Inclusión de la robustez en la optimización multi objetivo para problemas de secuenciación de tareas tipo Job Shop
75
0
0
Texto completo
(2) Dictamen El que suscribe, Erick David Rodríguez Bazán, hago constar que el trabajo titulado Inclusión de la robustez en la optimización multi-objetivo para problemas de secuenciación de tareas tipo Job Shop fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Licenciatura en Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ______________________ Firma de la Autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ________________________________ Firma del Tutor. ______________________________ Firma del Jefe del Laboratorio.
(3) DEDICATORIA A mis padres y hermana por siempre estar ahí, servirme incondicionalmente de ejemplo y de guía, darme todo sin cuestionarme ni pedirme nada a cambio, aguantar mis pesadeces pero, a la vez, haber sabido educarme, por el inmenso amor que me profesan todos los días y sobre todo por haberme posibilitado crecer en una familia tan unida..
(4) AGRADECIMIENTOS A Beatriz, que más que tutora fue una compañera en la confección de esta tesis, por sus largas horas de dedicación, su invaluable ayuda, por su agradable sonrisa y ternura ante cualquier adversidad. A mi mamá y mi papá, por su casi agobiante preocupación y por nunca dejarme bajar la guardia. A mi hermanita, por todos los consejos y revisiones y siempre ser incondicional. A toda mi familia, por siempre esperar lo mejor de mí y hacerme esforzar para estar a la altura. A todos los amigos que de una forma u otra lo hicieron posible..
(5) RESUMEN Durante las últimas décadas, los algoritmos multi-objetivo han captado considerable atención. El problema de secuenciación tipo Job Shop, uno de los principales problemas de optimización, también ha capturado la atención. Sin embargo, la mayoría de los algoritmos multi -objetivos que se han desarrollado para este problema están basados en enfoque no profesionales.e s decir, la mayoría de ellos combinan sus objetivos y resuelven el problema multi -objetivo a través de enfoques basados en un solo objetivo, exceptuando a un pequeño grupo de investigadores que utilizan algoritmos basados en la Frontera de Pareto. En esta tesis se consideran dos objetivos, makespan y robustez. La robustez es dada por el valor esperado de la diferencia relativa entre el makespan determinístico y el real. Se implementaron dos medidas para la robustez. La primera medida está basada en la probabilidad de que una maquina se rompa, mientras la segunda se basa en intervalos críticos de acuerdo a un umbral. Se implementó un algoritmo basado en la Frontera de Pareto usando Aprendizaje Reforzado. El algoritmo propuesto se aplicó a un conjunto de instancias para optimizar los objetivos tratados y finalmente los resultados experimentales muestran que la secuenciación robusta asociada al makespan óptimo no siempre es la más robusta, en algunas ocasiones es mejor sacrificar optimalidad y ganar en robustez.. Palabras Claves: Multi-Objetivo – Secuenciación – Job Shop – Aprendizaje Reforzado Frontera de Pareto. i.
(6) ABSTRACT. During the last decades, developing multi-objective algorithms for optimization problems has found considerable attention. Job Shop scheduling problem, as one of the main important scheduling optimization problem, has found this attention too. However, most of the multiobjective algorithms that have been developed for this problem use nonprofessional approaches. In another words, most of them combine their objectives and then solve multi objective problem through single objective approaches, except some scarce researcher that uses Pareto-based algorithms. In this paper, two objectives – makespan and robustness – are simultaneously considered. Robustness is indicated by the expected value of the relative difference between the deterministic and actual makespan. Two measures for robustness are developed; the first measure is based on the probability of machine breakdowns, while the second measure is based in critic intervals according to a threshold. To address this problem, a multi-objective algorithm using reinforcement learning and based in the Pareto Front is presented. The proposed algorithm is applied to benchmark problems for objectives optimized: the experimental results show that the robust scheduling associate to optimum makespan is not always the most robust, sometimes is better sacrifice the optimality and to win in robustness.. Keywords: Multiple Objectives - Scheduling – Job Shop - Pareto Front – Reinforcement Learning. i.
(7) TABLA DE CONTENIDOS INTRODUCCIÓN ____________________________________________________________ 1 CAPÍTULO 1 FUNDAMENTACIÓN TEÓRICA ___________________________________ 5 1.1. Problemas de secuenciación de tareas _____________________________________ 5. 1.1.1. Tipos de problemas de secuenciación de tareas___________________________ 6. 1.1.2. Métodos de solución para problemas de secuenciación ____________________ 8. 1.2. Incertidumbre y robustez en una planificación. ______________________________ 9. 1.2.1. Métodos proactivos y métodos reactivos _______________________________ 11. 1.2.2. Técnicas para planificaciones robustas ________________________________ 12. 1.3. Optimización multi-objetivo ____________________________________________ 16. 1.3.1. Frontera de Pareto ________________________________________________ 16. 1.3.2. Métodos para resolver problemas multi-objetivo ________________________ 18. 1.4. Sistemas Multi-Agente ________________________________________________ 19. 1.5. Aprendizaje Reforzado ________________________________________________ 20. 1.5.1. Aprendizaje Reforzado para problemas de secuenciación de tareas __________ 21. 1.5.2. Q-Learning ______________________________________________________ 22. 1.6. Conclusiones parciales ________________________________________________ 23. CAPÍTULO 2. ALGORITMO MULTI-OBJETIVO PARA JSSP ______________________ 25 2.1 Aprendizaje Reforzado para problemas tipo Job Shop __________________________ 25 2.2 Modelación del Q-Learning para resolver problemas de secuenciación de tareas tipo Job Shop ____________________________________________________________________ 28 2.2.1 Estrategia de selección de una acción ____________________________________ 29 2.3 Instancias JSSP_________________________________________________________ 30 2.4 Construcción del Frente de Pareto __________________________________________ 32 2.5 Modo de funcionamiento general del algoritmo _______________________________ 34 2.5.1 Descripción del algoritmo en pseudocódigo _______________________________ 34 2.6 Análisis de la complejidad temporal del algoritmo _____________________________ 36 ii.
(8) TABLA DE CONTENIDOS. 2.7 Formas de manejo de la robustez ___________________________________________ 36 2.7.1 Regiones críticas ____________________________________________________ 37 2.7.2 Protección Temporal _________________________________________________ 42 2.8 Interfaz Gráfica ________________________________________________________ 44 2.9 Conclusiones Parciales ___________________________________________________ 46 CAPÍTULO 3. PRUEBAS EXPERIMENTALES Y ANÁLISIS DE LOS RESULTADOS __ 47 3.1 Marco experimental estadístico ____________________________________________ 47 3.1.1 Pruebas estadísticas utilizadas __________________________________________ 48 3.2 Perturbaciones _________________________________________________________ 49 3.3 Resultados Experimentales _______________________________________________ 52 3.4. Conclusiones Parciales ________________________________________________ 59. CONCLUSIONES ___________________________________________________________ 60 RECOMENDACIONES ______________________________________________________ 61 REFERENCIAS BIBLIOGRÁFICAS ___________________________________________ 62. iii.
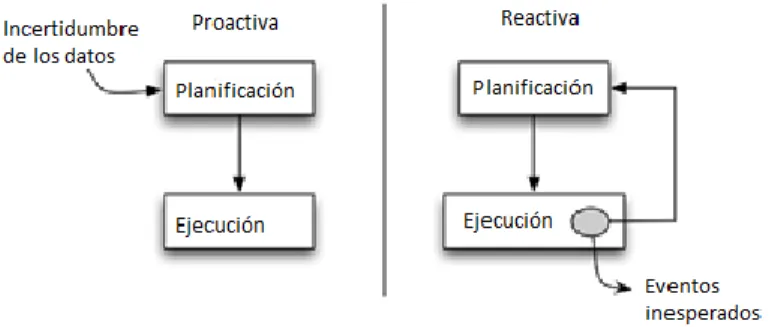
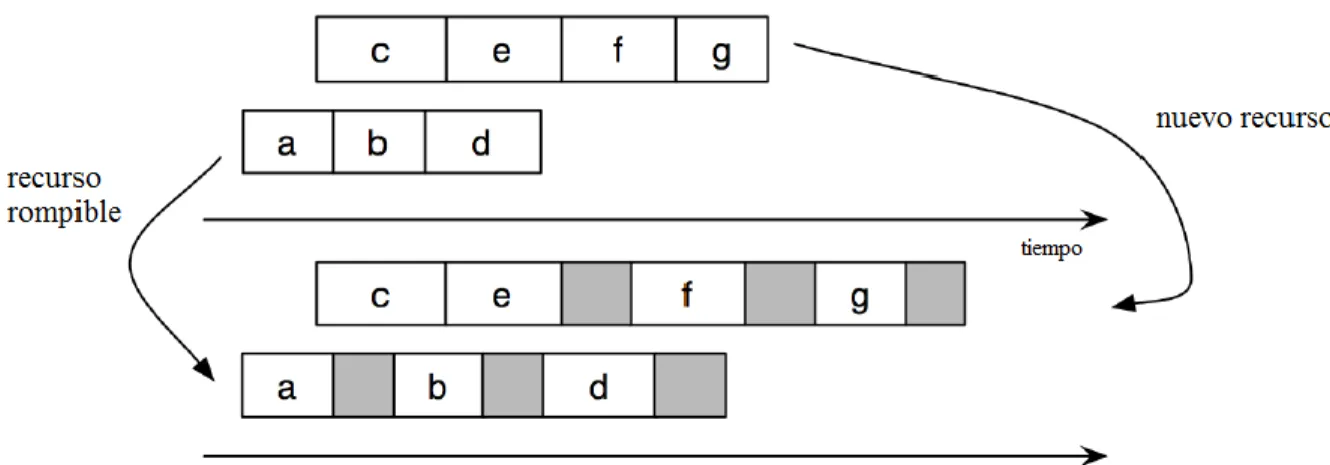
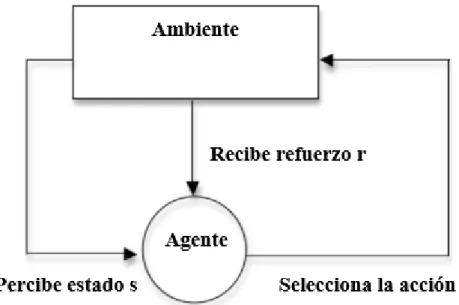
(9) LISTA DE FIGURAS Figura 1.1 Tipos de problemas secuenciación de tareas._______________________________6 Figura 1.2 Enfoque proactivo vs reactivo._________________________________________12 Figura 1.3 Ejemplo de dos operaciones consecutivas ejecutadas sobre un recurso rompible.__13 Figura 1.4 Ejemplo de cómo se adiciona tiempo extra con el enfoque TWS.______________15 Figura 1.5 Ejemplo de cómo se adiciona tiempo extra en el enfoque FTWS.______________15 Figura 1.6 Aprendizaje Reforzado._______________________________________________21 Figura 1.7 Pseudocódigo del algoritmo Q-Learning._________________________________23 Figura 2.1 Agentes en ambientes Job Shop.________________________________________25 Figura 2.2 Dos agentes con su conjunto de acciones (estado actual).____________________26 Figura 2.3 Instancia ft06 de OR-library.___________________________________________32 Figura 2.4 Descripción de un trabajo en la instancia ft06._____________________________32 Figura 2.5 Pseudocódigo del procedimiento usado para agregar una nueva solución al Frente de Pareto._____________________________________________________________________33 Figura 2.6 Solución óptima para la instancia ft06, Cmax=55.___________________________38 Figura 2.7 Solución óptima para la instancia ft06 después de agregar tiempos de inactividad a cada una de las operaciones en una región crítica, C max=64.___________________________40 Figura 2.8 Solución óptima para la instancia ft06 después de agregar tiempos de inactividad a cada una de las operaciones en la posición (Z-1)*k en una región crítica con Z=3, Cmax=59.___________________________________________________________________ 41 Figura 2.9 Pseudocódigo del algoritmo general utilizando un umbral Z.__________________42 Figura 2.10 Solución óptima para la instancia ft06 después de agregar tiempos de inactividad a cada una de las operaciones considerando a todas las máquinas como críticas, Cmax=64.___________________________________________________________________4 Figura 2.11 Ventana Principal.__________________________________________________44 Figura 2.12 Frente de Pareto obtenido para la instancia la01 y la Protección Temporal._____45 Figura 2.13 Lista de perturbaciones.______________________________________________45 Figura 3.1 Formato de una perturbación.__________________________________________49 Figura 3.2 Secuenciación con perturbaciones.______________________________________50. iv.
(10) LISTA DE TABLAS Tabla 2.1 Óptimos para las instancias de OR-Library de acuerdo al tiempo de terminación de todas las tareas.______________________________________________________________31 Tabla 3.1 Lista de perturbaciones para la instancia ft06.______________________________50 Tabla 3.2 Estudio comparativo para el JSSP._______________________________________54 Tabla 3.3 Óptimos para la técnica basada en máquinas críticas.________________________55 Tabla 3.4 Óptimos para la técnica Protección Temporal protegiendo todas las máquinas.____56 Tabla 3.5 Resultados obtenidos con la prueba de McNemar para la solución robusta asociada al makespan óptimo.____________________________________________________________57 Tabla 3.6 Resultados obtenidos con la prueba de Wilcoxon para la solución robusta asociada al makespan óptimo.____________________________________________________________57 Tabla 3.7 Resultados obtenidos con la prueba de McNemar para la solución robusta óptima._58 Tabla 3.8 Resultados obtenidos con la prueba de Wilcoxon para la solución robusta óptima._59 Tabla 3.9 Resultados obtenidos con la prueba de Wilcoxon para la técnica basada en máquinas críticas para la dos soluciones robustas.___________________________________________59. v.
(11) INTRODUCCIÓN El desarrollo actual de las computadoras y la aparición de nuevas técnicas de simulación y optimización heurística, que aprovechan plenamente las disponibilidades de cálculo intensivo proporcionadas por estas, han abierto una nueva vía para abordar los problemas de secuenciación de tareas, suministrando un creciente arsenal de métodos y algoritmos cuyo uso se extiende de manera paulatina al sustituir las antiguas reglas y algoritmos usados tradicionalmente. El problema de la secuenciación de tareas consiste en la asignación de recursos a diferentes actividades que se ejecutan de forma simultánea a lo largo del tiempo. El rango de aplicación de la teoría de secuenciación abarca áreas del conocimiento que van desde la producción hasta la computación, pasando por logística, servicios y otros. El problema de secuenciación de tareas tipo Job Shop (JSSP) consiste en la programación temporal de las operaciones o tareas en las que se descompone un conjunto de t rabajos teniendo en cuenta que estas deben ser ejecutadas en varias máquinas y que cada máquina solamente puede ejecutar una tarea de forma simultánea. Se busca aquella solución que dé lugar a un tiempo total de ejecución (C max) mínimo, aunque pueden existir otras funciones objetivos como la minimización de la suma de tiempos de espera o la suma de los tiempos de ejecución, o tratar de obtener una secuenciación lo más robusta posible. Este es uno de los problemas de optimización combinatoria más difíciles de resolver. Muchos problemas de la vida real, como el JSSP, persiguen varios objetivos a la vez, por lo que han hecho de la optimización multi-objetivo un área de interés investigativo. Un enfoque común resulta combinar los objetivos dentro de una función de escalarización donde se optimiza la suma de estos usando un vector de peso. Esta combinación no siempre muestra un buen desempeño debido a que se necesitan hacer demasiadas iteraciones para obtener buenos resultados. Un enfoque multi-objetivo adecuado permitiría encontrar la Frontera Óptima de Pareto. La mayoría de los algoritmos que existen para tratar estas problemáticas están basados en algoritmos evolutivos, esencialmente algoritmos genéticos. Estos obtienen buenos resultados pero necesitan una codificación del problema a resolver que no siempre es fácil de obtener, también se necesitan parámetros asociados a este tipo de algoritmo como el factor de peso 1.
(12) INTRODUCCIÓN. usado en funciones de agregación, las prioridades usadas en el ordenamiento lexicográfico y en el ranking de Pareto. Encontrar los valores apropiados para estos parámetros es, la mayor parte del tiempo, tan difícil como encontrar la solución del problema. Recientemente el Aprendizaje Reforzado ha recibido considerable atención a la hora de tratar con la optimización multi-objetivo. La primera propuesta conocida para resolver problemas de optimización multi-objetivo fue el algoritmo Multi-objective Ant-Q (MOAQ) (Mariano and Morales, 1999a, Mariano and Morales, 2000, Mariano and Morales, 1999b). MOAQ puede ser visto como una extensión de Ant-Q (Gambardella and Dorigo, 1995). Este algoritmo presenta las mismas dificultades que Ant-Q pero, a pesar de esto, se utilizó para resolver con éxito muchos problemas de optimización multi-objetivo complejos y restringidos. En años posteriores surge una nueva propuesta basada en Aprendizaje Reforzado, esta nueva propuesta es llamada Multi-objective Distributed Q-Learning (MDQL) (Mariano y Morales, 2000). Muchos problemas de secuenciación de tareas se asumen que van a ser ejecutados en ambientes estáticos. Pero el mundo real no resulta estable: las máquinas se rompen, ejecutar las operaciones toma más tiempo del esperado, las órdenes pueden ser canceladas o adicionarse nuevas operaciones. Una solución al problema de secuenciación de tareas que sea robusta permite la anticipación a eventos inesperados y para así evitar la reprogramación del sistema. La robustez en este tipo de problema ha sido tratada en varias ocasiones, pero siempre aplicada a una planificación obtenida por un algoritmo determinado. Sin embargo, resultaría más útil incluir la robustez a la vez que se construye la planificación, porque no necesariamente la planificación de menor makespan es la más robusta. Por todo esto se plantea como objetivo general de esta tesis: -. Diseñar un nuevo enfoque capaz de incorporar la robustez a medida que se va construyendo la planificación desde un punto de vista multi-objetivo usando Aprendizaje Reforzado.. Este objetivo se desglosa en los siguientes objetivos específicos: -. Definir cuáles técnicas usar de acuerdo a la literatura para tratar la robustez en los problemas de secuenciación de tareas.. 2.
(13) INTRODUCCIÓN. -. Implementar un algoritmo multi-objetivo usando Aprendizaje Reforzado y basado en la Frontera de Pareto que construya planificaciones robustas optimizando el tiempo total de terminación de todas las tareas.. -. Simular eventos inesperados mediante distribuciones conocidas para ver cuál de las técnicas escogidas para tratar la robustez es más eficiente.. Para la solución a los objetivos específicos de esta tesis se dará respuesta a las siguientes preguntas de investigación: -. ¿Cuáles técnicas usar para tratar la robustez en problemas de secuenciación tipo Job Shop?. -. ¿El algoritmo multi-objetivo implementado brinda soluciones capaces de absorber eventos inesperados que puedan ocurrir durante la producción?. -. ¿Cuál de las técnicas implementadas para manejar la robustez es la más eficiente?. -. ¿Es mejor brindar al usuario la solución robusta óptima que la solución robusta del makespan óptimo?. Justificación de la investigación. En ambientes reales como la industria, la probabilidad de ejecutar una secuencia de tareas en el tiempo planeado es muy baja, ya que las máquinas pueden romperse, los recursos agotarse, entre otros inconvenientes. Estas interrupciones provocan altos costos debido a que evita que se cumpla con las fechas de entrega y por otra parte los trabajadores tienen que trabajar más horas , lo que conlleva a pagarles mayor salario. Un algoritmo que permita incrementar la robustez de las planificaciones sería de gran utilidad para evitar estos problemas, además, serviría para aplicarlo a otros problemas de secuenciación de tareas, no solo a los problemas de la industria. Todo esto justifica y hace viable la realización de esta investigación. La tesis está estructurada en tres capítulos. En el capítulo 1 se realiza un estudio de los problemas de secuenciación de tareas, su clasificación y los diferentes métodos que existen para resolverlos. También se explica qué es incertidumbre y robustez para estos problemas y se define la optimización multi-objetivo y los métodos que se utilizan para resolverla. Por último, se hace un estudio de los sistemas multi-agente y del Aprendizaje Reforzado haciendo énfasis en el algoritmo Q-Learning y sus variantes para resolver problemas multi-objetivo. 3.
(14) INTRODUCCIÓN. Seguidamente, en el capítulo 2 se describe el formato que tienen las instancias de este tipo de problemas y se explica en qué consiste la dominancia de Pareto. Además se ofrece una descripción general del algoritmo. Por su parte en el capítulo 3 se describen, en el marco experimental, las pruebas estadísticas que se realizaron, se generan perturbaciones a las distintas instancias del problema y se realizan pruebas para determinar cuál de las técnicas implementadas para manejar la robustez brinda mejores resultados de acuerdo a las simulaciones realizadas. El documento culmina con las conclusiones y las recomendaciones del autor para futuras investigaciones en este tema.. 4.
(15) CAPÍTULO 1 FUNDAMENTACIÓN TEÓRICA Este capítulo aborda todo lo referente a la base teórica que fundamenta esta investigación. Se hace una profunda revisión de la bibliografía para determinar las técnicas de optimización que han sido utilizadas para resolver problemas de secuenciación de tareas en configuraciones de tipo Job Shop. Además, se describen las diferentes técnicas que existen para implementar la robustez en los problemas de secuenciación de tareas y por último se exponen los principales aspectos del Aprendizaje Reforzado y la optimización multi-objetivo basada en la Frontera de Pareto. 1.1 Problemas de secuenciación de tareas Los problemas de secuenciación son típicamente clasificados como NP-Completos (Garey et al., 1976), lo que significa que encontrar una solución óptima se torna imposible si no se usa un algoritmo esencialmente enumerativo, y el tiempo de cómputo se incrementa exponencialmente de acuerdo al tamaño del problema, representando los problemas secuenciación en ambientes de manufactura uno de los más complejos (Martínez, 2012, Shen, 2002) Los problemas de secuenciación se pueden clasificar de acuerdo al ambiente de las máquinas, las características de los trabajos y la función objetivo. Esta clasificación se conoce como α|β|γ (Graham et al. 1979), donde α representa el ambiente de las máquinas, β las características de los trabajos y γ el criterio a optimizar (Martínez, 2012). En estos problemas se tiene un conjunto de N trabajos que van de ser procesados por M recursos o máquinas físicas. Una secuenciación consiste en encontrar para cada trabajo un tiempo o un intervalo de tiempos en los que este pueda procesarse en una o varias máquinas. El objetivo es encontrar una secuencia sujeta a una serie de restricciones que optimice una o varias funciones objetivo. En general, en un problema de secuenciación (scheduling) intervienen los siguientes elementos: trabajos, actividades, máquinas, patrón de flujo y objetivos. Cualquier problema de secuenciación de tareas consta de uno o más trabajos. Un trabajo resulta el término usado para designar un único elemento o una serie de elementos que tienen que ser procesados en los distintos recursos (máquinas). Los trabajos, en la mayoría de los casos, tienen restringido su tiempo de comienzo (ready time: tiempo a partir del cual puede comenzar la ejecución del 5.
(16) CAPÍTULO 1. trabajo), y su tiempo de terminación (due time: tiempo máximo permitido para finalizar la ejecución del trabajo). Cada trabajo, a su vez, está compuesto de una o más activid ades. Se denomina actividad (u operación) al procesamiento de un trabajo sobre un recurso particular, y por lo tanto, constituyen las unidades elementales de procesamiento. Las actividades pertenecientes a un mismo trabajo guardan un orden de precedencia conocido a priori (restricciones de precedencia o tecnológicas), que debe respetarse, pudiendo haber variaciones en cuanto a posibles solapamientos entre las actividades de un mismo trabajo, o si las actividades están separadas por intervalos de tiempo amplios. 1.1.1. Tipos de problemas de secuenciación de tareas. Los problemas de secuenciación de tareas se pueden enmarcar en dos grandes grupos, deterministas y estocásticos; en los primeros todos los parámetros son conocidos, mientras que en los segundos los tiempos de procesamiento de las tareas son modelados como variables aleatorias. Dentro de los diferentes problemas de secuenciación estocásticos que se estudian se encuentran: Flow Shop Híbrido, Online Scheduling y Flexible Job Shop Estocástico. Entre los que pertenecen a la clase determinista se encuentran el Open Shop, el Flow Shop y el Job Shop. La principal diferencia entre ellos es el orden en que se ejecutan los trabajos y la forma de asignar estos a las máquinas. En la figura 1.1 se muestran los distintos tipos de problemas de secuenciación de tareas antes mencionados.. Figura 1.1 Tipos de problemas de secuenciación de tareas.. 6.
(17) CAPÍTULO 1. Este epígrafe se enfoca en los problemas de tipo Job Shop que son de los más conocidos e investigados debido al alto grado de dificultad que presentan, y su aplicabilidad a una gran cantidad de situaciones reales. El JSSP tiene la característica de que los trabajos son unidireccionales, es decir, tienen solo una dirección. Otra característica importante es que la máquina que inicia no lo hace precisamente con el primer trabajo, cualquier máquina puede empezar o terminar, ya que el orden de procesamiento de los trabajos en las máquinas es una característica de cada uno de los problemas (Rivera and Eléctrica, 2004). Ahora se describirá el JSSP clásico: Hay m máquinas donde tienen que ser procesados n trabajos con m operaciones por trabajo. Cada operación tiene que ser procesada en una máquina. El orden de procesamiento de cada una de las operaciones de cada trabajo está dado por el problema y es inamovible. Una vez que una operación comienza a ser procesada no puede interrumpirse. Todas las operaciones de todos los trabajos tienen la misma prioridad. A continuación se listan las restricciones del JSSP clásico dadas en (González, 2011): -. No está permitido que dos operaciones de un mismo trabajo sean procesadas simultáneamente.. -. Ninguna operación tiene prioridad sobre las demás.. -. Ningún trabajo puede ser procesado más de una vez en la misma máquina.. -. Cada trabajo es procesado hasta concluirse, aunque haya que esperar y retardarse entre las operaciones procesadas.. -. Un trabajo puede iniciarse en cualquier momento siempre y cuando esté disponible la máquina y no se haya especificado un tiempo de inicio.. -. Los trabajos tienen que esperar a que la siguiente máquina esté disponible para que este sea procesado.. -. Ninguna máquina puede procesar más de un trabajo a la vez.. -. Los tiempos de configuración y cambio de máquina son independientes del orden de procesamiento y está incluido en los tiempos de procesamiento.. -. Hay sólo una máquina de cada tipo. 7.
(18) CAPÍTULO 1. -. Las máquinas pueden estar ociosas en cualquier momento del proceso.. -. Las máquinas están disponibles durante todo el proceso siempre y cuando no estén procesando alguna operación.. -. Las restricciones tecnológicas están bien definidas y son previamente conocidas, además de que son inamovibles.. Para los investigadores constituye un hecho que el JSSP resulta uno de los problemas NPCompletos más complejos y que posee consecuentemente un constante reto intelectual: 40 años de esfuerzo, resultados publicados en cientos de artículos de revistas, disertaciones, y aún los algoritmos del estado del arte fallan frecuentemente en encontrar soluciones óptimas a instancias relativamente pequeñas del problema (Garrido et al., 2000). 1.1.2. Métodos de solución para problemas de secuenciación. Los métodos para resolver problemas de secuenciación provienen de las técnicas de la optimización combinatoria. A estos se les da solución usando principalmente técnicas de Investigación de Operaciones (IO) y técnicas de Inteligencia Artificial (IA). Los métodos basados en IO se han centrado en representaciones que han demostrado la habilidad de identificar soluciones óptimas pero están restringidos a modelos rígidos con un limitado poder expresivo además de no ser factibles cuando la magnitud del problema a resolver es muy grande, estos métodos son generalmente exactos (Programación Dinámica, Ramas y Cotas, Satisfacción de Restricciones, etc.). Mientras que los basados en IA proveen representaciones más ricas y flexibles que pueden resolver problemas insolubles por métodos exactos, usando métodos aproximados que aunque no siempre conllevan a la solución óptima en un tiempo razonable, proporcionan heurísticas capaces de encontrar buenas soluciones de forma eficiente (Recocido Simulado, Búsqueda Tabú y Algoritmos Genéticos). La mayoría de las investigaciones en el área de los problemas de secuenciación de tareas se han enfocado en el desarrollo de procedimientos exactos para la generación de una solución base asumiendo que se tiene toda la información necesaria y un ambiente determinístico (Herroelen and Leus, 2004). Sin embargo, el mundo real no es inalterable, los proyectos están sujetos a eventos inesperados durante su ejecución, lo cual puede llevar a numerosas interrupciones, por ejemplo, los recursos pueden tornarse inaccesibles (rupturas o mantenimiento), nuevos pedidos 8.
(19) CAPÍTULO 1. pueden llegar al sistema, la ejecución de las operaciones puede tomar más tiempo del esperado, etc. Un enfoque para lidiar con dichas interrupciones resulta generar soluciones robustas, donde robustez se refiere al desempeño de un algoritmo bajo incertidumbre (Davenport et al., 2001). El objetivo de este enfoque consiste en generar planificaciones que sean capaces de absorber cierto nivel de incertidumbre sin tener que replanificar (Martínez, 2012). Para dar solución a todos estos requerimientos se hace necesario alcanzar algún tipo de unificación entre ambos enfoques (IA, IO) para obtener buenas representaciones del problema y al mismo tiempo lidiar con la incertidumbre e incrementar la robustez. 1.2 Incertidumbre y robustez en una planificación. Durante el proceso de secuenciación, como se ha mencionado anteriormente, pueden ocurrir diversas interrupciones, las máquinas pueden romperse, las operaciones pueden tardar más de lo esperado, nuevas órdenes pueden llegar, la prioridad de las operaciones puede variar. Todas estas interrupciones eventualmente puede provocar fallas en el sistema, causando retrasos en la entrega de los productos (las fechas de finalización pueden ser violadas), el aumento de los tiempos de espera de la máquinas, entre otras consecuencias. Por lo tanto, en entornos reales no sería muy útil gastar demasiados recursos ni esfuerzos en producir soluciones óptimas ya que se consigue la optimalidad sólo si la solución puede ser ejecutada como estaba previsto. Por el contrario, una solución sub-óptima al problema que sea capaz de tener cierta flexibilidad para hacer frente a acontecimientos imprevistos, podría proporcionar características útiles. Por lo que, la eficiencia de las técnicas de secuenciación empleadas dependerá de la capacidad de adaptación al grado de incertidumbre de la información proporcionada al comienzo de esta (Policella, 2005). En muchos procesos de decisión, es común que las soluciones tengan un cierto nivel de robustez con el fin de mantener su viabilidad en entornos incompletos o con datos imprecisos. Las soluciones deben tolerar un cierto grado de incertidumbre durante la ejecución, en otras palabras, deben ser capaces de absorber variaciones dinámicas en el problema. A menudo hablamos de problemas de secuenciación robustos, pero hay varias cuestiones que tienen que ser respondidas con el fin de captar realmente el significado de la robustez, por ejemplo: ¿Cómo se define la robustez? 9.
(20) CAPÍTULO 1. ¿Cómo podemos medir la robustez en un problema de secuenciación? ¿Cómo incorporar la robustez en los problemas de secuenciación? El desarrollo de optimizaciones robustas fue iniciado por (Soyster, 1973). Este enfoque ha sido ampliamente estudiado y extendido aunque se consideró demasiado conservador, ya que las soluciones obtenidas sacrificaban demasiado la optimalidad del problema en cuestión con el fin de asegurar la robustez (Bertsimas and Sim, 2004). Después de este trabajo inicial se propusieron algunos otros modelos (Ben-Tal and Nemirovski, 2000, Bertsimas and Sim, 2004, Lui Cheng, 2008). En todos ellos la principal preocupación radicaba en cómo hacer que los problemas de secuenciación fueran más robustos sin perder demasiado en optimalidad (Martínez, 2012) La robustez es fácil de definir, pero compleja de medir de forma cuantitativa. En (Sabuncuoglu and Goren, 2009) los autores presentan un estudio detallado sobre el tema, el cual muestra que los distintos enfoques se centran en diferentes objetivos por lo que, la forma de medir la robustez no resulta siempre la misma. Las formas más comunes de medir la robustez de acuerdo con la literatura son las siguientes: -. desviación de la planificación original;. -. el costo real de la ejecución de la planificación;. -. estabilidad, relacionada con el criterio de desempeño;. -. número de cambios requeridos para arreglar la planificación.. Las dos primeras medidas fueron propuestas en (Gao, 1996). Según este autor, la desviación de la planificación original se puede calcular mediante el análisis de la diferencia entre el makespan planificado y el makespan real. En el segundo caso, los costos pueden estar asociados, por ejemplo, a llegadas tardías, lo que significa que hay una penalización por unidad de tiempo programado sobre la fecha de culminación o los costos podrían estar asociados a la ociosidad de los recursos, lo que significa que hay una penalización por cada unidad de tiempo que el recurso se mantuvo inactivo (Martínez Jiménez, 2012). En el caso de la estabilidad (tercera métrica), podemos decir que es muy similar a la del primer indicador. De acuerdo con su definición en (Billaut et al., 2008), la estabilidad constituye una medida de la diferencia en la secuencia entre las dos planificaciones, que en otras palabras es cómo se desvía el horario real del original. 10.
(21) CAPÍTULO 1. La esencia de la última métrica, que se introdujo en (Gomes, 2000), consiste en que: dado un conjunto C de los cambios en la formulación inicial de la instancia del problema, una solución A es más robusta que la solución B en lo que respecta al conjunto C si el número de cambios necesarios para fijar la solución A es menor que el número de cambios necesarios para fijar la solución B (Martínez Jiménez, 2012). Existen diferentes enfoques que se pueden utilizar con el fin de hacer frente a la incertidumbre y la solidez en la planificación , ya sea la búsqueda de soluciones que se adapten dinámicamente a los cambios o que incorporen los conocimientos disponibles sobre los posibles cambios en la solución (Herroelen and Leus, 2005). 1.2.1. Métodos proactivos y métodos reactivos. De acuerdo con la literatura consultada, hay dos maneras de lidiar con la incertidumbre en entornos de programación, la primera es utilizar enfoques proactivos (también llamados predictivos) y la segunda utilizar enfoques reactivos. El objetivo de la programación proactiva consiste en tomar en cuenta las posibles eventualidades al construir la solución, esto permite que la planificación sea más robusta, pues valora el conocimiento estadístico sobre la incertidumbre (Davenport et al., 2001). Por otro lado, los métodos reactivos reoptimizan una solución cuando ocurre un evento inesperado, por tanto, las decisiones se toman en tiempo real y se basan en información actual sobre el sistema. Estos enfoques se utilizan cuando el nivel de incertidumbre es significativo o cuando los datos no están disponibles en tiempo, lo cual implica que no es posible calcular una solución de forma predictiva (Martínez Jiménez, 2012). La programación proactiva también se ha definido como las técnicas que tratan de producir una secuencia que es robusta y flexible a los eventos que ocurren en tiempo de ejecución (Beck and Wilson, 2007). La utilidad de este tipo de enfoque depende de si la incertidumbre se puede cuantificar de alguna manera (como saber el tiempo medio entre fallos de las máquinas, etc.). Si la información está disponible, pueden ser utilizadas las técnicas proactivas. Si por el contrario, el grado de incertidumbre es muy alto, se necesita un enfoque más reactivo (Martínez Jiménez, 2012).. 11.
(22) CAPÍTULO 1. La programación reactiva implica revisar o reoptimizar una planificación cuando se produce un suceso inesperado. Enfoques completamente reactivos se basan en la información puesta al día sobre el estado del sistema (Davenport and Beck, 2000). Las decisiones se toman en tiempo real, basadas en las reglas de secuenciación prioritarias. Estos enfoques se utilizan cuando el nivel de perturbaciones es siempre significativo o cuando los datos se conocen muy tarde, por lo que predecir los horarios resulta imposible (Aloulou and Portmann, 2005). La figura 1.2 muestra una representación gráfica de las propiedades de ambos tipos de enfoques.. Figura 1.2 Enfoque proactivo vs reactivo.. 1.2.2. Técnicas para planificaciones robustas. Según la bibliografía revisada las técnicas más usadas para hacer planificaciones robustas son las basadas en reajustes en los tiempos de terminación de las operaciones. Las mismas consisten en darle a cada actividad un tiempo extra para poder manejar en ese tiempo posibles percances sin necesidad de una replanificación. Estas técnicas se basan en el conocimiento que se tiene de las máquinas (cuántas veces se ha roto una máquina, la frecuencia con que se rompe, etc.), por lo que son técnicas proactivas. A continuación se describen tres técnicas para hacer planificaciones más robustas. 1. Protección Temporal: fue propuesta por (Chiang and Fox, 1990) y se basa en la idea de construir la planificación teniendo en cuenta el historial o conocimiento previo de las máquinas. A los recursos cuya probabilidad de romperse es distinta de cero se les llama recursos rompibles. La duración de todas las actividades que involucran recursos rompibles se extiende con el objetivo de tener tiempo extra para tratar las posibles roturas y entonces se resuelve el problema de secuenciación con las técnicas que se utilizan habitualmente (Gao, 1996). Un ejemplo de esta técnica se obtiene de 12.
(23) CAPÍTULO 1. (Davenport et al., 2001) y se expone en la figura 1.3. La figura muestra dos actividades, A y B, las cuales tienen que pasar por recursos rompibles. Los rectángulos blancos representan el tiempo de procesamiento original, y los grises el tiempo extra que se le añadió a cada actividad de acuerdo a la técnica de Protección Temporal. Si el recurso se rompe cuando está ejecutando la actividad A entonces ese tiempo extra puede ser empleado para arreglarlo. Si no se necesita más tiempo que el extra, entonces, la planificación sigue como se había planificado. Si se necesita más tiempo es necesario hacer algunos ajustes con el fin de mantener el resto de las actividades en sus tiempos (replanificar). Si no hay ninguna rotura mientras se está ejecutando la actividad A entonces la actividad B puede empezar a ejecutarse antes y el tiempo extra planificado en la A puede ser adicionado a la actividad B. La cuestión más importante para este tipo de técnicas es la cantidad de tiempo extra que se va a adicionar por cada actividad. Si protegemos mucho la planificación (mucho tiempo extra) podríamos tener una planificación de poca calidad, pero altamente robusta. Por el contrario, si la protegemos muy poco resulta una planificación de muy baja calidad en caso de que se rompa un recurso durante la ejecución de una actividad.. Figura 1.3 Ejemplo de dos operaciones consecutivas ejecutadas sobre un recurso rompible.. El enfoque presentado en (Gao, 1996) propone una fórmula para calcular cuánto tiempo extra debe asignársele a una actividad. La fórmula es la siguiente: (1.1). 13.
(24) CAPÍTULO 1. Donde,. es el tiempo de procesamiento original de la actividad, F representa el. tiempo esperado entre los fallos de las máquinas y D es la duración de la rotura, es el tiempo de procesamiento extendido, que no es más que la adición del tiempo original y el tiempo que se va a agregar, durante la ejecución y. da el número de roturas que se esperan. el tiempo extra que se le debe adicionar debido a la rotura. de las máquinas. 2. Ventana de Tiempos de Inactividad (TWS): hay situaciones en las cuales no es posible aplicar la técnica de Protección Temporal debido a que no es posible compartir el tiempo extra agregado. Para evitar estas situaciones se cambia la forma de agregar el tiempo extra a las operaciones de manera que sea seguro que la planificación tiene el suficiente tiempo extra para cada actividad. El tiempo extra adicionado por esta técnica es mucho mayor que en la Protección Temporal. La cantidad de tiempo extra agregada a cada actividad por este enfoque es igual a la suma de la duración de todas las roturas esperadas en el recurso R, esto se debe a que este enfoque se basa en que el tiempo extra de todas las actividades sobre cada recurso sea compartido. A continuación se muestra la fórmula utilizada por este enfoque para calcular el tiempo extra que se va a adicionar. (1.2). donde. representa la duración de la actividad,. fallos del recurso R,. es el tiempo medio entre los. representa el tiempo medio que duró la rotura del recurso R. y el conjunto de actividades que pueden ser ejecutadas por el recurso R está dado por . La figura 1.4 muestra la manera en que este enfoque adiciona el tiempo extra a cada actividad asumiendo que el tiempo extra de todas las actividades sobre cada recurso debe ser compartido. 3. Ventana de Tiempos de Inactividad Enfocada (FTWS): la manera en que se colocan las actividades en la planificación se toma en cuenta con el objetivo de decidir si se necesitará agregar tiempo extra. Este enfoque tiene en cuenta que si llega una máquina 14.
(25) CAPÍTULO 1. nueva no tiene sentido agregar tiempo extra desde la primera operación que se va a ejecutar porque en ese momento la probabilidad de romperse es muy baja. Es decir, agregar o no tiempo extra se basa en distribuciones conocidas. La función utilizada por este enfoque es la probabilidad de que la rotura ocurra antes o durante la ejecución de la operación. La figura 1.5 muestra cómo se agrega tiempo extra de acuerdo a este enfoque cuando se trabaja sobre una máquina nueva. Como puede observarse la operación C por ser la primera en ejecutarse no tiene tiempo extra.. Figura 1.4 Ejemplo de cómo se adiciona tiempo extra con el enfoque TWS.. Figura 1.5 Ejemplo de cómo se adiciona tiempo extra en el enfoque FTWS.. 15.
(26) CAPÍTULO 1. 1.3 Optimización multi-objetivo Muchos problemas de secuenciación de tareas en la vida real son multi-objetivo por naturaleza propia. Es decir, existen varios criterios que deben ser tomados en consideración cuando se evalúa la calidad de la solución obtenida en un problema de secuenciación de tareas. Es común encontrar que algunos o todos estos criterios entran en conflicto entre sí. Entre estos criterios podrían mencionarse por ejemplo, el tiempo total de terminación de todas las tareas, hacer una solución lo más robusta posible, entre otros. Tradicionalmente, estos problemas se han abordado como problemas de optimización de un solo objetivo, combinando los objetivos dentro de una función de escalarización donde se optimiza la suma de estos usando un vector de peso. Por otro lado, un alto número de metaheurísticas para resolver problemas multi-objetivo han sido propuestas en los últimos años con el fin de obtener un conjunto de soluciones bastantes cercanas a la óptima para problemas de optimización multi-objetivo en una sola pasada y sin la necesidad de convertir el problema a uno de un solo objetivo. La mayoría de estas técnicas se han probado con éxito. Sin embargo, la aplicación de estos métodos para resolver este tipo de problemas es aún poco explorada. La optimización multi-objetivo difiere de la optimización de un solo objetivo en muchas formas. Para dos o más objetivos en conflicto, a cada objetivo le corresponde una solución óptima diferente, pero ninguna de estas soluciones es óptima para todos los objetivos a la vez. Por lo que la optimización multi-objetivo no trata de encontrar una solución óptima sino que busca un equilibrio entre todas las soluciones. Además de tener varios propósitos, la principal diferencia es que la optimización multi-objetivo tiene dos intenciones. La primera es encontrar un conjunto de soluciones lo más cercano posible a la Frontera Óptima de Pareto. La segunda intención es encontrar un conjunto de soluciones lo más diverso posible (Garen, 2002). 1.3.1. Frontera de Pareto. La primera decisión que debe ser valorada al tratar con un problema de optimización multiobjetivo es precisamente cómo combinar la búsqueda y los procesos de toma de decisiones de lo que se ocupa la Optimalidad de Pareto. En este enfoque, un vector que contiene todos los valores objetivos representa la aptitud de la solución y el concepto de dominancia se utiliza para establecer la preferencia entre las soluciones. Una solución. se dice que es no dominada si no hay otra solución que sea mejor 16.
(27) CAPÍTULO 1. que. en todos los criterios. Formalmente, la relación de dominancia se describe de la siguiente. forma (Zitzler and Thiele, 1999): Suponiendo que existen dos vectores distintos V = (v1, v2,…, vk) y U = (u1, u2,…, uk) que contienen los valores objetivos de dos soluciones para un problema de minimización de kobjetivos, luego: V domina estrictamente U si vi < ui, para i = 1, 2,.., k. Aquí se considera principalmente el problema de minimización, pero la definición anterior se define de manera análoga para problemas de maximización. Es importante conocer que el tipo de dominancia puede tener efecto sobre la manera en que se realizará la búsqueda. Esto es porque si una solución está estrictamente dominada significa que se superó por la otra solución en todos los criterios. El Frente Óptimo de Pareto (o Frontera de Pareto) es el conjunto de todas las soluciones no dominadas en el espacio multi-objetivo. Sin embargo, cuando las soluciones en el conjunto obtenido no se encuentran en la Frontera de Pareto, debemos referirnos a ese conjunto como el frente no dominado obtenido o el Frente de Pareto conocido. La optimización de Pareto se refiere a la búsqueda de este frente o un conjunto que representa una buena aproximación a él y usualmente los métodos de optimización multi-objetivo se basan en técnicas para la Optimización de Pareto. El atractivo de la Optimización de Pareto viene del hecho de que en la mayoría de los problemas de optimización multi-objetivo no hay tal cosa como una única mejor solución o óptimos globales, y también de que es muy difícil establecer preferencias entre los criterios antes de la búsqueda. Y aún si esto es posible, puede que estas preferencias cambien. Dado que en la Optimización de Pareto el resultado final debe ser un conjunto de soluciones no dominadas, otro aspecto importante a considerar es la forma de evaluar la calidad del frente no dominado obtenido. Existen varios criterios para evaluar que tan bueno fue el frente obtenido entre los cuales se encuentran (Silva and Burke, 2004) -. El número de soluciones no dominadas obtenidas.. -. La cercanía entre el frente obtenido y el Frente Óptimo de Pareto (si se conoce).. 17.
(28) CAPÍTULO 1. -. El cubrimiento del frente, es decir, la difusión y distribución de las soluciones no dominadas.. 1.3.2. Métodos para resolver problemas multi-objetivo. La optimización multi-objetivo es un área de investigación muy interesante, no solo porque constituye una realidad la naturaleza multi-objetivo de muchos problemas sino porque queda mucho por explorar en este tema. Aun así varios han sido los métodos usados hasta el momento para resolver problemas multi-objetivo. Uno de los paradigmas más usados ha sido el de los algoritmos evolutivos, principalmente los algoritmos genéticos, de estos podemos encontrar varios ejemplos que han mostrado soluciones satisfactorias como son el Vector Evaluated Genetic Algorithm (VEGA) (Schaffer, 1985), el Multi-objective Genetic Algorithm (MOGA) (Fonseca and Fleming, 1993), el Niche Pareto Genetic Algorithm (NPGA) (Horn et al., 1994), el Pareto-Archived Evolutionary Strategy (PAES) (Knowles and Corne, 2000a)y Pareto converging genetic algorithm (PCGA) (Kumar and Rockett, 2002), entre otros. También pueden encontrarse otras meta-heurísticas enfocadas a resolver problemas multiobjetivo como son Multi-objective Tabu Search (MOTS) (Hansen, 1997), Pareto Simulated Annealing (PSA) (Czyżak and Jaszkiewicz, 1997), Memetic Pareto Archived Evolutionary Strategy (M-PAES) (Knowles and Corne, 2000b), entre otros (Silva and Burke, 2004). Generalmente, en los algoritmos evolutivos para resolver problemas multi-objetivo se usan operadores genéticos estándares y la diferencia entre estos algoritmos se concentra en la estrategia usada para la selección, la mutación o el cruzamiento. Casi todos los algoritmos evolutivos para resolver problemas multi-objetivo usan la dominancia de Pareto para la selección de los individuos durante la búsqueda, mientras que muchas de las alternativas meta-heurísticas para estos problemas (las que usan búsquedas locales) emplean un método diferente, que en la mayoría de los casos es una función de agregación ponderada. En los problemas de secuenciación de tareas pueden considerarse varios objetivos como son: makespan, lateness, tardinnes, earliness, flowtime, robustez, etc. La mayoría de las aplicaciones meta-heurísticas en problemas de secuenciación de tareas multi-objetivo que han sido reportadas, han considerado dos o tres objetivos y muchas de ellas se han concentrado en los 18.
(29) CAPÍTULO 1. problemas de secuenciación tipo Flow Shop. Dentro de los algoritmos más conocidos se encuentran la meta-heurística basada en Búsqueda Local, los Algoritmos Genéticos Multiobjetivo y extensiones de estos, Algoritmos Evolutivos Híbridos Multi-objetivo, e Implementación del Algoritmo Genético con Ordenamiento No Dominado. En la literatura consultada no se pudo encontrar casi ningún enfoque multi-objetivo que trate con los problemas de secuenciación de tareas tipo Job Shop, lo que deja ver que esta es un área donde deben enfocarse las investigaciones. 1.4 Sistemas Multi-Agente Un Sistema Multi-Agente resulta un sistema en el cual varios agentes actúan en el mismo ambiente para cumplir con una tarea específica. El creciente interés en el uso de este tipo de sistemas en problemas del mundo real viene dado por la habilidad de resolver problemas muy grandes por un agente centralizado, y también por la habilidad de obtener soluciones donde la experiencia es distribuida, como por ejemplo, problemas de secuenciación en ambientes de manufactura (Sycara, 1998). El campo de los sistemas multi-agente se centra en procesos descentralizados (sistemas distribuidos), ya que cada agente del sistema tiene su propia percepción (pueden estar en ubicaciones distintas y ser responsables de diferentes partes del sistema), control (diferente experiencia) y forma de actuar (diferentes acciones potenciales) (Kalech and Kaminka, 2005). Todo esto se resume en la siguiente definición: “Un Sistema Multi-Agente es una red de agentes que trabajan juntos para resolver problemas que están más allá de las capacidades individuales o el conocimiento de cada agente” (Jennings et al., 1998) Los Sistemas Multi-Agente se caracterizan porque cada agente tiene un punto de vista limitado, no existe un control global del sistema, los datos pueden ser descentralizados y el cálculo puede ser asíncrona (Martínez Jiménez, 2012). Existen dos posibles escenarios cuando se trabaja con múltiples agentes, ellos pueden trabajar juntos tratando de alcanzar un objetivo común, o pueden tener sus propios objetivos e intereses que entran en conflicto, lo que significa que puede darse que sean aprendices independientes o en conjunto. Cuando se utilizan aprendices en conjunto se asume que las acciones que toman. 19.
(30) CAPÍTULO 1. los otros agentes pueden ser observadas. Los aprendices independientes no necesitan observar las acciones tomadas por los otros agentes. 1.5 Aprendizaje Reforzado El aprendizaje denota cambios en un sistema que lo hacen capaz de realizar la misma tarea o tareas de forma más eficiente y más efectiva la próxima vez (Simon, 1978). El Aprendizaje Reforzado (RL, por sus siglas en inglés) constituye una popular plataforma para el diseño de agentes que interactúan con su ambiente a través de la ejecución de acciones. De estas acciones se recibe una señal de retroalimentación que indica cuán buenas han resultado, y se aprende de esta manera a resolver una tarea específica. Un agente es un sistema computacional situado en algún ambiente, que es capaz de actuar de manera autónoma y flexible en dicho ambiente en aras de cumplir con su objetivo (Jennings et al., 1998) Si se puede garantizar que un ambiente en específico es fijo, entonces es relativamente fácil diseñar un agente para operar en él. Pero el mundo real no es estático, las cosas están constantemente cambiando, la información usualmente no está completa y es por esto que la posibilidad de fallo debe tenerse en cuenta. Un sistema reactivo es aquel que mantiene una interacción constante con su ambiente y responde a los cambios que ocurren en él de forma tal que la respuesta aún es útil. Se espera que los agentes sean reactivos, pero también que trabajen en función de objetivos a largo plazo, por tanto, es importante mantener un buen balance entre proactividad y reactividad. Sin embargo, algunos objetivos solo pueden ser alcanzados a través de la cooperación con otros agentes y es aquí donde la habilidad social entra a jugar un papel importante. Los agentes deben ser capaces de interactuar con otros agentes situados en el mismo ambiente para poder lograr su objetivo. Para poder aprender de la experiencia los agentes pueden ser entrenados, por ejemplo, a través del aprendizaje supervisado, donde se les brindan ejemplos de pares estado-acción, junto con una indicación que dice si la acción fue correcta o incorrecta. El objetivo en el aprendizaje supervisado es inducir una política general a partir de los ejemplos de entrenamiento, la cual se generaliza para lidiar con ejemplos no vistos. De este modo, el aprendizaje supervisado requiere de un “profesor” que pueda proveer ejemplos correctamente etiquetados. 20.
(31) CAPÍTULO 1. Por su parte, el Aprendizaje Reforzado puede ser aplicado a problemas donde el conocimiento no está disponible o es difícil de obtener (Grefenstette et al., 2011). No requiere conocimiento previo sobre decisiones correctas o incorrectas, por lo tanto, el agente tiene que explorar activamente su ambiente para observar el efecto de sus acciones, donde por cada acción que tome recibe una señal numérica indicando cuán buena fue. Esta interacción “prueba y error” con el ambiente es más apropiada para el tipo de problema que se resuelve en este trabajo (Martínez, 2012).. Figura 1.6 Aprendizaje Reforzado.. En la figura 1.6 se observa el modelo estándar del Aprendizaje Reforzado; un agente está conectado con su ambiente vía percepción y acción, en cada interacción el agente percibe el estado actual ‘s’ del ambiente y selecciona una acción „a’ para cambiar dicho estado. Esta transición genera una señal „r’ que es recibida por el agente, cuya tarea es aprender una política de selección de acciones en cada estado para recibir la mayor recompensa acumulada a largo plazo (Zhang, 1996). 1.5.1. Aprendizaje Reforzado para problemas de secuenciación de tareas. En (Gabel and Riedmiller, 2007) los autores sugieren y analizan la aplicación de Aprendizaje Reforzado para resolver problemas de secuenciación de tipo `Job Shop'. En estos trabajos se demuestra que interpretar y resolver este tipo de escenarios a través de sistemas multi-agentes y Aprendizaje Reforzado resulta beneficioso para obtener soluciones cercanas a las óptimas y 21.
(32) CAPÍTULO 1. puede muy bien competir con enfoques de solución alternativos. El objetivo de la presente investigación consiste en incorporar estas ideas y proponer un enfoque multi-objetivo, multiagente con Aprendizaje Reforzado que puede ser adaptado para resolver problemas de secuenciación, obtener soluciones cercanas a las óptimas y además dar la posibilidad de lidiar con eventos inesperados sin perder mucho en optimalidad. 1.5.2. Q-Learning. Q-Learning es un algoritmo de Aprendizaje Reforzado que trabaja con una función acciónvalor. Esta función brinda la utilidad esperada de tomar una acción determinada en un estado dado y seguir una política óptima después de esto. Una ventaja de Q-Learning es que puede comparar la utilidad esperada de las acciones disponibles sin requerir un modelo del ambiente. El centro del algoritmo es la actualización de un valor sim ple en una iteración, cada par (s, a) tiene un Q-valor asociado (s es un estado del conjunto de estados S, y a es una acción del conjunto de acciones A). Cuando la acción a es seleccionada por el agente que se encuentra en el estado s el Q-valor para ese par estado-acción es actualizado en base a la recompensa recibida cuando se seleccionó esa acción, y el mejor Q-valor para el subsecuente estado s. La regla de actualización para cada par estado-acción es la siguiente: (1.3). En esta expresión ∝ ∈ ]0,1] es la velocidad de aprendizaje del agente y r la recompensa o penalidad resultante de tomar la acción a en el estado s. La velocidad de aprendizaje determina el grado por el cual el valor anterior es actualizado. Por ejemplo, si la velocidad de aprendizaje es α=0, entonces el Q-valor no se actualiza; por otro lado, si α=1 el valor anterior es remplazado por el nuevo estimado. Usualmente se utiliza un valor pequeño para la velocidad de aprendizaje, por ejemplo, α=0.1. El factor de descuento (parámetro γ) está en el rango de valores desde 0 hasta 1 (0 ≤ γ< 1). Si γ es cercano a cero el agente tiende a considerar solo la recompensa inmediata. Si γ es cercano a uno el agente considerará la recompensa futura en mayor medida. Q-Learning tiene la ventaja converger a una política óptima (Martínez, 2012). El algoritmo de la figura 1.7 es usado por los agentes para aprender de las experiencias o entrenamientos. Cada iteración es equivalente a una sesión de entrenamiento, en cada sesión, el agente explora el ambiente y toma una recompensa mientras el estado objetivo no haya sido alcanzado. El objetivo de cada sesión de entrenamiento es aumentar el conocimiento del agente, 22.
(33) CAPÍTULO 1. este conocimiento es representado por los Q-valores. Mientras más sesiones de entrenamiento o iteraciones, más valores pueden ser usados para encontrar una solución más óptima (Martínez, 2012).. Figura 1.7 Pseudocódigo del algoritmo Q-Learning.. 1.6 Conclusiones parciales Después de realizarse una revisión bibliográfica de los principales conceptos y definiciones necesarios para comprender el problema se arriban a las siguientes conclusiones parciales: -. Los problemas de secuenciación de tareas tipo Job Shop son de los problemas de secuenciación más complejos de implementar.. -. Existen diferentes técnicas para manejar la robustez en este tipo de problemas siendo las más eficientes las basadas en tiempos de inactividad aunque estas tienen la desventaja de que se necesita conocer el historial de las máquinas, algo de lo que no siempre se puede disponer.. 23.
(34) CAPÍTULO 1. -. Existen diferentes métodos para dar solución a los problemas multi-objetivo siendo el más utilizado el basado en la Frontera de Pareto, el cual no brinda una solución única, sino un conjunto de soluciones no dominadas.. 24.
(35) CAPÍTULO 2. ALGORITMO MULTI-OBJETIVO PARA JSSP En este capítulo se describe la configuración del Aprendizaje Reforzado para los problemas JSSP, se define cuál va a ser la estrategia a utilizar para escoger la próxima operación a procesar por una máquina. Además, se describen las instancias de este tipo de problema y cómo se construye el Frente de Pareto. Por último se da una breve descripción del algoritmo general, se evalúa su complejidad temporal y se explica detalladamente cómo es el funcionamiento del mismo para el manejo de la robustez de acuerdo a las dos técnicas que fueron implementadas tomando la instancia ft06 como ejemplo. 2.1 Aprendizaje Reforzado para problemas tipo Job Shop Este epígrafe está enfocado a cómo se configura un ambiente en Aprendizaje Reforzado haciendo énfasis en el algoritmo Q-Learning para problemas de secuenciación de tareas tipo Job Shop, esta configuración puede verse en la figura 2.1. Como puede observarse un agente en el ambiente estará representado por una máquina, y para este agente un estado será el conjunto de operaciones que esperan a ser ejecutadas por él. El agente se encarga en un momento dado de realizar una acción, una acción no es más que la selección de la próxima operación que será ejecutada (de las disponibles en ese instante de tiempo).. Figura 2.1 Agentes en ambientes Job Shop.. En la figura 2.2 se muestra cómo una máquina (agente) tiene un conjunto de operaciones disponibles pertenecientes a distintos trabajos que esperan ser ejecutadas por esta, además del 25.
(36) CAPÍTULO 2. tiempo que toma ejecutar cada una de estas operaciones. La recompensa obtenida por seleccionar una acción vendrá dada por la calidad de la solución y el t iempo de procesamiento de esta.. Figura 2.2: Dos agentes con su conjunto de acciones (estado actual).. El ambiente del problema de secuenciación define el número de agentes y la relación entre ellos. Los agentes pueden no conocer el estado global del sistema y para obtener un mejor desempeño del sistema se comunican entre ellos para determinar sus acciones, basadas en información limitada. Claramente, el enfoque centralizado es aplicable a problemas en los cuales la información global está disponible y los agentes son cooperativos (Martínez, 2012). Las principales características que deben ser consideradas cuando se modela un problema de secuenciación de tareas se resumen en (Gabel, 2009)como sigue: • Conjunto de estados factorizados: El conjunto de estados de un problema de secuenciación J puede ser factorizado. Se asume que cada recurso tiene un agente i asociado que observa el estado local en su recurso y controla su comportamiento. Es decir, existen tantos agentes como recursos existan en el problema (|Ag| = |R| = m). • Observabilidad local y completa: El estado si del agente i, y por tanto la situación del recurso ri, es completamente observable. Adicionalmente, la composición de todos los recursos determina el estado global del problema de secuenciación. • Acciones Factorizadas: Las acciones corresponden al inicio de las operaciones de los trabajos (expedición de los trabajos). Por tanto, una acción local del agente i refleja la decisión de procesar un trabajo particular (más específicamente, la próxima operación de ese trabajo) entre un conjunto Ai de operaciones que se encuentran esperando por el recurso ri. 26.
(37) CAPÍTULO 2. • Conjuntos de acciones cambiantes: Si las acciones denotan la expedición de las operaciones que esperan por ser procesadas, entonces el conjunto de acciones disponibles para un agente varía en el tiempo, ya que el conjunto de operaciones esperando en un recurso cambia a medidas que dichas operaciones se van ejecutando.. corresponde al conjunto de operaciones. oj,k que debe ser procesado en el recurso r i, es decir (oj,k) = i, donde j es el trabajo al que pertenece la operación y k es el identificador de la operación. Además, el estado local si del agente i está completamente descrito por el conjunto cambiante de acciones esperando por ser procesadas en el recurso ri, por tanto, si = Ai. Funciones de dependencia: como antes mencionamos, el orden y los recursos en que deben procesarse las operaciones pertenecientes a un trabajo en problemas de tipo JSSP se conocen. Estos órdenes implican que, después que un agente ejecute una acción (procese una operación), el estado local de a lo sumo un agente será modificado. Sea a∈Ai una operación del trabajo k, la cual está siendo procesada actualmente por el recurso ri. Una vez que esta operación finalice, el conjunto de acciones Ai del agente i se actualiza y el nuevo conjunto sería Ai = Ai\{a}, mientras que si una nueva acción es enviada al agente i´=ϱ (ok,. a + 1). el conjunto A i´ del agente i´ es. extendido (Ai´=Ai´ {a}). Además, se pueden definir las funciones de dependencia σ:. Ag { } para todos los agentes i (y recursos ri, respectivamente) como sigue: (2.1). Ag se define como el conjunto de agentes, a es el id de la operación correspondiente al trabajo k, que va a ser procesada en el recurso ri, esto es k tal que. . σi (a) = j significa que si el. agente i selecciona la acción a, y esto afecta el estado del agente j, la acción a es añadida a Aj(Aj=Aj∪a) y es removida de Ai(Ai=Ai\a). Lo que indica que más de un agente verá afectado su estado luego de la selección de una acción. Hay dos casos particulares para los cuales la función devolverá el conjunto vacío, uno es cuando la acción seleccionada no esté disponible y el otro cuando la acción seleccionada sea la última del trabajo correspondiente.. 27.
(38) CAPÍTULO 2. 2.2 Modelación del Q-Learning para resolver problemas de secuenciación de tareas tipo Job Shop Q-Learning es de los algoritmos de RL de los más utilizados, además de brindar, de acuerdo a la literatura, excelentes resultados para problemas de secuenciación de tareas tipo Job Shop. Para la utilización de este algoritmo existen elementos importantes que deben ser definidos, para la presente investigación estos elementos pueden ser descritos de la siguiente manera: Estados y Acciones: existe un agente asociado a cada recurso, y este agente tomará las decisiones sobre las acciones futuras. Que cada agente elija una acción significa decidir cuál operación será la próxima a procesar del conjunto de operaciones disponibles (el conjunto de operaciones que están en espera del recurso correspondiente), por lo que un estado de un recurso será un conjunto de operaciones que esperan en cola a ser procesadas. Cada agente tiene una vista local, lo que significa que solo tiene información sobre el r ecurso asociado y las operaciones que están en espera. Estrategia de selección de la acción: en el algoritmo presentado la estrategia usada para seleccionar una acción (próxima operación a ser ejecutada por un recurso) es la estrategia εgreedy, la cual se describe más adelante, y ha sido empleada con éxito en entornos multiagentes (Rodrigues Gomes and Kowalczyk, 2009). Q-Valores: tomando la instancia ft06 como ejemplo (figura 2.3). En este caso hay 6 agentes (uno por recurso, o lo que es lo mismo, uno por máquina) y 6 trabajos involucrados, de acuerdo a las restricciones de los JSSP, cada agente ejecutará 6 acciones. De acuerdo a (Gabel, 2009), el conjunto de estados para el agente i se denota como: Si=P(. ), en el ejemplo tratado la cantidad. de estados locales posibles para el agente i será |Si| = 26 = 64, por lo que la cantidad de posibles estados del sistema está acotado superiormente por |S|. (26)6 = 236. Debido a las restricciones. de orden del problema, muchos de estos estados puede que nunca sean alcanzados. Además, el nuevo algoritmo solo almacena los estados por los que transita. Estos estados son almacenados en el orden en que aparecen. Por ejemplo, si el algoritmo se ejecuta solo una vez entonces solo se almacenarán 6 estados, que son los estados donde se encontraba el agente cuando se eligieron las acciones. Otras ejecuciones del algoritmo conllevan a la creación de nuevos estados.. 28.
(39) CAPÍTULO 2. Recompensa: Para las señales de retroalimentación se usaron diferentes alternativas, todas basadas en la regla que da prioridad al tiempo de procesamiento más bajo. Las recompensas usadas para la retroalimentación fueron: 1. Si la operación seleccionada op tiene un tiempo de procesamiento ti la recompensa obtenida es 1/ti, nótese que mientras más bajo sea el tiempo de procesamiento de la operación, más alta es la recompensa obtenida. Esta recompensa fue usada en una actualización local del estado actual (cada vez que una operación es seleccionada se actualiza el estado local de la máquina en que se ejecutó dando 1/ti como recompensa). 2. Se define Suma_Total_op como la suma total de los tiempos de ejecución de todas las operaciones de todos los trabajos, luego si seleccionamos una operación op la recompensa obtenida será Suma_Total_op–ti (ti al igual que en el caso anterior es el tiempo de procesamiento de la operación seleccionada). Está recompensa se utilizó también para una actualización local, y la recompensa obtenida será inversamente proporcional al tiempo de procesamiento de la operación (a mayor tiempo de procesamiento menor recompensa). 3. Después de obtenido el makespan (C max ) de un episodio dado se hace una actualización de todos los estados por los que el sistema pasó durante este proceso. Estos estados son almacenados en una lista y la recompensa dada a cada uno de ellos fue 1/C max, esta recompensa da una buena medida y mejora las soluciones obtenidas ya que es proporcional a la calidad de la solución encontrada. Para actualizaciones globales también puede ser usado 1/(C max–op.initial_time) donde op.initial_time es el momento en que se empieza a ejecutar la operación seleccionada del estado analizado. Para la mejora de las soluciones obtenidas en el algoritmo cada vez que se seleccionó una nueva operación se realizaron dos actualizaciones locales utilizando las recompensas 1 y 2 para de esta forma modificar el Q-valor del par estado-acción. Luego de una iteración completa del algoritmo se realiza una actualización global tomando como recompensa 1/C max. 2.2.1 Estrategia de selección de una acción Uno de los retos que se plantean en el Aprendizaje Reforzado, al igual que en el resto de las meta-heurísticas, resulta el equilibrio entre la exploración y la explotación. Para obtener buenas recompensas, un agente debe preferir acciones que ya se hayan seleccionado y para las cuales 29.
Figure

+7





Documento similar
