Paquete sobre el Mathematica 8 0 para variantes del análisis de Regresión Categórica
87
0
0
Texto completo
(2) Dictamen. El que suscribe, Claudia Orama Gómez, hago constar que el trabajo titulado “Paquete sobre el Mathematica 8 para variantes del análisis de Regresión Categórica” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio. Fecha. I.
(3) “Mejor es adquirir sabiduría que oro preciado; Y adquirir inteligencia vale más que la plata.” Proverbios 16:16 “Porque mejor es la sabiduría que las piedras preciosas; Y todo cuanto se puede desear, no es de compararse con ella.” Proverbios 8:11. II.
(4) Dedicatoria. …al Rey de los siglos, inmortal, invisible, al único y sabio Dios, sea honor y gloria por los siglos de los siglos… 1 Timoteo 1:17. III.
(5) Agradecimientos. Agradecimientos. En primer lugar a Dios porque por Él he llegado hasta aquí. A mi familia por apoyarme en todo. A mi tutores: Dra. Gladys Casas Cardoso y MSc. Juan Manuel Navarro Céspedes por dedicarme su tiempo y experiencia. A Jorge Luis por haberme ayudado incondicionalmente. A mi esposo Jorge por ayudarme y apoyarme en todo, en los buenos y en los malos momentos. A mi amiga Lisette por ayudarme y estar dispuesta para lo que necesitara. A mis suegros por alentarme todo este tiempo. A los profesores que me llevaron a ser un profesional. A mis amigos y hermanos que siempre se preocuparon por mí. A todos los que de una forma u otra en algún momento contribuyeron a realizar este trabajo.. IV.
(6) Resumen. Resumen El análisis de datos categóricos es una rama importante de la estadística. Su campo de aplicación es amplio. Las ciencias sociales y las ciencias médicas son buenos ejemplos de ello. Esta tesis trata sobre un método de análisis de datos categóricos: el análisis de regresión categórica. El trabajo comienza con un estudio exhaustivo del análisis de regresión múltiple y la verificación de los supuestos. Se describen numerosas pruebas gráficas y estadísticas para verificar la normalidad de los residuales y la homogeneidad de sus varianzas. Se explican en detalle el modelo de regresión categórica y su algoritmo. Se creó y probó un paquete sobre el Mathematica 8.0 para realizar los cálculos fundamentales. Se utilizaron datos simulados para mostrar y comentar los resultados más importantes. Además se presentó un problema con datos reales: el diagnóstico de la hipertensión arterial en la ciudad de Santa Clara.. V.
(7) Abstract. Abstract The categorical data analysis is an important branch of Statistic. Their field of application is wide. Social Sciences and Medical Sciences are good examples. This thesis is about the method of analysis of categorical data: the categorical regression analysis. The work begins with an exhaustive study of the multiple regression analysis and the verification of the assumptions. Many graphical and statistical tests to verify the residual normality and the homogeneity of their variances are described. The model of the categorical regression analysis and its algorithm are carefully explained. A Mathematical package to do the fundamental calculus was created and proved. A simulated data was used in order to show and comment the most important results. Also a real data of a medical problem was presented: the diagnosed of the hypertension in the Santa Clara City.. VI.
(8) Índice. Índice. Introducción ........................................................................................................... 1 1. Análisis de regresión lineal múltiple y de regresión categórica ........................... 6 1.1. Análisis de regresión .................................................................................. 6. 1.1.1 Análisis de regresión lineal simple .......................................................... 7 1.1.2 Análisis de regresión lineal múltiple ........................................................ 9 1.2. Verificación de los supuestos................................................................... 13. 1.2.1 Algunas pruebas gráficas ...................................................................... 14 1.2.2 Prueba de la homogeneidad de varianzas ............................................. 17 1.2.3 Pruebas de normalidad ......................................................................... 18 1.3. Análisis de regresión categórica............................................................... 22. 1.3.1 Niveles de escalamiento óptimo ........................................................... 24 1.3.2 Estimación de las Transformaciones ..................................................... 28 1.3.3 Formulación del modelo de regresión categórica ................................. 29 1.3.4 Algoritmo para la regresión categórica ................................................. 31 1.4. Consideraciones finales del capítulo ........................................................ 35. 2. Implementaciones sobre el Mathematica ........................................................ 36 2.1 La entrada de los datos ............................................................................... 36 2.2 Análisis de regresión lineal múltiple ............................................................ 39 2.2.1 Propiedades del LinearModelFit relacionadas con la suma de los cuadrados de los errores: .............................................................................. 40 2.2.2 Propiedades del LinearModelFit relacionadas con los parámetros ....... 41 2.2.3 Propiedades del LinearModelFit que miden la bondad de ajuste .......... 42 VII.
(9) Índice. 2.3 Verificación de los supuestos ...................................................................... 43 2.3.1 Prueba de Kolmogorov Smirnov ............................................................ 43 2.3.2 Prueba de Jarque Bera .......................................................................... 44 2.3.3 Prueba de Anderson Darling ................................................................. 46 2.3.4 Prueba de Shapiro Wilk ......................................................................... 47 2.4 Implementación de la regresión categórica sobre el Mathematica ............. 48 2.5 Consideraciones finales del capítulo ........................................................... 56 3. Diagramas y Aplicaciones ................................................................................ 57 3.1 Modelado con UML. Diagramas .................................................................. 57 3.1.1 Diagrama de casos de uso ..................................................................... 57 3.1.2 Diagrama de Actividades....................................................................... 59 3.2 Paquete RegCatNum ................................................................................... 62 3.3 Función RegresionLineal ............................................................................. 63 3.3 Aplicaciones ................................................................................................ 64 3.3.1 Estudio con datos simulados ................................................................. 64 3.3.2 Estudio de la Hipertensión Arterial ....................................................... 67 3.4 Consideraciones finales del capítulo ........................................................... 71 Conclusiones ........................................................................................................ 72 Recomendaciones ................................................................................................ 73 Referencias Bibliográficas .................................................................................... 74 Anexos ................................................................................................................. 76. VIII.
(10) Introducción. Introducción El cambiante mundo moderno está sustentado por un conjunto de ciencias empleadas por el hombre para, entre otras cosas, controlar y perfeccionar los procesos; tal es el caso de la Estadística. Son varios los métodos que se ocupan de los modelos matemáticos en general y que en los últimos años se han desarrollado, métodos que gracias al desarrollo de la informática han sido automatizados, por lo que resultan de gran utilidad práctica para solucionar problemas presentes en la sociedad. La tecnología informática con que se dispone hoy en día, casi inimaginable hace sólo dos décadas, ha posibilitado avances extraordinarios en el análisis de datos ya sea en áreas del conocimiento como la medicina, la meteorología, la bioinformática y la educación o de tipo psicológico, sociológico y de otros referidos al comportamiento humano. Este impacto es más evidente en la relativa facilidad con la que los ordenadores pueden analizar enormes cantidades de datos complejos y en menos tiempo. Hoy en día casi cualquier problema se puede analizar fácilmente por un número ilimitado de programas estadísticos, incluso en ordenadores personales. Además, los efectos del progreso tecnológico han extendido mucho más la capacidad de manipular datos, liberando a los investigadores de las restricciones del pasado y permitiéndoles así abordar investigaciones más sustantivas y ensayar sus modelos teóricos. Las limitaciones metodológicas no son ya un asunto crítico para el teórico empañado en la búsqueda de evidencia empírica. Gran parte de esta creciente comprensión y pericia en el análisis de datos ha venido a través del estudio y desarrollo de la estadística y de la inferencia estadística. En las investigaciones, fundamentalmente las de corte social, intervienen conjuntos de datos que reflejan alguna cualidad o categoría. A estos datos se les conoce como datos categóricos. Dichos datos pueden contener una mezcla de diferentes tipos de variables, muchas de las cuales están medidas en categorías ordenadas o desordenadas. Variables como las estaciones del año, los tipos de determinado producto en el mercado, o el hecho que un estudiante apruebe o no un examen, son 1.
(11) Introducción. ejemplos de variables con categorías desordenadas. Variables como el nivel de educación o la frecuencia con que se desarrolla cierta actividad (nunca, a veces o siempre), son ejemplos de variables con categorías ordenadas. Las variables continuas pueden considerarse variables categóricas, coincidiendo cada categoría o cualidad con su valor. Estos tipos de variables requieren diferentes tratamientos en el proceso de análisis de datos, los cuales no siempre son tan evidentes como pudieran parecer. Además, muchas de estos conjuntos pueden contener variables que pueden o no estar relacionados linealmente, lo cual también tendrá que ser reflejado en el resultado del análisis. De aquí entonces que el análisis de datos categóricos no siempre se realizará tan fácilmente como el investigador desearía. No son pocos los métodos que introducen las denominadas variables “dummy” para trabajar con variables que no tienen propiedades numéricas reales. En estos métodos las variables categóricas son divididas en variables indicadoras de cada categoría, donde el “uno” representa la presencia de la misma y el “cero” la ausencia. Estas variables “dummy” son utilizadas como variables numéricas en el análisis. Tales métodos, sin embargo, suelen ser muy intensivos, especialmente cuando las variables tienen muchas categorías(Agresti 2002). El trabajo con datos categóricos data desde 1902 con el descubrimiento más importante de Karl Pearson: el test chi cuadrado. Sobre la década de los 60 hubo una explosión, dado en gran medida por el desarrollo de la informática, de métodos de análisis estadísticos para datos categóricos(Agresti 2002). Para el análisis de datos categóricos se han desarrollado varios métodos, uno de los cuales se estudiará en detalle en el presente trabajo: el análisis de Regresión Categórica. Resulta interesante conocer cómo influyen los métodos de discretización y las transformaciones del escalamiento que se aplican a las variables en los resultados de la regresión. Estos procedimientos se encuentran implementados en el SPSS, por lo que resulta imposible realizar esos análisis utilizando dicho paquete. El paquete. 2.
(12) Introducción. Mathematica (http://www.wolfram.com) es un sistema para hacer matemáticas utilizando una computadora personal. Es a la vez: . Una calculadora científica.. . Un paquete de subrutinas de cálculo numérico.. . Un instrumento de cálculo simbólico.. . Un sistema de graficación.. . Un lenguaje de programación de alto nivel.. . Un sistema interactivo para crear documentos multimedia.. . Un sistema de apoyo a otros programas.. . Una gran fuente de información matemática (Wolfram 1999).. Este software (Mathematica) contiene paquetes para hacer análisis de regresión y realizar verificación de los supuestos, los cuales servirán de punto de partida para la elaboración del paquete de regresión categórica. La versión que se ha utilizado es la 8.0 pues es la primera en incorporar pruebas de hipótesis para probar normalidad como Kolmogorov Smirnov, Anderson Darling, Jarque Bera y muchas otras más. Consecuentemente el objetivo general de la presente tesis es desarrollar una implementación computacional, utilizando el paquete Mathematica, de algunas variantes del método de regresión categórica. Para lograr dicho objetivo, se proponen los objetivos específicos: 1. Implementar en el Mathematica el método de regresión lineal múltiple con el análisis de los supuestos. 2. Estudiar el algoritmo de regresión categórica para seleccionar las variantes factibles de implementación inmediata sobre el paquete Mathematica. 3. Crear un paquete en el Mathematica con los procedimientos necesarios para realizar los cálculos de la variante seleccionada. 3.
(13) Introducción. 4. Obtener e interpretar aplicaciones con datos simulados y reales. Para dar cumplimiento a estos objetivos fue necesario plantearse y solucionar algunas tareas de investigación, entre las que se encuentran: 1. Estudiar las funciones del Mathematica que permiten realizar análisis de regresión lineal. 2. Estudiar las facilidades que brinda el Mathematica 8.0 para realizar el análisis de los supuestos. 3. Implementar una función que aglutine los dos aspectos anteriores. 4. Implementar una entrada cómoda de datos en la que se especifique por cada variable su escalado. 5. Estudiar el algoritmo de regresión categórica. Seleccionar las variantes que sean factibles de implementar de manera inmediata. 6. Implementar en el Mathematica una primera variante del algoritmo de regresión categórica y realizar el análisis de los supuestos a la ecuación obtenida. El primer paso para la realización de este trabajo fue la confección del marco teórico. Para ello se realizó una amplia revisión de la literatura consultando libros, artículos y páginas de internet, entre otras fuentes. Sus elementos esenciales se encuentran expuestos de manera resumida en el primer capítulo de la presente tesis. Como conclusión de la elaboración del marco teórico se enuncia la siguiente hipótesis de investigación: H1: “Utilizando el software Mathematica se implementa un paquete que permite realizar variantes del análisis de regresión para datos categóricos” H2: “El paquete implementado permite resolver problemas reales de varios campos de aplicación, entre los que se encuentra la Medicina”. 4.
(14) Introducción. El trabajo está conformado por tres capítulos: El capítulo 1 constituye una revisión bibliográfica sobre el tema de regresión lineal múltiple y la importancia que tiene la verificación de los supuestos, describiendo luego la regresión categórica, técnica relativamente nueva. En el capítulo 2 se hace énfasis en las implementaciones realizadas en el Mathematica para el desarrollo del paquete de regresión categórica. En el capítulo 3 se muestran aplicaciones obtenidas del método de regresión categórica explicado en los capítulos anteriores, mediante un estudio de la Hipertensión Arterial (HTA) y de un juego de datos simulados. Finalmente. se. presentan. las. conclusiones de. la. tesis, así como algunas. recomendaciones que abren futuras líneas de investigación.. 5.
(15) Capítulo 1. 1. Análisis de regresión lineal múltiple y de regresión categórica En este capítulo se describe brevemente la conocida técnica de regresión lineal múltiple, haciendo énfasis en la importancia de la verificación de los supuestos. Posteriormente se presenta y describe una técnica relativamente nueva: la regresión categórica.. 1.1. Análisis de regresión. Desde un punto de vista más general, el análisis de un proceso conduce a la concepción del mismo bajo el principio de la caja negra, como se muestra en la figura 1.1. Figura 1.1 Principio de la caja negra en un análisis de regresión. donde:. X : es el vector de variables de entrada (que incluye las variables controlables) Y : es el vector de variables de salida. Y el rectángulo o caja negra es el proceso que se desconoce y que se desea investigar. Se desea encontrar la función que relaciona las variables de entrada y salida a partir de conjuntos de valores experimentales de esas variables. El objetivo del análisis de regresión es determinar para cada componente y j , del vector Y , la función f j que la relaciona con las componentes x1 , x2 ,, xn del vector. X : y j f j x1 , x2 ,, xn .. 6.
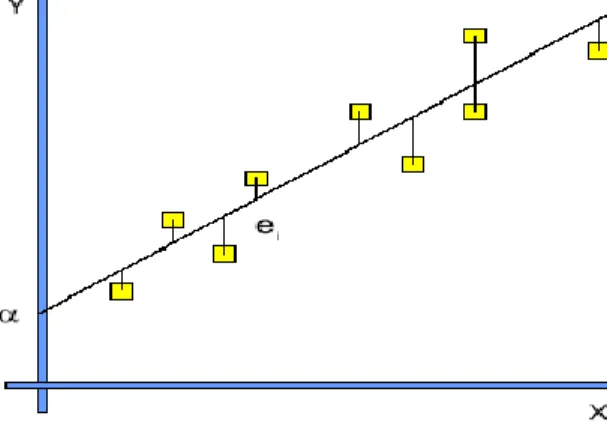
(16) Capítulo 1. Es necesario tener resultados experimentales donde para cada conjunto de variables de entrada se haya medido el valor de las variables de salida objeto de análisis. El caso más simple, frecuente en la práctica, es aquel en que las funciones f j son lineales, o sea, se buscan coeficientes k tales que: y j 1 x1 2 x2 n xn . (1.1). donde representa el error de estimación. No siempre este modelo es el más adecuado y por ello son importantes también los casos en que, por ejemplo, las funciones f j son cuadráticas, más generalmente polinomios, o incluso, expresiones más complejas en que aparezcan funciones trascendentes. Los problemas de regresión no lineal pueden ser reducidos a problemas de regresión lineal siempre y cuando las igualdades y j f j x1 , x2 ,, xn puedan ser reducidas a ciertas dependencias lineales entre funciones de las variables mencionadas.. 1.1.1 Análisis de regresión lineal simple La figura 1.2 muestra la relación lineal que existe entre dos variables cualesquiera X, Y. Figura 1.2 Relación lineal entre las variables X e Y.. 7.
(17) Capítulo 1. Se quiere obtener la ecuación que mejor ajuste la nube de puntos, o sea una ecuación de la forma y a bx . El método de los mínimos cuadrados intenta minimizar los cuadrados de los residuales, es decir: 2. n. 2. n. n. 2. min yi yˆ i min yi a bxi min i i 1. Sea: S . i 1. n. 2. yi yˆ i i 1. n. (1.2). i 1. 2. yi a bxi . (1.3). i 1. Se necesita hallar el mínimo de S. Para ello se calculan:. S 2 yi a bxi 1 a. (1.4). S 2 yi a bxi xi b. (1.5). Igualando a 0 se obtienen las ecuaciones:. y y. i. a bxi 0. (1.6). i. a bxi xi 0. (1.7). Trabajando algebraicamente:. yi na b xi. (1.8). xi yi a xi b xi2. (1.9). Resolviendo el sistema de ecuaciones se llega a la solución: b. xi x yi y xi x 2. a y bx. (1.10) (1.11). 8.
(18) Capítulo 1. Además puede probarse que:. 2S a 2 2S b. 2. 2n 0 (1.12). 2 xi2 0. (1.13). Los estimadores hallados son estimadores mínimos cuadráticos de los parámetros originales. Ellos cumplen varias propiedades, como por ejemplo son insesgados(Calero 1998).. 1.1.2 Análisis de regresión lineal múltiple El procedimiento regresión lineal permite utilizar más de una variable independiente. La ecuación de regresión ya no define una recta en el plano, sino un hiperplano en un espacio multidimensional. La ecuación será de la forma: y j 1 x1 2 x2 n xn . (1.14). Este modelo, al igual que cualquier otro modelo estadístico, se basa en una serie de supuestos (linealidad, independencia, normalidad, homocedasticidad y no-colinealidad) que se verán más adelante. La ecuación de regresión mínimo-cuadrática se construye estimando los valores de los coeficientes i del modelo de regresión. Estas estimaciones se obtienen intentando hacer que las diferencias al cuadrado entre los valores observados y los pronosticados sean mínimas. Métodos para hallar ecuaciones múltiples Enter: En un sólo paso todas las variables independientes entran a formar parte de la ecuación.. 9.
(19) Capítulo 1. Remove: Parte de una ecuación con todas las variables independientes incorporadas y en un único paso elimina todas las variables que cumplen con el criterio de eliminación. Forward: Es un método paso a paso en el que las variables independientes entran paso a paso en el modelo. La primera variable en entrar es aquella que mayor correlación tenga con la variable dependiente y. Esta variable entra en la ecuación sólo si satisface el criterio de entrada. En los pasos siguientes entra la variable que mayor coeficiente de correlación parcial tenga. El procedimiento finaliza cuando no queden variables que satisfagan el criterio de entrada. Backward: Es un método paso a paso, que comienza con todas las variables incluidas en el modelo. En cada paso elimina la variable que menor coeficiente de correlación parcial tenga con la variable dependiente y. Para eliminar esta variable se necesita además que ella cumpla un criterio de eliminación. El procedimiento finaliza cuando no queden variables en el modelo que satisfagan el criterio de eliminación. Stepwise: Es un método paso a paso que combina las dos técnicas anteriores. En cada paso entra a la ecuación la variable independiente más importante, si cumple el criterio de entrada. Las variables que ya están en el modelo, pueden ser eliminadas si cumplen con el criterio de eliminación. El método termina cuando ninguna variable puede ser incluida o eliminada. Estimaciones y predicciones Como resultado de un análisis de regresión lineal simple se obtiene una ecuación lineal de y en función de x. Para hacer pronósticos, los nuevos valores de x deben pertenecer al dominio de las x utilizadas en la construcción del modelo. Debe verificarse la validez del modelo, probando la bondad del ajuste mediante una prueba de hipótesis(Scheffe 1959): Ho : b 0 H1 : b 0. 10.
(20) Capítulo 1. Que conduce a la tabla ANOVA: Tabla 1.1 Tabla ANOVA Fuente de variación. g.l.. Suma de cuadrados. F. Cuadrados medios. Regresión. SCReg. 1. CMReg. Residual. SCRes. n-2. CMRes. Total. SCTot. n-1. F. CM Re g CM Re s. Significación. Sig. donde: SCReg: suma de cuadrados de la regresión SCRes: suma de cuadrados residual SCTot: suma de cuadrados total Puede verificarse que: SCTot = SCReg + SCRes CMReg: cuadrado medio de la regresión CMRes: cuadrado medio residual De manera general puede decirse que la variabilidad total se descompone en variabilidad explicada por la regresión y variabilidad residual. Si esta última es mayor que la primera, entonces el modelo hallado no es útil. En ese caso debe cuestionarse el uso de una línea recta para modelar el problema y se sugiere probar variantes de regresiones no lineales. 2 Coeficiente de determinación R. El coeficiente de determinación representa la proporción de la varianza total que es explicada por la regresión. 11.
(21) Capítulo 1. Este valor se encuentra entre 0 y 1 (0 R 2 1) y es una medida que puede utilizarse para determinar si se ha hecho un buen ajuste de X e Y. Por ejemplo, si R 2 0.90 puede afirmarse que el 90% de la varianza total es explicada por la suma de cuadrados de la regresión, por lo tanto existe una fuerte relación entre X e Y. El valor del R 2 aumenta en la medida en que se incrementan las variables en el modelo. Por tanto, no es correcto comparar el valor del R 2 de dos regresiones con un número de variables explicativas diferentes. Coeficiente R 2 ajustado Para subsanar la tendencia del. R 2 se ha definido un R2-ajustado de la siguiente. manera: SSE /( n p) n 1 1 (1 R 2 ) SST /( n 1) n p donde p es el número de parámetros en el modelo. 2 Rajus 1. (1.15). El modelo que se busca es aquel que tiene un R2-ajustado alto con pocas variables. El R 2 ajustado podría disminuir al incluirse una variable adicional en el modelo. El valor R 2 ajustado siempre es un poquito más bajo que el valor R 2 múltiple porque refleja la complejidad del modelo (el número de variables) a medida que se relaciona con los datos. Por consiguiente, el valor R 2 ajustado es una medida más precisa del rendimiento del modelo. Criterio de información Akaike (AIC) El criterio de información Akaike (AIC) es una medida relativa de bondand de ajuste para un modelo estadístico. Fue desarrollado por Hirotsugu Akaike y publicado por él mismo en 1974. En el caso general, el AIC se calcula como: (1.16). 12.
(22) Capítulo 1. donde k es el número de parámetros en el modelo estadístico y L es el valor maximizado de la función de probabilidad para el modelo estimado. De un conjunto de modelos candidatos para el juego de datos, se escoge el de menor valor AIC. Por consiguiente, el AIC no sólo ofrece la bondad del ajuste sino que también incluye una función de incremento del número de parámetros estimados en forma de multa. Esta multa pone freno al overfitting (incremento del número de parámetros en el modelo que mejora la bondad de ajuste sin tener en cuenta el número de parámetros libres en el proceso de generación de datos)(Wikipedia).. 1.2. Verificación de los supuestos. Para validar un modelo, se necesita verificar los supuestos de un análisis de regresión ya que el incumplimiento de uno de ellos puede ocasionar errores sistemáticos. Entre los más importantes se pueden mencionar: . Independencia. Los residuos son independientes entre sí, es decir, los residuos constituyen una variable aleatoria (recordemos que los residuos son las diferencias entre los valores observados y los pronosticados). Es frecuente encontrarse con residuos autocorrelacionados cuando se trabaja con series temporales.. . Homocedasticidad. Para cada valor de la variable independiente (o combinación de valores de las variables independientes), la varianza de los residuos es constante.. . Normalidad. Para cada valor de la variable independiente (o combinación de valores. de. las. variables. independientes),. los. residuos se. distribuyen. normalmente con media cero. . No-colinealidad. No existe relación lineal exacta entre ninguna de las variables independientes. El incumplimiento de este supuesto da origen a colinealidad o multicolinealidad. 13.
(23) Capítulo 1. El examen de los residuos es necesario y útil, no sólo porque permite comprobar la validez de los supuestos hechos en el Análisis de Regresión, sino también porque, en el caso de fallar algunos de ellos, da indicaciones para lograr su cumplimiento: cambiando. la. forma. del. modelo,. transformando. las. variables,. rechazando. observaciones o utilizando pesos (Mínimos Cuadrados Ponderados). Una vez que los residuos han sido calculados se presentan varias alternativas para su examen: . Analizar la relación de los residuos y las variables.. . Analizar los residuos en conjunto para rechazar observaciones o probar si su distribución es Normal.. . Graficar. los. residuos. contra. los. valores. estimados. para. verificar. la. homogeneidad de la varianza experimental y la adecuación del modelo.. 1.2.1 Algunas pruebas gráficas La figura 1.3 muestra un ejemplo en el que los residuos se agrupan en forma de una banda horizontal. Esto no da evidencia de fallos en los supuestos. Figura 1.3 Representación gráfica de los residuales contra los valores predichos sugiriendo homogeneidad de varianzas.. En el gráfico siguiente, los residuos varían en magnitud notablemente al aumentar los valores de la Y. Esto indica que la varianza de las observaciones no es constante y 14.
(24) Capítulo 1. que se deben utilizar pesos (Mínimos Cuadrados Ponderados) o transformar las observaciones. Figura 1.4 Representación gráfica de los residuales contra los valores predichos sin sugerir homogeneidad de varianzas.. Este último gráfico muestra que los residuos se relacionan con los valores predichos en forma de parábola o similar. Ello es un indicador de que el modelo es inadecuado, se necesitan términos extras en el modelo o transformaciones de la variable dependiente. Figura 1.5 Representación gráfica de los residuales contra los valores predichos mostrando una relación cuadrática.. 15.
(25) Capítulo 1. Observaciones extremas (OUTLIERS) Una de las razones más importante para calcular los residuos es la detección de observaciones extremas. La mayoría de los procedimientos para examinar residuos son sensibles a la presencia de valores atípicos. Las pruebas numéricas para detectar la no adecuación del modelo y la varianza no constante a veces reaccionan a las observaciones extremas, (un resultado positivo podría indicar una observación extrema o la presencia de lo que debía detectar el procedimiento numérico). Por ejemplo, si existiera un error en las mediciones, la recta se puede afectar enormemente, al igual que el coeficiente de determinación, como lo muestra la figura 1.6. Figura 1.6 Influencia de un valor atípico en una ecuación de regresión 6 5. y = 0.14x + 1.4334 R2 = 0.5592. 4 3 2 1 0 0. 5. 10. 15. 20. 25. Utilizar una regla fija para rechazar observaciones extremas da protección contra errores groseros, pero puede ocasionar que, aún si todas las observaciones fueran buenas y se cumplieran los supuestos iniciales, se rechazará alguna de ellas, lo cual incrementaría la varianza de los parámetros estimados. Podría considerarse el 16.
(26) Capítulo 1. porcentaje de incremento de esta varianza como el precio que se paga por la regla de rechazo, la cual es una garantía contra observaciones malas. Un tipo posible de regla a usar es: “Rechazar la observación con el residuo de mayor magnitud y mayor que Cs donde C es una constante dada. Si esta observación se rechaza, recalcular todos los residuos y S y aplicar la regla nuevamente hasta que no haya más rechazo”. Examen gráfico de los residuos contra los valores de ŷ i Al preparar un gráfico en el cual cada observación está representada por un punto cuya ordenada es el residuo y cuya abscisa es el valor estimado ŷ i se pueden detectar los siguientes casos: 1. Los residuos se agrupan en forma de una banda horizontal lo cual no da evidencia de fallo de los supuestos hechos. 2. Los residuos varían en magnitud notablemente al aumentar o disminuir los valores de ŷ i . Esto indica que la varianza de las observaciones no es constante y que se deben utilizar pesos (Mínimos Cuadrados Ponderados) o transformar las observaciones y antes de efectuar el análisis de regresión. 3. Los residuos se relacionan con las ŷ i en forma de parábola o similar. Esto indica que el modelo es inadecuado, se necesitan términos extras en el modelo o transformaciones de la variable dependiente.. 1.2.2 Prueba de la homogeneidad de varianzas El método consiste en calcular un coeficiente de regresión lineal de los i2 contra ŷ i dividido por s 2 : 2. n. h. yˆ i 1. i. i. yi . s2H. (1.17) 17.
(27) Capítulo 1. donde H, en general, es un poco más pequeño que la suma de cuadrados del total pero, sin mucho error, puede ser sustituido por ésta. Para probar la significación de la desviación de h de cero se utiliza que: V h . 2n p n p 2H. (1.18). Si h es significativamente diferente de cero se puede elegir la transformación potencia. y p con el estimado: p 1 0.5h * y cuando. p 0 . Si p 0 se considera que la. transformación a efectuar es ln y .. 1.2.3 Pruebas de normalidad Según la cantidad de observaciones n se aplica una de las tres pruebas siguientes: . Prueba W si 3 n 50. . Prueba W 2 si 50 n 100. . Prueba de KOLMOGOROV-SMIRNOV (100 < n). Entre otras podemos destacar también: . Prueba de Kolmogorov-Smirnov con corrección de Lilliefors. . Prueba de Jarque Bera. . Prueba de Anderson-Darling. Todas exigen que lo errores sean colocados en orden creciente tal que. e1 e2 en y la de KOLMOGOROV-SMIRNOV requiere además de la definición de función de distribución de probabilidad empírica siguiente:. para x 1 0 Fn X k / n para k x k 1 1 para x n . 18.
(28) Capítulo 1. Prueba W Se calcula el estadígrafo:. n2 ai * ni 1 i i 1 W n p * S 2. 2. (1.19). donde los valores de ai dependen de n y se determinan mediante tablas y la suma se extiende sólo hasta la parte entera inferior de n Si. 2. debido a la simetría de la tabla.. W W se rechaza la hipótesis de normalidad a un nivel de confianza de. 1 . Los valores de W . están también tabulados en la literatura.. Prueba W2 Se calcula el estadígrafo:. 2i 1 2i 1 W n 2 LnF ei 1 Ln1 F ei 2n i 1 2n n. 2. (1.20). donde F x es la función de distribución de probabilidades teórica, en este caso la Normal: F x x . Si W W 1 se rechaza la hipótesis de normalidad a un nivel de confianza 2. . 1 . Los valores de W para 1 desde 0 hasta 0.95 se encuentran en tablas de la literatura.. 19.
(29) Capítulo 1. Prueba de KOLMOGOROV-SMIRNOV Se calcula el estadígrafo:. D max Fn x F x . (1.21). xR y si. n D D se rechaza la hipótesis de normalidad. Los valores de D se. presentan a continuación:. . D . 0.01. 1.03. 0.05. 0.89. 0.10. 0.80. 0.20. 0.74. Prueba de Kolmogorov-Smirnov con corrección de Lilliefors La prueba de Kolmogorov-Smirnov con la modificación de Lillierfors es la más utilizada y se considera uno de los test más potentes para muestras mayores de 30 casos. En este test la Hipótesis nula Ho: es que el conjunto de datos siguen una distribución normal. Y la Hipótesis Alternativa H1: es que no sigue una distribución normal. Este test se basa en evaluar un estadístico: Dn = ⎟Fn (x) – F(x)⎟. (1.22). Fn (x): es la distribución empírica F (x): es la distribución teórica, que en este caso es la normal. 20.
(30) Capítulo 1. Si el valor del estadístico supera un determinado valor, que depende del nivel de significación con el que uno quiera rechazar la hipótesis nula, diremos que esa colección de datos no se distribuye según una distribución normal. Lillierfors tabuló este estadístico para el caso más habitual en el que desconocemos la media y la varianza poblacional y las estimamos a partir de los datos muestrales (SPSS). Prueba de Jarque Bera El Test de Jarque-Bera es una medida de bondad de ajuste para el análisis de la normalidad, basado en la kurtosis y el sesgo. El test estadístico JB es definido como:. (1.23). donde n es el número de observaciones (o grados de libertad en general); S es la muestra del sesgo y K es la muestra de la kurtosis:. (1.24). (1.25). donde. y. son los estimados de los terceros y cuartos momentos centrales. respectivamente,. es la media de la muestra y. es el estimado del segundo. momento central, la varianza. Una muestra tiene distribución normal si el sesgo es 0 y la kurtosis es 3. Como se muestra en la definición de JB, cualquier desviación en estos valores incrementa el estadístico JB (Guerra Bustillo 1991).. 21.
(31) Capítulo 1. Prueba de Anderson Darling La prueba de Anderson-Darling es una prueba no paramétrica sobre si los datos de una muestra provienen de una distribución específica, en este caso normal. La fórmula para el estadístico A determina si los datos. (observar que los datos se deben. ordenar) vienen de una distribución con función acumulativa F: A2 = − N – S. (1.26). donde. (1.27). El estadístico de la prueba se puede entonces comparar contra las distribuciones del estadístico de prueba (dependiendo de qué F se utiliza) para determinar el P-valor (Wikipedia).. 1.3. Análisis de regresión categórica. El análisis de regresión categórica se aplica a datos cualitativos con el propósito de predecir la probabilidad de ocurrencia de una categoría particular de la respuesta como función de una o más variables independientes(Haber 2001). La regresión categórica (RegCat) se ha desarrollado como un método de regresión lineal para variables categóricas. La regresión categórica cuantifica los datos categóricos mediante la asignación de valores numéricos a las categorías, obteniéndose una ecuación de regresión lineal óptima para las variables transformadas. RegCat extiende la regresión lineal ordinaria, considerando variables continuas, ordinales y nominales. Las variables categóricas se cuantifican de manera que ellas reflejen las características de las categorías originales, utilizando transformaciones no lineales para hallar el modelo que mejor ajuste. Finalmente las variables cuantificadas se tratan de la misma forma que las variables continuas (Van der Kooij 1997). 22.
(32) Capítulo 1. El objetivo fundamental de la regresión categórica con escalamiento óptimo consiste en describir las relaciones entre una variable respuesta y un conjunto de variables predictoras (De Leeuw 1990). El escalamiento óptimo es un método para encontrar valores numéricos óptimos que reemplazan los valores de las categorías, por lo tanto transforma los datos categóricos en datos numéricos. En la terminología del escalamiento óptimo, a este proceso, se le denomina “cuantificación”. Las transformaciones de las variables categóricas se estiman simultáneamente con la estimación de los coeficientes de la regresión, usando una alternativa del procedimiento de los mínimos cuadrados que maximiza el cuadrado del coeficiente de regresión múltiple, para la regresión lineal en las variables transformadas. Como resultado de estos criterios de optimización, las transformaciones de escalamiento óptimo linealizan la relación entre la respuesta y los predictores. Entonces, el método RegCat resulta en variables categóricas transformadas que tienen valores con propiedades numéricas óptimas para describir la relación entre la respuesta y los predictores. Las cuantificaciones de las variables categóricas por lo general resultan una transformación no lineal, que puede ser no monótona o por la aplicación de alguna restricción, monótona o lineal. Algunas restricciones se especifican seleccionando un nivel de escalamiento óptimo. En la metodología de escalamiento óptimo, las variables numéricas se tratan como variables categóricas, con el número de categorías igual al número de los diferentes valores de la variable. Seleccionando el nivel de escalamiento numérico, para una variable numérica se obtiene una transformación lineal. Incluyendo transformaciones lineales, RegCat puede también aplicarse a datos que contienen variables numéricas. Una variable numérica puede también ser no linealmente transformada, en este caso no se respetará el espacio relativo de los valores de las categorías. Luego, el escalamiento óptimo es aplicable a ambas variables categóricas (para cuantificar) y para variables numéricas (para transformaciones no lineales) (Van der Kooij 2007).. 23.
(33) Capítulo 1. El propósito de RegCat es el mismo que cualquier otro análisis de regresión, lo interesante es que ella puede aplicarse para aquellas variables, en las que los análisis clásicos de regresión fallan.. 1.3.1 Niveles de escalamiento óptimo En el proceso de cuantificación ciertas propiedades de los datos se preservan en la transformación. Las propiedades que se seleccionan para ser preservadas se especifican seleccionando un nivel de escalamiento óptimo para las variables. Es importante para realizarlo, que el nivel de escalamiento óptimo es el nivel en el que una variable se analiza, el que no necesariamente coincide con el nivel de medición de la variable. Las propiedades de los datos que se distinguen en el enfoque de la regresión categórica son las de grupos, orden e igual espacio relativo. En dependencia del nivel de medición (nominal, ordinal o intervalo) las variables tendrán una, dos o todas estas propiedades. Las variables con nivel de medición nominal solamente tiene propiedades de agrupación, esto es, los valores de las categorías solamente sirven para codificar las observaciones en clases. Las variables ordinales tienen propiedades de agrupación y orden. Las variables con nivel de medición de intervalo (numéricas) tienen todas las propiedades. Si el investigador desea preservar todas las propiedades de medición de la variable en las variables cuantificadas, el nivel de escalamiento debe seleccionarse en concordancia con el nivel de medición de la variable. Con nivel nominal, sólo se preserva la propiedad de agrupación, el nivel de escalamiento ordinal preserva la agrupación y el orden, y el nivel de escalamiento numérico preserva la agrupación, el orden e igual espacio relativo. Seleccionando el nivel de escalamiento numérico para una variable medida categóricamente implica que en el análisis los valores categóricos se tratan como valores numéricos (y cuando todas las variables se tratan 24.
(34) Capítulo 1. numéricamente, RegCat es equivalente a la regresión lineal estándar). La forma de la curva, cuando se grafican los valores cuantificados contra los valores de las categorías, está relacionada con el nivel de escalamiento: con nivel de escalamiento nominal la curva de transformación puede descender debido a que el ordenamiento de los valores cuantificados no necesitan ser el mismo que el de los valores de la categoría original. Para el nivel de escalamiento ordinal, el ordenamiento de los valores cuantificados y de los valores de la categoría original es el mismo, resultando una curva de transformación monótona. El nivel de escalamiento numérico resulta una línea recta, debido a que los intervalos entre las cuantificaciones por categorías consecutivas son proporcionales a los intervalos entre los valores de categoría. El nivel de escalamiento, y por tanto la forma de la curva de transformación, está también relacionado con el número de grados de libertad de la transformación, y por tanto al ajuste del modelo. Las transformaciones con más libertad resultan transformaciones menos suaves y ajustan mejor, mientras que transformaciones más restrictivas son más suaves pero los resultados ajustan menos. De manera que, existe un equilibrio entre las propiedades de preservación de los datos y la preservación de la información relacional en los datos: restringiendo las transformaciones, preservando más propiedades de los datos, se alcanza un costo de ajuste y se pierde información relacional. La transformación con el máximo de libertad es el resultado a partir del nivel de escalamiento nominal, donde el número de grados de libertad es igual al número de categorías menos uno. El nivel de escalamiento ordinal requiere una restricción de orden sobre las cuantificaciones categóricas, resultando el número de grados de libertad igual al número de categorías con diferentes valores cuantificados menos uno. El escalamiento numérico impone una restricción de intervalo adicional a la restricción de orden y tiene un grado de libertad. El nivel de escalamiento nominal y el ordinal dan lugar a transformaciones que son funciones paso, la cuales son adecuadas para variables con un número pequeño de categorías. Para variables con un número más grande de categorías, las funciones spline son más apropiadas, entre estas distinguimos splines no monótonos para 25.
(35) Capítulo 1. transformaciones no ordenadas y splines monótonos para transformaciones ordenadas. Las funciones spline son funciones polinomiales por trozos, las cuales son más restrictivas que las funciones paso, dando lugar a curvas de transformación más suaves, pero con un ajuste menor. Para obtener una transformación spline, el rango de la variable se divide en un número de intervalos, igual al número de nodos especificado menos uno. Los nodos son los puntos extremos de los intervalos. Entonces las funciones polinomiales de un grado específico se ajustan en cada intervalo y se empatan en cada nodo. La suavidad y el número de grados de libertad de una curva de transformación spline depende del número de nodos y del grado de las funciones polinomiales(Van der Kooij 2007). En términos de restricciones, o sea, de suavidad de la curva de transformación y ajuste, la transformación spline no monótona está entre una nominal y una transformación lineal. Con número de nodos interiores igual al número de categorías menos dos y usando un polinomio de primer grado, la transformación spline es la misma que la transformación nominal. Con el número de nodos interiores igual a cero y con un polinomio de primer grado, la transformación spline es la misma que la transformación lineal. De la misma manera, una transformación spline monótona está entre una ordinal y una transformación lineal. Lo expresado en el párrafo anterior se ilustra en la figura 1.7 que se muestra a continuación, la cual muestra la gráfica de transformación de la variable dependiente Diagnóstico de Expertos (DiagExp), que tiene tres categorías: (1-normotenso, 2hiperreactivo, 3-hipertenso) y la variable independiente categórica Edad de los Pacientes (Edad). A la variable dependiente se le fijó el nivel de medición ordinal mientras que a la independiente se le variaron los niveles de medición. Con el nivel de medición nominal aplicada a la variable independiente se obtiene una curva bastante dentada (Figura 1.7.1). En el mismo se puede apreciar que ambas variables que a medida que se incrementan alcanzan valores máximos. El R 2 que se obtiene es igual a 0.128. Al aplicar una transformación spline no monótona (2do grado 26.
(36) Capítulo 1. con 10 nodos interiores) las irregularidades son más suaves (Figura 1.7.2), mucho más si se tienen dos nodos interiores (Figura 1.7.3). Los R 2 para estos casos son 0.088 y 0.081 respectivamente. Obsérvese que el R 2 disminuye en la medida en que el nivel de escalado utilizado conserva más propiedades. Como las transformaciones ordinales se obtienen mediante el average de las cuantificaciones nominales que están en el orden equivocado, la aplicación de niveles de escalamiento ordinales da lugar a transformaciones que restringen todos los valores cuantificados en forma de mesetas (Figura 1.7.4). El R 2 que se obtiene en esta transformación es 0.094. Cuando se aplica una transformación monótona (2 grados con 10 nodos interiores) muchas de las mesetas desaparecen (Figura 1.7.5) y con 2 grados y 2 nodos interiores la transformación es casi lineal (Figura 1.7.6). Los valores de los. R 2 en estos casos son 0.085 y 0.078(Van der Kooij 2007). En la figura 1.7.7 se muestra la transformación con nivel de escalado numérico. El R 2 que se obtiene es 0.073. En todas estas gráficas de observa que a medida que se gana en suavidad se pierde en ajuste.. 27.
(37) Capítulo 1. Figura 1.7 Gráfica de transformación de la variable dependiente DiagExp, y la variable independiente categórica Edad.. 1.3.2 Estimación de las Transformaciones En el método de regresión categórica, el modelo de regresión y las cuantificaciones se estiman simultáneamente en un proceso iterativo usando los mínimos cuadrados alternantes. El algoritmo alterna entre la estimación de la transformación de la variable respuesta y la estimación de las transformaciones y regresión ponderada de las 28.
(38) Capítulo 1. variables predictoras. La transformación de la respuesta en una iteración se estima a partir de la combinación lineal de los predictores transformados desde las iteraciones previas. Las cuantificaciones nominales son el punto de partida (y el punto final si el nivel de escalamiento es nominal) en la estimación de las cuantificaciones restringidas. La cuantificación nominal para una categoría es la media de los valores predictores de la categoría cuando se estima la respuesta y la media de los residuos parciales de las categorías cuando se estima el predictor. Si el nivel de escalamiento no es nominal, estas cuantificaciones se restringen según sea el nivel de escalamiento. La restricción se impone aplicando la regresión ponderada (ponderando con las frecuencias de las categorías) de las cuantificaciones nominales, en los valores de las categorías para el nivel de escalamiento ordinal y numérica, y en I-spline base(Ramsay 1988) para las transformaciones spline, con restricciones no negativas para los splines monótonos. Para el nivel de escalamiento ordinal, se usa la regresión monótona ponderada, la cual se reduce al promedio ponderado de las cuantificaciones nominales de las categorías que están en el orden equivocado. Con nivel de escalamiento numérico, los valores de las categorías se convierten en scores estándar, lo cual es equivalente a la regresión lineal ponderada de las cuantificaciones nominales en los valores de las categorías. Finalmente, la variable cuantificada se normaliza, y se estima el coeficiente de regresión para una variable predictora. En el método RegCat una transformación monótona es siempre creciente con los valores de las categorías. Si el nivel de escalamiento de un predictor es ordinal o spline monótono, y la relación con la respuesta (después de quitar la influencia de otros predictores) es decreciente de manera monótona, entonces el coeficiente de regresión será negativo(Van der Kooij 2007).. 1.3.3 Formulación del modelo de regresión categórica La regresión lineal múltiple es una técnica que estudia la relación lineal entre la variable respuesta y un conjunto de variables predictoras. La regresión categórica múltiple es 29.
(39) Capítulo 1. una técnica no lineal, donde la no linealidad radica en las transformaciones de las variables. El modelo de la regresión categórica es el modelo de la regresión lineal clásica, aplicado a las variables transformadas:. r y . J. j j x j e. (1.28). j 1. con la función de pérdida:. . . J. . 2. L r , 1 ,, j ; 1 , j r y j j x j. (1.29). j 1. …donde:. J es el número de variables predictoras, y representa la variable respuesta observada o discretizada,. x j representa las variables predictoras observadas o discretizadas,. j los coeficientes de regresión,. r las transformaciones de la variable respuesta, j las transformaciones de las variables predictoras y e el vector error. Todas las variables son centradas y normalizadas para obtener la suma de los cuadrados igual a N , y . 2. representa el cuadrado de la norma euclidiana.. La forma de las transformaciones depende del nivel de escalamiento óptimo, el cual puede seleccionarse para cada variable por separado y es independiente del nivel de medición. El nivel de escalamiento define qué parte de la información que está en la variable observada o discretizada (según sea el nivel de medición) se retiene en la transformación de la variable. Con nivel de escalamiento numérico, los valores de la categoría de una variable se tratan como cuantitativos. Entonces toda la información se 30.
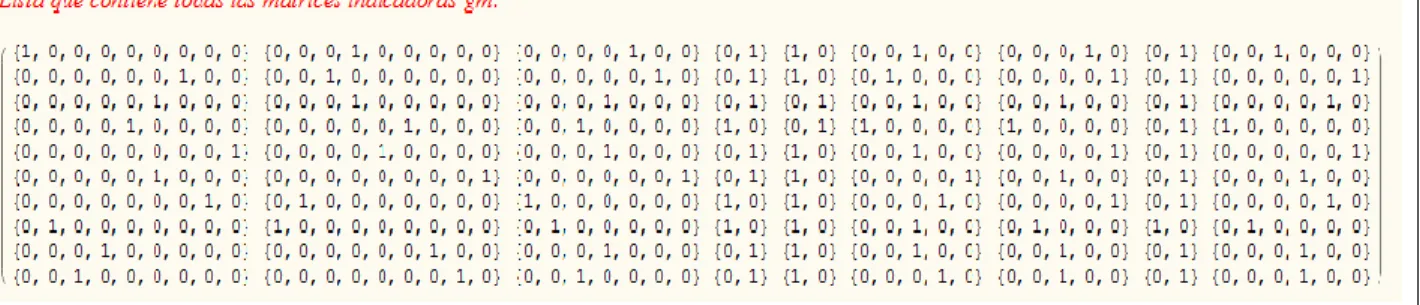
(40) Capítulo 1. retiene y la única transformación aplicada es la estandarización, resultando una transformación lineal. Luego, cuando para todas las variables se aplica el nivel de escalamiento numérico, el resultado de la RegCat es igual al resultado de la regresión lineal múltiple con las variables estandarizadas. Con niveles de escalamiento no numérico, los valores de las categorías se tratan como cualitativos, y se transforman en valores cuantitativos. En este caso, alguna parte de la información en la variable observada o discretizada se pierde. Con nivel ordinal o spline monótono, la información de intervalo se pierde y solamente la información de grupo y orden se retienen, así se posibilita una transformación monótona. Con nivel nominal y spline no monótono sólo la información de agrupación tiene que conservarse, dando lugar a una transformación no monótona. Aplicando niveles de escalamiento no lineales, las relaciones no lineales entre la variable respuesta y las variables predictoras se linealizan, por lo tanto el modelo de regresión lineal del término es todavía aplicable.. 1.3.4 Algoritmo para la regresión categórica En RegCat las variables observadas o discretizadas se codifican en una matriz indicadora Gm de tamaño N C m , donde N es el número de observaciones y C m representa el número de categorías de la variable m, m 1, , M , donde M es el número total de variables. Una entrada g icm de Gm , donde c 1, , Cm , es 1 si la observación i está en la categoría c de la variable m y 0 en otro caso. Entonces las variables transformadas pueden escribirse como el producto de la matriz indicadora Gm y el C m - vector de las cuantificaciones categóricas v m :. . r y Gr v r j x j G j v j. (1.30). 31.
(41) Capítulo 1. donde v r es el vector de las categorías cuantificadas de la variable respuesta, y v j el vector de categorías cuantificadas para una variable predictora. Luego, el modelo de RegCat con las variables transformadas escrito en términos de matrices indicadoras y categorías cuantificadas es: J. Gr vr j G j v j e. (1.31). j 1. Con la función de pérdida mínimos cuadrados asociada:. Lvr ; v1 ,, v j ; 1 , j Gr vr j G j v j J. 2. (1.32). j 1. La función de pérdida (1.32) se minimiza por el algoritmo de mínimos cuadrados alternantes, que alterna entre la cuantificación de la variable respuesta por un lado, y la cuantificación de las variables predictoras y estimación de los coeficientes de regresión por el otro. Primero se inicializan las cuantificaciones y los coeficientes de regresión. RegCat tiene dos formas de inicialización: aleatoria y numérica. Una inicialización aleatoria usa valores aleatorios estandarizados para las cuantificaciones iniciales, y los coeficientes de regresión iniciales son las correlaciones de orden cero de la variable respuesta cuantificada aleatoriamente con las variables predictoras cuantificadas de manera aleatoria. Con una inicialización numérica los valores se obtienen a partir de un análisis con nivel de escalamiento numérico para todas las variables. En el primer paso del algoritmo, las cuantificaciones de las variables predictoras y los coeficientes de regresión se mantienen fijos. Con nivel de escalamiento numérico las cuantificaciones v r de la variable respuesta son los valores de las categorías de la variable observada o discretizada centrada y normalizada.. 32.
(42) Capítulo 1. Con nivel de escalamiento no numérico las cuantificaciones son actualizadas en la siguiente forma: v~r Dr1Gr. J. jG jv j. (1.33). j 1. donde Dr Gr Gr . Las cuantificaciones v~r son las cuantificaciones no estandarizadas para el nivel de escalamiento nominal. Para los niveles ordinal, no monótono o spline monótono, se aplica una restricción para v~r , en relación con el nivel de escalamiento, produciendo v r . Por tanto, vr v~r para el nivel de escalamiento nominal, y vr v~r restringida para los niveles ordinales y spline. Entonces v r se estandariza:. . . 1 / 2 vr N 1 / 2 vr vr Dr vr. (1.34). En el segundo paso del algoritmo, las cuantificaciones de la variable respuesta se mantienen fijas, y las cuantificaciones v j de las variables predictoras con nivel de escalamiento no numérico, y los coeficientes de regresión se actualizan para cada variable al mismo tiempo. El enfoque trabaja como sigue. Primero se calcula el N vector de los valores predichos: J. z. jG jv j. (1.35). j 1. Para actualizar las cuantificaciones de la variable j , la contribución de la variable j a la predicción (la combinación lineal ponderada de los predictores transformados) se sustrae de z: z j z jG j v j. (1.36). 33.
(43) Capítulo 1. Las cuantificaciones no restringidas se actualizan de la manera siguiente:. . v~j sign j D 1 j G j Gr v r z j. . (1.37). Para variables con nivel de escalamiento no numérico v~ j se restringe según sea el nivel de escalamiento, y se normaliza como en (1.34), produciendo v j . Para variables con nivel de escalamiento numérico, v j contiene los valores de las categorías de los datos observados o discretizados centrados y estandarizados. Luego los coeficientes de regresión j se actualizan:. j N 1v~ j D j v j. (1.38). Luego, la contribución actualizada de la variable j para la predicción se adiciona a z j : z z j j G j v j ,. (1.39). y el algoritmo continúa con la actualización de la cuantificación para la próxima variable predictora, hasta que todos los predictores sean actualizados. 2. Los valores perdidos se calculan como Gr vr z . Estos dos pasos se repiten hasta que se alcance el criterio de convergencia especificado por el usuario. Para el nivel de escalamiento ordinal, se usa la regresión monótona ponderada de las cuantificaciones nominales en la variable observada o discretizada. Para la restricción en relación con los niveles de escalamiento spline se usa la regresión ponderada de las cuantificaciones nominales en un I-spline base(Ramsay 1988), con restricciones no negativas adicionales para el nivel de escalamiento spline monótono. En este punto, pudiera ocurrir una complicación adicional. Una restricción creciente de manera monótona puede a veces dar lugar a una variable transformada con valores constantes. 34.
(44) Capítulo 1. Por ejemplo, cuando los valores de v~ son decrecientes de manera monótona, excepto para el primer y el último valor, las cuantificaciones restringidas son la media de v~ para todas las categorías. En este caso, la transformación en una constante puede evitarse dando lugar a una función monótona decreciente(Van der Kooij 2007).. 1.4. Consideraciones finales del capítulo. En este capítulo se han presentado de manera resumida, los conceptos fundamentales del análisis de regresión lineal. Se describe la fundamentación matemática del análisis de regresión lineal simple y se muestran las ideas esenciales de su generalización a la regresión lineal múltiple. Se dedica un epígrafe al análisis de la validez de la ecuación obtenida. Se muestran pruebas gráficas y analíticas para verificar la validez de los supuestos. Finalmente se presenta el método de regresión categórica. Se formula el modelo y se describen los niveles de escalado. El capítulo culmina con la exposición del algoritmo de regresión categórica y la descripción matemática de sus dos pasos fundamentales.. 35.
(45) Capítulo 2. 2. Implementaciones sobre el Mathematica En este capítulo se explican brevemente las implementaciones realizadas en el paquete Mathematica.. 2.1 La entrada de los datos Para la entrada se tienen dos ficheros texto, uno con el nombre de cada variable y su escalado y el otro con los valores de cada variable en cada observación. Existen cinco tipos de escalados posibles: Numérico. Num. Ordinal. Ord. Spline ordinal. SO(g,ni). Nominal. Nom. Spline nominal. SN(g,ni). En el caso de los Spline, “g” es el grado del polinomio y “ni” el número de nodos o puntos interiores. El SPSS trae por defecto que el grado del polinomio es dos y el número de nodos interiores es dos también. Estos dos tipos de escalado (Spline Ordinal y Nominal) se recomiendan cuando hay muchas categorías en una variable con nivel de medición Ordinal o Nominal respectivamente. A continuación se muestra cómo quedaría el primer fichero para un subconjunto de datos tomados del estudio realizado en la ciudad Santa Clara sobre la Hipertensión Arterial (HTA) en personas adultas. Ejemplo del fichero 1: Edad. Num. Peso. Num. Talla. Num. Sexo. Num. Raza. Num. DiastBasal. Num 36.
(46) Capítulo 2. SistMin1. Num. Asma. Num. SistBas. Num. Luego se crea una matriz cuyos datos se leen de otro fichero texto que sólo contiene números. La matriz de datos tiene una columna de números por cada una de las variables previamente definidas: Edad Peso Talla. Sexo. Raza DiastBasal. SistMin1. Asma SistBas. 155 160 150 130 160 150 160 140 150 150. 135 160 150 120 160 140 150 130 140 140. Ejemplo del fichero 2: 18 55 49 47 73 49 57 23 44 43. 70 68 70 75 93 93 64 51 90 91. 1.67 1.74 1.66 1.64 1.66 1.83 1.50 1.51 1.66 1.64. 2 2 2 1 2 2 1 1 2 2. 1 1 2 2 1 1 1 1 1 1. 90 85 90 80 90 105 100 90 90 100. 2 2 2 2 2 2 2 1 2 2. Estos dos ficheros son los parámetros de la función RegCatNum una vez que se carga dicho paquete. Para la entrada de los datos se utilizó la función Import[“file”] la cual importa datos del fichero “file” especificado como parámetro en la función RegCatNum a través de su camino.. El contenido de dat1 en este caso particular sería:. Para un fácil acceso a los datos, esta entrada se requirió de forma “Table” quedando almacenado en la variable dat1 una lista de listas.. 37.
(47) Capítulo 2. Si se desea ver los datos de la forma original con la función TableForm[ ], se logra:. De la misma manera se cargan los datos del segundo fichero, encabezando la matriz con las variables del primer fichero. La forma de matriz se le da a través de la función MatrixForm[ ] y para el encabezado se utiliza la opción TableHeadings, guardándose previamente en la variable. l. los nombres de las variables que aparecen en el fichero 1. mediante un ciclo:. Obteniéndose entonces:. En caso de haber errores, o sea, la cantidad de columnas no coincide con la cantidad de variables reportadas o faltan datos en la matriz, se imprime mediante la función Print[ ] un cartel de “Error en datos”.. 38.
(48) Capítulo 2. 2.2 Análisis de regresión lineal múltiple El software Mathematica contiene un paquete para hacer análisis de regresión. En la versión que actualmente se trabaja: 8.0, Regress (nombre de la función que realizaba la regresión lineal en el paquete LinearRegress) ha sido reemplazada por LinearModelFit, la cual está incorporada al Kernel del Mathematica, por lo que ya no es necesario cargar el paquete con anterioridad.. El resultado se retorna como el objeto FittedModel que representa el modelo lineal construido. Este contiene un conjunto de propiedades, como se muestra a continuación:. Para obtener la forma funcional del objeto FittedModel, se usa Normal:. La función Normal encuentra el ajuste de los mínimos cuadrados a una lista de datos como una combinación linear de la funciones base especificadas, tal y como se explicó en el capítulo 1. Las funciones bases. son las que especifican a las predictoras como. funciones de las variables independientes Usando LinearModelFit Existen tres formas de llamar a la función LinearModelFit, pero la que se implementa en este caso está estructurada de la siguiente manera: LinearModelFit[{{x11,x12,…,y1},{x21,x22,…,y2},…},{f1,f2,…},{x1,x2,…}]: Construye un modelo lineal de la forma las variables. donde las. dependen de. .. 39.
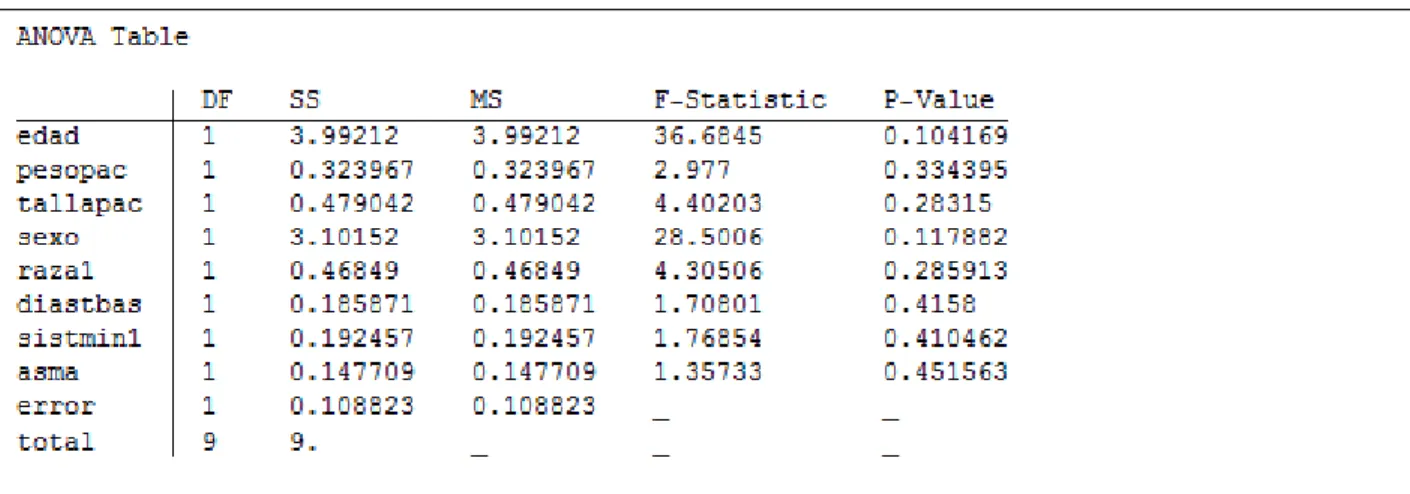
(49) Capítulo 2. LinearModelFit produce un modelo lineal de la forma suposición de que los con media. bajo la. originales están independientemente distribuidos normalmente. y desviación estándar común.. Si se utiliza el subconjunto de datos presentados en el epígrafe 2.1 para el análisis de regresión lineal:. donde variables contiene todas las variables predictoras consideradas para este caso particular (ocho variables independientes), se obtiene como resultado el modelo lineal construido que se muestra en la figura 2.1: Figura 2.1 Ecuación de regresión usando el LinearModelFit del paquete Mathematica. Algunas de sus propiedades más importantes se explican y muestran a continuación.. 2.2.1 Propiedades del LinearModelFit relacionadas con la suma de los cuadrados de los errores: . ANOVATable: Tabla de Análisis de varianza. La construcción de esta tabla quedó explicada en el capítulo 1.. Como propiedades también, se tienen las opciones de la Tabla ANOVA por separado: . ANOVATableDegreesOfFreedom: Grados de libertad a partir de la Tabla ANOVA.. . ANOVATableFStatistics: Estadístico F de la tabla.. . ANOVATableMeanSquares: Cuadrado de la media de los errores de la tabla.. . ANOVATablePValues: p-valores de la tabla. 40.
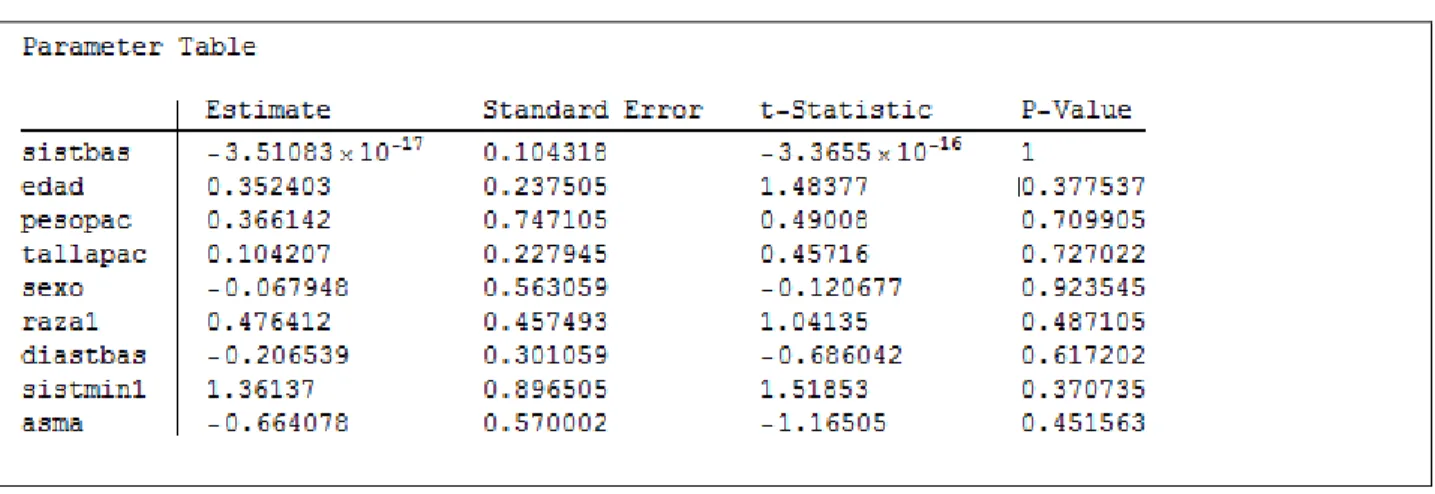
(50) Capítulo 2. . ANOVATableSumsOfSquares: Suma de los cuadrados de la tabla.. La figura 2.2 muestra la Tabla ANOVA resultante del análisis realizado al ejemplo anterior, usando la propiedad. :. Figura 2.2 Tabla ANOVA. 2.2.2 Propiedades del LinearModelFit relacionadas con los parámetros A continuación se describen las propiedades que están relacionadas con los parámetros y con su estimación: . ParameterTable: Tabla que contiene información de los parámetros ajustados.. Como propiedades también, se tienen las opciones de la Tabla de parámetros por separado: . BestFitParameter: Parámetros estimados.. . ParameterErrors: Errores estándar para parámetros estimados.. . ParameterPValues: p-valores para parámetros t-estadísticos.. . ParameterTStatistics: t-estadísticos para parámetros calculados.. La figura 2.3 contiene la información de la tabla de parámetros resultante del análisis realizado al ejemplo anterior, usando la propiedad. :. 41.
(51) Capítulo 2. Figura 2.3 Tabla de los parámetros. 2.2.3 Propiedades del LinearModelFit que miden la bondad de ajuste Este conjunto de propiedades es sumamente importante porque nos da un criterio de la calidad de la ecuación hallada. Entre los más importantes se tienen: . RSquared: Coeficiente de Determinación R2.. . AdjustedRSquared: Coeficiente de determinación R2 ajustado para el número de parámetros del modelo.. . AIC: Criterio de Información Akaike.. La figura 2.4 muestra los valores del Coeficiente de Determinación R2, R2 Ajustado y Criterio de Información Akaike (AIC) resultante del análisis realizado al ejemplo anterior, usando la propiedades. ,. ,. :. Figura 2.4 Propiedades de bondad de ajuste. . DurbinWatsonD, estadístico para detectar si existe o no autocorrelación entre los residuos.. 42.
(52) Capítulo 2. El valor del estadístico Durbin Watson retornado del análisis realizado al ejemplo anterior, usando esta propiedad del LinearModelFit,. aparece. calculado en la figura 2.5. Figura 2.5 Resultados del test de Durbin Watson. 2.3 Verificación de los supuestos Para la verificación de supuestos, el Mathematica 8.0 contiene un paquete llamado “Hypothesis Test”, que cuenta con varios tests de Bondad de Ajuste para el tratamiento de los datos. Tiene entre otras funciones, aquellas que prueban si un conjunto de datos está distribuido normalmente o no.. 2.3.1 Prueba de Kolmogorov Smirnov KolmogorovSmirnovTest [data]: Prueba si los datos “data” están distribuidos normalmente usando el test de Kolmogorov-Smirnov. A continuación se especifican algunas de sus propiedades: . Por defecto se devuelve el p-valor.. . Los. datos. pueden. ser. univariados. o. multivariados. {{x1,y1,…},{x2,y2,…},…}. . Asume que los datos vienen de una distribución continua.. . Usa de forma eficaz el estadístico basado en. . Para pruebas multivariadas, se usa la media de la prueba estadística marginal univariada. Los p-valores se calculan usando simulación de Monte Carlo.. . El nivel de significación que tiene por defecto es 0.05, pero se puede modificar utilizando la opción SignificanceLevel.. 43.
Figure



+7



Documento similar