Implementación de métodos para la clasificación de series temporales
84
0
0
Texto completo
(2) El que suscribe, Osmani Rosado Falcón, hago constar que el trabajo titulado “Implementación de métodos para la clasificación de series temporales” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe del Laboratorio.
(3) Dedicado a mi familia, especialmente a mis padres y a mı́ hermana.. iii.
(4) Agradecimientos A mi tutora Mabel por confiar en mı́, por su apoyo y paciencia. A mis padres, mi hermana y toda mi familia. A todos mis amigos y compañeros de estudio. A los profesores que me impartieron clases durante estos cinco años y a aquellos otros que me formaron entes de llegar a la universidad. Al colectivo de Inteligencia Artificial. A las personas que han colaborado para llevar a cabo el proyecto R, por compartir sus conocimientos con los demás. A todos los que de una forma u otra colaboraron en la realización de este trabajo. A todos muchas gracias.. iv.
(5) Resumen El presente trabajo trata la implementación de métodos de aprendizaje supervisado para la clasificación de series temporales. Los dos métodos implementados tienen la ventaja de ser aplicables directamente sobre las series originales, a diferencia de otros métodos que basan su funcionamiento en la extracción de caracterı́sticas a partir de las series. Uno de los métodos se basa en árboles de decisión y el otro en máquinas de soporte vectorial (SVMs). El método de árboles de decisión permite crear cuatro tipos diferentes de árboles dependiendo de la naturaleza de las series. Mientras el método basado en SVMs permite crear las máquinas a partir de una matriz de distancias calculada entre las series de entrenamiento. Esto facilita el uso de cualquier medida de distancia siempre que se suministre la matriz ya calculada. Las funciones obtenidas a partir de cada método se usaron para crear un paquete en R. En los experimentos realizados se compararon los métodos implementados entre sı́ y con el método 1-NN. Los resultados indican que el 1-NN supera ligeramente al método de las SVMs y significativamente al método basado en árboles de decisión.. v.
(6) Abstract This work discusses the implementation of supervised learning methods to classify time series. The two implemented methods have the advantage of its direct applicability on the original series, unlike other methods that base their operation in the extraction of features from the series. One method is based on decision trees and the other in support vector machines (SVMs). The decision tree method lets you create four different types of trees depending on the nature of the series. While SVMs based method allows create the machines from a distance matrix calculated between training sets. This feature facilitates the use of any distance measure as long as the distance matrix is provided. The functions obtained from each method were used to create an R package. The classification methods implemented were compared with 1-NN method. The results obtained indicate that 1-NN method slightly outperforms the SVMs and outperforms significantly the decision tree method.. vi.
(7) Tabla de contenidos Introducción. 1. 1. Clasificación supervisada de series temporales 1.1. Series de tiempo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.1.1. Análisis de series temporales . . . . . . . . . . . . . . . . . . . . . 1.1.2. Minerı́a de datos para series temporales . . . . . . . . . . . . . . . 1.2. Aprendizaje automático . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2.1. Aprendizaje supervisado . . . . . . . . . . . . . . . . . . . . . . . 1.2.1.1. Clasificación supervisada de series temporales . . . . . . 1.3. Algunos enfoques de aprendizaje supervisado . . . . . . . . . . . . . . . . 1.3.1. K-NN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3.2. Árboles de decisión . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3.3. Máquinas de soporte vectorial . . . . . . . . . . . . . . . . . . . . 1.3.3.1. Problema linealmente separable . . . . . . . . . . . . . . 1.3.3.2. Problema linealmente separable con datos no separables 1.3.3.3. Problema linealmente no separable . . . . . . . . . . . . 1.3.3.4. Funciones núcleo . . . . . . . . . . . . . . . . . . . . . . 1.3.3.5. Solución general . . . . . . . . . . . . . . . . . . . . . . 1.4. Propuestas para la clasificación de series temporales . . . . . . . . . . . . 1.4.1. K-NN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.4.2. Árboles de decisión . . . . . . . . . . . . . . . . . . . . . . . . . . 1.4.3. SVMs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5. El lenguaje R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5.1. El ambiente R . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.5.2. Recursos disponibles para R . . . . . . . . . . . . . . . . . . . . . 1.5.3. Buenas prácticas de programación en R . . . . . . . . . . . . . . . 1.5.4. Funciones de distancia para series temporales en R . . . . . . . . vii. . . . . . . . . . . . . . . . . . . . . . . . .. 4 4 6 6 7 8 8 9 10 11 13 14 15 15 17 17 18 18 18 21 24 24 25 26 26.
(8) TABLA DE CONTENIDOS. viii. 1.5.5. Clasificación supervisada de series temporales en R . . . . . . . . . 1.6. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 26 27. 2. Implementación de clasificadores 28 2.1. Método basado en árboles de decisión . . . . . . . . . . . . . . . . . . . . . 28 2.1.1. Selección del método a implementar . . . . . . . . . . . . . . . . . . 29 2.1.2. Clasificación de medidas de similitud . . . . . . . . . . . . . . . . . 30 2.1.2.1. Medidas basadas en valor . . . . . . . . . . . . . . . . . . 31 2.1.2.2. Medidas basadas en comportamiento . . . . . . . . . . . . 33 2.1.2.3. Medidas basadas en valor y en comportamiento . . . . . . 34 2.1.3. Impureza de un nodo usando el ı́ndice de Gini . . . . . . . . . . . . 35 2.1.4. Algoritmo de construcción de árboles de decisión . . . . . . . . . . 36 2.1.4.1. Algoritmo general . . . . . . . . . . . . . . . . . . . . . . 36 2.1.4.2. Selección de la mejor partición . . . . . . . . . . . . . . . 37 2.1.4.3. Decisión de cuándo declarar un nodo hoja . . . . . . . . . 39 2.1.4.4. Información de los nodos hoja . . . . . . . . . . . . . . . . 40 2.1.4.5. Complejidad temporal . . . . . . . . . . . . . . . . . . . . 41 2.1.4.6. Variantes del procedimiento TSTree . . . . . . . . . . . . 42 2.1.5. Construcción de un árbol de decisión . . . . . . . . . . . . . . . . . 43 2.1.6. Clasificación de instancias . . . . . . . . . . . . . . . . . . . . . . . 46 2.1.7. Obtención de las probabilidades de pertenencia de una instancia a cada clase . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 2.2. Método basado en máquinas de soporte vectorial . . . . . . . . . . . . . . . 47 2.2.1. Selección de una función núcleo . . . . . . . . . . . . . . . . . . . . 48 2.2.2. Implementaciones de las SVMs . . . . . . . . . . . . . . . . . . . . 49 2.2.3. Método de creación de núcleos a partir de distancias . . . . . . . . 49 2.2.4. Función dsvm para la creación de SVMs . . . . . . . . . . . . . . . 51 2.3. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 3. Evaluación de los métodos de clasificación 3.1. Estimación de la calidad . . . . . . . . . . 3.2. Conjuntos de aprendizaje . . . . . . . . . . 3.3. Marco experimental . . . . . . . . . . . . . 3.4. Resultados del método 1-NN . . . . . . . . 3.5. Resultados del método TsTree . . . . . . . 3.5.1. Análisis de la precisión de TsTree .. implementados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. 55 55 57 58 59 59 60.
(9) TABLA DE CONTENIDOS. 3.5.2. Análisis de la interpretabilidad de 3.6. Resultados del método DSVM . . . . . . 3.7. Comparación entre los métodos . . . . . 3.8. Conclusiones . . . . . . . . . . . . . . . .. ix. TsTree . . . . . . . . . . . . . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. . . . .. 60 61 64 66. Conclusiones. 67. Recomendaciones. 68. Bibliografı́a. 69.
(10) Lista de figuras 1.1. 1.2. 1.3. 1.4. 1.5.. Ejemplo de una serie temporal . . . . . . . . . . . . . . . . . . . . . . . . . Ejemplo de un árbol de decisión . . . . . . . . . . . . . . . . . . . . . . . . Ejemplo del hiperplano de separación óptimo para las SVMs . . . . . . . . Ejemplo del hiperplano generalizado de separación óptimo para las SVMs . Estructura de una SVM donde se mapean los datos de entrada a un espacio caracterı́stico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.6. Ejemplo del mapeo de las instancias del espacio de entrada a un espacio caracterı́stico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 5 11 14 15. 2.1. Tres series de tiempo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2. Árbol almacenado en la variable model$frame. . . . . . . . . . . . . . . . .. 32 45. x. 16 16.
(11) Lista de tablas 2.1. Resultados experimentales extraı́dos del artı́culo Douzal-Chouakria and Amblard [2012] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31 2.2. Resultado del cálculo de la impureza de un nodo para un ejemplo especı́fico 35 2.3. Variantes del procedimiento TSTree . . . . . . . . . . . . . . . . . . . . . . 43 3.1. 3.2. 3.3. 3.4. 3.5. 3.6.. Juegos de datos empleados para realizar los experimentos . . . . . . . . . . Resultados experimentales del 1-NN . . . . . . . . . . . . . . . . . . . . . . Resultados experimentales de las variantes de TSTree . . . . . . . . . . . . Ranking de las variantes de TSTree según el accuracy obtenido . . . . . . . Cantidad de nodos obtenida en los árboles con las variantes de TSTree . . Ranking de las variantes de TSTree según la cantidad de nodos obtenida en los árboles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.7. Resultados experimentales de DSVM con los núcleos GEucl y GDTW . . . 3.8. Resultados experimentales de algunas variantes para poner los parámetros a DSVM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.9. Resultados experimentales de las mejores variantes de los métodos estudiados 3.10. Ranking promedio para las mejores variantes de los métodos estudiados . . 3.11. Resultados al aplicar el método de Holm . . . . . . . . . . . . . . . . . . .. xi. 58 59 61 61 62 62 63 64 65 65 65.
(12) Introducción En la práctica es frecuente el uso de técnicas de inteligencia artificial en la solución de problemas reales. Resulta común la necesidad de transformar los datos obtenidos para poder aplicar muchas de estas técnicas. Las transformaciones efectuadas pueden producir pérdida de información valiosa, conduciendo a errores en la solución. La inclusión de las series temporales como un tipo de dato, en el contexto de la inteligencia artificial, constituye un intento de lograr una representación más natural de las series temporales. Una serie temporal está formada por los valores de varias variables medidos sucesivamente en el tiempo. Diversas aplicaciones de las series temporales se han implementado en campos como la estadı́stica, el procesamiento digital de señales, el reconocimiento de patrones, el pronóstico del tiempo y la predicción de terremotos. La minerı́a de datos para series temporales constituye un área ya establecida de la minerı́a de datos. Los métodos desarrollados resuelven las limitaciones de las técnicas tradicionales de análisis ya que adaptan los conceptos de la minerı́a de datos, para tratar este tipo de series como una clase especial de datos. El estudio en esta área se divide en las tareas: representación e indexado, clasificación, medidas de similitud, emparejamiento de subsecuencias, segmentación, visualización, y descubrimiento de patrones y conglomerados. La clasificación de series temporales, trata el problema de encontrar a qué clase pertenece una serie. Esta es una de las tareas más estudiadas en la última década y constituye el principal objeto de estudio del presente trabajo.. Problemática La comunidad cientı́fica ha propuesto métodos para la clasificación de series temporales. Se ha tratado el problema desde diversos enfoques, pero la mayorı́a se basan en el K-NN por. 1.
(13) Introducción. 2. su sencillez y el buen desempeño logrado. Como consecuencia, las funciones de similitud entre series temporales se han comparado, por lo general, usando el 1-NN. No obstante, existen nuevos trabajos enfocados en árboles y máquinas de soporte vectorial. Por otra parte, el lenguaje R es ampliamente usado para desarrollar programas estadı́sticos y de minerı́a de datos. El ambiente de investigación desarrollado en torno al lenguaje R cuenta con paquetes para la minerı́a de datos de series temporales. Existen funciones y paquetes para la descomposición y la predicción de series temporales. Resulta significativa la ausencia de paquetes en R especı́ficos para la clasificación de series temporales, aunque ésta es posible mediante la aplicación de métodos tradicionales sobre las caracterı́sticas extraı́das a partir de las series. Las investigaciones que abordan nuevas propuestas para la clasificación de series temporales se ven afectadas por la no disponibilidad de paquetes con esta finalidad en un ambiente de trabajo como R. Las razones expuestas llevan al planteamiento del siguiente. Objetivo general Obtener un paquete en R con los algoritmos de clasificación de series temporales representativos de varios enfoques para compararlos y ponerlos a disposición de la comunidad cientı́fica.. Objetivos especı́ficos 1. Seleccionar algoritmos para la clasificación de series temporales representativos de varios enfoques. 2. Implementar los algoritmos para la clasificación de series temporales seleccionados en un paquete. 3. Comparar la precisión de los algoritmos implementados..
(14) Introducción. 3. Preguntas de investigación ¿Cuáles algoritmos de clasificación de series temporales se han propuesto en cada enfoque? ¿Tendrán una exactitud comparable a la obtenida con el K-NN los algoritmos de otros enfoques?. Justificación En los últimos años ha aumentado el interés en las series temporales ası́ como la popularidad del lenguaje R. La disponibilidad de métodos en la literatura para clasificación de series temporales hace posible su implementación. Por otro lado, el desarrollo de investigaciones en el área se encuentra en pleno auge. Todo esto apunta a la necesidad de contar con la implementación de métodos para su uso en las investigaciones y en aplicaciones prácticas.. Estructura de la tesis La tesis se compone por la presente introducción y tres capı́tulos. En el capı́tulo 1 se discute la clasificación de series temporales mediante aprendizaje supervisado. El capı́tulo 2 aborda la implementación de los métodos escogidos para la clasificación de series temporales. En el capı́tulo 3 se evalúan los métodos de clasificación implementados..
(15) Capı́tulo 1 Clasificación supervisada de series temporales En el presente capı́tulo se introduce la teorı́a necesaria para la clasificación de series temporales mediante aprendizaje supervisado. En el epı́grafe 1.1 se puntualizan los conceptos básicos acerca de las series temporales como: definición, análisis y minerı́a. En el epı́grafe 1.2 se trata el aprendizaje automático, especı́ficamente el aprendizaje supervisado, para la clasificación de series temporales. El epı́grafe 1.3 se dedica a los enfoques de aprendizaje automático: k vecinos más cercanos (k-NN), árboles de decisión y máquinas de soporte vectorial. En el epı́grafe 1.4 se discuten propuestas existentes para la clasificación de series temporales pertenecientes a los enfoques antes mencionados. El epı́grafe 1.5 está dedicado a destacar las potencialidades del lenguaje R. En el último epı́grafe 1.6, se dan las conclusiones del capı́tulo.. 1.1.. Series de tiempo. Una serie de tiempo consiste en una colección de observaciones realizadas de manera secuencial en el tiempo [Chatfield, 1995]. Ejemplos de series de tiempo son el volumen de precipitaciones en dı́as sucesivos, los beneficios de una compañı́a medidos al año y la cantidad de habitantes en una región por año. Las series de tiempo se han usado en áreas como: el procesamiento digital de señales, el reconocimiento de patrones, la estadı́stica, la predicción del tiempo y la economı́a.. 4.
(16) 300. 500. 5. 100. AirPassengers. Capı́tulo 1. Clasificación supervisada de series temporales. 1950. 1954. 1958. Time. Figura 1.1. Cantidad de pasajeros al mes.. En una serie de tiempo se miden los valores de varias variables. Si la cantidad de variables medidas es uno, se llama univariada, y cuando es mayor a uno, se llama multivariada. La figura 1.1 muestra una serie univariada. La variable medida fue la cantidad total de pasajeros en vuelos internacionales al mes entre los años 1949 y 1960. Una serie de tiempo es considerada continua cuando las observaciones son hechas de forma continua en el tiempo. Si las observaciones tienen lugar solo en momentos especı́ficos entonces es considerada como una serie temporal discreta. La continuidad de una serie se determina por el modo de tomar los valores en el tiempo y es independiente de la naturaleza continua o no de las variables medidas. Por ejemplo, en una empresa donde se paga a los trabajadores mensualmente, se pueden construir series de tiempo donde la variable observada sea la cantidad total pagada por la empresa. Una serie continua se obtiene al medir la variable mensualmente y una discreta al hacerlo anualmente. Las series de tiempo tienen una caracterı́stica especial, las observaciones sucesivas son casi siempre no independientes y el análisis tiene que tener en cuenta el orden de las observaciones. Cuando las observaciones sucesivas no son independientes, los valores futuros pueden ser pronosticados. Si una serie de tiempo puede ser predicha de manera perfecta, se dice que es determinista. Pero la mayorı́a de las series de tiempo son estocásticas, dado que los valores futuros son parcialmente determinados por los valores pasados. Las series de tiempo se han procesado usando técnicas del análisis matemático y la minerı́a de datos. Existen dos ramas de estudio: el análisis de series temporales y la minerı́a de datos para series temporales..
(17) Capı́tulo 1. Clasificación supervisada de series temporales. 1.1.1.. 6. Análisis de series temporales. El análisis de series temporales comprende métodos tanto matemáticos como estadı́sticos que ayudan a interpretar este tipo de datos teniendo en cuenta las correlaciones temporales existentes en los mismos. El análisis de las series de tiempo fue dividido en cuatro objetivos, propuestos en [Chatfield, 1995]. Los objetivos son: descripción, explicación, predicción y control, y se describen a continuación. Descripción: permite mediante la aplicación de técnicas descriptivas definir las principales propiedades de la serie. La más simple consiste en visualizar gráficamente la serie analizada. Explicación: en ocasiones es posible usar la variación de unas series de tiempo para explicar la variación en otras. Los modelos de regresión múltiple resultan útiles en esta tarea. Predicción: es uno de los principales objetivos y consiste en predecir los valores futuros de las series analizadas. Resulta de vital importancia en los análisis económicos e industriales. Control: este se aplica cuando se desea controlar la calidad de determinado proceso y existen múltiples tipos de procedimientos de control. El control incluye poder tomar medidas oportunas frente al proceso que se está controlando.. 1.1.2.. Minerı́a de datos para series temporales. La minerı́a de datos es un campo de la ciencia de la computación, dedicado al descubrimiento de información a partir de los datos. Según [Larose, 2005], se puede definir que: “La minerı́a de datos es el proceso de descubrir nuevas correlaciones significativas, modelos y tendencias, filtrando grandes cantidades de datos guardados en repositorios, a través del uso de tecnologı́as de reconocimiento de modelos ası́ como de técnicas estadı́sticas y matemáticas”. Existen categorı́as que agrupan los diferentes tipos de tareas existentes para la minerı́a de datos, correspondiendo a los objetivos del análisis y los tipos de problemas que enfrentan. Desde el punto de vista de los problemas, los podemos agrupar en distintas tareas, tales como: clasificación, agrupamiento, asociación y regresión..
(18) Capı́tulo 1. Clasificación supervisada de series temporales. 7. La minerı́a de datos para series temporales requiere tener claramente definidos cuáles serán los eventos a “minar”. De manera similar es necesario definir las formas que apuntan a eventos significativos. En el contexto de la minerı́a de datos para series temporales estas formas son llamadas patrones temporales [Povinelli, 1999]. Un patrón temporal puede estar asociado a un evento por lo cual es necesario en la predicción de eventos. Las series temporales tienen caracterı́sticas especiales que dificultan su minerı́a, estas son: la alta numerosidad, el gran número de dimensiones y la constante actualización de sus datos. Por esto, los métodos tradicionales de la minerı́a de datos no son aplicables directamente sobre las series temporales, es necesario adaptarlos. En la minerı́a de datos tradicional la similitud entre dos valores es exacta. En la minerı́a para las series de tiempo no sucede ası́, dos series iguales según una función de similitud no tienen que ser exactamente idénticas. Los estudios en minerı́a de datos para series de tiempo se clasifican en las tareas siguientes [Fu, 2011]: Representación e indexado Clasificación Medidas de similitud Emparejamiento de subsecuencias Segmentación Visualización Descubrimiento de patrones y conglomerados. 1.2.. Aprendizaje automático. El aprendizaje automático (machine learning) es una rama de la Inteligencia Artificial cuyo objetivo es la construcción y estudio de sistemas que puedan aprender de los datos. De forma más concreta, se trata de crear programas capaces de generalizar comportamientos a partir de una información no estructurada suministrada en forma de ejemplos. El Aprendizaje Automático tiene una amplia gama de aplicaciones, incluyendo motores de búsqueda, diagnósticos médicos, detección de fraude en el uso de tarjetas de crédito,.
(19) Capı́tulo 1. Clasificación supervisada de series temporales. 8. análisis del mercado de valores, clasificación de secuencias de ADN, reconocimiento del habla y del lenguaje escrito, juegos y robótica.. 1.2.1.. Aprendizaje supervisado. El aprendizaje supervisado es la tarea del aprendizaje automático que se encarga de inferir modelos o funciones a partir de un conjunto de entrenamiento etiquetado. El conjunto de entrenamiento se compone por instancias. Cada instancia tiene los valores de los rasgos o atributos y la etiqueta de la clase a la que pertenece. Un algoritmo de aprendizaje supervisado analiza el conjunto de entrenamiento y produce un modelo, el cual es utilizado después para etiquetar nuevas instancias. Los algoritmos se basan en algún enfoque el cual identifica su estructura general. Los enfoques siguientes son algunos de los usados en los algoritmos de aprendizaje supervisado: K vecinos más cercanos (K-NN) Árboles de decisión Redes neuronales Redes Bayesianas Máquinas de soporte vectorial (SVM) El conjunto de entrenamiento para el caso de las series de tiempo difiere del convencional. Igualmente, una instancia puede estar compuesta por varios atributos. La diferencia aparece en el valor que toman los atributos. Mientras el valor de un atributo convencional es un número, en una serie, es una lista de números en un orden temporal. El escenario más parecido al convencional se presenta cuando las series son univariadas, donde cada instancia tiene un solo atributo. La definición de series univariadas y multivariadas se introdujo en el epı́grafe 1.1.. 1.2.1.1.. Clasificación supervisada de series temporales. La clasificación de series de tiempo ha sido enfrentada de diversas maneras. Uno de los enfoques propuestos consiste en mapear las series de tiempo a un nuevo espacio descriptivo donde los clasificadores convencionales pueden ser aplicados. El procesamiento de señales.
(20) Capı́tulo 1. Clasificación supervisada de series temporales. 9. o las herramientas estadı́sticas son comúnmente usados para proyectar las series dentro de un espacio funcional básico. Por ejemplo, tales proyecciones pueden ser efectuadas por la transformación de Fourier o wavelet, un polinomio o una aproximación ARIMA [Yamada et al., 2003]. Algunos trabajos en este enfoque son [Garcia-Escudero and Gordaliza, 2005, Serban and Wasserman, 2005, Caiado et al., 2006, Kakizawa et al., 1998, Maharaj, 2000]. Otro tipo de trabajos proponen otras heurı́sticas, generalmente empiezan por la segmentación de las series para extraer los prototipos que mejor caractericen las clases. Los prototipos, definidos por un conjunto de subsecuencias o regiones de valores, son seguidamente descritos por un conjunto de caracterı́sticas numéricas donde los clasificadores estándares pueden ser aplicados. Entre los trabajos en este enfoque se tienen [Kadous and Sammut, 2005, Geurts and Wehenkel, 2005, Geurts, 2002, 2001, Rodrı́guez et al., 2001]. En otra categorı́a, se distinguen las propuestas que trabajan directamente sobre las series, usando por ejemplo, medidas de similitud. Tal tipo de propuestas [Yamada et al., 2003, Marteau and Gibet, 2014, Pree et al., 2014], constituyen en general, adaptaciones de los clasificadores convencionales. En resumen, las propuestas se pueden agrupar en dos enfoques: Métodos clásicos: identifica las propuestas que construyen caracterı́sticas a partir de las series para generar el modelo con clasificadores convencionales. Métodos especı́ficos para series temporales: identifica las propuestas capaces de procesar directamente las series originales para generar el modelo.. 1.3.. Algunos enfoques de aprendizaje supervisado. Los enfoques de aprendizaje que se discuten en este epı́grafe representan un subconjunto de los enfoques mencionados en el epı́grafe 1.2.1. Los enfoques seleccionados son: el k-NN, los árboles de decisión y las máquinas de soporte vectorial. Las razones para cada selección son: El k-NN es un representante sencillo y robusto del aprendizaje basado en casos. Los árboles de decisión tienen una utilidad adicional a la predicción. Teniendo en cuenta el proceso de inducción del árbol, puede ser elaborada una explicación del resultado, analizando el camino de la raı́z hasta el nodo hoja al cuál arribó la instancia objeto de la predicción..
(21) Capı́tulo 1. Clasificación supervisada de series temporales. 10. Las máquinas de soporte vectorial tienen un gran poder de generalización. En los trabajos [Zhang et al., 2010, Lei and Sun, 2007], se refieren como el mejor clasificador en el estado del arte.. 1.3.1.. K-NN. El k-NN es un tipo de aprendizaje basado en casos o perezoso. La idea básica de la regla del vecino más cercano (Nearest Neighbour, NN) es predecir la clase objetivo de una instancia no etiquetada usando la clase de su instancia más cercana en el conjunto de entrenamiento [T.M. Cover, 1967]. Dado el conjunto de entrenamiento {(xi , yi ), i = 1, 2, ..., N } donde xi es una instancia y yi ∈ {1, 2, ..., C} es la etiqueta de su clase. Cuando una instancia nueva xN +1 es dada para clasificación, la etiqueta de su clase yN +1 es predicha por:. yN +1 = yN N (xN +1 ). (1.1). donde N N (xN +1 ) denota el ı́ndice de la instancia de entrenamiento más cercana a xN +1 . La métrica Euclidiana y la métrica de Manhattan han sido algunas de las usadas para medir la distancia entre las instancias. En el trabajo [T.M. Cover, 1967], se ha probado que la optimalidad asintótica de la regla NN es: C L∗ ) (1.2) L∗ ≤ LN N ≤ L∗ (2 − C −1 donde LN N es la proporción del error del NN, L∗ es la probabilidad de Bayes óptima del error y C es el número de clases. De acuerdo a la inecuación 1.2, en [Wang et al., 2010] se concluye que, la regla NN es asintóticamente óptima cuando L∗ = 0. Por ejemplo, cuando las clases diferentes no se solapan en el espacio de entrada. Si las clases se solapan, la optimalidad de la regla NN puede ser alcanzada por el k-NN. El k-NN clasifica a xN +1 teniendo en cuanta las clases de sus k vecinos más cercanos. Varios métodos de decisión han sido propuestos [Yang et al., 1999] para escoger la clase, incluyendo los métodos de votación, votación pesada y promedio estratificado. En el método de votación, comúnmente usado, la clase de xN +1 , se selecciona como la clase mayoritaria entre los k vecinos. En caso de varias clases mayoritarias entre los k vecinos, se toma cualquiera de las clases ganadoras..
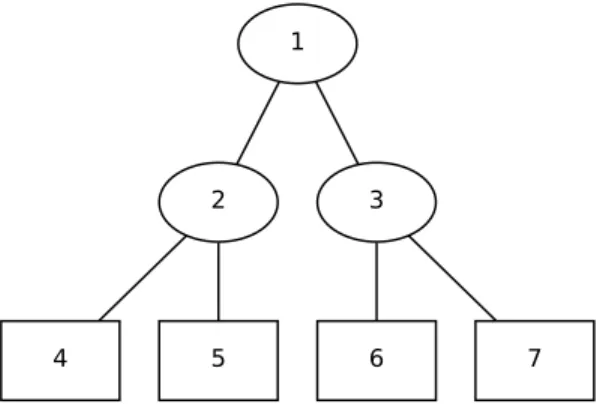
(22) Capı́tulo 1. Clasificación supervisada de series temporales. 1.3.2.. 11. Árboles de decisión. La aplicación del enfoque divide y vencerás al problema de aprender a partir de un conjunto de instancias X, induce un modelo llamado árbol de decisión. El árbol es construido al dividir repetidamente subconjuntos de X en varios subconjuntos, empezando por X. El resultado del proceso, para un ejemplo hipotético con 3 clases, se muestra en la figura 1.2. X. X2. X5 | B. X6 | C. X3. X8 | A. X11 | B. X4. X7. X9 | C. X10 | A. X12 | C. Figura 1.2. Ejemplo de un árbol de decisión. En la figura 1.2, los subconjuntos X2 , X3 y X4 son disjuntos, con X = X2 ∪ X3 ∪ X4 . En general, se cumple que los subconjuntos hijos en una división son disjuntos y la unión de los hijos resulta en el conjunto padre. Los subconjuntos que no se dividieron, X5 , X6 , X8 , X9 , X10 , X11 y X12 , son los conjuntos terminales. En la figura 1.2, los conjuntos no terminales se indican por cı́rculos y los terminales por cuadrados. Para los efectos de un árbol, los conjuntos terminales conforman los nodos terminales (hojas) y el resto representa a los nodos no terminales (internos). Los subconjuntos terminales forman una partición de X. A cada subconjunto terminal se le asigna: la etiqueta de una clase, las etiquetas de varias clases o las probabilidades de pertenencia a cada una de las clases. En la figura 1.2, se pueden apreciar los nodos terminales etiquetados con una de las clases: A, B, o C. En los nodos terminales aparece a la izquierda de la barra vertical “|”, el nombre y a la derecha, la clase del nodo. Varios nodos pueden pertenecer a una misma clase. La partición se puede resumir al formar grupos con los nodos de cada clase. De ese modo, se obtiene:.
(23) Capı́tulo 1. Clasificación supervisada de series temporales. 12. PA = X8 ∪ X10 PB = X5 ∪ X11 PC = X6 ∪ X9 ∪ X12. Las particiones son formadas por condiciones sobre los atributos de las instancias. Dadas las instancias de la forma x = (x1 , ..., xn ), se presentan los ejemplos siguientes. La partición de X en X2 , X3 y X4 pudo ser de la forma:. X2 = {x ∈ X; x2 = alto}, X3 = {x ∈ X; x2 = medio} y X4 = {x ∈ X; x2 = bajo} (1.3) donde x2 es un atributo nominal. Mientras, la partición de X2 en X5 y X6 pudo ser dada por:. X5 = {x ∈ X2 ; x1 >= 9} y X6 = {x ∈ X2 ; x1 < 9}. (1.4). donde x1 es un atributo continuo. En el caso de un árbol de clasificación donde cada hoja está etiquetada con una clase. Para clasificar una instancia nueva a se procede de esta manera: empezando desde el nodo raı́z, se prueba la condición en cada nodo interno visitado para determinar la rama a seguir hasta alcanzar un nodo hoja h; por último, se asigna a la instancia a la etiqueta de h. Por ejemplo, para a = (8, alto, ...), y las condiciones 1.3 y 1.4. Al evaluar en la raı́z, a2 es igual a alto, se pasa a X2 . En X2 se encuentra que a1 es menor que 9 y se sigue por X6 . Como X6 es un nodo hoja, a recibe la clase C. La definición de un método para el aprendizaje basado en árboles tiene que abarcar los 3 elementos siguientes [Breiman et al., 1984]. 1. La selección de las divisiones 2. La decisión de cuando declarar un nodo hoja o seguir dividiendo 3. La asignación de cada nodo hoja a una clase El problema es cómo usar los datos en L para determinar las divisiones, los nodos terminales y sus valores. La asignación de los valores a los nodos terminales es simple. La.
(24) Capı́tulo 1. Clasificación supervisada de series temporales. 13. dificultad está en encontrar buenas divisiones y saber cuándo parar de dividir [Breiman et al., 1984]. Existen dos algoritmos para la construcción de árboles desarrollados por Ross Quinlan: ID3 (Iterative Dichotomiser 3 ) [Quinlan, 1986] y C4.5 [Quinlan, 2014]. El ID3 está diseñado para aprender sobre conjuntos de entrenamiento con todos sus atributos nominales. El C4.5 es una extensión del ID3 capaz de manejar ambos, atributos nominales y continuos. Además se incorpora un método de poda para atacar el problema de sobre entrenamiento. Existe también una versión mejorada, C5.0, del C4.5. En el libro Classification and regression tree (CART) [Breiman et al., 1984], se puede encontrar otro algoritmo de aprendizaje basado en árboles binarios, que también incluye un método de poda. Para encontrar buenas divisiones en cada nodo, la idea fundamental es seleccionar la partición del subconjunto a dividir, que mejor aumente la “pureza” de los datos determinada por todos los subconjuntos obtenidos. El cálculo de la pureza en un nodo, se resuelve en los algoritmos ID3 y C4.5 empleando la entropı́a o ganancia de información, mientras en CART se usa el ı́ndice de impureza de Gini.. 1.3.3.. Máquinas de soporte vectorial. El fundamento de las máquinas de soporte vectorial (Support Vector Machine, SVM) ha sido desarrollado por Vapnik [1995]. Han ganado popularidad debido a sus caracterı́sticas atractivas. Su formulación se basa en el principio de Minimización del Riesgo Estructural (Structural Risk Minimisation, SRM), el cual ha mostrado ser superior que el principio tradicional de Minimización del Riesgo Empı́rico (Empirical Risk Minimisation, ERM) [Gunn et al., 1998]. El principio SRM minimiza un lı́mite superior sobre el riesgo esperado, mientras ERM, minimiza el error sobre los datos de entrenamiento. Es esta diferencia la cual provee a las SVMs con una mayor habilidad para generalizar. Las SVMs fueron desarrolladas para resolver problemas de clasificación, pero han sido extendidas al dominio de los problemas de regresión. En el resto de esta sección se trata de manera general la clasificación..
(25) Capı́tulo 1. Clasificación supervisada de series temporales. 1.3.3.1.. 14. Problema linealmente separable. La idea básica del algoritmo de las SVMs es encontrar un hiperplano que maximice el margen de separación entre las instancias de cada clase [Wang and Fu, 2006]. En la figura 1.3, se puede apreciar que existen muchos hiperplanos que separan los datos, pero solo el hiperplano resaltado en color verde, lo hace de manera óptima.. Figura 1.3. Hiperplano de separación óptimo [Gunn et al., 1998].. El hiperplano buscado tiene la forma. hw, xi + b. (1.5). donde w es un vector perpendicular al hiperplano y b es su distancia convenientemente normalizada desde el origen. El vector w es una combinación lineal de vectores del conjunto de entrenamiento los cuales son cercanos al hiperplano. Estos vectores son llamados vectores soporte. La etiqueta de una instancia nueva x depende de su posición respecto al hiperplano, de acuerdo a. f (x) = sgn[hw, xi + b]. (1.6). el resultado es 1 o −1. La función f es buscada resolviendo un problema de optimización cuadrático bajo ciertas restricciones..
(26) Capı́tulo 1. Clasificación supervisada de series temporales. 1.3.3.2.. 15. Problema linealmente separable con datos no separables. Si los datos de entrenamiento no son linealmente separables, porque contengan instancias erróneas, entonces no es posible encontrar ningún hiperplano. En este caso, donde se espera que un hiperplano pueda separar correctamente las clases, se relajan las restricciones para permitir errores en la separación de los datos de entrenamiento. En la figura 1.4, se muestra un ejemplo donde el hiperplano separa los datos dejando algunos puntos en el lado incorrecto.. Figura 1.4. Hiperplano generalizado de separación óptimo [Gunn et al., 1998].. 1.3.3.3.. Problema linealmente no separable. Si un hiperplano no puede separar los datos, porque el problema no es linealmente separable, se hace un mapeo no linear de los datos a un espacio caracterı́stico de alta dimensión. El objetivo es transformar los datos a un espacio donde sean linealmente separables al menos permitiendo algunos errores como en el caso anterior. En la figura 1.5, se muestra la estructura resultante. La cantidad de puntos dan una noción de la dimensión de cada espacio. En el ejemplo de la figura 1.6, se puede ver a la izquierda los datos no linealmente separables en el espacio original <2 , mientras a la derecha están separados por un plano en el espacio caracterı́stico <3 . La función usada para el mapeo fue (x1 , x2 ) 7→ (z1 , z2 , z3 ) :=.
(27) Capı́tulo 1. Clasificación supervisada de series temporales. 16. Figura 1.5. Estructura de una SVM donde se mapean los datos de entrada a un espacio caracterı́stico de alta dimensión [Gunn et al., 1998].. √ (x21 , 2x1 x2 , x22 ). Efectivamente se ha logrado un mapeo de los datos a otro espacio donde son linealmente separables.. Figura 1.6. Ejemplo del mapeo de las instancias en el espacio de entrada <2 al espacio caracterı́stico <3 [Schölkopf, 2006].. En [Gunn et al., 1998], se explica que no es necesario conocer la función de mapeo. En la búsqueda del hiperplano óptimo solo se necesita calcular los productos escalares de los vectores, para este caso, en el espacio caracterı́stico. La idea para evitar el mapeo se basa en el uso de una función núcleo. Las funciones núcleos permiten calcular los productos escalares en el espacio de entrada, en lugar del espacio caracterı́stico, obteniendo los mismos resultados..
(28) Capı́tulo 1. Clasificación supervisada de series temporales. 1.3.3.4.. 17. Funciones núcleo. Las funciones núcleos son aquellas que satisfacen el teorema de Mercer, donde se establece que una función k(x, y) simétrica y continua en el espacio de entrada representa un producto escalar en un espacio caracterı́stico si y solo si k es semi-definida positiva. En [Lei and Sun, 2007], se afirma que solo los núcleos simétricos definidos positivos (Positive Definite Symmetric, PDS) son admisibles para la formulación estándar de las SVMs. El uso de núcleos PDS garantiza que la matriz del núcleo sea convexa y la solución sea única. También explican que los núcleos simétricos definidos negativos (Negative Definite Symmetric, NDS) pueden ser empleados para construir núcleos PDS dado que existe un teorema que los relaciona. Algunos de los núcleos básicos encontrados en la literatura son [Lin et al., 2003]: Linear K(x, y) = hx, yi. (1.7). K(x, y) = (γhx, yi + r)d , γ > 0. (1.8). Polynomial. Gaussian Radial Basis (GRB) K(x, y) = exp(−γkx − yk2 ), γ > 0. 1.3.3.5.. (1.9). Solución general. La solución descrita para los problemas linealmente no separables es la más general. El uso de las funciones núcleos es la clave. Para los problemas lineales se puede emplear la función núcleo: Linear (1.7). Mientras para el resto, existen funciones núcleo no lineales tales como: Polinomial (1.8) y Gaussian Radial Basis (1.9)..
(29) Capı́tulo 1. Clasificación supervisada de series temporales. 1.4.. 18. Propuestas para la clasificación de series temporales. Los trabajos para clasificación de series temporales se pueden identificar en una de las dos clases definidas en el epı́grafe 1.2.1.1. El objetivo en este epı́grafe es exponer las propuestas encontradas pertenecientes al segundo enfoque, donde se encuentran los métodos que generan sus modelos a partir de las series originales. Cada propuesta presentada se agrupa según su pertenencia a uno de los tres enfoques discutidos en el epı́grafe 1.3.. 1.4.1.. K-NN. El método k-NN fue introducido en el epı́grafe 1.3.1, ahora se discute su aplicación para la clasificación de series temporales. El k-NN es fácilmente adaptado para las series. En principio basta con utilizar una distancia adecuada para medir la cercanı́a entre las series. La distancia DTW está entre las más usadas para este propósito. En muchos trabajos como [Yamada et al., 2003, Marteau and Gibet, 2014, Grabocka et al., 2012], se ha encontrado al método 1-NN con la distancia DTW como el algoritmo de referencia, a superar, cuando se propone un algoritmo nuevo. También ha sido empleado para comparar el desempeño de distancias nuevas respecto a las existentes. Por ejemplo en [Chen and Ng, 2004], la distancia ERP se ha presentado y comparado con las distancias L1, DTW, LCSS, EDR usando el k-NN. Este método de comparación de distancias ha sido sugerido por Keogh and Kasetty [2003].. 1.4.2.. Árboles de decisión. Los árboles de decisión se introdujeron en el epı́grafe 1.3.2. La adaptación para series temporales de los métodos basados en árboles no es tan natural como en el caso del k-NN. No obstante, se encontraron algunos trabajos en este sentido, los cuales son presentados en este epı́grafe. De los tres elementos para la construcción de árboles tratados en el epı́grafe 1.3.2, es la selección de las divisiones, el descrito en cada propuesta. Los elementos restantes son aplicables como en los algoritmos clásicos de árboles..
(30) Capı́tulo 1. Clasificación supervisada de series temporales. 19. Decision-tree Induction from Time-series Data Based on a Standard-example Split Test [Yamada et al., 2003] En el artı́culo [Yamada et al., 2003], se prueban dos métodos para dividir las series en un nodo: Standard-example split test (SE-split) y Cluster-example split test (CE-split). En la construcción de los árboles se usa poda. La medida de similitud DTW es empleada para obtener la cercanı́a entre las series. El método SE-split, realiza una búsqueda exhaustiva para encontrar una serie de referencia que maximice la ganancia de pureza de la división. El hijo derecho se compone por las series a una distancia de la serie de referencia menor o igual a un umbral dado, el hijo izquierdo se queda con el resto. Si más de una serie provee la mejor ganancia, se aplica un criterio de aislamiento entre las clases para seleccionar la división con sus nodos más diferentes. El método CE-split, busca de manera exhaustiva, en lugar de una, dos series de referencia. Las series de referencia se asocian a cada nodo, una al izquierdo y la otra al derecho. El conjunto de instancias se divide poniendo a las series en cada nodo hijo según estén más cercanas a la respectiva serie de referencia. Igualmente, la ganancia en pureza y el criterio de aislamiento entre las clases es usado para escoger el par de series de referencia. Este método evita la necesidad de especificar un valor umbral. En los experimentos se evalúan los métodos de árboles propuestos: SE-split y CE-split. La comparación se realiza con otros seis métodos donde se encuentra el k-NN con DTW. El accuracy obtenido por SE-split y CE-split supera en un solo caso al k-NN con DTW, mientras para el resto se acerca. No se concluye que uno de los métodos: SE-split y CEsplit, sea mejor que el otro, pues obtienen resultados parecidos.. Decision Trees for Functional Variables [Balakrishnan and Madigan, 2006] En el artı́culo [Balakrishnan and Madigan, 2006], el método de división de los nodos se basa en la búsqueda de dos series de referencia. Para este propósito se emplea al algoritmo k-means. Este algoritmo garantiza una partición que optimiza el agrupamiento: compactación y aislamiento de las clases, pero no la pureza del nodo. Para aliviar el problema se ejecuta el algoritmo varias veces y se escoge la partición con mejor ı́ndice de Gini. No obstante, puede fallar con divisiones de menor criterio de agrupamiento, pero con mayor pureza..
(31) Capı́tulo 1. Clasificación supervisada de series temporales. 20. La comparación con otros métodos no es muy rigurosa. El método propuesto FDT, es comparado con otros cuatro, donde no se incluye al k-NN. La medida de calidad empleada es el error. Los datos suministrados están incompletos. Falta el valor del error en al menos un conjunto de datos para todos los clasificadores usados excepto para el propio FDT.. Classification trees for time series [Douzal-Chouakria and Amblard, 2012] En el trabajo [Douzal-Chouakria and Amblard, 2012], se utiliza un enfoque basado en distancias para la construcción de árboles a partir de series temporales. El conjunto de instancias en un nodo es dividido por el uso de dos series de referencia. Las dos series son seleccionadas, de todas las combinaciones posibles, la que mejor divida al nodo. El método tiene dos caracterı́sticas que lo distinguen. La primera, es el uso de una métrica adaptativa para cubrir las similitudes de comportamiento y valor entre las series. La segunda, se refiere a la extracción automática de la subsecuencia que mejor discrimine. La métrica adaptativa combina una distancia basada en valor y un costo basado en comportamiento. Las distancias basadas en valor que emplearon fueron la Euclidiana y la DTW. Para el costo basado en comportamiento usaron la Correlación de Pearson y una variante temporal de ésta. Los conjuntos de datos escogidos para las pruebas, reúnen una diversidad de caracterı́sticas diferentes, que pueden encontrarse en las series y que afectan el desempeño de los métodos de clasificación. Vale destacar que entre los conjuntos de datos empleados se encuentran conjuntos reales. Los métodos de comparación estuvieron compuestos por seis clasificadores existentes, más algunas variantes del método propuesto. Las variantes tienen como objetivo contrastar: el uso de medidas adaptativas contra no adaptativas; el uso o no, de la búsqueda de la subsecuencia; y el uso de la correlación de Pearson contra su variante temporal. Los experimentos arrojaron varios resultados. La búsqueda de la subsecuencia no es necesaria cuando las instancias de las clases se diferencian por su comportamiento global. Esto no sucede ası́, cuando las instancias de una misma clase difieren en su comportamiento global y es el comportamiento local de una subsecuencia de la serie, el que identifica sus elementos. Usando medidas adaptativas el algoritmo supera a la variante que no las usa en determinados casos. Las medidas adaptativas fueron necesarias en instancias donde las clases incluyen periodicidad, efectos de tendencia y variaciones en el rango de valores. El rendimiento fue siempre mejorado cuando se usó la variante temporal de la correlación de Pearson en lugar de su versión original..
(32) Capı́tulo 1. Clasificación supervisada de series temporales. 21. No se compararon con el 1-NN con DTW. Pero se hace notar que el método propuesto es capaz de enfrentarse a caracterı́sticas de las series para las cuales el 1-NN con DTW no está preparado. Por ejemplo, el 1-NN con DTW no está diseñado para detectar las instancias de clases que se identifican por el comportamiento local en lugar que por el global.. 1.4.3.. SVMs. Las máquinas de soporte vectorial se introdujeron brevemente en el epı́grafe 1.3.3. En la literatura existen investigaciones y aplicaciones a la clasificación de series temporales usando máquinas de soporte. En este epı́grafe se presentan las propuestas encontradas. Debido al problema de la distorsión del tiempo presente en las series, los núcleos clásicos, tales como: Gaussian RBF (GRBF, función 1.9) y polynomial (función 1.8), generalmente no son apropiados. En aras de resolver este problema se han propuesto extensiones basadas en distancias elásticas.. A Study on the Dynamic Time Warping in Kernel Machines [Lei and Sun, 2007] La distancia DTW ha sido ampliamente usada en el reconocimiento de patrones en series de tiempo y mejora los resultados de la distancia Euclidiana en muchos de los casos por ser elástica y robusta. En un intento por mejorar el núcleo GRBF se propuso, en [Noma, 2002, Bahlmann et al., 2002], el núcleo GDTW. En GDTW se ha sustituido la distancia Euclidiana en GRBF por DTW. Los resultados experimentales [Zhang et al., 2010, Lei and Sun, 2007], indican que el núcleo GDTW no mejora al 1-NN con la distancia DTW o al núcleo GRBF. Por otro lado, en [Lei and Sun, 2007], se ha demostrado que el núcleo GDTW no cumple la propiedad PDS (ver sección 1.3.3.4) necesaria para las SVMs. También, en [Lei and Sun, 2007], se asegura que existe la posibilidad de demostrar que las distancias elásticas no son elegibles para construir núcleos con la propiedad PDS..
(33) Capı́tulo 1. Clasificación supervisada de series temporales. 22. Time Series Classification Using Support Vector Machine with Gaussian Elastic Metric Kernel [Zhang et al., 2010] En el artı́culo [Zhang et al., 2010], se asume que el desempeño pobre de GDTW puede estar atribuido a que la distancia DTW no es una métrica. Motivados por la existencia de otras distancias, proponen una clase de núcleos basados en métricas elásticas. Escogieron las métricas: Edit distance with real penalty (ERP) [Chen and Ng, 2004] y Time warp edit distance (TWED) [Marteau, 2009] para construir los núcleos: GERP y GTWED. En consecuencia se obtienen las máquinas: GERP-SVM y GTWED-SVM. En los experimentos comprobaron, que estas propuestas son superiores, que el método 1-NN con diferentes distancias (Euclidean, DTW, etc.) y las máquinas de soporte con los núcleos GRBF y GDTW. Además reconocen no haber demostrado que los núcleos propuestos cumplan la propiedad PDS. Pero hacen notar que en los experimentos, no se violó la propiedad PDS por parte de los núcleos sobre los conjuntos de entrenamiento probados.. On Recursive Edit Distance Kernels with Application to Time Series Classification [Marteau and Gibet, 2014] Desafortunadamente ha sido visto que las medidas elásticas comunes derivadas de DTW, no son directamente inducidas por ningún producto interno, aun cuando tales medidas son métricas [Marteau and Gibet, 2014]. Pudiera pensarse que no es posible construir núcleos apropiados con estas medidas para SVMs. No obstante, en [Marteau and Gibet, 2014] se propone un método para crear un tipo de núcleos denominado Recursive Edit Distance Kernels (REDK) a partir de estas medidas. Este trabajo continúa las labores iniciadas por otros autores en los núcleos REDK. El método desarrollado permite construir núcleos con la propiedad PDS si algunas condiciones suficientes son cumplidas. Estas condiciones son más débiles que las propuestas en otros trabajos y necesitan la introducción de un término de regularización para obtener la prueba de la propiedad PDS. Explican que esta estrategia es más general y puede ser aplicada a una familia grande de distancias. La idea para construir los núcleos se basa en modificaciones a las distancias. En los experimentos se emplearon los métodos: 1-NN con las distancias DTW, ERP y TWED; las SVMs basadas en los núcleos Gaussianos (GRBF, GDTW, GERP y GTWED); y las SVMs basadas en los núcleos Gaussianos del tipo REDK (DTW-REDK, ERP-REDK y TWED-REDK). Los resultados indican que las máquinas ERP-REDK-SVM.
(34) Capı́tulo 1. Clasificación supervisada de series temporales. 23. y TWED-REDK-SVM tienen un rendimiento ligeramente mejor que sus rivales GERPSVM y GTWED-SVM, mientras la máquina DTW-REDK-SVMs es mucho mejor que GDTW-SVM. Se encontró que, en general, las SVMs mejoran al 1-NN.. Invariant Time-Series Classification [Grabocka et al., 2012] Un enfoque diferente para mejorar los resultados de clasificación de las máquinas de soporte vectorial se presenta en [Grabocka et al., 2012]. La idea está inspirada en las razones que provocan el fallo de éstas para construir los lı́mites de decisión óptimos. Explican que en muchos conjuntos de entrenamiento, las variaciones de las instancias que pertenecen a una misma clase son numerosas. Pero existen muchas variaciones más, teóricamente infinitas maneras posibles del patrón de una clase. Concluyen entonces, que la insuficiencia de instancias para cubrir todas las variaciones posibles puede afectar la generalización de las SVMs. Con el objetivo de suplir la falta de instancias proponen insertar instancias virtuales al conjunto de entrenamiento. El proceso de construcción de la máquina de soporte está compuesto por dos fases de entrenamiento. Primero se entrena un modelo usando las instancias originales. Luego transformando los vectores de soporte, se crean nuevas instancias. Por último, se entrena el modelo definitivo usando las instancias originales y las nuevas. Este enfoque es nombrado: Invariant SVMs. Para crear las nuevas instancias se presenta un método nuevo de transformación de series de tiempo. En sus resultados demuestran que el método ISVM mejora al 1-NN con la distancias DTW en la mayorı́a de los casos y es siempre superior a la configuración por defecto de las SVMs.. On general purpose time series similarity measures and their use as kernel functions in support vector machines [Pree et al., 2014] En [Pree et al., 2014], se prueban varias medidas de similitud como núcleos en máquinas de soporte vectorial. Entre las medidas usadas se tienen las lineales: Euclidiana (EUC), triangular, polynomial (POLY), probabilı́stica (dos variantes HELL y KL2) y shape space distances (SSD), y las no lineales: DTW, TWED y Longest common subsequence similarity (LCSS). En este estudio no se demuestra el cumplimiento de la propiedad PDS por los núcleos construidos. Afirman que en la práctica es difı́cil la demostración del cumplimiento de dicha propiedad para muchas de las medidas. Mientras, para el conjunto de.
(35) Capı́tulo 1. Clasificación supervisada de series temporales. 24. entrenamiento de un problema especı́fico, es sencillo comprobar si la matriz obtenida por una función núcleo es PDS. En los experimentos compararon las medidas usando el clasificador 1-NN y las SVMs. Los resultados respecto al accuracy indican que: En el caso de las SVMs, la distancia TWED mejora al resto seguida por las distancias SSD, POLY y EUC. Aunque hacen notar que un estudio anterior se encontró que la distancia TWED puede generar núcleos indefinidos. Las distancias: TWED, SSD, EUC, HELL, and POLY obtienen resultados significativamente mejores cuando se combinan en las SVMs en lugar de con el 1-NN. Especialmente el incremento de rendimiento de EUC es considerable.. 1.5.. El lenguaje R. En este epı́grafe se comentan brevemente las bondades del ambiente R. Los epı́grafes 1.5.4 y 1.5.5 se dedican al trabajo con series temporales en R. Los paquetes con medidas de similitud son introducidos en 1.5.4 y las posibilidades para la clasificación se analizan en 1.5.5.. 1.5.1.. El ambiente R. R es un ambiente integrado de facilidades de software para la manipulación de datos, el cálculo y la visualización de gráficos [Team, 2013]. Entre otras facilidades cuenta con: facilidad de manejar la manipulación y el almacenado de datos un conjunto de operadores para el cálculo sobre arreglos, en particular matrices una larga, coherente e integrada colección de herramientas intermedias para el análisis de datos facilidades gráficas para el análisis de datos y el dibujo de los gráficos en la computadora o en copia dura un lenguaje de programación bien diseñado, simple y efectivo, basado en “S”, el cual incluye facilidades de entrada y salida, sentencias condicionales, ciclos y la posibilidad de definición de funciones recursivas y clases.
(36) Capı́tulo 1. Clasificación supervisada de series temporales. 1.5.2.. 25. Recursos disponibles para R. El lenguaje R se apoya en una variedad de recursos disponibles en internet. La lista siguiente resume algunos de los más importantes y otros usados en este trabajo. 1. Sitio oficial del proyecto R http://www.r-project.org 2. Repositorios de paquetes para R Repositorio oficial http://cran.r-project.org Repositorio de paquetes para R del proyecto Bioconductor. http://www.bioconductor.org Repositorio de paquetes para R del proyecto Omega. http://www.omegahat.org/R http://www.omegahat.org/cranRepository.html 3. Motor de búsqueda basado en Google para asistir en búsquedas relacionadas con el lenguaje R http://rseek.org/ 4. Documentación de R http://www.rdocumentation.org 5. Wiki de R, mantenida por la comunidad http://rwiki.sciviews.org/doku.php 6. La revista de R http://journal.r-project.org http://journal.r-project.org/archive (números antiguos) 7. Blog de R: sitio de noticias diarias de R, con artı́culos, tutoriales y casos de estudio. http://www.r-bloggers.com 8. R-Forge ofrece una plataforma para el desarrollo de paquetes y software relacionados con R. http://r-forge.r-project.org 9. Minerı́a de datos con R..
(37) Capı́tulo 1. Clasificación supervisada de series temporales. 26. Sitio http://rdatamining.com Paquete para minerı́a de datos http://www.rdatamining.com/package Proyecto para implementar algoritmos de minerı́a de datos en R http://r-forge.r-project.org/projects/rdatamining 10. RStudio: IDE para R http://www.rstudio.org 11. Deducer: interfaz gráfica para hacer análisis de datos usando paquetes de R. http://www.deducer.org/pmwiki/index.php?n=Main.DeducerManual?from=Main. HomePage. 1.5.3.. Buenas prácticas de programación en R. El objetivo de las buenas prácticas de programación es hacer el código fácil de leer, compartir y verificar. El lenguaje R no tiene convenciones de código bien definidas [Bengtsson, 2009]. No obstante, se encontraron algunos trabajos al respecto: el artı́culo R Coding Conventions[Bengtsson, 2009] (en desarrollo) y la guı́a Google’s R Style Guide [goo, 2015]. Estos materiales fueron de gran ayuda para lograr un código limpio.. 1.5.4.. Funciones de distancia para series temporales en R. En el lenguaje R se encuentran disponibles varios paquetes con medidas de similitud para series de tiempo. Los paquetes encontrados son: dtw [Giorgino, 2009], TSclust [Montero and Vilar, 2014] y TSdist [Mori et al., 2015]. En el artı́culo [Mori et al.], se presenta una tabla comparativa con las distancias en cada uno de los paquetes mencionados. Los tres paquetes proveen un total de 22 distancias, entre las que se encuentran: DTW y ERP. Mientras la distancia TWED no está implementada.. 1.5.5.. Clasificación supervisada de series temporales en R. El ambiente R cuenta con paquetes para la minerı́a de datos de series temporales. En este epı́grafe solo se hace referencia a las facilidades para la clasificación de series temporales..
(38) Capı́tulo 1. Clasificación supervisada de series temporales. 27. Existen muchos paquetes disponibles para la descomposición y predicción de series de tiempo en R. Pero no existen funciones ni paquetes especı́ficos para la clasificación y el agrupamiento. En el libro Zhao [2013], se sugiere para clasificar series de tiempo en R, extraer caracterı́sticas y utilizar los clasificadores convencionales. En la literatura se encuentran publicaciones donde se proponen técnicas especialmente diseñadas para la clasificación de series temporales, pero no están implementadas todavı́a en R. Un subconjunto de dichas propuestas se presentó en el epı́grafe 1.4.. 1.6.. Conclusiones. 1. Las series de tiempo permiten representar de manera natural datos originados de forma secuencial en el tiempo. Las caracterı́sticas especiales que distinguen este tipo de datos dificultan la aplicación de las técnicas de minerı́a tradicionales. 2. En la literatura existen métodos propuestos, especialmente diseñados, para la clasificación de series temporales. Entre estos, se encuentran propuestas basadas en árboles de decisión y máquinas de soporte vectorial. 3. En el ambiente R no existen paquetes con métodos diseñados para la clasificación de series temporales. Esta tarea, solo es posible en R extrayendo caracterı́sticas de las series para usar los clasificadores convencionales o usado el k-NN con la distancia apropiada..
(39) Capı́tulo 2 Implementación de clasificadores La implementación de dos métodos especı́ficos para la clasificación supervisada de series temporales es discutida en este capı́tulo. El primer epı́grafe 2.1, es dedicado a la implementación de un método basado en árboles de decisión. En el segundo epı́grafe 2.2, se explica la implementación de una función para la creación de SVMs. Las conclusiones del capı́tulo aparecen en el epı́grafe 2.3.. 2.1.. Método basado en árboles de decisión. El presente epı́grafe se dedica a la implementación de un método basado en árboles de decisión. En el primer epı́grafe 2.1.1 se dan las razones que motivaron a la selección del método implementado. En el segundo epı́grafe 2.1.2, se presenta la definición de un conjunto de medidas de similitud que se utilizan en el método seleccionado. El uso del ı́ndice de Gini para calcular la pureza en un nodo, es tratado en el epı́grafe 2.1.3. La descripción del algoritmo seleccionado para la construcción de árboles se realiza en el epı́grafe 2.1.4. En los tres epı́grafes siguientes, son dados, entre otras explicaciones, ejemplos de uso del algoritmo implementado en R. El primero 2.1.5 ejemplifica la construcción de un árbol. En el segundo 2.1.6 y tercero 2.1.7 se muestra cómo predecir la clase y las probabilidades de pertenencia a cada una de ellas.. 28.
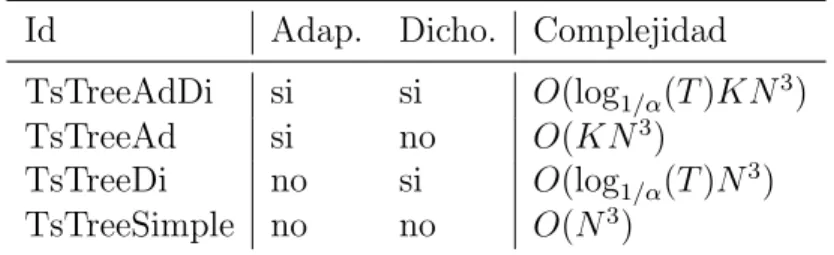
(40) Capı́tulo 2. Implementación de clasificadores. 2.1.1.. 29. Selección del método a implementar. En el capı́tulo anterior, especı́ficamente en el epı́grafe 1.4.2, se presentaron tres propuestas [Yamada et al., 2003, Balakrishnan and Madigan, 2006, Douzal-Chouakria and Amblard, 2012] para la clasificación de series temporales mediante árboles de decisión. La propuesta Classification trees for time series [Douzal-Chouakria and Amblard, 2012] fue la escogida para implementar. El método de [Douzal-Chouakria and Amblard, 2012] a diferencia de los otros dos [Yamada et al., 2003, Balakrishnan and Madigan, 2006], está diseñado para enfrentar de forma robusta la clasificación de series temporales con caracterı́sticas diversas. En el caso donde la identificación de las instancias de una clase esté determinada por el comportamiento local en un subintervalo, los métodos [Yamada et al., 2003, Balakrishnan and Madigan, 2006] presentan dificultades. Esto es, porque las distancias se calculan sobre toda la serie, es decir, solo pueden identificar satisfactoriamente las instancias de las clases que se identifican por el comportamiento global de sus elementos. El conjunto de datos LOCAL-DISC es un ejemplo donde la discriminación entre las clases depende de caracterı́sticas locales. En los resultados para LOCAL-DISC, expuestos en la tabla 2.1, se encuentra que los algoritmos con la búsqueda del subintervalo que mejor discrimina activada (valor si en la columna Dicho.) presentan mejores resultados comparados con el resto donde está desactivada. Dichas configuraciones obtuvieron valores menores en el error y el número de hojas de sus árboles. Como el algoritmo no hace poda, se puede concluir que las configuraciones con menor cantidad de hojas en los árboles generados, se desempeñaron mejor dividiendo el conjunto de datos. Se hace notar que el algoritmo con la configuración, distancia = dDtw , Adap. = Dicho = no, representa a la propuesta CE-split en [Yamada et al., 2003] y el resto, son variantes del método [Douzal-Chouakria and Amblard, 2012]. Otros problemas pueden aparecer cuando las series son periódicas o tienen efectos de tendencia. Para enfrentar esos dos problemas, en [Douzal-Chouakria and Amblard, 2012], se proponen distancias adaptativas, que tienen en cuenta la similitud en comportamiento, además de la similitud en valor que usan los métodos [Yamada et al., 2003, Balakrishnan and Madigan, 2006]. El conjunto de datos Genes presenta las caracterı́sticas mencionadas. Los resultados para Genes, en la tabla 2.1, demuestran cómo los algoritmos usando la distancia adaptativa (valor si en la columna Adap.) superan al algoritmo sin esta caracterı́stica. La distancia base usada ha sido la Euclidiana (DE) dado que los datos de Genes no presentan el problema de la distorsión del tiempo..
(41) Capı́tulo 2. Implementación de clasificadores. 30. Un problema más fácil de resolver se tiene cuando los valores de las series en un conjunto de datos aparecen medidos en rangos diferentes. Por ejemplo, las series univariadas a = {1, 2, 4, 1} y b = {5, 10, 20, 5} tienen el mismo comportamiento (b = 5 × a). La distancia entre ambas no es cero, porque a tiene sus valores en el rango 1 a 4 y b en el rango de 5 a 20. El problema es resuelto en [Douzal-Chouakria and Amblard, 2012], con el uso de distancias adaptativas. Los resultados para CBF-RANGVAR, en la tabla 2.1, demuestran cómo los algoritmos con la distancia adaptativa DT WkCort superan al resto. Además se evidencia qué la distancia adaptativa DT WkCor y la distancia basada en valor dDtw , presentan problemas en este tipo de datos. Los dos últimos conjuntos de datos en la tabla 2.1, han sido empleados para probar el método propuesto en [Douzal-Chouakria and Amblard, 2012] sobre series multivariadas. Ambos CHAR-TRAJ y DIGITS contienen datos reales.. 2.1.2.. Clasificación de medidas de similitud. En el artı́culo [Douzal-Chouakria and Amblard, 2012], se presentan tres categorı́as para las medidas entre series de tiempo. La primera categorı́a agrupa dos medidas basadas en valor: las distancias Euclidiana y DTW. En la segunda categorı́a, se dan dos coeficientes de correlación, los cuales se usan como medidas basadas en comportamiento. En la tercera categorı́a, se presenta un modelo hı́brido para cubrir ambas componentes de las series de tiempo: valor y comportamiento. En la discusión siguiente, se presentan dichas categorı́as. Las medidas se han analizado solo para series de igual longitud. En el artı́culo [Douzal-Chouakria and Amblard, 2012], se tratan las medidas de forma más general, para series de longitudes diferentes. Dadas las series S1 = (u1 , ..., up ) y S2 = (v1 , ..., vp ), ambas con p valores observados en los intervalos de tiempo (t1 , ..., tp ) y (t01 , ..., t0p ), respectivamente. Un emparejamiento r entre S1 y S2 se define como la secuencia de m pares de observaciones ((ua1 , vb1 ), ..., (uam , vbm )), con ai , bi ∈ {1, ..., p} y i ∈ {1, ..., m} según las restricciones de orden:. ai+1. a1 = b1 = 1, am = bm = p, = ai o ai + 1, bi+1 = bi o bi + 1. con m ∈ [p, 2p − 1]. Las restricciones reducen el conjunto de emparejamientos a aquellos que utilizan todos los puntos de ambas series. Se denota por R al subconjunto de tales emparejamientos, posiblemente satisfaciendo algunas restricciones adicionales y se toma.
(42) Capı́tulo 2. Implementación de clasificadores. Conjuntos de datos LOCAL-DISC. Distancia DT WkCort DT WkCor DT WkCort DT WkCor dDtw DT WkCort DT WkCor DT WkCort DT WkCor dDtw DEkCort DEkCor DEkCort DEkCor dE DT WkCort DT WkCor DT WkCort DT WkCor dDtw DT WkCort DT WkCor DT WkCort DT WkCor dDtw. CBF-RANGVAR. GENES. CHAR-TRAJ. DIGITS. 31. Adap. si si si si no si si si si no si si si si no si si si si no si si si si no. Dicho. si si no no no si si no no no si si no no no si si no no no si si no no no. Error 0.020 0.020 0.073 0.096 0.096 0.006 0.053 0.006 0.070 0.060 0.004 0.004 0.004 0.004 0.036 0.075 0.082 0.075 0.095 0.080 0.065 0.141 0.141 0.161 0.247. No. hojas 3 5 13 22 30 3 10 3 15 21 5 5 5 5 8 20 20 24 24 24 12 11 13 12 16. Cuadro 2.1. Resultados experimentales extraı́dos del artı́culo Douzal-Chouakria and Amblard [2012]. Las distancias que aparecen en la columna Distancia se definen en el epı́grafe 2.1.2.. c(r)(r ∈ R) como la función de costo que mide las distancias entre dos series según el emparejamiento dado por r. Se define un formalismo unificado para las medidas de proximidad entre dos series: dU nif(c,R) (S1 , S2 ) = mı́n c(r) r∈R. 2.1.2.1.. Medidas basadas en valor. Para la función de costo c(r) = DTW:. Pm. i=1. |uai − vbi |, dU nif(c,R) se transforma en la distancia.
(43) Capı́tulo 2. Implementación de clasificadores. 8. 32. S(t). 4. Sj(t) Si(t). −4. 0. Sk(t). 0.0. 1.0. 2.0. 3.0. Tiempo Figura 2.1. Tres series de tiempo. m X dDtw (S1 , S2 ) = mı́n( |uai − vbi |) r∈R. En el caso de la función de costo c(r) = ( obtiene la distancia Euclidiana:. i=1. Pm. i=1 (uai. dE (S1 , S2 ) = c(r0 ) = (. − vbi )2 )1/2 minimizada en R = {r0 }, se. p X. (ui − vi )2 )1/2. i=1. con r0 = ((u1 , v1 ), ..., (up , vp )) (note que m = p). En el ejemplo 2.1.1, se evidencia un problema que presentan estas distancias para medir la similitud entre dos series de tiempo. Ejemplo 2.1.1 Dadas las series Si = (0, 1, −3, −2), Sj = (4, 8, 5, 8) y Sk = (2, −2, −1, −3) mostradas en la figura 2.1. Notar que Si y Sj son cercanas en comportamiento y lejanas en valor, Si y Sk son cercanas en valor y opuestas en comportamiento. Ambas distancias, la Euclideana y la DTW, dan a Si más cercana a Sk que a Sj , con los valores: dE (Si , Sk ) = 4,24 < dE (Si , Sj ) = 15,13 < dE (Sj , Sk ) = 16,15 dDtw (Si , Sk ) = 6 < dDtw (Si , Sj ) = 29 = dDtw (Sj , Sk ) = 29.
(44) Capı́tulo 2. Implementación de clasificadores. 2.1.2.2.. 33. Medidas basadas en comportamiento. Se define que dos series de tiempo S1 y S2 son similares en comportamiento si, durante cualquier perı́odo observado [ti , ti+1 ], las series crecen y decrecen simultáneamente con la misma proporción. En contraste, ellas son consideradas opuestas en comportamiento si, durante cualquier perı́odo observado [ti , ti+1 ] en el cual S1 crece, S2 decrece y a la inversa, con la misma proporción (en valor absoluto). El coeficiente de correlación de Pearson, ha sido usado como medida basada en comportamiento para señales. Una fórmula equivalente para el coeficiente de correlación basada en las diferencias entre parejas de valores es: P. − uai0 )(vbi − vbi0 ) qP 2 2 (u − u ) ai ai0 i,i0 i,i0 (vbi − vbi0 ) i,i0 (uai. Cor(S1 , S2 ) = qP. En Cor se asume la independencia de los datos debido al uso de todos los pares de valores observados en [ti , ti0 ]; en contraste, una medida basada en comportamiento solo necesita capturar cómo las series se comportan en [ti , ti+1 ]. Por ejemplo, para las series de la figura 2.1, el coeficiente de correlación Cor falla al dar a Si cerca de Sk en lugar de Sj con Cor(Sj , Sk ) = −0,89 < Cor(Sj , Si ) = 0,18 < Cor(Si , Sk ) = 0,25. Para los datos temporales, se usa una variante de la correlación de Pearson que envuelve las diferencias de primer orden: P. − uai+1 )(vbi − vbi+1 ) pP 2 2 i (uai − uai+1 ) i (vbi − vbi+1 ). Cort(S1 , S2 ) = pP. i (uai. con Cort(S1 , S2 ) ∈ [−1, 1]. El valor de Cort(S1 , S2 ) = 1 indica que S1 y S2 exhiben un comportamiento similar. El valor de Cort(S1 , S2 ) = −1 indica que S1 y S2 exhiben un comportamiento opuesto. Mientras, Cort(S1 , S2 ) = 0 indica que S1 y S2 son linealmente independientes, identificando series de comportamiento diferente. La medida Cort, pasa la prueba de las series de la figura 2.1, al poner a Si cercana a Sj y no a Sk , con. Cort(Sj , Sk ) = −0,93 < Cort(Si , Sk ) = −0,51 < Cort(Si , Sj ) = 0,77.
(45) Capı́tulo 2. Implementación de clasificadores. 2.1.2.3.. 34. Medidas basadas en valor y en comportamiento. Para definir una medida de proximidad que cubriera las componentes de comportamiento y valor de las series, en [Douzal-Chouakria and Amblard, 2012] se propuso la función de costo:. ck (r) =. 2 c(r), k >= 0 1 + exp(k Co(r)). donde Co(r) y c(r) definen, respectivamente, las funciones de comportamiento y valor. La función ck modula la medida basada en valor de acuerdo con la medida basada en comportamiento. El valor de k afecta la modulación de ck . La función de modulación crece cuando la correlación temporal decrece de 0 a −1, tal que, ck se acerca a una función de costo basada en valor. La función de modulación decrece cuando la correlación temporal crece de 0 a 1 y ck se acerca a una función de costo basada en comportamiento. Finalmente, ck usa solo la componente basada en valor cuando la correlación temporal es cero o k = 0. El parámetro k define la relativa contribución de las componentes de comportamiento y valor en ck . Basado en la función de costo ck (r), se define la medida adaptativa que cubre las componentes de comportamiento y valor como:. Dk (S1 , S2 ) = mı́n( r∈R. 2 c(r)) 1 + exp(k Co(r)). P 2 1/2 , se define En particular, para R = {r0 }, Co(r) = Cort(r), y c(r) = ( m i=1 (ui − vi ) ) una extensión de la distancia Euclidiana para cubrir las proximidades de comportamiento y valor:. DEkCort (S1 , S2 ). m X 2 = ( (ui − vi )2 )1/2 1 + exp(k Cort(r0 )) i=1. P Para Co(r) = Cort(r), y c(r) = m i=1 |uai − vbi |, se obtiene una extensión de la distancia DTW para cubrir las proximidades de comportamiento y valor:. DT WkCort (S1 , S2 ). m X 2 = mı́n( |uai − vbi |) r∈R 1 + exp(k Cort(r)) i=1.
Figure


![Figura 1.3. Hiperplano de separaci´ on ´ optimo [Gunn et al., 1998].](https://thumb-us.123doks.com/thumbv2/123dok_es/7347403.458164/25.918.333.650.305.550/figura-hiperplano-de-separaci-on-optimo-gunn-et.webp)
![Figura 1.4. Hiperplano generalizado de separaci´ on ´ optimo [Gunn et al., 1998].](https://thumb-us.123doks.com/thumbv2/123dok_es/7347403.458164/26.918.342.667.359.688/figura-hiperplano-generalizado-de-separaci-on-optimo-gunn.webp)
+7
![Figura 1.5. Estructura de una SVM donde se mapean los datos de entrada a un espacio carac- carac-ter´ıstico de alta dimensi´ on [Gunn et al., 1998].](https://thumb-us.123doks.com/thumbv2/123dok_es/7347403.458164/27.918.339.654.139.290/figura-estructura-donde-mapean-entrada-espacio-ıstico-dimensi.webp)
![Cuadro 2.1. Resultados experimentales extra´ıdos del art´ıculo Douzal-Chouakria and Amblard [2012]](https://thumb-us.123doks.com/thumbv2/123dok_es/7347403.458164/42.918.224.769.127.689/cuadro-resultados-experimentales-extra-ıculo-douzal-chouakria-amblard.webp)


Documento similar
