Sistema para la gestión de recursos para la herramienta TAC OmegaT
89
0
0
Texto completo
(2) ii. El que suscribe, Pabel Ulacia Villavicencio, hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ciencia de la Computación autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(3) i. PENSAMIENTO. “La humanidad avanza no sólo gracias a los potentes empujones de sus grandes hombres, sino también a los modestos impulsos de cada hombre responsable” Graham Greene.
(4) ii. DEDICATORIA A mis padres Maritza Villavicencio y Pablo Ulacia por ser los mejores padres del mundo, amigos y consejeros que siempre creyeron en mí y me ayudaron a alcanzar mis metas..
(5) iii. AGRADECIMIENTOS A mis padres que siempre me apoyaron en todo. A mi hermano, mis tías, a mis abuelos, a mis primos. A mis amigos de la universidad por apoyarnos mutuamente a lo largo de la carrera. A mis tutores Michel y Llanes por prestarme su tiempo y dedicación. A los profesores Yaimara Granados y Gálvez por dedicar un poco de su tiempo a supervisarme y atender mis dudas..
(6) iv. RESUMEN. El presente trabajo da solución al problema de los especialistas en lenguas extranjeras de la Universidad Central “Marta Abreu” de las Villas de una herramienta de asistencia a la traducción con características que se adapten a sus necesidades, las que incluyen consulta de diccionarios en ambos sentidos del flujo de la traducción, ampliar la búsqueda de los diccionarios con palabras similares o relacionadas, y exportación e importación de términos de glosarios ,memorias de traducción, búsqueda de proyectos similares e importación de diccionarios. La solución consiste en un sistema que utiliza como base por parte del cliente la herramienta TAC OmegaT, se construyó una herramienta para la administración del sistema así como servicios web para la comunicación de las partes del sistema y el empleo de bibliotecas como Lucene para realizar búsquedas rápidas y precisas y Wordnet para extender las búsquedas en los diccionarios y un servidor ftp para la importación de los diccionarios. Como resultado se obtuvo un sistema que asiste a la traducción y además permite compartir los recursos desarrollados por diferentes especialistas para un uso compartido..
(7) v. ABSTRACT. This paper provides a solution to the problem of foreign language specialists of the Central University "Marta Abreu" of Las Villas a tool to assist with the translation features that suit their needs, including consultation of dictionaries in both directions the flow of translation, expand the search for dictionaries with similar or related words, and export and import of terms of glossaries, translation memories, search for similar projects and importing dictionaries. The solution is a system using as a base by customer OmegaT CAT, a tool for system administration and web services for communication of the parties built system and the use of libraries such as Lucene for fast, accurate and searches for extending Wordnet search in dictionaries. As a result a system that assists the translation and allows sharing of resources developed by different specialists for shared use was obtained..
(8) vi TABLA DE CONTENIDOS PENSAMIENTO ....................................................................................................................i DEDICATORIA .................................................................................................................... ii AGRADECIMIENTOS ....................................................................................................... iii RESUMEN ...........................................................................................................................iv ABSTRACT ........................................................................................................................... v INTRODUCCIÓN ................................................................................................................. 1 Objetivo general .................................................................................................................. 3 Objetivos específicos .......................................................................................................... 3 Preguntas de Investigación ................................................................................................. 4 Justificación de la investigación ......................................................................................... 4 Capítulo 1. Tecnologías para la implementación del sistema ............................................. 6 1.1. La herramienta TAC OmegaT ................................................................................. 6 1.1.1. Memorias de traducción.................................................................................... 8 1.1.1.1. Memorias de traducción compartidas ...................................................... 10 1.1.1.2. Formato común para las memorias de traducción ................................... 10 1.1.1.3. Traslation Memory eXchange ................................................................. 11 1.1.2. Glosarios ......................................................................................................... 11 1.1.3. Diccionarios .................................................................................................... 12 1.2. Lucene .................................................................................................................... 12 1.2.1. Adquisición del contenido ............................................................................ 13 1.2.2. Análisis de Documents ................................................................................ 14 1.2.3. Indexación ..................................................................................................... 15 1.2.4. Consultas....................................................................................................... 17 1.3. WordNet ................................................................................................................. 20 1.4. Servicios web ......................................................................................................... 20 1.4.1. Simple Object Access Protocol (SOAP) ......................................................... 29 1.4.2. RESTful .......................................................................................................... 30 1.4.3. RESTful contra SOAP .................................................................................. 30 1.5. Conclusiones parciales ........................................................................................... 33 Capítulo 2. Diseño e implementación del sistema ............................................................. 35 2.1. Modelado del negocio ............................................................................................ 35 2.2. Requisitos funcionales y no funcionales ................................................................ 36 2.3. Casos de uso y actores............................................................................................ 38 2.3.1. Actores del sistema ......................................................................................... 38 2.3.2. Casos de uso.................................................................................................... 39 2.4. Arquitectura del sistema ......................................................................................... 47 2.5. Principios de diseño ............................................................................................... 48 2.6. Diagrama de clases ................................................................................................ 49 2.7. Diagrama de Componentes .................................................................................... 56 2.8. Diagrama de despliegue ......................................................................................... 57 2.9. Conclusiones parciales ........................................................................................... 58 Capítulo 3. Pruebas del sistema ......................................................................................... 59 3.1. Prueba de las respuestas de los servicios web ........................................................ 59 3.1.1. Servicio compartirM ....................................................................................... 59 3.1.2. Servicio compartirP ........................................................................................ 60 3.2. Prueba de exportación ............................................................................................ 62.
(9) vii 3.3. Prueba de importación de términos de glosarios.................................................... 63 3.4. Prueba de importación de diccionarios .................................................................. 64 3.5. Pruebas de indexación de recursos ......................................................................... 64 3.6. Pruebas de eliminación de recursos ....................................................................... 65 3.7. Conclusiones parciales ........................................................................................... 66 Conclusiones ...................................................................................................................... 67 Recomendaciones ............................................................................................................. 67 Anexos .................................................................................................................................. 68 Anexo 1. Características del lenguage TMX .............................................................. 68 Anexo 2. Creación del archivo .TAB ......................................................................... 72 Anexo 3. Relaciones Semánticas en WordNet ........................................................... 75 Referencias bibliográficas ................................................................................................. 77 ÍNDICE DE IMÁGENES Ilustración 1 Arquitectura de los servicios web ................................................................................................. 22 Ilustración 2 Arquitectura de WSDL 1.1 y 2.0 ................................................................................................... 23 Ilustración 3 Arquitectura de UDDI ................................................................................................................... 25 Ilustración 4 Arquitectura de SOAP ................................................................................................................... 26 Ilustración 5 Casos de uso y actores ................................................................................................................. 38 Ilustración 6Arquitectura del Sistema ............................................................................................................... 48 Ilustración 7 Diagrama de clases ...................................................................................................................... 49 Ilustración 8 Código de la preparación de las palabras para la búsqueda en diccionarios............................... 51 Ilustración 9 Código de la preparación de las palabras para la búsqueda en diccionarios (continuación) ...... 52 Ilustración 10 Código del nuevo listener en la clase EditorTextArea3 .............................................................. 52 Ilustración 11 Código de la búsqueda de memorias de traducción .................................................................. 54 Ilustración 12 Código de la búsqueda de memorias de traducción (continuación) .......................................... 54 Ilustración 13 Código de la búsqueda de proyectos similares........................................................................... 55 Ilustración 14 Código de la búsqueda de proyectos similares (continuación) .................................................. 55 Ilustración 15 Código de la búsqueda de proyectos similares (continuación) .................................................. 55 Ilustración 16 Diagrama de Componentes ........................................................................................................ 56 Ilustración 17 Diagrama de despliegue ............................................................................................................ 57 Ilustración 18 Archivo compartidos.txt de los memorias de traducción compartidas ...................................... 59 Ilustración 19 Archivo de los proyectos compartidos........................................................................................ 60 Ilustración 20 Archivos de los términos de glosario compartidos ..................................................................... 60 Ilustración 21 Respuesta de la llamada al servicio web glosario ...................................................................... 61 Ilustración 22 Respuesta de la llamada al servicio web memoria .................................................................... 61 Ilustración 23 Respuesta de la llamada al servicio web proyecto ..................................................................... 62 Ilustración 24 Mensaje de éxito de la aplicación cliente al exportar correctamente términos del glosario ..... 63.
(10) viii Ilustración 25 Archivo compartidos.txt de los términos de glosario tras la exportación .................................. 63 Ilustración 26 Aplicación tras la importación de nuevos términos de glosario ................................................. 64 Ilustración 27 Aplicación de administración tras indexar nuevos términos de glosario ................................... 65 Ilustración 28 Respuesta del servicio web glosario tras las indexación de nuevos términos de glosario ......... 65 Ilustración 29 Aplicación de administración tras la eliminación del término de glosario señalado ................. 66 Ilustración 30 Configuración del archivo.TAB ................................................................................................... 72 Ilustración 31 Ejemplo de configuración de un archivo .TAB ........................................................................... 72 Ilustración 32 Ejemplo de archivo .TAB con markup Pango .............................................................................. 73 Ilustración 33 Ejemplo de archivo .TAB con markup de HTML .......................................................................... 73 Ilustración 34Ejemplo de salida en una sola línea ............................................................................................ 73 Ilustración 35Ejemplo de salida en varias líneas para un término .................................................................... 73 Ilustración 36 Composición de un mensaje SOAP ............................................................................................. 76. ÍNDICE DE TABLAS Tabla 1 Protocolos por capas de los servicios web ........................................................................................... 23 Tabla 2 Comparación de REST y SOAP ............................................................................................................. 31 Tabla 3 Requisitos funcionales y no funcionales ............................................................................................... 36 Tabla 4 Caso de uso: Insertar elementos al repositorio .................................................................................... 39 Tabla 5 Caso de uso: Eliminar elementos de repositorio .................................................................................. 40 Tabla 6 Caso de uso: Crear diccionarios ............................................................................................................ 42 Tabla 7 Caso de uso: Exportar recursos de traducción ..................................................................................... 43 Tabla 8 Caso de uso: Importar recursos de traducción ..................................................................................... 44 Tabla 9 Compartir recursos de traducción ........................................................................................................ 45 Tabla 10 Buscar recursos de traducción ........................................................................................................... 46 Tabla 11 Descripción del diagrama de despliegue ............................................................................................ 57 Tabla 12 Ejemplos de markups ......................................................................................................................... 74.
(11) INTRODUCCIÓN. 1. INTRODUCCIÓN El creciente desarrollo de las tecnologías de comunicaciones ha permitido que exista una cantidad inmensurable de información digital, la cual suele ser traducida en diferentes idiomas con el objetivo de su publicación y distribución en la web. El resultado de este proceso es un producto multilingüe al alcance de clientes de varios países. Las actividades determinantes de la comunicación global multilingüe más significativas son: la elaboración de documentación técnica multilingüe (DTM), la localización de productos, la realización de campañas corporativas y publicitarias a escala mundial, la creación de diccionarios especializados y la comunicación oral. Estas actividades y las relaciones que establecen entre sí dan cuenta de su complejidad y de la necesidad de sincronizarlas. Las exigencias y necesidades del mercado mundial se han visto cambiadas en la esfera de la Sociedad de la Información, donde se ha hecho completamente ineludible la adaptación de la capacidad técnica a las necesidades de la comunicación global, que precisa de la superación del uso del inglés como lengua franca incorporando otras lenguas determinantes en diferentes mercados a fin de eliminar las fronteras de la información. La creciente producción de DTM no es solo producto de la necesidad de instituciones o empresas que desean estar presentes en todos los mercados mediante, por ejemplo, sitios web multilingües. En muchos casos responde a los requerimientos legislativos de grupos de mercados internacionales. La Unión Europea, por ejemplo, exige desde hace varios años que todos los productos comercializados dentro del continente estén marcados con la etiqueta de certificación de calidad (CE) que corresponde al cumplimiento de la normativa estipulada para cada producto. Además de los requisitos de calidad impuestos, se obliga a que todos los productos que se introduzcan en un mercado europeo contengan sus especificaciones descriptivas y técnicas en el idioma del país en cuestión u otros idiomas de los países que componen la UE (MINCETUR, 2010). Este nuevo panorama no sólo afecta a los países de la Unión Europea, sino también a otras comunidades económicas internacionales como los países integrantes del Tratado de Libre Comercio norteamericano (TLC) firmado por Estados Unidos, Canadá y México, o el del.
(12) INTRODUCCIÓN. 2. MERCOSUR, acordado entre los países del Cono Sur Americano (Argentina, Uruguay, Chile, Paraguay y Brasil), por citar algunos ejemplos. Esto da como resultado que empresas e instituciones que pretenden llegar a mercados extranjeros, busquen estrategias y herramientas para la producción DTM de manera periódica. La producción de esta información se ve estrechamente relacionada con la aparición de nuevos productos por lo que el desarrollo de estas estrategias y herramientas es de vital importancia. Como es de esperar el desarrollo de computación que va emparejado con las necesidades de los hombres permitió resolver este problema con el desarrollo de un nuevo grupo de herramientas conocidas como TAC por las siglas de Traducción Asistida por Computadoras. Las herramientas TAC ofrecen solución a la mayoría de los problemas con respecto a la traducción e interpretación, ya sea la lectura de una amplia gama de formatos de documentos, de archivos de diccionarios, la reutilización de traducciones para acelerar el proceso, estandarización de formatos, entre otros, haciéndalas casi indispensables para la producción de documentación multilingüe. Existen muchas herramientas especializadas para la asistencia en la traducción tanto como privativas como de uso libre. En el mercado internacional resalta como las más utilizadas las herramientas de la empresa SDL International con las suites SDL Trados Studio con las versiones del 2009 y 2011. Existen otras alternativas a Trados en el mercado como son Wordfast que se ha convertido en uno de los competidores más eficaces de Trados, Transit desarrollada por STAR, Déjà Vu desarrollada por la empresa española Atril, MemoQ una de las herramientas surgidas recientemente. Existen otras pero estas son las más destacadas en el mercado (Sánchez, 2014). Dentro del software libre existen herramientas TAC que se abren camino entre las privadas como son el caso de OmegaT que es probablemente la opción más extendida y utilizada por los traductores que buscan una alternativa gratuita a Trados; Across esta herramienta sigue una línea muy similar a Trados o MemoQ; Anaphraseus es una herramienta muy cómoda parecida a Wordfast Classic; Google Translator Toolkit a diferencia de las anteriores es online; Wordfast Anywhere, sigue la filosofía de Google Translator Toolkit, funciona online y combina funciones avanzadas de Wordfast Classic y Wordfast Pro (Sánchez, 2014)..
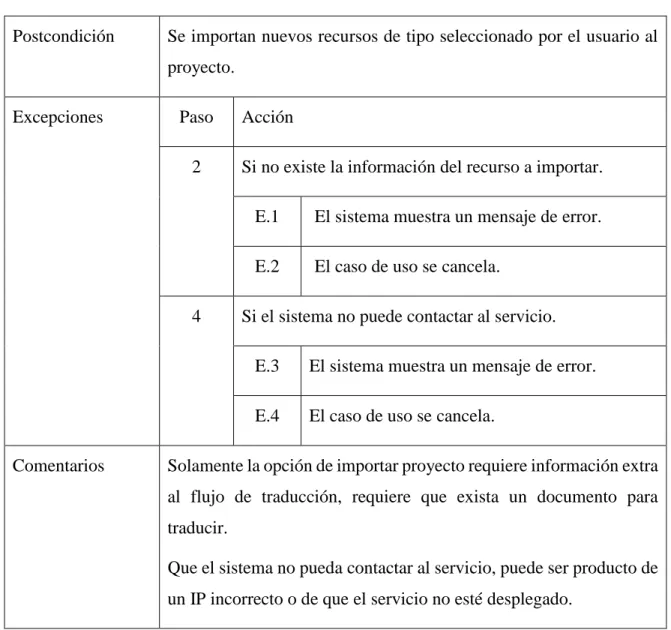
(13) INTRODUCCIÓN. 3. Los especialistas en Lenguas Extranjeras de la Universidad Central “Marta Abreu” de las Villas (UCLV), actualmente durante el proceso de traducción tienden a utilizar varios recursos computacionales como son: diccionarios generales y especializados del tema o área en la que se hace la traducción, traducciones propias o de otros especialistas de artículos sobre el mismo tema o área y otras informaciones disponibles en la red que apoyan su trabajo. Este uso simultáneo de múltiples fuentes de información hace su trabajo engorroso, consume recursos de forma ineficiente y sobrecargan el sistema operativo con múltiples ventanas y aplicaciones abiertas simultáneamente, además puede atrasar un trabajo la indisponibilidad de un medio como puede ser un diccionario especializado, o de una traducción como referencia. Objetivo general Incorporar nuevas funcionalidades a la herramienta TAC OmegaT integrando varios recursos computacionales que tributen a la asistencia de los profesionales de la carrera de Lengua Inglesa en la Universidad Central “Marta Abreu” de las Villas durante el proceso de traducción de documentos de diferentes idiomas. Objetivos específicos 1. Crear diccionarios con la información recopilada por los especialistas de lengua inglesa para que sean usados por el software. 2. Implementar servicios web que permitan al software OmegaT realizar búsquedas de documentos traducidos que sean similares al que se está traduciendo, memorias de traducción y términos de glosarios con idiomas origen y destino iguales al del proyecto en traducción. 3. Desarrollar una aplicación desktop que permita controlar (agregar, eliminar) los recursos que conformarán el repositorio a utilizar por los servicios web. 4. Modificar la aplicación OmegaT para permitir la exportación e importación de sus recursos así como la consulta personalizada de diccionarios..
(14) INTRODUCCIÓN. 4. Preguntas de Investigación 1. ¿Qué herramienta puede ser utilizada para la creación de los diccionarios a partir de la información recopilada por los especialistas, la integración con un software de implementado en JAVA? 2. ¿Qué herramientas se pueden utilizar para la implementación de las búsquedas de contenido similar al que se está traduciendo, así como para la consulta personalizada de diccionarios teniendo en cuenta las particularidades de OmegaT? 3. ¿Qué estándar de servicio web (SOAP o RESTful) será más factible utilizar para la implementación de las soluciones, partiendo de las características propias de OmegaT y los objetivos propuestos? Justificación de la investigación Las herramientas TAC están muy difundidas en el mundo de creación de documentación multilingüe, la mayoría de las herramientas son privativas y sus licencias de utilización son caras. Existen herramientas TAC gratis y de código abierto entre las que se encuentra OmegaT, cuyas bondades están abaladas por especialistas de la materia ya que incorpora la mayoría de las características que deben tener este tipo de herramienta. Por otra parte al personalizar y adaptar OmegaT a las necesidades de los especialistas de Lengua Inglesa de la UCLV añadiéndole nuevas funcionalidades permite entre otras cosas aumentar la eficiencia de los traductores que utilicen el software. Además esta adaptación de OmegaT enfocada a necesidades puntuales de especialistas de la UCLV, permite una mayor competitividad a los mismos, les ahorraría considerables sumas de dinero. Sin contar que constituye un paso más de avance para la informatización e independencia tecnológica de la UCLV. Como consecuencia el proyecto está compuesto por cuatro capítulos; el primer capítulo describe los principales recursos utilizados por OmegaT, explica las ventajas y desventajas de la utilización de las memorias de traducción en el trabajo de los traductores, así como las ventajas del uso compartido de las memorias de traducción y, describe el lenguaje TMX como lenguaje estándar para las memorias de traducción, además se tratan los recursos glosarios, tanto los formatos utilizados, como su creación; y diccionarios..
(15) INTRODUCCIÓN. 5. En el segundo capítulo se realiza un estudio de las posibles herramientas a utilizar para el desarrollo del sistema, entre las cuales destaca Lucene como herramienta de búsqueda e indexado, realizando una descripción de cada proceso junto las ventajas que permite, se realizan comparaciones de dos posibles arquitecturas de servicios web, así como de dos posibles servidores web para soportarlas. En el tercer capítulo se propone una implementación del sistema, se define los requisitos funcionales y no funcionales del sistema, los actores y casos de uso del sistema y muestra la arquitectura del sistema en función de los mismos mediante los diagramas de clase, componentes y flujo. En el cuarto capítulo se describen un grupo de pruebas realizadas al sistema con el fin de comprobar su correcto funcionamiento..
(16) CAPÍTULO 1. Tecnologías para la implementación del sistema. 6. Capítulo 1. Tecnologías para la implementación del sistema Con el fin de dar solución a la problemática del proyecto es necesario la utilización de un conjunto de tecnologías útiles para el desarrollo del sistema como: herramienta TAC, búsquedas e indexación de texto, creación de servicios web, ftp y su despliegue; para ello en el capítulo se realiza un análisis de opciones de estas tecnologías, comparación de las mismas, y elección de las más favorables para el sistema a implementar. Por lo tanto, se exponen las características principales de OmegaT, se realiza un análisis de la biblioteca Lucene explicando en un orden lógico los pasos necesarios para la indexación y búsqueda, se realiza un análisis de las tecnologías SOAP y RESTful en cuanto a la ventajas e implementación de cada uno así como una comparación de las dos, en adelante se analizan los servidores web Glassfish y Tomcat, se detallan cada una de sus características y sus componentes, y se realiza una comparación entre los dos, luego se realiza una descripción del servidor ftp Svftpd de Linux y al final se exponen las tecnologías elegidas en cada parte del sistema. 1.1. La herramienta TAC OmegaT OmegaT es una aplicación libre de memoria de traducción escrita en Java, se puede instalar en Windows, Mac y varias versiones de Linux. Entre sus principales ventajas se encuentra la compatibilidad con diferentes formatos de archivo de texto más empleados como: HTML, XML, XLIFF (XML Localization Interchange File Format), DOCX, texto ASCII (*.txt), texto codificado (*.UTF8), paquetes de recursos Java (*.properties), etc (Anica, 2014). Cuenta con un poderoso motor de memorias de traducción, siendo el componente más importante de aplicación, cada vez que se entra a un nuevo segmento de la traducción busca y muestra memorias de traducciones exactas o aproximadas a la que se traduce. Dado a su compatibilidad con TMX (Translation Memory Exchange), el estándar de memorias de traducción, puede trabajar con memorias de traducción realizadas con otras aplicaciones y crear nuevas que a su vez puede ser utilizada por aplicaciones similares o de gestión de memorias de traducción (Flórez and Alcina, 2011). Dentro de los atractivos de OmegaT cabe destacar la gestión terminológica, utiliza glosarios que contiene frases o palabras sueltas con su traducción y comentarios que hacen función de un pequeño diccionario, si existen coincidencias de alguno de estos términos, aparecerán en.
(17) CAPÍTULO 1. Tecnologías para la implementación del sistema. 7. la sección del glosario, además de los glosarios también utiliza diccionarios que pueden ser generales u ortográficos, para búsquedas más especializadas, las que realiza de manera automática para los segmentos del texto origen, mostrándose en el área de diccionarios. OmegaT presenta muchas características que lo hacen peculiarmente cómodo para el aprendizaje rápido de su uso, pero además es muy útil a la hora de trabajar con idiomas tanto de derecha a izquierda como de derecha a izquierda, sin contar que posee diversos filtros que permiten realizar la segmentación de los textos en dependencia al lenguaje origen. Diferente a otras herramientas TAC clásicas como WordfastClassic o las versiones de SDLTrados previas a Trados Studio, OmegaT no precisa del procesador de texto Microsoft Word, por el contrario crea un proyecto de traducción al que se le importan los documentos a traducir, así como los diccionarios y glosario. Los proyectos de traducción están contenidos en un directorio con el nombre del proyecto, dentro se pueden encontrar seis subdirectorios, también pueden estar distribuidos fuera del directorio del proyecto, además de cuatro archivos: . Dictionary: Es el subdirectorio donde se almacenarán los diccionarios; cualquier diccionario que esté fuera de este directorio no será reconocido como tal.. . Glossary: Es el subdirectorio que contiene los glosarios del proyecto; cualquier archivo con formato de glosario mientras esté en esta carpeta será reconocido como tal, pero el glosario principal, será glossary este es el creado a partir de la aplicación.. . Omegat: Es el subdirectorio más importante contiene archivos que tienen información única del proyecto: o Project_save.tmx: existe al menos uno contiene las memorias de traducción con que trabaja la aplicación, por lo que es el más importante. o Project_save.tmx.<fecha. y. hora>.bak:. Son. salvas. del. archivo. project_save.tmx que se crearán cada vez que se abra el proyecto. o Stats.txt: contiene las estadísticas del proyecto actual: cantidad de palabras, segmentos, segmentos traducidos, segmentos faltantes, etc. o Ignore_words.txt y learned_word.txt: Son archivos utilizados por el corrector ortográfico..
(18) CAPÍTULO 1. Tecnologías para la implementación del sistema. 8. o Files_order: Contiene el orden en que se fueron agregando los documentos a traducir y este se mantiene. o Last_entry.properties: Contiene la información del último segmento en que trabajo, el proyecto al abrirse nuevamente comienza en este segmento. . Source: Es el subdirectorio donde se almacenarán los archivos a traducir.. . Target: Es el subdirectorio donde se crearán los archivos ya traducidos con el mismo formato de los archivos a traducir.. . Tm: Este directorio puede contener cualquier número de memorias de traducción auxiliares es decir, archivos TMX. El contenido de las memorias de traducción en el subdirectorio tm sirve para generar sugerencias para el texto a traducir. Cualquier texto, ya traducido y almacenado en estos archivos, aparece entre las coincidencias parciales, si es lo suficientemente similar al texto que se está traduciendo.. . Omegat.project: Es el archivo que contiene la información de todos los subdirectorios del proyecto.. . <nombre>-level1.tmx, <nombre>-level2.tmx y <nombre>-omegat.tmx: El archivo level1 sólo contiene información textual. El archivo de nivel 2 encapsula etiquetas específicas de OmegaT en etiquetas tmx correctas para que el archivo se pueda utilizar con su información de formato en una herramienta de traducción compatible con memorias tmx nivel 2, u OmegaT en sí mismo. El archivo OmegaT incluye etiquetas de formato específicas de OmegaT para que el archivo se pueda utilizar en otros proyectos OmegaT. Estos archivos son copias del archivo project_save.tmx. 1.1.1.. Memorias de traducción. Las memorias de traducción son almacenes compuesto por textos originales de una lengua origen alineados con su traducción en una o varias lenguas destino. Es básicamente un tipo especial de base datos.(PAULINE CASTIAU, Guohua, 2009, Odriozola et al., 1997). Están alineados por unidades de traducción o segmentos. Las unidades de traducción que se almacenan junto con sus equivalentes se definen de forma variable siendo la segmentación tras un signo de puntuación que marca el final de la frase (., ?, !, :, ...) o un salto de párrafo las más frecuentes ofrecidas por defecto en el entorno de los sistemas de traducción asistida..
(19) CAPÍTULO 1. Tecnologías para la implementación del sistema. 9. Una memoria de traducción (MT) es una base de datos lingüística que les permite a los traductores reutilizar traducciones ya existentes. Son herramientas de almacenamiento y acumulación de información que están en constante crecimiento. Le permiten al traductor identificar unidades de traducción (por lo general frases enteras) que ya han sido traducidas anteriormente para luego reutilizarlas, de manera que una misma frase nunca se traduce dos veces. (Gutiérrez, PAULINE CASTIAU, 2011) La principal función de las MT es extraer sugerencias totales y parciales de una frase y concordancias para términos. A lo largo de la traducción, se buscan en la base de datos de las MT segmentos que coincidan al 100% y se muestran en la ventana de las MT. Las coincidencias parciales o segmento no exacto son llamados fuzzy match también son incluidos en la ventana de las MT, el grado de similitud puede es adaptable en todos los sistemas de MT. El contenido de estos recursos lingüísticos paralelos es fundamental, pero también es crucial el motor de búsqueda que permite explorar una gran cantidad de texto e identificar patrones lingüísticos y terminológicos comunes. Por tanto, si el contenido de las memorias y si su sistema de indización ofrece buenos resultados, estas memorias se convierten en el mejor instrumento de trabajo del mediador lingüístico. El almacén de MT va creciendo en función del volumen y frecuencia de alimentación de las memorias de traducción, las que se crean a medida que se valida la traducción de un segmento del texto a traducir en un entorno de traducción asistida. Otra de las técnicas utilizadas para generación de MT es la alineación de textos con sus traducciones, esta se lleva a cabo con herramientas conocidas como alineadores. El uso de memorias de traducción es más útil en textos repetitivos como manuales técnicos o documentos con vocabulario especializado. También son útiles para hacer traducciones incrementales de documentos traducidos anteriormente. Si un traductor de memoria se usa de forma consistente durante un cierto tiempo puede ahorrar un trabajo considerable a los traductores..
(20) CAPÍTULO 1. Tecnologías para la implementación del sistema. 1.1.1.1.. 10. Memorias de traducción compartidas. Una de las ventajas de las MT es la posibilidad de reutilización de las mismas por otros sistemas o usuarios por lo que no es de extrañar la existencia de usuarios que sistemas destinados a guardar MT de varios usuarios con el fin de compartir la información, como por ejemplo la Nube en Internet. Las memorias pueden compartirse desde un archivo centralizado de memorias gestionado por uno de los proveedores del cliente. Cuando el proveedor 1 recibe un trabajo de traducción deberá descargar toda la memoria. Deberá realizar las labores de preprocesado necesarias y analizar el trabajo con la memoria que ha descargado. Cuando el proveedor 2 recibe un encargo de traducción, repite esta misma operación. Al finalizar los trabajos, es preciso incluir las unidades de memoria nuevas o cambiadas en la memoria principal. Esta tarea será responsabilidad exclusiva de uno de los proveedores en calidad de custodio de la memoria, o, si dispone de los recursos adecuados, del cliente. (Abaitua, 2001) La principal ventaja del uso compartido de memorias de traducción es que permite a profesionales de la traducción especialistas en determinadas áreas tener acceso a información traducida de otras áreas. A pesar de ello herramientas como Trados y OmegaT están ideadas para el uso diario del traductor profesional y no para facilitar al usuario este tipo de práctica. 1.1.1.2.. Formato común para las memorias de traducción. En la última década del siglo XX se fue expandiendo la idea de que la traducción automática no iba ser la herramienta definitiva para la comunicación entre todos los idiomas debido a obstáculos infranqueables del lenguaje natural para el procesamiento automático. Producto a ello comienzan a seguirse las investigaciones más avanzadas del tema en el momento en distintos campos, como la idea de TAC dando paso a la idea de las MT. La gran cantidad de herramientas de MT dejó al descubierto el problema de la incompatibilidad de las MT en diferentes software por lo que si se comenzaba en uno no se podía cambiar a otro sin tener que comenzar desde cero. De la necesidad creciente de un método de intercambio de MT entre las diferentes aplicaciones surge TMX; producto del consorcio Lisa en 1998..
(21) CAPÍTULO 1. Tecnologías para la implementación del sistema. 1.1.1.3.. 11. Traslation Memory eXchange. TMX (Gómez, 2001) es un lenguaje que cumple las especificaciones XML, cuyo propósito es proporcionar un estándar para el intercambio de TM. El único requerimiento es que la aplicación soporte este lenguaje, una vez exportada este lenguaje desde una aplicación puede ser importada por otra y utilizada. La mayoría de las aplicaciones más importantes del mercado admiten la importación y exportación de memorias TMX en distintos grados. Quizás gracias a sus disimiles características, ver Anexo 1. 1.1.2.. Glosarios. La palabra proviene del latín glossarium, es un catálogo de palabras de una misma disciplina o de un campo de estudio que aparecen definidas, explicadas y comentadas. También se trata de un catálogo de palabras desusadas o del conjunto de comentarios y glosas sobre los textos de un autor. El término se utiliza para hacer referencia a un conjunto de breves anotaciones explicando la definición de palabras o frases. La mayoría de libros que tienen contenido específico como científico o religioso, poseen glosarios al final del mismo. Son similares a los diccionarios, la diferencia se encuentra en la cantidad de palabras o términos que soporta cada uno, mientras que los diccionarios son creados para almacenar un gran número de términos, los glosarios solo almacenan un pequeño número(Young, 1988). En OmegaT un glosario puede ser definido desde un archivo con extensión txt, cada línea debe contener un trío con el formato, [palabra/frase] [TAB] [equivalente] [TAB] [comentarios (opcional)], en el caso de no escribir comentarios no es necesario el segundo TAB. OmegaT es compatible con el formato CSV, en este caso la separación de los elementos del trío sería con comas y no con TAB, además los elementos deben encerrarse entre comillas dobles. El archivo se puede codificar por medio del sistema de archivo predeterminado (se indica mediante la extensión .tab) o en UTF-8 (con la extensión .utf8)..
(22) CAPÍTULO 1. Tecnologías para la implementación del sistema. 12. Si bien los glosarios se pueden definir con cualquiera de los formatos y codificaciones, es preferible utilizar el primer formato puesto a que la tabulación separa muy bien visualmente los elementos del trío y la codificación Unicode (UTF-8). Además de texto sin formato, OmegaT también es compatible con el formato TBX (Term Base eXchange), un estándar libre basado en XML para el intercambio estructurado de datos terminológicos que ha sido aprobado como un estándar internacional por LISA e ISO. 1.1.3.. Diccionarios. Los diccionarios utilizados por OmegaT deben ser compatibles con la plataforma StarDict, una herramienta para la lectura de diccionarios disponible para múltiples plataformas como Windows, Linus, DSD y Mac. La plataforma StarDict proporciona una gran variedad de herraminetas en su juego de herraminetas StarDict-Tools las que poseen un conjunto de utilidades para manipular diccionarios de StarDict y convertir de otros formatos de diccionarios electrónicos al formato de StarDict(Popov, 2006, Ding et al., 2011, Lertsuksakda et al., 2014). Cada diccionario StarDict es creado a partir de un archivo .TAB (Anexo 2) que contiene la información del diccionario; este se puede obtener de tres formas diferentes: . Creando el archivo TAB desde cero.. . Convirtiendo un diccionario existente de StarDict de su archivo binario DICT a .TAB.. . Convirtiendo un diccionario existente de otro formato (dictd, Lingvo, MOVA, Babylon o DSL) a los archivos binarios de StarDict y luego estos convertirlos a .TAB.. 1.2. Lucene Lucene es una biblioteca de Recuperación de Información (RI) de gran rendimiento y escalable que añade a una aplicación la capacidad de búsqueda y RI. Es un proyecto maduro, libre y de código abierto implementado en Java como proyecto de la fundación de software Apache y bajo la licencia de la misma. En los últimos años ha alcanzado gran popularidad, convirtiéndose en la biblioteca de RI más difundida, empleándose tanto en aplicaciones web como aplicaciones de escritorio. Debido a este alcance puede encontrarse integrada mediante.
(23) CAPÍTULO 1. Tecnologías para la implementación del sistema. 13. puertos a otros lenguajes además de Java como son: C/C++, C#, Perl, Ruby, Phyton, PHP, etc (Liang et al., 2015, Entrup, 2015). Dada su gran sencillez no son necesarios profundos conocimientos sobre cómo Lucene indexa la información a la hora de la utilización pero al menos es necesario conocer los pasos que realiza cualquier sistema de RI a la hora de realizar el proceso de indexación, búsqueda y recuperación de la información. Sin tener en cuenta las particularidades de la interfaz del usuario o cualquier otro componente que pueda estar en el software a desarrollar, se pueden definir 7 etapas en todo el proceso: Adquisición del Contenido, Creación del objeto Document, Indexación del objeto Document, Construcción de la Consulta, Ejecución de la Consulta y Obtención de los Resultados; de estas la primera no es realizada por Lucene. 1.2.1.. Adquisición del contenido. La adquisición del contenido es el primer paso en el proceso de indexación de la información, es a menudo realizado por crawler (rastreador) o spider, sin los cuales el proceso sería complicado, engorroso y desordenado. Por lo general se desea adquirir información contenida en ficheros que pueden estar en un directorio específico en el sistema de ficheros, base de datos, en una red local, en la web o pequeñas partes de cada uno dispersa en todos estos sitios. Para tener acceso a algunos de estos lugares es necesario tener privilegios especiales de administración, además es necesario adquirir documentos a los que se le realizan cambios, o se añaden en cuanto estén disponibles. Lucene como biblioteca de búsqueda no posee esta funcionalidad, por lo que debe implementarse en una parte diferente de la aplicación o por separado. Para esto existen diferentes crawler con código abierto: . Nutch: Es un crawler Web de código abierto escrito en Java, está basado en Lucene y a su vez es parte del proyecto Lucene de la Apache Software Foundation. Mediante su uso se pueden encontrar hipervínculos de páginas web de forma automatizada, reduciendo el trabajo de mantenimiento. Guarda una copia de las páginas visitadas para visitar otras, esta copia es utilizada por otras herramientas. (Wu, 2015, Frampton, 2015, Mcgibbney, 2015)..
(24) CAPÍTULO 1. Tecnologías para la implementación del sistema. . 14. Heritrix: Heritrix es un crawler de ficheros web a través de internet. Su licencia es de código abierto y está escrito completamente en JAVA. Su interfaz de configuración es accesible usando un navegador web, haciéndolo muy versátil y cómodo de usar, aunque también puede ser lanzando desde línea de comandos. Heritrix fue desarrollado conjuntamente por "Internet Archive" y "Nordic National Libraries" a principios de 2003. La primera versión fue publicada en enero de 2004 y ha sido continuamente actualizado por los miembros de "Internet Archive" y terceras partes (Erik Hatcher, 2009, Mohr et al., 2004, Guohua, 2009).. . Apache Droids: Es un proyecto de la Apache Software Fundation, que se dedica a la creación de un framework para la definición de web crawlers. Estos robots para la búsqueda de información en línea se construyen por medio de elementos genéricos tales como(Tittle, 2011, Jackson, 2012): 1. Colas. 2. Protocolos. 3. Analizadores sintácticos (Apache Tika). 4. Handlers.. . Aperture: (http://aperture.sourceforce.net): Aperture es un framework de Java para la extracción y consulta de contenido de texto completo y metadatos de los diversos sistemas de información como: sistemas de archivos, sitios web, buzones de correo; y formatos de archivos como documentos e imágenes que utilizan estos sistemas(Erik Hatcher, 2009).. Si la aplicación se encargará de buscar información dispersa es natural utilizar alguno de los crawlers existentes, pero si la información a buscar se encuentra en un solo lugar es muy fácil crear tu propio crawlers.(Erik Hatcher, 2009) 1.2.2.. Análisis de Documentos. Antes de la indexación el texto es dividido en unidades menores llamadas tokens. Cada token corresponde a una palabra del lenguaje natural, esta tiene que tener un significado con un peso, o sea: artículos, conjunciones, preposiciones, pronombres, etc; no se añaden como tokens, estas palabras sin significado son llamadas stop words. En este paso se decide que token utilizar en la indexación. Puede parecer simple pero no lo es, en muchos casos hay.
(25) CAPÍTULO 1. Tecnologías para la implementación del sistema. 15. palabras compuestas o derivadas de otras, hay palabras en plural y singular, palabras que pueden tener errores ortográficos; cuando suceden estas cosas aparecen muchas preguntas de cómo se debe dividirse el texto, que token utilizar, mantener la independencia en algunos o llevarlos a un punto en común. Lucene provee analizadores que permitirá tener un fino control sobre el proceso. Es muy fácil crear un analizador propio o combinar los tokenizadores de Lucene y los filtros de tokens para personalizar la creación de las fichas(D. Vadim Paz Madrid Gorelow, 2007). Para ello cuenta con varios analizadores léxicos que dan características diferentes a los campos: . ANALIZED: divide el valor del campo en diferentes tokens, para ello es posible utilizar cuatro de sus opciones: 1. WhitespaceAnalyzer: Separa el valor del campo en diferentes tokens antes de guardarlo. 2. SimpleAnalyzer: Separa el valor del campo en diferentes tokens además separa las cadenas con caracteres especiales (@, -, &, etc) en tokens y elimina los caracteres especiales antes de guardarlo. 3. StopAnalyzer: Realiza las funciones de los dos anteriores pero además elimina las llamadas stopwords (artículos, conjunciones, preposiciones, etc) antes de guardar el valor del campo. 4. StandarAnalyzer: Es el analizador más avanzado realiza las funciones de los tres anteriores pero detecta cuando se encuentra frente a nombres de compañías, correos electrónicos, páginas web, etc y los mantiene como un solo token.. . NOT_ANALIZED: A diferencia de ANALYZER toma el valor de la cadena como un solo token.. . TOKENIZER: Divide el valor de la cadena en diferentes tokens.. . NOT_TOKENIZER: Toma el valor de la cadena como un solo token. 1.2.3.. Indexación. En la indexación los Documents son añadidos a un índice que tiene como base estructuras de datos que permiten el rápido acceso a la información contenida por ellas. Como ya se mencionó anteriormente no es necesario tener conocimientos profundos de cómo se crean,.
(26) CAPÍTULO 1. Tecnologías para la implementación del sistema. 16. pero hay que tener presente que existen dos tipos fundamentales de índices: Índice invertido y Patricia Tree (PAT). Los índices invertidos son conjunto de documents, donde a cada documento es asignada una lista de palabras claves o atributos, con un peso de relevancia que se le asocia opcionalmente a cada palabra clave (atributo). Un fichero invertido es una lista ordenada (o índice) de palabras claves (atributos), donde cada palabra clave tiene enlaces a los documents que contienen esa palabra clave. Construir y mantener un índice invertido es relativamente barato. En principio, puede construirse un índice invertido para un texto de n caracteres en un tiempo O(n). El mayor problema que se presenta en la práctica a la hora de construir un índice invertido es que la RAM se termine antes de poder procesar todo el texto. En este caso, cada vez que la RAM se agota, se graba en disco un índice parcial y se libera la memoria. Al final, se realiza una merge de los índices parciales. La mezcla consiste en combinar los vocabularios ordenados. Si aparece el mismo término en ambos índices se mezclan sus listas de ocurrencias. Esta mezcla no requiere demasiada memoria (se trata de un proceso secuencial) y resulta relativamente rápido en I/O. Este método se adapta fácilmente para actualizar el índice. Los ficheros invertidos utilizan pueden utilizar como estructuras de datos: . Arreglos ordenados.. . Árboles (B-trees, tries).. . Tablas Hash.. . Combinación de las tres.. Las principales ventajas: . Son utilizados por la mayoría de los sistemas de bibliotecas comerciales.. . El uso de los ficheros invertidos mejora la eficiencia de la búsqueda por varios órdenes de magnitud (una necesidad para ficheros de textos muy grandes).. Las principales desventajas: . La penalidad por la eficiencia es la necesidad de almacenar una estructura de datos que consume del 10% al 100% o más del tamaño del texto en sí..
(27) CAPÍTULO 1. Tecnologías para la implementación del sistema. . 17. Es necesario actualizar el índice cuando el conjunto de datos cambia.. Restricciones de estos índices: . Un vocabulario controlado correspondiente a la colección de palabras claves que serán indexadas. Palabras en el texto que no estén en el vocabulario no serán indexadas, y por tanto no serán buscadas.. . Una lista de palabras gramaticales (stopwords) que por razones de volumen o precisión, no serán incluidas en el índice, y por tanto no serán buscadas.. . Un conjunto de reglas que decide el comienzo de una palabra o parte de un texto que es indexable. Estas reglas están relacionadas con el tratamiento de espacios, marcas de puntuación o algunos prefijos estándares, y pueden tener un impacto significativo en qué términos son indexados.. . Una lista de secuencia de caracteres a ser indexadas (o no indexadas). En grandes bases de datos textuales, no todas las secuencias de caracteres son indexadas.. Lucene utiliza un índice invertido y provee todo lo necesario para la realización de esta operación a través de una API sorprendentemente simple. Debe entenderse que hacer un índice es indispensable antes de realizar cualquier búsqueda. 1.2.4.. Consultas. La búsqueda es el proceso de mirar palabras en el índice para encontrar documents y una vez diseñado un sistema para resolver consultas sobre una colección de datos es necesario establecer parámetros para la evaluación del sistema con determinadas consultas. Esto es útil para las consultas ranqueadas donde la posición del resultado es fundamental en la calidad del resultado de la búsqueda. Existen ciertos parámetros y técnicas estandarizadas para evaluar la eficiencia de un sistema de búsqueda como son: precisión y recall. La precisión se define como la cantidad de documentos relevantes recuperados sobre el total de documentos recuperados.(Saubiedet). El recall se define como la cantidad de documentos relevantes recuperados sobre el total de documentos relevantes.(Saubiedet)..
(28) CAPÍTULO 1. Tecnologías para la implementación del sistema. 18. Otro método muy utilizado consiste en medir la precisión para un cierto número de documentos recuperados fijo, este método es muy usado en buscadores web midiendo por ejemplo la precisión para los primeros “n” resultados. A este método se lo llama precisión fija.(Saubiedet) Para la búsqueda se deben considerar varios factores, ya se la velocidad, el procesamiento de textos largos, que se había tenido en cuenta a la hora de crear el índice; pero existe otros factores como son: el soporte para una o varias consultas, consultas de frases, comodines, consultas borrosas, etc. El primer paso hacia la búsqueda es la construcción de la consulta. Este paso consiste en convertir la cadena que el usuario pasa por la interfaz en una consulta (Query), para esto Lucene posee un poderoso paquete llamado QueryParse, el resultado de esta conversión es un objeto de la clase Query. La creación de los objetos Query puede ser muy fácil o muy difícil, esto es producto a la complejidad de la consulta; podemos encontrarnos consultas con operadores booleanos, consultas de frases, consultas con comodines, etc. Si la aplicación tiene restricciones por usuarios o sea no todos los usuarios tienen privilegios sobre la misma cantidad de archivos entonces es necesario realizar un filtro a la consulta. A menudo el paquete por defecto de Lucene es suficiente para crear una Query, pero puede utilizar el QueryParse y añadirle una nueva lógica para refinar el objeto de consulta, esto lleva la consulta más lejos. En muchas ocasiones el usuario necesita que algunos resultados resalten más que otros por cual es necesario modificar la consulta para resaltar los resultados, esto también puede hacerse en el proceso de indexación, pero no está de más hacerlo aquí por dos razones: en el proceso de indexación pudo no realizarse esta acción, las consultas pueden variar y lo que para algunos representaba los resultados más importantes para otros no lo son. Lucene presenta varias formas de consultas, todas con un alcance diferente y entre las cuales están: . TermQuery: Similar a QueryParse pero se utiliza principalmente para campos con valores específicos que se pueden tomar como identificadores..
(29) CAPÍTULO 1. Tecnologías para la implementación del sistema. . 19. BooleanQuery: Es una consulta muy útil permite unificar los resultados de distintos tipos de consultas en una sola, aprovechando esta posibilidad se puede agregar varias restricciones a una búsqueda.. . MoreLikeThis: Compara los vectores de los documents de consultas anteriores para buscar coincidencias de vectores similares.. Lucene puede expandir sus consultas utilizando el su biblioteca lucene-wordnet en la que puede utilizar la función expand de la clase SynExpand. Lucene utiliza un modelo de representación de los objetos denominado “Modelo de espacio vectorial” el cual permite entre otras cosas que los documentos se ordenen según el grado de similitud, teniendo en cuenta también los documentos que parcialmente emparejan con la consulta. Los documentos dj y la consulta se representan como vectores t-dimensionales, siendo t el número de términos diferentes en el conjunto de documentos. El modelo vectorial propone evaluar el grado de similitud entre el documento dj y la consulta q como la correlación entre sus vectores. Esta correlación puede ser cuantificada, por ejemplo, como el coseno del ángulo entre los dos vectores, este es uno de los más utilizados. El modelo vectorial tiene una desventaja, por lo menos teóricamente, al asumir que los términos índice son independientes, aunque en la práctica el asumir esta dependencia puede ser una desventaja. Debido a la localidad de muchas dependencias entre términos, su aplicación indiscriminada a todos los documentos de la colección puede repercutir negativamente en el performance total. Sin embargo, aún con su simplicidad y defectos es considerado mejor o tan bueno como alternativas más sofisticadas haciéndolo el modelo más popular de RI y Lucene lo utiliza para la representación de los documentos y sus tokens lingüísticos. Algunos modelos alternativos de recuperación de información son: . Booleano y sus extensiones: Booleano Extendido, Conjuntos Difusos.. . Extensiones al modelo Vectorial: Vectorial generalizado, LSI (Latent Semantic Indexing), Redes neuronales.. . Probabilístico y sus extensiones: Redes Bayesianas, Redes de Inferencia Bayesiana..
(30) CAPÍTULO 1. Tecnologías para la implementación del sistema. 20. 2.1.7 Obtención de los resultados Una vez obtenida una lista ordenada provisional de documentos que coinciden con la consulta es una buena política mostrar los resultados al usuarios de una forma lo más natural posible, brindándole posibilidades de seguimiento como hacer clic a la siguiente página, refinado de la búsqueda, la búsqueda de documentos similares a alguno de los obtenidos; la idea es no permitir que el usuario se encuentre con callejón sin salida. El núcleo de Lucene no ofrece componentes para presentar plenamente los resultados, pero la Sandbox contiene el highlighter (resaltador) package, para la producción de resúmenes dinámicos y resaltado exitoso. 1.3. WordNet Wordnet es una base de datos léxica del idioma inglés. Agrupa palabras en inglés en conjuntos de sinónimos llamados synsets, proporcionando definiciones cortas y generales, almacena las relaciones semánticas entre los conjuntos de sinónimos. Su propósito es doble: producir una combinación de diccionario cuyo uso sea más intuitivo, y soportar el análisis automático de texto y a aplicaciones de inteligencia artificial(Miller et al., 1990, Miller, 1995, Fellbaum, 1998). La mayoría de los synsets están conectados a otros synsets mediante numerosas relaciones semánticas, estas varían basándose en el tipo de palabra, ver Anexo 3. Las bases de datos y las licencias del software se han liberado bajo una licencia BSD y pueden ser descargadas y usadas libremente. 1.4. Servicios web Actualmente en el desarrollo de software existe la tendencia de un diseño modular. Las aplicaciones con este diseño se componen de una serie de componentes reutilizables que se pueden encontrar distribuidos por toda la red. La principal ventaja de un diseño de este tipo es que el mantenimiento y expansión de una aplicación es mucho más simple que si la aplicación fuese centralizada, además que las afectaciones a los usuarios que utilizan la aplicación serían solo para aquellos que utilicen este módulo..
(31) CAPÍTULO 1. Tecnologías para la implementación del sistema. 21. Uno de estos componentes con que puede contar una aplicación es el Servicio Web. Un Servicio Web es un componente al que podemos acceder mediante protocolos Web estándar, utilizando XML para el intercambio de información. Los Servicios Web pueden ser referidos como una colección de procedimientos a los que se pueden llamar desde cualquier lugar de la red, la principal ventaja de su utilización es que pueden llamarse independientemente del lenguaje en que se desarrolle el servicio internamente o la plataforma y lenguaje en la aplicación debido a que los vendedores han admitido estándares comunes de Servicios Web. El W3C (World Wide Web Consortium) define un Servicio Web como un sistema software diseñado para soportar interacciones máquina a máquina a través de la red. Dicho de otro modo, los servicios Web proporcionan una forma estándar de interoperar entre aplicaciones software que se ejecutan en diferentes plataformas. Por lo tanto, su principal característica su gran interoperabilidad y extensibilidad así como por proporcionar información fácilmente procesable por las máquinas gracias al uso de XML. Características de un componente como Servicio Web: . Implementa los métodos de una interfaz descrita mediante un WSDL. Estos se implementan utilizando un EJB de sesión de tipo Stateless/Singleton o bien un componente web JAX-WS.. . Puede tener publicada su interfaz en uno o más registros durante su despliegue.. . La implementación de un Servicio Web utiliza solamente la funcionalidad descrita por su especificación, puede desplegarse en cualquier servidor de aplicaciones que cumple con las especificaciones Java EE.. . Los servicios requeridos en tiempo de ejecución (run-time), tales como atributos de seguridad, se separan de la implementación del servicio, para ello se utilizarán herramientas que definen estos requerimientos en el ensamblado o despliegue.. . Un contenedor que actúa como mediador para acceder al servicio..
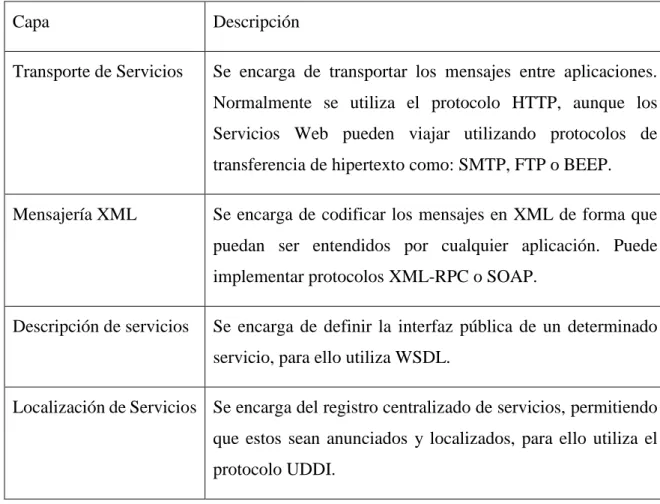
(32) CAPÍTULO 1. Tecnologías para la implementación del sistema. 22. La especificación de Java EE para servicios Web define una serie de relaciones arquitectónicas requeridas para dichos servicios. Se trata de relaciones lógicas que no imponen requerimiento para el proveedor del contenedor sobre como estructurar los contenedores y los procesos. Como añadido para la plataforma Java EE se incluye un componente port que depende de la funcionalidad de contenedor proporcionada por los contenedores web y EJB, y del transporte SOAP/HTTP.. Ilustración 1 Arquitectura de los servicios web. Los Servicios Web para Java EE requieren un componente Port que pueda ser referido desde el cliente, así como desde los contenedores Web y EJB. No se requiere que haya un port accesible desde un contenedor applets. Los Servicios para Java EE pueden implementarse de dos formas: . Como una clase Java que se ejecuta en un contenedor Web.. . Como un EJB de sesión Stateless o Singleton en un contenedor EJB.. Acompañados de estas características existen una serie de protocolos organizados por capas..
(33) CAPÍTULO 1. Tecnologías para la implementación del sistema. 23. Tabla 1 Protocolos por capas de los servicios web. Capa. Descripción. Transporte de Servicios. Se encarga de transportar los mensajes entre aplicaciones. Normalmente se utiliza el protocolo HTTP, aunque los Servicios Web pueden viajar utilizando protocolos de transferencia de hipertexto como: SMTP, FTP o BEEP.. Mensajería XML. Se encarga de codificar los mensajes en XML de forma que puedan ser entendidos por cualquier aplicación. Puede implementar protocolos XML-RPC o SOAP.. Descripción de servicios. Se encarga de definir la interfaz pública de un determinado servicio, para ello utiliza WSDL.. Localización de Servicios Se encarga del registro centralizado de servicios, permitiendo que estos sean anunciados y localizados, para ello utiliza el protocolo UDDI. WSDL (Web Services Description Language o Lenguaje de Descripción de Servicios Web) es un lenguaje basado en XML utilizado para describir la funcionalidad que proporciona un Servicio Web. Proporciona un descripción entendible por la máquina (machine readable) de la interfaz del Servicio Web, indicando cómo se debe llamar el servicio, que parámetros espera, y que estructuras de datos devuelve.. Ilustración 2 Arquitectura de WSDL 1.1 y 2.0.
(34) CAPÍTULO 1. Tecnologías para la implementación del sistema. 24. WSDL describe un servicio utilizando varios elementos que pueden clasificarse en abstractos o concretos. . La parte abstracta describe las operaciones y mensajes con detalle (¿qué hace el servicio?). Se puede ver como la interfaz o una clase abstracta en el mundo de Java. Cuenta con dos componentes principales: o Las operaciones que forman la definición de la interfaz. o Los tipos de datos para los parámetros de entrada, salida y error, de las operaciones.. . La parte concreta describe el cómo y dónde del servicio. Se puede ver como la implementación de la parte abstracta en el mundo de Java, aunque solamente describe dónde se encuentra dicho implementación para utilizarse. Cuenta con dos componentes principales: o Información de enlazado (binding) sobre el protocolo a utilizar. o La dirección en donde localizar el servicio.. UDDI (Universal Description, Descovery and Integration) nos permite localizar Servicios Web, para lo que define una especificación para construir un directorio distribuido de Servicios Web donde los datos se almacenan en un XML. Además almacenan información sobre las organizaciones que proveen el servicio, el estado en que se encuentran y la forma de uso. Por lo que tenemos tres tipos de información relacionados entre sí: . Páginas blancas: Datos de las Organizaciones (dirección, información de contacto, etc).. . Páginas amarillas: Clasificación de las Organizaciones (según tipo de industria, zona geográfica, etc)..
(35) CAPÍTULO 1. Tecnologías para la implementación del sistema. . 25. Páginas verdes: Información técnica sobre los servicios que se ofrecen así como las instrucciones de utilización.. Ilustración 3 Arquitectura de UDDI. UDDI define también una API para trabajar con dicho registro, que nos permitirá buscar datos almacenados en él, y publicar datos nuevos. Dentro de los estilos de arquitectura de Servicios Web pueden resaltarse tres: . RPC (Remote Procedure Call o Llamadas de procedimiento remoto): Los Servicios Web basados en RPC presentan una interfaz de llamada a procedimientos y funciones distribuidas, lo cual es familiar a muchos desarrolladores. Su unidad básica es la Operación WSDL (Web Services Description Language o Lenguaje de Descripción de Servicios Web). Es considerada por algunos como la primera generación de Servicios Web por y las primeras herramientas para servicios web estaban centradas en su idea. A pesar de ello ha sido criticada por no ser débilmente aclopado, muchos especialistas creen que este estilo debe desaparecer.. . SOA (Services Oriented Arquitectura o Arquitectura Orientada a Servicios): Los Servicios Web pueden también ser implementados siguiendo los conceptos de la.
(36) CAPÍTULO 1. Tecnologías para la implementación del sistema. 26. arquitectura SOA, donde la unidad básica de comunicación es el mensaje, más que la operación. Esto es típicamente referenciado como servicios orientados a mensajes. Los Servicios Web basados en SOA son soportados por la mayor parte de desarrolladores de software y analistas. Al contrario que los Servicios Web basados en RPC, este estilo es débilmente acoplado, lo cual es preferible ya que se centra en el “contrato” proporcionado por el documento WSDL, más que en los detalles de implementación subyacentes.. Ilustración 4 Arquitectura de SOAP. El proveedor del servicio define la descripción abstracta de dicho servicio utilizando WSDL. Luego se crea el servicio en concreto a partir de la definición abstracta del servicio, produciendo así una descripción concreta del servicio WSDL, la que va a publicarse en un servicio de registro como por ejemplo UDDI. Un cliente de un servicio puede utilizar un servicio de registro para localizar una descripción de un servicio, a partir de la cual podrá seleccionar y utilizar una implementación concreta de dicho servicio..
(37) CAPÍTULO 1. Tecnologías para la implementación del sistema. 27. La descripción abstracta se define en un documento WSDL como un PortType. Una instancia concreta de un servicio se define mediante un elemento port de un WSDL (consistente a su vez en una combinación de un PortType, un binding de codificación y transporte, más una dirección). N conjunto de ports definen un elemento service de un WSDL. . REST (REpresentation State Transfer o Transferencia de Estado de REpresentación): Es un estilo de arquitectura de software para sistemas hipermedias distribuidos como la Web. Los Servicios Web basados en REST intentan emular al protocolo HTTP o protocolos similares mediante la restricción de establecer la interfaz a un conjunto conocido de operaciones estándar (por ejemplo GET, PUT,…). Por tanto, este estilo se centra más en interactuar con recursos con estado, que con mensajes y operaciones. En realidad, REST se refiere estrictamente a una colección de principios para el diseño de arquitecturas en red. Estos principios resumen como los recursos son definidos y diseccionados. El término frecuentemente es utilizado en el sentido de describir a cualquier interfaz que transmite datos específicos de un domino sobre HTTP sin una capa adicional, como hace SOAP. El término REST fue introducido por primera vez por Roy Fielding (Uno de los principales autores de la especificación de HTTP) en su Tesis Doctoral en el 2000, en ese momento no se prestó mucha atención en él. Aunque REST no es un estándar, está basado en basado en estándares: . HTTP.. . URL.. . XML, HTML, GIF, JPEG, etc.. . Text/xml, text/html, etc.. REST tiene cuatro objetivos en su arquitectura:.
Figure



+7




Documento similar