Análisis de desempeño del protocolo MAC multicanal del estándar IEEE 802 15 4
74
0
0
Texto completo
(2) Pensamiento. “Hello world!” Brian Kernighan..
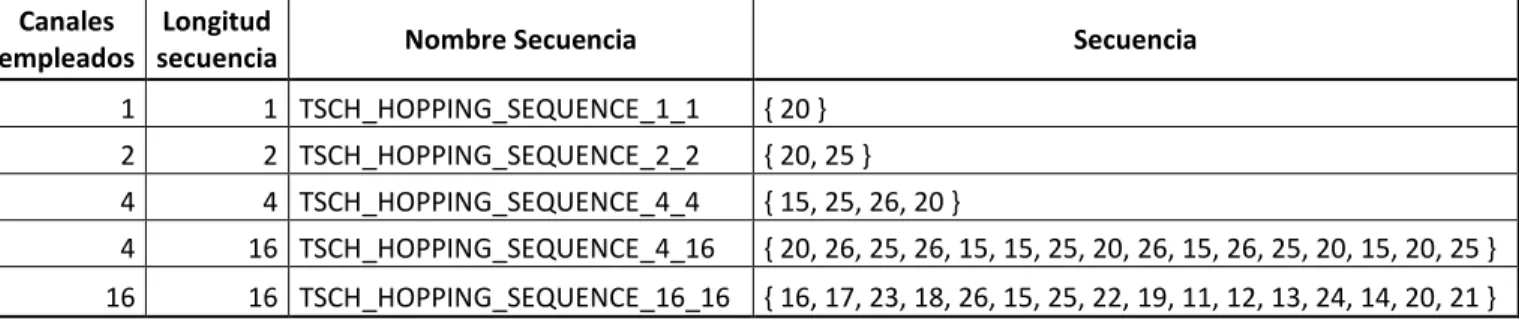
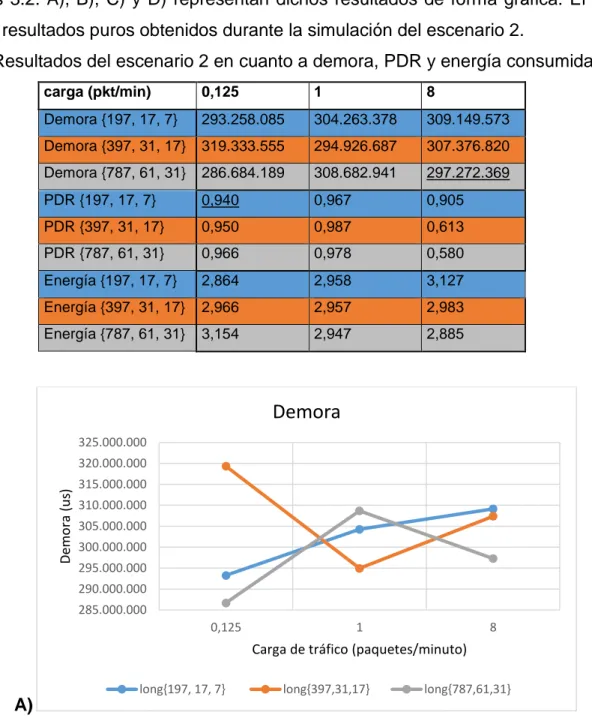
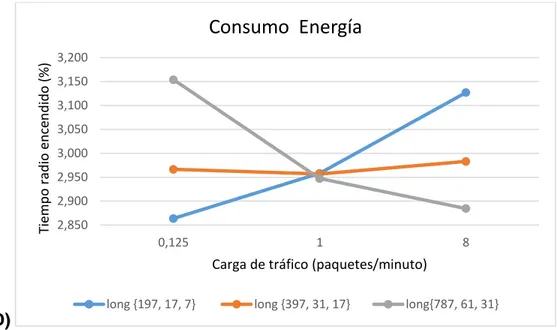
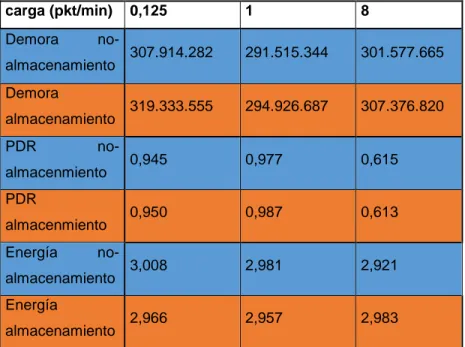
(3) Resumen: Con la aparición en los últimos tiempos de soporte de hardware para el trabajo a múltiples frecuencias, los protocolos MAC para las LLNs han experimentado una evolución hacia la operación multicanal, para aumentar la razón de datos y disminuir los efectos de la interferencia y el desvanecimiento multipunto. Uno de los protocolos MAC multicanal de estado del arte es el modo TSCH del estándar IEEE 802.15.4, que está basado en TDMA. TSCH no define cuál es la entidad funcional que programa la comunicación de los nodos en la red. Orchestra puede actuar como dicha entidad: es un programador con enfoque autónomo mediante el cual los nodos adaptan su horario explotando la información de la topología de RPL y un conjunto de reglas de programación, lo que resulta en patrones de actividad periódicos, con bloques de ranuras asignados a diferentes planos de tráfico tales como EBs TSCH, señalización RPL o datos de aplicación. En este trabajo se realiza una comparación entre las diferentes configuraciones que permite la combinación de TSCH y Orchestra: secuencias de salto de canal, longitud de los bloques de ranura y operación de Orchestra (basada en el modo almacenamiento o modo no-almacenamiento de RPL). Para el logro de este objetivo se usan implementaciones de TSCH y Orchestra en el sistema operativo ContikiOS, las cuales se corren en el simulador COOJA sobre el nodo sensor Z1. La comparación se basa en tres escenarios de simulación que permiten evaluar el desempeño cada configuración bajo diferentes cargas de tráfico. Los resultados de la simulación de estos escenarios demuestran que la mejor secuencia de salto de canal de TSCH es 16_16, la mejor longitud de bloques de ranuras es la que permita manejar justo el tráfico generado por la red y el modo no-almacenamiento de RPL es recomendable para aplicaciones de sensores dedicados a la recolección de información y el monitoreo de parámetros..
(4) Índice Introducción 1 Capítulo 1 6 1.1. LLNs: Generalidades y arquitectura ...........................................................................................................6 1.2. TSCH 7 1.2.1. Ranuras de Tiempo y Bloques de Ranuras .................................................................................8 1.2.2. Horario TSCH y Celdas Programadas .........................................................................................8 1.2.3. Número de Ranura Absoluta y Salto de Canales .....................................................................10 1.2.4. Sincronización de tiempo..............................................................................................................11 1.2.5. El consumo de energía .................................................................................................................12 1.2.6. Horario .............................................................................................................................................12 1.2.7. Proceso de unión ...........................................................................................................................13 1.2.8. Resumen de características destacadas de TSCH ..................................................................13 1.3. Programador ...........................................................................................................................................15 1.3.1. Enfoques del programador ...........................................................................................................15 1.3.2. Enfoque centralizado .....................................................................................................................15 1.3.3. Enfoque descentralizado ..............................................................................................................15 1.3.4. Enfoque autónomo ........................................................................................................................16 1.3.5. Consideraciones de diseño ..........................................................................................................16 1.3.6. Programador basado en enlaces ................................................................................................16 1.3.7. Programador basado en contador de salto ...............................................................................17 1.3.8. Identificador de bloque de ranuras..............................................................................................17 1.3.9. En sentido ascendente: basado en enlace; en sentido descendente: basado en nodo. ...17 1.3.10. Programador ascendente ...........................................................................................................18 1.4. ORCHESTRA..........................................................................................................................................18 1.4.1. Diseño de Orchestra......................................................................................................................19 1.4.2. Inicialización ...................................................................................................................................19 1.4.3. Mapeo de topología TSCH-RPL ..................................................................................................19 1.4.4. Sincronización de tiempo TSCH..................................................................................................20 1.4.5. Programador con direccionamiento de rutas.............................................................................20 1.4.6. Celdas de Orchestra......................................................................................................................20 1.4.7. Bloque de ranuras de Orchestra .................................................................................................22 1.4.8. Reglas de programación ...............................................................................................................22 Capítulo 2 24 2.1. Selección de la tecnología a emplear. ................................................................................................24 2.1.1. El Sistema Operativo Contiki .......................................................................................................24 2.1.2. El simulador COOJA .....................................................................................................................27 2.1.3. Plataforma Z1 .................................................................................................................................29 2.2. Escenarios ...............................................................................................................................................29 2.2.1. Escenario 1: "Tiempo requerido para unirse a la red." ............................................................31 2.2.2. Escenario 2: "Longitud de los bloques de ranuras.".................................................................32 2.2.3. Escenario 3: "RPL en modo almacenamiento contra RPL en modo no-almacenamiento." 33 Capítulo 3 ................................................................................................................................................................34 3.1. Discusión de los resultados obtenidos en el escenario 1: "Tiempo requerido para unirse a la red." 34 3.2. Discusión de los resultados obtenidos en el escenario 2: "Longitud de los bloques de ranuras." 35.
(5) 3.3. Discusión de los resultados obtenidos en el escenario 3: "RPL en modo almacenamiento contra RPL en modo no-almacenamiento." ...................................................................................................40 Conclusiones ..........................................................................................................................................................43 Recomendaciones .................................................................................................................................................45 Bibliografía ..............................................................................................................................................................46 Anexo A: Resultados del escenario 1....................................................................................................................48 Anexo B: Resultados del escenario 2 ....................................................................................................................61 Anexo C: Resultados del escenario 3 ....................................................................................................................68.
(6) Introducción El surgimiento de la Internet de las cosas (IoT, por sus siglas en inglés) y su desarrollo exponencial supone el empleo de nodos limitados en potencia, memoria y capacidad de procesamiento puesto que se emplean como dispositivos empotrados en los objetos cotidianos y que pueden actuar como sensores para la recolección y el monitoreo de parámetros y como equipos terminales de datos que responden de forma remota o autónoma en coordinación con otros objetos [2]. La interconexión de estos nodos se logra mediante Redes de Baja Potencia y con Pérdidas (LLNs, por sus siglas en inglés) en las que resulta primordial establecer el mejor equilibrio entre flexibilidad y fiabilidad [5]. Las LLNs encuentran gran diversidad de aplicaciones en la domótica, la administración de recursos (agua, energía, iluminación, ventilación…), la automatización de la actividad industrial y comercial, el monitoreo de variables ambientales y meteorológicas (empleadas en la agricultura, en el control de incendios forestales, la reducción de daños por sismos…), entre otras [1]. El desarrollo actual de la ciencia y la técnica apunta a un incremento exponencial de la demanda de soluciones basadas en LLNs. El creciente interés por las LLNs se observa en el aumento de la cantidad de publicaciones y artículos en revistas y sitios de connotado prestigio como IEEE Communications Society. En IEEE Xplore Digital Library se recogen desde el 2000 hasta la actualidad 15238 trabajos de ellos 1378 artículos en revistas y 13860 presentaciones en congresos, siendo el 78% de dichos trabajos posterior a 2010 y el 34% posterior a 2014. Las LLNs se caracterizan por estar formadas por nodos restringidos en potencia, memoria y capacidad de procesamiento; además los enlaces presentan inestabilidad, bajas tasas de transferencia y pérdidas. Normalmente estos nodos son dispositivos cuyo precio promedio resulta bajo y cuya fuente de alimentación generalmente son baterías, por lo que el ahorro energético es el tema primordial [1, 2, 5]. Teniendo en cuenta que el mayor costo energético lo provoca la interfaz de radio, se necesita optimizar la comunicación para conmutar dicha interfaz entre los estados de actividad e hibernación para lograr el mejor equilibrio entre costo energético y requerimientos de red. Atendiendo a esto, se necesita un modelo de protocolos de red que comprende tanto las capas del modelo TCP/IP como un grupo de capas de adaptación necesarias para adecuar estas a las limitaciones de las LLNs como son el protocolo de aplicación restringida (CoAP, por sus siglas en inglés) [11], el protocolo de enrutamiento IPv6 1.
(7) para LLNs (RPL) [8], el protocolo de compresión de formatos para datagramas IPv6 (6LowPAN) [10], e IEEE 802.15.4 [2]. El Protocolo de Aplicación Restringido (CoAP, por sus siglas en inglés) proporciona un modelo de interacción solicitud/respuesta entre los puntos finales de la aplicación, admite el descubrimiento integrado de servicios y recursos e incluye conceptos clave de Internet como URLs y tipos de medios de Internet. CoAP está diseñado para interactuar fácilmente con HTTP para la integración con la Web mientras cumple con requisitos especializados tales como soporte de multidifusión, gastos generales muy bajos y simplicidad para entornos restringidos. El protocolo de enrutamiento IPv6 para las LLNs (RPL, por sus siglas en inglés) es el estándar de facto propuesto por IETF para LLNs y proporciona mecanismos para encaminar el tráfico punto a punto (entre dispositivos dentro de la LLN), punto a multipunto (desde un punto de control central a un subconjunto de dispositivos dentro de la LLN) y multipunto a punto (desde dispositivos dentro de la LLN hacia un punto de control central). Para ser útil en una gran variedad de aplicaciones de LLNs, RPL separa el procesamiento de paquetes y el reenvío de enrutamiento con el objetivo de optimizar el costo energético, la latencia y satisfacer las limitaciones de los sistemas. RPL crea un árbol de ruteo, cuya raíz es el punto de colección de información (conocido como sumidero) en forma de grafo acíclico orientado y dirigido (DODAG, por sus siglas en inglés). De forma general RPL organiza a los nodos en padres e hijos en dependencia de la topología: el sumidero es padre y los extremos son hijos, pero los intermedios son hijos de los más cercanos al sumidero y padres de los más alejados, como capas superpuestas. La comunicación se realiza padre a hijo o hijo a padre (ascendente o descendente). De esa forma se optimiza la comunicación desde cualquier punto hacia el núcleo de la red que es el nodo sumidero en la mayoría de las aplicaciones [8]. 6LowPAN es una capa de adaptación entre la capa de red y la capa de acceso al medio y su función consiste en proporcionar mecanismos de encapsulación y compresión de cabeceras para permitir que los paquetes IPv6 viajen sobre tramas IEEE 802.15.4. A su vez, IEEE 802.15.4 [2] es el estándar propuesto por la IETF para la capa de acceso al medio de las LLNs que define diferentes modos de operación orientados en dos líneas opuestas: las deterministas y las no deterministas. En las primeras la comunicación se planifica de antemano independiente del tráfico, en las segundas la comunicación es rd uns respuesta a la demanda de tráfico. En un principio se pretendía que las soluciones deterministas eran inadecuadas para las LLNs cuyas aplicaciones mayormente generan patrones de tráfico 2.
(8) aleatorios y las topologías crecen y cambian con dinamismo. Pero se ha demostrado que las soluciones no deterministas o asíncronas como ContikiMAC [9, 5] presentan tasas de pérdidas de hasta el 1% [5] y los costos de energía y latencia son bastantes similares a las soluciones deterministas o síncronas como las que se mencionan a continuación. De las soluciones deterministas, una de las más relevantes es la de Salto de Canal por ranuras de Tiempo (TSCH, por sus siglas en inglés) que está basada en Acceso Múltiple por División de Tiempo (TDMA, por sus siglas en inglés). TSCH propone dividir el tiempo en ranuras, agrupadas en bloques de ranuras que se repiten periódicamente. La cantidad de ranuras determina el tamaño de los bloques. En una misma ranura varios nodos pueden trasmitir empleando diferentes canales. Para el correcto funcionamiento de TSCH los nodos deben sincronizarse y coordinar en qué ranura y canal de frecuencia le corresponde hibernar, escuchar o trasmitir a cada uno. Los algoritmos de planificación (en este documento se emplean los términos “programador” para referirse a los algoritmos de planificación, y “horario” para referirse al plan en sí) son precisamente los encargados de disponer el orden en el que cada nodo conmuta de estado y de canal para lograr comunicación exitosa y libre de colisiones. [9] Dos de los principales programadores son Orchestra [5] y Scheduling Function 0. El reto fundamental de estos es crear horarios para TSCH que no afecten la flexibilidad de las LLNs y se adecúen a los requerimientos del tráfico no determinista exigido por la mayoría de las aplicaciones en IoT [5]. Scheduling Function 0 [12, 13] propone una programación muy básica que apenas permite la comunicación de los nodos dentro de la red. Por otra parte, Orchestra ha demostrado tener un buen desempeño, incluso en comparación con otros protocolos del estado del arte [7]. Atendiendo a que la combinación de TSCH y Orchestra aún está en la fase de desarrollo y evaluación los autores de esta investigación proponen como problema científico: ¿Cuál es el desempeño de la combinación de TSCH y Orchesta ante diferentes cargas de tráfico, secuencias de canales longitudes de bloques de ranuras y operación de Orchestra (basada en modo almacenamiento o no-almacenamiento de RPL)? Para dar solución al problema científico, se define como objetivo general evaluar el desempeño de TSCH y Orchestra empleando herramientas de simulación. A fin de alcanzar el objetivo general se proponen los siguientes objetivos específicos: 1. Caracterizar el funcionamiento de la capa MAC de las LLNs. 3.
(9) 2. Describir el funcionamiento de TSCH y Orhestra propuestos para la operación multicanal síncrona en las LLNs. 3. Diseñar escenarios de simulación para la medición del desempeño de TSCH y Orchestra. 4. Describir el desempeño de TSCH y Orchestra a partir de los datos obtenidos en los escenarios simulados. Los objetivos específicos tienen como propósito dar respuesta a las siguientes interrogantes científicas: 1. ¿Cuáles son las características del funcionamiento de la capa MAC dentro del contexto de las LLNs? 2. ¿Qué elementos permiten describir el protocolo TSCH y Orchestra propuestos para operación multicanal síncrona en LLNs? 3. ¿Qué escenarios permiten medir el desempeño de TSCH y Orchestra en ambientes de simulación? 4. ¿Cuál es la configuración óptima de los protocolos TSCH y Orchestra según los datos obtenidos en los escenarios de simulación diseñados? En la obtención de los resultados que validen esta investigación se emplea el sistema operativo ContikiOS y el simulador COOJA contenido en él para realizar las simulaciones. ContikiOS es un sistema operativo de código abierto orientado al trabajo en el IoT que provee poderosas herramientas para la construcción de complejos sistemas inalámbricos. TSCH y Orchestra se encuentran implementados en ContikiOS, específicamente para la plataforma Z1 de la compañía española Zolertia. La novedad científica y el principal aporte de esta investigación es la evaluación del desempeño de TSCH y Orchestra atendiendo a sus diferentes parámetros configurables. Organización del informe: El informe de investigación está compuesto por una introducción, capitulario, conclusiones, recomendaciones para investigaciones futuras en el tema, referencias bibliográficas y anexos: Capítulo 1: Se caracterizan las LLNs y se enuncian los retos y beneficios de la operación MAC multicanal. Se describen a fondo los protocolos TSCH y Orchestra. Capítulo 2: Se fundamenta la selección de las tecnologías ContikiOS, COOJA y Z1. Se describen detalladamente los escenarios de simulación que se utilizan para comparar el desempeño de TSCH y Orchestra con sus diferentes configuraciones. 4.
(10) Capítulo 3: Se discuten los resultados de las simulaciones. Se realiza una comparación entre las distintas configuraciones de TSCH y Orchestra según los datos recolectados en las tareas de simulación.. 5.
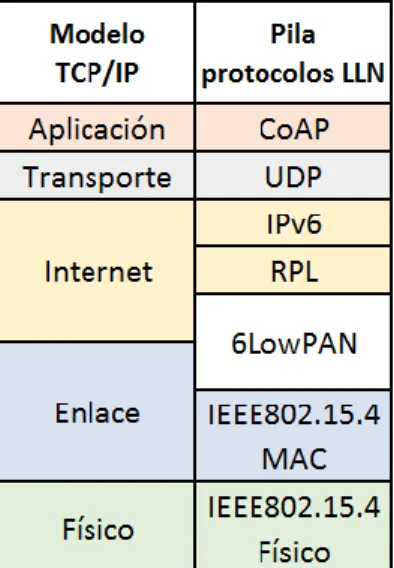
(11) Capítulo 1 1.1. LLNs: Generalidades y arquitectura Una LLN consiste básicamente en un conjunto de dispositivos alimentados por baterías que se despliegan en posiciones desconocidas a priori y se comunican entre sí usando enlaces inalámbricos. Forman topologías de árbol, malla o estrella y se comunican entre sí usando tramas cortas y bajas razones de datos. En la figura 1.1 puede apreciarse la pila de protocolos habilitados para IPv6 en la arquitectura de las LLNs.. Figura 1.1: Pila de protocolos habilitados para IPv6 en la arquitectura de las LLNs en relación con el modelo TCP/IP. El Protocolo de Aplicación Restringida (CoAP, por sus siglas en inglés) es un protocolo de transferencia web especializado para uso con nodos restringidos y redes limitadas como las LLNs. Está diseñado para aplicaciones de máquina a máquina como la redes inteligentes de distribución de energía y la automatización de edificios. CoAP proporciona un modelo de interacción solicitud/respuesta entre los puntos finales de la aplicación, admite el descubrimiento integrado de servicios y recursos e incluye conceptos claves de la Web, como identificadores de recursos uniforme (URIs, por sus siglas en inglés) y tipos de medios de Internet. CoAP está diseñado para interactuar fácilmente con HTTP en la integración con la Web mientras cumple con requisitos especializados tales como soporte de multidifusión, gastos generales muy bajos y simplicidad para entornos restringidos. RPL es el protocolo de enrutamiento para las redes IPv6 de baja potencia estandarizadas por la IETF. Se trata de un protocolo de enrutamiento de vector distancia orientado que crea un 6.
(12) árbol de ruteo en forma de grafo acíclico orientado y dirigido (DODAG, por sus siglas en inglés). El DODAG está enraizado en el nodo de borde que conecta una LLN a Internet, conocido como sumidero o enrutador de borde. De forma general RPL organiza a los nodos en padres e hijos en dependencia de la topología: el sumidero es padre y los extremos son hijos, pero los intermedios son hijos de los más cercanos al sumidero y padres de los más alejados, como capas superpuestas. La comunicación se realiza padre a hijo o hijo a padre (ascendente o descendente). De esa forma se optimiza la comunicación desde cualquier punto hacia la raíz, que es el nodo sumidero en la mayoría de las aplicaciones. Cada nodo se encuentra a una distancia o rango de la raíz determinado por alguna función de coste. Un nodo envía un paquete hacia la raíz enviándolo a un nodo vecino con un rango más pequeño. El enrutamiento desde la raíz a uno de los nodos se realiza utilizando los enlaces inversos. El enrutamiento de un nodo a otro se realiza primero por enrutamiento ascendente hasta un ancestro común (si se emplea el modo almacenamiento de RPL; si se empleara el modo no-almacenamiento el paquete tendría que retroceder hasta la raíz) y luego descendente hasta el destino. La operación de TSCH y Orchestra se centra en el modo de almacenamiento de RPL: cada nodo mantiene una tabla de enrutamiento con respecto a sus hijos de enrutamiento. En las LLNs el consumo de energía es una cuestión primordial. Los dispositivos desactivan su interfaz de radio la mayor parte del tiempo para ahorrar energía. Asimismo, el carácter inalámbrico de los enlaces significa que no son confiables. Debido a estas cuestiones no resulta fácil adaptar IPv6 en la parte superior de las LLNs. Ejemplo típico es que el tamaño mínimo de un paquete IPv6 es de 1280 Bytes por lo que resulta demasiado grande para caber en una trama IEEE.802.15.4 y la sobrecarga debido a la cabecera de 40 Bytes desperdicia el poco ancho de banda disponible en la capa física. Para solucionar estas cuestiones se define 6LoWPAN como capa de adaptación entre la capa de enlace de IEEE.802.15.4 y la capa de red. Las prestaciones fundamentales de 6LowPAN son que incluye información de clase de tráfico y compresión de etiquetas de flujo, comprime dirección de multidifusión de estado, comprime encabezado siguiente de IPv6, comprime cabeceras de extensión IPv6, comprime cabeceras UDP, comprime puertos UDP y comprime chequeo de paridad de UDP. 1.2. TSCH TSCH es un modo de operación de IEEE.802.15.4 de 2015 definido para la capa MAC de LLNs y encaja bajo la pila de protocolos habilitados para IPv6 en la arquitectura de las LLNs (ver 7.
(13) figura 1.1). TSCH fue diseñado para permitir que las LLNs basadas en IEEE.802.15.4 soportasen una gran variedad de aplicaciones dentro de las que se tuvo en cuenta las industriales. La técnica MAC de TSCH emplea sincronización de tiempo (para lograr un funcionamiento de baja potencia) y salto de canal (para lograr alta fiabilidad) [9]. La sincronización impacta directamente en el consumo de energía y puede variar de milisegundos a microsegundos dependiendo de la solución. Gracias a su naturaleza de salto de canal TSCH puede enfrentar ambientes con difíciles condiciones de trabajo, como los ambientes industriales donde suele haber grandes entornos de despliegue con equipamiento metálico que causa desvanecimiento e interferencia multi-ruta haciendo inviable las soluciones basadas en un solo canal. IEEE.802.15.4 no define la entidad funcional que actúa de programador. 1.2.1. Ranuras de Tiempo y Bloques de Ranuras El funcionamiento de una red TSCH se basa en el sincronismo. Para lograr este sincronismo el tiempo se divide en “ranuras” lo suficientemente largas para que un nodo envíe una trama MAC de tamaño máximo a otro y reciba un acuse de recibo (ACK) de éste que indique la recepción satisfactoria. El estándar no define la duración de una ranura pero normalmente con radios compatibles con IEEE.802.15.4 que operan en la banda de 2,4 GHz, una trama MAC máxima (127 bytes) tarda 4 ms en ser transmitida y un ACK tarda 1 ms. De esta forma, la duración típica de una ranura (10 ms), deja 5 ms libres para preparación de la interfaz de radio, procesamiento de la trama y operaciones de seguridad. Las ranuras se agrupan en bloques de ranuras. Un bloque de ranuras se repite continuamente en el tiempo. TSCH no impone un tamaño del bloque de ranuras. Dependiendo de las necesidades de la aplicación, estos tamaños pueden variar de 10 a 1000 ranuras. Cuanto más corto sea el bloque de ranuras, más frecuentemente se repetirá una ranura, resultando en un mayor ancho de banda disponible, aunque también en un mayor consumo de energía. 1.2.2. Horario TSCH y Celdas Programadas Es importante recordar que en este informe se maneja “horario” para referirse a la planificación en sí y “programador” a la entidad funcional que gestiona la planificación, así como al algoritmo de planificación. El horario indica a cada nodo qué hacer en cada ranura: transmitir, recibir o dormir. De esta forma, para cada ranura activa se planifica la acción a realizar, transmitir o recibir; un canal y la dirección del vecino con el cual comunicarse. Una vez que un nodo obtiene su horario, lo ejecuta: 8.
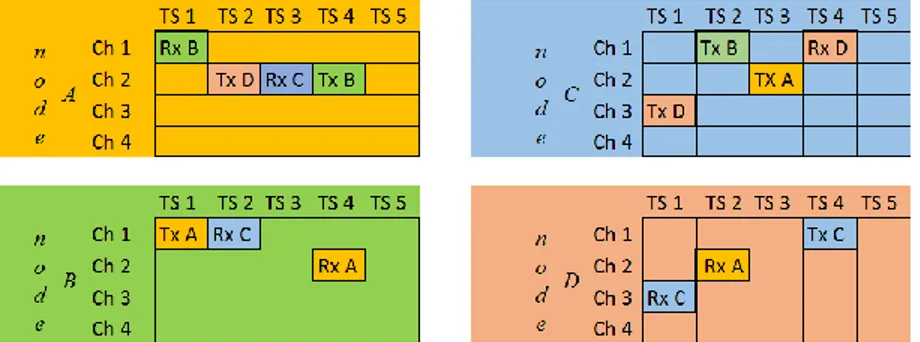
(14) . Para cada ranura de transmisión: el nodo comprueba si hay algún paquete en el búfer saliente que coincida con el vecino indicado por el horario para esa ranura. Si no hay ninguno, el nodo mantiene su radio apagado durante la duración de la ranura. Si hay alguno, el nodo lo envía al vecino, en cuyo caso debe esperar el ACK tras la transmisión.. . Para cada ranura de recepción: el nodo escucha las posibles tramas entrantes. Si no se recibe ninguna después de un período de escucha, apaga su radio. Si se recibe una trama, dirigida al nodo en cuestión y pasa el control de seguridad, el nodo devuelve un ACK.. Cómo se crea, actualiza y mantiene el horario, y por qué entidad, está fuera del alcance del estándar IEEE 802.15.4e. En la sección 1.3 se aborda el tema. Suponiendo que el horario esté bien construido, si el nodo A está preparado para transmitir al nodo B en la ranura 5 y el canal 11, el nodo B se preparará para recibir desde el nodo A en la misma ranura y canal. Un único elemento del horario caracterizado por una ranura y un canal, y reservado para que el nodo A transmita al nodo B (o para que el nodo B reciba desde el nodo A) dentro de un bloque de ranuras dado, se denomina “celda”. Si hay una gran cantidad de datos que fluyen desde el nodo A al nodo B, el horario podría contener varias celdas de A a B, en diferentes ranuras. Múltiples celdas para el mismo vecino pueden ser equivalentes, es decir, la capa MAC envía la trama en la primera de estas celdas que aparezca después de que la trama se pone en la cola MAC. La unión de todas las celdas entre dos vecinos, A y B, se denomina "haz". Dado que el bloque de ranuras se repite en el tiempo (y la longitud del bloque de ranuras es típicamente constante), cada celda da una "cantidad" de ancho de banda a un vecino determinado. La modificación del número de celdas equivalentes en un haz modifica la cantidad de recursos asignados entre dos vecinos. La figura 1.2 representa un horario genérico: nótese que una celda es un punto inequívoco en el sistema de coordenadas (ranura; canal). La figura 1.3 representa un ejemplo de horario estático para una red de 4 nodos.. 9.
(15) Figura 1.2: Representación del horario (“TS” se emplea para referirse a las ranuras y “Ch” para referirse al canal).. Figura 1.3: Ejemplo de horario estático para una red TSCH de 4 nodos (“TS” se emplea para referirse a las ranuras y “Ch” para referirse al canal). Por defecto, cada celda de transmisión del horario está dedicada, es decir, reservada únicamente para que el nodo A transmita al nodo B. IEEE 802.15.4 también permite que una celda sea marcada como compartida. En una celda compartida, múltiples nodos pueden transmitir al mismo tiempo y en la misma frecuencia. Para evitar la contención, TSCH define un algoritmo de backoff para las celdas compartidas. Una celda puede ser marcada como transmisión y recepción. En el primer caso, el nodo transmite si tiene un paquete apropiado en su búfer de salida, y en el segundo escucha. Marcar una celda como [transmitir, recibir, compartir] da como resultado un comportamiento de ALOHA (medio compartido) con ranura. 1.2.3. Número de Ranura Absoluta y Salto de Canales TSCH define un contador de ranuras denominado Número Absoluto de Ranura (ASN, por sus siglas en inglés). Cuando se crea una nueva red, el ASN se inicializa a 0; a partir de entonces, se incrementa 1 en cada ranura. En detalle: ASN = (k * S + t) Donde k es el ciclo del bloque de ranuras (es decir, el número de repeticiones del bloque de ranuras desde que se inició la red), S la longitud del bloque de ranuras y t la ranura de apertura. Un nodo aprende la ASN actual cuando se une a la red. Dado que los nodos están sincronizados, todos conocen el valor actual de la ASN, en cualquier momento. La ASN está codificada como un número de 5 bytes: esto le permite incrementarse durante cientos de años (el valor exacto depende de la duración de una ranura) sin que se desborde o reinicie. El ASN. 10.
(16) se utiliza para calcular la frecuencia para comunicarse y se puede utilizar para operaciones relacionadas con la seguridad. Para cada celda, el horario especifica una ranura y un canal. El canal es traducido por ambos nodos en una frecuencia usando la siguiente función: 𝐹𝑟𝑒𝑐𝑢𝑒𝑛𝑐𝑖𝑎 = 𝐹 ∗ {(𝐴𝑆𝑁 + 𝑐𝑎𝑛𝑎𝑙)𝑚𝑜𝑑 𝑛𝐹𝑟𝑒𝑞} La función F consiste en una tabla de búsqueda que contiene el conjunto de canales disponibles. El valor nFreq (el número de frecuencias disponibles) es el tamaño de esta tabla de consulta. Hay tantos valores de canales como frecuencias disponibles (por ejemplo, 16 cuando se utilizan todos los canales en radios que cumplen con IEEE 802.15.4 a 2,4 GHz). Dado que ambos nodos tienen el mismo canal escrito en su horario para esa celda, y el mismo contador ASN, calculan la misma frecuencia. Sin embargo, en el siguiente ciclo del bloque de ranuras, mientras que el desplazamiento de canal es el mismo, la ASN ha cambiado, dando como resultado el cálculo de una frecuencia diferente. Esto resulta en "salto de canal": incluso con un horario estático, los pares de vecinos "saltan" entre las diferentes frecuencias en la comunicación. Una manera de asegurar que la comunicación ocurre en todas las frecuencias disponibles es establecer el número de ranuras de un bloque de ranuras en un valor primo. El salto de canal es una técnica conocida para combatir eficazmente el desvanecimiento multipunto y la interferencia externa. 1.2.4. Sincronización de tiempo Debido a la naturaleza ranurada de la comunicación en una red TSCH, los nodos tienen que mantener la sincronización. Se supone que todos los nodos están equipados con osciladores para controlar el tiempo. Sin embargo, debido a que los osciladores en diferentes nodos fluctúan entre sí, los nodos vecinos necesitan resincronizarse periódicamente. Cada nodo necesita sincronizar periódicamente su tiempo de red con otro nodo, y también proporciona su tiempo de red a sus vecinos. Corresponde al programador asignar un vecino como fuente de tiempo adecuado a cada nodo, es decir, indicar a cada nodo en el horario cuál es su vecino de origen temporal. Al establecer la fuente de tiempo vecino, es importante evitar bucles de sincronización, lo que podría dar lugar a la formación de grupos independientes de nodos sincronizados entre sí pero desincronizados con el resto de la red. TSCH añade información de sincronismo en todas las tramas que se intercambian (tanto datos como tramas ACK). Esto significa que los nodos vecinos pueden resincronizarse entre sí cuando 11.
(17) intercambian tramas. Se definen dos métodos en IEEE 802.15.4 para permitir que un dispositivo se sincronice en una red TSCH. En ambos casos, el receptor calcula la diferencia de tiempo entre el tiempo esperado de llegada de la trama y su llegada real. . Sincronización basada en el ACK: El receptor proporciona dicha información al nodo emisor en su ACK. En este caso, es el nodo emisor el que se sincroniza con el reloj del receptor.. . Sincronización basada en tramas: El receptor utiliza el delta calculado para ajustar su propio reloj. En este caso, es el nodo receptor que se sincroniza con el reloj del trasmisor.. Diferentes políticas de sincronización son posibles. Los nodos pueden mantener la sincronización exclusivamente intercambiando EBs. Los nodos también pueden mantenerse sincronizados enviando periódicamente paquetes válidos a un vecino de origen temporal y utilizar el ACK para volver a sincronizarse. Ambos métodos (o una combinación de los mismos) son políticas de sincronización válidas; cuál usar depende de los requisitos de la red. 1.2.5. El consumo de energía Sólo hay 3 actividades que un nodo puede realizar durante una ranura: transmitir, recibir o dormir. Cada una de estas operaciones tiene algún costo energético asociado a ellas; el valor exacto depende del hardware utilizado. Dado el horario de un nodo, es fácil calcular el consumo de energía promedio esperado de ese nodo. 1.2.6. Horario El horario define completamente la sincronización y la comunicación entre los nodos. Mediante la adición o eliminación de celdas entre vecinos, se puede adaptar un horario a las necesidades de la aplicación. Por ejemplo: . Hacer el horario "escaso" para aplicaciones en las que los nodos necesitan consumir la menor cantidad de energía posible, al precio de un ancho de banda reducido.. . Hacer el horario "denso" para aplicaciones donde los nodos generan una gran cantidad de datos, al precio de un mayor consumo de energía.. . Agregar más celdas a lo largo de una ruta de salto múltiple sobre la cual fluyen muchas tramas.. 12.
(18) 1.2.7. Proceso de unión Los nodos que ya forman parte de la red pueden enviar periódicamente tramas EB para anunciar la presencia de la red. Éstas contienen información sobre el tamaño del bloque de ranuras utilizado en la red, la ASN actual, información sobre los bloques de ranuras y las ranuras que el nodo que intenta unirse está escuchando y 1 byte de prioridad de unión. El campo de prioridad de unión proporciona información para tomar una mejor decisión de qué nodo debe unirse. Incluso si un nodo está configurado para enviar todas las tramas EB en el mismo canal, debido a la naturaleza de salto de canal de TSCH descrita, este canal se traduce en una frecuencia diferente en diferentes ciclos del bloque de ranuras. Como resultado, las tramas EB se envían a todas las frecuencias. Un nodo que desee unirse a la red escucha los EBs. Como los EB se envían a todas las frecuencias, el nodo que intenta unirse puede escuchar en cualquier frecuencia hasta que escuche un EB. Qué frecuencia escucha por defecto al encender depende de la implementación. Una vez que ha recibido uno o más EBs, el nuevo nodo habilita el modo TSCH y utiliza el ASN y la otra información de temporización del EB para sincronizarse con la red. Usando el bloque de ranuras y la información de la celda de los EB, sabe cómo ponerse en contacto con otros nodos de la red. TSCH no define los pasos más allá de esta sincronización inicial. 1.2.8. Resumen de características destacadas de TSCH . Comunicación sin colisiones: TSCH permite diseñar un horario que produzca una comunicación sin colisiones. Esto se hace construyendo el horario con celdas dedicadas de tal manera que, como máximo, un nodo se comunique con un vecino específico en cada celda (ranura; canal). Varios pares de nodos vecinos pueden intercambiar datos al mismo tiempo, pero en frecuencias diferentes.. . Salto de canales: Un horario se parece a una matriz de ancho "tamaño del bloque de ranuras", S, y de altura "número de frecuencias", nFreq. Para un programador, las celdas pueden ser consideradas "unidades" autónomas para programar. En particular, debido a la naturaleza de salto de canal de TSCH, el programador no debe preocuparse de que la comunicación de frecuencia real varíe, ya que cambia en cada ciclo del bloque de ranuras.. 13.
(19) . Coste de la sincronización (continua): Cuando hay tráfico en la red, los nodos que se están comunicando se resincronizan implícitamente utilizando las tramas de datos que intercambian. En ausencia de tráfico de datos, se requiere que los nodos se sincronicen periódicamente con sus vecinos de fuente de tiempo para no derivarse en el tiempo. Si no han estado comunicándose durante algún tiempo (normalmente 30 s), los nodos pueden intercambiar una trama de datos vacía para resincronizarse. La frecuencia con la que estos mensajes deben transmitirse depende de la estabilidad de la fuente de tiempo y de la forma en que cada nodo comienza a escuchar los datos (el "tiempo de guarda"). Teóricamente, con un reloj de 10 ppm y un tiempo de guarda de 1 ms, este periodo puede ser de 100 s. Suponiendo que este intercambio hace que la radio del nodo esté encendida durante 5 ms, esto produce un ciclo de trabajo de radio necesario para mantener sincronizado 5 ms / 100 s = 0,005%. Aunque TSCH requiere que los nodos vuelvan a sincronizarse periódicamente, el costo de hacerlo es muy bajo.. . Estabilidad de la topología: La naturaleza de salto de canal de TSCH hace que los enlaces sean muy "estables". Los fenómenos inalámbricos, como el desvanecimiento multipunto y la interferencia externa, afectan de forma diferente a cada frecuencia en un enlace inalámbrico entre dos nodos. Si una transmisión desde el nodo A al nodo B falla, la retransmisión en una frecuencia diferente tiene una mayor probabilidad de éxito que la retransmisión en la misma frecuencia. De esta forma, incluso cuando algunas frecuencias están "comportándose mal", el salto de canal "suaviza" la contribución de cada frecuencia, dando como resultado enlaces más confiables y por lo tanto una topología más sólida.. . Múltiples bloques de ranuras concurrentes: El estándar TSCH permite que múltiples bloques de ranuras coexistan en el horario de un nodo. Es posible que, en una ranura, un nodo tenga múltiples actividades programadas (por ejemplo, transmitir al nodo B en el canal 2, recibir desde el nodo C en el canal 1). Para manejar esta situación, el estándar TSCH define las siguientes reglas de prioridad: a. Las transmisiones tienen prioridad sobre las recepciones. b. Los identificadores de bloque de ranuras inferior tienen prioridad sobre los identificadores de bloque de ranuras más altos. En el ejemplo anterior, el nodo A transmitirá al nodo B en el bloque de ranuras 2. 14.
(20) 1.3. Programador 1.3.1. Enfoques del programador En TSCH si dos nodos situados muy cerca tratan de enviar paquetes en la misma celda, entrará en conflicto y la transmisión de ambos fallará. Por lo tanto, para evitar la contención mientras se logra una alta utilización de los canales y la eficiencia energética, se debe usar un programador inteligente y prudente en la planificación de celdas TSCH. Los métodos actuales apuntan a tres enfoques: centralizado, descentralizado y autónomo. 1.3.2. Enfoque centralizado En las redes TSCH que utilizan un programador centralizado, un nodo representativo programa el despertar y el dormir de cada nodo en la misma red. Dado que sólo un nodo programa toda la comunicación en la red, para ese nodo, se necesita una gran cantidad de información. Dependiendo del programador, se puede utilizar una gran cantidad de información para elaborar un horario optimizado. Sin embargo, dado que sólo un nodo específico puede ejecutar la programación, no hay respuesta rápida cuando la topología de red cambia repentinamente. Además, cada nodo tiene que entregar la información que se utiliza en el nodo central, lo que provoca la sobrecarga de comunicación utilizando energía aditiva y recursos de ancho de banda. Además, el enfoque centralizado requiere mucho tiempo para la inicialización. Se clasifican los siguientes tipos de programación como enfoque centralizado. La red está dividida en varias regiones. En cada región, un nodo central ejecuta la programación para cada nodo situado en la misma región que ese nodo. En esta red, aunque múltiples nodos ejecuten la programación, no es totalmente descentralizada. Por el contrario, se puede ver como una combinación de múltiples programadores centralizados. 1.3.3. Enfoque descentralizado En las redes TSCH que utilizan un programador descentralizado, cada nodo gestiona su propio horario. Cada nodo se comunica con sus vecinos para evitar conflictos causados por el uso simultáneo del mismo canal entre nodos interferentes. Para implementar esta red, debe decidirse un protocolo de negociación específico. En comparación con el enfoque centralizado, cada nodo que utiliza el programador descentralizado necesita sólo una pequeña cantidad de información recibida de sus vecinos cercanos. Como resultado, es robusto para un repentino cambio de red. Sin embargo, debido a la escasa información, el enfoque descentralizado carece de visión global de la red. 15.
(21) 1.3.4. Enfoque autónomo Aunque el enfoque descentralizado muestra una respuesta rápida para los repentinos cambios de la topología de la red, todavía necesita una comunicación aditiva para la negociación entre vecinos. En el enfoque autónomo, no se necesita negociación para programar el horario. (Un método representativo es Orchestra, que se aborda en detalle en la sección 1.3.) Sólo se utiliza la información recibida del protocolo de enrutamiento RPL. No se utiliza comunicación aditiva para negociar la entre los vecinos el horario. Cada nodo calcula de forma autónoma su horario basado en la estructura RPL. Utilizando NodeID como la dirección MAC del nodo padre RPL se ejecuta la programación basada en nodos. Por ejemplo, en el programador basado en receptor, los nodos receptores están en el horario de cada nodo. El nodo indicado escucha en la celda correspondiente y cualquier nodo que quiera enviar una trama a ese nodo despierta y contiende por enviar la trama. El programador basado en remitente se ejecuta de la misma manera. Aunque el programador autónomo también carece de otra información disponible, los mayores beneficios de este son su ejecución sencilla y ligera sin ninguna negociación y su respuesta rápida a los repentinos cambios de red. 1.3.5. Consideraciones de diseño En el diseño del programador, uno de los mayores desafíos es hacer el horario evitando conflictos entre los nodos que interfieren. Sin embargo, como el programador autónomo no utiliza ninguna negociación, carece de información. En esta condición, lo que el programador autónomo puede hacer es reducir la probabilidad de conflicto. 1.3.6. Programador basado en enlaces Consideración 1: Un nodo no puede recibir tramas de dos nodos diferentes en la misma ranura. Por ejemplo, en una topología donde un nodo padre A tiene dos nodos hijos B y C respectivamente, si B y C envían tramas al nodo A en la misma celda, A no recibirá ninguna de las 2 tramas correctamente. En esta situación, el programador puede colocar el enlace A-B y el enlace A-C en el mismo canal o en diferentes canales. En el primer caso, si los dos nodos hijos envían paquetes simultáneamente al nodo padre, las dos transmisiones estarán en conflicto en el mismo canal y A no recibe ninguna de las dos. En el último caso, dependiendo de la selección de canal del nodo A, uno de los paquetes enviados desde el nodo B o el nodo C puede ser recibido satisfactoriamente.. 16.
(22) 1.3.7. Programador basado en contador de salto Consideración 2: Un nodo no puede escuchar y enviar paquetes simultáneamente en la misma ranura. Por ejemplo, en la topología descrita en la sección 1.3.6, si el nodo B tuviese a su vez dos nodos hijos D y E respectivamente, y el enlace B-A y el D-B están programados en el mismo TS, el nodo D enviará al nodo B y el nodo B enviará al nodo A. Sin embargo, el nodo B no puede escuchar y enviar simultáneamente en la misma ranura. 1.3.8. Identificador de bloque de ranuras Consideración 3: En un nodo específico, el horario de diferentes bloques de ranuras debe cambiarse para evitar conflictos consistentes. Si el horario para un bloque de ranuras persiste, los nodos en conflicto en una celda volverán a entrar en conflicto en el siguiente bloque de ranuras. Por ejemplo, en la topología descrita en 1.3.6, en el enlace ascendente, hay dos enlaces B-A y C-A. Si estos enlaces están programados en la misma celda y el nodo B y el nodo C envían tramas al nodo A, las dos transmisiones fallarán. Si este horario persiste, en el siguiente ciclo del bloque de ranuras se producirá la misma situación de nuevo. 1.3.9. En sentido ascendente: basado en enlace; en sentido descendente: basado en nodo. Consideración 4: El programador de enlaces ascendentes y descendentes debe ser diferenciado. En las LLNs, la cantidad de tráfico ascendente es mucho mayor que la del tráfico descendente. Por otra parte, si la topología de árbol se utiliza para el protocolo de enrutamiento como se describe en 1.3.6 y 1.3.7, un nodo tiene múltiples nodos secundarios y sólo un nodo padre. En esta estructura, en el caso del enlace ascendente, cada nodo hijo tiene paquetes diferentes para enviar a su nodo padre. Por lo tanto, un nodo padre debe escuchar a sus múltiples hijos usando diferentes celdas. Sin embargo, en el caso de enlace descendente, el servidor puede solicitar o responder a cada nodo de la red o al nodo específico. Además, la cantidad de tramas descendentes es menor que la de tramas ascendentes y la celda para el flujo descendente puede no ser usada con alta probabilidad. Por lo tanto, en la topología descrita en 1.3.6 y 1.3.7, cuando el enlace B-D y el enlace B-E están en la misma celda, es más eficiente que si estos enlaces estuviesen en diferentes celdas. Haciendo esto, en el caso en que el servidor envía una trama a cada nodo de la red, el nodo B puede reenviar esta trama a todos sus nodos secundarios en una sola transmisión. En el otro caso en el que el nodo B envía una trama a uno de sus nodos secundarios, puede enviar la trama al nodo específico mientras varios nodos secundarios escuchan en la misma ranura. 17.
(23) 1.3.10. Programador ascendente Consideración 5: Un nodo no puede recibir o enviar paquetes desde su nodo padre y su nodo hijo simultáneamente. En otras palabras, para un nodo específico los enlaces ascendente y descendente no pueden ocurrir en la misma ranura. Por ejemplo, en la topología descrita en la figura 1.2, el nodo B está conectado tanto al nodo A como al nodo D. Si tanto el nodo A como el nodo D están programados para enviar tramas al nodo B en la misma ranura o el nodo B es programado para enviar tramas al nodo A y al nodo D en la misma ranura como resultado del cálculo de la celda usando un programador autónomo, al menos una transmisión fallará ya que el nodo B no puede recibir tramas diferentes de los diferentes nodos y enviar tramas diferentes a los diferentes nodos. 1.4. ORCHESTRA En Orchestra, los nodos emplean horario simple y actualizan estos de forma automática e instantánea a medida que evoluciona la topología de enrutamiento. Un horario en Orchestra consiste en un conjunto de bloques de ranuras superpuestos dedicados cada uno a un plano de comunicación específico: MAC, enrutamiento y aplicación. Como resultado, Orchestra permite construir una columna de enrutamiento genérico, flexible y de bajo consumo usando RPL y aprovechando la robustez de TSCH. Estos horarios permiten reducir drásticamente la contención, o incluso eliminarla en ciertos casos. Con Orchestra los nodos mantienen su horario de forma local y autónoma, basado en sus vecinos y padres de RPL. Como resultado, Orchestra hace que TSCH sea tan flexible como las capas MAC asíncronas, y capaz de soportar tráfico de acceso aleatorio. Un horario de Orchestra contiene diferentes bloques de ranuras de diferentes longitudes. Cada bloque de ranuras está dedicada a un tipo particular de tráfico. Los nodos seleccionan los bloques de ranuras usando reglas de programación que reducen drásticamente la contención, o en ciertos casos elimina la contención. Esto hace a Orchestra de especial interés para los escenarios IPv6 de baja potencia que en diferentes aplicaciones generan datos basados en eventos, sin ningún tipo de patrón de tráfico predefinido. El horario de Orchestra contiene: . Una celda dedicada de la difusión de cada nodo padre a sus nodos hijos para las balizas de TSCH, repitiéndose cada X ranuras.. 18.
(24) . Una celda común para todos los nodos en la red para multidifusión + unidifusión, para señalización RPL (DIO, DIS, DAO), repitiéndose cada Y ranuras.. . Una celda unicast dedicada de cada nodo hijo a su nodo padre RPL, repitiéndose cada Z ranuras.. . N celdas dedicadas desde cada nodo padre a cada uno de sus nodos hijos, repitiéndose cada Z ranuras.. Orchestra utiliza longitudes de bloque de ranuras que son mutuamente primos, asegurando que las celdas se superponen de manera uniforme, sin efectos de sincronización no deseados. La clave es que selecciona la ranura y el canal de cada celda como una función del identificador del remitente o del receptor (dirección MAC o un ID de nodo de red único). Dependiendo de las reglas de programación que se le configuren, Orchestra puede alcanzar niveles muy bajos de contención, u operar libre de contención. 1.4.1. Diseño de Orchestra En Orchestra, los nodos adaptan su horario mediante la explotación de la información de la topología de RPL, y siguiendo un conjunto de reglas de programación. Esto da como resultado patrones de actividad periódicos, con bloques de ranuras asignados a diferentes planos de tráfico tales como EBs, señalización RPL o datos de aplicación. 1.4.2. Inicialización Cuando se enciende un nodo, este se une a la red TSCH escuchando hasta que recibe un EB, ya sea desde el coordinador de PAN o de otro nodo. Después de sincronizarse con ese EB, el nodo ejecuta Orchestra. Una configuración viable de Orchestra requiere celdas para enviar y recibir paquetes desde y hacia cualquier vecino. Esto emula un enlace permanente con todos los vecinos, permitiendo que los nodos RPL descubran a sus vecinos y construyan una topología. 1.4.3. Mapeo de topología TSCH-RPL Orchestra utiliza constantemente al padre preferido RPL como su fuente de tiempo. A medida que evoluciona la topología RPL y se producen cambios de padre, los nodos actualizan su fuente de tiempo en consecuencia. Esto produce una estructura de sincronización sin bucles (un árbol en este caso), aprovechando el mecanismo para evitar bucles de RPL. Además, se utiliza el rango RPL como prioridad de combinación TSCH, como se define en la arquitectura 19.
(25) de las LLNs. Haciendo esto, también se aprovecha los mecanismos RPL para la convergencia y estabilidad del gradiente. En caso de que un nodo pierda la sincronización, también abandona la red RPL, asegurando una inicialización limpia después de la reincorporación. 1.4.4. Sincronización de tiempo TSCH. La sincronización de tiempo de TSCH ocurre en cualquier paquete (o ACK) del vecino de origen de tiempo. En Orchestra, la sincronización de tiempo ocurre principalmente a través de la transmisión periódica de balizas TSCH y RPL. Esto es eficiente, ya que un único mensaje de difusión permite a todos los nodos hijos actualizar sus relojes. Cada vez que un nodo no se ha comunicado con su vecino de fuente de tiempo tras un tiempo determinado (por defecto se usa 12 s), envía un mensaje keepalive unicast. El paquete se reenvía hasta que se reconoce y la resincronización se realiza utilizando la información de temporización incorporada en el ACK mejorado IEEE 802.15.4. 1.4.5. Programador con direccionamiento de rutas A lo largo de la vida útil de la red, Orchestra instala y actualiza los horarios utilizando la información de la capa de enrutamiento. RPL se ejecuta sin modificaciones, con celdas que se configuran automáticamente a medida que evoluciona la topología, garantizando la conectividad de la red y permitiendo que las capas superiores se ejecuten de forma transparente. Un ejemplo básico es donde Orchestra mantiene una celda dedicada para que los nodos padres se comuniquen con los nodos hijos. 1.4.6. Celdas de Orchestra Se identifican cuatro tipos principales de celdas en Orchestra: . Celdas comunes compartidas (CS): Las CS consisten en una celda compartida usada por todos los nodos en la red para recepción (Rx) y transmisión (Tx). La celda se instala en coordenadas fijas (ranuras; canales), dando como resultado un comportamiento similar al ALOHA ranurado. Esto emula un vínculo siempre activo, lo que permite a RPL descubrir vecinos y transmitir información de control. Debe tenerse en cuenta que TSCH utiliza un back-off exponencial para resolver la contención en las celdas compartidas, que se activa cada vez que una transmisión de unidifusión no se confirma con un ACK.. . Celdas Compartidas Basadas en Receptor (RBS, por sus siglas en inglés): Las RBS se asignan para la comunicación entre dos vecinos, en las coordenadas (ranura; canal) 20.
(26) derivadas de las propiedades del receptor. En cada nodo, una celda de Orchestra RBS tiene como resultado una celda Rx (coordenadas basadas en el nodo receptor), y una celda Tx por vecino (coordenadas basadas en el vecino). Para calcular las coordenadas de la celda, se puede usar un hash de la dirección MAC del nodo, modulo la longitud del bloque de ranuras o explotar identificadores de nodo únicos cuando están disponibles. Un ejemplo típico es la comunicación de hijo a padre: los nodos padres escuchan cualquier tráfico en una celda y los hijos mantienen una celda de transmisión hacia sus padres. Cuando los nodos cambian de padre, ellos actualizan su celda de transmisión de forma autónoma. Debido a que varios nodos pueden instalar celdas hacia el mismo receptor, la contención puede surgir en dichas celdas. . Celdas Compartidas Basadas en Remitentes (SBS, por sus siglas en inglés): Las SBS son similares a las RBS, excepto que las coordenadas de la celda se obtienen de las propiedades del nodo emisor en lugar del receptor. En cada nodo, una celda SBS resulta en una celda Rx por vecino (coordenadas basadas en el vecino) y una sola celda Tx (coordenadas basadas en el nodo remitente). Esto resulta en un mayor consumo de energía que el RBS (las celdas Tx no cuestan nada cuando no hay tráfico, mientras que las celdas Rx siempre requieren una activación), pero también puede ayudar a disminuir la contención evitando la asignación de celdas por receptor. Por ejemplo, para la comunicación de hijo a padre, los nodos tienen una celda Tx fija, y los padres mantienen una celda Rx para cada uno de sus hijos. Siempre que cambie de padre, el hijo no necesita actualizar su celda de Tx, pero el padre debe eliminar una celda de Rx y el nuevo padre instalar una nueva.. . Celdas Dedicadas al Emisor (SBD, por sus siglas en inglés). En un bloque de ranuras lo suficientemente larga como para acomodar las celdas de transmisión únicas a cada nodo, y suponiendo que se disponga de identificadores de nodo únicos, es posible la comunicación libre de contención. Orchestra logra comunicación libre de contención con SBD, que son similares a SBS excepto que utilizan celdas dedicadas en lugar de compartidas. Debe tenerse en cuenta que con las celdas dedicadas, los paquetes perdidos son reenviados sin back-off (utilizando la siguiente celda hacia el mismo vecino). Los identificadores de nodo únicos pueden ser codificados durante la implementación u obtenidos durante la ejecución desde un administrador de red. 21.
(27) 1.4.7. Bloque de ranuras de Orchestra Orchestra administra varios bloques de ranuras en cada nodo, cada uno de los cuales se asigna a un plano de tráfico particular, por ejemplo, balizamiento TSCH, el tráfico de enrutamiento, aplicación. Los bloques de ranuras consisten en un conjunto de celdas, con propiedades definidas por simples reglas de programación. Los bloques de ranuras se repiten en periodos que son mutuamente primos, asegurando que funcionan de forma independiente. En caso de que celdas de diferentes bloques de ranuras se superpongan, la celda en el bloque de ranuras de prioridad más alta tiene prioridad. La longitud de un bloque de ranuras introduce una relación de compromiso en capacidad de tráfico, latencia de red y consumo de energía: . Capacidad de tráfico: Los bloques de ranuras más cortas repiten sus celdas activas más a menudo, resultando en una mayor capacidad de tráfico. El enfoque de Orchestra es sobre-provisionar TSCH para soportar el tráfico no determinista y la longitud de los bloques de ranuras es la principal manera de controlar la cantidad de sobreprovisionamiento para un plano de tráfico dado.. . Latencia de red: La latencia por salto en un plano de tráfico dado es básicamente proporcional a la longitud de los bloques de ranuras para este plano particular de tráfico.. . Consumo de energía: Del mismo modo, cuanto más corto sea el bloque de ranuras, más frecuentemente los nodos tienen que despertarse para escuchar o transmitir, lo que resulta en una línea de base de energía más alta.. 1.4.8. Reglas de programación Orchestra mantiene sus horarios usando reglas de programación simples. Las reglas de programación son un conjunto de bloques de ranuras con una serie de propiedades específicas de Orchestra. Las propiedades de un bloque de ranuras Orchestra son: . Handle: Un entero positivo único para la identificación y la prioridad. Cuanto menor es, mayor es la prioridad.. . Longitud: Número de ranuras que componen el bloque de ranuras. Debe ser mutuamente primo con todas las otras longitudes de bloques de ranuras en la red.. . Filtrar el tráfico: El plano de tráfico para el que está previsto el bloque de ranuras. Propiedades de los filtros de paquetes (por ejemplo, unicast, broadcast) y protocolos (por ejemplo, TSCH, RPL). 22.
(28) Los bloques de ranuras están formados por celdas de Orchestra, cada una asignada en 0, 1 o múltiples celdas TSCH dependiendo del estado de TSCH y RPL. Por ejemplo, una celda de Orchestra puede ser reservada para la comunicación con todas las fuentes de tiempo de TSCH, hijos de RPL o el padre preferido de RPL. Las propiedades de una celda son: . Vecinos: El vecino o conjunto de vecinos de la celda de Orchestra se declara, como el padre RPL o todos los hijos RPL. Las ranuras TSCH resultantes se actualizan automáticamente cuando se producen cambios en el estado TSCH o RPL.. . Coordenadas: La ranura y el canal dentro del bloque de ranuras. Puede ser fijo o una variable como un ID de nodo o un hash de la dirección MAC vecina.. . Opciones: Opciones estándar de una celda TSCH. Incluye: Rx, Tx y compartida (S), la definición de para qué se puede utilizar la ranura, y si es compartida o dedicada.. 23.
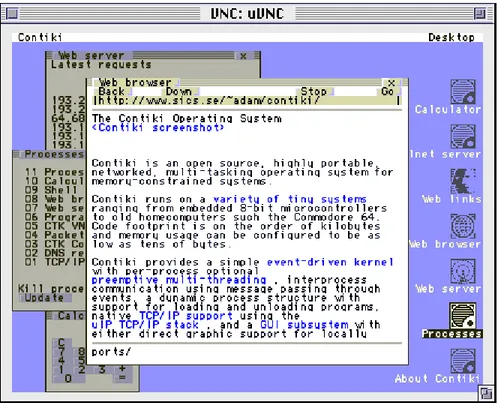
(29) Capítulo 2 2.1. Selección de la tecnología a emplear. Para correr las simulaciones que fundamentan esta investigación, los autores decidieron emplear el sistema operativo ContikiOS, el simulador COOJA y el mote Z1 de la compañía española Zolertia atendiendo a las poderosas características de estos, las cuales son analizadas en detalle en las secciones 2.1.1, 2.1.2 y 2.1.3. 2.1.1. El Sistema Operativo Contiki Para seleccionar el sistema operativo se tuvo en cuenta las siguientes alternativas: TinyOS, FreeRTOS, Contiki, QNX y RTEMS. Se selecciona Contiki atendiendo a que es el más desarrollado y lo respalda una enorme comunidad puesto que está desarrollado por personas tanto del ámbito industrial como del académico [16, 17]. Lo dirige Adam Dunkels, del Instituto Sueco de Ciencias de la Computación. Este coordina un equipo formado por miembros de SICS, SAP, Cisco, Atmel, NewAE y TU Munich. Una instalación completa de Contiki incluye las siguientes características: • Núcleo multitarea. • Subscripción opcional por tarea a multihilo. • Protohilos. • Protocolo de red TCP/IP, incluyendo IPv6. • Interfaz gráfica para el usuario y sistema de ventanas. • Acceso mediante virtual network computing. • Un navegador web (decía ser el más pequeño del mundo). • Servidor de web personal. • Cliente sencillo de Telnet. • Protector de pantalla. Se ha transferido a múltiples arquitecturas, incluyendo la AVR de Atmel. En la figura 2.2 se muestra el aspecto de este SO en un terminal VNC. Como se puede observar, el resultado es notable trabajando sobre un pequeño microcontrolador.. 24.
(30) Figura 2.2: Aspecto de Contiki en un terminal VNC corriendo sobre un AVR. Contiki es un sistema operativo diseñado para entornos con restricciones de memoria, como los nodos utilizados en LLNs. Está basado en un nucleo orientado a eventos, sus características incluyen cargas y descargas dinámicas de programas y servicios individuales, así como multihilo opcional preventivo. También admite una pila TCP/IP completa a través de la biblioteca uIP, así como la abstracción de programación mediante Protohilos. Contiki está implementado en el lenguaje C y ha sido diseñado para ser fácilmente exportable a nuevas plataformas de hardware. Ha sido exportado a más de 20 plataformas diferentes desde su lanzamiento en 2003. Los procesos pueden ser creados por el usuario para desarrollar tareas específicas. Estos se guardan en una lista encadenada: solo se necesita conocer la dirección del primero puesto que cada proceso conoce la dirección del siguiente. Cada proceso tiene un Protohilo asociado, el cual se ejecuta cuando el proceso es llamado. Los estados posibles de los procesos son: desactivado, activado y llamado. Un proceso está en estado llamado cuando se está corriendo su Protohilo. Está activado cuando puede ser llamado mediante eventos y está desactivado cuando ningún evento puede despertar al Protohilo. En un sistema puramente basado en eventos, se implementa un proceso como manejador de eventos, permitiendo que se ejecuten distintos bloques de código, dependiendo de qué evento ocurre. Estos bloques siempre se ejecutan hasta su finalización una vez llamados. Dado que 25.
(31) un solo bloque de código nunca se interrumpirá, estos bloques se pueden diseñar para que todos puedan compartir la misma pila. En comparación, un modelo de múltiples hilos requiere menos memoria y sobrecarga computacional al tener varios procesos simultáneos. El kernel de Contiki contiene un manejador de eventos que envía los eventos a los procesos y periódicamente sondea los procesos que registraron una función de manejador de encuestas. Utiliza una única pila para todos los procesos, que es rebobinada entre cada invocación de un manejador de eventos. A diferencia de la mayoría de los sistemas basados en eventos, Contiki soporta multihilo preventivo. Esto se realiza a través de una biblioteca que puede estar opcionalmente enlazada con programas que lo requieran. Permite a los nodos ejecutar aplicaciones que normalmente no funcionan bien en sistemas basados en eventos, como los cálculos criptográficos. Tal cálculo ocuparía de otro modo el sistema entero durante mucho tiempo. Además de los hilos preventivos, Contiki también soporta Protohilos. Normalmente, cuando se escriben programas para sistemas basados en eventos, éstos deben escribirse como máquinas de estado explícitas con un código resultante que puede ser difícil de entender y mantener. Protohilos son una abstracción de programación utilizada en la parte superior de estos sistemas, con el propósito de simplificar las implementaciones de funcionalidad de alto nivel. Mediante el uso de Protohilos, los programas pueden realizar bloqueo condicional sin la sobrecarga de subprocesos regulares; los Protohilos son apilados y solo se requieren 2 bytes de RAM para cada uno. Un proceso regular de Contiki consiste en un solo Protohilo. En una puesta en marcha regular de Contiki el sistema, entre otras cosas, inicializa algunos procesos. A continuación, llama repetidamente a la función del sistema process_run (). Esta función llama a todos los manejadores de encuesta registrados y a continuación procesa un evento de la cola de eventos del sistema actual. Después de procesar el evento único, la función devuelve el número de eventos no procesados que todavía están en la cola. Si la cola de eventos se vacía, el sistema puede optar por hibernar para ahorrar energía. Si una alarma externa despierta al sistema más tarde, vuelve a realizar los bucles alrededor de la misma función process_run () hasta que se manejan todos los nuevos eventos. UIP (micro IP) es una pequeña implementación TCP / IP adecuada para nodos de sensores y otros dispositivos de recursos limitados. Está diseñado para tener sólo el mínimo absoluto de las características necesarias para una pila TCP / IP completa, y se centra en los protocolos TCP, ICMP e IP. UIP utiliza un solo proveedor global para mantener paquetes, lo 26.
(32) suficientemente grande como para contener sólo un paquete de tamaño máximo. Cuando un nuevo paquete de datos llega de la red, el controlador del dispositivo de red lo coloca en el proveedor global y llama a uIP a manejar los nuevos datos. Después de analizar los datos de paquetes entrantes, uIP notifica la aplicación deseada. Debido a la única fuente, esta aplicación debe actuar de inmediato para evitar que los datos sean sobrescritos por otro paquete entrante. En este punto, la aplicación también puede optar por enviar inmediatamente una respuesta utilizando el mismo proveedor global. De forma similar, cuando una aplicación desea enviar datos, pasa un puntero a los datos, así como la longitud de uIP, que escribe los encabezados y llama al controlador de dispositivo de red para enviar el paquete a la red. 2.1.2. El simulador COOJA COOJA es un simulador de aplicaciones de Contiki OS, no un emulador de nodo. Cuando un usuario crea un nuevo tipo de nodo, el sistema Contiki resultante se compila para la plataforma de simulación, en el entorno regular de Contiki. Mientras que los controladores de una plataforma de hardware operan en el hardware, los controladores de la plataforma de simulación operan en la parte Java del simulador. Pero como la plataforma de simulación soporta las mismas intefaces que cualquier plataforma de hardware, no hay diferencia entre ellos desde el punto de vista de una aplicación. El mismo código de aplicación se compila y ejecuta en ambas plataformas. Así que los periféricos de hardware de una plataforma no son emulados, sino que son reemplazados por otros dispositivos simulados. Una alternativa sería emular todo el hardware de un nodo sensor, lo que podría dar resultados más precisos, pero también limitaría el simulador a una o dos plataformas de hardware soportadas. Mediante el uso del primer método, diferentes plataformas de hardware pueden ser soportadas simplemente conectando todos los controladores deseados. En resumen, una simulación COOJA consiste en un número de nodos que se están simulando. Cada nodo está conectado a un tipo de nodo. Cuando se ejecuta la simulación, todos los nodos actúan a su vez. Cuando todos los nodos han actuado, el tiempo de simulación se actualiza y se repite el proceso. En detalle, cada nodo tiene su propia memoria y un número de interfaces. La memoria consiste en uno o varios segmentos de memoria, cada uno con una dirección de inicio y datos. Los segmentos de memoria deben incluir todas las partes necesarias y de interés de un sistema operativo Contiki simulado. 27.
Figure
+7


Documento similar
En la base de datos de seguridad combinados de IMFINZI en monoterapia, se produjo insuficiencia suprarrenal inmunomediada en 14 (0,5%) pacientes, incluido Grado 3 en 3
En este ensayo de 24 semanas, las exacerbaciones del asma (definidas por el aumento temporal de la dosis administrada de corticosteroide oral durante un mínimo de 3 días) se
En un estudio clínico en niños y adolescentes de 10-24 años de edad con diabetes mellitus tipo 2, 39 pacientes fueron aleatorizados a dapagliflozina 10 mg y 33 a placebo,
• Descripción de los riesgos importantes de enfermedad pulmonar intersticial/neumonitis asociados al uso de trastuzumab deruxtecán. • Descripción de los principales signos
Debido al riesgo de producir malformaciones congénitas graves, en la Unión Europea se han establecido una serie de requisitos para su prescripción y dispensación con un Plan
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
Abstract: This paper reviews the dialogue and controversies between the paratexts of a corpus of collections of short novels –and romances– publi- shed from 1624 to 1637:
E Clamades andaua sienpre sobre el caua- 11o de madera, y en poco tienpo fue tan lexos, que el no sabia en donde estaña; pero el tomo muy gran esfuergo en si, y pensó yendo assi
