Robust, fuzzy, and parsimonious clustering based on mixtures of Factor Analyzers
Texto completo
Figure
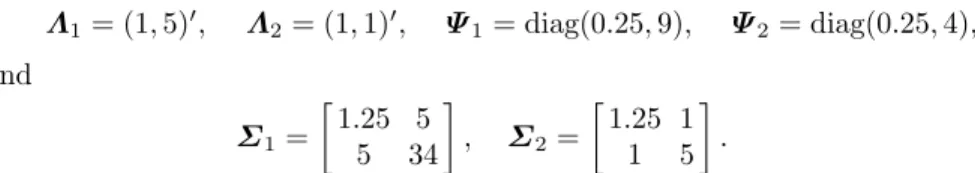
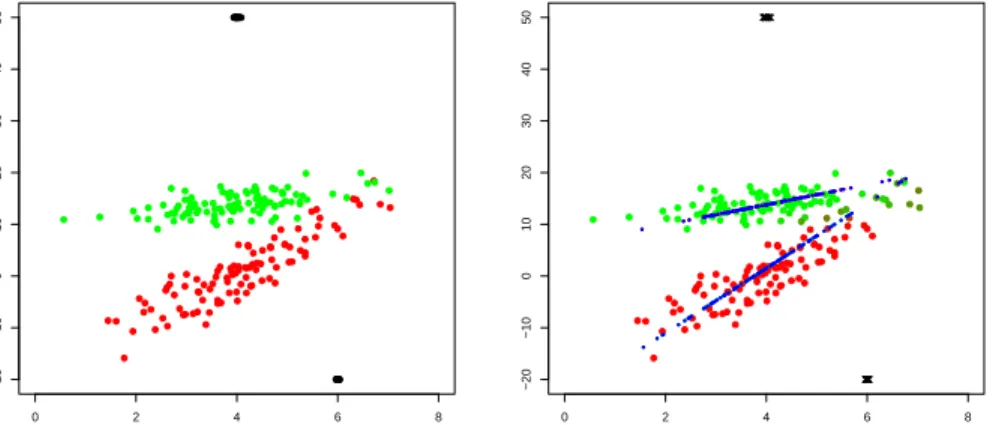
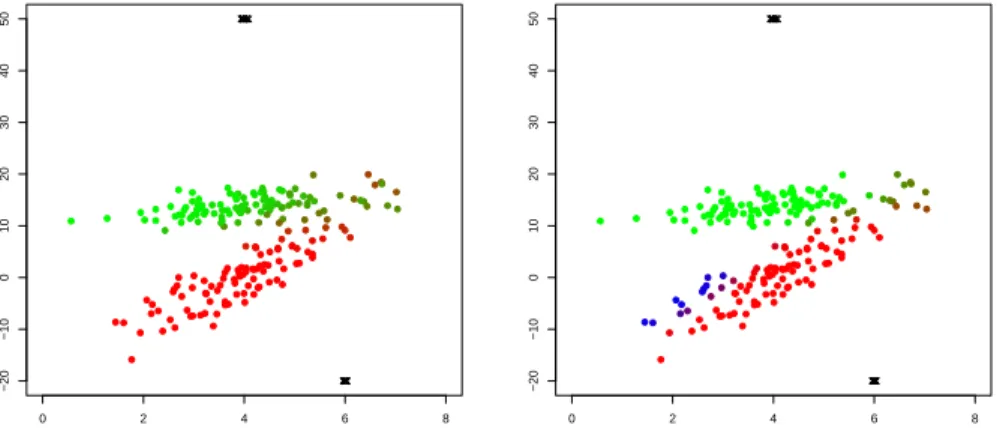

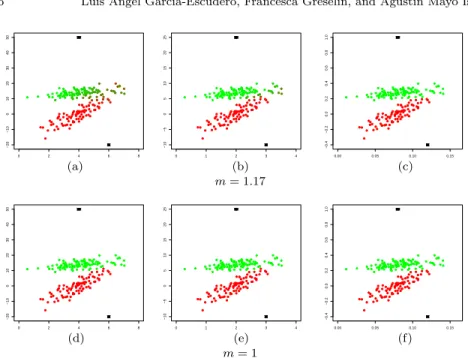
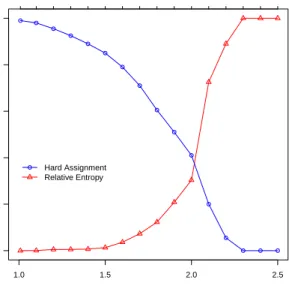
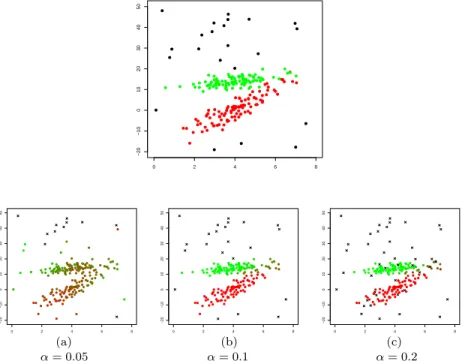
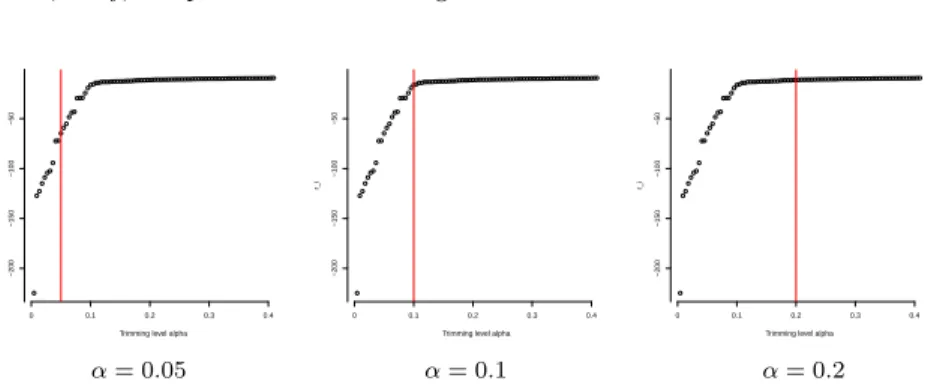
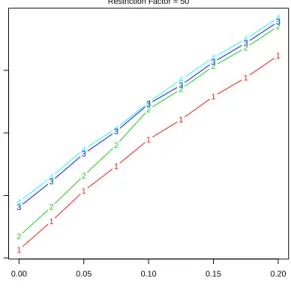
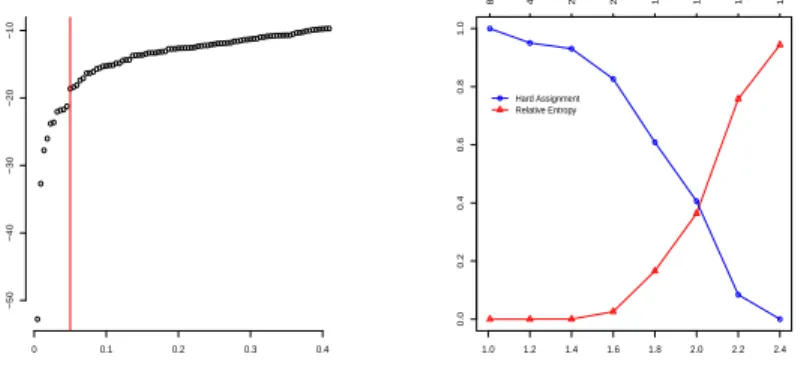
Documento similar
A conditional sampling technique based on a Fuzzy Clustering algorithm has been applied to the analysis of time series of spanwise vorticity fields obtained from time resolved PIV
No obstante, como esta enfermedad afecta a cada persona de manera diferente, no todas las opciones de cuidado y tratamiento pueden ser apropiadas para cada individuo.. La forma
The expansionary monetary policy measures have had a negative impact on net interest margins both via the reduction in interest rates and –less powerfully- the flattening of the
As shown in the previous section, our results can contribute to find approximate solutions of constrained fuzzy optimization problems by realizing utility fuzzy- valued functions
For this, 1 use a model of monopolistic competition (Kmgman, 1980) in which the consumers have a preferente for diversity and the economies of scale aren't determining factor.
Clustering error and estimation of an upper bound for the documents complexity obtained for all the word selection methods when the asterisk substitution method is used.. The
In this study, the application of one data-driven method, RBFLN, and two knowledge-driven methods (Fuzzy AHP_OWA and fuzzy group decision making) has been
Paper I: The clustering of galaxies in the SDSS-III Baryon Oscillation Spectroscopic Survey: modelling the clustering and halo occupation distribution of BOSS CMASS galaxies in
