Paquete estadístico para análisis de regresión
67
0
0
Texto completo
(2) El que suscribe, Sandro Herrera Pallares, hago constar que el trabajo titulado “Paquete estadístico para análisis de regresión” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del laboratorio. Fecha.
(3) Mucho mejor atreverse a hacer cosas grandes, a obtener triunfos gloriosos, aun cuando matizados con fracasos, que formar en las filas de aquellos pobres de espíritu que ni gozan mucho ni sufren mucho porque viven en el crepúsculo gris que no conoce la victoria ni la derrota. Theodore Roosevelt..
(4) Dedicatoria A mis padres por todo el sacrificio que han hecho por mí. A mis hermanas, que siempre trato de ser mejor por ellas. A mi novia que estado conmigo en cada paso. A mis abuelos por todo el cariño que he recibido de ellos..
(5) Agradecimientos A mis padres por haber siempre confiado en mí y por todo lo que han hecho en pos de mi formación profesional. A Lisette, ni novia, por todo su amor, su paciencia, su inteligencia y por haber estado siempre cuando la necesité. A mis primas Katia , Kenia y Yadira, por todo el apoyo que siempre me han dado y por confiar siempre en mí. A mi tío Ginarte y mi tía Isabel, por el apoyo logístico y el cariño recibido. A mi tío Alexis y Miriam por tener las puertas de su casa siempre abiertas para mí. A toda mi familia por quererme tanto. A mis abuelos santaclareños, Inés y Enrique. A Gladita , mi tutora, por todo el tiempo dedicado, por su paciencia, dedicación, por ser un ejemplo cómo profesional y por haberme elegido para hacer la tesis con ella. A mi futura suegra Rosy, por las comidas ricas. A mis compañeros de cuarto, Chinong, Albanis, Dustin, Polo y el David. A Millo por saber siempre todo. A mis amigos de siempre, Sergio, Adan, Gabi, Tati, Addel. A los compañeros de bioinformática, Mario, Abdel, Oscar, Laureano. A todos mis compañeros de estudio con los que he compartido estos cinco años. Sandro Herrera Pallares.
(6) .. Resumen Esta tesis resume los conceptos fundamentales del análisis de regresión. Se muestra una descripción detallada de los algoritmos "paso a paso", "introducir todas las variables" y "mejores subconjuntos". Se explican cuidadosamente los supuestos de los modelos matemáticos. Se presentan varias pruebas de hipótesis para demostrar la normalidad de los residuos y la homogeneidad de sus varianzas. Se presentan los aspectos principales del análisis, diseño e implementación del software “Linear Regression Package 1.0”. Además se elaboró un manual de usuario. Se presentan dos aplicaciones con datos reales. En la primera se encuentran varios modelos para resolver un problema de quimioinformática utilizando los métodos “paso a paso” y “mejores subconjuntos”. En la segunda aplicación se resuelve un problema de Ingeniería Civil. Se obtienen modelos para predecir la fortaleza del hormigón. El primer modelo usa las variables originales, mientras que el segundo usa sus interacciones. En todos los casos se probó el cumplimiento de los supuestos. Todos los cálculos se realizaron con ayuda del software elaborado..
(7) Abstract This thesis shows the fundamental concepts of regression analysis. The full description of the algorithms “stepwise”, “enter” and “best subsets” are provided. The assumptions of the mathematical models are carefully explained. Several hypothesis tests to prove the normality of the residuals and the homogeneity of their variances are explained. The main aspects of the analysis, design and implementation of software "Linear Regression Package1.0" are provided. Also a user manual was developed. Two different applications with real data are presented. In the first there are calculated several models to solve a cheminformatics problem using stepwise method and best subsets method. The second application solves a problem of Civil Engineering. Models to predict the strength of concrete are presented. The first model uses the original variables, while the second one uses their interactions. The required assumptions of the equations are proved in all cases. All calculations were performed using the software developed..
(8) Índice. Introducción ............................................................................................................................................... 1 Capítulo 1. Análisis de Regresión ..................................................................................................... 5 1.1 Regresión lineal ............................................................................................................................... 6 1.1.1. Regresión lineal simple ........................................................................................................... 6. 1.1.2. Regresión lineal múltiple ......................................................................................................... 8. 1.2 Análisis de varianza ...................................................................................................................... 14 1.3 Regresión no lineal ....................................................................................................................... 15 1.4 Regresión reducible a lineal ....................................................................................................... 15 1.4.1. Modelos polinomiales............................................................................................................ 16. 1.4.2. Modelos polinomiales con interacciones ............................................................................... 16. 1.4.3. Modelos exponenciales.......................................................................................................... 16. 1.4.4. Regresión logarítmica ............................................................................................................ 16. 1.5 Supuestos del modelo de regresión .......................................................................................... 17 1.5.1. Examen gráfico de los residuos ............................................................................................. 18. 1.5.2. Valores atípicos (OUTLIERS) .............................................................................................. 20. 1.5.3. Homocedasticidad ................................................................................................................. 20. 1.5.4. Prueba de la homogeneidad de varianzas .............................................................................. 21. 1.6 Estimaciones y predicciones ...................................................................................................... 24 1.7 Consideraciones finales ............................................................................................................... 24. Capítulo 2. Linear RegressionPackage. Diseño, implementación y plataforma de desarrollo ................................................................................................................................................... 26 2.1 Selección del lenguaje a utilizar ................................................................................................ 26 2.2 Plataforma de desarrollo .............................................................................................................. 26 2.2.1 Cliente enriquecido ....................................................................................................................... 26 2.2.2 Plataforma de cliente enriquecido ................................................................................................ 27 2.2.3 Algunas características de la plataforma de Netbeans .................................................................. 28 2.2.4 Conclusiones parciales ................................................................................................................. 28.
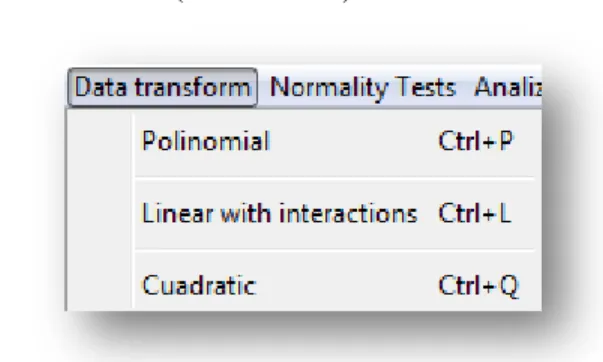
(9) 2.3 Algo de la implementación ......................................................................................................... 28 2.4 Análisis, diseño e implementación de Linear RegressionPackage 1.0 .......................... 30 2.5.1 Diagrama de casos de uso ............................................................................................................. 31 2.5.2 Diagrama de clases ....................................................................................................................... 33 2.5.3 Diagramas de actividad ................................................................................................................ 33 2.6 Metodología para la creación de la ayuda ....................................................................................... 36. 2.5 Consideraciones finales ............................................................................................................... 38. Capítulo 3. Linear Regression Package. Aplicaciones .............................................. 39 3.1 Manual de usuario ......................................................................................................................... 39 3.1.1 Requerimientos ............................................................................................................................. 39 3.1.2 Ficheros de entrada ....................................................................................................................... 39 3.1.3 Ventana inicial del software ......................................................................................................... 40 3.1.4 Ventana principal del software ..................................................................................................... 41 3.1.5 Barra de menú............................................................................................................................... 42. 3.2 Algunas aplicaciones .................................................................................................................... 49 3.2.1 Predicción de la relación estructura - actividad en estudios QSAR ............................................. 49 3.2.2 Predicción de la fortaleza del hormigón ....................................................................................... 51. Conclusiones............................................................................................................................................ 54 Recomendaciones .................................................................................................................................. 55 Anexos........................................................................................................................................................ 56 Referencias bibliográficas .................................................................................................................. 57.
(10) Introducción Numerosos son los desafíos a los que se enfrenta a diario la Estadística. En sus inicios, fueron problemas agrícolas e industriales de relativamente pequeño alcance, los que propiciaron su desarrollo. Con el advenimiento de la era de las computadoras y de la información, los problemas estadísticos se han incrementado de manera notable en tamaño y complejidad. El almacenamiento de grandes volúmenes de datos, su organización e interpretación, han propiciado la aparición de un nuevo campo llamado “minería de datos”. Se pretende entonces “descubrir conocimiento”, es decir extraer modelos y tendencias que tengan una explicación “aceptable”. En resumen, se pretende comprender “lo que datos dicen”. (Hastie, Tibshirani et al. 2008) Por otra parte, también en los últimos años han ocurrido grandes avances en las ciencias biomédicas como resultado del proyecto del Genoma Humano. Los nuevos modelos, basados en la Genética Molecular y en la Informática, constituyen puntos importantes en este desarrollo, pues suministran potentes instrumentos para la obtención y el análisis de la información genética. (Febles and González 2002 ) El surgimiento de las nuevas tecnologías ha posibilitado el desarrollo de la genómica, al facilitar el estudio de las interacciones de los genes y su influencia en el desarrollo de enfermedades. Todo esto influye en el diagnóstico clínico, en las investigaciones de nuevos fármacos, en la evolución de la Epidemiología como ciencia y de la Informática Médica. Enormes cantidades de datos se han generado y continúan generándose como resultado de las secuenciaciones de los genomas y producto de muchas otras fuentes. Es trabajo de la llamada Estadística Computacional “darle sentido” a esos datos, extrayendo patrones y tendencias. (Hastie, Tibshirani et al. 2008) La unión de todas estas áreas del saber (biológicas, informáticas y matemáticas) ha traído consigo el surgimiento de una nueva disciplina con grandes retos: la Bioinformática. A continuación se muestran algunos ejemplos a solucionar: •. •. Predicción de la actividad biológica de un compuesto a partir de una representación vectorial de su estructura molecular. A estos estudios se les denominan QSAR (Quantitative Structure – Activity Relationship). (Manchester and Czermin´ski 2009) Predecir la intensidad de un ataque cardíaco de pacientes hospitalizados con alto riesgo cardiovascular. La predicción estará basada en un conjunto de variables como la edad, el sexo, la dieta, los antecedentes patológicos personales y familiares entre muchos otros aspectos.. 1.
(11) • •. Estimar la cantidad de glucosa en la sangre de una persona diabética, a partir del espectro de absorción infrarrojo de la sangre de esa persona. Analizar tendencias de datos históricos para poder predecir comportamientos futuros de variables tan decisivas como las ventas, la producción o los costos.. El análisis de regresión lineal es una técnica estadística que se utiliza para construir un modelo matemático que pueda explicar la relación entre una variable dependiente y una o múltiples variables independientes o predictoras. Puede utilizarse en una amplia variedad de situaciones como las explicadas anteriormente. Para que una ecuación de regresión hallada sea válida es necesario probar una serie de supuestos sobre los residuales. Los paquetes estadísticos tradicionales como el SPSS, el Statistica, etc no lo realizan de manera automática, por tanto es responsabilidad del usuario probar el cumplimiento de todos los supuestos. Hace más de veinte años se elaboró en el entonces Instituto de Informática, actual Centro de Estudios de Informática, un software llamado “Stepwise” (Izada 1984). Su ventaja fundamental consistía en la obtención de manera automática de la ecuación de regresión usando el método paso a paso y realizaba de manera automática la verificación del cumplimiento de los supuestos. El sistema tenía la limitante de ejecutarse sobre DOS y por tanto no afrece un ambiente de trabajo amigable. El trabajo que se pretende desarrollar tiene gran importancia debido a la alta aplicabilidad de los métodos de regresión en la solución de problemas ingenieriles, de ciencias agropecuarias, sociales y en Bioinformática, por sólo mencionar algunos ejemplos. Además, existe una restricción adicional en cuanto al número de variables y de casos que el “Stepwise” puede procesar. Esta última limitación es una consecuencia del incremento exponencial de grandes bases de datos que contienen por ejemplo, información de miles de millones de secuencias de pares de bases nucleotídicas. Para estos casos, la utilización del antiguo “Stepwise” deja de ser una opción viable. El trabajo actual tiene como objetivo general obtener un paquete para realizar regresión que se ejecute cómodamente sobre Windows y que permita la verificación de los supuestos de modo automático. Este objetivo puede desglozarse en los siguientes objetivos específicos: 1. Realizar el diseño general de un software que permita la incorporación de varios métodos de regresión. 2. Realizar Implementar el método paso a paso (stepwise) interactivo.. 2.
(12) 3. Implementar el método de los mejores subconjuntos (bests subsets) considerando varios criterios. 4. Implementar los procedimientos necesarios para la verificación de los supuestos: o Normalidad: test de Jarque-Bera, de Kolmogorov-Smirnov, de Shapiro – Wilks, entre otros. o Homogeneidad de varianzas: prueba H 5. Realizar aplicaciones que demuestren la utilidad del paquete implementado. Para dar cumplimiento a estos objetivos fue necesario plantearse y solucionar algunas tareas de investigación, entre las que se encuentran: 1. Estudiar elementos de estadística y de métodos de regresión lineal, reducible a lineal y no lineal, así como el análisis de los supuestos que las ecuaciones deben cumplir para que sean válidas, (para cumplimentar los objetivos específicos 2 y 3). 2. Estudiar varios métodos para probar el ajuste a distribuciones normales y seleccionar los que se van a implementar, (para cumplimentar al objetivo específico 4). 3. Estudiar el algoritmo clásico del método paso a paso (stepwise) publicado inicialmente por (Breaux 1967), luego mejorado en (Breaux 1968) e implementado por(Izada 1984), (para cumplimentar el objetivo específico 2). 4. Implementar el método de “introducir todas las variables predictoras”, pues esta es la base para la implementación del método de los “mejores subconjuntos”. 5. Validar todos los métodos y supuestos implementados comparando sus resultados con paquetes profesionales, como el SPSS y el Statistica y con el “Stepwise” para DOS. El primer paso para la realización de este trabajo fue la confección del marco teórico. Para ello se realizó una amplia revisión de la literatura consultando libros, artículos y páginas de internet, entre otras fuentes. Sus elementos esenciales se encuentran expuestos de manera resumida en el primer capítulo de la presente tesis. Como conclusión de la elaboración del marco teórico se enuncia la siguiente hipótesis de investigación: “El sistema “Linnear Regression Package” permite obtener modelos de regresión mediante los métodos: introducir todas las variables, paso a paso en modo automático, paso a paso interactivo y mejores subconjuntos, así como la verificación automática de los supuestos utilizando un ambiente amigable.” El trabajo está formado por tres capítulos: el primero constituye una revisión bibliográfica sobre la regresión lineal, reducible a lineal y no lineal. Se hace una descripción amplia y detallada de sus fundamentos matemáticos, de los supuestos que deben cumplir los modelos para que sean válidos, entre otros aspectos. Se presenta además un pseudocódigo de cada uno. 3.
(13) de los algoritmos de los métodos de regresión que se implementaron. El capítulo culmina con un epígrafe de consideraciones finales que resume los aspectos de mayor importancia tratados. En el capítulo 2 se hace énfasis en el diseño y en la implementación del software elaborado. Se presentan y explican los diagramas de casos de uso, de actividades y de clases. Se describe la plataforma de desarrollo del software y se expone brevemente la metdología para extender la ayuda. El tercer capítulo está dedicado a las aplicaciones. Comienza con una presentando el manual de usuario del sistema. A continuación se describen algunas aplicaciones, mostrándose en cada caso el planteamiento del problema y la explicación de la solución hallada con ayuda del software elaborado. Finalmente se presentan las conclusiones de la tesis, así como algunas recomendaciones que abren futuras líneas de investigación.. 4.
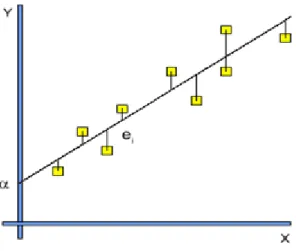
(14) Capítulo 1. Análisis de Regresión El análisis de regresión es una técnica estadística utilizada para estudiar la relación entre varias variables independientes o predictoras con una variable dependiente. El término regresión se utilizó por primera vez al comparar la estatura de padres e hijos. Los hijos cuyos padres tenían una estatura muy superior al valor medio tendían a igualarse a éste, mientras que aquellos cuyos padres eran muy bajos tendían a reducir su diferencia respecto a la estatura media; es decir, "regresaban" al valor promedio. Esta técnica estadística tiene hoy en día numerosas aplicaciones en disímiles ramas del saber. Por ejemplo, un modelo de regresión puede dar información acerca de si el “producto interno bruto”, el “precio del petróleo” o el “valor de las acciones” han aumentado o decrementado en un determinado período. Dado un conjunto de puntos, o resulta difícil dibujar una línea de tendencia, pero su posición y pendiente se calcula de manera más precisa utilizando técnicas estadísticas como las regresiones lineales. En ocasiones, la relación entre las variable independientes y dependiente no es lineal, así que el modelo matemático pudiera un polinomio de mayor grado y otra función. (Wachsmuth, Wilkinson et al. ; Galton 1886) En medicina se tienen también numerosas aplicaciones al relacionar por ejemplo la mortalidad de una determinada enfermedad con el hábito de fumar. Los investigadores incluyen una gran cantidad de posibles variables predictoras en su análisis de regresión en un esfuerzo por eliminar factores que pudieran producir correlaciones espurias. En el caso del tabaquismo, los investigadores incluyeron el estado socio-económico para asegurarse que los efectos de mortalidad por tabaquismo no sean un efecto de su educación o posición económica. (Wachsmuth, Wilkinson et al. ; Galton 1886) El análisis de un proceso puede conducir en muchos casos a una representación en un esquema como el que se muestra en la figura 1.1.. X. Y. Figura 1.1 Esquema de caja negra de la regresión Figura 1.1 Esquema de caja negra de la regresión. En esta figura:. X : vector de variables de entrada (que incluye las variables controlables) Y : vector de variables de salida.. 5.
(15) Y el rectángulo o caja negra es el proceso cuyo interior se desconoce y es lo que se desea investigar. En estos casos la investigación se formula como el problema de encontrar el modelo matemático que relaciona las variables de entrada y salida a partir de conjuntos de valores experimentales de esas variables. El objetivo del análisis de regresión y de los paquetes de programas que la realizan, con mayor o menor grado de generalidad, es precisamente determinar para cada componente del vector Y la función f j que la relaciona con las componentes. del vector X , es. decir: y j f j x1 , x2 ,, xl . Es necesario tener resultados experimentales en los que para cada conjunto de variables de entrada, se haya medido el valor de las variables de salida objeto de análisis. La base de datos necesaria para el análisis debe tener la forma descrita en la tabla 1.1 Tabla 1.1 Estructura de los datos para realizar un análisis de regresión. 1 2 … n. …. …. … … … … …. …. …. 1.1 Regresión lineal El caso más simple y muy frecuente en la práctica, es aquel en que la función es lineal, o sea se necesita hallar los coeficientes k ,. tales que:. y 0 1 x1 2 x2 l xl . (1.1). donde representa el error de estimación. Veamos a continuación algunos casos particulares. 1.1.1 Regresión lineal simple Se quiere obtener la ecuación que mejor ajuste la nube de puntos (figura 1.2), o sea una ecuación de la forma: y 0 1 x .. 6.
(16) Método de los mínimos cuadrados para resolver el problema de la regresión lineal simple. Figura 1.2 Representación gráfica del método de los mínimos cuadrados para obtener la recta de regresión. El método de los mínimos cuadrados intenta minimizar los cuadrados de los residuales, es decir: 2. n. 2. n. n. 2. min yi yˆ i min yi 0 1 xi min i i 1. i 1. n. 2. n. i 1. 2. Sea: S yi yˆ i yi 0 1 xi i 1. i 1. Se desea hallar el mínimo de S. Para ello se calculan:. S 2 yi 0 1 xi 1 0 S 2 yi 0 1 xi xi 1 Igualando a 0 se obtienen las ecuaciones:. y. i. y. i. 0 1 xi 0 0 1 xi xi 0. Trabajando algebraicamente:. y. i. n 0 1 xi. 7.
(17) x y i. i. 0 xi 1 xi2. Resolviendo el sistema de ecuaciones se llega a la solución:. 1 . xi x yi y 2 xi x . 0 y 1 x. (1.2). (1.3). Además puede probarse que:. 2S 2n 0 2 0. 2S 2 xi2 0 2 1 Los estimadores hallados son estimadores mínimos cuadráticos de los parámetros originales. Ellos cumplen varias propiedades, como por ejemplo son insesgados. (Calero 1987) 1.1.2 Regresión lineal múltiple El procedimiento regresión lineal permite utilizar más de una variable independiente y por tanto, permite llevar a cabo análisis de regresión múltiple. Pero en el análisis de regresión múltiple, la ecuación de regresión ya no define una recta en el plano, sino un hiperplano en un espacio multidimensional. La ecuación tendrá la forma: y j 0 1 x1 2 x2 l xl . (1.4). Este modelo, al igual que cualquier otro modelo estadístico, se basa en una serie de supuestos como linealidad, independencia, normalidad, homocedasticidad y no-colinealidad. La ecuación de regresión mínimo-cuadrática se construye estimando los valores de los coeficientes k del modelo de regresión. Estas estimaciones se obtienen intentando hacer que las diferencias al cuadrado entre los valores observados y los pronosticados sean mínimas.. 8.
(18) Método paso a paso (stepwise). El método paso a paso es una heurística muy buena en la difícil tarea de encontrar una ecuación de regresión válida. El no encuentra la óptima, pero por lo general, es capaz de hallar un modelo suficientemente bueno con poco costo computacional. El algoritmo 1 muestra un pseudocódigo de idea esencial del método paso a paso (stepwise) para la construcción de una ecuación de regresión. Algoritmo 1: Método paso a paso (stepwise) para hallar un modelo de regresión Entrada: n valores de las variables independientes y de la variable dependiente , p_ent: probabilidad de entrada de una variable predictora al modelo p_sal: probabilidad de salida de una variable predictora del modelo Inicialización: Ecuación sin ninguna variable Mientras existan variables significativas: 1. Calcular el estadígrafo t-student para todas las variables candidatas. 2. Se selecciona el más significativo. 3. Si cumple con la condición de entrada, entonces pasa a formar parte del modelo. 4. Se calcula el estadígrafo t para las variables que ya están en el modelo. 5. Si alguna cumple con la condición de salida, se elimina del modelo. Salida: Modelo Stepwise. El algoritmo termina cuando no se pueden añadir ni eliminar más variables. En un primer paso se realiza el cálculo de la matriz de correlación de todas las variables. Los coeficientes de regresión, la covarianza de los residuales y la inversa de los elementos se obtienen en cada etapa con un simple re escalamiento. Los elementos de la matriz de correlación se denotan por. ,. donde. representa el número total de variables(independientes y dependiente). A continuación se realiza un proceso de transformación de la matriz Los elementos transformados se denotan por. de manera iterativa.. . (Breaux 1967; Breaux 1968). Para seleccionar la variable que entra o sale de la ecuación se calcula . Esta. tiene un doble propósito:. A. Para las variables que no están en la ecuación es igual a la cantidad de varianza en que serán reducidos los residuales una vez que esta variable entre en la ecuación. Para las variables en la ecuación es igual a la cantidad de varianza en que se verán incrementados los residuales cuando sea eliminado de la ecuación.. 9.
(19) B. El singo de es utilizado para saber si la variable está o no en la ecuación, si positivo, significa que la variable está en la ecuación y viceversa.. es. El índice k representa la variable que se introduce en la ecuación. Para cada una de las variables se realiza las siguientes transformaciones: (Breaux 1967; Breaux 1968). Los coeficientes beta de la ecuación de regresión se obtienen mediante el siguiente cálculo: Para ⁄. Dónde: : representa la media de la variable i, representa la desviación estándar de la variable i y. : representa la desviación estándar de la variable dependiente.. Este modelo, al igual que cualquier otro modelo estadístico, se basa en una serie de supuestos como linealidad, independencia, normalidad, homocedasticidad y no-colinealidad. A la verificación del cumplimiento de estos supuestos se le dedicará un epígrafe más adelante. La ecuación de regresión mínimo-cuadrática se construye estimando los valores de los coeficientes i del modelo de regresión. Estas estimaciones se obtienen intentando hacer que las diferencias al cuadrado entre los valores observados y los pronosticados sean mínimas. Método Introducir todas las variables predictoras. Este método incluye en la ecuación de regresión todas las variables predictoras.. 10.
(20) Se quiere encontrar la ecuación: En forma matricial:. [ ]. [. ]. [ ]. [ ]. El modelo es entonces:. O lo que es lo mismo:. [ ]. [. ][ ]. [ ]. La solución es: ̂. (. ). (1.5). Dónde: es la matriz traspuesta de X es la matriz inversa de X El cálculo de la matriz inversa en ocasiones puede ser computacionalmente costoso. Para evitarlo, se decidió utilizar la misma idea del método paso a paso para incluir variables al modelo, sin preguntar si son o no significativas. A continuación se muestra el pseudocódigo del algoritmo “Introducir”. Algoritmo 2: Introducir (Enter) Entrada: n valores de las variables independientes Para i = 1 hasta hacer: 1. Entrar la variable i al modelo. Salida: Modelo con todas las variables incluidas. y de la variable dependiente ,. 11.
(21) Método de los mejores subconjuntos (best subsets). Bajo este nombre se agrupan algoritmos que buscan el mejor subconjunto de variables entre C_Min y C_Max para formar parte de la ecuación, siguiendo un determinado criterio. Entre los criterios más utilizados se encuentran: . R2p: Se basa en el uso del coeficiente de determinación múltiple mayor como criterio para elegir el mejor subconjunto de variables.. . R2a,p: Modificación del R2pque tiene en cuenta el número de parámetros presente en el modelo de regresión. Su valor puede disminuir si p es muy grande.. . Cp: Criterio basado en el error cuadrático medio. Identifica subconjuntos de variables en los que el Cp es pequeño o está cerca de p.. . PRESSp : Es una medida de cuán bueno resulta el modelo ajustado para la predicción de las respuestas observadas Yi. Puede usarse en la etapa de validación.. . AICp: Se basa en el criterio de información de Akaike. Penaliza los modelos con muchos parámetros.. . SBCp: Se basa en el criterio bayesiano de Schwarz. Penaliza los modelos con muchos parámetros.. Este método calcula una pequeña fracción de todas las posibles regresiones y de ellas selecciona las mejores según el criterio elegido. Las ecuaciones más sencillas tienen C_Min variables, mientras que las más complejas tienen C_Max variables predictoras. La diferencia fundamental con los otros algoritmos es que este no ofrece una única solución, sino un conjunto de ellas (C_Sol) a petición del usuario ordenadas según el valor que tengan del criterio seleccionado. Algoritmo 3: Mejores subconjuntos (BestSubsets) Entrada: n valores de las variables independientes y de la variable dependiente , C_Min: cantidad mínima de variables predictoras en el modelo C_Max: cantidad máxima de variables predictoras en el modelo Crit: criterio para seleccionar las mejores ecuaciones C_Sol: cantidad de soluciones a mostrar Modelos_y_criterio: estructura de datos que permita almacenar los C_Sol modelos mejores y el valor de su criterio. Inicialización: Modelos_y_criterios en 0 Para i = C_Min hasta C_Max hacer: 1. Subconj = ( ) // Subconj tiene la cantidad de subconjuntos que de las. variables 12.
(22) predictoras de tamaño . 2. Para j = 1hastaihacer: Obtener subconjunto Calcular el modelo usando el método Introducir para ese subconjunto Calcular el criterio asociado al modelo Si el criterio es mejor que los C_Sol modelos entonces Actualizar Modelos_y_criterios Salida: En Modelos_y_criterios quedará la información de los C_Sol mejores modelos y los valores de sus criterios. A continuación se describen brevemente los criterios que pueden utilizarse para la selección de los mejores modelos. Los términos y se refieren a la suma de cuadrado de los residuales o errores y a la suma de cuadrados total. Ambos aparecen explicados en el epígrafe 1.2 Análisis de varianza. Coeficiente de determinación R 2 El coeficiente de determinación representa la proporción de la varianza total que es explicada por la regresión. . Donde es la cantidad de variables predictoras, SCE es la suma de cuadrados del error y SCT es la suma cuadrada total (ver tabla 1.2 de análisis de varianza).. 0 R2 1 El R 2 es una medida que puede utilizarse para determinar si se ha hecho un buen ajuste de X e Y. Por ejemplo, si R 2 0.90 puede afirmarse que el 90% de la varianza total es explicada por la suma de cuadrados de la regresión, por lo tanto existe una fuerte relación entre X e Y. El valor del R 2 aumenta en la medida en que se incrementan las variables en el modelo. Por tanto, no es correcto comparar el valor del R 2 de dos regresiones con un número de variables explicativas diferentes. Coeficiente de determinación R 2 ajustado. 13.
(23) Elimina las desventajas del criterio anterior debido que el valor del coeficiente no necesariamente aumenta con el número de variables en el modelo. (. ). (. ). .. Donde n es la cantidad de observaciones. Este criterio penaliza modelos con muchas variables predictoras por lo que es una opción 2 mejor que el R para problemas bioinformáticos y quimioinformáticos que se caracterizan por tener un gran número de variables predictoras.. Criterio de Akaike (AIC) y criterio Bayesiano de Schwarz (SBC) Estos criterios también penalizan los modelos con muchas variables. Las medidas están dadas por las ecuaciones: (. ). ( ). (. ). ( ). ( ). Notar que para estos dos criterios el primer término es la medida en la que el número de variables en el modelo. (. ). Este término decrece en. se incrementa.. 1.2 Análisis de varianza Sobre la base de la no existencia de falta de ajuste y de la adecuacidad del modelo, puede probarse la hipótesis estadística:. Para que este análisis sea válido para todos los métodos anteriores, se decidió utilizar la letra para identificar el número de variables que tiene el modelo final. La tabla 1.2 muestra el análisis de varianza. Tabla 1.2 Análisis de varianza para la regresión Origen. Suma cuadrados. de g.l.. Cuadrado medio. Razón F. Regresión ∑( ̂. ̅). ∑. (̂. ). ∑. (̂. ∑. (. Significación ) ̂). ( ). 14.
(24) Error ∑(. ̂). ∑(. ̅). ∑. (. ̂). Total. Si el valor de la significación es menor que 0.05 se rechaza la hipótesis fundamental modelo será adecuado.. y el. La variabilidad total se descompone en variabilidad explicada por la regresión y variabilidad residual. Si esta última es mayor que la primera, entonces el modelo hallado no es útil. En ese caso debe cuestionarse el uso de una función lineal para modelar el problema y se sugiere probar variantes de regresiones no lineales.. 1.3 Regresión no lineal No siempre el modelo lineal es el más adecuado y por ello son importantes también los casos en que, por ejemplo, las funciones f j son cuadráticas, más generalmente polinomios, o incluso, expresiones más complejas en que aparezcan funciones trascendentes. Los problemas de regresión no lineal pueden ser reducidos a problemas de regresión lineal siempre y cuando. las igualdades y j f j x1 , x2 ,, xL puedan ser reducidas a ciertas dependencias lineales entre funciones de las variables mencionadas. La regresión no lineal es un problema de inferencia de la forma: ( donde. ). (1.6). es una función no lineal respecto a algunos parámetros desconocidos θ.. Al igual que en la variante lineal, se desea obtener los valores de los parámetros de la mejor curva de ajuste (habitualmente, con el método de los mínimos cuadrados).. 1.4 Regresión reducible a lineal Los modelos lineales son útiles en numerosas situaciones, pero existen casos particulares en los que la relación entre la variable respuesta y las variables predictoras no es lineal. En muchos de ellos, dicha relación es “linealizable”, es decir al realizar una transformación a las variables, la relación se torna lineal. A continuación se mostrarán algunos ejemplos.. 15.
(25) 1.1.3. Modelos polinomiales. Las regresiones polinomiales se pueden ajustar la variable independiente con varios términos: Polinomio de segundo grado:. Polinomio de tercer grado:. Polinomio de grado m:. Todos estos casos pueden considerarse como regresiones lineales con parámetros desconocidos , , … . Este es el sentido del término "lineal" en el contexto de la regresión estadística. Los procedimientos computacionales para la regresión polinomial son procedimientos de regresión lineal múltiple, con las variables predictoras , ,…, . 1.1.4. Modelos polinomiales con interacciones. Se refiere a los modelos "lineales" con las variables predictoras , , y así sucesivamente. Debe notarse que en la medida en la que la cantidad de variables predictoras aumente, aumentará también la cantidad de interacciones. 1.1.5. Modelos exponenciales. Algunos problemas de regresión no lineal pueden “linealizarse” mediante una transformación en la formulación del modelo. Por ejemplo, sea el problema de regresión no lineal (ignorando el término del error):. Aplicando logaritmos a ambos lados de la ecuación, se obtiene: ( ). ( ). lo cual sugiere una estimación de los parámetros desconocidos a través de un modelo de regresión lineal de ( )con respecto a . La “linealización” debe usarse con cuidado ya que la influencia de los datos en el modelo cambia, así como la estructura del error del modelo y la interpretación e inferencia de los resultados. 1.1.6 Regresión logarítmica La curva logarítmica: 16.
(26) ( ) es también una recta, pero en lugar de estar referida a las variables originales referida a ( )y a .. e. , está. 1.5 Supuestos del modelo de regresión Para poder crear un modelo de regresión válido, es necesario que se cumpla con los siguientes supuestos: 1. La relación entre las variables es lineal. 2. Los errores en la medición de las variables explicativas son independientes entre sí. 3. Los errores tienen varianza constante. (Homocedasticidad) 4. Los errores tienen una esperanza matemática igual a cero (los errores de una misma magnitud y distinto signo son equiprobables). 5. El error total es la suma de todos los errores. Supuestos del modelo de regresión lineal: 1. Linealidad: La ecuación de regresión adopta una forma particular. En concreto, la variable dependiente es la suma de un conjunto de elementos: el origen de la recta, una combinación lineal de variables independientes o predictoras y los residuos. El incumplimiento del supuesto de linealidad suele denominarse error de especificación. Algunos ejemplos son: omisión de variables independientes importantes, inclusión de variables independientes irrelevantes, no linealidad (la relación entre las variables independientes y la dependiente no es lineal), parámetros cambiantes (los parámetros no permanecen constantes durante el tiempo que dura la recogida de datos), no aditividad (el efecto de alguna variable independiente es sensible a los niveles de alguna otra variable independiente), etc. 2. Independencia. Los residuos son independientes entre sí, es decir, los residuos constituyen una variable aleatoria (recordemos que los residuos son las diferencias entre los valores observados y los pronosticados). Es frecuente encontrarse con residuos autocorrelacionados cuando se trabaja con series temporales. 3. Homocedasticidad. Para cada valor de la variable independiente (o combinación de valores de las variables independientes), la varianza de los residuos es constante.. 17.
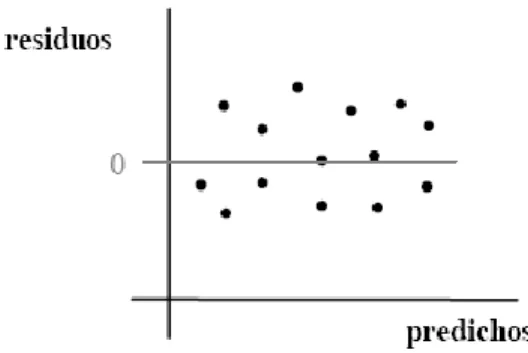
(27) 4. Normalidad. Para cada valor de la variable independiente (o combinación de valores de las variables independientes), los residuos se distribuyen normalmente con media cero. 5. No-colinealidad. No existe relación lineal exacta entre ninguna de las variables independientes. El incumplimiento de este supuesto da origen a colinealidad o multicolinealidad. 1.1.7 Examen gráfico de los residuos El examen de los residuos es necesario y útil, no sólo porque permite comprobar la validez de los supuestos hechos en el análisis de regresión, sino también porque, en el caso de fallar algunos de ellos, da indicaciones para lograr su cumplimiento: cambiando la forma del modelo, transformando las variables, rechazando observaciones, entre otras. Las pruebas gráficas no son tan precisas como las basadas en pruebas de hipótesis, pero sin dudas, pueden ser de mucha utilidad. Una vez que se han calculado los residuos se presentan varias alternativas para su examen: 1. Analizar los residuos en conjunto para rechazar observaciones o probar si su distribución es normal. Las pruebas de normalidad se discutirán más adelante, en el epígrafe 1.5.5 2. Graficar los residuos contra los valores estimados para verificar la homogeneidad de la varianza experimental y la adecuación del modelo. Veamos algunas de las variantes posibles. Las figura 1.3 a la 1.5 muestran posibles relaciones de los valores predichos por el modelo hallado contra los residuales. En el primer caso: figura 1.3, los residuos se agrupan en forma de una banda horizontal lo cual no da evidencia de fallo de los supuestos hechos. Esta es la situación deseada.. 18.
(28) Figura 1.3 Relación entre los valores predichos y los residuales. No muestra evidencia de fallo de los supuestos.. La figura 1.4 por su parte, muestra otra relación de los valores predichos contra los residuales. En este caso los residuos aumentan notablemente su variabilidad al aumentar o disminuir los valores predichos de la variable dependiente Y. Esto indica que la varianza de las observaciones no es constante y que se sugiere utilizar pesos (mínimos cuadrados ponderados) o transformar las observaciones antes de efectuar el análisis de regresión.. Figura 1.4 Relación entre los valores predichos y los residuales. Muestra evidencia de fallo de la homogeneidad de varianzas. La figura 1.5 presenta una situación diferente. En ella los residuos se relacionan con los valores predichos en forma de parábola o similar. Este comportamiento no es apropiado y es un indicador de que el modelo que se ha obtenido es inadecuado. Probablemente se necesiten términos extras en la ecuación o sea necesario realizar transformaciones a la variable dependiente.. 19.
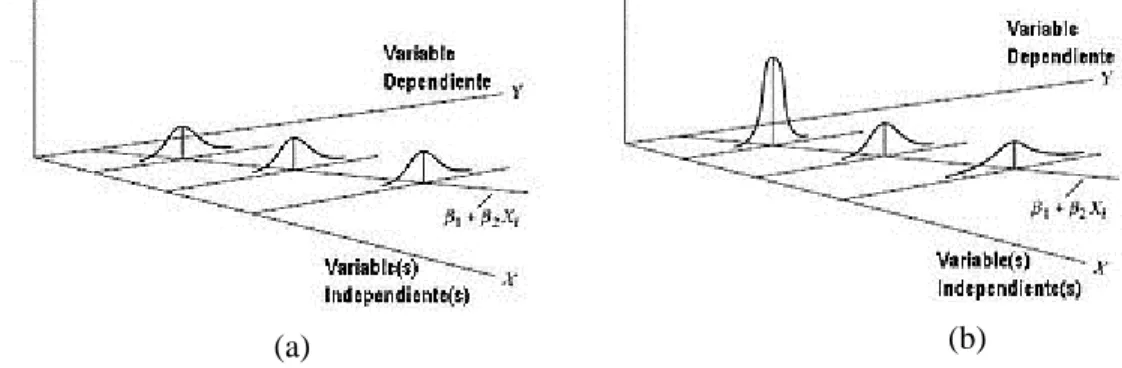
(29) Figura 1.5 Relación entre los valores predichos y los residuales. Modelo no adecuado. 1.1.8 Valores atípicos (OUTLIERS) Probablemente la razón más importante para calcular los residuos sea detectar observaciones extremas que tienen residuos muy grandes en comparación con las otras y deben ser tratadas especialmente. La mayoría de los procedimientos para examinar residuos son sensibles a la presencia de observaciones extremas. Las pruebas numéricas para detectar la no adecuación del modelo y la varianza no constante a veces reaccionan a las observaciones extremas. La figura 1.6 muestra la afectación de un modelo de regresión lineal simple por la aparición de una observación extrema. 6 5. y = 0.14x + 1.4334 R2 = 0.5592. 4 3 2 1 0 0. 5. 10. 15. 20. 25. Figura 1.6 Influencia de una observación extrema en la ecuación de regresión. 1.1.9 Homocedasticidad La homocedasticidad u homogeneidad de varianzas se presenta en un modelo cuando los errores presentan en todas las observaciones la misma varianza. Esta propiedad es necesaria para que los coeficientes estimados sean eficientes e insesgados. (Calero 1987). 20.
(30) Cuando no se cumple esta situación, se dice que existe heterocedasticidad, es decir la varianza de cada término residual no es constante. Si se obtiene un modelo de regresión usando mínimos cuadrados ordinarios y existe heterocedasticidad, los coeficientes siguen siendo lineales e insesgados pero ya no poseen mínima varianza (eficiencia). (Calero 1987) La figura 1.7muestra: (a) distribución homocedástica y (b) distribución heterocedástica.. (b) (a) Figura 1-7Distribución de los errores (a) homocedástica y (b) heterocedástica. 1.1.10 Prueba de la homogeneidad de varianzas El método consiste en calcular un coeficiente de regresión lineal de los i2 contra ŷ i dividido por s 2 : 2. n. h. i yˆ i yi i 1. s2H. donde H, en general, es un poco más pequeño que la suma de cuadrados del total pero, sin mucho error, puede ser sustituido por ésta. Para probar la significación de la desviación de h de cero se utiliza que: V h . 2n p n p 2H. Si h es significativamente diferente de cero se puede elegir la transformación potencial y p con el estimado: p 1 0.5hv cuando. p 0 . Si p 0 se considera que la transformación a. efectuar es ln y . (Izada 1984). 21.
(31) 1.1.11 Pruebas de normalidad El software tiene implementadas: 1. Prueba de Shapiro –Wilks 2. Prueba. si 3 n 50 (Shapiro and Wilk 1965). si 50 n 100 . Tomado de (Izada 1984). 3. Prueba de Kolmogorov-Smirnov( 4. Prueba de Jarque – Bera(. ) (Stephens 1974). ) (Jarque and Bera 1980; Jarque and Bera 1981). 5. Prueba de Anderson - Darling (Anderson and Darling 1952) Como puede observarse, se implementó una amplia variedad de pruebas de normalidad, lo que garantiza que, para cada modelo obtenido, existan varias variantes. Ello ayuda al proceso de toma de decisiones ante modelos con dudoso cumplimento de los supuestos. Prueba de Shapiro- Wilks W. Se calcula el estadígrafo:. n2 ai * ni1 i i1 W 2 n p * S. 2. donde los valores de ai dependen de n y se determinan mediante tablas y la suma se extiende sólo hasta la parte entera inferior de n. 2. debido a la simetría de la tabla.. Si W W se rechaza la hipótesis de normalidad a un nivel de confianza de. 1 . Los. valores de W están también tabulados en la literatura.(Shapiro and Wilk 1965) Prueba W 2. Se calcula el estadígrafo: n 2i 1 2i 1 W 2 n 2 LnF ei 1 Ln1 F ei 2n i 1 2n . donde F x es la función de distribución de probabilidades teórica, en este caso la Normal:. F x x .. 22.
(32) Si W 2 W 1 se rechaza la hipótesis de normalidad a un nivel de confianza 1 . Los valores de W para 1 desde 0 hasta 0.95 se encuentran en tablas de la literatura. Prueba de Kolmogorov - Smirnov Se calculan los valores (. (. definidos cómo:. ). ( (. y. ( )). ). ( ). ). Asumiendo que las observaciones están ordenadas ascendentemente. Los valores calculados (distribución empírica) son comparados con los valores de la distribución normal teórica. El valor de la significación se obtiene a partir de tablas simuladas. (L’Ecuyer 2012) Prueba de Jarque–Bera. Se calcula es estadígrafo JB: ((. ). (. ). ). Dónde n es el tamaño de la muestra. Es un test de bondad de ajuste específicamente usado para probar normalidad. Utiliza un estadístico en prueba que involucra la curtosis y la asimetría (Jarque and Bera 2006). Prueba de Anderson - Darling. Se calcula el estadístico Anderson-Darling como: ∑{(. ) (. ( )). (. ) (. Asumiendo que los datos están ordenados ascendentemente y. ( ) )}. (). es laprobabilidad de. la función de distribución teórica para la observación j.(D'Agostino and Stephens 1987; L'Ecuyer and Simard 2002). 23.
(33) 1.6 Estimaciones y predicciones Como resultado de un análisis de regresión lineal se obtiene una ecuación de la variable dependiente en función de las variables predictoras: que pasaron a formar parte del modelo:. Una vez obtenida esa ecuación, las observaciones de la base (u otras nuevas) pueden evaluarse en ella y así se obtendrá, para cada observación, un valor estimado de , que se denotará por ̂. Por ejemplo, para la observación. :. ̂ Dónde: ̂ es el valor estimado por el modelo para la observación es el resultado de evaluar en variable. con el valor de la observación. Debe recalcarse el hecho de que no es correcto evaluar en el modelo obtenido observaciones que estén muy lejanas de aquellas que se utilizaron para su construcción. El dominio de validez del modelo es aquel comprendido por los valores de las variables que participaron en su elaboración, ya que no se conoce nada sobre el comportamiento de la relación de X e Y fuera del dominio en la que se estudió esta relación.. 1.7 Consideraciones finales La regresión es un método que intenta pronosticar el valor de una variable dependiente Y a partir de los valores de una o múltiples variables predictoras. Es una técnica muy poderosa y ampliamente utilizada en diversas investigaciones en nuestros días. En dependencia de la forma de la ecuación, la regresión puede ser lineal, reducible a lineal o no lineal. Existen numerosos métodos para hallar una ecuación de regresión lineal múltiple. Los explicados en este marco teórico son: método paso a paso (stepwise), método que introduce todas las variables predictoras a la vez (enter) o método de los mejores subconjuntos (best subsets). El primero de ellos es una buena heurística para encontrar rápidamente un modelo aceptable, aunque no sea el óptimo. El último es un procedimiento bastante complejo desde el punto de vista computacional porque requiere del cálculo y la comparación de numerosos modelos. Puede hallarse la ecuación óptima siguiendo un determinado criterio. El más sencillo 24.
(34) de todos es el segundo. Es también el menos atractivo, pues generalmente las ecuaciones que incluyen todas las variables predictoras no son muy útiles, pero este método es la base del tercero. Esa fue la causa de su implementación. Si el conjunto de variables independientes es muy grande (mayor de cuarenta, por ejemplo), obtener todas las posibles regresiones puede ser sumamente complejo desde el punto de vista computacional, a pesar de contar con equipos de cómputo poderosos, o de implementaciones paralelas. Se recomienda en esos casos aplicar primero un método paso a paso y con las variables seleccionadas, ejecutar el de los mejores subconjuntos para tratar de obtener el mejor de los modelos con esas variables. Para que un modelo de regresión sea válido es necesario se cumplan determinados requisitos o supuestos que se verifican a posteriori. Uno de ellos es la normalidad de los residuales. Para ello se discutieron en este capítulo cinco técnicas diferentes, además de pruebas gráficas. El otro requisito es la homogeneidad de sus varianzas, para la que se mostró una prueba de hipótesis y un método gráfico.. 25.
(35) Capítulo 2. Linear Regression Package. Diseño, implementación y plataforma de desarrollo En este capítulo se abordan las generalidades acerca de análisis, diseño e implementación del software “Linear RegressionPackage 1.0” para realizar análisis de regresión con la verificación automática de los supuestos. Se exponen las ideas fundamentales de la plataforma de desarrollo utilizada y de los diagramas elaborados en la fase de análisis y diseño de la aplicación.. 2.1 Selección del lenguaje a utilizar Se seleccionó el lenguaje de programación Java desarrollado por Sun Microsystems para la implementación de Linear RegressionPackage. Java actualmente es libre, siendo esto muy conveniente para su uso en el desarrollo de aplicaciones en los países del tercer mundo. Este lenguaje fue creado para trabajar con objetos y es independiente de la plataforma. Al compilar un programa, Java genera un seudocódigo para una máquina genérica, que corre indistintamente en cualquiera de los ordenadores disponibles en el mercado, así funcionen sobre Windows, Linux, Mac u otro sistema operativo. Es un lenguaje robusto justamente por la forma en que está diseñado, no permite el manejo directo del hardware ni de la memoria, implementa mecanismos de seguridad que limitan el acceso a recursos de las máquinas donde se ejecuta. Además, con el JDK (Java Development Kit) vienen incorporadas muchas herramientas, entre ellas un generador automático de documentación.. 2.2 Plataforma de desarrollo Existe un conjunto de Entornos de Desarrollo Integrado (IDE, por sus siglas en inglés) que permiten el desarrollo de proyectos en Java. De los IDE disponibles para Java se seleccionó el NetBeans 7.1.1 ya que presenta un ambiente de programación cómodo, que compila en tiempo real y es fácil de usar para depurar un programa. Además posee una plataforma para el desarrollo de aplicaciones enriquecidas o “richclient” la cual se utilizó como marco de trabajo para el desarrollo del software “Linear RegressionPackage 1.0”. 2.2.1 Cliente enriquecido En la arquitectura cliente servidor este término se utiliza para clientes donde la mayor parte del procesamiento de los datos ocurre en el cliente y no en el servidor. El cliente también provee una interfaz visual al usuario (GUI). Muchas veces los clientes enriquecidos son aplicaciones que se pueden extender vía plugins y módulos. De esta manera, los clientes enriquecidos pueden resolver más de un problema.. 26.
(36) Los clientes enriquecidos generalmente se desarrollan sobre una plataforma o marco de trabajo (framework) que ofrece un punto de partida básico desde el cual el desarrollador puede ensamblar lógicamente las partes que se relacionan de la aplicación (módulos). Esto provee una arquitectura modular muy favorable para el trabajo en equipo, dónde módulos independientes pueden cooperar para lograr un objetivo final. Los clientes enriquecidos tienen la ventaja también de ser fáciles de distribuir así cómo dar mantenimiento.(Böck 2011) A continuación se muestra de manera resumida un resumen de las principales características de los clientes enriquecidos: •. Arquitectura flexible y modular. •. Independiente de la plataforma. •. Adaptabilidad a las necesidades del usuario final. •. Fácil distribución para el usuario final. •. Fácil mantenimiento y actualización de la aplicación. 2.2.2 Plataforma de cliente enriquecido Una plataforma de cliente enriquecido es la base para la construcción y desarrollo de aplicaciones. La mayoría de las aplicaciones tienen características similares, tales como: menús, barra de estado, visualización de resultados, carga de datos, manipulación de datos, entre muchas otras. Para esas y otras características típicas de las aplicaciones, una plataforma de cliente enriquecida provee un marco de trabajo para el desarrollo rápido y eficiente de todas estas características. El aspecto más importante de una plataforma de cliente enriquecido es su arquitectura modular, donde las partes lógicas de un programa pueden estar separadas. Los módulos se describen declarativamente y son automáticamente cargados por la plataforma. Esto posibilita independencia entre el código fuente y la aplicación, de esta manera se logra lo que se conoce cómo relación tardía entre los módulos independientes que están funcionando.(Böck 2011) Algunas de las ventajas que provee usar una plataforma de desarrollo son: •. Reducción del tiempo de desarrollo.. •. Una interfaz de usuario consistente.. •. Fácil actualización del sistema.. •. Independencia de la plataforma.. •. Reusabilidad y fiabilidad.. 27.
(37) 2.2.3 Algunas características de la plataforma de Netbeans Para el desarrollo de la aplicación se utilizó la plataforma que brinda el IDE Netbeans, en su versión 7. Aparte de todas las ventajas antes mencionadas de las plataformas de clientes enriquecidos, NetbeansPlatform ofrece numerosos marcos de trabajos y características adicionales que pueden ser muy útiles para el desarrollo de numerosas aplicaciones. Las más importantes, que constituyen las principales características de NetbeanPlatform, se mencionan a continuación. 2.2.3.1 Marco de trabajo para la interfaz de usuario. La plataforma define de manera cómoda ventanas, menús, barras de menú y otros componentes. Como resultado, el trabajo se centra en las acciones y no en cómo hacerlas. Ello reduce el código necesario a escribir haciéndolo más claro y menos propenso a errores. Toda la interfaz de usuario brindada por la plataforma de Netbeans está basada en los componentes AWT/Swing y puede ser extendida con nuestros propios componentes.(Böck 2011) 2.2.3.2 Editor de datos. El poderoso editor integrado en el Netbeans IDE puede ser usado por la aplicación que se desea desarrollar. Todas las herramientas y funcionalidades pueden ser fácil y rápidamente adaptadas a las necesidades de la aplicación que se está desarrollando. (Böck 2011) 2.2.3.3 Sistema de ayuda. La plataforma Netbeans ofrece un sistema de ayuda basado en el sistema de ayuda de Java (JavaHelpSystem). Mediante este sistema usted puede visualizar los diferentes tópicos que desee mostrar al usuario final. En epígrafes posteriores se explica la metodología a seguir para incorporar el sistema de ayuda. (Böck 2011) 2.2.4 Conclusiones parciales Hasta ahora se han explicado las principales ventajas de las plataformas de clientes enriquecidos, tales como su arquitectura modular, la consistencia de las interfaces de usuario, la reducción del tiempo de desarrollo y específicamente las principales características de NetbeansPlatform, de la cual sólo se mencionaron las más usadas en la implementación del software en cuestión.. 2.3 Algo de la implementación La Programación Orientada a Objetos (POO) es el método de implementación en el que los programas se organizan como colección corporativas de objetos, cada uno de los cuales representa una instancia de una clase.(Booch 1991). 28.
(38) El enfoque orientado a objetos ha sido un paso evolutivo en el análisis, diseño e implementación del software. Se utiliza por sus características para lograr sistemas poco resistentes a los cambios y de fácil mantenimiento; lo cual constituye una valiosa característica para cualquier aplicación. El software desarrollado cuanta con seis módulos: 1. 2. 3. 4. 5. 6.. FileIO GUI NormalityTest MyFunctions Plots LinearRgressionMethods. A continuación se muestra una breve descripción de las funciones que realiza cada uno de estos módulos que componen Linear RegressionPackage 1.0. El módulo FileIO posee dos clases: Results y FileHandler. La clase Results se encarga de almacenar los resultados tales como: tabla de análisis de varianza, prueba de rechazo, criterios de selección, entre otros para un modelo. La clase FileHandler se encarga del manejo de entrada y salida de datos para ficheros. Cuando la entrada o salida se hace para un fichero .txt, se utiliza para el proceso de lectura-escritura las clases StreamTokenizer y PrintWriter respectivamente, incluidas en el JDK del Java. Cuando la entrada – salida se hace para archivos.xls se utilizan las clases WritableWorkbook, Workbook, WritableSheet de la biblioteca JXL. El móduloNormalityTest contiene las clases encargadas de hacer las pruebas de normalidad que se explicaron en el capítulo 1. Cada test posee una clase que realiza los cálculos necesarios paro obtener los estadísticos que permitan aceptar o rechazar la adecuación del modelo a una distribución normal. El módulo MyFunctions contiene dos clases, DataTransform y Functions. La clase DataTransform tiene tres métodos estáticos que realizan las transformaciones a los datos (cuadrática, lineal con interacciones y polinomial), todas explicadas en el capítulo 1. La clase Functions tiene funciones estadísticas importantes que son necesarias utilizar durante la creación del modelo de regresión (Student, Fisher, ttab). Todas ellas están declaradas cómo estáticas. El módulo Plots contiene una clase, PlotsChart: Esta clase utiliza la biblioteca SSJ para mostrar gráficos QQ, PP y de dispersión.. 29.
(39) El módulo LinearRegressionMethods tiene dos clases CriteriaModelSelection que tiene un método estático por cada criterio de selección del modelo implementado y la clase LinearRegressionMethod que es dónde se realizan los algoritmos para obtener los modelos de regresión. Tanto los criterios de selección de los modelos como los algoritmos fueron explicados en el capítulo anterior. El módulo GUI contiene todo lo que tiene que ver con la interfaz de usuario. Está divido en paquetes que agrupan las clases que comparten características similares. Una de las clases principales es RegressionExecuter. En esta clase, primero se preparan los datos con el modelo seleccionado por el usuario, recuperándolos de la clase MainFrame, después se ejecuta el método de regresión seleccionado y finalmente se muestran los resultados. Esta clase establece la comunicación entre los diferentes módulos que componen el software creando instancias de sus clases y utilizando los métodos necesarios para obtener un modelo de regresión calcular de manera automática los supuestos sobre los que se sustenta la teoría de regresión y finalmente mostrar los resultados al usuario final.. 2.4 Análisis, diseño e implementación de Linear RegressionPackage 1.0 El lenguaje UML (UnifiedModelingLanguage) (Rumbaugh and Booch 2000) se utilizó para el diseño de la herramienta Linear RegressionPackage 1.0.Tiene como objetivos principales la especificación, visualización, construcción y documentación de los productos de un sistema de software. Este lenguaje es usado por el RUP (RationalUnifiedProcess) (Jacobson, Booch et al. 2000) como lenguaje de modelado para lo cual se basa en todos sus tipos de diagramas, que constituyen diferentes vistas del modelo del producto. La siguiente figura ilustra los diagramas que componen la estructura de un producto escrito por el lenguaje UML:. 30.
(40) Figura 2.1 Diagramas de UML. De los diagramas UML que muestra la figura anterior, se mostrarán los diagramas de Casos de Uso, de Actividad y de Clases. La herramienta empleada para el modelado de todos los diagramas correspondientes a las fases de análisis y diseño fue Visual Paradigm para UML versión 6.0. 2.4.1 Diagrama de casos de uso Los modelos de casos de uso proporcionan un medio sistemático e intuitivo de capturar requisitos funcionales del sistema basándose en los requerimientos de los usuarios. Ellos dirigen todo el proceso de desarrollo de un software ya que constituyen el punto de partida para llevar a cabo la mayoría de las actividades: el análisis, diseño y prueba del software(Jacobson, Booch et al. 2000). Este modelo se realiza identificando cada actor del sistema como los posibles usuarios para los cuales está realizado el mismo. La herramienta Linear Regression Package 1.0 está destinada a cualquier tipo de usuario, pudiendo ser un estudiante, un ingeniero de cualquier rama, un especialista o investigador en computación, matemática entre otros.. 31.
(41) Figura 2.0Diagrama de casos de uso. Mediante el primer caso de uso, el usuario puede salvar los datos que se están mostrando en la tabla principal en un archivo .txt o .xls, el guardado se realiza de tal manera que los datos puedan ser utilizados de nuevo por el programa, en la primera fila se guardan los nombres de las variables definidas y seguidamente los datos numéricos correspondientes. El segundo caso de uso permite al usuario entrar los datos y definir las variables vía teclado. El tercer caso de uso da la posibilidad al usuario de realizar pruebas de normalidad a los datos que estén cargados en la tabla principal. El cuarto caso de uso está relacionado con la transformación de los datos, esto es muy útil cuando los modelos de regresión lineal fallan, el software está equipado para realizar tres transformaciones: cuadrática, lineal con interacciones y polinomial.. 32.
(42) El quinto caso de uso es el más importante ya que es el objetivo principal de la herramienta, que es obtener modelos de regresión por los diferentes métodos con los que cuenta el software y que fueron mencionados en el capítulo 1. El último caso de uso permite al usuario salvar los datos obtenidos de la regresión en formato .xls o .txt. 2.4.2 Diagrama de clases La técnica del diagrama de clase se ha vuelto medular en los métodos orientados a objetos. El diagrama de clase describe los tipos de objetos que hay en un sistema y las diversas clases de relaciones estáticas (asociaciones, subtipos) que existen entre ellos. También muestra los atributos y operaciones de una clase y las restricciones a que se ven sujetos, según la forma en que se conecten los objetos (Fowler and Scott 1997) El módulo GUI dónde se implementa la interfaz de usuario y se realizan la mayoría de las operaciones cuenta con seis paquetes que agrupan los objetos con características similares. Las clases que se encuentran en el paquete Actions son las que desencadenan las acciones a petición del usuario, se va a explicar la acción de obtener un modelo de regresión por ser la más importante. Lo primero que se hace se mostrar al usuario un diálogo donde éste puede seleccionar el modelo que desea así como otras opciones que se explicarán en detalle en el capítulo 3. Cuando el usuario pulsa el botón aceptar indicando que desea obtener un modelo de regresión se realizan cuatro acciones fundamentales. El primer paso es la verificación de que el modelo seleccionado sea correcto (existan variables dependientes e independientes). Seguidamente se preparan los datos, recuperando de la clase MainFrame sólo aquellas variables que fueron seleccionadas para participar en el modelo y poniendo la variable dependiente en la última posición de la matriz de datos a la cual se le va aplicar el análisis de regresión. Con posterioridad se llama al método de regresión seleccionado por el usuario. Finalmente se realiza el análisis de regresión y se muestran los resultados. Todo esto ocurre en la clase RegressionExecuter que cuenta con los métodos necesarios para realizar estas acciones. El diagrama de clases de la aplicación aparece en el Anexo 1. 2.4.3 Diagramas de actividad Los diagramas de actividades se utilizan para modelar los aspectos dinámicos de un sistema, lo que generalmente implica modelar los pasos secuenciales (y posiblemente concurrentes) de un proceso computacional.. 33.
(43) La figura 2.3 muestra el diagrama de actividad para el caso de uso “realizar pruebas de normalidad”. Como se puede apreciar, el primer paso es la preparación de los datos, luego seleccionar la opción “realizar pruebas de normalidad”. A continuación se deben seleccionar aquellas variables que se desea conocer si siguen o no una distribución normal. En este momento debe seleccionarse la prueba de normalidad que se desea aplicar. El sistema tiene implementadas cinco pruebas diferentes que fueron explicadas en el capítulo 1. Luego se aplica la prueba en cuestión, se muestran los resultados, los que además pueden ser salvados. La figura 2.4 muestra el diagrama de actividad para el caso de uso “obtener modelos de regresión realizar pruebas de normalidad”. Este es el objetivo fundamental del software elaborado. El primer paso es seleccionar “ejecutar regresión”. Debe seleccionarse también el algoritmo de regresión. Para los métodos “introducir todas las variables”, “paso a paso” y “paso a paso interactivo”, se procede directamente a obtener el modelo matemático. En caso de seleccionar el algoritmo de los mejores subconjuntos, primero se deben establecer los parámetros, como la cantidad de modelos resultantes que se desean obtener, la cantidad mínima y máxima de variables que deben tener los modelos y el criterio de calidad de las ecuaciones. Una vez ajustados estos parámetros (todos tienen valores por defecto), se procede a la ejecución del algoritmo. Posteriormente se muestran los resultados.. 34.
(44) Figura 2.3 Diagrama de actividad para el caso de uso “Realizar pruebas de normalidad”. 35.
(45) Figura 2.4 Diagrama de actividad para el caso de uso “Obtener modelo de regresión”. 2.5 Metodología para la creación de la ayuda Gracias al uso de la plataforma de Netbeans, sobre la cual se desarrolló el software, la incorporación de la ayuda es bastante simple a continuación se brinda una pequeña metodología a seguir para su ampliación.. 36.
Figure


+7



Documento similar