Predicción de parámetros de energía eólica utilizando modelos de regresión
65
0
0
Texto completo
(2) El que suscribe, Omar González Amor, hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ciencia de la Computación autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica. II.
(3) PENSAMIENTO. “Cada fracaso enseña al hombre algo que necesita aprender”. Charles Dickens. III.
(4) DEDICATORIA A mi familia por su apoyo, esfuerzo y consistencia brindada durante tanto tiempo. A mi novia por creer en mí y ofrecerme todo su amor. A mis amigos por ayudarme a alcanzar mis metas.. IV.
(5) AGRADECIMIENTOS A mi familia por su apoyo incondicional en todo momento. A mi novia Arachely por su necesaria presencia en mi vida. A mis suegros Olga Lidia y Víctor por comportarse como padres. A mis tutores Ricardo y Víctor Samuel por brindarme su tiempo y dedicación. A mis amigos universitarios por ser mis hermanos, por su ayuda y por compartir tantas cosas juntos. A todos los docentes que influyeron en mi educación durante toda mi vida académica.. V.
(6) RESUMEN. Actualmente la empresa CITMA en Santa Clara utiliza varios tipos de fuentes de energía, con el objetivo de generar energía mecánica, eléctrica o térmica que resultan indispensables para el desarrollo laboral del local. Se utiliza la energía hidráulica, solar, biomasa, energía química (combustibles), pero solo será objeto de estudio en este trabajo la energía eólica. Este portador energético forma parte de los recursos renovables y posee parámetros que se encuentran en constante variación ya que su disponibilidad cambia constantemente según el tiempo y espacio, pues es un recurso natural.. Por tal motivo se definen parámetros relacionados con estos portadores energéticos en aras de lograr almacenar de alguna manera su comportamiento en datos históricos, los cuales conformarían la base de casos sobre la cual se debe trabajar con el empleo de algún modelo de regresión eficiente para lograr predecir con efectividad la línea de actividad que tendrán los parámetros de dichos portadores en algún instante de tiempo, ya que este tipo de energía, luego de aplicarse un proceso de energización determinado sobre ella va a producir o generar electricidad( energía eléctrica), aumento o decremento de la temperatura (energía térmica), movimiento de maquinaria (energía mecánica), por lo que resulta necesario predecir el estado en el cual deben encontrarse los rasgos de este portador energético en algún momento especificado para facilitar la toma de decisiones de la empresa.. Palabras claves: fuente de energía, portador energético, energía eólica, comportamiento de sus parámetros, datos históricos, predecir, generar, consumo energético.. VI.
(7) ABSTRACT. At present the enterprise CITMA in Santa Clara utilizes several types of energy sources, generating mechanical energy, electric or thermic which are indispensable for the labor development of this Enterprise. The waterpower, biomass, solar energy, chemical energy (fuels) are utilized, but only it is needed to examine the aeolian energy. This energetic bearer is a part of the renewable resources and it has parameters that are in constant variation, because his availability changes constantly according to the time and space, after all it is a natural resource.. That’s why have been defined parameters relating to this type of source of energy with the goal of store somehow his behavior in historic data, which would conform the base of cases that must be worked up with the use of any efficient regression model in order to predict with efficiency the line of activity that the parameters of this source in some instant of time will has, because this kind of energy, next of being applicable a process of energizing determined on ti, it is going to produce or to generate electricity ( electric power ), increase or decrement of temperature ( thermic power ), movement of machinery ( mechanical energy ), so it proves to be necessary to predict the status of the energetic bearer’characteristics in some specified moment.. Keywords: source of energy, energetic bearer, aeolian energy, behavior of parameters, historic data, predicting, generating, energetic consumption.. VII.
(8) TABLA DE CONTENIDOS PENSAMIENTO..................................................................................................................... III DEDICATORIA ..................................................................................................................... IV AGRADECIMIENTOS............................................................................................................ V RESUMEN………………………………………………………………………………….. VI ABSTRACT…………………………………………………………………………………VII INTRODUCCIÓN .....................................................................................................................1 PLANTEAMIENTO DEL PROBLEMA ................................................................................2 OBJETIVO GENERAL ............................................................................................................2 OBJETIVOS ESPECÍFICOS ...................................................................................................3 JUSTIFICACIÓN ......................................................................................................................4 VIABILIDAD DE LA INVESTIGACIÓN ..............................................................................4 ESTRUCTURA DE LA TESIS ................................................................................................4 CAPÍTULO 1. ESTUDIO DE DATOS Y HERRAMIENTAS ..............................................5 1.1 ENERGÍA EÓLICA ........................................................................................................5 1.2 ESTADO DEL ARTE DE LA PREDICCIÓN EÓLICA .............................................6 1.3 CONJUNTO DE DATOS INICIAL ...............................................................................7 1.3.1 DIRECCIÓN DEL VIENTO MÁXIMO................................................................8 1.3.2 VIENTO MÁXIMO Y VIENTO MEDIO..............................................................8 1.3.3 TEMPERATURA MÁXIMA, MEDIA Y MÍNIMA .............................................9 1.3.4 HUMEDAD RELATIVA MEDIA .......................................................................10 1.4 SERIES DE TIEMPO...................................................................................................11 1.4.1 APLICACIONES DE LAS SERIES DE TIEMPO .............................................12 1.5 MÉTODO DE TRABAJO............................................................................................12 1.6 WEKA ............................................................................................................................13 1.6.1 LA INTERFAZ DE USUARIO .............................................................................13 1.7 VISUAL PARADIGM ..................................................................................................17 CAPÍTULO 2. TRANSFORMACIÓN DE DATOS Y MODELOS DE REGRESIÓN ....19 2.1 CONFORMANDO LOS CASOS DE ES TUDIO .......................................................19 2.2 PREPROCESAMIENTO DE DATOS .......................................................................19 VIII.
(9) 2.2.1 DEPENDENCIA ENTRE LAS VARIABLES .....................................................19 2.2.2 TRANSFORMACIONES DE DATOS .................................................................20 2.2.3 CÓDIGO PARA TRANSFORMAR LOS DATOS .............................................21 2.2.4 ESTRUCTURA DEL CÓDIGO............................................................................21 2.3 MODELOS DE REGRESIÓN EN WEKA .................................................................22 2.4 RESULTADOS DE LOS MODELOS DE REGRESIÓN .........................................28 2.4.1 PRIMER ESTUDIO ..............................................................................................28 2.4.2 SEGUNDO ESTUDIO ..........................................................................................29 2.4.3. TERCER ESTUDIO ............................................................................................33. CAPÍTULO 3. EEPP. HERRAMIENTA PARA LA PREDICCION DE PARÁMETROS DE LA ENERGÍA EOLICA ...................................................................................................38 3.1 INGENIERÍA DE SOFTWARE DE LA HERRAMIENTA ....................................38 3.1.1 CASOS DE USO DE LA HERRAMIENTA ........................................................38 3.1.2 DIAGRAMAS DE ACTIVIDADES DE LA HERRAMIENTA ........................40 3.1.3 DIAGRAMA DE PAQUETES DEL SISTEMA ..................................................41 3.1.4 DIAGRAMA DE CLASES DEL SISTEMA ........................................................43 3.2 EEPP. HERRAMIENTA PARA LA PREDICCIÓN DE PARÁMETROS DE ENERGÍA EOLICA ............................................................................................................44 3.2.1 DESCRIPCIÓN Y REQUISITOS MÍNIMOS .....................................................44 3.2.2 IMPLEMENTACIÓN DE LOS CLASIFICADORES .......................................45 3.2.3 DESPLIEGUE DE LA APLICACIÓN ................................................................46 3.3 ANÁLISIS DE COSTO TEMPORAL ........................................................................50 CONCLUSIONES Y RECOMENDACIONES GENERALES ...........................................52 REFERENCIAS BIBLIOGRÁFICAS...................................................................................54. IX.
(10) ÍNDICE DE TABLAS Tabla 1 Dependencia entre variables .....................................................................................20 Tabla 2 Nueva estructura de datos.........................................................................................20 Tabla 3 Resultados del Primer Estudio .................................................................................28 Tabla 4 Resultado del segundo estudio (2009) ......................................................................29 Tabla 5 Resultado del segundo estudio (2009-2010) .............................................................30 Tabla 6 Resultado del segundo estudio (2009-2011) .............................................................31 Tabla 7 Resultado del segundo estudio (2009-2012) .............................................................32 Tabla 8 Resultado del te rcer estudio (Invierno) ...................................................................33 Tabla 9 Resultado del te rcer estudio (Primavera) ................................................................34 Tabla 10 Resultado del te rcer estudio (Verano) ...................................................................35 Tabla 11 Resultado del te rcer estudio (Otoño) .....................................................................36 Tabla 12 Casos de Uso de la herramienta .............................................................................39. ÍNDICE DE FIGURAS Figura 1 ventana Inicial de WEKA........................................................................................14 Figura 2 WEKA Explorer .......................................................................................................16 Figura 3 Diagrama de Casos de Uso de la herramienta .......................................................39 Figura 4 Diagrama de Actividad de la operación Crear Nueva Instancia .........................40 Figura 5 Diagrama de Actividad de la operación Realizar Predicciones ...........................41 Figura 6 Diagrama de Paquetes de la herramienta ..............................................................42 Figura 7 Diagrama de Clases del sistema ..............................................................................44 Figura 8 Ventana Inicial de EEPP .........................................................................................46 Figura 9 Ventana de Datos de EEPP .....................................................................................47 Figura 10 Ventana de Ope raciones de datos .........................................................................48 Figura 11 Ventana de Predicciones de EEPP........................................................................48 Figura 12 EEPP realizando predicciones ..............................................................................49 Figura 13 Gráfico de costo de tiempo general.......................................................................50 Figura 14 Gráfico de costo temporal por modelos ...............................................................51 X.
(11) INTRODUCCIÓN El consumo de energía es uno de los grandes medidores del progreso y bienestar de una sociedad. Puesto que las fuentes de energía fósil y nuclear son finitas, es inevitable que en un determinado momento la demanda no pueda ser abastecida y todo el sistema colapse, salvo que se descubran y desarrollen otros nuevos métodos para obtener energía: éstas serían las energías alternativas, entre las que se encuentran la energía solar y la energía eólica. Por otra parte, el empleo de las fuentes de energía actuales tales como el petróleo, gas natural o carbón acarrea consigo problemas como la progresiva contaminación, o el aumento de los gases invernadero, sin mencionar que son recursos finitos.(Gheorghe, 2009) Apenas un 2% de la energía solar que llega a la Tierra se convierte en energía eléctrica y sólo podemos aprovechar una pequeña parte de ella. Aun así, se ha calculado que el potencial eólico es unas veinte veces el actual consumo mundial de energía, lo que hace de la energía eólica una de las fuentes de energía renovable más importantes.(Moragues, 2003) Diversas empresas y locales utilizan la energía eólica para la generación de energía eléctrica, aunque además se puede generar energía térmica y energía mecánica, tal es el caso de la empresa CITMA en Santa Clara, la cual no solo utiliza fuentes de energía tradicionales (combustibles), sino que también hace uso de la energía proporcionada por el viento y el sol, independientemente de las constantes variaciones en su comportamiento, debido a que son procesos naturales y están sujetos a sufrir las consecuencias de los distintos fenómenos de la naturaleza. Por lo tanto resulta de gran interés y utilidad realizar algún tipo de predicción o pronóstico sobre el comportamiento de la energía eólica para cualquier momento o instante deseado con el propósito de suponer el estado de sus parámetros. La realización de este proyecto será determinante para la toma de decisiones de la empresa en cuestión, ya que va a proporcionar el estado de la energía eólica en cualquier momento deseado y así se podrá determinar qué cantidad de energía es capaz de aportar esta fuente y, de esta manera, conocer también cuándo y cómo hacer uso eficiente de la misma. 1.
(12) PLANTEAMIENTO DEL PROBLEMA. Para cubrir la demanda energética de un sistema existen diversas fuentes de energía, como los combustibles fósiles, los alternativos, la energía solar, hidráulica, geotermal y la energía eólica entre otras. A todas estas fuentes se les aplica un proceso de transformación para la obtención de energía eléctrica, térmica o mecánica, entre otras. El comportamiento de la disponibilidad de. los combustibles, de manera general, es constante y precisa ya que siempre que exista. reserva de estos portadores o capacidad para adquirirlos se garantiza eficientemente el aporte energético que estos pueden ofrecer al sistema, por otra parte el comportamiento de la energía eólica tiene grandes variaciones debido a que depende de las condiciones climáticas, por lo que sus parámetros sufren cambios constantemente con respecto al tiempo, por tanto varía también su disponibilidad en distintos instantes de tiempo y debido a esto se necesita realizar un modelo de predicción para determinar eficientemente el comportamiento de los rasgos (parámetros) que esta energía posee para que el experto logre conocer de manera eficaz la cantidad de energía de cualquier tipo que esta fuente le podría aportar a la empresa.. OBJETIVO GENERAL Desarrollar un sistema capaz de predecir el comportamiento de los parámetros de la energía eólica contenidos en series de tiempo utilizando modelos de regresión.. 2.
(13) OBJETIVOS ESPECÍFICOS 1. Obtener a partir del conjunto de datos históricos inicial distintos subconjuntos como casos de estudio. 2. Determinar el conjunto óptimo de variables predictoras a través del análisis del experto. 3. Explorar los modelos de aprendizajes de WEKA aplicables al problema en cuestión. 4. Proponer un modelo de aprendizaje óptimo para cada variable existente. 5. Desarrollar un mecanismo para la obtención de las predicciones utilizando los modelos más eficientes.. PREGUNTAS DE INVESTIGACIÓN 1.. ¿Cuáles son las dependencias entre las variables más influyentes en el comportamiento de la energía eolica?. 2.. ¿Cuál es la cantidad de instancias o días pasados necesarios para lograr una predicción eficiente?. 3.. ¿Cómo definir un criterio de comparación entre los modelos de regresión de WEKA según sus resultados?. 3.
(14) JUSTIFICACIÓN Es de vital importancia la utilización de las energías renovables y naturales para disminuir el uso de los combustibles que son limitados y propagan la contaminación. Con pronósticos sobre el comportamiento de los parámetros de la energía eólica se puede conocer el tiempo de consumo disponible de las energías generadas a partir de estas fuentes, algo que es una necesidad vigente de la empresa CITMA en Santa Clara para poder optimizar la toma de sus decisiones. Además con la aplicación de este sistema se puede obtener una mejora significativa de alguna manera cuanto al ahorro de energía eléctrica. El sistema a desarrollar ofrece una metodología novedosa y bien definida para la utilización de técnicas de regresión en problemas de series de tiempo multivariadas.. VIABILIDAD DE LA INVESTIGACIÓN Conjunto de datos históricos ofrecidos por la empresa CITMA a la Facultad de Mecánica para el desarrollo de sus proyectos que constituye la base de casos sobre la cual se debe trabajar, así como locales dotados con la técnica necesaria para la realización del trabajo.. ESTRUCTURA DE LA TESIS La tesis cuenta con la siguiente estructura: luego de la Introducción, la tesis cuenta con tres capítulos. En el primer capítulo se realiza un estudio del conjunto de datos inicial y sobre las herramientas utilizadas en el trabajo posterior. En el segundo capítulo se realiza el preprocesamiento de los datos y se analizan distintos modelos de regresión sobre las variables para obtener el más óptimo. En el tercer y último capítulo se desarrolla una aplicación que realice y muestre las predicciones de cada una de las variables. Finalmente se formulan las conclusiones y recomendaciones y se relacionan las Referencias Bibliográficas.. 4.
(15) CAPÍTULO 1. ESTUDIO DE DATOS Y HERRAMIENTAS 1.1 ENERGÍA EÓLICA La energía eólica es la energía obtenida a partir del viento, es decir, la energía cinética generada por efecto de las corrientes de aire, y que es convertida en otras formas útiles de energía para las actividades humanas (El término eólico viene del latín Aeolicus, perteneciente o relativo a Eolo, dios de los vientos en la mitología griega).(Antezana, 2004) En la actualidad, la energía eólica es utilizada principalmente para producir electricidad mediante aerogeneradores, conectados a las grandes redes de distribución de energía eléctrica. Los parques eólicos construidos en tierra suponen una fuente de energía cada vez más barata, competitiva o incluso más barata en muchas regiones que otras fuentes de energía convencionales. Pequeñas instalaciones eólicas pueden, por ejemplo, proporcionar electricidad en regiones remotas y aisladas que no tienen acceso a la red eléctrica, al igual que hace la energía solar fotovoltaica. Las compañías eléctricas distribuidoras adquieren cada vez en mayor medida el exceso de electricidad producido por pequeñas instalaciones eólicas domésticas. El auge de la energía eólica ha provocado también la planificación y construcción de parques eólicos marinos, situados cerca de las costas. La energía del viento es más estable y fuerte en el mar que en tierra, y los parques eólicos marinos tienen un impacto visual menor, pero los costes de construcción y mantenimiento de estos parques son considerablemente mayores.(Moragues, 2003) A finales de 2014, la capacidad mundial instalada de energía eólica ascendía a 370 gigavatios, generando alrededor del 5% del consumo de electricidad mundial. Dinamarca genera más de un 25 % de su electricidad mediante energía eólica, y más de 80 países en todo el mundo la utilizan de forma creciente para proporcionar energía eléctrica en sus redes de distribución, aumentando su capacidad anualmente con tasas por encima del 20 %. En España la energía eólica produjo un 21,1 % del consumo eléctrico en 2013, convirtiéndose en la tecnología con mayor contribución a la cobertura de la demanda, por encima incluso de la energía nuclear.. La energía eólica es un recurso abundante, renovable, limpio y ayuda a disminuir las emisiones de gases de efecto invernadero al reemplazar fuentes de energía a base de. 5.
(16) combustibles fósiles, lo que la convierte en un tipo de energía verde. El impacto ambiental de este tipo de energía es además, generalmente, menos problemático que el de otras fuentes de energía. La energía del viento es bastante estable y predecible a escala anual, aunque presenta significativas variaciones a escalas de tiempo menores. Al incrementarse la proporción de energía eólica producida en una determinada región o país, se hace imprescindible establecer una serie de mejoras en la red eléctrica local. Diversas técnicas de control energético, como una mayor capacidad de almacenamiento de energía, una distribución geográfica amplia de los aerogeneradores, la disponibilidad de fuentes de energía de respaldo, la posibilidad de exportar o importar energía a regiones vecinas o la reducción de la demanda cuando la producción eólica es menor, pueden ayudar a mitigar en gran medida estos problemas. Adicionalmente, la predicción meteorológica permite a los gestores de la red eléctrica estar preparados frente a las previsibles. variaciones. en. la. producción. eólica. que. puedan. tener. lugar. a. corto. plazo.(Hernández, 2013, Zhou, 2012). 1.2 ESTADO DEL ARTE DE LA PREDICCIÓN EÓLICA Existen dos aproximaciones básicas para la predicción de la energía eólica: los modelos físicos y los modelos estadísticos. Los modelos físicos tienen en cuenta consideraciones físicas para adaptar las predicciones de viento en una zona a las condiciones concretas del emplazamiento del parque. Para hacer esta adaptación se utilizan modelos de meso-escala o micro-escala que, partiendo de las condiciones iniciales y de contorno obtenidas de un modelo atmosférico de mayor escala, calculan la velocidad del viento incidente en las turbinas del parque para posteriormente calcular la predicción de potencia por medio de la curva de potencia. (Dorronsoro, 2011) Por otro lado, de entre los modelos estadísticos podemos encontrar la familia de las series temporales, que solo utilizan valores pasados de las variables como datos de entrada del modelo, y los que además de valores pasados utilizan como entradas los valores de predicción meteorológica de modelos atmosféricos, relacionándolos con los valores de potencia histórica u otros valores históricos medidos. (Blanco, 2012a, MARTÍN, 2010). 6.
(17) El modelo de predicción podría además ser una combinación de ambos, es decir, tener en cuenta consideraciones físicas para estimar con detalle el viento en el emplazamiento de las turbinas y usar modelos estadísticos avanzados que utilicen esta información localizada, además de las medidas de potencia, para minimizar el error.(Blanco, 2012b) Existen además un conjunto de modelos ya desarrollados con un enfoque moderno y tecnológico que realizan predicciones sobre la energía eolica, aunque no constituyen líneas de estudio fundamental en este trabajo.Ejemplos de estos tipos de modelos de predicción son los siguientes: -Modelo ARPS (Advanced Regional Prediction System). -Modelo MASS (Mesoscale Atmospheric Simulation System). -Modelo MM5 (Modelo de Mesoesscala de Quinta Generación). -Modelo WRF (Weather Research and Forecasting Model). -Fabricantes de software de previsión de viento. WindPRO y WASP: modelos de software de predicción.. 1.3 CONJUNTO DE DATOS INICIAL Los datos brindados y necesarios se encontraban en una tabla en un documento Excel, llamado Valores 2009-2013.xls, en la cual por fila se indicaba el tiempo (diario durante 5 años) y por columna el nombre de la variable y en cada celda el valor de la variable para cada día, constituyendo así el conjunto de datos una serie temporal, ya que constituyen una secuencia de valores observados a lo largo del tiempo, y por tanto ordenados cronológicamente.(Blanco, 2012a, Ríos, 2008) Las variables en cuestión son: 1.. Dirección del viento máximo (DVM). 2.. Viento Máximo (VMAX). 3.. Temperatura Mínima (TMIN). 4.. Temperatura Media (TMED). 5.. Temperatura Máxima (TMAX). 7.
(18) 6.. Humedad Relativa Media (HRM). 7.. Viento Medio (VMED). 1.3.1 DIRECCIÓN DEL VIENTO MÁXIMO Se llama dirección del viento el punto del horizonte de donde viene o sopla. El instrumento más antiguo para conocer la dirección de los vientos es la veleta que, con la ayuda de la rosa de los vientos, define la procedencia de los vientos, es decir, la dirección desde donde soplan. Para distinguir uno de otro se les aplica el nombre de los principales rumbos de la brújula. Los cuatro puntos principales corresponden a los cardinales: Norte (N), Sur (S), Este (E) y Oeste (W). Se consideran hasta 32 entre estos y los intermedios, aunque los primordiales y más usados son los siguientes con su equivalencia en grados. del azimuth(Gheorghe, 2009,. Moragues, 2003):. -NNE Norte Noreste 22,50º. -NE Noreste 45,00º. -ENE Este Nordeste 67,50º. -E Este 90,00º. -ESE Este Sudeste 112,50º. -SE Sudeste 135,00º. -SSE Sur Sudeste 157,00º. -S Sur 180,00º. -SSW Sur Sudoeste 202,50º. -SW Sudoeste 225,00º. -WSW Oeste Sudeste 247,50º. -W Oeste 270,00º. -WNW Oeste Noroeste 292,50º. -NW Noroeste 315,00º. -NNW Norte Noroeste 337,50º. -N Norte 360,00º. 1.3.2 VIENTO MÁXIMO Y VIENTO MEDIO El viento produce energía porque está siempre en movimiento. Se estima que la energía contenida en los vientos es aproximadamente el 2% del total de la energía solar que alcanza la tierra. El contenido energético del viento depende de su velocidad. Cerca del suelo, la velocidad es baja, aumentando rápidamente con la altura. Cuanto más accidentada sea la 8.
(19) superficie del terreno, más frenará ésta al viento. Es por ello que sopla con menos velocidad en las depresiones terrestres y más sobre las colinas. No obstante, el viento sopla con más fuerza sobre el mar que en la tierra.(Antezana, 2004) Otras fuerzas que mueven el viento o lo afectan son la fuerza de gradiente de presión, el efecto Coriolis, las fuerzas de flotabilidad y de fricción y la configuración del relieve. Cuando entre dos masas de aire adyacentes existe una diferencia de densidad, el aire tiende a fluir desde las regiones de mayor presión a las de menor presión. En un planeta sometido a rotación, este flujo de aire se verá influenciado, acelerado, elevado o transformado por el efecto de Coriolis en cualquier parte de la superficie terrestre en la que nos encontremos. La creencia de que el efecto de Coriolis no actúa en el ecuador es un error: lo que sucede es que los vientos van disminuyendo de velocidad a medida que se acercan a la zona de convergencia intertropical y esa disminución de velocidad queda automáticamente compensada por una ganancia en altura del aire en toda la zona ecuatorial. A su vez, esa ganancia en altura da origen a la formación de nubes de gran desarrollo vertical y a lluvias intensas y prolongadas, ampliamente repartidas en la zona de convergencia intertropical, en especial en la zona ecuatorial. La fricción superficial con el suelo genera irregularidades en estos principios afectando al régimen de vientos.(Roth, 2003) 1.3.3 TEMPERATURA MÁXIMA, MEDIA Y MÍNIMA La temperatura es una magnitud referida a las nociones comunes de calor, frío, templado o tibio, medible mediante un termómetro. En física, se define como una magnitud escalar relacionada con la energía interna de un sistema termodinámico, definida por el principio cero de la termodinámica. Más específicamente, está relacionada directamente con la parte de la energía interna conocida como «energía cinética», que es la energía asociada a los movimientos de las partículas del sistema, sea en un sentido traslacional, rotacional, o en forma de vibraciones. A medida de que sea mayor la energía cinética de un sistema, se observa que éste se encuentra más «caliente»; es decir, que su temperatura es mayor.(Yunus A, 2009) Temperatura mínima: Se trata de la menor temperatura alcanzada en un lugar en un día, en un mes o en un año y también la mínima absoluta alcanzada en los registros de temperaturas de un lugar determinado. También en condiciones normales, las temperaturas mínimas diarias 9.
(20) se registran en horas del amanecer, las mínimas mensuales se obtienen en enero o febrero en el hemisferio norte y en julio o agosto en el hemisferio sur. Y también las temperaturas mínimas absolutas dependen de numerosos factores.(Hernández, 2013) Temperatura media: Se trata de los promedios estadísticos obtenidos entre las temperaturas máximas y mínimas. Con las temperaturas medias mensuales (promedio de las temperaturas medias diarias a lo largo del mes) se obtiene un gráfico de las temperaturas medias de un lugar para un año determinado. Y con estos mismos datos referidos a una sucesión de muchos años (30 o más) se obtiene un promedio estadístico de la temperatura en dicho lugar. Estos últimos datos, unidos al promedio de los montos pluviométricos (lluvias) mensuales de ese mismo lugar ofrecen los datos necesarios para la elaboración de un gráfico climático (a veces identificado como climograma) de dicho lugar. En el climograma empleado como ejemplo, la temperatura mínima se produce en diciembre y la máxima en julio. El gráfico podría servir como ejemplo de un clima templado mediterráneo.(Hernández, 2013) Temperatura máxima: Es la mayor temperatura del aire alcanzada en un lugar en un día (máxima diaria), en un mes (máxima mensual) o en un año (máxima anual). También puede referirse a la temperatura máxima registrada en un lugar durante mucho tiempo (máxima absoluta). En condiciones normales, y sin tener en cuenta otros elementos del clima, las temperaturas máximas diarias se alcanzan en las primeras horas de la tarde; las máximas mensuales suelen alcanzarse durante julio o agosto en la zona templada del hemisferio norte y en enero o febrero en el hemisferio sur. Las máximas absolutas dependen de muchos factores, sobre todo de la insolación, de la continentalidad, de la mayor o menor humedad, de los vientos y de otros.(Hernández, 2013) 1.3.4 HUMEDAD RELATIVA MEDIA La humedad relativa es el porcentaje de saturación de un volumen específico de aire a una temperatura específica. La humedad relativa del aire depende de la temperatura y la presión del volumen de aire analizado. Como la unidad de humedad relativa es por ciento, varía entre 0 (aire completamente seco) y 100% (aire saturado).. 10.
(21) La cantidad de vapor de agua contenida en el aire, en cualquier momento determinado, normalmente es menor que el necesario para saturar el aire. La humedad relativa es el porcentaje de la humedad de saturación, que se calcula normalmente en relación con la densidad de vapor de saturación.. O sea, la humedad relativa es la cantidad de humedad en el aire, comparado con la que el aire puede "mantener" a esa temperatura. Cuando el aire no puede "mantener" toda la humedad, entonces se condensa como rocío.(Cruz, 2008, Meruane, 2006) 1.4 SERIES DE TIEMPO Se llama Series de Tiempo a un conjunto de observaciones sobre valores que toma una variable (cuantitativa) en diferentes momentos del tiempo. Los datos se pueden comportar de diferentes formas a través del tiempo, puede que se presente una tendencia, un ciclo; no tener una forma definida o aleatoria, variaciones estacionales (anual, semestral, etc.). Las observaciones de una serie de tiempo serán denotadas por Y1; Y2,..., YT, donde Yt es el valor tomado por el proceso en el instante t. Los modelos de series de tiempo tienen un enfoque netamente predictivo y en ellos los pronósticos se elaborarán sólo con base al comportamiento pasado de la variable de interés.(Ríos, 2008) El conjunto de datos constituye una serie de tiempo, pues es una secuencia de observaciones, medido en determinados momentos del tiempo, ordenado cronológicamente y, espaciado entre sí de manera uniforme, así los datos usualmente son dependientes entre sí. Existen diferentes formas de trabajar con series de tiempo, con el objetivo principal de realizar pronósticos, normalmente para analizarlas se utilizan los modelos AR (Autoregresivos), MA (Medias Móviles), ARMA (Autoregresivo de Medias Móviles) y ARIMA (Autoregresivo Integrado y de Media Móvil). Otra forma de trabajar con series temporales es haciendo uso de Redes Neuronales Recurrentes, también a través de los modelos KNN (K-Nearest Neighbor), entre otras vías. (Villavicencio, 2011, Ríos, 2008, Mauricio, 2007, Molinero, 2004, Molinero, 2002). 11.
(22) 1.4.1 APLICACIONES DE LAS SERIES DE TIEMPO. Hoy en día diversas organizaciones requieren conocer el comportamiento futuro de ciertos fenómenos con el fin de planificar, prevenir, es decir, se utilizan para predecir lo que ocurrirá con una variable en el futuro a partir del comportamiento de esa variable en el pasado. En las organizaciones es de mucha utilidad en predicciones a corto y mediano plazo, por ejemplo ver qué ocurriría con la demanda de un cierto producto, las ventas a futuro, decisiones sobre inventario, insumos, etc. Algunas de las áreas de aplicación de Series de Tiempo son : _ Economía: Precios de un artículo, tasas de desempleo, tasa de inflación, índice de precios, precio del dólar, precio del cobre, precios de acciones, ingreso nacional bruto, etc. _ Meteorología: Cantidad de agua caída, temperatura máxima diaria, Velocidad del viento (energía eólica), energía solar, etc. _ Geofísica: Series sismológicas. _ Química: Viscosidad de un proceso, temperatura de un proceso. _ Demografía: Tasas de natalidad, tasas de mortalidad. _ Medicina: Electrocardiograma, electroencefalograma. _ Marketing: Series de demanda, gastos, utilidades, ventas, ofertas. _ Telecomunicaciones: Análisis de señales. _ Transporte: Series de tráfico. 1.5 MÉTODO DE TRABAJO A pesar de que el conjunto de datos de partida constituye una serie temporal no se trabaja sobre esta como tal, sino que se realizan transformaciones sobre los datos para poder aplicar sobre estos distintos modelos de regresión, o sea, se forman varios conjuntos de datos convencionales a partir de la serie de tiempo, específicamente uno para cada variable existente. Para realizar esta operación se implementa un código sobre el lenguaje de programación java utilizando la herramienta NetBeans IDE (versión 7.1.2). Una vez. 12.
(23) conformados los nuevos datos se utiliza la herramienta WEKA para generar los distintos modelos de regresión sobre cada conjunto formado y se realiza una evaluación de los modelos para seleccionar el más óptimo para cada variable, atendiendo principalmente al resultado del coeficiente de correlación obtenido para cada modelo generado. Una vez determinados los mejores modelos para cada variable se desarrolla una aplicación como mecanismo de obtención de las predicciones de cada variable diariamente según la cantidad de días deseada.. 1.6 WEKA Weka (Waikato Environment for Knowledge Analysis - Entorno para Análisis del Conocimiento de la Universidad de Waikato) es una plataforma de software para aprendizaje automático y minería de datos escrito en Java y desarrollado en la Universidad de Waikato. El paquete Weka contiene una colección de herramientas de visualización y algoritmos para análisis de datos y modelado predictivo, unidos a una interfaz gráfica de usuario para acceder fácilmente a sus funcionalidades. Weka soporta varias tareas estándar de minería de datos, especialmente, preprocesamiento de datos, clustering, clasificación, regresión, visualización, y selección. Todas las técnicas de Weka se fundamentan en la asunción de que los datos están disponibles en un fichero plano (flat file) o una relación, en la que cada registro de datos está descrito por un número fijo de atributos (normalmente numéricos o nominales, aunque también se soportan otros tipos). (Abernethy, 2010, Aler, 2009, Witten, 2000) 1.6.1 LA INTERFAZ DE USUARIO. La primera pantalla de Weka muestra una serie de opciones en su parte superior. La más importante es Applications, donde se pueden ver las distintas subherramientas de Weka. Las más importantes son Explorer (para explorar los datos) y Experimenter (para realizar experimentos que comparen estadísticamente distintos algoritmos en distintos conjuntos de datos, de manera automatizada).(Bouckaert, 2013, Aler, 2009). 13.
(24) Figura 1 ventana Inicial de WEKA SIMPLE CLI Simple CLI es la abreviatura de Simple Command-Line Interface (Interfaz Simple de Línea de Comandos); se trata de una consola que permite acceder a todas las opciones de Weka desde línea de comandos.(Bouckaert, 2013, Aler, 2009). EXPERIMENTER La interfaz Experimenter (Experimentador) permite la comparación sistemática de una ejecución de los algoritmos predictivos de Weka sobre una colección de conjuntos de datos.(Bouckaert, 2013, Aler, 2009). KNOWLEDGE FLOW Knowledge Flow (Flujo de Conocimiento) es una interfaz que soporta esencialmente las mismas funciones que el Explorer pero con una interfaz que permite "arrastrar y soltar". Una ventaja es que ofrece soporte para el aprendizaje incremental.(Bouckaert, 2013, Aler, 2009). 14.
(25) EXPLORER De todas estas funcionalidades que contiene la herramienta WEKA en este trabajo se utiliza principalmente el Explorer. La interfaz Explorer (Explorador) dispone de varios paneles que dan acceso a los componentes principales del banco de trabajo: - El panel "Preprocess" dispone de opciones para importar datos de una base de datos, de un fichero CSV, etc., y para preprocesar estos datos utilizando los denominados algoritmos de filtrado. Estos filtros se pueden utilizar para transformar los datos (por ejemplo convirtiendo datos numéricos en valores discretos) y para eliminar registros o atributos según ciertos criterios previamente especificados. - El panel "Classify" permite al usuario aplicar algoritmos de clasificación estadística y análisis de regresión (denominados todos clasificadores en Weka) a los conjuntos de datos resultantes, para estimar la exactitud del modelo predictivo resultante, y para visualizar predicciones erróneas, curvas ROC, etc., o el propio modelo (si este es susceptible de ser visualizado, como por ejemplo un árbol de decisión). -El panel "Associate" proporciona acceso a las reglas de asociación aprendidas que intentan identificar todas las interrelaciones importantes entre los atributos de los datos. -El panel "Cluster" da acceso a las técnicas de clustering o agrupamiento de Weka como por ejemplo el algoritmo K-means. Este es sólo una implementación del algoritmo expectaciónmaximización para aprender una mezcla de distribuciones normales. -El panel "Selected attributes" proporciona algoritmos para identificar los atributos más predictivos en un conjunto de datos. -El panel "Visualize" muestra una matriz de puntos dispersos (Scatterplot) donde cada punto individual puede seleccionarse y agrandarse para ser analizados en detalle usando varios operadores de selección.(Bouckaert, 2013, Aler, 2009). 15.
(26) Figura 2 WEKA Explorer. Weka garantiza varias ventajas: . Está disponible libremente bajo la licencia pública general de GNU.. . Es muy portable porque está completamente implementado en Java y puede correr en casi cualquier plataforma.. . Contiene una extensa colección de técnicas para preprocesamiento de datos y modelado.. . Es fácil de utilizar por un principiante gracias a su interfaz gráfica de usuario. La principal carencia es que hay un área importante que actualmente no cubren los algoritmos incluidos en Weka y es el modelado de secuencias.(Bouckaert, 2013, Abernethy, 2010). 16.
(27) 1.7 VISUAL PARADIGM Para la realización de la ingeniería de software de la aplicación a través de los diagramas UML se utilizó la herramienta Visual Paradigm versión 9.0, mediante la cual se logran desarrollar los siguientes diagramas: -Diagrama de Clases -Diagrama de Casos de Uso -Diagrama de Actividad. Visual Paradigm for UML es una herramienta CASE que soporta el modelado mediante UML y proporciona asistencia a los analistas, ingenieros de software y desarrolladores, durante todos los pasos del Ciclo de Vida de desarrollo de un Software.(Norvell, 2010). Las ventajas que proporciona Visual Paradigm for UML son: - Dibujo. Facilita el modelado de UML, ya que proporciona herramientas específicas para ello. Esto también permite la estandarización de la documentación, ya que la misma se ajusta al estándar soportado por la herramienta. -Corrección sintáctica. Controla que el modelado con UML sea correcto. -Coherencia entre diagramas. Al disponer de un repositorio común, es posible visualizar el mismo elemento en varios diagramas, evitando duplicidades. -Integración con otras aplicaciones.. Permite integrarse con otras aplicaciones, como. herramientas ofimáticas, lo cual aumenta la productividad. -Trabajo. multiusuario.. Permite el trabajo en grupo, proporcionando herramientas de. compartición de trabajo. -Reutilización. Facilita la reutilización, ya que disponemos de una herramienta centralizada donde se encuentran los modelos utilizados para otros proyectos. -Generación de código. Permite generar código de forma automática, reduciendo los tiempos de desarrollo y evitando errores en la codificación del software.. 17.
(28) -Generación de informes. Permite generar diversos informes a partir de la información introducida en la herramienta.(Norvell, 2010). Conclusiones En este capítulo se realizó un estudio teórico referente a los conceptos relacionados con la energía eolica y se explicaron un conjunto de parámetros o variables determinadas que la conforman, se explicó además la novedosa metodología de trabajo tomada a partir de los estudios realizados sobre las series temporales. Se desarrolló también una investigación orientada a destacar y explicar las diferentes herramientas utilizadas para el desarrollo del trabajo y sus funcionalidades.. 18.
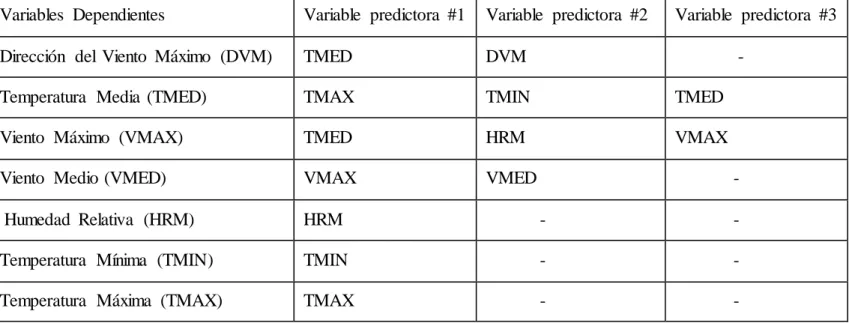
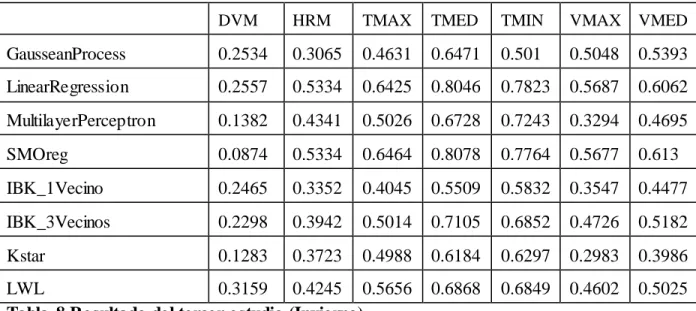
(29) CAPÍTULO 2. TRANSFORMACIÓN DE DATOS Y MODELOS DE REGRESIÓN 2.1 CONFORMANDO LOS CASOS DE ESTUDIO. Con el objetivo de alcanzar mejores resultados de los modelos de regresión se conforman distintos casos de estudio para determinar con cual subconjunto de datos se obtienen mejores resultados de los modelos para cada una de las variables. Por lo que partir del conjunto de datos inicial se obtienen nuevos subconjuntos: a. Todo el conjunto de datos inicial. b. Comenzando desde el año inicial (2009) se van agregando años hasta obtener todo el conjunto de datos (2009-2013). c. Para cada estación del año se obtiene un nuevo subconjunto de datos donde influyen todos los años. 2.2 PREPROCESAMIENTO DE DATOS. Para la transformación de los datos es necesario conocer la dependencia entre las variables, con el objetivo de determinar cuáles son las variables predictoras o independientes y las variables dependientes. También es necesario conocer un tamaño de ventana (la cantidad de días pasados necesarios para la predicción). Como resultado de un análisis realizado por parte del especialista o experto en el tema se determinó un tamaño de ventana de 5 días.. 2.2.1 DEPENDENCIA ENTRE LAS VARIABLES. El análisis de la dependencia entre las variables fue realizado por parte del experto en este tema y se obtuvieron los siguientes resultados:. 19.
(30) Variables Dependientes. Variable predictora #1. Variable predictora #2. Variable predictora #3. Dirección del Viento Máximo (DVM). TMED. DVM. Temperatura Media (TMED). TMAX. TMIN. TMED. Viento Máximo (VMAX). TMED. HRM. VMAX. Viento Medio (VMED). VMAX. VMED. Humedad Relativa (HRM). HRM. -. -. Temperatura Mínima (TMIN). TMIN. -. -. Temperatura Máxima (TMAX). TMAX. -. -. -. -. Tabla 1 Dependencia entre variables. 2.2.2 TRANSFORMACIONES DE DATOS. Una vez conocido las dependencias entre las variables y el tamaño de ventana se procede a transformar los datos iniciales de manera tal que puedan ser procesados por los modelos de regresión contenidos en la herramienta WEKA. La transformación consiste en tomar 5 días pasados (tamaño de ventana) de cada una de las variables predictoras según el análisis de dependencia realizado anteriormente y colocar todos esos datos en una fila, donde la variable objetivo estará localizada en la última columna de cada fila y para predecirla se utilizan todos los datos de esa fila, por ejemplo, la variable Dirección del Viento Máximo depende directamente de la variable Temperatura Media, por lo que una fila del nuevo conjunto de datos tendría la estructura siguiente:. T MED_DIA1. T MED_DIA2. T MED_DIA3. T MED_DIA4. T MED_DIA5. DVM_DIA1. DVM_DIA2. DVM_DIA3. DVM_DIA4. DVM_DIA5. Tabla 2 Nueva estructura de datos. 20. Var OBJ.
(31) Así se continúa formando filas hasta que se disponga de todos los datos con el nuevo formato, donde la variable VarOBJ (variable objetivo) constituye la Dirección del Viento Máximo del día siguiente (día 6). 2.2.3 CÓDIGO PARA TRANSFORMAR LOS DATOS. Para realizar la transformación inicial de datos explicada anteriormente se implementa un código utilizando el lenguaje de programación java y la herramienta NetBeans IDE versión 7.1.2. Para la implementación del código se necesita realizar trabajos sobre un documento Excel, principalmente las operaciones de lectura y escritura, por lo que es necesario de importar bibliotecas que permitan y faciliten estas operaciones. Se importa la siguiente biblioteca: i. jxl.jar: Para realizar todo el trabajo realizado con los documentos Excel de entrada y salida, así como las operaciones de lectura y escritura sobre los mismos.(D, 2010). 2.2.4 ESTRUCTURA DEL CÓDIGO. Se crea la clase SplitData en la cual se implementa el método runprocess, el cual acepta como parámetros de entrada los siguientes: 1. int [] columnas_independientes: Identificadores (números) de las columnas donde se encuentran las variables predictoras o independientes. 2. int columna: Identificador (número) de la columna donde se encuentran la variable objetivo o dependiente. 3. int ventana: Tamaño de ventana (en este caso 5 días).. 21.
(32) 4. String urlEntrada: URL del fichero Excel de lectura. 5. String urlSalida: URL del fichero CSV de escritura.. Este método crea un nuevo fichero CSV para cada una de las variables objetivo con el formato explicado anteriormente. 2.3 MODELOS DE REGRESIÓN EN WEKA. La herramienta WEKA proporciona y facilita la generación y el uso de varios modelos de regresión. Para evaluar la calidad de los modelos de regresión generados se atiende principalmente al coeficiente de correlación obtenido tras generar cada modelo, En probabilidad y estadística, la correlación indica la fuerza y la dirección de una relación lineal y proporcionalidad entre dos variables estadísticas. Se considera que dos variables cuantitativas están correlacionadas cuando los valores de una de ellas varían sistemáticamente con respecto a los valores homónimos de la otra: si tenemos dos variables (A y B) existe correlación si al aumentar los valores de A lo hacen también los de B y viceversa. La correlación entre dos variables no implica, por sí misma, ninguna relación de causalidad.(Tusell, 2011, Novak, 2009, Gambhir, 2006, Molinero, 2002) Para solucionar nuestra problemática se utilizaron los siguientes modelos de dicha herramienta: Paquete Functions: 1.. GaussianProcesses. En teoría de la probabilidad y estadísticas, los procesos de Gauss son una familia de procesos estocásticos. En un proceso Gaussiano, cada punto en un cierto espacio de entrada está asociado con una distribución normal variable aleatoria. Además, cada conjunto finito de esas variables aleatorias tiene una distribución normal multivariante. La distribución de un proceso Gaussiano es la distribución conjunta de todos esos (infinitamente muchos) variables aleatorias, y como tal, es una distribución de las funciones.. 22.
(33) El concepto de procesos Gaussianos lleva el nombre de Carl Friedrich Gauss, ya que se basa en la noción de la normal de la distribución que a menudo se llama la distribución de Gauss. De hecho, los procesos de Gauss pueden ser vistos como una generalización de dimensión infinita de distribuciones normales multivariantes. Los procesos Gaussianos son importantes en la modelización estadística debido a las propiedades heredadas de la normal. Por ejemplo, si un proceso aleatorio se modela como un proceso Gaussiano, las distribuciones de diversas magnitudes derivadas se pueden obtener de forma explícita. Tales cantidades incluyen el valor medio del proceso en un rango de tiempos y el error en la estimación de la media usando valores de muestras en un conjunto pequeño de veces. Un proceso de Gauss es un proceso estocástico X t, t ∈ T, para la que cualquier finito combinación. lineal de las muestras tiene una distribución gaussiana. conjunta.. Más. exactamente, cualquier lineal funcional aplicada a la función de ejemplo X t dará resultado una distribución normal. -Notación sabio, uno puede escribir X ~ GP (m, K), es decir, la función aleatoria X se distribuye como un GP con la función de media m y la función de covarianza K. Cuando el vector de entrada t es de dos o multidimensional, un proceso Gaussiano podría también conocido como un campo aleatorio gaussiano.(Rasmussen, 2010, Ebden, 2008, Rasmussen, 2006). 2.. LinearRegression. En estadística la regresión lineal o ajuste lineal es un método matemático que modela la relación entre una variable dependiente Y, las variables independientes Xi y un término aleatorio ε. Este modelo puede ser expresado como:. : Variable dependiente, explicada o regresando. : Variables explicativas, independientes o regresores.. 23.
(34) : Parámetros, miden la influencia que las variables explicativas tienen sobre el regresando. Donde. es la intersección o término "constante", las. respectivos a cada variable independiente, y. son los parámetros. es el número de parámetros independientes. a tener en cuenta en la regresión. La regresión lineal puede ser contrastada con la regresión no lineal.(Hoffmann, 2010, Torres-Reyna, 2007, Rodríguez, 2007). 4.. MultilayerPerceptron. El perceptrón multicapa es una red neuronal artificial (RNA) formada por múltiples capas, esto le permite resolver problemas que no son linealmente separables, lo cual es la principal limitación del perceptrón (también llamado perceptrón simple). El perceptrón multicapa puede ser totalmente o localmente conectado. En el primer caso cada salida de una neurona de la capa "i" es entrada de todas las neuronas de la capa "i+1", mientras que en el segundo cada neurona de la capa "i" es entrada de una serie de neuronas (región) de la capa "i+1". Las capas pueden clasificarse en tres tipos: . Capa de entrada: Constituida por aquellas neuronas que introducen los patrones de entrada en la red. En estas neuronas no se produce procesamiento.. . Capas ocultas: Formada por aquellas neuronas cuyas entradas provienen de capas anteriores y cuyas salidas pasan a neuronas de capas posteriores.. . Capa de salida: Neuronas cuyos valores de salida se corresponden con las salidas de toda la red. Limitaciones:. . El Perceptrón Multicapa no extrapola bien, es decir, si la red se entrena mal o de manera insuficiente, las salidas pueden ser imprecisas.. . La existencia de mínimos locales en la función de error dificulta considerablemente el entrenamiento, pues una vez alcanzado un mínimo el entrenamiento se detiene aunque no se haya alcanzado la tasa de convergencia fijada.. 24.
(35) Cuando caemos en un mínimo local sin satisfacer el porcentaje de error permitido se puede considerar: cambiar la topología de la red (número de capas y número de neuronas), comenzar el entrenamiento con unos pesos iniciales diferentes, modificar los parámetros de aprendizaje, modificar el conjunto de entrenamiento o presentar los patrones en otro orden. Aplicaciones: El perceptrón multicapa se utiliza para resolver problemas de asociación de patrones, segmentación de imágenes, compresión de datos, etc.(Novak, 2009, Witten, 2000) 5.. SMOreg. SMOreg implementa las máquinas de soporte vectorial para la regresión (SVM). Las máquinas de soporte vectorial o máquinas de vectores de soporte (Support Vector Machines, SVMs) son un conjunto de algoritmos de aprendizaje supervisado desarrollados por Vladimir Vapnik y su equipo en los laboratorios AT&T. Estos métodos están propiamente relacionados con problemas de clasificación y regresión. Dado un conjunto de ejemplos de entrenamiento (de muestras) podemos etiquetar las clases y entrenar una SVM para construir un modelo que prediga la clase de una nueva muestra. Intuitivamente, una SVM es un modelo que representa a los puntos de muestra en el espacio, separando las clases por un espacio lo más amplio posible. Cuando las nuevas muestras se ponen en correspondencia con dicho modelo, en función de su proximidad pueden ser clasificadas a una u otra clase. Más formalmente, una SVM construye un hiperplano o conjunto de hiperplanos en un espacio de dimensionalidad muy alta (o incluso infinita) que puede ser utilizado en problemas de clasificación o regresión. Una buena separación entre las clases permitirá una clasificación correcta. La idea básica es que dado un conjunto de puntos, subconjunto de un conjunto mayor (espacio), en el que cada uno de ellos pertenece a una de dos posibles categorías, un algoritmo basado en SVM construye un modelo capaz de predecir si un punto nuevo (cuya categoría desconocemos) pertenece a una categoría o a la otra.(Witten, 2013, Aler, 2009, Witten, 2000, Castro, 2013). 25.
(36) Paquete Lazy: 6.. IBK (K=1 y K=3). Este algoritmo está basado en instancias, por ello consiste únicamente en almacenar los datos presentados. Cuando una nueva instancia es encontrada, un conjunto de instancias similares relacionadas es devuelto desde la memoria y usado para clasificar la instancia consultada. Se trata, por tanto, de un algoritmo del método lazy learning. Este método de aprendizaje se basa en que los módulos de clasificación mantienen en memoria una selección de ejemplos sin crear ningún tipo de abstracción en forma de reglas o de árboles de decisión (de ahí su nombre, lazy, perezosos). Cada vez que una nueva instancia es encontrada, se calcula su relación con los ejemplos previamente guardados con el propósito de asignar un valor de la función objetivo para la nueva instancia. La idea básica sobre la que se fundamenta este algoritmo es que un nuevo caso se va a clasificar en la clase más frecuente a la que pertenecen sus K vecinos más cercanos. De ahí que sea también conocido como método K-NN: K Nearest Neighbours. El algoritmo K-NN en WEKA se conoce como IBK. Este algoritmo es de la familia de algoritmos incluidos en “lazy learning”. Este algoritmo se basa en instancias, por lo que únicamente almacena los datos presentados. Cuando al ejecutarlo se encuentra una nueva instancia, se devuelve desde memoria el conjunto de instancias similares relacionadas y usado para clasificar la instancia en concreto. Cada vez que se encuentra una nueva instancia, el algoritmo calcula su relación con el resto de ejemplos almacenados previamente con el fin de asignar un valor de la función objetivo para esta instancia encontrada. El concepto principal que fundamenta este algoritmo, es que cada instancia encontrada se va a clasificar en la clase más frecuente a la que pertenezcan sus K vecinos más cercanos. Es por esto que este algoritmo también es conocido como el método K-NN. K Nearest Neighbours.(Witten, 2013, Novak, 2009, Aler, 2009). 26.
(37) 7.. Kstar. K * es un clasificador basado en instancia, que es la clase de una instancia de prueba, se basa en la clase de esas instancias de capacitación similares a la misma, según lo determinado por una función de similitud. Se diferencia de otros aprendizajes basados en instancia en que utiliza una función de la distancia basada en la entropía.(Novak, 2009, Witten, 2000). 8.. LWL. LWL (Locally Weighted Learning) o aprendizaje localmente ponderado. Utiliza un algoritmo basado en instancia para asignar pesos de instancia que luego son utilizados por un WeightedInstancesHandler especificado. Puede hacer la clasificación (por ejemplo, el uso de naive Bayes) o regresión (por ejemplo, mediante regresión lineal).(Witten, 2013, Witten, 2000). 27.
(38) 2.4 RESULTADOS DE LOS MODELOS DE REGRESIÓN 2.4.1 PRIMER ESTUDIO. Todo el conjunto de datos original (2009-2013):. DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.273. 0.3898. 0.4156. 0.625. 0.4309. 0.505. 0.6903. LinearRegression. 0.282. 0.7354. 0.8296. 0.914. 0.8995. 0.542. 0.7339. MultilayerPerceptron. 0.14. 0.6395. 0.7818. 0.884. 0.8959. 0.495. 0.6466. SMOreg. 0.29. 0.7358. 0.8296. 0.914. 0.8992. 0.54. 0.734. IBK_1Vecino. 0.156. 0.5482. 0.6832. 0.813. 0.8014. 0.237. 0.5351. IBK_3Vecinos. 0.206. 0.657. 0.7769. 0.871. 0.8663. 0.375. 0.6513. Kstar. 0.171. 0.7084. 0.7817. 0.85. 0.8679. 0.319. 0.5595. LWL. 0.308. 0.6543. 0.7303. 0.796. 0.7977. 0.4519. 0.5952. Tabla 3 Resultados del Primer Estudio. Análisis parcial de los resultados: Se obtienen resultados satisfactorios para casi todas las variables excepto VMAX con resultados regulares y DVM con malos resultados. Se observa claramente que los mejores resultados para las variables objetivo HRM, TMAX, TMED, TMIN, VMAX y VMED se obtienen con los modelos SMOreg y LinearRegression. Para la variable DVM el modelo óptimo es LWL.. 28.
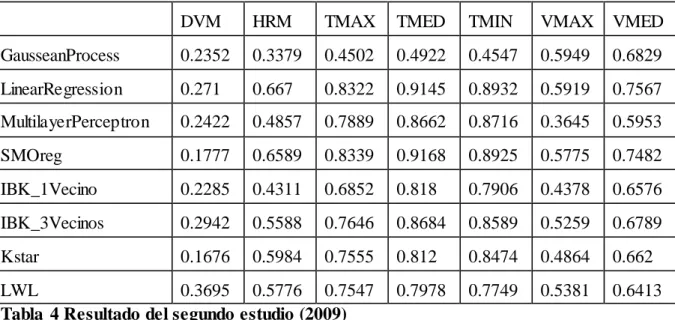
(39) 2.4.2 SEGUNDO ESTUDIO Añadiendo años (2009): DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.2352. 0.3379. 0.4502. 0.4922. 0.4547. 0.5949. 0.6829. LinearRegression. 0.271. 0.667. 0.8322. 0.9145. 0.8932. 0.5919. 0.7567. MultilayerPerceptron. 0.2422. 0.4857. 0.7889. 0.8662. 0.8716. 0.3645. 0.5953. SMOreg. 0.1777. 0.6589. 0.8339. 0.9168. 0.8925. 0.5775. 0.7482. IBK_1Vecino. 0.2285. 0.4311. 0.6852. 0.818. 0.7906. 0.4378. 0.6576. IBK_3Vecinos. 0.2942. 0.5588. 0.7646. 0.8684. 0.8589. 0.5259. 0.6789. Kstar. 0.1676. 0.5984. 0.7555. 0.812. 0.8474. 0.4864. 0.662. 0.7978. 0.7749. 0.5381. 0.6413. LWL 0.3695 0.5776 0.7547 Tabla 4 Resultado del segundo estudio (2009). Análisis parcial de los resultados: Se obtienen muy buenos resultados para casi todas las variables excepto VMAX con resultados regulares y DVM con malos resultados. Se observa claramente que los mejores resultados para las variables objetivo HRM, TMIN y VMED se obtienen para este conjunto de datos con el modelo LinearRegression. Para las variables TMAX y TMED el mejor resultado lo proporciona el modelo SMOreg para este conjunto de datos. Para. la. variable. VMAX. el. mejor. resultado. lo. proporciona. el. modelo. GaussianProcesses para este conjunto de datos. Para la variable DVM el mejor resultado lo proporciona el modelo LWL para este conjunto de datos. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 29.
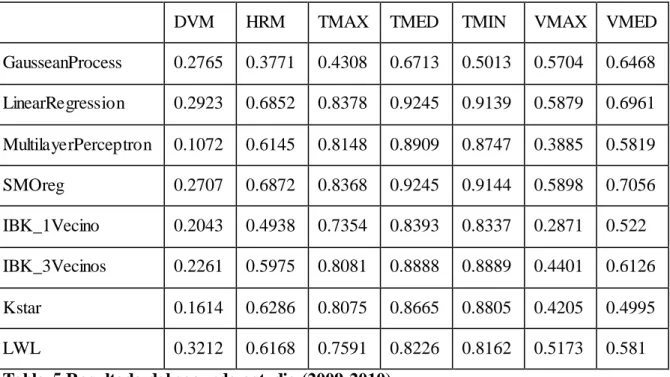
(40) Añadiendo años (2009-2010): DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.2765. 0.3771. 0.4308. 0.6713. 0.5013. 0.5704. 0.6468. LinearRegression. 0.2923. 0.6852. 0.8378. 0.9245. 0.9139. 0.5879. 0.6961. MultilayerPerceptron. 0.1072. 0.6145. 0.8148. 0.8909. 0.8747. 0.3885. 0.5819. SMOreg. 0.2707. 0.6872. 0.8368. 0.9245. 0.9144. 0.5898. 0.7056. IBK_1Vecino. 0.2043. 0.4938. 0.7354. 0.8393. 0.8337. 0.2871. 0.522. IBK_3Vecinos. 0.2261. 0.5975. 0.8081. 0.8888. 0.8889. 0.4401. 0.6126. Kstar. 0.1614. 0.6286. 0.8075. 0.8665. 0.8805. 0.4205. 0.4995. LWL. 0.3212. 0.6168. 0.7591. 0.8226. 0.8162. 0.5173. 0.581. Tabla 5 Resultado del segundo estudio (2009-2010). Análisis parcial de los resultados: Se obtienen muy buenos resultados para casi todas las variables excepto VMAX con resultados regulares y DVM con resultados insatisfactorios. Se observa claramente que los mejores resultados para las variables objetivo TMAX y TMED se obtienen para este conjunto de datos con el modelo LinearRegression. Para las variables HRM, TMIN, VMAX y VMED el mejor resultado lo proporciona el modelo SMOreg para este conjunto de datos. El modelo LWL resulta el óptimo para la predicción de la variable DVM. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 30.
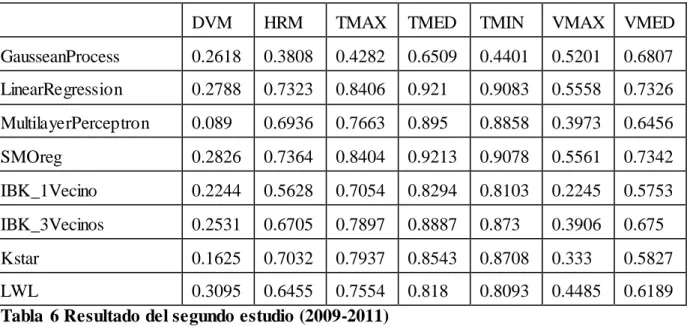
(41) Añadiendo años (2009-2011): DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.2618. 0.3808. 0.4282. 0.6509. 0.4401. 0.5201. 0.6807. LinearRegression. 0.2788. 0.7323. 0.8406. 0.921. 0.9083. 0.5558. 0.7326. MultilayerPerceptron. 0.089. 0.6936. 0.7663. 0.895. 0.8858. 0.3973. 0.6456. SMOreg. 0.2826. 0.7364. 0.8404. 0.9213. 0.9078. 0.5561. 0.7342. IBK_1Vecino. 0.2244. 0.5628. 0.7054. 0.8294. 0.8103. 0.2245. 0.5753. IBK_3Vecinos. 0.2531. 0.6705. 0.7897. 0.8887. 0.873. 0.3906. 0.675. Kstar. 0.1625. 0.7032. 0.7937. 0.8543. 0.8708. 0.333. 0.5827. 0.818. 0.8093. 0.4485. 0.6189. LWL 0.3095 0.6455 0.7554 Tabla 6 Resultado del segundo estudio (2009-2011). Análisis parcial de los resultados: Se obtienen satisfactorios resultados para casi todas las variables excepto VMAX con resultados regulares y DVM con resultados insatisfactorios. Se observa claramente que los mejores resultados para las variables objetivo TMAX y TMIN se obtienen para este conjunto de datos con el modelo LinearRegression. Para las variables HRM, TMED, VMAX y VMED el mejor resultado lo proporciona el modelo SMOreg para este conjunto de datos. El modelo LWL resulta el óptimo para la predicción de la variable DVM.. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 31.
(42) Añadiendo años (2009-2012):. DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.261. 0.394. 0.4142. 0.6361. 0.426. 0.499. 0.6934. LinearRegression. 0.2784. 0.7286. 0.8366. 0.9184. 0.9041. 0.5479. 0.7374. MultilayerPerceptron. 0.0714. 0.6947. 0.7822. 0.8794. 0.8805. 0.446. 0.6526. SMOreg. 0.2879. 0.7288. 0.8365. 0.9177. 0.9037. 0.5487. 0.7374. IBK_1Vecino. 0.1689. 0.5434. 0.6892. 0.8164. 0.8135. 0.2541. 0.535. IBK_3Vecinos. 0.1885. 0.6573. 0.7886. 0.8773. 0.8681. 0.377. 0.6481. Kstar. 0.1565. 0.6896. 0.7891. 0.8466. 0.8687. 0.3013. 0.5693. LWL. 0.294. 0.6499. 0.7385. 0.8006. 0.806. 0.4593. 0.6032. Tabla 7 Resultado del segundo estudio (2009-2012). Análisis parcial de los resultados: Se obtienen muy buenos resultados para casi todas las variables excepto VMAX con resultados regulares y DVM con resultados insatisfactorios. Se evidencia que los mejores resultados para las variables objetivo TMAX, TMED, TMIN y VMED. se obtienen para este conjunto de datos con el modelo. LinearRegression. Se observa claramente que los mejores resultados para las variables objetivo HRM y VMAX se obtienen para este conjunto de datos con el modelo SMOreg. Para la variable objetivo DVM el resultado óptimo se obtiene con el modelo LWL. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 32.
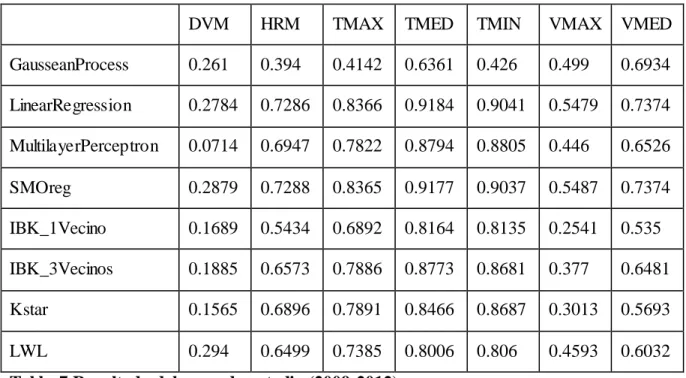
(43) 2.4.3. TERCER ESTUDIO Estaciones: Invierno: DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.2534. 0.3065. 0.4631. 0.6471. 0.501. 0.5048. 0.5393. LinearRegression. 0.2557. 0.5334. 0.6425. 0.8046. 0.7823. 0.5687. 0.6062. MultilayerPerceptron. 0.1382. 0.4341. 0.5026. 0.6728. 0.7243. 0.3294. 0.4695. SMOreg. 0.0874. 0.5334. 0.6464. 0.8078. 0.7764. 0.5677. 0.613. IBK_1Vecino. 0.2465. 0.3352. 0.4045. 0.5509. 0.5832. 0.3547. 0.4477. IBK_3Vecinos. 0.2298. 0.3942. 0.5014. 0.7105. 0.6852. 0.4726. 0.5182. Kstar. 0.1283. 0.3723. 0.4988. 0.6184. 0.6297. 0.2983. 0.3986. LWL 0.3159 0.4245 0.5656 Tabla 8 Resultado del tercer estudio (Invierno). 0.6868. 0.6849. 0.4602. 0.5025. Análisis parcial de los resultados: Se obtienen satisfactorios resultados para casi todas las variables excepto para DVM con resultados insatisfactorios y VMAX con resultados regulares. Se evidencia que los mejores resultados para las variables objetivo TMIN y VMAX se obtienen para este conjunto de datos con el modelo LinearRegression. Para las variables HRM, TMAX, TMED y VMED se evidencia que el mejor resultado se obtiene con el modelo SMOreg. Para la variable DVM se muestra que el mejor resultado se obtiene para este conjunto de datos con el modelo LWL. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 33.
(44) Primavera:. DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.1818. 0.4738. 0.4841. 0.5876. 0.5114. 0.2234. 0.6415. LinearRegression. 0.2027. 0.7005. 0.7671. 0.853. 0.8298. 0.2281. 0.6467. MultilayerPerceptron. 0.0748. 0.5772. 0.6643. 0.7922. 0.7661. 0.0787. 0.4346. SMOreg. 0.2269. 0.7068. 0.7703. 0.8593. 0.8257. 0.2602. 0.6457. IBK_1Vecino. 0.039. 0.4467. 0.6343. 0.6765. 0.622. 0.0897. 0.4409. IBK_3Vecinos. 0.0975. 0.6043. 0.6815. 0.7601. 0.7436. 0.1806. 0.5207. Kstar. 0.0665. 0.604. 0.6348. 0.687. 0.729. 0.1976. 0.3944. 0.6886. 0.2926. 0.537. LWL 0.2697 0.6658 0.6574 0.7401 Tabla 9 Resultado del tercer estudio (Primavera). Análisis parcial de los resultados: Se obtienen satisfactorios resultados para casi todas las variables excepto para DVM y VMAX, con las cuales se obtienen malos resultados. Se evidencia que los mejores resultados para las variables objetivo TMIN y VMED se obtienen para este conjunto de datos con el modelo LinearRegression. Para las variables HRM, TMAX y TMED se evidencia que los mejores resultados se obtiene con el modelo SMOreg. Para la variable VMAX y DVM se muestra que el mejor resultado se obtiene para este conjunto de datos con el modelo LWL.. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 34.
(45) Verano: DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.23. 0.3678. 0.2659. 0.4603. 0.3443. 0.4132. 0.6055. LinearRegression. 0.2488. 0.5357. 0.6341. 0.6081. 0.5121. 0.4146. 0.6738. MultilayerPerceptron. -0.0494 0.4486. 0.5527. 0.3992. 0.3031. 0.218. 0.5779. SMOreg. 0.251. 0.5406. 0.6374. 0.6011. 0.5068. 0.4268. 0.6803. IBK_1Vecino. 0.0837. 0.2889. 0.3191. 0.3245. 0.277. -0.009. 0.4045. IBK_3Vecinos. 0.1543. 0.4043. 0.4735. 0.3914. 0.3014. 0.1642. 0.5537. Kstar. 0.1469. 0.4202. 0.4343. 0.2829. 0.3568. 0.1272. 0.4575. LWL. 0.1666. 0.4977. 0.5069. 0.4974. 0.4813. 0.416. 0.5819. Tabla 10 Resultado del tercer estudio (Verano). Análisis parcial de los resultados: Se obtienen satisfactorios resultados para casi todas las variables excepto para DVM con malos resultados y VMAX con resultados regulares. Se observa claramente que los mejores resultados para las variables objetivo DVM, HRM, TMAX, VMAX y VMED se obtienen para este conjunto de datos con el modelo SMOreg. Se evidencia que para las variables objetivos TMED y TMIN en este conjunto de datos se obtienen los mejores resultados con el modelo LinearRegression.. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 35.
(46) Otoño:. DVM. HRM. TMAX. TMED. TMIN. VMAX. VMED. GausseanProcess. 0.3533. 0.3942. 0.4307. 0.5551. 0.4415. 0.4949. 0.7178. LinearRegression. 0.3915. 0.6033. 0.7825. 0.8694. 0.8332. 0.5481. 0.7642. MultilayerPerceptron. 0.2455. 0.51. 0.7246. 0.7932. 0.7738. 0.2954. 0.6893. SMOreg. 0.4038. 0.6006. 0.7861. 0.8649. 0.8335. 0.5335. 0.7664. IBK_1Vecino. 0.1725. 0.3332. 0.5985. 0.716. 0.6478. 0.3604. 0.5517. IBK_3Vecinos. 0.2272. 0.4609. 0.7017. 0.7851. 0.7614. 0.4633. 0.6664. Kstar. 0.1768. 0.4973. 0.6879. 0.731. 0.7335. 0.2985. 0.5081. LWL. 0.3894. 0.4933. 0.6929. 0.7649. 0.7186. 0.428. 0.6494. Tabla 11 Resultado del tercer estudio (Otoño). Análisis parcial de los resultados: Resultados satisfactorios para casi todas las variables excepto para DVM con malos resultados y VMAX con resultados regulares. Se evidencia que para las variables objetivo DVM, HRM, TMED y VMAX en este conjunto de datos se obtienen los mejores resultados con el modelo LinearRegression. Se observa claramente que los mejores resultados para las variables objetivo TMAX, TMIN y VMED se obtienen para este conjunto de datos con el modelo SMOreg.. Se evidencia que no existen mejoras significativas con respecto a los resultados obtenidos con el primer estudio realizado (Conjunto de datos inicial 2009-2013).. 36.
Figure

+7

Documento similar
