TítuloStatistical learning in complex and temporal data: distances, two sample testing, clustering, classification and Big Data
Texto completo
Figure
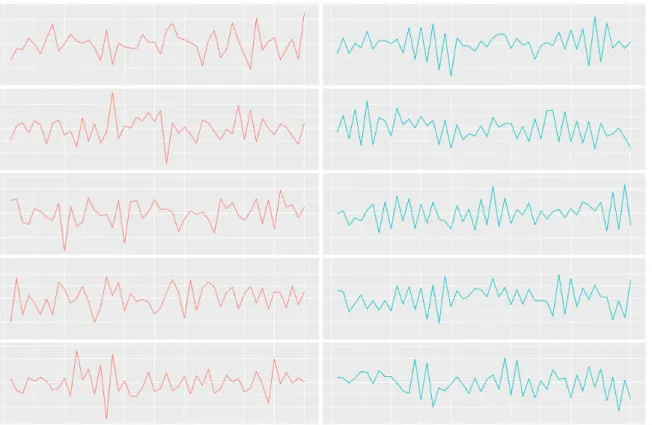
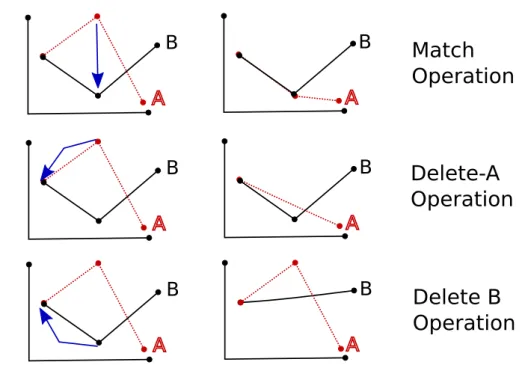
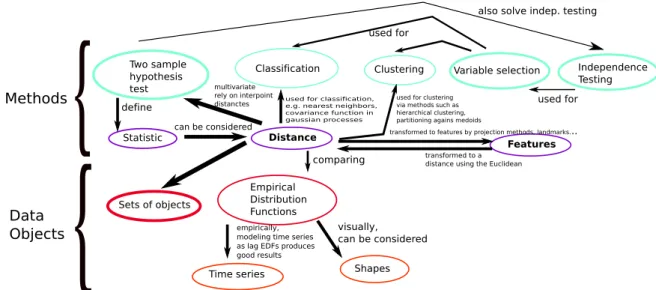
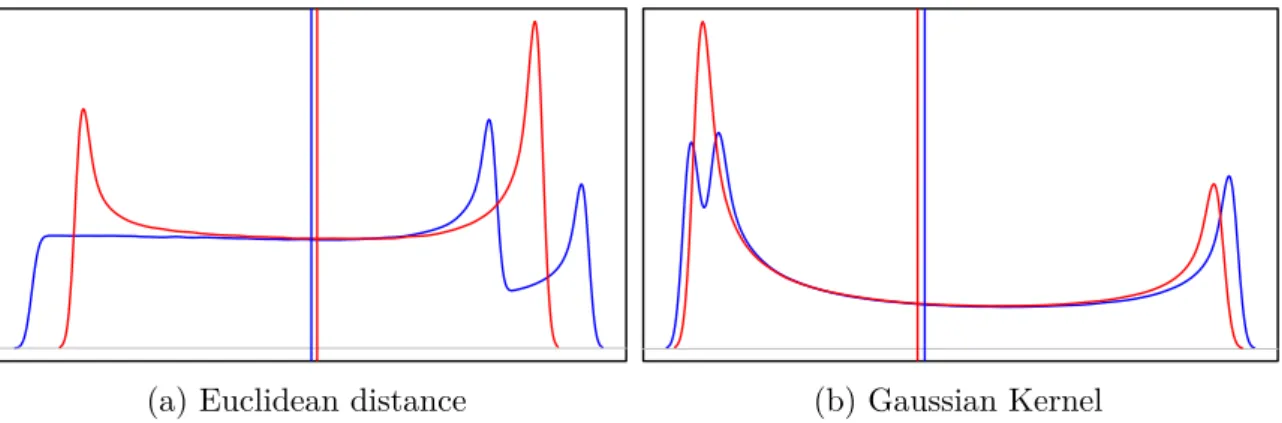
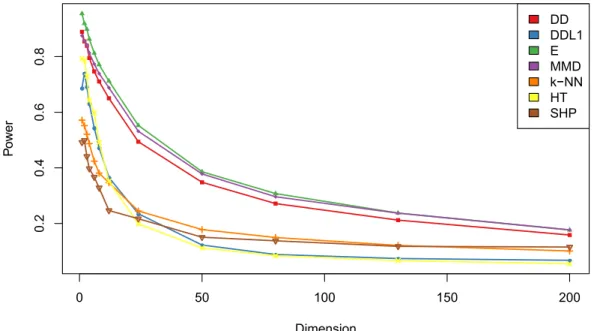

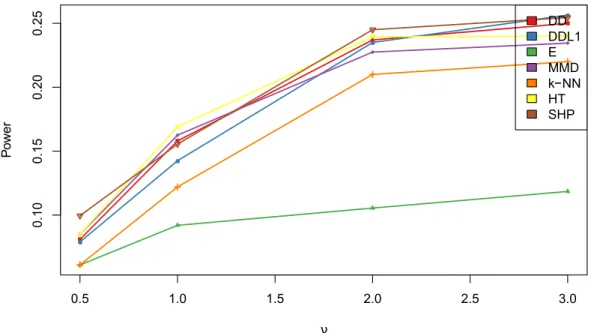

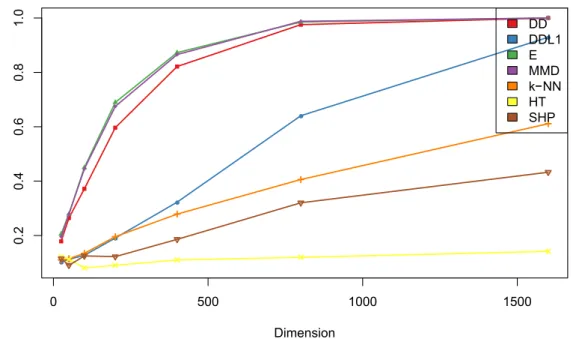
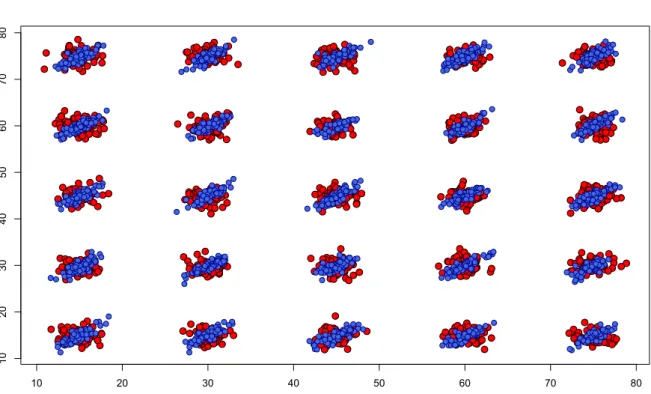
Documento similar
Furthermore, some concepts that require specific attention are:.. In Chapter 2, we studied and classified all types of metadata that can be used by systems that intelligently
4th International Conference of Intelligent Data Engineering and Automated Learning (IDEAL 2003) In "Intelligent Data Engineering and Automated Learning" Lecture Notes
As mentioned before, algorithms for mining frequent patterns in data stream can also be distinguished depending on whether they consider the frequency of the patterns from the
Google Fusion Tables Visualisation application/service Yes Web application, API JavaScript, Flash Free Browser External server Yes Tableau Public
Linked data, enterprise data, data models, big data streams, neural networks, data infrastructures, deep learning, data mining, web of data, signal processing, smart cities,
We have presented a method to protect categorical microdata based on a pre-clustering approach which performs better protections based on sta- tistical and clustering-based
The density of points in parameter space gives you the posterior distribution To obtain the marginalized distribution, just project the points. To obtain confidence intervals,
In this chapter we briefly motivate manifold learning methods from the point of view of having to deal with high dimensional problems in big data and then we present and analyze
