Heurísticas en la Optimización de Máquinas de Soporte Vectorial
79
0
0
Texto completo
(2) ÍNDICE GENERAL 1. Introducción. 4. 2. Estado del Arte 2.1. Las Máquinas de Soporte Vectorial . . . . . . . . . . . . . . . . . . . . . . . . . 2.1.1. Principio de Minimización del Riesgo Empı́rico . . . . . . . . . . . . . . 2.1.2. Principio de Minimización del Riesgo Estructural . . . . . . . . . . . . . 2.1.3. Las MSV lineales y el caso linealmente separable . . . . . . . . . . . . . 2.1.4. Las MSV lineales y el caso no linealmente separable . . . . . . . . . . . 2.1.5. Las MSV no-lineales . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2. Estrategias de solución para las Máquinas de Soporte Vectorial . . . . . . . . . . 2.2.1. Chunking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.2. Algoritmo de Osuna . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2.3. Optimización Secuencial Mı́nima . . . . . . . . . . . . . . . . . . . . . 2.3. Algoritmo Perceptrón . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.3.1. Kernel-Perceptrón: extensión del Perceptrón a funciones Kernel . . . . . 2.4. Algoritmo de Schlesinger-Kozinec . . . . . . . . . . . . . . . . . . . . . . . . . 2.4.1. KSK: la extensión del algoritmo Schlesinger-Kozinec a funciones Kernel 2.5. Procedimiento de corrección de baricentros (PCB) . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . .. 8 8 8 11 11 18 20 22 24 26 28 29 30 31 34 35. 3. Heurı́sticas de optimización para las Máquinas de Soporte Vectorial 3.1. Inicialización de las Máquinas de Soporte Vectorial con la ayuda del Perceptrón . . 3.2. Inicialización de las Máquinas de Soporte Vectorial mediante el algoritmo PCB . . 3.3. Otra heurı́stica que mejora el uso del Perceptrón y del PCB en la inicialización de las Máquinas de Soporte Vectorial . . . . . . . . . . . . . . . . . . . . . . . . . . 3.3.1. Problemas encontrados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.4. Inicialización de las Máquinas de Soporte Vectorial por medio de Kernel-Perceptrón 3.5. Inicialización de las Máquinas de Soporte Vectorial utilizando KSK . . . . . . . .. 39 42 45. 4. Experimentación y Análisis de Resultados 4.1. Bases de datos a utilizar para probar las diferentes heurı́sticas . . . . 4.2. Inicialización de las MSV por medio del algoritmo Perceptrón . . . 4.2.1. Resultados obtenidos . . . . . . . . . . . . . . . . . . . . . 4.2.2. Análisis de Resultados . . . . . . . . . . . . . . . . . . . . 4.3. Inicialización de las MSV utilizando PCB . . . . . . . . . . . . . . 4.3.1. Resultados obtenidos . . . . . . . . . . . . . . . . . . . . . 4.3.2. Análisis de Resultados . . . . . . . . . . . . . . . . . . . . 4.4. Inicialización de las MSV a través del algoritmo Kernel-Perceptrón . 4.4.1. Resultados obtenidos . . . . . . . . . . . . . . . . . . . . . 4.4.2. Análisis de Resultados . . . . . . . . . . . . . . . . . . . . 4.5. Inicialización de las MSV con KSK . . . . . . . . . . . . . . . . . 4.5.1. Resultados obtenidos . . . . . . . . . . . . . . . . . . . . . 4.5.2. Análisis de resultados . . . . . . . . . . . . . . . . . . . .. 49 49 55 55 58 59 59 62 63 63 67 67 68 73. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. . . . . . . . . . . . . .. 46 46 48 48.
(3) 5. Conclusiones. 74. 3.
(4) 1.. INTRODUCCIÓN. Gracias a los avances tecnológicos presentes en la actualidad se ha impulsado el estudio de aplicaciones y técnicas de clasificación de datos. El problema de clasificación de datos surge a partir de la necesidad de categorizar información presente en la vida real como caras, texto, enfermedades, música, etc. Actualmente existen diversas comunidades de investigación que trabajan en el desarrollo de aplicaciones que requieren clasificación de datos convirtiéndose en una de las principales áreas de estudio para la inteligencia artificial. La clasificación consiste en proporcionar nuevos datos al sistema para que éste los etiquete utilizando el conjunto de clases disponibles. Las diferentes fases para llevar a cabo este proceso son: la adquisición de los datos, el aprendizaje del clasificador y la evaluación del mismo. Los puntos que se consideran para evaluar un clasificador son exactitud, rapidez y tiempo de aprendizaje. A la fecha, existen diversos métodos entre los que se encuentran: métodos estadı́sticos clásicos [1], modelos de dependencias [2], aprendizaje simbólico y redes neuronales [3], los cuales resuelven con buenos resultados el problema de clasificación. La desventaja en el uso de estos métodos es que no se tiene la seguridad de que la solución obtenida sea la mejor, por esta razón se.
(5) sugiere el uso de las Máquinas de Soporte Vectorial (MSV). Las Máquinas de Soporte Vectorial aseguran que la solución obtenida al clasificar un conjunto de datos es la mejor. Desafortunadamente el entrenamiento de las MSV es muy lento además de que se trata de un método complejo tanto en su proceso interno como en su implementación. Las MSV fueron desarrolladas por Vladimir Vapnik, [4], como una potente herramienta en el área de reconocimiento de patrones. Este método, además de ser utilizado en clasificación, se utiliza en tareas de regresión y en estimación de todo tipo funciones. En tareas de clasificación, se sabe que dentro del conjunto de datos a clasificar existen elementos clave que permiten identificar a que clase pertenece cada dato. Dichos elementos son llamados vectores de soporte y son estos el objetivo de búsqueda de las MSV ya que mediante ellos se determina si un elemento del conjunto pertenece a una clase o a otra. Además, es necesario enfatizar que, para clasificar un conjunto de patrones, los únicos datos necesarios son los vectores de soporte y no el conjunto de datos completo. En el desarrollo las MSV se ve involucrada la resolución de un problema de programación cuadrático identificado por una matriz cuadrada, semidefinida positiva y densa (hessiana). La complejidad del problema cuadrático crece de manera exponencial O(n2 ) según aumenta el numero de observaciones. En problemas en los que el número de datos es grande, el calculo del hessiana es muy difı́cil además de que su almacenamiento no es posible en cualquier equipo de computo. Lo anterior implica que la solución de las MSV sea un proceso lento el cual puede tardar dı́as, por lo que es necesario encontrar métodos o heurı́sticas que permitan acelerar este proceso de solución. Para evadir el problema del tiempo de entrenamiento de las MSV, Vapnik desarrolló un método que divide el problema en sub problemas para los que se encuentran los vectores de soporte. Ası́, las diferentes soluciones encontradas son combinadas hasta encontrar la solución global del problema, dicho procedimiento es llamado Chunking [5], [4]. Chunking es un algoritmo aleatorio por lo que es ahı́ donde se tiene su principal desventaja ya que se puede tener alguno de los siguientes casos: * Los subconjuntos formados por Chunking contienen algunos o todos los vectores de soporte que dan solución al problema, por lo que el tiempo de entrenamiento es reducido notoria-. 5.
(6) mente. * En los subconjuntos formados no se encuentra ninguno de los vectores de soporte por lo que el tiempo de entrenamiento se incrementa de manera exponencial. Debido a que este método es aleatorio, es necesario desarrollar procedimientos heurı́sticos que aseguren el correcto funcionamiento del algoritmo, lo que tiene como consecuencia la disminución del tiempo de entrenamiento de las Máquinas de Soporte Vectorial. Por otro lado, existen diferentes métodos como: Perceptrón [6], Schlesinger-Kozinec [7], [8] y Procedimiento de Corrección de Baricentros (PCB), [9], los cuales trabajan sobre bases de datos linealmente separables y cuyo resultado es un hiperplano que separa correctamente un conjunto de datos en dos clases. La idea es aprovechar las ventajas de estos métodos para seleccionar los patrones más cercanos al hiperplano y, entonces, identificar los vectores de soporte antes de realizar el entrenamiento de las MSV. Ası́, se puede realizar el entrenamiento de las MSV con un conjunto de datos de tamaño reducido del cual se tiene la certeza que contiene los vectores de soporte, por lo que el entrenamiento se realiza muy rápido y la solución deseada es obtenida. La desventaja de utilizar los métodos antes mencionados es que trabajan con bases de datos linealmente separables por lo que su aplicación en problemas reales no es muy útil. Debido a lo anterior, se ve la necesidad de extender el uso de estos métodos al caso no linealmente separable, por lo que se trabajara con métodos como Kernel-Perceptrón [10], Kernel Schlesinger-Kozinec [7], [8] y una extensión del algoritmo PCB [9] al caso no linealmente separable. El objetivo principal de esta investigación es mostrar los diferentes resultados obtenidos al utilizar diversos métodos basados en heurı́sticas para reducir el tiempo de entrenamiento las MSV. La hipótesis es combinar los métodos antes mencionados con la estrategia de Vapnik, de tal forma que se tenga un Chunking-heurı́stico en el que los subconjuntos de trabajo se formen con datos que representen los mejores candidatos a ser vectores de soporte, entonces el tiempo de entrenamiento de las MSV será reducido. Algunas otras ideas para tratar las desventajas de las MSV han sido desarrolladas y son comentadas en [11] y [12]. La estructura de esta investigación es la siguiente: en el capı́tulo 2 se presenta un análisis teórico y matemático tanto de las MSV como de las teorı́as de las que se derivan. Además, en 6.
(7) este capı́tulo se presentan algunos métodos que han sido desarrollados para tratar el problema del lento aprendizaje de las MSV. En el capı́tulo 3 se presenta el desarrollo teórico de las diferentes heurı́sticas que se utilizaron para disminuir el tiempo de entrenamiento de las MSV. En el capı́tulo 4 se da una descripción de las diferentes bases de datos utilizadas para probar las diferentes heurı́sticas, además de presentar los resultados obtenidos y un análisis de los mismos. Por último las conclusiones y el trabajo futuro son presentados. Este trabajo fue realizado gracias al apoyo del CONACyT con el número de proyecto 37368.. 7.
(8) 2.. ESTADO DEL ARTE. 2.1. LAS MÁQUINAS DE SOPORTE VECTORIAL La idea principal de las Máquinas de Soporte Vectorial, en el área de clasificación, es separar un conjunto de datos en dos clases mediante un hiperplano clasificador. Existe un sin número de hiperplanos que separan correctamente un conjunto de datos y por lo tanto existen diferentes soluciones. Entre los diferentes hiperplanos existe uno y solo uno que tiene el margen máximo de separación el cual es encontrado por las MSV. La definición matemática del método ası́ como su solución fueron presentados por V. Vapnik y A. Chervonenkis, [4], como una técnica para reconocimiento de patrones. A continuación se presentan los métodos generadores de las MSV, además de la derivación matemática del método tanto para el caso linealmente separable como para el no linealmente separable.. 2.1.1.. PRINCIPIO DE MINIMIZACIÓN DEL RIESGO EMPÍRICO. Dados un conjunto de patrones de entrenamiento xi ∈ <n , i = 1, . . . , N y una salida esperada asociada yi , se desea encontrar una máquina que identifique el mapeo xi → yi es decir, a partir de una entrada x la máquina debe ser capaz de determinar de manera correcta la salida y que le corresponde. Para llevar a cabo el mapeo correcto se define una función f (x, λ) con lo que el mapeo queda como xi → f (x, λ) donde f : <n → {−1, +1}. λ es un valor ajustable que puede.
(9) ser visto como un umbral o el vector de pesos en una red neuronal con una estructura fija. Con lo anterior, se espera que la función f (x, λ) dé como resultado el valor mı́nimo de riesgo esperado el cual esta definido como:. Z R(λ) =. |f (x, λ) − y|P (x, y)dxdy. (2.1). Como se observa en la fórmula anterior, es necesario conocer la distribución de probabilidad de los datos P (x, y), la cual es desconocida por lo que no se puede aplicar la fórmula de minimización del riesgo esperado (ec. 2.1). Para compensar esta desventaja es posible realizar una aproximación estocástica de la función de riesgo que es llamada riesgo empı́rico y que se define de la siguiente manera: Remp. N 1 X = |f (x, λ) − yi | 2N i=1. (2.2). Con lo anterior, y tomando en cuenta la teorı́a de convergencia uniforme presentada por Vapnik y Chervonenkis, se observa que el Riesgo Empı́rico Remp es una parte de la función de Riesgo R por lo que, el mı́nimo de Riesgo Empı́rico Remp converge hacia el mı́nimo de la función de riesgo R. De esta manera, es más factible minimizar el Riesgo Empı́rico que la función de riesgo como tal. El problema es que existen casos en los que la convergencia del Remp a R no es posible por lo que se dice que el problema es inconsistente. Para poder saber si un problema es consistente, Vapnik y Chervonenkis demuestran que es condición necesaria y suficiente que la dimensión Vapnik-Chervonenkis (VC) del espacio de hipótesis (H : f (x, λ) sea finita. La dimensión VC se refiere al número más grande de datos que pueden ser separados por la máquina de aprendizaje por lo que si h < ` es la dimensión VC de una clase de funciones que la máquina de aprendizaje puede implementar, entonces para todas la funciones de esa clase las cuales tengan una probabilidad de almenos 1 − η (η esta entre 0 y 1) se define la función: ¶ µ h log(η) , R(λ) ≤ Remp (λ) + φ ` ` donde φ es el valor de confianza VC y esta definido por la ecuación: s µ ¶ + 1) − ln η4 h(ln 2N h log(η) h φ , = ` ` N. (2.3). (2.4). El parámetro h de la ecuación anterior, representa la dimensión VC, la cual, como se mencionó, es el número máximo de datos k que pueden ser separados en dos clases y en un numero 2k de formas posibles. La ecuación (2.3) es totalmente independiente de los datos y se relaciona directamente con la máquina de aprendizaje y con la dimensión VC, por lo que se puede separar y ver de la siguiente manera: 9.
(10) Intervalo de Confidencia: Aprendizaje. Sn. S2. S. 1. Riesgo Empirico: Generalización. h1. *. H. h. n. (a). (b). Figura 2.1: (a) Aprendizaje y Generalización: a menor riesgo, mayor confianza VC. conjunto de funciones con una estructura jerárquica.. (b) S es un. * El término Remp (λ) (correspondiente al nivel de aprendizaje), q h(ln 2N +1)−ln η4 h * El término que representa la confianza VC de la máquina de aprendizaje N (Figura 2.1), (correspondiente al nivel de generalización). Con lo anterior tenemos que la ası́ntota sobre el riesgo es la suma del riesgo empı́rico y del intervalo de confianza. La ası́ntota sobre el riesgo tiene las siguientes caracterı́sticas: * Los datos observados y sus correspondientes salidas son independientes. * Las probabilidades de x y y P (x, y) también son independientes. * Si se conoce h, entonces se puede calcular facilmente el valor del intervalo de confianza. De acuerdo con la ecuación (ec. 2.3) es posible controlar el valor del riesgo esperado considerando el valores de Riesgo Empı́rico y el valor de h. El valor de Riesgo Empı́rico depende de los valores que tome λ, mientras que el valor de h es controlado por la función f (x, λ) para lo cual se puede definir una estructura jerárquica de funciones Sn := f (x, λn ) ∈ f (x, λ) como: (Figura 2.1) S1 ⊂ S2 ⊂ . . . ⊂ Sn Para los cuales, los correspondientes valores de h satisfacen: h1 ≤ h2 ≤ . . . ≤ hn 10.
(11) La desventaja que se ve en la ecuación (ec. 2.3) es que el cálculo de la dimensión VC es complicado (este cálculo puede ser comparado con la búsqueda de la estructura de red apropiada en una red neuronal a capas múltiples), por lo que es necesario cambiar el principio de minimización del Riesgo Empı́rico por algún otro método.. 2.1.2.. PRINCIPIO DE MINIMIZACIÓN DEL RIESGO ESTRUCTURAL. El cálculo de la dimensión VC del espacio de hipótesis H es complicado por lo que principio de minimización del Riesgo Empı́rico no es una alternativa muy adecuada. Vapnik demostró que un valor pequeño del Riesgo Empı́rico no necesariamente implica que se te tenga un valor pequeño del Riesgo Esperado. Por este motivo, se desarrolla el Principio de Minimización del Riesgo Estructural (SRM) el cual realiza la minimización del Riesgo Empı́rico al mismo tiempo que minimiza la dimensión VC del espacio de Hipótesis H (condición necesaria para obtener un mı́nimo del Riesgo Esperado). Las MSV minimizan el Riesgo Empı́rico y obtienen el valor mı́nimo de dimensión VC de un problema. Las Máquinas de Soporte Vectorial estiman una función f : <N , dados un conjunto de patrones de entrenamiento (x1 , x2 , . . . , xl ) de los cuales a cada xi | i = 1, . . . , l. le. corresponde un valor o una etiqueta denotada por yi = {+1, −1}. Ası́, la idea principal del método es transformar los vectores de entrada x (de N dimensiones) en vectores de dimensión más alta Z (dimensión que podrı́a ser infinita) en la que el problema teóricamente tiene solución.. 2.1.3.. LAS MSV LINEALES Y EL CASO LINEALMENTE SEPARABLE. Dados un conjunto de patrones de entrenamiento que son linealmente separables 1 , el objetivo es encontrar un hiperplano que separe el conjunto de datos en 2 clases de manera correcta; la separación de los datos se lleva a cabo mediante un hiperplano definido por: w · x + b w ∈ <N , b ∈ <. (2.5). Los datos x que satisfacen la ecuación w · x + b = 0 son aquellos que se encuentran sobre el hiperplano donde: * w es un vector normal al hiperplano, * b es el término bias, * 1. |b| kwk. es la distancia perpendicular del hiperplano al origen y,. Datos linealmente separables , son aquellos que son separados correctamente por una lı́nea.. 11.
(12) (w ⋅ x) + b = (−1). yi = (−1) X2. ρ. y = (+1) i. (−). ρ. (+). X1. (w ⋅ x) + b = 0. W (w ⋅ x) + b = (+1). Figura 2.2: Dados un conjunto de patrones linealmente separables, el hiperplano con el margen máximo de separación está definido por un vector de pesos w y un umbral b que satisfacen (w · x) + b = 0. Ası́ mismo, los vectores de soporte son los patrones más cercanos al hiperplano que cumplen la condición | (w · x) + b |= 1.. * kwk representa la norma Euclidiana de w. Definiendo ρ(+) como la distancia del dato positivo más cercano al hiperplano separador y ρ(−) como la distancia del dato negativo más cercano, el margen de separación de los patrones de entrenamiento queda expresado como: ρ = ρ(+) + ρ(−) La tarea de las MSV en el caso linealmente separable es encontrar un hiperplano que tenga el margen máximo de separación entre las clases (Figura 2.2) por lo que es necesario encontrar un par de hiperplanos que satisfagan respectivamente: w · xi + b = 1. para yi = +1,. (2.6). w · xi + b = −1. para yi = −1.. (2.7). donde cada uno de los hiperplanos tienen una distancia perpendicular al origen definida por: 1 yi (w · x + b) = kwk kwk Ası́, el margen de separación es: ρ = ρ(+) + ρ(−) =. 1 1 2 + = kwk kwk kwk 12.
(13) Si se desea encontrar el margen máximo de separación para un clasificador, es necesario minimizar la norma de w, por lo que el problema se formula de la siguiente manera: mı́n | w · xi + b | = 1. i=1...`. (2.8). Existen diversos hiperplanos que satisfacen la ecuación (2.8) llamados hiperplanos canónicos. Las MSV buscan entre los diferentes hiperplanos canónicos aquel que tenga la norma mı́nima ya que al tener un hiperplano con norma mı́nima, también se tiene un valor pequeño de dimensión VC. Es importante notar que minimizar kwk es equivalente a encontrar un hiperplano separador con el márgen ρ máximo. Ası́, si se desea encontrar el hiperplano con el márgen máximo de separación es necesario minimizar la norma de w, por lo que el problema se formula de la siguiente manera: minimizar. 1 kwk2 2. (2.9). s.a. yi (w · xi + b) ≥ 1 ∀i. (2.10). donde la restricción (2.10) nos indica que la región factible de la función objetivo (2.9) se encuentran fuera del rango {−1, 1}. La formulación anterior nos indica que se trata de un problema de programación cuadrático bajo restricciones, el cual se caracteriza por tener una función objetivo no-lineal (2.9) y restricciones lineales (2.10). El problema de optimización puede ser resuelto en el espacio primal, pero se resuelve en el espacio dual por las siguientes razones: * Las restricciones forman parte de la función objetivo como Multiplicadores de Lagrange. * La formulación del problema aparece el producto entre vectores (que es la base para la extensión al caso no linealmente separable). Multiplicadores de Lagrange Esta técnica trata el problema de maximizar una función sujeta a una o mas restricciones de igualdad. Además, se permite que la función objetivo sea no-lineal mientras ésta sea dos veces diferenciable. Para iniciar, se formula un problema de maximización con una restricción como sigue: 13.
(14) Figura 2.3: Los aros concéntricos ilustran el conjunto de soluciones factibles de la función f . En la solución óptima x∗ el gradiente es perpendicular a este conjunto.. f (x). maximizar. g(x) = 0. sujeto a:. La geometrı́a de este problema se observa en la figura (fig. 2.3). El gradiente de la función f , denotado por ∇f es un vector que apunta en la dirección en la que la función f se incrementa más rápido. En optimización no restringida, este vector se iguala a cero, se determinan los puntos crı́ticos de la función f y el máximo, si es que existe, debe estar contenido en este conjunto. Sin embargo, el caso que se trata contiene la restricción g(x) = 0 por lo que no es correcto utilizar los datos para los cuales el gradiente desaparece. En vez de lo anterior, el gradiente debe ser ortogonal al conjunto de soluciones factibles {x : g(x) = 0}. Ası́, se desea encontrar un punto crı́tico x∗ que sea solución factible y que el valor de ∇f (x∗ ) sea proporcional al valor de ∇g(x∗ ). Si expresamos lo anterior como un conjunto de ecuaciones se tiene: g(x∗ ) = 0 ∇f (x∗ ) = α∇g(x∗ ) Donde α es una constante de proporcionalidad que puede ser un número real, positivo, negativo o cero. Esta constante de proporcionalidad es llamada Maultiplicador de Lagrange .. 14.
(15) Figura 2.4: La región factible es una curva formada por la intersección de las restricciones g1 (x) = 0, g2 (x) = 0, . . . , gm (x). El punto x∗ es óptimo ya que el gradiente de la función f en ese punto es perpendicular al conjunto factible.. Ahora se considera el caso en que se tienen varias restricciones: f (x). maximizar. g1 (x) = 0. sujeto a:. g2 (x) = 0 .. . gm (x) = 0. Para la ecuación anterior, la región óptima factible esta compuesta por la intersección de m hiperplanos (Figura 2.4), por lo que las ecuaciones de puntos crı́ticos se denotan por: g(x∗ ) = 0 ∗. ∇f (x ) =. m X. (2.11) αi ∇g(x∗ ).. (2.12). i=1. Una vez introducidas la ecuaciones anteriores, se presenta una ecuación equivalente llamada función Lagrangiana L(x, α) = f (x) −. X. αi gi (x),. i. para la cual es necesario encontrar los puntos crı́ticos tanto para x como para α. Ya que este es un problema de optimización no restringido, entonces los puntos crı́ticos se encuentran igualando las 15.
(16) primeras derivadas a cero: X ∂gi ∂L ∂f = − αi ∂xj ∂xj ∂xj i. = 0,. j = 0, 1, . . . , n.. ∂L = −gi ∂αi. = 0,. i = 0, 1, . . . , m.. Las ecuaciones anteriores son usualmente llamadas Condiciones de Optimalidad de Primer Orden. Determinar si una de las soluciones a las Condiciones de Optimalidad de Primer Orden es un máximo global es una tarea difı́cil, pero al tratarse de restricciones lineales, entonces es posible hacer uso de la matriz de segundas derivadas: ·. ∂ 2f Hf (x) = ∂xi ∂xj. ¸. Esta matriz es llamada hessiano de f en x. Una vez obtenido el hessiano se tiene: TEOREMA 1.1. Si las restricciones son lineales, un punto crı́tico en x∗ es un máximo local si: ξ T Hf (x∗ )ξ < 0. (2.13). donde para ∀ξ 6= 0 satisface que: ξ T ∇gi (x∗ ) = 0,. i = 1, 2, . . . , m.. (2.14). En las ecuaciones anteriores, el vector ξ representa un vector de movimiento o de direcciones desde el punto actual x∗ . Los únicos movimientos relevantes de ξ son aquellos que se hacen dentro de el conjunto de soluciones factibles. Por consecuencia, si la ecuación (ec. 2.13) la satisface cualquier valor de x (no solo x∗ ), entonces se dice que se ha encontrado un máximo global. Formulación dual del problema Ya que se conoce la formulación primal del problema (ec. 2.9, 2.10) para el caso linealmente separable, se hace un cambio a la representación dual y se hace uso de los multiplicadores de Lagrange, lo que permite hacer la extensión a problemas no linealmente separables. Ahora, se define un conjunto de valores positivos (multiplicadores de Lagrange) como α = α1 , α2 , . . . , αN donde cada α le corresponde a la restricción i de la ecuación (ec. 2.10). Para realizar el cambio de la forma primal (ec. 2.9) a la forma dual se agregan las restricciones a la función. 16.
(17) objetivo. Es necesario multiplicar la restricciones del tipo ≥ 0 por los coeficientes positivos α y restar las restricciones a la función objetivo. Ası́, la formulación dual del problema es: N. N. X X 1 L ≡ kwk2 − αi yi (w · xi + b) + αi 2 i=1 i=1. (2.15). La solución a este problema es obtenida minimizando el Lagrangiano con respecto a w y b y maximizando con respecto a α ≥ 0. Para lo anterior es necesario derivar (ec. 2.15) con respecto a w y b, y ası́ encontrar las ecuaciones de estacionaridad de primer orden, N. X ∂L(w, b, α) =w− αi yi xi = 0 ∂w i=1. (2.16). N. ∂L(w, b, α) X = λyi = 0 ∂b i=1. (2.17). Por lo que siguiendo (ec. 2.16) se obtiene que w∗ es: ∗. w =. N X. λi yi xi. (2.18). i=1. Ahora, es necesario sustituir las ecuaciones (ec. 2.17 y 2.18) en el lagrangiano (ec. 2.15) como sigue: N. X 1 L(w, b, α) = kwk2 − αi [yi (w · xi + b) − 1] 2 i=1 N. =. N. N. N. X X X 1X αi yi xi αj yj xj − αi yi (w · xi + b) + αi 2 i=1 j=1 i=1 i=1. N N N N N N X X X X 1 XX αi αj yi yj (xi · xj ) − αi yi ( αj yj xj · xi + αi yi ) + αi = 2 i=1 j=1 i=1 j=1 i=1 i=1. =. N N N N N X X X 1 XX αi αj yi yj (xi · xj ) − αi yi ( αj yj xj · xi ) + αi 2 i=1 j=1 i=1 j=1 i=1 N. N. N. N. N. XX X 1 XX = αi αj yi yj (xi · xj ) − αi αj yi yj (xi · xj ) + αi 2 i=1 j=1 i=1 j=1 i=1 N. =−. N. N. X 1 XX αi αi αj yi yj (xi · xj ) + 2 i=1 j=1 i=1. 17.
(18) Por lo tanto, la formulación dual del problema en términos de matrices queda como sigue: 1 máx F (Λ) = Λ · 1 − Λ · HΛ 2 s.a.. (2.19). Λ·y =0 Λ≥0 Donde H (hessiano) es una matriz simétrica de n x n donde n es el número de elementos en la base de aprendizaje. Los valores del hessiano se calculan con la siguiente ecuación: Hij = yi yj xi · xj El término bias b se calcula utilizando la restricción (ec. 2.10) y se define por: b∗ = yi − w∗ · xi. (2.20). Y la definición de la función de decisión es: N X f (x) = sign( yi αi∗ (x · xi ) + b∗ ). (2.21). i=1. 2.1.4.. LAS MSV LINEALES Y EL CASO NO LINEALMENTE SEPARABLE. Una vez que hemos analizado MSV lineales es necesario extender este tipo de clasificadores a problemas no linealmente separables es decir, problemas reales de clasificación en los que los datos no pueden ser separados por un hiperplano lı́neal (patrones de ambas clases quedarı́an traslapados). El objetivo es encontrar el par w∗ y b∗ que realicen el menor número de errores posibles. Para resolver lo anterior es necesario que las restricciones (ec. 2.6 y 2.7) sean flexibles en ciertos casos, es decir darles cierto costo a aquellos datos que queden fuera de la función de decisión lineal. El costo se ve traducido como un aumento en la función objetivo. Al realizar los incrementos en la función objetivo es necesario introducir un conjunto de variables ξ = 1, . . . , N de tal manera que las restricciones quedan: xi · w + b ≥ +1 − ξi. ∀yi = +1,. (2.22). xi · w + b ≤ −1 + ξi. ∀yi = −1.. (2.23). Las variables de relajación introducidas indican que tanto se han violado las restricciones por lo que ayudan a lograr que el margen de separación sea maximizado al mismo tiempo que se paga 18.
(19) una penalización proporcional a la cantidad de restricciones violadas. Además del cambio en las restricciones es necesario actualizar el valor de la función objetivo de tal manera que es necesario minimizar n X 1 ξi ) f (w, Ξ) = kwk2 + C( 2 i=1. mı́n. s.a.. (2.24). yi (w · xi + b) ≥ 1 − ξi ξi ≥ 0. El parámetro C nos indica el tamaño de la penalización de los errores. Esta nueva definición también es posible llevarla al espacio en el que αi y βi son los multiplicadores de Lagrange. Ã n ! µ ¶ X n n X X 1 2 Lp (w, b, ξ, Λ, β) = kwk + C ξi − αi yi (w · xi + b) − 1 + ξi − βi ξi (2.25) 2 i=1 i=1 i=1 Como en el caso linealmente separable, la solución se encuentra en el espacio dual usando las condiciones de optimalidad de primer orden para una función con restricciones: n. X ∂L(w, b, Λ) =w− αi yi xi = 0, ∂w i=1. (2.26). n. ∂L(w, b, Λ) X = αi yi = 0, ∂b i=1. (2.27). ∂L(w, b, Λ) = C − αi − ξi = 0. ∂ξ. (2.28). Si despejamos C de (ec. 2.28) se tiene: C = αi + ξi. (2.29). Las variables del Lagrangiano F (Λ) ya no se encuentran en función de β y son las mismas que en el caso linealmente separable. F (Λ) =. n X i=1. n. n. 1 XX αi − αi αj yi yj xi · xj 2 i=1 j=1. (2.30). Como se observa en la ecuación anterior, el problema de optimización cuadrático es el mismo que el definido para el caso linealmente separable (2.8), con la diferencia de que se ha introducido una cota superior a las variables de optimización en el espacio dual α. 19.
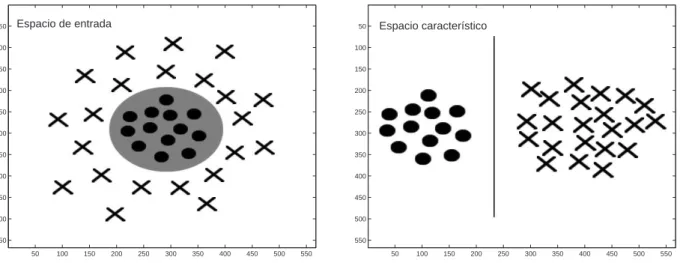
(20) El parámetro de penalización C se convierte en el lı́mite superior sobre αi mientras que en el caso linealmente separable se tiene como lı́mite superior ∞. La representación matricial del problema es la siguiente: 1 máx Λ · 1 − Λ · HΛ 2 s.a.. (2.31) Λ·y =0 0 ≤ Λ ≤ C.. 2.1.5.. LAS MSV NO-LINEALES. Espacios de realización no-lineal: Funciones Kernel Las máquinas de aprendizaje lineales tienen muchas limitantes en aplicaciones reales, por esto, se han propuesto múltiples métodos que han llevado al desarrollo de redes neuronales con capas múltiples y algoritmos de aprendizaje como retropropagación para el entrenamiento de dichos sistemas. Una de las ideas básicas en el diseño de las MSV es mapear el vector de entrada x ∈ <N a un vector Z en un espacio de mayor dimensión Z = Φ(X), en el que sea posible resolver un problema no-linealmente separable mediante un clasificador lineal, de tal manera que: x ∈ <n −→ z(x) = [a1 φ1 (x), a2 φ2 (x), . . . , an φn (x)]T ∈ <f ,. (2.32). Con este mapeo, se espera que las MSV sean capaces de separar linealmente los elementos de la base de datos (Figura 2.5). La solución obtenida es una función de decisión lineal en el espacio caracterı́stico Z, por lo que se crea una superficie de separación no-lineal en el espacio de entrada original N . Hay dos problemas importantes al aplicar esta técnica: * La selección de la función Φ, que realiza el mapeo de los datos de entrada al espacio caracterı́stico Z. El problema radica en que el costo computacional es muy alto cuando la dimensión de Z es grande.. 20.
(21) 50. Espacio de entrada. 50. 100. 100. 150. 150. 200. 200. 250. 250. 300. 300. 350. 350. 400. 400. 450. 450. 500. 500. 550. Espacio característico. 550 50. 100. 150. 200. 250. 300. 350. 400. 450. 500. 550. 50. 100. 150. 200. 250. 300. 350. 400. 450. 500. 550. Figura 2.5: Las funciones Kernel mapean un espacio de entrada N a un espacio caracterı́stico Z en el que los datos pueden ser separados linealmente.. * Cálculo de los productos escalares. Al tener Z una dimensión muy alta, el cálculo de los productos escalares se convierte en una tarea difı́cil. El problema de tener a Z en una dimensión muy alta, se puede evitar si se sustituyen los productos escalares por funciones Kernel (Cuadro 2.1), donde k : XxX → < corresponde al producto escalar del mapeo no-lineal de los datos. Ası́, se tiene: k(xa , xb ) = hΦ(xa ), Φ(xb )i. Las funciones trabajan en el espacio de entrada, por lo que su principal ventaja es que se evita realizar un mapeo Φ(x). En lugar de realizar este mapeo, los productos escalares requeridos en el espacio caracterı́stico Z son calculados directamente por la función K(xi , xj ) para los datos de entrenamiento en el espacio de entrada. De esta manera, se puede construir una máquina de soporte vectorial que trabaje en un espacio caracterı́stico con una dimensión muy alta, incluso infinita. Otra ventaja de las funciones es que no es necesario saber cual es el actual mapeo Φ(x). Reformulando la solución de las MSV se tiene la siguiente función de decisión: Ã n ! X f (x) = sign yi αi∗ K(x, xi ) + b∗. (2.33). i=1. Esta superficie de decisión es una función no-lineal, dada por una superposición lineal de funciones Kernel , una por cada vector de soporte.. 21.
(22) K(xa , xb ) = (hxa , xb i + 1)d. Función Polinomial de grado d. 2 /2σ 2. K(xa , xb ) = (exp−kxa −xb k. Función de Base Radial con radio σ. ). Función Sigmoidal multicapa. K(xa , xb ) = tanh(γhxa , xb i + β). Función Exponencial de Base Radial. exp−γkxa −xb k. Función Gaussiana de Base Badial. 2. exp−γkxa −xb k. Tabla 2.1: Ejemplos de funciones Kernel que pueden ser utilizadas El problema de programación cuadrática queda de la siguiente manera:. M aximizar. 1 F (Λ) = Λ · 1 − Λ · HΛ 2 (2.34). sujeta a Λ·y =0 0 ≤ Λ ≤ C1. donde H es la matriz Hessiana y es simétrica, semidefinida positiva, de tamaño nxn y con los elementos Hij = yi yj K(xi , xj ).. Algunas de las ventajas de utilizar MSV son: * Poder de generalización * Cambian un problema de orden n a un problema cuadrático con lo que se asegura matemáticamente la convergencia al óptimo global. * Este método parametriza al mismo tiempo la arquitectura y los parámetros de la red.. 2.2.. ESTRATEGIAS DE SOLUCIÓN PARA MÁQUINAS DE SOPORTE VECTORIAL. LAS. Algunos de los principales problemas que se presentan en la utilización de las MSV son: * La construcción y almacenamiento de la matriz hessiana H presente en el problema de programación cuadrático. 22.
(23) * Cuando el volumen de datos es grande, se requiere de una gran cantidad de tiempo para realizar la optimización. * El número de vectores de soporte puede ser muy grande cuando se trata con un problema no linealmente separable. Para resolver los problemas anteriores, se han propuesto diferentes estrategias: √. Generar los elementos de la matriz H conforme estos sean requeridos. La matriz hessiana no se construye con todos los patrones de la base de datos ya que ésta se construye solo con los valores correspondientes a aquellos patrones que se estén optimizando en cada iteración. El problema de esta estrategia es que el calculo de los elementos requeridos en la matriz hessiana, se vuelve muy costoso cuando algunos elementos se ocupan en diferentes iteraciones.. √. Vapnik propone un algoritmo llamado Chunking, [4], [5], en el cual el problema original es divido en pequeños sub problemas (conjunto de trabajo2 ) de los que se pueden obtener los vectores de soporte. Una vez resueltos los sub problemas, es necesario combinar los vectores de soporte con aquellos patrones que violan las condiciones de optimalidad y repetir el proceso hasta encontrar la solución óptima del problema. La principal desventaja de esta estrategia, es que, en cada iteración del algoritmo, el número de elementos a ser optimizados se incrementa, por lo que, en problemas reales el conjunto a ser optimizado puede crecer tan grande que se caiga de nuevo en problemas de almacenamiento de la matriz hessiana.. √. Edgar Osuna, [11], propone un método similar al Chunking, pero a diferencia de éste, mantiene un conjunto de trabajo fijo, es decir el conjunto de datos que se optimiza en cada iteración es del mismo tamaño siempre por lo que se evita el problema de que éste crezca a un punto en el que se vuelva un problema intratable computacionalmente. La desventaja de este método es que, para que el algoritmo converja, es necesario llevar a cabo muchas iteraciones, por lo que el tiempo de entrenamiento se ve incrementado notoriamente.. √. John Platt desarrolla una mejora extrema al algoritmo de Osuna, ya que su algoritmo Optimización Secuencial Mı́nima, [12], establece conjuntos de trabajo de tamaño 2, es decir, realiza una optimización iterativa con 2 datos del conjunto de entrenamiento y repite hasta encontrar la solución óptima del problema. El algoritmo utiliza heurı́sticas para determinar la dirección de descenso factible y ası́ seleccionar los 2 mejores datos a ser optimizados durante. 2. Conjunto de trabajo, también conocido por su nombre en inglés working set. 23.
(24) cada iteración. El desempeño de este algoritmo es bueno aunque, al realizar las diferentes evaluaciones Kernel en cada iteración, le quita cierta funcionalidad y en ciertos problemas se torna un algoritmo lento. √. Thorsten Joachism implementa diferentes mejoras al algoritmo de Osuna en su llamado SV M light3 , [13]. Este algoritmo incorpora las siguientes ideas: * Implementa un efectivo método para seleccionar el conjunto de trabajo en cada iteración. * Además de la descomposición original del problema, se realizan descomposiciones sucesivas, tomando en cuenta que muchos de los vectores de soporte se encuentran en el lı́mite superior del problema (Shrinking). * En cada iteración se almacena el valor de la función Kernel de aquellos patrones que constantemente entran al conjunto de trabajo (Caching).. 2.2.1.. CHUNKING. Vladimir Vapnik, [4], [5], propone un algoritmo basado en el hecho de que la solución del problema de programación cuadrático generado por las MSV es la misma para los dos casos siguientes: √. Resolver el problema utilizando una matriz hessiana construida con todos los datos de la base de aprendizaje.. √. Obtener la solución del problema utilizando una matriz hessiana construida únicamente con los vectores de soporte.. Vapnik considerando lo anterior, decide dividir el problema en pequeños sub problemas para los cuales obtiene solución. Una vez obtenida la solución de los sub problemas, identifica aquellos patrones cuyo multiplicador de Lagrange es diferente de cero (vectores de soporte) y los agrega al conjunto de trabajo a optimizar. Ası́ mismo, en cada iteración, el algoritmo verifica cuáles patrones violan las condiciones de Karush-Kuhn-Tucker y los agrega al conjunto de trabajo (Figura 2.6). Una vez formado el conjunto de trabajo, éste se optimiza y se repite el proceso hasta que la solución óptima del problema es encontrada. Una ventaja importante de este algoritmo, es que el tamaño de la matriz hessiana es notablemente reducido, debido a que la matriz hessiana es construida considerando únicamente los patrones cuyo lagrangiano es diferente de cero. 3. La implementación de SV M light esta disponible en www-ai.cs.uni-dortmund.de/svm light. 24.
(25) 2. 1. (−1). (+1). (+1). (+1). D. A. B. C. Figura 2.6: Chunking . El hiperplano 1 separa correctamente los datos B y C de D pero el dato A es un error por lo que debe ser agregado al conjunto de trabajo y entonces obtener el hiperplano 2 que separa correctamente los datos A, B y C del dato D.. (a) Establecer un tamaño q (llamado Chunking size. ) (b) Seleccionar q elementos aleatorios de la base de aprendizaje y formar el conjunto de trabajo. (c) Realizar la optimización del conjunto de trabajo mediante algún método de optimización cuadrático. (d) Identificar aquellos valores cuyo multiplicador de Lagrange fué diferente de cero (vectores de soporte) y agregarlos al conjunto de trabajo. (e) Identificar aquellos patrones de la base de datos que violan las condiciones KKT y agregarlos al conjunto de trabajo. (f) En el caso de encontrar patrones que violen las condiciones KKT, regresar al punto (c). En caso contrario, terminar el algoritmo.. Tabla 2.2: Estructura del algoritmo Chunking. 25.
(26) Una de las principales desventajas que se presentan en este algoritmo es que cuando el número de vectores de soporte es grande es necesario construir una matriz hessiana también grande, por lo que podemos caer en el problema de almacenamiento inicial. La forma que toma el algoritmo se muestra en el cuadro (2.2). La convergencia del algoritmo se asegura ya que en cada iteración, el hiperplano de separación se mueve en la dirección de aquellos patrones que no cumplen las condiciones de optimalidad hasta lograr que el hiperplano quede lo mejor pocisionado posible.. 2.2.2.. ALGORITMO DE OSUNA. Para llevar a cabo el entrenamiento de las máquinas de soporte vectorial, Edgar Osuna, [11], propuso una forma de descomponer el problema en diversos sub problemas. Este algoritmo es similar al Chunking pero con la diferencia de que mantiene un tamaño fijo al conjunto de trabajo durante las diferentes iteraciones. El algoritmo se basa en el hecho de que el número de vectores de soporte es muy pequeño cuando se trata con bases de datos grandes y, en consecuencia existirán muchos patrones para los cuales el valor de su correspondiente multiplicador de Lagrange sea igual a cero. La idea principal es dividir el problema original y resolver iterativamente hasta encontrar la solución óptima del problema. Para identificar que hemos encontrado una solución óptima en cierta iteración, es necesario verificar que se cumplan las condiciones de optimalidad. Ası́, si alguna de las soluciones encontradas no es óptima, entonces se busca mejorar la función de costo, la cual se asocia con aquellas variables que violan las condiciones de optimalidad. En cada iteración, el valor de la función objetivo es mejorado optimizando aquellos patrones que violan las condiciones de optimalidad. Dicho lo anterior, el algoritmo divide el conjunto de variables a optimizar en dos subconjuntos: ΛB y ΛN , donde el conjunto de patrones que cumplen con las condiciones de optimalidad están contenidos en el subconjunto B y representa el conjunto de trabajo que es optimizado en cada iteración. La definición de los subconjuntos B y N es como sigue: √. El subconjunto B, en el que se almacenan aquellas variables que son llamadas libres y que son las variables a ser optimizadas en cada iteración (conjunto de trabajo).. 26.
(27) (a) Se define el tamaño del conjunto de trabajo B, el cual es lo suficientemente pequeño como para ser almacenado por la computadora y está denotado por q. (b) Seleccionar aleatoriamente q elementos de la base de datos (c) Se optimiza el problema definido en el subconjunto B mediante algún método de optimización cuadrático. (d) Mientras existan patrones j ∈ N , tal que g(xj )yj < 1, donde g(xj ) =. l X. λp yp K(xj , xp ) + b. (2.35). p=1. entonces, se remplazan aquellos patrones con λi = 0, i ∈ B, por aquellos cuyo λj = 0, j ∈ N y se resuelve el nuevo sub problema encontrado.. Tabla 2.3: Estructura del algoritmo de Osuna √. El subconjunto M , el cual contiene el resto de las variables. Este subconjunto puede contener variables que ya han sido optimizadas ası́ como variables que violen las condiciones de optimalidad.. Una vez dividido el problema, el algoritmo realiza lo siguiente: √. Se intercambian aquellos patrones cuyo λi = 0, i ∈ B, con los patrones cuyo λj = 0, donde j ∈ N . Este remplazo es posible ya que el valor de la función objetivo no se ve afectado.. √. Se verifica que el nuevo sub problema sea óptimo mediante yj g(xj ) ≥ 1.. La idea general es: optimizar el conjunto de trabajo B y obtener aquellas variables con λi = 0, i ∈ B. Dichas variables son sustituidas por aquellas variables del subconjunto N que satisfacen la condición de yj g(xj ) < 1. Una vez realizado el remplazo de variables, un nuevo sub problema es formado. Conforme se realiza la optimización de los diferentes sub problemas, nos aseguramos que el valor de la función objetivo sea mejorado además de mantener factible la. 27.
(28) solución del problema. La estructura del algoritmo de Osuna se muestra el en cuadro (2.3). Este algoritmo tiene asegurada la convergencia hacia el óptimo en un número finito de iteraciones ya que en cada iteración se va mejorando el valor de la función objetivo.. 2.2.3.. OPTIMIZACIÓN SECUENCIAL MÍNIMA. Optimización Secuencial Mı́nima (OSM), [12], es un algoritmo que no requiere almacenar la matriz hessiana correspondiente a todos los elementos de la base de datos a ser optimizada. Este algoritmo, ası́ como Osuna y Chunking , descompone el problema en sub problemas, resolviéndolo en forma iterativa. La principal diferencia con los algoritmos previamente analizados es que el tamaño del conjunto de trabajo en cada iteración es de 2 elementos, es decir, el problema de programación cuadrático de las MSV lo reduce a su tamaño mı́nimo, lo que significa optimizar solo dos datos de la base de aprendizaje. Otra diferencia importante de este algoritmo con respecto a los anteriores es que al ir optimizando solo dos datos en cada iteración, esta optimización puede llevarse a cabo de manera analı́tica y no de forma numérica (uso de métodos de optimización cuadrática) por lo que el tiempo de computo puede ser reducido notoriamente. Ası́, este algoritmo esta compuesto de dos partes fundamentales: √ √. Un método de solución analı́tico para optimizar los 2 datos en cada iteración. Una heurı́stica que permita seleccionar la pareja de datos a ser optimizados.. 28.
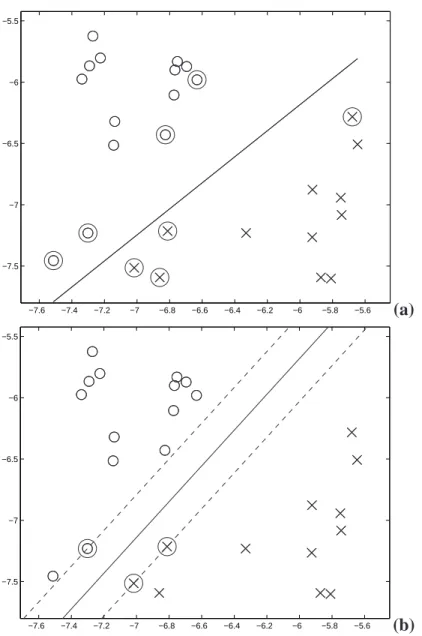
(29) 2.3. ALGORITMO PERCEPTRÓN El algoritmo Perceptrón, [6], fué uno de los principales procedimientos de aprendizaje de clasificadores lineales. Es un algoritmo incremental que inicia con un vector de pesos (o de conexiones) igual a cero w = 0 y en cada iteración se realizan pequeñas modificaciones al vector de pesos w de acuerdo con la salida y de cada dato. Este algoritmo (Tabla 2.4) asegura la convergencia en un número finito de iteraciones para problemas linealmente separables.. 1. Inicializar el vector de pesos w y el término b (bias) en cero. 2. Establecer el valor del paso de aprendizaje η. 3. Mientras exista un i : i ∈ N , tal que f (xi ) 6= yi a) Calcular el valor de la función f (xi ) = sgn((w · xi ) + b) b) Si f (xi ) 6= yi entonces • Actualizar los valores de w y b con: ∆w = wold + (η/2)(yi · xi ) ∆b = bold + (η/2)(yi ) 4. Regresar al punto 3.. Tabla 2.4: Algoritmo Perceptrón. La actualización del vector de pesos w y del término bias b se realizan cuando el valor de la función f (xi ) es diferente al valor del objetivo yi , por lo que la actualización se realiza con respecto a los ejemplos que han quedado mal clasificados. Este proceso se repite hasta obtener w∗ y b∗ de manera que ∀i , i ∈ N : f (xi ) = yi De forma general, el Perceptrón traza diferentes hiperplanos durante cada iteración hasta que encuentra un hiperplano que clasifica correctamente los datos (ver Figura 2.7).. 29.
(30) −7.6 −7.4 −7.2 −7 −6.8 −6.6 −6.4 −6.2 −6 −5.8 −5.6 −5.5. −6. −6.5. −7. −7.5. Figura 2.7: El Perceptrón traza diferentes hiperplanos hasta que encuentra uno que clasifica correctamente los datos. 2.3.1. KERNEL-PERCEPTRÓN: EXTENSIÓN DEL PERCEPTRÓN A FUNCIONES KERNEL Para extender el uso del Perceptrón a problemas no linealmente separables, este algoritmo se combina con funciones Kernel, [10], de tal forma que el algoritmo trabaje en una dimensión más alta en la que la base de datos pueda ser separada de manera lineal por el Perceptrón. Para lograr lo anterior, se realiza un mapeo no lineal de los datos al espacio caracterı́stico Z, por lo que es necesario redefinir la función f (x) como sigue: f (x) =. N X. wi Φi (x) + b. i=1. Este algoritmo es tratado en su forma dual, por lo que f (x) queda definida como: f (x) =. N X. γi yi hφ(xi ) · φ(x)i + b. i=1. Donde γ representa el conjunto de variables duales que son actualizadas durante cada iteración. La variable γ se define como un conjunto de valores positivos γ = γ1 , γ2 , . . . , γN donde el valor de γi esta asociado al patrón xi de la función f (x). El producto punto que aparece en la ecuación anterior es sustituido por una función Kernel, evitando la construcción explı́cita del espacio caracterı́stico φ y queda la representación como sigue: f (x) =. N X. γi yi K(xi , x) + b. i=1. 30.
(31) Una vez definida la notación del Perceptrón con funciones Kernel, la estructura del algoritmo se muestra en (Tabla 2.5):. 1. Establece el valor del término b = 0. 2. Inicializar el vector de variables duales γ = γ1 , γ2 , . . . , γN con ceros. 3. Mientras la condición de paro no se cumpla: a) Para todos los elementos en i , i ∈ N 1) Calcular f (xi ) = sgn(yi γi K(xi, x) + b) 2) Si f (xi ) 6= yi * Incrementa el valor de γi con ∆γi = γiold + 1 * Incrementa el valor del bias con ∆b = bold + yi. Tabla 2.5: Algoritmo Kernel-Perceptrón. 2.4. ALGORITMO DE SCHLESINGER-KOZINEC La idea de este algoritmo es presentar una solución alternativa a las máquinas de soporte vectorial mediante un algoritmo que evada el problema de programación cuadrático y devuelva como resultado el hiperplano de separación de margen máximo. El algoritmo Schlesinger-Kozinec, [8], busca el hiperplano clasificador de los datos que tenga el margen máximo de separación entre ellos por lo que, dados un conjunto de patrones (xi , yi ) ∈ <n , i = 1, . . . , N , se define I (+1) = {i ; yi = 1}, I (−1) = {i ; yi = −1}, X (+1) = {xi ; yi = 1}, X (−1) = {xi ; yi = −1} que corresponden a indices de datos positivos y negativos respectivamente. Además, para identificar el margen máximo de separación, es necesario definir: ρ = máx ρ(fw,b ) = ρ(f∗ ). (2.36). (w,b). Ahora definimos los vectores w(+1) , w(−1) ∈ <n donde fw(+1) , w(−1) (x) = fw,b (x) = w · x + b 31. ∀x ∈ <n ,. (2.37).
(32) Ası́, w y b están definidos por: w= b=−. w(+1) − w(−1). (2.38). kw(+1) k2 − kw(−1) k2 2. (2.39). La función de decisión lineal que separa los datos en los conjuntos X (+1) y X (−1) se puede representar por: hw · xi i ≥ b. ∀i ∈ I (+1) ,. hw · xi i < b. ∀i ∈ I (−1) .. El margen de separación entre los conjuntos X (+1) y X (−1) esta definido como la distancia de los patrones más cercanos de cada subconjunto de tal forma que: Ã ! hw · xi i − b b − hw · xi i ρw,b = mı́n mı́n , mı́n . kwk kwk i∈I (+1) i∈I (−1). (2.40). Por consecuencia, el hiperplano de separación con el margen máximo hw∗ · xi = b∗ se define por: ¡. ¢ w∗ · b∗ = arg máx ρ(w · b). (2.41). w,b. El hiperplano óptimo que divide X (+1) y X (−1) esta determinado por los patrones más cercanos entre ambos conjuntos por lo que, ∗ ∗ w∗ = w(+1) − w(−1) ,. b∗ =. ¢ 1¡ ∗ ∗ kw(+1) k2 − kw(−1) k2 , 2. donde: ∗ ∗ (w(+1) , w(−1) ) = arg. mı́n. w(+1) ∈X (+1) ,w(−1) ∈X (−1). kw(+1) − w(−1) k,. ρ(w∗ , b∗ ) − ρ(w, b) ≤ ². (2.42). En la implementación del algoritmo, para verificar que la condición (2.42) se cumpla, es necesario que, 1 (+1) kw − w(−1) k≥ρ(w∗ ,b∗ ) − mı́n 2. Ã. b − hw, xi i hw, xi i − b , mı́n mı́n (−1) (+1) kwk kwk i∈I i∈I. La estructura del algoritmo se muestra en (Tabla 2.6).. 32. ! ≤ =ρ(w,b). ² (2.43).
(33) 1. Inicializar los valores de w(+1) ∈ X (+1) y de w(−1) ∈ X (−1) para lo cual podemos elegir cualquier patrón que pertenezca al conjunto correspondiente de nuestra base de datos. 2. Verificar que se cumpla la condición de optimalidad (2.43). Si dicha condición no se cumple, entonces ir al paso siguiente. Si la condición se cumple, el margen óptimo ha sido encontrado. 3. Realizar la actualización del margen para lo cual es necesario verificar: a) Si xi ∈ X (+1) no cumple con la condición de optimalidad, entonces se realiza la actualización del valor w(+1) y se mantiene fijo el valor de w(−1) . Dicha actualización se realiza mediante: (+1) wnew = w(+1) · (1 − k) + xi · k. donde: k = arg mı́n kw(+1)new (k) − w(−1) k k∈(0,1). b) En el caso contrario, cuando xi ∈ X (−1) no cumple con la condición de optimalidad, la actualización se realiza en w(−1) y el valor de w(+1) se mantiene fijo. La actualización se realiza con: (−1) wnew = w(−1) · (1 − k) + xi · k. donde: k = arg mı́n kw(−1)new (k) − w(+1) k k∈(0,1). 4. Regresar al punto 2.. Tabla 2.6: Algoritmo Schlesinger-Kozinec Ya que el algoritmo busca los patrones más cercanos entre los subconjuntos, en la figura (2.8) (+1). se seleccionan 2 puntos aleatorios de cada subconjunto y se obtienen w1 (+1). se forma el hiperplano hw1. (−1). − w1. (−1). y w1. con los que. · xi = b. Cada patrón de la base de datos es proyectado 33.
(34) sobre el hiperplano encontrado y un valor es obtenido. Dicho valor indica qué tan cerca o lejos se encuentra del hiperplano. Los datos con valor de proyección más pequeño son seleccionados para (+1). formar los nuevos w2. (−1). y w2. , con los que el hiperplano de separación óptimo es encontrado. ∗ ∗ hw(+1) − w(−1) · xi = b∗ .. −3.5. (+1). X −4. w(+1) 1 −4.5. w(−1). w(+1). 1. 2. −5. w(−1) 2. −5.5. ⟨w −6 −6. −5.5. −5. (+1). − w(−1) ⋅ x ⟩ = b. −4.5. −4. X(−1) −3.5. (a). Figura 2.8: Búsqueda del hiperplano óptimo. 2.4.1. KSK: LA EXTENSIÓN DEL ALGORITMO SCHLESINGER-KOZINEC A FUNCIONES KERNEL Para extender el algoritmo Schlesinger-Kozinec al caso no linealmente separable, [7], se hace uso de las funciones Kernel, de tal forma que asumiremos la existencia de una función φ que representa un mapeo del espacio de entrada a un espacio caracterı́stico Z en el que (z1 , z2 ) → z1 ·z2 representa un producto escalara en Z de tal forma que: φ(x1 ) · φ(x2 ) = k(x1 , x2 )∀x1 , x2 ∈ <n. 34.
(35) De esta forma, la idea es buscar el hiperplano separador óptimo en el espacio caracterı́stico Z por lo que es necesario sustituir el vector xi por su correspondiente imagen φ(xi ) y ası́ utilizar una función Kernel para calcular el producto punto. Como es de esperarse, los valores de w(+1) yw(−1) no pueden ser almacenados de igual forma en el espacio caracterı́stico Z por lo que es necesario representarlos utilizando lagrangianos. De tal forma, se tiene qué, X X w(+1) = λi · xi , λi = 1, i∈I (+1). X. w(−1) =. i∈I (+1). X. λ i · xi ,. i∈I (−1). λi = 1.. i∈I (−1). Ya en la implementación del algoritmo, es necesario realizar los siguientes productos escalares: XX hwa , wb i = λi · λj · hxi , xj i, a, b ∈ {(1), (−1)} i∈Ia j∈Ib. hwa , xj i =. X. λi · hxi , xj i,. a, b ∈ {(1), (−1)}. i∈Ia. Mientras que las actualizaciones para w serán de la siguiente forma: (1 − k) · λj , ∀j 6= i, j ∈ Ia new wj = (1 − k) · λj + k, ∀j = i, j ∈ Ia Por lo que la nueva función de decisión queda definida como: f (x) = hw, xi − b X X λi hxi , xi − b λi hxi , xi − = i∈I (−1). i∈I (+1). =. X. λi yi hxi , xi − b.. i∈I. =. X. λi yi k(xi , x) − b. i∈I. 2.5.. PROCEDIMIENTO DE CORRECCIÓN DE BARICENTROS (PCB). El algoritmo PCB 4 es un algoritmo iterativo basado en conceptos geométricos para entrenar unidades por umbral 5 El algoritmo encuentra un hiperplano que clasifica correctamente un conjunto de patrones en dos clases. PCB fué desarrollado para tratar los problemas de convergencia 4 5. BCP por sus siglas en inglés (Barycentric Correction Procedure). Unidad por umbral , se refiere a un sistema de una unidad el cual esta conectado a n entradas ei. 35.
(36) de algoritmos como el Perceptrón. Ası́ mismo, el algoritmo ha mostrado ser muy eficiente para problemas linealmente separables, ya que converge muy rápido hacia la solución. Este algoritmo es libre de parámetros, por lo que no necesita ningún valor de inicialización. PCB realiza una búsqueda guiada para encontrar un vector de pesos W . Ası́, en cada iteración del algoritmo el vector de pesos es modificado tomando en cuenta patrones que han sido clasificados correctamente, además de considerar aquellos que han sido mal clasificados. De esta forma, el vector de pesos W está definido como un vector que conecta 2 diferentes baricentros, donde cada uno pertenece a una clase diferente. Los baricentros son elementos cercanos a la media tanto para patrones que pertenecen a la clase +1 como para aquellos que pertenecen a la clase −1. Para lograr que el algoritmo converja, es necesario que, en cada iteración del algoritmo, los baricentros sean modificados para ası́ lograr una mejor dirección del hiperplano y ası́ lograr una solución óptima. Como se menciono antes, PCB es un sistema de una salida s conectada a N entradas xi donde cada una de las conexiones tiene un valor asociado (un peso) representado por wi . Ası́, PCB calcúla el valor de salida del sistema s mediante s = φ(A) donde A esta definido por: A=w·x+θ =. N X. wi · xi + θ. i=1. y φ(A) es una función de activación de la salida s la cual toma los siguientes valores:. φ(A) =. 1 si A ≥ 0, 0 si A < 0.. PCB define un hiperplano H : w · x + θ = 0 donde, x = x1 , x2 , . . . , xN son las entradas del algoritmo, θ es el término bias y w es el vector de pesos que conectan las entradas con la salida. El hiperplano calculado divide el espacio de entrada en dos subespacios abiertos, donde uno contiene los datos cuya A ≥ 0 y el otro aquellos cuya A < 0. Con lo anterior, se sabe que cualquier elemento xi pertenece a la clase {+1} si A >= 0 o que pertenece a la clase {−1} si A < 0. Ahora definimos el conjunto de entrenamiento C = C1 ∪ C0 donde C1 = p1 , p2 , . . . , pN1 y C0 = q1 , q2 , . . . , qN0 , donde N = N1 + N0 y el conjunto de indices I1 = {1, . . . , N1 } y 36.
(37) I0 = {1, . . . , N0 }. La definición de los baricentros de C1 y C0 para los cuales b1 corresponde al subconjunto etiquetado con {+1} y b0 que corresponde al subconjunto etiquetado con {−1}. Los baricentros tienen un peso, el cual está determinado por los coeficientes positivos λ = (λ1 , λ2 , . . . , λN1 ) para los datos en C1 y µ = (µ1 , µ2 , . . . , µN0 ), para aquellos que se encuentran en C0 . Estos coeficientes son denominados coeficientes de peso. La definición matemática de los baricentros es como sigue:. P j∈I µj · pj b0 = P 0 j∈I0 µj. P i∈I1 αi · pi b1 = P , i∈I1 αi. (2.44). De esta forma, tenemos que el vector de pesos w queda definido por: w = b1 − b0. (2.45). En cada iteración del algoritmo, el vector de pesos (αi , µi ) es modificado y, en consecuencia, los baricentros también son modificados. El incremento en los baricentros se hace con respecto a los elementos mal clasificados, lo que implica que el hiperplano separador se mueva en esa dirección. La modificación en los baricentros se realiza mediante:. ∀i ∈ I1. ∆λi = λi + βi. (2.46). ∀j ∈ I 0. ∆µi = µi + δi. (2.47). Donde β y δ son valores positivos que incrementan el valor de los coeficientes de peso λ y µ cuando algún patrón es mal clasificado. La definición matemática es la siguiente: ½ ¾ £ N1 ¤ β = máx βmı́n , mı́n βmáx , N0 ½ ¾ £ N0 ¤ δ = máx δmı́n , mı́n δmáx , N1. (2.48) (2.49). Una ventaja que presenta este algoritmo es que no sólo trabaja para problemas linealmente separables ya que en cada iteración 2 hiperplanos son calculados: * H que nos asegura la convergencia en problemas no linealmente separables. * Hpoc que nos obtiene la mejor orientación del hiperplano en problemas no linealmente separables, maximizando el numero de patrones excluidos y minimizando el numero de datos mal clasificados. El hiperplano Hp oc es el mejor hiperplano obtenido durante cada iteración de PCB. Debido a que PCB tiene un número finito de iteraciones, una vez que termina el algoritmo se verifica si 37.
(38) se obtuvo un hiperplano que clasifique correctamente todos los datos (si ası́ fuera, el problema es linealmente separable). En el caso de que hayan sido mal clasificados algunos datos, entonces se toma en cuenta el hiperplano que mejor ha clasificado durante las diferentes iteraciones. Para realizar el calculo del término bias θ, es necesario definir la función ϑ : <n → < como sigue: ϑ(p) = −w · p donde ϑ = ϑ1 ∪ ϑ0 , para lo cual, ϑ1 = {ϑ(pi )/pi ∈ C1 }, ϑ0 = {ϑ(qj )/qj ∈ C0 }, por lo que el cálculo del término bias θ se representa por: θ=. máx ϑ1 + mı́n ϑ0 . 2. Por último, el algoritmo PCB se muestra en (Tabla 2.7):. 1. Inicializar λ y µ de forma aleatoria. 2. Calcular los baricentros b1 y b0 usando (2.44) 3. Calcular el vector de pesos w con (2.45). 4. Calcular ϑ1 y ϑ0 . 5. Calcular el término bias θ con (2.50). 6. Evaluar H : w · x + θ y mientras existan elementos mal clasificados a) Calcular las modificaciones de los pesos β y δ. b) Realizar la actualización de λ y µ usando (2.46) y (2.47). c) Regresar al punto dos.. Tabla 2.7: Algoritmo PCB. 38. (2.50).
(39) 3.. HEURÍSTICAS DE OPTIMIZACIÓN. PARA LAS MÁQUINAS DE SOPORTE VECTORIAL Los diferentes algoritmos desarrollados para entrenar las MSV (entre ellos Chunking [5], Osuna [11] y SMO [12]) han disminuido notablemente el tiempo de entrenamiento y la memoria necesaria en comparación con los métodos de optimización cuadrática tradicionales. Sin embargo, el tiempo de entrenamiento requerido por dichos métodos para problemas reales sigue siendo prohibitivo, por lo que es necesario desarrollar heurı́sticas que permitan tratar dichos problemas. Como ya se mencionó, los vectores de soporte son aquellos datos que se encuentran sobre el margen de separación, es decir, son los ejemplos más cercanos al hiperplano que separa el conjunto de datos. También se sabe que para llevar a cabo el entrenamiento de las MSV sólo es necesario conocer los vectores de soporte y no el conjunto de datos completo. Por esta razón, se puede afirmar que si se conocen los vectores de soporte antes de llevar a cabo el entrenamiento de las MSV, entonces se puede realizar el entrenamiento con un conjunto de datos muy reducido que contenga los vectores de soporte y ası́ disminuir tanto el tiempo de entrenamiento como la memoria requerida para almacenar el problema..
(40) El objetivo principal del presente trabajo es encontrar algún método de clasificación preliminar que encuentre un hiperplano de separación cercano al encontrado por las MSV. Una vez encontrado dicho hiperplano, se identifican los patrones más cercanos al él (realizando el calculo de la Distancia Euclidiana) y se forma un subconjunto de datos. Dicho subconjunto contiene los vectores de soporte del problema, por lo que es utilizado para realizar el aprendizaje de las MSV. El proceso anterior se enumera a continuación: 1. Encontrar un hiperplano que clasifique correctamente los datos (Figura 3.1 a). 2. Formar un subconjunto de datos con los patrones más cercanos al hiperplano (Figura 3.1 a). 3. Iniciar el aprendizaje de las MSV con el subconjunto formado (Figura 3.1 b). La principal ventaja de la inicialización de las MSV con un conjunto de datos pequeño es la disminución del tiempo de computo y la memoria necesaria para encontrar la solución del problema. Para identificar el subconjunto de datos que contiene los vectores de soporte se pueden utilizar diferentes algoritmos con las siguientes caracterı́sticas: * Encuentra un hiperplano de separación óptimo para un conjunto de datos. * Fácil implementación. * Mı́nimos requerimientos de procesamiento. Algunos de los algoritmos que cumplen con estas caracterı́sticas y que serán utilizados son: * Perceptrón, [6]. * Procedimiento de Corrección de Baricentros (PCB), [9]. Una vez identificado el conjunto reducido de datos, es posible utilizar cualquier método de optimización cuadrática para optimizarlo. La desventaja observada en problemas no linealmente separables, es que al realizar aproximaciones lineales a la solución con los algoritmos preliminares, el conjunto de vectores de soporte encontrado es un conjunto incompleto que en la mayorı́a de los casos representa un poco más del 50 % del total de vectores de soporte del problema. Ası́, es necesario realizar diferentes iteraciones hasta encontrar el total de vectores de soporte. Para lograr lo anterior se decide utilizar el algoritmo Chunking, el cual, como se mostró en el capı́tulo 2, es un algoritmo iterativo que busca los patrones que violan las condiciones de KKT y los agrega al conjunto de trabajo. Debido a que los métodos de clasificación preliminar obtienen una gran 40.
(41) −5.5. −6. −6.5. −7. −7.5. −7.6. −7.4. −7.2. −7. −6.8. −6.6. −6.4. −6.2. −6. −5.8. −5.6. (a). −7.6. −7.4. −7.2. −7. −6.8. −6.6. −6.4. −6.2. −6. −5.8. −5.6. (b). −5.5. −6. −6.5. −7. −7.5. Figura 3.1: En la figura (a) se muestra un hiperplano que separa correctamente los datos. La figura (b) muestra el hiperplano de separación encontrado por las MSV.. parte de los vectores de soporte, entonces el número de elementos que violan las condiciones de KKT es reducido, por lo que la combinación de los métodos de clasificación preliminar con el algoritmo Chunking trae como consecuencia la disminución del número de iteraciones necesarias para obtener la solución óptima, al mismo tiempo que se disminuye el tiempo de entrenamiento y la memoria requerida por las MSV. Como se menciona en el párrafo anterior, se realizan aproximaciones lineales a la solución, por lo que el resultado obtenido no es tan exacto. Para lograr un mayor grado de exactitud con los métodos de clasificación preliminar, se decide utilizar:. 41.
(42) * Kernel Perceptrón, [10]. * Kernel Schlesinger-Kozinec, [7]. Estos algoritmos son extensiones de métodos lineales al caso no lineal mediante el uso de funciones Kernel. La idea básica es lograr que el conjunto de datos reducido contenga el mayor número de vectores de soporte posible. Lo anterior es posible debido a que tanto los clasificadores preliminares como el algoritmo Chunking trabajan en el mismo espacio dimensional, lo que facilita encontrar el conjunto completo de vectores de soporte del problema. Es importante hacer notar que el algoritmo Chunking utiliza en su proceso interno un optimizador cuadrático para encontrar los vectores de soporte del problema. Algunos de los algoritmos de optimización cuadráticos más utilizados son: M IN OS, [14], LOQO [15], QP . En esta investigación se decide utilizar la implementación de QP . Desafortunadamente, métodos como Chunking, Kernel-Perceptrón y Kernel SchlesingerKozinec llevan consigo un gran número de evaluaciones Kernel que disminuyen notablemente su rendimiento. Las diferentes evaluaciones Kernel, indican el numero de veces que el algoritmo realiza el mapeo de un patrón i de entrada a una dimensión más alta Z. El problema de procesar un gran número de evaluaciones Kernel puede evitarse incorporando la heurı́stica de Caching, [13], desarrollada por J. Platt e implementada en SV M light , en la que en cada iteración almacenan las evaluaciones Kernel de los vectores de soporte encontrados de tal forma que, cuando se requieren, no es necesario calcularlas nuevamente, sólo se necesita extraerlas de la memoria. El problema es que, si se almacenan todas las evaluaciones Kernel, es posible que la memoria crezca hasta el punto en el que se agote. Esto puede ser evitado si durante las diferentes iteraciones se eliminan las evaluaciones Kernel de aquellos patrones que no se han ocupado recientemente, sólo se mantienen las evaluaciones que más se requieren durante las diferentes iteraciones.. 3.1.. INICIALIZACIÓN DE LAS MÁQUINAS DE SOPORTE VECTORIAL CON LA AYUDA DEL PERCEPTRÓN. Como se describe en el capı́tulo 2, el algoritmo Perceptrón está dirigido a problemas linealmente separables por lo que su aplicación en problemas reales (del tipo no linealmente separables) se ve limitada. Para evitar el problema anterior es necesario realizar algunas modificaciones al. 42.
(43) 10. 8. 6. 4. 2. 0. −2. 7. 7.5. 8. 8.5. 9. Figura 3.2: Inicialización de W en ceros. Es posible que se quede muy lejos de la solución por lo que se requieren más iteraciones para llegar al óptimo. algoritmo, de tal forma que pueda trabajar con bases de datos no linealmente separables. Las modificaciones que se proponen son las siguientes: * Modificar la condición de paro del algoritmo de manera que se maximize el número de elementos bien clasificados. * Utilizar la extensión del Perceptrón a funciones Kernel . Al tratar con problemas no linealmente separables se modifica el algoritmo para que busque el hiperplano que maximiza el número de elementos bien clasificados. Lo anterior representa la búsqueda del hiperplano óptimo, donde en cada iteración se guarda el hiperplano que mejor clasifica los datos. Existen dos puntos importantes a considerar para el entrenamiento del algoritmo Perceptrón: * La inicialización del vector de pesos W . * El tamaño del paso de aprendizaje η. El tipo de inicialización de W es una variable que indica qué tan rápido se puede llegar a la solución óptima del problema. Normalmente se inicializa con valores de cero, pero es posible que el primer hiperplano trazado quede muy alejado de la solución y, en consecuencia, aumenta el número de iteraciones necesarias para llegar al hiperplano óptimo (Figura 3.2). Para evitar lo 43.
(44) anterior, se decide inicializar con valores aleatorios, lo que incrementa la probabilidad de quedar cerca de la solución en la primera iteración. El paso de aprendizaje η nos indica de qué tamaño son los movimientos que se realizan en la búsqueda del óptimo durante las diferentes iteraciones del algoritmo. Se pueden tener 2 casos: * Un valor de η grande. En este caso es posible que el algoritmo oscile y no se encuentre la mejor solución al problema. * El valor de η muy pequeño. Lo que posiblemente haga que el algoritmo tarde mucho en encontrar la solución. Para lograr que el algoritmo tenga un mejor desempeño se propone iniciar con un paso de aprendizaje grande y en cada iteración disminuirlo, de tal forma que en las última iteraciones se tengan movimientos muy pequeños que aseguren encontrar la solución óptima del problema. Una vez realizado el entrenamiento del Perceptrón, este sirve para inicializar el algoritmo Chunking el cual encuentra los vectores de soporte del problema. La heurı́stica propuesta se muestra en (Tabla 3.1).. 1. Entrenar el conjunto de datos completo utilizando el Perceptrón. 2. Obtener los q patrones más cercanos al hiperplano obtenido por el Perceptrón y formar el conjunto T RN . 3. Optimizar el conjunto T RN mediante QP para obtener los vectores de soporte. 4. Utilizar T RN para buscar los datos que violan las condiciones de optimalidad y formar T RNerr . 5. Si. T RNerr. ==. 6. En caso contrario,. Ø. terminar el algoritmo.. T RN = T RN ∪ T RNerr. e ir al punto (3).. Tabla 3.1: Inicialización de las MSV con el algoritmo Perceptrón. 44.
Figure




+7




Documento similar
Cedulario se inicia a mediados del siglo XVIL, por sus propias cédulas puede advertirse que no estaba totalmente conquistada la Nueva Gali- cia, ya que a fines del siglo xvn y en
No había pasado un día desde mi solemne entrada cuando, para que el recuerdo me sirviera de advertencia, alguien se encargó de decirme que sobre aquellas losas habían rodado
De acuerdo con Harold Bloom en The Anxiety of Influence (1973), el Libro de buen amor reescribe (y modifica) el Pamphihis, pero el Pamphilus era también una reescritura y
You may wish to take a note of your Organisation ID, which, in addition to the organisation name, can be used to search for an organisation you will need to affiliate with when you
Where possible, the EU IG and more specifically the data fields and associated business rules present in Chapter 2 –Data elements for the electronic submission of information
The 'On-boarding of users to Substance, Product, Organisation and Referentials (SPOR) data services' document must be considered the reference guidance, as this document includes the
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
