Integración de ayudas al diseño de bases de datos distribuidas
67
0
0
Texto completo
(2) ___________________________________________________Dedicatoria. Dedicatoria. A mi familia y amigos.. II.
(3) ______________________________________________Agradecimientos. Agradecimientos. A mi familia por todo el cariño y preocupación en todo momento. A mi amigo y tutor Abel por su apoyo y dedicación. A mis amigos Leandro, Lemay, Yuniesky…etc.. III.
(4) _________________________________________________Resumen. Resumen El proceso de distribución en el área de las Bases de Datos necesita información que puede estar dividida en cuatro categorías: información sobre la base de datos, información sobre las aplicaciones, información sobre el sistema de las computadoras e información sobre la comunicación de la red. Debido a la necesidad de contar con un software para el diseño de Bases de Datos Distribuidas, se hace imprescindible la caracterización de los sitios de procesamiento y de la red. En este trabajo se realizará un estudio de algunas tecnologías y herramientas que ayudan a obtener la información sobre la red de comunicación y los sitios de procesamiento relevantes en el proceso de diseño de Bases de Datos Distribuidas, se implementa una nueva versión de NetWizard, aplicación capaz de obtener toda esa información, y se crea una aplicación que integra esta y otras herramientas ya creadas para completar diseños de Bases de Datos Distribuidas.. IV.
(5) _____________________________________________________Abstract. Abstract The distribution process in the area of distributed databases requires information that can be divided into four categories: information about the database, information about the applications running on it, and information about the communication network and sites. Due to the need for a tool for the design of distributed databases it is essential to characterize the sites and the communication network. In this thesis we conduct a study about some technologies and tools that help to obtain the information about the communication network and processing sites in the process of distributed databases design. Therefore, a new version the application that obtains all this information is implemented, and an integrated tool for designing distributed databases is also implemented.. V.
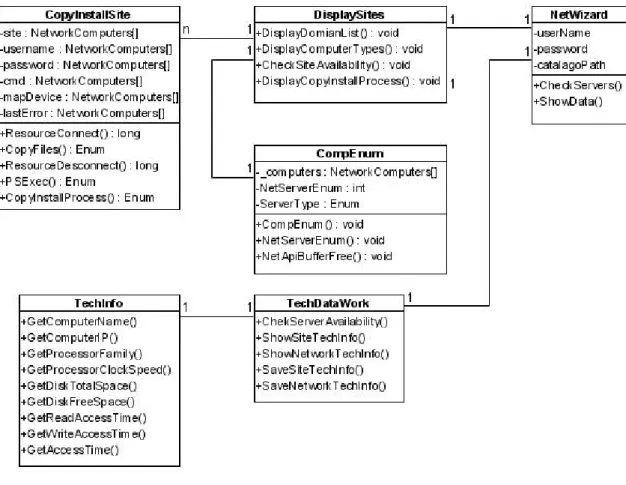
(6) _______________________________________________________Índice. Índice Introducción...................................................................................................................... 1 CAPÍTULO 1. MARCO TEÓRICO ................................................................................ 4 1.1. Bases de Datos Distribuidas ............................................................................. 4 1.1.1. Caracterización general del diseño de BDD............................................. 5 1.1.2. Diseño de distribución de datos................................................................ 6 1.1.3. La red de comunicación de datos ............................................................. 7 1.1.4. Necesidades de información para el diseño de BDD ............................... 9 1.1.5. Antecedentes........................................................................................... 10 1.2. Tecnologías y herramientas de soporte a la caracterización de los sitios y la red 12 1.2.1. WMI (Windows Management Instrumentation) .................................... 12 1.2.2. API.......................................................................................................... 15 1.2.3. .Net Remoto............................................................................................ 19 1.2.4. PSExec de SysInternals .......................................................................... 32 1.3. Conclusiones parciales ................................................................................... 34 CAPÍTULO 2. CARACTERIZACIÓN DE LA RED DE COMUNICACIÓN Y LOS SITIOS DE PROCESAMIENTO................................................................................... 35 2.1. Antecedentes........................................................................................................ 35 2.2. Necesidades de información sobre los sitios de procesamiento y la red de comunicación.............................................................................................................. 35 2.2.1. Red................................................................................................................ 35 2.2.2. Sitios ............................................................................................................. 36 2.3. Concepción del asistente NetWizard 3.0............................................................. 36 2.3.1. Arquitectura de NetWizard 3.0..................................................................... 37 2.3.2. Diagrama de actividad .................................................................................. 38 2.3.3. Diseño de clases ........................................................................................... 39 2.3.4. Caracterización de los sitios de procesamiento y la red ............................... 44 2.4. Conclusiones parciales ........................................................................................ 48 CAPÍTULO 3. INTEGRACIÓN DE HERRAMIENTAS DE AYUDA AL DISEÑO DE BDD................................................................................................................................ 49 3.1. Herramientas de ayuda al diseño de BDD........................................................... 49 3.2. Herramienta integradora SIADBDD ................................................................... 51 3.2.1. Diseño SIADBDD ............................................................................................ 52 3.4. Conclusiones parciales ........................................................................................ 55 CONCLUSIONES.......................................................................................................... 56 RECOMENDACIONES ................................................................................................ 57 REFERENCIAS BIBLIOGRÁFICAS ........................................................................... 58. VI.
(7) _________________________________________________Introducción. Introducción El continuo descenso de los costos del hardware, a pesar del incremento de la complejidad y costos del software a gran escala, ha estimulado el interés en el desarrollo e implementación de los Sistemas de BDD (SBDD), los cuales han resuelto, de manera sutil, la aparente dicotomía existente entre dos puntos de vista del procesamiento de datos: los sistemas de bases de datos centralizados y la tecnología de redes de computadoras, representativas, respectivamente de integración y distribución. El proceso de distribución en el área de las BDD (BDD) ha sido usualmente dividido en las etapas de fragmentación y ubicación, donde se necesita información que puede estar dividida en cuatro categorías: información sobre la base de datos, información sobre las aplicaciones, información sobre el sistema de las computadoras e información sobre la comunicación de la red. Las últimas dos categorías son completamente cuantitativas en cuanto a su naturaleza y son usadas en los modelos de ubicación y no en los algoritmos de fragmentación.. Antecedentes Como resultado de los trabajos de diploma presentados por (Cárdenas, 2006, López, 2001) se obtuvieron dos versiones del asistente NetWizard para la caracterización de los sitios de procesamiento y la red de comunicación para la obtención de la información necesaria en el diseño de BDD como respuesta al déficit de herramientas de apoyo al diseño de tales bases de datos; entonces, este trabajo ayudaba a mitigar esa carencia. Este asistente presenta algunas características que pueden ser perfeccionadas y algunos errores que necesitan ser corregidos, como por ejemplo la incapacidad de instalación y activación remota de un servicio requerido para la caracterización, la imposibilidad de continuar con la caracterización cuando algún sitio no se encuentra disponible, etc. Este asistente junto otras herramientas para el diseño de BDD que han sido desarrolladas en el laboratorio de Bases de Datos del Centro de Estudios de Informática de la Universidad Central “Marta Abreu” de Las Villas no se encuentran debidamente integradas a través de una interfaz común que brinde un acceso homogéneo a los usuarios de las mismas.. Formulación del problema. 1.
(8) _________________________________________________Introducción Un diseñador de BDD requiere de mucho tiempo para realizar la caracterización de los sitios de procesamiento y la red de comunicación donde se debe capturar la información relevante para el diseño, como son: costos de comunicación, tiempos de retardo en el envío de mensajes, la capacidad de procesamiento, el tiempo de acceso de lectura y escritura en disco, la velocidad del procesador, el espacio libre en disco, entre otros factores. Como se pudo observar en la sección de antecedentes, se ha desarrollado la herramienta NetWizard para recopilar estos parámetros, aunque aún posee características objeto de perfección, adaptación y corrección. Por otra parte, existe la necesidad de contar con un software que sirva de ayuda al proceso del diseño de BDD y que integre armónicamente el funcionamiento de las distintas herramientas que en conjunto realizaran este trabajo.. Preguntas de investigación •. ¿Qué características debe poseer NetWizard como caracterizador de los sitios de procesamiento y la red de comunicación para obtener los datos relevantes para el proceso de diseño de forma fácil y ágil?. •. ¿Qué aspectos de NetWizard deben ser perfeccionados para que resulte correcto y sea favorable para el diseñador?. •. ¿Cómo integrar varias herramientas de ayuda al diseño de BDD y lograr la comunicación entre ellas mediante un catálogo común?. Objetivo General Crear una nueva versión de NetWizard que supere las limitaciones identificadas a las versiones anteriores e implementar una aplicación que integre armoniosamente distintas herramientas para el diseño de BDD.. Objetivos específicos •. Rediseñar el caracterizador de los sitios de procesamiento y la red de comunicación para que resulte correcto, fácil de usar y amigable al usuario.. •. Diseñar una aplicación integradora que coordine el funcionamiento de las distintas herramientas.. •. Integrar las herramientas usando un catálogo como elemento común para el funcionamiento de las mismas.. 2.
(9) _________________________________________________Introducción •. Generar los informes que le muestren al usuario un resumen del progreso en el diseño de la BDD a partir de los resultados obtenidos por las diferentes herramientas integradas.. Justificación de la Investigación Relacionado con los antecedentes antes planteados, se puede decir que este estudio se justifica por su importancia desde el punto de vista práctico en la integración que tendrán los resultados esperados en una herramienta de ayuda al diseño de BDD. Desde el punto de vista metodológico se sistematiza en el proceso de diseño de de bases de datos distribuidas. La presente tesis está organizada en tres capítulos: En el capítulo 1 se presentan los aspectos generales sobre el diseño de BDD, conceptos y otros elementos teóricos que son útiles para abordar este trabajo. También se reseñan las herramientas que se utilizaron para la implementación la caracterización de los sitios y la red. En el capítulo 2 se exponen los elementos necesarios para el desarrollo e implementación del asistente de caracterización de los sitios y red, así como los parámetros que brindan cada uno de asistentes, se muestra la interfaz del caracterizador de los sitios y la red y algunos aspectos relacionados con su uso. En el capítulo 3 se trata el diseño e implementación de la aplicación que integra las distintas herramientas que ayudaran el diseño de BDD así como del catálogo que sirve como elemento de integración entre las distintas herramientas. La tesis culmina con las conclusiones, recomendaciones y bibliografía.. 3.
(10) ____________________________________________________Capítulo 1. CAPÍTULO 1. MARCO TEÓRICO En este capítulo se exponen algunos elementos teóricos relacionados con las BDD, y se reseñan las herramientas y estrategias estudiadas para realizar el diseño e implementación de del caracterizador de los sitios y la red.. 1.1. Bases de Datos Distribuidas El término de BDD se puede definir como una colección de bases de datos lógicamente interrelacionada y distribuida sobre una red de comunicación (Ceri et al., 1987, Őzsu and Valduriez, 1999). En esta definición están imbricados los aspectos neurálgicos de las BDD. Por una parte la distribución, el hecho de que los datos no residen en el mismo sitio; y por otra las implicaciones lógicas que hacen que estos datos posean algunas propiedades comunes que los vinculan, y a los que se accede a través de una interface común. Es necesario destacar que el enlace ente los datos se llevan a cabo en una red de comunicación, lo que determina que los sitios - por generalización - estén localizados en diferentes áreas geográficas y con capacidad de procesamiento autónomo. Por todo lo anterior se puede decir que un Sistema de Gestión de Base de Datos Distribuidas (SGBDD) es el software capaz de realizar la administración de la BDD y donde ésta distribución es totalmente transparente al usuario. Estos sistemas heredan las complejidades propias de los sistemas centralizados e incorporan una nueva problemática asociada al hecho de que los datos están distribuidos sobre una red de computadoras. Las tecnologías de los SBDD son la unión de conceptos tácitamente opuestos para el procesamiento de los datos. Por una parte están los Sistemas de Bases de Datos y por otro las redes de computadoras. Los Sistemas de Bases de Datos han eliminado el concepto tradicional de procesamiento de ficheros, donde cada aplicación define y mantiene sus propios datos, para convertirse en un sistema en el cual los datos son definidos y administrados centralizadamente. Estos nuevos derroteros conllevan a una deseada independencia de datos, y que los programas de aplicación se hagan poco sensibles a cambios en la organización física o lógica y viceversa. Uno de los principales incentivos para el uso de los Sistemas de Bases de Datos es integrar los datos involucrados en las operaciones y permitir su acceso centralizado. Pero en el otro lado encontramos la perspectiva distinta que impone las tecnologías de. 4.
(11) ____________________________________________________Capítulo 1 redes de computadoras, con proyecciones opuestas a la centralización. Pudiera parecer un tanto contradictoria la posibilidad de hacer coincidir ambas perspectivas a fin de promover una tecnología más poderosa y prometedora que ambas por sí solas. Esto pudiera ser explicado dado que la proyección más importante de las BDD en la integración, no la centralización. De igual forma no resulta ocioso resaltar que un término no implica el otro, o sea, es posible hablar de integración, sin que esto conduzca necesariamente a una centralización. El objetivo fundamental de los SBDD es integrar la manipulación de datos para presentarlos como una única colección global y coherente En muchos casos de la práctica se presentan organizaciones geográficamente distribuidas para las cuales las vías centralizadas no representan una alternativa factible, y la migración hacia SBDD resulta natural, ya que esta alude de manera natural la estructura descentralizada de la organización.. 1.1.1. Caracterización general del diseño de BDD Las diferentes técnicas de diseño de las BDD (generalmente basadas en la semántica de los datos) se rigen por idénticos principios que las BD centralizadas, pero se incorporan detalles específicos, como la fragmentación de las entidades y su posterior localización en los diferentes sitios de la red. Esta fragmentación es muy útil a fin de mejorar los tiempos de respuesta y garantizar el paralelismo del sistema. Las BDD brindan importantes beneficios, entre los cuales podemos enumerar: 1. Incremento del rendimiento 2. Paralelismo 3. Confiabilidad. 4. Participación directa y control de los usuarios sobre los datos y recursos La principal desventaja se refiere al control y manejo de los datos. Dado que éstos residen en muchos nodos diferentes y se pueden consultar por nodos diversos de la red, la probabilidad de violaciones de seguridad es creciente si no se toman las precauciones debidas. La habilidad para asegurar la integridad de la información en presencia de fallas no predecibles tanto de componentes de hardware como de software es compleja. La integridad se refiere a la consistencia, validez y exactitud de la información. Dado que. 5.
(12) ____________________________________________________Capítulo 1 los datos pueden estar replicados, el control de concurrencia y los mecanismos de recuperación son mucho más complejos que en un sistema centralizado. Esto amplía el grado de complejidad de los sistemas con respecto a los sistemas centralizados. Para garantizar estas metas es necesario desarrollar soluciones óptimas o con un grado aceptable de optimalidad que derivan en la implementación de algoritmos sumamente engorrosos, generalmente de complejidad exponencial. El problema del diseño de BDD podría enfocarse a través de esta trama de opciones. En todos los casos, excepto aquel en el que no existe compartimentación, aparecerán una serie de nuevos problemas que son irrelevantes en el caso centralizado. A la hora de abordar el diseño de una BDD se puede optar principalmente por dos tipos de estrategias: la estrategia ascendente y la estrategia descendente (Ceri et al., 1987, Őzsu and Valduriez, 1999). Ambos tipos no son excluyentes, y no resultaría extraño a la hora de abordar un trabajo real de diseño de una BD que se pudiesen emplear en diferentes etapas del proyecto una u otra estrategia. La estrategia ascendente podría aplicarse en aquel caso donde haya que proceder a un diseño a partir de un número de pequeñas BD existentes, con el fin de integrarlas en una sola. En este caso se partiría de los esquemas conceptuales locales y se trabajaría para llegar a conseguir el esquema conceptual global. Aunque este caso se pueda presentar con facilidad en la vida real, se prefiere pensar en el caso donde se parte de cero y se avanza en el desarrollo del trabajo siguiendo la estrategia descendente. Incluir en los SBDD todas las funcionalidades, es una tarea compleja, pero lo es más encontrar soluciones optimales. Nuevas retos se crean al considerar el diseño la distribución de SBDD, el decidir cómo fragmentar y distribuir los datos sobre los diferentes sitios y cuales de estos datos deben ser replicados.. 1.1.2. Diseño de distribución de datos En un primer momento esquemas globales se dividen en subconjuntos llamados fragmentos; y en un segundo momento los fragmentos son localizados (con o sin réplica) en los diferentes sitios distribuidos. Esta distribución de datos es una cualidad deseable porque permite al administrador desplegar los datos en los sitios particulares donde serán más frecuentemente usados, con lo cual se incrementa la localidad de referencia y se reduce el tráfico en la red.. 6.
(13) ____________________________________________________Capítulo 1 El resultado primordial del proceso de diseño de un SBDD es la fragmentación y su posterior distribución óptima en los diferentes sitios de la red. Las redes de computadoras, son pues, el soporte físico sobre el que se implementan las arquitecturas multiusuario. Cuando los datos son ubicados, éstos pueden estar replicados, o mantenidos como una sola copia. Las razones para la replicación son la disponibilidad y la eficiencia de las solicitudes de sólo lectura. Si existen múltiples copias de determinados datos, habrá una mayor probabilidad de que alguna copia de ellos esté accesible en algún lugar, incluso si ocurriera una falla en el sistema. Además, las solicitudes de sólo lectura que acceden a los mismos artículos de datos pueden ser ejecutadas en paralelo ya que las copias existen en múltiples sitios. Por otra parte, la ejecución de solicitudes de actualización causa problemas, ya que el sistema tiene que asegurar que todas las copias de los datos sean propiamente actualizadas. De aquí que la decisión con relación a la replicación es una cuestión que depende de la proporción de la solicitudes de sólo lectura con respecto la solicitudes de actualización. Esta decisión afecta a casi todos los algoritmos del SGBDD y a las funciones de control.. 1.1.3. La red de comunicación de datos El concepto de redes que se usa en este caso es el de colección interconectada de estaciones autónomas. Se dice que dos ordenadores están conectados si estos son capaces de intercambiar información. Al indicar que los ordenadores son autónomos, se excluye de esta relación a todos los sistemas organizados sobre la arquitectura cliente/servidor, ya que un sistema constituido por una unidad central de control y varios clientes no es propiamente una red (Hababeh et al., 2004, Lee and Baik, 2004, Pentaris and Ioannidis, 2006, Savsar and Al-Anzi, 2006). En una forma más general, el argumento aquí consiste en compartir recursos, y el objetivo es hacer que todos los programas, datos y equipos estén disponibles para cualquiera en la red que así los solicite, sin importar la localización física del recurso ni del usuario. En otras palabras, el hecho de que un usuario se encuentre a mucha distancia de los datos no debe evitar que éste los pueda utilizar como si fueran originados localmente. Otro objetivo de las redes de computadoras consiste en proporcionar una alta fidelidad, al poder contarse con fuentes alternativas de información. Por ejemplo, todos los 7.
(14) ____________________________________________________Capítulo 1 archivos podrían duplicarse en dos o tres máquinas, de tal manera que si una de ellas no se encuentra disponible, podría utilizarse alguna de las otras copias. Además, la presencia de múltiples procesadores significa que si una deja de funcionar, las otras pueden encargarse de su trabajo, aunque se tenga un rendimiento global menor. Para aplicaciones militares, bancarias, de control de tráfico aéreo y muchas otras es indispensable la capacidad de los sistemas de continuar funcionando a pesar de existir problemas de disponibilidad. Un aspecto de importancia y en el que se vierte el interés de las redes de computadoras es el renglón económico. Las estaciones pequeñas tienen una mejor relación costo/rendimiento comparada con la ofrecida por máquinas grandes. En muchos casos, las máquinas grandes son diez veces más rápidas que el más rápido de los microprocesadores, pero su costo es miles de veces mayor. Este equilibrio ha determinado que muchos desarrolladores de sistemas construyan sistemas constituidos por poderosos procesadores personales. La mayoría de las redes están organizadas en una serie de capas o niveles con el objetivo de reducir la complejidad de su diseño. Cada una de ellas se construye sobre su predecesora. El número de capas, el nombre, contenido y función de cada una varían de una red a otra. Independientemente de esto, el propósito de cada capa es el de ofrecer ciertos servicios a las capas superiores. De tal manera que entre cualquier par de capas se define una interfaz, la que aglutina servicios y funcionalidades que la capa anterior le brinda a la superior. Al conjunto de capas e interfaces de una red de computadoras se denomina arquitectura de la red. Independientemente de su arquitectura, cada red de comunicación deberá asegurar ciertas funcionalidades de manera global. Se necesita definir un medio a través del cual un proceso defina con quién desea establecer conexión, así como de un mecanismo para terminarla. Otro conjunto de funcionalidades que deben quedar definidas son las referidas con la transferencia de datos: determinar el número de canales lógicos que corresponden a una conexión y cuales son sus prioridades, la detección y recuperación de errores de transmisión, los controles de flujo de sincronización, entre otras. Es fundamental detenerse alrededor de las especificaciones básicas de transferencia de datos a fin de aclarar ciertos conceptos usados a continuación. En algunos sistemas los datos viajan en una sola dirección (comunicación unilateral o simplex). En otros los. 8.
(15) ____________________________________________________Capítulo 1 datos pueden viajar en ambas direcciones, aunque no en forma simultánea (comunicación semidúplex o bilateral alternada). Existen también otros sistemas en que los datos viajan a la misma vez y en ambas direcciones (comunicación dúplex o bilateral simultanea). Un número considerable de redes poseen al menos dos canales lógicos por conexión: uno para datos normales y otro para datos urgentes. Otra de las complejidades propias de las redes es lo referente a los enrutamientos. Siempre que existan varios caminos entre la fuente y el destino se tienen que tomar decisiones de encaminamiento lo cual implica un gasto adicional de procesamiento a nivel de los sitios. Algunas veces estas decisiones deben tomarse en dos o más capas. Como se ha podido apreciar son muchos los puntos de coincidencia entre los objetivos que animan a los SBDD y a las redes de computadoras. Estas semejanzas están basadas en un conjunto de problemáticas comunes que deben enfrentar en su gestión de comunicación, así como en la proyección de sus objetivos. Existe confusión en la literatura entre una red y un sistema distribuido, la clave de la diferencia radica en que en un sistema distribuido la existencia de múltiples estaciones es transparente al usuario, él puede teclear un comando (ejecutar un proceso o una solicitud) y constatar que se ejecuta, pero el hecho de seleccionar el mejor procesador, encontrar y transportar los datos de entrada al procesador y poner los resultados en el lugar apropiado dependen íntegramente del sistema operativo (Rodríguez et al., 2007, Őzsu and Valduriez, 1999, Ceri et al., 1987). Con una red, el usuario debe explícitamente iniciar una sesión en una estación, acceder a ficheros remotos, mover archivos y por lo general gestionar de maneras personal toda la administración de la red. Un sistema distribuido es, a partir de estos razonamientos, un caso especial de red; aquel donde el software brinda un alto grado de cohesión y transparencia.. 1.1.4. Necesidades de información para el diseño de BDD En el diseño óptimo de distribución influyen muchos factores: la organización lógica de la BD, la ubicación de las aplicaciones, las características de acceso de las aplicaciones a la BD, y las propiedades de los sistemas de computación en cada sitio; todas tienen influencia sobre la decisiones de distribución. Esto hace que sea muy complicada la formulación de un problema de distribución (Őzsu and Valduriez, 1999).. 9.
(16) ____________________________________________________Capítulo 1 El concepto de optimalidad que se usa durante el proceso de distribución y localización de fragmentos, hace necesario el manejo y medición de alguno de los parámetros que caracterizan las redes de computadoras, ya que de su control y conocimiento depende en mucho el buen desempeño del sistema que se esta diseñando. Para simplificar, se define una red de computadoras como un grafo orientado, donde cada uno de los nodos corresponde a un sitio de procesamiento y cada arco una línea de comunicación. Sería muy atinado etiquetar los caminos según algunos factores que midan el desempeño de la red, estos podría ser: distancia geográfica, ancho de banda, promedio de tráfico, costo de comunicación, longitud promedio de la cola de espera, tiempo de retardo medido, entre otros. También se hace necesario analizar otros factores, ya no directamente relacionados con las redes de computadoras, pero de igual importancia durante el proceso de diseño de SBDD. Estos parámetro son los referidos con los propios sitios de procesamiento: la capacidad de procesamiento, el tiempo de acceso de lectura y escritura en disco, la velocidad del procesador, el espacio libre en disco, la cantidad de memoria RAM y su disponibilidad en un momento determinado, etc. Dichos parámetros determinan, y en cierta medida, caracterizan una red de computadoras sobre la cual en definitiva va a estar implementado el SBDD. Dada la combinación de estos factores, un sitio es más conveniente que otro para recibir determinado fragmento, y asociado a esto un determinado tiempo de respuesta a transacciones que le involucren.. 1.1.5. Antecedentes Se han reportado trabajos que analizan parcialmente el problema de la comunicación en la red y proponen soluciones con limitaciones (Tamhankar and Ram, 1998, Ma et al., 2006, Roosta, 2005, Sun et al., 2004, Lee and Baik, 2004, Hababeh et al., 2004, Mei et al., 2003, Hababeh et al., 2003, Awerbuch et al., 2003, Tsai et al., 2002, Huang and Chen, 2001, Fornaciari et al., 2001, Chang et al., 2001, Pérez et al., 2000, Daudpota, 1998, Bellatreche et al., 1998, Park and Baik, 1997, Lim and Ng, 1997, Wolfson and Jajodia, 1995, March and Rho, 1995, Lin and Orlowska, 1995). En este sentido es necesario analizar las propiedades de los sistemas de computación en cada sitio y la red de comunicación.. 10.
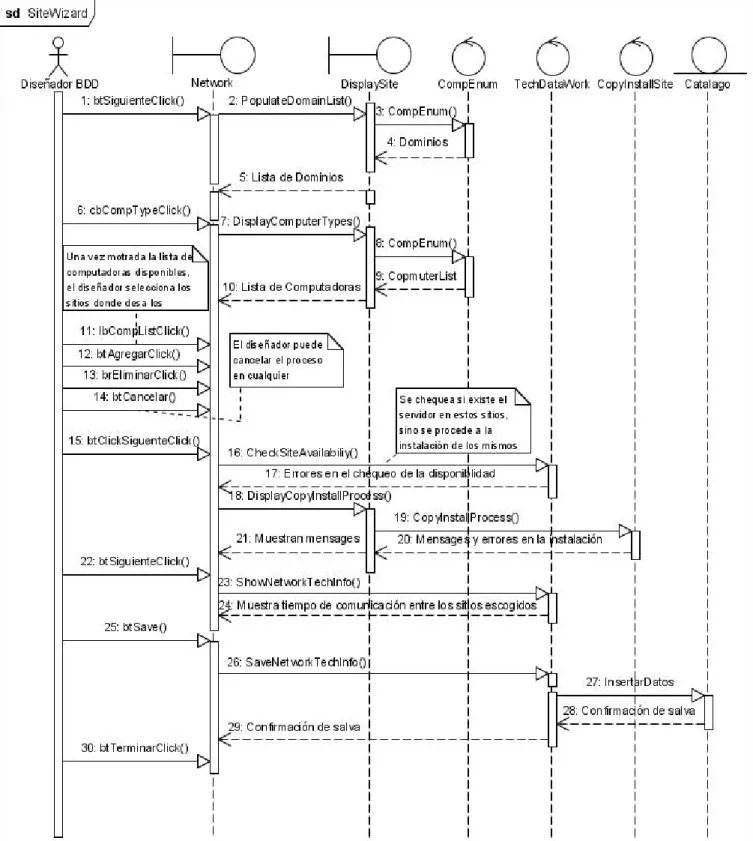
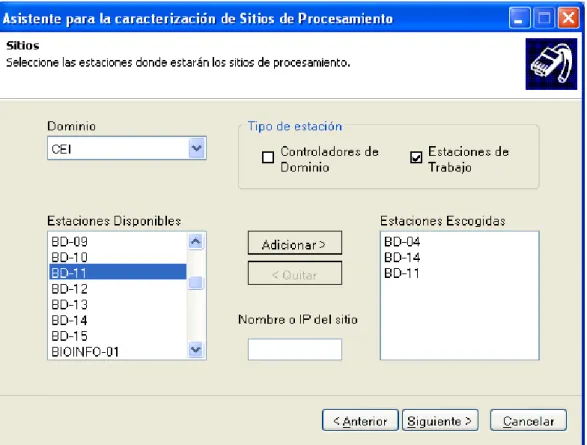
(17) ____________________________________________________Capítulo 1 La gran cantidad de aplicaciones distribuidas en la actualidad sólo han sido posibles debido a la evolución constante de tecnologías remotas. La realización de aplicaciones comerciales de alguna manera distribuida, fue posible sólo después que se solucionaran algunos problemas técnicos de estas tecnologías. CORBA, COM+, y EJB comenzaron este proceso hace varios años, el cual se vio simplificado con la aparición de .Net Remoto, que tiene la ventaja de utilizar los estándares opensource muy bien establecidos, como SOAP para mensajería, y HTTP y TCP como protocolo de comunicación, eliminando así las dificultades que tiene DCOM para atravesar firewalls. Además, es más flexible y más personalizable, permitiendo definir nuevos formateadores y canales de comunicación, no necesita definir las interfaces en un lenguaje abstracto, y oculta todos los detalles de implementación del trabajo con sockets, entregando al programador final una interfaz de programación que se distingue por las facilidades de uso y su potente alcance. Con .Net el concepto de facilidad de implementación ha sido ampliado al desarrollo de aplicaciones distribuidas. No hay ciclos de compilaciones como en Java RMI. No se tienen que definir las interfaces en un lenguaje abstracto como en CORBA o DCOM. Una característica única es que se tiene que decidir el formato de codificación de las peticiones remotas; en cambio, se puede cambiar de un formato binario rápido a SOAP, cambiando solo una palabra en un archivo de configuración. Se puede proporcionar incluso, ambos canales de comunicación para los mismos objetos añadiendo otra línea a la configuración. No se está atado a una plataforma ni a un lenguaje de programación como con DCOM, COM+, o Java EJB. La configuración y el desarrollo es mucho más fácil que como era en DCOM. La herramienta NetWizard versión 2.0 realiza la caracterización de los sitios de procesamiento mediante la captura del nombre que identifica a cada sitio, su dirección IP, la velocidad del procesador dado en gigahertz, el espacio total en disco y el espacio libre medidos en gigabytes, los tiempo de lectura de disco y de escritura hacia disco, dados en milisegundos. En cuanto a las redes, la herramienta almacena en el catálogo las mediciones de tiempos de respuesta (en milisegundos) al enviar un frame de un sitio a otro. Concretamente, almacena la dirección IP de origen, la dirección IP de destino, y el tiempo de respuesta como medida de costo de comunicación entre sitios. Posteriormente, todos estos parámetros capturados por NetWizard sirven de entrada para la ubicación de los fragmentos que se obtengan durante el diseño de BDD.. 11.
(18) ____________________________________________________Capítulo 1 Esta versión de NetWizard presenta una arquitectura cliente-servidor que usa la tecnología de comunicación .Net Remoto (Rammer, 2002, Richter, 2002, Vitter and Templeman, 2002). En cada sitio reside un servidor y el asistente actúa como un cliente que guarda los datos recopilados sobre las características físicas de cada uno de los sitios y los tiempos de comunicación entre ellos, en el catálogo de la aplicación. La realización de estas actividades no tiene un orden predefinido, se puede comenzar por una u otra indistintamente. En este proceso de NetWizard se buscan los sitios mediante difusión, usando NetServerEnum de netapi32.dll de Windows® (Matthew Lavy, 2001). Después se encarga de manejar las peticiones directas del diseñador para buscar los dominios, los tipos de máquinas, así como de chequear la disponibilidad de los sitios manualmente añadidos. Se recopilan los tiempos de comunicación entre sitios, comprobando la existencia de los objetos remotos en los sitios escogidos previamente. Estos objetos remotos se encargan de las comunicaciones para obtener una referencia al proxy que atenderá las peticiones hechas por ellos y recuperar la información necesaria sobre los sitios de procesamiento. El objeto servidor del asistente reside en un servicio Windows y es el encargado de escuchar las peticiones de los objetos clientes. Este objeto remoto usa un canal HTTP para la comunicación con los clientes, logrando pasar a través de firewalls. Es necesario instalar manualmente el servicio en cada uno de los sitios que se desee tomar como servidor para la BDD. El objeto remoto en sí es el encargado de resolver la información asociada a los sitios. Este asistente presenta algunas características que pueden ser perfeccionadas y algunos errores que necesitan ser corregidos, como por ejemplo la incapacidad de instalación y activación remota de un servicio requerido para la caracterización, la imposibilidad de continuar con la caracterización cuando algún sitio no se encuentra disponible.. 1.2. Tecnologías y herramientas de soporte a la caracterización de los sitios y la red En este acápite se realiza un estudio de algunas tecnologías y herramientas que ayudan a obtener la información sobre la red de comunicación y los sitios de procesamiento relevantes en el proceso de diseño de BDD.. 1.2.1. WMI (Windows Management Instrumentation) El Instrumental de Administración de Windows (WMI) es la implementación de Microsoft de WBEM (Web-Based Enterprise Management), una iniciativa de la 12.
(19) ____________________________________________________Capítulo 1 industria que pretende establecer estándares para el acceso y el uso compartido de la información de administración a través de una red empresarial. WMI es compatible con WBEM y proporciona compatibilidad integrada para el CIM (Common Information Model), el modelo de datos que describe los objetos existentes en un entorno de administración (Cole and Tunstall, 2002). WMI incluye un repositorio de objetos compatible con CIM, que es la base de datos de definiciones de objetos, y el Administrador de objetos CIM, que controla la recopilación y manipulación de objetos en el repositorio y reúne información de los proveedores de WMI. Los proveedores de WMI actúan como intermediarios entre WMI y los componentes del sistema operativo, las aplicaciones y otros sistemas. Por ejemplo, el proveedor del Registro extrae su información del Registro, mientras que el proveedor de SNMP (Simple Network Management Protocol) proporciona datos y sucesos de los dispositivos SNMP. Los proveedores ofrecen información acerca de sus componentes y podrían proporcionar métodos para manipular los componentes, las propiedades que se pueden establecer o los sucesos que pueden alertarle de las modificaciones efectuadas en los componentes. Se puede utilizar WMI con sistemas de programación o de secuencias de comandos para obtener información de configuración acerca de la mayoría de los aspectos de sus sistemas informáticos, incluidas las aplicaciones de servidor, o para realizar cambios en los sistemas. Para localizar la gran cantidad de información disponible en el repositorio CIM, WMI brinda su propio lenguaje SQL (Structured Query Language) llamado WQL (WMI Query Language), el cual es un subconjunto del estándar ANSI SQL con cambios semánticos menores. WQL está diseñado para recuperar información del repositorio CIM. En CIM se definen 3 niveles de clases: Clases que representan objetos pertenecientes a todas las áreas administrativas de un sistema. Clases que representan objetos de áreas específicas, pero independientes de una implementación o tecnología concreta.. 13.
(20) ____________________________________________________Capítulo 1 Clases que representan objetos dependientes de una tecnología dada (por ejemplo, específicas de UNIX o de Win32). WMI suministra los siguientes servicios: Soporte de notificación de eventos. Lenguaje de consultas. Soporte de seguridad. Almacenamiento de funciones de múltiples lenguajes en el CIM.. WMI para .NET Debido a la complejidad implícita al trabajar con las API de WMI, Microsoft decidió simplificar el proceso creando diferentes namespaces que facilitan el trabajo con estas API. .Net proporciona algunas clases para el trabajo con WMI. El namespace System.Management permite usar las API de WMI, ocultando todos los detalles complejos de la arquitectura y permitiendo un trabajo directo con todos los objetos de WMI. Las clases que proporcionan están bien documentadas y lo mejor es que con la llegada del Framework .NET se ha simplificado enormemente su uso. WMI implementa clases para consultas de información del sistema operativo, se divide en tres grandes grupos: Hardware Software Sistema Operativo A continuación se muestra un resumen de algunas clases útiles en este namespace: Nombre de la clase. Descripción. ManagementBaseObject. Clase base para el control de los objetos básicos de Windows. ManagementObject. Objeto de control de Windows. Permite acceder a las propiedades y métodos de un objeto en particular de WMI. Hereda de ManagementBaseObject. 14.
(21) ____________________________________________________Capítulo 1 ManagementClass. Clase de control de Windows, es usada para acceder a las propiedades de una clase en particular. Hereda de ManagementObject. ManagementObjectCollection. Colección de ManagementBaseObjects (los cuales pueden. ser. ManagementObjects. o. ManagementClasses) ManagementQuery. Clase base para las consultas. ObjectQuery. Objeto consulta para encuestar a instancias y clases. Hereda de ManagementQuery. EventQuery. Objeto consulta para encuestar eventos en WMI. ManagementScope. Ámbito en el cual se realizan las operaciones de control. Generalmente se refiere a un namespace de WMI como root\cimv2. ManagementEventWatcher. Usado para monitorear eventos procedentes del servicio WMI.. ManagementObjectSearcher. Devuelve. una. colección. de. ManagementObjects. basándose en una consulta en particular. 1.2.2. API Interfaz de Programación de Aplicaciones, cuyo acrónimo en inglés es API (Application Programming Interface), es un conjunto de funciones residentes en bibliotecas (generalmente dinámicas, también llamadas DLLs por sus siglas en inglés, término usado para referirse a éstas en Windows) que permiten que una aplicación se ejecute bajo un determinado sistema operativo. En este caso se refiere a las aplicaciones Windows. Debido a su estrecha relación con el desarrollo de software, los programas en sus especificaciones generalmente explicitan la versión de la API del sistema operativo, mediante diversas nomenclaturas tales como la versión específica del sistema operativo. 15.
(22) ____________________________________________________Capítulo 1 (para Windows 98, por ejemplo), o explicitando la versión del conjunto de bibliotecas (Plataforma Win32, etc.). Las funciones API se dividen en varias categorías: Depuración y manejo de errores Entada/Salida de dispositivos DLLs, procesos e hilos Comunicación entre procesos Manejo de la memoria Monitoreo del desempeño Manejo de energía Almacenamiento Información del sistema GDI (interfaz para dispositivos gráficos) de Windows (tales como impresoras) Interfaz de usuario de Windows Las mismas se alojan en el directorio System32 de Windows, aunque se pueden situar en otros directorios y para utilizarlas se debe hacer referencia a esta mediante su camino en su unidad de almacenamiento. Con ellas se pueden realizar casi todas las tareas del Sistema Operativo Windows, como por ejemplo cambiar la resolución de la pantalla, comprobar si existe un archivo, ejecutar programas, acceder al registro, etc. Las DLLs principales son: user32.dll (Maneja la interfaz de usuario) kernel32.dll (Trabaja con los archivos y la memoria de la Computadora) gdi32.dll (Funciones gráficas) winmm.dll (Multimedia) shell32.dll (Ejecución de programas) advapi32.dll (Funciones avanzadas). 16.
(23) ____________________________________________________Capítulo 1 Existen más archivos .DLL con funciones propias, pero estas tres nombradas anteriormente son las principales. Las ventajas de saber usar las funciones API son principalmente que pueden ser usadas por varios lenguajes de programación que trabajen bajo Windows. El propósito de las APIs de Windows es permitirle desarrollar programas coherentes con el sistema operativo y la interfaz de usuario de Windows. En lugar de escribir código para crear componentes del sistema operativo Windows, como formularios, botones de comando y menús, se pueden realizar llamadas a las funciones adecuadas en la API de Windows y permitir que el sistema operativo cree esos componentes.. ¿Por qué utilizar las API? La ventaja de utilizar las APIs de Windows en el código es que pueden ahorrar tiempo porque contienen numerosas funciones útiles ya escritas y listas para utilizar. La desventaja es que puede resultar difícil trabajar con ellas. La razón para usar la API de Windows es la necesidad de llevar a cabo una tarea que no esté disponible en el leguaje en el que se esté desarrollando el programa. Por ejemplo, no puede determinar o establecer la velocidad de intermitencia del cursor a través de ninguna instrucción, propiedad, procedimiento o método a través de un lenguaje estándar de programación como C++, C#, Visual Basic, etc. Para ello puede llamar a la función GetCaretBlinkTime, que devuelve la velocidad de intermitencia del cursor en milisegundos. Si desea configurar el cursor para que parpadee con otra velocidad de intermitencia en las condiciones especificadas, puede llamar a la función SetCaretBlinkTime y pasarle el tiempo especificado en milisegundos, otras utilidades como conectarse y desconectarse a determinadas unidades de red, obtener información sobre la red , conocer los dominios disponibles, tipo de conexión, etc. Se puede obtener la misma funcionalidad que con casi cualquiera de las características de los leguajes de alto nivel llamando a las funciones adecuadas de la API de Windows. Sin embargo, llamar directamente a estas funciones suele ser más complicado y puede ocasionar un comportamiento imprevisible si no se hace de forma correcta, con lo que se provocan errores del sistema. Para conseguir el máximo rendimiento y un comportamiento predecible debería utilizar la funcionalidad intrínseca incluida en los leguajes de programación.. 17.
(24) ____________________________________________________Capítulo 1 Las APIs de Windows representan una categoría especial de interoperabilidad. Estas no utilizan código administrado, no tienen bibliotecas de tipos integradas y utilizan tipos de datos que son diferentes a los que se utilizan en Visual Studio. Debido a estas diferencias y a que las API de Windows no son objetos COM, la interoperabilidad con ellas y Framework .NET se lleva a cabo mediante la invocación de la plataforma o PInvoke. La invocación de la plataforma es un servicio que permite al código administrado llamar a funciones no administradas implementadas en archivos DLL.. Trabajando con APIs en .NET Como se espera que las aplicaciones .NET tengan que interactuar por largo tiempo con las tecnologías de Windows existentes, esta proporciona una capa de programación a objetos que se sitúa encima de la APIs de Windows, pero en ocasiones se necesita hacer una llamada al API que no es accesible a través de .NET. En estos casos se puede utilizar el mecanismo .NET Plataform Invoke (P/Invoke o Invoke) para hacer llamadas a funciones escritas en C o C++ a través de .NET, ya que las funciones APIs de Windows residen en DLL, P/Invoke proporciona un mecanismo general para acceder a estas funciones en ficheros DLL a partir de códigos en .NET. Cuando P/Invoke llama a una función no supervisada, se realizan los siguientes pasos: Localiza la DLL que contiene la función. Carga la DLL en memoria Encuentra la dirección de la función a llamar y coloca los argumentos en la pila Llama a la función Para llamar a una función que reside en una DLL primero se debe conocer el nombre de la función o su número ordinal y el nombre de la DLL que la contiene. Para usar una función de una DLL necesita crear un prototipo en el código que le diga al compilador el nombre de la función, sus argumentos y cuál DLL la contiene. La forma en que se construye este prototipo será dependiente del lenguaje. El siguiente ejemplo muestra como declarar el prototipo para llamar a la función MessageBox en C#. [DllImport(“user32.dll”, CharSet=CharSet.Auto)] public static extern int MessageBox(int hwnd, String text, String caption, uint type). 18.
(25) ____________________________________________________Capítulo 1 1.2.3. .Net Remoto .Net Remoto es la tecnología elegida por los programadores .Net para hacer llamadas a objetos remotos desde sus aplicaciones .Net. Una llamada remota es una petición enviada a una interfaz de un objeto fuera del proceso en que este se encuentra. Este objeto remoto estaría en el mismo sitio o en un sitio separado. Cuando el objeto que está siendo llamado no está en el mismo proceso que el que está llamándolo, los datos que se intercambian entre estos dos objetos deben ir a través de un proceso especial de orden o de paquete para transferir entre los procesos. Sus llamadas a la interfaz no utilizarán .Net Remoto cuando el objeto que está siendo llamado está en el mismo proceso o dominio de la aplicación que el que está llamando. Se puede considerar que las llamadas remotas son como tener que atravesar un portador de teléfono a grandes distancias, y hacer llamadas en el mismo proceso como usar un portador telefónico local. Éstas son llamadas a larga distancia que pueden realmente ejecutarse con la cuenta telefónica local (Vitter and Templeman, 2002). Los programadores con experiencia en DCOM deben encontrar a .Net Remoto un poco más fácil para trabajar con él, aunque aquellos programadores que son nuevos en las comunicaciones con objetos distribuidos pueden encontrarse que aún con .Net Remoto este proceso es complicado. Probablemente una de las mejores noticias dadas cuando surgió .Net Remoto fue que se aprovecharían las tecnologías opensource tales como SOAP y HTTP para hacer las llamadas de objeto a objeto. Este cambio de protocolo no derriba el muro que previamente separaba los componentes de la aplicación Visual Studio desde componentes que no sean de Microsoft, aunque también extiende la obtención de sus llamadas a objetos más allá de sus límites previos. En la siguiente sección se muestran algunos conceptos de alto nivel en los cuales se basa .Net Remoto.. Clientes y servidores remotos Cuando un objeto llama a otro objeto, el que hace la llamada inicial se llama objeto cliente. El que responde y proporciona alguna función o datos de retorno se llama objeto servidor. La conexión que se forma entre estos dos objetos se llama canal. Antes de entrar en los detalles de cómo se comunican estos objetos, es importante establecer los roles correspondientes a cada uno de ellos. Durante una llamada sencilla, sólo un objeto puede ser el cliente y el otro puede ser el servidor. Éste es un concepto sencillo, aunque crítico, que es necesario entender cuando 19.
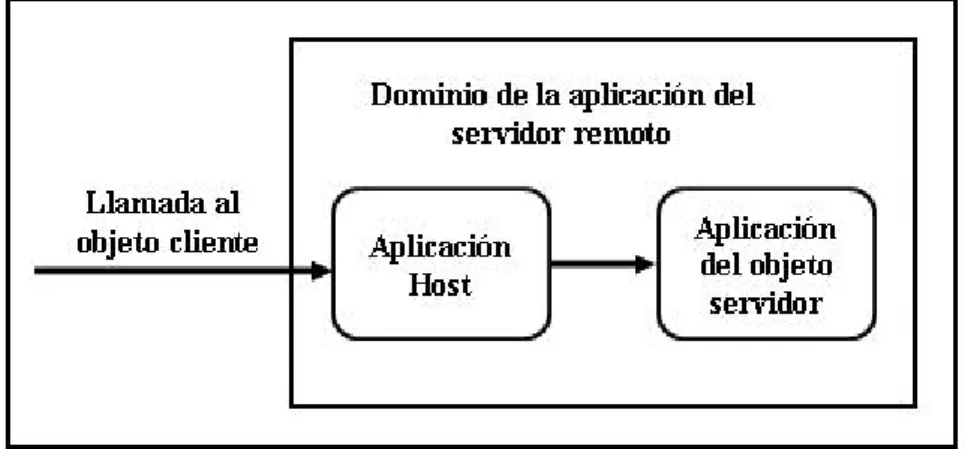
(26) ____________________________________________________Capítulo 1 se está desarrollando objetos para usarlos con .Net Remoto. Es posible crear un objeto que permita actuar como ambos, o sea, como un servidor de otros objetos y como un cliente que llama a otro objeto servidor. Un objeto, en un proceso de un dominio de una aplicación, se puede poner como remoto o no. Un objeto no se puede poner remoto cuando no se puede llamar fuera de su dominio de la aplicación. Dependiendo de las necesidades del diseño se puede elegir hacer que pueda ser remoto, haciéndolo disponible sólo para una aplicación simple. Las clases base en la plataforma .Net son no remotas por definición, aunque se pueden derivar clases de las clases base que sí lo puedan ser.. Servidores Remotos Los objetos servidores son un poco más difíciles de crear que los objetos cliente, así que una vez que se obtenga la clave de cómo se crea un objeto servidor, el resto de .Net Remoto es sencillo. Un objeto servidor no es parte de la aplicación del objeto cliente, aunque las llamadas del objeto cliente al objeto servidor sean para pedir ayuda. El objeto servidor está en su propio dominio de aplicación, normalmente, en un sitio diferente al del objeto cliente. Un equipo de desarrollo podría estar trabajando en objeto servidor, o su aplicación podría llamar a un objeto servidor desde una fuente exterior (también conocidas como “cajas negras” ya que no se conoce qué hay dentro de esos objetos). En muchas circunstancias el objeto servidor no se ejecutará cuando el objeto cliente haga una llamada, por tanto el objeto necesitará inicializarse y conectarse al canal remoto. Como los objetos servidores son muy complicados, necesitan una gran cantidad de ideas para su desarrollo y configuración.. Aplicaciones Host Un objeto servidor debe escuchar activamente las peticiones de los objetos cliente. Estos se crearán normalmente en proyectos de la clase Library, que no son capaces de estar activos y escuchar un puerto en un sitio host por sí mismos. En MTS y COM+ existía la posibilidad de registrar la clase Libraries dentro de un paquete MTS que manejaba la labor de escucha. Para un objeto servidor .Net se necesita crear una aplicación que actúe como el oyente y el agente para su objeto servidor. Esta aplicación se cargará en el servidor host y se quedará activa para mostrar los canales registrados. Si. 20.
(27) ____________________________________________________Capítulo 1 la aplicación host del objeto servidor se cierra, el objeto servidor no será accesible a sus clientes. Se puede alojar un objeto servidor desde muy diferentes tipos de aplicaciones, incluidos servicios Windows o un proyecto de consola. En la mayoría de los casos, hacer que la aplicación se aloje en un servicio Windows, que se carga cuando el servidor arranca, es la mejor solución. Los servicios Windows están estrechamente vinculados con el sistema operativo, pueden comenzar automáticamente y pueden operar detrás del escenario sin abrir formularios o ventanas. Cuando se inicia la aplicación host, registra el canal y el objeto servidor con la plataforma .Net. Una vez que el objeto servidor se ha inicializado, la aplicación host escucha las peticiones del cliente en el canal registrado. Cuando se recibe una petición, la aplicación host carga el objeto servidor en su dominio de aplicación y pasa la llamada del cliente al servicio. En la figura 2.1 se observa una aplicación host y un proyecto de la clase Library que contiene un objeto servidor. Ambas aplicaciones se ejecutan en el mismo proceso aplicación.. Figura 1.1 Las aplicaciones host y objeto servidor Vale recordar que ésta es la aplicación host que registra el canal y configura el medio remoto mediante programación o a través del uso de un archivo de configuración externa. La clase Library, que contiene el objeto servidor actual, puede permanecer inactiva hasta que la llame un cliente. Si la clase que contiene el servidor no está contenida en la aplicación host, esa aplicación necesitará una referencia a la clase para que pueda cargarla cuando necesite. Cuando se llame al objeto servidor, se cargará en el dominio de la aplicación host y se procesará.. Clientes Remotos 21.
(28) ____________________________________________________Capítulo 1 El objeto cliente es el receptor en una transacción cliente-servidor. Un cliente no tiene ningún control sobre cómo trabaja el objeto servidor o cómo hace su trabajo. Sólo tiene la posibilidad de preguntar algo y esperar obtener los resultados esperados. Para usar un objeto servidor, el objeto cliente debe tener una comprensión de la interfaz del objeto servidor y de cómo el objeto servidor se comunica con el mundo exterior. Obtener el código fuente del objeto servidor o una descripción detallada de la configuración de sus interfaces y de su canal es un primer paso crucial para usar este objeto. Por supuesto, si su equipo de desarrolladores creó el objeto servidor, esta información es fácil de obtener. Pero si está trabajando con un objeto de una tercera parte, el trabajo puede ser un poco más costoso (Vitter and Templeman, 2002). Cuando un objeto cliente necesita trabajar con un objeto servidor, este objeto cliente necesita configurar un canal de comunicación para utilizar su llamada. Si el objeto servidor está usando la activación simple o llamada única, el objeto cliente no tiene control sobre el intervalo de tiempo de ese objeto servidor (véase Activación y Tiempo de Vida más adelante). Si el servidor permite CAO (Client-Activated Objects), el cliente tendrá alguna configuración adicional para hacer el control del tiempo de vida del objeto servidor.. Llamando a un servidor remoto Desde la perspectiva del objeto cliente, hay dos formas de llamar a un objeto servidor: usando la activación del lado del servidor remota o utilizando la activación del lado del cliente. No hay diferencia entre objetos servidores de activación simple y llamada única desde el punto de vista del objeto cliente. En las próximas dos secciones se discuten los dos modos en que los objetos cliente pueden llamar a los objetos servidor remotos y se explica cómo estos pueden trabajar usando los archivos externos de configuración del objeto cliente y los comandos de configuración programada.. Activación y tiempo de vida Cuando un objeto de una aplicación cliente llama a un objeto servidor, el objeto servidor debe estar activado para responder a las peticiones. El comienzo de un objeto en el lado del servidor se llama activación, y el tiempo que el objeto está activo se llama tiempo de vida del objeto. En .Net Remoto, hay tres métodos de activación, cada uno de los cuales tienen sus tiempos de vida, estos son:. 22.
(29) ____________________________________________________Capítulo 1 •. Llamada única.. •. Activación simple.. •. Objetos activados por los clientes (CAO).. Llamada única (Singlecall) Un objeto se dice que tiene una activación de llamada única cuando una copia de ese objeto se activa por cada petición del cliente. Si simultáneamente cuatro objetos clientes hacen la misma petición al mismo objeto del lado del servidor, se crearán cuatro instancias de ese objeto para manejar esas cuatro llamadas. Una llamada única desde un cliente da por resultado uno nuevo, haciendo que se cree un objeto en el lado del servidor. El tiempo de vida de un objeto con llamada única es el suficiente para satisfacer la llamada del objeto cliente. Si el cliente hace una segunda llamada al objeto servidor, se creará completamente una nueva petición del objeto del lado del servidor para manejar la llamada. Con el recolector de basura decidiendo cuándo eliminar las peticiones del objeto desde la memoria en .Net, es posible, para un objeto de llamada única, estar en la memoria del servidor cuando llegue la segunda llamada desde el mismo objeto cliente. Un objeto de llamada única creará una nueva instancia para responder a la nueva petición del cliente.. Activación simple (Singleton) Cuando un servidor utiliza una activación simple, sólo se activará una petición de ese objeto en el servidor. Si esos mismos cuatro objetos clientes utilizados en el ejemplo anterior, hacen una llamada a un objeto del lado del servidor Singleton, se creará uno y sólo un objeto para servir a los cuatro objetos clientes requeridos. En la primera llamada cliente, el servidor creará una petición simple del objeto servidor Singleton. Tan pronto como el primer objeto Singleton se cargue en memoria, todas las llamadas a objetos adicionales se conectarán a este objeto activo. Un objeto Singleton tiene un tiempo de vida limitado y, cuando expira, la petición actual del objeto se destruye necesitando que el servidor cree una nueva petición para la próxima llamada cliente. Por esta razón, un objeto cliente podría hacer múltiples llamadas a objetos servidor que usen la misma petición del objeto Singleton y, a continuación, hacer otra llamada y, de repente, encontrar una nueva petición de ese objeto. 23.
(30) ____________________________________________________Capítulo 1 Cada objeto Singleton tiene un tiempo de vida que dicta que la vida de ese objeto se va a acabar. De hecho, este período de vida es tan estricto que si un objeto cliente está utilizando el objeto servidor en el mismo momento en que este objeto Singleton alcanza su límite de tiempo de vida, éste se destruye y se reemplaza por su versión más actual.. Objetos activados por los clientes (CAO) La activación, tiempo de vida y desactivación de los objetos de llamada única y de activación simple se controlan por el servidor que hospeda a estos objetos. Al trabajar con objetos de llamada única y de activación simple se necesita pensar un poco más que al tratar con objetos locales que su aplicación activa y desactiva directamente. Con los CAOs, sus objetos clientes pueden tener la misma influencia en objetos remotos como tiene en objetos locales. Al igual que los objetos de llamada única, el servidor crea una nueva petición del objeto servidor para cada cliente que lo llame a través de CAO. Cada petición del objeto servidor creada soportará una referencia directa al cliente que llama, y su tiempo de vida se controla por ese objeto cliente. Cuando se observa el tiempo de vida de un CAO, se puede ver un tiempo de vida similar al de los objetos Singleton. La gran diferencia con el tiempo de vida del CAO es que el cliente define y controla ese intervalo, no el objeto servidor.. Objetos sin estado frente a objetos con estado Un objeto sin estado no mantiene el estado de una llamada a la siguiente. Cada vez que se llama a un objeto sin estado, es como hablar con un extraño que no recuerda nada sobre su última llamada. A consecuencia de que el método de activación de llamada única conecta el objeto cliente a una nueva petición del objeto servidor cada vez, esto es una forma sin estado de .Net Remoto. El método de activación simple continúa para conectar llamadas cliente a la misma petición de un objeto servidor hasta que expire el tiempo de vida del objeto. Esto significa que el objeto de activación simple puede recordar partes de información de una llamada a la siguiente. El CAO también es un método de comunicaciones con estado porque la misma petición del objeto servidor está activa hasta que el objeto cliente decide liberarla.. Canales Cuando un objeto cliente y uno servidor se conectan, crean un canal de comunicaciones entre ellos. DCOM también crea un canal entre objetos y usa un protocolo propio para. 24.
(31) ____________________________________________________Capítulo 1 intercambiar mensajes entre los dos objetos. .Net Remoto tiene la posibilidad de crear y utilizar dos tipos de canales diferentes para sus objetos cliente y servidor: el canal TCP y el canal HTTP. El canal TCP es muy parecido al predecesor de .Net Remoto, DCOM. El canal HTTP concuerda con el tema de fuente recurrente abierta de .Net. El canal a utilizar depende del objetivo de la comunicación. A continuación se resumen los dos tipos de canales de .Net Remoto y se analiza cuándo se debería utilizar un tipo determinado de canal.. El canal TCP Similar al método de transmisión propio de DCOM, el canal TCP de .Net Remoto envía los datos entre los objetos cliente y servidor usando un formato binario propio. Los objetos finales en un canal TCP deben permitir entender este mensaje en formato binario, lo que significa que sólo se debería pensar en utilizar el canal TCP para comunicarse entre objetos .Net. El canal TCP es bidireccional, es decir, que sus objetos pueden enviar y recibir datos a través de este canal. Desafortunadamente, aparte del hecho de que los mensajes que se intercambian sobre un canal TCP son codificados en binario, no se pueden encriptar sus comunicaciones TCP. Despreciando esta limitación, cuando se compara con el canal HTTP, el canal TCP es el canal remoto más rápido y el más eficiente que puede utilizar.. El canal HTTP SOAP es una herramienta que permite a las aplicaciones enviar sus llamadas objeto a objeto a través de Internet usando el protocolo de transmisión HTTP. Las llamadas HTTP van tradicionalmente por el puerto 80 de los sitios de procesamiento, que es el mismo puerto usado para las peticiones y respuestas del navegador estándar Web. Debido a que SOAP le permite enviar sus peticiones de objetos a través de este puerto aceptado universalmente, sus llamadas pueden pasar a través de muchos firewalls. Esta posibilidad de pasar a través de firewalls le da al canal HTTP una mayor libertad que el canal TCP, más restrictivo, y que al antiguo método DCOM. Como al canal TCP, el canal HTTP permite el tráfico de mensajes en ambas direcciones. SOAP se basa en la tecnología XML, lo que significa que el mensaje y su entorno cerrado se autodescriben y pueden leerse y crearse por otra aplicación. Debido a esto, los objetos cliente y servidor involucrados en un escenario .Net Remoto que utilicen el. 25.
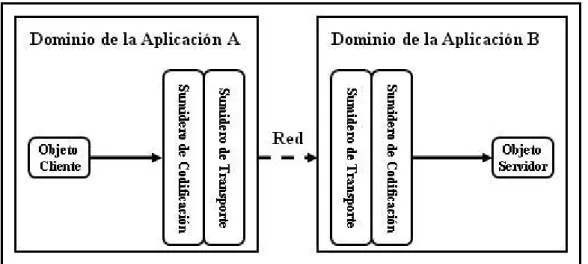
(32) ____________________________________________________Capítulo 1 canal HTTP no tienen que ser creados en .Net. Como se precisó en la descripción del canal TCP, no se cuenta con este tipo de libertades cuando se conectan objetos a través del canal TCP porque un objeto que usa este canal debe ser capaz de entender su formato propio de mensajes binarios. Como consecuencia del formato de texto XML del canal HTTP y al hecho de que utiliza el popular y a veces ocupado puerto 80, el canal HTTP es un poco menos eficiente que el canal TCP.. Registrando un canal Antes de que un objeto cliente y servidor se puedan comunicar a través de un canal, se debe configurar dicho canal y registrarlo con el servidor. El objeto cliente registrará un canal en el sitio que realiza la llamada y el objeto servidor tendrá un canal registrado para escuchar las peticiones de los clientes. Dado que un objeto servidor puede tener configurados múltiples canales que escuchen, el desarrollador del objeto cliente debe conocer qué tipo de canal se está usando para configurar y registrar el canal del cliente apropiadamente. Los canales se pueden crear con el código de su aplicación o se puede utilizar un canal predefinido que use una plantilla de canal o archivos de configuración. Las plantillas de canales son archivos de configuración externos que se pueden abrir en la aplicación al comienzo y ahorrar un gran esfuerzo en el código.. Sumideros Una cadena de sumideros de comunicaciones es el punto de entrada y salida que los mensajes usan cuando entran o abandonan un dominio de una aplicación particular. En esta cadena son múltiples los sumideros, cada uno de ellos con su función propia. Un sumidero maneja el formato del mensaje preparándolo para su transmisión, mientras otro maneja la tarea de transmitir ese mensaje con formato a través de la red. En la recepción otro sumidero recibe el mensaje de la red y lo pasa al sumidero que decodifica el formato del mensaje y entrega el mensaje original al dominio de la aplicación receptora. Este proceso podría sonar muy familiar a alguien con conocimientos de las siete capas de red y de cómo trabajar para dar formato y transmitir datos de aplicaciones a través de una red. La figura 1.2 muestra un objeto cliente y uno servidor, cada uno encerrado en su dominio de aplicación. El objeto cliente en este ejemplo envía una petición a una. 26.
(33) ____________________________________________________Capítulo 1 función situada en el objeto servidor. Se puede observar en esta figura cómo el mensaje original se pasa desde un sumidero a otro en el dominio de la aplicación cliente hasta que los mensajes llegan a la red. En los servidores de la red, los mensajes realizan un proceso similar pero en orden inverso hasta que el mensaje original se presenta en el objeto servidor.. Figura 1.2 Sumideros de comunicación y .Net Remoto. Puertos Las comunicaciones salen o entran de un ordenador a través de un puerto. Cuando su navegador Web pide una página Web desde un servidor remoto Web, normalmente esta llamada sale a través del puerto 80, y el servidor Web escucha sus peticiones en su puerto 80. Otras utilidades de Internet como Telnet o FTP (File Transfer Protocol) utilizan sus propios puertos para enviar datos a la red. DCOM usa diferentes puertos para comunicarse, y muchos firewalls bloquean los puertos que DCOM usa para la comunicación. En .Net Remoto se tiene la posibilidad de definir qué puerto usará el canal para comunicarse. Por defecto, el canal HTTP usa el puerto 80 para enviar sus peticiones mezcladas con el tráfico Web, que al menos asegura que las llamadas no serán bloqueadas por firewalls entre los objetos cliente y servidor. Se puede optar por usar otro puerto para enviar las peticiones, aunque se necesitará examinar la red entre los objetos cliente y servidor para asegurarse de que este puerto no se bloquee a lo largo del camino, lo que produciría que fallen las llamadas a objetos. Incluso, se pueden cambiar los puertos con el canal HTTP, que permite enviar mensajes que usan el protocolo. 27.
(34) ____________________________________________________Capítulo 1 HTTP y mensajes SOAP a través de cualquier puerto de la misma forma que se usaría el puerto 80. Cuando se elije un puerto, se debe tener cuidado de no utilizar uno que ya esté en uso. No se deberá emplear un número de puerto personalizado por debajo de 100, puesto que la mayoría de estos números están reservados para usos de aplicaciones específicas.. Comunicaciones remotas Una vez que se ha entendido cómo .Net Remoto usa los canales para enviar mensajes entre los objetos cliente y servidor, se deben observar sus mensajes. A continuación se examina cómo se formatea la llamada cliente y cómo se ordenan los parámetros que se pasan al objeto servidor; se precisa el papel que juega el sumidero de formateo en el proceso remoto y cómo sus objetos del lado del cliente trabajan con versiones proxy del objeto del lado del servidor.. Mensajes remotos Los datos se envían a través del canal de comunicaciones de un mensaje .Net Remoto. Durante el envío, este mensaje se puede transformar y modificar de muchas formas. El mensaje inicial se genera por una rutina que llama al objeto servidor remoto. Esta llamada al procedimiento remoto puede incluir parámetros para pasar la información necesaria por el objeto servidor para realizar sus tareas. El mensaje pasa a través de la cadena de sumideros del cliente y servidor, y se altera el formato del mensaje preparándolo para la transmisión al cliente que extrae el mensaje original durante la transmisión a través de CallContext del mensaje. Los mensajes creados en .Net Remoto implementan la interfaz IMessage que, en esencia, es un objeto diccionario que contiene los datos y las propiedades de ese mensaje. La interfaz IMessage se encuentra en la plataforma .Net bajo el ámbito System.Runtime.Remoting.Messaging. Vale recordar que el mensaje es la petición del cliente y sus parámetros asociados. Este mensaje se envía desde un objeto a otro a través de un canal y el formato del mensaje se modifica por uno o más sumideros. A continuación se expresa cómo los parámetros se ordenan en una llamada .Net Remoto.. Marshalling de datos en .Net Remoto Cuando se utiliza el método para llamar a objetos locales hay que elegir si pasar sus datos por referencia (ByRef) o por valor (ByVal). La opción ByRef guarda una copia de. 28.
Figure

+7
Documento similar