Pronóstico de temperaturas mínimas en todas las estaciones meteorológicas cubanas utilizando redes neuronales artificiales
73
0
0
Texto completo
(2) Dictamen. El que subscribe, Julio Cesar Roque Rodríguez, hago constar que el trabajo titulado “Pronóstico de temperatuuras mínimas en todas las estaciones meteorológicas cubanas utilizando redes neuronales artificiales” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ingeniería Informática, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del Autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Seminario. II.
(3) Agradecimientos En primer lugar agradezco a mi mamá Norma que es la persona que me ha guía desde muy pequeño, que fue construyendo con mano fuerte pero con mucho amor la persona que soy hoy, muchas gracias a ti MIMA por confiar siempre en mí, por ser incondicional en todo momento, gracias por ser la mejor mamá del mundo y es de tu total conocimiento que describir lo que representas para mí, no podría ser representado con algunas palabras. A mi papá Fidel que a pesar de estar lejos de mí siempre estuvo al pendiente, preocupado por si yo heredaba su maldición del 4to año. Gracias por educarme, me ha servido para desarrollarme mejor como persona. A mi novia Vida Lis por su amor, dedicación, por ser mi amiga y mi amante. A su familia que en mis últimos años me han acogido como uno de los suyos ayudándome y apoyándome para que terminara lo mejor posible. A toda mi familia que de una forma u otra siempre han estado ahí para lo que ha hecho falta. A mi tutora la MSc. Adis Perla por aceptar ser mi tutora desde que se lo plantee, por la gran ayuda que me ha brindado en el desarrollo de este trabajo y por ser además de mi profesora una buena amiga. A otra tutora la Dra. María del Carmen Chávez por su exigencia y ayuda brindada para que este trabajo se terminara en el tiempo adecuado. A todas las personas que me han colaborado en el desarrollo de este trabajo, si usted ha ayudado siéntanse mencionado. También a mis compañeros de aula por compartir conmigo tanto buenos como malos momentos durante estos 5 años que han sido extraordinarios y en. III.
(4) IV. especial a Adonnis (El flacooo) por ser ese amigo y compañero de guerrilla, que siempre convencí para irnos de fiesta y que estuvo ahí para contarle algunos secretos, a Rigoberto (Rigacho) y a Nailet (Nylon) por su amistad sincera, a Luis Enrique (El rebosado mayor) que a pesar que siempre lo estábamos jodiendo nos brindaba su ayuda incondicional, también a Geily, otra gran compañera de muchas fiestas y una persona maravillosa. Bueno en fin a todos los compañeros de aula y no quiero que por no ver su nombre explícitamente no crean que no son importantes en esta etapa de mi vida que acaba con este trabajo..
(5) Resumen En la actualidad los pronósticos de temperaturas extremas han llamado la atención de especialistas e investigadores de diferentes campos, principalmente en el área de las ciencias computacionales donde se han realizado un grupo de investigaciones, demostrando que las técnicas de Aprendizaje Automatizado (AA) ofrecen mejores resultados que los métodos convencionales. A partir de información suministrada por el CMPVC y tratando de mejorar los modelos utilizados en dicho centro, en el presente trabajo se utilizan las “Redes Neuronales Artificiales” (RNAs) como una técnica eficaz para tal fin. En la búsqueda de los modelos por estación o de modelos que se ajusten a la mayor cantidad de las mismas se realizó una experimentación bastante extensa con todas las estaciones teniendo en cuenta que cada una de estas debe ser analizada para las dos temporadas del año (Invierno y Verano). El potencial predictivo de estos modelos se analiza en función de: error medio absoluto y de la desviación estándar, en búsqueda de una reducción de errores durante la predicción de las temperaturas para una determinada estación meteorológica. Los resultados finales se comparan con los del modelo MOS (Model Output Stadistic) lo que muestra que los modelos propuestos ofrecen predicciones más certeras para este tipo de datos en los que existe una relación compleja entre ellos. La capacidad predictiva de los modelos de la aplicación PronMLP resultó ser mejor en cuanto al % de casos positivos obtenidos, comparado con el alcanzado por el modelo MOS en el período de tres años, desde 2/4/2012 hasta 20/4/2015.. V.
(6) Abstract At present extreme temperature forecasts have drawn attention of specialists and researchers from different fields, mainly in the area of computer science which have made a research group, showing that Automated Learning techniques (AA) offer better results than conventional methods. From information provided by the CMPVC and trying to improve the models used in the center, in the present study Artificial Neural Networks (RNAs) as an effective technique used for this purpose. In the search for models by station or models that fit as many of them quite extensive experimentation was carried out with all seasons considering that each of these must be analyzed for two seasons (winter and Summer). The predictive power of these models is analyzed according to: mean absolute deviation and standard error in seeking a reduction in errors when predicting temperatures for a given weather station. Final results are compared with MOS model (Model Output Stadistic) which shows that the proposed models provide more accurate for this type of data in which there is a complex relationship between them predictions. The predictive ability of the models of the application PronMLP proved to be better in terms of % of obtained positive cases compared to that achieved by the MOS model in the three-year period from 2/4/2012 to 20/04/2015. VI.
(7) Índice general Introducción Antecedentes . . . . . . . . . . Planteamiento del Problema . . Objetivo General . . . . . . . . Objetivos Específicos . . . . . . Preguntas de Investigación . . . Hipótesis . . . . . . . . . . . . Tareas de Investigación . . . . . Justificación de la Investigación .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 1. Fundamentos Teóricos 1.1. Clasificación del aprendizaje según los datos . . . . . . . . . . 1.1.1. Aprendizaje supervisado . . . . . . . . . . . . . . . . 1.1.2. Aprendizaje no supervisado . . . . . . . . . . . . . . 1.1.3. Aprendizaje semisupervisado . . . . . . . . . . . . . 1.1.4. Aprendizaje por refuerzo . . . . . . . . . . . . . . . . 1.2. Clasificación del aprendizaje según el conocimiento que genera 1.2.1. El aprendizaje inductivo . . . . . . . . . . . . . . . . 1.2.2. Aprendizaje perezoso . . . . . . . . . . . . . . . . . . 1.2.3. Aprendizaje basado en instancias . . . . . . . . . . . 1.2.4. Modelos conexionistas . . . . . . . . . . . . . . . . . 1.3. Predicción numérica o regresión . . . . . . . . . . . . . . . . 1.3.1. Regresión lineal . . . . . . . . . . . . . . . . . . . . 1.3.2. Árboles de regresión . . . . . . . . . . . . . . . . . . 1.3.3. Máquinas de vectores soporte . . . . . . . . . . . . . 1.3.4. KNN . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3.5. Procesos Gaussianos . . . . . . . . . . . . . . . . . . 1.3.6. Las Redes Neuronales Artificiales(RNAs) . . . . . .. VII. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . . . . . . . . . . .. . . . . . . . .. 1 2 5 6 6 6 7 7 7. . . . . . . . . . . . . . . . . .. 8 9 10 11 11 11 12 12 13 13 13 14 15 15 15 16 17 17.
(8) ÍNDICE GENERAL 2. Construcción de los modelos predictivos 2.1. Preprocesamiento de los datos . . . . . . . . . . . . . 2.1.1. Normalizar . . . . . . . . . . . . . . . . . . . 2.1.2. Discretizar . . . . . . . . . . . . . . . . . . . 2.1.3. Fusificar . . . . . . . . . . . . . . . . . . . . 2.2. Selección del Modelo . . . . . . . . . . . . . . . . . . 2.2.1. Características Principales de las RNAs . . . . 2.2.2. Multilayer Perceptron (MLP). . . . . . . . . . 2.3. Requisitos Funcionales . . . . . . . . . . . . . . . . . 2.3.1. Metodología de Verificación de los Resultados 2.3.2. Java . . . . . . . . . . . . . . . . . . . . . . . 2.3.3. Geotools . . . . . . . . . . . . . . . . . . . . 2.3.4. Weka . . . . . . . . . . . . . . . . . . . . . .. VIII. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. . . . . . . . . . . . .. 21 22 24 26 26 26 26 28 28 28 29 30 30. 3. La aplicación PronMLP v1.0 3.1. La aplicación PronMLP v1.0 . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.1. Diseño de la aplicación PronMLP . . . . . . . . . . . . . . . . . . . . 3.1.2. Interfaz gráfica de usuario . . . . . . . . . . . . . . . . . . . . . . . . 3.1.3. Realizar un pronóstico . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2. Análisis Experimental . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2.1. Validación de los Clasificadores . . . . . . . . . . . . . . . . . . . . . 3.3. Comparación de los resultados de los modelos de PronMLP con los del modelo MOS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 37 37 37 42 43 48 48. Conclusiones. 57. Recomendaciones. 58. Anexo 1. 62. 51.
(9) Introducción El pronóstico del tiempo constituye un tema de gran importancia que se ha convertido en un problema desafiante, debido a su valor práctico en la meteorología, las comunicaciones, la aviación, las series de consumo eléctrico, agricultura, la protección de vidas humanas y de recursos de vital importancia para la economía de los países, etc. Por tanto la modelación de variables y su posterior utilización en la predicción de este, es una herramienta de gran importancia. La temperatura constituye una de las variables ambientales más importantes para los seres vivos y la que mayor influencia ejerce en casi todos los factores de la vida del hombre, los animales y las plantas en el planeta. De las temperaturas depende en gran medida el estado de confort en que nos desenvolvemos día a día, a la vez que tienen una influencia marcada en el comportamiento de la humedad relativa. Estas dos variables en su conjunto son determinantes en el desarrollo de disímiles cultivos, a la vez que definen la aparición, o no, de numerosas plagas y enfermedades que frecuentemente atacan a las plantas [1, 2]. Es importante la influencia de la temperatura en la salud humana, principalmente sobre aquellos pacientes que padecen enfermedades respiratorias [3]. Los factores fundamentales que modifican las temperaturas son la humedad, la nubosidad, las precipitaciones y la velocidad del viento. Las bajas temperaturas en Cuba están dadas por la presencia de masas de aire con muy baja humedad. El factor nubosidad juega un papel importante, pues la presencia de nubes bajas y medias en la bóveda celeste inhibe el enfriamiento nocturno (irradiación nocturna) , produciendo un efecto “invernadero” sobre la zona afectada por la nubosidad. El descenso de las temperaturas en el horario de la madrugada. 1.
(10) 2. depende en gran medida por la velocidad del viento. Las bajas temperaturas están estrechamente relacionadas con la velocidades bajas del viento o “calmas” [4]. Todos estos elementos alimentan los modelos de pronóstico de temperaturas y se conocen como las variables del tiempo o variables meteorológicas.. Antecedentes En el año 2008 se implantó en Cuba un modelo para el pronóstico de temperaturas mínimas desarrollado por investigadores del Centro Meteorológico de la Provincia de Villa Clara (CMPVC), basado en el modelo MOS (Model Output Statistics por sus siglas en inglés) [5], a este se le realizó algunas modificaciones en el año 2010 con el objetivo de mejorar su operatividad. Este modelo es empleado en el servicio operativo del Centro Nacional de Pronósticos y de los Grupos Provinciales como una de las herramientas para realizar los pronósticos de temperaturas para todo el país. En el año 2014 en la Universidad Marta Abreu de las Villas (UCLV) se desarrolló una aplicación de software la cual implementa técnica de AA con el fin de realizar pronósticos para las temperaturas mínimas. Los resultados alcanzados con la utilización de estas técnicas de AA, tomando como base de conocimiento, los datos registrados de las temperaturas mínimas en las 5 estaciones de la provincia de Villa Clara en las épocas de invierno y verano, fueron comparados con los alcanzados por el modelo MOS, obteniendo que las técnicas de AA podían conseguir mejores predicciones para el pronóstico de las temperaturas mínimas para el Centro Meteorológico Provincial de Villa Clara (CMPVC). El MOS es una técnica objetiva de pronóstico de tiempo que consiste en determinar una relación entre las variables exógenas y las variables endógenas mediante un modelo numérico. El método se basa en la incorporación de las salidas de los modelos hidrodinámicos de pronóstico tanto en la fase de desarrollo de las ecuaciones de regresión como en la aplicación operativa de las relaciones obtenidas [6]. Actualmente el modelo MOS emplea múltiple regresiones linea-.
(11) 3. les como un método estadístico [7] aunque se podrían utilizar otros métodos estadísticos como por ejemplo: regresión polinomial o regresión logística. En nuestro país se desarrollaron ecuaciones de pronóstico para cada estación de la red del Sistema Meteorológico Nacional y sobre esta base se construyeron los campos de las temperaturas mínimas para todo el archipiélago. La expresión (1) muestra el prototipo de la ecuación de pronóstico de temperaturas mínimas y el parámetro “R” mostrado en la expresión (2) alcanzado a partir del proceso de regresión para el período poco lluvioso, obtenidas para la estación meteorológica 78314, de la provincia de Pinar del Río.. T n = −5,518+0,401∗NGFS +1,087∗T nGFS +0,17∗UGFS −0,041∗VGFS (1). R = 0,892. (2). T n: Temperatura mínima a pronosticar. NGFS : Nubosidad pronosticada por el GFS(Global Forecast System), correspondientes al día para el que se elabora el pronóstico. T nGFS : Temperatura mínima para los períodos 09 – 15, correspondiente al día para el que se elabora el pronóstico. UGFS : Componente zonal del viento pronosticada por el GFS, correspondiente al día para el que se elabora el pronóstico. VGFS : Componente meridional del viento pronosticada por el GFS correspondientes al día para el que se elabora el pronóstico. El trabajo con los componentes zonales y meridionales del viento permiten tomar en consideración no solo la fuerza del viento, sino también su dirección. El MOS es matemáticamente simple y demuestra tener gran poder pero presenta algunas limitantes:.
(12) 4. El MOS no permite corregir un pronóstico malo. La precisión para pronósticos a largo plazo y plazos extendidos. A veces los efectos de pronósticos para los terrenos locales son un problema para el MOS. El MOS puede resultar incorrecto si las condiciones son altamente irregulares. Sin embargo, las relaciones estadísticas entre las salidas de los modelos hidrodinámicos y las variables medidas en la red de estaciones en Cuba, se buscó de manera lineal, con ayuda del método definido anteriormente. Precisamente, conociendo que la relación entre las variables que influyen en el comportamiento de las temperaturas mínimas, es complejo y no es lineal, los modelos hidrodinámicos sufren cambios continuamente que influyen en la calidad de los pronósticos realizados con las ecuaciones de regresión construidas previamente, presentando esto como una desventaja del modelo existente [6]. Esto implica que, aunque los modelos estadísticos y los modelos numéricos de pronóstico existentes han sustituido los engorrosos e inexactos cálculos manuales de antaño, todavía la precisión de sus resultados está mediada. Continuar perfeccionando los resultados obtenidos mediante los modelos estadísticos y los modelos numéricos de pronóstico es un reto para la comunidad científica actual. El campo de AA ha abierto un camino a las investigaciones de los sistemas complejos por la importancia de la precisión en el aspecto predictivo. Las técnicas de este campo sirven entonces como herramienta alternativa para dar solución a los problemas de predicción. Pues si bien el pronóstico de temperaturas mínimas es una tarea difícil, se piensa que un enfoque basado en aprendizaje automatizado, sería capaz de inferir un modelo útil y aplicable en los Centros Meteorológico de Cuba (CMC), de manera tal que complemente los modelos existentes y aumentar el nivel de acierto en los pronósticos de las temperatura mínimas..
(13) 5. Dentro de las técnicas de AA que permiten hacer análisis de regresión se encuentran las Redes Neuronales Artificiales. El concepto de las RNAs se originó cuando se propuso desarrollar un modelo matemático capaz de reconocer patrones complejos de la misma forma que las neuronas biológicas [8]. Estas han mostrado ser eficientes en investigaciones relacionadas con la predicción con variables de tipo ambiental, contaminantes ambientales, entre otros. Ejemplo de estas investigaciones estan reflejadas en los aticulos siguientes: “Modeling minimum temperature using adaptive neuro-fuzzy inference system based on spectral analysis of climate indices: A case study in Iran”, “Temperature Forcasting Based on Neural Network Approach”, “An EfficientWeather Forecasting System using Artificial Neural Network”, “Intelligent Weather Monitoring Systems Using Connectionist Models”, “”, “”, “”, “”. Las RNAs no requieren de conocimiento a priori del sistema bajo consideración y son muy apropiadas en la modelación de sistemas dinámicos en tiempo real. Por tanto, es posible montar un sistema de tal forma que estas puedan adaptarse a los eventos observados, por esto, son útiles en el análisis real. En los últimos años, este tipo de modelado probabilístico ha ganado gran aceptación.. Planteamiento del Problema Con el fin de dar solución al problema del pronóstico de las temperaturas mínimas se han desarrollado múltiples métodos estadístico, un ejemplo de estos es el MOS, utilizado en los centros de meteorología del país. La búsqueda de manera lineal de las relaciones estadísticas entre las salidas de los modelos hidrodinámicos y las variables medidas en la red de estaciones del país utilizando el modelo MOS se dificulta las tareas de pronóstico meteorológico a corto y mediano plazo debido a que los fenómenos meteorológicos son bien conocidos por tener comportamientos de tipo no lineal. El modelo convencional existente tiende a carecer de precisión para el pronóstico de temperaturas mínimas, al no poder considerar las características de las relaciones complejas entre variables..
(14) 6. En diferentes partes del mundo algunos investigadores han empleado RNAs para dar solución al problema del pronóstico de temperaturas. Sin embargo en Cuba, en esta área, no se han implantado estas aplicaciones operativas que ayudan a los servicios de pronósticos meteorológicos en la construcción de métodos más precisos y con mayor cobertura que los empleados actualmente. Por lo que resulta interesante el empleo de RNAs, técnica novedosa en la predicción de las temperaturas mínimas, en las Estaciones Meteorológicas de Cuba (EMC), ya que han demostrado tener una buena capacidad predictiva en problemas de clasificación y regresión.. Objetivo General Desarrollar una aplicación informática para el pronóstico de las temperaturas mínimas para 68 estaciones meteorológicas de Cuba utilizando Redes Neuronales Artificiales.. Objetivos Específicos 1. Realizar un diseño experimental que permita obtener una propuesta de mo-. delo, para pronosticar las temperaturas mínimas en las 68 estaciones meteorológicas cubanas. 2. Desarrollar una aplicación de software que permita realizar el pronósti-. co de las temperaturas mínimas en cada estación meteorológica según el modelo de RNA seleccionado en el estudio experimental.. Preguntas de Investigación 1. ¿Qué modelo de RNA utilizar, de modo que garantice un balance adecuado. entre eficiencia y eficacia en el pronóstico de corto y mediano plazo de temperaturas mínimas para las EMC?.
(15) 7 2. ¿Los modelos propuestos según los resultados del análisis experimental. garantizan la predicción de las temperaturas mínimas para todas las estaciones?. Hipótesis El desarrollo de pronósticos mediante técnicas de AA puede incrementar el grado de adaptación de los mismos frente a los cambios en la atmósfera.. Tareas de Investigación 1. Estudiar las técnicas de AA incorporadas al WEKA que permiten realizar. análisis de regresión. 2. Realizar un estudio de los parámetros del modelo RNAs para pronósticos. de temperaturas mínimas en las EMC. 3. Diseñar e implementar una aplicación utilizando paquetes del WEKA para. el pronóstico de las temperaturas mínimas de las EMC.. Justificación de la Investigación Las RNAs han sido aplicadas satisfactoriamente para resolver problemas tanto de clasificación como de regresión; no obstante, en las EMC no se han empleado estas técnicas para resolver problemas de pronóstico de las temperaturas mínimas. El aporte al campo de la Meteorología consiste en introducir esta técnica como un marco potencialmente competitivo para pronosticar las temperaturas en las EMC. Así, se ha considerado trascendente emplear el enfoque de las RNAs para resolver el problema de pronóstico de temperaturas mínimas en las EMC..
(16) Capítulo 1 Fundamentos Teóricos El estudio dotará a los meteorólogos en las EMC de otra alternativa para el pronóstico de temperaturas mínimas. No se intenta sustituir con este enfoque computacional lo que con otros medios está probado con calidad, sino el de aprovechar las características del mismo para fortalecer el proceso de pronóstico de temperaturas mínimas. Se trata de complementar a los modelos existentes para lograr obtener los resultados más óptimos posibles. En este capítulo se presentan algunos conceptos de la teoría del aprendizaje automatizado.. Aprendizaje Automatizado La capacidad de aprender se considera como una de los atributos distintivos del ser humano y ha sido una de las principales áreas de investigación de la Inteligencia Artificial desde sus inicios. En los últimos años se ha visto un crecimiento acelerado en la capacidad de generación y almacenamiento de información, debido a la creciente automatización de procesos y los avances en las capacidades de almacenamiento de información. Debido a esto, se han desarrollado una gran cantidad de herramientas y técnicas relacionadas con el análisis de información. El desarrollo en el área de AA ha sido primordial para esto. El AA es el área de la Inteligencia Artificial que se ocupa de desarrollar técnicas capaces de aprender, es decir, extraer de forma automatizada conocimiento subyacente en la información. Constituye, junto con la estadística, el corazón 8.
(17) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 9. del análisis inteligente de los datos [9]. El principio seguido en el AA es que se genera un modelo a partir de ejemplos y lo usa para resolver algún nuevo problema que se le presente. Una de las categorías del aprendizaje más estudiado es el aprendizaje inductivo, que engloban técnicas que aplican inferencias inductivas sobre un conjunto de datos para adquirir conocimiento inherente a ellos. Concretando, se acostumbra crear programas capaces de generalizar comportamientos a partir de información no estructurada suministrada en forma de ejemplos. Por lo que es un proceso de inducción del conocimiento. En muchas ocasiones el campo de actuación del mismo se solapa con el de la estadística, ya que las dos disciplinas se basan en el análisis de datos. Sin embargo, el AA se centra más en el estudio de la complejidad computacional de los problemas. Muchos problemas son de clase NP-hard, por lo que gran parte de la investigación realizada en esta rama se enfoca al diseño de soluciones factibles a esos problemas. El AA tiene una amplia gama de aplicaciones, incluyendo motores de búsqueda, diagnósticos médicos, detección de fraude en el uso de tarjetas de crédito, análisis del mercado de valores, clasificación de secuencias de ADN, reconocimiento de patrones tanto de voz como de lenguaje escrito, juegos y robótica. Algunos sistemas de este tipo intentan eliminar toda necesidad de intuición o conocimiento experto de los procesos de análisis de datos, mientras otros tratan de establecer un marco de colaboración entre el experto y la computadora. De todas formas, la intuición humana no puede ser reemplazada en su totalidad, ya que el diseñador del sistema ha de especificar la forma de representación de los datos, los métodos de manipulación y caracterización de los mismos.. 1.1.. Clasificación del aprendizaje según los datos. El aprendizaje es un proceso por el cual el sistema modifica sus pesos en respuesta a una información de entrada, es decir, es el proceso que produce el ajuste de los parámetros libres del modelo a partir de un proceso de estimulación por el.
(18) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 10. entorno que rodea ese sistema. El aprendizaje es de particular interés, pues para que la red resulte operativa es necesario entrenarla para que sea capaz de realizar un determinado tipo de procesamiento o cómputo aprendiéndolo a partir de un conjunto de patrones de ejemplos, lo que constituye el modo aprendizaje. 1.1.1.. Aprendizaje supervisado. El aprendizaje supervisado es una técnica para deducir una función a partir de datos de entrenamiento. El objetivo del aprendizaje supervisado es el de crear una función capaz de predecir el valor correspondiente a cualquier objeto de entrada válida, después de haber visto una serie de ejemplos. Los datos de entrenamiento consisten en pares de objetos (normalmente vectores): un componente del par son los datos de entrada, y el otro, los resultados deseados. Para este tipo de aprendizaje se distinguen perfectamente rasgos predictores o rasgos de entrada y los rasgos objetivos o de salida, respondiendo estos a una etiqueta. La salida de la función puede ser un valor numérico (como en los problemas de regresión) o una etiqueta de clase (como en los de clasificación). Para ello, tiene que generalizar a partir de los datos presentados a las situaciones no vistas previamente. Este tipo de entrenamiento necesita un conjunto de datos de entrada previamente clasificado o cuya respuesta objetivo se conoce a modo de que el sistema tenga los objetivos como punto de referencia para evaluar su desempeño en base a la diferencia de estos valores y modificar los parámetros libres, en base a esta diferencia. La tarea entonces es estimar una cierta función multivariable desconocida a partir de muestras tomadas aleatoriamente, por medio de la minimización iterativa de una función que representa el error esperado de la operación del sistema mediante alguna forma de aproximación. De esta forma se dice que el aprendizaje es supervisado ya que el proceso de aprendizaje se realiza mediante un entrenamiento controlado por un agente externo (supervisor, maestro) que determina la respuesta que debería generar el sistema a partir de una entrada determinada. El supervisor controla la salida del sistema y en caso de que ésta no coincida con la deseada, se procederá.
(19) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 11. a modificar los parámetros, con el fin de conseguir que la salida obtenida se aproxime a la deseada. 1.1.2.. Aprendizaje no supervisado. Es un método de AA donde un modelo es ajustado a las observaciones. Los sistemas con aprendizaje no supervisado no requieren influencia externa para ajustar los parámetros, es decir, no hay un conocimiento a priori. Todo el proceso de modelado se lleva a cabo sobre un conjunto de ejemplos formado tan sólo por entradas al sistema. No se tiene información sobre las categorías de esos ejemplos, o sea la base de conocimiento del sistema está formada por ejemplos no etiquetados. Por lo tanto, en este caso, el sistema tiene que ser capaz de reconocer patrones para poder etiquetar las nuevas entradas. Una forma de aprendizaje no supervisado es la agrupación o clustering. 1.1.3.. Aprendizaje semisupervisado. Este tipo de aprendizaje es la combinación de los dos métodos de aprendizaje anteriores con el objetivo de clasificar de una forma adecuada, teniendo en cuenta tanto los datos etiquetados como los no lo estan. 1.1.4.. Aprendizaje por refuerzo. Se trata de un aprendizaje supervisado que se basa en la idea de no disponer de un ejemplo completo del comportamiento deseado, es decir, no se suministra explícitamente la salida deseada ante una determinada entrada. En este aprendizaje no se conoce la repuesta adecuada que debería presentar el sistema, pero dispone de algún mecanismo que indica si la repuesta es buena o no. El algoritmo aprende observando el mundo que le rodea. Su información de entrada es de feedback o retroalimentación que obtiene del mundo exterior como respuesta a sus acciones. Por lo tanto, el sistema aprende a base de ensayo-error..
(20) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 1.2.. 12. Clasificación del aprendizaje según el conocimiento que genera. El problema del aprendizaje se ha enfrentado desde diferentes perspectivas: el enfoque simbólico, el conexionista y el evolutivo. El enfoque simbólico puede ser inductivo o perezoso. El enfoque conexionista está orientado al aprendizaje cuando se resuelven problemas usando RNAs. El enfoque evolutivo cuando se emplean los algoritmos genéticos. El AA, como hemos visto, permite resolver problemas mediante el empleo del conocimiento obtenido de problemas resueltos en el pasado, similares al actual. La diferencia fundamental entre estas técnicas radica en la forma en que se almacena el conocimiento. Así, en las RNAs, el conocimiento se traduce en una serie de pesos y umbrales que poseen las neuronas. En cambio, en el aprendizaje inductivo, el conocimiento se transforma en un árbol de decisión o un conjunto de reglas. 1.2.1.. El aprendizaje inductivo. El aprendizaje inductivo se usa para adquirir conocimiento (formulado en forma de descripciones intencionales) a partir de ejemplos. El objetivo de la inducción es formular afirmaciones que explican los hechos dados y se pueden aplicar a hechos no vistos con anterioridad. Estas afirmaciones pueden expresarse como patrones, y estos patrones se representan por vectores, ecuaciones, árboles, reglas o enunciados lógicos. Muchos problemas de inducción se pueden describir como sigue. Se parte de un conjunto de entrenamiento de ejemplos preclasificados, donde cada ejemplo (también llamado observación o caso) se describe por un vector de valores para rasgos o atributos, y el objetivo es formar una descripción que pueda ser usada para clasificar ejemplos previamente no vistos con alta precisión [10]..
(21) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 1.2.2.. 13. Aprendizaje perezoso. En el aprendizaje perezoso, al igual que en el aprendizaje inductivo, se aprende a partir de ejemplos, pero a diferencia de este: Se usa descripción extensional, sin generar descripciones intencionales. El proceso de aprendizaje y el proceso de usar el conocimiento aprendido para resolver nuevos problemas no se separan. El paso de generalización se retrasa para la fase de solución de problemas. Cuando se resuelve un nuevo problema P, la solución de un problema viejo se transfiere (quizás transformada) a P. Hay una generalización implícita entre el viejo y el nuevo problema. Un método clásico de aprendizaje perezoso es el algoritmo de los k-vecinos más cercanos(k-NN). Métodos de aprendizaje perezoso bien conocidos son: el aprendizaje basado en instancias, el razonamiento analógico, y el razonamiento basado en casos. 1.2.3.. Aprendizaje basado en instancias. La esencia del aprendizaje basado en instancias es retornar como solución a un problema la solución conocida a un problema similar. Los algoritmos de aprendizaje basado en instancias se basan en ejemplos modelos; cada concepto se representa por un conjunto de ejemplos, cada ejemplo puede ser una abstracción del concepto o una instancia individual del concepto. Una extensión del aprendizaje basado en instancias consiste en usar los k casos más parecidos en lugar del más cercano, lo cual es apropiado cuando los ejemplos se describen mediante datos mezclados, no sólo mediante rasgos con dominio real. 1.2.4.. Modelos conexionistas. Busca descripciones generales mediante el uso de la capacidad de adaptación de redes de neuronas artificiales. La red neuronal explora muchas hipótesis simultáneamente usando redes masivamente paralelas compuestas de muchos.
(22) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 14. elementos de procesamiento conectados por enlaces con pesos. Los modelos de redes neuronales son especificados por la topología de la red (estructura y tipo de enlace), las características de los nodos (modelo de la neurona) y las reglas de aprendizaje (método de ajustar los pesos).. 1.3.. Predicción numérica o regresión. La predicción numérica o regresión consiste en dado un conjunto de variables predictoras o atributos, predecir el valor numérico para una variable objetivo a partir de los valores predictores conocidos. No existe un modelo de regresión mejor que otro de manera general; para cada problema nuevo es necesario determinar con cuál se pueden obtener mejores resultados, y es por esto que han surgido varias medidas para evaluar la calidad de los modelos de regresión y comparar los modelos empleados para un problema determinado[10]. Con el objetivo de validar la efectividad de un modelo de regresión y dar una idea de cuan efectivo es el mismo en la solución de un problema determinado al que se quiere aplicar, han surgido varias medidas para evaluar y comparar los modelos empleados para dicho problema. Métodos para dar solución al problema de regresión Diferentes métodos se han empleado para dar solución al problema de regresión entre los cuales aparecen métodos estadísticos como: regresión lineal, árboles de regresión, las máquinas de vectores soporte (Support Vector Machines,SVM), Procesos Gaussianos, métodos basados en modelos de RNAs como MLP, LVQ, etc. y métodos basados en instancias como k-NN. A lo largo del trabajo se denomina clasificador a cualquier modelo con capacidad de predecir un valor numérico (regresión). Por tanto se usarán los dos términos con el mismo significado..
(23) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 1.3.1.. 15. Regresión lineal. En estadística la regresión lineal o ajuste lineal es un método matemático que modela la relación entre una variable dependiente Y , las variables independientes Xi y un término aleatorioe. 1.3.2.. Árboles de regresión. Es un árbol de decisión cuyas hojas predicen una cantidad numérica, ese valor numérico se calcula como la media del valor para la variable clase de todos los ejemplos que han llegado a esa hoja durante el proceso de construcción del árbol. La evaluación de un nuevo ejemplo es idéntico a los árboles de decisión, durante el proceso de predicción es posible utilizar un suavizado de los valores del ejemplo a tratar, con el fin de salvar las posibles discontinuidades presentes en los datos. El criterio de selección de una variable en la construcción del árbol está basado en una reducción del error esperado: reducción de la desviación o varianza en la variable objetivo. En un final el árbol se poda para evitar el sobreajuste. 1.3.3.. Máquinas de vectores soporte. Las máquinas de vectores soporte son un conjunto de algoritmos de aprendizaje supervisado desarrollados en los últimos años, partiendo de la teoría de aprendizaje estadístico y basada en el principio de minimización de riesgo estructural. Concretamente, fundamenta las decisiones de predicción o clasificación, no basadas en todo el conjunto de datos sino en un número finito y reducido de casos, que constituyen los “vectores soporte”. Se ha usado tanto para clasificación (aprendizaje supervisado con función objetivo discreta), como para regresión (aprendizaje supervisado con función objetivo continua) [11]. Dado un conjunto de ejemplos de entrenamiento (de muestras) podemos etiquetar las clases y entrenar una SVM para construir un modelo que prediga el rasgo objetivo de una nueva muestra. Intuitivamente, un SVM es un modelo que representa a los puntos de muestra en el espacio, separando las clases por.
(24) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 16. un espacio lo más amplio posible. Cuando las nuevas muestras se ponen en correspondencia con dicho aproximador, en función de su proximidad puede ser predicho un valor objetivo. 1.3.4.. KNN. La esencia del aprendizaje basado en instancias es retornar como solución a un problema la solución conocida a un problema similar. La regla de clasificación o predicción por vecindad más general es la regla de los k vecinos más cercanos o simplemente k-NN. Se basa en la suposición de que los prototipos más cercanos tienen una probabilidad a posteriori similar. El método básicamente consiste en comparar la nueva instancia a predecir con los datos o casos existentes del problema en cuestión, recuperando los k casos más cercanos, lo cual depende del parecido entre los atributos del nuevo caso con los casos de la muestra de aprendizaje o entrenamiento. Como resultado del mismo se devuelve la clase mayoritaria de aquellos k casos más cercanos a él. Para realizar esta tarea este clasificador puede utilizar tanto distancias como funciones de semejanza. Obviamente, si se calculan distancias se seleccionaran los k ejemplos de menor distancia al problema, mientras que si se usan funciones de semejanza se seleccionaran los k ejemplos más similares. Funciones: 1. Distancia Euclidiana. q E (x, y) = ∑ (xa − ya )2 2. Distancia de Chebychev. Ch (x, y) = máx |xa − ya | 3. Distancia de Manhattan. M (x, y) = ∑ |xa − ya |.
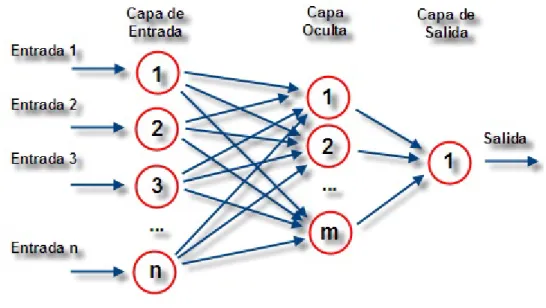
(25) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 1.3.5.. 17. Procesos Gaussianos. Los Procesos Gaussianos (PG) son una generalización de distribuciones de densidad multivariadas Gaussianas a conjuntos de funciones infinitas continuas y se han utilizado para tareas de inferencia de datos al menos durante los últimos cien años. Los PG mantienen estrecha conexión con las RNAs siempre y cuando ambos se estudien desde una perspectiva Bayesiana. Sin embargo, en contraste con las RNAs, los PG tienen la ventaja de modelar de forma flexible y sin la limitación de tener que adaptar un gran número de parámetros, algo que comúnmente restringió la aplicación de RNAs en muchos problemas [12]. La clave a la hora de realizar con éxito un PG, es la selección del kernel adecuado. Los PG nos proporcionan una aproximación probabilística para problemas de regresión con kernels. El modelo PG establece una relación entre los datos de entrada y la variable de salida, de la siguiente forma: y = f (x) = ∑ αi K(Xi , X) + α0 Es posible manejar directamente la incertidumbre con respecto a los valores de la función en los puntos que nos interesan, lo que representa la perspectiva del espacio funcional (o PG) del problema. El punto clave de por qué se dejó de usar el enfoque basado en parámetros para modelar datos es que las proyecciones también se pueden manejar como variables aleatorias. 1.3.6.. Las Redes Neuronales Artificiales(RNAs). Las RNAs imitan la estructura hardware del sistema nervioso, con la intención de construir sistemas de procesamiento de la información paralelos, distribuidos y adaptativos, que puedan presentar un cierto comportamiento "inteligente" [12]. Estas son herramientas matemáticas para la modelación de problemas, que permiten obtener las relaciones funcionales subyacentes entre los datos involucrados en problemas de clasificación, reconocimiento de patrones, regresiones,.
(26) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 18. etc. Son consideradas excelentes aproximadores de funciones esencialmente no lineales, siendo capaces de aprender las características relevantes de un conjunto de datos, para luego reproducirlas en entornos ruidosos o incompletos. Usualmente las RNAs reciben la información proveniente del exterior mediante un conjunto de neuronas de entrada y cuentan con un conjunto distinto, llamado neuronas de salida, para ofrecer los resultados. El resto de las neuronas se organizan en capas ocultas ver la Figura (1.1). Se concibe el cálculo general de la red a partir de la información que es procesada por cada una de sus neuronas en forma independiente. Cada una de ellas puede recibir información de las restantes y calcular su propia salida a partir de dicha entrada y de su estado actual, transitando eventualmente hacia un nuevo estado .. Figura 1.1: Representación gráfica de una RNA.. Por lo general, el flujo de cálculo de la red avanza progresivamente desde las neuronas de entrada hacia las neuronas de salida, en un proceso en el que cada una de las neuronas ocultas va activándose progresivamente según el esquema de conexión particular de cada red [12, 13]. El aprendizaje de los pesos se adapta en función del error cometido, y por tanto es suficiente con medir de forma adecuada el error. Una RNA se caracteriza por el modelo de la neurona, el esquema de conexión que presentan sus neuronas, o sea su topología, y el algoritmo de aprendizaje.
(27) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 19. empleado para adaptar su función de cómputo a las necesidades del problema particular. Se ha producido una amplia variedad y clasificación de topologías de RNAs, que pueden agruparse en dos grandes grupos: las redes multicapa de alimentación hacia delante (Feed-Forward Neuronal Networks, FFN) y las redes neuronales recurrentes (Recurrent Neuronal Networks, RNN)[12, 13]. Los algoritmos de entrenamiento constituyen métodos que se aplican sobre los modelos de red para ajustar sus pesos y obtener un comportamiento determinado. Con frecuencia los algoritmos de entrenamiento son caracterizados por la clase de topologías sobre las que se aplica, los tipos de parámetros libres que afecta (pesos de las conexiones entre neuronas, parámetros del algoritmo de entrenamiento, la topología misma de la red, etc.) y la regla de modificación de los mismos. Existe una amplia variedad de algoritmos de entrenamiento disponibles, y generalmente se clasifican en supervisados o no supervisados. El algoritmo de propagación del error hacia atrás (Backpropagation, BP), es el de más amplio uso, aplicado a redes con conexiones hacia adelante. Este algoritmo aplica la técnica gradiente descendente para la minimización del error de funcionamiento de la red [12, 13]. El perceptrón multicapa (MultiLayer Perceptron, MLP) es una RNAs formada por múltiples capas, la cual tiene al menos una capa oculta con suficientes unidades no lineales que le permite aproximar cualquier tipo de función o relación continua entre un grupo de variables de entrada y salida, lo cual es la principal limitación del perceptrón simple. Esta propiedad convierte a las redes MLP en herramientas de propósito general, flexibles y no lineales [12, 13, 14]. Las redes MLP han sido aplicadas satisfactoriamente para solucionar alguna dificultad y diversos problemas entrenándolos de una manera supervisada con el algoritmo conocido como algoritmo del error de la propagación hacia atrás. Este algoritmo se basa en la regla de aprendizaje por corrección de error. De esta manera, la red tiene la capacidad de generalización: facilidad de proporcionar salidas satisfactorias a entradas que el sistema no ha visto nunca en su fase de entrenamiento..
(28) CAPÍTULO 1. FUNDAMENTOS TEÓRICOS. 20. Se han desarrollado RNAs que son utilizadas en meteorología para resolver problemas de predicción y clasificación [15, 16], representando una técnica de modelización matemática que intenta imitar el proceso de aprendizaje que ocurre en el sistema nervioso.. Conclusión parcial del capítulo En este capítulo se ha mostrado de manera breve una introducción al AA, los tipos de aprendizaje y se ha caracterizado como se resuelve un problema de regresión para lo que se describen algunos métodos de AA: las SVM, el método de los k-NN, los PG y las RNAs. De estos métodos se hará uso de las RNAs en el estudio experimental que se desarrolla en el segundo capítulo con el fin de proponer modelos predictivos para las distintas EMC. Las RNAs tienen una amplia gama de aplicaciones, entre las que se encuentran los problemas de regresión. En regresión o la predicción numérica se tienen variables predictoras y un rasgo objetivo que en este caso es continuo..
(29) Capítulo 2 Construcción de los modelos predictivos para el pronóstico de las temperaturas mínimas En este capítulo se muestra como se crean los modelos de clasificación o regresión realizando un análisis del problema al que nos enfrentamos. Se describen algunos procedimientos a realizar en esta investigación con el objetivo de que los modelos sean más confiables, teniendo estos un alto grado precisión y se muestran las herramientas que se utilizaron para el desarrollo de este trabajo.. Introducción al problema del pronóstico de temperaturas mínimas La problemática sería: dado un conjunto de variables ambientales de una estación, predecir la temperatura mínima en dicha estación. Para este problema los meteorólogos consideran las variables ambientales que se enumeran en la Tabla(2.1); las cuales constituyen un conjunto de datos históricos de las temperaturas mínimas comprendidas entre 2009 y 2011. Esta información fue obtenida del CMPVC. Cuatro de ellas son consideradas como atributos predictores del problema y poseen valores continuos. En total son 4 atributos predictores y un atributo objetivo.. 21.
(30) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. Atributo Día. Interpretación El día para el que se elabora el pronóstico Mes El mes para el que se elabora el pronóstico Año El año para el que se elabora el pronóstico Pron_Nub Nubosidad pronosticada por el GFS U_Viento Componente zonal del viento pronosticada por el GFS V_Viento Componente meridional del viento pronosticada por el GFS Pro_Tn Temperaturas mínima pronosticada por el GFS Tn_Real Temperaturas mínima real. 22. Tipo Numérico Numérico Numérico Numérico Numérico Numérico Numérico Numérico. Cuadro 2.1: Atributos de la base de casos para el pronóstico de las temperaturas mínimas. La tabla muestra el día, mes, año, la nubosidad, componente zonal del viento, componente meridional del viento y la temperatura mínima pronosticadas por el GFS. La última variable corresponde a la variable objetivo o la temperatura mínima a pronosticar. El dominio del rasgo objetivo se considera numérico. En este caso los valores que toman los rasgos son números de un universo finito. Por tanto se trata de un problema de regresión ya que el atributo clase es de tipo numérico [10]. El monitoreo de temperaturas mínimas se hace a lo largo del año pero se divide en dos etapas, verano e invierno. Cuando se quiere buscar solución para problemas de clasificación o regresión se deben de identificar y entender la naturaleza de problema.. 2.1.. Preprocesamiento de los datos. A pesar de que un conjunto de datos haya sido adecuadamente preparado es probable que en él aún permanezcan problemas que pueden influir de manera determinante en los algoritmos de minería de datos. Por ello es importante determinar y, en su caso, aplicar los métodos de preprocesamiento y transformación.
(31) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 23. [17, 18] adecuados a fin de mejorar el rendimiento obtenido en las fases posteriores. La Figura (2.1) representa esquemáticamente distintos tipos de tareas de preprocesamiento.. Figura 2.1: Taxonomía de tareas de preprocesamiento. Con este tipo de técnicas es posible abordar tareas como la reducción de la dimensionalidad en el espacio de entrada mediante la selección de características, el tratamiento de variables correlacionadas mediante la creación de características, la discretización de valores en las variables, la reducción del número de instancias en conjuntos de datos muy grandes a través de la selección de instancias, el reequilibrio en la distribución de clases mediante técnicas de remuestreo, etc. A continuación se detallan las técnicas de transformación que se utilizan en este trabajo..
(32) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 24. Cuando se opera con información cuantitativa es habitual aplicar ciertas transformaciones a los datos de entrada a fin de mejorar el comportamiento posterior de los algoritmos de minería de datos. Entre estas transformaciones las tres más usuales son: la normalización: consistente en llevar los valores de distintos atributos a una escala común. la discretización: cuya finalidad es convertir datos cuantitativos en cualitativos [19]. Fusificar: tiene como objetivo convertir valores crisp o valores reales en valores difusos. En la fusificación se asignan grados de pertenencia a cada una de las variables de entrada con relación a los conjuntos difusos previamante definidos utilizando las funciones de pertenencias asociadas a los conjuntos difusos. Si bien las tres mencionadas son las más habituales, también caben en esta categoría otras técnicas como la agregación de datos o la construcción de nuevos atributos a partir de los existentes. La transformación de los datos puede ser también necesaria en casos en los que no es posible determinar algoritmos de minería de datos apropiados para su estructura original o, a pesar de sí hallarlos, es más eficiente o se obtiene mejor rendimiento tras aplicar a los datos una conversión determinada. A continuación se detallan cada una de estas técnicas: 2.1.1.. Normalizar. La normalización de los datos o como también es conocido normalización de rango consiste en transformar los valores de las variables dentro de un rango especificado, como por ejemplo de -1 a 1. La normalización se realiza con el objetivo de acelerar el aprendizaje y para evitar problemas numéricos tales como pérdida de precisión y desbordamiento aritmético..
(33) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 25. En el presente trabajo se normalizaron los datos en un rango de 0 a 1 haciendo uso de la expresión 2.1, para una vez normalizados sean utilizados en el entrenamiento de los modelos seleccionados.. Xn =. Xi − Xmean σ. (2.1). Dónde: Xn: Simboliza el valor de la variable a normalizar. Xmean: Denota el valor de la media. Xi: Representa el valor que se desea normalizar. σ : Simboliza la desviación estándar. Después de realizar el análisis con los datos normalizados se hizo necesario transformar el valor obtenido a su escala original, para esto se utilizó la expresión 2.2. Xdn = eXn. (2.2). Dónde: Xdn: Representa el valor de la variable a transformar a su escala original. Xn: Simboliza el valor normalizado. e: Denota la constante de “Euler”. Una vez terminada la experimentación, se decidió implementar esta transformación en la aplicación, de tal manera que para cada entrada de datos, que se le introduzca a esta la aplicación le realice esta transformación por haber ofrecido resultados verdaderamente prometedores..
(34) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 2.1.2.. 26. Discretizar. Es el proceso mediante el cual los valores se incluyen en depósitos para que haya un número limitado de estados posibles. Los depósitos se tratan como si fueran valores ordenados y discretos. En este trabajo se realizó un experimento donde se discretizaron un conjunto de los datos haciendo uso de un filtro llamado Discretize implementado en Weka. Este experimento no ofreció resultados determinantes para la investigación por lo que se decidió no hacer uso de este. 2.1.3.. Fusificar. Es un proceso de traducción, para obtener la representación difusa a partir de los valores actuales o crisp (por ejemplo temperatura), para lo cual utiliza las funciones de pertenencia[5]. En este proceso se hace uso de lenguaje natural ya que ofrece gran simplicidad a la hora de configurarlo y se obtienen resultados con gran precisión. Para el análisis de estos datos se realiza una evaluación de reglas o inferencia difusa, esta es la manera de producir respuestas numéricas difusas a partir de reglas lingüísticas aplicadas a los valores difusos de entrada. A partir de la información difusa que produce la evaluación de reglas, se inicia un proceso de traducción que permite obtener valores numéricos representativos, al cual se le denomina Defusificación.. 2.2.. Selección del Modelo. Las RNAs son capaces de aprender de la experiencia, generalizan de casos anteriores a un nuevos casos y son capaces de abstraer características esenciales a partir de entradas que presentan información irrelevante. 2.2.1.. Características Principales de las RNAs. Las RNAs poseen una serie de características, como son: el procesamiento.
(35) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 27. paralelo, la memoria distribuida, el aprendizaje adaptativo y la auto organización. Las cuales describen su proceder y su funcionalidad. A continuación se realizará una descripción de cada una de estas características. Procesamiento Paralelo: Esta inspirado en sus orígenes biológicos, ya que las neuronas reales trabajan en paralelo. A pesar de, si usamos un solo procesador no podrá existir dicho paralelismo, este procesamiento en paralelo esta inherente en las RNAs debido a como se estructura con un conjunto de unidades de procesamiento simples (neuronas) y sus conexiones entre las neuronas, dado por el proceder con que trabajan las mismas. Memoria Distribuida: Debido a que la información se encuentra distribuida por la sinapsis de la red (conexiones), de modo que si alguna sinapsis se daña solo se perdería una pequeña parte de la información, esto tiene como consecuencia la tolerancia a fallos, siendo capaz de continuar su funcionamiento a pesar de haber sufrido lesiones. Aprendizaje Adaptativo: Es la capacidad de aprender a realizar tareas basadas en un entrenamiento o una experiencia inicial elimina la necesidad de elaborar modelos a priori o de especificar funciones de distribución de probabilidad. Las RNAs son sistemas dinámicos auto adaptativos. Son adaptables debido a la capacidad de auto-ajustarse que tienen las neuronas y dinámicos pues son capaces de estarse adaptando constantemente a las nuevas condiciones. Auto Organización: Estas utilizan su capacidad de aprendizaje adaptativo para organizar la información que reciben durante el aprendizaje y/o la operación. Mientras el aprendizaje adaptativo es la modificación de cada elemento procesal, la auto-organización consiste en la modificación de la red neuronal completa par llevar a cabo un objetivo específico..
(36) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 28. Esta característica da lugar a la generalización: facultad de responder apropiadamente cuando se le presentan datos o situaciones a los que no habían sido expuestas anteriormente. 2.2.2.. Multilayer Perceptron (MLP).. Esta es una de las arquitecturas de RNAs más utilizadas ya que presenta gran simplicidad a la hora de ajustar los modelos. Consta de un conjunto de parámetros que son ajustables con el fin de mejorar su rendimiento y funcionalidad. Los parámetros fundamentales que se le pueden ajustar se muestran en la Tabla 2.2. Opción -L. Weka Learning Rate. -M. Momentum. -N. Training Time. -H. Hidden Layers. Significado (Tasa de aprendizaje).Se utilizada para afectar la velocidad de aprendizaje. Se utiliza dentro del cálculo de la actualización de los pesos para impulsar el cambio de estos. Tiempo de entrenamiento El número de neuronas en cada capa oculta, el orden coincide con el orden dado a las capas ocultas.. Cuadro 2.2: Principales parámetros ajustables en los MLP. 2.3.. Requisitos Funcionales. 2.3.1.. Metodología de Verificación de los Resultados. La verificación de los resultados se realizó aplicando la técnica de “comparación punto a punto” entre el pronóstico realizado y el valor real. En este caso, la verificación se realizó para cada una de las EMC con ayuda de las fórmulas 2.3 y 2.4 correspondiantes al Error Medio Absoluto (AME) y la desviación estándar (STD). Esta última puede ser interpretada como una medida de incertidumbre y nos da la precisión de las medidas de los modelos: si la media de las medidas está demasiado alejada de la predicción (con la distancia medida en desviaciones estándar) entonces consideramos que las medidas contradicen la teoría..
(37) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. AMEi =. 1 |[Pi − Ai ]| n∑ s. ST Di =. 29. (2.3). 2. ∑ (Pi − Ai ) n−1. (2.4). Donde: AMEi y ST Di : Error medio absoluto y la desviación estándar respectivamente en los puntos a comparar. Pi ,Ai : Pronóstico y Temperatura Real respectivamente en cada nodo (i, j) de la malla. Ni : Número de puntos a avaluar (coincide con la cantidad de estaciones meteorológicas de Cuba). También se evaluó la efectividad de los modelos en “ % de acierto”, tomando como umbral de precisión el valor de 2, establecido en la actualidad en la “Metodología de evaluación de los pronósticos”, del Sistema Nacional de Pronósticos del Instituto de Meteorología de Cuba [4]. 2.3.2.. Java. Java es un lenguaje de programación orientado a objetos, desarrollado por Sun Microsystems a principios de los años 90, tiene una gran herencia del lenguaje C, aunque con una gran simplificación en los aspectos de bajo nivel ya que no es necesario el tratamiento de punteros, ni de memoria[20]. Su gran versatilidad radica en que no se necesita ningún sistema operativo en concreto para que funcione, utiliza una máquina virtual que puede ser instalada en cualquier sistema operativo y dispositivo, incluyendo dispositivos móviles[20]. En el año 2006 se convierte en un lenguaje con licencia libre por lo que su utilización aumenta, así es como surgen aparte de las librerías (API) propias del código, otras que son de gran utilidad, en nuestro caso hemos utilizado el API de Weka.
(38) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 30. [21]. Esta plataforma está desarrollada en el lenguaje de programación Java. En el presente trabajo se utilizó el Java Development Kit (JDK) en su versión 1.7. 2.3.3.. Geotools. GeoTools es una librería de código abierto (LGPL ) en Java. La cual provee métodos para la manipulación representación de datos geoespaciales. Las estructuras de datos que emplea están basadas en las especificaciones de Open Geospatial Consortium (OGC). Esta librería es utilizada en numerosos proyectos que hacen uso de Servicios Web(Web Services), herramientas de líneas de comandos y aplicaciones desktop. Soporta un conjunto amplio de formatos que serán nombrados a continuación: Raster y acceso a los datos: arcsde, arcgrid, geotiff, grassraster, gtopo30, image (JPEG, TIFF, GIF, PNG), imageio-ext-gdal, imagemoasaic, imagepyramid, JP2K, matlab Conexión con bases de datos “jdbc-ng”: db2, h2, mysql, oracle, postgis, spatialite, sqlserver Vectores y acceso a los datos: app-schema, arcsde, csv, dxf, edigeo, excel, geojson, org, property, shapefile, wfs Estructuración XML: Estructuras de datos en Java y estructuras facilitadas por: xsd-core(xml), fes, filter, gml2, gml3, kml, ows, sld, wcs, wfs, wms, wps, vpf. 2.3.4.. Weka. Para el desarrollo de este trabajo se utilizará el API de Weka (proveniente de Waikato Environment for Knowledge Analysis), empleando esta plataforma en.
(39) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 31. su versión 3.7.5, es un paquete de software libre, desarrollado en la Universidad de Waikato, Nueva Zelanda. Está desarrollado en el lenguaje de programación Java y se distribuye bajo los términos de la licencia GNU (GNU is Not Unix) [21, 22]. Se ejecuta sobre cualquier plataforma y ha sido probado en los sistemas operativos Linux, Windows y Macintosh. Weka expone una extensa colección de algoritmos genéricos implementados en Java, útiles para ser aplicados mediante las interfaces que ofrece o para ser encapsulado dentro de cualquier aplicación a través de su API (Application Programming Interface en sus siglas en inglés). Weka posee una gran gama de herramientas las cuales posibilitan realizar análisis de regresión y clasificación, transformación y agrupamiento de los datos. Presenta una interfaz uniforme que permite que sus usuarios puedan comparar los resultados de aplicar diferentes métodos a un problema en cuestión y seleccionar aquellos que sean más apropiados para dicho problema. La API de Weka proporciona a los programadores un alto nivel de interoperabilidad, integración y reusabilidad de sus funcionalidades, posibilitando extenderlas, o integrarle funcionalidades ya implementadas y probadas en proyectos independientes. Weka está constituida por paquetes generales que se extienden de la raíz denominada Weka, y estos a su vez contienen subpaquetes. Los paquetes principales son los siguientes: “core”: Paquete central que contiene las clases controladoras del sistema. “gui”: Paquete con la implementación de las interfaces gráficas. “associations”: Contiene las clases que implementan los algoritmos de asociación. “filters”: Está constituido por las clases que implementan algoritmos de preprocesamiento de datos. “classifiers”: Agrupa todas las clases que implementan algoritmos de clasifi-.
(40) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 32. cación y éstas a su vez se organizan en subpaquetes de acuerdo al tipo de clasificador. “clusterers”: Contiene las clases que implementan algoritmos de agrupamiento. “experiment”: Agrupa las clases controladoras que permiten la realización de experimentos con varias bases de casos y diferentes algoritmos. “datagenerators”: Contiene clases útiles en la generación de conjuntos de datos atendiendo al tipo de algoritmo que será usado. “attributeSelection”: Contiene las clases que implementan técnicas de selección de atributos. “estimators”: Contiene las clases que realizan estimaciones (generalmente probabilísticas) sobre los datos. De los algoritmos disponibles en la API de Weka, contenida en el subpaquete “classifiers” se utilizó el algoritmo “Multilayer Perceptron” nombrada en Weka como “MultilayerPerceptron”. Estructuras de datos de Weka. El trabajo con las estructuras de datos en el API de Weka es a través de la clase Instances la cual está compuesta por una o un conjunto de objetos de la clase Instance. Esta clase define una estructura de datos basada en filas y columnas, donde las columnas son representadas por objetos de la clase Attribute y las filas por objetos de la clase Instance ver la Figura(2.2)..
(41) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 33. Figura 2.2: Representación de las estructuras de datos del Weka.. Generación y evaluación de un clasificador Todos los algoritmos de clasificación implementan la interfaz Classifier, esta interfaz declara una serie de funciones. Funciones: “buildClassifier (Instances data)”: Permite entrenar un clasificador con un conjunto de datos. “classifyInstance (Instance instance)”: Permite clasificar un caso que le sea dado a un clasificador siempre que este este entrenado entrenado. Para la evaluación se emplea la clase Evaluation la cual proporciona algunas funciones para realizar esta tarea. Funciones: “evaluateModel (Classifier c, Instances data)”: Evalúa un clasificador con un conjunto de datos dedicados. “crossValidateModel(Classifier cls, Instance data, Integer numFolds, new Random(Interger seed))”: Realiza una validación cruzada al clasificador,.
(42) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 34. fraccionando el conjunto de datos en el valor que tome la variable numFolds. Para proporcionar los resultados de la evaluación existen implementados varios métodos como toSummaryString() y toClassDetailsString(). Métodos de validación de los modelos La forma en que se dividen los datos en conjunto de entrenamiento y prueba es también muy importante. La mejor forma de organizar el experimento en entrenamiento y prueba realmente depende de las características de la base de conocimiento. Muchos de los algoritmos disponibles en Weka antes de ser usados necesitan especificar qué datos serán usados como conjunto de entrenamiento y cuáles cómo conjunto de prueba [10, 21]. Estos son conjuntos disjuntos, el primero de ellos utilizado por los algoritmos de AA para realizar el proceso de aprendizaje fijando sus parámetros (ejemplo, los pesos de una RNA), mientras que los ejemplos del conjunto de prueba se utilizan para medir el desempeño del algoritmo. El método boostrap se basa en la generación de n conjuntos de cardinalidad I desde el conjunto de datos original, con reemplazo [10]. A continuación se exponen algunos variantes que se suele emplear para la resolución de problemas de clasificación y predicción numérica. Use training set: Usar los mismos datos como conjunto de entrenamiento y de prueba, conformado con todas las instancias del archivo de datos . Esta técnica es la más vieja y simple que se basa en entrenar y probar el clasificador con la misma base de conocimiento. Este método puede traer como consecuencia un sobre-aprendizaje del clasificador, o sea, que el clasificador más que generalizar el conocimiento de los datos, aprenda estos “de memoria”, pues no se tiene en cuenta cómo reacciona el modelo ante casos que no ha visto antes. k-fold cross-validation: Realizar una validación cruzada estratificada con un.
(43) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 35. número de particiones dado. Es uno de los más usados, este método se basa en dividir la base en k particiones y realizar k procesos de entrenamientos y pruebas, donde el proceso i se basa en tomar la partición i para prueba y el resto para entrenamiento. Se dice estratificada porque cada una de las partes conserva las propiedades de la muestra original (porcentaje de elementos de cada clase). Percentage split: Tomar un porcentaje del conjunto de datos como muestra de entrenamiento y lo restante como muestra de prueba. Esta técnica es conocida como el método H (Hold-out) y también como Percentage split, que divide la base, en un por ciento para entrenamiento y otro por ciento para prueba o muestra de control. Una versión de éste es el Data Shuffle que realiza n veces el método H y promedia los resultados. Este método no es efectivo para bases pequeñas, pues los ejemplos pudieran no ser representativos si se diera el caso de que los casos no fueran divididos convenientemente [10, 22, 23]. Supplied test set: Usar todas las instancias del conjunto de datos solamente como conjunto de entrenamiento, y proporcionar como conjunto de prueba un nuevo archivo de datos. Esta técnica se emplea cuando se cuenta con suficiente cantidad de datos para el entrenamiento y para el control o prueba [10, 22]. Actualmente se usa en vez de dos conjuntos de datos, tres: uno para entrenamiento, uno para prueba y un tercero para validación. Este último se usa como seudoentrenamiento, de tal manera que el proceso de entrenamiento se detiene cuando comience a decrecer el rendimiento sobre el conjunto de validación, aunque continúe aumentando sobre el conjunto de entrenamiento. Este método es muy útil para evitar el sobre entrenamiento. También se usa para ajustar parámetros y seleccionar un modelo apropiado. Tiene como desventaja que necesita un conjunto de datos muy grande [10]..
(44) CAPÍTULO 2. CONSTRUCCIÓN DE LOS MODELOS PREDICTIVOS. 36. Conclusiones parciales del capítulo En este capítulo se describen los datos utilizados en la construcción de los modelos de RNA para el pronóstico de temperaturas extremas en el CMPVC. Se describe el reprocesamiento de datos realizado así como las herramientas necesarias para lograr la aplicación PronMLP. Se explica la forma en que se pretende evaluar los modelos que se proponen en el trabajo para el objetivo planteado..
Figure



+7





Documento similar
