Patrones de diseño para acceder a servicios web de datos
92
0
0
Texto completo
(2) “Año 56 de la Revolución”. Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del Autor Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Laboratorio.
(3) PENSAMIENTO.
(4) DEDICATORIA.
(5) AGRADECIMIENTO.
(6) RESUMEN. Resumen Guardar en memoria cache el resultado de una consulta realizada por un servicio web a la fuente de datos disminuye la cantidad de accesos a base de datos y el tiempo de respuesta al cliente. Los patrones de diseño para acceder a datos pretenden contribuir a la solución de este problema mediante distintas estrategias independientes de cacheo. Nuestro trabajo propone modificaciones a varios de estos patrones existentes en la literatura, para lograr la integración de estos en un en un único patrón de comportamiento con el objetivo de crear diferentes estrategias de cacheo de datos en un servicio web. Además se implementó una aplicación cliente que servirá de guía a arquitectos y desarrolladores de software que quieran acceder a datos mediante servicios Web..
(7) ABSTRACT. Abstract Save to cache the result of a query by a Web service data source decreases the amount of database accesses and the response time to the customer. Design patterns for data access are intended to contribute to solving this problem through various independent caching strategies. Our work proposes amendments to several of these patterns in the literature, to achieve an integration of these into a single pattern of behavior in order to create different strategies for caching data in a web service. Also a client application that will guide architects and software developers who want to access data using Web services is implemented..
(8) TABLA DE CONTENIDOS. INTRODUCCIÓN .................................................................................................................. 1 CAPÍTULO 1.. PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE. DATOS Y CACHEO DE DATOS ......................................................................................... 5 1.1. Patrones de Diseño ................................................................................................... 5. 1.1.1. Categorías de los Patrones de Diseño ............................................................... 8. 1.1.2. Patrones enfocados a la arquitectura ................................................................. 8. 1.2. SOA Arquitectura orientada a servicios ................................................................... 9. 1.2.1. Etapas en la evolución de SOA....................................................................... 10. 1.2.2. Arquitectura de capas en SOA ........................................................................ 11. 1.2.3. Capa de acceso a datos.................................................................................... 14. 1.2.4. Servicio de acceso a datos .............................................................................. 16. 1.3. Tendencias y tecnologías actuales en los Servicios Web....................................... 17. 1.3.1. Servicios Web SOAP ...................................................................................... 17. 1.3.2. Servicio Web REST ........................................................................................ 19. 1.3.3. Fundamentación del Entorno de Desarrollo, Lenguaje, Gestor de Base de. Datos y Tecnología utilizados....................................................................................... 21 1.4. Cacheo de Datos ..................................................................................................... 23. 1.4.1. Tipos de Cacheo de Datos .............................................................................. 23. 1.4.2. Ventajas y desventajas del Cacheo ................................................................. 24. 1.5. Conclusiones parciales ........................................................................................... 24.
(9) TABLA DE CONTENIDOS. CAPÍTULO 2. 2.1. PATRONES DE CACHÉ........................................................................ 26. Patrones de acceso a datos ..................................................................................... 26. 2.1.1. Data Accessor ................................................................................................. 27. Aplicabilidad ............................................................................................................. 27 Estructura .................................................................................................................. 28 2.1.2. Cache Accessor ............................................................................................... 29. Aplicabilidad ............................................................................................................. 29 Estructura .................................................................................................................. 29 2.1.3. Demand Cache ................................................................................................ 31. 2.1.4. Primed Cache .................................................................................................. 31. Aplicabilidad ............................................................................................................. 32 Estructura .................................................................................................................. 32 2.1.5. Cache Search Sequence .................................................................................. 33. Aplicabilidad ............................................................................................................. 33 Estructura .................................................................................................................. 34 2.1.6. Cache Collector............................................................................................... 34. Aplicabilidad ............................................................................................................. 34 Estructura .................................................................................................................. 35 2.2. Integración de los Patrones de Acceso a Datos ...................................................... 36.
(10) TABLA DE CONTENIDOS. 2.3. Requisitos a considerar .......................................................................................... 37. 2.3.1. Requisitos funcionales .................................................................................... 37. 2.3.2. Requisitos no funcionales ............................................................................... 38. 2.4. Diagrama de casos de uso del sistema ................................................................... 38. 2.4.1 2.5. Descripción de los casos de uso del sistema ................................................... 39. Conclusiones parciales ........................................................................................... 41. CAPÍTULO 3.. DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN ....................... 42. 3.1. Modelo de componentes ........................................................................................ 42. 3.2. Diagrama de clases ................................................................................................. 43. 3.3. Diagrama de Secuencias ........................................................................................ 45. 3.4. Principios de Diseño .............................................................................................. 48. 3.5. Diagrama de Despliegue ........................................................................................ 50. 3.6. Conclusiones parciales ........................................................................................... 51. CAPÍTULO 4.. PRUEBAS Y ANÁLISIS DE FACTIBILIDAD ..................................... 52. 4.1. Pruebas ................................................................................................................... 52. 4.2. Planificación basada en uno de los métodos de estimación ................................... 54. 4.2.1. Estimación basada en casos de uso ................................................................. 54. 4.2.2. Conclusiones ................................................................................................... 65. 4.3. Conclusiones parciales ........................................................................................... 65.
(11) TABLA DE CONTENIDOS. Conclusiones ......................................................................................................................... 66 Recomendaciones ................................................................................................................. 67 Referencias Bibliográficas .................................................................................................... 68 Manual del desarrollador ...................................................................................................... 69.
(12) INTRODUCCIÓN. 1. INTRODUCCIÓN Con el advenimiento de dispositivos móviles y la computación en la nube las restricciones de acceso a datos a través de la web han aumentado. Cada día son necesarios datos de mayor calidad en menos tiempo, para lo cual actualmente se investigan procesos, técnicas, algoritmos y operaciones encaminados a mejorar la calidad de los datos existentes. De esta forma se obtienen beneficios en la calidad de datos como el ahorro de costes directos evitando tener información duplicada y por lo tanto evitar el envío replicado a un mismo cliente con lo cual también se disminuye el tiempo de respuesta. Los servicios web juegan un papel importante en este contexto pues permiten a distintas aplicaciones de software desarrolladas en lenguajes de programación diferentes, y ejecutadas sobre cualquier plataforma, acceder a datos en redes de ordenadores como Internet. La interoperabilidad se consigue mediante la adopción de estándares abiertos. Entre estos estándares de encuentra el XML (Extensible Markup Language) que es el formato estándar para el intercambio de datos. Disminuir la cantidad de accesos a la fuente de datos y el tiempo de respuesta enviados por un servicio a las aplicaciones traerá beneficios al proveedor y al cliente del mismo. Formalizar una solución a este problema mediante patrones de diseño servirá de guía a desarrolladores y arquitectos de software pues se facilitará la reutilización de diseños y arquitecturas de software exitosos en este contexto, por tanto nos planteamos el siguiente problema de investigación: ¿Qué patrones diseño pueden utilizarse para acceder a servicios web de datos de modo que se disminuya la cantidad de accesos a la fuente de datos y el tiempo de respuesta al cliente? Objetivo general de la investigación:.
(13) INTRODUCCIÓN. 2. Proponer modificaciones a los patrones de diseño existentes en la literatura para acceder a datos, de modo que un servicio de datos disminuya la cantidad de estos solicitados a las fuentes y el tiempo de respuesta a los clientes. Para cumplir con el objetivo general se plantean los siguientes Objetivos específicos: 1. Identificar los patrones de diseño existentes en la literatura científica que disminuyan la cantidad de datos solicitados a la fuente de datos y el tiempo de respuesta a los clientes. 2. Proponer modificaciones a los patrones de diseño identificados que acceden a datos, de modo que se consiga disminuir la cantidad de información solicitada a la fuente de datos por un servicio web y el tiempo de respuesta a los clientes. 3. Desarrollar un ejemplo que use nuestra propuesta de solución y que sirva de guía a arquitectos y desarrolladores de software Para la solución del objetivo general y los específicos nos trazamos las siguientes Preguntas de investigación: 1. ¿Qué patrones de diseño de los existentes en la literatura científica disminuyen la cantidad de datos solicitados a la fuente de datos y el tiempo de respuesta a los clientes? 2. ¿Qué modificaciones se pueden hacer a patrones de diseño que acceden a datos de modo que se disminuyan los datos solicitados y la cantidad de datos enviados por un servicio web de datos al cliente? Como Justificación del proyecto tenemos la siguiente:.
(14) INTRODUCCIÓN. 3. Disminuir la cantidad de datos solicitados y el tiempo de respuesta enviados a las aplicaciones traerá beneficios al proveedor del servicio enviando datos de mayor calidad en menos tiempo. De este modo los clientes consumirán menos ancho de banda, disminuyendo así sus costos por el uso del servicio. Nuestra propuesta ayuda a cumplir con las restricciones de memoria y procesamiento de las tecnologías móviles así como del almacenamiento de datos en la nube. Ambas precisan enviar datos de calidad a los clientes y con tiempo de respuesta cada vez menor. Para darle solución al problema científico se plantea la siguiente Hipótesis de investigación: Integrando los patrones de diseño para el acceso a datos mediante servicios web optimizaríamos el flujo de datos entre el cliente y el proveedor del servicio, de modo que el tiempo de respuesta y la cantidad accesos a la fuente disminuirán. La estructura de la tesis es la siguiente: Capítulo I. Patrones de diseño, Servicios Web de Acceso a datos y Cacheo de Datos Se introducirá el tema relacionado con los patrones de diseños destacando su arquitectura y enfoques arquitectónicos. Seguidamente se hace una introducción a la arquitectura orientada a servicios profundizando en las capas y servicios de acceso a datos. Hablaremos de tendencias y tecnologías actuales en los servicios web, así como el cacheo de datos. Capítulo II. Patrones de caché Analizaremos los patrones de acceso a datos existentes en la literatura científica, integrándolos finalmente en un solo patrón de acceso. Consideraremos los requisitos de la integración de los patrones y estableceremos el diagrama de caso de uso del sistema..
(15) INTRODUCCIÓN. 4. Capítulo III. Descripción de la propuesta de solución Se comenzara describiendo la propuesta de solución con el modelo de componente, luego será mostrado el diagrama de clase. El diagrama de secuencia establecerá la función de los principales casos de usos del sistema. Serán mencionados los principios de diseños utilizados en la solución de la problemática y será visto el despliegue estático del sistema mediante el diagrama de despliegue. Capítulo IV. Pruebas y análisis de factibilidad Se realizarán las pruebas del sistema encaminadas al tiempo de respuesta mediante diferentes estrategias de cacheo de datos. Se hará la planificación basada en uno de los métodos de estimación.
(16) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 5. CAPÍTULO 1. PATRONES DE DISEÑO, SERVICIOS WEB DE. ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS En el siguiente capítulo se realizará una caracterización de los patrones de diseño, particularmente su estructura, las categorías de patrones, así como sus ventajas y desventajas.. Se enfocarán los patrones relacionados con los Servicios Web y SOA.. También serán vistos los tipos de servicios web en una arquitectura SOA, sus principales estándares y las características de los servicios de acceso a datos. Serán mostradas las tendencias y tecnologías en los servicios web actuales enfatizando en SOAP y REST, se fundamentara el entorno de desarrollo, lenguaje, gestor de base de datos y tecnologías utilizadas. Por último se tratará la memoria caché, sus tipos, ventajas y desventajas. 1.1. Patrones de Diseño. Según (Alexander, 1979) los patrones no son principios abstractos que requieran su redescubrimiento para obtener una aplicación satisfactoria, ni son específicos a una situación particular o cultural; son algo intermedio. Un patrón define una posible solución correcta para un problema de diseño dentro de un contexto dado, describiendo las cualidades invariantes de todas las soluciones. "Cada patrón describe un problema que ocurre infinidad de veces en nuestro entorno, así como la solución al mismo, de tal modo que podemos utilizar esta solución un millón de veces más adelante sin tener que volver a pensarla otra vez.".
(17) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 6. Uno de los principales componentes de los patrones es su estructuración las cuales están estandarizadas de forma que se expresen uniformemente y puedan constituir efectivamente un medio de comunicación uniforme entre diseñadores. Las más utilizadas dentro de estos estándares es la de (Gamma, 1997) la cual consta de los siguientes apartados: Nombre del patrón: nombre estándar del patrón por el cual será reconocido en la comunidad (normalmente se expresan en inglés para evitar confusiones). Clasificación del patrón: está dada por su categoría (creacional, estructural, comportamiento…). Intención: ¿Qué problema pretende resolver el patrón? También conocido como: Otros nombres de uso común para el patrón, aquí saldría el alias del patrón o su españolización en caso de llevarlo al español lo cual no es recomendable a la hora de nombrarlo. Motivación: Escenario de ejemplo para la aplicación del patrón. Aplicabilidad: Usos comunes y criterios de aplicabilidad del patrón. Estructura: Diagramas de clases oportunos para describir las clases que intervienen en el patrón. Participantes: Enumeración y descripción de las entidades abstractas (y sus roles) que participan en el patrón. Colaboraciones: Explicación de las interrelaciones que se dan entre los participantes..
(18) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 7. Consecuencias: Consecuencias positivas y negativas en el diseño derivadas de la aplicación del patrón. Implementación: Técnicas o comentarios oportunos de cara a la implementación del patrón. Código de ejemplo: Código fuente ejemplo de implementación del patrón. Usos conocidos: Ejemplos de sistemas reales que usan el patrón. Patrones relacionados: Referencias cruzadas con otros patrones Los patrones de diseño pretenden: Proporcionar catálogos de elementos reusables en el diseño de sistemas software. Evitar la reiteración en la búsqueda de soluciones a problemas ya conocidos y solucionados anteriormente. Formalizar un vocabulario común entre diseñadores. Estandarizar el modo en que se realiza el diseño. Facilitar el aprendizaje de las nuevas generaciones de diseñadores condensando conocimiento ya existente. Asimismo, no pretenden: Imponer ciertas alternativas de diseño frente a otras. Eliminar la creatividad inherente al proceso de diseño. Los patrones están organizados en categorías las cuales favorecen la agrupación de patrones con características comunes..
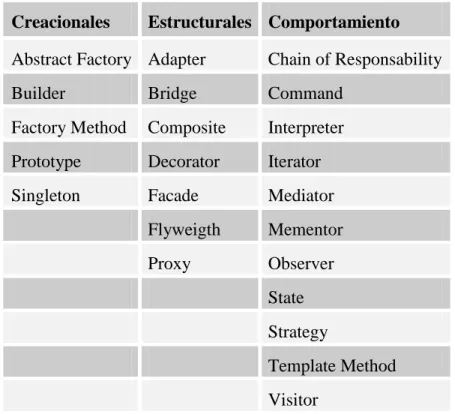
(19) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 8. 1.1.1 Categorías de los Patrones de Diseño En la Tabla 1 se muestran las categorías básicas de los Patrones de diseño. Existen tres grupos, estos son los creacionales, estructurales y de comportamiento (Freeman, 2004). Tabla 1 Categorías de los Patrones de Diseño. Creacionales. Estructurales Comportamiento. Abstract Factory Adapter. Chain of Responsability. Builder. Bridge. Command. Factory Method. Composite. Interpreter. Prototype. Decorator. Iterator. Singleton. Facade. Mediator. Flyweigth. Mementor. Proxy. Observer State Strategy Template Method Visitor. Además de esta tres categorías existen otras, como nuestro trabajo se enfoca en patrones para el acceso a datos en una arquitectura orientada a servicios (SOA) a continuación mostramos los patrones arquitectónicos. . 1.1.2 Patrones enfocados a la arquitectura Existen tres niveles de patrones fundamentales entre los cuales se encuentran (Mestras, 2004): Bajo nivel: Patrones elementales específicos de un lenguaje de programación..
(20) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 9. Nivel Medio: Patrones de diseño. Alto Nivel: Los patrones de arquitectura son formas predefinidas de resolver problemas de arquitectura. La arquitectura de un sistema de software casi nunca se limita a un solo patrón o estilo. En la Tabla 2 se muestran los principales estilos de patrones arquitectónicos. Tabla 2 Estilos de patrones arquitectónicos. Note SOA como un estilo de comunicación. Categorías. Estilos. Comunicación SOA (Servicie Oriented Arquitecture) Bus de Mensajes Distribución. Cliente/Servidor 3-Capas N-Capas. Estructuras. Basado en Componentes Orientado a Objetos Arquitectura de Capas. Otras. Dirigido por eventos Modelo-Vista-Controlador. El estilo arquitectónico a seguir será SOA el cual se trata en el siguiente epígrafe. 1.2. SOA Arquitectura orientada a servicios. SOA es un tipo de arquitectura tecnológica que cumple con los principios de la orientación a servicios. Cuando se implementa a través de la plataforma tecnológica de servicios web, SOA brinda el potencial para soportar y proveer estos principios a lo largo de los procesos de negocio y los dominios de automatización de una empresa(Erl, 2005)..
(21) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 10. 1.2.1 Etapas en la evolución de SOA Una vez que se decide implementar SOA, es muy típico pasar por todas estas fases en el camino de evolución hacia la madurez SOA. (Roncero, 2007). 1) Creación de los Servicios dentro de la organización. Estos Servicios incluyen funcionalidades reutilizables, accesibles de manera estándar y que pueden formar parte de procesos de negocio. 2) Orquestación de los Servicios previamente creados, mediante la definición de Procesos que utilizarán dichos servicios disponibles en la organización. 3) Construcción de nuevos servicios según sean necesarios para la orquestación de los nuevos Procesos y reutilización de los Servicios ya existentes en distintos Procesos. 4) Enterprise Service Bus (ESB). Una vez que el número de procesos orquestados es importante, la organización descubre que es difícil controlarlos y es difícil escalar procesos existentes, y en ese momento es cuando las organizaciones realmente descubren que es muy complicado gestionar y escalar una Arquitectura SOA si se carece de un ESB. 5) Monitorización de los Procesos en SOA. Una vez se definen los primeros procesos SOA, surge la necesidad de tener visibilidad en quién está utilizando estos servicios, qué tiempos de respuesta se están ofreciendo, etc. Este punto será tenido en cuenta en distintos momentos en el camino hacia la madurez SOA..
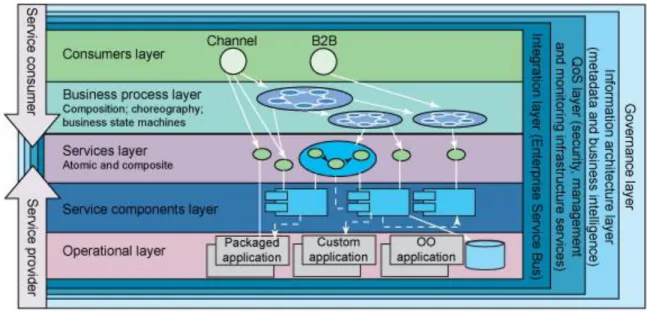
(22) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 11. SOA es también visto como una arquitectura basada en n-capas a continuación mostraremos la referenciada por IBM, pero estas capas varían de acuerdo a la necesidad del problema a resolver. 1.2.2 Arquitectura de capas en SOA La arquitectura SOA que propone IBM es lo suficientemente sólida para convertirse en un auténtico estándar. Tanto, que muchas organizaciones definen su propia visión de SOA indicando en qué se parece o en qué se diferencia de la que propone IBM Figura 1.2 (IBM, 2009).. Figura 1.2 La arquitectura de referencia IBM define 9 capas.. 1. Sistemas operacionales (Operational Layer): Es el inventario de todas las aplicaciones existentes y que proporcionan la lógica de negocio o núcleo de la empresa. Aplicaciones hechas a medida, aplicaciones comerciales, sistemas legacy, bases de datos, etc..
(23) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 12. 2. Capa de componentes de servicio (Service Components Layer): Es la implementación de un servicio y según IBM debe cumplir con SCA (Service Componente Architecture) y con SDO (Service Data Objects). 3. Capa de servicios (Services Layer): Esta capa contienen los servicios de negocio. Están implementados con una tecnología estándar independiente de la plataforma. Tiene un descriptor WSDL que igualmente es estándar y define la interfaz del servicio (con qué parámetros se invoca y cuáles devuelve). Se pueden crear servicios compuestos, combinando otros servicios más simples. 4. Capa de procesos de negocio (Business Process Layer): En esta capa se ubican los servicios compuestos, formados por la combinación de servicios más sencillos. También se encuentran los procesos BPM (coreografías de servicios) que modelan casos de uso específicos y procesos de negocio de la organización. Cada proceso es un flujo de tareas automáticas o humanas (tienen que ser realizados por una persona). 5. Capa de consumidores (Consumers Layer): Aquí se encuentran todos los posibles consumidores de los servicios. Debido a las características de múltiples canales de los propios servicios y dado la cantidad de dispositivos existentes actualmente para acceder a los mismos, los consumidores pueden ser de tipo heterogéneo: aplicaciones de oficina, aplicaciones con interfaz web de internet, usuarios finales con sus Smartphone, etc. Es importante recalcar que los servicios son “agnósticos” respecto a la forma de su consumo o a la presentación que se le haría al usuario final. Todos los servicios están dados de alta en el registro de.
(24) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 13. servicios a fin de que los consumidores puedan localizar el servicio que necesiten y sean independientes de la localización física del servicio. 6. Capa de integración (Integration Layer): Esta es una capa de infraestructura que proporciona las capacidades de mediación, enrutado y transporte de la petición del cliente hasta el servicio concreto. Estas capacidades se implementan mediante un Enterprise Service Bus (ESB). 7. Capa de calidad del servicio (QoS Layer): Esta capa proporciona la capacidad de realizar los requerimientos no funcionales necesarios, por ejemplo, monitorización de los servicios, trazas, alertas de no cumplimiento del nivel de servicio acordado (SLA), etc., asegurando que se cumplen los niveles mínimos de escalabilidad, disponibilidad y seguridad necesarios. Desde el punto de vista de negocio, proporciona la funcionalidad de Business Actitivity Monitor (BAM), es decir, el estado en tiempo real del proceso desde el punto de vista de negocio. Esto se hace mediante el desarrollo dentro del proceso de KPI (Key Performance Monitor) que son recogidos por el BAM y mostrados al usuario. 8. Capa de información (Information Architecture Layer): En esta capa se recolecta información susceptible de forma datamarts y data wharehouses para su posterior análisis. 9. Capa de Gobierno (Governance Layer): Cubre todos los aspectos relativos al ciclo de vida de los servicios. Incluidos los aspectos de seguridad, capacidad y rendimiento..
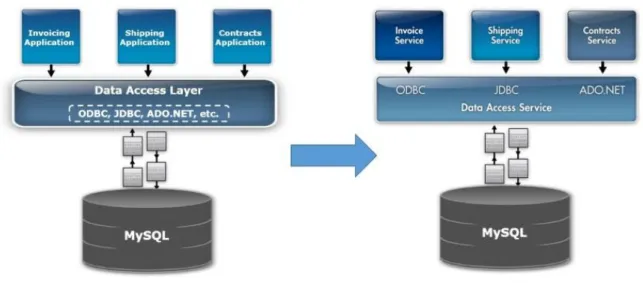
(25) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 14. Visto en esta ejemplificación de capas para una arquitectura SOA la capa de acceso a datos es la relacionada con la Capa de componentes de servicio, aunque utiliza las fuentes de datos de la capa operacional. A continuación se enfatizara sobre esta capa de forma general cuando se utilizada en una aplicación tradicional. 1.2.3 Capa de acceso a datos En la actualidad cuando se habla de acceder a datos existen interfaces que nos permiten el acceso a las fuentes de datos, las principales dedicadas a esta función son: ODBC: (Open Database Connectivity) hace posible accede a cualquier dato desde cualquier aplicación sin importar que gestor de base de datos se use. JDBC: (Java Database Connectivity) permite la ejecución de operaciones sobre base de datos con el lenguaje de programación Java. ADO.NET: Conjunto de componentes del software usado para acceder a datos y servicios de datos. OLE DB: (Object Linking and Embedding for Databases) para tener acceso a diferentes fuentes de información de manera uniforme. En una aplicación tradicional el mecanismo de acceso a datos con las interfaces mencionadas serian como se muestra en la siguiente Figura 1.3.
(26) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 15. Figura 1.3 Arquitectura de acceso a datos.. Esta arquitectura no es aplicable para un ambiente SOA por las siguientes razones: Su rendimiento de escalabilidad es por debajo del nivel exigido. o Los servicios son reutilizables diseñados inicialmente para 50 usuarios, sin embargo en un ambiente SOA es posible llegar hasta unos 500 usuarios. Retrasos de despliegue. o Un despliegue pequeño se convierte en un gran problema cuando el número de servicios aumenta. Para una mejor práctica de acceso a datos en una arquitectura SOA se recomienda desacoplar la lógica de la entidad así como de la fuente de datos, optimizar el uso de los ambientes heterogéneos, abordar los problemas de rendimientos de acceso a datos persistentes y dinamizar el acceso de datos con técnicas de integración de datos. Por estas.
(27) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 16. razones cuando se quiere trabajar con una arquitectura orientada a servicios se recomienda desarrollar un servicio de acceso a datos. 1.2.4 Servicio de acceso a datos En un ambiente SOA la capa de acceso a datos pasara a verse como un servicio de datos el cual accede a los mismos como un servicio web Figura 1.4. Figura 1.4 De la capa de acceso a dato a servicios de acceso a datos. De esta manera se logran servicios de acceso a datos mejores, escalables, fáciles de desplegar y reutilizables. Una de las razanos de asumir SOA es la de compartir servicios frente a un conjunto de aplicaciones y acceder a los datos de una manera optimizada la cual no sería posible utilizando la capa de acceso a datos. Service Data Objects es una tecnología que permite que los datos heterogéneos sean accedidos de una manera uniforme. La especificación de esta fue desarrollada en el año 2004 y aprobada por la comunidad Java con JSR 235. La versión 2.0 de la especificación fue presentada en noviembre del 2005 como parte de la arquitectura de componentes de.
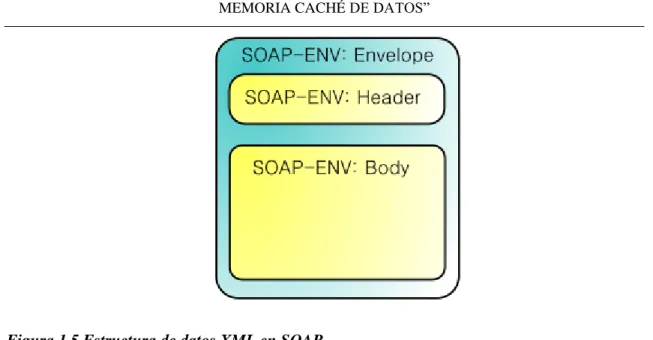
(28) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 17. servicios. Service Data Objects denotan estructuras de datos que facilitan la comunicación entre gradas estructurales y entidades proveedoras de servicios. Requieren el uso de una estructura de árbol con un nodo de raíz y suministran mecanismos trasversales de amplitud y profundidad que permite que clientes o programas naveguen por determinados elementos. La forma más habitual de implementar esta arquitectura es mediante Servicios Web, una tecnología basada en estándares e independiente de la plataforma, con la que SOA puede descomponer aplicaciones monolíticas en un conjunto de servicios e implementar esta funcionalidad en forma modular. 1.3. Tendencias y tecnologías actuales en los Servicios Web. Existen múltiples definiciones sobre lo que son los Servicios Web, lo que muestra su complejidad a la hora de dar una adecuada definición que englobe todo lo que son e implican. Una posible sería hablar de ellos como un conjunto de aplicaciones o de tecnologías con capacidad para interactuar en la Web. Estas aplicaciones o tecnologías intercambian datos entre sí con el objetivo de ofrecer servicios. Los proveedores ofrecen sus servicios como procedimientos remotos y los usuarios solicitan un servicio llamando a estos procedimientos a través de la Web. A continuación entraremos en detalle de algunas tendencias y tecnologías referentes a los Servicios Web. 1.3.1 Servicios Web SOAP SOAP por sus siglas en inglés (Simple Object Access Protocol), es un protocolo estándar que define cómo dos objetos en diferentes procesos pueden comunicarse por medio de intercambio de datos XML los cuales tienen la siguiente estructura Figura 1.5(W3C, 2007)..
(29) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 18. Figura 1.5 Estructura de datos XML en SOAP. La estructura de datos XML para este protocolo se compone de las siguientes partes(Erl, 2005): Envelope: elemento raíz, contiene declaraciones de namespaces y atributos adicionales. Header: contiene atributos relacionados con el procesamiento por el servidor o los intermediarios. Body: contiene la carga útil "payload" del mensaje, para ser procesada por el servidor. El protocolo SOAP tiene tres características principales: Extensibilidad (seguridad con extensiones aplicadas en el desarrollo). Neutralidad (SOAP puede ser utilizado sobre cualquier protocolo de transporte como HTTP, SMTP, TCP o JMS). Independencia (SOAP permite cualquier modelo de programación)..
(30) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 19. Los procedimientos SOAP pueden ser utilizados de la siguiente forma. Un mensaje SOAP podría ser enviado a un sitio Web que tiene habilitado un servicio, para realizar la búsqueda de algún precio en una base de datos, indicando los parámetros necesitados en la consulta. El sitio podría retornar un documento formateado en XML según muestra la Figura 1.5, ejemplo, precios, localización, características. Teniendo los datos de respuesta en un formato estandarizado, este puede ser integrado directamente en un sitio Web o aplicación externa. La arquitectura SOAP consiste de muchas capas de especificación: para el formato del mensaje, subyacentes enlaces de protocolo de transporte, modelo de procesamiento de mensajes, y extensibilidad del protocolo. Por estas razones es recomendable utilizarlo en servicios complejos y de gran envergadura. Para la implementación de servicio más simples se recomienda usar REST el cual será tratado en el siguiente epígrafe. 1.3.2 Servicio Web REST REST por sus siglas en inglés (Representacional State Transfer) es una técnica de arquitectura de software para sistemas hipermedia distribuidos como la World Wide Web. Esta técnica se usa para cualquier interfaz web simple que utilice XML y HTTP sin las abstracciones adicionales de los protocolos basados en patrones de intercambio de mensajes como el protocolo de servicio web SOAP (Leonard Richardson, 2007). Con REST la web ha disfrutado de una escalabilidad con resultado de una serie de diseños claves como:.
(31) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 20. Protocolo cliente/servidor sin estado, cada mensaje HTTP contiene toda la información necesaria para comprender la petición. Como resultado, ni el cliente ni el servidor necesitan recordar ningún estado de las comunicaciones entre mensajes. Operaciones bien definidas aplicadas a todos los recursos de información, HTTP en sí define un conjunto pequeño de operaciones. o POST: Actualiza un recurso sobre el servidor. El recurso es contenido en el cuerpo del pedido de POST. Post es análogo a una declaración de actualización de SQL. o GET: Recupera un recurso del servidor. El recurso es especificado con una URL para delinear el pedido de los parámetros de solicitud. GET es análogo a una declaración seleccionar de SQL. o PUT: Añade un recurso sobre el servidor. El recurso es contenido en el cuerpo del pedido de POST. El lanzamiento es análogo a un declaración de Insertar de SQL o DELETE: Elimina un recurso sobre el servidor. El recurso es especificado en el URL solamente. El Eliminar es análogo a una declaración de eliminar en SQL. Sintaxis universal para identificar los recursos. En un sistema REST, cada recurso es direccional únicamente a través de su URI. Uso de hipermedias, tanto para la información de la aplicación como para las transiciones de estado de la aplicación, la representación de este estado en un sistema REST son típicamente HTML o XML. Como resultado de esto, es posible.
(32) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 21. navegar de un recurso REST a muchos otros, simplemente siguiendo enlaces sin requerir el uso de registros u otra infraestructura adicional. 1.3.3 Fundamentación del Entorno de Desarrollo, Lenguaje, Gestor de Base de Datos y Tecnología utilizados En el desarrollo de la presente investigación se utilizó el siguiente entorno de desarrollo: NetBeans IDE 7.1.2: por ser un entorno de desarrollo integrado libre gratuito sin restricciones de uso, este es una herramienta para escribir, depurar, y ejecutar programas. Además soporta todo tipo de aplicaciones Java como J2SE, web services, EJB y aplicaciones móviles. El lenguaje utilizado es Java ya que es de propósito general, concurrente, orientado a objetos y basado en clases el cual fue diseñado específicamente para tener tan pocas dependencias de implementación como fuese posible. Las fuentes de datos se gestionan con el Gestor de Base de Datos PostgreSQL aunque el desarrollador puede utilizar cualquier otro para gestionar las fuentes de datos. PostgreSQL este es relacional orientado a objetos, libre y de código abierto. Una de las principales características de este gestor es su alta concurrencia, esta nos permite que mientras un proceso escribe en una tabla, otros accedan a la misma tabla sin necesidad de bloqueos. Cada usuario obtiene una visión consistente de lo último a lo que se ha actualizado. Esto nos sería de gran utilidad en un servicio ya que este pudiera estar disponible de manera permanente sin interrupciones. Además se utilizaron las siguientes tecnologías para desarrollar un servicio web de acceso a datos, las cuales se escriben a continuación:.
(33) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 22. Apache Tomcat: contenedor de Java Servlet es usado como servidor web autónomo en entornos con alto nivel de tráfico y alta disponibilidad. Dado que Tomcat fue escrito en Java, funciona en cualquier sistema operativo que disponga de la máquina virtual de Java por esta razón es el más indicado debido a que el lenguaje a tratar es Java. Java Runtime Environment: es un conjunto de utilidades que permite la ejecución de programas Java, este es accedido por el servidor web de Java Tomcat en el momento que es desplegado un servicio web. Servicio Web tipo REST: será el utilizado para la realización de este proyecto ya que cumple con los estándares necesarios para la solución de una aplicación sencilla como anteriormente se había comentado. Jersey: es un framework utilizado para implementar servicios web de código abierto, este suministra un juego de anotaciones que son usadas para definir un servicio web. Un ejemplo de estas anotaciones son @Patch, @Context, @GET, @Produces entre otras. JSON: es un formato ligero para el intercambio de datos, es un subconjunto de la notación literal de objetos de JavaScript que no requiere el uso de XML. Además representa mejor la estructura de los datos y requiere menos codificación y procesamiento Para hacer el tiempo medio de acceso a datos menor, cuando se accede por primera vez a una fuente de datos se hace una copia en el caché, de esta forma los accesos siguientes se.
(34) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 23. realizan a dicha copia. En esto consiste el cacheo de datos lo cuál será tratado a continuación. 1.4. Cacheo de Datos. La caché es un sistema especial de almacenamiento de alta velocidad. Puede ser tanto un área reservada de la memoria principal como un dispositivo de almacenamiento de alta velocidad independiente. 1.4.1 Tipos de Cacheo de Datos Hay dos tipos de caché frecuentemente usados en las computadoras personales(Behrouz A. Forouzan, 2003): Memoria caché: llamada también a veces almacenamiento caché o RAM caché, es una parte de memoria RAM estática de alta velocidad (SRMA) más rápida que la RAM dinámica (DRAM) usada como memoria principal. La memoria caché es efectiva dado que los programas acceden una y otra vez a los mismos datos o instrucciones. Guardando esta información en SRAM, la computadora evita acceder a la lenta DRAM. Cuando se encuentra un dato en el caché, se dice que se ha producido un acierto, siendo un caché juzgado por su tasa de aciertos (hit rate). Los sistemas de memoria caché usan una tecnología conocida por caché inteligente en la cual el sistema puede reconocer cierto tipo de datos usados frecuentemente. Las estrategias para determinar qué información debe de ser puesta en el caché constituyen uno de los problemas más interesantes en la ciencia de las computadoras..
(35) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 24. Caché de disco: trabaja sobre los mismos principios que la memoria caché, pero en lugar de usar SRAM de alta velocidad, usa la convencional memoria principal. Los datos más recientes del disco duro a los que se ha accedido (así como los sectores adyacentes) se almacenan en un buffer de memoria. Cuando el programa necesita acceder a datos del disco, lo primero que comprueba es el caché del disco para ver si los datos ya están ahí. El caché de disco puede mejorar drásticamente el rendimiento de las aplicaciones, dado que acceder a un byte de datos en RAM puede ser miles de veces más rápido que acceder a un byte del disco duro. 1.4.2 Ventajas y desventajas del Cacheo Debemos considerar como nuestra aplicación interactuará con la caché, las caché en un principio suelen estar vacías. En algún momento el sistema accederá a la fuente de datos para llenarlas lo cual varía según la estrategia determinada. En un principio la caché puede ser una gran ventaja cuando nos enfrentamos a constantes consultas de datos ya que el tiempo de respuesta disminuye considerablemente en los aciertos, pero el mal uso de la cache sería un problema aun mayor que el de su inexistencia, ya que una caché mal poblada sobrecargada o dejaría de ser útil. La caché debe ser poblada solo con los datos necesarios, por un lado solo bastaría un identificador para acceder a un objeto de una fuente de dato. Si llenáramos la cache con datos innecesarios la estaríamos sobrecargando lo cual sería un sobrepeso en la aplicación que afectaría considerablemente su rendimiento(Nock, 2003). 1.5. Conclusiones parciales. En el presente capitulo se realizó un estudio de los patrones de diseños, donde se vio su estructuración y categorización de acuerdo a sus propósitos. Se enfocaron los patrones de.
(36) CAPÍTULO 1.” PATRONES DE DISEÑO, SERVICIOS WEB DE ACCESO DE DATOS Y MEMORIA CACHÉ DE DATOS”. 25. diseños a la arquitectura donde se destacó SOA como una arquitectura que cumple con los principios de la orientación a servicios. Fueron abordadas las capas de acceso a datos y como en SOA estas pasarían a verse como un servicio de acceso a datos. Se analizaron las distintas tecnologías y tendencias actuales en los servicios web destacándose REST como la más óptima para la solución de nuestro problema. Finalmente se trató el tema relacionado con la caché de datos, donde se vio la importancia de la memoria caché y la desventaja que traería su mal uso..
(37) CAPÍTULO 2.” PATRONES DE CACHÉ”. 26. CAPÍTULO 2. PATRONES DE CACHÉ En el siguiente capítulo se dará una introducción a los patrones de acceso a datos, haciendo hincapié en los relacionados con la memoria caché. Algunos de estos serán propuestos a una integración mediante el patrón Strategy con el objetivo de integrarlos en un solo patrón. Serán propuestos los requisitos funcionales y no funcionales del sistema siendo útiles estos para la creación de los casos de usos del sistema. De esta forma quedaría detallada la estructura y funcionalidad de una biblioteca para acceder a datos mediante patrones de diseños.. 2.1. Patrones de acceso a datos. Los desarrolladores de software de las empresas enfrentan los mismos problemas de acceso de datos sin considerar su dominio en la aplicación. Éstos son algunos ejemplos de los problemas comunes que surgen cuando se quieren diseñar componentes de acceso de datos (Nock, 2003): Las aplicaciones tienen que funcionar en productos de base de datos múltiples. Las interfaces de usuarios tienen que esconder semántica de la base de datos. La inicialización de recurso de la base de datos es lento. Los detalles de acceso de datos hacen que la aplicación sea difícil de desarrollar y mantener. Las aplicaciones tienen que almacenar los datos a los que acceden frecuentemente. Múltiples usuarios tienen que acceder a los mismos datos simultáneamente..
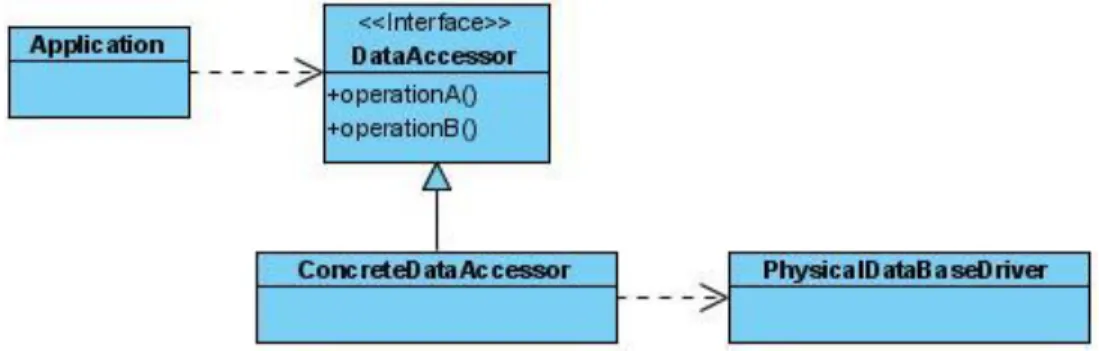
(38) CAPÍTULO 2.” PATRONES DE CACHÉ”. 27. Hay soluciones comunes para estos problemas. Algunas de estas soluciones son instintivas y han sido descubiertas por separado por miles de desarrolladores. Los otros son más obscuros, y han sido solucionados solamente en accesos de datos más robustos. Los patrones de acceso de datos describen las estrategias genéricas para solucionar problemas de diseño comunes como éstos. A continuación serán mostrados una serie de patrones de acceso a datos cumpliendo con en el criterio planteado en los objetivos específicos que son disminuir la cantidad de datos enviados y el tiempo de respuesta en el acceso a los datos: DataAccessor CacheAccessor DemandCache PrimedCache CacheSearchSequence CacheCollector 2.1.1 Data Accessor Encapsula los detalles de acceso de datos físicos en un solo componente, sacando a la luz solamente las operaciones lógicas. La clave de aplicación, mantiene conocimientos sobre el modelo de datos subyacente. Aplicabilidad Este patrón es necesario utilizarlo cuando:.
(39) CAPÍTULO 2.” PATRONES DE CACHÉ”. 28. Se quiere ocultar el modelo de datos físico y la complejidad de acceso de datos de la lógica de aplicación. Hace guardar la lógica de la aplicación más limpia y con mayor calidad los procesos del modelo. Encapsula todo el modelo de datos y los detalles de acceso de datos, se interesa solo en un concepto de dominio dentro de un componente. Agrupa todos los accesos para una tabla o juego de tablas relacionadas así se hace más fácil pronosticar el efecto. Oculta contradicciones del modelo de datos u oscuros códigos de la aplicación. Algunos modelos de datos de legado no gravan semántica. Encapsula estos detalles dentro de un componente impidiéndole de contaminar el código de la aplicación. Estructura La interfaz de DataAccessor define el concepto abstracto de acceso de datos en relación con las operaciones lógicas que el código de la aplicación usa. Se define estas operaciones de ser suficientemente extensivo con el propósito de que las aplicaciones pueden hacer el trabajo útil sin forzar a aplicaciones a usar conceptos anormales o modos indirectos. Se puede adaptar para que la semántica de la operación lógica guarde el código de aplicación lo más sencillo posible. Hay que tener cuidado de no sacar a la luz cualquier semántica física en estas operaciones lógicas. Permite que el código de la aplicación dependa de físicos expuestos, haciéndolo difícil de cambiar después. No se necesita definir el juego entero de las operaciones lógicas como una interfaz. Es común separar pregunta lógica, actualización, resultado fijó, y las operaciones de transacción en interfaces múltiples como se muestra en la Figura 2.1..
(40) CAPÍTULO 2.” PATRONES DE CACHÉ”. 29. Figura 2.1 DataAccessor. 2.1.2 Cache Accessor Aplicabilidad Es necesario la utilización de este patrón cuando: La aplicación tienen que leer un juego específico de los datos muchas veces y acceder a la base de datos física repetidamente degrada el rendimiento. Los datos almacenados cambian muy poco. Las actualizaciones frecuentes requieren la interacción de base de datos física adicional. Estructura La clase de CacheAccessor define el punto de entrada para las operaciones de acceso de datos del cliente mientras Cache pone en funcionamiento el mecanismo de almacenamiento del caché verdadero, sus operaciones consultan los datos almacenados. Nótese como CacheAccessor delega las operaciones de base de datos a un componente de DataAccessor como se ve en la Figura 2.2..
(41) CAPÍTULO 2.” PATRONES DE CACHÉ”. 30. Figura 2.2 CacheAccessor. En el diagrama de secuencia Figura 2.3 se muestra un cliente que hace público la operación de escritura a un CacheAccessor. Además de escribir a la base de datos física, el CacheAccessor también debe asegurar que Cache refleje los datos cambiados.. Figura 2.3 Diagrama de secuencia de CacheAccessor.
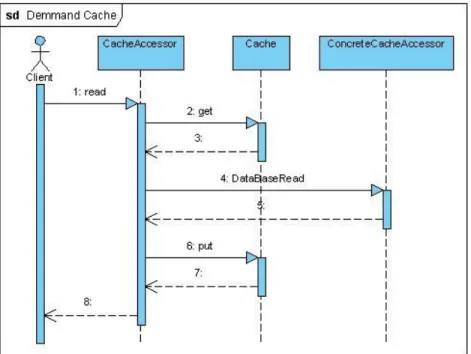
(42) CAPÍTULO 2.” PATRONES DE CACHÉ”. 31. 2.1.3 Demand Cache Este patrón es similar al CacheAccessor su diferencia se muestra en el diagrama de secuencia Figura 2.4. Cuando un cliente solicita una información determinada este accede a la memoria caché en busca de estos datos. Si los datos son encontrados son devueltos al cliente, de lo contrario lo busca en la memoria física, los gurda en memoria caché y se los retorna al cliente. La próxima vez que un cliente solicite los mismos datos su acceso será más rápido ya que los datos buscados se encuentran guardados en memoria caché.. Figura 2.4 diagrama de secuencia de DemandCache. 2.1.4 Primed Cache Precarga la caché explícitamente con un juego pronosticado de los datos. Un caché precargada es útil para los datos que son leídos frecuentemente y de manera previsible..
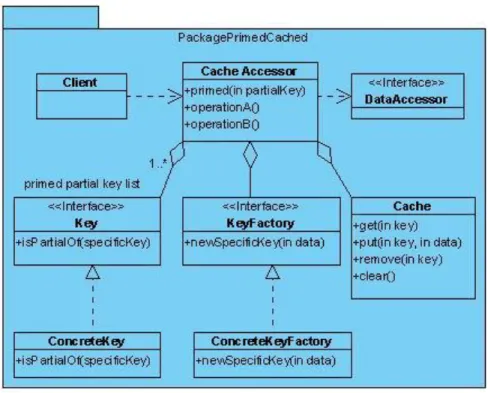
(43) CAPÍTULO 2.” PATRONES DE CACHÉ”. 32. Aplicabilidad En ocasiones poblar la caché con grandes cantidades de datos no es viable porque requiere uno importante monto de almacenamiento principal lo cual disminuye la velocidad de inicialización del sistema. Poblar la caché con todos los datos no es necesario porque la mayoría de los datos son necesitados en cualquier momento. Es posible pronosticar un subconjunto pequeño y relevante de los datos para preparar en previsión de los clientes en pedidos futuros. Este subconjunto debe ser usado eficientemente en el almacenamiento de la caché. Estructura Su estructura es similar a CacheAccessor la clase CacheAccessor define el punto de entrada para las operaciones de acceso de datos de los clientes. El Cache pone en funcionamiento el mecanismo de almacenamiento de caché y DataAccessor es responsable de hacer público las operaciones de la base de datos física. La clase Key es fundamental para poder realizar el acceso a los datos físicos ya que esta contiene la o las identificaciones necesarias para hacer el filtrado de las búsquedas, estas establecen la relación de la columna con elemento, KeyFactory es una interfaz para construir estos identificadores, como se muestra en la Figura 2.5..
(44) CAPÍTULO 2.” PATRONES DE CACHÉ”. 33. Figura 2.5 PrimedCache. 2.1.5 Cache Search Sequence Inserta anotaciones en la caché para optimizar el número de las operaciones que requieren futuras búsquedas. Aplicabilidad Una operación de lectura lógica requiere una secuencia de operaciones de lectura de caché múltiples, reflejando una relación jerárquica o una búsqueda gradual que empieza con los criterios específicos. Las secuencias de buscar que requieren caché múltiple leerá las operaciones optimizado al grado de reducir el número de operaciones de caché, esto perceptiblemente mejora el rendimiento del sistema..
(45) CAPÍTULO 2.” PATRONES DE CACHÉ”. 34. Estructura Este patrón es similar a CacheAccessor la diferencia radica en la adición de la clase de CacheSearchSequence que sostiene el estado de una secuencia de caché asociada a las operaciones leídas, ver Figura 2.6.. Figura 2.6 CacheSearchSequence. 2.1.6 Cache Collector Se deshace de anotaciones cuya presencia en cache atenten contra el rendimiento. Aplicabilidad El tamaño en la caché aumenta constantemente hasta que consume una cantidad importante del almacenamiento en memoria. El impacto de usar demasiado almacenamiento para caché es que puede dificultar el rendimiento de sistema. Con este patrón la aplicación elimina los datos en la cache cuando su presencia deja de ser eficaz y hace sitio para los datos más relevantes..
(46) CAPÍTULO 2.” PATRONES DE CACHÉ”. 35. Estructura CacheCollector, CacheEntry y CacheEntryFactory son interfaces que definen los varios conceptos abstractos para las estrategias de colección de caché sin determinar los algoritmos específicos o las reglas y permiten aislar la lógica de colección dentro de su propio componente, ver Figura 2.7.. Figura 2.7 CacheCollector Una vez mostrados estos patrones propuestos nótese que los mismos guardan una relación con CacheAccessor. En el siguiente epígrafe se realizara un análisis teniendo en cuenta las clases generales y específicas de todos los patrones para llegar a integrarlos en un solo patrón compuesto..
(47) CAPÍTULO 2.” PATRONES DE CACHÉ”. 2.2. 36. Integración de los Patrones de Acceso a Datos. Se integraron los patrones Data Accessor, Cache Accessor, Demand Cache y Primed Cache en un patrón compuesto basado en el patrón strategy. Los patrones Cache Search Sequence y Cache Collector no fueron integrados a esta versión de la solución, pero se encuentran dentro de los objetivos de futuras versiones. El patrón compuesto es capaz de leer datos a demanda, precargar la caché, realizar lectura mixta de datos y realizar lectura directa, es decir leer datos a demanda y precargar la caché. En la figura 2.8 se observan las clases principales, las cuales son DemandCache, encargada de leer datos a demanda, PrimedCache para la precarga de datos, DemandPrimedCache que realiza la lectura mixta y NoCacheReader para leer directamente de la fuente de datos. Estas clases heredan de la clase base CacheAccessor, que contiene referencias a las interfaces IPrime e IReader. IPrime es implementada por las clases Primed y NoPrime. Ambas clases sobrescriben el método prime() que en el caso de Primed precarga la caché y en NoPrime no lo hace. Primed y NoPrime son dos estrategias de precarga de caché. La interfaz IReader es implementada por las clases CacheReader, Demand y DirectReading. Ellas sobrescriben el método read() que en el caso de CacheReader realiza una lectura directa de caché. En la clase Demand la lectura de datos se realiza bajo demanda, es decir, primero se intenta leer de la cache, si la información no es encontrada ahí se intentará leer de la base de datos, por ultimo DirectReading leerá directamente de la base de datos de manera tradicional. Las clases CacheReader, Demand y DirectReading representan tres estrategias de lectura de la caché..
(48) CAPÍTULO 2.” PATRONES DE CACHÉ”. 37. Figura 2.8 Clases principales del patrón compuesto. 2.3. Requisitos a considerar. En el proceso de diseño del sistema son planteados los requisitos funcionales y no funcionales con que debería funcionar dicho sistema. Una vez definido los requisitos funcionales se podrían definir los casos de uso del mismo. 2.3.1 Requisitos funcionales Estos requisitos nos indican las responsabilidades del sistema de una forma clara, son aquellos que especifican una acción que debe ser capaz de realizar el sistema, sin considerar restricciones físicas; requisito que especifica comportamiento de entrada/salida de un sistema (Jacobson, 2000). A partir del análisis de la funcionalidad del sistema se detectaron los siguientes requisitos funcionales: RF 1 Lectura bajo demanda RF 2 Lectura precargada RF 3 Lectura bajo demanda y precargada RF 4 Lectura directa.
(49) CAPÍTULO 2.” PATRONES DE CACHÉ”. 38. 2.3.2 Requisitos no funcionales Los requisitos no funcionales son aquellos que especifican propiedades del sistema, como restricciones del entorno o de implementación, rendimiento, dependencias de la plataforma, mantención, extensibilidad o fiabilidad. Estos especifican restricciones físicas sobre un requisito funcional. En este trabajo se tienen los siguientes: Requisitos del sistema por parte del servidor: Servidor web apache Tomcat 7. Sistema gestor de base de datos en un principio preferentemente PostgreSQL. Máquina virtual de java (Java Runtime Environment 1.6) en el sistema operativo. Requisitos del sistema por parte del cliente: Contar con un navegador web Mozilla Firefox 4.0 o superior, aunque también se pudieran utilizar otros como Internet Explorer, Chrome y Opera. Requisitos de rendimiento: El tiempo de respuesta accediendo a la memoria caché deberá ser menor que el tiempo de respuesta al acceder directamente a la fuente de datos. 2.4. Diagrama de casos de uso del sistema. Un caso de uso es un fragmento de funcionalidad del sistema que proporciona al usuario un resultado importante. Los casos de uso representan los requisitos funcionales. Todos los casos de uso juntos constituyen el modelo de casos de uso (Jacobson, 2000). Los diagramas de casos de uso muestran el comportamiento del sistema a partir de los usuarios que.
(50) CAPÍTULO 2.” PATRONES DE CACHÉ”. 39. interactúan con él. Describe gráficamente quién utiliza el sistema y la forma en que los usuarios esperan interactuar con él Figura 2.9.. Figura 2.9 Diagrama de casos de uso 2.4.1 Descripción de los casos de uso del sistema En las siguientes tablas se describen de forma detallada en qué consisten los casos de uso del sistema: Tabla 3 Descripción del caso de uso: Lectura bajo demanda Caso de Uso:. Lectura bajo demanda. Actor:. Usuario, Desarrollador o Sistema. Propósito:. Lee datos de la caché, de no existir accede a la fuente de datos y los guarda en la caché para luego devolverlo al cliente. Resumen:. El caso de uso se inicia cuando un actor realiza un lectura (doRead) a la caché mediante una estrategia de demanda (Demand) la cual verifica si existen los datos, de no existir este los pide bajo demanda a la fuente de datos. El cliente no podrá precargar (doPrime) la caché de este, lo cual.
(51) CAPÍTULO 2.” PATRONES DE CACHÉ”. 40. no es permitido en esta estrategia (NoPrime) ver Figura 2.8 Tabla 4 Descripción del caso de uso: Lectura precargada Caso de Uso:. Lectura precargada. Actor:. Usuario, Desarrollador o Sistema. Propósito:. Precarga la cache para cuando el cliente lee sobre esta no tenga que acceder a la fuente de datos.. Resumen:. El caso de uso se inicia cuando un actor precarga (doPrime) los datos mediante una estrategia de precarga (Prime), una vez precargada lee (doRead) directamente de la cache (CacheReader) ver figura 2.8. Tabla 5 Descripción del caso de uso: Lectura bajo demanda y precargada Caso de Uso:. Lectura bajo demanda y precargada. Actor:. Usuario, Desarrollador o Sistema. Propósito:. Leer datos de la caché bajo demanda y precargar datos de la fuente. Resumen:. El caso de uso se inicia cuando un actor realiza una lectura (doRead) a la caché mediante una estrategia de demanda (Demand) también podrá realizar una precarga (doPrime) precargando los datos en la caché (Prime) ver Figura 2.8. Tabla 6 Descripción del caso de uso: Lectura directa.
(52) CAPÍTULO 2.” PATRONES DE CACHÉ”. 41. Caso de Uso:. Lectura directa. Actor:. Usuario, Desarrollador o Sistema. Propósito:. Realizar la lectura directa de la fuente de datos.. Resumen:. El caso de uso se inicia cuando un actor realiza una lectura (doRead) directa a la fuente de datos mediante una estrategia de lectura directa (DirectReading) El cliente no podrá realizar la precarga (doPrime), lo cual no es permitido en esta estrategia (NoPrime) ver figura 2.8. 2.5. Conclusiones parciales. En el presente capitulo fueron expuestos los patrones relacionados con el acceso a datos, teniendo en cuenta los relacionados con la memoria caché. De estos patrones fueron seleccionados aquellos que acceden a las fuentes de datos con el objetivo de integrarlos en un patrón de comportamiento basado en estrategias de cacheo (Strategy), en esta integración se encontraron los patrones Data Accessor, Cache Accessor, Demand Cache y Primed Cache. Una vez integrados fueron identificados los requisitos funcionales basados en diferentes estrategias para acceder a datos, definidos estos realizamos los casos de usos del sistema con sus descripciones correspondientes..
(53) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. 42. CAPÍTULO 3. DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN En el presente capítulo se describirá la propuesta de solución del sistema mediante el modelo de componente y diagramas de clases. También se abordaran los principales diagramas de secuencias para los principales casos de usos del sistema. Se abordara la justificación del principio de diseño utilizado y mostraremos el diagrama de despliegue.. 3.1. Modelo de componentes. Un diagrama de componente muestra la organización y las dependencias entre un conjunto de componentes. Los diagramas de componentes se utilizan para modelar la vista de implementación estática de un sistema (Grady Booch, 2005). En la siguiente Figura 3.1 se muestra la arquitectura del sistema mediante su diagrama de componentes.. Figura 3.1 Diagrama de Componentes A continuación describimos la relación entre los distintos componentes de la arquitectura anterior. Inicialmente un cliente accede a través del navegador web, aplicación desktop o cualquier software que sea capaz de invocar el servicio de cacheo desplegado en el servidor.
(54) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. 43. web Tomcat. Dependiendo de la estrategia de cacheo que seleccione el cliente se accederá a la base de datos, gestionada por PostgreSQL.. 3.2. Diagrama de clases. Los diagramas de clases se utilizan para modelar la vista estática de diseño de un sistema. Esta vista soporta principalmente los requisitos funcionales de un sistema, los servicios que el sistema debe proporcionar a sus usuarios finales (Grady Booch, 2005). A continuación se muestra y describe el diagrama de clase de la estructura del sistema..
(55) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. 44. Figura 3.2 Diagrama de clases En el diagrama de clases anterior Figura 3.2 se muestra la estructura del sistema el cual está compuesto por dos paquetes CacheStrategy y DataAccess. En el primer paquete se encuentra la estructura integrada de los patrones de cacheo en un patrón Strategy el cual nos permite decidir la estrategia a tomar para realizar el acceso a los datos. Este paquete usa el paquete DataAccess, que contiene las clases necesaria para realizar el acceso a los datos.
(56) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. existentes en la fuente de datos. DBAccessor. 45. es una interfaz implementada por. ConcreteDBAccessor encargada de realizar la conexión con el gestor de base de datos en caso de que los datos no se encuentren cacheados. DBAccessor hace uso de Key quien es un identificador de datos necesario para realizar la consulta en el momento que se ejecuta la conexión con la base de datos. DBAccessor es utilizada únicamente por las clases Primed y Demand quienes son encargadas de precargar y demandar los datos respectivamente de una base de datos, sin embargo no ocurre lo mismo con Key ya que esta es utilizada por todos para tener la identificación de los datos que se quiere acceder.. 3.3. Diagrama de Secuencias. Un diagrama de secuencia destaca la ordenación temporal de los mensajes. Esto una señal visual clara del flujo de control a lo largo del tiempo (Grady Booch, 2005). Los siguiente diagramas de secuencia está estructurados por una arquitectura vista-modelocontrolador donde el Cliente iniciara los casos de usos mediante una interfaz gráfica, como modelo tenemos la caché y las fuentes de datos, por último la parte controladora estaría a cargo del servicio de cacheo, las estrategias de cacheo y la clase para realizar la conexión a las fuentes de datos. Seguidamente serán mostrados los principales diagramas de secuencias de la aplicación A continuación en la figura 3.3 se muestra el diagrama de secuencia relacionado con el caso de uso lectura directa..
(57) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. 46. Figura 3.3 Diagrama de secuencia: Lectura directa El caso de uso es iniciado cuando un cliente selecciona una funcionalidad en la interfaz gráfica donde es ejecutado un recuso para acceder a datos mediante una lectura directa a la fuente de datos. Los datos serán buscados directamente mediante el acceso de ConcreteDBAccessor a la base de datos, una vez encontrado los datos serán retornados al cliente como se describe en el diagrama de secuencia anterior Figura 3.3. A continuación en la figura 3.4 se muestra el diagrama de secuencia relacionado con el caso de uso lectura bajo demanda..
(58) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. 47. Figura 3.4 Diagrama de secuencia: Lectura bajo demanda El caso de uso es iniciado cuando un cliente selecciona una funcionalidad en la interfaz gráfica la cual ejecutará un recurso para acceder a datos bajo demanda en el servicio web, los datos serán buscados en la memoria caché de encontrarse allí serán devueltos al cliente, de lo contrario ConcreteDBAccessor accederá a la base de datos en la búsqueda de estos, una vez encontrados los datos serán retornados al cliente siguiendo los pasos mostrados en el anterior diagrama de secuencia Figura 3.4. A continuación en la figura 3.5 se muestra el diagrama de secuencia relacionado con el caso de uso lectura precargada..
(59) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. 48. Figura 3.5 Diagrama de secuencia: Lectura precargada El caso de uso en iniciado cuando un cliente selecciona una funcionalidad en la interfaz gráfica la cual ejecuta un recurso para precargar los datos en el servicio web, primeramente la estrategia de precarga (PrimedCache) solicitara los datos mediante ConcreteDBAccessor a la base de datos, una vez obtenidos los datos estos serán guardados en memoria caché. La próxima vez que el cliente decida acceder a los datos ya estos se encuentran precargados en la memoria cache como es mostrado en el anterior diagrama de secuencia Figura 3.5. 3.4. Principios de Diseño. Para diseñar la propuesta de solución se tuvieron en cuenta los siguientes principios de diseño: Reutilización de soluciones probadas.
(60) CAPÍTULO 3. “DESCRIPCIÓN DE LA PROPUESTA DE SOLUCIÓN”. 49. Mediante el uso de patrones de diseño existentes para el acceso a datos y para la integración de diferentes estrategias aprovechamos el conocimiento existente en estas áreas de modo que reutilizamos técnicas que han sido probadas por otros desarrolladores. Identificar los aspectos de la aplicación que varían y sepáralos de los que no lo hace para poder cumplir el principio de la reutilización de código. Aplicando el primer principio de diseño que vimos anteriormente separamos lo que varía de lo que no lo hace. Es decir tenemos varias estrategias de lectura y precarga las cuales estarían separadas por dos interfaces IReader e IPrime. Cumpliendo con esto tenemos dos comportamientos uno en cada interfaz, para leer read() y el otro para precargar prime() de esta forma se aíslan los comportamiento y se encapsulan. Mantener la flexibilidad programando para una interfaz, no para una clase. Una vez definido los comportamientos y especificadas las interfaces las cuáles nos darán la presentación de los comportamientos a otras clases. De esta forma estaríamos cumpliendo con el segundo principio de diseño consiguiendo flexibilidad ya que lo que se quiere es agregarle comportamiento a las subclases de CacheAccessor. Diseñar una interfaz significa diseñar un comportamiento que será sobrescrito por las clases que lo implementan, así de esta manera podemos utilizar polimorfismo y hacer que la instancia de la superclase pueda referirse a cualquiera de sus subclases, en tiempo de ejecución, por lo que hicimos una interfaz IPrime e IReader con sus clases concretas correspondientes. Anteponer la composición a la herencia. Una vez aislado el comportamiento y construidas las interfaces se aplicó el último de los principios, integrar los comportamientos con CacheAccessor. Hicimos una composición.
Figure


+7

Documento similar