Herramientas de paralelización de la generación de medios
80
0
0
Texto completo
(2) A mis padres y mi hermana, por el amor y el apoyo que me han brindado..
(3) Mi más profundo agradecimiento para Mi amigo, Alcides Viamontes, por su valiosa ayuda y mis tutores por su apoyo en la creación de este trabajo..
(4) Resumen Se presenta un conjunto de herramientas realizadas para la paralelización de aplicaciones secuenciales, entre ellas NoMS. Se tratan dos problemas inherentes al paralelismo, balance de carga y tráfico. Además, contiene mecanismos para manipular la comunicación paralela usando programación orientada a objetos.. Abstract A toolset aimed at parallelizing sequential applications, among them NoMS, is presented. In this toolset different methods for two inherent internal problems of parallelism are developed: workload balancing and traffic. Besides, a small mechanism to handle parallel communications using object oriented paradigms was implemented..
(5) Herramientas de paralelización de la generación de medios.. Indice Introducción............................................................................................................3 Capitulo 1 Estado del arte.......................................................................................5 1.1 Generalidades de la programación paralela.................................................5 1.1.1 Razones de uso.......................................................................................5 1.1.2 Técnicas de descomposición...................................................................6 1.1.3 Herramientas y tecnologías existentes...................................................8 1.2 Definiciones relacionadas con grafos..........................................................11 1.3 Problemas de satisfacción de restricciones................................................13 1.4 Métodos heurísticos....................................................................................14 1.4.1 Algoritmos de colonias hormigas..........................................................15 1.5 Sincronización.............................................................................................18 1.5.1 Problema de coloreamiento de grafos..................................................19 1.6 Particionamiento.........................................................................................22 1.6.1 Particionamiento estático.....................................................................23 1.6.1.1 Esquema de bisección recursiva....................................................24 1.6.1.2 Técnicas geométricas.....................................................................25 1.6.1.3 Técnicas combinatorias..................................................................26 1.6.1.4 Estrategias multinivel....................................................................27 1.7 Paralelización de los métodos de partículas...............................................28 1.8 Conclusiones parciales................................................................................29 Capitulo 2 Formulación matemática y computacional..........................................31 2.1 Funcionamiento de las herramientas de paralelización..............................31 2.2 Esquema organizativo de las herramientas de paralelización....................33 2.3 Generalidades de la formulación.................................................................35 2.3.1 Enfoques del modelo paralelo...............................................................35 2.3.2 Modelo de particiones..........................................................................37 2.4 Planificación interna....................................................................................39 2.4.1 Algoritmo de hormigas para el coloreamiento de grafo.......................40 2.4.2 Algoritmo con heurística simple para el coloreamiento de grafo.........45 2.5 Balance de carga estático............................................................................47 2.5.1 Método de optimización por colonias de hormigas para el particionamiento de grafos............................................................................47 2.5.2 Estrategia multinivel para el particionamiento de grafo......................51 2.6 Conclusiones parciales................................................................................53 Capitulo 3 Análisis de resultados y marco de paralelización................................54 3.1 Parte 1: Análisis de resultados....................................................................54 3.1.1 Resultados en la planificación de acceso a recursos............................54 3.1.2 Resultados de los métodos de particionamiento de dominio................59 3.2 Parte 2: Diseño e implementación del marco de paralelización.................62 3.3 Conclusiones parciales................................................................................69 Conclusiones.........................................................................................................70 Recomendaciones..................................................................................................71 1.
(6) Herramientas de paralelización de la generación de medios. Bibliografía............................................................................................................72. 2.
(7) Herramientas de paralelización de la generación de medios.. Introducción. Hoy día la computación se encuentra en todas las ramas de las ciencias y las ingenierías, además de otras esferas, aportando herramientas imprescindibles para sus desarrollos. En ramas. específicas existen retos muy impresionantes. donde la forma tradicional de resolver problemas computacionales da al traste con las necesidades. Las principales deficiencias se encuentran relacionadas con el tiempo de cómputo que consume un procesador en la búsqueda de soluciones a problemas muy complejos. También resulta problemático el límite en cuanto a la capacidad de almacenamiento en memoria RAM. El desarrollo de la computación a llegado a niveles fabulosos en cuanto a potencia de cálculos, donde han surgido tecnologías como la programación paralela. Este paradigma resulta una solución a todo lo anterior pero la complejidad de usarlo aún es alta. Ante problemas prácticos para la paralelización de aplicaciones secuenciales es necesario un mecanismo que brinde alternativas modulares ante el método clásico, “reimplementación del programa”. Además estos módulos deben ser capaces de proveer soluciones ante las disímiles situaciones que puedan presentarse en este tipo de aplicaciones. Entre estas se encuentran el balance de carga estático y dinámico, y el nivel de sobrecarga producido por el tráfico de datos inter-procesador. El objetivo principal de este trabajo es el desarrollo de un conjunto de herramientas de programación que satisfagan soluciones paralelas, brindándole mayores posibilidades al programador de centrarse en el problema en cuestión. En el afán por lograr esto, se encuentran temas indisolublemente ligados a la temática del paralelismo, los cuales son objetivos específicos que también deben ser resueltos.. 3.
(8) Herramientas de paralelización de la generación de medios. Estos son: ●. Realizar un estudio de cuales son las tecnologías disponibles y determinar cual es la más viable para llevar a cabo el proyecto.. ●. Construir un diseño general para las herramientas.. ●. Investigar cual es el mejor modelo de control, centralizado o distribuido, para desarrollar aplicaciones paralelas con determinados requisitos.. ●. Creación de un mecanismo de balance de carga estático.. ●. Diseñar una vía para establecer el control de acceso a datos distribuidos.. ●. Desarrollar un mecanismo que independice al programador de las especificidades de las tecnologías disponibles.. El aporte de este trabajo radica principalmente en la forma de enfocar el desarrollo. de. estas. herramientas. en. módulos. independientes. para. la. paralelización de aplicaciones. También contiene un conjunto de clases que forman una capa de abstracción a las tecnologías de paralelización. Además, en futuras aplicaciones no es necesario reimplementar estas herramientas, solo mejorarlos de ser necesario. El capítulo 1 muestra los resultados de la investigación bibliográfica, realizada para el análisis de temas de las aplicaciones paralelas. El segundo capítulo contiene los diferentes aspectos teóricos que justifican el diseño y la formulación de los métodos propuestos. Y el capítulo 3 muestra un conjunto de resultados para analizar la eficiencia de los métodos implementados, además, una jerarquía de clases muy simples para el tratamiento de las comunicaciones.. 4.
(9) Herramientas de paralelización de la generación de medios.. Capitulo 1. Estado del arte.. El contenido de este capítulo está enfocado en realizar un estudio sobre los temas de interés para llevar a cabo la paralelización de la generación de medios. Entre los temas a tratar se encuentra el mecanismo de sincronización intra e inter-procesador, los métodos existentes para distribuir la información entre los procesadores y el análisis de las tecnologías relacionadas con la problemática.. 1.1. Generalidades de la programación paralela.. La programación paralela es el paradigma mediante el cual se desarrollan programas que ejecutan código simultáneamente en diferentes procesadores ya sea en una computadora multiprocesador o en grupos de estaciones de trabajo que forman clusters de computadoras. En dependencia de cual de las dos vías anteriores se use es el modelo de memoria que se impone y determina todos los mecanismos de implementación, lo que la convierte en la característica más importante a tener en cuenta. También es de vital importancia el modelo de descomposición a utilizar en la aplicación por su decisiva influencia en las estrategias para combatir los problemas internos de este paradigma como la concurrencia y la descomposición de dominios.. 1.1.1. Razones de uso.. Por las posibilidades que brinda contar con recursos muy numerosos en comparación a una simple computadora es que hoy día la programación paralela se ha convertido en una de las herramientas más útiles para implementar problemas complejos y. resultan la única solución para tratar los problemas. categorizados como grandes retos en ramas como: 1. Dinámica de los fluidos. 2. Biomecánica. 5.
(10) Herramientas de paralelización de la generación de medios. 3. Modelos micro-estructurales. El desarrollo en expansión de estas y otras aplicaciones donde también existe tratamiento intensivo de datos como: ●. Procesamiento de transacciones y recuperación de información.. ●. Minería y análisis de datos.. ●. Servicios multimedia.. ●. Generación de imágenes en tiempo real.. marcaron el inicio de una generación de nuevas aplicaciones que requieren grandes volúmenes de datos que actualmente se encuentran en crecimiento constante con el objetivo de lograr un nivel lo más detallado posible de las actividades reales a simular en computadoras, cuando se trata de aplicaciones científicas o porque simplemente la información a procesar en una rama específica se reproduce rápidamente, como es el caso de aplicaciones comerciales y a la par de los datos los cálculos representan también grandes problemas en cuanto al tiempo de computo en PC convencionales. Estas características representan los requerimientos de esta clase de sistemas y son más que suficientes para poner en práctica el uso del computo en paralelo.. 1.1.2. Técnicas de descomposición.. Según (Grama et al., 2003: 86) la descomposición es el proceso de dividir un computo en partes más pequeñas de los cuales algunas o todas pueden potencialmente ser ejecutadas en paralelo. En. la. solución. de. problemas. usando. algoritmos. paralelos. la. cuestión. fundamental no solo es tener especial cuidado en la elaboración de los pasos a seguir, sino, que al añadirse la concurrencia a un nivel diferente al visto en aplicaciones secuenciales se debe analizar el conjunto de pasos que se ejecutan de forma simultanea. Estos modelos exigen de un conjunto de aspectos a tener en cuenta para su selección (Grama et al., 2003: 85): 1. Identificar porciones del trabajo que se desarrollan concurrentemente.. 6.
(11) Herramientas de paralelización de la generación de medios. 2. Asignación de tareas concurrentes en procesos en paralelo. 3. Distribución de la entrada, salida y datos intermedios asociados con el programa. 4. Manipulación. de. los. accesos. a. datos. compartidos. en. múltiples. procesadores. 5. Sincronización de los procesadores en varios estados de la ejecución del programa paralelo. Con toda esta información es posible construir un grafo de dependencias entre las tareas que componen la solución del problema y es posible elegir que tipo de descomposición usar. (Karypis et al., 2003: 95-147). Como producto de este. análisis se deriva un resultado muy útil que es el grado de concurrencia que puede lograr la aplicación y con este se puede tener una idea desde muy temprano de cuan mejorada puede llegar a ser la solución en una versión paralela de una aplicación. Los mecanismos para realizar la descomposición de un algoritmo se encuentran estrechamente vinculados con el tipo de problema o la estructura de este, entre ellos se pueden encontrar la descomposición recursiva, la exploratoria, especulativa, por datos e híbrida. La descomposición recursiva es un método para inducir la concurrencia en los problemas que pueden ser resueltos mediante la estrategia divide y vencerás, subdividiendo el problema y asignando la nueva tarea a un nuevo procesador hasta agotarse las capacidades, un claro ejemplo de su uso es en programas que necesiten usar algoritmos de ordenamiento como el quick-sort. La descomposición exploratoria corresponde a aquellos algoritmos que basan su funcionamiento en operaciones en un espacio de búsqueda para lograr encontrar. una. solución,. dividiendo. dicho. espacio. entre. los. diferentes. procesadores, ejemplo el problema 15-puzzle. Otra técnica es la descomposición especulativa, esta es aplicable cuando existen varias ramas del algoritmo que dependen del resultado de una tarea anterior, de 7.
(12) Herramientas de paralelización de la generación de medios. forma análoga al ensamblaje paralelo de instrucciones en un microprocesador (pipeline). Mientras un procesador se encuentre realizando la tarea precedente a la ramificación se pueden mapear las diferentes ramas hacia procesadores desocupados y adelantar los próximos resultados. El ejemplo más evidente de esta técnica son las simulaciones de eventos discretos. Y la más común es la descomposición de datos que cuenta con varias estrategias de particionamiento de datos. ●. Datos de entrada.. ●. Datos de salida.. ●. Ambos tipos de datos, entrada y salida.. ●. Datos intermedios.. Solo se analizarán los casos sencillos. El particionamiento de datos de salida es posible cuando los resultados pueden ser calculados independientemente en función de los datos de entrada, un ejemplo es la multiplicación de matrices. Por otro lado en algunos casos es imposible realizar este tipo de particionado, por ejemplo en la búsqueda de un mínimo, un máximo o la suma de un conjunto de números. Estas tareas tienen en común que los datos de salida son un solo número y por tanto lo que es útil en esta ocasión es particionar los datos de entrada por bloques y realizar el cómputo necesario.. 1.1.3. Herramientas y tecnologías existentes.. Para el desarrollo de aplicaciones paralelas ya se cuenta con una gran variedad de herramientas que en la medida de las posibilidades y en dependencia del problema resultan provechosas utilizarlas. Existen herramientas para mejorar diferentes áreas de este paradigma, como la plataforma que permite el paralelismo y la forma para lograr un balance de carga adecuado. Las herramientas que forman el conjunto de plataformas son las librerías de paso de mensajes como MPI, librerías de tratamiento de hilos como POSIX y modelos basados en directivas como OpenMP. 8.
(13) Herramientas de paralelización de la generación de medios. Las librerías como POSIX están encaminadas para el desarrollo de aplicaciones multihilos, este modelo es muy flexible pues es una característica propia de los sistemas operativos que puede ser explotada por la mayoría de los lenguajes de programación. Esta característica puede utilizarse en cualquier ambiente ya sea computadoras uniprocesador, multiprocesador o cluster. Independientemente del uso que puedan tener múltiples hilos para este tipo de aplicaciones, no tiene una utilidad relevante pues en un procesador al fin y al cabo solo se ejecuta un hilo al mismo tiempo. Al ser tan general no se encuentra preparado para tratar problemas típicos de paralelismo como la concurrencia por lo se tendría que implementar el mecanismo de sincronización a recursos compartidos. Por otra parte es muy atractivo el uso de librerías como OpenMP para las aplicaciones pensadas en ambientes paralelos con memoria compartida. Tiene amplias ventajas sobre la programación multihilos pues las operaciones de paralelismo se realizan implícitamente. Otra característica de este mecanismo y que prácticamente es lo que identifica que un código está usando dicha librería es la forma de especificar las secciones criticas mediante directivas. El hecho de ser una herramienta diseñada específicamente para memoria compartida presenta la deficiencia de no ser portable hacia otras plataformas paralelas como la de memoria distribuida, además de que representa un riesgo la decisión de tomar este tipo de modelo de memoria pues las tecnologías quedan obsoletas con una velocidad bastante alta y el costo de una computadora de este tipo con un fuerte poder de calculo son extremadamente grandes. El otro tipo de modelo pendiente son las interfaces de paso de mensajes como la librería MPI. MPI (Message Passing Interface por sus siglas en inglés) brinda un conjunto de funciones que establecen el mecanismo de comunicación en las aplicaciones paralelas. Están diseñada por excelencia para sistemas de memoria distribuida y presenta varias características adicionales que la convierten en una opción elegible. 1. Está diseñada para trabajar no solo en ambientes de clusters de. 9.
(14) Herramientas de paralelización de la generación de medios. computadoras sino en simples grupos de estaciones de trabajo e incluso en supercomputadoras que usen memoria compartida. 2. El standard fue diseñado para soportar portabilidad y es independiente de la plataforma. 3. Está bajo licencia de software libre. 4. Actualmente cuenta con soporte y en fase de expansión con el standard MPI-2 en desarrollo. Otra de las ventajas que ofrecen estas librerías, es que representan una solución segura para las aplicaciones en cuanto a riesgos con la tecnología sobre la que vaya a ejecutarse, además de encontrarse en constante actualización. Mientras que uno de los aspectos que más influyen negativamente al escribir código paralelo, radica en lo primitivo del mecanismo para establecer la comunicación entre procesadores. Esto se debe a la falta de abstracción que existe en los servicios que brinda. En otro plano se encuentran las herramientas que facilitan soluciones a problemas como el balance de carga, muy común en sistemas de memoria distribuida, ejemplo de estas son las librerías Metis (Karypis y Kumar, 1998b), ParMetis (Karypis et al., 2003) y DRAMA (Maerten et al., 1999). Todas estas librerías tienen en común resolver el problema de particionamiento de grafo, ventaja que a primera vista no deja lugar a dudas, pero internamente se encuentran algunas deficiencias o incompatibilidades entre los modelos de la aplicación y el de estas librerías. DRAMA, por ejemplo, enfoca sus soluciones al método de elementos finitos. Este modelo resulta diferente en algunos aspectos al modelo de elementos distintos o discretos que es la base de la aplicación secuencial que se desea paralelizar. Por otro lado Metis es una librería impresionante pues implementa la mayoría de los métodos más usados para el particionamiento de grafos como se verán en próximos epígrafes. Su principal debilidad es que está pensada para ejecutar 10.
(15) Herramientas de paralelización de la generación de medios. secuencialmente y cuando el volumen de datos sea extremadamente grande sería necesario recurrir a estrategias nuevas. Mientras ParMetis es una versión de Metis en paralelo. El problema general en estas librerías es que enfocan sus acciones a datos primitivos, los cuales, son muy sencillos de trabajar. Pero la complejidad asumida al utilizarlas en aplicaciones diseñadas para explotar el paradigma de programación orientada a objetos supone una conversión de los objetos a secuencias de bit serializables para lo cual estas librerías no se encuentran preparadas. Por estas razones se hace necesario implementar un mecanismo propio que garantice la tarea de balance de carga que cumpla con los nuevos requerimientos,. entre. ellos. la. transferencia. de. objetos. que. manipulen. estructuras complejas.. 1.2. Definiciones relacionadas con grafos.. En todo algoritmo es necesario definir estructuras para representar los datos. En la clase de problemas que se tienen que resolver comúnmente en aplicaciones paralelas, como la sincronización y el particionamiento, es común y trivial la elección de los grafos. Los grafos representan el mecanismos de almacenamiento de datos perfecto para. muchos. problemas,. principalmente. combinatorios.. Existen. varias. clasificaciones de grafos en dependencia de la interrelación de sus elementos y características, pero solo se abordará la principal, referente a la dirección de los arcos que unen los nodos. Estos se clasifican en dirigidos y no dirigidos, a continuación se muestran sus respectivas definiciones.. Definición 1: Grafo no dirigido. Un grafo no dirigido es un par G= N, A . Donde N es el conjunto de nodos y A es el conjunto de arcos formados por pares i , j que definen la existencia de una relación directa entre los nodos i , j ∈N donde se cumple la relación i , j= j ,i .. 11.
(16) Herramientas de paralelización de la generación de medios.. Definición 2: Grafo dirigido. Esta definición solo difiere de la anterior en la relación de los arcos. En este caso i , j≠ j,i . Ambas definiciones tienen enfocadas la representación de los arcos mediante conjunto de pares por una cuestión de simplicidad. Pero existen otras vías como, listas de adyacencia donde el grafo es definido como un vector de m nodos n1, n2, ... ,n m. . En cada nodo n i se definen los datos necesarios del problema y. adicionalmente un vector i 1, i 2, ... , i k indicando los k índices de los nodos que presentan relación de adyacencia. Mientras que la representación por matrices de adyacencia es una matriz cuadrada con dominio binario que rige sus valores: M i , j =. {01. si existe relación entre los nodos i y j delo contrario. }. (1). En cuanto a ventajas las matrices son las más rápidas pues el acceso a un elemento es un O 1 , mientras que en cuanto al almacenamiento tiene una complejidad promedio de un n 2 . El acceso en las listas de pares resultan el más costoso pues es del orden O n2 al igual que su almacenamiento y las listas de adyacencias tienen una complejidad de un O n en el acceso y un O n2 en el almacenamiento. En la teoría de grafos se encuentran una extensa cantidad de definiciones, pero solo se tratarán aquellas que presentan cierta importancia en el modelo del problema. Entre ellas se encuentra la vecindad de un nodo i :. V i = { j /∃ i , i , j∈ A }. (2). Otras definiciones de interés es la referida a los caminos y la densidad en los grafos.. Definición 3: Camino. Un camino abierto P desde el nodo n1 hasta n k es una secuencia de nodos n1, n2, n3, ... , nk ●. que cumplen las siguientes condiciones:. ni ≠ni1 , 1≤ i k. 12.
(17) Herramientas de paralelización de la generación de medios. ●. ∀ ni , ni 1 ∈ V ni . Definición 4: Grafo denso. Un grafo denso G es un grafo en el cual número de arcos es muy próximo a la cantidad máxima de arcos posibles. La densidad es definida como D=. ∣A∣ , donde ∣A∣ es la cantidad de arcos y ∣N∣ es la cantidad de ∣N∣2. nodos en el grafo. Esta definición es valida solo para grafos que contengan al menos un nodo y en este caso D=0 . Como última definición se menciona una característica de los grafos que resulta la principal de todas en las estructuras a modelar en los problemas. Representa un requisito indispensable que deben cumplir los grafos de los diferentes problemas relacionados anteriormente, la conexidad.. Definición 5: Grafo no dirigido conexo Un grafo no dirigido conexo es un par G= N, A en el cual 2,. ∀ i , j ∈N ∃ Pij .. Analizando todas las definiciones anteriores resulta conveniente realizar la implementación de los métodos mediante grafos con listas de adyacencia debido a que presenta un balance en sus propiedades. Aunque en una simple inspección aparenta ser una equivocación enorme por el análisis anterior. Por datos de la etapa de diseño se conoce que los grafos no son densos. Esta nueva propiedad mejora el rendimiento de las listas mientras que las matrices por ser estructuras que dependen de la cantidad de nodos mantienen su complejidad.. 1.3. Problemas de satisfacción de restricciones.. Según Javier Larrosa Bondia (Larrosa, 1998) un problema de satisfacción de restricciones PSR consiste en un conjunto de variables; donde cada variable tiene asociado un conjunto finito de posibles valores; y además existe un conjunto de restricciones controlando lo valores que pueden tomar estas 13.
(18) Herramientas de paralelización de la generación de medios. variables simultáneamente. Los problemas de satisfacción de restricción representan una clase muy usada en problemas de múltiples naturalezas. Por ejemplo en casos en que se desee una solución exacta se necesita del cumplimiento de todas las restricciones. Este caso se clasifican como métodos de satisfacción total de restricciones. Mientras que en otros problemas no es posible encontrar una solución. En estos casos se buscan aquellos valores que obtengan un valor promedio en la función objetivo y se les denominan como métodos de satisfacción parcial de restricciones. Ambos métodos, satisfacción total y parcial de restricciones son llamados problemas de decisión y optimización respectivamente. Estos métodos son usados ampliamente en otras ramas y presentan motivo de investigación esencial en ramas como inteligencia artificial. Entre ambos métodos existen diferencias muy evidentes y no resulta de interés entrar en su análisis pues tienen muy bien definido cual es su campo de acción y pueden ser usados como base de los algoritmos para resolver las problemáticas de la aplicación. Algunos ejemplos que pertenecen a la categoría PSR y que pueden ser modelados por ambos métodos en dependencia de los objetivos son: ●. El problema de las 8 reinas.. ●. Coloreamiento de mapas.. Y algunos de los algoritmos que proponen soluciones a esta familia de problemas: ●. AC-3.. ●. Backtracking.. ●. Conflictos mínimos.. 1.4. Métodos heurísticos.. Una heurística (regla heurística o método heurístico) es una regla para engañar, simplificar o para cualquier otra clase de ardid, el cual limita drásticamente la búsqueda de soluciones en grandes espacios de solución según Feigenbaum y 14.
(19) Herramientas de paralelización de la generación de medios. Feldman. La heurística no garantiza que siempre se tome la dirección de la búsqueda correcta, por eso este enfoque no es óptimo sino suficientemente bueno. Los métodos heurísticos son muy aceptados porque cuando se aplica la heurística deben ser capaces de reducir el factor de ramificación del algoritmo, logrando visitar la menor cantidad de instancias del espacio de búsqueda, además se garantiza alcanzar una solución muy buena y en ocasiones la óptima. Cuando. el. método. heurístico. no. brinda. la. solución. o. no. es. práctico. implementarlo puede modificarse y utilizar mecanismos mucho más flexibles llamados meta-heurísticos. En la práctica los métodos heurísticos son muy utilizados y muchas veces representan la única solución. A continuación se expone una breve explicación de los mecanismos y la estructura principal de algunos de los métodos más usados para resolver los problemas de la rama de optimización combinatoria.. 1.4.1. Algoritmos de colonias hormigas.. Los algoritmos de optimización por colonias de hormigas (Dorigo et al., 1996) fueron introducidos por Marco Dorigo y actualmente conforman una de las ramas más novedosas de la inteligencia artificial llamada “inteligencia colectiva” (swarm intelligence en inglés). Estos métodos pertenecen al grupo de métodos meta-heurísticos por su comportamiento probabilístico. Estos. algoritmos. son. usados. en. problemas. de. optimización. y. en. su. funcionamiento tratan de imitar a las hormigas de la vida real. Las tareas de búsqueda son distribuidas sobre “hormigas artificiales”, las cuales, son tratadas como agentes que tienen capacidades muy básicas de ahí el termino de inteligencia emergente. En la tarea de desarrollar un comportamiento similar al real se introduce una propiedad que manipula el rastro a seguir por los agentes, la feromona. Esta es la sustancia con la cual se comunican y señalizan cuales fueron los caminos tomados anteriormente. De esta forma un sistema con 15.
(20) Herramientas de paralelización de la generación de medios. múltiples hormigas puede tornarse autocatálico pues cuando una hormiga percibe un rastro existen altas probabilidades de que lo siga. En estos sistemas los agentes tienen la característica de determinar mediante una fórmula de transición que decisión tomar en el siguiente paso. Esta es libremente personalizada en dependencia de las necesidades del problema. Los principales cambios se manifiestan en el diseño de la heurística y la forma en que se desea que heurísticas y feromonas sean afectadas. Hay que mencionar que estos ambientes son recreados sobre grafos donde las transiciones de las hormigas se definen entre nodos. La fórmula (Dorigo et al., 1996: 6) que caracteriza la probabilidad de transición entre los nodos i y j desde la hormiga k en el instante t de la simulación es la siguiente:. k. ij t =. {. . . [ ij t ] ⋅[ ij ]. ∑. l ∈adyacentes i. . . [ il t ] ⋅[ il ]. ,. j∈adyacentes i j∉ adyacentesi. 0,. }. (3). Donde: ij t es la información de la feromona en el instante t que determina cuan. aceptable es el arco (i,j) para formar parte del camino de una hormiga. ij es la información heurística asociada al problema específico. y representan la medida en que se favorecen la feromona y la heurística. respectivamente. Es necesario detallar que para =0 el algoritmo estaría a merced de la selección aleatoria inicial que haga cada agente, siendo inminente la selección de un solo camino en pocas iteraciones de lo que se induce que no existirá análisis de cuan buena es la solución. Cuando =0 el algoritmo se comportaría según una estrategia greedy, la cual no obtiene buenos resultados en la mayoría de los casos.. 16.
(21) Herramientas de paralelización de la generación de medios. En conjunto con la feromona también se define un mecanismo para el desvanecimiento de la misma y es la velocidad de evaporación, característica que propicia la exploración de nuevos caminos o combinaciones. El. siguiente. pseudocódigo. propone. un. marco. genérico. del. método. de. optimización con hormigas.. Algoritmo 1: Esquema genérico del algoritmo de optimización de colonias de hormigas. inicialización de las hormigas mientras (condición_de_parada = falso) por cada hormiga aplicar_regla_transición_estado aplicar_regla_local_actualización_feromona aplicar_regla_global_actualización_feromona realizar_otras_operaciones_globales Este esquema presenta múltiples variantes respecto al modo y el orden en que se realiza la actualización de la feromona. En dependencia del problema puede ser mejor realizar el recorrido de cada hormiga de forma independiente, o sea, que en cada instante solo se esté analizando el problema desde la perspectiva individual de un agente y luego de terminar todas las trayectorias. También puede cambiarse el orden de actualización, donde se evapore primero para que la feromona recientemente depositada no sufra cambios en esa iteración. Otras variantes más agresivas respecto al tema es actualizar solo aquellos caminos recorridos que brindan mejor resultados en base a los objetivos aunque estos corren el riesgo de tener un efecto parecido a cuando se anula el parámetro . Los algoritmos de hormigas presentan ciertas ventajas sobre otros métodos como el de recocido simulado cuando la naturaleza del problema cambia dinámicamente, por ejemplo al utilizarse un grafo para la representación de la información del problema el cual esté sujeto a cambios estructurales como la eliminación o la adición de un arco. En estos casos los agentes seguirán 17.
(22) Herramientas de paralelización de la generación de medios. funcionando como si nada hubiera pasado debido al análisis completamente local realizado por los agentes.. 1.5. Sincronización.. De las tareas más necesarias y comunes en aplicaciones paralelas se encuentra la sincronización. La misma se define de forma general como la operación de coordinación de hilos o procesos simultáneos para completar determinadas tareas. La sincronización se realiza con el objetivo de obtener un correcto orden de ejecución, lo cual posibilita evitar una situación. anómala en la aplicación. respecto a los resultados que dependan de cierto orden en los eventos. Esta definición esta dada en términos de procesos que son muy comunes en la programación paralela, pero también es interés ver el concepto desde el punto de vista de los estados con los que pudieran estar más familiarizados la sincronización de datos entre procesos. El principal objetivo es el de mantener actualizada la información a utilizar cuando estos se encuentran compartidos en un ambientes de memoria distribuida (figura 1).. Fig 1: Ejemplos de tipos de sincronización: a) Actualización de datos; b) Control de ejecución. El primer caso necesariamente necesita establecer una barrera en el código pero no exactamente en la misma zona ni en el mismo estado de la aplicación como el caso b).. En la especificación de MPI se ofrecen mecanismos para realizar el sincronizado de operaciones, pero no existe de forma explícita un mecanismo para garantizar el mapeo de los cambios de una entidad1 compartida entre múltiples 1 Entiéndase por entidad un objeto, datos primitivos o cualquier conjunto de datos que puedan. 18.
(23) Herramientas de paralelización de la generación de medios. procesadores. El conjunto de instrucciones disponible establece una dependencia muy fuerte respecto a que tipo de datos se usen. Este mecanismo implícitamente brinda el beneficio de asegurar la actualización de los datos compartidos entre procesadores cosa que no se puede evitar si se quiere un resultado eficiente, pero trae consigo una sobrecarga de tráfico, que representa el mayor problema de las aplicaciones paralelas. El problema del trafico impone la necesidad de encontrar de alguna forma un mecanismo que mitigue los efectos negativos de la transmisión de datos complejos. Como solución se propone la planificación en cuanto a que zonas del problema pueden ser modificadas simultáneamente sin afectar el hecho de que se encuentren en paralelo. Según el planteamiento anterior existe un método que puede resolver dicho modelo, es el problema de coloreamiento de grafos usado ampliamente para problemas de planificación.. 1.5.1. Problema de coloreamiento de grafos.. El coloreamiento de grafos es implícitamente el problema de coloreamiento de vértices (Mermet et al., 2002) en un grafo pues, es el más general entre los problemas de coloreamiento. Además se conoce que el resto de los problemas -entiéndase coloreamiento de arcos, total, completo, exacto entre otros- pueden transformarse a uno de coloreamiento de vértices (Wikipedia, 2006b). El problema de coloreamiento de vértices de un grafo se define de la siguiente forma.. Definición 6: Coloreamiento de vértices. Sea G= N, A un grafo, y C i el color asociado al nodo i , un coloreamiento es aquella configuración en la cual se cumple la condición ∀ i , j ∈ A , C i ≠ C j . siempre y cuando los valores asignados a los elementos del grafo pertenezcan al dominio de los k representar una abstracción del modelo de la aplicación.. 19.
(24) Herramientas de paralelización de la generación de medios. valores admisibles. Bajo estas condiciones se dice que el grafo G es k-coloreable.. Fig 2: Configuraciones de grafos que cumplen la definición 6: a) 4 colores b) 2 colores. El principal objetivo de la mayoría de las aplicaciones para las que se resuelve este problema buscan la cantidad mínima de colores (ver figura 2b) que no es más que el número cromático y se denota como G . El coloreamiento de grafos es un problema NP-Completo2 dada su naturaleza combinatoria para lograr obtener una solución óptima. Este método ha sido ampliamente abordado en problemas de planificación (Burke et al., 1994; Miner et al., 1995), asignación de registro en un compilador, asignación de frecuencias en radios móviles (Hao y Perrier, 1996). Debido a las ventajas de esta técnica es adecuado su uso para establecer un control de acceso a recursos compartidos en diferentes procesadores. Las condiciones que establece el problema de coloreamiento lo categorizan como un. problema. compromete. de la. satisfacción complejidad. total. de. temporal. restricciones. del. algoritmo,. Esta. característica. pues. lograr. un. coloreamiento óptimo, o sea, usar tantos colores como el número cromático del problema resulta muy costoso. Los algoritmos abordados anteriormente (epígrafe 1.2.2) proponen soluciones a este problema. En algunos casos lógicamente no resultan convenientes para resolver el problema bajo sus condiciones. La variante usando backtracking tiene por naturaleza visitar los nodos del grafo 2 Problemas con una complejidad temporal no acotada polinomialmente.. 20.
(25) Herramientas de paralelización de la generación de medios. y generar las combinaciones candidatas a solución mediante el mecanismo primero en profundidad y realizar todas las búsquedas hasta encontrar una solución, situación esta muy crítica respecto al consumo de tiempo. Por otro lado el algoritmo AC-3 (consistencia en arcos, versión 3 – por sus siglas en inglés) en sus versiones anteriores fueron consideradas por especialistas, como muy ineficientes y difíciles de implementar. La implementación actual es usada con éxito en problemas muy sencillos y no se recomienda usar en problemas con alta complejidad. La tercera variante es el algoritmo de conflictos mínimos (Wikipedia, 2006c) que es un mecanismo bastante general según se expresa a grandes rangos en el siguiente recuadro.. Algoritmo 2: Conflictos mínimos Sea R el conjunto de restricciones, V. el conjunto de variables,. dominio i . el conjunto de. valores admisibles de la variable i y R i 0 el predicado para chequear que la restricción R i no queda satisfecha con la configuración actual de las variables que intervienen en la restricción, el algoritmo se rige por los siguientes pasos.. ●. Asignar valores aleatorios a todas las variables del PSR.. ●. Mientras (solución = falso) e (iteraciones < max_iteraciones) ●. Seleccionar aleatoriamente una variable que represente un conflicto con una de las restricciones. v =random i , si R i 0 i∈V. ●. Buscar un valor m que minimice el conflicto.. {. m= i /. min i ∈ dominio v . R i . }. ●. Si existen varios valores escoger uno aleatoriamente.. ●. Asignar a la variable el valor escogido.. 21.
(26) Herramientas de paralelización de la generación de medios. ●. Chequear si el nuevo estado es una solución. Verdadero, {Falso ,. solucion =. si ∀ r ∈ R , r i =0 de lo contrario. }. El algoritmo de conflictos mínimos representa una posible vía para desarrollar un método de coloreamiento de grafo pues es un algoritmo fácilmente adaptable para resolver problemas con restricciones absolutas.. 1.6. Particionamiento.. El particionamiento es una la tarea encargada de subdividir un dominio. Cuando esta. división. tiene. la. característica. de. dividir. el. dominio. en. partes. aproximadamente iguales estamos en presencia del mecanismo usado para solucionar el balance de carga de una aplicación paralela. La tarea de realizar un particionamiento depende del contexto en que se realice. Cuando se crean divisiones en los datos para que sean distribuidos en el inicio de la aplicaciones se denomina particionamiento estático, y cuando se realiza en medio de la ejecución de una simulación para nivelar los cambios producidos es un particionamiento dinámico. Para el particionamiento estático existen múltiples métodos que serán analizados posteriormente. El particionamiento dinámico se realiza en plena simulación por lo que los datos se encuentran distribuidos, en esas condiciones se necesita adicionalmente que la cantidad de datos a mover sea mínima. Para lograr los nuevos objetivos se encuentra la propuesta de (Oliker y Biswas, 1998) donde se brindan varias métricas para medir la redistribución. Estas son, la suma total de los tamaños de aquellos nodos que se necesitan mover y el tamaño máximo entre la suma de los nodos a redistribuir en cada partición. La primera ha demostrado que es más eficiente, incluso provoca una mejora en cadena en la segunda métrica. En conjunto con esas métricas, los métodos mas reconocidos en esta temática son el reparticionamiento y reasignación de los datos, y el método de difusión. 22.
(27) Herramientas de paralelización de la generación de medios.. 1.6.1. Particionamiento estático.. El particionamiento estático de grafos representa una vía para generar configuraciones iniciales para la ejecución de simulaciones científicas en cluster o. computadoras. paralelas.. Encontrar. algoritmos. que. obtengan. buenas. particiones en grafos es una tarea crítica. Los datos que se definen para esta tarea tienen la estructura de un grafo G y los nodos que lo forman deben ser agrupados en k – subdominios, con los cuales queda listo el proceso para realizar la asignación de datos a los k procesadores. De forma general el problema de particionamiento estático de grafos (Schoegel et al., 2000) está definido de la siguiente forma.. Definición 7: Problema de particionamiento estático de grafo. Dado un grafo no dirigido G= N, A con pesos en sus nodos y arcos, se define un particionamiento de un grafo en k partes como la división de los nodos que forman el conjunto. N en k subconjuntos disjuntos Pi , o sea. P1∪P2∪P3∪∪Pk =N y ∀ i , j Pi / P j=∅. si i ≠ j. tal que cada subconjunto tenga aproximadamente el mismo peso en nodos. ∀ Pi , P j. ∑. n ∈ Pi. W n ≈ ∑ W m m∈ P j. donde W es el peso de un nodo determinado y la suma de los pesos de los arcos incidentes en vértices que pertenecen a subdominios diferentes sea mínima. min. ∑. W a k tal que a k ∈ A 2. 0 k ∣A 2∣. siendo. 23.
(28) Herramientas de paralelización de la generación de medios. A2={ n , m ∈ A / n ∈Pi , m ∈P j , i≠ j}. La definición anterior se ajusta a un cluster de computadoras homogéneas, con las mismas especificaciones de hardware, pero en la práctica podría ser de interés calcular particiones para un ambiente heterogéneo donde la cantidad de elementos a asignar por procesadores está relacionada lógicamente con la velocidad del procesador. Los. aspectos. carga. de. trabajo. y. tráfico. entre. particiones. representan. contradicciones cuando los indicadores se acercan al óptimos en cada uno. Esto provoca la introducción de una tolerancia en algunos de los dos. Para resolver este problema del particionamiento estático existe una serie de algoritmos entre los cuales se encuentran esquemas genéricos que sirven de plataforma para el desarrollo de otros mecanismos como: 1. La bisección recursiva. 2. El método multinivel. También existen técnicas que representan familias de algoritmos como los geométricos y los combinatorios de los cuales se abordarán a continuación sus características, ventajas y desventajas. 1.6.1.1. Esquema de bisección recursiva.. El esquema de bisección recursiva (Simon y Teng, 1997) es la solución más sencilla que puede ser adoptada para particionar un grafo y utiliza la estrategia divide y vencerás. El esquema de bisección recursiva es una estrategia muy general y puede ser combinada con múltiples métodos los cuales, se encargan de definir exactamente el como o por donde realizar la división del dominio. En caso de que el orden de particiones k, no sea potencia de dos deben especificarse las proporciones de cada partición en cada etapa.. 24.
(29) Herramientas de paralelización de la generación de medios. Este método se acopla perfectamente en aplicaciones que sean modeladas mediante la descomposición recursiva, pero cuando se usa para estos fines presenta algunas deficiencias. Entre ellas se encuentra el hecho de consumir mucho tiempo al replicar tanta información en las primeras subdivisiones. Según (Simon y Teng, 1997) en estos métodos aún asumiendo que se cuenta con un algoritmo de bisección recursiva óptimo, puede producir k particiones extremadamente alejadas de las óptimas. 1.6.1.2. Técnicas geométricas.. Las técnicas geométricas (George y Liu, 1981) solo se basan en las coordenadas de los nodos de la malla para realizar el particionamiento y no toman en cuenta la conectividad de los mismos. Por esta razón en esta técnica no existe el concepto de control de comunicación inter-procesador, y para suplir el mecanismo se minimiza el área de los límites de una partición. Al no realizar análisis de la información de conexión este método tiene una ventaja y es que puede ser usado sobre la misma malla geométrica, esto es a lo que se le llama esquema de particionamiento de mallas, evitando pasos de conversión hacia grafos como se procede en otros métodos. Estas son algunas de las variedades de algoritmos que cumplen con este esquema, bisección coordenada recursiva (Heath y Raghavan, 1995), bisección recursiva inercial, curvas de relleno de espacio (space-filling curve en ingles) (Patra y Kim, 1998; Pilkington y Baden, 1994) y corte de esferas (Miller et al., 1993). Normalmente estos métodos son muy rápidos respecto a los demás, pero el hecho de no contar con la conectividad de los elementos produce particiones muy pobres respecto a las restricciones de la definición 7. Este aspecto es debido a que dos zonas de un cuerpo pueden estar cercas y sin embargo la linea recta que los une no pertenece a la malla, lo cual produce particiones que internamente tienen secciones disjuntas (figura 3b). 25.
(30) Herramientas de paralelización de la generación de medios. 1.6.1.3. Técnicas combinatorias.. Los métodos combinatorios (Hager et al., 1999) en cambio realizan el particionamiento usando solo la información de adyacencia. Estas técnicas explotan la conectividad para agrupar aquellos nodos que presentan mayores grados de conexión entre sí.. Fig 3: Ejemplos de particionamiento: a) combinatorio; b) geométrico. Aunque suelen ser más lentos que los métodos geométricos alcanzan reducir mucho más la métrica de comunicación y no permiten que existan regiones desconectadas asignadas a un mismo subdominio (figura 3a). Dentro de estas técnicas se encuentran la disección anidada por niveles (Ashcraft y Liu, 1994) y el algoritmo Kernighan-Lin/Fiduccia-Mattheyses (KL/FM) (Fiduccia y Mattheyses, 1982) que está diseñado para refinar particiones iniciales ya computadas por otros métodos. Estas variantes están basada en operaciones sobre matrices. Presentan deficiencias palpables al tratar de usarse con matrices dispersas, debido a que es muy costoso espacialmente cuando el grado del grafo es alto y tiene poca densidad. como. sucede. con. frecuencia.. Además. se. necesita. relajar. las. restricciones del problema para lograr particiones con calidad. Ante esta problemática se propone el uso de métodos heurísticos que estén 26.
(31) Herramientas de paralelización de la generación de medios. familiarizados con la optimización combinatoria como colonias de hormigas (epígrafe 1.3.3) por su forma de atacar las soluciones desde múltiples puntos y ser un mecanismo muy flexible ante los cambios. 1.6.1.4. Estrategias multinivel.. En el espectro de métodos que tratan el problema de particionamiento, los métodos que usan el paradigma multinivel (Hendrickson y Leland, 1995) son uno de los más recientes. Los mismos están compuestos por tres etapas: 1. Empaquetamiento de grafo. 2. Particionamiento inicial. 3. Refinamiento multinivel. En la primera fase se procede a construir grafos más compactos, colapsando grupos de nodos determinados mediante un criterio de selección, obteniéndose así estructuras más simples que representan un problema relajado respecto al original. Esta operación se repite hasta obtener el nivel de compactación deseado. Luego se procede al particionamiento por el método que se estime conveniente para el problema, en esta fase no es fundamental obtener resultados muy buenos. Finalmente, la fase de refinamiento se encarga de mejorar el balance del grafo en cada uno de los niveles a medida que se va descompactando para obtener el estado inicial. En esta etapa se usan preferiblemente métodos combinatorios que puedan ser modelados para realizar esta operación. Este método por tener varias fases y poder asignar a cada fase múltiples algoritmos tiene una gran cantidad de combinaciones, pero solo se hará referencia a aquellas que más resultado han demostrado: 1. Bisección recursiva multinivel. 2. Particionamiento en k partes usando paradigma multinivel. La primera variante (Bui y Jones, 1993) ha sido utilizada en el trabajo de 27.
(32) Herramientas de paralelización de la generación de medios. reordenamiento. y. reducción. de. matrices. dispersas. así. como. en. el. particionamiento de mallas de elementos finitos (Hendrickson y Leland, 1995). Este algoritmo se encuentra disponible en varias librerías de dominio público como Chaco (Hendrickson y Leland, 1994), Metis (Karypis y Kumar, 1998b) y hMetis (Karypis y Kumar, 1998a) diseñada particularmente para hipergrafos. El segundo método fue presentado en (Karypis y Kumar, 1998c) donde se propone una generalización del método de refinamiento para el particionamiento inicial en k secciones. Este algoritmo presenta una complejidad del orden de la cantidad de arcos que presenta el grafo O ∣A∣ . Según estudios (Karypis y Kumar, 1998c) es la variante más rápida de los algoritmos que usan el paradigma multinivel, y aunque en tiempo es comparable con la variante híbrida del método de bisección recursiva geométrica logra mejor calidad en las particiones. Este método también se encuentra en librerías disponibles en internet como: ●. JOSTLE (Walshaw et al., 1995).. ●. Metis.. Estas librerias tienen un inconveniente en el modelo para el que fueron diseñadas ya expresada (epígrafe 1.1.3) donde se analizaron las herramientas existentes. El mecanismo multinivel es muy apropiado y ha demostrado ser muy efectivo en múltiples aplicaciones (Bouhmala et al., 1996:8), por lo que se propone su uso utilizando las mejores combinaciones para cada etapa, aprovechando la rapidez de métodos que generan particiones no tan buenas con métodos muy eficientes para la etapa de refinamiento.. 1.7. Paralelización de los métodos de partículas.. Mediante la paralelización de los métodos de partículas se han desarrollado múltiples aplicaciones e investigaciones dirigidas a disímiles objetivos con base común en técnicas muy comunes de la programación paralela.. 28.
(33) Herramientas de paralelización de la generación de medios. Dentro de las investigaciones se encuentra la implementación paralela del método de elementos distintos para simulaciones de medios granulares en computadoras Cray T3D (Ferrez, et al., 1996:4). Estas investigaciones están basadas en el modelo Cundall, donde los elementos representan granos independientes. En la misma se usan estructuras de datos basados en la triangulación de la malla para la determinación de la vecindad de los elementos mediante el método de triangulación de Delaunay y además se emplean tecnologías paralelas de memoria compartida con modelos de paralelización basados en granulado grueso. Por las características de la aplicación el particionamiento se realiza mediante listas verticales ya que el medio se encuentra en un contorno rectangular y las fuerzas que se desean simular así lo permiten. El reparticionamiento es basado en el movimiento de datos situados en la frontera permitiendo un balance de carga casi perfecto gracias a la simplicidad del modelo de las particiones. Otras aplicaciones de la programacion paralelas se han enfocado a simulaciones de flujos incompresibles para el estudio de propiedades del diseño de prototipos de autos solares (Sawley et al., 1996:24). Las mismas se han realizado en computadoras Cray T3D de 256 procesadores usando un modelo de memoria distribuida con el objetivo de garantizar un mecanismo flexible de comunicación para el intercambio de. datos entre. los bloques. vecinos en diferentes. procesadores. Otras investigaciones han sido dirigido en áreas muy específicas de los problemas que acarrea la programación paralela como el particionamiento de mallas no estructuradas para el procesamiento paralelo (Bouhmala et al., 1996:8) donde se comprueba la efectividad de esquemas de particionamiento multinivel.. 1.8. Conclusiones parciales.. El ámbito de simulaciones de mediano y gran poder de cálculo han hecho cada. 29.
(34) Herramientas de paralelización de la generación de medios. día más necesario el uso de la programación paralela. Esta contiene retos cada vez mayores y en el presente capítulo se realizó un estudio de las líneas de interés para el desarrollo de estas aplicaciones. Se evaluó que el mecanismo de memoria distribuida resulta la vía de solución más conveniente y aplicable para esta problemática en nuestras condiciones. El acceso a datos compartidos entre procesadores requiere de un mecanismo de planificación. Para problemas de este tipo se encuentran modelos como el coloreamiento de grafos, en el cual es viable el uso de métodos heurísticos en su implementación. De los métodos de particionamiento de grafos el esquema multinivel es el más flexible en el contexto de la aplicación.. 30.
(35) Herramientas de paralelización de la generación de medios.. Capitulo 2. Formulación matemática y computacional.. Las aplicaciones paralelas tienen generalmente como precedente una aplicación secuencial debido a las limitaciones de capacidad en cuanto a almacenamiento en memoria y potencia de cálculo. En este capítulo se detalla el conjunto de herramientas que se propone desarrollar para ser acopladas a cualquier aplicación secuencial que sigan un patrón de diseño en el cual se cumplan las condiciones siguientes: 1. La aplicación secuencial debe poder trabajar solo con secciones de los datos sin grandes dependencias entre ellas y poder emitir resultados parciales con los datos que posee. 2. Los datos de salida del problema deben poder obtenerse por simple unión de los datos de salida de cada procesador o mediante una transformación secuencial de dicha unión. 3. Los datos deben poder no solo dividirse en particiones con el objetivo de distribuirse entre los procesadores sino también en pequeños clusters de datos para el intercambio de datos de las fronteras de las particiones para tareas de actualización y balance de carga. La aplicación de la cual surgió la necesidad de estas herramientas es una aplicación de generación de medios para simulaciones y cálculos de ingeniería relacionadas con la mecánica computacional, en específico método de partículas y métodos sin mallas de ahí su nombre NoMS (Non Meshing Simulation) de donde derivaron los requisitos anteriores.. 2.1. Funcionamiento de las herramientas de paralelización.. En síntesis, la idea del mecanismo de funcionamiento se refleja en los siguientes pasos: 1. Tomar volumen de datos (malla geométrica). 31.
(36) Herramientas de paralelización de la generación de medios. 2. Configurar los accesos a datos. 3. Particionar la malla. 4. Ejecutar la aplicación secuencial en paralelo. 5. Balancear la carga de trabajo, ir a paso 4. Detallando las tareas que se realizan en cada paso, se comienza al solicitar al programa secuencial la información de la malla geométrica agrupada por celdas, cuadrados en 2D (figura 4b) y cubos en 3D, y su relación de vecindad. Con estos datos se forma un grafo (figura 4c) y se procede a su coloreamiento y particionamiento, en procesadores distintos al mismo tiempo. Al finalizar estas tareas se unen los datos en un grafo común y se distribuyen las particiones hacia los procesadores. A partir de este estado comienza realmente la etapa paralela, donde cada procesador ejecuta la aplicación secuencial usando solo las celdas de un color a la vez. Entre cada etapa los procesadores envían al procesador central (o procesadores) los datos de la vecindad que fueron modificados y luego este los redistribuye a los procesadores que tengan relación con cada celda. Una vez terminadas todas las etapas se balancean dinámicamente las particiones. Luego se comienza por el primer color nuevamente y se repite el proceso hasta que el objetivo de la aplicación secuencial es cumplido.. Fig 4: Transiciones de los datos de entrada: a) contorno de una malla de entrada; b) malla subdividida por celdas; c) grafo asociado. Una de las ventajas de este diseño respecto a la forma tradicional de construir aplicaciones paralelas, radica en la forma de separar físicamente el módulo que resuelve el problema y los mecanismos necesarios para realizar la paralelización. 32.
(37) Herramientas de paralelización de la generación de medios. Realizar la implementación de una versión paralela de una aplicación por la vía tradicional, supone un consumo de tiempo igual o mayor al dedicado en la versión secuencial. Mientras que realizando estas divisiones en módulos permite desarrollar las herramientas y la aplicación secuencial al mismo tiempo. Esto solo es la primera vez, de ser una segunda aplicación se reutilizan los módulos con un mínimo de cambios. Otra ventaja radica en que las aplicaciones paralelas en su mayoría son reescritas a partir de una versión secuencial y la lógica del paralelismo queda indisolublemente ligada al mecanismo que obtiene la solución. Esto dificulta de manera abrumadora tareas de cooperación entre los programadores, además de las dificultades que impone la búsqueda de errores. Evidentemente la principal desventaja del diseño es que existe la posibilidad de que una versión paralelizada por la vía tradicional sea más rápida. Este aspecto en opinión de los desarrolladores no fue motivo suficiente para realizar la implementación paralela como es habitual, debido a la complejidad de la aplicación final.. 2.2. Esquema organizativo de las herramientas de. paralelización. Los elementos del esquema (figura 5) conforman un sistema que intenta dar solución a la complejidad de las aplicaciones paralelas, basándose en la modularidad del diseño.. 33.
(38) Herramientas de paralelización de la generación de medios.. Módulos secuenciales Planificación de acceso a datos. Balance de carga estática. Módulo coordinador (Punto de entrada de la aplicación paralela). Sincronización de datos. Aplicación secuencial (NoMS). Balance de carga dinámico. Módulos paralelos Leyenda Módulos Módulos Módulos Módulos. genéricos. externos al kit de herramientas. terminados o en fase prueba. en fase de desarrollo.. Fig 5: Esquema general de las relaciones entre las herramientas de paralelización y la aplicación secuencial. Los módulos secuenciales están formados por métodos heurísticos encargadas de las tareas de planificación y particionamiento estático. El módulo de planificación contiene implementaciones de varios algoritmos que intentan resolver el problema de coloreamiento de grafos. Por otro lado el módulo de particionamiento usa un mecanismo multinivel para la creación de divisiones en los datos. Los módulos paralelos se conforman de una librería para la sincronización de datos utilizando los mecanismos de comunicación paralela y métodos de balance de carga dinámica que usan técnicas de difusión. Del esquema anterior solo son objetivos del trabajo los módulos estáticos y el módulo paralelo de sincronización. 34.
(39) Herramientas de paralelización de la generación de medios.. 2.3. Generalidades de la formulación.. La aplicaciones paralelas necesitan una estrategia bien definida y acertada para llevar a cabo sus objetivos. Entre los aspectos primordiales a tener en cuenta antes de comenzar el desarrollo de aplicaciones paralelas se encuentra el análisis del tipo de descomposición que se usará, lo cual influye en las estrategias a seguir en el diseño de la aplicación. Ejemplo de estos problemas lo es el tipo de organización que tendrán los datos en los procesadores y la forma en que los procesos interactúan entre sí para actualizarlos. A continuación se argumentará el modelo de paralelización que rige las ideas por las que fueron concebidas las diferentes herramientas.. 2.3.1. Enfoques del modelo paralelo.. Un esquema visual de cual es el funcionamiento de la aplicación se muestra en la figura 6. En esta imagen es intuitiva que la descomposición de datos es la más indicada. A continuación se expresan algunos detalles técnicos relativos a las estrategias de descomposición (Grama et al., 2003) y sus limitaciones respecto a los requisitos con que se desea la aplicación.. Fig 6: Esquema a grandes rasgos del funcionamiento en paralelo. 35.
(40) Herramientas de paralelización de la generación de medios. En la descomposición recursiva al tener un fuerte vínculo con los datos solo se utilizaría un proceso al inicio para distribuir la información entre los procesadores. Esto prácticamente realiza la función de un mecanismo de particionamiento estático mediante el esquema de bisección recursiva, acción que interviene directamente en el mecanismo de particionamiento. Este aspecto no da libertad a usar técnicas híbridas además de eliminar toda posibilidad de centralizar operaciones simples, por ejemplo, el establecimiento de un control de ejecución. Por otra parte la descomposición exploratoria tiene un uso muy común en algoritmos donde se desea buscar una solución a problemas combinatorios. En estos problemas se deben conocer todos los posibles valores que conforman el dominio de las variables. Los datos que se manejan en la aplicación secuencial son continuos, pues representan coordenadas en el espacio y de usar la vía anterior se volvería un problema no soluble por la infinidad que representan los mismos. De modelar el problema de forma continua se incurriría en un gasto innecesario de recursos al enviar diferentes configuraciones iniciales a los procesadores. Una vez distribuidos los datos, buscarían una solución desde su punto inicial de forma independiente y probablemente sin retroalimentación entre sí, pues tienen el mismo objetivo y cuentan con todos los datos. Además, el hecho de que cada proceso necesita manipular todos los recursos, es ya suficientemente inadecuado por las limitaciones en cuanto a capacidad de memoria. En la descomposición especulativa que prácticamente no permite independizar las tareas que conforman la solución. Esto es debido a que se produce un vínculo muy fuerte dentro del código para controlar la secuencia de ejecución, tanto para ejecutar una nueva operación fuera de orden como para eliminar el resultado de un procesador. Esta situación supone muchas dificultades, pues se trata de construir una herramienta que sirva de marco de trabajo y mediante este mecanismo se limita extraordinariamente la modularidad. Además este modelo impone una división lógica entre procesadores con control de datos y 36.
(41) Herramientas de paralelización de la generación de medios. procesadores para cálculo fuera de orden que probablemente para tenerlos disponibles en cualquier momento no se les debe asignar una tarea permanente. Lo que ocasiona un malgasto de recursos al tenerlos desocupados. Mientras. todas. las. descomposiciones. analizadas. hasta. ahora. presentan. deficiencias para ser implementadas, la descomposición de datos brinda el modelo perfecto para tratar el problema, porque permite el desarrollo modular de los diferentes algoritmos. Este método considera solo los datos, en este caso los datos de la malla que conforman la información de entrada al programa. La malla puede ser dividida entre los procesadores y mediante algunos ajustes procesarse de forma independiente en cada uno. Mientras la salida la conforman, el conjunto de coordenadas que determinan la posición de los elementos a insertar dentro de cada partición de la malla, con lo que es suficiente para asegurar que se está en presencia de un particionamiento de datos de entrada y de salida.. 2.3.2. Modelo de particiones.. El trabajo con particiones no puede verse fríamente como las subdivisiones de los datos como unidades independientes, sino como un sistema de elementos que presentan en algunos casos dependencias externas. Estas dependencias son las relaciones que existe entre las celdas que se encuentran en la frontera de las particiones. Las celdas necesitan conocer la información interna de sus vecinas en las fronteras de las particiones adyacentes, con el objetivo de poder brindar información al programa externo para sus cálculos. Para lograr la obtención de esa información existen muchas variantes, algunas de estas son las siguientes. 1. Consultar la información al procesador propietario de la celda vecina cada vez que sea necesario. 2. Crear particiones extendidas.. 37.
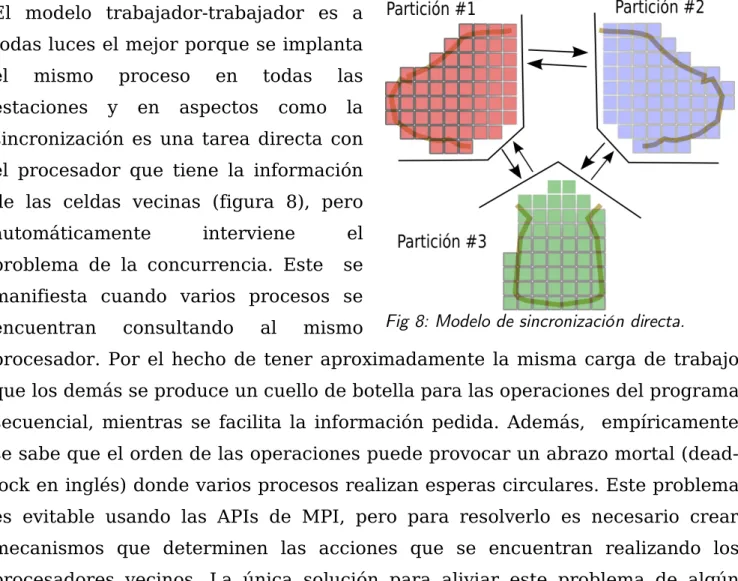
(42) Herramientas de paralelización de la generación de medios. La primera vía a simple vista incurre en una sobre carga en el tráfico por parte de todos los procesadores. Esto no es viable pues minimizar el tráfico es uno de los objetivos principales de toda aplicación paralela. Sin embargo de la segunda se desarrollaron varios esquemas sobre la base de formar particiones mixtas que se componen de la información de cada partición. y adicionalmente las. celdas vecinas inmediatas de las particiones, (figura 7).. Fig 7: Composición de las particiones mixtas.. Las variantes que se proponen usan los modelos maestro-esclavo y trabajadortrabajador. Estos solo se usarán para el control de datos de toda la aplicación, el resto de las operaciones seguirán sin afectarse. El modelo trabajador-trabajador es a todas luces el mejor porque se implanta el. mismo. estaciones. proceso y. en. en. todas. aspectos. como. las la. sincronización es una tarea directa con el procesador que tiene la información de las celdas vecinas (figura 8), pero automáticamente. interviene. el. problema de la concurrencia. Este. se. manifiesta cuando varios procesos se encuentran. consultando. al. mismo. Fig 8: Modelo de sincronización directa.. procesador. Por el hecho de tener aproximadamente la misma carga de trabajo que los demás se produce un cuello de botella para las operaciones del programa secuencial, mientras se facilita la información pedida. Además, empíricamente se sabe que el orden de las operaciones puede provocar un abrazo mortal (deadlock en inglés) donde varios procesos realizan esperas circulares. Este problema es evitable usando las APIs de MPI, pero para resolverlo es necesario crear mecanismos que determinen las acciones que se encuentran realizando los procesadores vecinos. La única solución para aliviar este problema de algún 38.
Figure




+7





Documento similar