TítuloMetodología para el desarrollo de sistemas de extracción de concimiento en RNA
106
0
0
Texto completo
(2) 147. Capítulo 7. Resultados. Una comparativa entre los resultados obtenidos para este tercer problema y otros existentes se encuentra reflejada en la siguiente tabla. 1^1étodo. Nivel de Ajuste. Aquí propuesto. 97.22%. AQ 17-DCI. 94.2%. AQ 17-HCI. 100%. AQ 17-GA. 100%. Assistant Pro.. 100%. mFOIL. 100%. IDSR. 95.2%. ID3. 94.4%. AQR. 87.0%. CN2. 89.1 %. CLASSWEB 0.10. 80.8%. CLASSWEB 0.15. 85.4%. CLASSWEB 0.20. 75.2%. PRISM. 90.3%. ECOWEB, ext. 68.0%. MLP. 93.1 %. MLP+regularization. 97.2%. Cascade Correlation. 97.2%. FSM, fuzzy rules. 95.5%. SSV, crisp rules. 97.2%. C-MLP2LN rules. 100%. 7.4 Problemas de Clasificación 7.4.1 Iris Este ejemplo sirve para comprobar el funcionamiento del sistema ante tareas de clasificación múltiples. Este ejemplo ha sido muy analizado en campos como las RR.NN.AA y la extracción de reglas desde que Fisher lo documentara por vez primera en 1936 [FISH 36]. En este caso se dispone de 150 ejemplos con 4 variables de tipo continuo que representan 4 características de la forma de la flor. La tarea consiste en identificar el tipo de planta: Iris setosa, Iris versicolor e Iris virginica. Para ello, se han modificado los patrones de aprendizaje siendo de 4 entradas y 3 salidas. Las tres salidas son.
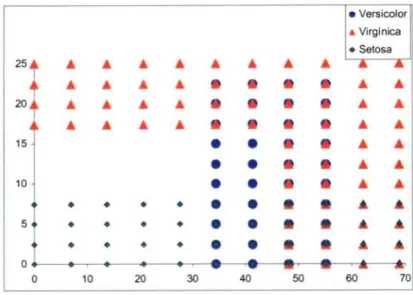
(3) Capitulo 7. Resultados. 148. booleanas y representan cada una de las clasificaciones. A1 hacerlo de esta manera se puede dar información adicional de si las salidas proporcionadas por el sistema son fiables o no. Esto es, por característica intrínseca de las salidas, sólo una debe tener el valor cierto, representando el tipo de flor que ha clasificado, y el resto el valor falso. Por lo tanto, si se encuentran dos o tres valores cierto o todos falso se puede concluir que el valor clasificado por el sistema no es correcto y se debe descartar. Los cuatro valores de entrada representan medidas en milímetros de las siguientes caracteristicas: (X,) Ancho del pétalo: (XZ). Longitud del pétalo:. continuo continuo. (X3) Ancho del sépalo:. continuo. (X4) Longitud del sépalo:. continuo. Una de las razones de aplicar este problema es debida a la ubicación fisica de los miembros de las clases en un espacio de cuatro dimensiones. En la figura 25 se puede ver la distribución del espacio para las variables X^ y X2. Según Duch, Adamczak y Grabczewski [DUCH 00] con estas variables se consigue una mayor discriminación para las tres clases. Concretamente, se puede conseguir un ajuste del 98% de aciertos utilizando solamente estas dos variables. Por lo tanto, son un punto de referencia importante para poder comparar los resultados obtenidos de forma gráfica. ♦ u ♦. 25 ,. •. ♦ Setosa. • • Y • ^ ♦ •♦ ♦ ^Y^ • • W^ • ♦ Y • ♦ ^ ♦ Y ^ • •. • Versicolor 20. • Virginica. •s. ,5 ^. •Ñ. 5. 0 0. 10. 20. 30. 40. 50. Fig. 25 - Dŭ tribución original de las tres clases. 60. 70.
(4) /49. Capítulo 7. Resultados. Los valores conespondientes a las cuatro variables de entrada se han nonnalizado en el intervalo [0-1] para poder ser tratadas por las RR.NN.AA. Sobre estos valores normalizados se ha aplicado el algoritmo de extracción de reglas para comparar los resultados obtenidos con otros métodos de extracción de conocimiento. Posterionnente, se ha entrenado una RNA y con las salidas que ésta produce se procede a extraer las reglas que la RNA ha aprendido y poder comprobar las diferencias y las similitudes con lo que deberia aprender. Hay que destacar que no se ha dejando que la RNA alcance el ajuste máximo de los patrones de entrenamiento, ya que de hacerlo habria menos diferencias entre extraer las reglas de los patrones originales de los producidos por la RNA. En las extracciones de reglas conespondientes a las tres clasificaciones se han probado varias combinaciones de parámetros y finalmente se han aplicado los mismos parámetros relativos a la simulación de la computación evolutiva y a los operadores involucrados para las tres clasificaciones. Los parámetros que mejores resultados producen son los siguientes: Constantes: Variables: Operadores Relacionales: Operadores Lógicos: Algoritmo de Selección: Tasa de cruces: Tasa de mutaciones: Tamaño de la población: Nivel de parsimonia:. 20 valores aleatorios en el rango [0-1] Xl, XZ, X3, X4 <, >, RANGO AND, OR, NOT Torneo 95% 4% 500 individuos 0.0001. Si se obliga al sistema a producir una única salida donde se establece una de las tres clasificaciones, se obtiene una serie de reglas que producen un ajuste del 99.33% debido a que de los 150 casos se comete 1 enor de clasificación. Las reglas obtenidas en este caso son las siguientes: (IF (XZ< 25.370) THEN Setosa ELSE (IF ((((((Xz - 40.959) % Xz) < ( Xz - (X^ - (X i % (X i -(Xd - 23.969)))))) AND (((Xi % (Xi 42.760)) < (XZ - (23.969 % (XZ - (X. - (X: - 34.507)))))) AND (((X^- 10.856) % (X2 - 40.959)) < (Xz - (Xj - ((Xz - 42.760) % (X^ - 21.777))))))) AND ((((Xz - Xl) < (X4 - (Xz % (Xi - (X^ - (Xz (Xa -íXz - (Xa - ((Xz - 40.959) % (X ^- 21.777))))))))))) AND (((Xz % (Xz - ( X4 - (Xi - (X3 {X ^ %.
(5) Capitulo 7. Resultados. 1 SO. (Xz - 40.959))))))) % (Xz - 40.959)) < (XZ - (X3 - (X^ % (X^ - 21.777)))))) AND ((23.969 % (X^ 10.856)) < ((Xz - (23.969 % (X^ - (X4 - (Xz - (X3 - (( Xz - 40.959) % ((Xz - X3) - 21.777)))))))) (Xz % (Xz - (Xy - (Xz - 40.959))))))))) AND ((X3 - ((Xz - 40.959) % (X^ - 21.777))) > 21.777)) THEN Virgínica ELSE Versicolor)). Sin embargo, si el sistema produce tres salidas, de tipo booleano, identificando cada una de ellas con la clasificación o no de cada tipo de flor se obtienen tres conjuntos de reglas diferentes y se obtiene un conocimiento adicional, poder saber si se ha cometido error o no, si el sistema no produce ninguna clasificación o si produce más de una. La regla obtenida de los patrones originales correspondientes a la clasificación de la Iris setosa produce un ajuste del 100% de aciertos y es la siguiente: (X, < 0.3141). Las reglas obtenidas de los patrones originales correspondientes a la clasificación de la Iris versicolor producen un ajuste del 100% de aciertos y son las siguientes: (((0.6773 > X,) OR ( 0.5266 < Xz <(0.7364))) AND (((0.6104 < X, < 0.7217) OR ((0.3360 < X, < 0.5266) OR (0.5266 < Xz < 0.7217))) AND ((X3 > X,) OR ( 0.6773 > X,)))). Las reglas obtenidas de los patrones originales correspondientes a la clasificación de la Iris virgínica comenten 1 error produciendo un ajuste del 99.33% de aciertos y son las siguientes: (((X, > Xz) OR (Xz > 0.7182)) AND ((Xz > X,) OR (((0.7390 < Xz < 0.7650) OR (X4> 0.9028)) OR (X, > X3)))). Hay que destacar que el error cometido por esta última expresión produce como salida del sistema, en su conjunto de las tres salidas, la clasificación de Iris versicolor e Iris virgínica (salida "FALSE - TRUE - TRUE") lo cual es una salida inválida y se elimina. Por tanto, se puede considerar que el sistema no produce ningún error siendo el ajuste del 100% de aciertos. La comparativa con otras técnicas de extracción existentes se encuentra reflejada en la siguiente tabla. Método. Referencia. Tipo. tii^^el de Ajuste. Aquí propuesto. Reglas. 100%. ReFuNN. Fuzzy. 95.7%. [KASA 96]. C-MLP2LN. Crisp. 98.0%. [DUCH 00].
(6) Capitulo 7. Resultados. l5/. Crisp. 98.0%. [DUCH 00]. ANN. Pesos. 98.67%. [MART O 1]. Grobian. Rough. 100.0%. [BROW 98]. SSV. GA+NN. Pesos. 100.0%. [JAGI96]. NEFCLASS. Fuzzy. 96.7%. [NAUC 96]. FuNe-I. Fuzzy. 96.0%. [HALG 94]. Para analizar más en detalle el comportamiento de las reglas obtenidas se ha construido un fichero de test con todos los valores posibles para las cuatro variables tomando intervalos regulares. Para Xi, cada 7 mm, para XZ cada 2.5 mm, para X3 cada 4.4 mm y para X4 cada 7.9 mm. Con estos intervalos, el fichero de test tiene 14641 ejemplos y se puede analizar todo el rango posible de clasificaciones que realizan las reglas. En la figura 26 se puede observar la distribución obtenida para las tres clases de las reglas extraídas. En estos gráficos, al igual que en los posteriores, el eje X hace referencia al ancho del pétalo (Xi) y el eje Y a la longitud del pétalo (XZ).. 0. 0. ^ m s. m m „ ....... ......... ......... 0. ^0. A. lD. ^0. !Y. O. '. ° , a. .. .. .. .. .......... .......... .. .. .. - - -_ _ _ A. l0. nT ^1 „i ,ot sr ^{ 0. 0 ......... ......... ......... ...... .. ..... .. .... .. . . . . . .. .. .. . .. t0. A. A. Fig. 26 - Distribución obtenida de las tres clases. Agrupando en una misma gráfica las tres clases, y comparándolas con las obtenidas del fichero de entrenamiento, se puede observar que el sistema de extracción de reglas busca la agrupación de los valores de entradas que dependen de cada clasificación y aislarlas de aquellos valores dependientes de las otras clasificaciones. Las zonas de intersección son aquellas donde el sistema produce valores de salida incorrectos indicando que la salida producida no es correcta y es necesario un análisis individual de esos valores para determinar la clase a la que pertenece..
(7) Capitulo 7. Resultados. /52. ^-1. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. !. •. !. •. •. •. ♦. •. •. ♦. !. ♦. ♦. !. ♦. ♦. •. •. •. •. !. •. •. •. •. •. •. •. •. •. ♦. ♦. ♦. •. •. •. •. •. •. ^. ^ T r -eT^ .^^^ ^ ^ 0. 10. 20. 30. 40. 50. 60. 70. Longitud del pétalo (mm). Fig. 27 - Distribución obtenida de las tres clases y las procedentes del aprendizaje. Entrenando una RNA de funciones de activación hiperbólica tangente con 1 capa oculta y 10 neuronas en esta capa se ha parado el entrenamiento de la misma cuando alcanzaba un ajuste del 96.67%. Con este ajuste se obtienen un total de 5 errores de clasificación. Este ajuste se divide en un 100% para la Iris setosa, un 98% de ajuste (3 errores) para la Iris versicolor y un 96.67% de ajuste (5 errores) para la Iris virgínica. De los 5 errores globales, en 2 de ellos la RNA no produce ninguna clasificación, por lo que son 2 errores detectables. La matriz de pesos de la RNA es la siguiente: W^x^: 18.37. W^x^: 16.39. W^^,^: 6.51. W^^s: 8.44. W^u: 0.75. W^y,^: 3.74. Wi^: -18.11. W^^y -4.62. W^=,,: 1.70. W^x,: 7.74. W^y: 6.49. W^o^: -4.06. W^^a: ^.77. W^u: -8.26. W^y,^: -7.57. W^u: 15.33. W,,^: 3.74. We,^: 18.97. W^,i: -I0.80. W^^: -19.63. Ws,i: 14.58. W^o,i: 1.80. W^^,^: 1.49. W,,=: 19.28. Wu: 7.66. W,^: -6.03. W^: -6.70. W,,=: -13.07. W^os: -17.37. WS,,: -16.69. W^,,: -7.12. Wi,: 3.61. W^: 1.22. W,y 9.73. W^o^: 16.63. V1'y,^: -8.95. WM: -17.04. W^,,: 6.54. Wu: 2.50. W,a: -9.83. Wiys:-15.06. W^^:-S.S2. W^,,^:-2.90. W^,,e:-1.37. Wi,,e. 13.72. W^x^e: 19.87. W^^,^^:8.43. W^y^: -1.07. N'^,,^^:-17.47. W^y,^e:16.10. W^^y:-17.66. W^^: -9.41. W^^,,: -4.95. W^^,e:-11.44. W'i^,,: 13.57. W^i^e:-I1.31. W'^^,^^: -6.82. W^^,^^: -7.17. W^^,^^: 18.02. W^^,^^:-10.13. W^^,e:-12.07. K'^^_,:-14.37. W'^^_^e:5.21. N'^,,^^: 15.89. W^^,t=: 10.21. W'^^,^^:3.86. W^,,^^:-I5.80. W'i^y 15J5. W'^,,^: I8.15. K'^^,,:-2.08. Aplicando el sistema de extracción de reglas, con la misma configuración de parámetros que la vista anteriormente, sobre los patrones "entradas entrenamiento / salidas RNA" se han obtenido las siguientes reglas..
(8) 1 S3. Capítulo 7. Resultados. La regla obtenida de los patrones producidos por la RNA correspondientes a la clasificación de la Iris setosa produce un ajuste del 100% de aciertos y es la siguiente: (X, < 0.3470). Las reglas obtenidas de los patrones producidos por la RNA correspondientes a la clasificación de la Iris versicolor producen un ajuste del 100% de aciertos y son las siguientes: (((0.4284 < Xz < 0.8291) AND (Xz < Xa)) AND ((( 0.3638 < X, < 0.6190) AND (0.000 < XZ < 0.7140)) OR (X, < X3))). Las reglas obtenidas de los patrones producidos por la RNA correspondientes a la clasificación de la Iris virgínica producen un ajuste del 100% de aciertos y son las siguientes: ((((X3 < X,) AND ((X, > 0.6307) OR (0.7198 < Xz < 0.8753))) OR (Xa < Xz)) OR (0.8690 < Xz < 0.8753)). Martínez y Goddard [MART O 1] han probado que, con 6 neuronas en la capa oculta, se alcanza un ajuste máximo del 98.67% (2 errores) de aciertos. Con el sistema propuesto en trabajos previos del autor del presente documento [RABU 99] y 5 neuronas ocultas y funciones de activación hiperbólica tangente se ha mejorado el anterior registro, en cuanto al número de neuronas ocultas, alcanzando también el 98.67% de aciertos. Este ajuste se divide en un 100% para la Iris setosa, un 98 67% de ajuste ( 2 errores) para la Iris versicolor y un 98.67% de ajuste (2 errores) para la Iris virgínica. Estos errores no son detectables porque la RNA produce una clasificación válida (sólo una salida a TRUE) pero errónea. La arquitectura y los pesos de las conexiones obtenidos se pueden observar a continuación, en la figura 28. La matriz de pesos de la RNA es la siguiente: Ws,,: -13.79. W^,,: 2.21. W,,,: -8.82. Wa,,: 5.68. W9,,: 10.59. Ws,^: -10.34. W^: 19.16. W7a^ -8.58. Wg,^: 18.11. Wq,^: -10.02. Ws^: 19.04. W^,: -16.29. W^a: -1.54. We,^: -19.99. W9^: -11.44. Ws,e^ -1.49. W^,a: 6.14. W^,a: 16.78. W^,a: -0.68. W9,a: 10.27.
(9) Capítulo 7. Resultados. 154. W10s: 6.99. W,o,b: -18.88. W,o,^: 7.88. W10,8:8.48. W10,9:1.00. W,,,s: -17.00. W,,,6: 6.29. W,,,,: 13.19. W,,,a: -10.85. W,,,9: 3.10. W,Z,s: 3.11. W,Z,6: -4.73. W12,,: -14.39. W12.8: 12.25. W,Z,q: -4.80. Setosa. Versicolor. Virginica. Fig. 28 - RNA obtenida. Aplicando de nuevo el sistema de extracción de reglas, con la misma configuración de parámetros que la vista anteriormente, la regla obtenida de los patrones producidos por la RNA correspondientes a la clasificación de la Iris setosa produce un ajuste del 100% de aciertos y es la siguiente: (X, < 0.3116). Las reglas obtenidas de los patrones producidos por la RNA correspondientes a la clasificación de la Iris versicolor producen un ajuste del 100% de aciertos y son las siguientes: ((0.2892 < X, < 0.5316) OR (((X3 > XZ) OR ((X4 > 0.7643) AND (XZ > Xi))) AND (0.5316 < Xz < 0.7268))). Las reglas obtenidas de los patrones producidos por la RNA correspondientes a la clasificación de la Iris virgínica producen un ajuste del 100% de aciertos y son las siguientes: (((Xi > X3) AND (X, > XZ)) OR (((0.5497 < X,) AND ((0.5497 > X3) OR (0.7279 < Xz))) AND (0.6787 < Xz))).
(10) Capitulo 7. Resultados. /SS. Analizando los resultados obtenidos se pueden observar las distribuciones que realizan las dos RR.NN.AA y las reglas obtenidas de cada una de ellas mediante el uso del fichero de test. Para la primera RNA (10 neuronas ocultas y 96.67% de ajuste) las distribuciones para las tres clasificaciones son las reflejadas en la figura 29: 0. O AI. n. • •. • •. • •. • •. • •. A. •. •. •. •. •. •. •. •. 15. •. •. •. •. •. •. •. •. •. •. t0. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. n. • •. • •. • •. • •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. rol. 10. S. •. 0 0. ^0. 10. A. .0. !0. !^. N. ^a 0 0. .0. l^. t0. .0. 50. ao. m. .o. n. eo. EO. Fig. 29 - Distribución aprendida por la primera RNA de las tres clases. En cambio para la segunda RNA (5 neuronas ocultas y 98.67% de ajuste) las distribuciones para las tres clasificaciones son las siguientes (figura 30):. 0. 0 ^. •. .. •. ^. •. n m. 10 ^. .. .. •. •. •. .. .. .. .. .. .. .. •. •. •. •. •. •. ^e. • • • • • • • •. • • • • • • •. • • • • • • •. . • • • • • • •. • • • • • • • •. •. '. •. 0 0 0. ID. lU. b. !Y. A. ]p. • • • • • • • •. • • • • • • • •. •. •. •. •. •. •. •. -. .0. !0. • • • • • • • •. . • • • • • • •. •. •. •. •. ♦. •. EO. s. .. •. •. •. •. .. .. •. •. •. •. .. .. .. .. .. m • • • • • •. m ro 6. • •. •. • 0 0. ^0. A. ]0. M. b. M. N1. Fig. 30 - Distribución aprendida por la segunda RNA de las tres clases. Como se puede observar en las figuras anteriores, en el caso de la RNA más entrenada, con mayor ajuste y menos neuronas, las distribuciones de las diferentes clases está mucho más acotada que en la RNA con peor ajuste. De estas dos RR.NN.AA es interesante comprobar las diferentes distribuciones que se obtienen de las reglas observadas. De las reglas obtenidas de la primera RNA (10 neuronas ocultas y 96.67% de ajuste) las distribuciones para las tres clasificaciones son las siguientes (figura 31):.
(11) Capitulo 7. Resultados. /S6. 0. .o. O. n.. n, 30. 15. tp. 10. 0 t0. i0. A. 10. l0. ^0. 9. m. Fig. 31 - Distribuciones obtenidas de las• reglas de la primera RNA. En cambio, de las reglas obtenidas de la segunda RNA (5 neuronas ocultas y 98.67% de ajuste) las distribuciones para las tres clasificaciones son (figura 32):. .n. 0. ... n. •. 0. 5}. •. Q I^. •. • •. •. •. •. •. • •. •. •. .. •. • •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. S. •. •. •. •. •. •. •. •. ^0. to. L. tl. ]0. !0. .. .. .. .. .. .. .. .. A ŭ. •. •. •. •. •. •. •. •. •. •. 1!^. •. •. •. •. .. •. •. •. •. •. 0♦ 0. ^0. .. 10 {. 0 0. .. •. •. IS. n1. t0. A. b. D. ^0. EO. 0. 10. ]0. A. .0. !0. M. /M. Fig. 32 - Distribuciones obtenidas de las reglas de la segunda RNA. • Versicolor • Virginica 25 ^ ^ 20 ^. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. ♦. !. •. •. •. ♦. ♦. ♦. ♦. ^. ♦. •. ^. ^. •. ♦. ♦. ♦. ♦. ♦. ♦. ^. ^. ^. ^. ♦. ♦. •. •. ^. ^. ♦. ♦. •. •. ^. ^. ♦. ♦. ^. ^. ^. ^. ♦. ♦. •. •. !. •. •. •. •. •. •. •. •. !. l. ♦. 15 ^. 10 ^. 5 +. • Setosa I T. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. 0 ♦}II 0. 10. 20. 30. 40. 50. 60. 70. Fig. 33 - Distribución conjunta de las reglas de la primera RNA. Si se agrupan las tres distribuciones en un mismo gráfico se puede observar que para la primera RNA existen zonas donde las reglas no producen una clasificación válida (figura 33), esto significa que la RNA no ha adquirido suficiente conocimiento.
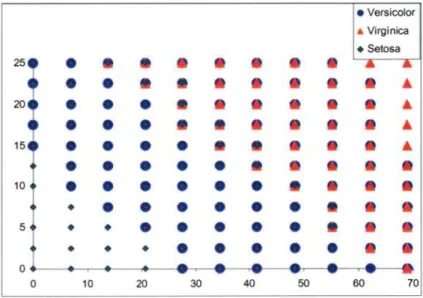
(12) 157. Capítulo 7. Resultados. sobre dicha zona. En cambio, para la segunda RNA, existe una clasificación para cada zona (figura 34). Además, los puntos de intersección están mucho más delimitados debido a que la RNA sabe bien hacia qué clasificación debe dirigirse en cada caso. Además, existen bastantes similitudes entre las distribuciones obtenidas de la mejor RNA y de las obtenidas de los patrones de aprendizaje originales. . versico^or ♦ Virgínica • Setosa 25^. ♦. ♦. ♦. ♦. ♦. !. !. ♦. ♦. ♦. !. !. ♦. ♦. ♦. t. ♦. ♦. ♦. 20^. ♦. ♦. ♦. ♦. ♦. •. !. ♦. ♦. ♦. ^. ♦. ♦. ♦. ♦. ♦. !. !. ♦. ♦. ♦. 15 ^. ♦. ♦. ♦. ♦. ♦. •. !. ♦. ♦. ♦. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. ♦. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. •. 10 • I. 5. 0 0. 10. 20. 30. 40. 50. s0. 70. Fig. 34 - Distribución conjunta ^le las reglas ^fe la segunda RNA. De todas formas, el comportamiento de las reglas ante los nuevos casos presentes en el test deberían aproximarse de una forma mucho más fiel de lo que realmente lo hacen. Esto es debido a que en el fichero de entrenamiento existen sólo datos representativos de las zonas "posibles" que puedan presentarse para cada planta, y no existen casos donde la existencia de dicha planta suponga algo imposible. Por ejemplo, una distancia de cero para cualquiera de sus cuatro variables no es algo posible, sin embargo la RNA y las reglas obtenidas, optan por una clasificación porque son valores posibles dentro del rango [0-1]. También se producen clasificaciones para multitud de valores que no han sido presentados en el proceso de entrenamiento pero que pueden considerarse como válidos. De estos valores se desconoce su clasificación exacta pero cada RNA realiza una elección en función del conocimiento adquirido y que se supone será más exacta para la RNA que tiene un mayor valor de ajuste en el proceso de entrenamiento. Esto es lo que se conoce en el mundo de las RR.NN.AA como la capacidad de generalización..
(13) /58. Capítulo 7. Resultados. Para la búsqueda de reglas que ajusten su funcionamiento a esta capacidad de generalización se deben incorporar más casos ejemplos y así poder emular de forma más exacta los espacios de distribución de las tres clasificaciones vistas anteriormente.. 7.4.2 Setas comestibles Este problema consiste en determinar, en función de una serie de características, si una seta es comestible o no. Para ello se parte de una base de datos [UCI] que consta de 8124 ejemplos con 22 características simbólicas de hasta 12 valores alguna de ellas. Partiendo de estos 22 valores se debe determinar si la seta es comestible o no. De los 8124 casos el 51.8% representan setas comestibles y el resto no, de hecho, la mayoría de estas son venenosas. Este es un problema lineal que servirá para comprobar el correcto funcionamiento del algoritmo de extracción en tareas de clasificación con elevados casos de ejemplo. Inicialmente se aplicará el algoritmo utilizando valores simbólicos para las entradas, introducidas inicialmente, y posteriormente se complicará el proceso al tener que determinar el algoritmo los valores para cada variable de entrada. Además, en este último caso, las entradas estarán normalizadas entre 0 y 1. De esta forma, se podrá comprobar si el algoritmo funciona igualmente bien en los rangos de valores en los que trabajan las RR.NN.AA y ser aplicable, por tanto, a valores de datos que ellas tratan y producen. De los 8124 ejemplos existen algunos que presentan valores erróneos en algunas entradas, sin embargo 5644 (el 69.47% de ellos) tienen todos los valores correctos, por lo tanto estos se utilizarán para el proceso de extracción de reglas y los restantes para el proceso de test o comprobación del funcionamiento correcto de las reglas extraídas. Inicialmente se aplica el algoritmo sobre valores simbólicos añadidos al conjunto de terminales. Para ello se han aplicado varias pruebas y la siguiente configuración de parámetros produce los mejores ajustes: Función de decisión: Constantes:. )F-THEN-ELSE aplicado sobre valores reales 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12.
(14) /S9. Capitulo 7. Resultados. variabtes: Operadores Relacionales: Operadores Lógicos: Algoritmo de Selección: Tasa de cruces: Tasa de mutaciones: Tamaño de la población: Nivel de parsimonia:. Xli X2i X3i ^4i X5i ^6i X7i ^Hi X9i X10i Xlli X12i. X13i X14i Xlsi X16i X17r X18i X 19r X20i X21i X22 <,>,_. AND, OR, NOT Torneo 95% 4% 1000 individuos 0.0001. El valor de ajuste que se ha obtenido es la correcta clasificación del 100% de los casos. Sin embargo, debido a la cantidad de casos necesarios para la evaluación de las reglas obtenidas, se han necesitado 14 horas para la obtención de una regla que ajustara al 100% y 3 horas más para optimizarla. Para esta última tarea se ha incrementado el valor del nivel de parsimonia hasta dejarlo en 0.001 y así poder extraer una serie de reglas de reducida complejidad. Las reglas obtenidas son las siguientes: ((X20=4) OR ((X15=3) OR ((^F (X3<X5) THEN (XS>7) ELSE (X,o<X8)) OR (X20=5)))). Posteriormente se ha aplicado el algoritmo sobre los casos de prueba normalizado entre 0 y 1 y sin incluir las constantes que determinan cada entrada. Lo que se le ha indicado al algoritmo es que genere 50 constantes aleatorias en el rango 0-1 y con ellas busque para cada variable de entrada su mejor adecuación a esas constantes. Para ello se ha utilizado la siguiente configuración de parámetros: Función de decisión: Constantes:. IF-THEN-ELSE aplicado sobre valores reales 50 valores en el rango 0-1. variables: Operadores Relacionales:. Xl, X2i X3r ^ai XSi ^6i X7i ^8i X9i X10i Xlli X12i X13^ Xla^ Xls^ X16^ Xl^^ Xla^ X19^ Xzo, Xzl, X22 <, >, _. Operadores Lógicos: Algoritmo de Selección: Tasa de cruces: Tasa de mutaciones: Tamaño de la población: Nivel de parsimonia:. AND, OR, NOT Torneo 95% 4% 1000 individuos 0.0001. De nuevo, se ha conseguido la correcta clasificación del 100% de los casos. Sin embargo, ha necesitado muchas más generaciones (645) y por consiguiente mucho más.
(15) 160. Capitulo 7. Resultados. tiempo para alcanzar dicho ajuste (1 día y 2 horas). Las reglas obtenidas son las siguientes: ((0.3193<X5) AND ((X5<0.7641) OR ((X8>X4) OR ((0.2529<X^) AND (X^<X14))))). En este caso, el algoritmo ha prescindido de la utilización de la función de decisión "IF-THEN-ELSE" y, además, necesita menos variables de entrada para ajustar todos los casos de prueba. Se ha obtenido una expresión mucho más reducida y coherente que en el caso anterior. De esto se puede deducir que el algoritmo de extracción puede y"sabe" trabajar sobre secuencias de ejemplos que sólo tengan valores en los rangos de operatividad de las RR.NN.AA. Por lo tanto, las entradas salidas generadas de ellas se pueden aplicar y utilizar directamente en el algoritmo de extracción sin temor a que se reduzca la habilidad y destreza del algoritmo de extraer reglas de dichos datos. El siguiente paso es aplicar los casos de test a las reglas obtenidas, para ello se generan valores al azar para los valores desconocidos y se pasan a ambas expresiones obtenidas. Para la primera de ellas se ha obtenido la correcta clasificación del 50.97% de los casos y para la segunda del 71.61 %. Con ello se corrobora lo comentado anteriormente, las reglas obtenidas sobre los datos normalizados no sólo son comparables a las obtenidas sobre los valores simbólicos sino que además son mejores. La comparación de los resultados obtenidos con otros métodos se puede observar en la siguiente tabla: Método Aqui propuesto. Nivel de Ajuste. Referencia. 100%. C-MLP2LN. 100.0%. [DUCH 00]. SSV. 100.0%. [DUCH 00]. RULENEG. 91.0%. [DUCH 00]. REAL. 98.0%. [DUCH 00]. DEDEC. 99.8%. [DUCH 00]. TREX. 100.0%. [DUCH 00]. C4.5. 99.8%. [DUCH 00]. RULEX. 98.5%. [DUCH 00].
(16) 16/. Capítulo 7. Resultados. 7.4.3 Hepatitis Este es un problema extraído de la base de datos médicas [UCI]. Contiene 155 muestras sobre dos clases: 32 muertos y 123 vivos. Por lo tanto, el objetivo del proceso a modelar es la detección de si es un tipo de hepatitis mortal o no partiendo de una serie de entrada de datos. El fichero de entradas consta de 19 atributos, de los cuales 13 son datos binarios y 6 son valores discretos. Además, muchos de los valores de entrada son erróneos. (X^) (XZ) (X^) (Xa) (/Xs) lX6). (X^) (X8) (XQ) (%t^o) (Xi^) (Xiz) (XI3). (Xia) (Xis) (Xie) (Xi^) (Xia) (X 19). AGE: SEX: STERO[D: ANTI V 1 RA LS: FAT[GUE: MALAISE: ANOREXIA: LIVER BIG: L[VER FIRM: SPLEEN PALPABLE: SPIDERS: ASCITES: VARICES: BILIRUBIN: ALK PHOSPHATE: SGOT: ALBUMIN: PROTIME: HISTOLOGY:. 10, 20, 30, 40, S0, 60, 70, 80 hombre, mujer no, si no, si no, si no, si no, si no, si no, si no, si no, si no, sí no, si 0.39, 0.80, /.20, 2.00, 3.00, 4.00 33, 80, 120, 160, 200, 250 /3, 100, 200, 300, 400, 500 2. l, 3. 0, 3. 8, 4. S, S. 0, 6. 0 l0, 20, 30, 40, S0, 60, 70, 80, 90 no, si. De los 155 casos, 80 no contienen ningún error y 75 contienen al menos un error en alguno de sus campos. Debido a esto se han utilizado los 80 casos libres de error para el aprendizaje y se dejan los 75 casos con errores para la etapa de test. Se normalizan los datos en punto flotante entre 0 y 1 para simular el funcionamiento de las RR.NN.AA y se utilizan los 80 patrones sin entradas incorrectas para comprobar y comparar con otras técnicas existentes si el proceso de extracción obtiene reglas de forma fiel al conocimiento residente en estos patrones. Los parámetros relativos al algoritmo que mejores resultados han producido son los siguientes: Funciones Aritméticas:. +, -, •, %. Constantes:. 20 valores aleatorios en el rango [0,1 ]. Variables:. 19 Entradas (13 booleanas y 6 continuas). Operadores:. <, >, _, AND, OR, NOT, IF-THEN-ELSE sobre booleanos y reales (umbral 0.5).
(17) Capítulo 7. Resultados. 162. El valor de ajuste que se ha obtenido es la correcta clasificación del 100% de los casos. Las reglas que se han obtenido son las siguientes: (((0.2706+((((0.9495%X15)*(X,8*0.7976))%(-0.7766))%0.5229))%(((-0.7766)*(( (IF X13 THEN X,g ELSE 0.2706)+(0.1202-0.5229))*0.2637))* (IF X,Z THEN (IF X„ THEN (0.2254+(0.4857-X15)) ELSE (0.5431 % 0.3089)) ELSE (-0.0635))))+((( (IF X^ THEN ( (-0.1883) % (0.2706 *(X18*0.7976))) ELSE 0.2883)*((-0.7766)-((-0.7766)% (IF X6 THEN 0.5408 ELSE 0.0828))))%(((-0.8084)*( (IF X13 THEN X,g ELSE 0.2706)+(0.1202-0.5229)))* (IF X1z THEN ((0.9495 % X15)+0.8746) ELSE 0.0256)))-(0.7475 % ((-0.0635)*0.1367)))). Si se prescinde de la utilización de funciones aritméticas, el valor de ajuste que se obtiene se reduce a la correcta clasificación del 98.75% de los casos, pero se obtiene un conjunto de reglas más reducido y entendibles. Las reglas que se han obtenido en este caso son las siguientes: (IF XZ THEN 0.8826 ELSE (IF ( (IF XZ THEN 0.8859 ELSE X18)<0.6247) THEN (IF (IF ((IF X6 THEN 0.9800 ELSE 0.6205)>0.9380) THEN (NOT X12) ELSE X^) THEN X,g ELSE 0.8826) ELSE (IF X13 THEN X,$ ELSE 0.2338))). Con el fin de comprobar la fiel extracción de reglas del proceso de aprendizaje del algoritmo se ha construido una RNA que simule el problema. Una vez entrenada se le aplicarán los casos de test sobre la RNA y sobre las reglas obtenidas para comprobar si los resultados son similares..
(18) 16.3. Capítulo 7. Resultados. Para el entrenamiento se han probado diferentes combinaciones de parámetros de número de capas internas, neuronas ocultas y tipos de funciones de activación, hasta conseguir la arquitectura que mejor ajusta el problema a resolver. Utilizando la función de activación hiperbólica tangente, una capa oculta y 9 neuronas en esta capa se consigue ajustar al 100% los 80 casos de prueba del fichero de entrenamiento. De los casos de test que contienen en alguna variable datos erróneos, se han generado valores aleatorios para estos datos. De aplicar los casos anteriores a la RNA se obtiene un 76% de ajuste. De aplicarlos a las reglas que ajustan al 100% en el entrenamiento (al igual que en la RNA), también produce un 76% de ajuste, y el error es producido en los mismos casos de prueba que la RNA. De esto se puede concluir que el funcionamiento operativo a nivel de ejemplos de entrenamiento y de test es similar, por lo que las reglas extraídas son un fiel reflejo del funcionamiento de la RNA y del conocimiento embebido en esos ejemplos. La comparación de los resultados aquí presentados con otros métodos existentes de extracción de reglas se puede observar en la siguiente tabla: Método. Nivel de Ajuste. Referencia. Aquí propuesto. 100%. C-MLP2LN. 96.1 %. [DUCH 00]. k-NN, k=18, Manhattan. 90.2%. [DUCH 00]. FSM + rotaciones. 89.7%. [DUCH 00]. LDA. 86.4%. [STER 96]. Naive Bayes. 86.3%. [STER 96]. IncNet + rotaciones. 86.0%. [JANK 97J. QDA. 85.8%. [STER 96]. 1-NN. 85.3%. [STER 96]. ASR. 85.0%. [STER 96]. FDA. 84.5%. [STER 96]. LVQ. 83.2%. [STER 96]. CART. 82.7%. [STER 96]. MLP con BP. 82.1%. [STER 96].
(19) 164. Capitulo 7. Resultados. ASI. 82.0%. [STER 96]. LFC. 81.9%. [STER 96]. Defecto. 79.4%. 7.4.4 Cáncer de pecho El siguiente conjunto de datos corresponde a la detección del tipo de cáncer de pecho. Se dispone, también, de una base de datos obtenida de UCI [UCI] de Wisconsin. Contiene 699 ejemplos para dos clasificaciones: 458 casos de cáncer benigno (65.5%) y 241 casos de cáncer maligno (34.5%). Hay 9 atributos, todos ellos con valores de carácter discreto en el intervalo 1-10 con 10 posibles valores para cada entrada. (X^) CLUMP THICKNESS: (XZ) UNIFORMITY OF CELL SIZE: (Xj) UNIFORMIT^ OF CELL SHAPE: (X,) MARG[NAL ADHESION: (XS) S[NGLE EPITHELIAL CELL S[ZE: (X6) BARE NUCLEI: (X^) BLAND CHROMATIN: (Xg) NORMAL NUCLEOLL• (X9) MITOSES:. l - 10 I- 10 l- 10 / - /0 1-/0 / - /0 1 - 10 l - 10 / - /0. Se han entrenado varias RR.NN.AA, pero en ningún caso se ha logrado alcanzar el 100% de clasificaciones. Se ha conseguido llegar al 98.28% de aciertos con 1 capa oculta y 7 neuronas en esta capa, y las neuronas con función de activación lineal. Con la misma arquitectura, pero con funciones de activación Hiperbólica Tangente, se ha mejorado el ajuste alcanzando el 98.68% de aciertos. Antes de aplicar los patrones de entrada-salida al proceso de extracción de reglas se han normalizado los datos entre 0-1, de esta forma se comprobará el correcto funcionamiento del sistema cuando éste trabaja con datos dentro del rango operativo de las RR.NN.AA. Esto supone un aliciente y complica de forma cuantiosa el proceso de extracción debido a que los nodos terminales referidos a las constantes "NO" se determinan de antemano, es el algoritmo el que obtiene valores que se adecuen a las diferentes clasificaciones de entradas. Lo que se le indica es el rango de valores (0-1) que tendrán las constantes generadas por él. Aplicando el algoritmo de extracción a los patrones entrada-salida generados por la anterior RNA, el valor del mejor ajuste obtenido es la clasificación correcta del.
(20) 165. Capitulo 7. Resultados. 99.71 % de los casos; sin embargo, para una correcta comparación con otras técnicas de extracción de reglas, se aplica el algoritmo directamente sobre el conjunto de patrones de entrada-salida iniciales (prescindiendo de las salidas de la RNA), pero sobre los valores normalizados, simulando el comportamiento de la RNA. En este caso el valor de ajuste global obtenido es la correcta clasificación de199.56% de los casos. Las reglas obtenidas de los patrones generados por la RNA con un ajuste del 99.71 % son las siguientes: (IF (0.3261> (IF (IF (X6>X3) THEN (Xz<0.2009) ELSE (X8>X3)) THEN (IF (0.5877>X6) THEN (IF (X^> (IF (X3>0.4744) THEN Xz ELSE 0.7835)) THEN (IF (X^>X6) THEN (IF (X6>0.2229) THEN X3 ELSE 0.3261) ELSE X,) ELSE X3) ELSE X^) ELSE (IF ( (IF (X6>0.1365) THEN Xi ELSE X6)>0.4744) THEN (IF (X3>X,) THEN 0.2229 ELSE X6) ELSE 0.7835))) THEN (IF (X8<0.8619) THEN Xz ELSE 0.7981) ELSE 0.9285).
(21) l66. Capitulo 7. Resultados. Las reglas obtenidas de los patrones de aprendizaje normalizados con un ajuste de199.56% son las siguientes: (0.3404+((((0.2277-Xz)-X6)%((-0.0149) % (0.1266*X3))) (IF ((^+Xs)>Xz) THEN (IF ((^+XsY(X^*(X6+Xz))) THEN (IF (0.3461> (IF (0.3461>(X,*(X6+Xz))) THEN XZ ELSE 0.8197)) THEN (IF ( (IF ((0.8197*(X6+X5))>X6) THEN 0.6456 ELSE 0.2388)>X,) THEN 0.6456 ELSE 0.0149) ELSE (0.8197 % (IF (X3<0.5466) THEN ( (IF ((0.8197*(X6+Xz))> (IF ((0.8197*(0.2092+X5))> (IF (0.8197>(X6+Xs)) THEN Xz ELSE 0.9617)) THEN X3 ELSE 0.9617)) THEN 0.8197 ELSE (0.2277-Xz))) ELSE (X6+( (IF (0.3288>X,) THEN Xz ELSE (0.2092+X5))))))) ELSE (X3-(-0.2388))) ELSE (0.9294+X,)))). La comparación con otros métodos existentes de extracción de reglas está representada en la siguiente tabla. Método. Yi^^el de Ajuste. Referencia. Aquí propuesto. 99.56%. C-MLP2LN. 99.0%. [DUCH 00]. IncNet. 97.1. [JANK 97]. k-NN. 97.0. [DUCH 00]. Fisher LDA. 96.8. [STER 96]. MLP with BP. 96.7. [STER 96].
(22) 167. Capítulo 7. Resultados. LVQ. 96.6. [STER 96]. Bayes (pares dependientes). 96.6. [STER 96]. Naive Bayes. 96.4. [STER 96]. DB-CART. 96.2. [SHAN 96]. LDA. 96.0. [STER 96]. LFC, ASI, ASR CART. 94.4-95.6. [STER 96]. 93.5. [SHAN 96]. 7.4.5 Disfunción del tiroides El siguiente conjunto de datos corresponde a la detección del tipo de disfunción del tiroides. Se dispone, también, de una base de datos obtenida de UCI [UCI]. Contiene 3772 casos de entrenamiento y 3428 casos de test. En este caso el sistema debe establecer tres clasificaciones: primario, compensado y normal. En los casos de entrenamiento hay, para cada clasificación, 93, 191 y 3488 ejemplos. En los casos de test hay 73, 177 y 3178 ejemplos. Hay 22 atributos de los cuáles 15 son booleanos y 7 valores continuos. (Xi) AGE: (XZ) SEX: (X}) ON THYROXINE: (XQ) QUERY ON THYROXINE: (XS) ON ANTITHYROID MEDICATION: (X6) SICK: (X^) PREGNANT: (X8) THYROID SURGERY: (X9) 1131 TREATMENT: (X^o) QUERY HYPOTHYROID: (Xii) QUERY HYPERTHYROID: (X^Z) LITHIUM: (X13) GOITRE: (X14) TUMOR: (X15) HYPOP[TUITARY: (Xib) PSYCH: (Xi^) TSH: (Xi$) T3: (X19) TT4: (X20) T4U: (XZi) FTI: (X2z) TBG:. continuo. hombre, mujer no, si no, si no, si no, si no, si no, si no, si no, si no, si no, si no, si no, si no, si no, si continuo continuo continuo continuo continuo continuo. Con estos ejemplos se comprobazá el funcionamiento del sistema ante situaciones con varias clasificaciones de salida y de cierta cantidad de casos a explorar. Paza la extracción de reglas se ha subdividido el problema en tres, cada uno paza cada clasificación. Para mantener fija el tipo de salida que se desea del algoritmo a booleana.
(23) Capítulo 7. Resultados. 168. es la forma natural de división. Para los 3772 casos se construyen los patrones de aprendizaje en la forma que puede versa en la figura 35: Primaria (true-false) 3772 Entradas. Compensada (true-false) Normal (true-false). Fig. 35 - División de la salirta rle clasiftcación. De esta manera se obtendrán tres árboles sintácticos independientes procedentes de tres ejecuciones independientes del algoritmo. Los valores continuos se han normalizado entre [0-1] y, al igual que en los casos anteriores, para una correcta comparación con otras técnicas de extracción de reglas, se aplica el algoritmo directamente sobre los tres conjuntos de patrones de entrada-salida iniciales normalizados. La regla obtenida para la clasificación primaria produce un ajuste del 99.6% de aciertos en el entrenamiento y 99.27% en el test: ((0.0038 < X») AND (X2, < 0.0606)). La regla obtenida para la clasificación compensada produce un ajuste del 99.2% de aciertos en el entrenamiento y 98.92% en el test: ((((0.0060 < X» < 0.0201) AND (X^e < 0.0416)) AND (((0.040 < X^9 < 0.1550) AND (0.0505 < XZ° < 0.1660)) AND (XZ, > 0.0635)) AND ((NOT X3) AND (NOT Xe))). Y la regla obtenida para la clasificación normal produce un ajuste del 99.02% de aciertos en el entrenamiento y 98.22% en el test: ((X3 OR ((Xe OR ((X8 AND (((Xi^ < 0.0097) OR (((-0.5587) ' ((-0.5587) ' ((-0.7715} 0.8511))) < X,^ < (((-0.5587) - (-0.7715)) ' (-0.7715)))) OR ((X,^ < 0.0097) OR ((-0.8521) < X,^ < ((-0.5587) ' (((-0.5587}(-0.7715)) ' (-0.7715))))))) OR ((X,^ < 0.0097) OR (X,^ <.
(24) Capítulo 7. Resultados. 169. 0.0097)))) AND (((0.0227 % ((-0.0754) ' ((-0.5587) - (-0.7715)))) < X» < (((-0.8521) ' (( 0.5587)-(-0.7715))) ' (((-0.5587) - (-0.7715)) ' ((-0.5587) - (-0.4100))))) OR ((Xe OR XB) AND ((X» < 0.0097) OR ((((-0.5587) - (-0.7715)) ' ((-0.5587) - (-0.4100))) < X» < (( 0.5587) ' ((-0.8521) ' ((-0.5587)-(-0.7715)))))))))) AND ((X^^ < 0.0097) OR (((((-0.8521) ' ( 0.7715)) ' ((-0.8521) ' ((-0.5587) - (-0.7715)))) ' 0.0227) < X» < (-(0.0227 % ((-0.8521) ' ((-0.5587) - (-0.7715)))))))). Analizando los resultados de las tres reglas, agrupándolas como salida única se tiene que, para los casos de entrenamiento, se obtienen 77 casos erróneos (supone un ajuste del 97.96% de aciertos), pero al tratar las tres salidas independientes se dispone de información adicional: se puede conocer si se produce error o no. Esto es muy importante porque ante casos reales cuando se desconozca la salida correcta es de especial importancia conocer si la salida producida es correcta o no. Para ello, si se analizan los 77 casos de salida incorrecta se puede comprobar que las reglas no producen ninguna clasificación en 61 de ellas y más de una clasificación en 12 de las restantes. Por consiguiente, de los 77 errores el sistema sabe que en 73 ya está produciendo error, por lo que se pueden descartar los resultados producidos en esos 73 casos y en ellos es necesario la presencia de un médico experto para analizarlos. Por lo tanto, como errores se consideran los 4 en los que el sistema produce una de las clasificaciones y es incorrecta. De esto se puede suponer que el sistema tiene un ajuste de199.89% de aciertos. Analizando los resultados para los casos de test de igual manera a lo visto anteriormente, se obtiene un ajuste de las tres reglas conjuntamente del 96.97% de aciertos con 104 errores. De ellos, 69 no producen ninguna clasificación y 16 producen varias clasificaciones simultáneas, por consiguiente se pueden detectar 85 de los 104 errores. Esto supone que los errores cometidos son 19, y producen un ajuste del 99.45% de acierto. Por lo tanto, se tiene un ajuste del 99.89% de ajuste en el entrenamiento y un 99.45% en el test. La comparación con otros métodos existentes de extracción de reglas está mostrada en la siguiente tabla:.
(25) Capítulo 7. Resultados. Método. 170. Ni^^el de Ajuste. Referencia. "/^ Entrenamiento. "/^ Test. Aquí propuesto. 99.89%. 99.45%. C-MLP2LN. 99.89%. 99.36%. [DUCH 00]. CART. 99.79%. 99.36%. [WEIS 90]. PVM. 99.79%. 99.33%. [WEIS 90]. SSV rules. 99.79%. 99.33%. [DUCH 00]. FSM 10 rules. 99.60%. 98.90%. [DUCH 00]. 100%. 98.50%. [SCHI 93]. MLP with BP. 99.60%. 98.50%. [SCHI 93]. 3-NN, 3features used. 98.70%. 97.90%. [DUCH 00]. Bayes. 97.00%. 96.10%. [WEIS 90]. Cascade correlation. 7.5 Problemas de Predicción de Series Temporales Para la predicción de series temporales es necesario la utilización de arquitecturas recurrentes de RR.NN.AA para modelizar este tipo de problemas. La extracción de reglas a RR.NN.AA de arquitectura recurrente supone un reto adicional debido a que éstas RR.NN.AA se caracterizan por su gran capacidad de representación y de conocimiento distribuido en sus conexiones, especialmente aplicables a problemas de carácter temporal y dinámico. El primer problema a resolver será la predicción de una serie temporal caótica de laboratorio muy clásica en el campo de las series temporales: la serie de Mackey-Glass. Posteriormente, se utilizarán dos problemas reales de series temporales: la producción de tabaco anual en Estados Unidos y el número de manchas solares anuales. Ambas son series temporales clásicas pero que difieren en su estructura, mientras la primera es de tipo incremental la segunda es de tipo estacionario en la media [VEMU 94][WILL 94][URIE 95].. De esta forma, se puede comprobar el. funcionamiento del sistema ante casos reales de series temporales pero diferentes. Se podrá observar en los siguientes resultados que las reglas que se pueden obtener de éstas RR.NN.AA deben incorporar mecanismos para el tratamiento de valores temporales. Se utilizarán, por tanto, nodos no terminales que representen operaciones matemáticas y trigonométricas y variables de las entradas en "n" instantes previos (Xn). La mayoría de casos de series temporales son estructuras con una única.
(26) Capítulo 7. Resultados. 171. entrada y una única salida. La entrada corresponde a un valor numérico del instante "t" y la salida del sistema es la predicción del valor numérico en el instante "t+l". Para las comparaciones con otros métodos existentes de predicción de series temporales se mostrarán varios valores procedentes de distintos métodos de calcular el error cometido, tanto en la fase de entrenamiento como en la de test. Se mostrará el error medio (en adelante EM), el error cuadrático medio (en adelante ECM) y el error cuadrático medio normalizado (en adelante ECMN). En las tablas comparativas de las series Mackey-Glass y manchas solares se indicará el ECMN por ser el que aparece en los diversos artículos referenciados, aunque es el ECM el que se utiliza como función de ajuste en el entrenamiento de las RR.NN.AA y el EM el que se utiliza como función de ajuste en el algoritmo de extracción mediante PG. Se ha realizado así, porque el EM es el que más rápido se calcula (computacionalmente hablando) y de las pruebas inicialmente hechas no supone ninguna ventaja adicional implementar como función de ajuste el ECM o el ECMN.. 7.5.1 Predicción de la serie de "Mackey-Glass" El problema a resolver será la predicción de una serie temporal caótica de laboratorio muy clásica en el campo de las series temporales: la serie de Mackey-Glass [MACK 77]. Se puede observar en los siguientes resultados que las reglas que se pueden obtener de ésta RNA deben incorporar mecanismos para el tratamiento de valores temporales. Se utilizarán, por tanto, nodos no terminales que representen operaciones matemáticas y trigonométricas y variables de las entradas en "n" instantes previos (X„). La mayoría de casos de series temporales son estructuras con una única entrada y una única salida. La entrada corresponde a un valor numérico del instante "t " y la salida del sistema es la predicción del valor numérico en el instante "t+l ". La ecuación de Mackey-Glass es una ecuación diferencial:. dx - ax(t-i) -b x (t) dt l+x`(t-r).
(27) 172. Capítulo 7. Resultados. Eligiendo i= 30 la ecuación llega a ser caótica y solamente son factibles las predicciones a corto plazo. Integrando la ecuación en el rango [t, t+ 8t] se obtiene:. x(t + Ot) = 2- bOt x(t) + x(t + Ot) = 2- bOt x(t) + 2 + bOt 2 + bOt El primer paso a realizar es obtener una RNA recurrente que emule el comportamiento de esta serie. Para ello, se han utilizado diferentes funciones de activación siendo la hiperbólica tangente la que mejores resultados produce. Además, se han utilizado 3 neuronas de este tipo con interconexión total. Los ficheros de entrenamiento que se han utilizado corresponden a los 200 primeros valores de la serie temporal (figura 37). La RNAR resultante del proceso de entrenamiento que ha producido el menor ECM = 0.000072 se puede observar en la figura 36. El ECMN que produce esta RNAR es de 0.0010. En cuanto a la fase de test, se utilizan los 1000 primeros valores de la serie temporal (figura 37) y la RNAR produce un ECM de 0.000077 y un ECMN de 0.0014.. Fig. 36 - RNAR que emula la función de Mackey-Glass. Para comparar el ajuste que puede llegar a alcanzar el algoritmo de extracción de reglas con otras técnicas de predicción de series temporales se ha ejecutado el algoritmo directamente sobre los patrones de datos de la función de Mackey-Glass. Para ello, se han probado diferentes combinaciones de elementos terminales y no terminales y varios parámetros propios de la PG utilizando los siguientes:.
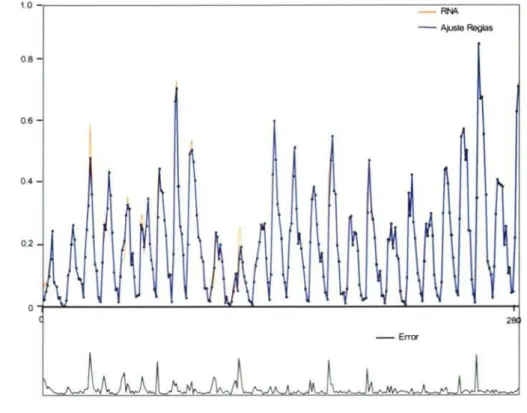
(28) l 73. Capitulo 7. Resultados. Funciones Aritméticas: Constantes: Yariables: Algoritmo de Selección: Tasa de cruces: Tasa de mutaciones: Tamaño de la población: Máxima profundidad: Nivel de parsimonia:. +, -, *, % (división protegida) 10 valores aleatorios en el rango [0,1 ] Xni Xn-li Xn-2i Xn-3. Torneo con estrategia elitista 95% 4% 1000 individuos 9. 0.0001. La regla en forma de función matemática obtenida que produce los mejores resultados es la siguiente: (-((((Xn - Xn-1) * ( 0.9225 - Xn-1)) * ((X n - Xn-1) % (-Xn-1 ))) + ( ((Xn - Xn-1) * (-0.9829)) - Xn))). Con esta expresión matemática se consigue un ajuste del EM de 0.00321, ECM de 0.000022 y ECMN de 0.00033. Sobre los ficheros de test, la expresión obtenida produce un ajuste del EM de 0.00388, ECM de 0.000026 y ECMN de 0.00026. Con estos resultados se mejoran los obtenidos por la RNAR anteriormente probada. La comparación con otros métodos existentes de extracción de reglas está representada en la siguiente tabla. Los valores mostrados corresponden al ECMN. Método. Ajuste Normalizado. Referencia. Aquí propuesto. 0.00026. RNN con CBPTT. 0.00014. RNN con BPTT. 0.00024. [BONE 00]. TDNN. 0.0008. [LOGA 93]. RNN con AG. 0.0014. [RABU 99]. RNN. 0.0031. [LOGA 93]. FIR MLP. 0.0049. [WAN 93]. MLP. 0.0100. [WAN 93]. RBF. 0.0107. [WAN 93]. Local approach 1. 0.0331. [SVAR 93]. Local approach 2. 0.0129. [SVAR 93]. Rational. 0.0724. [SVAR 93]. Polynomial. 0.0112. [CASD 89]. Linear. 0.2690. [CASD 89]. [BONE 00]. Una vez se tiene la RNAR se procede a obtener, mediante regresión simbólica, las reglas que rigen su funcionamiento. Para ello, se ha utilizado un fichero de test que.
(29) 174. Capitulo 7. Resultados. contiene los 1000 primeros valores de la serie temporal. Estos 1000 valores se le pasan a la RNAR y se obtienen las salidas correspondientes a los mismos. Con este fichero de entradas-salidas, se procede a ejecutar el algoritmo de extracción. Se ha utilizado la misma configuración de parámetros que en el caso de los patrones originales. La regla en forma de función matemática obtenida es la siguiente: (\Xn * ((( (((Xn * \Xn * Xn-2)) % Xn-2) * (((0.9834 * (((((Xn * (Xn_2 % Xn-3)) * Xn-3) * Xn-3) % Xn-3) % (Xn % Xn-3))) % Xn-3) % ((Xn-2 * Xn-2) % Xn-3))) % Xn-3) * Xn-2) % Xn-2)) % ((Xn * Xn_2) % Xn_3) * 0.9834)). Esta función obtiene un valor de ajuste (EM) sobre los 1000 valores que produce la RNAR de 0.0029. Una gráfica comparativa entre los valores que produce la función de Mackey-Glass y las salidas obtenidas de la expresión matemática anterior se puede ver en la figura 37, donde se puede observar que el nivel de ajuste alcanzado entre la salida que produce la RNAR y la expresión obtenida es realmente satisfactorio. io. RNAR. Test. Entrenamiento. ^ Ajusb reglas. ^. o.s -. i;. :,. ^. _. . ^'. ' ;^.. ^. os. ^;. ^' .. ^. .. 1 '} •J. o.a . ^:. i. ^. ^. ^. ^. , . .. j; ^. .. :. :. . , A ^: • ,. .. , ; ^ ^ ^ ;^ .; + ; :^:r; • • : t :i ^, ^i .. ;. ^. ^'. .. ,. •^. `:. .. '.. .. .. % ' .. ^ ' •. ^ ^_ • ^ ^. `. ''. •'. ^. ^. •. .:^.. .. •j,. .. ^^. :. o.z ^. . ^' :: :. oy 0. f; ^. ^.. ;.. ^ .. .. . ^. .. '. •. '; •. '^^. •. •••. . ^ ;. . ^. ^ •. •. .^:•..^. ' t. : • • : .. ^. ; ^.. '. _•. :.. 4. ^. ^ :; y. ,.. - Error. 200. .i. ••. ^ooo. Fig. 37 - Comparativa entre la salida de la RNAR y la función obtenida del proceso de extracción. 7.5.2 Predicción del número de "manchas solares" Para comparar el ajuste que puede llegar a alcanzar el algoritmo de extracción de reglas con otras técnicas de predicción de series temporales, se ha ejecutado el.
(30) /7S. Capitulo 7. Resultados. algoritmo directamente sobre los patrones de datos de entrenamiento. Estos ficheros contienen el número de manchas solares que se han producido entre los años 1700 y 1920. Posteriormente, para comprobar el nivel de ajuste conseguido se tienen dos conjuntos de patrones "entrada-salida" denominados de test. El primero agrupa las manchas producidas entre 1700 y 1955 y el segundo entre 1700 y 1979. Aunque se disponen de datos de manchas producidas hasta el año 2000, para comparar los resultados obtenidos con otras técnicas existentes se ha utilizado hasta 1979 porque los ficheros de test utilizados por estas técnicas abarcan solamente hasta ese año. Se han probado diferentes combinaciones de elementos terminales y no terminales y la configuración que mejores resultados produce es la siguiente: Funciones Aritméticas: Funciones Trigonométricas: Funciones Logarítmicas: Función de decisión: Constantes: Yariables: Algoritmo de Selección: Tasa de cruces: Tasa de mutaciones: Tamaño de la población: Mcíxima profundidad: Nivel de parsimonia:. +, -, *, %( división protegida), cuadrado, raíz cuadrada seno, coseno, tangente exponencial IF-THEN-ELSE aplicado sobre valores reales 50 valores aleatorios en el rango [0,1 ] Xn, Xn_l, Xn_z, Xn-3^ Xn-a, Xn-5^ Xn-^ Torneo con estrategia elitista 95% 4% 1000 individuos 20 0.00001. Con estos parámetros se ha alcanzado un ajuste en el entrenamiento de EM=0.02959, ECM=0.002035 y ECMN=0.0696. El ajuste sobre los ficheros del primer test es de EM=0.03384, ECM=0.00277 y ECMN=0.0864. Y el ajuste sobre los ficheros del segundo test es de EM=0.03972, ECM=0.00445 y ECMN=0.2604. Las reglas con expresiones matemáticas obtenidas son las siguientes: (IF ((((-0.0967)*X°^)>((0.8375+ (IF (X„^<((-0.0967) * X„^)) THEN X„^ ELSE ( X°^+0.8375))) % (-((((X°^ + 0.8375) % X°^)*0.7802) % (IF ( (IF (0.1400<(0.0776 + X„)) THEN X„^ ELSE (-0.6646))< logslg(((0.0776-((X°^+ 0.8375)+0.9741))* sqrt((((-0.0967)*X„^)+ (0.8375+(0.2728 % Xn_z))))))) THEN 0.2826 ELSE sqrt((((((0.5848 - Xo) +(X^+ 0.8375)) % X°)*X°^)+(-0.3308)))))))) AND ((-(((0.5848.
(31) Capítulo 7. Resultados. 176. X„) * (X°^+0.8375))*((0.7055*((0.5848 - X°)*((X°^,+ 0.8375) % 0.9741))) * (X°.6+ 0.8375)))) > ((Xn_z*X°_Z) % (-(0.07986 % (IF ((0.0798 % (IF (sqr((0.7055 + X°))<0.8966) THEN sqrt((0.2728 % X„_z)) ELSE X°))<((X°^+ (((X°^+ 0.8375)+0.8375) * X°^)) % 0.9741)) THEN sqrt((((0.5848 - X°) % (X°^ + 0.8375))+((0.4085 + (-X°)) + 0.8375))) ELSE ((0.5848 - X°) % 0.9741))))))) THEN (IF ((0.1400 < (0.0776 + X^)) AND (((0.0798 % (IF (sqr((1.1103 * X°^)) < X,,.^). THEN sqrt(((-0.3308) + X„)) ELSE X°)) < logsig(((X°^ + X^^) % 0.9741))) AND (((-0.8347)+((X°^ * X°^) + Xn)) >((Xn-z * X°_Z) %((-0.0967)*((((((-0.0967)*((X°^+ X°^) + 0.8375))+X°) *(X°^+ 0.8375))+X°) + Xn)))))) THEN (IF ((X°> (((0.5848 - Xo) % 0.9741) % (-(((0.0776-((0.5848 - X°) + (((-0.0967) * X°^) + 0.8375))) * sqrt((0.9204 + (X°_6+ 0.8375)))) % 0.8966)))) AND (((((X°^+ 0.8375) * (((-0.5848) * sqrt((0.8966+(((-0.0967) * X°_a) + (X°^+ 0.8375))))) * ((((0.5848 - X°) % 0.9741) + (X°^+ 0.8375)) % 0.9741)))-(-0.8189)) * (0.4883 % X°^)) < ((-0.0967) * X°^))) THEN ((((-0.0967) * X°^) + X°) * (((((-0.0967) * X„^) * (logsig(((0.4085 + ((0.5848-X„) * 0.8597)) % X°^)) * (((X°^ + ((X°_6 + 0.8375) % 0.9741)) + 0.8375) * (((-0.3892) * (((X° + 0.8375) + 0.8966) * X„^)) - (-0.8189))))) + 0.8375) * sqrt(((0.5848 - X°) + (X°_6+ 0.8375))))) ELSE ((((-0.0967) * X°^) + X^) * ((((-0.0967) * X°^) + 0.8375) * ((0.0798 % (IF (Sqr((logslg((X„^+ 0.8375)) * X„^)) < (0.0776 + X„)) THEN Sqrt((((((X°^,+ 0.8375) +(X°^+ 0.8375)) % X°) * X°^) + 0.2826)) ELSE X„)) - (-0.8189))))) ELSE ((0.7118 + logsig( (IF (((((-0.0967) * X°^) * ((X°^ + 0.8375) % 0.9741)) * ((X°^ + ((0.4085 + (-X°)) + 0.8375)) % 0.9741)) < ((-0.0967) * X,,.,)) THEN ((-0.5848) * ((X°^+ ((0.8375 % X°) * X°^)) % 0.9741)) ELSE (-0.8189)))) * X„)) ELSE ((logsig(((Xi_z * Xr_z) % (((-0.0967) + (((((-0.0967) * X„^) + X„) * (0.7055 * (X°^+ (Xo^+ (0.5848 - ((-0.0967) * X°^)))))) + Xn))*((((((-0.0967) * X°^) + X°) * ((0.5924 * X°^) * (0.2728 % (((0.8375 % X°) * X°^) - X°)))) + X°) + ((-0.0967) * X°^))))) + (0.8966 * ((((0.7673 * ((0.5848 X°) * ((0.5848 - ((0.7055 + X„) * X°-a)) + ((0.2728 % Xn-z) * X„-a))))-(-0.8189)) * ((((((Xi-2 * Xr-z) + 0.8375) + 0.8375) * X°^) + ((0.5848 * Xn_z) - (-0.8189))) % 0.9741)) % 0.9741))) * X°)). La comparación con otros métodos existentes de extracción de reglas está representada en la siguiente tabla. Los valores mostrados corresponden al ECMN. Método. Referencia. Aprendizaje. Test 1. Test 2. Aquí propuesto. 0.0696. 0.0864. 0.2604. RNN con CBPTT. 0.098. 0.092. 0.251. RNN con BPTT. 0.064. 0.084. 0.300. [BONE 00]. IIR MLP. 0.101. 0.097. 0.436. [MCDO 94]. MLP. 0.082. 0.086. 0.350. [WEIG 90]. TAR. 0.097. 0.097. 0.280. [TONG 80]. Carbon Copy. 0.289. 0.427. 0.966. [PRIE 81 ]. [BONE 00].
(32) Capitulo 7. Resultados. 177. Se han entrenado varias RR.NN.AA.RR con diferentes funciones de activación y neuronas ocultas. Utilizando los resultados alcanzados en trabajos de investigación previos [RABU 99][DORA 99], se ha utilizado la función de activación lineal en todas las neuronas ya que es la que mejores resultados produce. Con 3 neuronas en la capa oculta, el mejor valor de error cuadrático medio (ECM) conseguido es de 0.0060. Con este ECM se pueden obtener mejores resultados de predicción que los obtenidos por métodos estadísticos como el ARIMA [RABU 99][DORA 99]. A diferencia de la tabla previa, se utiliza el ECM como medida de ajuste. Esto es debido a que el ECM se ha utilizado como función de ajuste del AG de entrenamiento. En los casos anteriores se ha calculado el valor ECMN cometido a posteriori por las reglas para compararlo usando otros métodos existentes [OUT 00] en los que el nivel de error viene expresado en ECMN.. Fig. 38 - RNAR que predice a corto plazo las manchas solares.. Con las entradas del proceso de entrenamiento y las salidas que produce la RNAR anterior se construyen los patrones de aprendizaje para el algoritmo de extracción. Se han probado varias configuraciones de elementos terminales y no terminales para el algoritmo siendo la que mejores resultados produce la siguiente: Funciones Aritméticas: Funciones Trigonométricas: Funciones Logarítmicas: Función de decisión: Constantes: Variables: Algoritmo de Selección:. +, -, *, % (división protegida), cuadrado, Raíz cuadrada seno, coseno, tangente exponencial IF-THEN-ELSE aplicado sobre valores reales 50 valores aleatorios en el rango [0,1 ] ^ni Xn-li ^n-2i ^n-3i Xn^i ^n-5i Xn^ Torneo.
(33) Capitulo 7. Resultados. Tasa de cruces: Tasa de mutaciones: Tamaño de la población: Máxima profundidad: Nivel de parsimonia:. /78. 95% 4% 1000 individuos 25 0.00001. Las reglas obtenidas con esta configuración y dejando evolucionar la población hasta alcanzar 3000 generaciones (2.5 días de ejecución) son las siguientes: (IF (}^°_^ > (IF (((X„_8 % (0.8272 * cos(X„-,))) * X„) > X„-g) THEN X„ ELSE ( (IF (X„> X^_g) THEN (0.8272 * X„) ELSE (IF (0.6563 o X^_g) THEN (X° % (0.6629 + X^_,)) ELSE 0.8272)) % (0.6629 + X^_, )))) THEN ( (IF (((X„ % (X„ * 0.8536)) - X„) > X„-s) THEN (X^ * 0.8536) ELSE X^) * (((X^ % ( 0.6629 + ( (IF (Xo_g > (IF (((((0.6629 + X„_,) + X„_,) - (0.6629 + X^_,))) > X„-s) THEN (X^ % ((0.6629 + ( (IF ((((X^ % (X^ % (X^ * COS(Xn-1)))) - Xn) + Xn-I) > Xn-S) THEN (. (IF (}{°_^ > (IF ((X^-s + X^-i) > X^-s) THEN X„ ELSE X„_,)) THEN (X„ * 0.8536) ELSE (( 0.8272 * (((0.6629 + X„_,) + X„_,) -(-0.7521))) % (0.6629 + X„_,))) * 0.8536) ELSE X„_,) % ( (0.8272 * (X„_g + X„_,)) + X„_,))) - ( (IF ((X^ - (X° % 0.7521)) > X^_,) THEN ( X„ * 0.8536) ELSE X^_,) % ( (IF (X„ 0 0.1145) THEN (( X^ * 0.8536) % (0.6629 + X^_,)) ELSE Cos(X^_t)) + (0.8272 * Xn))))) ELSE (IF (0.6563 o X^) THEN ( X„ % (0.6629 + X°)) ELSE (-0.7521)))) THEN (( Xo % (X^*0.8536)) - X^) ELSE Xo_,) % ( (IF (((X„ * ((0.6629 + X„_,) - cos(((0.6629+ (IF (X„ > X„-s) THEN X„_,.
(34) Capitulo 7. Resultados. ELSE 0.1145)) * Xn)))) * Xn) > Xn_g) THEN Xn. ELSE (((0.6629 + Xn_,) - ( (IF (((((0.6629 + Xn_,) + Xn_,) + 0.7521) * cos(Xn-^)) > Xn-s) THEN Xn_, ELSE Xn_,) % ((Xn % (0.6629 + Xn_,)) + (0.8272 * Xn)))) % (( (IF (Xn > Xn-S) THEN Xn_, ELSE 0.6629) +(0.8272 * Xn)) + Xn_,))) + Xn_,)))) + 0.7521) * Cos(Xn_,))) ELSE (IF ((Xn * 0.8536) > Xn_g) THEN ( (IF ( (IF \Xn-^ > Xn-s) THEN ((Xn % (Xn * 0.8536)) - Xn) ELSE ( 0.6629 + Xn_,)) > Xn_g) THEN. (IF (((0.6629 + Xn-^) - Xn) > Xn-s) THEN ( 0.8272 * Xn) ELSE Xn) ELSE (0.8272 * Xn)) * ((0.8272) * cos(Xn_^))) ELSE (IF ( (IF ( (IF ((Xn % (0.8272 * Cos(Xn_,))) > Xn_8) THEN ( (IF (Xn > Xn-s) THEN Xn ELSE Xn_,) * Xn) ELSE ((Xn * 0.8536) * ((((0.6629 + Xn_,) + Xn_,)) + 0.7521) * Cos(Xn_,)))) > Xn_g) THEN Xn ELSE Xn_,) > (Xn * 0.8536)) THEN (0.8272 * Xn) ELSE ( (IF (( (IF ((Xn % (0.6629 + ( (IF (Xn_, > (IF ((0.8272 * Xn) > Xn-s) THEN Xn ELSE Xn_,)) THEN Xn ELSE Xn_,) % ( (IF (Xn > Xn_s) THEN ( 0.6563 * Xn) ELSE (IF (((Xn % (Xn * 0.8536)) - Xn) > Xn-s) THEN ((0.6629 + Xn_,) - Xn) ELSE Xn_,)) + (Xn * 0.8536))))) > Xn_g) THEN (IF \Xn > Xn-8) THEN ( 0.8272 * Xn). 179.
(35) Capítulo 7. Resultados. l80. ELSE ((Xn % (Xn * 0.8536)) - Xn)) ELSE Xn_^) % (0.6629 + Xn-^)) > Xn-g) THEN (Xn % (0.6629 + (IF ((Xn * 0.8536) > Xn_g). THEN (Xn % (Xn % (Xn * 0.8536))) ELSE 0.1145))) ELSE (IF (cos(Xn_^) > Xn_g) THEN ( Xn % (0.6629 + ( (IF ((Xn * 0.8536) > Xn_g) THEN ( Xn * 0.8536) ELSE Xn_^) % (( (IF (Xn > (IF (}{n > Xn-g) THEN (Xn % ((0.6629 + Xn_^) + Xn_^)) ELSE (Xn_^))) THEN (Xn_g % ( 0.8272 * cos(Xn_^))) ELSE ( 0.8536)) % (0.6629 + Xn_^)) + Xn_^)))) ELSE ( Xn % (0.6629 + Xn_^)))) % (0.6629 + Xn_^))))). Con esta combinación de expresiones aritméticas Y reglas de decisión se obtiene un valor de ajuste (normalizado o error medio) sobre los valores que produce la RNAR de 0.012 y un ECM de 0.00058. ,o. o.s. os. oa. oz. Fig. 39 - Serie Manchas Solares.
(36) Capítulo 7. Resultados. 18/. Una gráfica comparativa entre los valores que produce la RNAR y las salidas obtenidas de la expresión se puede ver en la figura 39, donde se puede observar que el nivel de ajuste alcanzado entre la salida que produce la RNAR y la expresión obtenida es realmente satisfactorio.. 7.5.3 Predicción de la producción de tabaco anual en USA Se han entrenado varias RR.NN.AA.RR con diferentes funciones de activación y neuronas ocultas. Utilizando los resultados alcanzados en trabajos de investigación anteriores [RABU 99][DORA 99] se ha utilizado la función de activación lineal en todas las neuronas porque es la que mejores resultados produce. Con 3 neuronas ocultas, el mejor valor de ECM obtenido es de 0.00577. Con este ECM se pueden obtener mejores resultados de predicción que los obtenidos usando métodos estadísticos como el ARIMA [RABU 99][DORA 99]. Si se aplica el algoritmo de extracción directamente sobre los ficheros de aprendizaje se puede obtener un ECM de 0.007243, lo cual hace pensar que los valores de ajuste que se pueden conseguir para este problema son de nuevo comparables a los obtenidos mediante RR.NN.AA.RR y modelos ARIMA.. Fig. 40 - RNAR que predice a corto plazo la producción de tabaco en USA.. La matriz de pesos de la RNAR de la figura 40 es la siguiente:.
(37) Capitulo 7. Resultados. /82. W,,,: 1.616. Wz,,: 6.941. W3,,: 5.107. W,,,: -1.162. Ws,,: 6.039. W,,z: 3.305. Wz,z: 9.509. W,,z: -4.763. W,,z: -6.287. Ws,z: -7.023. W,,,: 6.653. Wz,,: -6.414. W,,^: 9.751. W,,,: 4.571. Ws,^: 2.270. W,,4: 4.739. Wz,,: 9.978. W,,,: -1.050. W,,,: 7.386. Ws,,: -8.456. W,s: 0.158. Wzs: -2.943. W,s: -7.081. W,s: 1.227. Wss: -1.017. Con las entradas del proceso de entrenamiento y las salidas que produce la RNAR anterior se construyen los patrones de aprendizaje para el algoritmo de extracción. Se han probado varias configuraciones de elementos terminales y no terminales para el algoritmo siendo la que mejore resultados produce la siguiente: Funciones Aritméticas:. +, -, *, % (división protegida). Función de decisión: Constantes: variables:. IF-THEN-ELSE aplicado sobre valores reales 50 valores aleatorios en el rango [0,1 ] Xnr Xn-lr Xn-2r Xn-3r Xn-4r X n-5r Xn-6. Algoritmo de Selección: Tasa de cruces: Tasa de mutaciones: Tamaño de la población: Mcíxima profundidad: Nivel de parsimonia:. Torneo 95% 4% 1000 individuos 20 0.00001. Las reglas obtenidas con esta configuración y dejando evolucionar la población hasta alcanzar 1000 generaciones (1 día de ejecución) son las siguientes: (0.8264 * ((Xn_, * 0.2005) + (0.8264 * ((((Xn_3 * 0.2OOS) + (0.8264 * ((IF ((Xn_3 * 0.2005)= (IF (Xn_z = Xn-a) THEN Xn^ ELSE 0.2005)) THEN (0.2005 *((0.8264 * Xn) * 0.2005)) ELSE (Xn^ * 0.2005)) + (IF ((0.8264 * Xn) = 0.8264) THEN Xn_, ELSE (IF (NOT (Xn_z= Xn_,)) THEN (IF (Xn_z = Xn-s) THEN 0.2005 ELSE ÍIF (Xn^ = Xo^) THEN Xa, ELSE (0.8264 * Xn))) ELSE 0.0016))))) * 0.2005) +.
(38) Capitulo 7. Resultados. l83. (IF (NOT ((Xn_, * 0.2005) = 0.2005)) THEN ((Xn_z * (IF ((Xn_z * 0.2005) = 0.2005) THEN (Xn^ * (Xn_; * 0.2005)) ELSE 0.2005)) +(0.8264 *((0.8264 *((0.8264 *((0.8264 *((0.8264 *((Xn.ó* 0.2005)+ ((((IF (NOT ((0.8264 * Xn) = 0.8264)) THEN (IF ((Xn_z * 0.2005) = 0.2005) THEN 0.2005 ELSE (0.8264 * Xn)) ELSE 0.0402) *((Xn-6 *(((Xn-4 * Xn) *(Xn-6 * 0.2005))+(((Xn^ * Xn) *(Xn_; * 0.2OOS)) + ((Xn-6 * ((((Xn_; * 0.2OOS) + (Xn-a * Xn)) * 0.2OOS) + (Xn-e*Xn))) * 0.2OOS)))) * 0.2OOS)) + (Xn^*0.2OOS))* 0.2OOS)))+((Xn_;*0.2OOS) # (IF (Xn-6 = Xn-4) THEN (Xn_6 * 0.2005) ELSE 0.2005)))) + ((Xn_, * (IF ((Xn^y * 0.2005) _ (Xn_; * 0.2005)) THEN (IF (Xn_6 = Xn-a) THEN Xn_z ELSE (0.2005 * Xn)) ELSE (IF ((Xn_z * 0.2005) _ (Xn_; * 0.2005)) THEN 0.0402 ELSE 0.2005))) * 0.2005))) + ((Xn_, * (IF ((Xn^ * 0.2005) = 0.2005) THEN (Xn_, * (Xn_, * (X^_, * 0.2005))) ELSE 0.2005)) * 0.2005))) + (IF (Xn_z = Xn-a) THEN Xn ELSE (0.8264 * Xn))))) ELSE (IF (NOT (Xn_z = Xn^)) THEN ((Xn-a * Xn-z) * X^) ELSE 0.2005)))))). Con esta combinación de expresiones aritméticas y reglas de decisión se obtiene un valor de ajuste (normalizado o error medio) sobre los valores que produce la RNAR de 0.009944. Una gráfica comparativa entre los valores que produce la RNAR y las salidas obtenidas de la expresión se puede observar en la figura 41 donde se puede observar que el nivel de ajuste alcanzado entre la salida que produce la RNAR y la expresión obtenida es realmente satisfactorio..
(39) Capítulo 7. Resultaclos. 184. 1.0 -. RNA - Ajuste Reglas. 109. Fig. 41 - Comparativa entre la salida de la RNAR y la función obtenida del proceso de extracción. 7.6 Obtención de la capacidad de generalización Una vez comparado el correcto funcionamiento y obtenida la capacidad de extracción que posee del algoritmo propuesto con otras técnicas existentes, tanto en la extracción de conocimiento de redes multicapa como en las redes recurrentes, el siguiente paso es extraer la capacidad de generalización que poseen las RR.NN.AA entrenadas. Para ello, se aplica el algoritmo de creación de ejemplos dinámico expuesto en el capítulo anterior. Este algoritmo se ha aplicado al problema de la clasificación del tipo de planta Iris analizado en el punto 7.4.1. Se ha utilizado este problema debido a que se ha realizado un estudio detallado del comportamiento tanto de las reglas extraídas directamente de los conjuntos de entrenamiento, como de las RR.NN.AA diseñadas para esta tarea y de las reglas extraídas de las RR.NN.AA anteriores abarcando. los. patrones. relativos. a. sus. entrenamientos.. Además,. dichos. comportamientos se pueden analizar de forma gráfica. Resumiendo, el algoritmo se centra en la extracción de reglas de un conjunto de patrones. Para extraer la capacidad de generalización de las RR.NN.AA entrenadas para la clasificación de la planta en forma de reglas y expresiones se ha dotado al sistema de.
(40) Capítulo 7. Resultados. 185. un algoritmo de creación dinámico de patrones de ejemplo que iterativamente va creando nuevos patrones de aprendizaje a medida que el proceso de extracción de reglas va mejorando su ajuste. Posteriormente, se aplicará la extracción de la capacidad de generalización a una RNA recurrente para analizar el tipo de reglas extraídas de estas redes. Se ha utilizado el problema de predicción de la función de Mackey-Glass debido a que es una serie caótica de laboratorio de la cual se conoce su comportamiento debido a que es el resultado de una expresión matemática. Por ello, los resultados que se obtengan de estos experimentos son fácilmente analizables.. 7.6.1 Capacidad de generalización de las RRNNAA no recurrentes Para esta tazea se han utilizado las RR.NN.AA diseñadas en el punto 7.4.1. Se han creado dos RR.NN.AA con diferentes azquitecturas sobre las cuales se han aplicado entrenamientos diferentes. Una de ellas ha sido altamente entrenada, buscando el menor ECM que pudiera cometer la RNA, y la otra ha sido entrenada hasta que ha alcanzado un nivel de ajuste aceptable. La primera es una RNA con 1 capa oculta con 5 neuronas y la segunda tiene 1 capa oculta con 10 neuronas. En la figura 29 se puede observar la distribución aprendida por la RNA de 10 neuronas en la capa oculta y en la figura 30 se observa la distribución aprendida por la RNA de 5 neuronas en la capa oculta. En la figura 31 se puede observar la distribución de las reglas obtenidas de la primera RNA y en la figura 32 se observa la distribución de las reglas extraídas de la segunda RNA. Como se puede observar en los gráficos de las figuras anteriores, el aspecto de las tres distribuciones para cada RNA es muy similar, pero para la RNA de 5 neuronas se obtiene un ajuste más perfecto en las zonas correspondientes a los patrones de entrenamiento. Esto es debido a que es una RNA más entrenada. Si se observan estas distribuciones con las obtenidas por el sistema de extracción de reglas de las RR.NN.AA correspondientes se puede comprobaz de forma visual que el parecido es más bien escaso. Esto es debido a que las reglas proporcionadas por el sistema de.
(41) Capítulo 7. Resultados. /86. extracción toman formas muy geométricas ya que utiliza reglas de tipo "IF-THENELSE" sobre rangos y como consecuencia se obtienen reglas que proporcionan un ajuste perfecto en las zonas que corresponden con ejemplos de entrenamiento, pero un ajuste pésimo al comportamiento global que tienen las RR.NN.AA. Para subsanar estas deficiencias se utiliza el algoritmo de creación dinámica de patrones de entrenamiento mediante el cual se crean nuevos datos de ajuste que corresponderán a aquellos comportamientos de la RNA que no han sido establecidos por sus patrones de entrenamiento. Inicialmente, se han hecho diferentes pruebas para establecer la configuración de parámetros del algoritmo de creación de ejemplos que mejores resultados produce. En cuanto a los parámetros del algoritmo de extracción se han utilizado los mismos que se han utilizado para extraer las reglas de las RR.NN.AA anteriores. Los parámetros involucrados son: 3 Porcentaje de patrones nuevos: utilizando como base los patrones de aprendizaje utilizados para el entrenamiento de las RR.NN.AA se amplia el número de secuencias un porcentaje relativo al número de estos patrones. 3 Probabilidad de cambio: el proceso de creación de nuevos patrones se centra en generar nuevas secuencias a partir de los datos de entrenamiento. Se elige una secuencia de entradas al azar del fichero de entrenamiento y por cada entrada se deja el mismo valor o se genera uno nuevo al azar con una cierta probabilidad. Técnica similar al proceso de mutación de la CE. 3 Error mínimo para supervivencia: cuando el porcentaje de error para un patrón nuevo se considera lo suficientemente pequeño se elimina (ya que se puede entender que se ha adquirido el conocimiento que este representa) y se genera otro patrón nuevo. Teniendo en cuenta estos parámetros se ha obtenido que con un valor entre 20% y 35% de patrones nuevos y entre 20% y 25% de probabilidad de cambio son los valores.
Figure



+7



Documento similar
