IMMAN Herramienta para la selección de rasgos basado en la Teoría de Información
73
0
0
Texto completo
(2) Resumen. Resumen El trabajo presenta la definición de varios métodos de selección de rasgos en dos categorías, estos son supervisados y no supervisados: en el primer grupo se encuentran la Entropía Diferencial, Información de Jeffrey e Información Mutua de la Entropía Diferencial; y en el segundo las basadas en: 1) el uso de un intervalo de discretización 2) las que no usan tal esquema y por tanto no necesitan configuración. La anterior propuesta se fundamenta en los postulados de la Teoría de Información.. Se. proponen. nuevos. conceptos. y estrategias. de. trabajo. sustentados. fundamentalmente en el concepto de entropía, estos son: Índice de Gini, Negentropía, Índice de Redundancia, Información de Energía Contenida, Entropía del Valor Degenerado, los cuales hasta el momento no se han utilizado en la literatura especializada con este fin. En este mismo sentido, se crean tres nuevas medidas para seleccionar rasgos constituyendo aportes teóricos de la investigación. Además, se extienden y modifican otras medidas existentes, proporcionando mejoras a las mismas, y se re-implementan varias medidas “clásicas” de selección de rasgos. Todas las medidas se han implementado en la herramienta IMMAN (acrónimo de Information Theory based Chemometric Analysis), diseñada para la selección de rasgos y la comparación de conjuntos de datos de aprendizaje. Finalmente, con el propósito de evidenciar las potencialidades del uso del programa se han realizado varias aplicaciones usando conjunto de datos con alta dimensión. En todos los casos, los resultados obtenidos con el enfoque del uso de la Teoría de Información se comparan favorablemente con lo reportado en la literatura y/o con parámetros clásicos que también emplean conceptos de esta teoría.. i.
(3) Abstract. Abstract. The report presents the definition of several feature selection methods comprised of two categories, these are supervised and unsupervised: in the first group are the Differential Entropy, Jeffrey’s Information and Mutual Information of Differential Entropy, and the second those based on: 1) the use of a discretization interval 2) those which do not use such a scheme and therefore need no configuration. The above proposal is based on the principles of Information Theory. It proposes new concepts and strategies supported primarily on the concept of entropy, these are: Gini Index, Negentropy, Redundancy Index, Information Contained Energy, and Entropy Degenerate Value, which so far have not been used in the literature for this purpose. In this sense, three new measures to feature selection measures have been created, constituting an important theoretical contributions of the research. Also, other existing methods have been extended, re-implemented and modified. All of this measures have been implemented in the tool IMMAN (acronym for Information Theory based Chemometric Analysis), designed for the selection of features and comparing learning datasets. Finally, in order to demonstrate the potential of the use of the program there have been several applications using dataset with higher dimension. In all cases, the results obtained with the approach of the use of Information Theory compare favorably with those reported in the literature and/or classic parameters that also use concepts of this theory.. ii.
(4) Índice. Índice. Resumen........................................................................................................................................... i Abstract ........................................................................................................................................... ii Índice.............................................................................................................................................. iii Introducción .................................................................................................................................... 1 Capítulo 1: Selección de Rasgos ..................................................................................................... 5 Selección de rasgos ..................................................................................................................... 6 Métodos de selección de rasgos .................................................................................................. 9 Filtro........................................................................................................................................ 9 Envolvente .............................................................................................................................. 9 Empotrado ............................................................................................................................. 10 Métodos de selección de rasgos basados en ranking ................................................................ 10 La Teoría de Información aplicada a la selección de rasgos .................................................... 10 Métodos de selección de rasgos en aplicaciones ...................................................................... 12 Capítulo 2: Criterios de evaluación no supervisados basados en Teoría de Información ............ 16 Definiciones .............................................................................................................................. 16 Distribución de Valores ........................................................................................................ 16 Distribución de Probabilidades ............................................................................................. 17 Entropía de Shannon ............................................................................................................. 17 Entropía de Shannon Estandarizada...................................................................................... 19 Índice de Gini ........................................................................................................................ 19 Entropía del Valor de Descomposición Singular. ................................................................. 20 Índice de Redundancia .......................................................................................................... 21 Negentropía ........................................................................................................................... 21 iii.
(5) Índice Información de Energía Contenida .................................................................................... 22 Valor Degenerado ................................................................................................................. 22 Entropía del Valor Degenerado ............................................................................................ 23 Entropía basada en Distancia ................................................................................................ 24 Selección de rasgos no supervisados en la herramienta IMMAN ............................................ 25 Conclusiones ............................................................................................................................. 28 Capítulo 3: Criterios de evaluación supervisados basados en Teoría de Información ................. 29 Definiciones .............................................................................................................................. 29 Entropía de Shannon Diferencial .......................................................................................... 29 Entropía de Shannon Diferencial Estandarizada................................................................... 30 Ganancia de Información ...................................................................................................... 30 Razón de Ganancia ............................................................................................................... 30 Incertidumbre Simétrica........................................................................................................ 31 Información Mutua de la Entropía de Shannon Diferencial ..................................................... 31 Información de Jeffrey .......................................................................................................... 31 Clase Continua ...................................................................................................................... 33 Clase Discreta ....................................................................................................................... 34 Conclusiones ............................................................................................................................. 34 Capítulo 4: Aplicación de los conceptos de la Teoría de Información implementados en la herramienta IMMAN .................................................................................................................... 35 Estudio 1: Comparación de software de cálculo de descriptores .............................................. 35 Estudio 2: Comparación entre familias de descriptores moleculares del Software Dragón ..... 36 Estudio 3: Selección de genes para la predicción de metástasis en pacientes con cáncer de mamas. ...................................................................................................................................... 38 Conclusiones ............................................................................................................................. 41 Capítulo 5: IMMAN Herramienta para la selección de rasgos ..................................................... 42 iv.
(6) Índice Casos de uso del sistema IMMAN............................................................................................ 42 Diagrama de actividades ........................................................................................................... 44 Diagrama de Secuencia ............................................................................................................. 46 Diagrama de clases ................................................................................................................... 47 Diagrama de Paquetes ............................................................................................................... 49 Diagrama de Despliegue ........................................................................................................... 50 IMMAN. Herramienta para la selección de rasgos basado en la Teoría de Información. ........ 50 Requerimientos Mínimos .......................................................................................................... 52 Los Datos .................................................................................................................................. 52 Conclusiones ............................................................................................................................. 55 Conclusiones y Recomendaciones ................................................................................................ 56 Conclusiones ............................................................................................................................. 56 Recomendaciones ..................................................................................................................... 57 Referencias .................................................................................................................................... 58. v.
(7) Introducción. Introducción La captura de información, con la revolución digital es un proceso que puede realizarse fácilmente y su almacenamiento es extremadamente barato. Los datos se almacenan porque se consideran un activo valioso, además, constituyen observaciones recogidas de algún fenómeno en estudio. Los datos en bruto son raramente provechosos, su verdadero valor radica en extraer información para la comprensión de fenómenos que dieron lugar a los datos y la posterior toma de decisiones. El crecimiento exponencial de los volúmenes de datos y el número de parámetros en todas las áreas del conocimiento constituye un problema para el análisis y comprensión de los mismos, lo cual hace necesaria la aparición de nuevas metodologías y herramientas para un tratamiento automático de los registros depositados en bases de datos. Para solucionar este problema se han creado técnicas computacionales para el Descubrimiento de Conocimiento en Bases de datos (Knowledge Discovery in Databases, KDD) (Ian et al., 2011). KDD, este es el proceso global no trivial de identificar patrones válidos, novedosos, potencialmente útiles y comprensibles a partir de datos. Dicho proceso se lleva a cabo mediante diversas etapas comprendidas desde la obtención de los datos hasta la aplicación del conocimiento adquirido en la toma de decisiones. Entre esas etapas, se encuentra la que puede considerarse el núcleo del proceso KDD y que se denomina DM (Minería de Datos o Data Mining). Esta fase es crucial para la obtención de resultados apropiados pues, durante la misma, se aplica el algoritmo de aprendizaje automático encargado de extraer el conocimiento inherente a los datos. No obstante, esta fase se ve influenciada en gran medida por la calidad de los datos que llegan para su análisis desde la fase previa, siendo la elección correcta de características, propiedades, rasgos o atributos que caracterizan los datos, una de las tareas más notables. En este trabajo, entre la gran cantidad de técnicas de pre-procesado existente, se abordarán las relacionadas con la selección de rasgos o características. Dentro de los problemas comunes asociados a la mayoría de los algoritmos de aprendizaje automático encontramos la alta complejidad computacional y la generalización o la incomprensión de los resultados obtenidos. Por ello, desde la década de los sesenta, las investigaciones relacionadas con la selección de atributos intentan reducir el espacio de hipótesis de las bases de datos en tareas concretas, en un. 1.
(8) Introducción intento de encontrar subconjuntos de rasgos que proporcionen un mejor rendimiento de los algoritmos de aprendizaje. Existen numerosos algoritmos de selección de características en la bibliografía, donde se combinan técnicas de búsqueda y de evaluación de subconjuntos de rasgos, llegando incluso a analizar todas las combinaciones posibles de atributos. Sin embargo, dado el escenario cambiante de las bases de datos, donde ha aumentado tanto, el número de instancias como el número de atributos, la mayoría de estas técnicas no son aplicables. En este contexto, el punto de partida de la investigación es el nuevo marco de trabajo que se abre a las técnicas de selección de características, con la necesidad de algoritmos capaces de obtener subconjuntos predictivos en grandes conjuntos de datos de aprendizaje. La presente investigación tiene como objetivo el estudio y propuestas de nuevos métodos de selección de rasgos, así como la implementación de estos en una herramienta que apoye al proceso de descubrimiento en conjunto de datos de aprendizaje, aplicables en bases de datos de alta dimensión en el marco del aprendizaje no supervisado y supervisado. La selección de rasgos es considerada el proceso que recorre un espacio de búsqueda hasta encontrar una combinación reducida de atributos. De forma general un algoritmo de selección consta de dos componentes básicos: la medida de evaluación y el método de búsqueda. En la investigación se propone una aplicación que implementa varias medidas de evaluación de rasgos basadas en la Teoría de Información. Son escasos los métodos de selección de rasgos no supervisados que han sido elaborados e implementados para la reducción de conjuntos de datos de aprendizaje de alta dimensión. Hasta donde se ha investigado, no existen métodos de selección atributos no supervisados que usen conceptos de la Teoría de Información para evaluar la calidad de los rasgos y que estén implementados en una aplicación, por lo que constituye otra de las carencias que se ha constatado para esta investigación. Lo planteado anteriormente constituye la situación problémica de la presente investigación, de esta problemática expuesta se deriva el problema científico siguiente: ¿Cómo lograr, usando la Teoría de información, reducir la alta dimensionalidad en las bases de conocimiento y la selección de atributos deseables? Como hipótesis científica de la investigación se determinó que es posible desarrollar una serie de métodos que permita reducir la alta dimensión de conjuntos de datos de aprendizaje a partir de seleccionar rasgos deseables usando conceptos de la Teoría de Información que no han sido 2.
(9) Introducción utilizados anteriormente en problemas no supervisados para este fin e implementarlos en una aplicación. Para dar respuesta al problema planteado se define como objetivo general: Desarrollar una aplicación que permita reducir la alta dimensionalidad a partir de seleccionar rasgos deseables en conjunto de datos usando conceptos de la Teoría de Información que no han sido utilizados anteriormente para este fin. Este objetivo general fue desglosado en los siguientes objetivos específicos: 1. Fundamentar teóricamente la aplicación de los conceptos de la Teoría de Información a los problemas de la reducción de la alta dimensionalidad y selección de atributos deseables en conjunto de datos de aprendizaje. 2. Diseñar una aplicación que permita reducir la alta dimensionalidad usando conceptos de la Teoría de Información, implementando métodos de selección de atributos supervisados y no supervisados basados en ranking. 3. Implementar la aplicación diseñada usando conceptos de la Teoría de Información que permiten reducir la alta dimensionalidad y la selección de atributos deseables. 4. Validar usando conjunto de datos provenientes de la Informática Química u otras ciencias la aplicación que hace uso de conceptos de la Teoría de Información para reducir la alta dimensionalidad y la selección de atributos deseables El presente documento contiene los resultados obtenidos en el desarrollo de la investigación y se estructurará en cinco capítulos: Capítulo 1: Se realiza la descripción del estado del arte de los métodos de selección de rasgos en conjunto de datos de aprendizaje, así como los fundamentos teóricos de la Teoría de Información y su aplicación en la selección de rasgos. Capítulo 2: Se describen los métodos de selección de rasgos no supervisados basados en la Teoría de Información que se proponen, así como detalles de su implementación y uso en la herramienta. Capítulo 3: Se describen los métodos de selección de rasgos supervisados basados en la Teoría de Información que son propuestos, así como detalles de su implementación y uso en la herramienta.. 3.
(10) Introducción Capítulo 4: Se llevan a cabo varios estudios con la aplicación desarrollada en el campo de la Informática Química y la Bioinformática con el fin de validar el trabajo realizado y comprobar la efectividad de los conceptos implementados. Capítulo 5: Se realiza una breve explicación de algunas de las interioridades de la aplicación mediante el uso de técnicas de modelado Unified Modeling Language (UML). 4.
(11) Capítulo 1. Capítulo 1: Selección de Rasgos En los últimos años gracias al desarrollo tecnológico se ha evidenciado el crecimiento exponencial de los volúmenes de datos en todas las áreas del conocimiento, tanto para la adquisición como para el almacenamiento de datos. Estos beneficios han superado significativamente la capacidad del ser humano de analizar, resumir y obtener conocimiento a partir de la información, por lo que se necesita de formas, mecanismos, vías que le permitan manejar el creciente volumen de información. Para solucionar este problema se han creado técnicas computacionales para el Descubrimiento de Conocimiento en Bases de datos (Knowledge Discovery in Databases, KDD) (Ian et al., 2011) KDD constituye el proceso global no trivial de identificar patrones válidos, novedosos, potencialmente útiles y comprensibles. Dentro del proceso KDD, la Minería de Datos (DM) se ve influenciada en gran medida por la calidad de los datos que llegan para su análisis desde la fase previa, es decir, la utilidad de la extracción de los datos depende en gran medida de la calidad de éstos. Pyle (Pyle, 1999)explica que el propósito fundamental de la fase de preparación es manipular y transformar los datos en bruto, de manera que la información contenida en el conjunto de datos pueda ser descubierta, o más fácilmente accesible. La preparación o pre-procesamiento de los datos engloba todas aquellas técnicas de análisis de datos que permiten mejorar la calidad del conjunto de estos, de modo que a través de los métodos de extracción de conocimientos (minería de datos) se pueda obtener mayor y mejor información. Las tareas en esta fase son: recopilación de datos, limpieza, transformación y reducción. Las técnicas de reducción de conjunto de datos de alta dimensión están orientadas a dos objetivos: técnicas de reducción vertical (casos o número de ejemplos) y técnicas de reducción horizontal o selección de atributos (eliminación de aquellos atributos que no sean relevantes). Para la mejor comprensión de los métodos de la selección de rasgos se organiza el capítulo de la siguiente forma: en la primera sección se introduce el proceso de selección de rasgos, para dejar plasmado el esquema de la investigación que se realiza. Se enumeran algunos de los métodos provenientes de la literatura así como se hace un análisis de las aplicaciones más utilizadas para la reducción de la dimensionalidad y sus métodos de selección de rasgos implementados. Se tiene un acercamiento a la Teoría de Información y su aplicación en la selección de rasgos.. 5.
(12) Capítulo 1. Selección de rasgos Se parte de la siguiente premisa, en el proceso de selección de atributos se escoge un subconjunto de atributos del conjunto original, este proceso pretende elegir atributos que sean relevantes para una aplicación y lograr el máximo rendimiento con el mínimo esfuerzo. El problema de reducción (horizontal) de la dimensionalidad puede ser tratado de dos formas: la transformación y selección de rasgos. La trasformación de rasgos es el proceso a través del cual se crea un nuevo conjunto de parámetros de dos formas distintas: 1. Construcción de parámetros: es el proceso de descubrir información oculta sobre relaciones entre parámetros, aumentando el espacio de los atributos. Después de la construcción de parámetros, se obtienen atributos adicionales en el conjunto de datos. 2. Extracción de parámetros: es el proceso de extraer un conjunto de nuevos atributos de los. originales, a través de algunas funciones. Por otra parte la selección de rasgos consiste en seleccionar un subconjunto de variables dentro del conjunto de datos de aprendizaje, sin que se pierda la información realmente importante del sistema. Todo algoritmo de selección de rasgos consta de dos componentes básicos: función de evaluación y método de búsqueda o generación de subconjuntos. La variedad de técnicas de selección de rasgos está dada precisamente por la diversidad de algoritmos utilizados como métodos de búsqueda en la generación de los subconjuntos candidatos o la exploración del espacio de búsqueda como otra interpretación, y las disímiles variantes de evaluación de estos subconjuntos. Los procedimientos de selección de rasgos pueden dividirse según la naturaleza de su función de evaluación. Los métodos tipo filtro son aquellos que realizan un procesamiento previo a la fase de inducción por lo que puede entenderse como un filtrado de atributos. Los métodos de tipo envolvente (del inglés “wrapper”) se caracterizan por combinar la selección de atributos y el algoritmo de aprendizaje, ya que la selección de rasgos usa el proceso de inducción para evaluar la calidad de cada conjunto de atributos seleccionados. en cada momento. Los métodos. empotrados o integrados, por otra parte, al igual que los envolventes unen el algoritmo de. 6.
(13) Capítulo 1 aprendizaje con el proceso de selección, con la diferencia de hacer este proceso en la fase de entrenamiento y contar con su propio algoritmo de selección. La función de evaluación de rasgos de los métodos tipo filtro se dividen en diferentes categorías (Dash and Liu, 2003). Estas pueden ser: la medida de distancia también conocida por divergencia o discriminación, la medida de información o incertidumbre, la medida de dependencia o correlación y la medida de consistencia. Conocidas también como medidas de separabilidad, divergencia o discriminación, las medidas de distancia estiman la capacidad de un subconjunto de atributos en separar las clases. Suponiendo que instancias de la misma clase forman una región compacta en el espacio. El conjunto de atributos a seleccionar es aquel que logre una separación entre estas regiones sea máxima. Ejemplos de medidas de distancia son: Euclidea, Manhattan, Mahalanobis, Bhattaacharya, etc. Las medidas de información se basan en la ganancia de información de un atributo. Esta propiedad estadística no es más que la entropía (desorden) de los datos al conocer el valor de un atributo. Entre las medidas de información más frecuentes se encuentran: la entropía de Shannon, de Renyi, de grado α, cuadrática, estrictamente cóncava y de Daroczy, MDLC, información mutua, etc. Las medidas de dependencia o correlación (asociación) evalúan la habilidad para predecir el valor de una variable en función de otra. El coeficiente de correlación es una medida de dependencia clásica que se utiliza para calcular la correlación entre un atributo y la clase, prefiriéndose aquellos atributos con mayor correlación. Las medidas de consistencia se caracterizan por su fuerte dependencia con el conjunto de entrenamiento. Estas medidas intentan extraer el subconjunto mínimo que satisfaga una tasa de inconsistencia aceptable, establecida normalmente por el usuario. En otra dirección, los métodos de selección de rasgos también se clasifican según su forma de obtención de los rasgos: búsquedas completas, heurísticas y aleatorias. Dentro de las búsquedas completas se encuentran aquellas que tienen una gran complejidad (exponencial) pero que obtienen el subconjunto óptimo de atributos. Las heurísticas recorren solo una parte de todo el espacio de búsqueda por lo que no aseguran la obtención del subconjunto optimo aunque su coste 7.
(14) Capítulo 1 computacional se reduce considerablemente con respecto a los métodos completos. Las estrategias aleatorias se basan en visitar diferentes regiones del espacio de búsqueda sin un orden claramente predefinido. Otra clasificación de los métodos de selección de rasgos es según la forma en que son concebidos, supervisado y no supervisado (Ordóñez et al., 2009). Un método supervisado es aquel que de alguna forma utiliza el atributo de decisión para caracterizar el atributo que se analiza. Por el contrario, un método no supervisado trabaja independiente o no requiere de la clase que clasifique las instancias para llevar a cabo el proceso de análisis del atributo. Según la salida que arroja cada método de selección de rasgos este puede ser de dos formas: un ranking de atributos o un subconjunto de atributos. El primero de ellos devuelve una lista ordenada de los mejores atributos del conjunto de datos del aprendizaje, mientras que el segundo devuelve el subconjunto óptimo de atributos. En este trabajo se desarrollan métodos de tipo filtros usando, como función de evaluación, medidas de información que realizarán la selección de los mejores rasgos de forma supervisada y no supervisada a través de un ranking de las mejores variables. Cómo se ha mencionado anteriormente los métodos de selección de rasgos basados en ranking asignan un peso a cada variable del sistema que se analiza y ordena según su importancia. El algoritmo de ranking de rasgos se define de la siguiente forma: Ranking de atributos Entrada: Ɛ- conjunto de datos , U – medida de evaluación Salida: L lista de atributos con el más relevante en primer lugar. L = {} para i=1 hasta n hacer 𝑣𝑖 ← 𝑒𝑣𝑎𝑙𝑢𝑎𝑟(𝑋𝑖 , 𝑈) Posicionar 𝑋𝑖 en L con respecto a 𝑣𝑖. 8.
(15) Capítulo 1 fin para. Métodos de selección de rasgos A continuación, se presentan algunos algoritmos extraídos de la literatura diferenciados por la medida de evaluación que implementan.. Filtro En (Kira and Rendell, 1992) se propone un método supervisado de tipo filtro llamado Relief. Es un algoritmo inspirado en el aprendizaje basado en casos que intenta obtener los atributos estadísticamente más relevantes. El algoritmo supervisado de tipo filtro FCBF (Yu and Liu, 2003) se basa en el concepto de Markov blanket: aplican una técnica basada en la entropía cruzada para eliminar los atributos redundantes. Laplacian Score (He et al., 2006) es un algoritmo no supervisado que evalúa el atributo de acuerdo a su poder de preservación local. Por cada rasgo se estudia la distribución de los casos en un plano, observando cuál tiene más poder discriminante. El algoritmo HSIC (Song et al., 2007) es un algoritmo que usa las medidas de dependencia entre la clase como forma de eliminar rasgos de la base de conocimiento. SPEC(Liu and Zhao, 2007) es un algoritmo aplicado en el aprendizaje supervisado y no supervisado que se basa en una matriz de similitud para realizar la selección de los rasgos.. Envolvente En (John et al., 1994) se propone el uso de las estrategias de selección hacia adelante y eliminación hacia atrás seleccionado los rasgos según su relevancia, combinándolos con clasificadores basados en árboles de decisión. Skalak (Skalak, 1994) propone la búsqueda Random Mutation Hill Climbing (RMHC), que consiste en partir de un conjunto aleatorio de atributos y de forma aleatoria añadir uno nuevo o eliminar alguno de los contenidos en el conjunto e ir conservando el subconjunto que menor error produce con el clasificador del vecino más cercano. Otro método envolvente basado en la búsqueda secuencial hacia atrás es OBLIVION (Langley and Sage, 1994) en el que se utiliza como clasificador el árbol de decisión oblivious.. 9.
(16) Capítulo 1. Empotrado ID3 desarrollado por Quinlan (Quinlan, 1983) es un método de clasificación que genera un árbol de decisión paralelo de forma recursiva. El C4.5 fue propuesto por Quinlan (Quinlan, 1993) para mejorar las carencias de su predecesor ID3. CART desarrollado por Breiman (Breiman et al., 1984) pertenece a la familia de los árboles de decisión. En ellos el atributo más importante constituye la raíz del árbol y los nodos intermedios se colocan en dependencia de este criterio.. Métodos de selección de rasgos basados en ranking El método χ2 (CH) propuesto por (Liu and Setiono, 1995) como método de discretización y más tarde se mostró que era capaz de eliminar atributos redundantes y/o no relevantes. El ya mencionado método Relief (RL) basándose en la técnica del vecino más cercano asigna un peso a cada rasgo y devuelve como resultado una lista ordenada. Sus creadores fueron Kira y Rendell (Kira and Rendell, 1992) y posteriormente fue modificado por Kononenko (Kononenko, 1994). El peso de cada atributo se va modificando en función de la habilidad para distinguir entre los valores de la variable clase. En (Yu and Liu, 2003) se propone otra medida de evaluar la calidad del rasgo, la cual se basa en un único valor denominado NCE (Número de Cambios de Etiqueta), que relaciona cada atributo con la etiqueta que sirve de clasificación. Este valor se calcula proyectando ordenados los ejemplos del conjunto de datos de aprendizaje sobre el eje correspondiente a ese atributo, para a continuación recorrer el eje desde el menor hasta el mayor valor del atributo contabilizando el número de cambios de etiqueta que se producen.. La Teoría de Información aplicada a la selección de rasgos La información, tal como se utiliza en la Teoría de las Comunicaciones (Shannon, 1948) es una magnitud medible y presupone la existencia de una fuente y un destinatario de la información, que se asocian a los extremos transmisor y receptor del canal de comunicaciones. En el proceso de descubrimiento de conocimiento, los rasgos que conforman el conjunto de datos, constituyen la fuente de información que se va a analizar. En los trabajos de Shannon se introducen tres conceptos básicos: 10. La medida de la información..
(17) Capítulo 1 . La capacidad de un canal de comunicación para la transmisión de información.. . El límite teórico de aprovechamiento de un canal de comunicaciones para la transmisión de información, y la codificación como un medio de aproximarse a ese límite.. Estos conceptos son reutilizados para cuantificar la información contenida en los rasgos del conjunto de datos del aprendizaje. La Teoría de Información, ésta se relaciona con la incertidumbre asociada a un mensaje y no con su contenido semántico. Mientras menos probable es un mensaje, mayor es su contenido de información. Así, si 𝑥𝑖 denota un mensaje arbitrario cuya probabilidad de ocurrencia es 𝑃(𝑥𝑖 ) = 𝑃𝑖 se define la medida de información asociada a ese mensaje como: 𝐼𝑖 = − 𝑙𝑜𝑔𝑏 𝑃𝑖 = 𝑙𝑜𝑔𝑏. 1 𝑃1. Donde 𝐼𝑖 es la auto-información Es necesario observar que I i 0 , 0 Pi 1 I i 0 , Pi 1 Ii I j. , Pi Pj. La base utilizada para los logaritmos define la unidad de medida de la información. Cuando b=2, que es la base comúnmente empleada, la unidad de medida es el bit. Es necesario hace una analogía entre los términos que se usan. Los conjuntos de datos de aprendizaje usualmente están compuestos por rasgos que cuentan con valores continuos por lo que para cuantificar la información contenida es necesario dividir en intervalos para agrupar los valores en cada uno de ellos. Cada intervalo de discretización en el que se divide el rasgo a estudiar constituye el mensaje que se mencionaba anteriormente. El uso de conceptos provenientes de la Teoría de Información como función de evaluación en métodos de selección de rasgos en conjunto de datos de aprendizaje no constituye una novedad científica. Conceptos como Ganancia de Información descrita en el libro C4.5: Programs for Machine Learning (Quinlan, 1993), Razón de Ganancia presentado en el libro Induction of decisión tres (Quinlan, 1986), Incertidumbre Simétrica (Press et al., 1988), Relief publicado en. 11.
(18) Capítulo 1 (Kira and Rendell, 1992), el Índice de Gini (Breiman et al., 1984) y Entropía del Valor de Descomposición Singular utilizado como método de selección de atributos no supervisado por Devakumari (Devakumari and Thangavel, 2010), han sido utilizados para este fin anteriormente, constituyendo antecedentes de la presente investigación. En el estudio y análisis de rasgos en la Informática Química han sido utilizados otros conceptos de la Teoría de Información para evaluar la calidad de la variable, como por ejemplo: Entropía de Shannon, empleada por Bajorath (Godden et al., 2000), Entropía de Shannon Diferencial, siendo propuesta por Bajorath en el año 2001 (Godden and Bajorath, 2001), Información Mutua de la Entropía de Shannon Diferencial (Anne Mai et al., 2010) y la Información Mutua (Vishwesh et al., 2004). Los conceptos mencionados anteriormente no son los únicos que provienen de esta teoría y que son aplicables en el proceso de selección de rasgos. La Negentropía, utilizada para la codificación de estructuras químicas (Kier, 1980), la Información de Energía Contenida (Onicescu, 1966) y el Índice de Redundancia (Brillouin, 1962) pueden proporcionar una medida de evaluar la calidad de un rasgo analizando la variabilidad de los datos que estos contienen. Algunas de las definiciones que se han mencionados miden la calidad del rasgo a través de su relevancia en el conjunto de datos mientras que otros proponen un valor midiendo la redundancia de la variable. En el presente trabajo, se hace énfasis en el análisis de los rasgos medidos por su relevancia por lo que se van a desarrollar los siguientes conceptos: Entropía de Shannon(SE), Entropía de Shannon Estandarizada (sSE), Negentropía (nSE), Índice de Redundancia (rSE), Índice de Gini (gSE),. Información de Energía Contenida (iSE), Entropía de Shannon. Diferencial(dSE), Entropía de Shannon Diferencial Estandarizada (sdSE) ,Información Mutua de la Entropía de Shannon Diferencial (MI-DSE), Ganancia de Información (IG), Razón de Ganancia (GR), Incertidumbre Simétrica (SU) e Información de Jeffrey (JI). En el siguiente epígrafe se describen con más detalle los conceptos mencionados.. Métodos de selección de rasgos en aplicaciones Existen diversas herramientas que apoyan al proceso de selección de rasgos en conjunto de datos de aprendizaje, siendo algunas de estas desarrolladas para su libre uso y distribución. Algunas de las herramientas libres son Weka, RapidMiner, KEEL, Orange, mientras que otras como 12.
(19) Capítulo 1 STATISTICA necesitan de una licencia para su uso. En un estudio realizado se recopilaron 8 herramientas entre las que se mencionaron anteriormente y se chequearon los métodos de selección de rasgos supervisados y no supervisados que tenían implementados. Como resultado se evidencia la carencia de métodos no supervisados de selección de rasgos. En las siguientes tablas se presentan la cantidad de métodos supervisados y no supervisados de selección de atributos implementados en ocho herramientas distintas. Tabla 1: Número de criterios de selección de atributos de aplicaciones que apoyan al proceso de descubrimiento de conocimiento. Aplicación. Número de criterios de Número de criterios de Total de criterios selección. de. rasgos selección de rasgos no de. selección. supervisados. supervisados. Tooldiag. 4. 0. 4. Weka. 15. 7. 22. Statistica. 2. 0. 2. Orange. 10. 0. 10. RapidMiner. 17. 3. 20. R. 7. 0. 7. KEEL. 5. 3. 8. Tanagra. 12. 0. 12. de. rasgos. Se hizo énfasis en recopilar los métodos basados en la Teoría de Información que tenían cada una de las herramientas. Se eliminaron los que no tenían ninguno. Tabla 2: Criterios de selección de atributos basados en la Teoría de Información implementados en aplicaciones que apoyan al proceso de descubrimiento de conocimiento. Aplicación. Criterios basados en la Teoría de Información SymmetricalUncertAttributeSetEval GainRatioAttributeEval. Weka. InfoGainAttributeEval ReliefFAttributeEval SymmetricalUncertAttributeEval. 13.
(20) Capítulo 1 Relief Orange. Information Gain Gain Ratio Gini Gain Information Gain Gain Ratio. RapidMiner. Gini Index Uncertainty Relief Information Gain. R. Gain Ratio Symmetrical Uncertainty. KEEL. Mutual Information Relief Symmetrical uncertainty. Tanagra. MIFS filtering Relief. Se evidencia la carencia de la utilización de conceptos de la Teoría de Información aplicado a la selección de rasgos en conjuntos de datos de aprendizaje y no se han encontrado implementados en ninguna aplicación métodos no supervisados de selección de rasgos basados en esta teoría. Este estudio del estado del arte de la selección de atributos proporciona una guía general en los diversos aspectos que comprende esta tarea; además de comentar sobre algunos algoritmos que se encuentran en la literatura. Se hizo énfasis en algunos métodos de selección basados en ranking de atributos, así como se tuvo un acercamiento a la Teoría de Información y su aplicación en la selección de rasgos. Lo planteado anteriormente responde a la hipótesis de que es posible desarrollar una serie de métodos que permita reducir la alta dimensión de conjuntos de datos de aprendizaje a partir de seleccionar rasgos deseables usando conceptos de la Teoría de Información que no han sido utilizados anteriormente para este fin. Se puede concluir que la selección de atributos permite mejorar la precisión e interpretabilidad de los métodos de aprendizaje 14.
(21) Capítulo 1 automático, además de reducir el tamaño de los conjuntos de datos de aprendizaje y el tiempo de los algoritmos de aprendizaje.. 15.
(22) Capítulo 2. Capítulo 2: Criterios de evaluación no supervisados basados en Teoría de Información En este capítulo se proponen nuevos conceptos y estrategias de trabajo sustentados fundamentalmente en el concepto de entropía, que proviene de la Teoría de Información, estos son los que abordan la selección de rasgos desde un punto de vista no supervisados: Entropía de Shannon, Entropía de Shannon Estandarizada, Índice de Gini, Entropía del valor de Descomposición Singular, Índice de Redundancia, Negentropía, Información de Energía Contenida, el Valor Degenerado, La Entropía del Valor Degenerado y La Entropía basada en Distancia. Además se presentan aspectos de su uso en la herramienta IMMAN. Estas medidas permiten ordenar los atributos por orden de importancia. La simplicidad y rapidez en la evaluación de los atributos son sus principales ventajas y uno de los objetivos primordiales de este trabajo de investigación.. Definiciones A continuación se describen formalmente una serie de definiciones y algoritmos que constituyen el núcleo de la investigación.. Distribución de Valores Casi todos los algoritmos implementados en la investigación requieren de un valor para dividir el rasgo en intervalos discretos. A continuación se presenta dicho procedimiento. Distribución de Valores Entrada: R- conjunto de datos , b – intervalo de discretización Salida: L lista de valores por cada intervalo 𝐿 = {}el tamaño de L va a ser igual que b Para i=1 hasta n hacer Para j=1 hasta b hacer Si 𝑹𝒊 pertenece al intervalo 𝑳𝒋. 16.
(23) Capítulo 2 Aumentar en 1 el valor de𝑳𝒋 fin si fin para fin para. Distribución de Probabilidades Para poder llevar a cabos algunos de los algoritmos que se presentan en la investigación se requiere de conocer la probabilidad de cada intervalo de discretización que se crea por ello se propone el siguiente procedimiento: Distribución de Probabilidades Entrada: R- conjunto de datos , b – intervalo de discretización Salida: L lista de valores de probabilidad por cada intervalo L=distribución de valores(R, b) parai=1 hasta nhacer 𝑳𝒊 =𝐿𝑖 /R fin para. Entropía de Shannon En (Shannon, 1948) se define como entropía la medida de indeterminación de uno de los rasgos del conjunto de datos del aprendizaje. La misma se denomina entropía (SE) de la fuente discreta de información o entropía del conjunto finito, representándose de la siguiente forma. 𝑁. 𝑆𝐸(𝑋) = −𝐶 ∑ 𝑝𝑖 𝑙𝑜𝑔 𝑝𝑖 𝑖=1. 17.
(24) Capítulo 2 Es necesario decir que la Entropía de Shannon en particular y cualquier otra que se defina debe cumplir: . La entropía es una magnitud real y no negativa, ya que para cualquier valor i (1 ≤ i ≤ N), pi varia en el intervalo de 0 a 1.. . La entropía se reduce a cero solo en el caso cuando la probabilidad de uno de los estados es igual a la unidad; entonces las probabilidades de todos los demás estados, naturalmente, serán iguales a cero.. . La entropía es máxima cuando todos los estados de la fuente son equiprobables. 𝑁. 𝐻𝑚𝑎𝑥 (𝑋) = − ∑ 𝑖=1. . 1 1 log = log 2 𝑁 𝑁 𝑁. La entropía de la fuente u con dos estados 𝑢1 y 𝑢2 varía desde cero hasta unidad, alcanzando el valor máximo cuando sus probabilidades son iguales. Cabe señalar que la entropía depende continuamente de las probabilidades de estados independientes, lo cual se deduce de forma directa de la continuidad de la función −𝑝log 𝑝.. . La entropía de unión de varias fuentes de información estadísticamente independientes es igual a la suma de entropías de las fuentes iniciales.. . La entropía caracteriza la indeterminación media de la elección de uno de los estados del conjunto. Para determinarla solo se utilizan las probabilidades de los estados, menospreciando por completo su contenido sustancial.. El procedimiento para calcular el valor de Entropía de Shannon para cada rasgo quedaría implementados de la siguiente forma: Entropía de Shannon Entrada: R- conjunto de datos , b – intervalo de discretización Salida: X valor de la Entropía de Shannon L=distribución de probabilidades(R, b) X=0 18.
(25) Capítulo 2 parai=1 hasta nhacer X X+ 𝐿𝑖 log 𝐿𝑖 fin para X = -1*X. Entropía de Shannon Estandarizada La Entropía de Shannon se Estandariza o Entropía de Shannon Escalada es la normalización de la Entropía de Shannon con respecto al número de estados cuya definición es dada por la siguiente ecuación: 𝑠𝑆𝐸(𝑋) =. 𝑆𝐸(𝑋) log 𝑁. Esta entropía representa la medida de la eficiencia relativa de la información recolectada.. Índice de Gini El concepto Índice de Gini (Breiman et al., 1984) propone otra medida diferente a la Entropía de Shannon. Esta evalúa la diversidad de información contenida en el rasgo, incrementando su valor según aumenta la diversidad en las instancias. Es definida matemáticamente: 𝑁. 𝑔𝑆𝐸(𝑋) = ∑ 𝑝𝑖 ∗ 𝑝𝑖+1 𝑖=0. 0 gSE . Este concepto cuenta con la propiedad de que el valor que arroja va a estar entre. N 1 2N. El procedimiento para llevar a cabo el cálculo del Índice de Gini en un rasgo se representa de la siguiente forma: Índice de Gini Entrada: R- conjunto de datos , b – intervalo de discretización. 19.
(26) Capítulo 2 Salida: X valor del Índice de Gini L=distribución de probabilidades(R, b) X=0 parai=1 hasta n-1hacer X X+𝐿𝑖 *𝐿𝑖+1 fin para. Como se puede apreciar el índice de Gini como concepto proveniente de la Teoría de Información, es retomado y aplicado en nuestra investigación a la selección de rasgos no supervisados, constituyen un aporte de la investigación debido a su implementación por vez primera en una herramienta para la selección de rasgos.. Entropía del Valor de Descomposición Singular. En (Devakumari and Thangavel, 2010) se readapta el concepto de Valor Descomposición Singular, utilizado anteriormente en el análisis del genoma (Alter et al., 2000); para evaluar la calidad de un rasgo al medir la cantidad de información que este aporta al conjunto de datos. El valor de Descomposición Singular (𝑆𝑗 ) del conjunto de datos (𝐴) son los auto-valores de la matriz 𝑛 ∗ 𝑛 de 𝐴 ∗ 𝐴𝑡 . Si definimos el valor relativo normalizado como: 𝑉𝑗 =. 𝑆𝑗2 ∑𝐾 𝑆𝐾2. Como resultado se define que la entropía de la base de conocimiento (CE) es: 𝑁. 1 𝐶𝐸(𝐴) = − ∗ ∑ 𝑉𝑗 ∗ log 𝑉𝑗 log 𝑁 𝑗=1. Esa entropía tiene su valor entre 0 y 1. Un valor de entropía 0 implica que todo conjunto de datos puede ser explicado por un solo rasgo; todo lo contrario al valor de entropía 1 el cual indica. 20.
(27) Capítulo 2 variabilidad total en el conjunto de datos de aprendizaje. La contribución al valor de entropía del conjunto de datos de uno de sus rasgos (𝑋) está definido por: 𝑉𝐷𝑆𝐸(𝑋) = 𝐶𝐸(𝐴) − 𝐶𝐸(𝐴′ ) Donde 𝐴′ es el conjunto de rasgos sin el rasgo que se analiza.. Índice de Redundancia Es una extensión de la media de la información contenida (Brillouin, 1962), se considera un cuantificador complementario. El Índice de Redundancia Brillouin o Índice de Redundancia, (rSE) es así mismo una medida de información redundante en el conjunto de valores del rasgo. Matemáticamente el concepto se define: 𝑟𝑆𝐸(𝑋) = 1 − 𝑠𝑆𝐸(𝑋) El resultado obtenido a partir de esta medida se encuentra entre 0 y 1, siendo 0 el mejor valor posible a alcanzar ya que representa el mínimo de información perdida. El concepto de Índice de Redundancia proviene de la Teoría de Información aplicada a la Química Informática y ha sido readaptado de esta forma, en la presenta investigación, para utilizarlo en la selección de rasgos.. Negentropía La Negentropía (Kier, 1980) o también conocida por Información Total Contenida representa la información residual que existe en el rasgo X. La forma de calcular esta medida entrópica está dada por las siguientes ecuaciones: 𝑛𝑆𝐸(𝑋) = 𝑁 ∗ 𝑆𝐸(𝑋) 𝑛𝑆𝐸(𝑋) = 𝑆𝐸𝑚𝑎𝑥 (𝑋) − 𝑆𝐸(𝑋) La Negentropría, al igual que el concepto de Índice de Redundancia proviene de la Teoría de Información aplicada a la Química Informática y ha sido también readaptada para utilizarlo en la selección de rasgos.. 21.
(28) Capítulo 2. Información de Energía Contenida Un cuantificador complementario del Índice de Gini es la Información de Energía Contenida (Onicescu, 1966). El resultado presentado por esta expresión matemática quedaría. 1 iSE 1 N. siendo el valor más bajo el de mejor variabilidad. 𝑛. 𝑖𝑆𝐸(𝑋) = ∑ 𝑝𝑖2 𝑖=0. De forma muy sencilla e presenta a continuación el procedimiento Información de Energía Contenida Entrada: R- conjunto de datos , b – intervalo de discretización Salida: X valor de la Información de Energía Contenida L=distribución de probabilidades(R, b) X=0 parai=1 hasta n-1hacer X X+𝐿𝑖 2 fin para. La Información de Energía Contenida, como la Negentropría y el concepto de Índice de Redundancia también provienen de la Teoría de Información, aunque no ha sido utilizada en la Informática Química, este concepto fue re-adaptado para utilizarlo en la selección de rasgos.. Valor Degenerado El valor degenerado (DV) pretende evaluar la cantidad de casos diferentes que tiene un rasgo, mostrando así la diversidad en la información contenida. 22.
(29) Capítulo 2 𝐷𝑉(𝑋) = 𝐶𝑎𝑠𝑜𝑠𝑡𝑜𝑡𝑎𝑙 − 𝐶𝑎𝑠𝑜𝑠𝑑𝑖𝑓𝑒𝑟𝑒𝑛𝑡𝑒𝑠 El Valor Degenerado constituye una representación evidente de lo diverso del universo de valores que comprende el rasgo. El procedimiento queda definido de la siguiente forma: Valor Degenerado Entrada: R- conjunto de datos Salida: X Valor Degenerado 𝐿 = {} Para i=1 hasta n hacer si 𝑅𝑖 no está incluido en L Incluir 𝑅𝑖 en L fin si fin para X= cantidad de casos en R menos la cantidad de casos en L. El concepto de Valor Degenerado fue elaborado para ser aplicado en esta investigación por vez primera, constituyendo uno de sus aportes.. Entropía del Valor Degenerado Como su nombre lo indica la Entropía del Valor degenerado pretende evaluar la variabilidad del rasgo estudiado según el valor degenerado 𝐷𝑉𝑆𝐸(𝑋) = 𝐷𝑉(𝑋) ∗. 23. 𝑆𝐸(𝑋)𝐷𝑉(𝑋) 𝑆𝐸(𝑋)𝑐𝑎𝑠𝑜𝑠.
(30) Capítulo 2 La Entropía del Valor degenerado (DVSE) constituye otro de los aportes de la investigación, la misma utilizada como medida de evaluación permite ordenar según su relevancia el conjunto de rasgos de la base de conocimiento, caracterizando así los rasgos más relevantes.. Entropía basada en Distancia La Entropía basada en Distancia evalúa la información contenida en un rasgo midiendo la diversidad de los casos que contiene un rasgo, calculando el valor de la distancia euclidiana entre casos y a su vez la entropía entre las distancias. 𝐸𝐷𝑆𝐸(𝑋) = ∑ ∑[𝐷𝑖𝑗 log 2 𝐷𝑖𝑗 + (1 − 𝐷𝑖𝑗 )log 2 (1 − 𝐷𝑖𝑗 )] 𝑖. 𝑗. Este valor de entropía pretende cuantificar la diversidad de un rasgo mediante la distancia entre sus valores. Mientras más alta sea el valor de entropía más diversa es la información que este rasgo contiene. El procedimiento quedaría representado con el siguiente pseudocódigo: Entropía basada en Distancia Entrada: R- conjunto de datos Salida: X valor de la Entropía basada en Distancia 𝐿 = {}arreglo de casos normalizados 𝑀 = {{}} arreglo bidimensional de distancias X=0 Para i=1 hasta n hacer normalizar𝐿𝑖 fin para para i=1 hasta n hacer para j=i hasta n hacer. 24.
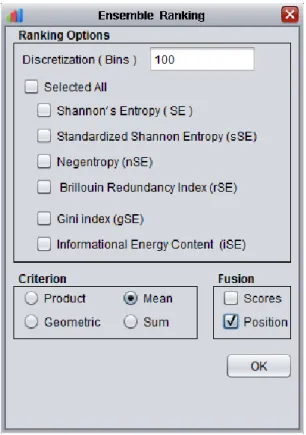
(31) Capítulo 2 𝑀𝑖𝑗 𝑀𝑗𝑖 |𝐿𝑖 − 𝐿𝑗 | fin para fin para para i=1 hasta n hacer para j=1 hasta n hacer Z= 𝑀𝑖𝑗 multiplicado por el logaritmo de𝑀𝑖𝑗 Y=1 − 𝑀𝑖𝑗 ∗ log 1 − 𝑀𝑖𝑗 X X+ Z+Y fin para fin para. La Entropía basada en Distancia proviene de la teoría de Información, y es otro de los aportes de la investigación.. Selección de rasgos no supervisados en la herramienta IMMAN Los algoritmos propuestos anteriormente están implementados en la herramienta IMMAN en la interface de análisis no supervisados de selección de rasgos. La siguiente imagen representa la parte de la herramienta IMMAN donde está implementado los conceptos presentados anteriormente. 25.
(32) Capítulo 2. Figura 1 Ventana de la Entropía de Shannon A la izquierda de la imagen se presenta el panel de las entropías. Es aquí donde se seleccionan los conceptos que se desean ser calculados para cada uno de los rasgos de los conjunto de datos que se introducen para su análisis en la aplicación. El campo “Discretization (Bins)” es el lugar donde se escriben, separados por punto y coma, los valores de los intervalos que se deseen calcular para cada una de las medidas entrópicas seleccionadas en el panel. En la parte superior de la derecha de la imagen se puede observar el panel de ranking de variables, donde se pueden seleccionar los distintos tipos de ranking: . Simple: se selecciona la medida de evaluación a utilizar para hacer el ranking de las mejores variables, así como el valor del intervalo para discretizar (en caso de que se requiera). Esta forma ordena los valores según su relevancia de acuerdo a la medida entrópica seleccionada.. . Multicriterio: selecciona una configuración de medidas de evaluación e intervalos de discretización para llevar a cabo unaevaluación multicriterio de los rasgos.. 26.
(33) Capítulo 2. Figura 2 Ventana de la Configuración Multicriterio Otro de los apartados que se presenta en la imagen 1 es la salida en número de los rasgos. Se definen 4 formas de salida: . total de variables donde se muestran todas las variables del conjunto de datos de aprendizaje ordenadas según su valor de relevancia.. . se pueden elegir el número de las mejores y las peores variables a mostrar.. . se puede usar un punto de corte según el criterio que se haya seleccionado donde se mostraran las variables que están por encima de ese punto.. . así como el nivel de contribución de la variable agrupado en tres de estossiguiendo el criterio de la media de todos los valores para establecer el punto de corte:. 27. -. alta contribución. -. media contribución. -. baja contribución.
(34) Capítulo 2. Conclusiones En este capítulo se presentan 10 métodos no supervisados de selección de rasgos basados en la Teoría de Información, se han destacado las principales aportaciones de la investigación, así como se ha realizado una breve descripción de su implementación en la herramienta IMMAN. En capítulos posteriores se hará usos de algunos de estos conceptos aplicados en diferentes áreas de la ciencia, por ejemplo Entropía de Shannon.. 28.
(35) Capítulo 3. Capítulo 3: Criterios de evaluación supervisados basados en Teoría de Información En este capítulo se explicará en detalles sobre los métodos supervisados que propone la investigación así como algunas de los problemas relacionados con su implementación en la herramienta IMMAN.. Definiciones Entropía de Shannon Diferencial Godden y Bajorath (Godden and Bajorath, 2001). proponen una medida de cuantificar la. información equivalente en dos rasgos analizando la variabilidad entre ellos, lo que se conoce como Entropía de Shannon Diferencial. Esta se define matemáticamente con la siguiente ecuación: 𝑑𝑆𝐸(𝑋, 𝑌) = 𝑆𝐸(𝑋, 𝑌) −. (𝑆𝐸(𝑋) + 𝑆𝐸(𝑌)) 2. Donde dSE es la medida de la complementariedad de las variables por lo que un valor cercano a 0 de la Entropía Diferencial muestra muy poca o ninguna diferencia entre las variables en análisis. Por el contrario, los valores que más se alejen de 0, tanto negativos como positivos, muestran gran variabilidad en entre sus contenidos de información. Como aporte de la presente investigación se realiza una extensión del concepto, ampliando el análisis para más de dos rasgos; quedando representada de la siguiente forma: 𝑑𝑆𝐸(𝑈) = 𝑆𝐸(𝑈) −. ∑𝑁 𝑖=0 𝑆𝐸(𝑈𝑖 ) 𝑁. Siendo U un conjunto de rasgos, y N la cantidad de rasgos a analizar. El procedimiento puede ser descrito mediante el siguiente pseudocódigo: Entropía de Shannon Diferencial Entrada: R- lista de rasgos, b – intervalo de discretización Salida: X valor de la Entropía de Shannon Diferencial. 29.
(36) Capítulo 3 S= Entropía de Shannon Total(R, b) Z=0 para i=1 hasta n hacer Z Z + Entropía de Shannon (𝑅𝑖 , b ) fin para X= S + Z dividido por la cantidad de R. Entropía de Shannon Diferencial Estandarizada Como la Entropía de Shannon Estandarizada la Entropía de Shannon Diferencial Estandarizada (sdSE) es la normalización de la Entropía de Shannon Diferencial. 𝑠𝑑𝑆𝐸 =. 𝑑𝑆𝐸(𝑈) 𝑙𝑜𝑔2 𝑁. También se amplía el concepto Entropía de Shannon Diferencial Estandarizada, aumentando su interpretación a más de dos variables.. Ganancia de Información El concepto de Ganancia de Información como se describe en la literatura especializada (Ian et al., 2011) ha sido utilizado anteriormente en aprendizaje automático en la conformación árboles de decisión, cuantificando la información que se obtiene para cada rasgo según la conformación del árbol. La Ganancia de Información fue concebida 𝐼𝐺(𝑋|𝑌) = 𝑆𝐸(𝑋) + 𝑆𝐸(𝑌) − 𝑆𝐸(𝑋, 𝑌). Razón de Ganancia La Razón de Ganancia (GR del inglés Gain Ratio ) (Quinlan, 1986) representa una razón de la Ganancia de Información de un conjunto de rasgos con respecto a la entropía total del conjunto de rasgos. 30.
(37) Capítulo 3. 𝐺𝑅(𝑋, 𝑌) =. 𝐼𝐺(𝑋|𝑌) 𝑆𝐸(𝑋, 𝑌). Maximizando el valor de la razón según la ganancia aumente con respecto a la entropía del conjunto. Incertidumbre Simétrica La Ganancia de Información tiende a aumentar según aumenta el valor de entropía por lo que se hace necesario normalizar para comparar un rasgo con otro por lo que surge la Incertidumbre Simétrica (Press et al., 1988). 𝑆𝑈(𝑋, 𝑌) =. 𝐼𝐺(𝑋|𝑌) 𝑆𝐸(𝑋) + 𝑆𝐸(𝑌). La Incertidumbre Simétrica (SU) abarca valores entre 0 y 1 donde el valor 0 indica que los dos rasgos son completamente independientes mientras que el valor 1 indica que cada uno de los rasgos predicen los valores del otro.. Información Mutua de la Entropía de Shannon Diferencial Anne Main y Bajorath (Anne Mai et al., 2010) realizan un análisis de su concepto de Entropía de Shannon Diferencial, explicando la incapacidad de la formulación propuesta para analizar rasgos cuya cantidad de instancias representadas en el conjunto de datos de aprendizaje fueran muy diferentes. Debido esta conclusión propone una nueva medida que intenta corregir esta falla. La Información Mutua de la Entropía de Shannon Diferencial queda expresada de la siguiente forma: 𝑀𝐼𝐷𝑆𝐸(𝑋) = 𝑆𝐸𝑛𝑜𝑟𝑚 (𝑋, 𝑌) −. 𝑆𝐸(𝑋) − 𝑆𝐸(𝑌) 2. Información de Jeffrey Como una extensión del concepto de Kullback-Leibler (Press et al., 2007)la Información de Jeffrey es la medida imparcial de la similitud (o diferencia) entre dos rasgos. Inicialmente fue valorada la utilización del concepto de Kullbak-Leibler para la selección de rasgos pero su definición establece una dependencia entre la selección de cuál variable es experimental y cuál es teórica, por lo que no es simétrica. La Información de Jeffrey resuelve la dependencia presentando la variabilidad entre dos rasgos. Es calculada de la siguiente forma: 31.
(38) Capítulo 3 𝑁. 𝑋 𝑌 𝐽𝐼(𝑋||𝑌) = ∑ 𝑝𝑖 (𝑋) ∗ log 𝑝𝑖 ( ) +𝑝𝑖 (𝑌) ∗ log 𝑝𝑖 ( ) 𝑌 𝑋 𝑖=0. Información de Jeffrey Entrada: Q- rasgo , P- rasgo, b – intervalo de discretización Salida: X valor de la Información de Jeffrey 𝑃𝑄 = {} distribución de probabilidades (Q, b) 𝑃𝑃 = {} distribución de probabilidades (P, b) X=0 Para i=1 hasta n hacer 𝑃𝑄. tQ 𝑃𝑄𝑖 ∗ 𝑃𝑃𝑖 𝑖. 𝑃𝑃. tP 𝑃𝑃𝑖 ∗ 𝑃𝑄𝑖. 𝑖. X X+ tP + tQ fin para. La Información de Jeffrey es un concepto de la Teoría de Información utilizado como una medida de distancia, mientras en este trabajo se utiliza como una medida de evaluación de rasgos supervisados. La herramienta IMMAN implementa 3 módulos que contienen los algoritmos supervisados, explicados anteriormente, cada uno de ellos separados por sus orígenes conceptuales. En la imagen que se presenta a continuación se observa la ventana de la Entropía de Shannon Diferencial donde están la mayoría de los algoritmos implementados.. 32.
(39) Capítulo 3. Figura 3 Ventana de la Entropía Diferencial. Las medidas de evaluación: la Información de Jeffrey y el la Información Mutua de la Entropía de Shannon Diferencial, no aparecen en la imagen anterior, pues están implementadas en otros dos módulos de la aplicación. Todos estos módulos funcionan de forma muy sencilla con el cálculo de las medidas para cada rasgo: si se seleccionan al menos dos conjuntos de datos, estas tienen que tener los mismos rasgos (comparados por el nombre) para poder llevar a cabo las corridas de los algoritmos. En caso de que se seleccione un solo conjunto de datos se deberá seleccionar la variable objetivo (ya sea discreta o continua).. Clase Continua La herramienta que se propone en la presente investigación permite manejar rasgos continuos como si fueran una clase. El proceso se obtiene discretizando los valores que el rasgo contiene en la cantidad de clases que se desean crear con este. El procedimiento es el mismo que distribuyendo los valores en un intervalo determinado explicado en el capítulo anterior. 33.
(40) Capítulo 3. Clase Discreta También la herramienta maneja de forma similar, las variables que contienen valores discretos. El procedimiento radica en distribuir cada caso según el valor discreto que contenga el rasgo que se considere como clase. Otras de las bondades de estos módulos es la posibilidad de hacer combinaciones entre conjuntos de datos de aprendizaje o entre clases, seleccionando solo la cantidad de valores a combinar en el panel de selección de conjuntos de datos. Cada uno de los algoritmos implementados permiten que se use un punto de corte antes de ejecutar el análisis, es decir, se puede evaluar la calidad un rasgo a través de cualquiera de los conceptos supervisados implementados, teniendo como premisa que los valores de las medidas no supervisadas implementadas del rasgo que se evalúe sea elevado.. Conclusiones En este capítulo se presentan la implementación de siete algoritmos supervisados basados en la Teoría de Información, los cuales apoyan al proceso de descubrimiento de conocimientos reduciendo la dimensión en conjunto de datos de aprendizaje, seleccionando los rasgos más relevantes de estos. Se explica brevemente algunas de las características de la herramienta donde se implementan estos algoritmos.. 34.
(41) Capítulo 4. Capítulo 4: Aplicación de los conceptos de la Teoría de Información implementados en la herramienta IMMAN En este capítulo se describirán 3 aplicaciones que hacen uso de los conceptos de la Teoría de Información implementados en la herramienta IMMAN con el fin de comprobar la eficacia de la misma. Se aplica en dos áreas de la ciencia: La Informática Química y la Bioinformática.. Estudio 1: Comparación de software de cálculo de descriptores Uno de las aplicaciones realizadas con la herramienta que propone esta investigación es la comparación de aplicaciones que calculan diferentes grupos de descriptores moleculares. Un descriptor (Todeschini and Consonni, 2009) es un procedimiento por el cual la estructura química se transforma en números permitiendo el tratamiento matemático de la información química contenida en la molécula, es considerado una representación matemática de las moléculas que se obtienen al aplicar algoritmos específicos sobre una representación molecular definida o a partir de procedimientos experimentales específicos. La información estructural y propiedades fisicoquímicas se representan numéricamente en descriptores que codifican a las moléculas, sin embargo, a pesar de la investigación teórica y experimental en este campo, no existe acuerdo acerca de aquel conjunto de descriptores óptimos, por tanto, dado que diferentes descriptores codifican distinta información, la estrategia consiste en aplicar aquellos más relevantes según la particularidad del caso de estudio.En este sentido se pretende verificar la calidad de los descriptores que se implementan en diferentes software de este campo comerciales o no comerciales. Se calcula para una base de moléculas (Spectrum) todos los descriptores implementados en diferentes software para medir cuál de estos aporta más información. Los software a comparar son: MIDAS, PADEL, CDK, DRAGON, PowerMV, Mol2 y BlueDesc. Con el objetivo de evaluar la información capaz de captar cada uno de estos software se aplica el concepto de Entropía de Shannon y usando como intervalo de discretización el valor 1000.. 35.
(42) Capítulo 4. Figura 4: Gráfico de comparación de software en función de la cantidad de información que aportan. Como resultado se puede obtener que los softwares implementados en el grupo de investigación CAMB-BIR Unit y el departamento de Inteligencia Artificial del CEI de la UCLV aportan mayor información que todos las demás aplicaciones comerciales o no comerciales con las que se comparó.. Estudio 2: Comparación entre familias de descriptores moleculares del Software Dragón Otra de las aplicaciones de esta metodología basada en la Teoría de Información puede ser el análisis y comparación de información captada por variables, por ejemplo los parámetros (descriptores) que codifican la información química en las moléculas. En este sentido, con el objetivo de evaluar la calidad de los descriptores implementado en el software DRAGON se calculan estos parámetros para dos conjunto de moléculas de dos de las bases de compuestos más reconocidas internacionalmente llamadas PrimScreen (contiene 1000 moléculas) y Spectrum (contiene 2000 moléculas) caracterizadas por su gran diversidad. Esta aplicación (DRAGON) agrupa sus 3224 descriptores en 22 familias distintas donde cada descriptor puede ser 0D, 1D, 2D, 3D. Es objetivo del estudio ver qué familia de descriptores aporta mayor información sobre esa base de compuestos, es por ello que como un primer paso se calculan todos descriptores del sistema 36.
(43) Capítulo 4 y se agrupan en las 22 familias obteniendo para cada una de ellas un conjunto de datos de aprendizaje. Para analizar el contenido de la información de estos conjuntos de descriptores se aplica la medida de la Entropía de Shannon usando como esquema de intervalos discretos (bins, en el inglés) 1000 a todos los conjuntos de datos de aprendizaje. Como un resultado para el conjunto de datos de la base de moléculas “PrimScreen” se obtiene que la familia de descriptores “1D-fragment” son los que menos información aportan de la base de moléculas mientras que los descriptores tipo 3D en especial 3D-Randic-Geometrical son los que mayor información aportan. Estos resultados se pueden apreciar en la siguiente figura. Por otra parte en el análisis realizado sobre la base de moléculas “Spectrum” se evidencia que la familia de descriptores 3D-GATEWAY es la que información provee.. Figura 5:Gráfico de Distribución de la Entropía de Shannon para la Bases de moléculas PrimScreen. 37.
(44) Capítulo 4. Figura 7; Gráfico de Distribución de la Entropía de Shannon para la Bases de moléculas Spectrum. Para ambas bases de moléculas las familias de descriptores implementados en el software DRAGON que más información aportan de estas son las 3D y las mejores en entre ellas son: 3DGATEWAYy 3D-Randic-Geometrica.. Estudio 3: Selección de genes para la predicción de metástasis en pacientes con cáncer de mamas. En el estudio realizado por Laura van’tVeer (van't Veer et al., 2002) sobre la expresión de un conjunto de 24189 genes en 78 pacientes con cáncer de mamas, propone los 70 mejores genes que son capaces de predecir con mayor exactitud si el paciente tiene alto riesgo o no de tener metástasis en tiempo de menor de diez años. A partir de este estudio se comercializa una prueba llamada MammaPrint. La prueba MammaPrint estudia este grupo de 70 genes para determinar su nivel de actividad, y luego calcula una puntuación de recurrencia que se expresa en términos de riesgo bajo o riesgo alto:. 38.
Figure



+7




Documento similar