Estandarización de cadenas en grandes volúmenes de información
80
0
0
Texto completo
(2) Declaración de auditoría Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ____________________________ Firma de los autores. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _________________________. __________________________. Firma de los tutores. Firma del jefe del Seminario.
(3) Pensamiento. “…la ciencia no es…ni misterio de iniciados, ni privilegio de los aristócratas de la mente, sino el medio único que tiene el hombre de explicarse las leyes de la vida…” José Martí.
(4) Dedicatoria. A mami, papi y Miri.
(5) Agradecimientos. A mis padres y mi hermana por su amor, desvelo y dedicación, A toda mi familia por su confianza y optimismo, A mis tutores, en especial a Bety, por su paciencia, A Moreira por su cariño y ser lo que fuese necesario (hasta mago) por ayudarme, A David por ser el mejor amigo del mundo, A las muchachitas: Leidys, Arazay y Anailys por su apoyo e historias, A Manuel por sus críticas y consejos, A las personas del grupo de Bases de Datos por su comprensión, A María, Laureano, Gladita, Oscar y demás personas de Bioinformática por acogerme como una más del grupo, A todos los que me han escuchado en este año tan diferente a los anteriores, A Silverio y todos en el Mejunje por regalarme viernes tan lindos, A mis amigos y amigas por las sonrisas y los abrazos, A aquellos profesores que me han ayudado a lo largo de estos cinco años, de forma profesional y afectiva, especialmente a Isis y Bety (otra vez), En fin, a todos los que han contribuido directa o indirectamente con lo que soy y lo que he logrado..
(6) Resumen En la actualidad la administración de grandes volúmenes de datos es cada vez más frecuente, los mismos conforman la base para la toma de decisiones y la gestión del conocimiento; por tanto, contar con datos normalizados resulta imprescindible. La estandarización, como parte de la limpieza de datos, es la encargada de dar solución a esta problemática. La herramienta DBStandardS fue creada para automatizar el proceso de estandarizar los campos tipo cadena, utilizando para esto la formación de grupos de elementos semejantes. Su puesta en práctica mostró varias deficiencias en presencia de grandes volúmenes de información, provocadas fundamentalmente por una demora inadmisible en el paso de agrupamiento de cadenas; haciéndose necesario la incorporación de un método más eficiente. En esta investigación se propone una modificación de los algoritmos sugeridos en la literatura de forma tal que las operaciones de intercambio se realicen solo entre objetos de un mismo cluster, buscando un equilibrio entre calidad de grupos formados y tiempo de ejecución del algoritmo. Su implementación, junto a otros cambios, conforman las novedades de la segunda versión del software, obteniéndose un producto con mucho más alcance..
(7) Abstract Nowadays the great data volumes management is more frequent. These conform the base for the taking of decisions and the administration of the knowledge. Therefore, to have normalized data is indispensable. The standardization, like part of the cleaning of data, is the one in charge of giving solution to this problem. The tool DBStandardS was created to automate the process of standardizing the fields type chain, using for this the clustering of similar elements. Its setting in practice showed several deficiencies in presence of big volumes of information, provoked fundamentally for an inadmissible delay in the step of cluster of chains; becoming necessary the incorporation of a more efficient method. This investigation proposes a modification of the algorithms suggested in the literature in such way that the exchange operations are carried out alone among objects of oneself cluster. The implementation of the algorithm, next to other changes, it conform the novelties of the second version of the software, being obtained a product with much more reach..
(8) Tabla de contenidos ………………………………………………………………………………………………... Introducción ..........................................................................................................................1 1. MARCO TEÓRICO – REFERENCIAL DE LA INVESTIGACIÓN......................6 1.1. Limpieza de Datos....................................................................................................6. 1.2. Estandarización ........................................................................................................8. 1.2.1 1.3. Estandarización de cadenas ................................................................................9. Análisis de conglomerados ....................................................................................10. 1.3.1. Clasificación de las técnicas de agrupamiento .................................................11. 1.3.2. Principales algoritmos de agrupamiento que forman particiones.....................12. 1.3.2.1. Algoritmo de k-medias .............................................................................13. 1.3.2.2. Algoritmo de k-medoides .........................................................................13. 1.3.2.2.1. Algoritmo PAM (Partitioning Around Medoids) ..............................14. 1.3.2.2.2. Algoritmo CLARA (Clustering LARge Aplications)..........................17. 1.3.2.2.3 Algoritmo CLARANS (Clustering Large Applications based upon RANdomized Search) .............................................................................................19. 2. 1.4. Estandarización de cadenas en la limpieza de datos ..............................................20. 1.5. Herramienta DBStandardS.....................................................................................21. 1.6. Consideraciones finales del capítulo......................................................................23. UN MÉTODO DE AGRUPAMIENTO DE CADENAS..........................................24 2.1. Un algoritmo de agrupamiento...............................................................................24. 2.2. Estudio comparativo...............................................................................................26. 2.2.1. Aspectos generales............................................................................................26. 2.2.1.1 2.2.2. Promedio de silueta...................................................................................27. Descripción del experimento ............................................................................29.
(9) 2.2.2.1. Análisis de las diferencias en la calidad de los grupos obtenidos ............32. 2.2.2.2. Análisis de las diferencias del tiempo de ejecución de los algoritmos.....33. 2.2.2.3. Interpretación de los resultados ................................................................38. 2.3 3. Conclusiones parciales del capítulo .......................................................................39. INCORPORACIÓN DE CAMBIOS A LA HERRAMIENTA DBSTANDARDS 40 3.1. Agrupamiento dividiendo el conjunto de datos .....................................................40. 3.2. Diseño y análisis de los cambios en la herramienta ...............................................43. 3.2.1. Caso de uso “Estandarizar campos” .................................................................44. 3.2.2. Tabla de eventos ...............................................................................................45. 3.2.3. Diagrama de actividad ......................................................................................51. 3.2.4. Diagrama de clases ...........................................................................................52. 3.3. Ejemplos reales de estandarización........................................................................57. 3.4. Conclusiones parciales del capítulo .......................................................................65. Conclusiones ........................................................................................................................66 Recomendaciones ................................................................................................................67 Referencias bibliográficas ..................................................................................................68 ………………………………………………………………………………………………... Figuras ………………………………………………………………………………………………... Figura 1.1: Ejemplo de posibles entradas de direcciones. ......................................................9 Figura 2.1: Representación del tiempo empleado por cada algoritmo en los diferentes casos estudiados..............................................................................................................................38 Figura 3.1: Cantidad de elementos en las particiones obtenidas aplicando las dos variantes de agrupamiento propuestas..................................................................................................42.
(10) Figura 3.2: Gráfico de porcentajes para la partición obtenida con la aplicación del algoritmo con todo el conjunto de datos. ..............................................................................................43 Figura 3.3: Gráfico de porcentajes para una de las particiones obtenidas con la aplicación del algoritmo dividiendo el conjunto de datos......................................................................43 Figura 3.4: Casos de uso. ......................................................................................................44 Figura 3.5: Especificación del caso de uso “Estandarizar campos”. ....................................44 Figura 3.6: Interfaz correspondiente a la estandarización. ...................................................45 Figura 3.7: Diagrama de actividad para estandarizar campos. .............................................51 Figura 3.8: Diagrama de clases actual. .................................................................................52 ………………………………………………………………………………………………... Tablas ………………………………………………………………………………………………... Tabla 2.1: Resultado de la prueba de Friedman para las variables CA1, CA2 y CA3. ........32 Tabla 2.2: Resultado de la prueba de Friedman para las variables TA1, TA2 y TA3..........33 Tabla 2.3: Rangos de la prueba de Wilcoxon para las variables TA1 y TA2.......................34 Tabla 2.4: Resultados de la prueba de Wilcoxon para las variables TA1 y TA2 .................34 Tabla 2.5: Estadísticos descriptivos de las variables TA1 y TA2. .......................................34 Tabla 2.6: Rangos de la prueba de Wilcoxon para las variables TA1 y TA3.......................35 Tabla 2.7: Resultados de la prueba de Wilcoxon para las variables TA1 y TA3. ................35 Tabla 2.8: Estadísticos descriptivos de las variables TA1 y TA3. .......................................36 Tabla 2.9: Rangos de la prueba de Wilcoxon para las variables TA2 y TA3.......................36 Tabla 2.10: Resultados de la prueba de Wilcoxon para las variables TA2 y TA3. ..............37 Tabla 2.11: Estadísticos descriptivos de las variables TA2 y TA3. .....................................37 Tabla 3. 1: Comparación de la cantidad de elementos en los grupos formados aplicando las dos variantes de agrupamiento propuestas............................................................................41.
(11) Tabla 3. 2: Tabla de eventos de la ventana “Estandarización mediante el agrupamiento de cadenas”. ...............................................................................................................................50 Tabla 3.3: Datos generales del primer caso de ejemplo de estandarización.........................57 Tabla 3.4: Errores y sustituciones en el cluster 49 del caso 1. .............................................58 Tabla 3.5: Datos generales del segundo caso de ejemplo de estandarización. .....................58 Tabla 3.6: Errores y sustituciones en el cluster 1 del caso 2. ...............................................59 Tabla 3.7: Errores y sustituciones en el cluster 5 del caso 2. ...............................................59 Tabla 3.8: Errores y sustituciones en el cluster 7 del caso 2. ...............................................60 Tabla 3.9: Errores y sustituciones en el cluster 27 del caso 2. .............................................60 Tabla 3.10: Errores y sustituciones en el cluster 36 del caso 2. ...........................................61 Tabla 3.11: Errores y sustituciones en el cluster 38 del caso 2. ...........................................61 Tabla 3.12: Datos generales del tercer caso de ejemplo de estandarización. .......................61 Tabla 3.13: Errores y sustituciones en el cluster 8 del caso 3. .............................................62 Tabla 3.14: Errores y sustituciones en el cluster 40 del caso 3. ...........................................62 Tabla 3.15: Datos generales del cuarto caso de ejemplo de estandarización. ......................62 Tabla 3.16: Errores y sustituciones en el cluster 12 del caso 4. ...........................................63 Tabla 3.17: Errores y sustituciones en el cluster 22 del caso 4. ...........................................63 Tabla 3.18: Datos generales del sexto caso de ejemplo de estandarización. ........................63 Tabla 3.19: Errores y sustituciones en el cluster 11 del caso 5. ...........................................64 Tabla 3.20: Errores y sustituciones en el cluster 16 del caso 5. ...........................................64 ………………………………………………………………………………………………....
(12) Introducción En la actualidad, debido a la gran ventaja que proporciona en tiempo y efectividad para la toma de decisiones la información y la gestión del conocimiento, las comunidades científicas, organizaciones de todo tipo, así como los gobiernos, están invirtiendo en función de su perfeccionamiento, a través de proyectos, congresos, postgrado y desarrollo de sistemas con este fin (García 2008). La información y el conocimiento se pueden gestionar de diversas formas, frecuentemente requiriendo la integración de varias áreas del saber. Independientemente de la manera de obtenerlos, su base se encuentra en los datos almacenados, por lo que la calidad de los mismos alcanza un gran impacto. La calidad de los datos se ve afectada principalmente por un mal diseño de las bases de datos. La carencia de medidas como restricciones de llave primaria, de controles de referencia y chequeos de dominio pueden causar varios problemas: existencia de dos objetos diferentes con el mismo identificador (atributos no únicos como llaves), valores fuera de rango (Ej., más de dos valores para el atributo sexo) o ausentes, entre otros. Si se está en presencia de la integración de múltiples fuentes, los errores pueden ser causados por modelos heterogéneos de diseño en las diferentes bases de datos. Por ejemplo, se pueden encontrar contrariedades como: atributos con el mismo nombre pero significados incompatibles y viceversa, diferentes niveles de estandarización, restricciones y tipos de datos (LOSHIN 2006). Por otra parte, pueden ocurrir errores en el momento de la entrada de los datos dentro del sistema, como: faltas de ortografía originadas por imperfecciones de transcripción, (Ej., “1” (dígito uno) puede ser reemplazado por “l” (minúscula de L)), errores fonéticos y errores tipográficos (introducción de caracteres erróneos por presión de una tecla cercana a la correcta en el teclado), establecimiento de valores por defecto incorrectos para atributos obligatorios, valores correctos pero mal ubicados en los atributos, etc. Para evitar estas situaciones los diseñadores realizan grandes esfuerzos, incluyendo en la creación de los sistemas: reglas, restricciones, formularios con especificaciones y estándares. Sin embargo se ha demostrado estadísticamente (Redman 1998) que cualquier base de datos, sin importar los procesos de calidad que implemente, contará con alrededor 1.
(13) de un cinco por ciento de errores, por tanto, se hace necesario “limpiar” los datos de alguna forma. La realización de este proceso puede ser manual, semiautomático y automático y es considerada una nueva e importante área de trabajo científico conocida como limpieza de datos (data cleaning). Esta se encarga de la detección y corrección de errores en los datos para mejorar la calidad de los mismos (Rahm and Do 2000). La estandarización es una de sus expresiones, consiste en establecer una manera única de poner la información en elementos que pueden ser expresados de diversas formas (Ej., Las expresiones “Facultad de Matemática, Física y Computación”, “Fac. Matemática, Física y Computación” y “Fac. MFC” se refieren al mismo objeto, el establecimiento de la última variante como la apropiada para su almacenamiento constituye un ejemplo de estandarización del objeto). Esto es sumamente importante pues permite confiabilidad en las estadísticas, reportes, etc., ya que no se separarán en su construcción elementos que son los mismos. Un instrumento que puede ser utilizado en la estandarización, específicamente en la estandarización de los datos tipo texto, es el agrupamiento, técnica de minería de datos que divide un conjunto de datos poniéndolos en grupos separados, donde cada grupo está compuesto por elementos que poseen características similares (Shuai and Xue 2006). Existen varios métodos de agrupamiento y en cada uno de ellos podemos encontrar diversos algoritmos que los representan. De estos, los que forman particiones (Partitional clustering) generalmente obtienen una división inicial que van mejorando en un período de intercambio, en el que se realizan comparaciones y cambios que suelen involucrar a varios elementos. Basados en estas ideas surge como resultado de la tesis de diploma: “Desarrollo de un Marco de Trabajo para la Estandarización de Campos Tipo Cadena”, DBStandardS, una herramienta que automatiza el siguiente proceso (Durán 2008): 1. Elegir tabla y campo (Identificación del atributo a estandarizar). 2. Sustitución previa (Sustitución de abreviaturas, apócopes, etc. que se conozca con anterioridad su aplicabilidad). 3. Agrupamiento (Formación de grupos con los registros del campo seleccionado). 2.
(14) 4. Sustitución post-agrupamiento (Sustitución de los errores encontrados en los grupos formados en el paso tres). Siendo detectados y removidos errores existentes mediante un proceso de intercambio entre analista y sistema. El algoritmo implementado para resolver el paso tres es el algoritmo PAM (Partitioning Around Medoids) introducido por Kaufman y Rousseeuw (Kaufman and Rousseeuw 1990), cuya complejidad temporal es un O(k(n-k)2 ) siendo k la cantidad de grupos a formar y n la cantidad de elementos del conjunto de datos a analizar. La herramienta fue probada en varias bases de datos reales. De estos exámenes se concluyó que en presencia de tablas con más de cien registros requería excesivos tiempos de ejecución, específicamente en el paso de agrupamiento, haciéndose inoperante su aplicación en conjuntos de datos grandes 1 . Además, se detectó para estos mismos casos un aumento en la complejidad del análisis post agrupamiento, debido a la gran cantidad de elementos que contenían los grupos. Estas condiciones nos llevan al planteamiento del problema de investigación siguiente: En el proceso de estandarización de campos tipo cadena, en presencia de grandes volúmenes de información, el paso crítico se encuentra en el tiempo de ejecución empleado en la formación de los grupos de los registros. Por tanto, es necesario encontrar un algoritmo de agrupamiento de cadenas más eficiente que el empleado. El objetivo general de la investigación consiste en desarrollar un método de agrupamiento de cadenas, que mejore el rendimiento computacional del proceso de estandarización de estas como parte de la limpieza de datos en grandes volúmenes de información, mediante una modificación de los algoritmos existentes, de forma tal que las operaciones de intercambio se realicen solo entre objetos de un mismo grupo. De este objetivo se derivan los objetivos específicos siguientes:. 1. En esta investigación los términos: grandes volúmenes de información, conjunto de datos grandes, etc. se refieren a cantidad de elementos mayores que 100.. 3.
(15) 1. Analizar los algoritmos de agrupamiento que existen en la bibliografía para definir las causas de su ineficiencia en grandes volúmenes de información. 2. Diseñar un método de agrupamiento de cadenas para ser aplicado en la detección de errores en bases de datos extensas. 3. Comparar el método propuesto con los algoritmos PAM y CLARA, en cuanto a calidad del agrupamiento y tiempo de ejecución, para comprobar su desempeño. 4. Diseñar un procedimiento que permita eliminar una excesiva aglomeración de elementos en los grupos cuando el conjunto de datos es grande. 5. Aplicar los métodos diseñados en la estandarización de datos tipo texto almacenados en bases de datos reales. 6. Incorporar los métodos diseñados al software DBStandardS para lograr una mayor eficiencia en el proceso de estandarización. Las preguntas de investigación planteadas son: . ¿Cuáles son las causas de la ineficiencia de los algoritmos de agrupamiento existentes en grandes volúmenes de datos?. . ¿Qué método puede ser usado en el agrupamiento de cadenas para la aplicación específica en la detección de errores cuando el conjunto de datos a analizar es grande?. . ¿En qué medida este método es superior a los algoritmos PAM y CLARA en la detección de errores cuando los volúmenes de datos son grandes?. . ¿Es posible eliminar la excesiva acumulación de elementos en los grupos cuando el conjunto de datos es grande?. La investigación se justifica pues el mundo requiere que los datos que se procesan en los diferentes sistemas de información posean una buena calidad. Un paso muy importante en la limpieza de los mismos es la estandarización, ya que con ella se garantiza que los datos sean confiables y por consiguiente, que la información que aporte sea consistente. Disponer de un método, que trabaje de forma eficiente logrando un equilibrio entre tiempo de 4.
(16) ejecución y errores detectados, hace mucho más práctico y cómodo el proceso de la limpieza de datos. La tesis está estructurada en tres capítulos: Capítulo 1 Marco teórico – referencial de la investigación: Abordará todos los aspectos teóricos que tengan que ver con la investigación: limpieza de datos, estandarización de cadenas, agrupamiento y la herramienta DBStandardS. Capítulo 2 Un método de agrupamiento de cadenas: Presentará un método de agrupamiento de cadenas para ser aplicado en la detección de errores y una comparación estadística de éste con los algoritmos PAM y CLARA. Capítulo 3 Incorporación de cambios a la herramienta DBStandardS: Especificará un procedimiento para evitar grupos de gran tamaño y las características de la incorporación al software DBStandardS de éste y del método presentado en el capítulo anterior, así como ejemplos reales de estandarización.. 5.
(17) 1. MARCO TEÓRICO – REFERENCIAL DE LA INVESTIGACIÓN. La información es un elemento cada vez más influyente en la toma de decisiones y riesgos asumidos por las diferentes organizaciones. Debido a esto, la presencia de datos erróneos es inaceptable por las consecuencias que pueden acarrear consigo, pero ningún proceso preventivo garantiza 100 por ciento de escape a esta problemática. Así, surge la limpieza de datos como la encargada de la calidad de los mismos. La estandarización, una de sus etapas, tiene como objetivo lograr la integración y la unificación de los datos. Una forma de lograrla es mediante el agrupamiento de elementos similares. En esta dirección fue creada la herramienta DBStandardS. En este capítulo se presentan generalidades acerca de estos temas. 1.1. Limpieza de Datos. Las organizaciones y empresas comerciales invierten y arriesgan enormes sumas de dinero, en ocasiones, solo sobre la base de indicadores dados por herramientas de minería de datos (Benedikt 2006). Estas toman como fuente los datos almacenados y a partir de ellos basan todas las estadísticas y demás análisis. Una mala calidad de los mismos proporcionaría problemas nefastos tanto para la imagen como para la economía de las organizaciones. Este impacto negativo está presente no solo en el contexto de los negocios, sino que en otras áreas como la bioinformática, donde se llevan a cabo costosos procesos de análisis alimentados con enormes fuentes de datos, pueden arrojar resultados erróneos, debido a la presencia de datos “ruidosos”. Los errores en los datos aparecen debido a una mala escritura durante su entrada, información perdida, procesos de unificaciones deficientes, entre otros (Rahm and Do 2000). En (Redman 1998) se ha demostrado estadísticamente que su existencia, independientemente de las medidas que se puedan tomar, es inevitable. Por lo que la limpieza de datos (data cleaning) o el lavado de datos (data scrubbing), como también se conoce, es de vital importancia. Este proceso se encuentra formando parte de otras áreas de trabajo como: . Descubrimiento de conocimiento en bases de datos (KDD, knowledge discovery in databases) o minería de datos: 6.
(18) El KDD apunta a procesar automáticamente grandes cantidades de datos para encontrar conocimiento útil en ellos, usualmente utilizado en la toma de decisiones. Los datos del mundo real tienden a estar incompletos, incoherentes, etc. Si datos erróneos alimentan este proceso provocarían consecuencias negativas ya que la información obtenida no sería válida. En esta área, la limpieza de datos es uno de los pasos en la preparación de los datos o preprocesamiento ((Ronald and Tej 1996), (Usama, Gregory et al. 1996)) y está dirigida fundamentalmente a la detección de valores fuera de rango (outliers), eliminación de datos irrelevantes y completamiento de valores ausentes (Han and Kamber 2000). . Almacenes de datos (DW, datawarehouse) Los DW constantemente están cargando y refrescando cientos de datos de diferentes fuentes, por lo que la probabilidad de que contengan datos “sucios” es alta. Por ejemplo, elementos que representan la misma entidad pueden estar expresados de formas diferentes en los distintos orígenes y al integrarse producirían réplica de información. La limpieza de datos, en este contexto, está presente como una componente principal en la etapa de extracción, transformación y carga (ETL, Extract, Transform, and Load) y tiene como objetivo principal detectar y eliminar los registros duplicados. Frecuentemente se le conoce como el proceso de Merge/Purge, (Hernandez and Stolfo 1998) enlace de registros (Records Linkage), (Jin, C.L. et al. 2003) integración semántica, identificación de instancias, o como el problema de la identidad del objeto (Galhardas, D.F. et al. 2001).. . Manejo de calidad de los datos (TQMD, Total Quality Management Data) En el área de TDQM, algunos trabajos se refieren al proceso de limpieza de datos como el problema de gestión de calidad de datos en la empresa y comunidades comerciales (Wang, R. et al. 2001).. 7.
(19) En este marco, el proceso de limpieza de datos es aquel que trata de “precisar el grado de corrección en los datos y mejorarlo” (Fox, Levitin et al. 1994). Como se observa, no hay ninguna definición exacta para la limpieza de los datos, sino que de acuerdo a áreas de trabajo específicas, se hallan diversas formalizaciones (Maletic and Marcus 2000). No obstante, se puede plantear a modo más general que: “La limpieza de datos trata de detectar y remover errores e inconsistencias de los datos, con el objetivo de mejorar su calidad” (Rahm and Do 2000). Debe cumplir los principios siguientes: . Detectar y eliminar los errores e inconsistencias más graves.. . Estar soportado por herramientas computacionales, de manera que se haga mínima la inspección manual de los datos y los esfuerzos de programación.. . No debe aislarse del esquema de los datos.. Encargándose de varios problemas entre los que se encuentran: el tratamiento de valores ausentes o faltantes, la determinación de la utilidad de los registros, la eliminación de datos erróneos, la estandarización de los datos, etc. 1.2. Estandarización. La estandarización o normalización es un término referenciado en prácticamente todas las esferas, debido a la necesidad de patrones que rijan las diferentes organizaciones y entidades. Se considera como el proceso de elaboración, aplicación y mejora de las normas que son utilizadas en las distintas actividades científicas, industriales o económicas con el fin de ordenarlas y mejorarlas (Durán 2008). Estas deben poseer las cualidades siguientes: . Simplificación: reducción de los modelos permaneciendo exclusivamente los necesarios.. . Unificación: permitir intercambio a nivel internacional.. . Especificación: crear un lenguaje claro y preciso que evite errores de identificación.. 8.
(20) 1.2.1 Estandarización de cadenas En el mundo de los datos un estándar es un modelo, al cual todos los objetos de la misma clase deben responder. Cuando se habla de la estandarización se hace referencia al proceso que consigue que los datos de un determinado atributo estén conformados de acuerdo a un formato o estándar preestablecido (LOSHIN 2006). La forma en que se lleva a cabo la estandarización de datos tipo cadenas varía si se está en presencia o no de direcciones. Pues ellas poseen características particulares: tienen una estructura implícita que comprende elementos como Calle, Entre Calle, Número de Casa, etc. Para lograr estandarizar direcciones primeramente hay que lograr separarlas en las partes que la componen, proceso que no es trivial pues el orden de los atributos no es fijo y pudieran existir instancias donde no todos los campos estén presentes (figura 1.1). Luego se necesita analizar para cada fragmento su formato.. Figura 1.1: Ejemplo de posibles entradas de direcciones. Se han realizado varias investigaciones al respecto, por ejemplo en (Torres 2006) se propone una metodología basada en los modelos ocultos de Markov (HMM, Hidden Markov Model). 9.
(21) Según (Kimball 1996) el mercado y la tecnología de la limpieza de datos se han enfocado esencialmente en las listas de direcciones de clientes. Tres importantes compañías que dominan este mercado (Kimball 1996), especializadas en limpiar grandes listas de direcciones de clientes son Harte-Hanks Data Technologies, Innovative Systems Inc., y Vality Technology. Es evidente la importancia que tiene la limpieza de direcciones para las empresas comerciales. No obstante, la estandarización del resto de los atributos tipo texto no posee menor valor, pues a partir de ellos suelen basarse estadísticas y procesos de minería de datos con el fin de tomar decisiones o responder a diferentes consultas. La normalización permite confiabilidad de estos procesos pues no se separarán, en su construcción, elementos que realmente son los mismos. Para la unificación de estos atributos es posible recurrir al agrupamiento o clusterización de los mismos, tomando como función de similitud a alguna distancia de edición. Quedando dividido con esta técnica el conjunto de datos en subconjuntos de artículos con valores similares. Luego, el examen de los datos para determinar su posible unión se realiza individualmente sobre cada grupo, eliminando la agotadora tarea de analizar todas las posibilidades en el conjunto total de datos, aliviando así el trabajo de la limpieza (Porrero and Vasquez 2007). Esta investigación se centra solamente en el proceso de estandarización de los datos tipo texto que no simbolizan direcciones. 1.3. Análisis de conglomerados. El agrupamiento es una de las técnicas más útiles en el proceso de minería de datos, descubre grupos e identifica distribuciones interesantes y modelos en los datos subyacentes. El problema del agrupamiento es dividir un conjunto de datos dado, en grupos (clusters, conglomerados, clases) tal que los datos de un grupo sean más similares entre sí (alta homogeneidad interna) que entre los demás grupos (alta heterogeneidad externa), de acuerdo a algún criterio de selección predeterminado ((Guha, Rastogi et al. 1998), (García 2008)). Así, la preocupación principal en el proceso de agrupamiento es revelar modelos o patrones en los datos, que permitan descubrir similitudes y diferencias, así como arribar a 10.
(22) conclusiones útiles sobre ellos. Esta idea es aplicable en muchos campos, como las ciencias naturales, las ciencias médicas e ingeniería ((Theodoridis and Koutroumbas 2008), (Halkidi, Batistakis et al. 2001)). Su uso más frecuente es en la clasificación, donde no haya ninguna clase predefinida y ningún ejemplo que muestre qué tipo de relaciones deben ser válidas entre los datos por lo que se distingue como un proceso no supervisado (Halkidi, Batistakis et al. 2001). 1.3.1 Clasificación de las técnicas de agrupamiento Según el método adoptado para definir los clusters, los algoritmos pueden ser clasificados en los tipos siguientes ((Jain, Murty et al. 1999), (Han and Kamber 2000)): . Agrupamiento de particionamiento (Partitional clustering): Dado un número fijo de grupos a construir, se crea una partición inicial, y luego se aplica alguna técnica iterativa de relocalización de elementos de acuerdo a un criterio objetivo de particionamiento, conocido como función de “similitud”, que intenta mejorar las particiones formadas moviendo objetos de un grupo a otro. (Ej., PAM).. . Agrupamiento jerárquico (Hierarchical clustering): Crea una descomposición jerárquica del conjunto de objetos dado, resultando un árbol de particiones, llamado dendograma. Basándose en cómo se realiza dicha descomposición se subdividen en aglomerativos o dispersativos. El criterio aglomerativo (bottom-up), comienza generando un grupo para cada uno de los objetos de la base de datos. Luego estos se van mezclando y uniendo de manera tal que se encierren en un mismo grupo aquellos elementos más cercanos. Esta operación continúa hasta llegar a la formación de un único grupo o al cumplimiento de determinada condición. (Ej., AGNES). El criterio dispersativo (top-down), inicia con todos los objetos en un mismo cluster, y en cada una de las sucesivas iteraciones, los objetos se van moviendo a otros grupos hasta obtener particiones de un solo elemento u otro criterio de parada. (Ej., DIANA).. 11.
(23) . Agrupamiento basado en densidad (Density-based clustering): Los grupos, crecen hasta tanto la densidad (número de objetos o puntos de datos) en la vecindad no supere algún umbral; o sea, que por cada punto dentro de un cluster, la vecindad de un radio determinado tiene que contener al menos una cantidad mínima de puntos. (Ej., DBSCAN, DENCLUE).. . Agrupamiento basado en rejillas (Grid-based clustering): Está principalmente propuesto para minería de datos espacial. Representa el espacio a través de un número finito de celdas que forman una estructura de rejilla, sobre la cual se llevan a cabo todas las operaciones. La ventaja principal de esta técnica es su escaso tiempo de procesamiento, el cual típicamente es independiente de la cantidad de datos, y dependiente sólo de la cantidad de celdas en cada dimensión del espacio cuantificado. (Ej., STING, CLIQUE).. Teniendo en cuenta las características de cada una de las clasificaciones y el objetivo perseguido en esta investigación, se escoge para el estudio los algoritmos que crean particiones (Partitional clustering), ya que son los ideales para la formación de una cantidad de grupos a través de la minimización de una función, tomándose esta como una distancia de edición entre datos de tipo texto. 1.3.2 Principales algoritmos de agrupamiento que forman particiones En esta sección se inspeccionan los algoritmos que dividen los datos en varios subconjuntos. Estos comienzan con la definición de una función objetivo o de similitud que depende de la partición. Tienen como parámetro de entrada un número total de clusters a formar, que es menor que la cantidad de objetos en la base de datos. Se construyen las particiones iniciales y al contrario de los métodos jerárquicos tradicionales, en que no se vuelven a visitar los grupos después de construidos, estos algoritmos mediante una reagrupación iterativa mejoran los clusters gradualmente. Lo que produce grupos de mayor calidad con datos apropiados (Han and Kamber 2000). Las particiones resultantes tienen dos características: 1. Cada grupo debe contener al menos un objeto.. 12.
(24) 2. Cada objeto debe pertenecer a un único grupo (no siempre es válido en técnicas difusas (fuzzy)). Dependiendo de cómo se toman los representantes de cada grupo, la optimización reiterativa que divide los algoritmos se subdivide en los métodos: k-medoides (k-medoids) propuesto por (Kaufman and Rousseeuw 1990) y k-medias (k-means) propuesto por (MacQueen 1967). 1.3.2.1 Algoritmo de k-medias En el caso del k-medias los clusters son representados por su “centroide”, que es la media (normalmente el promedio) entre los puntos del grupo. Inicialmente se seleccionan k elementos aleatoriamente, los cuales representan el centro o media de cada cluster. A cada objeto restante se le asigna el cluster con el cual presenta mayor similitud, basándose en una distancia entre el objeto y su centroide. Después calcula la nueva media del cluster y se repite el proceso hasta que las medias se mantengan constantes (Han and Kamber 2000). Trabaja apropiadamente sólo con atributos numéricos y puede afectarse negativamente por valores fuera de rango o extremos ya que distorsionan la distribución de los datos. Por otro lado, los centroides tienen la ventaja de un significado geométrico y estadístico claro (Cios, Pedrycz et al. 2007). 1.3.2.2 Algoritmo de k-medoides En lugar de tomar el valor medio de los objetos como referencia de un grupo, estos métodos seleccionan un objeto representativo llamado “medoide”, que es el punto más centralmente localizado en un cluster. Estos métodos tienen dos ventajas, la primera es que no presentan ninguna limitación en los tipos de los atributos que entran en el análisis y la segunda, es que son menos sensibles a la presencia de valores fuera de rango (Cios, Pedrycz et al. 2007). Dos versiones tempranas de los métodos k-medoides son el algoritmo PAM (Kaufman and Rousseeuw 1990) y el algoritmo CLARA (Kaufman and Rousseeuw 1990). PAM es una optimización reiterativa que combina reagrupación de puntos entre los grupos con re13.
(25) nombrar los medoides potenciales. CLARA usa varias muestras, que son sujetas al PAM, la función objetivo se computa, y el sistema mejor de medoides se retiene. Las asignaciones finales se realizan en todo el conjunto de datos y los medoides resultantes. Otro popular algoritmo de este tipo es el presentado por (Ng and Han 1994), CLARANS (Clustering Large Aplications based upon RANdomized Search), en el contexto de agrupamiento en bases de datos espaciales. Los autores consideraron un grafo cuyos nodos son los conjuntos de medoides y una arista conecta dos nodos solamente si ellos difieren exactamente en un medoide. Usa la búsqueda aleatoria para generar al azar a los vecinos empezando por un nodo arbitrario. Si un vecino representa una partición buena, el proceso continúa con este nuevo nodo. El nodo mejor (conjunto de medoides) se devuelve para la formación de una partición resultante. Conforme a lo descrito, se seleccionan a los K-medoides como los algoritmos más apropiados para este estudio, por lo que sus principales representantes se detallan a continuación. 1.3.2.2.1 Algoritmo PAM (Partitioning Around Medoids) Este algoritmo tiene dos fases. En la primera fase, llamada BUILD, se obtiene una clusterización inicial por la selección sucesiva de k objetos representativos. El primer objeto es aquel para el cual la suma de sus distancias al resto de los objetos es tan pequeña como sea posible. Este objeto se ubica como centro del conjunto de objetos. Subsecuentemente, en cada paso otros objetos son seleccionados. La selección de este objeto como centro es la que permite hacer decrecer la función objetivo tanto como sea posible. Los pasos que se muestran a continuación ilustran como encontrar este objeto: 1. Considerar un objeto ‘i’ el cual no ha sido seleccionado aún. 2. Considerar un objeto ‘j’ no seleccionado y calcular la diferencia entre su distancia Dj con el objeto más similar seleccionado previamente, y la distancia d(j,i) con el objeto ‘i’. 3. Si la diferencia es positiva, el objeto ‘j’ puede contribuir a la decisión para seleccionar el objeto ‘i’. Por lo tanto calcular:. 14.
(26) C ji = max(D j − d ( j , i ),0). (1.1). 4. Calcular la ganancia total obtenida por seleccionar el objeto ‘i’:. ∑C. (1.2). ji. j. 5. Elegir un objeto ‘i’ no seleccionado aún tal que. maximice ∑ C ji i. (1.3). j. Este proceso continúa mientras no hayan sido encontrados ‘k’ objetos. En la segunda fase del algoritmo, llamado SWAP, se intenta mejorar el conjunto de objetos representativos y, por tanto también mejorar el conjunto de clusters obtenido. Esto se hace considerando todos los pares de objetos (i,h), para los que el objeto ‘i’ ha sido seleccionado y el objeto ‘h’ no. Se determina qué efecto se obtiene sobre el valor de la agrupación, cuando un intercambio se lleva a cabo, es decir, cuando el objeto ‘i’ ya no es seleccionado como un representante, sino el objeto ‘h’. El valor de una agrupación representada por ‘k’ objetos representativos se define como la suma de diferencias entre cada objeto y el objeto representativo más similar. Para calcular el efecto de un intercambio entre ‘i’ y ‘h’ en el valor de un cluster, a continuación, los pasos 1 y 2 muestran como se lleva a cabo este cálculo: 1. Considerar un objeto ‘j’ no seleccionado y calcular su contribución. C jih. al. intercambio. a. Si ‘j’ es más distante de ‘i’ y ‘h’ que de la unidad de otros objetos representativos, hacer. C jih = 0. b. Si ‘j’ no es aún más lejos de ‘i’ que de otro objeto representativo seleccionado. ( d ( j , i ) = D j ) , deben ser consideradas dos situaciones:. 15.
(27) b1. ‘j’ es más cercano a ‘h’ que al segundo objeto representativo mas cercano. d ( j , h) < E j. donde E j es la disimilitud. entre ‘j’ y el segundo objeto similar más representativo. En este caso la contribución del objeto ‘j’ al intercambio entre los objetos ‘i’ y ‘h’ es:. C jih = d ( j , h) − d ( j , i ). (1.4). b2. ‘j’ es al menos tan distante de ‘h’ como cercano del segundo objeto más representativo. d ( j , h) ≥ E j. en este caso la. contribución del objeto ‘j’ a el intercambio es. C jih = E j − D j . Se debe observar que en la situación b1 la contribución. (1.5). Cjih. puede tomar. valores positivos o negativos dependiendo de la posición relativa de los objetos ‘j’, ‘h’, e ‘i’. Solo si el objeto ‘j’ está más cercano a ‘i’ que a ‘h’ la contribución es positiva, esto indica que el intercambio no es favorable desde el punto de vista del objeto ‘j’. En la otra vía, en la situación b2, la contribución es siempre positiva, por esto, no es ventajoso remplazar ‘i’ por un objeto ‘h’ más lejano de ‘j’ que del segundo objeto representativo más cercano. c. ’j’ es más distante del objeto ‘i’ que de al menos uno de los otros objetos representativos, pero más cercano a ‘h’ que a cualquier objeto representativo. En este caso la contribución de ‘j’ al intercambio es:. C jih = d ( j , h ) − D j. (1.6). 2. Calcular el resultado total de un intercambio por adición de contribuciones. Tih = ∑ C jih. Cjih:. (1.7). j. 16.
(28) En los próximos pasos se decide si se lleva a cabo un intercambio: 3. Seleccionar el par (i,h) que:. minimice Tih. (1.8). i,h. 4. Si el mínimo de. Tih es negativo, el intercambio se lleva a cabo y el algoritmo. regresa al paso 1. Si el mínimo de. Tih. es positivo o 0(cero), el valor del objetivo no. es disminuido por el intercambio y el algoritmo se detiene. Escogiendo a n como el número de objetos del conjunto de datos y a k como la cantidad de grupos a formar, se puede escribir la complejidad temporal del PAM como un O (k(n-k)2) (Halkidi, Batistakis et al. 2001). En la fase de intercambio de este algoritmo en cada iteración se producen comparaciones dos a dos para cada uno de los objetos representativos entre todos los elementos restantes, para tratar de sustituir un solo medoide. Siendo esto un proceso muy costoso computacionalmente. 1.3.2.2.2 Algoritmo CLARA (Clustering LARge Aplications) CLARA en lugar de encontrar los medoides para el conjunto entero de datos, escoge aleatoriamente una muestra pequeña (se recomienda 40 + 2k) de los datos y aplica el algoritmo PAM generando los medoides correspondientes. La calidad de los medoides resultantes está dada por la medida de desigualdad entre cada objeto y el medoide de su grupo, definida como la función de costo siguiente: n. Cost ( M , D) =. ∑ dissimilarity(O , rep(M , O )) i. i =1. i. n. (1.9). Donde M es el conjunto de medoides seleccionados, dissimilarity(Oi,Oj) es la desigualdad entre los objetos Oi y Oj; y rep(M,Oi) retorna el medoide en M más cercano a Oi.. 17.
(29) CLARA repite el proceso un número q predefinido de veces (se recomienda q=5) y en cada iteración compara los costos obtenidos, reteniendo siempre el menor y el conjunto de medoides asociado a éste; con el objetivo de devolverlo como resultado final. El proceso descrito (Wei, Lee et al. 2003) se puede definir como sigue: Mincost = número grande Repetir q veces Crear una muestra S del conjunto original, seleccionando s objetos aleatoriamente de D Generar el conjunto de medoides M de S aplicando el PAM Sí Cost(M,D) < mincost Entonces Mincost = Cost(M,D) BestSet = M Fin - Sí Fin del ciclo Retornar M. Manteniendo el significado de k y n, la complejidad temporal del CLARA es un O(k(40+k)2 + k(n-k)) (Halkidi, Batistakis et al. 2001). Este algoritmo reduce el tiempo computacional a partir de una disminución en la cantidad de elementos a analizar. Pero aún así su calidad depende de la selección de estas muestras, donde es imposible asegurar una buena “representación” del conjunto de datos. Entonces, para evitar una pérdida notable de la calidad invierte tiempo en la repetición de todo el proceso.. 18.
(30) 1.3.2.2.3 Algoritmo CLARANS (Clustering Large Applications based upon RANdomized Search) CLARANS efectúa el proceso de encontrar k-medoides como la búsqueda en un grafo. En dicho grafo, un nodo representa un conjunto de k objetos O1;…; Ok; indicando a estos como los medoides seleccionados. Dos nodos son vecinos (están conectados por un arco), si sus conjuntos difieren solamente en un objeto. En otras palabras, dos nodos M1 y M2 son vecinos si y solo si la cardinalidad de la intercepción de ellos es k-1. Por tanto cada nodo del grafo tiene k(n-k) vecinos. Como cada nodo representa una colección de medoides, cada uno corresponde a una posible partición cuya calidad es medida por la misma función de costo definida en el algoritmo CLARA (expresión 1.9). En lugar de utilizar una estrategia de búsqueda exhaustiva, adopta una búsqueda aleatoria. Comienza por un nodo arbitrario del grafo y aleatoriamente escoge uno de sus vecinos. Si el costo de seleccionarlo es menor que el costo del nodo actual, lo reemplaza y continúa el proceso de selección y comparación. En otro caso, chequea aleatoriamente otro vecino hasta que se encuentra uno mejor o hasta que es alcanzado el máximo de vecinos visitados (fijado con anterioridad). Para evitar quedar atrapado en una solución local, se repite el proceso de búsqueda, un número predeterminado de veces, a partir de diferentes nodos iniciales. El nodo con el menor costo es seleccionado para construir la partición final. El proceso descrito (Wei, Lee et al. 2003) se puede definir como sigue: Mincost = número grande Desde i=1 a numlocal hacer Seleccionar aleatoriamente el nodo actual C J=1 Repetir Seleccionar aleatoriamente un vecino N de C Si Cost(N,D) < Cost(C,D) entonces C=N 19.
(31) J=1 Sino J =J+1 Fin del Sí Hasta que J > maxneighbor Si Cost(C,D) < mincost entonces Mincost = Cost(C,D) Bestnode = C Fin del Si Fin de Desde Devolver bestnode Manteniendo el significado de k y n, la complejidad temporal del CLARANS es un O(kn2) (Halkidi, Batistakis et al. 2001). El rendimiento de CLARANS está mayormente influenciado por el número máximo de vecinos a examinar y el número de repeticiones. Si estos valores son grandes, es probable que se consiga el óptimo pero a un costo muy grande de eficiencia. Por otra parte, para valores pequeños de estos parámetros puede ser muy eficiente. Aunque en este caso, no se garantiza alcanzar una partición óptima (o cercana a la óptima). 1.4. Estandarización de cadenas en la limpieza de datos. Los sistemas de información realizan grandes esfuerzos por lograr datos estandarizados. Desde la propia creación de las bases de datos, se incluyen reglas de integridad en los diferentes atributos que permitan solo los valores que cumplan con los estándares establecidos. Por ejemplo, al definir el atributo “sexo” se utiliza a menudo la restricción de solo permitir los caracteres “M” o “F”. Además, la entrada de los datos se ve apoyada por el uso de máscaras que implementan los estándares y de controles como: listas, cuadros combinados, cajas de chequeo, etc., que brindan la posibilidad de escoger entre los valores permitidos por la organización. También suele notificarse en la entrada de datos de alguna manera lo que se desea, unidad de medida, o formato. Por ejemplo, en la captura de fechas 20.
(32) tradicionalmente se especifica la forma de introducirla (día, mes, año, o alguna otra variante). A pesar de los esfuerzos que se puedan hacer en las etapas de análisis y diseño de los sistemas informativos de una organización, es muy difícil lograr la estandarización de los datos, en muchos casos por la ausencia de estándares para cada uno de ellos, por la no definición de los mismos, o porque la propia naturaleza de estos impiden crearlos. Cuando no se tienen patrones de referencia la captura de datos se hace de una forma “libre”, habitualmente se presenta un control que permite escribir prácticamente cualquier cosa (Porrero and Vasquez 2007). Por estas razones la estandarización aparece como una de las más importantes y complejas etapas en el proceso de limpieza de datos, con el objetivo de lograr la integración y la unificación (matching) de los datos. Prácticamente está dirigida a datos tipo texto, ya que estos son los que generalmente pueden ser representados de múltiples formas. 1.5. Herramienta DBStandardS. DBStandardS es una herramienta que forma parte de los resultados de la tesis de diploma: “Desarrollo de un Marco de Trabajo para la Estandarización de Campos Tipo Cadena”. Se concibió para la estandarización de dichos campos en los gestores de bases de datos: Microsoft SQL Server y Microsoft Office Access, aunque posteriormente se generalizó a varios gestores. Automatiza el marco de trabajo siguiente (Durán 2008): 1. Elegir tabla y campo. Es un paso trivial, encaminado a encontrar el atributo que se quiere estandarizar, para esto se le brinda la posibilidad al usuario de escoger el origen de la base de datos, la tabla y el campo al cual se le quiere realizar el proceso de estandarización. (Se comprueba la naturaleza tipo texto del mismo). 2. Sustitución previa. Se ha comprobado que uno de los problemas fundamentales que presentan los campos textuales que pueden ser entrados de forma “libre” en un sistema 21.
(33) informativo es la utilización, en la entrada, de abreviaturas, apócopes, etc., que pueden incluso no ser los mismos a lo largo de los datos. Por ejemplo, para “resolución 73” se pudiera encontrar “res 73”, “resol 73”, “resol 73”, “resol #73”, entre otras. Se propone que en este paso se sustituyan diferentes ocurrencias por una forma única, de conocerse con anterioridad la existencia de las mismas en los datos. Estas sustituciones son guardadas en un documento XML, con las etiquetas fundamentales “qué” y “por qué” cambiar. Son almacenadas como “Categorías” y dentro de cada una son recogidos cambios comunes establecidos por la experiencia de los expertos. Con la oportunidad de ser enriquecidas a medida que se utilice el software. 3. Agrupamiento. Devuelve k grupos del atributo, formados mediante la aplicación del algoritmo PAM, donde la similitud de los elementos se determina utilizando una extensión de la distancia de edición de Levenshtein 2 (LEVENSHTEIN 1966), la cual tiene en cuenta la distancia de un carácter a otro en el teclado. 4. Sustitución post-cluster. En este paso se escogen de los grupos creados en el paso anterior, cadenas que serán sustituidas y el objeto que las reemplazará, actualizándose luego en la base de datos mediante una consulta UPDATE. Es un proceso interactivo entre analista y sistema. La aplicación del software en bases de datos extensas resultó ser muy demorada, específicamente en el paso de formación de grupos. Por tanto es declarada su no operabilidad en grandes volúmenes de información. Además, para estos mismos casos se. 2. medida de distancia entre dos cadenas propuesta por el científico ruso Levenshtein en 1966 bajo los siguientes términos: “la distancia entre dos cadenas es la cantidad de inserciones, eliminaciones y reemplazos que son necesarios para transformar una cadena en la otra”.. 22.
(34) observó un incremento en la cantidad de elementos en los grupos formados, provocando una mayor complejidad en el siguiente paso de detección de errores. 1.6. Consideraciones finales del capítulo. La limpieza de datos es necesaria para proporcionar un acceso a datos exactos y consistentes, consolidación de representaciones de datos diferentes, eliminación de información doble, entre otras. Contar con datos normalizados, de forma tal que no existan diferentes representaciones de un mismo objeto del mundo real, resulta imprescindible en las empresas y organizaciones. Para lograr tal fin se hace necesario la limpieza de los mismos, específicamente la estandarización de estos. El software DBStandardS fue creado para dar respuesta a esta necesidad, utilizando la formación de grupos para lograr la estandarización. Del análisis de la bibliografía consultada referente a las técnicas de agrupamiento, específicamente de los métodos que forman particiones, se concluye que la principal desventaja de los algoritmos radica en sus elevadas complejidades temporales: O (k(n-k)2), O (k(40+k)2 + k(n-k)) y O (kn2) para el PAM, CLARA y CLARANS respectivamente. Provocadas fundamentalmente por las comparaciones necesarias en el paso de intercambio y en la repetición de procesos para asegurar calidad en el agrupamiento. Debido a esto, el tiempo de corrida de los algoritmos aumenta rápidamente con el tamaño de la muestra y el número de clusters deseado, por lo tanto resulta ineficaz su aplicación en presencia de grandes volúmenes de información.. 23.
(35) 2. UN MÉTODO DE AGRUPAMIENTO DE CADENAS. DBStandardS es una herramienta destinada a la estandarización de datos tipo texto que no sean direcciones, para lo cual forma grupos de objetos similares. Con su puesta en práctica se hizo evidente varias deficiencias en presencia de grandes volúmenes de información, provocadas fundamentalmente por una demora inadmisible en el paso de agrupamiento de cadenas; por lo que este estudio se encaminó a una búsqueda de mejores algoritmos de este tipo. Pero los algoritmos propuestos en la literatura son muy costosos computacionalmente. La propuesta de esta investigación es una modificación de los algoritmos existentes, de forma tal que las operaciones de intercambio se realicen solo entre objetos de un mismo cluster, logrando un equilibrio entre calidad de grupos formados y tiempo de ejecución del algoritmo. Los resultados que se presentan en este capítulo confirman la validez de este planteamiento. 2.1. Un algoritmo de agrupamiento. El algoritmo propuesto consta de dos fases principales. Al igual que el algoritmo PAM la primera está destinada a la obtención de los medoides iniciales y la segunda a una mejora de los grupos formados. Existen numerosas formas de elegir los medoides iniciales. Una de ellas es la sugerida por el propio algoritmo PAM, donde se tiene en cuenta la minimización de las distancias entre el resto de los elementos y los objetos representativos. Otra pudiera ser el resultado de una aplicación de cualquier algoritmo conocido (PAM, CLARA, etc.) a una pequeña muestra del conjunto de datos. En este trabajo se propone que sean generados aleatoriamente para proporcionarle a esta etapa una mayor sencillez y menor tiempo de ejecución. Luego de la obtención de los medoides iniciales, se plantea la formación de grupos. Para saber a qué grupo pertenece un elemento se calculan todas las distancias de éste a los objetos representativos seleccionados y se escoge el cluster representado por el medoide correspondiente al mínimo de estas distancias. Una vez hecha la partición inicial, se hace necesario mejorarla. Para esto se planea un posible reemplazo de los medoides. El cual es llevado a cabo mediante un examen de todos los medoides en cada iteración. Teniéndose en cuenta para esto solamente los elementos del 24.
(36) cluster que representan. O sea, para todos los grupos, se busca el objeto más centralmente localizado y si éste no coincide con el medoide actual, se intercambia con él. En el cálculo del objeto más centralmente localizado se obtiene, para cada elemento perteneciente al cluster, el promedio de las distancias al resto de los objetos y se escoge el elemento de menor valor. Una vez actualizado los nuevos medoides es necesario volver a formar los clusters correspondientes. Al igual que en los algoritmos CLARA y CLARANS, donde se repiten ciertas operaciones, (en el primero la elección de muestras y la aplicación del PAM para generar nuevos conjuntos de medoides y en el segundo la actualización del nodo actual y el proceso general en sí), los pasos de recálculo de medoides y reagrupamiento se repiten una cantidad fija de veces o hasta que no ocurran más alteraciones en ningún medoide anterior. El algoritmo sugerido se puede generalizar como sigue: Seleccionar aleatoriamente el conjunto de medoides iniciales M J=1 Repetir p = Formar los grupos Desde h=1 a k hacer Calcular el objeto central del cluster m’ Si m’ < > m entonces m = m’ Fin de Desde J=J+1 Hasta que J = q o no ocurran cambios Devolver p. 25.
(37) En esta descripción M representa un arreglo de medoides, J, h y q enteros, p un arreglo de clusters, m y m’ elementos del conjunto que simbolizan el medoide seleccionado y el elemento más centralmente localizado en un grupo respectivamente. 2.2. Estudio comparativo. Fue llevado a cabo un estudio experimental del rendimiento de los algoritmos PAM, CLARA y el propuesto 3 , con el objetivo de demostrar que este último alcanza un desempeño al menos comparable con los demás. 2.2.1 Aspectos generales A continuación se especifican los aspectos generales del estudio comparativo: . Rendimiento de la máquina El estudio se llevó a acabo en una PC P4, CPU 3.00 Ghz y 512 MB de RAM.. . Parámetros fijados para los algoritmos Los parámetros escogidos para el algoritmo CLARA fueron de 5 para la cantidad q de veces en que se repite el proceso y 40+2k para la dimensión de los conjuntos generados, tal y como se propone en la bibliografía consultada ((Wei, Lee et al. 2003), (Halkidi, Batistakis et al. 2001)), siendo k el número de grupos a formar. Para el algoritmo propuesto el valor de q seleccionado fue 10.. . Función de similitud La función de costo definida para medir la similitud entre las cadenas es la extensión de la distancia de edición de Levenshtein propuesta en (Durán 2008).. . Datos Se eligieron para el estudio atributos de más de 100 elementos de tipo cadena de tablas de dos Bases de Datos reales pertenecientes a los departamentos de recursos humanos y economía de la Universidad Central de Las Villas, que almacenaban fundamentalmente nombres y descripciones.. 3. En este capítulo serán referidos como A1, A2 y A3 respectivamente.. 26.
(38) . Software El procesamiento estadístico de esta investigación se hará con ayuda del paquete de software SPSS (Statistical Package for the Social Sciences) para Windows.. . Criterio de evaluación Los algoritmos fueron comparados en cuanto a tiempo de ejecución y calidad del agrupamiento, tomando para esto al promedio de silueta.. 2.2.1.1 Promedio de silueta La silueta de un objeto ‘i’ es una medida que refleja cuán buena es su ubicación dentro del cluster al que pertenece. Se denota por s(i) y es construida de la forma siguiente: 1. Tomar cualquier objeto i del conjunto de datos. Se denota por A al cluster al cual pertenece. 2. Calcular a(i) como el promedio de disimilitud de i a todos los objetos de A. Este paso asume que el conjunto A contiene otros objetos además de i, o sea, que su longitud es mayor que uno. 3. Calcular d(i, C) como la distancia promedio que existe entre i y los objetos del cluster C. Realizándose para todos los clusters diferentes de A. 4. Elegir el mínimo de los promedios.. b(i ) = min d (i, C ) C≠ A. (2.1). El cluster B, para el cual este mínimo se logra se conoce como el vecino del objeto ‘i’ y es la segunda – mejor elección para el objeto ‘i’. O sea, si el cluster A es descartado, el cluster B es el más cercano a ‘i’. La construcción de b(i) depende de la disponibilidad de otros clusters diferentes de A, por lo que no se define en presencia de particiones que tengan un solo cluster. 5. De acuerdo a los valores de a(i) y b(i) obtener s(i) como sigue: 27.
(39) a. Si a(i) es menor que b(i):. s(i ) =. 1 − a(i ) b(i ). (2.2). b. Si a(i) es igual a b(i):. s (i ) = 0. (2.3). c. Si a(i) es mayor que b(i):. s (i ) =. b(i ) a (i ). (2.4). Estas combinaciones se pueden generalizar a través de la fórmula:. s (i ) =. b (i ) − a (i ) max( b (i ), a (i )). (2.5). escogiendo el valor de s(i) igual cero cuando el cluster A contenga un único elemento. Esta elección es arbitraria, pero el valor de cero es el más neutral. De hecho, por la forma en que se define la silueta se puede ver fácilmente que:. − 1 ≤ s (i ) ≤ 1. (2.6). Se cumple para cualquier objeto i. Se puede detallar el significado de s(i) mediante un análisis de las situaciones extremas. Cuando s(i) es grande (cercano a 1), implica que la disimilitud a(i) es mucho más pequeña que la disimilitud con b(i). Por tanto, podemos decir que el elemento ‘i’ está bien clasificado, o sea, está bien asignado al cluster A y la segunda mejor elección no está tan cerca de la actual. Una situación diferente ocurre cuando s(i) está cercano a cero. En este caso a(i) y b(i) son aproximadamente iguales y por tanto no está claro dónde el valor de ‘i’ debe ser asignado, pues está a corta distancia de ambos (A y B), por lo que suele citarse como un caso intermedio. 28.
(40) La peor situación es tomada cuando s(i) está cercano a -1. Un valor semejante es debido a que a(i) es más grande que b(i), o sea, ‘i’ está más cercano a B que a A. Siendo mucho más natural asignar a ‘i’ al cluster B, por lo que se considera que ‘i’ está mal colocado. El promedio de s(i) para i=1,2,…,n es conocido como el promedio de silueta para todo el conjunto de datos 4 . Este número puede ser usado para la selección del mejor valor de k 5 , eligiendo la k correspondiente al valor de s_(k) más alto. O sea, se computan para todos los posibles k los valores s_(k) y el mayor, se considera la mejor partición posible. A este valor se le reconoce como el coeficiente de silueta:. CS = max S _(k ). (2.7). Puede ser empleado además para determinar la fortaleza de la estructura de la clasificación encontrada. Un CS cercano a 1 indica una buena estructura, mientras que valores pequeños indican que debe aplicarse otro método del análisis de datos. 2.2.2 Descripción del experimento El estudio requirió de los dos pasos siguientes: 1. Análisis de diferencias significativas en la calidad de los grupos para cada algoritmo. Esperando encontrar un aumento o ninguna diferencia significativa en la calidad de los grupos obtenidos para el algoritmo A3 con respecto a los restantes. 2. Análisis de diferencias significativas en los tiempos de ejecución de los algoritmos. Esperando encontrar diferencias significativas de forma tal que la variable tiempo fuera menor para el algoritmo A3 que para los restantes. Se recogieron datos correspondientes a los resultados de la corrida de los tres algoritmos en 16 casos (tabla 2.1). Tomándose como un caso a un atributo de tamaño n y una cantidad de grupos a formar k.. 4 5. Será representado mediante s_(k) Cantidad de grupos a formar. 29.
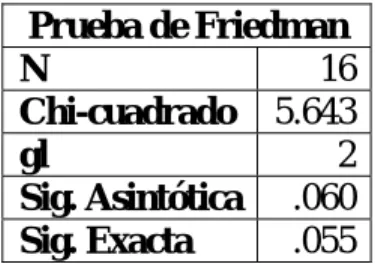
(41) C. n. k. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16. 480 480 480 406 406 406 347 347 662 662 662 175 175 897 897 897. 50 40 30 50 40 30 40 30 10 20 30 30 20 10 20 50. Tiempo de ejecución (segundos) A1 A2 A3 6299 1290 392 4197 719 356 2396 450 343 3527 908 102 2320 438 98 1452 201 90 1401 379 38 796 153 36 873 40 117 2919 78 85 5998 175 89 100 153 19 53 55 16 2321 72 192 7570 108 119 31063 957 138. Promedio de silueta A1 A2 A3 0.2 0.2 0.1 0.2 0.1 0.1 0.1 0.1 0.1 0.2 0.2 0.2 0.2 0.2 0.1 0.2 0.2 0.2 0.2 0.2 0.1 0.2 0.2 0.1 -0.01 0.1 0 0 0 0 0 0.1 0 0.2 0.3 0.2 0.2 0.2 0.2 0 0 0 0.1 0 0.1 0.1 0.1 0.1. Tabla 2.1: Datos obtenidos con las corridas de los algoritmos en atributos de bases de datos reales. Esta tabla fue llevada a un archivo SPSS con nueve variables: caso, n, k, TA1, TA2, TA3, CA1, CA2 y CA3 que representan: el número del caso (que relaciona las dos variables siguientes), la cantidad de elementos del atributo, la cantidad de grupos a formar, el tiempo de corrida del algoritmo A1, el tiempo de corrida del algoritmo A2, el tiempo de corrida del algoritmo A3, el promedio de silueta de la partición obtenida con la ejecución del algoritmo A1, el promedio de silueta de la partición obtenida con la ejecución del algoritmo A2 y el promedio de silueta de la partición obtenida con la ejecución del algoritmo A3 respectivamente. Posteriormente se realizó el siguiente procedimiento para los dos pasos ya mencionados: 1. Aplicar la prueba de Friedman para ver si existen diferencias significativas entre los tres algoritmos. Teniendo en cuenta para dicha conclusión un valor de significación de 0.01. 30.
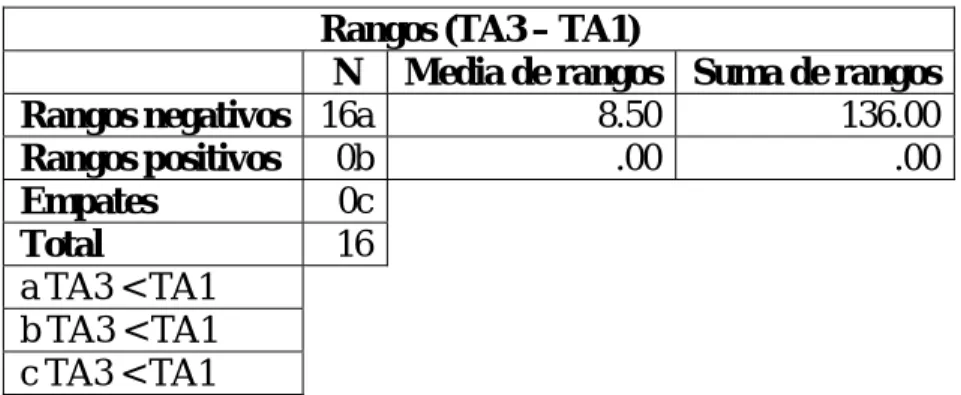
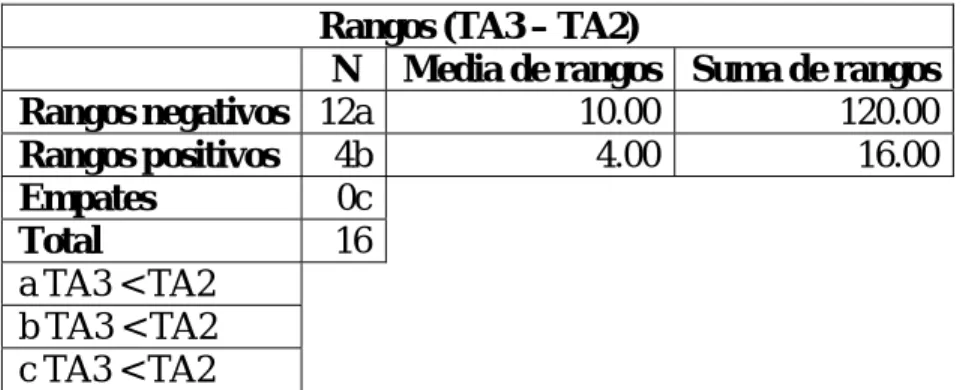
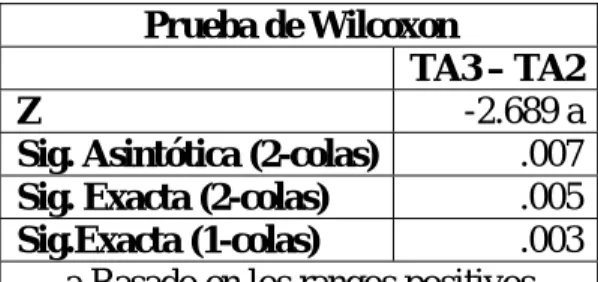
(42) Si el valor crítico es: A. Mayor que 0.01: No se rechaza la hipótesis de igualdad entre los tres algoritmos. B. Menor que 0.01: Se rechaza la hipótesis de igualdad entre los tres algoritmos. Hay diferencias significativas entre los algoritmos y es necesario encontrar en que pares de algoritmos se encuentran. Aunque existen procedimientos para efectuar comparaciones múltiples cuando el estadístico de Friedman resulta significativo, para analizar con el SPSS qué variables difieren entre sí se utiliza la prueba de Wilcoxon para dos muestras relacionadas, pero acompañada de la corrección de Bonferroni 6 para controlar la tasa de error. Con tres variables se necesita hacer tres pruebas dos a dos: 1-2, 1-3 y 2-3. La aplicación de la corrección de Bonferroni al hacer comparaciones por pares implica basar las decisiones en un nivel de significación de 0.01/3 = 0.003. En consecuencia, el procedimiento sigue como: I. Aplicar por pares la prueba de Wilcoxon considerando que los promedios de dos variables difieren significativamente para dicha prueba cuando el nivel crítico obtenido sea menor que 0.003. Para cada par (i, j) si el valor crítico es: a. Mayor que 0.003: No se rechaza la hipótesis de igualdad entre el algoritmo ‘i’ y ‘j’. b. Menor que 0.003: Se rechaza la hipótesis de igualdad entre el algoritmo ‘i’ y ‘j’.. 6. Consiste en dividir la significación entre la cantidad de pruebas que se necesita hacer. 31.
Figure



+7



Documento similar