Sintetizador de vocales sostenidas
70
0
0
Texto completo
(2) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería Biomédica, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(3) PENSAMIENTO Los mejores hombres son los de pocas palabras. William Shakespeare.
(4) DEDICATORIA A mi familia..
(5) AGRADECIMIENTOS Agradezco a mis padres por toda la ayuda, a mi tía por su apoyo incondicional, en general a toda mi familia que siempre me ayuda en las buenas y malas, a mi novia Anilet por estar conmigo en todo momento, a mi tutora Msc. Diana Torres Boza por la ayuda brindada, al Dr. Carlos Ariel Ferrer Riesgo por el apoyo. A mis compañeros de aula y a todo el que de una forma u otra me brindó su mano para la realización de este trabajo..
(6) Resumen. La voz contiene información útil para el diagnóstico médico. Entre los parámetros que frecuentemente se utilizan para evaluar el estado del paciente se encuentran los de calidad vocal, relacionados con las perturbaciones de la periodicidad de la señal la señal de excitación glotal. Estas mediciones de calidad vocal, al estar relacionadas con las patologías de cuerda vocal son usualmente estimadas durante la fonación de una vocal sostenida. En la investigación y desarrollo de estas mediciones las señales de voz sintétizadas, tanto normales como patológicas, son utilizadas para la comprobación de la eficacia de los diferentes métodos. Adicionalmente en la docencia, en la asignatura de procesamiento de voz, es de gran importancia mostrar el funcionamiento de cada una de las componentes involucradas en la síntesis así como la influencia de las diferentes formas de perturbación de la periodicidad en la señal de voz. En el sistema propuesto en este trabajo (Vowel_Synth) se implementan dos de las formas de ondas reportadas en la literatura para la generación de la señal de la glotis (el modelo B de Rosenberg y una alternativa más eficiente computacionalmente del modelo Liljencrants-Fant (LF)), para la generación del filtro se escogieron dos modelos, el primero basado en la suma de sinusoides el cual depende de las frecuencias centrales (formantes), sus anchos de banda y sus amplitudes; el segundo se basa en un filtro auterregresivo (AR) todo polos que solo depende de los coeficientes (polos) que introduzca el usuario. Las perturbaciones de la periodicidad como jitter, shimmer y ruido aditivo fueron consideradas de igual manera con el fin de sintetizar voces patológicas..
(7) TABLA DE CONTENIDOS. TABLA DE CONTENIDOS INTRODUCCIÓN .......................................................................................................................... 1 Problema científico ................................................................................................................... 2 Objetivo general ........................................................................................................................ 2 Objetivos Específicos ................................................................................................................ 2 Estructura del trabajo .............................................................................................................. 3 1.. CARACTERÍSTICAS DE LA SEÑAL DE VOZ .................................................................. 4 1.1.. Modelo de producción de la voz ...................................................................................... 4. 1.1.1. Modelo Fuente-Filtro ................................................................................................ 4. 1.1.2. Señal de exitación g(t) .............................................................................................. 6. 1.1.3. Conformación espectral de h(t) y r(t) ....................................................................... 7. 1.1.4. Perturbaciones de la periodicidad ............................................................................. 9. 1.1.5. Ruido aditivo........................................................................................................... 11. 1.2.. Síntesis ........................................................................................................................... 11. 1.2.1. Síntesis Concatenativa ............................................................................................ 12. 1.2.2. Síntesis de formantes .............................................................................................. 13. 1.3.. Herramientas de Software disponibles para la síntesis de vocales................................. 16. 1.3.1. Praat ........................................................................................................................ 16. 1.3.2. Sintetizadores de formantes de Klatt ...................................................................... 17. Conclusiones parciales .................................................................................................................. 23 2.. MATERIALES Y MÉTODOS ............................................................................................. 24 2.1.. Modelos de Síntesis de la señal de la glotis ................................................................... 24. 2.1.1. Modelos de Rosenberg ............................................................................................ 25. 2.1.2. Modelo de Liljencrats-Fant ..................................................................................... 27.
(8) TABLA DE CONTENIDOS. 2.1.1 2.2.. Modelo de Veldhuis (R++) ..................................................................................... 28. Modelos de Síntesis del Tracto Vocal ............................................................................ 30. 2.2.1. Suma de cosenos ..................................................................................................... 30. 2.2.2. Filto autoregresivo (AR) todo polos ....................................................................... 31. 2.3.. Perturbaciones de la periodicidad .................................................................................. 32. 2.3.1. Jitter ........................................................................................................................ 33. 2.3.2. Shimmer .................................................................................................................. 34. 2.3.3. Ruido ....................................................................................................................... 34. 2.3.4. Jitter y Ruido .......................................................................................................... 35. 2.3.5. Shimmer y Ruido..................................................................................................... 35. 2.3.6. Perturbaciones combinadas ..................................................................................... 35. 2.4.. Diseño de la interfaz de Usuario .................................................................................... 36. 2.4.1. Generalidades .......................................................................................................... 36. 2.4.2. Uso de Matlab para la construccion de la interfaz de usuario de Vowel_Synth ... 37. Concluciones Parciales ................................................................................................................. 40 3.. RESULTADOS Y DISCUSION .......................................................................................... 41 3.1.. Requerimientos de Vowel_Synth. .................................................................................. 41. 3.2.. Vowel_Synth .................................................................................................................. 42. 3.2.1. Configuración de la señal de la Glotis .................................................................... 44. 3.2.2. Configuración de Tracto Vocal ............................................................................... 47. 3.2.3. Configuración de Ruido .......................................................................................... 50. 3.2.4. Síntesis y Visualización .......................................................................................... 52. 3.3.. Ventajas y Limitaciones de Vowel_Synth ..................................................................... 54. Conlusiones Parciales ................................................................................................................... 56.
(9) TABLA DE CONTENIDOS. CONCLUSIONES Y RECOMENDACIONES ........................................................................... 57 Conclusiones ............................................................................................................................. 57 Recomendaciones ..................................................................................................................... 58 REFERENCIAS BIBLIOGRÁFICAS.......................................................................................... 59.
(10) INTRODUCCIÓN. 1. Introducción INTRODUCCIÓN El habla es de gran importancia por ser la principal vía de comunicación entre los seres humanos, en la actualidad se han reportado en la literatura innumerables trabajos relacionados con el procesamiento de voz. Es por esto que han surgido diferentes áreas de investigación del procesamiento de voz. como la síntesis y codificación, análisis,. reconocimiento del habla y de locutor, reconocimiento de idiomas entre otras. Este trabajo esta principalmente relacionado con la síntesis de señales de voz. Los primeros sintetizadores de voz sonaban muy robóticos y eran a menudo inteligibles a duras penas. Sin embargo, la calidad del habla sintetizada ha mejorado en gran medida, y el resultado de los sistemas de síntesis contemporáneos es, en ocasiones, indistinguible del habla humana real. El primer sistema de síntesis computarizado fue creado a final de la década de 1950 y el primer sistema completo texto a voz se finalizó en 1968. Desde entonces se han producido muchos avances en las tecnologías usadas para sintetizar voz. Estas herramientas de síntesis pueden ser aplicadas particularmente entre personas con discapacidades, por ejemplo los ciegos pueden para acceder a la información visualizada en pantalla; su objetivo es la lectura de información de la computadora al usuario mediante mensajes que suelen ser emitidos con voces total o parcialmente sintéticas. Otras aplicaciones de los sistemas de síntesis de voz están presente en los sistemas de telefonía celular (convierten un mensaje de texto en un mensaje de voz). Actualmente la gran mayoría de estos programas de síntesis de voz tienen como finalidad la transmisión por voz del contenido de archivos de texto (TTS), estos tienen utilidades en el.
(11) INTRODUCCIÓN. 2. aprendizaje de lenguas extranjeras o para ayudar a mejorar la pronunciación de sonidos y palabras a personas disléxicas o con otros defectos de habla. También existen herramientas que sintetizan las diferentes patologías pero no permiten modificar los parámetros para la síntesis de la voz. En el caso del grupo de procesamiento de voz del CEETI las señales de voz simuladas son utilizadas fundamentalmente para la prueba de diferentes mediciones de calidad vocal así como en la docencia (asignatura de Procesamiento de Voz en la carrera de Ing. Biomédica). En el caso de las aplicaciones médicas las señales más utilizadas para obtener mediciones de calidad vocal son las vocales sostenidas. Estas a su vez son de especial interés en la asignatura de Procesamiento de Voz por sus características particulares. Problema científico Dado que utilizando las aplicaciones comerciales es posible sintetizar vocales sostenidas pero no es posible manipular cada una de las partes del modelo de producción de voz, es necesaria, en el CEETI,. una aplicación que simule tanto fonaciones de vocales con. características de voces normales como patológicas. Además que permita manipular y visualizar las diferentes partes del modelo fuente-filtro. Para la realización de esta herramienta se presenta el siguiente objetivo general Objetivo general Desarrollar una aplicación que permita sintetizar vocales sostenidas (normales y patológicas) con el fin de utilizar las mismas en los experimentos de medición de calidad vocal y en la docencia. Para el cumplimiento del objetivo general se han planteado los siguientes objetivos específicos Objetivos Específicos Ofrecer al usuario la posibilidad de introducir variaciones en la forma de onda que simulen patologías de la voz. Ofrecer al usuario la posibilidad de manipular los diferentes elementos del modelo fuente-filtro..
(12) INTRODUCCIÓN. 3. Desarrollar una aplicación lo más amena posible a los usuarios finales de la misma (profesores, investigadores y estudiantes).. Estructura del trabajo En el Capítulo 1 se presentan los principales conceptos que se tratan en este trabajo así como las características de la señal de voz, también se muestran los diferentes softwares existentes en el mercado para la síntesis. Se brinda una panorámica general existente en torno al problema que se aborda y que motiva este trabajo. En el Capítulo 2 se muestran los modelos a seguir para la síntesis de la señal glotal, los modelos de los filtros utilizados así como una caracterización de cómo sintetizar los tipos de señales que se pueden realizar con Vowel_Synth y las bondades de Matlab para el diseño de interfaces gráficas de usuario. En el Capítulo 3 se presentan los resultados de esta herramienta así como un manual de usuario para la ayuda al personal que utilice Vowel_Synth y una breve comparación con otros programas de síntesis..
(13) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. Capítulo. 4. 1. 1. CARACTERÍSTICAS DE LA SEÑAL DE VOZ En este capítulo de darán a conocer varios conceptos relacionados con las características de la señal de voz y la generación del habla tanto fisiológica como sintetizada. Además se describen diferentes sistemas comerciales para la síntesis del habla particularmente de vocales sostenidas.. 1.1. Modelo de producción de la voz El proceso de producción de la voz humana comienza en el cerebro con la creación del mensaje, luego este envía los impulsos nerviosos necesarios para cada órgano involucrado en el proceso del habla para así lograr los movimientos adecuados en cada órgano motor, los pulmones son la fuente principal de aire, este aire es comprimido por el diafragma y debido a la presión se producen los sonidos al hacer pasar el aire por algún estrechamiento desde las cuerdas vocales hasta los labios.. 1.1.1. Modelo Fuente-Filtro. Los sonidos se clasifican en sonoros o sordos según la periodicidad, los sonoros son aquellos que tienen periodicidad y se producen cuando el estrechamiento es en las cuerdas vocales, este es el caso de las vocales y algunas consonantes como “b”, “m”, “n” entre otras. Los sonidos sordos son aquellos que no tienen periodicidad, esto es característico solo en las consonantes tales como “s”, “j”, “f” etc… debido al paso de aire por las constricciones en el tracto vocal, estas se denominan consonantes fricativas. Otro grupo de.
(14) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. consonantes son las explosivas sordas. 5. “p”, “t” y “k”, estas se producen al liberar. repentinamente una oclusión en el tracto vocal. El modelo más empleado en la síntesis es el modelo Fuente-Filtro (Ver Figura 1.1).donde los pulsos de aire generados por la glotis g(t) son conformados por la función de trasferencia del tracto vocal H(t) y posterior por el radiador de los labios R(t). La principal ventaja es la sencillez (Titze I, 1980) (Steinecke & Herzel, 1995) por lo que tiene tanto uso en los estudios de la codificación y transmisión del habla. Hay que tener presente considerar la estacionariedad del tracto vocal (20-50 milisegundos) (Malepati, 2010), o sea que el tracto no cambia su posición en el intervalo de análisis para así poder aplicar las técnicas más comunes de análisis tales como la correlación, la Transformada de Fourier y otras (Torres, 2008).. Figura 1.1 Modelo Fuente-Filtro de Producción de la Voz. La ecuación que representa este modelo es mostrada a continuación:. N st ht * r t g i (t ) * t (Ti 1 T0 Ti 1 ) et i 1 . (1.1). con r(t) la respuesta al impulso del radiador, gi(t) la forma de onda de la fuente en el pulso i-ésimo, que incluye también cualquier perturbación de amplitud, Ti-1 la perturbación de duración con respecto a T0 , Ti-1 representa el pulso anterior y e(t) representando el ruido. Si g(t) no depende del índice del pulso, las tres respuestas de frecuencia (h(t), r(t) y g(t)) son constantes, y concentrándolas en una única respuesta resultante h(t) se puede asumir un modelo más sencillo y práctico, descrito por la ecuación:.
(15) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. st ht a i t (Ti 1 T0 Ti ) et . 6. N. i 1. (1.2). En este caso se ha introducido el factor de proporcionalidad ai. La ecuación (1.2) resulta de mucha mayor utilidad que (1.1) pues representa una simplificación del modelo. Dado lo descrito anteriormente la señal de voz presenta las siguientes características: . Contiene una estructura de armónicos de la señal de excitación g(t) con gran atenuación de las altas frecuencias.. . Contiene resonancias en algunas frecuencias (formantes) presentes en la respuesta del tracto vocal.. . 1.1.2. El radiador presenta reforzamiento de las altas frecuencias.. Señal de exitación g(t). Han existido varios métodos para la estimación de la señal glotal g(t), los primeros fueron altamente invasivos debido a la colocación de transductores, otros basados en el cálculo del área de las cuerdas vocales como la electroglotografía, no tuvo éxito debido a la conductividad eléctrica transglotal, la laringoboscopía fue otro método pero era muy difícil la instrumentación para obtener una secuencia de imágenes adecuada para medir el área (Torres, 2008). El método más usado es el empleo de la señal residual del filtrado inverso para estimar la forma de onda de g(t), aunque este tiene apareadas una serie de limitaciones que se tornan rigurosas en voces patológicas. Las formas de onda obtenidas han sido representadas mediante modelos paramétricos donde se le asignan determinadas funciones matemáticas a las fases de apertura y cierre de la forma de onda de g(t) (ver Figura 1.2). Entre estos modelos los más empleados son los polinomiales y trigonométricos de Rosenberg (Rosenberg, 1971) y el modelo de Liljencrants-Fant (Fant, et al., 1985)..
(16) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. R. 7. I. 1n. e. Figura 1.2 Formas de onda y fases de la señal de excitación glotal g(t) y su derivada g’(t). Tp es la duración de la fase de apertura, Tn la del cierre, Tc la fase cerrada, y t la duración total del pulso.. s. t. Como indicador de cuán adecuado es el modelo se han empleado criterios de naturalidad de. u. la voz sintetizada y de minimización del error medio cuadrático con respecto a la señal. r. residual del filtrado inverso (Klatt, 1980) (Hillman, 1983). Ninguna de las dos alternativas resulta completamente convincente. Por ejemplo, en (Rosenberg, 1971) se reporta que. m. voces sintetizadas con su modelo polinomial fueron percibidas como más naturales que las. o. grabaciones originales (un resultado sin explicación), mientras que el modelo de Liljencrants-Fant (Fant, et al., 1985), con el que se reportan los menores valores de error. e. cuadrático medio en su ajuste a las señales residuales, ha producido “resultados. d. decepcionantes” (O´leidhin & Murphy, 2003) al sintetizar nuevamente la voz empleando la g(t) estimada. En este momento no existen motivos para preferir un modelo u otro de. n. estimación o síntesis de g(t).. 1.1.3. u Conformación espectral de h(t) y r(t). c. El empleo de técnicas de predicción lineal para estimar H(f) ha provocado que sea común simplificar este modelo fundiendo las características de frecuencia de la fuente G y el radiador R. Par ello se emplean fundamentalmente dos alternativas:. c. La primera aprovecha que G(f) y R(f) tienen características complementarias (G(f) pasabajos y R(f) pasa-altos), para fundirlas en una señal de espectro plano en la glotis (fuente) de manera que toda la conformación espectral de la señal acústica puede atribuirse a la. i. influencia del tracto vocal. La señal más simple que satisface las suposiciones de periodicidad y espectro plano para la fuente es un tren periódico de impulsos, y es. ó.
(17) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 8. empleada con frecuencia en aplicaciones de análisis, codificación y síntesis. En ese caso más sencillo la señal de voz s(t) es una suma de respuestas del tracto vocal al tren de impulsos delta de Dirac () de excitación:. 1 si t 0 0 si t 0. st ht t iT0 N. t . i 1. (1.3). donde N es la cantidad de pulsos glotales que se consideran, T0 es el período del tren de impulsos, y h(t) es la respuesta al impulso del tracto vocal. La segunda alternativa hace uso de que el radiador consiste físicamente en una operación de derivación (convirtiendo una señal de velocidad de flujo g(t) en una señal de presión acústica s(t)). De esta manera el modelo fuente filtro puede reducirse al mostrado en la siguiente figura:. TRACTO. s(t). g’(t). Figura 1.3 Modelo Fuente-Filtro con el efecto derivativo del radiador incluido en la excitación; g´(t) es la derivada de g(t).. La señal de presión acústica puede expresarse entonces como:. N. st ht g i 't . (1.4). i 1. Donde g’ i (t) la derivada del pulso glotal i-ésimo. Si todos los pulsos tienen igual forma de onda g(t) la ecuación (1.4) puede rescribirse:. N st ht g ' t * t iT0 i 1 . (1.5).
(18) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 9. que resulta equivalente a (1.3) si se considera a la convolución h(t)*g’(t) como la respuesta al impulso del sistema que conforma espectralmente a s(t), representado sólo por h(t) en (1.3). El inconveniente de esta alternativa con relación a la anterior radica en la necesidad de contar con un estimado de g(t) o su derivada g’(t), dado que ambas estiman h(t) mediante técnicas de filtrado inverso. Su ventaja principal es la mayor naturalidad de la voz sintetizada por esta vía, lo que ha provocado que sea la alternativa preferida en aplicaciones de síntesis (Torres, 2008).. 1.1.4. Perturbaciones de la periodicidad. La señal s(t) generada a partir de cualquiera de las dos alternativas descritas, (ecuaciones (1.3) o (1.5)) es perfectamente periódica, mientras que en las señales reales la periodicidad es sólo aproximada. El tracto puede considerarse estacionario en intervalos de algunas (2-5) decenas de milisegundos, lo cual es suficiente en la mayoría de las vocales, donde se puede aplicar el modelo. Si se considera que la configuración del tracto vocal permanece constante (y por tanto su respuesta al impulso h(t)) las perturbaciones de la periodicidad de s(t) están dadas completamente por las alteraciones en la excitación. Estas pueden ser divididas en cuatro factores: Perturbación de la duración de los pulsos (jitter), consiste en la separación de los pulsos en intervalos de tiempo no exactamente iguales a T0 . Perturbación de la amplitud de los pulsos (shimmer), consiste en que los pulsos puedan expresarse uno en función de otro a través de un factor de proporcionalidad diferente de la unidad. Presencia de ruido aditivo: Cada pulso se diferencia del otro en una magnitud aleatoria en cada instante de muestreo, de valor medio cero. Perturbación de forma de onda: La g(t) varía de pulso a pulso de manera que el cambio no se reduce a un factor de proporcionalidad..
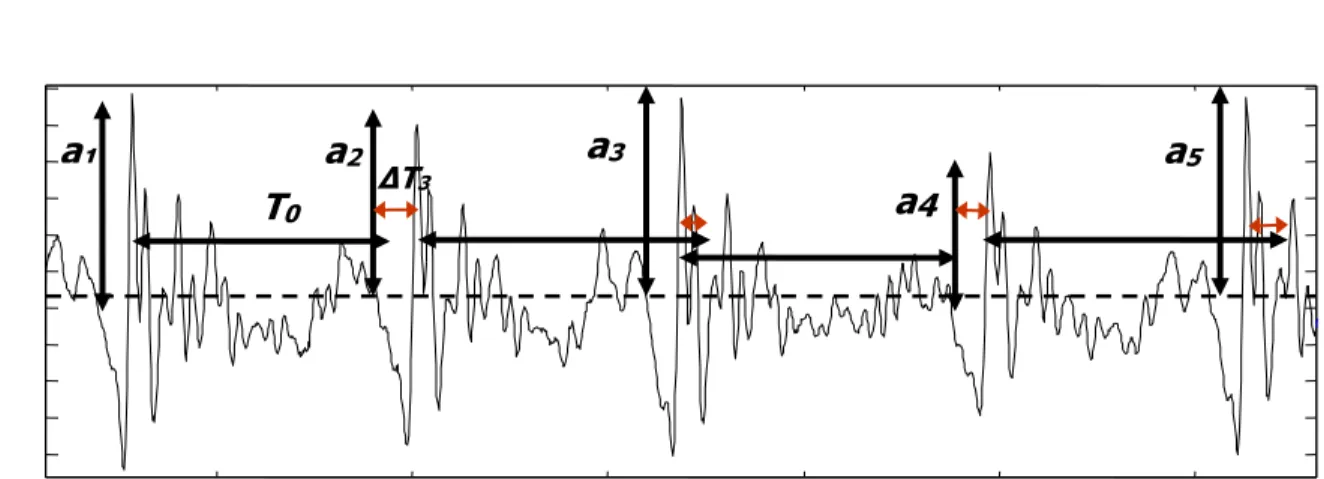
(19) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 10. Una expresión que incluye todos estos factores es:. N st ht * r t g i (t ) * t (Ti 1 T0 Ti 1 ) et i 1 . (1.6). con r(t) la respuesta al impulso del radiador, gi(t) la forma de onda de la fuente en el pulso i-ésimo, que incluye también cualquier perturbación de amplitud (factores 2 y 4), Ti la perturbación de duración con respecto a T0 (factor 1), y e(t) representando el ruido aditivo (factor 3). Si el cuarto factor de perturbación no está presente, o sea, g(t) no depende del índice del pulso, las tres respuestas de frecuencia (h(t), r(t) y g(t)) son constantes, y concentrándolas en una única respuesta resultante h(t) se puede asumir un modelo más sencillo y práctico, descrito por la ecuación siguiente e ilustrado en la Figura 1.4:. st ht a i t (Ti 1 T0 Ti ) et N. (1.7). i 1. 0. 0.2 3 50.. a1. a2 T0. 0.1 2. ΔT3. a3. a5 a4. 50. 0.0 1 5 0 0.05 - 0.1 0.15 0.2. 400. 420. 440. 0 0 0 Figura 1.4 Representación gráfica de la ecuación (1.7). 460. 480. 500. 0. 0. 0. En este caso se ha introducido el factor de proporcionalidad ai, anteriormente incluido en gi(t) para representar el segundo factor de perturbación (shimmer). La ecuación resulta de mucha mayor utilidad que (1.5) pues, aunque representa una simplificación del modelo, conduce a un problema frecuentemente abordado en la literatura: la determinación de los instantes de ocurrencia (Ti1 T0 Ti ) de las réplicas de una determinada señal (h(t)) en.
(20) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 11. presencia de ruido (e(t)) y atenuación (ai) desconocidos. Campos donde se encuentra el mismo problema son el radar, el sonar, el ultrasonido, la supresión de interferencia (Hertz, 1986), etc. Esta amplia difusión del problema permite que se cuente en la actualidad con una abundante literatura sobre el tema, con múltiples propuestas de solución. A pesar de esto, no puede ignorarse que (1.7) constituye una aproximación gruesa de la señal de voz, sobre todo en voces patológicas, donde la variabilidad de gi(t) dista de ser despreciable. El uso de (1.7) se justifica sólo en la obtención de modelos de análisis y expresiones de cálculo aproximado de parámetros, donde el trabajo con gi(t) variables resulta muy complicado. La utilidad práctica de los modelos y expresiones obtenidos puede ser evaluada posteriormente, ya sea en señales reales o sintéticas, empleando o no un modelo para gi(t).. 1.1.5. Ruido aditivo. Es de destacar que el último término de (1.7) (e(t)) es el ruido aditivo presente en s(t), la señal acústica radiada, cuando en principio el ruido turbulento se asume generado en la glotis. Se puede esperar entonces que e(t), resultado del paso a través de las respuestas del tracto vocal y el radiador del ruido original generado en la glotis, no sea espectralmente plano (ruido blanco) sino “coloreado”. La distribución espectral del ruido turbulento original tampoco es completamente plana (O´leidhin & Murphy, 2003), y por demás, e(t) es en principio no estacionario.. 1.2. Síntesis El primero en sintetizar vocales sostenidas para su estudio fue el científico danés Christian Gottlieb Kratzenstein, quien construyó modelos del tracto vocal que podía producir las cinco vocales largas (a, e, i, o, u) (Tordera, 2011). La calidad de un sintetizador esta dada por la naturalidad e inteligibilidad. La naturalidad de un sintetizador de voz se refiere hasta qué punto suena como la voz de una persona real. La inteligibilidad de un sintetizador se refiere a la facilidad de la salida de poder ser entendida. El sintetizador ideal debe de ser a la vez natural e inteligible..
(21) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 12. La síntesis del habla puede ser desarrolada mendiante el uso de dos alternativas: síntesis concatenativa y síntesis de formantes (Tordera, 2011). La síntesis concatenativa, se usa principalmente para aplicaciones que requieran alta naturalidad, mientras que por fomantes es muy útil para sistemas discretos computacionalmente.. 1.2.1. Síntesis Concatenativa. La síntesis concatenativa se basa en la concatenación de segmentos de voz grabados. Generalmente, produce los resultados más naturales. Sin embargo, las diferencias entre la variación natural del habla y las técnicas automatizadas de segmentación de formas de onda resultan en defectos audibles, que conllevan una pérdida de naturalidad. Hay tres tipos básicos de síntesis concatenativa. . Síntesis por selección de unidades: La síntesis por selección de unidades utiliza una base de datos de voz grabada (más de una hora de habla grabada). Durante la creación de la base de datos, el habla se segmenta en unidades del lenguaje: fonemas, sílabas, palabras, frases y oraciones. Normalmente, la división en segmentos se realiza usando un reconocedor de voz modificado para forzar su alineamiento con un texto conocido. La selección de unidades da la máxima naturalidad debido al hecho de que no aplica mucho procesamiento digital de señales al habla grabada, lo que a menudo hace que el sonido grabado suene menos natural, aunque algunos sistemas usan un poco de procesado de señal en la concatenación para suavizar las formas de onda. De hecho, la salida de la mejor selección de unidades es a menudo idéntica de la voz humana real, especialmente en contextos en los que el sistema ha sido adaptado. Por ejemplo, un sistema de síntesis de voz para dar informaciones de vuelos puede ganar en naturalidad si la base de datos fue construida a base grabaciones de informaciones de vuelos, pues será más probable que aparezcan unidades apropiadas e incluso cadenas enteras en la base de datos. Sin embargo, la máxima naturalidad a menudo requiere que la base de datos sea muy amplia, llegando en algunos sistemas a los gigabytes de datos grabados..
(22) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. . 13. Síntesis de dífonos: La síntesis de dífonos usa una base de datos mínima conteniendo todos los dífonos que pueden aparecer en un lenguaje dado. El número de dífonos depende de la fonotáctica del lenguaje: el español tiene unos 800 dífonos, el alemán unos 2500. En la síntesis de dífonos, la base de datos contiene un sólo ejemplo de cada dífono. La calidad del habla resultante es generalmente peor que la obtenida mediante la selección de unidades pero más natural que la obtenida mediante sintetización de formantes. La síntesis de dífonos padece de los defectos de la síntesis concatenativa y suena robótica como la síntesis de formantes.. . Síntesis específica para un dominio: La síntesis específica para un dominio concatena palabras y frases grabadas para crear salidas completas. Se usa en aplicaciones donde la variedad de textos que el sistema puede producir está limitada a un particular dominio, como anuncios de salidas de trenes o información meteorológica.. Esta tecnología es muy sencilla de implementar, y se ha usado comercialmente durante largo tiempo: es la tecnología usada por aparatos como relojes y calculadoras parlantes. La naturalidad de estos sistemas puede ser muy grande, porque la variedad de oraciones está limitada y corresponde a la entonación y la prosodia de las grabaciones originales. Sin embargo, al estar limitados a unas ciertas frases y palabras de la base de datos, no son de propósito general y sólo pueden sintetizar la combinación de palabras y frases para los que fueron diseñados (Tordera, 2011).. 1.2.2. Síntesis de formantes. Los formantes son las frecuencias de resonancias, por lo que cada sonido sonoro (periódico) tiene sus propios formantes. La síntesis de formantes no usa muestras de habla humana en tiempo de ejecución. En lugar de eso, la salida se crea usando un modelo acústico. Parámetros como la frecuencia fundamental y los niveles de ruido se varían durante el tiempo para crear una forma de onda o habla artificial..
(23) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 14. Varios sistemas basados en síntesis de formantes generan habla robótica y de apariencia artificial, y la salida nunca se podría confundir con la voz humana debido a la falta de naturalidad. Sin embargo, la naturalidad máxima no es siempre la meta de un sintetizador de voz, y estos sistemas tienen algunas ventajas sobre los sistemas concatenativos. La síntesis de formantes puede ser muy inteligible, incluso a altas velocidades, evitando los defectos acústicos que pueden aparecer con frecuencia en los sistemas concatenativos. La síntesis de voz de alta velocidad es a menudo usada por los discapacitados visuales para utilizar computadores con fluidez. Por otra parte, los sintetizadores de formantes son a menudo programas más pequeños que los sistemas concatenativos porque no necesitan una base de datos de muestras de voz grabada. De esta forma, pueden usarse en sistemas empotrados, donde la memoria y la capacidad de proceso son a menudo pequeñas y por tanto de menor costo. Dado que los sistemas basados en formantes tienen un control total sobre todos los aspectos del habla producida, pueden incorporar una amplia variedad de tipos de entonaciones (Tordera, 2011).. 1.2.2.1. Sintetizador de formantes de Klatt Denis H. Klatt (Klatt, 1980) utilizó el método de síntesis de formantes para realizar un software que permite sintetizar voces tanto normales como patológicas. Klatt describe que el tracto vocal puede simularse con dos tipos de resonadores, en cascada (ver Figura 1.5) y en paralelo (ver Figura 1.6), el primero tiene como ventaja que las amplitudes relativas de los picos de los formantes son correctas sin la necesidad de controlar la amplitud individual para cada formante como lo es en los resonadores en paralelo (cada formante necesita una amplitud individual). La desventaja es que todavía necesita una configuración de formantes en paralelo para la síntesis de las consonante fricativas y las explosivas, con esta configuración en cascada la función de transferencia del tracto vocal no puede ser creada adecuadamente, por lo que estos sintetizadores son más complejos como estructura global; el segundo resonador (paralelo) son varios formantes del tracto vocal conectados en paralelo con una amplitud de control delante que determina la amplitud de cada pico espectral (Klatt, 1980)..
(24) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 15. Figura 1.5 Resonadores en cascada del sintetizador por formantes de Klatt, tomado de (Klatt, 1980).. Figura 1.6. Resonadores en paralelo del sintetizador por formantes de Klatt tomado de (Klatt, 1980). Figura 1.7 Configuración cascada/paralelo del sintetizador por formantes de Klatt tomado de (Klatt, 1980).. Dadas las ventajas y desventajas de cada configuración que con una sola no podía sintetizar todas las letras, Klatt se inclinó por mostrar una configuración que tuviera presente estas dos configuraciones antes dichas y entonces diseñó la que se muestra en la Figura 1.7..
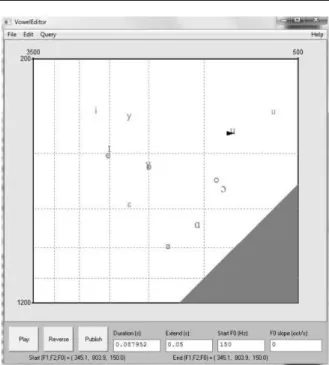
(25) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 16. 1.3. Herramientas de Software disponibles para la síntesis de vocales. En esta sección se hará una breve descripción de herramientas disponibles para la síntesis de voz. Estas herramientas están hechas para la síntesis del habla en general. 1.3.1. Praat. Praat es un software para el análisis fonético del habla creado por Paul Boersma y David Weenink del Intituto de Ciencias Fonéticas de la Universidad de Amsterdam. Este sistema permite el análisis, síntesis y manipulación de la señal de voz (Boersma & Weenink, 1992-2013). Debido a la amplia gama de herramientas implementadas en el mismo y la incorporación de un lenguaje compilado (script), este programa se ha convertido en uno de los más utilizados en la comunidad científica relacionada con el procesamiento del habla. Praat posee varias herramientas para la síntesis de sonidos. Específicamente se pueden sintetizar vocales mediante dos opciones: . La generación de un sonido mediante una fórmula matemática. Para las vocales sostenidas basta con introducir la ecuación (1.3). . Utilizando la herramienta Editor de Vocales (VowelEditor) según se muestra en la Figura 1.8. Específicamente la opción de síntesis 2 es la más recomendada para vocales pues la herramienta está desarrollada con este fin. VowelEditor utiliza una representación gráfica de la posición de las vocales en el plano F1F2 según se muestra en la Figura 1.8. Al señalar un punto en el plano con el ratón se establece la vocal que se desea sintetizar. La duración de la síntesis así como la frecuencia fundamental pueden ser controladas en VowelEditor. El valor de los cuatro primeros formantes puede ser establecido así como la dinámica de la frecuencia fundamental. Esta última es manipulada a través de las nombradas trayectorias (Boersma & Weenink, 19922013)..
(26) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 17. Figura 1.8 Ventana del VoweEditor implementada en Praat.. Este sistema no permite de forma secilla la manipulación de las diferentes partes del modelo de producción de la voz. Existe la posibilidad de que mediante el lenguaje de scripts incorporado en Praat sea posible controlar los parámetros del modelo de producción de voz así como la introducción de diferentes perturbaciones. Este procedimiento se torna muy engorroso y es necesario estar familiarizado con los scripts de Praat.. 1.3.2. Sintetizadores de formantes de Klatt. En la sección 1.2.2.1 se muestra un descripción de la arquitectura cascada/paralelo del sintetizador de Klatt. Varias herramientas han sido desarrolladas con este fin algunas de libre acceso, para otras es necesario pagar un elevado precio y otras son utilizadas por grupos específicos de investigación y los ejecutables no se encuentran disponibles, solo las descripciones de los sistemas. Dentro de las aplicaciones de libre acceso se encuentra KLSyn88, KLSyn, WinSnoori, Praat, KPE80 entre otros. Entre las variantes de compra de licencias esta SynthWorks distribuido por Scicon R&D Inc (Scicon R&D Inc, 1994-2013) cuyo precio establecido es de $395.0 y HLsyn de Sensimetrics Corporation (Scicon R&D Inc, 1994-2013). Existe también una variante online del sintetizador de Klatt elaborada por.
(27) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 18. el laboratorio de Investigaciones del Habla de la Universidad de Delaware (Speech Research Lab, 2013). Algunos autores han realizado también bibliotecas de código para la implementación del sintetizador de Klatt (Klatt, 1980).Estas bibliotecas han sido utilizadas en la construcción de algunas de las herramientas mencionadas anteriormente. En esta sección se describirán las variantes de libre acceso del sintetizador de Klatt.. 1.3.2.1.KLsyn 88 Es un software. desarrollado en el año 1991 por Dennis Klatt (Klatt, 1980). La. configuración general de este sintetizador puede ser modificada según se muestra en la Figura 1.9.. Figura 1.9 Ventana de configuración para KLSyn 88. Como se observa en la figura anterior es posible manipular diferentes parámetros del modelo de Klatt (Klatt, 1980) como la duración, la frecuencia de muestreo, número de formantes en cascada, la forma que puede tomar la fuente (g(t)), la configuración del tracto (cascada o paralelo), entre otras opciones (ver Figura 1.9). Para cada porción del modelo de producción de la voz KLSyn88 permite la manipulación de los parámetros correspondientes. En el caso de la función de la glotis g(t) es posible sintetizarla a través de un tren de impulsos, según se describe en (Klatt, 1980) y del modelo de Liljencrants-Fant (Fant, et al., 1985). La ventana de configuración se muestra en la Figura 1.10.
(28) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 19. Figura 1.10 Ventana de configuración de la fuente. Para establecer la configuración de la arquitectura en cascada o paralelo del filtro para el sintetizador de Klatt pueden utilizarse las ventanas de configuración de la Figura 1.11 A y B respectivamente.. A. B. Figura 1.11 Ventanas de configuración de KLSyn88 A: Configuración de la arquitectura en cascada B:Configuración de la arquitectura en paralelo. Es posible en KLSyn 88 generar señales que contengan ruidos de fricción. La configuración del filtro para la fuente generadora de ruidos de fricción es posible manipularla según se muestra en la Figura 1.12..
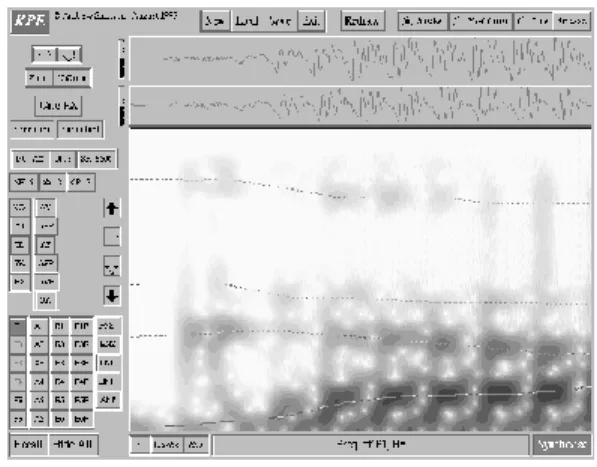
(29) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 20. Figura 1.12 Ventana de configuración del resonador para la fuente generadora de ruidos de fricción.. Varios trabajos han sido reportados en la literatura donde la generación de señales sintetizadas ha sido elaborada utilizando KLSyn88.. 1.3.2.2. KPE80 KPE80 es otra de las variantes para la síntesis utilizando el sintetizador de Klatt. Este sistema está desarrollado en C para plataforma Unix (Simpson, 2012). Este sistema fue creado por Andrew Simpson del departamento de Lingüística y Fonética de la Universidad de Londres.. Figura 1.13 Interfaz gráfica de KPE80. El sistema KPE80 provee una interfaz gráfica como la mostrada en la Figura 1.13. En esta ventana los parámetros de la arquitectura de Klatt pueden ser manipulados por el usuario..
(30) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 21. Es posible modificar la trayectoria de los formantes y refinar los valores de los parámetros utilizados en la síntesis. Permite llevar a cabo el proceso conocido como "síntesis por copia" mediante el cual pueden crearse estímulos sintetizados basados en un enunciado natural, editando los valores de los parámetros hasta conseguir una reproducción sintetizada lo más parecida posible a la natural. Además es posible realizar comparaciones espectrales, entre las señales sintetizadas y la original utilizando las facilidades incorporadas en el sistema.. 1.3.2.3. WinSnoori WinSnoori es un programa de análisis acústico del habla desarrollado en el LORIA (del francés, Laboratoire Lorrain de Recherche en Informatique et ses Applications) de Nancy. El programa incluye una interfaz gráfica con el sintetizador de Klatt, del que se usa la implementación de Jon Iles and Nick Ing-Simmons (Laprie, 2009).. Figura 1.14 Interfaz Gráfica del Winsnoori. La ventana en el interior de la interfaz principal pertenece al sintetizador de Klatt..
(31) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 22. WinSnoori permite llevar a cabo la síntesis a partir de los valores extraídos del análisis acústico de un documento y modificados mediante la interfaz gráfica según se muestra en la Figura 1.14. Para el manejo de los diferentes componentes del modelo de producción de voz, WinSnoori provee diferentes opciones. Es posible acceder a la configuración general a traves del menú Setup y en la ventana de configuración (Figura 1.5). En esta figura se puede observar. Figura 1.15 Ventana de configuración del sintetizador de Klatt en WinSnoori.. las diferentes opciones para la configuración del sintetizador. La fuente g(t) puede ser sintetizada utilizando la variante propuesta por klatt (Klatt, 1980) o el modelo de Liljencrats-Fant (Fant, et al., 1985). Además es posible escoger la forma de onda que se desea visualizar en el panel de Señal de Salida (Output waveform) según se muestra en la Figura 1.15. Para la configuración de los formantes varias opciones son implementadas. Es posible elaborar una estructura de formantes manualmente o extraerla de alguna señal real..
(32) CARACTERÍSTICAS DE LA SEÑAL DE VOZ. 23. Conclusiones parciales En este capítulo se dieron a conocer las diferentes características de la señal de voz, los modelos de síntesis más usados. Además se describen diferentes aplicaciones comerciales para la síntesis del habla, específicamente síntesis de vocales sostenidas..
(33) MATERIALES Y MÉTODOS. Capítulo. 24. 2. 2. MATERIALES Y MÉTODOS En este capítulo se describen las particularidades de las diferentes componentes del modelo de síntesis implementado en el sistema propuesto (Fuente-Filtro). Se brinda una detallada descripción de los diferentes modelos de la señal glotal considerados en la literatura asi como las variantes para la síntesis de la función de transferencia del tracto vocal. Además se describen las diferentes formas de perturbación de la periodicidad para la síntesis de voces patológicas (jitter, shimmer, ruido) y cómo fueron tratadas en el desarrollo del sistema propuesto. Adicionalmente se describen las propiedades principales para el desarrollo de interfaces de usuario así como las limitaciones y ventajas de Matlab para la elaboración del sistema propuesto.. 2.1. Modelos de Síntesis de la señal de la glotis En la actualidad la síntesis de voz ha tenido gran auge en diversas aplicaciones, para esto ha sido preciso simular los diferentes parámetros del modelo Fuente-Filtro. La variabilidad de la señal glotal es un factor donde no existe consenso en cuanto a las formas de onda a emplear y cómo efectuar la variación en las mismas (Rosenberg, 1971) (Klatt & Klatt, 1990) (Titze & Liang, 1993) (Murphy & Yegnanarayana, 1999). En este trabajo el Modelo B de Rosenberg y el R++ (Veldhuis, 1998), una alternativa más eficiente computacionalmente que fusiona el modelo original de la señal glotal de Rosenberg (Rosenberg, 1971) y el de Liljencrats-Fant (Fant, et al., 1985), son implementados. La.
(34) MATERIALES Y MÉTODOS. 25. elección de estas variantes esta dada por la sencillez con que estos modelos pueden ser desarrollados.. 2.1.1. Modelos de Rosenberg. En (Rosenberg, 1971) se plantea que la señal glotal no es mas que la concatenación de diferentes polinomios donde se establecen una fase de apertura y otra de cierre de las cuerdas vocales. Los diferentes modelos de la señal glotal reportados en este trabajo son: A. La simulación de este modelo está caracterizado por una onda triangular, siendo la fase de apertura. .. ( ) y la fase de cierre. B. Este modelo de síntesis está compuesto por polinomios, la fase de apertura está dada. por. y. la. fase. de. cierre. por. ]. C. El presente modelo está compuesto por funciones trigonométricas, la fase de apertura esta dada por. .. y el cierre. D. Este modelo presenta la misma forma de apertura que el anterior .. y cuenta con fase de cierre. E. Para la síntesis de este modelo se utiliza para la fase de apertura y para el cierre F. Este modelo está definido por un trapecio siendo la apertura .. el cierre. Donde. es la amplitud deseada,. las cuerdas vocales y. y. el tiempo de la onda glotal,. el tiempo de apertura de. el tiempo de cierre. Las variantes de forma glotal descritas.
(35) MATERIALES Y MÉTODOS. 26. anteriormente pueden ser observadas en la Figura 2.1. Estas formas de onda de la señal glotal representan el flujo de aire que pasa por las cuerdas vocales (Rosenberg, 1971). Para la estimación del flujo de aire es necesario estimar la derivada de la función de presión (Rosenberg, 1971) (ver Figura 2.2).. Figura 2.1 Comparación entre los seis modelos se síntesis de señales glotales de Rosemberg (Rosenberg, 1971).. Figura 2.2 Tipos de ondas de la señal de la glotis g(t) y g´(t) (derivada) sintetizadas con Vowel_Synth por modelo B de Rosemberg.. El modelo B se implementó por ser uno de los más semejantes y de los más económicos computacionalmente, en la Figura 2.1 se muestra un ejemplo donde se introdujeron los siguientes parámetros: frecuencia fundamental (F0) F0 = 150 Hz, período fundamental (T0).
(36) MATERIALES Y MÉTODOS. 27. T0 = 1\F0, amplitud a = 1, Tp = 0.33T0, Tn = 0.09 T0 y t = T0 como se muestra en la Figura 2.2.. 2.1.2. Modelo de Liljencrats-Fant. El modelo de Liljencrants y Fant (Fant, et al., 1985) obtiene la forma de onda glotal de presión g(t)´ por ser más sencilla de deducir que la señal de flujo, luego esta señal es integrada para obtener g(t). Una representación de este modelo puede ser observada en la Figura 2.3. La formulación matemática que representa el modelo de la señal glotal de Liljencrants-Fant se representa en la ecuación (2.1).. f(t) si 0 t te (-(t 0 -t e )/t a ) g ' t e(-(t-t e )/ta ) e si te t t0 (-(t 0 -t e )/t a ) f(t e ) 1-e . Figura 2.3 Representación gráfica del modelo de Liljencrant-Fant. Figura tomada de (Fant, et al., 1985).. (2.1).
(37) MATERIALES Y MÉTODOS. 28. donde tp es el tiempo donde ocurre el máximo flujo de aire, la máxima apertura ocurre a te, el intervalo antes de te es la fase de apertura, y después de te es la fase de cierre de las cuerdas vocales (ver Figura 2.3). La función f(t) utilizada en (2.1) se define como:. (2.2). Este modelo es muy complejo debido a que para el cálculo de α es necesario encontrar la solución de la ecuación (2.3) y el costo computacional es muy elevado. (Veldhuis, 1998).. (2.3). Para resolver esta limitante del modelo de Linljencrants-Fant se propone (Veldhuis, 1998) utilizar la simplicidad del modelo de Rosenberg y las ventajas del modelo descrito en esta sección. A continuación se describe esta variante.. 2.1.1. Modelo de Veldhuis (R++). El modelo R++ (Veldhuis, 1998) es una alternativa más eficiente computacionalmente del modelo de Liljencrants-Fant y también responde a la ecuación (2.2) pero partiendo del modelo de Rosenberg (Rosenberg, 1971) donde. se muestra en la ecuación (2.4) y. (2.5).. (2.4). (2.5).
(38) MATERIALES Y MÉTODOS. 29. El cálculo de tp responde a la ecuación (2.6). ( 2.6). donde tp es el tiempo donde ocurre el máximo flujo de aire, la máxima apertura ocurre a te, el intervalo antes de te es la fase de apertura, y después de te es la fase de cierre de las cuerdas vocales.. Figura 2.4 Comparación de un pulso glotal de presión g´(t) entre el método (LF) y R++ para los mismos parámetros, con línea discontinua el modelo (LF) y con línea contínua el R++, t en segundos y g’(t) en unidades arbitrarias. (Veldhuis, 1998).. Figura 2.5 Forma de onda glotal de presión (derivada) sintetizada con Vowel_Synth por el modelo R++.. La Figura 2.5 muestra la forma de onda glotal de presión (derivada) sintetizada con Vowel_Synth por el modelo R++..
(39) MATERIALES Y MÉTODOS. 30. 2.2. Modelos de Síntesis del Tracto Vocal Varios modelos del tracto vocal pueden ser utilizados para la síntesis de vocales (Quatieri, 2002). En este trabajo dos de estas variantes de función de transferencia del tracto vocal son consideradas: el filtro todo polos que sería el equivalente de diseñar un filtro digital, y la suma de cosenos. Ambas variantes serán descritas a continuación.. 2.2.1. Suma de cosenos. Como respuesta al impulso, típica del tracto vocal, h(t), se empleó la suma de sinusoides, este es el más frecuentemente empleado en la literatura para la síntesis de vocales. La h(t) puede obtenerse como la suma de M sinusoides amortiguadas (ver ecuación ( 2.7)) que son las representaciones temporales de los polos complejos conjugados del modelo:. M. h(t ) Ame Bm t cos(2Fmt ). (t 0 ). ( 2.7). m 1. Tabla 2.1 Valores de amplitud (A) ancho de banda (B) y frecuencia central (F) de los cinco resonadores del filtro. La amplitud en unidades arbitrarias (u. a.). Formantes. 1. 2. 3. 4. 5. A (u. a.). 250. 60. 215. 25. 40. B(Hz). 320. 720. 520. 770. 350. F(Hz). 520. 800. 1190. 1840. 2390. Parámetros. En este caso Am, Bm y Fm son las amplitudes, anchos de banda y frecuencias centrales respectivamente de cada una de las M resonancias del tracto vocal. Se seleccionó para los.
(40) MATERIALES Y MÉTODOS. 31. ejemplos trabajar con los mismos valores que en (Parsa & Jamieson, 1999) y (Medan, et al., 1991) fijando M = 5 y los formantes dados por los valores de la Tabla 2.1, que corresponden a su vez con los valores de una vocal “a” (Rabiner & Juang, 1993) pero el usuario los puede cambiar.. 2.2.2. Filto autoregresivo (AR) todo polos. Considerando el tracto vocal desde la glotis hasta fuera de los labios, el filtro todo polo responde a la siguiente ecuación (Quatieri, 2002).. (2.8). Donde A es la ganancia, M es el número de coeficientes,. los coeficientes de predicción. lineal (LPC, del inglés, Linear Predictive Coefficients), El modelo de secciones del tubo acústico es una simulación del tracto vocal, donde si se selecciona un orden M para el filtro se está asumiendo M secciones con sus equivalentes M coeficientes de reflexión (ver Figura 2.6), pero:. Figura 2.6 Modelo de secciones del tubo acústico.. 1. La velocidad de las vibraciones en el aire es un factor físico V = 340 m/s. 2. La longitud del tracto de la persona es de aproximadamente 17 cm. 3. Los coeficientes M implican que el sonido efectivamente se refleje en los límites de cada sección, esto ocurre cada. segundos..
(41) MATERIALES Y MÉTODOS. 32. 4. Los coeficientes k se aplican a muestras separadas a Ts, por lo que ser válido, pero en realidad es. , parece. porque el sonido tiene que regresar al. origen luego de la reflexión para llegar al estado estable. Como físicamente. y. , el orden del filtro debe cumplir con la. siguiente igualdad:. (2.9). O sea, M es aproximadamente igual a los kilohertzios de frecuencia de muestreo para tener sentido físico, pero se reporta que es posible adicionar cuatro o cinco polos (Markel & Gray, 1976).. 2.3. Perturbaciones de la periodicidad El uso de la ecuación (1.7) para sintetizar una vocal permite variar fácilmente el valor de jitter controlando, Ti, mientras ai puede emplearse para variar el shimmer, y la relación señal a ruido (SNR) puede ser controlada mediante la adición del ruido e(t). Teniendo en cuenta las perturbaciones de la periodicidad presentes en el modelo de la ecuación (1.7) es posible crear varios tipos de señales: las que presentan sólo jitter, sólo shimmer, sólo ruido y las combinaciones posibles de estas perturbaciones de la periodicidad simulando así una gran variedad de voces patológicas. A pesar de que las ecuaciones (1.6) y (1.7) permiten obtener s(t) para la variable continua de tiempo t, su implementación en la variante discreta resulta engorrosa y costosa desde el punto de vista computacional para un número elevado de pulsos, con la evaluación acumulativa de (1.7) para cada uno de ellos. Por esta razón el método empleado en este trabajo consiste en la discretización de h(t) descrita por ( 2.7) para una frecuencia de.
(42) MATERIALES Y MÉTODOS. 33. muestreo dada, su posterior convolución con el tren de impulsos y la adición de ruido según (1.6). El muestreo de h(t) se efectúa evaluando ( 2.7) para t = kTs, kN, y truncando su longitud a un determinado número de muestras. En esta variante, debido a que la convolución se efectúa en el dominio de tiempo discreto, el tren de impulsos tiene que satisfacer que los instantes de excitación y las separaciones entre ellos sean también múltiplos del período de muestreo (Ti-1+ T0 +T=k1Ts y T0 +T=k2Ts respectivamente, k1, k2N). Esto no constituye una fuerte limitante en cuanto a las posibilidades de generación de señales, pues las variabilidades de duración Ti introducidas en este trabajo superan ampliamente el tiempo correspondiente a un período de muestreo Ts (variabilidad mínima en un intervalo de 5 muestras). La frecuencia de muestreo (Fs=1/Ts) empleada para la generación de las señales simuladas fue de 22.05 kHz, mientras que el valor medio de frecuencia fundamental F0 1/ T0 se fija por el usuario al valor deseado. La respuesta al impulso del tracto se truncó al doble de T0 . Longitudes de h(t) por encima de dos T0 no aportan prácticamente ninguna potencia de señal adicional (99.2% de potencia contenida en la duración de un pulso, 99.99% de potencia contenida en la duración de dos T0 ) (Ferrer Riesgo, 2005). La longitud de las señales generadas se especifica por el usuario. Los detalles específicos de la generación de cada uno de los tipos de señales con perturbaciones de la periodicidad (sólo jitter, sólo shimmer, sólo ruido aditivo y las posibles combinaciones de estas) se describe a continuación.. 2.3.1. Jitter. En estas señales el factor ai, que involucra la variabilidad de la amplitud en el tren de impulsos en la ecuación (1.6), se fija a la unidad (ai=1), y se les anula el término correspondiente a ruido (e(t) = 0). La única alteración de la periodicidad está dada por la variación en la separación de los impulsos de excitación Ti, que en este caso es un número entero aleatorio con distribución de probabilidad uniforme en el intervalo TMáx (en muestras). Se puede emplear los valores deseados de TMáx pero se recomienda hasta un.
(43) MATERIALES Y MÉTODOS. 34. 25%, este límite superior se fija en correspondencia con (Medan, et al., 1991) donde se plantean límites razonables de hasta un 25% de jitter en voces patológicas.. 2.3.2. Shimmer. En estas señales se genera el factor que gobierna la amplitud de los impulsos de excitación como ai=1+Δai, siendo Δai un número real en el intervalo ±ΔaMáx y teniéndose una amplitud promedio unitaria. Al igual que en el caso de jitter, se puede emplear varios valores diferentes de ΔaMáx. Como los límites reportados de shimmer están alrededor del doble de los de jitter (límites de un 50% según (Titze, 1995) se decidió introducir las perturbaciones de shimmer de forma que los porcentajes de ΔaMáx sean, con relación a la unidad, el doble de los empleados en el caso de jitter. De esta forma los valores de ΔaMáx recomendados son de 0 a 50%. El resto de las perturbaciones son suprimidas (ΔTi=0, y e(t)=0).. 2.3.3. Ruido. En este caso una señal s(t) “limpia” obtenida para amplitud constante ai=1 (ai=0) y separación también constante e igual a T0 (Ti = 0), es contaminada con un ruido blanco Gaussiano e(t) tal que la relación entre las energías (varianzas) de la señal (s2) y el ruido (e2) (SNR) produzca un valor dado. Esto se logra manipulando la amplitud de una realización de ruido blanco e(t) con varianza unitaria para obtener el valor de SNR deseado. La expresión que relaciona ambas varianzas para una SNR (en dB) dada es:. e 2 s 2 /(10(SNR/10) ). (2.10). Los valores de SNR se introducen por el usuario pero se recomienda una SNR desde 30db hasta la más distorsionada con 2dB. Estos valores de SNR se han seleccionado de tal manera que la mayor perturbación (SNR=2dB) no supere la energía de la señal periódica,.
(44) MATERIALES Y MÉTODOS. 35. pues según (Titze, 1995) esta última debe ser mayor que la energía de las perturbaciones en señales hasta tipo 2 (no caóticas). El rango típico de SNR encontrado en la voz de 15 a 30 dB según (Murphy & Yegnanarayana, 1999).. 2.3.4. Jitter y Ruido. En estas señales el factor ai, que involucra la variabilidad de la amplitud en el tren de impulsos en la ecuación (1.6), se fija a la unidad (ai=1), y se les introduce el término correspondiente al ruido e(t) (igual a solo ruido). La alteración de la periodicidad está dada por el ruido y la variación en la separación de los impulsos de excitación ΔTi que al igual que en sólo jitter es un número entero aleatorio con distribución de probabilidad uniforme en el intervalo ±ΔTMáx (en muestras). Se puede emplear los valores deseados de ΔTMáx pero se recomienda hasta un 25% (Medan, et al., 1991) donde se plantean límites razonables de hasta un 25% de jitter en voces patológicas.. 2.3.5. Shimmer y Ruido. En esta señal al igual que sólo shimmer se genera el factor que gobierna la amplitud de los impulsos de excitación como ai=1+Δai, siendo Δai un número real en el intervalo ±ΔaMáx y teniéndose una amplitud promedio unitaria. Al igual que en el caso de Shimmer, se puede emplear varios valores diferentes de ΔaMáx. De esta forma los valores de ΔaMáx recomendados son de 0 a 50%. El ruido se comporta igual que solo ruido (e(t)) El resto de las perturbaciones es suprimido (ΔTi=0).. 2.3.6. Perturbaciones combinadas. En este último tipo de señales, todas las alteraciones de la periodicidad contempladas anteriormente fueron introducidas simultáneamente, en los mismos niveles que en los casos de sólo “jitter”, sólo “shimmer”, y sólo ruido. Las señales se combinan introduciendo niveles equivalentes de las perturbaciones individuales (n-ésimo nivel de jitter con n-ésimo nivel de shimmer con n-ésimo nivel de ruido). De esta forma se obtienen señales con las tres perturbaciones..
(45) MATERIALES Y MÉTODOS. 36. 2.4. Diseño de la interfaz de Usuario 2.4.1. Generalidades. El término Interfaz Gráfica de Usuario GUI del inglés (Graphical User Interface) se utiliza para llamar al conjunto de elementos visuales relacionados entre sí, que brinda un sistema o programa para que el usuario interactúe con él (www.mathworks.com, 2004). El estudio y desarrollo del diseño de una interfaz requiere de un trabajo donde están inmersas viarias disciplinas en función a un mismo objetivo: cubrir la necesidad del hombre de transmitir y comunicar, en este caso, a través de un medio virtual. Las disciplinas que intervienen pueden variar pero las que se mantienen de alguna manera constante son: la ingeniería, la programación y el diseño. Una interfaz gráfica, de forma general, debe ser básicamente: Sencilla. Los elementos están para apoyar, ayudar y guiar, no para confundir, hay que evitar la saturación y colocación innecesaria de los mismos. Clara. La información debe ser fácilmente localizable, es decir, debe estar organizada ya sea de manera lógica, jerárquica o temática. Predecible. A acciones iguales, resultados iguales. Flexible. Pensar en botones que puedan modificar textos, realizar cambios en algunas secciones según convenga, etc. Consistente. Aunque se realicen cambios en la programación, la representación gráfica de las funciones e imágenes debe permanecer igual. Intuitiva. El usuario se siente más seguro en una aplicación en la que no tenga que adivinar ni pensar como ejecutar acciones. Coherente. Tanto texto como gráficos, colores y demás elementos utilizados deben corresponder al contenido de la aplicación. Apoyados generalmente por una construcción de palabras, frases y elementos visuales (González, 2004)..
(46) MATERIALES Y MÉTODOS. 2.4.2. 37. Uso de Matlab para la construccion de la interfaz de usuario de Vowel_Synth. Matlab, cuyo nombre proviene del inglés (MATrix LABoratory) es un software matemático que tiene un lenguaje de programación propio (Lenguaje M) y es multiplataforma (Unix, Windows y Apple Mac Os X). Creado en 1984 por Cleve Moler con la idea de crear paquetes de subrutinas escritas en Fortran (del inglés Formula Translating System), un lenguaje orientado al cálculo numérico, diseñado en sus inicios para las computadoras IBM y usado en aplicaciones científicas y de ingeniería, se puede destacar que es el más antiguo de los lenguajes de alto nivel (Inc., 2005) El lenguaje de programación M se creó en 1970 proporcionando una acceso sencillo al software de matrices LINPACK (del inglés Linear System Package) y EISPACK (del inglés Eigen System Package) sin tener que hacer uso del lenguaje Fortran. Ya en el año 2004 se apreciaba que Matlab era usado por aproximadamente más de un millón de personas, tanto académicos como empresarios. Dentro de sus principales funciones se encuentran: Manipulación de matrices. Representación de datos y funciones. Implementación de algoritmos. Creación de interfaces de usuario (GUI). Comunicación con programas en otros lenguajes y con otros dispositivos Hardware. Además, posee herramientas adicionales como el Simulink (Plataforma de simulación multidominio) y el Editor de interfaces de usuario (GUI). El uso del Matlab ha posibilitado el desarrollo en áreas de investigación relacionadas con procesamiento digital de señales; ya sea audio, imágenes o video, debido a la gran diversidad de funciones y herramientas que presenta destinadas para ese fin. Posee una ayuda al usuario con numerosos ejemplos que, hace posible a un usuario de menor.
(47) MATERIALES Y MÉTODOS. 38. experiencia realizar los algoritmos, funciones y herramientas en un intervalo corto de tiempo. dependiendo. de. la. complejidad. del. problema. al. que. se. enfrente. (www.mathworks.com, 2004). Una de las herramientas que posee Matlab es el Editor de Interfaces de Usuario GUIDE (del inglés Graphical User Interface Development Environment), la cual presenta características que posibilitan el desarrollo de interfaces gráficas de usuario de manera sencilla e intuitiva. Para realizar la construcción de un GUI se utiliza el Editor de Diseño del GUIDE que permite de manera gráfica seleccionar y configurar los elementos y los componentes del GUI que se desea desarrollar. Los componentes en el GUIDE más utilizados dentro del área de diseño son: Push button o botones de presión son los encargados de generar una acción cuando se le hace clic encima de ellos. Slider o barra de desplazamiento, acepta valores de entrada de posición dentro de un rango especificado que son establecidos moviendo la barra deslizante. La localización de la barra deslizante indica la localización que es el valor que tomará la variable asociada al elemento. Check Box o cajas verificación, pueden generar una acción una vez que se activen e indican su estado de verificado o no verificado o sea en alto o en bajo. Las cajas verificadoras son útiles para proporcionar opciones independientes al usuario, por ejemplo, cuando se tienen los textos de una imagen la opción de ser mostrados o no puede estar asociada a un elemento de este tipo. Radio Button o botón circular, son similares a los check boxes o botones de chequeo con la diferencia de que están relacionados entre sí de manera que, si uno está seleccionado el otro por definición esta deseleccionado. Edit Text o texto editable, son campos que le permiten a los usuarios insertar o modificar cadenas de caracteres. Es importante destacar que este objeto manipula cadenas de caracteres por lo tanto cuando se insertan números para poder ser usados deben convertirse a sus equivalentes numéricos. Static Text o textos estáticos, es un objeto que permite mostrar líneas de texto que a diferencia del Edit Text se muestran fijas y no pueden ser modificadas por el.
(48) MATERIALES Y MÉTODOS. 39. usuario. Este tipo de objeto puede ser usado para etiquetar controles, proporciona las direcciones al usuario, o indica valores resultantes de algún cálculo. Pop-Up menú o menú desplegable, este objeto despliega una lista de opciones. Axes, permiten al GUI desplegar gráficos o imágenes. Tienen propiedades que pueden ser modificadas en función de los requerimientos de la aplicación. Panel o tablero, se usa para agrupar elementos del GUI en grupos según las funciones que realicen o a gusto del programador, lo cual hace más amigable el diseño (Inc., 2005). La Figura 2.7 muestra la herramienta GUIDE inicializada lista para comenzar un diseño.. Figura 2.7 Herramienta GUIDE lista para comenzar el diseño.. Una de las bondades que presenta el desarrollo de un GUI utilizando Matlab es la interactividad que presenta con el desarrollador y el amigable lenguaje de programación, por otro lado la propia herramienta genera de forma automática el código en un archivo *.m asociado a cada uno de los elementos, dentro de este fichero se reservan espacios específicos donde el programador introduce segmentos de código correspondiente a las instrucciones específicas para cada elemento que compone la herramienta en desarrollo. Cuando se desarrolla un GUI queda almacenado en dos archivos.
(49) MATERIALES Y MÉTODOS. 40. Un archivo con extensión *.m, llamado M-File (archivo *.m), mencionado anteriormente, el cual contiene el código que corresponde a cada elemento del GUI. Un archivo con extensión *.fig, llamado FIG-File (archivo *.fig), el cual contiene la estructura gráfica del diseño y de la configuración de los componentes del GUI. De modo que cuando se trabaja en la componente gráfica, es almacenado en el archivo *.fig y cuando se modifica el código de programación de los elementos del GUI es almacenado en el archivo *.m (Inc., 2005).. Concluciones Parciales En este capítulo se ha descrito de forma detallada los diferentes parámetros para la síntesis de los vocales. La función glotal es representada por los modelos B de Rosenberg y R++. La función de trasferencia del tracto es simulada utilizando la variante de suma de cosenos y el filtro autorregresivo todo polos. A las señales simuladas es posible introducirles perturbaciones de la periodicidad tanto de frecuencia, amplitud y ruido aditivo para representar las voces patológicas. La facilidad para el desarrollo de interfaces gráficas de Matlab fue escogida para la implementación del sistema propuesto..
Figure



+7




Documento similar