Chapter 5
Hypothesis testing
…...
..
…...
Objetive
Chapter
Introducción
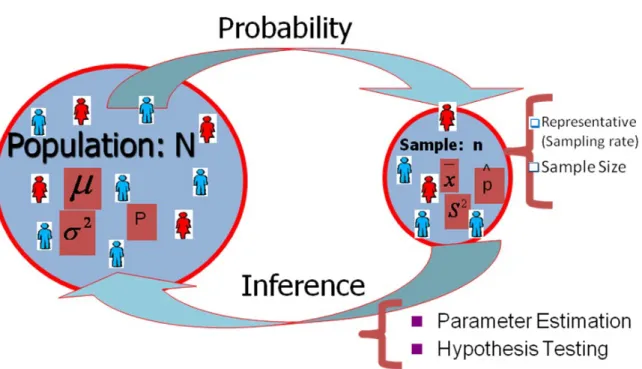
Inferential statistical methods are a way to extract conclusions about a population, the data obtained from a probability sample. Statistical Inference involves two main types of techniques: Parameter Estimation and Hypothesis Testing. Whatever the technique used, the overall purpose is to use data from a probability sample to extract conclusions about a population.
Hypothesis testing is very important in the scientific community and is necessary for advancing theories and ideas. Hypothesis tests are very useful and application in economics. An important component of the total quality management (TQM) is the use of Statistics and Statistical thinking in continuous improvement and in decision making. As Businesses have recognized the importance of Statistics, they have increasingly questioned the Statistical Education of business school graduates. Statistics play a vital role in a wide variety of business decisions today, from planning and interpreting market research and economic data to developing work volume forecasts.
The following figure 1 shows the process of inferential statistics:
Figure 1 Process of inferential statistics
Hypothesis Testing
A statistical hypothesis is an assumption on one or more populations that may be true or not. The statistical hypotheses can be compared with information extracted from the samples and whether they are accepted as if rejected can make a mistake. Since in practice not know if the decision is correct or not, we must choose contrasts that minimize the probability of error of type I and II. However, this is not possible because these probabilities are complementary sense, as when one increases the other decreases. Therefore, the criterion used is to set the significance level, choosing from all tests (statistical tests) possible, with a significance level that makes possible the risk or, which is, maximizes the power.
Purpose of hypothesis testing
The purpose of hypothesis testing is to determine whether there is enough statistical evidence in favor of a certain belief about a parameter.
Example: Is there statistical evidence in a random sample of potential customers that support the hypothesis that more than 10% of the potential customers will buy a new product?
The assumption made with intent to reject the null hypothesis is called and is denoted by Ho. Reject Ho implies accepting an alternative hypothesis (Ha).
The wise business leaders always conduct formal and informal research to inform their business decisions. Good research starts with a good hypothesis, which is simply a statement making a prediction based on a set of observations. For example, if you’re considering offering flexible work hours to your employees, you might hypothesize that this policy change will positively affect their productivity and contribute to your bottom line. The ultimate job of the hypothesis in business is to serve as a guidepost to your testing and research methods.
Types of Errors
Two types of errors may occur when deciding whether to reject H0 based on the statistic value.
Type I error ( ): Reject the null (Ho) hypothesis when it is true. Type II error ( ): Do not reject the null (H0) when it is false.
Realize, that a small p-value (or observed level of significance) suggests that the alternative hypothesis is true, but does not guarantee it is true.
Actual
situation
Our
decision
Null (Ho)
hypothesis is
false
Null (Ho)
hypothesis is
true
Reject the null (Ho) hypothesis
Correct
decision
Type I
error (α)
Called Level of Significance
Do not reject the null (Ho) hypothesis
Type II
error (β)
Correct
decision
(1-β)
Figure 2. Error Type
Note: do not reject the null hypothesis or Fail to Reject
Details to note:
and are inversely related.
Only both can be decreased by increasing the sample size "n".
Steps in Hypothesis Testing
1. Making Assumptions and Meeting Test Requirements Model: Random sampling
Level of measurement is interval-ratio
Sampling distribution is normal (we can be sure that this assumption is satisfied by using large samples. (Central Limit Theorem)
Specify the population value of interest
If you have two or more groups check assumption about homogeneity 2. Formulate the appropriate null and alternative hypothesis
Null Hypothesis, Ho: States the assumption (numerical) to be tested. This hypothesis is assumed to be true, and the collected data will be analyzed to see if it is contradictory to the null hypothesis.
Research Hypothesis
“We suppose that the monthly amount in Rwandan Francs that an AUCA student invests when using their cell phone is less than 5,000 Rwf.”
Example of the Null Hypothesis:
The average monthly expense that the AUCA student invests in using the telephone is at least five thousand Rwf.
Ha: m < 5000 (This is what you want to prove)
Alternative hypothesis never contains the “=” , “≤” or “³” sign May or may not be accepted
Is generally the hypothesis that is believed (or needs to be supported) by the researcher.
Practice: for the following examples give the null hypothesis and the alternative hypothesis
• The mean age of the students enrolled in evening classes at a certain college is greater than 26 years. • The mean weight of packages shipped on Air Express during the past month was less than 36.7 lb. • The mean life of fluorescent light bulbs is at least 1600 hours.
• Is there statistical evidence in a random sample of potential customers, which support the hypothesis that more than 10% of the potential customers will purc9hase a new product?
• You want to show that people find the new design for a recliner chair more comfortable than the old design.
3. Specify the desired level of significance (a). The probability of rejecting the null hypothesis when it is true. Is designated by a , (the Greek letter alpha). Sometimes called the level of risk.
Typical values are .01, .05, or .10, but any value between 0 and 1.00 is possible. Is selected by the researcher at the beginning (usually when you take the sample size) Provides the critical value (probabilistic values) of the test.
4. Select and computing the Test Statistic to use and Establishing the Critical Region (it depends on the hypothesis raised) For use the statistic test is necessary see the assumptions about type of data (numerical or categorical), sampling method (random), population distribution (e.g., normal), sample size (large enough?).
There are many test statistics, In this chapter, we use ‘Z’ or ‘t’ distribution (solving the equation), and the resultant value will be referred to as Z (obtained) or t(obtained) in order to differentiate the test statistic from the critical region. For example if we test hypothesis about μ:
Solving the equation (Z or t), and the resultant value will be referred to as Z (obtained) or t (obtained) in order to differentiate the test statistic from the critical region.
5. Making a Decision and Interpreting the Result of the Test
a. Reach a decision and interpret the result with a critical value:
The test statistic is compared with the critical region. If the test statistics fall into the critical region, our decision will be to reject the null hypothesis. If the test statistic does not fall into the critical region, we fail to reject the null hypothesis. • If we reject the null hypothesis, we conclude that there is enough evidence to infer that the alternative hypothesis is
true.
• If we do not reject the null hypothesis, we conclude that there is not enough statistical evidence to infer that the alternative hypothesis is true.
Figure .3. Level of Significance and the Rejection Region
b. Or reach a decision and interpret the result with P-value:
There is another popular procedure for considering the test of the null hypothesis. The most widely accepted cutoff point is 0.05.
If the P-value or Sig. is smaller than the significance level, Ho is rejected. If it is lager than the significance level, Ho is not rejected.
< .05 the test is said to be “significant at the .05 level”. (If the p-value is smaller than the significant level, Ho is rejected)
If the P-value is larger than the significant level, we fail to reject Ho or Ho is not rejected (then, Ho is not necessarily true, but it is plausible).
If decision needed, select a cutoff point (such as .05 or .01) and reject Ho if P-value < that value.
Figure .4. Making Decision with the P-value
When Population Standard Deviation is Unknown
When we unknown the population Standard Deviation, we must use test based on the Student’s t distribution. The Student’s t distribution depends on the degrees of freedom “n-1”. In addition, the Student’s t distribution becomes close to the normal distribution as the sample size increases. To write the null hypothesis we have 3 alternatives approach, this depends on the research question:
Where:
is the sample mean
is the hypothesized population ‘s’ is the sample standard deviation
‘n’ is the number of observation in the sample
There are actually many different t distributions. The particular form of the t distribution is determined by its degrees of freedom. The degrees of freedom refer to the number of independent observations in a set of data.
When estimating a mean score or a proportion from a single sample, the number of independent observations is equal to the sample size minus one. For example, the distribution of the 't' statistic from samples of size 12 would be described by a distribution 't' having 12-1 = 11 degrees of freedom, therefore Degrees of Freedom (df = n-1)
Example 1- Kigali Height
The manager of Kigali Height mall wants to estimate the mean amount spent per shopping visit by customer. A sample of 12 customers reveals the following amount spent.
48.16 42.22 46.82 51.45 23.78 41.86 54.86 37.92 52.64 48.59 50.82 46.94
a. What is the best estimate of the population mean? Determine a 95% confidence interval. Interpret the result. b. Would it be reasonable to conclude that the population mean is $50? What about $60?
Solution
Assumptions: The variable is interval, data obtained by random sampling, and the manager assumes the population of the amounts spent follows the normal distribution.
a. Confidence interval
Margin of error =
= 5.3364
The endpoints of the confidence interval are between 40.17 and 50.85. It is reasonable to conclude that the population mean is in that interval. The value of $60 is not in the confidence interval. Hence, we conclude that the population mean is unlikely to be $60
b. The null hypothesis (which we reject) is:
We set "a priori" the significance level of a = 0.05
Degrees of freedom: df = n-1, then in our example n=12 and df = 11
t
(,
n-1)=
t
(0.05, 11) =2.20 (statistic table) Statistic:Decision rule: Reject the null hypothesis if the compute “t” is into the critical region or fails to reject the null hypothesis if “t” does not fall in the "critical region".
Making a decision and interpreting the results: Since the manager of Kigali Heights test, t* = -1.852, is not less than -2.20 nor greater than 2.20, the manager fails to reject the null hypothesis. That is, the test statistic does not fall in the "critical
sample mean ( =45.51) population mean (μ =50)
region." There is insufficient evidence, at the α = 0.05 level, to conclude that the mean amount spent per shopping visit by customer differs from 50$.
Now, we will work with the same example using the statistical software and check that the same results will obtained:
Steps for requesting a hypothesis test in SPSS
Analyze <Compare Means <One-Sample T Test <Follow the steps as shown in the figure below
SPSS output (recommendation: work by formulas and checks if it is the same results).
One-Sample Statistics
N Mean Std. Deviation Std. Error Mean
Amount spent per customer 12 45.5050 8.39890 2.42455
Interpretation: The average amount spent per customer is 45.51 and standard deviation is the variability around mean is 8.399 dollar.
One-Sample Test
Test Value = 50
t df Sig. (2-tailed) Mean Difference
95% Confidence Interval of the Difference
Lower Upper
Amount spent per
customer -1.854 11
.091
-4.49500 -9.8314 .8414
We observe that the formula t = -1.854, is the same value calculated with the formula.
Interpretation: We cannot reject null hypothesis because the p-value or Sig. = .091 is more than a = 0.05, and conclude that the population mean is not significant different from $50
Note 1: The value of ‘p’ or Sig gives us the SPSS default is bilateral (2-tailed), if you need to transform for unilateral: For example: Sig. 2 tailed= 0.091, them 1 tailed = 0.014/2 = 0.0455.
Population: N
1 1 2 1 1:
,
n
Sample
s
x
Population: N
22 2 2 2
:
,
n
Sample
s
x
ComparisonIndependent samples
Hypothesis test for mean difference, if the samples are obtained from normally distributed populations with known or unknown population variances (independent)
A common research situation is to test for the significance of the difference between two populations. We develop procedures for testing the differences between two population means or proportion and for testing variances. The process for comparing two populations begins with an investigator forming a hypothesis about the nature of the two populations and the difference between their means or proportions. The hypothesis is stated clearly as involving two options concerning the difference, and then a decision is made based on the results of a statistic computed from random samples of data from the two populations.
When Populations Variances Unknown
Steps of a hypothesis test for independent samples
Step 1 Making Assumptions and Meeting Test Requirements
Remember that for proper use of the distribution "t" or normal distribution "Z", the data must satisfy the following assumptions:
Assume that the random samples are independent Level of measurement is interval-ratio
Randomness: samples were selected using a probabilistic method. Otherwise inference is not applied.
Normality: The variables of analysis, in both populations are normally distributed. (Boxplot, histogram with normal curve, Normal Q-Q plot, Shapiro-Wilk, KS, etc.). If not satisfy these conditions do using a nonparametric test or you transform your variable
Homogeneity of variances: The population variances are not different. That is: (Levene test, F, etc.). If not corrected the number of degrees of freedom and used the t test cuff applies a nonparametric test. When samples are very unequal are more likely to violate this assumption.
Ho: Ho: Ho:
Ha: Ha: Ha:
Step 3 Level significance: = (0.01, 0.05 or 0.10)
Step 4 Compute the test statistic:
The statistical work is the expression:
Step 5 Critical regions for testing (If is manually you check the probabilistic table or if you work with SPSS you focus in what is the value “Sig” in your result)
Step 6 Making a Decision and Interpreting the Result of the Test. Comparing the test statistic with the critical region. Take your decision according the following rules:
Alternative hypothesis Rejects Ho if
If the result is from SPSS or other software you take your decision with Sig < .05 you reject null hypothesis. If Sig is more than 5%, do not reject null hypothesis.
And interpret the result according the question in the problem and take your decision and your conclusion.
Example 2
A cigarette maker analyzes two different brands for determining the nicotine content. A sample was taken of each brand and got the following results (in milligrams).
Brand A: 24 26 25 22 23
Brand B: 27 28 25 29 26
Do the above results indicate that there is a difference in the average content of nicotine in both brands?
Solution
Ho: Ha:
Statistical data obtained through the samples:
Since we have finite populations and small samples ( ) and unknown population variances then the statistic will be:
,This is
Decision rule
If We reject Ho
Making a Decision and Interpreting the Test Result. Since the test statistic, t = -3 is less than -2.306, we reject null hypothesis. That is, the test statistic falls in the "critical region”. We can say at level of significance of 5% that there is a significant difference in the average content of nicotine in both brands, therefore it is concluded that brand B content more nicotine than brand A .
Note: In your interpretation when the report is a significant difference, you should verify how much is the average per group and conclude accordingly.
Step using SPSS (Create data file)
Enter the data in SPSS, with the variable “Nicotine” takes up one column, and the Brand variable for identifying whether the nicotine data was from brand A or brand B subject takes up another column.
The “Nicotine” is considered as the dependent, response or outcome variable, and the “Brand” variable is the independent or factor variable. The two variables should be created in the way as seen in the data editor on the right. The Brand variable takes on two possible values, 1 or 2. The value “1” for brand A, and the value “2” for brand B.
When the data is completed, follow the steps shown on the next slide.
To do this, click on Analyze, and then Compare means followed by independent samples T test and then continue the followed steps as shown in the figure below < continue < OK
Output from SPSS
So we ask the t test for independent samples, which we gives t = -3.00, same as we obtained manually. Looking at the next Sig. (2-tailed) the value is .017, lower than proposed.
Making a Decision and Interpreting the Test Result: We would reject the null hypothesis because the p-value or Sig. = .017 is less than a (.05), therefore at level of significance of 5% we can say the results indicate that there is a statistically significant difference in the average content of nicotine in both brands, i.e. Brand B content more nicotine than Brand A.
Basic assumptions:
Assumption of normality. To check if the variable is normally distributed, the following steps in the SPSS
Analyze <descriptive statistics <explore <follow the steps as shown in the figure below <accept
Box plot (to check if there are no outlier values and if the boxes behave symmetrically Note: Interpreting Box plots in general:
Box plots are used to show overall patterns of response for a group. They provide a useful way to visualize the range and other characteristics of responses for a large group.
The diagram below shows a variety of different box plot shapes and positions.
Some general observations about box plots:
About variability: The Box plot of 2, 3 and 4 show homogeneity, that is, they are symmetric distributions. However box plot 1 shows an asymmetric distribution (Asymmetry negative), i.e. data tend to be concentrated towards the top of the distribution and extend leftward. In the context (about marks), the majority marks or views, etc. is concentrated in a higher score and lowest score are more dispersed.
The box plot is comparatively short - see example (2). This suggests that overall students have a high level of agreement with each other.
One box plot is much higher or lower than another – compare (3) and (4) – This could suggest a difference between groups. For example, the box plot for (4) may be lower than the equivalent plot for (3).
Obvious differences between box plots – see boxes plots (1) and (2), (1) and (3), or (2) and (4). Any obvious difference between box plots for comparative groups is worthy of further investigation.
the example means that students’ views are varied amongst the most positive quartile group, and very similar for the least positive quartile group.
Same median, different distribution – See boxes plots (1), (2), and (3). The medians (which generally will be close to the average) are all at the same level. However the box plots in these examples show very different distributions of views. It always important to consider the pattern of the whole distribution of responses in a box plot.
Hypothesis testing to determine the normality
Ho: The variables follow a normal distribution Ha: Variables do not follow a normal distribution
Tests of Normality
Cigarette Brand
Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig.
Nicotine Brand A 0.136 5 .200* 0.987 5 0.967
Brand B 0.136 5 .200* 0.987 5 0.967
a. Lilliefors Significance Correction
Making a Decision and Interpreting the Result of the Test
We observed Shapiro-Wilk statistic given that the samples are small The p-values (Sig.) Brand A: Sig, 967
Brand B: Sig, 967
From Shapiro-Wilk test of normality are both greater than 0.05, which imply that it is acceptable to assume that the average content of nicotine distributions for Brand A and Brand B populations are both normal (or bell-shaped).
Assumption of Homogeneity
Through the Levene test can see if this assumption very important to compare groups met.
The report of SPSS gives without asking
Ho: The variances are equal or equal variances assumed Ha: Equal variances not assumed
Decision: The p-value or Sig provides the Levene test is greater than 5% (Sig. = 1.000), and then we cannot reject Ho, and conclude that equal variances assumed.
The procedure to compare means of two dependent samples is very different from that followed when the samples are independent.
One of the most common experimental designs is the "pre-post" design. A study of this type often consists of two measurements taken on the same subject, one before and one after the introduction of a treatment or a stimulus. The basic idea is simple. If the treatment had no effect, the average difference between the measurements is equal to 0 and the null hypothesis holds. On the other hand, if the treatment did have an effect (intended or unintended!), the average difference is not 0 and the null hypothesis is rejected.
For example, if we give training to a company employee and we want to know whether or not the training had any impact on the efficiency of the employee, we could use the paired sample test. We collect data from the employee on a five scale rating, before the training and after the training. By using the paired sample t-test, we can statistically conclude whether or not training has improved the efficiency of the employee.
Steps of a Hypothesis test for paired comparisons or related
Step 1 Formulate the appropriate null and alternative hypothesis
Ho: Ho: Ho:
Ha: Ha: Ha:
Step 2 Level significance = (0.01, 0.05, 0.10)
Step 3 Determine the rejection region with critical value (It depends on the hypothesis raised)
Step 4 Compute the test statistics
, d = x – y When de population variance is Unknown
Where:
= Assumed average difference of the population = The average difference of the sample
= Standard deviation of the sample difference results n = sample size
Assumptions:
The assumptions underlying the repeated samples t-test are similar to the one-sample t-test but refer to the set of difference scores.
1. The observations are randomness and independent of each other 2. The dependent variable is measured on an interval scale 3. The differences
(
di
)
are normally distributed in the population. `d = arithmetic mean of the differencesSd = standard deviation of the differences
Step 5 Compare the critical value with experimental value; which is obtained by replacing the data of the problem in Step 4 or if the result is from SPSS or other software you take your decision with Sig < .05 you reject null hypothesis. If Sig is more than 5%, do not reject null hypothesis.
It is also possible to estimate the mean difference in paired data. The formula used for this estimation.
Confidence Interval:
Example 4
Advertisements by fitness Center in Amahoro Studium claim that completing of physical training will result in losing weight. A random sample of ten recent participants showed the following weights before and after completing physical training. At the .05 significance level, can we conclude the participants
lost weight?
Participants 1 2 3 4 5 6 7 8 9 10
Before 155 228 141 162 211 164 184 172 176 141
After 154 207 147 157 196 150 170 165 167 140
Solution
Hypothesis approach Ho:
Ha:
Significance level: = 0.05
Procedure:
Participants Before After Differences (B-A)
1 155 154 1
2 228 207 21
3 141 147 -6
4 162 157 5
5 211 196 15
6 164 150 14
7 184 170 14
8 172 165 7
9 176 167 9
10 141 140 1
=
Critical value: t for (df=10-1=9, one tail) is ttabulate = 1.833 Making a Decision and Interpreting the Result of the Test
The experimental value t = 3.151> ttabulate = 1.833, therefore the experimental value is in the critical region, and we conclude at level of significance of 5% that the physical training was effective with respect to decrease the weight of participants.
Report on the statistical software SPSS 23.0
2° Process (order the t-test analysis for related samples)
3° Report
Paired Samples Statistics
Mean N Std. Deviation Std. Error Mean
Pair 1 Weight_Before 173.4000 10 28.23001 8.92711
Weight_After 165.3000 10 21.37522 6.75944
The report shows the descriptive statistics, the average weight being (before) is more than the average after implementing the physical training, but do not know whether this difference observed is significant.
So we ask the t test for related samples, which we gives t = 3.151, same as we obtained manually. Looking at the Next, Sig. (2-tailed) the value is .012, lower than proposed).
Decision rule: If Sig = .012/2 < 0.05, we reject Ho, therefore at level of significance of 5% we can say that the training program was effective with respect to reducing participants' weight.
Note: We divide Sig/2, because the alternative hypothesis is 1-tail, and the statistical software gives us by default 2-tails, therefore to transform into 1-tail, we have to divide.
Review problems of chapter
Follow the procedures covered in this chapter to generate appropriate to answer the following questions:
1. What is the purpose of a statistical hypothesis?
4. They have total cholesterol levels of a sample of eight patients before and after participating in a diet-exercise program. Can be concluded that the program had positive impact? (Before-After)
Patient Before After
1 201 200
2 231 236
3 221 216
4 260 233
5 228 224
6 237 216
7 326 296
8 235 195
Answer: (test statistic =2.678, and Critical value=1.895)
5. In 2014, consumer reports gave the following prices for a sample of 18
cellular cell phones:
600 300 289 499 615 279 475 425 445
255 612 353 530 322 375 580 250 399
Assuming a normally distributed population, test the hypothesis at the .05 level that the population mean price for cellular phones at the time of this survey was more than $350
a) Conduct the appropriate statistical test of your hypothesis, using a .05 statistical significance level. b) Interpret the following SPSS computer output for the t test
:
One-Sample Statistics
N Mean Std. Deviation Std. Error Mean
Prices 18 422.3889 128.09194 30.19156
Interpret each statistic of the table above:______________________________________________________________
One-Sample Test
Test Value = 350
t df Sig. (2-tailed) Mean Differenc e
95% Confidence Interval of the Difference
Lower Upper
Prices 2.398 17 0.028 72.389 8.6903 136.0875
Test statistic:_____________, Sig:_____________
Making a Decision and Interpreting the Result of the Test:_________________________________________
Testing the assumption of normality
Tests of Normality
Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic Df Sig.
Prices .117 18 .200* .922 18 .141
*. This is a lower bound of the true significance.
Ho: Ha:
Test statistic:_____________ Sig:_____________
Making a Decision and Interpreting the Result of the Test:_________________________________________
Interpretation:____________________________________________________________________________
6. A firm is to buy a fleet of cars for use by its salesmen and wishes to chose between two alternative models, A and B. it places an advertisement in a local paper offering 20 liters of petrol free to anyone who has bought a new car of either model in the last year. The offer is conditional on being willing to answer a questionnaire and to note how far the car goes (fuel consumption)
, under typical driving conditions, on the free petrol supplied. The following
data were obtained.
Km driven on 20 liters of petrol
Model A 187 218 173 235
Model B 157 198 154 184
202 174 146 173
Assuming these data to be random samples from two normal populations, test whether the populations mean may be assumed equal. List good and bad features of experimental design and suggest how you think it could be improved.
a) Conduct the appropriate statistical test of your hypothesis, using a .05 statistical significance level. b) Interpret the following SPSS computer output for the t test:
Group Statistics
Model N Mean Std. Deviation Std. Error Mean
Km Model A 4 203.2500 28.31225 14.15612
Model B 8 173.5000 20.46600 7.23582
b.1 Interpretdescriptive statistics:_______________________________________________________________________ Independent Samples Test
Levene's Test for Equality
of Variances t-test for Equality of Means
F Sig. t Df
Sig. (2-tailed)
Mean Difference
Std. Error Difference
Km Equal variances
assumed 1.244 .291 2.103 10 .062 29.750 14.147
Equal variances
not assumed 1.871 4.637 .125 29.750 15.898
b.2. Test statistic:_____________, Sig:_____________
Making a Decision and Interpreting the Result of the Test:_________________________________________
b.3 Basic assumptions for Homogeneity
Ha
Test statistic:_____________, Sig:_____________
Making a Decision and Interpreting the Result:__________________________________________________
b.4 Testing the assumption of normality
Ho: Ha:
Test statistic:_____________, Sig:_____________
Making a Decision and Interpreting the Result of the Test:_________________________________________
Tests of Normality
Model
Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic Df Sig.
Km Model A .217 4 .949 4 .709
Model B .165 8 .200* .943 8 .642
b.5 Interpret the following graphs:
7. The manufacturer of an MP3 player wanted to know whether a 10% reduction in price is enough to increase the sales of its product. To investigate, the owner randomly selected eight outlets and sold the MP3 player at the reduced price. At seven randomly selected outlets, the MP3 player was sold at the regular price. Reported below is the number of units sold last month at the sampled outlets. At the .05 significance level, can the manufacturer conclude that the price reduction resulted in an increase in sales?
Regular price 138 121 88 115 141 125 96
Reduced price 128 134 152 135 114 106 112 120
8. Bucyana Gerard is vice president for human resources for a large manufacturing company. In recent years, he has noticed an increase in absenteeism that the thinks is related to the general health of the employees. Four years ago, in an attempt to improve the situation, he began a fitness program in which employee
s exercise during the lunch
hour. To evaluate the program, he selected a random sample of eight participants and found the
number of days each was absent in the six months before the exercise program began and in the
last six month. At the .05 significance level, can he conclude that the number of absences has
declined?
Employee Before After
1 6 5
2 6 2
3 7 1
4 7 3
5 4 3
7 5 3
8 6 7