Open-Shop mediante Algoritmos Mem´
eticos
Angie Lizeth Blanco Ca˜
non
C´odigo: 20081015089Universidad Distrital Francisco Jos´
e de Caldas
Facultad de Ingenier´ıa
Modelo de Programaci´
on de la Producci´
on en Sistemas
Open-Shop mediante Algoritmos Mem´
eticos
Angie Lizeth Blanco Ca˜
non
C´odigo: 20081015089Trabajo de tesis para optar al t´ıtulo de
Ingeniero IndustrialDirector
MSc. Cesar Amilcar Lopez Bello.
Magister enL´ınea de investigaci´
on
Gesti´on de OperacionesUniversidad Distrital Francisco Jos´
e de Caldas
Facultad de Ingenier´ıa
Modelo de Programaci´on de la Producci´on en SistemasOpen-Shop mediante Algoritmos Mem´eticos
Title in English
Scheduling model of production in Open-shop systems using Mimetic Algorithms
Resumen: Actualmente, la correcta secuenciaci´on de trabajos en una l´ınea de producci´on open-shop es un problema de alto nivel de complejidad, que surge por la arbitrariedad de que cada trabajo puede seguir un orden de m´aquinas diferente. En esta tesis se propone un modelo computacional que permite hallar una secuenciaci´on apropiada haciendo uso de un algoritmo mem´etico, particularmente un h´ıbrido de un algoritmo gen´etico con la t´ecnica de recocido simulado para mejorar las b´usquedas locales. Como resultado, se obtienen soluciones apropiadas para problemas complejos comparando contra soluciones presentadas por otras t´ecnicas que se toman como l´ınea base de referencia.
Abstract: Nowadays, an appropriate jobs scheduling in an open-shop system is a problem with a high complexity level, due to arbitrariness of each job can move through a different machines order. In this thesis, we propose a computational model that leaves find an scheduling using a mimetic algorithm, mainly a hybrid strategy of a Genetic Algorithm mixed with a Simulated Annealing to improve local search. In the results, we find good solutions for some complex reference problems, and in comparison with another strategies of base line, we have a good performance.
Palabras clave: Algoritmos Mem´eticos, Algoritmos Gen´eticos, Recocido Simulado, Secuenciaci´on de Trabajos, Sistemas Open-shop
Nota de aceptaci´
on
Trabajo de tesis
Jurado
Ing. Juan Carlos Cano Rueda
Director
MSc. Cesar L´opez
´
Indice general
´Indice de tablas III
´Indice de figuras IV
Introducci´on V
1. Planteamiento del Problema 1
1.1. Problema . . . 1
1.1.1. Formulaci´on del Problema . . . 1
1.1.2. Descripci´on del Problema . . . 1
1.2. Objetivos . . . 2
1.3. Justificaci´on . . . 3
1.3.1. Delimitaci´on del Problema . . . 3
1.4. Metodolog´ıa . . . 4
1.4.1. Hip´otesis de la Investigaci´on . . . 4
1.4.2. Pregunta de la Investigaci´on . . . 4
1.4.3. Variables de la Investigaci´on . . . 4
1.4.4. Tipo de Investigaci´on . . . 5
1.4.5. Dise˜no Metodol´ogico . . . 5
2. Marco Te´orico 7 2.1. Antecedentes . . . 7
2.2. Marco Conceptual . . . 10
2.2.1. Programaci´on de Producci´on . . . 10
2.2.1.1. Programaci´on Predictiva de la Producci´on . . . 12
2.2.2.1. Modelo de programaci´on entera mixta para sistemas
open-shop . . . 12
2.2.3. M´etodos de Resoluci´on . . . 14
2.2.3.1. Algoritmos Evolutivos . . . 14
2.2.3.2. Algoritmos Gen´eticos . . . 14
2.2.3.3. Algoritmos Mem´eticos . . . 15
2.2.3.4. Recocido Simulado . . . 15
3. Desarrolo del Proyecto 17 3.1. Algoritmo Gen´etico . . . 17
3.1.1. Poblaci´on inicial y definici´on del Individuo . . . 17
3.1.1.1. Heur´ıstica para reducci´on de tiempos muertos . . . 18
3.1.2. Medida de Desempe˜no . . . 19
3.1.3. Mecanismo de Selecci´on . . . 20
3.1.4. Operadores Gen´eticos . . . 20
3.1.4.1. Mutaci´on . . . 21
3.1.4.2. Cruce . . . 21
3.1.5. Mecanismo de Reemplazo . . . 22
3.2. Recocido Simulado . . . 23
4. Resultados Obtenidos 24
Conclusiones 39
Trabajo futuro 40
´
Indice de tablas
1.1. Dise˜no metodol´ogico por etapas . . . 5
1.1. Dise˜no metodol´ogico por etapas . . . 6
2.1. Refencias destacadas en este trabajo . . . 9
2.1. Refencias destacadas en este trabajo . . . 10
4.1. Mejores resultados obtenidos Algoritm Gen´etico 4x4 . . . 26
4.2. Mejores resultados obtenidos Algoritm Mem´etico 4x4 . . . 27
4.3. Mejores resultados obtenidos Algoritm Gen´etico 5x5 . . . 28
4.4. Mejores resultados obtenidos Algoritm Mem´etico 5x5 . . . 29
4.5. Mejores resultados obtenidos Algoritm Gen´etico 7x7 . . . 29
4.5. Mejores resultados obtenidos Algoritm Gen´etico 7x7 . . . 30
4.6. Mejores resultados obtenidos Algoritm Mem´etico 7x7 . . . 30
4.6. Mejores resultados obtenidos Algoritm Mem´etico 7x7 . . . 31
4.7. Mejores resultados obtenidos Algoritm Gen´etico 10x10 . . . 31
4.7. Mejores resultados obtenidos Algoritm Gen´etico 10x10 . . . 32
4.8. Mejores resultados obtenidos Algoritm Mem´etico 10x10 . . . 32
4.8. Mejores resultados obtenidos Algoritm Mem´etico 10x10 . . . 33
4.9. Mejores resultados obtenidos Algoritm Gen´etico 15x15 . . . 33
4.10. Mejores resultados obtenidos Algoritm Mem´etico 15x15 . . . 34
4.11. Mejores resultados obtenidos Algoritm Gen´etico 20x20 . . . 35
4.12. Mejores resultados obtenidos Algoritm Mem´etico 20x20 . . . 36
4.13. Tiempos de ejecuci´on algoritmos propuestos . . . 37
3.1. Representacion Individuo . . . 18
3.2. Heuristica Propuesta . . . 19
3.3. Tabla de Adyacencias . . . 22
4.1. Porcentajes de diferencia respecto a Taillard . . . 38
4.2. Mejor resultado por conjunto de datos obtenido Vs. Taillard . . . 38
Introducci´
on
Las primeras d´ecadas del siglo XX constituyen un periodo clave en la historia de la optimizaci´on como disciplina; fue en aquel entonces cuando se encontraron problemas para los cuales no era posible obtener una soluci´on exacta de forma anal´ıtica (´o cuanto menos una soluci´on con garant´ıa de aproximaci´on a ella), desencadenando as´ı en un nuevo paradigma para la investigaci´on de operaciones.
Uno de los objetivos que persiguen los m´etodos de optimizaci´on empleados en investi-gaci´on de operaciones, es resolver problemas de asignaci´on y secuenciaci´on inmersos en la programaci´on de la producci´on. Esta ´area de la gesti´on de operaciones se caracteriza por su nivel operativo, es decir, requiere respuestas en tiempo real a las actividades desarrolladas en el diario vivir de la industria. Este hecho ha marcado el inicio de una b´usqueda por parte de los investigadores para aplicar algoritmia y programaci´on matem´atica a modelos capaces de brindar soluciones ´optimas, o cercanas al ´optimo, al problema de asignaci´on de cargas de trabajo.
En la actualidad se buscan adaptar meta-heur´ısticas, tales como algoritmos gen´eticos y recocido simulado unidas en los denominados algoritmos mem´eticos, cuyos or´ıgenes se remontan a finales de la d´ecada de los ochenta. Estos algoritmos pretenden combinar conceptos y estrategias de diferentes meta-heur´ısticas para integrar las ventajas de las mismas, aumentando la posibilidad de encontrar buenas soluciones a problemas dados.
Otro aspecto que revoluciono a los m´etodos de optimizaci´on, especialmente los relacio-nados con la programaci´on de la producci´on, corresponde a un factor responsable de cerrar la brecha entre el ´ambito acad´emico y la realidad a la que se enfrentan los profesionales; esto es debido a los cambios, tanto preventivos como inesperados, que sufren los modelos de producci´on a lo largo de su desarrollo. Bajo esta premisa, aparece el concepto de pro-gramaci´on de la producci´on din´amica, y espec´ıficamente en la d´ecada de los noventa, el de programaci´on de la producci´on predictiva, la cual se considera una de las estrategias para afrontar un problema de programaci´on en problemas futuros.
La integraci´on de los m´etodos de soluci´on para los problemas de programaci´on de la producci´n lleva al descubrimiento de nuevos algoritmos y mecanismos que reducen el error de las soluciones obtenidas respecto al ´optimo.
Como referente en problemas para evaluar t´ecnicas de secuenciaci´on de trabajos se tiene a Taillard [33], quien propuso un conjunto de problemas de l´ınea base, junto con la mejor soluci´on encontrada y la cota m´ınima te´orica. Aunque bastantes autores han trabajado con estos problemas para probar estrategias, muchas veces no se logra llegar a buenas soluciones en problemas de gran tama˜no, y en la mayor´ıa de los casos, no se ha
logrado encontrar una soluci´on que como resultado logre llegar a la cota m´ınima te´orica propuesta por Taillard.
CAP´
ITULO
1
Planteamiento del Problema
1.1. Problema
1.1.1. Formulaci´on del Problema
Realizar de manera eficiente la asignaci´on y secuenciaci´on de trabajos en las diferentes estaciones o puestos de trabajo en sistemas productivos open-shop.
1.1.2. Descripci´on del Problema
El problema de asignaci´on de cargas de trabajo, conocido generalmente como machi-ne scheduling, consiste en encontrar la secuencia tecnol´ogica que arroje una medida de desempe˜no eficiente en relaci´on a todas las posibles configuraciones en las que un trabajo es procesado en un conjunto de m´aquinas disponibles. El makespan es por excelencia el mecanismo empleado para evaluar la disposici´on para procesar un n´umero determinado de tareas en un conjunto de m´aquinas o estaciones de trabajo, teniendo en cuenta que el objetivo a minizar es el tiempo de terminaci´on de la ´ultima tarea.
Ahora bien, esto va ligado al tipo de sistema productivo en el cual se encuentra in-merso el proceso a realizar. Espec´ıficamente, el problema de programaci´on de un sistema open-shop, OSSP por sus siglas en ingl´es (Open-Shop Scheduling Problem), cuenta con la caracter´ıstica de ser arbitrario, es decir, las tareas a realizar no siguen una secuencia definida, cada una adopta una l´ınea diferente e independiente de las dem´as.
Uno de los principales retos para el modelamiento de sistemas productivos open-shop ha sido el de su naturaleza din´amica. La dificultad de recrear dicha propensi´on al cambio en ambientes tradicionales o determin´ısticos, ha sido el principal inconveniente que se ha presentado en este campo de la programaci´on a la hora de realizar la asignaci´on y secuenciaci´on de trabajos. Esto surge debido a las condiciones din´amicas relacionadas con el entorno (mercado) y la empresa en s´ı, lo que impide tener total certeza de los datos que representan totalmente al sistema.
Sin embargo, en el mundo real de la industria ocurren frecuentemente situaciones imprecisas o inciertas, en entornos en los que las metas, las restricciones y las consecuencias
de posibles decisiones no se conocen de manera exacta. En el campo particular de la programaci´on de producci´on, eventos como fallos en las m´aquinas, cancelaci´on de trabajos, cambios de fecha de entrega, falta de materia prima, problemas de calidad, variaci´on de la plantilla de trabajadores, entre otros, no se pueden prever con total exactitud, debido a que los ambientes reales de producci´on son din´amicos y no est´aticos en el tiempo.
Obtener la soluci´on ´optima de un problema que contempla todos los aspectos plantea-dos anteriormente o para problemas que sin contemplar esos aspectos tengan un n´umero considerable de trabajos y m´aquinas, puede llegar a ser complicado a causa de la com-plejidad del problema e incluso por el tiempo computacional que se debe emplear. La naturaleza de este tipo de casos impide el uso de t´ecnicas anal´ıticas, ya que incrementan los costos computacionales de manera considerable, haciendo necesaria la utilizaci´on de t´ecnicas metaheur´ısticas, que con costos computacionales aceptables, sean capaces de dar una soluci´on lo m´as cercana posible a la soluci´on ´optima.
El desarrollo de una metaheur´ıstica que sea capaz de resolver esta clase de problemas, debe alcanzar un comportamiento que satisfaga los requisitos del problema, es decir, debe ser una t´ecnica general (capaz de resolver una clase de problemas lo m´as amplia posible), y adem´as ser eficiente en el manejo de recursos computacionales en casos donde se deba procesar gran cantidad de datos.
En el presente trabajo se trabajar´a el caso en el que el sistema no cuenta con restriccio-nes que alteren el comportamiento del sistema a lo largo del ciclo productivo, el proposito ser´a encontrar buenas soluciones a los problemas donde el n´umero de m´aquinas y trabajos impiden hallar una soluci´on ´optima en un tiempo computacional aceptable.
1.2. Objetivos
Objetivo general
Formular un modelo de programaci´on de la producci´on para sistemas productivos open-shop mediante un algoritmo mem´etico que reduzca el makespan.
Objetivos Espec´ıficos
• Caracterizar los sistemas productivos open-shop, identificando su configuraci´on y comportamiento.
• Determinar el estado actual y los posibles desarrollos de los algoritmos gen´eticos y el recocido simulado, al igual que su aplicaci´on en la soluci´on de problemas de programaci´on de la producci´on en sistemas open-shop.
• Establecer y definir el algoritmo mem´etico, su funci´on objetivo, par´ametros, varia-bles de decisi´on y respectivas restricciones, y utilizar el makespan como medida de desempe˜no del mismo.
CAP´ITULO 1. PLANTEAMIENTO DEL PROBLEMA 3
1.3. Justificaci´
on
La programaci´on de la producci´on ha sido un ´area altamente estudiada, en la cual se destacan investigaciones y desarrollos en pro de la optimizaci´on de recursos a nivel indus-trial. Uno de los recursos que presenta mayor relevancia es el tiempo del ciclo productivo; esto se debe a que los dem´as recursos son empleados en funci´on del tiempo.
La presunci´on de condiciones determin´ısticas en el entorno de los sistemas productivos, espec´ıficamente open-shop, favorec´ıa la formulaci´on y obtenci´on de soluciones, es decir, se asum´ıa un modelo est´atico, en el cual los agentes propios de la variabilidad no ten´ıan lugar. Esto di´o origen a m´ultiples desviaciones respecto al comportamiento real del sistema (Dawkins, El Gen Egoista, Las bases biol´ogicas de nuestra conducta, 1993), que en algunos casos generaba situaciones contraproducentes en la asignaci´on y la secuenciaci´on de cargas de trabajo.
A partir de esto, la determinaci´on de una secuencia tecnol´ogica que arroje una medida de desempe˜no eficiente en relaci´on con todas las posibles configuraciones en las que un trabajo es procesado en las m´aquinas disponibles, incluyendo las posibles variaciones que se puedan presentar a lo largo del ciclo productivo, se convierte en la esencia de los modelos a desarrollar en la gesti´on de operaciones.
La evoluci´on de la programaci´on matem´atica, enfocada a la representaci´on de la reali-dad, ha permitido su aceptaci´on a nivel industrial. Una de las razones de este hecho se debe a la existencia de miles de problemas de optimizaci´on pertenecientes a la clase NP (No-Polinomiales) (Cotta, 2003), a los cuales los algoritmos mem´eticos han otorgado valor agregado debido a su acercamiento a la soluci´on ´optima de los mismos.
El dise˜no de un modelo en el cual se integren y potencien las caracter´ısticas de algo-ritmos gen´eticos y t´ecnicas de b´usqueda local, c´omo el recocido simulado (una de las m´as utilizadas en la resoluci´on de problemas de programaci´on de producci´on, entre otras meta-heur´ısticas), aplicado en un sistemaopen-shop, propone una herramienta cuantitativa que mida la utilizaci´on del recurso. Esta eficiencia se debe reflejar en el valor del makespan como medida de desempe˜no, ya que entre menor sea el tiempo de requerido procesar todos los trabajos, se asume que se est´an usando los recursos de manera m´as apropiada.
1.3.1. Delimitaci´on del Problema
Tem´atica
El modelo propuesto se aplicar´a exclusivamente para la programaci´on de la producci´on de sistemas tipo open-shop, el cual contempla un conjunto de n trabajos que deben ser procesados enm m´aquinas, contando con las siguientes caracter´ısticas :
• Cada m´aquina puede realizar una tarea correspondiente a un trabajo a la vez (R.L. Graham, 1979)
• En un instante determinado de tiempo cada trabajo debe estar siendo procesado cuando mucho por una m´aquina.
• Los tiempos de procesamiento son deterministicos y conocidos.
• A lo largo del ciclo productivo no se presentar´an variaciones en los recursos del sistema.
• El sistema no considera precedencias.
• El tiempo de terminaci´on de la ´ultima tarea, o makespan, ser´a la medida de desem-pe˜no empleada para evaluar la eficiencia del modelo.
Para el desarrollo del modelo se contar´a con un algoritmo mem´etico o h´ıbrido, como resultado de la uni´on de las caracter´ısticas de un algoritmo gen´etico (estrategia compu-taciona evolutiva) y recocido simulado (b´usqueda local).
1.4. Metodolog´ıa
1.4.1. Hip´otesis de la Investigaci´on
La integraci´on de algoritmos gen´eticos y recocido simulado en un algoritmo mem´etico aplicado en la programaci´on de la producci´on en un entornoopen-shop, arrojar´a soluciones que conduzcan a una disminuci´on del makespan como medida de desempe˜no con alta precisi´on frente a instancias dadas.
1.4.2. Pregunta de la Investigaci´on
¿C´omo desarrollar un algoritmo de programaci´on de m´aquinas(machine scheduling)en ambientesopen-shop bajo el criterio delmakespan, que proporcione soluciones aceptables en precisi´on frente a instancias dadas?
1.4.3. Variables de la Investigaci´on
Makespan
Variable de tipo independiente en el proyecto, que hace alusi´on al tiempo de termina-ci´on del procesamiento efectuado a la ´ultima operaci´on del ´ultimo trabajo en la ´ultima m´aquina, o tambi´en puede ser entendido como el tiempo total en el que son procesados todos los trabajos en las m´aquinas o estaciones de trabajo.
Esta medida de desempe˜no se obtiene de realizar la sumatoria de los tiempos de proce-samiento de los diferentes trabajos en las m´aquinas por las cuales pasaron, basados en la secuencia asignada. Una de las formas m´as comunes y pr´acticas de visualizar elmakespan es realizar un diagrama de Gantt; dicho diagrama es una herramienta que permite ver la distribuci´on de tiempo asignado a diferentes actividades en un periodo determinado.
Precisi´on de la Soluci´on
CAP´ITULO 1. PLANTEAMIENTO DEL PROBLEMA 5
la precisi´on de la respuesta del modelo frente a la mejor soluci´on posible. Esta precisi´on es la variable dependiente de la investigaci´on y es la encargada de indicar si el modelo es aceptado o no.
1.4.4. Tipo de Investigaci´on
Programar la producci´on de un sistema tipoopen-shopmediante un modelo matem´ ati-co requiere una investigaci´on cuantitativa de tipo anal´ıtico. Esto se debe a que permite el planteamiento de una hip´otesis, la cual se convierte en un reto para demostrar la veracidad de la premisa enunciada en dicha hip´otesis. Para conseguir el objetivo se analizar´an los datos de manera num´erica, es decir, se especificaran los par´ametros que va a manejar el modelo, y por medio de la obtenci´on de los valores de determinadas variables se realizar´a una comparaci´on de las diferente soluciones que se obtengan.
Por medio de la medida de desempe˜no escogida para determinar la mejor soluci´on, y el porcentaje de error que se defina, se podr´a verificar la validez de la hip´otesis del proyecto.
1.4.5. Dise˜no Metodol´ogico
Tabla 1.1.Dise˜no metodol´ogico por etapas
Objetivo Actividad Herramienta
Inge-nieril a Emplear
Caracterizar los sistemas productivos open-shop,
identificando su configuraci´on y comportamiento.
Analizar las caracter´ısticas del sistema para definir su na-turaleza.
Distribuci´on en planta (Tipolog´ıa de los siste-mas productivos). Realizar el dimensionamiento
del sistema.
Matriz de referencia cruzada.
Diagnosticar el estado actual y los posibles desarrollos de los
algoritmos gen´eticos y el recocido simulado, al igual que su aplicaci´on en la soluci´on de problemas de programaci´on de la producci´on en sistemas open-shop.
Efectuar una revisi´on de es-tudios desarrollados con me-taheur´ısticas.
Revisi´on bibliogr´afica.
Identificar las aplicaciones de estos algoritmos en la progra-maci´on de la producci´on.
Revisi´on bibliogr´afica.
Establecer y definir el modelo evolutivo h´ıbrido, su funci´on objetivo, par´ametros, variables de decisi´on y respectivas restricciones, e implementar el makespan como medida de desempe˜no del mismo.
Determinar los par´ametros con sus respectivos valores, junto con el n´umero de traba-jos y m´aquinas del sistema.
Programaci´on ma-tem´atica.
Dimensionar las variables del modelo definiendo su natura-leza.
Programaci´on ma-tem´atica.
Estructurar las restricciones requeridas para dar soluci´on al problema.
Programaci´on ma-tem´atica.
Definir la funci´on objetivo. Programaci´on ma-tem´atica.
Tabla 1.1.Dise˜no metodol´ogico por etapas
Objetivo Actividad Herramienta
Inge-nieril a Emplear
Evaluar los resultados obtenidos con el modelo frente a otras t´ecnicas de resoluci´on, y determinar de esta manera su eficiencia relativa.
Obtener las posibles solucio-nes seleccionando la que tenga mejor funci´on objetivo.
Programaci´on ma-tem´atica e inteligencia computacional.
Comparar las variaciones de los resultados obtenidos, a partir de modificaciones a las variables.
An´alisis de Sensibilidad.
Comparar la soluci´on arroja-da por el modelo con solucio-nes obtenidas mediante otros m´etodos.
An´alisis estad´ıstico
Determinar y aplicar medidas de desempe˜no que eval´uen la eficiencia del modelo.
An´alisis estad´ıstico
Determinar veracidad de la hip´otesis.
CAP´
ITULO
2
Marco Te´
orico
2.1. Antecedentes
La secuenciaci´on de sistemas productivos open-shop ha sido ampliamente estudiada por investigadores, quienes han propuesto diferentes estrategias que proporcionan solucio-nes aceptables a problemas de secuenciaci´on; una definici on de este tipo de problemas, aceptada por la comunidad cient´ıfica, es la que lo presentan Kononov et al.(Kononov, Sevastianov, & Tchernykh, 1999) : Hay un conjunto de m m´aquinas M1, . . . , Mm y un conjunto de n trabajos J ={J1, . . . , Jn}.Cada trabajo se compone de m operaciones Oji, dondei= 1, . . . , m,yj = 1, . . . , n.Una operaci´onOjide un trabajoJj tiene que ser proce-sado en la m´aquina Mi,y esto requiere de pji unidades de tiempo. Cada m´aquina procesa como m´aximo un trabajo a la vez, y cada trabajo se procesa m´aximo por una m´aquina a la vez. Sin preferencia, se permite en el procesamiento de cualquier operaci´on. Para cada trabajo, el orden de sus operaciones no se fija de antemano, sino que deben ser elegidos los diferentes trabajos que se les permita recibir diferentes ´ordenes.
En la b´usqueda de un programa que se adapte a las necesidades espec´ıficas de un entorno puntual, se han definido diversas medidas de desempe˜no que eval´uen las respuestas arrojadas por una soluci´on; entre otras, se pueden encontrar las mencionadas por [8]:
(i) Makespan (Cmax): Definido como el m´aximo tiempo de proceso de los trabajos.
(ii) M´axima tardanza (Lmax): M ˜A¡ximo tiempo de tardanza en la fecha de entrega de los trabajados.
(iii) Tiempo de terminaci´on (P
Cj): Sumatoria de los tiempos de terminaci´on de todos los trabajos
(iv) Tiempo de terminaci´on ponderado (P
wjCj): Sumatoria de los tiempos de termina-ci´on de los trabajos multiplicados por un factor de ponderaci´on para cada trabajo.
(v) Tardanza total (P
Tj): Sumatoria de la tardanza para todos los trabajos.
(vi) Tardanza ponderada total (P
wjTj): Sumatoria de la tardanza para todos los traba-jos multiplicada por un factor de ponderaci´on para cada trabajo.
(vii) N´umero de trabajos tard´ıos (P
Uj): N´umero de trabajos que son entregados despu´es de la fecha establecida.
En 1979 (Graham, Lawler, Lenstra, & Rinnooy Kan, 1979) presentaron la notaci´on α/β/γ empleada actualmente para identificar los problemas de scheduling, donde α re-presenta el tipo de sistema productivo empleado,β hace referencia a las restricciones que aplican al problema, yγ expresa la medida de desempe˜no o funci´on objetivo.
Para el caso denotado como [O2 —— Cm´ax] el cual hace referencia al problema en el
que se cuenta con dos m ˜A¡quinas en un ambienteopen-shopy la medida de desempe˜no es el makespan, se han presentado estrategias que encuentran una soluci´on ´optima al problema; [29] quienes presentan escenarios con tiempos de procesamiento estoc´asticos sujetos a distribuciones de probabilidad para n trabajos resueltos mediante m´etodos anal´ıticos en tres escenarios puntuales (m´aquinas con la misma funci´on de distribuci´on de probabilidad, m´aquinas con diferentes funciones de distribuci´on de probabilidad y m´aquinas id´enticas). Al igual que [20] desarrollan un algoritmo de tiempo polinomial para el caso de dos m´aquinas y tiempos de procesamiento determin´ısticos, y definen el problema con tres m´aquinas como un problema NP-hard. Bajo estas condiciones, la soluci´on otorgada por (Kononov, Sevastianov, & Tchernykh, 1999) es presentada en un esquema que permite, a partir de una secuencia para k m´aquinas, generar un programa para m m´aquinas, con m > k, bajo ciertas condiciones de VOD (vector of differentiation). De esto, se deriva una familia deEN−vectoresen Rm, que satisfacen y garantizan una funci´on m´ınima para la que existe un algoritmo de tiempo polinomial. En vista de la calidad de NP-hard de [O —— Cmax], se han desarrollado algoritmos heur´ısticos, enlazados y ramificados para este problema (Andresen, Br¨asel, M¨orig, Tusch, & Werner, 2008).
La investigaci´on presentada por (Sevastianov & Woeginger, 1998), se centr´o en la ob-tenci´on de algoritmos de aproximaci´on en tiempo polinomial para la soluci´on del problema open-shop descrito anteriormente, es decir, algoritmos r´apidos que construyen programa-ciones cuyo makespan no difiere mucho delmakespan ´optimo.
El desarrollo de un algoritmo de ramificaci´on y acotamiento fue presentado por (Bru-ker, Hurink, Jirish, & W¨ostman, 1997) con el fin de minimizar el makespan, donde la construcci´on del ´arbol de ramificaci´on se basa en grafos disyuntos que se rigen por la creaci´on de precedencias de operaciones del mismo trabajo o de operaciones que deben ser procesadas en la misma m´aquina. Un algoritmo exacto ha sido dado por Dorndorf (Dorndorf, Pesch, & Phan-Huy, 2001), el modelo propuesto se centr´o en los m´etodos de propagaci´on de restricciones para reducir el espacio de b´usqueda.
Varios problemas de referencia de la literatura se han resuelto encontrando un punto muy cercano a la optimalidad. En particular, en uno de los problemas propuestos por [33], se establecen una serie de instancias, entre ellas se han trabajadoOSSPde 10 trabajos y 10 m´aquinas, 15 trabajos y 15 m´aquinas, y 7 casos con 20 trabajos y 20 m´aquinas, todas han sido resueltas y actualmente son utilizadas como punto de referencia de trabajos desarrollados.
En el desarrollo de heur´ısticas se encuentra el modelo propuesto por (Jurisch & Kubiak, 1997) que resuelve el problema [O2 — pmtn — Cmax] mediante un algoritmo de flujo
m´aximo y demuestra que elmakespanes equivalente al de un problema [O2—— Cmax] que
CAP´ITULO 2. MARCO TE ´ORICO 9
problemas open-shop por medio de permutaciones es propenso a caer en redundancias, y proponen cuatro heur´ısticas basadas en los teoremas expuestos.
La implementaci´on de algoritmos de b´usqueda local m´as complejos en las denominadas meta-heur´ısticas, arrojan desarrollos como los presentados por (Ching-Fang, 1999) quien presenta un algoritmo de b´usqueda tab´u para problemas open-shop, donde la estructura del vecindario o espacio de b´usqueda est´a dado por la representaci´on de las soluciones como un grafo disyuntivo con el objetivo de minimizar el makespan.
Una comparaci´on entre dos meta-heur´ısticas es presentada por (Andresen, Br¨asel, M¨orig, Tusch, & Werner, 2008), quienes proponen un algoritmo gen´etico donde el individuo es representado por medio de una matriz que denota la secuencia en filas y columnas para m´aquinas y trabajos respectivamente. El algoritmo de recocido simulado que plantean los autores tambi´en representa a las posibles soluciones como la matriz descrita anteriormen-te, asegurando que para tener una mejor soluci´on en el algoritmo se debe iniciar con una buena soluci´on factible y una temperatura inicial baja.
En el caso de [8], resuelven mediante un algoritmo evolutivo un problemaJSSP:OSSP
con 15 m´aquinas y 20 trabajos, logrando mejores resultados respecto a t´ecnicas tradicio-nales empleadas en su desarrollo, como OMC, OML y Campbell.
La inclusi´on de restricciones sobre las habilidades de los trabajadores en un sistema open-shop es abordada por [10] en un algoritmo de colonia de hormigas con el objetivo de minimizar el tiempo medio de flujo.
La Tabla 2.1 resume los trabajos destacados en la b´usqueda de antecedentes para el trabajo a realizar, los trabajos mencionados permiten identificar que aspectos se han trabajado y que se puede implementar como novedad en busca de mejorar los resultados obtenidos
Tabla 2.1.Refencias destacadas en este trabajo.
Ref A˜no Algoritmo Medida desempe˜no Aporte realizado
[23] 2000 GA-TS makespan Integraci´on de las metaheur´ısticas TS y
GA donde los individuos generados por el GA son mejorados localmente por TS. [29] 1981 PL makespan Desarrollo de un modelo de programaci´on
lineal para el caso de dos m´aquinas con diferentes velocidades y tiempos de pro-cesamiento sujetos a una distribuci´on de probabilidad.
[16] 1994 GA,LPT,SPT makespan Uso de diferentes heur´ısticas para la cons-trucci´on de los individuos que van a for-mar la poblaci´on inicial del un algoritmo gen´etico.
[7] 1997 BB makespan Desarrollo de un algortimo de ramificaci´on y acotamiento que es usado actualmente como intancia y referencia de problemas de hasta 10 m´aquinas y 10 trabajos.
Tabla 2.1.Refencias destacadas en este trabajo.
Ref A˜no Algoritmo Medida desempe˜no Aporte realizado
[21] 1999 GA, LPT makespan Construcci´on de un algoritmo gen´etico
b´asico comparado con un algoritmo hibri-do hibri-donde una heur´ıstica se emplea para generar la poblaci´on inicial.
[2] 2008 GA, SA Tiempo medio de flujo Representaci´on de los individuos mediante una matriz y construcci´on de operadores gen´eticos propios.
2009 GA makespan Desarrollo para una configuraci´on open-shop donde se cuenta con un conjunto de m´aquinas identicas que pueden realizar la misma operaci´on en paralelo.
[39] 2008 SA Tardanza ponderada Inclusi´on de variables difusas para repre-sentar los cuellos de botella y mejorar el comportamiento del recocido simulado aplicado al problema propuesto.
2012 GA Tardanza y makespan Desarrollo de un algoritmo gen´etico mul-tiobjetivo para sistemas open-shop. [30] 2004 GA,Heur´ısticas makespan Generaci´on de individuos para la poblaci´ın
inicial mediante heur´ısticas de elaboraci´on propia.
[30] 2004 GA,Heur´ısticas makespan Generaci´on de individuos para la poblaci´ın inicial mediante heur´ısticas de elaboraci´on propia.
[4] 2016 GA,Heur´ısticas makespan Adaptaci´on de la heur´ıstica LPT y desa-rrollo de un algortmo gen´etico para el sis-tema open-shop flexible.
[10] 2015 AC, MIP Tiempo medio de flujo Desarrollo de un algoritmo de colonia de hormigas en un sistema que contempla restricciones sobre las habilidades de los trabajadores.
[27] 2014 MIP, LS makespan Desarrollo de algoritmos para
encon-trar soluciones ´optimas y aproximadas al problema open-shop no wait mediante b´usqueda en vecindades variables.
2.2. Marco Conceptual
2.2.1. Programaci´on de Producci´on
CAP´ITULO 2. MARCO TE ´ORICO 11
producci´on y capacidades, el proceso de programaci´on de la producci´on, y el proceso de ejecuci´on (tambi´en conocido por proceso de lanzamiento), de manera tal que no se puede entender de forma aislada ninguno de sus elementos.
En relaci´on al largo plazo, se encuentran las actividades directamente relacionadas con la toma de decisiones de car´acter estrat´egico. Como resultado de dichas actividades, se elabora un plan agregado de producci´on del cual se puede obtener un plan maestro provisional. En cuanto al mediano plazo, se desarrollan aspectos m´as pr´oximos al ´ambito operativo, tomando como elemento de partida el plan maestro provisional a partir del cual se elabora en primer lugar el plan maestro tentativo y posteriormente el plan maestro definitivo, del cual se desprenden el plan de requerimientos de materiales y la planifica-ci´on de los requerimientos de capacidad. En el ´ambito del corto plazo se encuentran los procedimientos de programaci´on de la producci´on y de lanzamiento.
La programaci´on de la producci´on (Apics 1994) define la programaci´on de operaciones como la asignaci´on efectiva de fechas de inicio y/o t´ermino a operaciones o grupos de operaciones para calcular el momento en que estas operaciones deben ser realizadas para que la orden de fabricaci´on se complete a tiempo. Es el paso previo a la ejecuci´on f´ısica de las operaciones de fabricaci´on (Companys, R. & Corominas , A. 1996). Estos ´ultimos diferencian entre tres sub-funciones que tradicionalmente se han distinguido dentro de la funci´on de Programaci´on de la Producci´on. ´Estas pueden ejecutarse simult´aneamente o no.
• Sub-funci´on carga (loading), consiste en la asignaci´on de las operaciones a centros de trabajo, decisi´on que se adoptar´a por comparaci´on entre la capacidad disponible del centro y la carga requerida por las operaciones ya asignadas al mismo.
• Sub-funci´on secuenciaci´on (sequencing), es la secuenciaci´on de las operaciones asig-nadas a un centro de trabajo para establecer su orden de ejecuci´on.
• Sub-funci´on temporizaci´on (scheduling), se encarga de determinar los instantes de inicio y fin (programados) de cada operaci´on. Algunos de los objetivos persegui-dos por la Programaci´on de la Producci´on (dentro de las consideraciones generales establecidas por la Planificaci´on) suelen ser:
• Terminar dentro de plazo un alto porcentaje de ´ordenes.
• Obtener una alta utilizaci´on del equipo o del personal.
• Reducir al m´ınimo las horas extra.
• Reducir al m´ınimo la obra en curso, entre otros.
de una prioridad superior a la que se est´a ejecutando actualmente. La Programaci´on de la Producci´on detallada de las tareas a realizar en un sistema de producci´on es necesaria para mantener la eficiencia y el control de las operaciones.
2.2.1.1. Programaci´on Predictiva de la Producci´on
La programaci´on predictiva de la producci´on es considerada, desde un enfoque din´ ami-co, como una estrategia para enfrentar un problema de programaci´on de producci´on. Di-cha estrategia proporciona un programa de forma anticipada que minimiza el efecto de los eventos sobre el valor de la medida de rendimiento (Gomez Gasquet, 2010).
Esta, no contempla escenarios de reprogramaci´on, por el contrario, busca que el plan generado inicialmente sea el mismo que se implementa, tenga la capacidad de afrontar y minimizar el impacto de las diferentes eventualidades (modificaciones en la plantilla de trabajadores, cambio de prioridades, entre otras) que se puedan presentar.
Desde otra perspectiva, la programaci´on predictiva se entiende como aquella estrategia que contempla diferentes escenarios que se pueden presentar a ra´ız de los cambios o even-tualidades frente al programa de producci´on, prestando mayor importancia al que genere mayor impacto (Aytug, 2005).
2.2.2. Configuraci´on Open-shop
La ruta que siguen los trabajos a realizar en un sistema productivo determina la confi-guraci´on del mismo. Cuando esta ruta es arbitraria, es decir, no existe un flujo predefinido para los trabajos, se dice que el sistema obedece a una configuraci´on tipo open-shop.
En un sistema productivo open-shop, el problema de programaci´on OSSP (Open-Shop Scheduling Problem) corresponde a un conjunto de trabajosJ tiene que ser procesado por un conjunto deM m´aquinas. Cada trabajo se compone de m operacionesOij, cada una de las cuales se deben procesar en una m´aquina diferente para un tiempo de procesamiento determinado pij. Las operaciones de trabajo se pueden procesar en cualquier orden, en cualquier momento; cada m´aquina procesa como m´aximo un trabajo a la vez, y cada trabajo se procesa m´aximo por una m´aquina a la vez. Por otra parte, cada trabajo tiene una fecha de lanzamiento, s´olo despu´es de que el funcionamiento de ese trabajo se puede procesar. En el tr´amite de cualquier operaci´on, sin derecho preferente, el retraso se permite, y los puestos de trabajo son independientes (Bai & Tang, 2009).
2.2.2.1. Modelo de programaci´on entera mixta para sistemas open-shop
Un modelo de programaci´on entera mixta para encontrar la soluci´on ´optima para el problema de scheduling en sistemas open-shop con la minimizaci´on del makespan como funci´on objetivo fue propuesto por [9]. A continuaci´on se describe la formulaci´on con sus respectivos ´ındices, par´ametros, variables, funci´on objetivo y restricciones.
• ´Indices: i=trabajos k=m´aquinas
CAP´ITULO 2. MARCO TE ´ORICO 13
• Par´ametros
M =Un n´umero positivo muy grande m=N´umero de m´aquinas
n= N´umero de trabajos disponibles en el tiempo cero rik =1 si el trabajo i requiere la m´aquina k; 0 en otro caso Ni =N´umero de operaciones del trabajo i
Pik =Tiempo de procesamiento del trabajo i en la m´aquina k
• Variables
sijk=Tiempo de inicio de la operaci´on Oijk
Cmax=Tiempo de finalizaci´on de la ´ultima operaci´on en ser procesada
xijk =
1 Si el trabajo i se procesa en la posici´on j en la m´aquina k 0 En otro caso
zkiji0j0 =
1 Si la operaci´onOijk precede la operaci´on Oi0j0k No necesariamente de inmediato 0 En otro caso • Funci´on Objetivo
M in Cmax (2.1)
• Sujeto a
xijk6rik∀i= 1,2, . . . , n;j = 1,2, . . . , Ni;k= 1,2, . . . , m (2.2) Ni
X
j=1
xijk=rik∀i= 1,2, . . . , n;k= 1,2, . . . , m (2.3)
m
X
k=1
xijk= 1∀i= 1,2, . . . , n;j= 1,2, . . . , Ni (2.4)
sijk6M xijk∀i= 1,2, . . . , n;j= 1,2, . . . , Ni;k= 1,2, . . . , m (2.5) sijk+pik 6sij+1k0+M(2−xijk−xij+1k0) (2.6) ∀i= 1,2, . . . , n;j= 1,2, . . . , Ni;k, k0= 1,2, . . . , m, k6=k0
sijk−si0j0k>pi0k−M(2−xijk−xi0j0k)−M(1−zijik 0j0) (2.7) ∀16i < i06n;j, j0= 1,2, . . . , Ni;k= 1,2, . . . , m
si0j0k−sijk >pik−M(2−xijk−xi0j0k)−M zijik 0j0 (2.8) ∀1< i6i06n;j, j0= 1,2, . . . , Ni;k= 1,2, . . . , m
siNik+pik6Cmax∀i= 1,2, . . . , n;k= 1,2, . . . , m (2.9)
Cmax >0;sijk>0∀i= 1,2, . . . , n;j = 1,2, . . . , Ni;k= 1,2, . . . , m (2.10)
(2.4) garantiza que un trabajo puede estar siendo procesado solo en una m´aquina en un instante de tiempo; el tiempo de inicio de una operaci´on en un instante de tiempo debe tomar valor solo si la operaci´on se va a iniciar en dicho instante, esto se asegura en el conjunto de restricciones (2.5); el conjunto de restricciones (2.6) se asegura de que el inicio de una operaci´on se dar´a despu´es de que su predecesora inmediatamente anterior haya terminado; los conjuntos de restricciones (2.7) y (2.8) garantizan que el tiempo de inicio de una operaci´on sea mayor o igual al tiempo de terminaci´on de todas sus predecesoras; el conjunto de restricciones (2.9) representa la funci´on objetivo, siendo el makespan un valor que representa el tiempo de terminaci´on del trabajo que m´as tarde en ser procesado en todas las m´aquinas que sea requerido; por ´ultimo las condiciones de no negatividad para el makespan y el tiempo de inicio de las operaciones se garantiza en el conjunto de restricciones (2.10).
2.2.3. M´etodos de Resoluci´on
2.2.3.1. Algoritmos Evolutivos
El origen de los algoritmos evolutivos proviene de la imitaci´on y adaptaci´on de procesos de evoluci´on natural, entendiendo esta como un proceso que act´ua sobre los individuos de una poblaci´on de la misma forma que lo hace la naturaleza con los organismos, utilizando los mismos mecanismos empleados para la creaci´on de un ser vivo en la generaci´on de un descendiente (Valeiras Reina & Mart ˜An Garc ˜Aa, 2004). La selecci´on natural es el mecanismo que da preferencia a la elecci´on de los individuos mejor adaptados al entorno para su posterior reproducci´on como sobrevivientes en la generaci´on siguiente.
Los procesos de evoluci´on tienen lugar durante la reproducci´on, donde los mecanismos m´as comunes son la mutaci´on (donde los descendientes se obtienen a partir de los cambios en los cromosomas de alg´un progenitor), y el cruce (donde se combinan los cromosomas de dos individuos para la obtenci´on de los descendientes) (Wang, Singh, & Kusiak, 2010) A partir de lo expuesto anteriormente, es posible entender un EA (Evolutive Algorithm) como un proceso iterativo que trabaja sobre un conjunto de individuos, denominado poblaci´on, en la que cada individuo presenta una potencial soluci´on del problema a resolver. De manera inicial la poblaci´on normalmente es generada aleatoriamente y cada individuo tiene asociada una medida que se realiza a trav´es de unafunci´on de calidad que representa la bondad del individuo respecto del problema a resolver. Este es el valor es la informaci´on que emplea el algoritmo para realizar la b´usqueda (Valeiras Reina & Mart ˜An Garc ˜Aa, 2004).
2.2.3.2. Algoritmos Gen´eticos
CAP´ITULO 2. MARCO TE ´ORICO 15
Los operadores cruce y mutaci´on son mecanismos de recombinaci´on gen´etica capaces de generar nuevos cromosomas a partir de los cromosomas de individuos de la poblaci´on. Un operador de cruce sencillo podr´ıa intercambiar las secuencias que se formar´ıan al cor-tar ambos cromosomas por un punto de corte. Este m´etodo suele funcionar bien para una representaci´on binaria, aunque para otras no suele ser el m´as indicado. La eficacia del operador de cruce est´a directamente relacionada con su capacidad de recoger las carac-ter´ısticas de los progenitores que los hacen buenos y recombinarlas para crear individuos mejores. El operador mutaci´on es el encargado de modificar espor´adicamente individuos de forma aleatoria, para evitar que en el transcurso de las iteraciones el operador de cruce genere individuos cada vez m´as homog´eneos y la poblaci´on se concentre alrededor de un m´ınimo local (Lopez de Haro, Sanchez Martin, & Conde Collado, 2004).
2.2.3.3. Algoritmos Mem´eticos
Desde un punto de vista algor´ıtmico, es com´un considerar un algoritmo mem´etico ( Me-metic Algorithm −MA), como un GA, al que se a˜nade un procedimiento de b´usqueda local (Local Search −LS). Sin embargo, aunque los MA toman ideas de ambos procedimientos, tambi´en se proponen nuevos operadores que los hacen diferentes e independientes de los GA. En este sentido, una de las caracter´ısticas m´as descriptivas de los MA es la incorpo-raci´on de todo el conocimiento del problema que se tenga disponible, en contraposici´on a los GA, que evitan, en la medida de lo posible, las particularidades del problema (Duarte Mu˜noz, 2007).
Un MA est´a compuesto por una poblaci´on de agentes, que son una extensi´on del in-dividuo. Cada agente contiene una o varias soluciones y un procedimiento de mejora de estas soluciones. Los agentes pueden mejorar durante su vida mediante procedimientos de b´usqueda local (Cotta, 2003). Adem´as, se establecen relaciones de cooperaci´on y compe-tici´on con el resto de agentes de la poblaci´on (Duarte Mu˜noz, 2007).
2.2.3.4. Recocido Simulado
El nombre de esta t´ecnica proviene del t´erminoSimulated Annealing(SA), a partir de la analog´ıa con el proceso t´ermico de calentamiento y posterior enfriamiento de una sustancia para obtener estados de baja energ´ıa en un s´olido (Valeiras Reina & Mart ˜An Garc ˜Aa, 2004). Dicho proceso inicialmente reblandece el s´olido mediante su calentamiento a altas temperaturas, y a continuaci´on reducirla poco a poco, hasta que las part´ıculas del solido tiendan hacia el estado fundamental del mismo. Para cada temperatura la simulaci´on se realiza varias veces hasta que el s´olido o el sistema alcance un estado de equilibrio t´ermico, siempre que el enfriamiento se realice de una forma lenta, ya que si se hace r´apidamente, el s´olido puede llegar a estados meta-estables, en los cuales el sistema no se encontrar´a en su m´as bajo nivel energ´etico, existiendo defectos en forma de estructuras de alta energ´ıa (Valeiras Reina & Mart ˜An Garc ˜Aa, 2004).
La introducci´on del concepto de recocido a la optimizaci´on combinatoria la realizaron Kirkpatrick (1983) y Cenry (1985), a trav´es de la siguiente analog´ıa: Las soluciones del problema de optimizaci´on corresponden a los diferentes estados del sistema, el criterio de evaluaci´on de la calidad de la soluci´on se hace con la energ´ıa de los estados; la soluci´on ´
meta-estables, y por ´ultimo, la temperatura como un par´ametro de control (Valeiras Reina & Mart ˜An Garc ˜Aa, 2004).
CAP´
ITULO
3
Desarrolo del Proyecto
El modelo propuesto en el presente trabajo se adapta a las caracter´ısticas del problema de secuenciaci´on de sistemas productivos open-shop, problema que cuenta con una com-plejidad derivada de la cantidad de posibles combinaciones de m m´aquinas por las que pueden pasar los diversos trabajosj para completar el ciclo productivo, donde la totalidad de los trabajos sean procesados la totalidad de las m´aquinas, con el objetivo de mejorar una medida de desempe˜no en este casomakespan [21].
Para ello se presenta un algoritmo mem´etico en el que se integran un algoritmo gen´ eti-co y la metaheur´ıstica reeti-cocido simulado eti-con el fin de aprovechar la eficiencia de los algoritmos gen´eticos resolviendo problemas de optimizaci´on combinatoria y la explotaci´on local del recocido simulado, en busca de encontrar una buena soluci´on a los problemas de secuenciaci´on de sistemas open-shop donde el n´umero de m´aquinas sea igual al n´umero de trabajos, garantizando que en el instante de tiempo cero todas las m´aquinas inicien procesando un trabajo.
3.1. Algoritmo Gen´
etico
3.1.1. Poblaci´on inicial y definici´on del Individuo
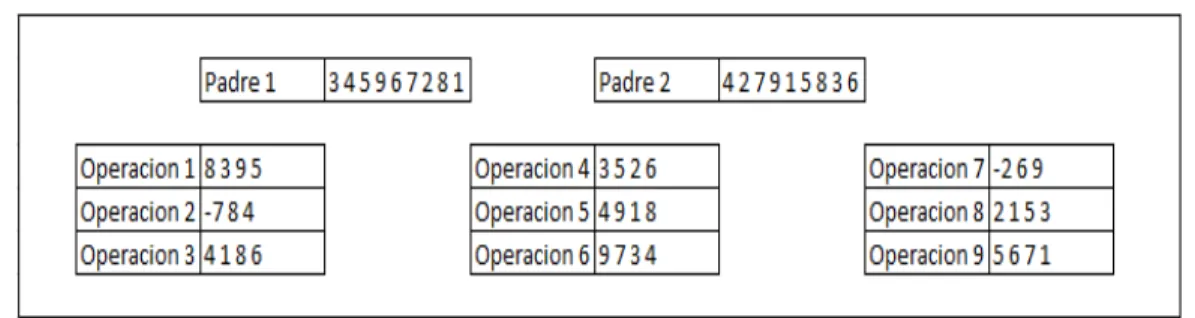
Se define una poblaci´on de tama˜no p donde cada individuo representa una soluci´on factible al problema de secuenciaci´on de sistemas open-shop, p no es un valor fijo per-mitiendo que el usuario determine el tama˜no que considere. El modelo propuesto presta atenci´on a las poblaciones con alta diversidad, debido a que estas poblaciones permiten mantener individuos con fenotipos diferentes que pueden representar mayor exploraci´on, incluyendo individuos que no necesariamente son buenas soluciones; por otro lado, se evita tener poblaciones elitistas, ya que este tipo de poblaciones buscan preservar solo aquellos individuos que representen buenas soluciones, y esa preservaci´on puede llevar a que el algoritmo caiga en ´optimos locales de los cuales es dif´ıcil salir. El fenotipo y el genotipo tienen la misma representaci´on en el modelo: una permutaci´on sin repeticiones de tama´no j∗m, donde j denota el n´umero de trabajos y m el n´umero de m´aquinas con las que cuenta el sistema, de esta manera cada n´umero dentro de la permutaci´on corresponde a una operaci´on del trabajo ((x−1)/n) + 1 en la m´aquina ((x−1) %m) + 1 . Con esta
representaci´on cada individuo contendr´a informaci´on sobre la soluci´on del problema que permitir´a al modelo analizar la combinaci´on de trabajos y m´aquinas que arroje la me-jor soluci´on. Al emplear como tipo de representaci´on una permutaci´on sin repeticiones, se busca a nivel de fenotipo conservar la factibilidad de la soluci´on que representa cada individuo, debido a que al asignar a cada posici´on dentro del individuo el n´umero de una operaci´on (´unico para cada operaci´on), logrando que cada operaci´on est´e una ´unica vez en el individuo y que la totalidad de las operaciones que corresponden al procesamiento de todos los trabajos en todas las m´aquinas est´en presentes en el individuo [24]. En la igura 3.1 se muestra la representaci´on de un individuo en un sistema de 3 trabajos y 3 m´aquinas, donde cada n´umero representa una operaci´on a realizar.
Figura 3.1. Representacion Individuo
Fuente in´edita
3.1.1.1. Heur´ıstica para reducci´on de tiempos muertos
En el presente trabajo se propone una heur´ıstica que reorganiza las posiciones de las operaciones dentro de los individuos de la poblaci´on inicial, en procura de reducir el tiempo en los que los trabajos deben esperar para ser procesados en cada una de las m´aquinas (tambi´en conocido como tiempo muerto), como producto de la restricci´on que establece que en cualquier instante de tiempo un trabajo puede ser procesado a lo sumo por una m´aquina, la heur´ıstica da una nueva organizaci´on a los indiviuos generados de manera aleatoria en la poblaci´on inicial de acuerdo a su aparici´on en el individuo.
La heur´ıstica propuesta toma el individuo generado y valida desde la posici´on n´umero 2 hasta la posici´on m∗n−m del inidividuo (ya que las ´ultimas m posiciones quedaran organizadas con la ubicaci´on de lasm∗n−m posiciones anteriores) que las operaciones que se encuentran am posicion´es de la que se est´e tomando de referencia no pertenezcan ni a la misma m´aquina ni al mismo trabajo, en algunos casos no se va a poder evitar que dos operaciones que pertenecen a la misma m´aquina o al mismo trabajo queden en posiciones cercanas debido a la reorganizaci´on previa de las posiciones que ya ha realizado la heur´ıstica.
CAP´ITULO 3. DESARROLO DEL PROYECTO 19
Figura 3.2.Heuristica Propuesta
Fuente in´edita
3.1.2. Medida de Desempe˜no
Actualmente existen diversas medidas de desempe˜no para evaluar una secuencia en sistemas open-shop, para el modelo propuesto se escoge la medida que eval´ua uno de los factores m´as importantes: el tiempo de procesamiento. Es el caso delmakespan encargado de determinar el tiempo de terminaci´on de la ´ultima m´aquina en procesar el ´ultimo trabajo, en otras palabras mide el tiempo total de ciclo donde todos los trabajos fueron procesados en todas las m´aquinas.
Al determinar elmakespande cada individuo de la poblaci´on, se obtiene una simulaci´on del ciclo productivo en el que cada individuo representa una asignaci´on diferente de los trabajos en las m´aquinas teniendo en cuenta que algunos instantes de tiempo ser´a posible que las m´aquinas van a estar ocupadas procesando operaciones de otros trabajos y la operaci´on asignada deber´a esperar generando tiempo muerto para el trabajo.
Los tiempos de procesamiento se representan con una matriz tque determina la dura-ci´on de cada operaci´on, las dimensiones de t son j∗m donde j representa trabajos y m representa m´aquinas, se puede presentar el caso donde el tiempo de procesamiento de un trabajo i= [1;j] en la m´aquinak= [1;m] sea cero, lo que indica que el trabajoino debe ser procesado por la m´aquinak.
De esta manera el makespan ser´a determinado por el ´ultimo trabajo que finalice su ciclo, y el tiempo de finalizaci´on de ciclo para un trabajo ser´a igual a la suma de los tiempos de procesamiento de las operaciones de trabajo en cada una de las m´aquinas m´as los tiempos muertos correspondientes al trabajo
Cmax=max m
X
k=1
tki+tmki∀i= 1,2, . . . , j
3.1.3. Mecanismo de Selecci´on
El modelo presentado emplea dos mecanismos de selecci´on, el primer mecanismo busca no caer en elitismo permitiendo la diversidad en los individuos, con el fin de evitar caer en ´optimos locales; el segundo es un mecanismo de selecci´on aleatorio donde cualquier individuo de la poblaci´on puede ser elegido como padre.
Basado en la premisa anterior el primer mecanismo de selecci´on propuesto se basa en un tipo de torneo, donde cuatro individuos son seleccionados aleatoriamente de la poblaci´on, el ganador de esos cuatro individuos es escogido como uno de padres encargados de crear nuevos individuos y posiblemente perdurar en la siguiente generaci´on.
El ganador del torneo se elige a trav´es de una ruleta, donde la ruleta es un mecanismo en el que se forman dos parejas con los cuatro individuos seleccionados, cada pareja enfrenta sus individuos de la siguiente manera: la probabilidad de cada uno de los individuos ser seleccionado corresponde a la raz´on del valor fitness sobre la sumatoria del valor delfitness de los dos individuos, permitiendo as´ı que un individuo con mejor funci´on fitness tenga mayor probabilidad de ser escogido en la ruleta, los ganadores de cada ruleta se enfrentar´an nuevamente en otra ruleta bajo las mismas condiciones y el ganador ser´a tambi´en el ganador del torneo.
El proceso anteriormente descrito se repetir´a para seleccionar al segundo padre y una vez obtenidos los dos padres se les aplicaran los operadores gen´eticos (encargados de obtener los hijos a partir de modificaciones en el genotipo de los padres, buscando preservar las caracter´ısticas que otorgan una buena soluci´on y corregir las falencias de los individuos). A cada operador gen´etico se le asignar´a una probabilidad de ser aplicado a la pareja de padres con el fin de aprovechar las ventajas que cada operador le brinda a los individuos. La probabilidad de aplicaci´on de cada operador ser´a asignada de forma arbitraria dependiendo del desempe˜no del operador.
El segundo mecanismo de selecci´on consiste en generar un n´umero aleatorio con distri-buci´on uniforme entre uno y el n´umero de individuos de la poblaci´on, ese n´umero determi-nar´a cu´al ser´a el individuo seleccionado para ser uno de los padres a los que se les aplicar´an los operadores gen´eticos. Este procedimiento se repetir´a para encontrar el segundo padre con la condici´on de que no se puede seleccionar el mismo individuo dos veces para que los padres no resulten siendo el mismo individuo.
Una vez se ha obtenido una pareja de hijos a partir de una pareja de padres (por medio de los operadores gen´eticos), se tienen cuatro individuos que competir´an entre ellos para ser seleccionados como dos de los individuos que conformar´an la nueva generaci´on.
3.1.4. Operadores Gen´eticos
CAP´ITULO 3. DESARROLO DEL PROYECTO 21
3.1.4.1. Mutaci´on
En la mutaci´on se emplear´a el operador conocido comoswap mutation, el cual ser´a el encargado de seleccionar mediante una distribuci´on uniforme dos posiciones dentro de la representaci´on del cromosoma; los n´umeros de las operaciones que se encuentran es esas posiciones ser´an intercambiados entre s´ı, con el fin de construir un nuevo individuo que conserve en gran parte las caracter´ısticas del padre, pero que tambi´en brinde la posibilidad de explorar localmente el espacio de soluciones factibles como se explicar´a a continuaci´on. El hijo creado a partir de cada individuo tendr´a un cromosoma con una leve variaci´on en su estructura que podr´ıa significar un incremento en el fitness del nuevo individuo. El incremento se puede presentar gracias a la exploraci´on local derivada de los peque˜nos cambios que se apliquen al individuo original (padre), cambios que pueden encontrar en el hijo un mejor desempe˜no que el del padre tan solo con intercambiar la posici´on de dos de sus operaciones.
Se ha seleccionado este operador debido a que conserva la propiedad del cromosoma de tener en su representaci ´On una permutaci ´On sin repeticiones. ´Esta conservaci´on se debe a que al intercambiar dos posiciones del cromosoma, que en otras palabras se entiende como tomar dos operaciones y cambiar su prioridad en el ciclo de procesamiento, no se altera la factibilidad de la soluci´on que representa el nuevo individuo, permitiendo que se realice la b´usqueda local respetando las restricciones del problema.
3.1.4.2. Cruce
Para el cruce ser ˜A¡ utilizado un operador de adyacencia denominadoRecombinaci´on de dos v´ertices(2-edge recombination), el cual se encarga de crear una tabla de adyacen-cias a partir de la ubicaci´on de las operaciones en los cromosomas de los padres, es decir, la tabla muestra las adyacencias de cada operaci´on para los dos padres, donde las filas representan cada una de las operaciones y las columnas hacen referencia a las operaciones adyacentes en los cromosomas de los padres.
En caso de que los dos padres cuenten con la misma adyacencia para una operaci´on, el operador marcar´a en la tabla con un signo negativo dicha adyacencia, y se registrar´a solo una vez. Para la construcci´on de cada hijo se seleccionar´a la primera operaci´on de manera aleatoria, una vez seleccionada la operaci´on se deben buscar cuales operaciones son adyacentes a ella, teniendo prioridad de asignaci´on la adyacencia que est´e marcada con signo negativo; si no hay adyacencias negativas, se seleccionar´a alguna de las operaciones adyacentes de manera aleatoria [25].
En la Figura 3.2 se observa una tabla de adyacencias para dos individuos que repre-sentan una soluci´on factible a un problema que cuenta con 3 m´aquinas y 3 trabajos. La tabla marca para dos posiciones una adyacencia con signo negativo, lo que indica que las operaciones 2 y 7 son adyacentes en los dos individuos.
si-Figura 3.3. Tabla de Adyacencias
Fuente in´edita
do asignadas y continuar con el proceso. Cada pareja de padres crear´a dos hijos con el operador descrito y cada hijo contar´a con la tabla de adyacencias para su construcci´on.
Se elige este operador debido a su capacidad de preservar en el paso de una generaci´on a otra las adyacencias que representen un mejor desempe˜no para los individuos; si una adyacencia que mejore el desempe˜no de la soluci´on persiste en los padres, ser´a marcada con el signo negativo y el operador obligar´a a que sea heredada por los hijos, impidiendo as´ı que se pierda una buena permutaci´on.
3.1.5. Mecanismo de Reemplazo
Una vez se han obtenido dos hijos a partir de dos padres, se emplear´an dos mecanis-mos de reemplazo que permitir´an a dos de estos cuatro individuos construir la siguiente generaci´on de la poblaci´on, as´ı se mantiene constante el tama˜no de la poblaci´on a lo largo de todas las generaciones que sean construidas. EN el primer mecanismo se espera que los individuos que sean seleccionados creen una mejor generaci´on con mejores soluciones al problema propuesto, debido a que el mecanismo de reemplazo propuesto est´a dise˜nado para favorecer a los mejores individuos.
Con el fin de no caer en ´optimos locales ni limitar el espacio de b´usqueda, se define a que un individuo que represente una mala soluci´on no se le va a restringir la posibilidad de avanzar a la siguiente generaci´on. Sin embargo, su probabilidad de ser seleccionado va a ser menor que la de un buen individuo. Por esta raz´on, se emplear´a un mecanismo steady-state en el que el padre y el hijo que cuenten con el valor defitness m´as bajo (considerado para este problema como un mejor desempe˜no), se enfrentar´an en una ruleta, y de igual manera el padre y el hijo con el mayor valor de fitness (peor desempe˜no) se enfrentar´an en otra ruleta.
CAP´ITULO 3. DESARROLO DEL PROYECTO 23
malo junto a un individuo bueno pueden potenciar las ventajas de los dos, y se obtiene una reducci´on en el elitismo, permitiendo mayor diversidad en la poblaci´on.
El segundo mecanismo ser´a generacional, donde sin importar el valor delfitness de los hijos con respecto al de los padres, ser´an los hijos los individuos seleccionados para formar la siguiente generaci´on, esto se hace con el fin de mantener la diversidad de los individuos en la poblaci´on.
3.2. Recocido Simulado
Un algoritmo b´asico de recocido simulado es aplicado a los inidividuos seleccionados para crear la siguiente generaci´on de la poblaci´on, el objetivo es realizar una exploraci´on local que permita realizar a los indiviuos una mejora que puede ayudar en el desempe˜no de cada inidividuo.
CAP´
ITULO
4
Resultados Obtenidos
Con el fin de contar con datos que permitan determinar qu´e elementos del modelo propuesto presentan un mejor rendimiento en la obtenci´on de individuos con bajofitness, se presenta diversos experimentos que ejercer´an presi´on en diferentes puntos del algoritmo. Se dise˜na un conjunto de experimentos donde se combinan los mecanismos de selecci´on y reemplazo descritos, junto con la heur´ıstica propuesta en el modelo para modificar los individuos de la poblaci´on inicial. Los operadores gen´eticos ser´an los mismos para todos los experimentos teniendo la mutaci´on un 0.6 de probabilidad y el cruce 0.4.
En total se plantean 8 experimentos que probados en su totalidad en el algoritmo gen´etico y los dos que presentaron un mejor rendimientos fueron probados con el algoritmo mem´etico. Los experimentos son:
• Experimento 1
En el experimento 1 se emplear´a la heur´ıstica propuesta que toma a los individuos creados de manera aleatoria para conformar la poblaci´on inicial aplicando una mejora en pro de reducir los tiempos muertos de la soluci´on que representa el individuo. El mecanismo de selecci´on se har´a mediante torneo y el reemplazo ser´a ejecutado por el mecanismosteady-state. La configuraci´on del algoritmo anteriormente descrita tiene como finalidad evaluar el impacto que tiene en las soluciones generadas el hecho de ejercer presi´on en la generaci´on de la poblaci´on inicial, la selecci´on y el reemplazo para mantener buenos individuos en la poblaci´on.
• Experimento 2
El experimento 2 utilizar´a la heur´ıstica propuesta encargada de proporcionar una mejora a los individuos de la poblaci´on inicial y as´ı reducir tiempos muertos en com-paraci´on con los individuos creados de manera aleatoria. El mecanismo de selecci´on se har´a mediante torneo y el reemplazo ser´a generacional, es decir, sin importar la soluci´on que representes los individuos hijos ser´an los seleccionados para pertenecer a la poblaci´on de la siguiente generaci´on. El fin del experimento es analizar el com-portamiento del algoritmo al obligarlo a ejercer presi´on en la poblaci´on inicial y en la selecci´on para mantener buenos individuos, permitiendo mantener la diversidad de los individuos en el reemplazo.
CAP´ITULO 4. RESULTADOS OBTENIDOS 25
• Experimento 3
En el experimento 3 se emplear´a la heur´ıstica propuesta que se encargar´a de propor-cionar una mejora respecto a los tiempos muertos a los individuos de la poblaci´on inicial. El mecanismo de selecci´on ser´a traves de una selecci´on uniforme, donde todos individuos de la poblaci´on tendr´an la misma probabilidad de ser seleccionados como padres y el reemplazo se har´a con el mecanismosteady-state. Estudiar el impacto que tiene forzar a la poblaci´on inicial y al reemplazo a tratar preservar buenos individuos mientras que la selecci´on permite diversidad, es el objetivo del presente experimento.
• Experimento 4
El experimento 4 cuenta con una configuraci´on del algoritmo donde no se les har´a ninguna modificaci´on a los individuos generados de manera aleatoria para conformar la poblaci´on inicial, el mecanismo de selecci´on se har´a mediante torneo y el reemplazo ser´a ejecutado por el mecanismosteady-state. El experimento tiene como fin analizar el comportamiento del algoritmo al forzar a los mecanismos de selecci´on y reemplazo a buscar la preservaci´on de los mejores individuos.
• Experimento 5
En el experimento 5 se evaluara el impacto de ejercer presi´on en la poblaci´on ini-cial para empezar el algoritmo con individuos que representen una reducci´on en los tiempos muertos en la soluci´on que representan mediante la heur´ıstica propuesta. El mecanismo de selecci´on ser´a uniforme donde todos los individuos tendr´an la mis-ma probabilidad de ser seleccionados como uno de los dos padres a los que se les aplicar´an los operadores gen´eticos, y el mecanismo de reemplazo ser´a generacional.
• Experimento 6
El experimento 6 emplea una configuraci´on en la que aquellos individuos que cuentan con un buenfitness y hayan sido seleccionados como uno de los cuatro participantes del torneo tendr´an mayor probabilidad de ser seleccionados en el mecanismo de selecci´on para ser los padres, mientras que la poblaci´on inicial ser´a aleatoria y el mecanismo de reemplazo ser´a generacional. El objetivo del experimento es evaluar el comportamiento del algoritmo al tratar de forzar al mecanismo de selecci´on de conservar buenos individuos.
• Experimento 7
Determinar el comportamiento del algoritmo al ejercer presi´on en el mecanismo de reemplazo para tratar de que los mejores individuos sean los que pasen a la siguiente generaci´on es el objetivo del experimento 7. Lo anterior se har´a a trav´es del mecanismo de selecci´on steady-state en el que padres e hijos son enfrentados en un torneo donde aquellos individuos que tengan un mejorfitness tendr´an mayor probabilidad de pasar a la siguiente generaci´on. La poblaci´on inicial ser´a aleatoria y el mecanismo de selecci´on ser´a uniforme.
• Experimento 8
Los resultados obtenidos con los algoritmos gen´etico y mem´etico propuestos son com-parados con dos trabajos realizados previamente, con el fin de analizar su rendimiento. El primer trabajo de referencia es el realizado por [33] quien gener´o una serie de instancias mediante un algoritmo de b´usqueda tab´u, el segundo trabajo de referencia fue el realizado por [7] donde mediante un algortimo de ramificaci´on y acotamiento se logra reducir el makespan obtenido por Taillard.
A continuaci´on se presentan una serie de tablas que resumen los resultados obtenidos para cada una de las intancias planetadas por [33], donde se muestra el min´ımo valor posible, los mejores resultados obtenidos en los trabajos de referencia y el mejor resultado obtenido en los algoritmos gen´etico y mem´etico propuestos (una tabla por cada algorit-mo propuesto), el mejor resultado del algoritalgorit-mo propuesto est´a acompa˜nado del o los experimentos que obtuvieron dicho resultado.
Tabla 4.1.Mejores resultados obtenidos Algoritmo Gen´etico 4x4
Tai4-1 Optimo´ Taillard Brucker Propuesto
1 186 193 193 193(2,4)
2 229 236 236 236(2)
3 262 271 271 271(1,2)
4 245 250 250 250(1,2)
5 287 295 295 295(1,2)
6 185 189 189 189(1,2,4)
7 197 201 201 201(1)
8 212 217 217 217(1,2,4)
9 258 261 261 261(1,2)
10 213 217 217 217(1,2)
En la Tabla 4.1 se presentan los resultados de las instancias generadas para 10 proble-mas que cuentan con 4 m´aquinas y 4 trabajos, el algoritmo gen´etico propuesto iguala los resultados obtenidos en los dos trabajos de referencia, se evidencia que para 8 de los 10 problemas dados, el Experimento 1 obtiene la mejor soluci´on del algoritmo, el Experimen-to 2 proporciona la mejor soluci´on en 9 problemas y el experimento 4 encuentra el mejor resultado en 3 de los problemas.
CAP´ITULO 4. RESULTADOS OBTENIDOS 27
mejor desempe˜no con la configuraci´on anterior se realizaron 25 replicas aumentando el tama˜no de la poblaci´on y el n´umero de iteraciones a 500 y 500 respectivamente con el fin de obtener mejores resultados, partiendo de la premisa de que con m´as individuos se obtiene mayor diversidad. Los 4 experimentos con mejor desempe˜no fueron 1, 2, 4 y 6.
Tabla 4.2.Mejores resultados obtenidos Algoritmo Mem´etico 4x4
Tai4-1 Optimo´ Taillard Brucker Propuesto
1 186 193 193 193(1)
2 229 236 236 236(1)
3 262 271 271 271(1)
4 245 250 250 250(1)
5 287 295 295 295(1,2)
6 185 189 189 189(1,2)
7 197 201 201 201(1,2)
8 212 217 217 217(1,2)
9 258 261 261 261(1,2)
10 213 217 217 217(1)
En la Tabla 4.2 se registran los mejores resultados obtenidos por el algoritmo mem´etico propuesto frente a los dos trabajos de referencia seleccionados, los resultados a los que llega el algoritmo igualan la mejor soluci´on de los 10 problemas de referencia desarrollados, el Experimento 1 obtiene el mejor resultado mientras que el Experimento 2 obtiene la mejor soluci´on en 5 problemas.
Tabla 4.3.Mejores resultados obtenidos Algoritmo Gen´etico 5x5
Tai5-1 Optimo´ Taillard Brucker Propuesto % Dif Tai-llard
1 295 300 300 302(2) 0.67
2 255 262 262 267(2) 1.91
3 321 328 323 334(2) 1.83
4 306 310 310 316(1) 1.94
5 321 329 326 333(2) 1.22
6 307 312 312 318(1) 1.92
7 298 305 303 308(1) 1.98
8 292 300 300 307(1,2) 2.33
9 349 353 353 359(1) 1.70
10 321 326 326 328(2) 0.61
Para los problemas que cuentan con 5 m´aquinas y 5 trabajos se presenta la Tabla 4.3 donde se a˜nade la columna % Dif Taillard, que indica el porcentaje de diferencia entre la mejor soluci´on obtenida por el algoritmo gen´etico propuesto y el mejor resultado logrado por los trabajos de referencia. En este caso el porcentaje promedio para los 10 problemas dados es de 1.61.
Los experimentos que presentan mejor rendimiento y obtuvieron las mejores soluciones del algoritmo fueron el 1 y el 2, donde el experimento 1 encuentra el mejor resultado en 5 problemas y el experimento 2 en 6 problemas, los dos experimentos encuentran la mejor soluci´on en el problema 8.
CAP´ITULO 4. RESULTADOS OBTENIDOS 29
Tabla 4.4.Mejores resultados obtenidos Algoritmo Mem´etico 5x5
Tai5-1 Optimo´ Taillard Brucker Propuesto % Dif Tai-llard
1 295 300 300 301(1) 0.33
2 255 262 262 262(1) 0
3 321 328 323 323(1) -1.52
4 306 310 310 315(1) 1.61
5 321 329 326 329(1) 0
6 307 312 312 318(1) 1.92
7 298 305 303 303(1) -0.66
8 292 300 300 302(1) 0.67
9 349 353 353 359(1) 1.70
10 321 326 326 330(1) 1.23
La Tabla 4.4 recopila la informaci´on correspondiente a los mejores resultados obtenidos en el algoritmo mem´etico propuesto en los 10 problemas propuestos en los trabajos de referencia que cuentan con 5 m´aquinas y 5 trabajos. Para los problemas 3 y 7 el algoritmo propuesto logra un mejor resultado que [33] igualando en los dos problemas el mejor resultado alcanzado por [7].
En los 8 problemas en los que no se logr´o obtener un mejor resultado a los de los referentes se tiene en promedio un porcentaje de diferencia respecto a Taillard de 0.74, la mejor soluci´on del algortimo mem´etico propuesto para cada uno de los problemas fue encontrada por el Experimento 1 a pesar de que fueron usados los experimentos 1 y 2. La configuraci´on empleada cuenta con 30 corridas de 100 individuos y 100 iteraciones.
Tabla 4.5.Mejores resultados obtenidos Algoritmo Gen´etico 7x7
Tai7-1 Optimo´ Taillard Brucker Propuesto % Dif Tai-llard
1 435 438 435 449(2) 2.51
2 443 449 443 478(1) 6.46