Integración de técnicas de visualización a algoritmos de agrupamiento basados en densidad
94
0
0
Texto completo
(2) Dedicatoria. A mis padres, familia y amigos..
(3) Agradecimientos. A mis profesores Leticia y Carlos por su guía y dedicación a este trabajo. A mis padres y familia por su apoyo incondicional. A mi tía Maribel por su entrega y las colaboraciones estadísticas. A mi novia por brindarme soporte y comprensión cuando más lo necesitaba. A Adrián, Ale y Ener por esa linda cofradía y tantos momentos agradables. A todos mis amigos, sin su apoyo hubiese sido imposible la realización de este trabajo..
(4) Resumen. RESUMEN La mayoría de los métodos de agrupamiento requieren la especificación a priori de varios parámetros que repercuten significativamente en la calidad de la solución. En muchos casos los usuarios no disponen de la información necesaria para predecir valores óptimos para estos parámetros. No se conocen mecanismos adecuados para seleccionar de forma interactiva y en tiempo real los parámetros necesarios para obtener agrupamientos basados en densidad más eficientes. Un exponente claro de lo anterior lo constituye el algoritmo de agrupamiento DBSCAN, el cual tiene una alta complejidad temporal. El objetivo de la investigación consiste en valorar la efectividad de integrar técnicas de visualización a algoritmos de agrupamiento basados en densidad, en especial al algoritmo DBSCAN, para mejorar su eficiencia, a partir de la interacción en tiempo real con el usuario. Los principales resultados obtenidos son: se identificaron las interacciones a establecer en el algoritmo DBSCAN, se creó un modelo de integración de las técnicas de visualización y este algoritmo, se desarrolló el software DAVIA que implementa el modelo de integración y se ilustró mediante la experimentación con varias colecciones de objetos que se obtienen agrupamientos con mejores valores de las medidas de calidad internas y externas y en menor tiempo cuando se integran las técnicas de visualización con el algoritmo de agrupamiento DBSCAN, respecto a lo resultados cuando se aplica el algoritmo DBSCAN original sin visualización..
(5) Abstract. Abstract Most of the clustering methods require the specification a priori of several parameters that rebound significantly in the quality of the solution. In many cases the users don't have the necessary information to predict good values for these parameters. Appropriate mechanisms are not known to select in an interactive way and in real time the necessary parameters to obtain density based clusters more efficiently. A clear exponent of the above-mentioned constitutes it the clustering algorithm DBSCAN, which has a high temporary complexity. The objective of the investigation consists on valuing the effectiveness of integrating visualization techniques to density based clustering algorithms, especially to the algorithm DBSCAN, to improve its efficiency, starting from the interaction in real time with the user. The main results obtained are: were identified the interactions to settle down in the algorithm DBSCAN, was created a model of integration of the visualization techniques and this algorithm, was developed the software DAVIA that it implements the integration pattern and it was illustrated by means of the experimentation with several collections of objects that clusters are obtained with better values of the internal and external measures of quality and in smaller time when they are integrated the visualization techniques with the cluster algorithm DBSCAN, regarding that been when the original DBSCAN algorithm is applied without visualization..
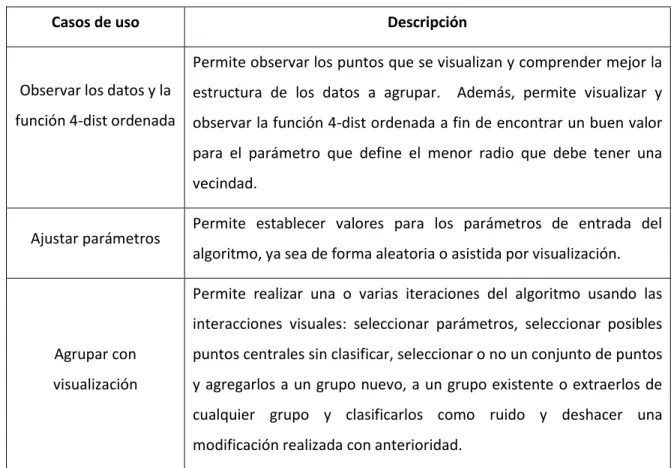
(6) Tabla de contenidos. Tabla de contenidos INTRODUCCIÓN ................................................................................................................................................. 1 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización ........................................ 5 1.1. Agrupamiento ............................................................................................................................................ 5. 1.2 Características generales del agrupamiento basado en densidad ............................................................ 8 1.2.1 Algoritmo DBSCAN (Density Based Spatial Clustering of Applications with Noise) .......................... 12 1.2.2 Determinación de parámetros iniciales para el algoritmo DBSCAN ................................................. 15 1.3 Visualización ............................................................................................................................................ 17 1.3.1 Tipos de visualización ....................................................................................................................... 18 1.3.2 Visualización de datos multiparamétricos ........................................................................................ 20 1.4 2. Consideraciones finales del capítulo ....................................................................................................... 24. Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN ................. 26 2.1. Contribuciones de la visualización a los algoritmos de agrupamiento basados en densidad ................. 26. 2.2. Interacciones que pueden implementarse en el algoritmo de agrupamiento DBSCAN ......................... 27. 2.3. Esquema general del modelo de integración de técnicas de visualización al algoritmo DBSCAN .......... 32. 2.4 Software DAVIA ....................................................................................................................................... 34 2.4.1 Análisis y diseño del software ........................................................................................................... 34 2.4.1.1. Casos de uso ............................................................................................................................................. 35. 2.4.1.2. Diagrama de clases ................................................................................................................................... 37. 2.4.2 Alcance del prototipo ....................................................................................................................... 43 2.4.3 Plataforma de desarrollo .................................................................................................................. 43 2.4.4 Funcionamiento de la herramienta DAVIA ....................................................................................... 44. 2.5 3. 2.4.4.1. Requerimientos .......................................................................................................................................... 44. 2.4.4.2. Interfaz principal de la aplicación................................................................................................................ 45. Conclusiones parciales del capítulo ......................................................................................................... 51. Estudio experimental y análisis de los resultados ................................................................................... 52 3.1. Descripción de los conjuntos de datos a utilizar ..................................................................................... 52. 3.2 Preprocesamiento de los conjuntos de datos ......................................................................................... 53 3.2.1 Análisis de componentes principales con SPSS ................................................................................. 53 3.2.2 Escalado multidimensional con R ..................................................................................................... 56 3.3 Medidas de validación del agrupamiento ............................................................................................... 60 3.3.1 Clasificación de las medidas de validación ....................................................................................... 61 3.3.2 Medida de validación externa F Global ............................................................................................ 62 3.3.3 Medidas de validación interna basadas en RST ............................................................................... 62 3.4 Experimentos que ilustran las ventajas que brinda la integración de técnicas de visualización al algoritmo de agrupamiento incorporado a DAVIA ........................................................................................... 67 3.5. Conclusiones parciales............................................................................................................................. 74. CONCLUSIONES GENERALES Y RECOMENDACIONES ........................................................................................ 75 Referencias bibliográficas ................................................................................................................................ 77.
(7) Tabla de contenidos. Anexos ............................................................................................................................................................ 83 Anexo 1. Distancias, similitudes y disimilitudes más usadas para comparar objetos ....................................... 83 Anexo 2. Descripción de los archivos sin clasificación de referencia considerados inicialmente para ilustrar la efectividad de la integración de técnicas de visualización y DBSCAN ............................................................... 85 Anexo 3. Descripción de los archivos con clasificación de referencia considerados inicialmente para ilustrar la efectividad de la integración de técnicas de visualización y DBSCAN ............................................................... 86 Anexo 4. Colección Iris transformada para trabajar con la herramienta DAVIA 1.0. ........................................ 87.
(8) Introducción. INTRODUCCIÓN El análisis de grupos permite descubrir la estructura interna de colecciones de datos e identificar distribuciones interesantes y patrones subyacentes en ellos, su importancia es evidente teniendo en cuenta que el volumen de datos a procesar crece cada día. Las técnicas de agrupamiento requieren en gran parte de los casos de una estimación de parámetros que es muy costosa computacionalmente. El agrupamiento basado en densidad (density-based clustering) agrupa objetos vecinos de un conjunto de datos basándose en condiciones de densidad. En la mayoría de los casos los algoritmos basados en densidad no funcionan correctamente con datos de alta dimensionalidad y dependen altamente de los parámetros iniciales (Kriegel and Pfeifle, 2005, Ester et al., 1996). Por ejemplo, el algoritmo DBSCAN requiere el conocimiento previo de dos parámetros: el número mínimo de objetos que pueden formar parte de un grupo y la distancia máxima a la que pueden estar separados dos objetos dentro de un mismo grupo. Estos parámetros son muy difíciles de determinar de forma computacional, por lo que dicho algoritmo tiene una elevada complejidad temporal (Kriegel and Pfeifle, 2005, Ester et al., 1996). Teniendo en cuenta las consideraciones anteriores se formula el siguiente problema de investigación. La mayoría de los métodos de agrupamiento basados en densidad requieren la especificación a priori de varios parámetros que repercuten significativamente en la calidad de la solución. En muchos casos los usuarios no disponen de la información necesaria para predecir valores óptimos para estos parámetros. No se conocen mecanismos adecuados para seleccionar de forma interactiva y en tiempo real los parámetros necesarios para obtener agrupamientos basados en densidad más eficientes. Por lo tanto, sería muy útil contar con un sistema capaz de visualizar las colecciones de datos a fin de que el usuario pueda tener contacto visual e interactuar con las mismas, logrando así una mejor interpretación de la información y una interacción con el algoritmo de agrupamiento que garantice una correcta estimación de los valores de los parámetros, y consecuentemente un agrupamiento eficiente. De ahí, que el objetivo general de este trabajo de diploma consiste en valorar la efectividad de integrar técnicas de visualización a algoritmos de agrupamiento basados en densidad, para mejorar su eficiencia, a partir de la interacción en tiempo real con el usuario. 1.
(9) Introducción. Este se desglosa en los siguientes objetivos específicos: . Identificar en cuáles algoritmos de agrupamiento basados en densidad la integración de técnicas de visualización puede reportar mayores ventajas.. . Identificar los tipos de interacciones que el usuario puede realizar mediante la visualización de algoritmos de agrupamiento basados en densidad, y sus ventajas.. . Proponer un modelo de integración de técnicas de visualización para un algoritmo específico de agrupamiento basado en densidad.. . Implementar computacionalmente un prototipo de software acorde al modelo propuesto.. . Evaluar los beneficios del modelo propuesto, a través de comparaciones experimentales con la herramienta implementada.. Las preguntas de Investigación planteadas son: . ¿En cuáles algoritmos de agrupamiento basados en densidad la integración de técnicas de visualización puede reportar mayores ventajas?. . ¿Cuáles tipos de interacciones pueden implementarse en algoritmos de agrupamiento basados en densidad y qué ventajas proporcionan?. . ¿Cómo podrían integrarse técnicas de visualización en los algoritmos de agrupamiento basados en densidad?. . ¿Qué beneficios presupone la integración de técnicas de visualización en algoritmos de agrupamiento basados en densidad?. La suposición fundamental de que el proceso visual induce a apreciaciones intuitivas de las características más destacadas de la información, unido a la aceptación de las técnicas de visualización como una vía para la extracción de información relevante, y después de haber realizado el marco teórico, permitieron que se formulara la siguiente hipótesis de investigación como presunta respuesta a las preguntas de investigación: Integrar técnicas de visualización a algoritmos de agrupamiento basados en densidad, permitiendo al usuario tener contacto visual con la colección de objetos e interactuar con la misma, a fin de contribuir a una estimación de parámetros más rápida y eficiente, mejora en gran medida el rendimiento de dichos algoritmos y la calidad de los resultados obtenidos.. 2.
(10) Introducción. El desarrollo de la Inteligencia Artificial, la Computación Gráfica y los lenguajes de programación de alto nivel permiten enfrentar con éxito el desafío de desarrollar una aplicación computacional como la que se pretende. El laboratorio de Inteligencia Artificial del Centro de Estudios de Informática (CEI) de la Universidad Central “Marta Abreu” de Las Villas (UCLV) tiene gran experiencia en el desarrollo y empleo de algoritmos de agrupamiento. Por otro lado, especialistas del laboratorio de Computación Gráfica de este mismo centro tienen experiencia en el desarrollo y empleo de técnicas de visualización científica. Además, existen experiencias previas en el empleo de técnicas de visualización para lograr mejores resultados al aplicar algoritmos de la Inteligencia Artificial. Este Trabajo de Diploma cuenta con una introducción, tres capítulos, conclusiones generales, recomendaciones para el trabajo futuro y un conjunto de tablas y anexos. En el capítulo uno se abordan aspectos teóricos sobre los temas del agrupamiento y la visualización, tanto de manera general como específica. Se da una definición de agrupamiento y una panorámica de algunos de los diferentes tipos de agrupamiento, ejemplificando con algoritmos en cada caso y se enfocan las características principales de los algoritmos de agrupamiento basados en densidad dando un tratamiento especial a DBSCAN. Se da una definición de visualización y se habla de algunos de los diferentes tipos de visualización, ejemplificando con técnicas y algoritmos en cada caso y se hace una descripción más completa de la visualización de datos multiparamétricos. En el capítulo dos se hace un estudio de las principales contribuciones de la visualización a los algoritmos de agrupamiento basados en densidad, se muestran las interacciones visuales que pueden implementarse en el algoritmo de agrupamiento DBSCAN para mejorar su desempeño y se propone un modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN. Se hace una descripción del software DAVIA donde se abordan elementos de ingeniería de software como los diagramas de casos de uso y de clases, se presenta el alcance del prototipo, la plataforma de desarrollo y el funcionamiento de la herramienta, mostrando los requerimientos de la misma y su interfaz principal. En el capítulo tres se hace un estudio ilustrativo para mostrar los resultados del trabajo realizado. Se realiza una descripción de los conjuntos de datos a utilizar y se explica de qué manera se hizo el preprocesamiento de estos y usando qué herramientas. Se da una definición de medidas de validación del agrupamiento y se caracterizan los diferentes tipos de medidas de validación, enfatizando en la medida de validación externa F Global y las medidas de validación interna basadas 3.
(11) Introducción. en la Teoría de los Conjuntos Aproximados que fueron las usadas. Se describe un conjunto de experimentos que ilustra las ventajas que brinda la integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN.. 4.
(12) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. 1 Algoritmos de agrupamiento basados en densidad y técnicas de visualización A continuación se tratan las generalidades del agrupamiento, y específicamente el agrupamiento basado en densidad. Se describe el algoritmo de agrupamiento DBSCAN (Ester et al., 1996) y se abordan los elementos principales de la Visualización Científica, enfatizando en la visualización de datos multiparamétricos, específicamente la utilización de gráficos de dispersión de dos dimensiones, que es la que se utilizará para integrar con el algoritmo de agrupamiento a implementar. 1.1. Agrupamiento. El análisis de grupos es descrito como una herramienta para el descubrimiento de conocimientos, porque tiene la potencialidad de revelar relaciones basadas en datos complejos no detectadas previamente. Los algoritmos de agrupamiento son usados para encontrar una estructura de grupos que se ajuste al conjunto de datos, logrando homogeneidad dentro de los grupos y heterogeneidad entre ellos (Anderberg, 1973). Debe existir un alto grado de asociación entre los objetos de un mismo grupo y un bajo grado entre los miembros de grupos diferentes. Cuando el agrupamiento se basa en la similitud de los objetos, se desea que los objetos que pertenecen al mismo grupo sean tan similares como se pueda y los objetos que pertenecen a grupos diferentes sean tan diferentes como sea posible. En otras palabras, seguir el principio de maximizar la similitud dentro del grupo y minimizar la similitud entre los grupos (Jain et al., 1999a). El concepto de “similitud” tiene que ser especificado acorde a los datos. En la mayoría de los casos los datos son vectores de valores reales, entonces se requieren algunas medidas (distancias, similitudes, o disimilitudes) para cuantificar el grado de asociación entre ellos. Los métodos de agrupamiento se clasifican siguiendo varios criterios: tipo de los datos de entrada del algoritmo, criterios para definir la similitud entre los objetos, conceptos en los cuales se basa el análisis y forma de representación de los datos, entre otros (Halkidi et al., 2001a). Una clasificación general distingue dos tipos: aquellos basados en una función objetivo y los jerárquicos (Han and Kamber, 2001, Pedrycz, 2005). Esta primera categoría más general se refiere a la construcción de particiones (grupos) del conjunto de datos sobre la base del perfeccionamiento de algún índice, conocido también como función 5.
(13) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. objetivo. Es, en esencia, dividir n objetos en un número positivo k de grupos, generalmente especificado a priori. El objetivo de estos métodos es encontrar la mejor división de los datos en k grupos basada en una medida de similitud dada y conservar el espacio de particiones posibles en k subconjuntos solamente. La mayoría de los algoritmos que siguen esta técnica son esencialmente basados en prototipos, comienzan con una partición inicial, usualmente aleatoria, y proceden con su refinamiento (Kruse et al., 2007). Uno de los algoritmos que sigue esta primera categoría y que ha sido ampliamente utilizado es el kmedias (k-means) (Jain and Dubes, 1988, Kaufman and Rousseeuw, 1990, McQueen, 1967, Xiong et al., 2006). A partir de él se han derivado varios, que intentan resolver sus desventajas como el PAM (Kaufman and Rousseeuw, 1990) y sus mejoras CLARA y CLARANS (Ng and Han, 1994). Los algoritmos jerárquicos, por su parte, hacen una descomposición jerárquica de los objetos. Dentro de ellos, los aglomerativos (bottom-up), consideran que cada objeto constituye un grupo, por tanto, inicialmente existen tantos grupos como objetos tiene la colección, y sucesivamente los unen, hasta que todos los objetos formen un único grupo, generalmente considerando alguna de las medidas de distancia entre grupos, dentro de las cuales se encuentran el enlace simple (Gower and Ross, 1969, Gotlieb and Kumar, 1968) y el enlace completo (Backer and Hubert, 1976), que son ampliamente utilizadas. Mientras que los divisivos (top-down) consideran inicialmente que existe un único grupo al cual pertenecen todos los objetos y sucesivamente dividen los grupos en grupos más pequeños, hasta que cada grupo contenga un único objeto. Algunos algoritmos jerárquicos de este tipo son: BIRCH (Zhang et al., 1996) es una variante con complejidad lineal, pero no descubre grupos con calidad, requiere de parámetros de entrada que pueden forzar el tamaño de los grupos, es sensible al orden de los datos de entrada y es cuestionable su uso en datos con alta dimensionalidad. CURE es capaz de captar grupos de varias formas y tamaños, tiene una alta complejidad y es sensible a varios parámetros de entrada (Guha et al., 1998). El agrupamiento basado en celdas (grid-based clustering) es esencialmente propuesto para la minería de datos espaciales (Halkidi et al., 2001b). Algunos algoritmos basados en celdas son: STING (Wang et al., 1997), WaveCluster (Sheikholeslami et al., 1998, Sheikholeslami et al., 2000) y CLIQUE (Agrawal et al., 1998). Estos algoritmos son escalables, tienen complejidad lineal, pero no son buenos para datos con alta dimensionalidad, porque se focalizan en la modelación de la estructura geométrica de objetos en el espacio y no dependen de una medida de distancia.. 6.
(14) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. Existe una clasificación que divide el agrupamiento en conceptual y estadístico (Halkidi et al., 2001b). Por otra parte, aquellos algoritmos que utilizan métodos geométricos y técnicas de proyección se clasifican en agrupamiento incompleto o heurístico (Höppner et al., 1999). Otras propuestas agrupan utilizando redes neuronales artificiales, por ejemplo, mapas auto-organizativos (Self Organizing Maps; SOM) (Halkidi et al., 2001b). Algunos agrupamientos se basan en modelos (model-based clustering), encontrando buenas aproximaciones de los parámetros del modelo que mejor ajusten a los datos. Otra clasificación, no mutuamente excluyente a las ya presentadas, considera la forma de manipular la incertidumbre en términos del solapamiento de los grupos: agrupamiento duro y borroso (Höppner et al., 1999). Las técnicas duras pueden ser deterministas o con solapamiento. Las deterministas crean una partición, donde los grupos son mutuamente excluyentes y exhaustivos del universo de objetos. Los algoritmos con solapamiento crean un cubrimiento, donde un objeto puede pertenecer a más de un grupo. Las técnicas borrosas se subdividen en probabilísticas y posibilísticas (Kruse et al., 2007). El algoritmo EM (Bradley et al., 1998), base del agrupamiento basado en modelos probabilísticos, y su mejora FREM (Ordonez and Omiecinski, 2002), son variantes del algoritmo kmedias y asignan a los objetos una distribución de probabilidad de pertenencia a cada grupo. Éstos manipulan datos de alta dimensionalidad, pero realizan un refinamiento muy costoso. Otra clasificación divide los algoritmos en estáticos e incrementales. Estos últimos tienen la habilidad de procesar nuevos datos que son adicionados a la colección; por ejemplo, el flujo de noticias (Gaber and Yu, 2006). El algoritmo k-medias incremental (incremental k-means) es una muestra de este tipo de algoritmos (Berry, 2004). Otros tipos de métodos han emergido para el análisis de grupos, principalmente motivados en problemas específicos de minería de datos (Han and Kamber, 2001). El agrupamiento basado en densidad (density-based clustering) agrupa objetos vecinos de un conjunto de datos basándose en condiciones de densidad. Éstos difieren de los algoritmos que obtienen particiones mediante la relocalización iterativa de puntos a partir del número de grupos. Los algoritmos DBSCAN (Ester et al., 1996) y DENCLUE (Hinneburg and Keim, 1998) son ejemplos de algoritmos basados en densidad. Ambos tienen una complejidad O(nlogn), donde n es la cantidad de objetos a agrupar, no funcionan correctamente con datos de alta dimensionalidad y dependen altamente de los parámetros iniciales. OPTICS (Ankerst et al., 1996) y el algoritmo propuesto en (Kriegel and Pfeifle, 2005), son variantes mejoradas del DBSCAN. Otros algoritmos basados en densidad se reportan en (Ruiz-Shulcloper et al.,. 7.
(15) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. 2000, Qian et al., 2004b, Dourisboure et al., 2007). Precisamente en el próximo subepígrafe se abordarán las principales características de los algoritmos de agrupamiento basados en densidad. 1.2. Características generales del agrupamiento basado en densidad. Los algoritmos basados en densidad obtienen los grupos basándose en regiones densas de objetos en el espacio de datos que están separadas por regiones de baja densidad (estos elementos aislados representan ruido). Este tipo de métodos es muy útil para filtrar ruido (Kriegel and Pfeifle, 2005). DBSCAN (Ester et al., 1996) es uno de los primeros algoritmos de agrupamiento que emplea este enfoque, el mismo introduce los conceptos de puntos centrales, puntos borde y puntos ruido. Comienza seleccionando un punto t arbitrario, si t es un punto central, se empieza a construir un grupo alrededor de él, tratando de descubrir componentes denso-conectadas; si no, se visita otro objeto del conjunto de datos. Puntos centrales (core points) son aquellos tales que en su vecindad de radio hay una cantidad de puntos mayor o igual que un umbral MinPts especificado. Un punto borde o frontera tiene menos puntos que MinPts en su vecindad, pero pertenece a la vecindad de un punto central. Un punto ruido (noise) es aquel que no es ni central ni borde. En la Figura 1.1 se muestran tres agrupamientos naturales donde se pueden detectar los grupos de puntos y los puntos ruidosos que no pertenecen a ningún grupo. Por ejemplo, en la muestra 3 de la Figura 1.1 aparecen varios puntos ruidosos.. (a) Muestra 1. (b) Muestra 2. (c) Muestra 3. Figura 1.1. Representación de conjuntos de datos en el plano (Ester et al., 1996).. 8.
(16) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. La razón principal por la que se reconocen los grupos es que dentro de cada grupo existe una densidad típica de puntos que es considerablemente mayor que fuera de los grupos. Además, la densidad dentro de las áreas de ruido es menor que la densidad en cualquiera de los grupos. A continuación se formaliza la noción intuitiva de agrupamiento y ruido en un conjunto de datos D de algún espacio k-dimensional S. La idea clave es que para cada punto el grupo con vecindad de un radio dado tiene que contener al menos un número mínimo de puntos, es decir, la densidad en una vecindad tiene que exceder un cierto umbral. El borde de la vecindad está determinado por la elección de una función de distancia para dos puntos p y q, denotada por dist(p,q). Por ejemplo, cuando se usa la distancia Manhattan en un espacio bidimensional, el borde de la vecindad es rectangular. Aunque los métodos de agrupamiento basados en densidad pueden emplear cualquier función de distancia, para alguna aplicación determinada debe ser elegida una función de distancia apropiada (Ver Anexo 1. Distancias, similitudes y disimilitudes más usadas para comparar objetos). A continuación se presentarán las definiciones publicadas en (Ester et al., 1996) para formalizar los elementos principales del agrupamiento basado en densidad. Definición 1 (-vecindad de un punto). La -vecindad de un punto p, denotada por N(p), está definida por N(p) = {qD | dist(p, q) ≤ }. Un enfoque ingenuo podría exigir que para cada punto en un grupo exista al menos un número mínimo de puntos (MinPts) en una -vecindad de ese punto. Como sea, esta propuesta falla porque hay dos tipos de puntos en un grupo, puntos dentro del grupo (puntos centrales) y puntos en el borde del grupo (puntos bordes). En general, una -vecindad de un punto borde contiene significativamente menos puntos que una -vecindad de un punto central. Por lo tanto, se tendría que establecer para el número mínimo de puntos un valor relativamente bajo a fin de incluir todos los puntos pertenecientes a un mismo grupo. Este valor, sin embargo, no será característico para el grupo respectivo, particularmente en presencia de ruido. Por consiguiente, se requiere que para cada punto p en el grupo C exista un punto q en C tal que p esté dentro de la -vecindad de q y N(q) contenga al menos MinPts puntos. Esta definición se presentó en (Ester et al., 1996) como sigue: Definición 2 (directamente denso-alcanzable). Un punto p se dice directamente denso-alcanzable desde un punto q si 1. pN(q) y. 9.
(17) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. 2. |N(q)| ≥ MinPts (condición de punto central). Es posible concluir que la denso-alcanzabilidad directa es simétrica para pares de puntos centrales. En general, sin embargo, no es simétrica si un punto central y un punto borde son los involucrados. En la Figura 1.2 se puede observar el caso asimétrico.. (a) p es punto borde y q es punto central. (b) p es directamente denso-alcanzable desde q y q no es directamente denso-alcanzable desde p. Figura 1.2. Puntos centrales y puntos bordes (Ester et al., 1996). Definición 3 (denso-alcanzable). Un punto p es denso-alcanzable desde un punto q si existe una cadena de puntos p1, …, pn, p1= q, pn= p tal que pi+1 es directamente denso alcanzable desde pi. La denso-alcanzabilidad es una extensión canónica de la denso-alcanzabilidad directa. Esta relación es transitiva pero no es simétrica. En la Figura 1.3 se pueden observar las relaciones de una muestra de puntos y, en particular, el caso asimétrico. Aunque no es simétrica en general, es obvio que la densoalcanzabilidad es simétrica para puntos centro. Dos puntos borde del mismo grupo C son posiblemente no denso-alcanzables desde algún otro ya que la condición de punto central podría no sostenerlos a ambos. Sin embargo, tiene que haber un punto central en C desde el cual ambos puntos borde de C sean denso-alcanzables. Por consiguiente, en (Ester et al., 1996) se introduce la noción de denso-conectividad que cubre esta relación de puntos borde. Definición 4 (denso-conectado). Un punto p está denso-conectado a un punto q si existe un punto o tal que ambos, p y q sean denso-alcanzables desde o. La denso-conectividad es una relación simétrica. Para puntos denso-alcanzables, la relación es también reflexiva, así se puede observar en la Figura 1.3. A continuación se presenta la noción basada en densidad de un grupo según (Ester et al., 1996). Intuitivamente, un grupo está definido por ser un conjunto de puntos denso-conectados. El ruido 10.
(18) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. puede ser definido relativo a un conjunto dado de grupos. El ruido es simplemente el conjunto de puntos en D no perteneciente a ninguno de los grupos.. (a) p es denso-alcanzable desde q y q no es denso-alcanzable desde p.. (b) p y q están denso-conectados uno al otro mediante o.. Figura 1.3.Denso-alcanzabilidad y denso-conectividad (Ester et al., 1996). Definición 5 (grupo). Sea D un conjunto de puntos. Un grupo C es un subconjunto no vacío de D que satisface las siguientes condiciones: 1. p, q; si pC y q es denso-alcanzable desde p, entonces qC (maximalidad). 2. p, qC; p es denso-conectado a q (conectividad). Definición 6 (ruido). Sean C1,…,Ck los grupos del conjunto de datos D, i = 1, …, k. Entonces se define el ruido como el conjunto de puntos en el conjunto de datos D que no pertenecen a ningún grupo Ci, o sea, ruido = {pD | i: pCi}. Es posible apreciar que un grupo C contiene al menos MinPts puntos por las siguientes razones. Ya que C contiene al menos un punto p, p tiene que estar denso-conectado a si mismo mediante algún punto o (que pudiera ser igual a p). Así, al menos o tiene que satisfacer la condición de punto central y, consecuentemente, la -vecindad de o contener al menos MinPts puntos. Dados los parámetros y MinPts, se puede encontrar un agrupamiento usando un enfoque de dos pasos. Lo primero sería elegir un punto arbitrario del conjunto de datos que satisfaga la condición de punto central como semilla. Luego, como segundo paso, se recuperarían todos los puntos que son denso-alcanzables desde la semilla obteniendo el grupo que contiene a la misma.. 11.
(19) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. Lema 1. Sea p un punto en D y |N(p)| ≥ MinPts, entonces el conjunto O = {o | oD y o es densoalcanzable desde p} es un grupo. No es obvio que un grupo C sea únicamente determinado por alguno de sus puntos centrales. Sin embargo, cada punto en C es denso-alcanzable desde cualquiera de los puntos centrales de C y, por tanto, un grupo C contiene exactamente los puntos que son denso-alcanzables desde un punto central arbitrario de C. Lema 2. Sea C un grupo y sea p cualquier punto en C con |N(p)| ≥ MinPts. Entonces C es igual al conjunto O = {o | oD y o es denso-alcanzable desde p}. 1.2.1. Algoritmo DBSCAN (Density Based Spatial Clustering of Applications with Noise). El algoritmo DBSCAN (Density Based Spatial Clustering of Applications with Noise) está diseñado para encontrar grupos y ruido en un conjunto de datos de acuerdo a las definiciones 5 y 6. Lo ideal sería que se conocieran los parámetros y MinPts apropiados de cada grupo y al menos un punto del grupo correspondiente. Entonces, se podrían recuperar todos los puntos que son denso-alcanzables desde el punto dado usando los parámetros correctos. Pero no hay una manera fácil de obtener esta información de antemano para todos los grupos del conjunto de datos, aunque es importante señalar que existe una heurística simple y efectiva para determinar los parámetros y MinPts del grupo “más fino”, es decir, el grupo menos denso del conjunto de datos. Por lo tanto, DBSCAN usa valores globales para y MinPts, o sea, los mismos valores para todos los grupos. Los parámetros de densidad del grupo “más fino” son buenos candidatos para esos valores de los parámetros globales especificando la menor densidad que no se considera ruido. Para encontrar un grupo, DBSCAN inicia con un punto arbitrario p y recupera todos los puntos densoalcanzables desde p. Si p es un punto central, este procedimiento encuentra un grupo (ver Lema 2). Si p es un punto borde, no hay puntos denso-alcanzables desde p y DBSCAN visita el siguiente punto en el conjunto de datos. Al utilizar valores globales para y MinPts, DBSCAN puede mezclar dos grupos en uno de acuerdo a la definición 5, si dos grupos de diferente densidad están “cerca” el uno del otro. Sea la distancia entre dos conjuntos de puntos S1 y S2 definida como dist(S1,S2) = min{dist(p, q) | pS1 ,qS2}. Entonces, dos conjuntos de puntos que tienen al menos la densidad del grupo más fino serán separados el uno del otro solo si la distancia entre los dos conjuntos es mayor que . Consecuentemente, una llamada. 12.
(20) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. recursiva a DBSCAN puede ser necesaria para los grupos detectados con altos valores de MinPts. Esto no es, sin embargo, una desventaja, porque la aplicación recursiva de DBSCAN da como resultado un algoritmo elegante y muy eficiente. Además, el agrupamiento recursivo de los puntos de un grupo es solamente necesario bajo condiciones en que pueden ser fácilmente detectados. Si dos grupos C1 y C2 están demasiado cerca uno del otro, puede suceder que algún punto p pertenezca a ambos, C1 y C2. Entonces p tiene que ser un punto borde de ambos grupos porque de otra forma C1 sería igual a C2 ya que se utilizan parámetros globales. En este caso, el punto p será asignado al grupo que sea encontrado primero. Excepto en estos casos excepcionales, el resultado de DBSCAN es independiente del orden en que los puntos del conjunto de datos sean visitados de acuerdo al Lema 2. Resumiendo las definiciones 2 y 3; un punto q es directamente denso-alcanzable desde otro punto t (con relación a los parámetros MinPts y ) si t es un punto central y q pertenece a la vecindad de t; un punto q es denso-alcanzable desde un punto t si existe una cadena de puntos t0, t1,…, tm, tales que ti-1 es directamente denso-alcanzable desde ti, 1≤ i ≤ m, t0=q y tm=t. En consecuencia, los puntos centrales están en regiones de alta densidad, los puntos borde en la frontera de regiones densas y los puntos ruido en regiones de baja densidad. Este algoritmo busca grupos comprobando la vecindad de cada punto del conjunto de datos y va añadiendo puntos que son denso-alcanzables desde un punto central. A continuación se presentan los pasos principales que componen el algoritmo DBSCAN, con el objetivo de esclarecer de forma simplificada el funcionamiento general de este algoritmo de agrupamiento. Algoritmo de agrupamiento DBSCAN: Entrada:. Conjunto de puntos a agrupar y los valores para los parámetros (radio de la vecindad de cada punto) y MinPts (número mínimo de puntos en una vecindad).. Salida:. Conjunto de puntos agrupados.. 1. Seleccionar aleatoriamente un punto t. 2. Si t es un punto central se forma un grupo alrededor de t con todos los. 13.
(21) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. puntos denso-alcanzables desde t. 3. Si t es un punto borde o ruido, se visita otro punto. 4. Si todos los puntos han sido visitados, terminar; si no, volver al paso 1.. Paso 1: La selección del punto t se realiza de forma aleatoria, en caso de que el punto elegido ya haya sido clasificado se procede a seleccionar otro y así sucesivamente hasta que el punto que va a ser analizado posteriormente no esté aún clasificado. Se supone que de una manera u otra hay que recorrer todo el conjunto de puntos. Paso 2: En este paso, de ser el punto t central (el tamaño de su -vecindad es mayor o igual a MinPts), borde o ruido, se clasifica como tal, si es central se clasifican todos los pertenecientes a su -vecindad como pertenecientes a su grupo. Luego se procede a realizar el Paso 2 de nuevo para cada punto del grupo del que t es centro y que estaba sin clasificar. Paso 3: Se pregunta si el punto t es borde o ruido y de ser así, se procede a visitar otro punto. Paso 4: Si todos los puntos del conjunto de datos fueron visitados se finaliza devolviendo los puntos agrupados, de lo contrario se regresa al Paso 1. A continuación se presenta un pseudocódigo del algoritmo para una mejor comprensión de cómo pudiera realizarse una implementación. Entrada:. SetOfPoints (estructura de datos que contiene para cada punto las coordenadas del mismo y un campo id que estará vacío, donde será puesto el id del grupo al que pertenece) y los valores para los parámetros (radio de la vecindad de cada punto) y MinPts (número mínimo de puntos en una vecindad).. Salida:. SetOfPoints (la misma estructura de datos de la entrada con los campos id actualizados). 1. Recorrer SetOfPoints y poner en el punto actual el que se está analizando 1.1. Si el punto actual (se pone en una variable llamada CurrentPoint) está clasificado, volver al paso 1, si no:. 14.
(22) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. 1.1.1. Si el tamaño de la -vecindad de CurrentPoint es menor que MinPts entonces CurrentPoint se deja vacío su campo id y se vuelve al Paso 1. 1.1.2. Si no, se clasifican como pertenecientes al grupo del punto actual todos los puntos que están en su -vecindad (se actualiza su campo id), dichos puntos serán incluidos en una variable CurrentCluster. 1.1.3. Eliminar de CurrentCluster el punto CurrentPoint. 1.1.4. Mientras que CurrentCluster no esté vacío hacer: 1.1.4.1. Poner en CurrentPoint el primer punto de CurrentCluster y quitarlo de CurrentCluster. 1.1.4.2. Determinar la -vecindad de CurrentPoint (se llamará NewCluster), y si su tamaño es menor que MinPts, regresar al paso 1.1.4, si no: 1.1.4.2.1.. Si algún punto de NewCluster está sin clasificar, se incorpora a CurrentCluster y se actualiza su campo id (básicamente esto significa clasificarlo como perteneciente al grupo de CurrentPoint).. 2. Devolver SetOfPoints. Es verdaderamente complejo determinar de manera automática buenos valores globales para los parámetros iniciales y MinPts (Ester et al., 1996). En el siguiente epígrafe se hace referencia a la manera de lograr una estimación adecuada de los valores de estos parámetros. 1.2.2. Determinación de parámetros iniciales para el algoritmo DBSCAN. En la literatura se ha definido una heurística simple, pero efectiva para determinar los parámetros y MinPts del grupo más “fino” del conjunto de datos (Ester et al., 1996). Esta heurística se basa en la siguiente observación. Sea d la distancia de un punto p a sus k vecinos más cercanos, entonces la dvecindad de p contiene exactamente k+1 puntos para la mayoría de los puntos p. La d-vecindad de p contiene más de k+1 puntos solo si muchos puntos tienen exactamente la misma distancia d desde p, que es bastante improbable.. 15.
(23) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. Para un k dado se define una función k-dist desde el conjunto de datos D a los números reales, haciendo corresponder a cada punto la distancia a sus k vecinos más cercanos. Cuando se ordenan los puntos del conjunto de datos en orden ascendente de sus valores k-dist, el gráfico de esta función, llamado gráfico k-dist ordenado, ofrece algunas sugerencias concernientes a la distribución de densidad en el conjunto de datos. Si se escoge un punto arbitrario p, se asigna al parámetro el valor de k-dist(p) y al parámetro MinPts se le asigna el valor de k, todos los puntos con un valor igual o menor que k-dist(p) serán puntos centrales. Si se encuentra un punto umbral con el valor maximal kdist en el grupo “más fino” de D, entonces se tiene los valores deseados para los parámetros. El punto umbral es el último punto en el primer “valle” del gráfico k-dist ordenado (ver Figura 1.4). Todos los puntos con valores mayores de k-dist, es decir, que se encuentran a la derecha del punto umbral, son considerados ruido. El resto de los puntos, es decir, aquellos que se encuentran a la izquierda del punto umbral, se asignan a algún grupo.. Figura 1.4. Gráfico 4-dist ordenado para un conjunto de datos de muestra. En general, es muy difícil detectar el primer “valle” automáticamente, pero es relativamente simple para un usuario ver tal valle en una representación gráfica. Por lo tanto, se propone seguir una aproximación interactiva para determinar el punto umbral. DBSCAN necesita dos parámetros: y MinPts. Sin embargo, los experimentos indican que los gráficos k-dist para k>4 no presentan diferencias significativas a los gráficos 4-dist y, además necesitan. 16.
(24) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. considerablemente mayor trabajo computacional. Por lo tanto, en (Ester et al., 1996) se sugiere eliminar el parámetro MinPts, considerando para cualquier conjunto de datos el valor 4. En (Ester et al., 1996) se propone la siguiente aproximación interactiva para determinar el parámetro. de DBSCAN: -. Calcular y mostrar el gráfico 4-dist ordenado del conjunto de datos.. -. Si el usuario puede estimar el porcentaje de ruido, entonces se considera este porcentaje para deducir una propuesta para el punto umbral a partir de él.. -. El usuario puede aceptar dicho punto umbral o seleccionar otro punto como umbral. El valor 4-dist del punto umbral se utiliza como el valor para DBSCAN.. En este trabajo se propone valorar la efectividad de integrar técnicas de visualización a algoritmos de agrupamiento basados en densidad, específicamente DBSCAN, para mejorar su eficiencia, a partir de la interacción en tiempo real con el usuario. De esta forma se podrían estimar los parámetros que permitan obtener un mejor desempeño del algoritmo. Es por ello, que a continuación se mostrarán las generalidades de las técnicas de visualización, enfatizando en la visualización de datos multiparamétricos, específicamente la utilización de gráficos de dispersión de dos dimensiones, que es la técnica que se utilizará para integrar con el algoritmo de agrupamiento a implementar. 1.3. Visualización. La visualización es un método de computación que transforma lo simbólico en geométrico y permite a los investigadores observar simulaciones y cálculos. Ofrece además un método para ver lo no visto y enriquece el proceso de descubrimiento científico. Es el proceso de transformación de datos, información y conocimiento en representaciones gráficas para apoyar tareas tales como: análisis de datos, exploración de la información, detección de patrones, etc. Sin la existencia de la visualización, habría menos percepción o comprensión de los datos, la información o el conocimiento por las personas, debido a una variedad de razones. Estas razones pueden incluir las limitaciones de la visión humana, o la invisibilidad y abstracción de los datos, la información y el conocimiento (Zhang, 2008). La visualización está revolucionando la manera de hacer ciencia en muchos campos, su objetivo fundamental es influenciar los métodos científicos existentes, proporcionando una nueva visión de los mismos a partir de métodos visuales (Hansen and Johnson, 2005).. 17.
(25) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. 1.3.1. Tipos de visualización. La visualización puede dividirse en tres campos fundamentales: visualización científica, visualización de software y visualización de información (Suárez, 2003). La visualización científica permite generar y manipular una representación gráfica de un conjunto de datos, y las técnicas de visualización científica son aceptadas como una vía para la extracción de información relevante de un conjunto de datos de gran tamaño. Esto se debe a que el cerebro humano es capaz de analizar con mayor facilidad una simple imagen que resume una gran cantidad de información (Andrews, 2005). Los algoritmos de visualización científica transforman un conjunto de datos en otro y también sus dimensiones. Estas transformaciones pueden categorizarse de acuerdo a su estructura, considerando los efectos que tienen las trasformaciones en la topología y geometría del conjunto de los datos, y de acuerdo al tipo del conjunto de datos con que opera el algoritmo en: escalares, vectoriales, tensoriales y modelados, estos últimos capturan todos los algoritmos que no se ajustan a ninguna de las categorías anteriores ni combinaciones entre estas (Johnson and Hansen, 2005). La visualización científica se usa para tres tipos de análisis: exploratorio, confirmativo y presentación. En el análisis exploratorio, dado un conjunto de datos sin hipótesis acerca de ellos y mediante un proceso de búsqueda interactiva de información, generalmente casual, la visualización sugiere hipótesis sobre los datos. En el análisis confirmativo, la visualización verifica o niega hipótesis dadas acerca de los datos. En la presentación, los datos representan un hecho conocido a priori y el resultado es una visualización de alta calidad que presenta el hecho (Salgado, 2003). Las técnicas de visualización científica se pueden agrupar de varias formas. Una forma de clasificarlas es de acuerdo al tipo de datos con los que operan. Así se tienen, según (Hansen and Johnson, 2005): . Algoritmos escalares que operan con datos escalares. Un ejemplo es la generación de líneas de contorno de temperatura en mapas climáticos.. . Algoritmos vectoriales que operan con datos vectoriales. Las flechas orientadas que muestran corrientes de aire (dirección y magnitud) en mapas climáticos es un ejemplo de visualización vectorial.. . Algoritmos tensoriales que operan con matrices de tensores. Un ejemplo de algoritmos tensoriales es cuando se muestran componentes de tensión en un material usando iconos orientados.. 18.
(26) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. . Algoritmos de modelado que generan topologías, geometrías, superficies normales o texturas a partir del conjunto de datos. Los algoritmos de modelado tienden a englobar aquellos tipos de algoritmos que no encajan de manera limpia en ninguna de las categorías anteriormente expuestas. Por ejemplo, la generación de glifos (Glyphs) orientados de acuerdo a vectores de dirección y escalados de acuerdo a valores escalares es un algoritmo híbrido que combina algoritmos escalares y vectoriales. Por conveniencia, se clasifica dicho algoritmo como un algoritmo de modelado, ya que no encaja a cabalidad dentro de ninguna otra categoría.. La visualización de software comprende la visualización de algoritmos y de programas computacionales. La primera consiste en visualizar abstracciones de alto nivel que describen el software, mientras que la segunda se refiere al código real del programa y a sus estructuras de datos. Ambas pueden darse en forma estática o dinámica. La estática está representada generalmente por medio de organigramas, mientras que la dinámica se denomina animación de algoritmos. La visualización estática de código puede incluir algún tipo de mejoramiento de la impresión, la representación dinámica del programa puede destacar las líneas de código cuando están siendo ejecutadas. Por ejemplo, en el área de la visualización de la programación lógica, el principal objetivo es la representación gráfica adecuada tanto de las reglas de inferencia como del flujo entre ellas (Suárez, 2003). Las representaciones visuales de programas son muy útiles, facilitan la comunicación entre el desarrollador y los expertos en un área específica del conocimiento, además pueden utilizarse para apoyar el aprendizaje y entendimiento de los algoritmos. La visualización de información consiste en el uso interactivo de representaciones visuales, auditivas y sensoriales, en general de datos abstractos, con el objetivo de aumentar el conocimiento. Es el proceso de interiorización del conocimiento mediante la percepción de información; interviene en el paso de los datos a información y la posibilidad de la construcción del conocimiento al revelar patrones que subyacen de los datos (S. K. Card, 1999). Esta área ha ampliado su espectro debido al desarrollo de la visualización en tiempo real. Algunas de las subáreas fundamentales de la visualización de información son: visualización de arquitecturas de software, minería visual de datos, visualización de grafos y visualización de datos multiparamétricos (Suárez, 2003).. 19.
(27) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. 1.3.2. Visualización de datos multiparamétricos. Existe una multitud de problemas en los que cada dato está descrito por más de un atributo. Estos atributos pueden ser fechas, lugares, precios o valores descriptivos, y pueden tener o no una referencia espacial. A este tipo de datos se les llama multiparamétricos y se encuentran generalmente en aplicaciones de minería de datos, estadística e inteligencia artificial (Keim, 2002). Una definición más precisa de datos multiparamétricos se puede encontrar en (Bergeron and Grinstein, 1989, Brodlie, 1992). El objetivo fundamental de los métodos de visualización para datos multiparamétricos es lograr que las representaciones revelen correlaciones o patrones entre los atributos (Keim, 2002, Salgado, 2003, Eick, 2000). Con este fin existe actualmente una amplia gama de técnicas de visualización para las cuales se han creado además diversas mejoras. Las técnicas pueden ser clasificadas en basadas en iconos, basadas en píxel y proyecciones, y geométricas (Keim, 2002, Salgado, 2003). Las técnicas basadas en iconos tienen dos parámetros que la caracterizan: el primero es el tipo de figura que representará cada observación, o sea, la forma del icono; el segundo parámetro es la forma en que se definirá la posición de cada icono en la imagen (Theisel, 2000). Estas técnicas no sufren de pérdida de información. Se logra evitar la pérdida de información al realizar una proyección de las dimensiones a diferentes atributos de un icono (Salgado, 2003, Theisel, 2000). Al crear una imagen a partir de un conjunto de datos el resultado es un conjunto de figuras con diferentes características visuales. Entre los métodos para crear iconos están los rostros de Chernoff (Chernoff Face) y los campos de Estrellas (StarField). Además, suelen crearse editores de iconos para aplicaciones específicas (Andrews, 2005, Salgado, 2003, Theisel, 2000). Por otro lado, la solución más popular para la colocación de los iconos en la imagen está basada en el uso de proyecciones (Andrews, 2005). Las técnicas basadas en píxel son las más eficientes cuando el número de dimensiones es grande y cuando crece el número de registros. Esto se debe a que utilizan un píxel para representar cada atributo de una observación. Los retos fundamentales en estos métodos son la elección del color para cada elemento y el modo de posicionamiento de los píxeles (Keim, 2002). En este esquema el asunto principal es como colocar los píxeles en la imagen. Este tipo de técnicas utilizan diferentes modos de posicionamiento para lograr diferentes objetivos. Colocar los píxeles en la forma apropiada ofrece la posibilidad de observar información sobre correlaciones, dependencias y. 20.
(28) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. regiones trascendentales. Dos de los modos de posicionamiento de los píxeles son: los patrones recursivos y los segmentos circulares (Johnson and Hansen, 2005). La técnica de los patrones recursivos se basa en un posicionamiento recursivo general de atrás hacia delante de los píxeles. Está particularmente dirigida a representar conjunto de datos con un orden natural de acuerdo a un atributo, propiedad que la convierte en una opción para problemas de series de tiempo (Keim, 2002, Theisel, 2000). Ver Figura 1.5.. Figura 1.5. La técnica de patrones recursivos. Las técnicas geométricas son aquellas que utilizan elementos como líneas, puntos o curvas como propiedades visuales para representar los datos. Existe gran número de ellas, como prosection views (Bergeron and Grinstein, 1989, Brodlie, 1992), hyper slices (Wijk and Liere, 1993), parahistogramas (Ong and Lee, 1996), coordenadas en forma de estrellas, gráficos de Andrews (Andrews, 1972), pero hay dos que sobresalen por su generalidad y amplio uso. Estas son los diagramas de dispersión (Cleveland, 1993) y las coordenadas paralelas (Inselberg and Dimsdale, 1990). El diagrama de dispersión es una técnica simple muy utilizada. Su forma más sencilla se manifiesta cuando los datos tienen solo dos dimensiones. Con dos dimensiones la técnica consiste en trazar un eje de coordenadas y utilizar los valores de las dimensiones. Así, se representan los puntos (x, y) resultando un gráfico donde se observan dispersos los puntos de datos. Por otro lado, visualizar datos de más de dos dimensiones no es obvio, para lograrlo pueden utilizarse proyecciones que provocan pérdida de información debido a la reducción de la dimensión (Johnson and Hansen, 2005, Theisel, 2000). Para datos multiparamétricos es muy frecuente utilizar matrices de diagramas de dispersión. Las matrices resultantes son cuadradas y el elemento (i, j) de la matriz es un diagrama de dispersión de la dimensión i y la j. El diseño evita la pérdida de información pero en cambio son engorrosos los análisis complejos. Una deficiencia adicional es que la diagonal principal 21.
(29) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. de la matriz es subutilizada. Algunos trabajo actuales están encaminados a aprovechar mejor esta región de la representación (Cui et al., 2005). Ver la Figura 1.6.. Figura 1.6. Matriz de diagramas de dispersión. La técnica de las coordenadas paralelas (Inselberg and Dimsdale, 1990) es un esquema simple de gran generalidad que permite visualizar conjuntos de datos multidimensionales. Esta técnica geométrica es una de las más utilizadas debido a su fácil implementación y los buenos resultados que se obtienen al aplicarla (Keim, 2002). Obsérvese la Figura 1.7. Esta técnica usa un sistema de coordenadas como base y consiste en crear un eje de coordenadas para cada atributo colocándolos paralelamente. El valor de cada dimensión en un determinado punto de datos es marcado en el eje correspondiente. La representación final para un objeto es una línea que recorre las posiciones marcadas en cada dimensión (Keim, 2002, Theisel, 2000). El color de las líneas que representan los objetos puede ser elegido por varios criterios. El más simple es utilizar un color constante para todos los objetos. Un criterio que maximiza la calidad de la imagen es seleccionar una dimensión para que sea el color del objeto, de tal forma que puntos con diferentes valores en el atributo de color serán mostrados con diferentes tonos y los similares serán mostrados con tonos equivalentes (Keim, 2002, Theisel, 2000). Así, por ejemplo, cuando se visualizan resultados de agrupamiento, puede emplearse el color para señalar el grupo o clase a que pertenece el objeto. De esta forma resulta fácil e intuitivo distinguir todos los objetos que pertenecen a un mismo grupo.. 22.
(30) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. De la misma forma pueden emplearse colores similares para grupos cercanos unos de otros, y obtener así una impresión visual acerca de la similitud o distancia entre grupos.. Figura 1.7. Coordenadas paralelas. Una idea similar para representar datos multiparamétricos es el gráfico de Andrews. En esta técnica cada observación es representada por una función f(t) que se evalúa en el intervalo [0,1]. Cada función es una serie de Fourier, cuyos coeficientes se igualan a los valores de las dimensiones para cada observación (Andrews, 1972). Esta técnica permite identificar con facilidad diferencias entre grupos de observación, ya que por lo general observaciones pertenecientes a un mismo grupo presentan una forma de la función similar, véase la Figura 1.8.. 23.
(31) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. Figura 1.8. Gráfico de Andrews. La virtud fundamental de la técnica es que puede representar conjuntos de datos de un tamaño relativamente grande y además con un número de dimensiones elevado. 1.4. Consideraciones finales del capítulo. La integración de técnicas de visualización a los algoritmos de agrupamiento y la interacción del usuario con el algoritmo DBSCAN en tiempo real, pueden mejorar la calidad del agrupamiento y obtener un agrupamiento con un menor tiempo de ejecución y con una correcta estimación de los parámetros, ya que el proceso visual induce a apreciaciones intuitivas de las características más destacadas de la información. El algoritmo DBSCAN parte de datos bidimensionales, por tanto, se sugiere utilizar la visualización de datos multiparamétricos, específicamente utilizando gráficos de dispersión de dos dimensiones. La integración que se propone presenta gran importancia, debido al disímil uso de estos métodos de agrupamiento en varias áreas en desarrollo en la actualidad. Unido, además, al hecho de que no existen muchas herramientas que hagan uso de esta integración, y estar este tema de investigación poco abordado. Por lo tanto, es apropiada la implementación de una herramienta, que mediante la integración de técnicas de visualización a algoritmos de agrupamiento basados en densidad, especialmente DBSCAN, permita la interacción del usuario en tiempo real con el algoritmo y evaluar la calidad del 24.
(32) Capítulo 1. Algoritmos de agrupamiento basados en densidad y técnicas de visualización. agrupamiento mediante esta interacción, con el fin de valorar la efectividad de dicha integración, y en qué medida se mejora o no la eficiencia del método de agrupamiento.. 25.
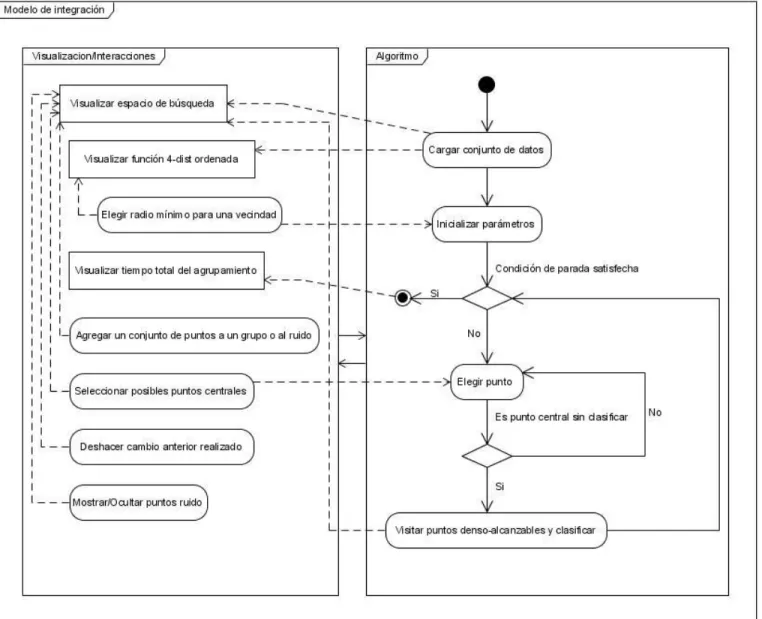
(33) Capítulo 2. Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN. 2 Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN Este capítulo está dedicado a exponer las principales contribuciones que brinda la visualización para la solución de problemas de agrupamiento a través de algoritmos basados en densidad, propone diversas formas de visualización de dichos algoritmos, y algunas interacciones que el usuario puede hacer con los mismos a fin de guiar el agrupamiento. Se presenta un modelo general de integración de técnicas de visualización a los algoritmos de agrupamiento basados en densidad, en específico al algoritmo DBSCAN. 2.1. Contribuciones de la visualización a los algoritmos de agrupamiento basados en densidad. Los algoritmos de agrupamiento basados en densidad obtienen los grupos basándose en condiciones de densidad donde los grupos representan regiones densas de objetos en el espacio de datos, que están separadas por regiones de baja densidad (estos elementos aislados representan ruido). Este tipo de algoritmos de agrupamiento no funciona correctamente con datos de alta dimensionalidad y dependen altamente de los parámetros iniciales. Como se ejemplificó anteriormente, la visualización de estos algoritmos puede contribuir a obtener mejores resultados. Entre las bondades de la visualización se pueden mencionar que: permite una mejor estimación de los parámetros iniciales que requieren los algoritmos para su corrida, permite describir el comportamiento de los algoritmos en cada momento de su ejecución, el estado de cada variable, el espacio de búsqueda, para así dar un tratamiento más directo al algoritmo y poder buscar comportamientos deseados o localizar regiones de interés, e interactuar con la información brindada con el fin de encontrar buenos resultados de una manera rápida (Andrews, 2005). Específicamente la integración de técnicas de visualización a los algoritmos de agrupamiento basados en densidad permitirá: estimar los valores de los parámetros de manera efectiva y rápida, problema fundamental de este tipo de algoritmos, predefinir grupos mediante la interacción, reduciendo notablemente el espacio de búsqueda y el tiempo de corrida del algoritmo, añadir o eliminar elementos de los grupos después de obtener el resultado del agrupamiento analítico, posibilitando la obtención de buenos resultados sin la necesidad de realizar más iteraciones.. 26.
(34) Capítulo 2. Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN. 2.2. Interacciones que pueden implementarse en el algoritmo de agrupamiento DBSCAN. Un sistema interactivo brinda la posibilidad al usuario de tener control externo sobre la información que se visualiza y le permite modificar el algoritmo cuya conducta está siendo observada, o bien los valores de los datos o parámetros que están siendo procesados. La información con la que trabajan los algoritmos de agrupamiento basados en densidad, en específico DBSCAN puede ser visualizada y así pueden implementarse un conjunto de interacciones. A continuación se proponen algunas variantes: Visualizar el gráfico de la función 4-dist ordenada para determinar el menor radio que pudiera tener la vecindad de un punto Haciendo uso de la heurística para determinar el parámetro que define el menor radio de la vecindad (véase el epígrafe 1.2.2), se pueden analizar visualmente todos los valores de dicha función y seleccionar interactivamente el valor deseado para dicho parámetro antes de realizar la primera iteración del algoritmo. Observe en la Figura 2.1 la visualización de la función 4-dist ordenada y la selección del punto que permite la estimación del umbral.. Figura 2.1. Visualización de la función 4-dist ordenada. Mostrar el conjunto de puntos en tiempo real Ver en tiempo real el conjunto de puntos es de gran importancia, ya que se puede identificar la estructura de los datos de una forma rápida. Por ejemplo, el mostrar los datos según el ejemplo de la. 27.
(35) Capítulo 2. Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN. Figura 2.2, pudiera sugerirle al usuario que los datos se agrupan en dos grandes grupos, que pudieran subdividirse, también el usuario puede percatarse que existen puntos ruidosos.. Figura 2.2. Visualización de los puntos antes de agrupar.. Figura 2.3. Visualización de los puntos después de la primera iteración del algoritmo.. 28.
(36) Capítulo 2. Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN. El usuario también puede ver como va quedando el agrupamiento durante cada iteración del algoritmo, así como los resultados luego de que termine la ejecución del mismo. Observe en la Figura 2.3 que el usuario puede efectivamente comprobar su suposición inicial sobre la distribución de los puntos en el plano, e incluso, mediante otras interacciones podrá redistribuir puntos en los grupos encontrados. Seleccionar o no un conjunto de puntos Esta interacción posibilita seleccionar un conjunto de puntos de manera interactiva sobre el gráfico donde se encuentran representados los datos a fin de realizar luego una acción determinada con dichos puntos seleccionados. También es posible deshacer la selección efectuada. La selección se puede realizar sobre los puntos de cualquier grupo, los puntos ruido o ambos (ver Figura 2.4).. Figura 2.4. Selección de puntos. Agregar los puntos seleccionados a un grupo nuevo, a un grupo existente o extraerlos de cualquier grupo y clasificarlos como ruido Esta interacción permite, a partir de la interpretación que realice el usuario con los datos, agregar los puntos seleccionados a cualquiera de los grupos existentes, a un grupo nuevo, o simplemente al conjunto de puntos que representan el ruido. Luego de cada interacción de este tipo, así al terminar la ejecución del algoritmo se actualizarán automáticamente las medidas de validación. 29.
(37) Capítulo 2. Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN. implementadas, brindando así a los usuarios información sobre la efectividad de la realización de dichos cambios. Observe la Figura 2.5.. Figura 2.5. Acciones a realizar con los puntos seleccionados. Deshacer una modificación realizada con anterioridad Esta interacción posibilita al usuario deshacer un cambio realizado con anterioridad si después de aplicar la modificación las medidas de calidad arrojan un peor resultado o si el usuario por su parte llega a comprender que se encuentra en un estado no deseado. Observe la Figura 2.6.. 30.
(38) Capítulo 2. Modelo de integración de técnicas de visualización al algoritmo de agrupamiento DBSCAN. (a) Resultado del agrupamiento luego de. (b) Resultado del agrupamiento luego de. realizar un cambio, donde la medida de. deshacer el cambio de (a), donde la. RST global es de 0.89700. medida de RST global es de 0.90666. Figura 2.6. Acción realizada que fue deshecha por arrojar peores resultados del agrupamiento. Mostrar u ocultar los puntos clasificados como ruido Esta interacción permite mostrar u ocultar del gráfico donde se están visualizando los puntos, aquellos que están clasificados como ruido o que simplemente aún no han sido asignados a ningún grupo. De esta forma el usuario puede identificar con más claridad los grupos encontrados y hallar un sentido al agrupamiento que se está obteniendo. Observe la Figura 2.7.. (a) Se muestran todos los puntos del conjunto de datos. (b) Se ocultaron los puntos clasificados como ruido. Figura 2.7. Mostrar y ocultar los puntos clasificados como ruido. Mostrar con mayor detalle una región seleccionada. 31.
Figure




+7



Documento similar