Agrupamiento de artículos científicos con formato semiestructurado basado en las referencias bibliográficas
85
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. _____________________. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. _____________________________. __________________________________. Firma del tutor. Firma del jefe del Seminario de Inteligencia Artificial.
(3) “Un hombre con idea nueva es un loco hasta que la idea triunfa” Mark Twain.
(4) A mi mamá, ella siempre fue la razón que me motivó a seguir adelante incluso cuando las fuerzas me faltaron. A Jose, por ser mi padre y mi ejemplo..
(5) Agradecimientos. AGRADECIMIENTOS A Dios. A mi mamá, a Jose, a mi hermana y a tía Mary por ser las personas más importantes en mi vida y las que más me han apoyado siempre. A mi abuela Célida y a mi papá por siempre estar pendientes de cómo iba todo. A Mary Cary porque ha sido quien ha cargado conmigo desde la secundaria y quien ha estado en todo momento. A Amanda porque sin ella no creo que yo y Ernesto hubiéramos llegado hasta el final, o al menos no de la forma en que lo hicimos. A Ernesto porque más que amigo ha sido un hermano durante estos cinco años. A Neysi por poder contar con ella cuando a veces no pude contar con nadie; y a Lázaro porque a pesar de no llevarnos muy bien al principio, y a pesar que sigue siendo un Yo-Yo, se ha convertido en un buen amigo. A Diane que a pesar de ser un poco recalcitrante, fue una de las compañeras de batalla durante estos cinco años y se convirtió en una de las sobrevivientes y a Jeni por también ser una persona con la que pude contar durante mi estancia en la UCLV. A toda la gente del barrio que siempre estuvo pendiente de mí (no los menciono para que no se quede ninguno fuera). A veces es importante que te pregunten como saliste en una prueba aunque cuando le expliques no entiendan nada. A los que quedaron en el camino pero fueron y siguen siendo bueno amigos: Rosmeiry, Amaya, Yudeiny, Hadel. A mi doctora Santa Yarelis por su apoyo durante todos estos años. A Roberto Vicente quien fue el que hizo todas las gestiones para poder facilitarme las cosas en la beca dadas mis condiciones de salud. A la profesora Beatriz López porque cuando yo pensé que la enfermedad me vencía y no podría continuar en la universidad, ella buscó la manera de que yo pudiera seguir adelante. A Bea que fue profesora y amiga, a la cual siempre tendré un chisme nuevo que contarle para que me diga: ¡Por Dios, que lengua tienes! A Mario, Marlon, Guillermo, Pedro, Pabel, Claudia, que fueron buenos amigos y cuando los necesité pude contar con ellos. A Olguita la recepcionista, que para todos era la tía mala, pero para mí siempre fue la tía buena. A mis tutores Damny y Marilyn por su ayuda incondicional en la realización de este trabajo..
(6) Resumen. Resumen La cantidad de información científica en formato semiestructurado que se encuentra disponibles en Internet, intranets corporativas, y otros medios de comunicación está creciendo vertiginosamente. Gestionar el conocimiento a partir de la información que se puede encontrar en las publicaciones científicas es fundamental para cualquier investigador. La gestión de la información científica cada vez resulta más compleja y desafiante, debido a que las colecciones de documentos generalmente son heterogéneas, grandes, diversas y dinámicas. Superar estos desafíos es esencial para dar a los científicos mejores condiciones de administrar el tiempo necesario para procesar la información científica. En este trabajo se implementó un nuevo método de agrupamiento de artículos científicos en formato XML basado en la información brindada por las referencias bibliográficas de los mismos. La utilización de este método contribuye de manera significativa al descubrimiento de conocimiento relevante. Se definió la función de similitud SimRefBib que facilita capturar el grado de semejanza entre los documentos tomando como base la información contenida en sus referencias bibliográficas. Se propone el uso del algoritmo de agrupamiento SemClustDML para la obtención de los grupos de documentos afines. La evaluación a través de los experimentos y los casos de estudios definidos arrojaron resultados relevantes en el agrupamiento de artículos científicos en formato XML..
(7) Abstract. Abstract The amount of scientific information in semi-structured format available in the internet, corporative intranets and other communication means, is growing at a very fast speed. The knowledge management from scientific publications is fundamental to any researcher today. The management of scientific knowledge becomes more complicated and challenging as days go by, given the fact that documents collections are generally heterogeneous, large, diverse and dynamic. Overcoming these difficulties becomes essential to provide the scientists with the necessary time administration to process scientific information. In this Major Paper a new method to clustering scientific articles in XML format has been implemented, based on the information provided by their own bibliographic references. The use of this method significantly contributes to the discovery of relevant knowledge. This Paper also defined the SimRefBib similarities facilitating the capture of the degree of similarities among the documents taking as a base the information contained within their bibliographic references. There is the proposal of a clustering algorithm SemClustDML to obtain groups of alike documents. The evaluation through experiments and definite case studies showed encouraging results in the clustering of scientific articles in XML format..
(8) Tabla de contenidos. Tabla de Contenidos. INTRODUCCIÓN ..................................................................................................................................1 1. AGRUPAMIENTO DE ARTÍCULOS CIENTÍFICOS EN FORMATO XML .......................5 1.1 1.1.1. Sistemas de Recuperación de Información ................................................................................... 6. 1.1.2. Modelos de recuperación de información ..................................................................................... 8. 1.1.3. Recuperación de información semiestructurada .......................................................................... 9. 1.2 1.2.1. 1.3. ARTÍCULOS CIENTÍFICOS EN FORMATO XML ...........................................................................14 Técnicas de minería de datos para artículos científicos en formato XML ............................... 15. MÉTODOS DE AGRUPAMIENTO.................................................................................................17. 1.3.1. Clasificación de las técnicas de agrupamiento ............................................................................ 17. 1.3.2. Medidas generales de agrupamiento ........................................................................................... 18. 1.3.3. Agrupamiento de documentos XML ........................................................................................... 19. 1.3.4. Agrupamiento de artículos científicos ......................................................................................... 22. 1.4 2. RECUPERACIÓN DE INFORMACIÓN ............................................................................................5. CONCLUSIONES PARCIALES .....................................................................................................24. MÉTODO DE AGRUPAMIENTO ESPECIALIZADO EN REFERENCIAS. BIBLIOGRÁFICAS..............................................................................................................................26 2.1 MÉTODO PARA EL AGRUPAMIENTO DE ARTÍCULOS CIENTÍFICOS......................................................26 2.1.1. Representación del corpus textual obtenido ............................................................................... 27. 2.1.2. Extracción de términos de la subunidad título ........................................................................... 28. 2.1.3. Extracción de términos de la subunidad autor ........................................................................... 31. 2.2. CÁLCULO DE LA SIMILITUD ENTRE ARTÍCULOS CIENTÍFICOS EN FORMATO XML ......................32. 2.2.1. Cálculo de la disimilitud autor ..................................................................................................... 33. 2.2.2. Cálculo de la Similitud Título (ST) .............................................................................................. 35. 2.2.3. Medida general de semejanza ...................................................................................................... 38. 2.2.4. Optimización de las estructuras de datos utilizadas .................................................................. 38. 2.3. ALGORITMO DE AGRUPAMIENTO .............................................................................................40. 2.3.1. Estimación del umbral de similitud ............................................................................................. 40. 2.3.2. Búsqueda de los centroides iniciales ............................................................................................ 42. 2.3.3. Asignación de los elementos a los grupos .................................................................................... 42. 2.3.4. Grupos solapados .......................................................................................................................... 42.
(9) Tabla de contenidos. 2.3.5. 2.4. Elementos sobrantes ..................................................................................................................... 43. REFINAMIENTO DEL RESULTADO DEL AGRUPAMIENTO ............................................................43. 2.4.1. División de clusters ....................................................................................................................... 44. 2.4.2. Tamaño de los clusters .................................................................................................................. 44. 2.4.3. Clusters agrupables ...................................................................................................................... 44. 2.5. PROCEDIMIENTO GENERAL PARA EL AGRUPAMIENTO DE LOS ARTÍCULOS CIENTÍFICOS EN. FORMATO XML ....................................................................................................................................45. 2.5.1. Módulo 1: Preprocesamiento del corpus de artículos científicos en formato XML ................ 46. 2.5.2. Representación de la colección ..................................................................................................... 46. 2.5.3. Módulo 3: Agrupamiento a partir de la matriz de similitud SimRefBib ................................. 47. 2.5.4. Módulo 4: Evaluación local y global de los resultados del agrupamiento. ............................... 47. 2.6 3. CONCLUSIONES PARCIALES .....................................................................................................48. EVALUACIÓN DEL MÉTODO DE AGRUPAMIENTO PROPUESTO ..............................50 3.1. EVALUACIÓN DE LOS RESULTADOS DEL MÉTODO DE AGRUPAMIENTO DE ARTÍCULOS. CIENTÍFICOS EN FORMATO XML ...........................................................................................................50. 3.1.1. Definición de los casos de estudio para la aplicación de los métodos de agrupamiento de. artículos científicos en formato XML. ....................................................................................................... 50 3.1.2. Validación del agrupamiento ....................................................................................................... 51. 3.1.3. Verificación de los resultados ....................................................................................................... 52. 3.1.4. Diseño de los experimentos ........................................................................................................... 54. 3.2. CONCLUSIONES PARCIALES .....................................................................................................58. REFERENCIAS BIBLIOGRÁFICAS ................................................................................................62 ANEXOS ................................................................................................................................................66 ANEXO 1 SIMILITUDES, DISTANCIAS MÁS USADAS PARA COMPARAR OBJETOS. ........................................66 ANEXO 2 MEDIDA EXTERNA OVERALL F-MEASURE Y MEDIDAS PROPUESTAS POR INEX PARA LA VALIDACIÓN DEL AGRUPAMIENTO.........................................................................................................69. ANEXO 3 DESCRIPCIÓN DE LOS CASOS DE ESTUDIO UTILIZADOS ...........................................................70 ANEXO 4: COMPARACIÓN DE LA CALIDAD DEL AGRUPAMIENTO PARA EL CÁLCULO DEL UMBRAL ..........71 ANEXO 5 RESULTADOS DEL EXPERIMENTO 1.........................................................................................72 ANEXO 6 RESULTADOS DEL EXPERIMENTO 2.........................................................................................74.
(10) Introducción. INTRODUCCIÓN La gran cantidad de información científica publicada hace que sea difícil para los usuarios de los motores de búsqueda identificar la información relevante (Aljaber et al., 2009). La creación y diseminación de información es soportada por un número creciente de herramientas, sin embargo, mientras que la cantidad de información disponible está continuamente creciendo, nuestra habilidad de procesarla y asimilarla permanece constante (Dixon, 1997, Lanquillon, 2001). Por lo cual se hace necesario que las computadoras resuelvan esta incapacidad humana. La gestión de información científica se vuelve cada vez más compleja y desafiante, sobre todo porque las colecciones de documentos generalmente son heterogéneas, grandes, diversas y dinámicas. Superar estos desafíos es esencial para dar a los científicos mejores condiciones de administrar el tiempo necesario para procesar la información científica, lo cual constituye la motivación principal de este trabajo. El agrupamiento automático de documentos ofrece una posible solución a este problema de la sobrecarga de información, mediante el cual los usuarios pueden visualizar rápidamente los resultados de la búsqueda, utilizando grupos etiquetados de artículos, que se han agrupado en categorías de tópicos y sub-tópicos (Aljaber et al., 2009). El agrupamiento nos permite organizar la información, delimitar la información relevante y descubrir nuevo conocimiento a partir de la información disponible en una colección especificada u obtenida como resultado de un proceso de recuperación de información (C.D. et al., 2008). Un algoritmo de agrupamiento intenta encontrar grupos naturales de datos, basándose principalmente en la similitud y las relaciones de los objetos, de forma tal que se obtenga una distribución interna del conjunto de datos mediante su particionamiento en grupos. Cuando el agrupamiento se basa en la similitud de los objetos, se desea que los objetos que pertenecen al mismo grupo sean tan similares como se pueda y los objetos que pertenecen a grupos diferentes sean tan disímiles como sea posible (Fuentes, 2013). El análisis de grupos es una herramienta para descubrir una estructura previamente oculta en los datos, asumiendo que. 1.
(11) Introducción. existe un agrupamiento natural o cierto en ellos. Sin embargo, la asignación de los objetos a las clases y la descripción de esas clases son desconocidas (Kruse et al., 2007). La tendencia actual de las publicaciones científicas ha sido el cambio hacia formatos estructurados y semiestructurados de documentos, dadas las ventajas que estos formatos brindan al porder etiquetar los documentos facilitando el acceso a partes específicas de los mismos. Los artículos científicos por su parte, tienen una estructura bien definida (título, autor, palabras claves, resumen, contenido, referencias bibliográficas) la cual es fácilmente adaptable a formatos semiestructurados, como lo es XML; es por ello que este formato se ha convertido en uno de los estándares más utilizados en la publicación de artículos científicos. Explotar la estructura específica que tienen los artículos científicos puede ofrecer resultados favorables en el agrupamiento de este tipo de documentos, y contribuir de manera significativa a la gestión del conocimiento. Sin embargo no son muchos los trabajos desarrollados que se centren en el agrupamiento de artículos científicos en formato XML y que usen las partes claves de este tipo de documentos para lograr mejores resultados en el agrupamiento. Por lo antes mencionado se propone como objetivo general de esta investigación: Desarrollar métodos de agrupamiento para artículos científicos con formato XML a partir de las referencias bibliográficas. Para dar cumplimiento al objetivo general se plantean los siguientes objetivos específicos: 1. Realizar un análisis crítico sobre agrupamiento y funciones de similitud para determinar propuestas a utilizar. 2. Definir una función de similitud para la comparación de documentos que tenga en cuenta la unidad estructural Referencias Bibliográficas. 3. Implementar los métodos de agrupamiento que favorezcan el trabajo sobre artículos científicos con formato semiestructurado, utilizando la función de similitud propuesta. 4. Evaluar los resultados de los métodos de agrupamiento utilizando corpora representativos del universo investigado.. 2.
(12) Introducción. Las preguntas de investigación planteadas son: 1. ¿Cómo representar en la información que recoge una función de similitud el tratamiento diferenciado de la unidad estructural Referencias Bibliográficas? 2. ¿Los distintos elementos de información analizados para tratar la unidad estructural Referencias Bibliográficas tienen igual peso? 3. ¿Qué métodos de agrupamiento emplear para conformar grupos de artículos basados en referencias bibliográficas en formato semiestructurado? 4. ¿Cómo evaluar la propuesta de los métodos de agrupamiento utilizados basados en la función de similitud definida? Como hipótesis de investigación se plantea: Tratar cada subunidad perteneciente a la Unidad Estructural Referencias Bibliográficas de manera diferenciada aporta mejores resultados en el agrupamiento de artículos científicos en formato XML que tratarla como una bolsa de palabras. El valor teórico de la investigación está directamente vinculado con su novedad científica. El valor práctico del trabajo está enfocado a: . Disponer de un algoritmo de agrupamiento, que permita procesar grandes volúmenes de datos y obtener conocimiento relevante a partir de la información recuperada, con el propósito de facilitar a los investigadores y docentes el inicio de una revisión del estado del arte, organizar materiales por equipos de estudiantes para la docencia, organizar por temáticas los artículos que han sido recopilados por el comité científico de un evento, así como tener una idea de las asociaciones que existen entre los documentos recuperados.. 3.
(13) 1 AGRUPAMIENTO DE ARTÍCULOS CIENTÍFICOS EN FORMATO XML. 4.
(14) Agrupamiento de artículos científicos en formato XML. 1 AGRUPAMIENTO DE ARTÍCULOS CIENTÍFICOS EN FORMATO XML El crecimiento exponencial de las publicaciones científicas en Internet ha traído consigo la necesidad de almacenar los artículos científicos en formatos que permitan un mejor procesamiento de los mismos, aumentando de esta manera la eficacia de los sistemas de recuperación de información. Es así que los formatos semiestructurados -entre ellos destacándose XML- han comenzado a jugar un papel fundamental en las publicaciones científicas a nivel mundial. Por esta razón, es necesario desarrollar nuevas técnicas que permitan el análisis exploratorio de estos datos y que capturen eficientemente las relaciones internas que describen la propia estructura jerárquica y autodescriptiva de estos documentos (Fuentes, 2013). Particularmente, a partir de la información disponible, el agrupamiento permite organizar, delimitar relevancia y descubrir nuevo conocimiento (Dixon, 1997, Tan, 1999). En este capítulo, se mencionan los principales métodos de recuperación de información utilizados en los documentos XML, así como los métodos de agrupamiento más usados para estos tipos de datos. Además se hace particular hincapié en la aplicación de ambas técnicas específicamente para los artículos científicos. 1.1. Recuperación de información. La Recuperación de Información (IR, Information Retrieval) es el área de la ciencia y la tecnología que trata de la adquisición, representación, almacenamiento, organización y acceso a elementos de información (Vilares, 2000). Desde un punto de vista práctico, dada una necesidad de información del usuario, un proceso de IR produce como salida un conjunto de documentos cuyo contenido satisface potencialmente dicha necesidad; es decir, la función de un sistema de recuperación de información no es devolver la información deseada por el usuario, sino indicar cuáles documentos son relevantes para satisfacer dicha necesidad de información. La teoría de recuperación de información ha saltado a la actualidad tecnológica debido a dos hechos fundamentales: el aumento incesante de la potencia de las computadoras y de su paralelo abaratamiento, provoca que cada vez más, empresas de productos de gestión. 5.
(15) Agrupamiento de artículos científicos en formato XML. documental incorporen en sus programas algunos de los fundamentos teóricos de la recuperación de información; por otra parte el aumento de la oferta informativa de Internet genera la imperiosa necesidad de instrumentos capaces de filtrar correctamente la información (Codina, 1995). La recuperación de información encierra diversos problemas cognitivos (Codina, 1995): . identificar y representar necesidades de información;. . identificar y representar el conocimiento contenido en documentos;. . seleccionar los documentos más relevantes de acuerdo con los dos problemas y;. . mostrarlos al usuario.. 1.1.1 Sistemas de Recuperación de Información La IR se realiza a través de Sistemas de Recuperación de Información (IRS, Information Retrieval Systems), los cuales son procesos capaces de almacenar, recuperar y mantener información (H. Kuna, 2014). Los IRS se diseñan para el procesamiento de texto en lenguaje natural (ya sea estructurado o no), por lo general, de semántica ambigua, por lo cual los resultados frecuentemente contienen errores, y no tienen por qué ser completos. De hecho, el objetivo de un sistema de Recuperación de Información es maximizar el número de documentos relevantes devueltos y minimizar el número de documentos no relevantes devueltos(Vilares, 2000). Cualquier IRS puede ser descrito como un conjunto de ítems de información (DOCS), un conjunto de peticiones (REQS) y algún mecanismo (SIMILAR) para determinar qué ítems satisfacen las necesidades de información expresadas por el usuario en la petición(Méndez, 2004).. Figura 1-1 Esquema simple de un sistema de recuperación de información1.. 1. Tomado de MÉNDEZ, F. J. M. 2004. Recuperación de información: modelos, sistemas y evaluación. .. 6.
(16) Agrupamiento de artículos científicos en formato XML. El esquema presentado en la Figura 1-1 es un poco simple debido a que en la práctica los documentos se convierten a un formato especial, por medio de un proceso de clasificación o de un sistema de indexación. En (Méndez, 2004) este proceso lo denominan LANG, y el esquema quedaría como se muestra en Figura 1-2.. Figura 1-2 Esquema avanzado de un SRI2.. Para Chowdhury el siguiente conjunto de funciones son las principales que debe cumplir un IRS (Chowdhury, 1999): 1. Identificar las fuentes de información relevantes a las áreas de interés de las solicitudes de los usuarios. 2. Analizar los contenidos de los documentos. 3. Representar los contenidos de las fuentes analizadas de una manera adecuada para compararlas con las preguntas de los usuarios. 4. Analizar las preguntas de los usuarios y representarlas de una forma adecuada para compararlas con las representaciones de los documentos de la base de datos. 5. Realizar la correspondencia entre la representación de la búsqueda y los documentos almacenados en la base de datos. 6. Recuperar la información relevante. 7. Realizar los ajustes necesarios en el sistema basados en la retroalimentación con los usuarios. Existen diversas propuestas en la literatura sobre la estructura básica que debe tener un IRS. En (H. Kuna, 2013) se define esta estructura a partir de la unión de cuatro elementos: . Los documentos de la colección sobre la que se realizará la recuperación.. . Las consultas que representan las necesidades de información por parte de los usuarios.. 2. Tomado de ibid.. 7.
(17) Agrupamiento de artículos científicos en formato XML. . La forma de modelar las representaciones de los documentos, consultas y las relaciones presentes entre ellos.. . La función de evaluación que determina para cada consulta y documento el orden que ocupará este último en los resultados a presentar.. 1.1.2 Modelos de recuperación de información Cuando se diseña un sistema de Recuperación de Información se necesita establecer previamente la forma como se representarán los documentos, las necesidades de información del usuario y la forma de comparar ambas representaciones. Es por ello, que se define el modelo de recuperación de información sobre el cual el sistema trabajará. Los modelos clásicos más representativos son: el modelo booleano, el vectorial y el probabilístico(Vilares, 2000). Modelo booleano El modelo booleano es el más sencillo de los tres mencionados anteriormente, y se basa en la teoría de conjuntos y el álgebra de Boole (Vilares, 2000). En este modelo, el usuario especifica en su consulta una expresión booleana formada por una serie de términos unidos mediante operadores booleanos. Dada la expresión lógica de la consulta, el sistema devolverá aquellos documentos que la satisfacen y se conformará el conjunto de documentos relevantes. Un documento por tanto, será simplemente relevante o no. Modelo Vectorial En el modelo vectorial las consultas y los documentos son representados mediante vectores dentro de un espacio multidimensional. La dimensión del espacio está definida por los propios términos, de esta forma cada término diferente define una nueva dimensión. De este modo, un vocabulario de tamaño t definirá un espacio t-dimensional donde un documento dj es representado como un vector dj=( w1j, w2j, . . . , wtj ) y una consulta q se representa como un vector q=(w1q, w2q, . . . , wtq ). Modelo probabilístico El modelo probabilístico formaliza el proceso de recuperación en términos de teoría de probabilidades. El objetivo perseguido en el modelo es calcular la probabilidad de que un documento sea relevante para la consulta dado que dicho documento posee ciertas propiedades. Es decir, dada una consulta q el modelo asigna a cada documento dj, como 8.
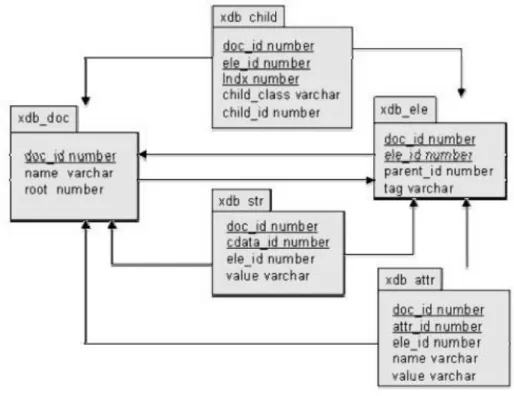
(18) Agrupamiento de artículos científicos en formato XML. medida de similaridad respecto a la consulta el valor, P(dj relevante para q)/P(dj no relevante para q), medida según la cual los documentos son devueltos, ordenadamente, al usuario. 1.1.3 Recuperación de información semiestructurada La generación de información es un proceso mucho más acelerado que nuestra capacidad de recolectarla y asimilarla, de ahí que se dedica mucho tiempo a buscar alternativas de cómo organizar y hacer accesibles rápidamente estas cantidades de información. La clasificación de los documentos de acuerdo a su estructura es: estructurada, no estructurada y semi-estructurada (Blanco, 2007). Los documentos no estructurados son aquellos en los que la información contenida en el documento no tiene ningún orden de estructura, esta información tiene mayor riesgo de no ser encontrada por los buscadores, pues no contiene parámetros establecidos que proporcionen la información a buscar. Los documentos estructurados, a diferencia de los documentos semiestructurados y no estructurados contienen una estructura predefinida la cual está definida por etiquetas cuyo objetivo es mostrar información relevante del documento. Los documentos semiestructurados se definen como aquellos documentos que en la mayoría de su contexto contienen elementos de un documento estructurado, dejando algunas partes del documentos sin estructurar (Rodriguez, 2004). Este último tipo de documentos es ampliamente utilizado en el mundo ya que incorpora la estructura y los datos en una misma entidad. Debido a la importancia de lograr un almacenamiento correcto de la información estructurada, se utilizan lenguajes específicos para esta labor. No es ningún secreto que XML es el lenguaje más utilizado hoy en día para este tipo de tarea (Martín, 2007). Un documento XML es una estructura jerárquica autodescriptiva de información, que consiste en un conjunto de átomos, elementos compuestos y atributos(Dalamagas et al., 2006). XML tiene un número de características que lo hace ampliamente utilizable como formato de representación de datos, entre las que se encuentran: su extensibilidad e independencia de la plataforma utilizada. Su extensibilidad está dada por el hecho que no tiene un conjunto de etiquetas fijas, por tanto, las palabras claves del lenguaje no están definidas desde el principio. 9.
(19) Agrupamiento de artículos científicos en formato XML. Así, con XML es posible definir un lenguaje específico para aplicaciones concretas. Por otra parte, es independiente de la plataforma utilizada, del sistema operativo, o del fabricante de software. Esta independencia permite interoperabilidad entre plataformas diferentes de programación y sistemas operativos(Fuentes, 2013). Algunas de las principales técnicas utilizadas para el análisis de documentos XML se basan en dos interfaces de aplicación: SAX (Simple Api for XML) y DOM (Document Object Model), las cuales analizan el documento y son capaces de construir su árbol de objetos (elementos, atributos, etc.) para poder realizar búsquedas o transformaciones en él (Blanco, 2007). SAX originalmente fue una interfaz de programación de aplicaciones (API) únicamente para el lenguaje de programación Java, convirtiéndose en la API estándar para usar XML en Java. Existen actualmente versiones de SAX para otros lenguajes de programación como por ejemplo Python. Una de las ventajas de usar SAX es la eficiencia en cuanto al tiempo y la memoria empleados en el análisis. Como desventaja, tiene que realizar una lectura secuencial del documento por lo que una vez leído no se puede volver atrás, algo que DOM sí permite. DOM es básicamente: una API que proporciona un conjunto estándar de objetos para representar documentos HTML y XML, un modelo estándar sobre cómo pueden combinarse dichos objetos, y una interfaz estándar para acceder a ellos y manipularlos. A través del DOM, los programas pueden acceder y modificar el contenido, estructura y estilo de los documentos HTML y XML. DOM es en esencia, una interfaz de programación de aplicaciones para acceder, añadir y cambiar dinámicamente contenido estructurado en documentos. A partir de DOM surge JDOM la cual es una biblioteca de código abierto para manipulaciones de datos XML optimizados para Java. La principal diferencia entre DOM y JDOM es que el primero se creó para ser un lenguaje neutral e inicialmente se usó para manipulación de páginas HTML con JavaScript sin embargo, JDOM se creó para usarse con Java y por tanto beneficiarse de las características de Java, incluyendo sobrecarga de métodos, colecciones, entre otras. En la Figura 1-3 se muestra un artículo científico en formato semiestructurado (XML) y su correspondiente transformación a un árbol JDOM se muestra en la Figura 1-4.. 10.
(20) Agrupamiento de artículos científicos en formato XML. Figura 1-3 Ejemplo de un XML correspondiente a un artículo científico.. Figura 1-4 Ejemplo de un árbol correspondiente a un artículo científico. 11.
(21) Agrupamiento de artículos científicos en formato XML. Otra de las técnicas utilizadas para el análisis de documentos XML son las llamadas bases de datos XML, (XMLDB). Esta técnica define un modelo lógico de un documento XML y almacena y recupera documentos de acuerdo a ese modelo, según (Blanco, 2007) existen dos tipos de XMLDB: • XML Enabled Databases (Bases de datos habilitadas para XML): son aquellas que desglosan la información de un documento XML en su correspondiente esquema relacional o de objetos. • XML Native Databases (Bases de datos nativas de XML): son aquellas que respetan la estructura del documento, se pueden hacer consultas sobre dicha estructura y es posible recuperar el documento tal como se insertó originalmente. El concepto detrás de este tipo de bases de datos es la facilidad de representar la estructura de un documento XML en una modelo relacional. El esquema de la Figura 1-5, se basa en la especificación de un DTD (Document Type Definition) para documentos XML. No sería conveniente utilizar una XMLDB para datos estructurados ya que el modelado obliga que cada atributo tenga una columna. La gran ventaja de las XMLDB radica en poder mantener la estructura de aquellos datos semiestructurados, de manera que utilizando XPath se pueden hacer consultas sobre determinados fragmentos no solo de uno sino de muchos documentos sin tener que hacer el análisis de cada documento al momento de realizar las consultas (Blanco, 2007). XPath (XML Path Language) es un lenguaje que permite construir expresiones que recorren y procesan un documento XML. XPath permite buscar y seleccionar teniendo en cuenta la estructura jerárquica del XML. Un documento XML es procesado por un analizador (o parser) construyendo un árbol de nodos. Este árbol comienza con un elemento raíz, que se diversifica a lo largo de los elementos que cuelgan de él y acaba en nodos hoja, que contienen solo texto, comentarios, instrucciones de proceso o incluso que están vacíos y solo tienen atributos. La forma en que XPath selecciona partes del documento XML se basa precisamente en la representación arbórea que se genera del documento. En la Figura 1-6 se muestra un ejemplo de una consulta XPath que muestra todos los títulos de las referencias bibliográficas de un documento.. 12.
(22) Agrupamiento de artículos científicos en formato XML. Figura 1-5 Esquema de almacenamiento en una XMLDB3.. Figura 1-6 Búsqueda con XPath. Al ser extensibles, con estructura de fácil análisis y procesamiento, XML se ha convertido en el formato de intercambio de datos estándar entre las aplicaciones Web(Dalamagas et al., 2006) teniendo un papel muy importante en la actualidad, ya que permite la compatibilidad entre sistemas para compartir la información de una manera segura, fiable y fácil. Las revistas de contenido científico no quedan ajenas a este proceso y es cada vez mayor la cantidad de artículos científicos en internet en formato XML.. 3. Tomado de BLANCO, J. 2007. Notas sobre almacenamiento y recuperacion de informacion.. 13.
(23) Agrupamiento de artículos científicos en formato XML. 1.2. Artículos científicos en formato XML. Los artículos científicos, en su mayor parte, aparecen en Internet en formato PDF en las revistas electrónicas correspondientes. Aunque los datos de título, autoría, publicación, dirección, filiación y resumen son datos rastreables a través de las bases de datos y de algunos buscadores académicos de Internet, no lo son así los contenidos en PDF. Sólo se puede buscar dentro del contenido del artículo una vez abierto el PDF, utilizando una herramienta de búsqueda de Acrobat Reader, Foxit o similares (Toledo, 2009). Toda la información de un artículo científico suele ser de interés para los investigadores. Estos documentos, incluso los más elementales, tienen una estructura básica que se debe respetar y que contiene al menos los elementos siguientes: autor, título, resumen, palabras claves, contenido principal del artículo, notas y referencias bibliográficas. Pero la búsqueda de información en Internet se hace a través de robots de búsqueda. Estos robots son máquinas ciegas que se limitan a leer códigos de información, por lo cual si la información rastreada no está marcada de tal manera que se diferencien cada uno de los elementos que componen un artículo científico, los robots no distinguirán entre los distintos elementos del documentos; así no sabrán que el título o las palabras claves tiene más importancia que un párrafo cualquiera, o que un mismo autor referenciado en dos artículos puede dar un indicio de que estos artículos traten temas similares. XML se usa para estructurar precisamente todos los elementos de los textos en los procesos de edición contemporánea de los artículos y otros tipos de documentos (Packer et al., 2014) . Es por ello que en los últimos años está ocurriendo un cambio en cuanto a la forma de publicación de los artículos científicos y XML comienza a jugar un papel fundamental en la comunidad científica internacional. XML tiene muchas características para mejorar la presencia en la web, la distribución y el presupuesto. Es por ello, que las grandes editoriales de revistas están utilizándolo como base para el desarrollo de sus publicaciones. Así revistas científicas de prestigio internacional y bases de datos internacionales han adoptado el formato XML como estándar en sus artículos científicos; se sabe por ejemplo, que el contenido de los libros y revistas de Elsevier se basan en el formato XML. Un ejemplo de lo que la tecnología XML puede facilitar es la publicación anticipada en línea (AOP). Los artículos AOP son publicados en línea por delante de su fecha de publicación 14.
(24) Agrupamiento de artículos científicos en formato XML. impresa, y estas versiones web son finales, es decir, no presentan cambios en cuanto a la versión impresa. La publicación web anticipada permite una producción más rápida de los datos sensibles al tiempo, lo que significa que puede ser leído y citado antes. Esto es especialmente importante para las revistas científicas (Hoekman, 2009). Una de las grandes ventajas que ofrece XML es la utilización de los metadatos en función de facilitar el proceso de recuperación de información para el usuario. Un ejemplo importante de cómo XML y los metadatos se pueden utilizar con este fin es CrossRef, que fue establecido por las editoriales académicas como "una infraestructura para la vinculación de las citas a través de los editores". En este sistema, un investigador a partir de la lectura de un artículo electrónico puede acceder directamente a otro artículo que sea referenciado en el artículo que está leyendo (Hoekman, 2009). 1.2.1 Técnicas de minería de datos para artículos científicos en formato XML Con el desarrollo de la Inteligencia Artificial (IA) y las técnicas de Minería de Datos (MD) en la actualidad pueden ser procesados grandes volúmenes de información con el objetivo de extraer patrones que residan en los datos almacenados. La Minería de Datos es una tecnología novedosa que integra diferentes técnicas de análisis de datos y extracción de modelos (Reyes and García, 2012). Las principales técnicas de minería de datos existentes se dividen en tres grandes grupos: la clasificación, la categorización y el agrupamiento. Estas técnicas han sido extendidas, claro está, al procesamiento de colecciones de documentos en formato XML, y por consiguiente a los artículos científicos en este formato. La clasificación como proceso, comprende la distribución de los objetos de cualquier género de clases, sobre la base de rasgos diferenciales correspondientes. Al clasificar documentos se realiza un análisis de su contenido y forma, y se sitúan en grupos mediante un sistema de clasificación desarrollado con estos fines (Giri et al., 2007). En la literatura se pueden encontrar varios trabajos relativos a la clasificación de documentos XML. Un enfoque simple para la clasificación de documentos XML será eliminar todas las etiquetas en el documento XML y aplicar cualquiera de los algoritmos de clasificación de texto para el. 15.
(25) Agrupamiento de artículos científicos en formato XML. documento resultante. Contrario a esta forma de clasificación existen algoritmos de clasificación XML que hacen uso solamente de la estructura del documento (Giri et al., 2007). Otros enfoques como el presentado en (Denoyer and Gallinari, 2009) hacen uso tanto de la estructura como del contenido. Los autores de este trabajo consideran que algunos campos en los documentos XML son más importantes que otros y por tanto asignan pesos diferentes a cada campo. La idea clave detrás de este enfoque es que se obtiene una mayor precisión en la clasificación cuando los documentos XML se clasifican teniendo en cuenta el contenido de algunos campos más que el de otros. La categorización de documentos es un tipo de problema perteneciente a la familia de problemas asociados a encontrar agrupamientos entre objetos de cualquier tipo. Si bien la categorización de documentos tiene características particulares que surgen de las propiedades de los documentos como objetos a agrupar, los principios generales coinciden con los que se aplican para categorizar cualquier otro tipo de elementos (Goldenberg, 2007). Se reportan en la literatura algunos trabajos referentes a la categorización de documentos XML como el desarrollado en (Denoyer and Gallinari, 2003) donde presentan un modelo bayesiano generativo para modelar documentos estructurados y semiestructurados, ejemplo XML. Según los autores este modelo permite tener en cuenta al mismo tiempo la estructura y la información del contenido, esto se utiliza en función de lograr una mejor categorización de documentos XML. El crecimiento de datos electrónicos en formato XML trae consigo un auge en el desarrollo de métodos de minería de texto cada vez más eficaces y eficientes. El agrupamiento es fundamental para una eficiente organización y recuperación de los documentos XML relevantes. Sin embargo, la mayoría de los métodos existentes explotan solo la información incluida en el contenido o sólo la información contenida en la estructura (Magdaleno et al., 2015). El agrupamiento4 es descrito como una herramienta para el descubrimiento porque tiene la potencialidad de revelar relaciones basadas en datos complejos no detectadas previamente (Anderberg, 1973, Kruse et al., 2007). El objetivo de los algoritmos de agrupamiento es 4. En esta tesis se emplean indistintamente los términos: grupos, conglomerados, clases, comunidades y subconjuntos.. 16.
(26) Agrupamiento de artículos científicos en formato XML. descubrir las agrupaciones naturales, y por lo tanto presentar una visión general de los temas en una colección de documentos (Shankar, 2012); esto lo hacen basándose en la similitud y relaciones de los objetos, de forma tal que se obtenga una distribución interna del conjunto de datos mediante su particionamiento en grupos, logrando que los objetos de un mismo grupo sean muy similares entre sí, y al mismo tiempo, sean muy diferentes a los objetos de otros grupos (XU et al., 2009). Por lo general, los algoritmos de agrupamiento se basan en funciones de similitud (o distancia). El conocimiento de las diferentes técnicas de agrupamiento contribuye a la selección de la mejor técnica dada una colección de datos específica. En el epígrafe siguiente se abordan de una manera más amplia las técnicas de agrupamiento y se hace énfasis en las desarrolladas para el agrupamiento de documentos XML y en particular para los artículos científicos en este formato. 1.3. Métodos de agrupamiento. El problema del agrupamiento puede definirse como sigue: dados n puntos en un espacio n-dimensional particionar los mismos en k grupos tales que los puntos dentro de un grupo sean más similares que cada uno de ellos con los de los otros grupos, dicha similaridad se mide atendiendo a alguna función distancia (función de disimilaridad) o alguna función de similaridad. (Pascual et al., 2007) 1.3.1 Clasificación de las técnicas de agrupamiento Para realizar análisis de grupos se han propuesto una gran variedad de algoritmos de agrupamiento. Estos pueden ser clasificados de diversas formas: tipo de los datos de entrada del algoritmo, criterios para definir la similitud entre los objetos, conceptos en los cuales se basa el análisis y forma de representación de los datos, entre otros. Esta clasificación puede dividirse en dos grupos: los algoritmos de agrupamiento jerárquicos y los que forman particiones. Los algoritmos jerárquicos a su vez se dividen en dos grupos: los aglomerativos (bottom-up) y los divisivos (top-down). Los algoritmos aglomerativos asignan inicialmente cada documento a su propio clúster y encuentran los grupos finales fusionando en varias ocasiones pares de grupos hasta que se cumple una determinada condición de parada. El resultado final puede ser 17.
(27) Agrupamiento de artículos científicos en formato XML. representado gráficamente como un dendrograma. Los algoritmos divisivos consideran inicialmente que existe un único grupo al cual pertenecen todos los objetos y continuamente van dividiendo los grupos en grupos más pequeños, hasta que cada grupo contenga un único objeto. Por su parte, los algoritmos de particionamiento encuentran los grupos finales por la partición del conjunto de documentos en un número predeterminado de grupos o un número derivado de forma automática. La colección se divide inicialmente en grupos cuya calidad es optimizada repetidamente hasta obtener una solución estable, de acuerdo con el criterio seleccionado. Uno de los algoritmos perteneciente a esta clasificación y que ha sido ampliamente utilizado es el k-medias (k-means). 1.3.2 Medidas generales de agrupamiento Una medida de similitud o función de similitud es una función real que cuantifica la similitud entre dos objetos. Aunque no existe una definición única, por lo general las medidas de similitud son en algún sentido la inversa de la disimilitud o distancia métrica. Toda función de similitud (o de distancia) calcula un valor que permite obtener una medida de proximidad o distancia entre dos documentos dados. Habitualmente es más fácil trabajar con atributos de dominio continuo, como puede ser un dominio numérico, que trabajar con dominios discretos como son los atributos con valores nominales (Camps et al., 2009). Para que una medida de similitud pueda ser convertida en una medida de distancia debe cumplir con las propiedades de no negatividad, identidad, simetría y desigualdad triangular (Camps et al., 2009), además: 𝑆𝑥,𝑦 ≤ 𝑆𝑥,𝑥 ∀𝑥, 𝑦 𝑐𝑜𝑛 𝑖𝑔𝑢𝑎𝑙𝑑𝑎𝑑 𝑠𝑜𝑙𝑜 𝑐𝑢𝑎𝑛𝑑𝑜 𝑥 = 𝑦 𝑆𝑥,𝑦 ∈ [0,1] Algunas de las funciones de distancia más conocidas son: distancia City-Block, Euclidea y Minkowski. La elección de una medida de similitud adecuada no es trivial. Para encontrar los agrupamientos naturales, la noción de similitud debe ser adaptada al problema particular; es. 18.
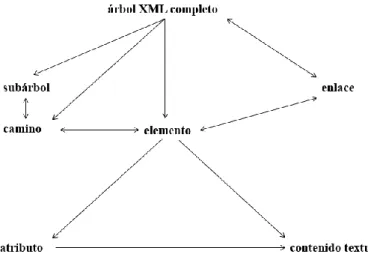
(28) Agrupamiento de artículos científicos en formato XML. por ello que actualmente en el mundo se trabaja en la obtención de medidas que trabajen sobre tipos de datos específicos. 1.3.3 Agrupamiento de documentos XML Dado el crecimiento exponencial de los datos XML disponibles en la WEB se plantea la necesidad de desarrollar técnicas de agrupamiento especializadas para este tipo de documentos. Cuando se habla de agrupamiento de documentos XML los algoritmos se dividen en tres categorías fundamentales: los centrados en la estructura, los centrados en el contenido y los centrados en ambas componentes, esta última categoría constituye un nuevo desafío, ya que la mayoría de los enfoques existentes no utilizan estas dos dimensiones dada su gran complejidad (Magdaleno et al., 2015). La aplicación de transformaciones estructurales y el agrupamiento de documentos XML estructuralmente similares son ejemplos de operaciones sobre la base de la estructura de los datos en formato XML. La agrupación de documentos XML estructuralmente similares se refiere a la aplicación de métodos de agrupamiento utilizando distancias que estiman la similitud entre las estructuras de árboles en términos de las relaciones jerárquicas de sus nodos (Dalamagas et al., 2006).. Figura 1-7 Relaciones entre los niveles de granularidad estructural de un documento XML5.. 5. Tomado de GUERRINI, G., MESITI, M. & SANZ, I. 2007. Web Data Management Practices: Emerging Techniques and Technologies.. 19.
(29) Agrupamiento de artículos científicos en formato XML. Los documentos XML son de naturaleza jerárquica y se pueden ver como composiciones de componentes sencillas, incluyendo elementos, atributos, enlaces y texto plano. La jerarquía de la composición es muy rica: los atributos y el texto están contenidos en los elementos, y los propios elementos son organizados en estructuras de orden superior, tales como caminos y subárboles (Guerrini et al., 2007) como se puede observar en la Figura 1-7. En (Guerrini et al., 2007) definen cada nivel en la estructura composicional de un documento XML como un nivel de granularidad. Una flecha de un nivel de granularidad A a un nivel de granularidad B significa que una medida de similitud en el nivel A puede formularse en términos de objetos en granularidad B. Muchas medidas de similitud para documentos XML son definidas en correspondencia con estas relaciones naturales de composición. Una manera de representar los documentos es a través de árboles etiquetados y definir la medida de similitud como una extensión de la distancia Tree-Edit (TE), la cual intenta transformar un árbol A1 en un árbol A2, realizando una secuencia de operaciones (inserción, eliminación y substitución de nodos), a las que le asigna un costo. De manera que mientras menor sea la cantidad de operaciones necesarias en la transformación, mayor será la similitud entre los árboles correspondientes a los documentos comparados. Utilizar la distancia TE tiene como inconveniente que se puede obtener una diferencia en cuanto a tamaño y a estructura muy alta debido a que los documentos XML presentan varios elementos repetidos y/o anidados. Es por ello que se ha propuesto el cálculo del Structural Summaries (Dalamagas et al., 2006) para reducir el anidamiento y las repeticiones, obteniéndose una representación lo más reducida que conserve la relaciones jerárquicas entre los elementos del árbol asociado al documento y luego se aplica el cálculo de la distancia TE. Otra variante es a través del cálculo de los Closed Frequent Subtrees (CFST). En (Kutty et al., 2007) se plantea que dado un conjunto de árboles T, existe para un árbol Ti un subárbol STi que mantiene la misma relación padre-hijo que Ti; se calcula la frecuencia f(STi), que no es más que la cantidad de árboles pertenecientes a T de los que STi es subárbol, y este es frecuente (FST) si f(STi) es mayor que un umbral determinado. Se puede decir que dos árboles pertenecen a un mismo grupo si tienen el mismo FST. Esto tiene como inconveniente que pueden existir muchos FST, por lo que se busca el CFST que es un FSTi que es superconjunto de otros FST que poseen la misma f(FSTi) y no existe 20.
(30) Agrupamiento de artículos científicos en formato XML. otro superconjunto para FSTi. Con esto se conforma una matriz (TxCFST) en la que cada celda va a tener la existencia o no de CFSTi en Tj. Para buscar los grupos se sigue un criterio muy parecido al antes mencionado. Un gran número de enfoques para el agrupamiento de documentos XML se ha propuesto en los últimos años; sin embargo, todavía hay muy poco trabajo en el agrupamiento de documentos semiestructurados que combinen eficazmente el contenido y la información de la estructura de los documentos XML (Tran et al., 2008b). Para obtener mejores resultados en el agrupamiento, es esencial utilizar ambas dimensiones (Kutty et al., 2008), algunos trabajos existentes en la literatura se describen a continuación. Una primera variante muy sencilla es mezclar en una representación Espacio Vectorial (Vector Space Model; VSM) (Salton et al., 1975) el contenido y las etiquetas del documento y aplicar un algoritmo de agrupamiento conocido. En la representación VSM cada documento se identifica como un vector de rasgo en el que cada dimensión corresponde a términos distintos que se han indexados con anterioridad. En una matriz VSM, se almacena un valor numérico que indica la importancia de cada término en cada documento, utilizando para esto su frecuencia de aparición. Esta matriz es la que combina el contenido y estructura de los documentos, y se utiliza para realizar el agrupamiento de los mismos. Otros trabajos realizan extensiones a la representación VSM, llamadas C-VSM y SLVM (Doucet and AhonenMyka, 2002, Giannopoulos and Veltkamp., 2002, Karmarkar, 1984, Yang and Chen, 2002). En ambas para cada documento se conforma una matriz Mext donde e es el número de elementos y t el número de términos; cada celda va a contener la frecuencia de cada término ti en el elemento ej. La diferencia radica en que para el caso de C-VSM solo se comparan términos que pertenezcan a elementos comunes en dos documentos y en SLVM se realiza la comparación de términos de un elemento con los términos correspondientes en cualquier elemento del otro documento. C-VSM al ignorar la relación semántica entre diferentes elementos presenta el problema de “baja contribución” y SLVM al no tener en cuenta la relación entre elementos comunes puede presentar el problema de “sobre contribución”. Con el propósito de eliminar estas dificultades en (Wan and Yang, 2006) se propone la Proportional Transportation Similarity, donde se trabaja con comparaciones pesadas según la semejanza o no de los elementos a comparar en dos documentos. 21.
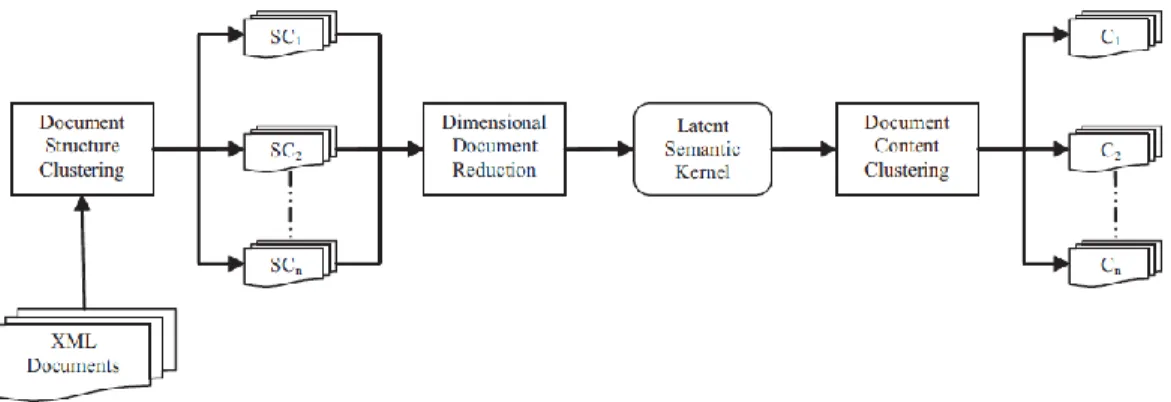
(31) Agrupamiento de artículos científicos en formato XML. Otro enfoque es el mostrado en (Tran et al., 2008a), donde después de haber realizado un agrupamiento teniendo en cuenta solo la estructura de los documentos se hace un refinamiento utilizando Latent Semantic Kernel (Cristianini et al., 2002) para determinar la similitud entre el contenido de los documentos y realizar un agrupamiento teniendo en cuenta el contenido, ver Figura 1-8. Además utilizan un método para reducir dimensionalidad basado en la información estructural común de los documentos, ya que el uso del singular vector decomposition es muy costoso computacionalmente cuando se tratan un gran número de rasgos.. Figura 1-8 Esquema de algoritmo que utiliza estructura y contenido para agrupar documentos XML.6. En (Nayak, 2006) se desarrolló el XCLSE que es una modificación al algoritmo de agrupamiento que utiliza solo la estructura XCLS (Nayak and Xu., 2006), incorporando una comparación a nivel semántico antes de realizar el agrupamiento. Esta propuesta no mejoró significativamente los resultados alcanzados por XCLS, aunque sí tuvo que realizar un importante esfuerzo de cálculo para la semántica de los datos. 1.3.4 Agrupamiento de artículos científicos El agrupamiento de artículos científicos es un tema que comienza a tomar auge en los últimos años. Esto ocurre debido a que la gran cantidad de información científica disponible para los usuarios, hace que sea difícil para los motores de búsqueda identificar la información relevante (Aljaber et al., 2009). Por ejemplo, solo en el ámbito biomédico alrededor de 1.800 nuevos. 6. Tomado de TRAN, T., KUTTY, S. & NAYAK, R. 2008a. Utilizing the Structure and Data Information for XML Document Clustering. INEX, 402-410.. 22.
(32) Agrupamiento de artículos científicos en formato XML. documentos se publican diariamente (Hunter and Cohen, 2006). A continuación se mencionan algunos de los trabajos realizados que se pueden encontrar en la literatura. En (Afonso and Duque, 2014) se muestran los resultados de un estudio realizado sobre el agrupamiento automático de texto aplicado a artículos científicos y texto periodísticos en portugués brasileño. También se reportan varios trabajos que hacen uso de las citas textuales en los documentos en función de lograr un mejor agrupamiento de los artículos científicos. Una de las obras pioneras en este tema fue la desarrollada por Garfield en (Garfield, 1964) en la cual se analiza el vínculo entre las citas en los artículos académicos. Otro de los trabajos relacionados con este tema se desarrolla en (Aljaber et al., 2009) donde demuestran que las citas textuales proveen sinónimos relevantes y vocabulario relacionado, los cuales ayudan a incrementar la efectividad del modelo bolsa de palabras. En (Shankar, 2012) se presenta un novedoso enfoque de supervisión al problema de la recapitulación multi-documento de artículos científicos. En este enfoque la colección de documentos es una lista de los documentos citados juntos dentro del mismo artículo fuente, también conocido como co-citación. El corazón del enfoque es un agrupamiento basado en el tema de los fragmentos extraídos de artículos co-citados y la clasificación de relevancia mediante una consulta generada a partir del contexto que rodea los documentos de la lista de co-citado. En (Wang and Blei, 2011), desarrollan un algoritmo para recomendar artículos científicos para los usuarios de una comunidad en línea. Este enfoque combina los méritos de filtrado colaborativo tradicional y el modelado probabilístico. El mismo proporciona una estructura latente interpretable para los usuarios y puede formar recomendaciones sobre otros artículos existentes y recién publicados. En (Magdaleno et al., 2015) se propone un nuevo modelo para el agrupamiento de documentos XML, ver Figura 1-9. Este modelo divide los documentos en dos representaciones. La Representación I selecciona las Unidades Estructurales (UE) de cada documento y obtiene para cada una de ellas un agrupamiento de los documentos. La Representación II obtiene la matriz de similitud de todos los pares de documentos usando la función de similitud coseno. Luego a través de la función OverallSimSUX obtienen la matriz de similitud global mezclando 23.
(33) Agrupamiento de artículos científicos en formato XML. los resultados de ambas representaciones. Posteriormente aplican un algoritmo de agrupamiento para obtener los grupos de documentos afines. Debido a que los artículos científicos presentan una estructura característica (título, autor, palabras claves, resumen, contenido, referencias bibliográficas) este modelo de agrupamiento puede ser aplicado al agrupamiento de artículos científicos logrando resultado relevantes.. Figura 1-9 Modelo de agrupamiento de documentos XML usando estructura y contenido7.. 1.4. Conclusiones parciales. XML se ha convertido en uno de los formatos principales de almacenamiento de los artículos científicos dada sus facilidades para el acceso a los datos contenidos en este tipo de documento. La mayoría de los trabajos realizados están dedicados al agrupamiento de artículos científicos en formatos no estructurados, tales como PDF. Las partes de los artículos científicos que los diferencian de otros tipos de documentos, tales como las referencias bibliográficas y las palabras claves pueden ser utilizadas en función de lograr un mejor agrupamiento de este tipo de documento específico.. 7. Tomado de MAGDALENO, D., FUENTES, I. E. & GARCÍA, M. M. 2015. Clustering XML Documents using Structure and Content Based in a Proposal Similarity Function (OverallSimSUX).. 24.
(34) 2 MÉTODO DE AGRUPAMIENTO ESPECIALIZADO EN REFERENCIAS BIBLIOGRÁFICAS. 25.
(35) Método de agrupamiento especializado en referencias bibliográficas. 2. MÉTODO. DE. AGRUPAMIENTO. ESPECIALIZADO. EN. REFERENCIAS. BIBLIOGRÁFICAS La cantidad de artículos científicos en formato XML disponibles en la web está creciendo exponencialmente, aún así no se encuentran muchos métodos especializados en el agrupamiento de este tipo de documentos. Los artículos científicos presentan características particulares que los distinguen de otros documentos, entre ellas la selección de las palabras claves del documento y la presencia de las referencias bibliográficas. Si estas características distintivas se usan en función de lograr un mejor agrupamiento de los artículos científicos pueden obtenerse resultados relevantes. En este capítulo se presenta: (1) una nueva medida de semejanza que facilita evaluar el grado de relación entre los artículos científicos en formato XML basado en las referencias bibliográficas; (2) un algoritmo de agrupamiento que permite obtener los grupos de documentos afines dada la matriz de semejanza obtenida a partir de la medida de similitud propuesta; (3) la implementación del procedimiento general que sustenta el método propuesto.. 2.1 Método para el agrupamiento de artículos científicos En este trabajo se propone una forma de utilización de las referencias bibliográficas en función de lograr un mejor resultado en el agrupamiento de artículos científicos almacenados en formato XML. La propuesta parte del resultado de un proceso de recuperación de información (Berry, 2004). Las salidas son grupos homogéneos de documentos afines y la calidad del agrupamiento; garantizando el control para la evaluación de los resultados. En la Figura 2-1 se muestra una visión gráfica de la nueva forma de agrupamiento basada en las referencias bibliográficas. Nótese que cada elemento de esta unidad estructural es tratado de forma independiente, de este modo se pretende obtener información más precisa a la hora de comparar los documentos. Finalmente el proceso concluye en la confección de una matriz de similitud general, donde se incluye el resultado obtenido por cada subunidad (i.e. Título y Autor), la cual es utilizada como entrada del algoritmo de agrupamiento a utilizar.. 26.
(36) Método de agrupamiento especializado en referencias bibliográficas. Figura 2-1 Representación gráfica del método de agrupamiento propuesto. 2.1.1 Representación del corpus textual obtenido La información contenida en los documentos XML se encuentra en formato semiestructurado, por lo que, la representación textual es indispensable para su procesamiento posterior (Fuentes, 2013). Por su efectividad para representar documentos y ser ampliamente reconocida en la comunidad de minería de textos, se seleccionó la representación VSM para el trabajo con la subunidad título y una modificación de la misma para la representación de la subunidad autor, ambas subunidades pertenecientes a la unidad estructural Referencias Bibliográficas. En VSM cada documento se identifica como un vector de rasgos en un espacio en el cual cada dimensión corresponde a términos indexados distintos (palabras). Un vector documento dado, en cada componente tiene un valor numérico para indicar su importancia. Según Lanquillon (Lanquillon, 2001), la representación textual está compuesta por la transformación del corpus, la extracción de términos, la reducción de la dimensionalidad, la normalización y el pesado de la matriz. Lucene8 provee herramientas para manipularlas. La subunidad título del corpus es transformada de la siguiente manera:. 8. http://lucene.apache.org. 27.
(37) Método de agrupamiento especializado en referencias bibliográficas. . Se convierte la subunidad título de los ficheros de entrada en una secuencia de tokens de palabras -en el paso subsecuente a la extracción de términos, estos tokens se usan para generar rasgos significativos (índices de términos)-.. . En la secuencia resultante de tokens se convierten todas las letras a minúsculas, se eliminan las marcas de puntuación al final de los tokens, se omiten los tokens que contienen caracteres alfa-numéricos, y se sustituyen las contracciones por sus expresiones completas (Lanquillon, 2001).. La transformación de la subunidad autor es diferente a la subunidad título, ya que no tiene sentido tratar cada palabra que compone el nombre de un autor como un término independiente, pues podría ocasionar ruido a la hora de ver qué tanto se parecen dos documentos dados. Ejemplo: Supóngase que se tienen los documentos di y dj. En el documento di se referencia al autor Pedro García Pérez y en el documento dj al autor Jorge García Álvarez, la palabra García como término independiente aportaría cierta similitud entre ambos documentos, sin embargo esta similitud realmente no existe debido a que se está hablando de autores totalmente diferentes. Es por ello que el contenido de la subunidad autor será tratado como una cadena de texto, así se considerará el nombre completo de un autor como un solo término. 2.1.2 Extracción de términos de la subunidad título Para obtener la representación de la subunidad título, se parte de una secuencia de tokens y se produce una secuencia de términos indexados basados en estos. El siguiente paso consiste en seleccionar solo aquellos tokens que constituyen palabras relevantes en la subunidad título del documento analizado. En este paso se considera una palabra como relevante cuando su frecuencia de aparición supera el umbral fap; fap es variable y depende de la cantidad de referencias bibliográficas (CRB(i)) del documento analizado, así: 2 3 𝑓𝑎𝑝(𝑖) = { 4 5. 𝑠𝑖 𝐶𝑅𝐵(𝑖) ≤ 10 𝑠𝑖 10 < 𝐶𝑅𝐵(𝑖) ≤ 20 𝑠𝑖 20 < 𝐶𝑅𝐵(𝑖) ≤ 25 𝑒. 𝑜. 𝑐. (2.1). 28.
(38) Método de agrupamiento especializado en referencias bibliográficas. Es válido aclarar la posibilidad que ninguno de los tokens presentes en la subunidad título del documento analizado supere el umbral fap; para estos casos extremos se seleccionarán los 4 términos con mayor frecuencia de aparición. Una vez obtenidos los tokens relevantes de la subunidad título se pasa al proceso de unión de tokens. Este proceso es de suma importancia ya que los tokens obtenidos no pueden verse como simples términos aislados, pues esto provocaría valores de similitud que no se correspondan con el grado de semejanza real que existe entre los pares de documentos. Ejemplo: Supóngase que para un documento di se obtienen los tokens relevantes (fuzzy, set, logic, precision) y para un documento dj se obtienen (set, rough, generalization, decision); para este caso se tiene el término relevante set en ambos documentos, sin embargo estos documentos no guardan relación, el documento di trata de conjuntos difusos (fuzzy set) y el documento dj trata de conjuntos aproximados (rough set). El proceso de unión de tokens, en su primera fase, consiste en buscar la frecuencia de aparición de los tokens relevantes (tomados dos a dos) en la subunidad título del documento. Luego de obtenidos los pares de tokens relevantes, los cuales serían aquellos que superen el umbral fap, se analiza si algunos de los pares formados pueden unirse, esto se hace solo para los pares que la subcadena inicial del primer par coincida con la subcadena final del segundo, o viceversa, tomando como subcadena inicial la primera palabra del par y como subcadena final la última palabra. Al terminar el proceso de unión de tokens se obtienen las frases relevantes para el documento, así como la importancia de cada una de ellas. La Definición 2.1 denota la importancia de la palabra relevante k en el documento i. Definición 2.1 (importancia de palabra relevante): Sea fki la frecuencia de aparición de la palabra relevante k en el documento i y CRB(i) la cantidad de referencias bibliográficas del documento i, se define la importancia de la palabra k en el documento i como:. 𝑓𝑘𝑖 ⁄𝐶𝑅𝐵(𝑖) 𝑠𝑖 𝑓𝑘𝑖 ⁄𝐶𝑅𝐵(𝑖) < 1 𝐼𝑚𝑝(𝑘, 𝑖) = {. (2.2) 1. 𝑒. 𝑜. 𝑐 29.
Figure



+7




Documento similar