Esta es una buena opción para manejar la información y hacer consultas, pero carece de interoperabilidad y portabilidad, ya que sólo sirve para las bases de datos programadas en la aplicación. Por lo tanto es necesario manejar una ontología para cada dominio mediante esquemas y a partir de cada esquema con dominio específico crear sus instancias mediante archivos de texto. Ya una vez definidos el esquema y los archivos de texto respectivamente, nuestro agente de web busca información específica en ellos. El agente viene siendo un ejemplo de cómo manejar información definida para un dominio específico, y en éste caso la presenta en web pero podría mandarla por mail, almacenarla en una base de datos, etc.. 1.2.. Objetivo. El objetivo del presente trabajo es el de presentar una metodología sencilla para definir información y manejarla en web. La definición de la información seguirá los estándares del World Wide Web Consortium (W3C)[14], lo cual permitirá que sea procesable y entendida por diversas entidades ya sean máquinas o personas.. 1.3.. Justificación. Diferentes sistemas pueden usar diferentes nombres para el mismo tipo de entidades, y en ocasiones, se llega a utilizar el mismo nombre para diferentes cosas[38]. Es por esto que es importante definir una ontología para cada dominio y relacionar los datos con su respectiva ontología. Estas relaciones de datos y ontologías son de gran utilidad en B2B e-commerce^ debido a que facilitan las búsquedas de productos y servicios para el usuario, quien descubre que comprar, cuanto cuesta, y disponibilidad. También las ontologías mantienen a la vanguardia 6. Business to biísiness e-commerce: comercion electrónico de negocio a negocio.. 6.
(17) la información de los productos y servicios mapeando constantemente los cambios en datos, de precios y productos, dados por el vendedor. Y, no sólo se puede modelar la información de productos y servicios, al mismo tiempo se puede modelar conocimiento de compradores y vendedores, es decir, usuarios. Estas modelaciones permitirán queries personalizados dependiendo de la experiencia e intereses del usuario. El presente trabajo nos muestra cómo modelar de una manera estándar la información del personal de una organización, lo cual nos da el punto de partida para modelar cualquier tipo de información o conocimiento ya sea como la mencionada anteriormente, o bien en el ejemplo de reservaciones de la página 3.. 1.4.. Hipótesis. Mediante RDF, un estándar de la W3C, podemos definir información de una organización como pequeñas bases de datos relaciónales portables en archivos. Dichos archivos constan de una ontología e instancias de dicha ontología para un dominio en específico, el cual, es definido en base a los requerimientos de la organización ó empresa. Estas definiciones nos facilitan la búsqueda específica de la información así como el manejo y la administración de los datos. Las facilidades en el manejo de la información definida mediante un estándar nos permitirá interoperabilidad entre aplicaciones e integración de bases de datos heterogéneas.. 1.5.. Agente de Semantic Web. Pensando en el problema se propuso crear un agente de web que realizara búsquedas específicas de información en archivos definidos mediante RDF. El agente se programa para web como CGI's (Common Gateway Interface) mediante un lenguaje de programación orientado a objetos. Éste -el agente- es el encargado de leer la ontología definida para un dominio. A partir de ella el agente le proporciona al usuario las opciones de búsqueda en los archivos RDF pertenecientes a esa ontología y/o dominio. Una vez vistas las opciones, el usuario selecciona una o varias de ellas y el agente busca la información deseada. Tanto el desarrollo de las ontologías, las instancias de las ontologías y el agente de búsquedas específicas se menciona a detalle en el presente trabajo.. 1.6.. Alcance y Limitaciones. Se propondrá una metodología para definir ontologías e instancias de ontologías para los datos de los empleados ó integrantes de una organización. Las ontologías y sus instancias serán en RDF y pueden ser generadas mediante una herramienta sencilla: The Protege Ontology Editor and Knowledge Acquisition System,\7}. Se implementará un prototipo funcional que muestre el manejo de la información a través de un Agente de Web. El agente de web es el encargado de leer la ontología y presentarle al usuario la información disponible mediante una interfaz en web. Mediante dicha interfaz el usuario podrá buscar por nombre de empleado la información que desee (del empleado) definida en la ontología disponible. Los resultados de las búsquedas de datos específicos por nombre de empleado serán presentados al usuario en web, y la manera en que se realizan las búsquedas permitirá al usuario conocer como se maneja la información definida en RDF. 7.
(18) 8.
(19) Capítulo 2 Marco Teórico En esta sección se habla sobre la investigación realizada para encontrar una solución al problema planteado en la sección anterior. Se comienza hablando sobre ontologías y la Semantic Web para posteriormente pasar a hablar sobre tecnologías relacionadas con ellas que ahora son parte de las recomendaciones de la W3C. Entre ellas se encuentran: XML, XML Schemas, RDF, RDF Schemas y OWL. Además se mencionan algunas tecnologías relacionadas con XML entre las que destacan DOM, SAX y XSLT.. 2.1.. Ontología. Ontología es una disciplina de la filosofía cuyo nombre data del año 1613 y se remonta hasta la época de Aristóteles. Es la ciencia de lo que es, de tipos y estructuras de objetos, propiedades, eventos, procesos, y relaciones en cada área de la realidad. Ontología es, puesto de una manera simple, acerca de lo que existe[41]. La cita más común sobre Ontología es la de Gruber[25], que dice en 1993, "Una Ontología es una especificación de una conceptualización". Esto, marca el comienzo de la investigación de ontologías en el campo de los sistemas computacionales, a pesar de que el término había sido utilizado anteriormente por McCarthy en 1980[30], Hayes en 1985(27], Sowa también en 1984[37], y Alexander et al. en 1986[17]. Un artículo de éste último define, a partir del significado filosófico de Ontología, un nuevo sentido de la palabra en el área de los sistemas computacionales. Y a partir de 1986 el uso del término se hace frecuente en inteligencia artificial, así como en las áreas de ingeniería de software y bases de datos. En bases de datos y diseño de sistemas de información esto juega un rol de suma importancia y se le conoce como conceptual modeling. En ingeniería de software se conoce como domain modeling, y se beneficia a partir de los sistemas orientados a objetos. Mientras que en inteligencia artificial se sabe que se intenta representar al mundo de una manera lógica, y a partir del surgimiento de los sistemas expertos se ha incrementado el interés por la representación del conocimiento mediante ontologías que representan una parte del mundo. No fue hasta mediados de los noventas que quedó claro el problema entre la falta de interoperabilidad entre los sistemas de información, lo cual, hace surgir la necesidad por definir lo que existe en un dominio -conocido como recursos- , su significado, y las relaciones entre los recursos. 9.
(20) 2.2.. Semantic Web. La semantic web tiene como principal característica la generación y el manejo del contenido procesable por máquinas[40]. Un ejemplo de ello son los agentes compradores que buscan las mejores tarifas y precios de viajes y productos. En esta búsqueda el agente debe conocer el contenido de la información que procesa, es decir, su semántica. Ahí entra el verdadero reto de la semantic web, que viene siendo la representación del contenido en un formato procesable para máquina. Cabe aclarar que el interés es la definición del contenido de una manera estándar y no mediante programación directa a los agentes ó aplicaciones web, ya que se perdería la interoperabilidad entre sistemas. Si se sigue un estándar, la información del sistema puede ser definida y manejada por diversos programadores y diferentes aplicaciones1, en cambio, si se programa el contenido directamente en las aplicaciones sin ningún estándar, futuros desarrollos de contenido deberán ser realizados por los programadores originales del sistema, ó gente que recibió manuales y/o entrenamiento sobre el sistema original. La evolución de la web ha dado lugar a su integración con la semántica, y algunos aspectos de esta evolución se mencionan a continuación. 1. Localización de recursos: las búsquedas por palabra clave y texto, ya no son las únicas. Ahora surgen búsquedas más específicas y sofisticadas que utilizan semántica. 2. Usuarios: los recursos ya no son sólo para humanos, también son para máquinas. 3. Tareas y servicios: se realizan tareas y brindan servicios en donde se requiere de la semántica. La semantic web es desarrollada por diversos laboratorios de investigación y la W3C. Algunas de sus definiciones son: La Semantic Web brindará estructura al contenido de las páginas de internet, creando ambientes donde los agentes de software navegando de página a página podrán llevar a cabo tareas sofisticadas. Un agente en un ambiente como tal, visitando la página de una clínica no sólo conocerá las keywords2 de la página como "tratamiento, medicina, terapia física", también sabrá que el Dr. Hartman trabaja en la clínica los lunes, miércoles y viernes y que el script3 toma fechas en el formato de yyyy-mm-dd y que regresa citas de consulta. "La Semantic Web es una extensión de la web actual en donde a la información se le da un significado bien definido que permite mejorar el trabajo cooperativo entre computadoras y gente[20]." La Semantic Web proporciona una base común (framework) que permite a los datos ser compartidos y reutilizados a través de aplicaciones, empresas, y comunidades. Es un esfuerzo colaborativo de la W3C con la participación de un gran número de investigadores y socios industriales. Se basa en el Resource Description Framework (RDF), que integra una variedad de aplicaciones utilizando XML para sintaxis y URI's (Uniform Resource Identifiers) para nombrarfll]". 'Punto primordial del presente trabajo Palabras clave de documentos html incluidas con el meta tag que dan una idea del contenido de la página 3 Página dinámica de html 2. 10.
(21) 2.3.. XML. XML es una tecnología para crear lenguajes de marcación que describen datos virtualmente de cualquier tipo en una manera estructurada[23]. A diferencia del HTML, en donde los tags se encuentran definidos, en XML el autor define sus propios tags para definir sus datos. XML puede ser utilizado para crear lenguajes de marcación casi en cualquier dominio como pueden ser: fórmulas matemáticas, estructuras moleculares químicas, gráficas, datos financieros, etc. Los documentos de XML pueden ser creados con cualquier editor de texto. En el mercado existe software para crear automáticamente dichos documentos y/o editarlos y guardarlos, software como xmlspy de Altova disponible en http://www.altova.com/. Todos estos documentos deben tener un elemento raíz que contiene a todos los otros elementos del documento, y los elementos contenidos dentro de otro se conocen como elementos hijos. Lo mencionado anteriormente se puede observar en el siguiente ejemplo: <?xml version="1.0"?> <miDocumento> <mensaje>Hola Mundo!</mensaje> </miDocumento> Figura 2.1: Ejemplo de XML Aquí el elemento raíz es miDocumento y el elemento hijo es mensaje que contiene el texto de Hola Mundo!. 2.3.1.. Historia. La herencia de XML viene del Standard Generalized Markup Language (SGML) creado por el Dr. Charles Goldfarb en los años setenta[36]. SGML surge como una innovación en las aplicaciones que procesan texto como lo es editar, formatear, archivar, e intercambiar documentos. Al mismo tiempo es útil para administrar y manejar bases de datos de documentos[35]. Es altamente utilizado en sistemas de publicación, aunque su complejidad preconcebida evitó que se distribuyera en la industria4. Su gran impulso fue hasta que Tim Berners-Lee en 1990 creó el HTML basándose en SGML[19], lo que dio lugar en un dos por tres a que toda la industria de sistemas utilizara un lenguaje de marcación para generar documentos y aplicaciones. Hoy en día HTML es el lenguaje de marcación más popular, pero sus tags son diseñadas para la interacción entre humanos y máquinas. Lo que da lugar al nacimiento del XML debido a la necesidad de manejar información entre aplicaciones. Supongamos que tenemos el siguiente elemento de HTML: <td>766818</td> • ¿Es un código postal? • ¿Es un costo? 4. Por lo que también se le conoce como "Sounds Great, Maybe Later" 11.
(22) • ¿Es una cantidad? • ¿Es una matrícula? La respuesta es que quzás sí ó quizás no. En realidad no se puede determinar sin inteligencia. Es necesaria la inteligencia para leer los campos y títulos de la tabla donde 766818 se encuentra. Por ejemplo, si la tabla se llama alumnos del campus Monterrey, y el nombre de la columna donde el dato se encuentra se llama matrícula, sabemos entonces que 766818 es la matrícula de un alumno del campus Monterrey. Como ser humano se puede interpretar el dato en las celdas de una tabla, pero para que una máquina lo interprete, es necesario definir los datos de una manera estructurada y es lo que nos brinda XML. HTML tiene como principal objetivo la presentación de la información en web, mientras que XML tiene como objetivo la definición del contenido de la información de una manera estructurada. Un documento de XML debe contener la información marcada con tags que la describen. Y al mismo tiempo, los tags, deben describir las relaciones entre los datos. Observemos el siguiente documento: <?xml versión»" 1. O" ?> <alumnos> <titulo>Alumnos de las Maestrías del ITESM campus Monterrey</titulo> <MIT> <Nombre>Leonardo</Nombre> <Apellido_Paterno>Maycotte</Apellido_Paterno> <Apellido_Materno>Felkel</Apellido_Materno> <matricula>766818</matricula> <email>al766818Qmail .mty . itesm.mz</email> </alumnos> Figura 2.2: Documento de XML Este documento contiene los datos personales de un alumno de la Maestría en Ciencias en Sistemas Inteligentes del ITESM campus Monterrey. Y el manejo de la información en aplicaciones es mucho más sencillo que si los datos estuvieran definidos en HTML con <table>,<tr>,<td>, etc.. 2.3.2.. Reglas. A diferencia de HTML, XML resulta muy estricto. Por ejemplo, si un navegador de internet no entiende la sintaxis del documento HTML adivina y presenta los resultados que cree convenientes. En cambio, en XML los documentos se parsean (parse) para ser posteriormente procesados, pero de no cumplir las especificaciones de XML el parser5 produce una exepcion y el documento XML no se procesa. En este caso el parser no tiene la libertad de interpretar lo que se quiso decir en el documento. Las reglas principales en XML son: 5. Programa de computadora que divide el texto en strings de caracteres reconocidos para análisis futuros 12.
(23) • Un documento de XML debe estar contenido en un solo elemento. Este elemento se llama document element ó root element. • Todos los elementos deben estar anidados. • Todos los atributos deben estar entre comillas, ya sea sencillas o dobles. • Existe diferencia entre mayúsculas y minúsculas en los tags. • Los documentos deben ser declarados como XML. Por ejemplo: <?xmlversion=" 1.0"encoding—"ISO8859-1"6. Entre los encodings mas utilizados se encuentran el UTF-8, UTF-16, e ISO8859-17.. 2.3.3.. Namespaces. Los namespaces son utilizados para diferenciar entre dos tags con el mismo nombre. Para ello cada namespace deberá tener su propio Uniform Resource Identifier (URI) que, por lo general, es un Uniform Resource Locator(URL) pero puede ser un Uniform Resource Name(URN). A continuación se menciona un ejemplo sobre como definir información sobre obras de arte en donde es necesario diferenciar entre títulos de pinturas y esculturas. Esta distinción se realiza mediante el uso de namespaces como se observa enseguida. <?xml version="1.0"?> <Arte xmlns = "http://www.misitio.com/arte.dtd" xmlns:pintura = "http://www.misitio.com/pinturas.xsd" xmlns¡escultura = "http://www.misitio.com/esculturas.dtd"> <obra ID"=456"> <titulo:pintura>La Noche Estrellada</titulo> <autor>Van Gogh</autor> <ciudad>Nueva York</ciudad> <pais>USA</pais> <lugar>Museo de Arte Moderna</lugar> </obra> <obra ID="457"> <titulo:escultura>David</titulo> <autor>Miguel Angel</autor> <ciudad>Florencia</ciudad> <pais>Italia</pais> <lugar>Museo de la Academia</lugar> </obra> Figura 2.3: Ejemplo de namespaces De no declararse el encoding se asume UTF-8 como encoding que viene siendo un Unicode standar con el que se pueden representar la mayoría de los caracteres de los lenguajes del mundo 7. Mayor información en http://otn.oracle.com/pub/notes/technote_encodings.html. 13.
(24) En el ejemplo anterior se cuenta con tres namespaces declarados mediante el atributo xmlns, en donde el default namespace no tiene prefijo. Aquí, el default namespace es el del url de arte.dtd, esto quiere decir que la definición de los tags sin prefijo se encuentra en el archivo de arte.dtd localizado en: http://www.misite.com/arte.dtd. Mientras tanto, las definiciones de los tags <titulo:pintura> y <titulo:escultura> se encuentran en los archivos de pinturas.xsd y esculturas.dtd respectivamente. A continuación se explican los archivos XSD's y DTD's.. 2.3.4.. Document Type Definitions (DTD's) y XML Schemas. Los DTD's y XML Schemas&, son metalenguajes9 utilizados para definir restricciones y características de un vocabulario en XML. Por ejemplo, si queremos definir un documento en XML que describa una orden de compra que comienza con el elemento <orden>, el cual contiene los elementos de <cliente-id>, <producto>, y <f echa>; en donde el elemento <producto> contiene como atributos numeroSerie y cantidad, podemos utilizar DTD's y XML schemas como se muestra en los siguientes ejemplos. Mediante DTD's (archivo.dtd): <?xml version="1.0" encoding="UTF-8"?> <!ELEMENT orden (cliente-id, producto+, fecha)> <!ELEMENT cliente-id (#PCDATA)> <!ELEMENT producto EMPTY>. <!ATTLIST producto numeroSerie CDATA #REQUIRED cantidad CDATA #REQUIRED> <!ELEMENT fecha EMPTY> <!ATTLIST fecha dia CDATA #REQUIRED mes año. CDATA #REQUIRED CDATA #REQUIRED>. Figura 2.4: Ejemplo de un DTD Y por medio de XML Schemas (archivo.xsd): <?xml version="1.0" encoding="UTF-8"?> <xsd:schema xmlns:xsd="http://www.w3.org/2000/10/XMLSchema"> <xsd:element name="orden"> <xsd:complexType> <xsd:sequence> <xsd:element ref="cliente-id"> <xsd:element ref="producto" maxOccurs="unbounded"> <xsd:element ref="fecha"> </xsd:sequence> </xsd:complexType> 8 Esquemas en español pero para evitar confuciones se utilizarla la palabra schemas cuando se hable de archivos que definen características de algún vocabulario 9 Lenguajes que hablan de otros lenguajes. 14.
(25) </xsd:element> <xsd:element name="cliente-id" type="xsd:string"/> <xsd:element name="producto"> <xsd:complexType> <xsd:attribute name="numeroSerie" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:string"> <xsd:pattern value="[0-9]{5}-[0-9]{4}-[0-9]{5}"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="cantidad" use="required" type="xsd:integer"/> </xsd:complexType> </xsd:element> <xsd:element name="fecha"> <xsd:complexType> <xsd:attribute name="dia" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:integer"> <xsd:maxlnclusive value="31"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="mes" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:integer"> <xsd:maxlnclusive value="12"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> <xsd:attribute name="año" use="required"> <xsd:simpleType> <xsd:restriction base="xsd:integer"> <xsd:maxlnclusive value="2050"/> </xsd:restriction> </xsd:simpleType> </xsd:attribute> </xsd:complexType> </xsd:element> </xsd:schema> En el ejemplo anterior los elementos se definen mediante <xsd: element name="nombreElemento">, en donde nombreElemento es el nombre del tag en el docuemnto XML. Si dicho elemento contiene elementos anidados esto se declara mediante <xsd:complexType>, en dado caso de que no tenga elementos anidados pero sí atributos o restricciones se utiliza <xsd: simpleTypeX Si 15.
(26) son varios los elementos anidados se declaran dentro de <xsd: sequence> mediante <xsd: element ref ="nomElem"; en donde nomElem es el nombre del elemento anidado. En este ejemplo primero se declara el elemento orden con sus elementos anidados y posteriormente se declaran los elementos anidados. En el caso del elemento cliente-id sólo se especifica que es de tipo string mientras que en producto y fecha sí se declaran atributos y restricciones. Para producto se definen los atributos numSerie y cantidad este último de tipo integer. Y para fecha se declaran los atributos dia, mes y año. Las restricciones se declaran dentro de <xsd:restriction base="xsd:tipo"> en donde tipo puede ser integer o string entre otros. Entre las restricciones del ejemplo anterior tenemos dos clases: <xsd: pattern value=" [0-9] {5}- [0-9] {4}- [0-9] y <xsd:maxlnclusive value="12"/>. En la primera se describe como debe ser el número de serie del producto mientras que en la segunda el número máximo que puede tomar el atributo mes. A continuación se mencionan dichas restricciones como ventajas de los XSD. Las ventajas de utilizar XML schemas en vez de DTD's son: 1. Se pueden definir tipos de datos (datatypes en inglés) como se observa en el ejemplo anterior para numSerie, dia, mes y año. En este caso se especifica que numSerie es un string con el formato de xxxx-xxxxx-xxxx, en donde cada x es un dígito entre O y 9; dia es un integer entre 1 y 31; mes entre 1 y 12; y año entre 1 y 2050. 2. Los schemas son documentos de XML que pueden ser manipulados y transformados mediante XSLT Stylesheets10 como se verá a continuación.. 2.4.. XSLT. La flexibilidad de XML para presentar datos estructurados ha hecho que sea el lenguaje ideal para el intercambio de información. Los primeros usuarios comenzaron con interfaces de programación como el Document Object Model (DOM)[S\ y el Simple API (Application Programming Interface^ for XML (SAX)[íO], para parsear y procesar documentos de XML. El uso de estas interfaces no resulta común para el usuario promedio de la web ya que no se espera que sepa mucho código de Java, Visual Basic, Perl, o Python; esto da lugar a un lenguaje flexible, poderoso y relativamente simple para procesar XML que se conoce como eXtensible Stylesheet Language for Transformations (XSLT)[39]. XSLT es una recomendación de la W3C y nos brinda una manera flexible y poderosa de transformar documentos de XML en algo más. Ese algo más puede ser un documento de HTML, PDF (Portable Document Format), SVG (Scalable Vector Graphics), VRML (Virtual Reality Modeling Language), código de java, archivo de texto, archivo JPEG, u otro documento de XML entre algunos. Para realizar dicha transformación se escribe una hoja de estilo (Stylesheet) en XSLT en donde se definen las reglas de transformación para el documento de XML, y por medio de un procesador de XSLT se realiza la transformación. Esto quiere decir que se requiere de dos archivos, uno de XML y otro de XSLT, y de un procesador de XSLT que tome como entrada ambos archivos y nos genere como salida un archivo con el formato deseado. La W3C ha definido dos tipos de hojas de estilo. La primera y más sencilla es la de Cascading Style Sheets (CSS) que a pesar de poder ser utilizada con XML, generalmente se utiliza para HTML en donde se definen las propiedades de los elementos. Esto quiere decir que todo el estilo -presentación en web- del documento HTML puede definirse en un archivo 10. eXtensible Stylesheet Language for Transformations. 16.
(27) CSS en donde se especifican colores, tipos de letra, tamaños, etc. A pesar de ello las CSS's son limitadas debido a que: • No pueden cambiar el orden en que aparecen los elementos. Si queremos ordenar de cierta manera o filtrar en base a ciertas propiedades las CSS son insuficientes. • Las CSS's no hacen cálculos. • Las CSS's no combinan múltiples documentos. Esto no quiere decir que las CSS's no sean útiles, sino que fueron diseñadas con propósitos de presentación para documentos de HTML y de hecho XSLT es utilizado para generar HTML con elementos de CSS. A continuación mencionaremos algunas características de XSLT. Una stylesheet de XSLT es un documento de XML y de hecho puede ser utilizada para generar otro documento de XML que puede ser otra stylesheet de XSLT. El lenguaje de XSLT se debe basar en igualdad de patrones. Las stylesheets deben consistir de reglas11 que se utilizan para transformar el documento. Estas reglas son mas o menos como: "Cuando veas esto...., conviértelo a esto...". Las variables en XSLT son estáticas, esto quiere decir que no pueden cambiar de valor una vez inicializadas. Por lo tanto varias reglas pueden ser procesadas simultáneamente sin el riesgo de que al procesar una regla se generen efectos laterales en otras reglas. Esto se debe a la influencia de lenguajes de programación funcional como Lisp[16] en donde las variables tampoco cambian. Lisp define programas como una serie de funciones en donde cada uno genera una salida bien definida en respuesta a una entrada bien definida. Debido a que el valor de las variables XSLT no cambia, se hace imposible utilizar ciclos como for o while lo que da lugar al uso de la iteración. Por iteración se quiere decir que en un témplate de XSLT se dice, "toma todas las cosas que se ven de esta manera..., y esto es lo que quiero que hagas con ellas...". En base a estas características vemos las ventajas del XSLT que nos permiten generar interoperabilidad entre diversos sistemas. El beneficio del uso de esta tecnología lo podemos observar en diversos ejemplos como: Ejemplo 1: Dispositivos. Se quiere distribuir información entre diversos dispositivos como browsers, celulares, bipers, etc. Esto significa que se quieren traducir los datos automáticamente a un formato específico dependiendo del dispositivo tecnológico donde va a ser desplegada la información. Solución: La información se estructura en documentos estándar de XML y mediante XSLT se transforma a los formatos requeridos. Ejemplo 2: Bases de Datos. Se necesita el intercambio de información entre socios que tienen diferentes bases de datos. Solución: Se define un formato común de XML para intercambiar la información entre socios, y por medio de XSLT cada quien la convierte a sus respectivas import files de SQL. 1. También se les conoce como templates 17.
(28) Ejemplo 3: Documento. Se tienen diferentes documentos y se quieren generar reportes en donde se calculen valores, desplieguen gráficas, etc. Solución: Los documentos se definen en XML y XSLT filtra y maneja la información para realizar cálculos y presentar gráficas.. 2.4.1.. Ejemplo de XSLT. Ahora veamos el ejemplo clásico de Helio World!. Primero definimos la información estructurada en un documento de XML llamado hello.xml. como se ve en la siguiente figura. <?xml version='1.0'?> <saludo>Hola Mundo ! </saludo> Figura 2.5: Helio World! en XML Posteriormente creamos nuestra stylesheet -hello.xslt- que define como transformar el documento de XML. <?xml version='1.0'?> <xsl: transí orm xmlns:xsl="http://www. w3.org/1999/XSL/Transform" version="1.0"> <xsl:output method="html" indent="yes"/> <xsl: témplate match='/>> <xsl : apply-templates select= ' saludo ' /> </xsl : template> <xsl: témplate match=' saludo '> <html> <body> l> <xsl : value-of select= ' .'/> </body> </html> </xsl : template> </xsl : transí orm> Figura 2.6: Stylesheet de hello.xml Por último transformamos hello.xml utilizando la stylesheet hello.xslt mediante un comando del procesador XSLT. A continuación se muestra el comando con un procesador de java y con un procesador de python. Por medio del procesador Xalan[15] de Java: java org. apache. xalan. xslt .Process -in hello.xml -xsl hello.xslt -out hello.html Por medio el procesador 4xslt de python: 4xslt -o hello.html hello.xml hello.xslt. 18.
(29) 4xslt es parte de una plataforma de código abierto (Open-source) diseñada para procesar XML y RDF. Dicha plataforma se llama 4Suite[l] y en el siguiente capítulo se hablará de ella más a detalle. Al correr el procesador XSLT mediante cualquiera de las instrucciones anteriores12 se genera el archivo hello.html que queda como: <html> <body> <hl>Hola Mundo!</hl> </body> </html> Figura 2.7: Helio World! en HTML Para generar esta salida primero el procesador XSLT leyó la hoja de estilo y guardó los elementos <xsl:output> y <xsl:template>, en donde el primero especifica la salida como un archivo de HTML y el segundo las partes del documento XML que deben transformarse 13 . Una vez procesada la hoja de estilo se lee el documento de XML y su información se representa mediante un árbol. Se comienza con el nodo raíz representado como "/" en donde se le indica la instrucción <xsl:apply-templates select =< saludo'/> para que se transforme la información del elemento saludo generándose así el documento de HTML con el texto de Hola Mundo!. La especificación de XSLT nos permite tres tipos de archivos de salida: HTML, XML y texto. Si se desea otro formato primero se debe generar otro archivo de XML con el vocabulario eXtensible Stylesheet Language for Formating Objects (XSL-FO), en donde se definen características de presentación, para luego convertir ese archivo de XML a su formato deseado.. 2.5.. DOM y SAX. Los dos API's más utilizados para parsear los documentos de XML son el Document Object Model (DOM) y el Simple API for XML (SAX). DOM es una recomendación oficial de la W3C disponible en http://www.w3.org/DOM/, mientras que SAX es un estándar "de facto" disponible en http://sax. sourceforge.net/.. 2.5.1.. DOM. DOM fue diseñado para representar en forma de árbol documentos de XML en donde todo el documento de XML debe de estar contenido en un sólo elemento, el cual, es el primer nodo del árbol generado a partir del documento. Este elemento es conocido como el elemento raíz (Root element del árbol y se representa (como se mencionó en la sección anterior) con "/". El nodo raíz tiene como hijos a todos los elementos del documento, los cuales pueden ser vistos y manipulados en el árbol mediante la especificación de DOM[4]. Esta especificación define interfaces neutrales al lenguaje14 y algunas de ellas son: 12. Dependiendo del procesador XSLT en el sistema Algunos procesadores utilizan tablas estructuradas optimizadas para representar la información de la styiesheet "Lenguaje de programación 13. 19.
(30) Node Es el datatype base de DOM. Element, document, text, comment, ft attr extienden la interfaz Nodo. Document Este objeto contiene la representación en DOM del documento XML. Dado el objeto Document, se puede obtener la raíz del árbol (el Document element); y a partir de la raíz es posible navegar por el árbol encontrando elementos, atributos, texto, comentarios, instrucciones, etc. del documento XML. Element Esta interfaz representa un elemento del documento XML. Attr Esta interfaz representa un atributo de un elemento del documento XML. Text Esta interfaz representa texto del documento XML y el texto del documento se convierte en nodos de texto. Estos nodos de texto pueden ser hijos de los nodos de elementos o de atributos. Comment Esta interfaz representa un comentario en el documento XML que comienza con <!— y termina con —>. Processing Instruction (PI) Esta interfaz representa una instrucción que se procesa en el documento XML. Este tipo de instrucciones se representan de la siguiente manera: <?xml-stylesheet href='témplate.xsl' type='text/xslj?> En el ejemplo anterior se asocia una hoja de estilo XSLT -template.xsl- con el documento XML. Ahora mencionaremos lo que hace el DOM parser. Al momento de parsear un documento de XML con DOM se: • Crean objetos (Elements, Attr, Text, Comments) representando el contenido del documento. • Arreglan dichos objetos en un árbol. Cada Element en el documento de XML tiene ciertas propiedades como su nombre e hijos (childElement). • Farsea el documento entero. Lo más significativo de DOM es que maneja los documentos en forma de árboles como lo hace un procesador de XSLT. Esto facilita acceder, consultar y editar las partes -ya sean elementos, atributos, texto, etc.- del documento. 20.
(31) Farseando XML con DOM A continuación se muestra un ejemplo en donde se parsea XML mediante una implementación de DOM en Python15. >» >» >» ... from xml.dom.ext .reader import PyExpat reader = PyExpat. Reader () textoXML="""<?xml version='1.0'?> . <Productos> <Televisor> <marca>sony</marca> <costo moneda=' pesos '>2999</costo> ... <monitor unidades='pulgadas'>21</monitor> </Televisor> <MP3Player> <marca>apple</marca> <capacidad>4 GB</capacidad> <costo moneda=' dolares '>289</costo> </MP3Player> . . . </Productos>. doc=reader.fromString(xmlText) >» doc <XML Document at 827b084> En este ejemplo el XML se lee como string pero puede leerse como archivo cambiando la instrucción doc=reader . f romString (textoXML) por doc=reader . f romUri ( ' /path/ archivo . Este documento de XML queda en un árbol como se ilustra en la figura 2.8.. Figura 2.8: Árbol de DOM Para ver cómo navegar en el árbol anterior consultar el apéndice A, mientras que para ver como crear un documento XML a partir de una clase de python ir al apéndice B. 5. La implementación de DOM utilizada es parte de 4Suite[l] 21.
(32) 2.5.2.. SAX. El Simple API for XML fue desarrollado por David Megginson y otros en la lista de discusión XML-DEV[13]. Algunas diferencias importantes con respecto a DOM son: • SAX es interactivo. Conforme el parser de SAX va procesando el documento, envía eventos. Es decir, conforme va parseando el documento de XML va indicando el inicio del documento, el inicio de un elemento, texto, el fin de un elemento, una instrucción procesable (PI), el fin del documento, etc. A diferencia de DOM en donde hay que esperar a que el parser termine todo el documento. • SAX utiliza menos recursos de memoria que DOM. Cuando el parser encuentra algo en el documento XML, depende del usuario si se guarda o no. • SAX no brinda la vista jerárquica que proporciona DOM. Esto quiere decir que SAX dice "aquí hay este texto" más no te dice a que elemento pertenece el texto. Es responsabilidad del usuario conocer la estructura del documento XML. Entre las principales ventajas de SAX es que es interactivo. La mayoría de las transformaciones hechas con XSLT ocurren en el lado del servidor. A pesar de ello la mayoría de los procesadores de XSLT se encuentran basados en DOM ya que ambos utilizan árboles para representar losdocumentos de XML.. 2.6.. RDF. El principal objetivo del Resource Descriptíon Framework (RDF) es facilitar el trabajo de los agentes autónomos mejorando los directorios de servicios y motores de búsqueda[33]. Hasta el momento la web cuenta con cuatro limitaciones ampliamente aceptadas: • El predominio de documentos HTML que combinan contenido con presentación. • La dificultad de mantener los sitios de Internet reflejando cambios actuales. • La dificultad de presentar perfectamente contenido dinámico. • Encontrar exactamente lo que uno busca. De estas limitan-tes la W3C espera atacar las últimas dos mediante RDF argumentando que facilita la automatización del manejo de datos. RDF es posible gracias al formato de datos estándar que brinda XML, es por ello que se habla de RDF como la mejor aplicación de XML[33]. RDF es simplemente una manera de dar afirmaciones mediante tripletas en donde cada tripleta se conoce como un statement. Por ejemplo: "Este documento fue escrito por Leonardo Maycotte". A esto se le conoce como un statement el cual consta de tres partes: un sujeto ("Este documento"), un predicado ("fue escrito por"), y un objeto ("Leonardo Maycotte"). RDF no es más que la descripción de recursos. Los recursos son representados por Uniform Resource Identifiers (URIs), de los cuales los URLs son un subconjunto. El sujeto de los enunciados RDF (RDF statements) debe ser un recurso así que el statement mencionado anteriormente quedaría como se muestra en la figura 2.9. 22.
(33) Figura 2.9: Un statement de RDF. Nacionalidad \. Figura 2.10: Varios statement's de RDF En el ejemplo de la figura 2.9 el objeto es un string: "Leonardo Maycotte". A esto se le conoce como literal en RDF. El objeto no necesariamente debe ser una literal también puede ser un recurso como se puede observar en lafigura2.10. En la figura 2.10 se reemplaza la literal "Leonardo Maycotte" de la figura 2.9 por un URI que representa a esta persona el cual viene siendo el sujeto de más statements de RDF. A esta colección de statementsse le conoce como modelo en RDF y sigue los estándares de la recomendación de la W3C: RDF Primer'[29]. La representación abstracta del ejemplo anterior es la base del RDF pero no resulta práctica para el intercambio de descripciones, es por ello que RDF/XML Syntax[18] brinda un formato señalizado16 en XML para RDF. A continuación podemos ver como quedaría señalizado el modelo RDF de lafigura2.10. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:hola="http://www.Imaycotte.com/schemas/ejemplo#"> <rdf¡Description rdf:about="http://www.Imaycotte.com/tesis"> <hola:fue-escrito-por> <rdf:Description rdf:about="http://www.Imaycotte.com/datos"> <hola:nombre>Leonardo Maycotte</hola:nombre> <hola:nacionalidad>Mexicana</hola:nacionalidad> </rdf:Description> </hola:fue-escrito-por> </rdf:Description> </rdf:RDF> Esta es una de varias maneras de señalizar el modelo mediante XML, lo que si es una constante para todas es el elemento <rdf :RDF> que envuelve los statements de RDF. Dentro del elemento RDF se encuentra el elemento Description que indica el sujeto de los statements. En este ejemplo se utiliza el atributo about que apunta hacia un recurso externo como sujeto. El statement con este recurso como sujeto tiene un predicado dado por el elemento <fue-escrito-por> y otro recurso como objeto. Este otro recurso viene siendo el sujeto de 16. Formato basado en texto. 23.
(34) dos statements, uno con el predicado "nombre" y objeto "Leonardo Maycotte"; y otro con el predicado "nacionalidad" y objeto "Mexicana". Es importante notar el uso de los XML namespaces para establecer la interpretación semántica de los elementos y atributos. En este ejemplo se utilizan los elementos y atributos definidos por RDF/XML en el URL dado por xmlns:rdf, utilizando el prefijo rdf para diferenciarlos de otros elementos17. Al mismo tiempo hay un namespace dado por el usuario donde él mismo define los elementos con el prefijo hola mediante un RDF schema. Hablaremos más sobre estos esquemas en la siguiente sección. Finalmente nos queda validar el código anterior mediante el servicio que nos proporciona la W3C: RDF Validation service disponible en http://www.w3.org/RDF/Validator/. Al validar y pedir los statments de RDF en el formato N-Triplesls se obtiene: <http://www.Imaycotte.com/datos> <http://www.Imaycotte.com/schemas/ej emplo#nombre> "Leonardo Maycotte" <http://www.Imaycotte.com/datos> <http://www.Imaycotte.com/schemas/ej emplo#nacionalidad> "Mexicana" <http://www.Imaycotte.com/tesis> <http://www.Imaycotte.com/schemas/ejemplo#fue-escrito-por> <http://www.Imaycotte.com/datos> Como podemos ver hay tres statements con sujeto, predicado y objeto en ese orden. Es importante notar que se le agrega el URL del esquema dado por el usuario a los elementos que pertenecen a dicho esquema. En los apéndices C y D se presenta como parsear, editar y/o serializar documentos RDF.. 2.7.. RDF Schemas (RDFS). Al hablar sobre las especificaciones de RDF, en realidad se habla sobre dos de ellas: • Especificación de sintaxis (Syntax. Specification). • Especificación de esquema (Schema Specification) La especificación de sintaxis es la mencionada en la sección anterior en donde elementos como hola:nombre y rdf ¡Description son utilizados para describir un recurso en específico proporcionando información como el autor del recurso. En el contexto RDF/XML (Syntax Specification)[18], un vocabulario o esquema es un diccionario basado en reglas que define los elementos de un dominio y describe como estos elementos se relacionan entre ellos. Esto quiere decir que la especificación de esquema proporciona un sistema para crear vocabularios RDF/XML para ciertos dominios. Por ejemplo, 17. A los prefijos en rdf se les conoce como QNames Más información en http://www.w3.org/2001/sw/RDFCore/ntriples/. 18. 24.
(35) hola ¡nombre es un elemento creado por el usuario19 para definir nombres de personas, mientras que rdf¡Description es un elemento del vocabulario de RDF (Syntax Specificaton) para describir recursos. Lo que significa que RDF Syntax Specification es un vocabulario de la W3C al cual rdf ¡Description pertenece mientras que hola es un vocabulario generado por el usuario. Eso sí, ambos siguen las reglas definidas en: RDF Vocabulary Description Language 1.0: RDF Schema[22]. Por lo tanto, si RDF es una manera de describir los datos entonces los esquemas de RDF son una manera de describir los metadatos20 y son utilizados para describir los datos de un vocabulario con dominio específico[34]. Por ejemplo, supongamos que tenemos un documento RDF con los siguientes elementos: <rdf:Description rdf:about="http://www.tienda.com/venta#1267"> <cliente:nombre>Edgar Degas</cliente:nombre> <libro:nombre>Pale Blue Dot</libro:nombre> <libro:autor>Carl Sagan</libro:autor> </rdf:Description> En este ejemplo nombre es parte de dos vocabularios, libro y cliente. En el primer vocabulario se define nombre como el título de un libro, mientras que en el segundo se define como el nombre de un cliente. 2.7.1.. Elementos. Los elementos del RDF Schema se encuentran marcados por un namespace específico identificado en un documento mediante la siguiente declaración: xmlns:rdfs="http://www.w3.org/2000/01/rdf-shema#" Dentro de la especificación RDFS se encuentra un grupo esencial de clases y propiedades utilizadas para describir elementos RDF pertenecientes a un dominio en particular. Esto, combinado con un grupo de restricciones es la parte fundamental del RDF schema.. Clases rdfs:Resource Todas las cosas descritas en RDF son llamadas recursos, y son instancias de la clase rdf s :Resource. Esta es la clase principal. Todas las otras clases son subclases de esta clase. rdfs:Resource es una instancia de rdfs:Class. rdfs:Class Tipo o categoría de recurso. Esta es la clase de recursos que son clases de RDF. rdfs:Class es una instancia de rdfs:Class. rdfs:Literal Es la clase de valores literales como strings e integers. Valores de propiedades como strings de texto son ejemplos de literales de RDF. rdfs:Literal es una instancia de rdfs:Class y una subclase de rdfs:Resource. rdfs:Datatype Es la clase de los tipos de datos, rdfs: Datatype es una instancia y subclase de rdfs:Class y cada instancia de rdfs:Datatype es una subclase de rdf s:Literal. '"Usuario de RDF Datos que describen datos. 20. 25.
(36) rdfcXMLLiteral Literales RDF que utilizan sintaxis de XML. Clase de valores literales de XML. rdf :XMLLiteral es una instancia de rdfs:Datatype y una subclase de rdfs: Literal. rdfrProperty Es la clase de las propiedades de RDF y una instancia de rdf s:Class. Propiedades rdfs:range Instancia de rdf: Property utilizada para definir que los valores de una propiedad son instancias de una o mas clases. Por ejemplo, P rdfs:range C quiere decir que los statements de RDF con predicado P tienen como objetos instancias de la clase C. rdfszdomain Instancia de rdf: Property utilizada para definir que cualquier recurso con una propiedad dada es una instancia de una o más clases. Por ejemplo, P rdfs:domain C quiere decir que los statements con predicado P tienen como sujetos instancias de la clase C. rdfctype Instancia de rdf: Property utilizada para definir que un recurso es una instancia de una clase. Por ejemplo, R rdf :type C quiere decir que C es una instancia de rdf s:Class y que R es una instancia de C. rdfs:subClassOf Instancia de rdf: Property utilizada para definir que todas las instancias de una clase son instancias de otra. rdfs:subPropertyOf Instancia de rdf: Property utilizada para definir que todos los recursos relacionados por una propiedad se encuentran relacionados por otra propiedad. rdfs:label Instancia de rdf: Property utilizada para darle al recurso un nombre entendible para el usuario. rdfs:comment Instancia de rdf: Property utilizada para describir el recurso. Clases y propiedades adicionales así como constructores para representar contenedores y statements de RDF se encuentran disponibles en el RDF Vocabulary Description Language 1.0: RDF Schema[22}. A continuación se presenta un ejemplo de lo que podría ser una parte de un RDF schema para publicaciones.. RDF Schema <?xml version="1.0"?> <rdf:RDF. xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#" xmlns:publ="http://www.Imaycotte.com/publicacion/elementos/1.0/"> <rdfs:Class rdf:about="http://www.Imaycotte.com/publicacion/elementos/1.0/Libro"> <rdfs:subClassOf 26.
(37) rdf:resource="http://www.w3.org/2000/01/rdf-schema#Resource"/> </rdf:Class> <rdf .-Property rdf:about="http://www.Imaycotte.com/publicacion/elementos/1.0/titulo"> <rdfsrdomain. rdf:resource="http://www.Imaycotte.com/publicacion/elementos/1.0/Libro"/> </rdf:Property> <rdf¡Property rdf:about="http://www.Imaycotte.com/publicacion/elementos/1.0/autor"> <rdfs:domain rdf:resource="http://www.Imaycotte.com/publicacion/elementos/1.0/Libro"/> </rdf:Property> </rdf:RDF> Ahora veamos como se puede utilizar este esquema en un archivo RDF.. RDF file <?xml version="1.0"?> <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:publ="http://www.Imaycotte.com/publicacion/elementos/1.0/"> <rdf:Description rdf:about="http://www.Imaycotte.com/libros/blackhole.html"> <publ:titulo>Black Holes and Time Warps</publ:titulo> <publ:autor>Kip S. Throne</publ:autor> </rdf:Description> </rdf:RDF>. 2.8.. OWL. OWL (Web Ontology Language) es un lenguaje diseñado para ser utilizado en aplicaciones que necesitan procesar el contenido de la información y no sólo presentarla[5]. OWL es una revisión del DAML+OIL web ontology language que incorpora el aprendizaje obtenido del diseño y aplicación de este último. OWL brinda mayor interoperabilidad que XML, RDF, y RDFS mediante vocabulario adicional y tres sublenguajes altamente expresivos: . OWL Lite . OWLDL . OWL Full La Semantic Web es una visión del futuro de la web en donde la información cuenta con significado explícito. Esto facilita a las máquinas procesar e integrar automáticamente la información de la web. La Semantic Web gracias a los tags personalizados de XML y el 27.
(38) beneficio de RDF para representar datos da lugar a un lenguaje de ontologías que puede describir formalmente terminologías utilizadas en documentos. Si se espera que las máquinas realicen tareas de razonamiento con estos documentos se requiere de un lenguaje que vaya más allá de la semántica proporcionada por el RDF Schema. OWL ha sido diseñado para satisfacer estas necesidades como parte de las recomendaciones de la W3C relacionadas con la Semantic Web que se mencionan a continuación. • XML: brinda sintaxis para estructurar documentos, pero no impone restricciones semánticas con respecto al significado de estos documentos. • XML Schema: lenguaje que proporciona restricciones con respecto a la estructura de los documentos XML y especifica tipos de datos en estos documentos. • RDF: es un modelo de datos para objetos, llamados recursos, y relaciones entre ellos. Brinda semántica simple para este modelo de datos que pueden ser representados mediante la sintaxis de XML. • RDF Schema: vocabulario que describe las propiedades y las clases de los recursos de RDF con semántica para jerarquías generales para estas propiedades y clases. • OWL: enriquece el vocabulario para describir propiedades y clases de RDF permitiendo definir relaciones entre clases, cardinalidad, igualdades, características, etc. Las ontologías son usualmente expresadas en lenguajes basados en lógica donde las distinciones entre clases, propiedades y relaciones se pueden realizar acertada y consistente-mente. Algunas herramientas mediante ontologías pueden realizar razonamiento automático para brindar servicios inteligentes como: búsquedas conceptuales y semánticas, extracción de información, agentes inteligentes, soporte para toma de decisiones, entendimiento del lenguaje natural, administración del conocimiento, bases de datos, y comercio electrónico[6]. Las ontologías destacan en el surgimiento de la Semantic Web como una manera de representar la semántica de los documentos y permitiendo que esta semántica sea procesada por aplicaciones web y agentes inteligentes que gracias a ellas pueden trabajar al nivel conceptual humano. Las ontologías son críticas para aplicaciones que quieren realizar búsquedas de información. A pesar que los XML DTD 's y los XML Schemas son suficiente para el intercambio de datos entre aplicaciones que han acordado de antemano las definiciones a utilizar, la falta de semántica en ellos hace difícil integrar nuevos vocabularios de XML en donde se pueden confundir significados. RDF y RDF Schema solucionan este problema permitiendo asociar semántica mediante identificadores. Con RDF Schema se pueden definir clases que tengan múltiples subclases y super clases, se pueden definir propiedades que tengan sub propiedades, dominio y rango. En este sentido, RDF Schema es un lenguaje simple de ontologías. Sin embargo, para alcanzar mayor interoperabilidad es necesario un lenguaje más amplio. Por ejemplo, RDF Schema no puede especificar que un auto y una persona son clases disjuntas, o que un trío cuenta con tres músicos. Aquí es cuando OWL llega a ser necesario.. 28.
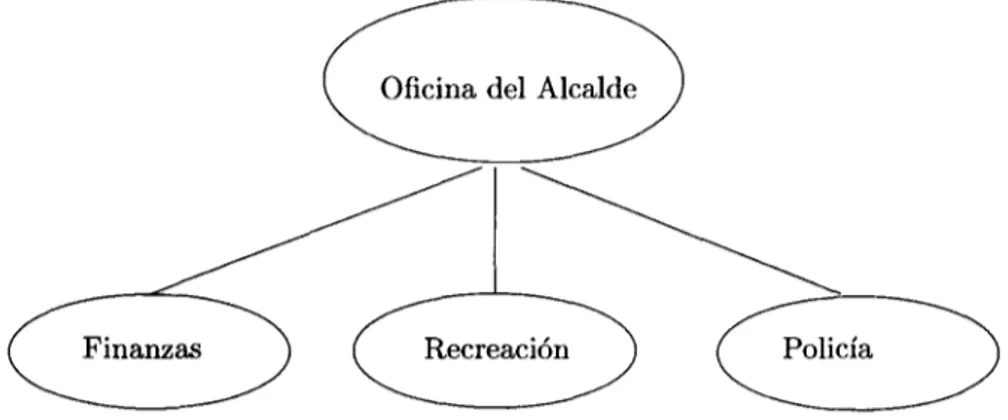
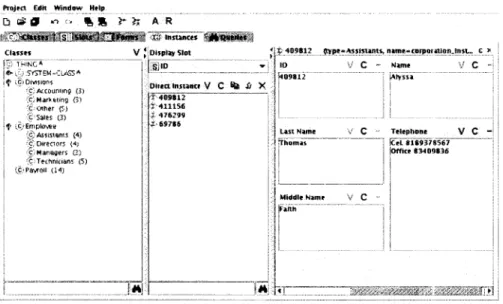
(39) Capítulo 3. Solución Propuesta El propósito del presente trabajo es el de presentar una metodología para describir y transportar información de una organización a través del Internet mediante definiciones ontológicas en archivos de texto. Esta metodología puede ser aplicada a cualquier tipo de organización desde educativa a de comercio y gobierno. En la figura 3.1 podemos observar una parte de la organización del gobierno de la ciudad en donde esta metodología puede ser aplicada para compartir y manejar información de los empleados entre la oficina del alcalde y sus respectivos departamentos (finanzas, policía, recreación, etc).. Figura 3.1: Ejemplo de una organización. 3.1.. Metodología: 5 Pasos. A continuación se presenta una metodología para definir información en archivos RDF, realizar búsquedas sobre dichos archivos, extraer información y manejarla. Primer Paso: Definiendo el esquema de su organización. Primero utilizamos Protégé[7] y su plugin de RDF para generar los archivos de texto con semántica. Las clases en protege son como las tablas de nuestras bases de datos y los protege slots son como los nombres de las columnas. En la figura 3.2 podemos observar el registro de un empleado en la tabla Payroll y un query realizado para obtener sus beneficios médicos (health benefits). La misma información puede verse definida en protege en la figura 3.3. 29.
(40) £!lc £dit View Terminal 2o Help nysql> select * from Payroll; | ID I | I I I. | Salary. 489812 489812 489812 489812 489812. | $35,000 | NULL | NULL | NULL I NULL. I Benefits I Paid vacatíons I Pensión Plan I Company Discounts I NULL I NULL. | Health_Benefits. I. 1 Dental Insurance I i Dísabílity Insurance I I Life Insurance I | Health Insurance I I Paid Sick Leave I. 5 rows in set (0.00 sec) nysql> select Health_benefits frotí Payroll where ID='489812' and Health_benefits ! ='NULL' ; I Health.benefits. I. | Dental Insurance i | Disability Insurance | | Life Insurance I I Health Insurance | | Paid Sick Leave I 5 rows in set (0.00 sec). Figura 3.2: Tabla de MySQL. Projttt Edil Wmdow Help "ü £¿fl». '**"<:«~ ft * Display Slol. Dtrca insana V C H* & X 476299 ^512309 í-546?ll í 569*73 í 629344 -i" 670914 1 661662 2 691003 -X 71*0«7 •%, 7567Í9 ^76681». vifuions an PUn Contpviy diitoumt. V C. íf*»hh Iniurant* ' <P«td Sick Lttvt. Figura 3.3: Tabla de base de datos en Protege. 30. V C -.
(41) Así definimos n clases de protege a partir del esquema de nuestra organización con un slot en común, el ID slot. Este es nuestro key slot y es utilizado para definir información relacional con otras clases de protege, en donde cada ID representa el número único de identificación personal de cada empleado. Protege es una herramienta que facilita la generación de documentos RDF y RDFS más no es indispensable para ello. En caso de no utilizarse protege véanse las clases de protege como simples clases de RDF y los protege slots como propiedades de una clase en RDF. Segundo Paso: Definiendo información de la organización. Una vez definido el esquema de nuestra organización, lo guardamos y hacemos público como un archivo RDFS en el URL dado como namespace en nuestro proyecto. Ahora el esquema de se encuentra disponible para que cualquier miembro de nuestra organización lo guarde y utilice para definir información. Esto lo puede hacer importando el archivo RDFS a su instalación local de protege, o culaquier otro editor de RDF, y a partir de él generar instancias basadas en el esquema de la organización. Estas instancias se guardan como archivos RDF para ser enviadas a aplicaciones que realicen búsquedas específicas de información, de los empleados, y manejen los datos a su conveniencia. Tercer paso: Farseando los archivos RDF. Los archivos RDF y RDFS se parsean con 4RDF que es parte de 4Suite, una plataforma de código abierto (open source) para procesar XML y RDF[1]. En la sección 3.2 se presenta un ejemplo de una aplicación web que parsea y realiza queries (consultas) a los archivos RDF y RDFS. Esta aplicación se encuentra programada en python y utiliza 4Suite. Los documentos de RDF se parsean como objetos que contienen los statements de RDF, es decir, las tripletas con sujeto, objeto y predicado. Para mayor información sobre 4RDF y python consultar los apéndices C y D. Cuarto Paso: Haciendo Consultas. Las consultas (comúnmente llamadas queries) se realizan con VERSA, un lenguaje para queries de RDF[32]. Primero, antes de utilizar VERSA, hacemos disponible la información que puede ser encontrada en los archivos RDF gracias a las propiedades definidas en el archivo RDFS, o más bien dicho en el archivo que define el esquema de nuestra organización gracias al RDF Schema. Esto se hace gracias al método complete O como se puede observar en la siguiente función de python. def getPropertiesQ : #d es el documento RDFS parseado resul = d.complete(None, "http://www.w3.org/1999/02/22-rdf-syntax-ns#type", "http://www.w3.org/1999/02/22-rdf-syntax-ns#Property") lista = [] select = []. for stmt in resul: lista.append(stmt.subject) for x in range(lendista)) : fi = lista[x].find('#') select.append(lista[x][fi+1:]) return select Ejemplo de una tripleta RDFS parseada por la función getProperties: 31.
Figure




+7




Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
que hasta que llegue el tiempo en que su regia planta ; | pise el hispano suelo... que hasta que el
dente: algunas decían que doña Leonor, "con muy grand rescelo e miedo que avía del rey don Pedro que nueva- mente regnaba, e de la reyna doña María, su madre del dicho rey,
Ciaurriz quien, durante su primer arlo de estancia en Loyola 40 , catalogó sus fondos siguiendo la división previa a la que nos hemos referido; y si esta labor fue de
En este trabajo estudiamos la obra poética en español del escritor y profesor argelino Salah Négaoui, a través de la recuperación textual y análisis de Poemas la voz, texto pu-
Las manifestaciones musicales y su organización institucional a lo largo de los siglos XVI al XVIII son aspectos poco conocidos de la cultura alicantina. Analizar el alcance y
En la parte central de la línea, entre los planes de gobierno o dirección política, en el extremo izquierdo, y los planes reguladores del uso del suelo (urbanísticos y
اهعضوو يداصتق�لا اهطاشنو ةينارمعلا اهتمهاسم :رئازجلاب ةيسلدنأ�لا ةيلاجلا« ،ينوديعس نيدلا رصان 10 ، ، 2 ط ،رئازجلاب يسلدنأ�لا دوجولاو يربي�لا ريثأاتلا
