Transformación de lenguaje natural en Sparql para consultas de tipo Factoid
177
0
0
Texto completo
(2) Dedicatoria A mis padres.. A mi amigo Fabiano en São Paulo.. Y a mis amigos del GREat en Fortaleza.. 2.
(3) Agradecimientos Agradezco a Dios por su amable don de la vida que me posibilitó vivir tantas cosas, incluyendo la construcción de esta tesis. Agradezco a mi mamá y a mi papá que dı́a a dı́a me incentivaron a acabar este trabajo. Ası́ mismo, agradezco a todos mis familiares que me apoyaron y siempre me apoyan en todas mis metas. Agradezco a mis amigos que supieron animarme, en especial a Alvaro que supo arrearme siempre que lo necesitaba. Agradezco al Grupo de Redes de Computadoras, Ingenierı́a de Software y Sistemas - GREat - Fortaleza - Brasil, en donde vivı́ inolvidables momentos durante el proyecto NLP. Y por último le doy las gracias a todos los colaboradores que me ayudaron con las evaluaciones y la recopilación de información ¡Muchas gracias!: Rute, Brian, Tiago, Daniel, Katiuska, Paulo, Bárbara, Jamile, Henrique y Macedo.. 3.
(4) Resumen Durante los últimos años, grandes empresas de internet y equipos móviles han invertido en mejorar la interacción hombre-computador a través de una interfaz en lenguaje natural. A estos dispositivos llamaremos AVI (Asistentes Virtuales Inteligentes) y ejemplo de estos tenemos a Google Now, Siri, Voice Mate, entre otros. Estos AVI en realidad son un Sistema de Pregunta-Respuesta programado para atender las demandas del usuario en un determinado dominio o un determinado hardware. Tales sistemas poseen 3 módulos: (i) procesamiento de la consulta, (ii) procesamiento de la información, y (iii) procesamiento de la respuesta. El presente trabajo se concentrará en el primer ı́tem y propondremos el uso de gramáticas y el patrón Interpreter para transformar una consulta en lenguaje natural a un lenguaje formal, en este caso escogimos SPARQL, que es un lenguaje propuesto para trabajar en Web Semántica y se emplea para consultar ontologias.. 4.
(5) Abstract During last years, big enterprises on Internet and mobile phones business have invested their efforts to look for a better human-computer interaction through a natural language interface. These devices we will call Virtual Assistant (VA) and we can mention in this group Google Now, Siri, Voice Mate, etc. Such VAs actually are Question-Answering (QA) Systems with the mission to attend the user’s demands about a determined domain or hardware functionality. A QA System have 3 modules: (i) query processing, (ii) information processing, and (iii) answer processing. Our work will focus on the first item (i) and we propose the use of grammars and the Interpreter design pattern to transform a natural language query into a formal language, in this case, we choose SPARQL which is a language designed to work in the Semantic Web and is used to query into ontologies.. 5.
(6) Índice general Dedicatoria. 2. Agradecimientos. 3. Resumen. 4. Abstract. 5. 1. Introducción. 17. 1.1. Preliminares . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 17. 1.2. Presentación del Problema . . . . . . . . . . . . . . . . . . . . . .. 18. 1.3. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 21. 1.3.1. Objetivo General . . . . . . . . . . . . . . . . . . . . . . .. 21. 1.3.2. Objetivos Especı́ficos . . . . . . . . . . . . . . . . . . . . .. 21. 1.4. Restricciones del trabajo . . . . . . . . . . . . . . . . . . . . . . .. 21. 1.5. Diseño de la Investigación . . . . . . . . . . . . . . . . . . . . . .. 22. 1.5.1. Tipo de la Investigación . . . . . . . . . . . . . . . . . . .. 22. 1.5.2. Población y Muestra . . . . . . . . . . . . . . . . . . . . .. 22. 1.6. Estructura del trabajo . . . . . . . . . . . . . . . . . . . . . . . .. 23. 2. Sistemas de Pregunta-Respuesta (PR). 25. 2.1. Marco Teórico . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 25. 2.1.1. Definición . . . . . . . . . . . . . . . . . . . . . . . . . . .. 25. 2.1.2. Arquitectura . . . . . . . . . . . . . . . . . . . . . . . . . .. 25. 2.1.3. Dimensiones . . . . . . . . . . . . . . . . . . . . . . . . . .. 25. 2.2. Sistema de PR con fuentes en Base de Datos . . . . . . . . . . . .. 27. 2.3. Sistemas de PR abiertos con fuentes en texto . . . . . . . . . . . .. 27. 2.4. Sistema de Pregunta-Respuesta Ontológicos . . . . . . . . . . . .. 28 6.
(7) Índice general. 7. 2.4.1. Fabiano . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 31. 2.4.2. Quepy . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 31. 2.4.3. AutoSPARQL . . . . . . . . . . . . . . . . . . . . . . . . .. 33. 2.4.4. TrueKnowledge . . . . . . . . . . . . . . . . . . . . . . . .. 34. 3. Gramáticas Computacionales. 36. 3.1. Definiciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 36. 3.2. Jerarquı́a de Chomsky . . . . . . . . . . . . . . . . . . . . . . . .. 37. 3.2.1. Tipo 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 37. 3.2.2. Tipo 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 38. 3.2.3. Tipo 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 38. 3.2.4. Tipo 0 . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 38. 3.3. Gramáticas Léxico-Funcionales (LFG). . . . . . . . . . . . . . . .. 39. 3.4. Análisis Sintáctica . . . . . . . . . . . . . . . . . . . . . . . . . .. 42. 3.4.1. Sintaxis . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 42. 3.5. Gramática Generativa . . . . . . . . . . . . . . . . . . . . . . . .. 45. 3.6. Análisis de Constituyentes . . . . . . . . . . . . . . . . . . . . . .. 45. 3.6.1. Gramática Transformacional . . . . . . . . . . . . . . . . .. 46. 3.6.2. Papeles temáticos . . . . . . . . . . . . . . . . . . . . . . .. 47. 4. Ontologias y Sparql. 49. 4.1. Ontologı́as . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 49. 4.1.1. Definición de Ontologias . . . . . . . . . . . . . . . . . . .. 49. 4.1.2. Tipos de ontologı́a . . . . . . . . . . . . . . . . . . . . . .. 49. 4.1.3. Componentes de la Ontologı́a . . . . . . . . . . . . . . . .. 51. 4.1.4. Lógicas de Descripción . . . . . . . . . . . . . . . . . . . .. 52. 4.2. Sparql . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 54. 4.2.1. Sintaxis . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 54. 5. Diseño y elaboración del corpus. 57. 5.1. Colección . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 57. 5.2. Etiquetación morfosintáctica . . . . . . . . . . . . . . . . . . . . .. 58. 5.3. Reconocimiento de Entidades Nombradas - REN . . . . . . . . . .. 59. 5.3.1. Validación cruzada . . . . . . . . . . . . . . . . . . . . . .. 61.
(8) Índice general. 6. Diseñando gramáticas. 8. 62. 6.1. Estrategia general . . . . . . . . . . . . . . . . . . . . . . . . . . .. 62. 6.2. Dominio: Comida Peruana . . . . . . . . . . . . . . . . . . . . . .. 63. 6.2.1. Consultas de tipo ¿Cuál? . . . . . . . . . . . . . . . . . . .. 63. 6.2.2. Consultas de tipo ¿Quién? . . . . . . . . . . . . . . . . . .. 68. 6.2.3. Consultas de tipo ¿Qué? . . . . . . . . . . . . . . . . . . .. 69. 6.2.4. Consultas de tipo ¿Dónde? . . . . . . . . . . . . . . . . . .. 73. 6.2.5. Consultas de tipo ¿Cuándo? . . . . . . . . . . . . . . . . .. 74. 6.2.6. Consultas de tipo ¿Cuánto? . . . . . . . . . . . . . . . . .. 74. 6.2.7. Consultas de tipo ¿Cómo? . . . . . . . . . . . . . . . . . .. 75. 6.2.8. Consultas de tipo ¿Por qué? . . . . . . . . . . . . . . . . .. 76. 6.3. Dominio: Comics . . . . . . . . . . . . . . . . . . . . . . . . . . .. 77. 6.3.1. Consultas de tipo ¿Cuál? . . . . . . . . . . . . . . . . . . .. 77. 6.3.2. Consultas de tipo ¿Quién? . . . . . . . . . . . . . . . . . .. 77. 6.3.3. Consultas de tipo ¿Qué? . . . . . . . . . . . . . . . . . . .. 78. 6.3.4. Consultas de tipo ¿Dónde? . . . . . . . . . . . . . . . . . .. 80. 6.3.5. Consultas de tipo ¿Cuándo? . . . . . . . . . . . . . . . . .. 81. 6.3.6. Consultas de tipo ¿Cuánto? . . . . . . . . . . . . . . . . .. 81. 6.3.7. Consultas de tipo ¿Cómo? . . . . . . . . . . . . . . . . . .. 83. 6.3.8. Consultas de tipo ¿Por qué? . . . . . . . . . . . . . . . . .. 84. 6.4. Dominio: Concesionaria Ford . . . . . . . . . . . . . . . . . . . . .. 85. 6.4.1. Consultas de tipo ¿Cuál? . . . . . . . . . . . . . . . . . . .. 85. 6.4.2. Consultas de tipo ¿Quién? . . . . . . . . . . . . . . . . . .. 86. 6.4.3. Consultas de tipo ¿Qué? . . . . . . . . . . . . . . . . . . .. 87. 6.4.4. Consultas de tipo ¿Dónde? . . . . . . . . . . . . . . . . . .. 87. 6.4.5. Consultas de tipo ¿Cuándo? . . . . . . . . . . . . . . . . .. 88. 6.4.6. Consultas de tipo ¿Cuánto? . . . . . . . . . . . . . . . . .. 88. 6.4.7. Consultas de tipo ¿Cómo? . . . . . . . . . . . . . . . . . .. 90. 6.4.8. Consultas de tipo ¿Por qué? . . . . . . . . . . . . . . . . .. 90. 6.5. Dominio: Fútbol Peruano . . . . . . . . . . . . . . . . . . . . . .. 90. 6.5.1. Consultas de tipo ¿Cuál? . . . . . . . . . . . . . . . . . . .. 90. 6.5.2. Consultas de tipo ¿Quién? . . . . . . . . . . . . . . . . . .. 91. 6.5.3. Consultas de tipo ¿Qué? . . . . . . . . . . . . . . . . . . .. 93. 6.5.4. Consultas de tipo ¿Dónde? . . . . . . . . . . . . . . . . . .. 96. 6.5.5. Consultas de tipo ¿Cuándo? . . . . . . . . . . . . . . . . .. 97.
(9) Índice general. 9. 6.5.6. Consultas de tipo ¿Cuánto? . . . . . . . . . . . . . . . . .. 97. 6.5.7. Consultas de tipo ¿Cómo? . . . . . . . . . . . . . . . . . .. 98. 6.5.8. Consultas de tipo ¿Por qué? . . . . . . . . . . . . . . . . .. 99. 6.6. Dominio: Institución UNSA . . . . . . . . . . . . . . . . . . . . .. 99. 6.6.1. Consultas de tipo ¿Cuál? . . . . . . . . . . . . . . . . . . .. 99. 6.6.2. Consultas de tipo ¿Quién? . . . . . . . . . . . . . . . . . . 100 6.6.3. Consultas de tipo ¿Qué? . . . . . . . . . . . . . . . . . . . 101 6.6.4. Consultas de tipo ¿Dónde? . . . . . . . . . . . . . . . . . . 102 6.6.5. Consultas de tipo ¿Cuándo? . . . . . . . . . . . . . . . . . 102 6.6.6. Consultas de tipo ¿Cuánto? . . . . . . . . . . . . . . . . . 103 6.6.7. Consultas de tipo ¿Cómo? . . . . . . . . . . . . . . . . . . 103 6.6.8. Consultas de tipo ¿Por qué? . . . . . . . . . . . . . . . . . 104 7. Implementación. 105. 7.1. Gramática . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105 7.2. Uso del patrones de diseño . . . . . . . . . . . . . . . . . . . . . . 106 7.2.1. Interpreter . . . . . . . . . . . . . . . . . . . . . . . . . . . 107 7.3. Construyendo las clases para nuestro modelo . . . . . . . . . . . . 107 7.3.1. Llamada Inicial . . . . . . . . . . . . . . . . . . . . . . . . 109 7.3.2. Delegando responsabilidades y la Estructura General . . . 110 7.3.3. Construyendo parcialmente la respuesta . . . . . . . . . . 111 7.3.4. Fin de la llamada a Interpret 8. Evaluación. . . . . . . . . . . . . . . . . 112 114. 8.1. Evaluación de MDS basada en prácticas y promesas . . . . . . . . 114 8.1.1. Métricas . . . . . . . . . . . . . . . . . . . . . . . . . . . . 115 8.2. Prácticas de nuestro sistema . . . . . . . . . . . . . . . . . . . . . 116 8.2.1. Corpus anotado . . . . . . . . . . . . . . . . . . . . . . . . 116 8.2.2. Construcción de gramáticas . . . . . . . . . . . . . . . . . 117 8.2.3. Uso del padrón Interpreter. . . . . . . . . . . . . . . . . . 118. 8.3. Promesas de nuestra metodologı́a . . . . . . . . . . . . . . . . . . 119 8.3.1. Mayor cobertura . . . . . . . . . . . . . . . . . . . . . . . 119 8.3.2. Escalabilidad . . . . . . . . . . . . . . . . . . . . . . . . . 119 8.3.3. Curva de aprendizaje acentuada . . . . . . . . . . . . . . . 120 8.3.4. Equipo de trabajo diversificado . . . . . . . . . . . . . . . 120 8.3.5. Trabajo sistematizado . . . . . . . . . . . . . . . . . . . . 120.
(10) Índice general. 10. 8.4. Esquema de evaluación . . . . . . . . . . . . . . . . . . . . . . . . 121 8.5. Evaluaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 123 8.5.1. Sobre nuestros dominios y colaboradores . . . . . . . . . . 123 8.5.2. Sobre la construcción de corpus . . . . . . . . . . . . . . . 123 8.6. Comparación con otros trabajos . . . . . . . . . . . . . . . . . . . 128 9. Conclusiones. 131. 9.1. Experiencia con los colaboradores . . . . . . . . . . . . . . . . . . 131 9.1.1. Sobre la construcción del corpus . . . . . . . . . . . . . . . 131 9.1.2. Sobre la construcción de gramáticas . . . . . . . . . . . . . 131 9.1.3. Sobre la interpretación de lenguaje natural a Sparql . . . . 132 9.1.4. Sobre la curva de aprendizaje . . . . . . . . . . . . . . . . 132 9.2. Consideraciones finales . . . . . . . . . . . . . . . . . . . . . . . . 132 9.2.1. Recursión y ambiguedad . . . . . . . . . . . . . . . . . . . 132 9.2.2. Principales aportes . . . . . . . . . . . . . . . . . . . . . . 133 9.3. Trabajos futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134 A. Gramática de Comidas Peruanas. 136. B. Earley Parser. 142. B.1. Definición . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142 B.2. Operadores . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 143 B.2.1. Operador Predictor . . . . . . . . . . . . . . . . . . . . . . 143 B.2.2. Operador Completer . . . . . . . . . . . . . . . . . . . . . 144 B.2.3. Operador Scanner. . . . . . . . . . . . . . . . . . . . . . . 144. B.3. Ejemplo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145 C. Análisis de combinación, ejemplo para la sentencia Cual. 147. D. Resultados de transformación. 151. D.1. Sentencias del tipo ¿Cuál? . . . . . . . . . . . . . . . . . . . . . . 151 D.2. Sentencias del tipo ¿Quién? . . . . . . . . . . . . . . . . . . . . . 154 D.3. Sentencias del tipo ¿Qué? . . . . . . . . . . . . . . . . . . . . . . 154 D.4. Sentencias del tipo ¿Cuánto?. . . . . . . . . . . . . . . . . . . . . 156. D.5. Sentencias del tipo ¿Dónde? . . . . . . . . . . . . . . . . . . . . . 157 D.6. Sentencias del tipo ¿Cómo? . . . . . . . . . . . . . . . . . . . . . 158 D.7. Sentencias del tipo ¿Por qué? . . . . . . . . . . . . . . . . . . . . 159.
(11) Índice general. E. Entrevistas E.1. Cuestionario . . . . . . . . . . . . . . . . . . . . . . . . . . . . E.1.1. Sobre construcción de gramáticas . . . . . . . . . . . . E.1.2. Sobre modificaciones en la gramática . . . . . . . . . . E.1.3. Sobre Estrategia de Gramáticas y el patrón Interpreter E.2. Respuestas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Bibliografı́a. 11. . . . . .. . . . . .. 160 160 160 160 161 162 171.
(12) Lista de Abreviaturas AdvP CFG CC COMP CRF D DP EL FEM+ FEMGEN GLC HMM IP LFG LN MDS N NEG NP NUM OBJ OD OI OP OWL PERS. Sintagma adverbial Gramática Libre de Contexto Complemento circunstancial Complemento Conditional Random Fields Determinante Sintagma determinante Perfil OWL con la familia de lógica de descripción. Femenino Masculino Género Gramática Libre de Contexto Hiden Markov Models Sintagma de flexión Gramática Léxico-Fubncional Lenguaje natural Metodologı́as de Desarrollo de Software Substantivo Negativo Sintagma nominal Número Objeto Objeto Directo Objeto Indirecto Objeto Preposicional Ontology Web Language Persona 12.
(13) Índice general. PLUPLU+ P PoS PLN PP PR PRED PRES RAE REN RI S SA SNominal SPrep SUJ TDD TPO V VP W3C. 13. Singular Plural Preposición Part Of Speech (PoS tagging = etiquetado gramatical) Procesamiento de Lenguaje Natural Sintagma preposicional Pregunta-Respuesta Predicado Presente Real Academia de Lengua Española Reconocimiento de Entidades Nombradas Recuperación de la Información Sentencia Sintagma Adjetival Sintagma Nominal Sintagma Preposicional Sujeto Test-driven Development (Desarrollo guiado por pruebas). Tiempo Verbo Sintagma verbal World Wide Web Consortium.
(14) Índice de figuras 2.1. Arquitectura de un Sistema PR . . . . . . . . . . . . . . . . . . .. 26. 2.2. Ejemplos de transformación de la consulta ¿Cuál es el teléfono del IME? a Sparql. Fuente Ferreira-Luz (2013). . . . . . . . . . . . .. 31. 2.3. Ejemplos de transformación de la consulta ¿Cuántos accesorios tiene el E63? a Sparql. Fuente Ferreira-Luz (2013). . . . . . . . .. 32. 2.4. Árbol de consulta a la izquierda y su traducción a SPARQL a la derecha. Fuente: AutoSPARQL (Lehmann y Bühmann, 2011) . . .. 33. 2.5. Ejemplo de consulta quién es Alan Garcı́a usando la herramienta Evi. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 34. 3.1. Estructura-c. Ejemplo traducido del material de lectura en Falk (2001). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 40. 3.2. Estructura-f. Ejemplo traducido del material de lectura en Falk (2001) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 41. 3.3. Ejemplo de árbol sintáctico. . . . . . . . . . . . . . . . . . . . . .. 46. 3.4. Ejemplo de árbol sintáctico reducido . . . . . . . . . . . . . . . .. 47. 4.1. Ejemplo de Individuos y Propiedades . . . . . . . . . . . . . . . .. 51. 4.2. Ejemplo de propiedades inversas . . . . . . . . . . . . . . . . . . .. 52. 4.3. Ejemplo de propiedades inversas . . . . . . . . . . . . . . . . . . .. 52. 4.4. Ejemplo de clases . . . . . . . . . . . . . . . . . . . . . . . . . . .. 53. 4.5. Ejemplo de consulta en Sparql . . . . . . . . . . . . . . . . . . . .. 55. 4.6. Ejemplo de consulta en Sparql con prefijos . . . . . . . . . . . . .. 55. 5.1. Reducción de una sentencia usando Entidades Nombradas . . . .. 60. 7.1. Esquema general del Patrón Interpreter . . . . . . . . . . . . . . . 108 14.
(15) Índice de figuras. 15. 7.2. Distribución de clases para el patrón interpreter en nuestra implementación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 108 8.1. Prácticas en negrita, promesas en itálica y criterios de evaluación subrayados. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122 8.2. Creación del corpus Comida Peruana y Solicitudes a Celular . . . 124 C.1. Cálculo de sentencias posibles generadas a partir de una sola rama del tipo de sentencias con el pronombre Cuál. Total de 110700 posibles sentencias . . . . . . . . . . . . . . . . . . . . . . . . . . 150.
(16) Índice de cuadros 1.1. Principales Asistentes Virtuales Inteligentes en el mercado hasta Abril 2017. Fuente propia. . . . . . . . . . . . . . . . . . . . . . . 2.1. Adaptación propia al español de la clasificación de Moldovan et al. (1999) . . . . . . . . . . . . . . . . 2.2. Abordajes de diferentes Sistemas PR Ontológicos. trabajo de Lopez et al. (2011) . . . . . . . . . . . .. 19. preguntas de . . . . . . . . Extraı́do del . . . . . . . .. 30. 4.1. Algunos constructores que forman familias de lógicas de descripción de ALC . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 54. 5.1. Resultados de Precisión y Alcance para reconocimiento de Entidades Nombradas usando la herramienta de Stanford. . . . . . . . .. 61. 29. 7.1. Ejemplos de comparación entre una entrada de fuera del sistema, con el léxico de la gramática . . . . . . . . . . . . . . . . . . . . . 106 8.1. Comparación de Prácticas . . . . . . . . . . . . . . . . . . . . . 129 8.2. Comparación de Promesas . . . . . . . . . . . . . . . . . . . . . 130 B.2. Ejemplo de análisis usando EarleyParser para el ejemplo 2+3/4 . 146. 16.
(17) Capı́tulo 1 Introducción 1.1.. Preliminares. El sueño de Berners-Lee y Fischetti (1999), creador de la Web como la conocemos, consiste en dos partes. La primera que habla sobre la capacidad de interconexión entre las personas de forma intuitiva usando un conocimiento compartido y la segunda parte habla sobre la necesidad de crear una web con mayor riqueza semántica. Desde entonces, diferentes lı́neas de investigación han sido exploradas a fin de concretizar tal sueño y contamos en la actualidad con una mayor riqueza de recursos que están siendo regidos por el Consorcio World Wide Web (W3C). Para permitir el compartimiento de conocimiento a través de diferentes aplicaciones en la Web, se requiere el uso ciertos formalismos, en cuyo caso la W3C propone los lenguajes RDF - Resource Description Framework y el OWL - Web Ontology Language como estándares. Según Gruber (1993), Una ontologı́a no es más que la especificación de una conceptualización , y usamos ellas para poder especificar conceptos y relaciones de un determinado domı́nio de conocimiento y compartirlas con otros usuarios. El proyecto LinkedData (Bizer et al., 2009) es un proyecto que defiende las buenas prácticas para poder publicar e interconectar datos estructurados a través de la web. Los ingredientes claves para que una ontologı́a sea valiosa para el proyecto consiste en su formato RDF, es decir, la forma en que la ontologı́a fue diseñada, y además que tenga conceptos equivalentes con otras ontologı́as aprobadas para ser parte de Linked Data. Estos conceptos son identificados por el mismo URI - Universal Resource Identification. 17.
(18) Capı́tulo 1. Introducción. 18. Otros proyectos grandes como DBPedia 1 y BigData (Chen et al., 2014) tienen el objetivo de acumular la mayor cantidad de datos y relacionarlos entre si. De esta manera ofrecer una mayor riqueza de información para los usuarios y generar cientos de investigaciones para crear mayores relaciones entre los datos y crear mecanismos más robustos de recuperación de información.. 1.2.. Presentación del Problema. En la actualidad, las empresas de tecnologı́a de renombre están apostando en los Asistentes Virtuales Inteligentes (AVI), que son aplicaciones que interactúan con el usuario atendiendo las demandas del mismo realizadas en lenguaje natural. Vemos esta tendencia reflejada en la Tabla 1.1. Basándonos en las especificaciones encontradas en sus páginas oficiales, estos AVI poseen mı́nimamente las siguientes caracterı́sticas: 1. Comandos para celular, por ejemplo: Llamar a (nombre o número del contacto). Leer último mensaje. Abrir (nombre del aplicativo). 2. Comandos agendados, por ejemplo: Colocar la alarma para las (un cierto horario, con o sin fecha). Colocar un nuevo evento (nombre del evento) para el dı́a (fecha con o sin hora). 3. Consultas sobre clima, por ejemplo: ¿Cuál es la temperatura en (nombre de la ciudad). ¿Lloverá hoy?. 4. Consultas sobre elementos del celular, por ejemplo: ¿Cuánta carga tiene la baterı́a? ¿Cuántos contactos tengo? 1. http://wiki.dbpedia.org/about.
(19) Capı́tulo 1. Introducción. Asistente Virtual. 19. Puntos fuertes Posee al alcance, todo la ingenierı́a Web de Google. Integración Google Now. Todos los aparatos Empresa: Google. electrónicos con AnLanzamiento: Julio 2012. droid y de forma limitada en iOS Bixby (Antiguo S Entre su asociado más Diferentes versiones de importante se encuentra aparatos electrónicos de Mate.) Empresa: Samsung. la empresa Nuance Samsung, principalmenLanzamiento: Marzo te celulares y tablets. 2017.. Siri. Empresa: Apple. Lanzamiento: Octubre 2012.. Voice Mate. Empresa: LG Electronics. Lanzamiento: Agosto 2013.. Cortana. Empresa: Microsoft. Lanzamiento: Abril 2014.. Está asociado a diversas empresas especializas, entre ellas, sobre Procesamiento de Lenguaje Natural y PreguntaRespuesta: Nuance, Bing Answers, Wolfram Alpha, Evi Presente en la mayorı́a de los productos de LG. Todos los recurso de Microsoft, además de ofrecer una gran variedad de servicios. Iphone, Ipad, Apple Watch, Apple TV. Productos electrónicos de LG como celulares, televisores, relojes inteligentes y otros Todos los celulares con Windows Phone 8.1. Tabla 1.1: Principales Asistentes Virtuales Inteligentes en el mercado hasta Abril 2017. Fuente propia..
(20) Capı́tulo 1. Introducción. 20. 5. Consultas de temas generales, por ejemplo: ¿Quién es Barak Obama? ¿Cuándo se fundó Amèrica? ¿Dónde se realizó el último mundial de futbol? ¿Cómo nacen los bebés? ¿Por qué el cielo es azul? 6. Chat ¿Cómo te llamas? ¿Quién te programó? ¿Cómo estás?. Desconsiderando el tema del reconocimiento de lenguaje natural, los puntos del 1 al 4 son desarrollados dependiendo del hardward del celular y de las API que el programador posee para usar los servicios que o celular ofrece. El ı́tem 5 depende de un sistema inteligente con suficiente información para poder extraer la respuesta o inferirla. El ı́tem 6 corresponde a los esfuerzos por resolver el desafı́o de Alan Turing (Turing, 1950), que consiste en realizar preguntas a través de un computador y no poder distinguir si estamos conversando con una máquina o un ser humano. Los esfuerzos hasta la fecha pueden ser verificados revisando los trabajos presentados en el concurso Loebner Prize 2 . Tales esfuerzos tienen un denominador común: Una gran base de datos de preguntas y respuestas, ası́ como un mecanismo para identificar la respuesta más próxima dada una cierta pregunta. En este trabajo, nuestros esfuerzos se enfocarán en construir un mecanismo de transformación de lenguaje natural para un lenguaje intermediario que podamos usar para encontrar la información en una base de conocimientos. 2. Es un concurso internacional que premia al mejor chatterbot que los jueces consideran como más humano..
(21) Capı́tulo 1. Introducción. 1.3. 1.3.1.. 21. Objetivos Objetivo General. Presentar un mecanismo de traducción de lenguaje natural a Sparql usando gramáticas y el patrón de diseño Interpreter.. 1.3.2.. Objetivos Especı́ficos. Construir un corpus de consultas de tipo Factoid. A partir de nuestro corpus, elaborar una gramática usando un conjunto de buenas prácticas. Obtener una estructura gramatical a partir de un análisis léxico-sintáctico y de entidades nombradas sobre una determinada consulta que un usuario realize al sistema. Traducir tal estructura gramatical en una estructura de clases a fin de usar el patrón interpreter. Construir el mecanismo de interpretación a partir de la estructura con el patrón interpreter y retornar las consultas en Sparql. Medir el factor de manutención y escalabilidad.. 1.4.. Restricciones del trabajo. El trabajo puede ser aplicado a cualquier idioma o dialecto con representación escrita en que su análisis sintáctico no sea estrictamente dependiente de sus caracterı́sticas suprasegmentales, es decir, de la entonación, del acento, del ritmo y otros fenómenos fonéticos. Entre los formalismos en que queremos transformar nuestra sentencia en lenguaje natural, será el SPARQL, para poder realizar consultas en ontologı́as..
(22) Capı́tulo 1. Introducción. 1.5. 1.5.1.. 22. Diseño de la Investigación Tipo de la Investigación. De acuerdo con Sampieri et al. (1991), nuestra investigación será de carácter exploratoria al inicio pues analizaremos el problema y propondremos soluciones para llegar en nuestro objetivo de construir un mecanismo de transformación de lenguaje natural a SPARQL. Luego realizaremos una investigación descriptiva para medir los alcances de nuestra propuesta. Según Cazau (2006), esta investigación también puede ser definida como de tipo aplicada, pues nuestros objetivos son bien prácticos, deseamos que una persona que use nuestro mismo abordaje, pueda construir con éxito su propio mecanismo de transformación de lenguaje natural para un lenguaje formal. También Cazau menciona que la investigación puede ser de tipo cualitativa pues al final evaluaremos la capacidad de una persona seguir las pautas indicadas en nuestra propuesta para construir las ontologı́as y usar el patrón Interpreter.. 1.5.2.. Población y Muestra. Para probar la metodologı́a que será fruto de esta investigación, deberemos aplicarla en diferentes áreas de conocimiento. Debido a que nuestro interés está basado en la Web Semántica, verificamos que el proyecto Linked Data sugiere 16 temas interesantes para construir ontologı́as y abrazarse al proyecto, es por eso que nos basaremos en esta lista y apenas probaremos nuestros estudios con 5 temas: 1. Comida - Comida Peruana. 2. Entretenimiento - Comics Guerra Civil. 3. Ventas - Concesionaria de carros Ford. 4. Instituciones educativas - Universidad de San Agustı́n de Arequipa. 5. Deportes - Fútbol Peruano. Para la evaluación cualitativa, pediremos a 5 programadores para: 1. Idealizar una arquitectura para construir un sistema de pregunta-respuesta para los diferentes temas propuestos..
(23) Capı́tulo 1. Introducción. 23. 2. Propondremos nuestra metodologı́a para construir el mecanismo de transformación de lenguaje natural a lenguaje formal. 3. Para cada programador, capturaremos: El tiempo de experiencia construyendo este tipo de sistemas, Tiempo de aprendizaje de la metodologı́a, Tiempo estimado de desarrollo del sistema, y Anotaremos las opiniones de los usuarios.. 1.6.. Estructura del trabajo. El presente trabajo primero introducirá al lector en el tema de Sistemas Pregunta-Respuesta detallado en el Capı́tulo 2 en que hablaremos sobre los elementos básicos que componen uno de estos sistemas, ası́ como su evolución a partir de sistemas parecidos a los de recuperación de información y llegar a los sistemas que usan algún tipo de gramática y una base de conocimiento. Seguidamente, en el Capı́tulo 3 recordaremos conceptos básicos referente a las gramáticas e resaltaremos la amplia lı́nea investigación que aún falta por explorar en esta área. Revisaremos el tema de Ontologı́as en el Capı́tulo 4. Veremos los conceptos básicos y presentaremos a donde queremos llegar: las consultas de tipo Sparql. En el Capı́tulo 5 presentaremos los corpus que deseamos estudiar, ası́ también explicaremos brevemente los pasos que seguimos y las experiencias que obtuvimos construyendolos. El Capı́tulo 6 es el más extenso de nuestro trabajo y en él explicamos paso a paso la forma de construir nuestras gramáticas usando una serie de buenas recomendaciones. Posteriormente, en el Capı́tulo 7, explicamos la parte de programación, es decir, la implementación de nuestro sistema. Hablaremos de cómo construı́mos la interpretación de una consulta usando el patrón intepreter. El Capı́tulo 8 es uno de los más importantes pues a través de nuestras experiencias, este capı́tulo comienza por por sı́ mismo la importancia de nuestro trabajo. Finalmente, dedicamos el Capı́tulo 9 para concluir nuestra investigación y presentar los posibles trabajos futuros que pueden ser explorados..
(24) Capı́tulo 1. Introducción. 24. Además de nuestros capı́tulos principales, el presente trabajo adjuntó apéndices, no menos importantes, en los que presentamos: una gramática completa para nuestro dominio de comidas peruanas en el Apéndice A, la implementación de nuestro Earley parser en el Apéndice B, el análisis combinatorio de posibles sentencias que una gramática puede reconocer en el Apéndice C, algunos resultados de transformaciones que nuestro sistema retornó en el dominio de comida peruana en el Apéndice D, y las entrevistas que realizamos a nuestros colaboradores Apéndice E..
(25) Capı́tulo 2 Sistemas de Pregunta-Respuesta (PR) 2.1. 2.1.1.. Marco Teórico Definición. Los Sistemas de Pregunta-Respuesta (PR) están profundamente relacionados con las áreas de Recuperación de la Información (RI) y Procesamiento de Lenguaje Natural (PLN). Un Sistema PR se encarga de retornar una respuesta en lenguaje natural al usuario que realizó la consulta también en lenguaje natural.. 2.1.2.. Arquitectura. De acuerdo con Allam y Haggag (2012), los sistemas PR presentan en común 3 módulos de procesamiento: (i) Consulta, (ii) Documentos y (iii) Respuesta. Podemos ver en la Figura 2.1 cómo están conectados tales módulos. Deseamos resaltar la existencia del primer módulo pues el presente trabajo se enfocará en él.. 2.1.3.. Dimensiones. Según Lopez et al. (2011), los sistemas PR pueden ser clasificadas basándonos en 4 dimensiones: 1. El tipo de entradas que acepta: 25.
(26) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). Figura 2.1: Arquitectura de un Sistema PR Palabras clave Factoids (Preguntas con ¿cuál?, quién? y sus negativas). Entendimiento de causa y razonamiento (¿porqué?, ¿cómo?). Razonamiento de tiempo y espacio. Hechos de diferentes fuentes. Razonamiento de sentido común. Interacción por medio de diálogos. 2. Los tipos de fuentes de información que son consultadas. Datos estructurados. Datos semi-estructurados. Datos no estructurados (texto sin formato). Datos semánticos. 3. El tipo de dominio. Independiente del dominio. Dependiente del dominio. Base de conocimientos propietarias. 4. La forma de tratar con problemas tradicionales. Escalabilidad. Heterogeneidad (mapeo y desambiguación) Dominio abierto (fusión y clasificación).. 26.
(27) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). 27. Varios idiomas. Confianza.. 2.2.. Sistema de PR con fuentes en Base de Datos. De acuerdo a Lopez et al. (2011), los primeros sistemas que surgieron de pregunta-respuesta tenı́an como objetivo crear una Interface de Lenguaje Natural para consulta en Base de Datos (ILNBD) 1 . En los años 60-70s fueron construidos los primeros sistemas: el BASEBALL (Green et al., 1961) e LUNAR (Woods, 1973). Ambos eran de dominio cerrado. El primero respondı́a consultas referentes al la liga de baseball estadounidense mientras que el segundo respondı́a referente al análisis geológico de rocas retornado por la misión Apollo. Algunos sistemas como el de Androutsopoulos et al. (1993) y Popescu et al. (2003) utilizaron técnicas de búsqueda de padrones, que a principio parece una técnica no recomendable pues la falta de padrones reconocibles llevaba los sistemas al error, sin embargo, la facilidad para construir tales estrategias llevó a su práctica común para tratar sistemas con dominio cerrado. Estos sistemas incluyeron también un tratamiento sobre la consulta para extraer información semántica relevante y al final transformar la consulta para un lenguaje intermediario que el sistema pueda entender. El uso de gramáticas fue empleado en algunos trabajos como el de Minock (2010) para reconocer los padrones, extraer sus caracterı́sticas y transformar la consulta en un lenguaje intermediario.. 2.3.. Sistemas de PR abiertos con fuentes en texto. Estos sistemas son considerados un caso especial de un sistema de recuperación de información (RI). Una caracterı́stica nueva encontramos en este tipo de sistemas, es que la consulta es clasificada de acuerdo al tipo de respuesta esperado. Por ejemplo, vemos 1. Natural Language Interface DataBase (NLIDB).
(28) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). 28. en la Tabla 2.1, el trabajo de Moldovan et al. (1999) sobre la jerarquı́a de consultas. De acuerdo con Allam y Haggag (2012), los trabajos con mejor desempeño fueron los sistemas LASSO (Moldovan et al., 1999), el sistema FALCON (Harabagiu et al., 2000) y también el abordaje de Kangavari et al. (2008). El primero sigue una arquitectura de RI clásica salvo con una interface de lenguaje natural con el usuario; el segundo difiere del primero en el uso de WordNet para mejorar el proceso de elección de la respuesta y el tercero adiciona una base de conocimiento en el que acumula las respuestas correctamente respondidas para un futuro uso.. 2.4.. Sistema de Pregunta-Respuesta Ontológicos. Se caracterizan por tener una ontologı́a como base de conocimiento y también por disponibilizar para el cliente una interface en lenguaje natural. Tales sistemas varı́an en 2 aspectos: El grado de customización del dominio, y El grado de expresividad que soporta. El cual está limitado por la capacidad de análisis gramatical de la consulta, ası́ como la descubierta de padrones. De forma similar a los sistemas de recuperación de información, la consulta puede ser tratada como una bolsa de palabras y buscar los conceptos relacionados en la ontologı́a usando una simple comparación de caracteres o usando algún recurso léxico. Un factor nuevo, segun Lopez et al. (2011), en estos sistemas fue la aplicación de una estrategia guiada, en que el usuario escribe una consulta usando apenas las palabras reservadas que el sistema le permite . Tal autor también presenta una comparación de diferentes Sistemas PR ontológicos. Vemos tal comparación en la Tabla 2.2..
(29) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). Clase. Sub-Clase básico. Que. que/quien que/cuando Quien Como Cuanto. básico cuanto/número cuanto/precio. Donde Cuando. Cual. cual-quien cual-donde cual-cuando cual-que. nombrar-quien Nombrar nombrar-donde nombrar-que Por qué. Tipo de Respuesta Dinero, Número, Definición, Tı́tulo, Nombre propio, no definido. Persona, Organización Fecha. 29. Ejemplo ¿Cuál fue el resultado del partido?. ¿Qué profesor salió del colegio?. ¿Qué año se realizó el último censo del paı́s? Persona, Or- ¿Quién mató al presidente Kenganización, nedy? Manera ¿Cómo murió Jesús? Número ¿Cuántos jugadores tiene un equipo de fútbol? Dinero,Precio ¿Cuánto gastaste en las compras de ayer? Localización ¿Donde se encuentra el rı́o Nilo? Fecha ¿Cuando se celebra el dia de la madre? Persona ¿Cuál empleado pidió renuncia? Localización ¿Cuál es la ciudad es más calurosa del Peru? Fecha ¿Cuál es el año en que comenzó la primera guerra mundial? Nombre ¿Cuál es la concesionaria con mapropio, Orga- yor éxito del año? nización Persona Nombra el culpable del robo Localización Nombra la ciudad más polucionada del mundo Tı́tulo, Nom- Nombra una pelı́cula peruana de bre propio éxito Razón ¿Por qué es importante la vida?. Tabla 2.1: Adaptación propia al español de la clasificación de preguntas de Moldovan et al. (1999) ..
(30) PANTO QuestIO FreyA. +. +. +. +. +. +. +. + +. +. Customización Independiente de una Ontologı́a Gramáti- LéxiAprendizaje Relación Búsqueda ca de co del de Usuario (Tride padrodomı́nio domı́nio plas) nes (léxico / colleestructución ral) + + + + + + + + + + (solo entidades del léxico) + + + + + + +. Tabla 2.2: Abordajes de diferentes Sistemas PR Ontológicos. Extraı́do del trabajo de Lopez et al. (2011). QACID ORAKEL e-Librarian GINSENG NLPReduce Querix AquaLog. Subconjunto de Lenguaje Natural Lenguaje Bolsa GramátiNatural de Pala- ca SuGuiada bras perficial. Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR) 30.
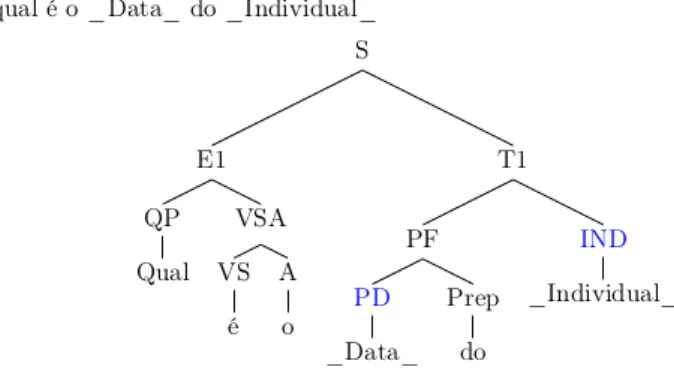
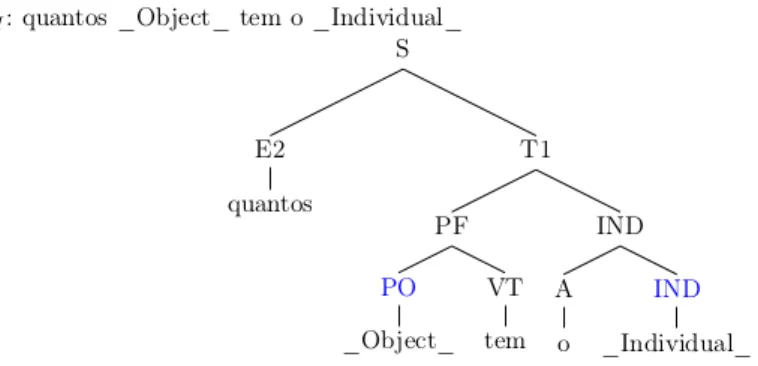
(31) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). 2.4.1.. 31. Fabiano. El trabajo de Ferreira-Luz (2013), es un perfecto ejemplo de Sistema PR Ontológico pues el autor propuso el uso de un lenguaje natural controlado para poder realizar consultas a una base ontológica. Fue construı́do especialmente para el portugués, enfocándose en atender las consultas: Cual, Quién y Cuántos. A continuación vemos en las figuras 2.2 y 2.3, dos ejemplos extraı́dos de trabajo de Fabiano. A partir de ellos resaltamos: La gramática que usa no es muy intuitiva, por ejemplo, el nombre e sus reglas son T 1 y T 2. Existen entidades nombradas que son identificadas por subguiones en los extremos, por ejemplo: Object . Tiene un proceso de análisis de árbol sintáctico. La transformación se realiza siguiendo reglas de conversión.. Figura 2.2: Ejemplos de transformación de la consulta ¿Cuál es el teléfono del IME? a Sparql. Fuente Ferreira-Luz (2013).. 2.4.2.. Quepy. Propuesto por Andrawos et al. (2014), se trata de un framework para transformar consultas en lenguaje natural a consultas en una base de datos. Entre sus principales caracterı́sticas están:.
(32) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). 32. Figura 2.3: Ejemplos de transformación de la consulta ¿Cuántos accesorios tiene el E63? a Sparql. Fuente Ferreira-Luz (2013). Software libre y de código abierto en python. La empresa que lo desarrolla actualmente se llama Machinalis 2 que se dedica a proyectos de Aprendizaje de Máquina, Procesamiento de Lenguaje Natural (PLN) y Minerı́a de Datos. De forma similar a un framework de python, basta configurar unos parámetros, ejecutar un comando y automáticamente una estructura vacı́a es creada. Tiene un parser que analiza sentencias en inglés y retorna las etiquetas morfosintácticas. Posee un reconocedor de entidades nombradas muy básico. De acuerdo con el manual técnico, es importante que el usuario coloque las entidades con la primera letra en mayúscula para ser reconocidas. Trabaja con expresiones regulares para reconocer las estructuras que el usuario determinó. Actualmente soporta SPARQL y SQL. Las consultas retornadas tienen una configuración por defecto para ser ejecutadas en DBPedia o Freebase que son dos tesauros famosos para web semántica. El proyecto sigue abierto y llama a la comunidad interesada en continuar aportando mejoras en el sistema. 2. https://www.machinalis.com/.
(33) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). 2.4.3.. 33. AutoSPARQL. El trabajo de Lehmann y Bühmann (2011) usa técnicas de Aprendizaje de Máquinas y permite que el usuario realice consultas sin siquiera conocer la estructura de la base de conocimiento que está por detrás y mucho menos tener conocimiento de SPARQL. Vemos en la Figura 2.4 una representación gráfica del modo de trabajo de AutoSPARQL.. Figura 2.4: Árbol de consulta a la izquierda y su traducción a SPARQL a la derecha. Fuente: AutoSPARQL (Lehmann y Bühmann, 2011) Sus principales caracterı́sticas: No require un conocimiento de la estructura de la ontologı́a. Su algoritmo de aprendizaje consiste en pedir al usuario preguntas de clarificación para que el sistema entienda qué es lo que el usuario está preguntando en realidad. No existe diferencia entre pregunta compleja o pregunta simple. Ambas reciben el mismo trato, el mismo tiempo y la misma cantidad de preguntas de clarificación. Depende de las respuestas de clarificación del usuario. Si hay conflictos con ellas, entonces el sistema no llega a una consulta y no obtiene resultados. En sus pruebas mostró un tiempo considerable de respuesta (máximo de 10 segundos) a pesar de varias mejoras en cuestión de performance. Sin embargo mostró también ser efectivo para los casos positivos (aquellos que el usuario guió correctamente al sistema)..
(34) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). 2.4.4.. 34. TrueKnowledge. Tunstall-Pedoe (2010) presentó un Sistema de PR comercial bastante robusto que responde con bastante precisión a cualquier tipo de consultas para un determinado dominio. Actualmente el nombre comercial de esta herramienta se llama Evi 3 y podemos ver su portada en la Figura 2.5:. Figura 2.5: Ejemplo de consulta quién es Alan Garcı́a usando la herramienta Evi. Tal proyecto comenzó como un proyecto personal en 1990, pasó a ser un emprendimiento en 2006 alojado en la Universidad de Cambridge y pasó a tener 30 empleados. La ontologı́a fue contruida de forma manual, contando con por lo menos 20 mil clases en 2010. El autor explicó que a pesar que la construcción de la ontologı́a de forma manual era lenta, este no fue su principal problema. Por ejemplo al adicionar una nueva clase en la ontologı́a, la búsqueda de posibles individuos y enlazarlos con sus respectivas clases demandaba una gran cantidad de tiempo. La traducción de lenguaje natural usa unas plantillas para aplicar en la consulta y obtener la transformación en un lenguaje interpretable que el sistema podı́a entender. El trabajo propone usar un formalismo para representar hechos, a través de este formalismo puede realizar las inferencias. Tales hechos alcanzaron una cantidad de 240 millones en 2010. Cifra considerablemente grande pues el proyecto comenzó con apenas unos cientos. 3. https://www.evi.com/.
(35) Capı́tulo 2. Sistemas de Pregunta-Respuesta (PR). 35. Además, el trabajo se autoalimenta de conocimiento almacenandolos en este repositorio de hechos que constituye, junto a su ontologı́a construida al menos 20 años, el éxito de su trabajo..
(36) Capı́tulo 3 Gramáticas Computacionales Desde un punto de vista lingüı́stico, de acuerdo con la Real Academia de Lengua Española (RAE) 2009, la gramática estudia la estructura de las palabras y comprende dos áreas: La Morfologı́a y la Sintaxis. La primera estudia la estructura de las palabras con sus variaciones y la segunda analiza la forma en que las palabras se combinan. Desde un punto de vista computacional, una gramática formal es un conjunto de reglas de producción para cadenas de caracteres en un lenguaje formal.. 3.1.. Definiciones. Alfabeto Es un conjunto finito de sı́mbolos. Ejemplo:. P. = {a, b, c, ...}.. Cadena O palabra, es una serie de sı́mbolos concatenados. Ejemplo: abc, cccbbaa, aba. Una sub-cadena es también una cadena. El sı́mbolo λ representa una cadena vacı́a. Lenguaje Es un conjunto finito o infinito de cadenas. Por ejemplo: L = λ, abc, cccbbaa, aba. Producción También conocido como Regla de Producción, es un regla que especifica la substitución de ciertos sı́mbolos, de forma recursiva o no, para generar más secuencias de sı́mbolos. Por ejemplo: S → aab, S → T ab, aSb → T . Gramática Es una tupla G =< P. N. P. N,. P. T , P, S. > donde:. Es un conjunto de sı́mbolos no terminales. 36.
(37) Capı́tulo 3. Gramáticas Computacionales. P. T. 37. Es un conjunto de sı́mbolos terminales (El alfabeto).. P Es el conjunto de producciones. S Es el axioma de la gramática, que pertenece a llamado de sı́mbolo inicial. Además: Alfabeto:. P. ∩. P. T. = ∅.. =. P. N. ∪. N. P. P. P. N. y que también es. T. Lenguaje asociado a una gramática Son todas las sentencias generadas por la gramática. La construcción de las gramáticas tiene diferentes intereses: Para representar un lenguaje. Para generar un lenguaje, que es el resultado de aplicar la inversión del punto anterior. Para reconocer la validad de una cadena de caracteres de entrada.. 3.2.. Jerarquı́a de Chomsky. Chomsky (1956) definió 4 tipos de jerarquı́as bajo una siguiente orden: GT ipo−3 ⊂ GT ipo−2 GT ipo−1 GT ipo−0. 3.2.1.. Tipo 3. También llamados de Lenguajes Regulares. Son de dos tipos: Gramática Regular Derecha Cuando los sı́mbolos no terminales aparecen del lado derecho de la regla de producción. Por ejemplo: S → aT Gramática Regular Izquierda Al contrario del anterior, cuando los sı́mbolos no terminales aparecen del lado izquierdo de la regla de producción. Por ejemplo: S → T a.
(38) Capı́tulo 3. Gramáticas Computacionales. 3.2.2.. 38. Tipo 2. También llamadas de Gramáticas Libres de Contexto (GLC). Las producP P P ciones tienen la forma α → β donde alpha ∈ N y β ∈ N ∪ T incluyendo λ. S → T S → a S → b S → cT T → cT. 3.2.3.. Tipo 1. También llamadas de Gramáticas Sensibles al Contexto. Las producciones P P P tienen la forma αAβ → αγβ donde A ∈ N y α, γ, β ∈ N ∪ T incluyendo λ. Los elementos α y β pueden ser vacı́os pero γ no lo puede ser. La producción S → λ es válida si S no aparece en el lado derecho de otra regla de producción. Por ejemplo: S → aT R S → bT R T R → cT R T R → RT T → a R → b. 3.2.4.. Tipo 0. También llamadas de Gramáticas sin Restricciones. Esta gramática genera todas los lenguajes producidos por una Máquina de Turing..
(39) Capı́tulo 3. Gramáticas Computacionales. 3.3.. 39. Gramáticas Léxico-Funcionales (LFG). Este tipo de gramáticas fueron estudiadas en la década del 70 y finalmente formalizadas por Bresnan (1982) por dos tipos de investigadores: un lingüista y un informático. Su objetivo era el de construir un formalismo capaz de representar todas los fenómenos lingüı́sticos del lenguaje humano y mantener una simplicidad tal suficiente para ser computacionalmente programable. Existen dos niveles sintácticos: La estructura de constituyentes (estructura-c) y la estructura funcional (estructura-f). La primera puede ser representada con una gramática del tipo GLC y la segunda tiene su propio formalismo para representar las funcionales gramaticales y otras propiedades presentes en la oración como por ejemplo: Concordancia verifica si el género y número en la sentencia guarda concordancia, asi: Los alumnos estudian está correcto, pero El alumnos estudia no lo está. Tiempo indica en que tiempo (pasado, presente, futuro) está construida la oración. Definitud dice si un cierto elemento está siendo definido o no, por ejemplo El alumno estudió y Un alumno estudió, solo la primera tiene un substantivo definido. Anáfora elementos que substituyen a otros mencionados anteriormente, por ejemplo ¿Dónde salió Julio?. Lo vi yendo al centro.. Catáfora cuando la oración posee un preliminar que se adelanta a la idea de la oración, por ejemplo: Te dije, estudia para triunfar, Los alumnos hicieron un buen trabajo: Julián, Jaime, Julio. Elipsis cuando no se menciona elementos que ya fueron mencionados anteriormente, por ejemplo Julián obtuvo buenas notas pero Jaime no, se sobre entiende que Jaime no obtuvo buenas notas. Por ejemplo, para a frase El dinosaurio no piensa que el hamster dará un libro al ratón, la estructura-c serı́a representada en la Figura 3.1 y su estructura-f en la Figura 3.2..
(40) Capı́tulo 3. Gramáticas Computacionales. 40. IP. DP. I’. D. NP. el. dinosaurio. VP. I no. V. CP. piensa IP. C que DP. I’. D. NP. el. hamster. I. VP. ∅ V dará. DP D. NP. PP P. NP. un libro al ratón Figura 3.1: Estructura-c. Ejemplo traducido del material de lectura en Falk (2001)..
(41) Capı́tulo 3. Gramáticas Computacionales. 41. . ". SU J T P O N EG P RED COM P . P RES + 0 0 pensar < SU J, COM P > " # DEF + SU J 0 0 P RED hamster F U T U RO T P O 0 0 P RED dar < SU J, OBJ, OBJ OBJ > meta " # DEF − OBJ 0 0 P RED libro P CASE OBL meta " # DEF + OBLmeta . DEF + P RED 0 dinosaurio0. OBJ. #. . P RED. 0. raton0. Figura 3.2: Estructura-f. Ejemplo traducido del material de lectura en Falk (2001).
(42) Capı́tulo 3. Gramáticas Computacionales. 3.4. 3.4.1.. 42. Análisis Sintáctica Sintaxis. Según Xavier y Mateus (1990-1992), la sintaxis es una área de la lingüı́stica que estudia el orden de los constituyentes en una oración. La oración encierra la menor unidad de sentido del discurso. Hablar de cada uno de los constituyentes puede tomarnos mucho tiempo, por lo tanto tocaremos aquellos que vale la pena nombrar pues tendrán un papel importante en el desarrollo del trabajo. Sujeto Indica la persona o cosa de la cual afirmamos o negamos alguna acción. Puede ser encontrado en la oración en diversas formas: Pronombre Yo acabé la tesis. Sustantivo Juan trabaja muy bien. Grupo nominal ¿Cuál de los estudiantes aprobó la materia? ; Ninguno de ellos es el estudiante. Oración Subordinada Sustantiva No nos dijeron si aceptarı́an o no los formularios. Predicado Indica la acción que recae en el sujeto. Está compuesto por una flexión verbal o una perı́frasis y sus complementos. Flexión verbal Corresponde a toda aquella modificación que se puede realizar en el verbo. Estas son: Número. Singular o plural. Por ejemplo: escribe, escriben. Persona. Yo, tú, él, nosotros, ustedes, ellos. Por ejemplo: yo escribo, él escribe. Modo. Imperativo, Indicativo y Subjuntivo. Por ejemplo: ¡escribe!, escribirı́a..
(43) Capı́tulo 3. Gramáticas Computacionales. 43. Tiempo. Presente, pretérito perfecto, pretérito imperfecto, pretérito pluscuamperfecto, pretérito indefinido, pretérito anterior, futuro imperfecto, futuro perfecto, condicional simple, condicional compuesto. Aspecto. Perfectivo e imperfectivo. La perı́frasis o frase verbal es la suma de un verbo auxiliar en su forma finita más un verbo principal. Por ejemplo: Tienes que acabar el trabajo. Directo / Objeto Directo Es una función sintáctica que corresponde a un argumento dependiente del verbo. Podemos decir que el OD recibe directamente la acción verbal. Por ejemplo: Abre | {z }. la | ventana. {z }. V. OD. ¿Cuál de estos |. {z. }. prefieres?. {z. |. OD. }. V. Complemento Indirecto / Objeto Indirecto Este papel es adoptado por los pronombres átonos de dativo ası́ como los grupos preposicionales en que la preposición puede ser reemplazada por un pronombre del dativo. Por ejemplo: del profesor Julio recibió las | {z } | {z } | notas {z } | {z } . SUJ V OD OI Julio | {z }. le |{z}. recibió | {z }. las | notas {z }. . sujeto OI V OD Y puede haber el caso de una repetición del pronombre átono de la siguiente al profesor Julio le recibió las |{z} | {z } | notas {z } | {z } 1. forma: | {z } OD OI V OD OI Puede ser reescrito asi:. Complementos Preposicionales Son aquellos que son exigidos para dar sentido al predicado. Por ejemplo: traducir. al español |. {z. OP. }. ..
(44) Capı́tulo 3. Gramáticas Computacionales. depender. de los amigos |. {z. 44. .. }. OP Adjunto También llamado de complemento circunstancial CC. Este término se aplica a los adjuntos del grupo verbal, de esta forma tenemos: De modo o manera: ¿Cómo fuiste atendido tan bien?. De instrumento: Salió a la calle con paraguas. De Medio: Consiguió la vacante con esfuerzo. De compañı́a: Almorzó con su familia. De cantidad: ¿Por qué estudias mucho? De lugar: ¿Cuándo vinisite aqui?. De tiempo: ¿Cómo llegaste tan rápido? De causa: Corrió por causa del peligro. De finalidad: Realizó todos los preparativos para la boda. Una caracterı́stica de estos elementos es que su omisión no altera el sentido de la oración. En algunas ocasiones, los CC pueden confundirse con otros elementos sintácticos, por ejemplo: con un colega. Alteramos el trabajo. |. {z. }. .. C. Circunstancial está correctamente marcado como CC, sin embargo, una frase similar seria:. Lo redactaste. con un amigo |. {z. }. Objeto Directo. ..
(45) Capı́tulo 3. Gramáticas Computacionales. 3.5.. 45. Gramática Generativa. En la lingüı́stica existen tres niveles de representación, la cuales fueron detalladas por Costa-Campos y Xavier (1991) de la siguiente manera: El nivel 1, que es inaccesible por el lingüista, posee los mecanismo y las representaciones abstractas de las actividades del lenguaje. Este nivel es adquirido desde la infancia a través de la experiencia con el mundo que nos rodea. Aquı́ son generadas secuencias lingüı́sticas que pueden ser observadas en el nivel 2. A partir del nivel 2, el lingüista tiene acceso al nivel 1, del cual formula hipótesis. podemos hablar de formas lingüı́sticas, por ejemplo casa nos da una idea de una estructura con paredes y techo donde pueden vivir personas. En el nivel 3 se construye un sistema de representación metalingüı́stico para responder por la relación entre las secuencias del nivel 2 y los mecanismo o representación del nivel 1. Por ejemplo, cuando realizamos un análisis gramatical de una oración y etiquetamos a casa con la clase gramatical substantivo. De acuerdo con Ruwet (1975), una gramática generativa es una gramática explı́cita que enumera explı́citamente todas las frases gramaticales de una lengua, ası́ como sus descripciones estructurales. Chomsky (1957) indicó que el verdadero objetivo de la lingüı́stica deberı́a ser la formulación de una gramática que, por medio de un número finito de reglas, fuese capaz de generar todas las frases de un idioma del mismo modo que un hablante puede formular un número infinito de frases en su lengua, incluso cuando nunca las habı́a oı́do o pronunciado.. 3.6.. Análisis de Constituyentes. De acuerdo con Silva y Koch (2001), el sintagma es un conjunto de elementos con valores significativos dentro de la oración y que mantienen entre si una relación de dependencia y de orden. Existen diferentes tipo: Sintagma Nominal (SN), cuyo núcleo es el substantivo Sintagma Verbal (SV), cuyo núcleo es el verbo..
(46) Capı́tulo 3. Gramáticas Computacionales. 46. Sintagma Adjetival (SA), cuyo núcleo es un adjetivo. Sintagma Preposicional (SP), que se trata de un SN, acompañado de una preposición. La estructura sintáctica es una configuración formada por unidades sintáctica, llamadas de categorı́as, de diferentes clases (nombre, verbo, adjetivo, preposición, flexión, sintagma nominal, sintagma verbal, etc). Entre las cuales establecemos dos tipos de relaciones fundamentales: dominio y precedencia. Cuando una frase es analizada, el lingüista construye un árbol sintáctico, que no es más que un gráfico en forma de árbol que representa la estructura sintáctica. Por ejemplo, para frase La hormiga comió la hoja, tenemos su analizador sintagmático en la Figura tal 3.3. SF SN La hormiga. F’ F. SV. -ió. V. SN. com-. la hoja. Figura 3.3: Ejemplo de árbol sintáctico Encontramos ciertas caracterı́sticas que llaman nuestra atención: Vemos que en la parte superior del árbol encontramos el sintagma flexional SF. La flexión verbal -ió se encuentra por encima del sintagma verbal para indicar el tiempo que ocurre el verbo.. 3.6.1.. Gramática Transformacional. Es una teorı́a linguı́stica que proviene de la corriente generativista de Chomsky que utiliza reglas transformacionales para representar los desplazamientos de los constituyentes y otros fenómenos del lenguaje natural..
(47) Capı́tulo 3. Gramáticas Computacionales. 47. F SN. SN. A formiga. V. SN. comer. a folha. Figura 3.4: Ejemplo de árbol sintáctico reducido La transformación es un conjunto de reglas para obtener una estructura superficial de este árbol sintáctico. De ese modo, podemos simplificar la árbol en la Figura 3.4. Algunas transformaciones son relatadas en Perini (1976), una de ellas es SSI: Supresión del sujeto idéntico; que consiste en suprimir el sujeto de una oración subordinada cuando este sea idéntico a cualquier otro SN en la oración. Por ejemplo en la sentencia: [Antonio querer [Antonio sambar con la Portela]]. Con la operación SSI, la sentencia seria simplificada ası́: [Antonio quiere sambar con la Portela].. 3.6.2.. Papeles temáticos. Estos son elementos semánticos que se encuentran en una sentencia. La relación entre los elementos sintácticos de la sentencia con tales papeles está interpretada por la teorı́a θ que nombrada como tal por Chomsky (1981). Diferentes papeles temáticos han sido propuestos, por ejemplo la propuesta de Dowty (1989) menciona los siguientes: Agente. Yo |{z} AGENTE. El trabajo Pasivo | {z } PASIVO Experimentador. trabajé.. fue hecho por mi. Me |{z} EXPERIMENTADOR. siento muy orgullo..
(48) Capı́tulo 3. Gramáticas Computacionales. Tema Yo realicé el trabajo de. Fuente Estudié bastante del. 48. Historia | {z } TEMA libro de{zcálculo} | FUENTE. .. buena {z nota} |. Meta Estudié bastante para obtener. META. .. Existen también otros papeles muy comunes que encontramos en la literatura: la raqueta. Instrumento Yo golpeé la bola con. {z. |. .. }. INSTRUMENTO Ubicación Yo jugué en. la | cancha {z } UBICACIÓN. Beneficiario Lancé una bola para. . mi amigo |. {z. }. .. BENEFICIARIO Finalmente resaltamos que la lista de estos papeles no se encuentran restringidos a un número. Por ejemplo el trabajo de Helbig (2005) propone cerca de 90 papeles temáticos y en cada uno especifica de manera formal como debe ser reconocido..
(49) Capı́tulo 4 Ontologias y Sparql 4.1. 4.1.1.. Ontologı́as Definición de Ontologias. Gruber (1993) definió una ontologı́a como una especificación de una conceptualización compartida. Ivan Kostial (2003) indica que el uso de una ontologı́a permite definir conceptos y relaciones representando conocimiento a respecto de un documento, en particular en un dominio especı́fico de términos. El desarrollo de una ontologı́a generalmente está sobre la responsabilidad de un especialista con conocimientos de un editor de ontologı́as. Tal proceso sigue un conjunto de buenas prácticas relatadas en diferentes artı́culos, por ejemplo Mizoguchi (2003) y Noy y Mcguinness (2001). Una ontologia posee los siguientes elementos: 1. Clases, también llamadas de conceptos; 2. Propiedades, también llamadas papeles en lógica de descripción; e 3. Individuos, que son instancias de las clases definidas.. 4.1.2.. Tipos de ontologı́a. De acuerdo con Mizoguchi (2003), los tipos de ontologı́a, según la riqueza semántica, pueden ser: 1. Ontologı́as pesadas: Son desarrolladas enfatizando en el significado de cada concepto, ası́ como a la orden de las relaciones. De esa manera se 49.
(50) Capı́tulo 4. Ontologias y Sparql. 50. garantiza la consistencia del modelo. 2. Ontologı́as ligeras: Son jerarquı́as de conceptos sin definiciones extensas. Ellas tienen la caracterı́stica que son eficientes para consultas, sin embargo, tienden a ser dependientes del contexto. En 2004, el W3C World Wide Consortium recomendó OWL (Ontology Web Language) como lenguaje para descripción de ontologı́as. Ella comenzó con tres sublenguajes: OWL-Lite diseñado para aquellos usuarios que necesitan principalmente de una clasificación jerárquica y restricciones simples. Permite un camino de migración más rápido de tesauros 1 y otras taxonomı́as. OWL-DL posee mayor expresividad, manteniendo la computabilidad y la decidibilidad, es decir, garantiza que todas las conclusiones sean computables en tiempo finito. OWL-Full hecha para usuarios que requieran la máxima expresividad y la libertad sintáctica del lenguaje RDF. En contrapartida, no hay garantı́as que la decibilidad computacional se mantenga. A partir de 2009, el W3C recomendó OWL2 como lenguaje estándar para escribir ontologı́as. OWL 2 substituye el antiguo estándar de 2004, de manera que son adicionadas nuevas caracterı́sticas. Este estándar introduce el concepto de perfil que es un fragmento de OWL 2 para negociar el poder expresivo por la eficiencia de raciocinio. Existen tres perfiles: OWL 2 EL Proporciona algoritmos de tiempo polinomial para todas las tareas comunes de raciocinio; es particularmente útil en aplicaciones cuyas ontologı́as poseen un gran número de propiedades o clases. La sigla EL fue tomada por causa de su similitud con la familia de lógica de descripción: EL (cuantificación existencial). OWL 2 QL Usada en sistemas que utilizan grandes volúmenes de instancias de datos y en las cuales la tarea más importante es la de devolver resultados para las consultas. La sigla QL indica que las preguntas y respuestas en este perfil pueden ser implementadas reescribiendo las preguntas en un lenguaje de consulta relacional común. 1. Son grandes repositorios de palabras o términos..
(51) Capı́tulo 4. Ontologias y Sparql. 51. OWL 2 RL Está destinada a aplicaciones que requieran raciocinio escalable sin sacrificar en exceso el poder expresivo. Sistemas de raciocinio OWL 2 RL pueden ser implementados usando mecanismos basados en reglas. La sigla RL indica que el raciocinio en este perfil puede ser implementado usando un lenguaje de reglas común.. 4.1.3.. Componentes de la Ontologı́a. Individuos Representan a los objetos del dominio que estamos representando. Debido a que OWL no usa la Suposición de Nombres Únicos ( en inglés UNA - Unique Name Assumptions), podemos tener diferentes nombres que se refieren al mismo individuo, por ejemplo, XP, Extreme Programming y Programación Extrema pueden referirse, en el mismo dominio, al mismo objeto.. Propiedades Son propiedades binarias entre individuos. Por ejemplo en la Figura 4.1, la propiedad programarEn puede comprometer dos individuos: Jorge y Java. La Figura programaEn Java. Jorge programaEn C++. Figura 4.1: Ejemplo de Individuos y Propiedades. Las propiedades pueden ser también del tipo inversa, como por ejemplo la propiedad tieneJefe y tieneEmpleado son inversas y vemos su representación en la Figura 4.2: La transitividad también se aplica entre las propiedades. Por ejemplo la Figura 4.3 muestra la transitividad de la propiedad tieneJefe entre Juan y Jonás..
(52) Capı́tulo 4. Ontologias y Sparql. 52. tieneJefe Jorge. Juan tieneEmpleado. Figura 4.2: Ejemplo de propiedades inversas tieneJefe Jorge. Jonás. tieneJefe. tieneJefe Juan. Figura 4.3: Ejemplo de propiedades inversas Clases Son conjuntos en los que los individuos están contenidos. Usualmente la palabra Concepto es usada en lugar de Clases. Vemos en la Figura 4.4 un ejemplo de 3 clases: PERSONAS, LENGUAJE DE PROGRAMACIÓN y SISTEMAS OPERATIVOS.. 4.1.4.. Lógicas de Descripción. Staab y Studer (2004) indicaron que las lógicas de descripción son una familia de lenguajes de representación de conocimiento, pudiendo representar el conocimiento de un dominio de manera formal y estructurada. Cada lógica se diferencia entre si por los constructores que posee, formando diferentes combinaciones a partir del lenguaje de atributos (AL) de diferentes extensiones. La Tabla 4.1 presenta las definiciones sintácticas y semánticas de diferentes constructores, siguiendo la notación: A,C,D: son nombres de conceptos. R: relación. I: o interpretación, es un par < ∆I , ·I >, en que : • ∆I es el universo. • ·I es una función de mapeamiento de: ◦ Conceptos para subconjuntos de ∆I , e.
(53) Capı́tulo 4. Ontologias y Sparql. 53. LENGUAJES DE PROGRAMACIÓN. PERSONAS C++ Java tieneJefe. Jorge. programaEn Python programaEn. Juan. usa SISTEMAS OPERATIVOS. usa Windows. Linux. Figura 4.4: Ejemplo de clases.
(54) Capı́tulo 4. Ontologias y Sparql. 54. ◦ Papéis para subconjuntos de ∆I × ∆I .. Constructor Sintaxis Nombre del Concepto A Top > Bottom ⊥ Conjunción C uD Disyunción (U) C tD Negación (C) ¬C Universal ∀R.C Existencial (E) ∃R.C Restricción numérica (N ) ≥ n.R Restricción numérica cualificada (Q) ≥ n.R.C Enumeración (O) {a1 , ...an } Selección F f :C. Semántica AI ⊆ ∆I ∆I 0 CI C I ∪ DD ∆I \C I {x|∀y : RI (x, y) → C I (y)} {x|∃y : RI (x, y)C I (y)} {x|]{y|RI (x, y) ≥ n}} {x|]{y|RI (x, y) ∧ C I (y)}} {a1 I , ..., an I } {x ∈ Dom(f I )|C I (f I (x))}. Tabla 4.1: Algunos constructores que forman familias de lógicas de descripción de ALC. 4.2.. Sparql. Es un lenguaje de consulta para documentos escritos en su forma nativa en RDF.. 4.2.1.. Sintaxis. La sintaxis es similar al SQL. Vemos un ejemplo en la Figura 4.5. Para facilitar la lectura de las consultas usamos unos prefijos que los colocamos al inicio. De este modo, la consulta anteriormente mencionada quedará como se aprecia en la Figura 4.6. Modificadores Similar a SQL, existen los modificadores para la consulta. Esto son: DISTINCT, para eliminar soluciones duplicadas. LIMIT, que restringe la cantidad de soluciones obtenidas..
(55) Capı́tulo 4. Ontologias y Sparql. 55. Seleccionando la variable SELECT. ?title. WHERE {. URI de libro. <http://example.org/book/book1> Elementos de la tupla. <http://purl.org/dc/elements/1.1/title> ?title URI de la propiedad tı́tulo. } Variable. Figura 4.5: Ejemplo de consulta en Sparql. PREFIX book: <http://example.org/book/> PREFIX prop: <http://purl.org/dc/elements/1.1/> SELECT. ?title. WHERE { book:book1 prop:title ?title . } Figura 4.6: Ejemplo de consulta en Sparql con prefijos.
(56) Capı́tulo 4. Ontologias y Sparql. 56. OFFSET, que muestra los resultados a partir de un cierto número de soluciones. ORDER BY, coloca un orden a las soluciones..
(57) Capı́tulo 5 Diseño y elaboración del corpus Para construir nuestro corpus, seguimos los siguientes pasos:. 5.1.. Colección. Como fue mencionado en el capı́tulo 1, escogimos cinco temas para realizar nuestro estudio de creación de corpus: Cultural - Comida Peruana. Entretenimiento - Guerra Civil de Marvel. Automóvil - Concesionaria de carros Ford. Institucional - Universidad Nacional de San Agustı́n. Deportes - Fútbol peruano. Para cada uno de estos temas, fueron coleccionadas diferentes preguntas del tipo Factoid con ayuda de personas adultas de ambos sexos. Sus edades oscilaban entre 17 y 45 años y todas eran nativas hablantes de la lengua española. Estas personas a quien a futuro llamaremos colaboradores, fueron instruı́das al inicio sobre el objetivo de la investigación y se les mencionó que deseabamos construir robots inteligentes que respondan toda clase de preguntas que el usuario realice sobre un determinado tema. El proceso duró un par de semanas y conseguimos coleccionar con la ayuda de 20 colaboradores la cantidad suficiente de consultas para iniciar con nuestro análisis. 57.
(58) Capı́tulo 5. Diseño y elaboración del corpus. 58. Filtramos las sentencias repetidas y obtuvimos: Comida Peruana: 205 sentencias. Guerra Civil de Marvel: 208 sentencias. Concesionaria de carros: 188 sentencias. Universidad Nacional de San Agustı́n: 181 sentencias. Fútbol peruano: 192 sentencias. El último tratamiento a estas sentencias consistió en colocarlas en minúsculas y quitar los sı́mbolos de interrogación.. 5.2.. Etiquetación morfosintáctica. En seguida, adicionaremos una etiqueta morfosintáctico para cada palabra en las sentencias. Existen diferentes herramientas para realizar este paso: El etiquetador de Carrasco y Gelbukh (2003) usó como entrenamiento el corpus CLiC-TALP de la Universidad Politécnica de Cataluña. La licencia de esta herramienta especifica para uso estrictamente académico. Sin embargo, esta herramienta carece de actualizaciones y en la actualidad, sólo puede ser usada en un ambiente de Windows para 32 bits. El trabajo de Nguyen et al. (2014) es un sistema de etiquetación morfológica entrenado para diferentes lenguajes. Para el lenguaje en español, usó el el IULA LSP Treebank de la Universidad Pompeu Fabra de Barcelona. Infelizmente notamos algunos problemas al tratar preguntas interrogativas. Stanford disponibilizó también un etiquetador en Java con diferentes corpus. El corpus usado para el Español fue Ancora V3.0. Decidicimos usar la herramienta disponibilizada por Stanford debido a que apreciamos menos problemas con respecto a las sentencias interrogativas..
(59) Capı́tulo 5. Diseño y elaboración del corpus. 5.3.. 59. Reconocimiento de Entidades Nombradas REN. Las entidades nombradas no son más que una o más palabras que juntas determinan un tipo de entidad. Por ejemplo, a continuación analizaremos un parágrafo, extraı́do de wikipedia que habla sobre el descubrimiento de américa: Se denomina "descubrimiento de América" al acontecimiento histórico que comenzó con la llegada a América[L] el 12 de octubre de 1492[D] de una expedición capitaneada por Cristóbal Colón[P] por mandato de los reyes Isabel[P] y Fernando[P] de Castilla[L] y Aragón[L] , que habı́a partido del puerto andaluz de Palos dos meses y nueve dı́as antes y, tras cruzar el océano Atlántico[L] , llegó a unas islas del continente americano, concretamente las Bahamas[L] y a su regreso dio a conocer por primera vez en Europa[L] la existencia de un Nuevo Mundo.. Notemos que algunas palabras se encuentran subrayadas, estas son las entidades nombradas y ellas tienen un pequeño ı́ndice que se refiere al tipo de entidad nombrada que pertenecen. P Persona: Cristóbal Colón, Isabel, Fernando. L Lugar geográfico: América, Castilla, Aragón, Bahamas, Europa. D Data / fecha especı́fica: 12 de octubre de 1492. La identificación de estas entidades nombradas es de carácter importante pues ellas ayudarán a ampliar el universo de consultas posiblemente reconocibles por nuestro sistema. Vemos un ejemplo de esto en la Figura 5.1: Para poder reconocer las entidades nombradas, usamos el método de Campos Aleatórios Condicionales (CRF - Conditional Random Fields), el cual es un método estadı́stico usado para etiquetar segmentos de una sentencia, teniendo en cuenta los elementos anteriores y sus caracterı́sticas. Este método constituye el actual estado del arte, con respecto al tema de reconocimiento de entidades nombradas y su preferencia se debe a su robustez y especificidad para datos estructurados..
(60) Capı́tulo 5. Diseño y elaboración del corpus. ¿Cómo se prepara el/la [PLATO]?. . ¿Cómo ¿Cómo ¿Cómo ¿Cómo ¿Cómo. 60. se se se se se. prepara prepara prepara prepara prepara. el Arroz Chaufa? el Ceviche? el Lomo Saltado? la Carapulcra? la Papa a la Huancaı́na?. Figura 5.1: Reducción de una sentencia usando Entidades Nombradas Existen diferentes herramientas que disponibilizan el CRF para reconocimiento de entidades nombradas: Mallet, el cual usa Scala. Stanford NER (Finkel et al., 2005). CRFsuite (Okazaki, 2007). Nosotros preferimos usar la herramienta de Stanford pues está escrita en Java y podemos usarla libremente para fines académicos. Analizando nuestros domı́nios, escogimos las siguientes entidades nombradas: Comida Peruana: • PLATO • INGREDIENTE • LOCALIDAD Comics: • PERSONAJE • EQUIPO Concesionária Ford: • MODELO • DATA Unsa: • Ninguno.
Figure


+7






Documento similar