Un modelo para el aprendizaje y la clasificación automática basado en técnicas de softcomputing
154
0
0
Texto completo
(2) Dedicatoria A mi familia por todo el tiempo que les he robado especialmente a: Mi esposa Esther Cristina Mis hijos Pedro Enrique y Carlos Manuel Mis padres Pedro y Ana Mi hermana Yadenis Ningún resultado que obtenga podrá devolverles a ellos todo el tiempo que les he robado. Con palabras no se puede expresar el significado de familia y seres queridos. Toda obra grande cuando comienza es pequeña, lo que hay es que tener valor para hacerla crecer R.A.H.L..
(3) Agradecimientos Agradezco a todos los que de alguna forma han contribuido a mi formación especialmente agradezco: A la Revolución que sin ella nada de esto fuera posible A mi tutora Marilin por su ayuda durante toda la tesis Al señor Rolando Alfredo y su esposa Sayda por toda la ayuda y el apoyo que me han brindado A Leticia, Isis y Yaile por su colaboración en cada momento A Zoila Zenaida García por su ayuda constante y desinteresada A los muchachos del proyecto especialmente a Raykenler, Alfredo y Rene por su colaboración y muestras de confianza A William por toda la ayuda prestada que me ha brindado en cada momento A Rafael Bello, Ricardo Grau y Daniel Gálvez por ayudar a formarme y la ayuda que me ha brindado A los señores José E. Medina Pagola y Juan Pedro Febles por sus magníficas oponencias durante la predefensa, que fueron de gran ayuda Al señor Alberto Ochoa por su asesoría en el tema de EDA.
(4) Resumen En esta tesis se investiga acerca de las técnicas del softcomputing y sus potencialidades en el aprendizaje automático y en la resolución de complejos problemas de ayuda a la toma de decisiones y la clasificación. Se presenta en ella un nuevo modelo que permite aprender y generalizar en forma de reglas borrosas el conocimiento implícito en bases de casos y que posibilita además la clasificación de nuevos casos tomando como base la explotación de un sistema de inferencia borroso del tipo Sugeno grado cero. Como parte del modelo desarrollado se presentan nuevos criterios de selección de rasgos y los algoritmos MLRUL y GENRUL para la generación de reglas borrosas. Se desarrollan además algoritmos para la optimización de bases de reglas borrosas tomando como base la aplicación de heurísticas y algoritmos evolutivos. Para lograr la explotación del modelo se desarrollaron un grupo de bibliotecas básicas que permiten una fácil adaptación a disímiles situaciones donde se presenten problemas de toma de decisiones. Se muestra la aplicación del modelo desarrollado sobre bases de datos internacionales utilizando el sistema MLCLASSIF y se comparan los resultados con otros sistemas y modelos para la clasificación. Finalmente se presenta la adaptación del modelo a la resolución del problema de la construcción de hipnogramas del sueño a través del sistema SICES.. Abstract In this thesis softcomputing techniques for machine learning, classification and making decision are discussed. We propose a new model to classify and to learn from data. This thesis systematically presents learning algorithms, which can be used to create fuzzy systems from data. The algorithms are especially designed for their capability to produce interpretable Sugeno grade cero fuzzy systems. Two algorithms to optimize fuzzy rules are proposed too. The first one inspired by the neural networks and the second based on estimation of distribution algorithms. The algorithms are presented in such a way that they can readily be used for implementations. As examples for neuro-fuzzy solutions using our model, the classification systems MLClassif 1.0 and SICES 1.0 are discussed. We compare our model (MLClassif 1.0) with different classifiers and use some medical databases published in the UCI Machine Learning Repository to obtain the results. We apply our model to solve the sleep stage classification problem and compare the SICES 1.0 results with other system..
(5) INDICE INTRODUCCIÓN .................................................................................................................................................. 1 ACTUALIDAD DEL TEMA ....................................................................................................................................... 1 FORMULACIÓN DEL PROBLEMA ............................................................................................................................. 2 HIPÓTESIS ............................................................................................................................................................. 3 OBJETIVOS ............................................................................................................................................................ 3 VARIABLES ........................................................................................................................................................... 3 TAREAS DE INVESTIGACIÓN CONCRETAS............................................................................................................... 4 MÉTODOS Y TÉCNICAS A UTILIZAR ....................................................................................................................... 4 NOVEDAD CIENTÍFICA ........................................................................................................................................... 5 VALOR PRÁCTICO ................................................................................................................................................. 5 PUBLICACIONES Y EVENTOS CIENTÍFICOS RELACIONADOS CON EL TEMA DE LA TESIS ........................................... 6 ESTRUCTURA DEL TRABAJO .................................................................................................................................. 9 ANÁLISIS DEL ESTADO DEL ARTE DE ESTRATEGIAS PARA EL APRENDIZAJE Y LA CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA ......................................................................... 10 1.1 ¿QUÉ ES EL APRENDIZAJE AUTOMATIZADO? ................................................................................................. 10 1.2 DIFERENTES ENFOQUES EMPLEADOS EN EL APRENDIZAJE Y LA CLASIFICACIÓN ............................................ 13 1.2.1 Estrategias estadísticas........................................................................................................................ 14 1.2.2 Algoritmos Lógico-Combinatorios para Reconocimiento de Patrones ............................................... 14 1.2.3 Estrategias basadas en árboles de decisión......................................................................................... 15 1.2.4 Sistemas basados en el conocimiento de la Inteligencia Artificial ...................................................... 16 1.2.4.1 Los sistemas de inferencia borrosos y neuroborrosos ...................................................................... 17 1.2.4.2 Interpretabilidad versus predicción en los sistemas basados en el conocimiento............................ 20 1.2.5 Conclusiones del epígrafe .................................................................................................................... 21 1.3 GENERACIÓN DE REGLAS BORROSAS ............................................................................................................. 21 1.3.1 Diferentes enfoques en la construcción de funciones de pertenencia.................................................. 23 1.3.2 Estrategia de generación de la base de reglas duras y transformación en reglas borrosas ............... 26 1.3.3 Estrategia de generación de la base de reglas borrosas candidatas y refinamiento........................... 27 1.3.4 Estrategia de generación de reglas borrosas a partir de la optimización de la base de reglas.......... 29 1.3.4.1 Estrategia de pesado de reglas ......................................................................................................... 30 1.3.4.2 Estrategia basada en la modificación de las funciones de pertenencia y la base de reglas............. 31 1.4 CONCLUSIONES DEL CAPÍTULO...................................................................................................................... 35.
(6) MODELO DE APRENDIZAJE Y CLASIFICACIÓN AUTOMÁTICA BASADO EN TÉCNICAS DE SOFTCOMPUTING ............................................................................................................................................ 37 2.1 MÓDULO DE APRENDIZAJE ............................................................................................................................ 37 2.1.1 Algoritmo MLRul ................................................................................................................................. 38 2.1.2 Algoritmo GenRul5 .............................................................................................................................. 54 2.2 MÓDULO OPTIMIZACIÓN DE LA BASE DE REGLAS BORROSAS ......................................................................... 57 2.2.1 Optimización de una base de reglas una estrategia basada en redes neuronales............................... 57 2.2.2 Optimización de una base de reglas utilizando algoritmos con estimación de distribuciones............ 63 2.2.2.1 Diseño de un UMDA para la optimización de conjuntos borrosos .................................................. 63 2.2.2.2 Diseño de una variante distribuida del EMNAglobal para la optimización de conjuntos borrosos.... 64 2.3 MÓDULO DE CONSTRUCCIÓN DEL SISTEMA DE INFERENCIA NEURO-BORROSO ............................................... 67 2.4 CONCLUSIONES DEL CAPÍTULO Y EVALUACIÓN CRÍTICA DEL MODELO .......................................................... 68 EXPERIMENTACIÓN Y DESARROLLO DE APLICACIONES A PARTIR DEL MODELO................. 71 3.1 DOS BIBLIOTECAS DE COMPONENTES DE APOYO AL APRENDIZAJE Y LA CLASIFICACIÓN................................ 71 3.1.1 Biblioteca GACom versión 2.0............................................................................................................. 71 3.1.2 Paquete de componentes FuzzyPack versión 1.0 ................................................................................. 72 3.2 SISTEMA MLCLASSIF VERSIÓN 1.0 ............................................................................................................... 72 3.2.1 Resultados experimentales ................................................................................................................... 73 3.3 SISTEMA PARA LA CLASIFICACIÓN DE ETAPAS DEL SUEÑO (SICES VERSIÓN 1.0).......................................... 81 3.3.1 Planteamiento general del estudio del sueño....................................................................................... 81 3.3.2 Tendencias y evolución en la clasificación automática de etapas del sueño....................................... 82 3.3.3 Implementación de los módulos del sistema SICES versión 1.0 .......................................................... 84 3.3.4 Resultados experimentales ................................................................................................................... 89 3.5 CONCLUSIONES DEL CAPÍTULO...................................................................................................................... 91 CONCLUSIONES ................................................................................................................................................ 95 RECOMENDACIONES ...................................................................................................................................... 96 BIBLIOGRAFÍA .................................................................................................................................................. 97 ANEXOS ............................................................................................................................................................. 111 ANEXO 1 AGRUPACIÓN DE DIFERENTES TIPOS DE MÉTODOS DE CLASIFICACIÓN ............................................... 111 ANEXO 2 DIAGRAMAS QUE REPRESENTAN EL PROCESO DE CLASIFICACIÓN BASADO EN EL DISCRIMINANTE. .... 112 ANEXO 3 DIFERENTES TIPOS DE SISTEMAS BASADOS EN EL CONOCIMIENTO ..................................................... 112.
(7) ANEXO 4 EJEMPLO DE VARIABLE LINGÜÍSTICA EJEMPLIFICADO CON LA TEMPERATURA ................................... 113 ANEXO 5 GRÁFICAS QUE REPRESENTAN FUNCIONES DE PERTENENCIA ............................................................. 113 ANEXO 6 FUNCIONAMIENTO DE LOS SISTEMAS DE INFERENCIA BORROSOS ....................................................... 114 ANEXO 7 TOPOLOGÍAS DE LAS REDES NEURONALES ......................................................................................... 117 ANEXO 8 TOPOLOGÍAS DE SISTEMAS NEUROBOROSOS ...................................................................................... 118 ANEXO 9 REPRESENTACIÓN DE FUNCIONES DE PERTENENCIA BASADAS EN MODELOS PROBABILÍSTICOS .......... 118 ANEXO 10 PROCESO DE CORRECCIÓN QUE APLICAN LOS ALGORITMOS DE NAUCK ........................................... 119 ANEXO 11: CÁLCULO DE LOS CONJUNTOS APROXIMADOS SUPERIOR E INFERIOR. ............................................. 120 ANEXO 12. ALGORITMO RSREDUCT ................................................................................................................. 120 ANEXO 13 ALGORITMOS CON ESTIMACIÓN DE DISTRIBUCIONES ...................................................................... 121 ANEXO 14 ESTRUCTURA DEL CROMOSOMA PARA REPRESENTAR LA BASE DE REGLAS ...................................... 122 ANEXO 15 SISTEMA BORROSO TIPO SUGENO GRADO CERO, TOPOLOGÍA RED DE 5 CAPAS ORIENTADA A NODOS 122 ANEXO 15 SISTEMA BORROSO TIPO SUGENO GRADO CERO, TOPOLOGÍA RED DE 5 CAPAS ORIENTADA A NODOS 123 ANEXO 16 INFORMACIÓN SOBRE BASES DE DATOS UTILIZADAS EN LA EXPERIMENTACIÓN,.............................. 123 ANEXO 17 ALGUNAS TABLAS PRUEBAS BUSCANDO EL MEJOR K PARA KNN .................................................... 123 ANEXO 18 ALGUNAS TABLAS COMPARACIÓN ALGORITMOS BASE DATOS, HEART .......................................... 125 ANEXO 19 ALGUNAS TABLAS COMPARACIÓN ALGORITMOS BASE DATOS, TYROIDS ...................................... 126 ANEXO 20 ALGUNAS TABLAS COMPARACIÓN ALGORITMOS BASE DATOS, BREAST CANCER ....................... 127 ANEXO 21 MÓDULO DE PARAMETRIZACIÓN DEL SISTEMA SICES 1.0............................................................... 129 ANEXO 22: FICHERO DE ENTRADA AL MÓDULO DE APRENDIZAJE (.DATA) ........................................................ 129 ANEXO 23 FICHERO DE ENTRADA AL MÓDULO DE INFERENCIA Y SALIDA DEL MÓDULO DE APRENDIZAJE (.RUL)132 ANEXO 25 FICHERO DE EVALUACIÓN GENERADO POR EL MÓDULO DE INFERENCIA (.EVAL).............................. 134 ANEXO 26 FICHERO DE SALIDA DEL MÓDULO DE INFERENCIA (.CLASS) ............................................................ 137 ANEXO 27 RELACIÓN DE REGLAS UTILIZADAS DURANTE LA CORRECCIÓN DE LA CLASIFICACIÓN ..................... 137 ANEXO 28 RELACIÓN DE ETAPAS POR PACIENTES ANALIZADOS EN EL ESTUDIO. ............................................... 139 ANEXO 29 ADICIÓN DE NUEVOS CASOS AL MÓDULO CORRECTOR DEL SISTEMA SICES 1.0 .............................. 140 ANEXO 30 MUESTRA DE HIPNOGRAMAS RESULTANTES DEL PROCESO DE CLASIFICACIÓN ................................ 141 ANEXO 31 DISTRIBUCIÓN DE ETAPAS POR PARTICIONES PARA LA PRUEBA DE SICES 1.0 ................................. 143 ANEXO 32 MUESTRA DE FICHERO DE EVALUACIÓN DE SALIDA AL PROCESAR UN CASO DEL CONJUNTO DE ENTRENAMIENTO DE LA PARTICIÓN 1................................................................................................................ 144. ANEXO 33 RESULTADOS DE COMPARACIÓN DE SISTEMAS SICES Y DREAM HUNTER ....................................... 145 ANEXO 34 COMPARACIÓN DEL USO DEL MÓDULO CORRECTOR CONTRA NO USARLO. ....................................... 146.
(8) Introducción Actualidad del tema El aprendizaje automático aparece frecuentemente como un paso necesario para la resolución de complejos problemas de clasificación y para la ayuda a la toma de decisiones. Entre las ramas que más han aportado a la resolución de esta problemática se encuentran: la estadística, la inteligencia artificial, el enfoque lógico combinatorio del reconocimiento de patrones entre otras. Las técnicas de aprendizaje basadas en la estadística tienen como base modelos probabilísticos [1, 2]. Tendencias actuales, muestran su uso en combinación con otros métodos o como parte de sistemas multiclasificadores [3] y generalmente presentes en las primeras capas de estos sistemas. Los algoritmos y técnicas que se agrupan en el enfoque Lógico-Combinatorio para Reconocimiento de Patrones parten de la evaluación de los objetos haciendo uso de diferentes métricas y algoritmos [4-9]. Dentro de la inteligencia artificial hay dos ramas que se destacan por sus aportes en el aprendizaje y la clasificación: los algoritmos de aprendizaje basados en árboles de decisión [10-13] y los sistemas basados en el conocimiento [11, 14-17]. Como parte de los sistemas basados en el conocimiento la aplicación de técnicas basadas en la lógica borrosa tales como los sistemas de inferencia borrosos y neuroborrosos han ganado popularidad [18-23]. Estas técnicas constituyen el pilar de las técnicas del softcomputing donde la teoría de la lógica borrosa, las redes neuronales y los algoritmos evolutivos se funden para ganar en: robustez, eficiencia, adaptabilidad y equilibrio adecuado entre predicción e interpretabilidad [24-26]. En el desarrollo de técnicas basadas en el softcomputing juega un importante papel la generación de reglas borrosas. Tendencia actuales [17, 19, 21, 27-30] muestran tres enfoques fundamentales utilizados en el aprendizaje y la optimización de las reglas borrosas: generar reglas duras y transformar estas reglas en reglas borrosas, generar una base de reglas borrosas candidatas, luego refinarla y como tercer opción generar una base de reglas borrosas inicial a partir de los datos, someterla a un proceso de optimización. De estos tres enfoques el más utilizado es el que se concentra en la optimización de la base de reglas. En la estrategia basada en la optimización se perciben tres líneas fundamentales: la aplicación de algoritmos derivados de redes neuronales basados en el gradiente [3, 16, 23, 29, 31, 32], algoritmos de derivados de redes neuronales basados en heurísticas que no usan el gradiente [24, 33] y el empleo de los algoritmos evolutivos [34-38]. Cada una de estas líneas tiene potencialidades y limitantes en su aplicación a diferentes problemas. En el caso del uso de los algoritmos evolutivos hay que destacar su facilidad de aplicación y las. 1.
(9) INTRODUCCIÓN. pocas restricciones que imponen a los problemas, destacándose en este sentido el uso de los algoritmos genéticos [19, 21, 34]. No obstante la popularidad en el uso de los algoritmos genéticos, resulta interesante que conociéndose la dificultad de los mismos en el manejo de datos correlacionados, no se reporten trabajos donde se exploten los algoritmos con estimación de distribuciones [39-44], que si resuelven esta dificultad.. Formulación del problema Existen numerosos métodos para el aprendizaje, la clasificación y la ayuda a la toma de decisiones cada uno con sus peculiaridades. Pero aún quedan muchas preguntas por resolver sobre todo en la aplicación de las técnicas de aprendizaje y clasificación en la resolución de problemas reales donde aparecen elementos como el ruido, la incertidumbre, la incompletitud de los datos y la vaguedad en los límites de los conceptos. Particularmente en campos como el diagnóstico médico especializado se torna difícil encontrar soluciones teniendo en cuenta además el necesario equilibrio que se debe mantener entre predicción e interpretabilidad de los resultados, veamos un ejemplo de problema donde se manifiesta esta dificultad. En la construcción automática de hipnogramas del sueño a partir de registros electrofisiológicos donde se pretende ayudar a los médicos en el análisis del sueño de pacientes se presenta la dificultad de que no existen estándares para la construcción de hipnogramas o los que existen presentan reconocidas dificultades [45, 46]. Esta situación propicia la aparición de múltiples criterios basados muchas veces en la subjetividad y la experiencia de los expertos. Por otra parte la lectura de los registros electrofisiológicos se produce a partir de equipos donde los procedimientos de acoplamiento, de lectura y la propia calibración de los equipos constituyen fuentes de error en las mediciones. En la resolución de este problema el empleo de técnicas de aprendizaje automático y clasificación que posibiliten descubrir conocimiento y explotar el conocimiento aún cuando se presenten imprecisiones, incompletitud de los datos y vaguedad en los límites de los conceptos, pueden resultar de notable ayuda para la toma de decisiones. En otros campos del diagnóstico médico especializado se presentan situaciones similares donde el empleo de técnicas apropiadas favorece el trabajo de los especialistas médicos. En el repositorio de aprendizaje automático de la Universidad de California [47] se concentran fuentes de datos suministradas por hospitales y proyectos que permiten validar los modelos computacionales para la resolución de diversos problemas de clasificación y diagnóstico médico especializado. Una vez mostrada la situación a que nos enfrentamos y luego de hacer un breve análisis del estado del arte estamos en condiciones de plantearnos nuestro problema científico.. 2.
(10) INTRODUCCIÓN. •. No disponer de un modelo basado en novedosos elementos del softcomputing para aprender, generalizar y explotar en forma de reglas borrosas el conocimiento encontrado en casos de estudio, afecta la ayuda en la toma de decisiones en la construcción automática de hipnogramas del sueño y en el uso potencial de técnicas de aprendizaje y clasificación basadas en softcomputing en el diagnóstico médico especializado y otros problemas de clasificación.. Hipótesis Si se desarrolla un modelo basado en técnicas del softcomputing que permita aprender, generalizar y explotar el conocimiento de conjuntos de casos, en forma de reglas borrosas, que resuelva las limitantes de los modelos propuestos en la bibliografía se obtendrán mejores resultados en la construcción automática de hipnogramas del sueño y potencialmente se podrán resolver otros problemas de clasificación, relacionados con la ayuda a la toma de decisiones, como los que se presentan en el diagnóstico médico especializado.. Objetivos El objetivo general de este trabajo es desarrollar un modelo que permita el aprendizaje de reglas borrosas a partir de casos y la clasificación automática, basado en las técnicas del softcomputing, para la ayuda a la toma de decisiones en: la construcción automática de hipnogramas del sueño y en el uso potencial en otros problemas de clasificación supervisada tales como el diagnóstico médico especializado. Para lograr este objetivo se plantean los siguientes objetivos específicos: 1. Desarrollar un modelo basado en técnicas de softcomputing que permita la construcción de reglas borrosas a partir de casos, la optimización de bases de reglas borrosas y su explotación en problemas de clasificación.. 2. Implementar y validar el modelo desarrollado a partir de su aplicación en la solución del problema de la construcción automática de hipnogramas el sueño y de otros problemas de clasificación relacionados con el diagnóstico médico.. Variables Variables independientes: algoritmos para el aprendizaje y la optimización de bases de reglas borrosas, modelo para el aprendizaje y la clasificación basado en técnicas de softcomputing y el desarrollo de herramientas de software que permitan la resolución de problemas específicos de diagnóstico médico especializado Variables dependientes: construcción automática de hipnogramas del sueño de pacientes y el uso potencial de técnicas basadas en el softcomputing en la. 3.
(11) INTRODUCCIÓN. resolución otros problemas relacionados con el diagnóstico médico especializado.. Tareas de investigación concretas •. Realizar un análisis del estado del arte que permita dejar definida la posición del investigador respecto al uso de técnicas basadas en softcomputing.. •. Desarrollar algoritmos que permitan el aprendizaje automatizado de reglas borrosas a partir de casos estudio. •. Desarrollar algoritmos que permitan el refinamiento y la optimización de bases de reglas borrosas. •. Desarrollar un modelo que permita haciendo uso de los algoritmos y herramientas desarrollados aprender reglas borrosas a partir casos y explotar el conocimiento extraído para la clasificación y la ayuda a la toma de decisiones.. •. Encapsular el modelo desarrollado en bibliotecas que permitan la reutilización del código y el desarrollo rápido de aplicaciones para el aprendizaje y la clasificación.. •. Desarrollar el sistema SICES 1.0 que posibilite la construcción automática de hipnogramas del sueño de pacientes.. •. Desarrollar el sistema MLClassif 1.0 que permita aprender reglas borrosas a partir de casos y explotar el conocimiento extraído en la resolución de problemas de clasificación.. •. Evaluar los algoritmos y aplicaciones desarrolladas en el diagnóstico médico a partir de se uso en bases de datos publicadas en el UCI repository for machine learning y en bases de casos de pacientes del Centro de Neurociencias de Cuba. Métodos y Técnicas a utilizar Entre las estrategias de investigación que utilizamos están la exploratoria y la explicativa. Exploramos diferentes técnicas y tendencias en el estudio del sueño y en el aprendizaje y la clasificación basados en técnicas de softcomputing con vistas a desarrollar un modelo computacional novedoso y que resuelva las deficiencias de otros reportados en la bibliografía. Métodos teóricos: Histórico lógico, Hipotético deductivo, Sistémico En cada caso nos plateamos el problema como un todo, donde los datos tomados de pacientes en el caso del sueño o de bases de datos internacionales, la propia dinámica del estudio del sueño y de cada uno de los problemas que resolvimos y las técnicas computacionales que desarrollamos para la ayuda a la toma de decisiones se funden en un sistema sostenible e integral. Enfocamos las problemáticas del aprendizaje automático, la. 4.
(12) INTRODUCCIÓN. clasificación, el diagnóstico y la toma de decisiones en general desde un enfoque histórico lógico, en la primera parte de nuestra investigación desarrollamos un estudio del estado del arte de la problemática analizada; revisamos las bondades y deficiencias de cada uno de los métodos y las tendencias en la resolución de esta problemática. Nuestra investigación sigue además un método hipotético deductivo porque a partir del problema concreto nos plantemos objetivos específicos e hipótesis que en el transcurso de la investigación son resueltas siguiendo métodos científicamente bien fundamentados. Método empírico: Experimentación, Medición Además de seguir métodos teóricos seguimos métodos empíricos basando nuestra investigación en la experimentación con datos provenientes de situaciones reales suministrados por las siguientes fuentes: 1. Heart suministrada por el European Statlog project, Strathclyde University [47] 2. Thyroids suministrada por el Garvan Institute of Medical Research, Sydney [47] 3. Breast Cancer suministrada por University of Wisconsin Hospitals, Madison [47] 4. Datos tomados de pacientes del Centro de Neurociencias de Cuba [48] Aplicamos pruebas estadísticas bien fundamentadas para analizar la capacidad de generalización del modelo desarrollado y la calidad de las respuestas finales. Se establecieron estadígrafos e indicadores adecuados que permiten realizar correctas mediciones de los resultados.. Novedad científica La novedad científica del presente trabajo se resume en los puntos siguientes: •. Se desarrollan dos nuevos algoritmos para la generación y optimización de reglas borrosas a partir de casos basados en técnicas de softcomputing [49-59].. •. Se elabora un modelo para el aprendizaje y la clasificación y se logra adaptar para la construcción automática de hipnogramas del sueño de pacientes y se muestra su uso potencial en la resolución de otros problemas de diagnóstico médico especializado [60-79].. Valor práctico El modelo para el aprendizaje y la clasificación propuesto en la tesis tiene un alto valor práctico que se manifiesta en su aplicación: •. En la construcción automática de hipnogramas de sueño mejorando significativamente los resultados reportados por el módulo automático del sistema Dream Hunter [62, 64, 66, 76, 80]. 5.
(13) INTRODUCCIÓN. •. En el desarrollo de módulos inteligentes del Sistema Hyperweb para el diagnóstico, control, tratamiento y seguimiento de pacientes con Hipertensión Arterial [74, 75, 78, 79].. •. En el desarrollo del sistemas y herramientas básicas potenciando: el desarrollo rápido de sistemas y plataformas para la ayuda a la toma de decisiones [57, 67, 68, 77, 81, 82]. •. En el desarrollo de herramientas para el diseño de experimentos con mezclas [67, 70, 72].. Se pretende proveer a los médicos y otros especialistas de herramientas complementarias para la clasificación y el aprendizaje automatizado que con frecuencia aparecen en su trabajo cotidiano. Estas herramientas no están diseñadas para sustituir a expertos humanos sino para la ayuda a la toma de decisiones de estos.. Publicaciones y eventos científicos relacionados con el tema de la tesis Publicaciones en revistas, libros y monografías 1. Piñero, P., M. García, et al. (2004a). "Sleep stage classification using fuzzy sets and machine learning techniques." Neurocomputing 58-60: 1137-1143 2. Bello, R., L. Arco, et al. (2004). Modelos y procedimientos de aprendizaje basados en Soft-Computing. Optimización inteligente. Técnicas de Inteligencia Computacional para Optimización. G. Joya, M. Atencia, A. Ochoa and S. Allende. Málaga, SPICUM e ISTANET. 1: 413-452 3. Piñero, P., L. Arco, et al., Two New Metrics for Feature Selection in Pattern Recognition. A. Sanfeliu, J. Ruiz-Shulcloper ed. Lecture Notes in Computer Science, ed. G. Goos, J. Hartmanis, and J.v. Leeuwen. Vol. 2905. 2003, Berlin: SpringerVerlag. 488-497. 4. Piñero, P., L. Arco, et al. (2003b). "Algoritmos Genéticos en la construcción de funciones de pertenencia borrosas." Revista Iberoamericana de Inteligencia Artificial 18: 45-54. 5. Del-Pino, U., D. Gálvez, et al. (2002). "Analysis of Mixture Experiments Using Genetic Algorithms." The Mathematic Preprints Server: p. 18 6. Piñero, P., M. García, et al. (2001). "Máquina de aprendizaje para la generación de reglas borrosas." Controle & Automacao 12: 241-252 7. Piñero, P., Biblioteca de componentes COM, DCOM para el trabajo con Algoritmos Genéticos, in Departamento de Ciencias de la Computación. 2000, Universidad Central "Marta Abreu" de Las Villas: Santa Clara. p. 107. Publicaciones en memorias de eventos. 6.
(14) INTRODUCCIÓN. 1. Piñero, P., et al. Sistema Inteligente para la Clasificación de Etapas de Sueño (SISES 1.0). in VIII Iberoamerican Conference on Artificial Intelligence Workshop "Bioinformatics and Artificial Intelligence". 2002a. Sevilla, Spain. 2. Piñero, P., et al. Two Machine Learning Algorithms. in X Convención Internacional y Feria Informática 2004. 2004b. Ciudad de la Habana. 3. Piñero, P., Z. Z. García, et al. (2004). Plataforma inteligente de ayuda a la toma de decisiones y el diagnóstico. XV Forum Provincial de Ciencia y Técnica, Premio Relevante Distinguido Especial, Ciudad de la Habana, Comisión Provincial Forum Ciencia y Técnica. 4. Caballero, Y., et al. Selección de rasgos relevantes para el análisis de datos a través de los conjuntos aproximados. in X Convención Internacional y Feria Informática 2004. 2004. Ciudad de la Habana: CITMATEL. 5. Piñero, P., et al. Discovering Patterns in Sleep Stage Classification Problems Using Fuzzy Sets. in VIII Congreso Iberoamericano de Reconocimiento de Patrones CIARP 2003. 2003d. La Habana 6. Piñero, P., et al. SICES: Sistema Inteligente para la clasificación de etapas del sueño. in IV Congreso Internacional de Informática Médica de la Habana. Informática 2003. 2003d. Palacio de las convenciones. La Habana Cuba. 7. Piñero, P., M.M. García, and L. Arco Plataforma para el desarrollo de sistemas de ayuda al diagnóstico y la clasificación. in Conferencia de la Sociedad de Matemática y Computación COMPUMAT2003. 2003. Sancti Spiritus: Sociedad de Matemática y Computación, Cuba. 8. Piñero, P., et al. Sistema para la ayuda al diagnóstico y la construcción de hipnogramas. in Congreso cubano de matemática y computación COMPUMAT 2003. 2003b. Sancti Spíritus: Sociedad Cubana de Matemática y Computación. 9. Piñero, P., et al. Sleep Stage Classification using Fuzzy Sets and Machine Learning Techniques. In Twelfth Annual Computational Neuroscience Meeting. 2003a. Alicante, Spain. 10. Piñero, P., et al. Sistema de ayuda al diagnóstico y la clasificación automatizada (MLClassif 1.0). in IV Congreso Internacional de Informática Médica de la Habana. Informática 2003. 2003a. Palacio de las convenciones. La Habana Cuba. 11. Piñero, P., et al. Diferentes enfoques en la construcción de funciones de membresía de los conjuntos borrosos. Aplicación potencial en Bioinformática. in I Congreso Internacional de Tecnologías y Contenidos Multimedia en Ambientes digitales. Informática 2002. 2002c. Palacio de las convenciones, La Habana cuba. 12. Piñero, P., et al. Aprendizaje de reglas borrosas a partir de Casos para la clasificación automatizada. Aplicación potencial en Bioinformática. in I Congreso. 7.
(15) INTRODUCCIÓN. Internacional de Tecnologías y Contenidos Multimedia en Ambientes digitales. Informática 2002. 2002b. Palacio de las convenciones, La Habana Cuba. 13. Piñero, P., et al. Computational Tools for Bioinformatics. In British-Cuban Bioinformatics Workshop. 2002. University of Havana. 14. Arco, L. and P. Piñero. Algoritmos genéticos en la construcción de funciones de membresía. Aplicaciones en Bioinformática. in Memorias VIII Encuentro Internacional de Informática de la Habana Informática 2002. 2002. La Habana. 15. Piñero, P. GACOM Biblioteca de Componentes de Algoritmos Genéticos. in COMAT 2001. 2001. Matanzas, Cuba: Universidad de Matanzas. 16. Piñero, P.-Y., et al. Un modelo para el aprendizaje y la clasificación basado en técnicas de softcomputing. in I Taller de Inteligencia Artificial de la UCI, Conferencia Científica UCiencia 2005. 2005. Universidad Ciencias Informáticas, Ciudad de la Habana: Universidad de Ciencias Informáticas. 17. Yzquierdo, R., et al. Un modelo basado en técnicas de Inteligencia Artificial para el desarrollo de sistemas para l diagnóstico, control y seguimiento de la hipertensión arterial. in I Taller de Inteligencia Artificial de la UCI. Conferencia Científica UCiencia 2005. 2005. Universidad de Ciencias Informáticas, Ciudad de la Habana: Universidad de Ciencias Informáticas. 18. Morales, A., et al. Sistema para la ayuda a la toma de decisiones en el diagnóstico, evaluación, control y seguimiento de pacientes con hipertensión arterial. in I Taller de Software para la Salud, Conferencia Científica UCiencia 2005. 2005. Universidad de Ciencias Informáticas, Ciudad de la Habana: Universidad de Ciencias Informáticas. 19. Medina, E., et al. Hyperweb un sistema para el diagnóstico, tratamiento y seguimiento de pacientes con hipertensión arterial. in TECBIOMED 05. 2005: Instituto Central de Investigaciones Digitales. 20. Piñero-Pérez, P., et al. Un modelo para la ayuda a la toma de decisiones basado en técnicas de softcomputing. Uso potencial en el diagnóstico médico especializado. in TECBIOMED 05. 2005: Instituto Central de Investigaciones Digitales. 21. Yzquierdo, R., et al. Combinación de un Sistema Basado en Reglas y Técnicas de Softcomputing para el tratamiento de la HTA. in TECBIOMED 05. 2005: Instituto Central de Investigaciones Digitales. Registros de software 1. García, M. and P. Piñero, Easy Simulation: Plataforma para el desarrollo de simulaciones estocásticas discretas versión 2.0. 2002, 010917-10917: Cuba. p. 22 2. Piñero, P., et al., FuzzyPack: Plataforma para el desarrollo rápido de sistemas de inferencia borrosos versión 1.0. 2002, 010915-10915: Cuba. p. 25. 8.
(16) INTRODUCCIÓN. 3. Piñero, P., U. Del-Pino, and D. Gálvez, GASMIX: Algoritmos Genéticos para mezclas versión 1.0. 2002, 09356-9356: Cuba. p. 30 4. Piñero, P., GACOM Biblioteca de Componentes para el trabajo con Algoritmos Genéticos versión 2.0. 2002, 09357-9357: Cuba. p. 28. Estructura del trabajo La tesis está conformada por tres capítulos. El primer capítulo discute las ideas básicas y las diferentes estrategias utilizadas en el aprendizaje y la clasificación. Se hace una evaluación crítica de las ventajas y desventajas de diferentes enfoques resaltando en cada momento cuando debe usarse cada uno de ellos. Se hace un análisis del estado del arte relacionado con diferentes estrategias para la generación y la optimización de las bases de reglas borrosas. En el capítulo 2 se presenta un modelo basado en técnicas de softcomputing con aplicación potencial en la resolución de problemas aprendizaje, clasificación y de ayuda a la toma de decisiones y que integra técnicas para el aprendizaje, la optimización y la explotación de bases de reglas borrosas. Se presentan los algoritmos MLRul y GENRUL5 para la generación de reglas borrosas a partir de datos numéricos y simbólicos. Se presenta un algoritmo que permite la optimización de una base de reglas borrosas utilizando estrategias heurísticas inspiradas en las redes neuronales. Se presentan dos diseños de algoritmos para la optimización de reglas borrosas basados en la aplicación de los algoritmos de estimación de distribuciones UMDA y EMNAglobal. En el capítulo 3 se describen la instrumentación del modelo en los sistemas: “Sistema Inteligente para la Clasificación de Etapas de Sueño” (SICES) [66] y “Machine Learning and Classification” (MLClassif) [65]. Se presenta la validación los sistemas desarrollados en la prueba con datos suministrados por el Centro de Neurociencias de Cuba, caso de SICES, y en bases de datos internacionales de aprendizaje automático en el caso de MLClassif. Finalmente se presentan las conclusiones y recomendaciones de esta tesis.. 9.
(17) Análisis del estado del arte de estrategias para el aprendizaje y la clasificación basados en la lógica borrosa. 1. Los procesos de aprendizaje con frecuencia son aplicados de forma previa o se muestran embebidos en procesos de clasificación, esta es la principal razón por lo que generalmente el aprendizaje y la clasificación son tratados juntos y no de forma aislada. En este capítulo se abordan temas como el aprendizaje automatizado (machine learning) como paso necesario para la resolución de complejos problemas de clasificación. Se discuten varios enfoques de aprendizaje y clasificación, sus principales ventajas y desventajas y se demuestran las potencialidades de usar técnicas basadas en el softcomputing. Se aborda la temática de la generación de bases de reglas borrosas, como paso indispensable en la construcción de los sistemas borrosos y neuroborrosos discutiéndose diferentes estrategias y tendencias actuales. Finalmente se presentan las conclusiones del capítulo.. 1.1 ¿Qué es el aprendizaje automatizado? La definición de aprendizaje (Learning) en el diccionario deriva frases tales como “para ganar conocimiento o entendimiento”, “habilidad en el estudio de instrucciones”, “ganar en experiencia” y “modificación de la tendencia situacional por la experiencia”. Zoologistas y psicólogos históricamente han estudiado el aprendizaje en animales y humanos y ciertamente muchas técnicas actuales del aprendizaje automatizado se derivan de sus esfuerzos para esclarecer aspectos del aprendizaje biológico a partir de modelos computacionales. Tom Mitchell plateó: “el aprendizaje automatizado implica la búsqueda en un gran espacio de posibles hipótesis para determinar una que sea la que mejor satisfaga los datos observados y algún conocimiento previo del aprendiz” [83]. Otra definición de aprendizaje automatizado es planteada por Oliver G. Selfridge [84] donde se presenta el aprendizaje como la capacidad de los sistemas de integrar y adquirir conocimiento a partir de la experiencia y la observación analítica. Esta capacidad permite que los sistemas estén continuamente en un proceso de mejora incrementando su eficiencia y efectividad. Para mejor comprensión del concepto de aprendizaje introduciremos la siguiente notación y nuestras consideraciones iniciales. Notación. Consideramos un universo U = (A, C) formado por un conjunto de objetos o casos w ∈ U. Tal que existe un conjunto de nd atributos A = { B i / i = 1, 2, …, n d } y un conjunto de nc clases. C = { c i / i = 1, 2, …, n c } . Entonces B = B1 x B2 x… B n d constituye el espacio nd. 10.
(18) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. dimensional de rasgos cubierto por los atributos y cada objeto w de nuestro universo U está caracterizado por un vector a ∈ B. Utilizando la notación introducida y las definiciones de aprendizaje mostradas con anterioridad; consideramos el aprendizaje como el problema de búsqueda en el espacio de las posibles hipótesis, que describen el comportamiento de los objetos del universo U, hasta encontrar aquella hipótesis que mejor describa y se adapte a los objetos de dicho universo . Además el aprendizaje debe garantizar ganar conocimiento que nos permita generalizar satisfactoriamente las leyes que rigen el comportamiento de los objetos de U más allá del alcance de estos objetos. En esencia podemos decir que el aprendizaje automatizado investiga los mecanismos por los cuales el conocimiento es adquirido a través de la experiencia y se muestra como un campo interdisciplinario donde intervienen: la estadística, la lógica, las matemáticas, las estructuras neuronales, la información teórica, la psicología, la biología y las técnicas de inteligencia artificial. Considerando lo anterior, mostramos el aprendizaje como un proceso dividido en dos importantes fases [85] como describe la siguiente fórmula: Aprendizaje. =. Análisis inteligente de fuentes de datos y selección. +. Adaptación y extracción de conocimiento. La primera fase tiene como primer objetivo la valoración, exploración, prueba y evaluación críticas de los modelos para tomar el más apropiado dependiendo del problema concreto a resolver y de la naturaleza de los datos. Este primer paso persigue convertir los datos en información que pueda ser utilizada para el proceso posterior de extracción de conocimiento, en este contexto se asume que los datos están en un nivel menor que la información [24]. Su segundo objetivo es la preparación de las fuentes de datos y la selección de las mismas; hay que tener en cuenta que en las fuentes de datos se concentra gran parte de la responsabilidad en la eficiencia de los mecanismos de aprendizaje y clasificación. Algunas de las técnicas que se aplican para garantizar el segundo objetivo son las siguientes: limpieza de datos donde se analiza el tratamiento de valores ausentes y el tratamiento de datos con ruido [86, 87] la integración y transformación de datos que persigue la detección y solución de conflictos en los valores de los datos [88], la reducción de datos que permite reducir la dimensión del espacio de búsqueda concentrándose en eliminar o seleccionar instancias o casos [89-91] y finalmente la selección de atributos, que es un método alternativo a la reducción y persigue los mismos objetivos que esta pero ataca el problema concentrándose en la determinación de los atributos relevantes [5-7, 50, 58, 92]. Hay que señalar que el segundo objetivo de esta primera etapa muchas veces se trata combinado con la segunda etapa y las técnicas se aplican de forma empotradas dentro de los modelos. La segunda fase es el proceso del cálculo de resúmenes y valores derivados. En esta etapa se perfeccionan constantemente las técnicas y algoritmos que se encargan de extraer y. 11.
(19) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. representar el conocimiento de forma adecuada en dependencia de nuestros intereses. Se combinan técnicas potenciando las ventajas de cada una y atenuando sus debilidades. En la segunda subsección de este capítulo se analizan algunas estrategias y técnicas de aprendizaje y clasificación que se usan en esta etapa del aprendizaje. Teniendo en cuenta diferentes formas de selección y adaptación algunos autores [85] clasifican las estrategias de aprendizaje en: aprendizaje deductivo, aprendizaje analítico, aprendizaje analógico, aprendizaje inductivo y aprendizaje mediante descubrimiento. Otra posible clasificación de los métodos de aprendizaje considerando el tipo de estrategia y las ayudas que recibe un sistema de aprendizaje [83, 84] es: supervisado, aprendizaje parcial o semisupervisado y no supervisado. En esta tesis se trata el problema del aprendizaje inductivo supervisado para la resolución de problemas de aprendizaje y clasificación. Se aprende a partir de un universo de objetos o ejemplos dados como entrada, y agrupados en un número determinado de clases. A partir de la muestra de objetos se induce nuevo conocimiento y el dilema consiste en, dado un nuevo objeto, poder establecer sus relaciones con cada una de dichas clases. De forma auxiliar se utiliza en la construcción de los conjuntos borrosos un algoritmo basado en un aprendizaje no supervisado. Dada la gran variedad de algoritmos relacionados con el aprendizaje inductivo supervisado se podría pensar que todo está resuelto y que solo bastaría escoger alguno de ellos. Pero el hecho es que aún los modelos son insuficientes. Cuando nos enfrentamos a situaciones reales con frecuencia aparecen elementos tales como: el ruido, la ambigüedad, la incertidumbre, la incompletitud, la inconsistencia y la imprecisión; elementos negativos que generalmente son evitados por los modelos clásicos de aprendizaje y clasificación pero que no pueden ser ignorados. Los problemas de incompletitud y la falta de información generalmente son tratados con técnicas de lógica no monotónica, los problemas de inconsistencia y datos contradictorios con frecuencia son atacados usando conjuntos aproximados (rough sets), la incertidumbre en la veracidad de las afirmaciones usualmente se maneja usando modelos basados en probabilidades y finalmente elementos relacionados con la vaguedad que parece cuando los conceptos no están bien definidos, cuando no hay límites entre los conceptos y la imprecisión que surge como resultado de errores en procesos de medición son generalmente tratados con técnicas basadas en la lógica borrosa [93, 94]. Una posible solución al tratamiento de estos elementos negativos de forma simultánea aparece con la aplicación de técnicas de softcomputing. El término softcomputing lo introduce Zadeh para denotar una aproximación al razonamiento humano que deliberadamente hace uso de la tolerancia humana a imprecisiones y vaguedades para obtener soluciones razonables que son fáciles de manipular. Bajo este principio, los sistemas borrosos, las redes neuronales, la computación evolutiva, el razonamiento probabilístico y las combinaciones de dichas técnicas son consideradas como softcomputing [26]. En general existen un grupo de propiedades que caracterizan a las. 12.
(20) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. técnicas y sistemas basados en softcomputing y que pueden ayudarnos a identificar los límites de este campo [28, 94] como mostramos a continuación: •. Es lo opuesto al hard computing, no es prescriptivo en la solución de un problema, en este campo no hay soluciones programadas para cada posible situación.. •. Sus técnicas son robustas ante entornos con entradas ruidosas y tienen una alta tolerancia a la imprecisión de los datos con los que opera.. •. Es una necesidad cuando la información de que disponemos es imprecisa; y segundo cuando existe una tolerancia a la imprecisión que podría ser explotada para ganar robustez, en soluciones de bajo costo y en mayor capacidad de modelación.. Ante los objetivos propuestos en esta tesis y teniendo en cuenta lo anteriormente explicado en la próxima subsección discutiremos brevemente algunos enfoques utilizados en el aprendizaje y la clasificación y analizaremos ventajas y desventajas de los mismos. Mostraremos además que ante las situaciones problémicas a resolver en el capítulo 3 necesitamos aplicar las técnicas de softcomputing.. 1.2 Diferentes enfoques empleados en el aprendizaje y la clasificación Comenzamos esta sección discutiendo que entendemos por clasificación puesto que ya discutimos con anterioridad el término aprendizaje. La clasificación se puede entender como el proceso de reconstrucción o predicción de clases cw de un objeto w dado su vector característico xw [19]. Un clasificador puede ser definido como una función g: A→ C. Podemos decir que el objeto de estudio del aprendizaje y la clasificación es el descubrimiento de modelos, familias de funciones, que permitan representar g apropiadamente para diferentes problemas así como el desarrollo de algoritmos que permitan aprender estos modelos a partir de datos. En general consideramos que todos los métodos de aprendizaje y clasificación son extensiones de técnicas clásicas tales como: el análisis de discriminante, los métodos basados en árboles de decisión como la técnica estadística CHAID: Chi-square Automatic Interaction Detector, los métodos de estimación de densidades (KNN: k-nearest neighbors) o las técnicas jerárquicas de formación de grupos; procedimientos clásicos que constituyen prototipos y que han sido refinados y extendidos de diversas formas [53]. Los métodos de aprendizaje y clasificación pueden ser organizados atendiendo a su naturaleza en métodos estadísticos, modelos o algoritmos matemáticos para el reconocimiento de patrones (RP), estrategias basadas en árboles de decisión, sistemas basados en el conocimiento (SBC) entre otras ver Anexo 1. 13.
(21) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. 1.2.1 Estrategias estadísticas Las técnicas estadísticas se caracterizan generalmente por tener un evidente modelo de probabilidades como base, el cual indica una probabilidad de un objeto de estar en cada una de las clases en lugar de una simple clasificación. Explicamos brevemente el funcionamiento de algunos métodos estadísticos [53, 95]: • Discriminante Lineal de Fisher es uno de los procedimientos de clasificación más antiguos. Los objetos o puntos son clasificados de acuerdo a la posición que ocupan respecto a dicho hiperplano ver Anexo 2, Figura 8. • Discriminante lineal por máxima probabilidad asume que los vectores de atributos de ejemplos pertenecientes a la clase Ci son independientes y siguen una cierta distribución de probabilidad con función de densidad f i . En la clasificación de un nuevo punto este es asignado a la clase para la cual la función de densidad probabilística sea mayor. • Discriminante cuadrático es similar al lineal, sólo que la frontera entre dos regiones discriminantes puede ser una superficie cuadrática. Un discriminante cuadrático es calculado para cada clase y en la clasificación de un nuevo objeto la clase donde se obtenga el mayor valor de pertenencia es seleccionada. • Regresión Logística también opera seleccionando un hiperplano para separar las clases tanto como sea posible, a diferencia del discriminante lineal esta técnica persigue maximizar una probabilidad condicional. En el Anexo 2, Figura 9 se muestra la separación de los objetos a partir de la aplicación de los métodos anteriormente discutidos. El aprendizaje en estos métodos se caracteriza por la estimación de los parámetros de las funciones de densidad probabilística y generalmente se basan en la determinación de la probabilidad máxima. Tendencias actuales en el uso de las técnicas estadísticas muestran el uso de estas combinadas con otros métodos o como parte de sistemas multiclasificadores [3]. Hay que señalar que estos métodos se deben aplicar cuando se puede encontrar un modelo ya sea lineal, logístico, cuadrático etcétera que permita aproximar la interrelación entre los datos adecuadamente [96]. En caso que la interrelación entre los datos sea excesivamente compleja es recomendable utilizar otras técnicas como por ejemplo las redes neuronales u otras.. 1.2.2 Algoritmos Lógico-Combinatorios para Reconocimiento de Patrones Este enfoque parte de la descripción de los objetos en forma de vectores donde cada componente del vector representa uno de los rasgos analizados y el valor de dicha componente, el valor particular que tiene un objeto respecto a ese rasgo [97]. La idea básica. 14.
(22) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. de la clasificación de los objetos según este enfoque es la evaluación de los objetos haciendo uso de diferentes métricas y algoritmos [98] tales como: •. Regla del máximo peso: Esta regla anuncia que un objeto pertenece a la clase respecto a la cual tenga un mayor peso informacional.. •. Regla del vecino más cercano: Esta regla le asigna a un objeto, la clase a la que pertenece el objeto que se encuentre más cercano de acuerdo a una distancia.. •. Regla de los k-vecinos más cercanos: mediante una distancia se determinan los k objetos más cercanos al cuestionado, la clase del nuevo objeto se toma como la más frecuente en los k-vecinos más cercanos [4].. •. Regla del ideal: Es la regla del vecino más cercano o el vecino más semejante aplicada a los ideales de la clase. Se entiende por ideal informativo al objeto w, tal que su peso informacional es maximal con respecto a su clase.. Otras tendencias en el análisis lógico combinatorio parten de la idea del análisis de subfamilias de rasgos (como proyecciones en subespacios del espacio n-dimensional) y sobre la base de esas subfamilias de rasgos, hacer conclusiones parciales, temporales, que permitan posteriormente sacar una conclusión final y más general. Esta es la idea fundamental en la que se sustentan los algoritmos de votación [7]. Otros trabajos y algoritmos se basan en el concepto de testor y el concepto de testor por clase [5, 6, 8]. El aprendizaje asociado a esta forma de clasificación esta sujeta a la posibilidad de poder encontrar métricas y distancias adecuadas en dependencia de la naturaleza de los datos, aspecto que con frecuencia se torna muy difícil y depende de la subjetividad de los expertos y las características propias de los problemas. Otra característica propia de estos modelos es que basan su funcionamiento en el cálculo de distancias entre los objetos a clasificar y los del conjunto de entrenamiento, por tanto, la clasificación de un nuevo objeto tiene un alto grado de dependencia del conjunto de entrenamiento. Esta alta dependencia del conjunto de entrenamiento afecta la robustez del modelo en entornos donde aspectos como el ruido y la imprecisión de los datos aparece.. 1.2.3 Estrategias basadas en árboles de decisión Una estrategia pionera en este campo es el análisis CHAID cuya extensión ha dado origen a otros métodos. La técnica CHAID divide a una población de objetos en grupos de acuerdo a los valores de los rasgos predictores de dichos objetos y sus interacciones [53, 99]. En general la inducción de los árboles de decisión está basada en algoritmos de aprendizaje discriminativo por medio de particionamientos recursivos. En cada nodo diferente de las hojas se plantea la pregunta ¿Cuál atributo de los no seleccionados aún es el que mejor discrimina los casos del conjunto de aprendizaje que pertenecen a clases diferentes? Se evalúan todos los atributos restantes y el que mejor discrimine a los casos se ubica en el nodo actual y por cada valor posible de este atributo se busca un nodo descendiente.. 15.
(23) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. El algoritmo CART [10] es otro algoritmo basado en árboles de decisión que permite el trabajo con datos incompletos, y que incorpora estrategias de poda con el fin de obtener árboles donde se combine apropiadamente la capacidad de predicción con la cantidad de nodos. Otros modelos basados en esta estrategia son los algoritmos ID3 [12], que solo permite el tratamiento de datos simbólicos, y sus extensiones C4.5 [13] y C5.0 [100] que posibilitan también el tratamiento de datos numéricos. En el caso de los algoritmos propuestos por Quinlan basan su funcionamiento en una heurística hill-climbing y el criterio de selección de rasgos que usa se basa en el cálculo de la ganancia de la entropía o de la ganancia radial [11]. El criterio de selección basado en la ganancia de la entropía tiene la dificultad que favorece la selección de rasgos con mayor cantidad de posibles valores, el criterio basado en la ganancia radial por su parte resuelve este problema pero ante determinadas situaciones puede caer en indefiniciones o provocar que atributos con una baja ganancia sean seleccionados por sobre otros con mayor calidad [101].. 1.2.4 Sistemas basados en el conocimiento de la Inteligencia Artificial En términos generales, la estructura de un sistema basado en el conocimiento (SBC) puede ser representada a partir de la siguiente fórmula: SBC = MI + BC + [Explicación] + [Adaptación e incorporación de nuevo conocimiento]… La base de conocimiento BC es uno de los elementos fundamentales de los SBC es la estructura encargada de almacenar el conocimiento. La máquina de inferencia MI es el otro elemento fundamental y constituye el método de solución que “razona” usando el conocimiento contenido en la BC. Como se puede ver una de las principales características que identifican a los SBC es la distinción entre conocimiento y estrategia de control utilizada para el manejo de este. Existe una gran variedad de SBC, estos se diferencian por la forma de representar el conocimiento y por la naturaleza de la máquina de inferencia asociada, ejemplo de ellos son: sistemas basados en probabilidades SBP, en reglas SBR, en frames SBF, sistemas basados en casos CBR, los modelos conexionistas o basados en pesos, los sistemas de inferencia borrosos etcétera [11, 14-17]. La tabla del Anexo 3 muestra un resumen de las principales propiedades de algunos sistemas basados en el conocimiento. Por su importancia para este trabajo discutiremos brevemente acerca de los siguientes sistemas basados en el conocimiento: sistemas basados en reglas, sistemas basados en casos, las redes neuronales, los sistemas de inferencia borrosos y neuroborrosos. Sistemas basados en reglas (SBR) se caracterizan porque la forma de representación del conocimiento son las reglas de producción y como método de inferencia utilizan la regla de modus ponens. Las reglas de este tipo de SBC expresan siempre una condicional, con. 16.
(24) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. antecedentes y un consecuente. La interpretación de una regla parte del hecho que si los antecedentes se satisfacen entonces se obtiene el consecuente, este tipo de reglas se conoce en la literatura como reglas duras[102]. Como ventaja fundamental muestran su capacidad de interpretación y explicación de la inferencia. Pero solo deben ser utilizados en los casos donde el conocimiento pueda ser representado de forma eficiente en forma de reglas duras evitando situaciones donde haya inconsistencia e imprecisión de los datos [17] y evitando su aplicación en problemas donde exista vaguedad en la definición de los conceptos [93]. Los sistemas basados en casos (CBR) basan sus potencialidades para el aprendizaje en los mecanismos de detección de similaridades entre casos y también en la propiedad de incorporar de forma natural nuevo conocimiento mejorando gradualmente su funcionamiento [15, 103]. Su principal limitación radica en la capacidad de representación de los valores de los rasgos [104], aspecto que dificulta su aplicación en situaciones que requieren representaciones de casos complejas como por ejemplo las que se presentan cuando existe un alto grado de interrelación entre los rasgos. También hay que señalar que la definición de las funciones de semejanza y los mecanismos de selección de rasgos para cada problema específico son problemas abiertos en este campo, cuya solución depende en gran medida de la experiencia de los expertos. Redes neuronales artificiales también conocidos como modelos conexionistas consiste de un conjunto de elementos computacionales simples (unidades Ui o neuronas artificiales), que están unidos por arcos dirigidos que le permiten comunicarse. Cada arco tiene asociado un peso numérico Wij que indica la significación de la información que llega por este arco, o sea, la influencia que tiene la activación alcanzada por la neurona Ui sobre la neurona Uj es precisamente en los pesos donde se almacena de forma intrínseca el conocimiento de este tipo de sistema. Hay tres aspectos que caracterizan a las redes neuronales y permiten distinguir a cada uno de los diversos modelos que se reportan en la bibliografía [16], ellos son: la topología de la red (Anexo 7), las características de los nodos (modelo de la neurona) y el mecanismo de aprendizaje. El uso de las redes neuronales ha mostrado una alta eficiencia en la resolución de diversos problemas, no obstante su efectividad se les señala que se comportan como cajas negras y no facilitan la interpretación de los resultados [16]. Tendencias actuales en el uso de estas se presenta en combinación con otros modelos [29, 105, 106] como partes integrantes de sistemas multiclasificadores, sistemas neuroborrosos [107, 108] y redes neuronales ensambladas [109].. 1.2.4.1 Los sistemas de inferencia borrosos y neuroborrosos Sistemas de inferencia borrosos. La base del funcionamiento de los sistemas de inferencia borrosos son los conjuntos borrosos. A diferencia de los conjuntos clásicos en estos conjuntos la pertenencia de un. 17.
(25) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. elemento se convierte en un problema de grado. Más formalmente podemos decir que un conjunto borroso A en un universo de discurso U está caracterizado por una función de pertenencia μ a la cual a cada elemento en el dominio le asigna un grado de pertenencia al conjunto en el intervalo [0,1] y se representa de la forma μ a :U→[0, 1] [18, 110]. De esta forma un mismo elemento puede pertenecer a varios conjuntos simultáneamente solo que con cierto grado de pertenencia. Cada conjunto borroso tiene asociado además un término lingüístico de forma tal que la función de pertenencia asociada a un conjunto está ligada a una palabra como por ejemplo: bajo, medio, más o menos alto, alto, muy alto, etcétera. En la representación y construcción de las funciones de pertenencia se pueden utilizar diferentes modelos matemáticos tales como: funciones triangulares, funciones trapezoidales, funciones campana, funciones simoidales, etcétera; ver Anexo 5 . Por la importancia para este trabajo más adelante en la sección “Diferentes enfoques en la construcción de funciones de pertenencia” se aborda con mayor profundidad esta temática. El centro de las técnicas de modelación borrosa lo constituyen las variables lingüísticas concepto que agrupa a los conjuntos borrosos asociados a una misma variable. Una variable lingüística [108, 110] se caracteriza por un quíntuplo (x, T(x), X, G, M) en el cual x es el nombre de la variable, T(X) es el conjunto de términos lingüísticos, X es el universo de discurso, M es una regla semántica la cual asocia a cada valor lingüístico Z su significado M(Z), donde M(Z) denota un conjunto borroso en X y G es el conjunto de reglas sintácticas de generación de términos compuestos, a partir de los términos atómicos que configuran las sentencias que dan lugar a cada valor lingüístico. Ver en Anexo 4 un ejemplo de variable lingüística. Las variables lingüísticas y sus conjuntos borrosos son usados para describir relaciones entre variables en forma de reglas If-then que se les conoce como reglas borrosas. Se define una regla borrosa R como una tupla (P,Q) donde P son los conjuntos borrosos que representan a los antecedentes y Q es el consecuente [18]. Los sistemas basados en reglas borrosas son llamados sistemas de inferencia borrosos (SIB). Estos sistemas se muestran como un espacio de hipótesis que nos permiten no tener necesariamente que distinguir entre valores muy similares. No son dependientes de la escala de los datos que ellos procesan y basan su funcionamiento en la aplicación de la regla de Modus Ponens generalizada [30]. Un elemento fundamental en los SIB lo constituye su base de conocimiento que es una base de reglas borrosas BR = {R 1 , … , R r } [18, 24]. Una característica importante que diferencia a los SIB de los Sistemas Basados en Reglas clásicos es que el resultado de la inferencia se obtiene de aplicar numerosas reglas1 y. 1. usualmente todas las de la base de reglas.. 18.
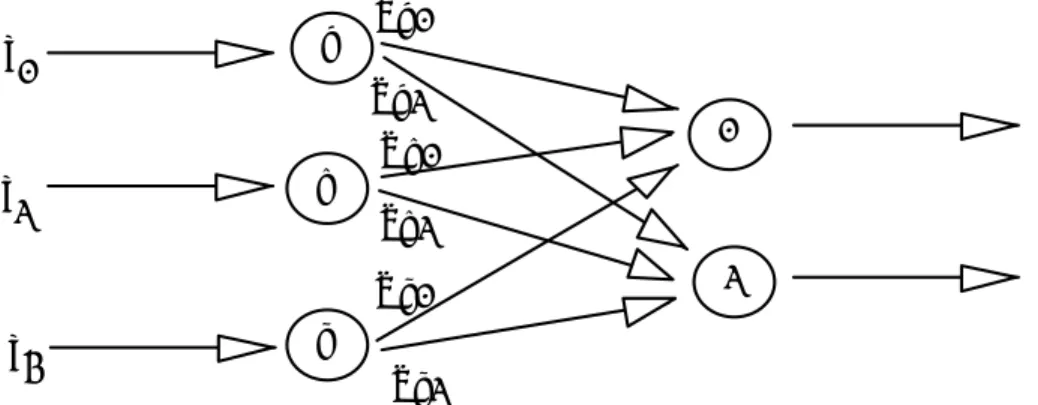
(26) ESTADO DEL ARTE EN LOS MODELOS DE APRENDIZAJE Y CLASIFICACIÓN BASADOS EN LA LÓGICA BORROSA. conciliar las inferencias parciales de estas a partir de un procedimiento de agregación Anexo 6 Figura 13. En general el esquema de evaluación de cada regla se basa en la aplicación de una TNorma mientras que el procedimiento de agregación se basa en la aplicación de una CoNorma. Como ejemplos de TNormas y CoNormas usualmente se usan las combinaciones min-max y producto-max [18, 111] ver Anexo 6. Existen tres tipos fundamentales de sistemas de inferencia borrosos: el modelo de Mamdami, Sugeno y Tsukamoto que se diferencian en la forma del consecuente de sus reglas borrosas [18] ver Anexo 6. Para la aplicación en problemas de clasificación, que es nuestro caso, con frecuencia se utiliza el Sugeno grado cero precisamente por la estructura de las reglas que este tipo de sistema representa [112]. Este modelo también conocido como TSK, por sus autores Takagi, Sugeno y Kang [113], utiliza reglas de la forma: Si “x es A” y “y es B” entonces z=f(x, y). Donde A y B son conjuntos borrosos en el antecedente y z usualmente f(x, y) es un polinomio cuyo grado determina el grado del modelo borroso Cuando f es una constante al sistema borroso correspondiente se le llama “modelo borroso Sugeno de grado cero”. El centro de los sistemas borrosos es la base de reglas. Si esta es construida solo a partir del conocimiento adquirido previamente por un experto o grupo de expertos podría usualmente no funcionar correctamente cuando es aplicado. Esto puede ocurrir porque los expertos podrían equivocarse acerca de la localización de determinados puntos característicos en las funciones de pertenencia, respecto al número de reglas o respecto a la indistinguibilidad de determinadas áreas del espacio de búsqueda. La aplicación de técnicas de aprendizaje automático ha contribuido a eliminar el cuello de botella que significada la construcción manual de la base, pero aún queda mucho por hacer. En la sección generación de reglas borrosas se discute esta problemática. Sistemas neuroborrosos. El término sistema neuroborroso se refiere a la combinación de las redes neuronales y los sistemas de inferencia borrosos. Es necesario aclarar que no basta que una red neuronal y un sistema de inferencia borroso sean usados juntos para estar en presencia de un modelo neuroborroso. Un sistema neuroborroso es una forma de crear un sistema de inferencia borroso utilizando algún tipo de heurística o método de aprendizaje inspirado en los mecanismos de aprendizaje usados en las redes neuronales [24]. Los sistemas neuroborrosos pueden ser clasificados por sus topologías. Veamos dos posibles representaciones para una mejor comprensión a través de los gráficos de la Figura 22 Anexo 8. Ambos gráficos representan un sistema borroso con las siguientes reglas: R1: Si x1 es grande y x2 es viejo entonces y es malo R2: Si x1 es pequeño y x2 es nuevo entonces y es bueno. 19.
Figure
![Tabla 1 Comparación respecto a prueba varios algoritmos. Datos con * extraídos de tesis doctoral de Detlef Nauck [27], Datos ** extraídos de [24]](https://thumb-us.123doks.com/thumbv2/123dok_es/7412361.470759/86.918.149.832.419.758/tabla-comparación-respecto-algoritmos-extraídos-doctoral-detlef-extraídos.webp)



+7





Documento similar