Implementaciones paralelas de métodos heurísticos para el cálculo de reductos
64
0
0
Texto completo
(2) Hago constar que el presente trabajo fue realizado en la Universidad Central Marta Abreu de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencias de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del tutor. Firma del jefe del Seminario.
(3) Pensamiento. Pensamiento. Emplearse en lo estéril cuando se puede hacer lo útil, Ocuparse en lo fácil cuando se tiene bríos para intentar lo difícil, Es despojar de su dignidad al talento. Todo el que deja de hacer lo que es capaz de hacer, Peca.. José Martí.
(4) Dedicatoria. Dedicatoria: A mis padres Luis Ramos Zamora y Alicia Ríos Pérez quienes con amor, constancia y sacrificio me han hecho lo que soy..
(5) Agradecimientos. Agradecimientos. A la Revolución, que me permitió hacer realidad un sueño. Al apoyo desinteresado de todos mis compañeros de estudio, los cuales a lo largo de mi carrera me han ayudado en momentos claves, por su amistad, sencillez y buen sentido del humor, en especial a Arley Vázquez Águila (Guajiro). Un agradecimiento especial a mi novia Yairen Hernández Torí y a Ismay Pérez Sánchez quienes me dieron el impulso necesario para llegar a la línea de esta meta, por sus acertadas y a veces tediosas críticas.. Pido disculpas a quien resulte olvidado o víctima de mi mala memoria..
(6) Resumen. Resumen. La selección de atributos en particular el cálculo de reductos ha encontrado aplicación en muchas áreas, en particular la relacionada con la extracción de conocimiento de grandes conjuntos de datos. Los Conjuntos Aproximados se han aplicado con bastante éxito en el procesamiento de estos conjuntos de datos aunque los mecanismos para la reducción de atributos que se ofrecen actualmente solo son adecuados para conjuntos de objetos y atributos relativamente pequeños. En este trabajo se describen fundamentalmente dos algoritmos utilizados en el cálculo de reductos usando Conjuntos Aproximados estos son el QuickReduct y ACO (Ant Colony Optimization) de estos dos se ofrecen dos variantes secuenciales y dos variantes en paralelo por cada uno basadas en los primeros. Además se muestran los resultados obtenidos experimentalmente sobre una serie de Sistemas de Información almacenados en repositorios internacionales..
(7) Abstract. Abstract. The Rough Set theory has a great interest now days, essentially in problems related to data analysis and uncertainty. One of the problems in knowledge extraction area is the reduct finding, the application mechanism that we have today only work for small datasets with small amount of attributes. In this work we propose four parallel implementations that combine reduct finding with rough set as quality measure. These implementations are based on Quick Reduct and ACO methods and have been tested in a computer cluster with some decision systems obtained from international repositories..
(8) Índice. Índice Introducción……………………………………………………………………………….………1 Capítulo 1 “Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software” ......................................................................................................... 3 Conjuntos Aproximados (Rough Sets) ........................................................................................... 3 1.1.1 Sistema de Información (SI) ....................................................................................... 4 1.1.1.1 Sistema de Decisión (SD) ....................................................................................... 5 1.1.2 Relación de Inseparabilidad........................................................................................ 5 1.1.3 Aproximación de Conjuntos: ...................................................................................... 6 1.1.4 Definición de Reducto ................................................................................................ 7 1.1.5 Núcleo ......................................................................................................................... 7 Acercamiento a los métodos utilizados en el cálculo de reductos. ................................................. 8 1.1.6 Técnicas basadas en Reconocimiento de Patrones ..................................................... 8 1.1.6.1 Yablonskii ............................................................................................................. 10 1.1.6.2 Algoritmo BT........................................................................................................ 10 1.1.6.3 Algoritmo LEX ..................................................................................................... 12 1.1.7 Método de Eliminación y Adición............................................................................ 13 1.1.7.1 Eliminación ........................................................................................................... 13 1.1.7.2 Adición.................................................................................................................. 14 1.1.7.3 Adición – Eliminación .......................................................................................... 14 1.1.8 Reductos Dinámicos ................................................................................................. 15 1.1.9 Métodos Heurísticos ................................................................................................. 16 1.1.10 Algoritmos Genéticos ............................................................................................... 17 1.1.11 Quick-Reduct ............................................................................................................ 18 1.1.12 Colonia de Hormigas (ACO) .................................................................................... 19 1.1.13 Otros enfoques relacionados ..................................................................................... 20 Conclusiones parciales.................................................................................................................. 21 1.1.14 Hipótesis de Investigación ........................................................................................ 21 Capítulo 2 Propuestas de paralelización.............................................................................. 22 Herramientas y medidas................................................................................................................ 22 Tecnologías utilizadas................................................................................................................... 23 Estructuras de Datos ..................................................................................................................... 24 Conjuntos Aproximados (Rough Set)........................................................................................... 26 2.1.1 El método paralelo .................................................................................................... 26 Quick - Reduct .............................................................................................................................. 28 2.1.2 La versión secuencial................................................................................................ 28 2.1.3 La versión paralela.................................................................................................... 31 ACO .............................................................................................................................................. 34 2.1.4 La versión secuencial................................................................................................ 34 2.1.5 La versión paralela.................................................................................................... 36 Conclusiones parciales.................................................................................................................. 38 Capítulo 3 Evaluación de los resultados y descripción de las funciones........................... 39 Conjuntos Aproximados (Rough Set)........................................................................................... 39 3.1.1 La versión secuencial................................................................................................ 39.
(9) Índice 3.1.2 El método paralelo .................................................................................................... 40 Quick Reduct ................................................................................................................................ 41 3.1.3 Versión Secuencial.................................................................................................... 42 3.1.4 Versión Paralela ........................................................................................................ 42 ACO .............................................................................................................................................. 44 3.1.5 Versión Secuencial.................................................................................................... 44 3.1.6 Versión Paralela ........................................................................................................ 45 3.1.7 Comparación de las versiones secuenciales.............................................................. 45 Descripción de las funciones ........................................................................................................ 46 3.1.8 Conjuntos Aproximados ........................................................................................... 46 3.1.9 Quick- Reduct ........................................................................................................... 48 3.1.10 ACO .......................................................................................................................... 49 Conclusiones parciales................................................................................................................ 51 Conclusiones generales ............................................................................................................... 52.
(10) Introducción Introducción En la actualidad la IA cuenta con un arsenal de técnicas importantes que permiten extraer conocimiento de Bases de Datos, los Conjuntos Aproximados (Rough Sets) son una de ellas y en esta el cálculo de reductos es una cuestión fundamental a la hora de extraer conocimiento de grandes volúmenes de datos sin perder calidad de la información. Los métodos utilizados para lograr esto. varían en formas e. implementaciones, aunque todas en común tienen el hecho de que hacen uso intensivo de los recursos computacionales y necesitan de un tiempo considerable. Es por esto que en la investigación se hace un estudio de las técnicas actuales para el cálculo de reductos en aras de lograr implementaciones paralelas que traten subsanar dichos inconvenientes. Existe una motivación por parte de los investigadores sobre el procesamiento paralelo y distribuido, ya que se ha hecho necesario solucionar los problemas que estos presentan. A través de los años han existido grandes avances tecnológicos. que. permiten el procesamiento paralelo efectivo. Con el desarrollo de las investigaciones se adquirieron nuevos conocimientos sobre este tema, por lo que se determinó otro problema que no se había identificado en los estudios iniciales y que surgen con la disponibilidad de ordenadores paralelos de gran alcance, todo esto ha permitido que los algoritmos distribuidos y paralelos se enfoquen no solo a los viejos problemas sino a los que han surgidos con el desarrollo tecnológico, por lo que ha existido nuevas necesidades de calculo. El objetivo principal. en este trabajo, es desarrollar e implementar una serie de. algoritmos que se usan para el cálculo de reductos sobre un cluster de computadoras que permitan mejorar el desempeño de estos métodos a la hora de analizar grandes volúmenes de datos. Los objetivos específicos que nos permitirán dar solución a esta problemática son: Identificar los métodos actuales para el cálculo de reductos y sus diferentes implementaciones tanto en versiones secuenciales como en paralelas. 1. Analizar y diseñar versiones paralelas para las técnicas del cálculo de reductos a utilizar. 1.
(11) Introducción 2. Implementar versiones paralelas de las técnicas del cálculo de reducto usando MPI sobre un cluster de computadoras. 3. Evaluar las diferentes implementaciones en cuanto a tiempo de ejecución y calidad de los resultados, usando bases de datos existentes en repositorios internacionales.. El aporte principal de el trabajo esta en el hecho de que crear un conjunto de librerías y aplicaciones que permitirán desarrollar nuevas herramientas así como ya se ha mencionado, el análisis mayoritariamente de grandes volúmenes de datos haciendo uso de las bondades de la programación en paralelo y del kit de funciones MPI en C. La estructura del trabajo comprende tres capítulos de los cuales: 1. El Capítulo 1 hace una revisión bibliográfica de las diferentes variantes que se ofrecen para el cálculo de reductos. 2. El Capítulo 2 muestra el conjunto de algoritmos propuestos para el cálculo de reductos y todo lo relacionado con el diseño y funcionalidad de los mismos. 3. El Capítulo 3 está dividido en dos fases, en una primera parte se analizan los resultados obtenidos de aplicar los diferentes algoritmos y en la segunda parte del mismo se detallan las diferentes funciones utilizadas en el cálculo de los reductos en uno y otro método.. 2.
(12) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software Capítulo 1 “Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software” En este capítulo se realiza una recopilación de información basadas en conceptos y definiciones de diferentes autores sobre las técnicas y métodos utilizados en el cálculo de reductos con el objetivo de lograr la paralelización de algunos de esos métodos y su posterior comparación con algunos de las aplicaciones que se han obtenido en la investigación.. Conjuntos Aproximados (Rough Sets) La teoría de Rough Set fue introducida inicialmente por Z. Pawlak [1], esta teoría ha tenido un amplio crecimiento durante estos años y se ha introducido en muchas ramas de la ciencia como lo es: -. Medicina.. -. Finanzas.. -. Telecomunicaciones.. -. Análisis de ruido.. -. Agentes inteligentes.. -. Análisis de Imágenes.. -. Reconocimiento de Patrones.. -. Procesos Industriales, etc.. La teoría clásica de Rough Set hace uso de una serie de conceptos tales como: Sistema de Información, Sistema de Decisión, Relación de Inseparabilidad, aproximaciones (inferior y superior) y reductos.. 3.
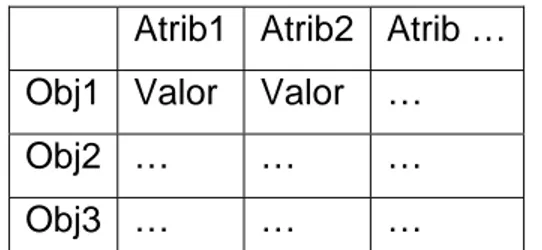
(13) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software. 1.1.1 Sistema de Información (SI) Un Sistema de Información usualmente esta compuesto por un conjunto de atributos (A) los cuales representan características o propiedades de un objeto o fenómeno y de una serie de casos u objetos (U) a los cuales se les evaluaron o se les midieron los valores de los atributos. Estos dos elementos se combinan en una tabla como la que se muestra en la Fig. 1 donde las columnas vienen siendo los atributos (A) y las filas los objetos (U), los valores que se toman en la tabla varían de acuerdo a las características del problema en cuestión estos pueden ser binarios, enteros, reales o simbólicos en algunos casos. Es decir, la entrada en columna q y en fila x tiene el valor f(x, q). Por tanto, para cada par (objeto, atributo) se conoce un valor denominado descriptor. Cada fila de la tabla contiene descriptores que representan información correspondiente a un objeto del universo. Utilizamos la noción de atributo en lugar de la de criterio porque el primero es más general que el segundo debido a que el dominio (escala) de un criterio ha de ordenarse de menor a mayor preferencia mientras que el dominio de los atributos no ha de ser ordenado. [2] Atrib1 Atrib2 Atrib … Obj1 Valor. Valor. …. Obj2 …. …. …. Obj3 …. …. …. Fig. 1 Ejemplo de un Sistema de Información. Mas formalmente un Sistema de Información esta compuesto por el par S = (U , A) donde U como ya se explico anteriormente es un conjunto no vació y finito de objetos o casos y A un conjunto de atributos no vació y finito de atributos. [3]. 4.
(14) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software. 1.1.1.1 Sistema de Decisión (SD) Un Sistema de Decisión (SD) es un Sistema de Información (Fig. 2) al cual se le adiciona un atributo que va a significar la decisión o resultado en cada caso u objeto de acuerdo a los valores de los atributos esto se platea como S = (U , A ∪ d ) donde d no pertenece a A.[3] Atrib1 Atrib2 Atrib … Obj1 Valor. Valor. …. Obj2 …. …. …. Obj3 …. …. …. d Valor. Fig. 2 Ejemplo de Sistema de Decisión. 1.1.2 Relación de Inseparabilidad Antes de introducir lo que es una relación de inseparabilidad se debe tener cuenta la definición de relación de equivalencia y clase de equivalencia el cual se define como: Una relación binaria R ⊆ X x X que cumple que es: Reflexiva (es cuando un objeto esta relacionado con el mismo xRx ), Simétrica (si xRy entonces yRx ) y Transitiva (si xRy y yRz entonces xRz ). Una clase de equivalencia de un elemento x ∈ X consiste en todo los objetos y ∈ X tal que xRy . La relación de inseparabilidad es cuando un par de objetos a, b de un (SI) S, tienen una relación de equivalencia con cualquier conjunto de atributos B ⊆ A para los cuales se cumple que: INS S ( B) = {(a, b) ∈ U 2. ∀ x ∈ B x(a ) = x(b)}. Esto se conoce como una relación de inseparabilidad de B. Si. (a, b) ∈ INS S ( B) entonces los objetos a y b son inseparables uno del otro teniendo en. cuenta los atributos en B. 5.
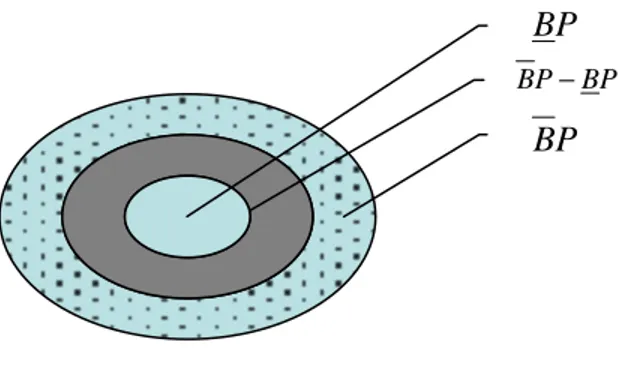
(15) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software La clase de equivalencia de la relación de inseparabilidad es denotada como [X ]B .. 1.1.3 Aproximación de Conjuntos: La Relación de Inseparabilidad aplicada a un (SI) causa una fragmentación del universo de objetos, estos fragmentos constituyen nuevos subconjuntos del universo. Supongamos que tenemos el (SI) S = (U , A) y definimos a B ⊆ A y P ⊆ U . Es posible aproximar a P usando solo la información de los atributos en B, construyendo lo que se conoce como aproximaciones inferiores y superiores de P, estos se denotan como BP y BP respectivamente, donde BP = {x. [x]B ⊆ P} y. BP = {x [x ]B ∩ P ≠ φ} .. Los objetos en BP son los elementos que pueden ser clasificados ciertamente como miembros de P sobre la base de los atributos en B, mientras que los objetos en BP solo pueden ser clasificados como posibles miembros de P sobre la base de B. [4]. Existe un grupo de objetos que no se encuentran en ninguna de las dos aproximaciones, este conjunto esta ubicado en una zona que se llama frontera (ver fig.3) (boundary region) BN la cual se define como BN = BP − BP . BP BP − BP. BP. Fig. 3 Representación de las aproximaciones y la frontera.. 6.
(16) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software 1.1.4 Definición de Reducto Un reducto no es más que la obtención del conjunto de atributos mínimo que preserve la relación de inseparabilidad y en consecuencia la aproximación del conjunto total.. Basándonos en las relaciones de inseparabilidad tenemos que dado un conjunto mínimo de atributos B ⊆ A de un (SI) S si cumple que INS S ( B) = INS S ( A) entonces es un reducto, dicha característica permite que un reducto preserve la partición del universo de objetos y clasifique igual al total de atributos del SI. Los atributos sobrantes son redundantes por lo que su eliminación no empeora la clasificación.. Partiendo de la matriz de separabilidad (M) que se define como una matriz simétrica y cuadrada (n x n donde n es la cantidad de objetos del sistema) con la diagonal nula, cuyas entradas son los atributos en los que difieren el objeto i del objeto j.. cij = {a ∈ A a(obji ) ≠ a(obj j )} i, j = 1, n Tenemos que un reducto R ⊆ A cumple con las siguientes dos restricciones[5]: 1) ∀x ∈ M , xi ∩ R ≠ φ 2) ∀a ∈ R,. ∃ x ∈ M | x ∩ ( R − {a}) = φ. Un conjunto de atributos B ⊆ A es un súper reducto del reducto R si cumple B ⊇ R ; es un reducto parcial de R si cumple B ⊆ R , por lo que podemos concluir que dado un reducto se pueden encontrar gran cantidad de súper-reductos y reductos parciales.[5]. 1.1.5 Núcleo En este epígrafe vamos a tratar lo que es un núcleo y para esto se comenzará por la definición del mismo.. 7.
(17) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software Núcleo: Es el subconjunto más importante de atributos, los cuales si son eliminados afectan la clasificación del resto de los atributos, estos atributos se encuentran incluidos en cada reducto de S. Partiendo de un (SI) S = (U , A). y B ⊆ A tenemos que el Nucleo( B ) = I R ( B ) donde. R( B) es el conjunto de todos los reductos en B además el Núcleo es el conjunto de todos los atributos que pertenecen a la intersección de todos los reductos.. Acercamiento a los métodos utilizados en el cálculo de reductos. En este epígrafe se van a analizar diferentes técnicas (Yablonskii, BT y LEX) empleadas en el cálculo de reductos, técnicas que están basadas en el Reconocimiento de Patrones. También se analizarán diferentes métodos como el de Eliminación y Adición, Reductos Dinámicos, Algoritmos Genéticos, QuickReduct, EBR y ACO incluidas algunas variaciones basadas en ellos.. 1.1.6 Técnicas basadas en Reconocimiento de Patrones Algunos de los métodos que se ilustran a continuación se apoyan en cuatro conceptos básicos que son el de Matriz de Diferencias, Matriz de Aprendizaje el de Testor y Testor Típico. Matriz de Diferencia. La Matriz de Diferencia (MD) se conforma teniendo en cuenta los rasgos de los objetos de las diferentes clases. MD tendrá m columnas como la Matriz de Aprendizaje (MA) y el número de filas estará determinado por las combinaciones de filas entre las clases. Los elementos presentes en MD son 0 y 1 (si los criterios de comparación son lógicos). 8.
(18) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software que indican semejanza del rasgo entre dos objetos analizados y diferencia del rasgo entre estos objetos, respectivamente.[6] Matriz de Aprendizaje Se encuentra formada solamente por filas básicas de la Matriz de Diferencia, se dice que una fila p es básica sí y solo sí no existe fila q alguna que sea subfila de p, por lo que se puede obtener que cada fila es básica o superfila de al menos una fila básica, de aquí que llegamos a la definición de lo que es una superfila : [7]. Para p y q, filas de MD, a qj , a pj , a qk , a pk elementos de MD, p es superfila de q sí y solo sí: [7]. •. ∀j , a qj = 0 ⇒ a pj = 0. •. ∃k a qk = 1 ∧ a pk = 0. Testor Un subconjunto de atributos B es un testor si y solo si todos los atributos fuera de B son eliminados, exceptuando aquellos en B para los cuales no hay descripción similar para diferentes clases.. Esta definición indica que un testor es un subconjunto de atributos que permite la completa diferenciación de los objetos de diferentes clases. Dentro del conjunto de testores existen algunos que no se pueden reducir más, estos son los llamados testores típicos cuya definición es la siguiente.[8]. Testor Típico Suponiendo que t es un testor entonces para todo k subconjunto de t, no siendo k testor, t es típico. esto no es mas que el subconjunto minimal de rasgos que permiten diferenciar objetos de clases distintas[9]. De acuerdo a la forma de calcular los testores los algoritmos se han clasificado en dos tipos los de escala exterior y de escala interior. Los de escala exterior obtienen los testores típicos generando elementos del conjunto. 9.
(19) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software potencia a través de las columnas de la matriz básica en un determinado orden [9] buscando la forma de evitar el análisis de todos los subconjuntos usando ciertos criterios. Los de escala interior obtienen los testores típicos a través de la estructura interna de la matriz, encontrando condiciones que garantizan las características de testor y la tipicidad de las columnas asociadas a las posiciones unitarias de la matriz[10].. 1.1.6.1 Yablonskii Este algoritmo parte en sus inicios con los trabajos expuestos en [11] y [12] donde se introduce el concepto de test y la idea es construir una conjunción de disyunciones a partir de la matriz básica, teniendo en cuenta solo los elementos que son 1. La conjunción representa la unión de todas las filas. Aplicando las Leyes de la Lógica se eliminan los elementos que representan superfilas hasta obtener una Forma Normal Disyuntiva donde cada conjunción conformará un testor típico[6]. Este método aunque es sencillo de llevar a cabo en la práctica, resulta inviable para el caso de que el Sistema de Información cuente con más de cinco rasgos, los cuales están presentes en la mayoría de los (SD) que existen.. 1.1.6.2 Algoritmo BT Este algoritmo tiene como principio la generación de números naturales en su forma binaria de forma ascendente. Esto conforma el orden total sobre los elementos no nulos del conjunto potencia del conjunto de rasgos.. Una vez generado cada vector (n-uplo) se comprueba si el mismo es un testor o un testor típico. Según los resultados continua la secuencia de generación o realiza un salto, el algoritmo termina cuando llega al vector (1… 11).[13].. 10.
(20) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software Algoritmo[14] Paso 1: Se toma α = (0,0,...,0,1) Paso 2: Si α > 2 n − 1 ir al paso 4, en caso contrario, verificar si α es testor y si es típico. Si es testor típico guardarlo. Paso 3: a) Si α es testor, generar α ' = α + k (siendo k la posición del uno más a la derecha en α ). b) Si α no es testor, generar α ' (como en la proposición 2), tomando de entre las filas responsables de que α no sea testor, aquella cuyo último uno (el más a la derecha) aparezca más a la izquierda. c) Tomar α = α ' e ir al paso 2. Paso 4: Imprimir la lista de testores típicos. Fin. Nota: La expresión α > 2 n − 1 constituye un abuso de notación y significa que el número del cual α es su representación en base 2, es mayor que 2n -1. Rigurosamente sería siendo α = (α 1 ,..., α n ) . Existen algunos cambios que se le pueden aplicar al algoritmo uno de ellos es el ordenamiento de la MB dicho ordenamiento puede influir de forma decisiva en los tiempos de ejecución, al reducir el espacio de búsqueda de la solución.[14] Aunque en [10] se llega a la conclusión de que el algoritmo genera muchos n-uplos que son súper conjuntos de testores típicos lo que es lo mismo, n-uplos que contienen al testor. Otro de los problemas detectados es que para chequear si un nuevo conjunto es testor o no, es preciso analizar la MB desde el principio como si nunca se hubiese hecho.. 11.
(21) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software Algoritmo TB El algoritmo TB es muy similar al BT, su diferencia principal radica en que el TB parte de un vector α formado por N elementos iguales a 1. Cuando los testores típicos tienen longitud mayor que N/2, es decir, la cardinalidad del conjunto de rasgos que permite diferenciar en el problema los objetos de clases distintas es mayor que la mitad de los rasgos que describen el problema, el algoritmo TB converge más rápidamente a la solución que el algoritmo BT. Si sucede lo contrario es más óptimo el BT. Esto tiene su explicación en la formación del vector α .[6]. 1.1.6.3 Algoritmo LEX Este algoritmo pertenece a la clase de escala exterior, el principio de este es ir construyendo listas de rasgos a partir de la MB que posean la propiedad de tipicidad y luego comprobar si el grupo de rasgos constituye un testor, cuando se comprueba que es testor se produce un salto, para esto realiza un ordenamiento sobre los elementos del conjunto potencia. La propiedad de tipicidad plantea que los rasgos de la lista pueden coexistir con los demás elementos de la misma es decir que no son excluyentes para formar un testor típico con filas típicas respecto a la lista.. Filas típicas Sea una lista de rasgos L = [ X j1 ,..., X js ] . Denominaremos conjunto de filas típicas de. X t con respecto a L al conjunto de los índices de las filas de MB que tienen valores unitarios en la columna correspondiente a X t y ceros en las correspondientes X jK ,. 1 ≤ k ≤ s, X jk ≠ X t . Este algoritmo presenta mejoras con respecto al BT por la forma en que realiza el recorrido por el conjunto potencia de los rasgos y evita el análisis de todos los subconjuntos consecutivos en el orden establecido. Otro elemento importante es que el. 12.
(22) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software ordenamiento que se realiza. de la MB requiere mucho menos cálculos y siempre. garantiza la generación de la menor cantidad de listas. [10]. 1.1.7 Método de Eliminación y Adición En este apartado se exponen dos estrategias básicas que son el método de adición y el de eliminación, como su nombre lo indica el método de adición consiste en partir de un conjunto vacío e ir introduciendo atributos hasta que se alcance el reducto y el de eliminación parte de todo el conjunto de atributos y valiéndose de diferentes heurísticas va eliminando atributos hasta que encuentra súper-reducto.. 1.1.7.1 Eliminación El método de eliminación parte de un (SI) S, R=A, C=A donde A es el total de atributos del sistema, R es el súper reducto de mayor tamaño, A es el total de atributos del sistema una función de calidad f. Los pasos son los siguientes: 1) Mientras ( C ≠ φ ): 1.1). Calcular la calidad de todos los atributos en C usando f.. 1.2). Seleccionar ( a ∈ C ) de acuerdo a su calidad, ( C = C − {a} ).. 1.3). Si ( R − {a} ) es un súper-reducto, ( R = R − {a} ).. Nótese que este método no es eficiente en los casos que el reducto sea pequeño siendo eliminados muchos atributos que pueden ser importantes en el súper-reducto después del chequeo. También es esencial el orden en que están los atributos para su eliminación este orden está dado por la función de calidad la cual puede concluir en la obtención de diferentes reductos[5]; existen diferentes funciones de calidad una de ellas está basada en la entropía de los atributos [15] .. 13.
(23) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software 1.1.7.2 Adición El objetivo de este método es construir reductos a partir de un conjunto vacío o el núcleo e ir adicionando elementos hasta que se obtiene un reducto. Este método parte de un (SI) S, R = φ , C = A donde R va a ser el reducto, C un conjunto intermedio y una función de calidad f, los pasos se describen a continuación: 1. Mientras R no sea súper reducto y C ≠ φ : 1.1). Calcular la calidad de todos los atributos en C usando f.. 1.2). Seleccionar un a ∈ C de acuerdo a su calidad C = C − {a}. 1.3). R = R ∪ {a} .. Una vez terminado el algoritmo este no garantiza la obtención de un reducto por lo que este método casi siempre viene a como parte de un algoritmo más robusto en el siguiente epígrafe se muestra una combinación de este método con el de eliminación.. 1.1.7.3 Adición – Eliminación En esta estrategia se comienza a partir de un conjunto vacío o el núcleo y se van adicionando atributos hasta encontrar un súper reducto, una vez hallado, se procede a eliminar los atributos sobrantes para obtener el reducto. El algoritmo de este método se muestra a continuación: Adición 1) Mientras R no sea súper reducto y C ≠ φ : 1.1. Calcular la calidad de todos los atributos en C usando f.. 1.2. Seleccionar un a ∈ C de acuerdo a su calidad C = C − {a}. 1.3. R = R ∪ {a} .. 2) Fin de Ciclo. Eliminación C=R. 3) Mientras ( C ≠ φ ):. 14.
(24) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software 3.1). Calcular la calidad de todos los atributos en C usando f.. 3.2). Seleccionar ( a ∈ C ) de acuerdo a su calidad, ( C = C − {a} ).. 3.3). Si ( R − {a} ) es un súper-reducto, ( R = R − {a} ).. 4) Retornar R.. Para este método el orden de los atributos para la adición o la eliminación es esencial para la obtención del reducto. En este caso la función de calidad es un aspecto importante puesto que es la que determina la entrada o no de los atributos al conjunto o la posterior eliminación del mismo. En ambos casos (eliminación y adición) la función de calida puede ser la misma o puede ser diferente en cada uno. Aunque este método es mejor que los dos propuestos anteriormente el mismo no es eficiente debido a que suele hacer muchas evaluaciones de la función de calidad en el proceso de obtención de un reducto.. 1.1.8 Reductos Dinámicos Los reductos dinámicos[16] es una técnica que parte de la idea de dividir el universo de objetos en pequeños fragmentos de forma aleatoria, una vez hecho esto se calculan los reductos para ese fragmento del universo. Este proceso se realiza de forma repetitiva para un número diferente de ejemplos de diferentes tamaños y se selecciona los reductos que mas apariciones tienen. Los reductos obtenidos pueden ser inconsistentes con el Sistema de Información original pero son buenos para generar reglas a partir de ellos. Como resultado del proceso, a menudo se encuentran buenos resultados pero el costo computacional depende del costo de calcular los reductos el cual puede ser substancial.. Los reductos dinámicos son obtenidos mediante el coeficiente de estabilidad de un reducto en una familia de subsistemas de un sistema de decisión.. 15.
(25) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software. Coeficiente de Estabilidad (Coef) Sea un Sistema de Decisión D, un subsistema S i = (U i , A ∪ {d }) tal que U i ⊆ U y F una familia de subsistemas de D tenemos que: Coef (C ) =. {S i ∈ F : C ∈ Re d ( S i , d )} F. , donde C ∈ Re d ( S i , d ). El algoritmo consta de los siguientes pasos: Dado el sistema de decisión (SD). 1. Inicializar i=0. 2. Mientras (Bandera sea verdadera) { 2.1) i=i+1. 2.2) Formar el subsistema de decisión Si=(Ui⊆U, A∪{d}) de S de tamaño g(i). 2.3) Computar el conjunto reductos REDi(Si) de Si. } 3. Computar DRε.. ε es un número real entre 0 y 1, DRε esta definida por la expresión siguiente: DRε (S , F ) = {C ∈ RED(S , d ) : Coef (C ) ≥ 1 − ε } Este método ofrece la ventaja de que el mismo opera sobre un subconjunto del universo U i por lo que la obtención de los reductos tiene menor costo computacional que si se calculara sobre todo el conjunto de objetos. Otro elemento a favor de este método es el hecho de que permite inferir conocimiento con un mayor grado de generalización debido a que el mismo se ha descubierto sin explorar todo el universo. Un implementación de este algoritmo se puede encontrar en el software RSES[17].. 1.1.9 Métodos Heurísticos La esencia de la palabra heurística es contraria a la de algoritmo en el sentido de que ella es un camino para buscar lo nuevo, mientras el algoritmo es un camino para realizar lo ya muy bien conocido. La solución orientada por la heurística, trata de. 16.
(26) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software reducir la explosión combinatoria que genera la búsqueda de todos los caminos posibles que se presenta en la mayoría de los problemas reales. La heurística no garantiza que siempre se tome la dirección de la búsqueda correcta, por eso este enfoque no es óptimo sino suficientemente bueno. En una gran variedad de problemas complejos es posible encontrar que las soluciones heurísticas son mejores que otros métodos como los de búsqueda a ciegas por ejemplo, las desventajas y limitaciones principales de la heurística son:. •. Flexibilidad inherente de los métodos heurísticos pueden conducir a errores o manipulaciones fraudulentas.. •. Ciertas heurísticas se pueden contradecir al aplicarse al mismo problema, lo cual genera confusión y hacen perder credibilidad a los métodos heurísticos.. •. Soluciones. óptimas. no. son. identificadas.. Las. mejoras. locales. determinadas por las heurísticas pueden cortar el camino a soluciones mejores por la falta de una perspectiva global por lo distancia entre la solución brindada por una heurística y la óptima puede ser grande.. 1.1.10. Algoritmos Genéticos. El uso de algoritmos genéticos (AG) para el cálculo se ha introducido como una alternativa más, aunque según [16] se aconseja que se utilicen en Bases de Datos cuyo conjunto de atributos sea relativamente pequeño debido a que puede tomar mucho tiempo llegar a la solución. Una variante del uso de AG para el calculo de reductos se encuentra en [18]. En este se presentan tres enfoques diferentes, uno de ellos es el clásico (AG), el segundo y tercero utilizan un algoritmo “greedy” y permutaciones respectivamente para obtener la solución. Estos dos últimos ofrecen mejores resultados que la primera. Existen otros métodos donde se usa la entropía para calcular los reductos mediante AG [19] y otros basados en el cubrimiento de conjuntos[20], en particular la búsqueda del conjunto mínimo.. 17.
(27) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software Algunas implementaciones de este algoritmo se encuentra en el software Rosetta:. -. SAVGenetic Reducer.. El algoritmo que implementa es el descrito por Vinterbo y Ohrn en [19] y [20]. Soporta soluciones por costo y por aproximación.. -. RSESGeneticReducer.. Implementa una variación del algoritmo genético descrito Wroblewski en [18] anteriormente mencionado.. También es posible encontrar una implementación del algoritmo en el software RSES[17].. 1.1.11. Quick-Reduct. Es uno de los algoritmos más utilizados para la obtención de reductos puesto que es fácil de implementar y permite obtener buenas soluciones, el mismo persigue en principio obtener el reducto mínimo sin revisar todo el espacio de búsqueda. El mismo comienza con un conjunto vacío o el núcleo y va adicionando un atributo a la vez, el elemento seleccionado es aquel que mayor medida de calidad presenta sobre todos los candidatos, esto se realiza hasta alcanzar el máximo valor posible [21]. Hay que aclarar que esto no garantiza que se encuentre el conjunto mínimo, puesto que no es posible usando la función de dependencia entre los atributos encontrar una combinación de los mismos que pueda llevar a un conjunto óptimo. En el capítulo siguiente se analiza una serie de elementos que permite dar cierta flexibilidad al algoritmo con el objetivo de obtener el mayor número de reductos en un SD. En [21] se implementa una variante de QuickReduct pero usando una función de calidad que se obtiene de los conjuntos borrosos (fuzzy sets). Esto permite lograr buenos resultados aunque es necesario realizar un proceso previo que consiste en normalizar el SD antes. 18.
(28) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software de realizar el cálculo, cuestión esta que le adiciona un costo computacional extra al proceso en general.. Algoritmo: C Å Conjunto de atributos condicionales. D Å Conjunto de todos los atributos de decisión. 1) R Å {} 2) Desde 2.1). TÅR. 2.2). ∀x ∈ (C − R). 2.3). If Calidad( R ∪ {x} )(D)> Calidad T(D) 2.3)1. TÅ R U {x}. 2.4). RÅT. 3. Hasta Calidad R(D) = Calidad C(D) 4. Return R. El algoritmo se encuentra implementado en el Rose 2 [22] bajo el nombre de Heuristic Search.. El EBR es una variante del cálculo de reductos que usa como medida de calidad la entropía, la cual ofrece resultados un poco mejores que los basados en las aproximaciones inferior y superior pero tiene la desventaja de que realiza más cálculos que el clásico.. 1.1.12. Colonia de Hormigas (ACO). La habilidad de las hormigas reales para encontrar caminos cortos es posible usando la feromona, sustancia que depositan en el camino por donde pasan, cada hormiga selecciona el camino que es más rico en dicho químico. La sustancia a medida que. 19.
(29) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software pasa el tiempo disminuye, resultando que los caminos menos frecuentados sean los de menos feromona y por lo tanto los menos populares, este algoritmo fue inicialmente introducido en [23] y actualmente conforman una de las ramas más novedosas de la inteligencia artificial llamada “inteligencia colectiva” (swarm intelligence). Este método ha sido ampliamente utilizado en muchos problemas del tipo NP dando buenos resultados. Entre los parámetros que se establecen en el algoritmo esta: -. Alpha. (Esta es una magnitud en la que se fortalece la feromona).. -. Beta. (Es la medida en que se favorece la información heurística de cada nodo de la solución).. En [24] se hace una introducción de esta técnica, aplicada al cálculo de reductos y se realizan algunas comparaciones con otros algoritmos (AG, Quick – Reduct, EBR), en la cual plantean que la utilización de Colonias de Hormigas ofrece mejores resultados que Quick – Reduct y EBR en detrimento del rendimiento de la aplicación aunque en este caso se tuvieron en cuenta Bases de Casos de pequeño y mediano tamaño. Sobre este modelo se han desarrollado una serie de enfoques paralelos como el que se muestra en [25] aquí las hormigas se encuentran repartidas por los nodos esclavos y calculan independientes, una vez terminado cada ciclo cada nodo envía la mejor solución al servidor, otras variantes de paralelización son propuestas en[26].. 1.1.13. Otros enfoques relacionados. En [27] se propone un método que se apoya en las relaciones de tolerancia para el cálculo de reductos usando matrices de extensión. Este método en vez de usar las relaciones de equivalencia entre los objetos usa una relación de tolerancia. La relación de tolerancia se plantea como una relación binaria de dos objetos de un conjunto X tal que cumpla que la relación es reflexiva y simétrica. En este documento se proponen dos algoritmos, uno secuencial y otro paralelo. Aunque en el mismo se. 20.
(30) Capítulo 1: Estudio sobre los diferentes métodos de obtención de reductos y su disponibilidad en software plantea que la versión paralela es óptima y no se ofrecen pruebas aplicadas a Bases de Casos.. Conclusiones parciales Como se ha podido comprobar a lo largo del estudio anterior, la disponibilidad de los diferentes métodos de cálculo de reductos se encuentran en su mayoría implementados en software cuya ejecución es secuencial. La capacidad de procesamiento de estos son limitadas en algunos casos por el número de atributos o la cantidad de objetos, aunque en general todos son incapaces de generar resultados en un tiempo aceptable para Sistemas de Decisión con un gran número de atributos. Es en estos casos donde el uso de enfoques paralelos puede generar resultados en tiempos muchos menores.. 1.1.14 -. Hipótesis de Investigación. Las implementaciones paralelas del cálculo de reductos tienen mejor rendimiento en grandes y pequeñas BC que las existentes (secuenciales y/o paralelas).. -. Los reductos obtenidos de las implementaciones paralelas hechas por nosotros son. superiores. o. igualan. a. los. métodos. secuenciales. y/o. paralelos. implementados existentes.. 21.
(31) Capítulo 2 Propuesta de paralelización Capítulo 2 Propuestas de paralelización. Las aplicaciones paralelas parten esencialmente de un modelo de paralelización y de una variante secuencial del problema, nuestra investigación no escapa a este planteamiento, en el presente capítulo se muestra el conjunto de algoritmos propuestos para el cálculo de reductos y todo lo relacionado con el diseño y funcionalidad de los mismos.. Herramientas y medidas En las pruebas aplicadas a los algoritmos se tuvieron en cuenta tres elementos fundamentales: 1. El tiempo que demora el algoritmo en hallar los reductos. 2. La longitud promedio de los reductos encontrados. 3. La cantidad de reductos obtenidos por el algoritmo.. Las pruebas realizadas a los algoritmos secuenciales se realizaron sobre una PC con las siguientes características: -. Intel Pentium 4 (R) a 2.8 GHz.. -. 2 Gb de Memoria Ram.. El cluster de computadoras que se utilizó en las pruebas estaba compuesto por 10 nodos los cuales contaban con las siguientes características: -. Intel Pentium 4(R) dual core a 3.0 GHz.. -. 1 Gb Ram (9 nodos tienen esta capacidad de memoria y 1 tiene solo la mitad de esto).. -. 100 Mbit Fast Ethernet.. Los Sistemas de Información que se utilizaron para las pruebas fueron tomados de repositorios internacionales (UCI Repository for Machine Learning)[28] las cuales fueron:. 22.
(32) Capítulo 2 Propuesta de paralelización. -. Bw (Breast – Cancer - Winsconsin). Contiene 699 objetos y 10 atributos incluyendo el de decisión. -. Isolet5. Contiene 1557 objetos con 618 atributos incluyendo el de decisión. -. Donors. Contiene 7000 objetos con 205 atributos incluyendo el de decisión. -. lrr (Letter Recognition). Contiene 20 000 objetos con 17 atributos incluyendo el de decisión. -. Connect4. Contiene 67 557 objetos con 43 atributos incluyendo el de decisión.. Se utilizaron además dos aplicaciones el ROSE 2.0 y el ROSETTA secuenciales que se pudieron obtener en la investigación para comparar los resultados obtenidos. Las aplicaciones incorporan algunos de los métodos mencionados en el Capítulo 1.. Tecnologías utilizadas Para la creación de los diferentes algoritmos se utilizó como base el lenguaje C, la selección del mismo se basó en los siguientes aspectos: -. Es un lenguaje portable por el hecho de que existe una gran variedad de compiladores y librerías para diferentes plataformas.. -. Ofrece buenos resultados de rendimiento en comparación a otros lenguajes de programación.. -. Inicialmente ya se encontraban una serie de módulos hechos de antemano de investigaciones anteriores, los cuales se reutilizaron en la construcción posterior de los algoritmos.. En las versiones paralelas se utilizó el conjunto de librerías MPICH2 contenidas en un paquete de librerías y aplicaciones llamado OSCAR 5.0[29],. las cuales permiten. desarrollar aplicaciones en paralelo sobre un cluster de computadoras con memoria distribuida.. 23.
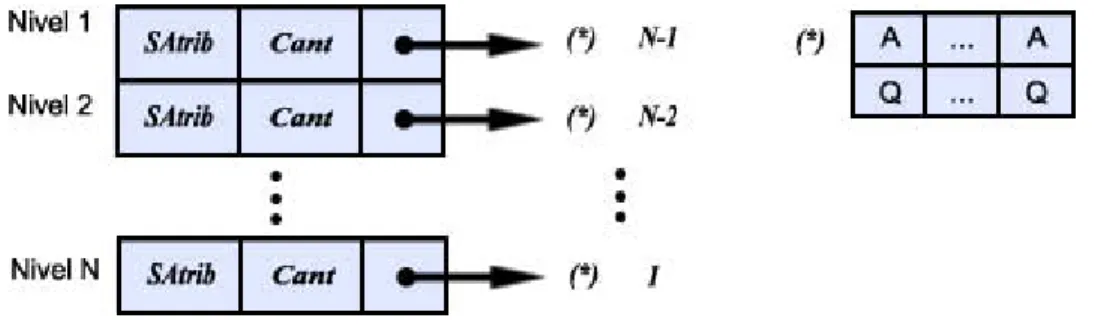
(33) Capítulo 2 Propuesta de paralelización Se utilizó para la confección de los diagramas una herramienta muy popular de generación automática (Doxygen) de documentación a partir de código fuente, la misma permite: -. Generar documentación en diferentes idiomas.. -. Generar diagramas compatibles con UML.. -. Los lenguajes soportados son C, C++ y Java.. -. El mismo utiliza Latex lo cual permite que la documentación una vez generada se modificable y portada a varios formatos como pdf, ps, html ó rtf.. Estructuras de Datos En este epígrafe se tratan las estructuras de datos empleadas en la construcción de las clases de equivalencia y en la búsqueda y exploración de los reductos.. La estructura utilizada en la búsqueda de los reductos debía ser capaz de mantener una lista de los estados con sus calidades pendientes a explorar en cada momento.. Para lograr la implementación del método se utilizó una estructura de datos similar a la que se muestra en la figura:. Fig. 2 Estructura de Datos que se usó con Quick Reduct En este gráfico cada nivel esta ordenado de forma ascendente de acuerdo a la calidad, con esto evitamos tener que hacer operaciones innecesarias a la hora de aplicar la selección del atributo, en nuestro caso escogemos el mejor de todos los disponibles en. 24.
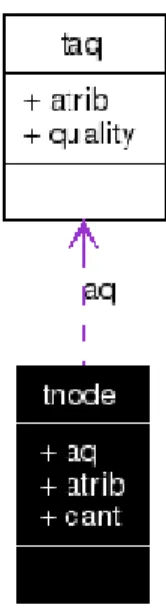
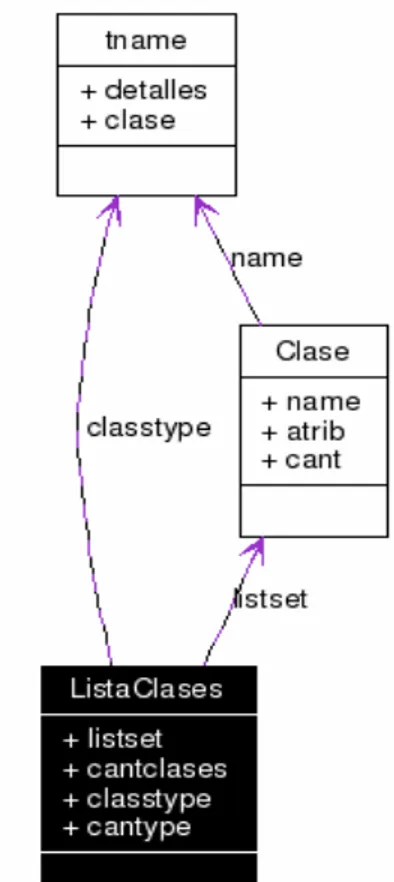
(34) Capítulo 2 Propuesta de paralelización cada ocasión, la letra A representa a un Atributo condicional, Q representa la calidad del atributo en ese nivel unido a los atributos seleccionados anteriormente. Este diagrama corresponde al diagrama de las estructuras utilizadas en la aplicación que permitieron construir el árbol antes mencionado (figura 3):. Fig. 3 Diagrama UML de la estructura utilizada. Para esta estructura se definieron un conjunto de operaciones: -. Generar el primer nivel. (GenerateLevelIni(int * Latrib, int cLatrib)). -. Generar un nivel (GenerateLevel()).. -. Ordenar el ultimo nivel (SortLevel()).. -. Eliminar el ultimo nivel (DeleteLevel()).. -. Devuelve el reducto (GetReduct()).. 25.
(35) Capítulo 2 Propuesta de paralelización Este es el diagrama de las estructuras que permiten construir la lista de Clases de Equivalencias:. Fig. 4 Diagrama UML de las estructuras. Conjuntos Aproximados (Rough Set) En este apartado vamos a referirnos a la versión paralela sobre el cálculo de la calidad usando los conjuntos aproximados (Rough Sets) utilizado en las implementaciones de los algoritmos así como sus características.. 2.1.1 El método paralelo La versión paralela de este módulo fue basado originalmente en el modelo de paralelización propuesto en [30].. Este modelo presenta mejores resultados de. rendimiento que sus predecesores puesto que implementaba una mejor distribución de las clases de equivalencia y eliminaba las etapas de reducción y mezcla (muy costosas). Por lo mencionado anteriormente se decidió incluir ese modelo fig. 1 para. 26.
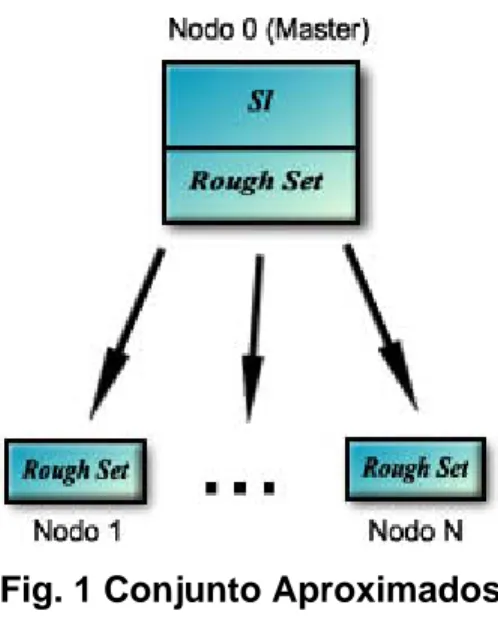
(36) Capítulo 2 Propuesta de paralelización integrar el módulo de cálculo de la calidad usando Conjuntos Aproximados en nuestras variantes paralelas. El algoritmo a modo general consta de dos pasos [30] los cuales se describen a continuación: 1). En este paso inicial se procede a la construcción de las Clases de Equivalencias (CE), el nodo 0 procede a difundir cada objeto (filas del Sistema de Información) al resto de los nodos. Una vez recibido el objeto por los nodos estos buscan si el mismo concuerda con alguna de las CE construido por ellos en caso de que haya alguno, este lo adiciona, en caso de que no haya nadie, el nodo que le corresponde por rotación crea una nueva CE y adiciona el objeto.. 2). Una vez terminado el paso 1 completo el 0 se bloquea en espera de los resultados de los esclavos. Los esclavos proceden al cálculo de las aproximaciones inferiores y superiores, aquí cada nodo en particular realiza el cálculo para cada clase de decisión diferente que el nodo haya recibido en el paso 1. Una vez hecho esto, se suman estos cálculos parciales y se envían al nodo 0, quien posteriormente hace la suma total y devuelve el resultado.. Fig. 1 Conjunto Aproximados A esta versión le fueron realizadas algunas modificaciones, de las cuales se pueden mencionar las siguientes:. 27.
(37) Capítulo 2 Propuesta de paralelización -. Se añadió un módulo para que se pudieran utilizar otros SI con otras características (diferentes separadores, números de filas, columnas y atributos, etc.). -. Se modificó la función de cálculo de la calidad para que la misma calculara las aproximaciones inferiores de todas las clases de decisión disponibles de un arreglo.. -. Se eliminaron envíos masivos de datos relacionados con el cálculo de la calidad sin afectar la eficiencia.. Quick - Reduct Este algoritmo fue seleccionado como base para el desarrollo de estos métodos por la estructura en árbol que describe para la exploración de las posibles soluciones característica que se presta a su paralelización. Además como se mencionó en el Capítulo 1, el mismo es sencillo de implementar y es uno de los más utilizados.. A continuación se hará referencia a la versión secuencial que se tomó como base para la creación de los diferentes modelos paralelos que se muestran aquí.. 2.1.2 La versión secuencial A la heurística Hill – Climbing fue necesario adicionarle el retroceso (backtracking) con el objetivo de buscar una posible mejor solución, para el caso en que el SI tuviera una gran cantidad de atributos y se necesitara buscar más de un reducto. Para evitar en lo posible explorar soluciones que puedan a la larga ser malas, se le dio la posibilidad que el algoritmo trabajara sobre un subconjunto del total de atributos y se añadió un parámetro real (P) entre 0 y 1 que es utilizado para podar los nodos una vez hallado un reducto que no cumplan con lo siguiente:. ( AM − X ) >= P Donde: AM Å Es el atributo de mayor calidad del nivel.. 28.
(38) Capítulo 2 Propuesta de paralelización X Å atributo Es decir que son desechados aquellos en que la distancia entre el mejor y el resto de los atributos del nivel sea mayor que un P determinado. Para el caso en que se quiera explorar todo el amplio espacio de soluciones el parámetro se puede fijar a 1 y en caso de que se quieran podar mayor cantidad de elementos se puede establecer cercano a 0 Ej.: P= 0.01 A continuación se muestra el diagrama de colaboración entre los módulos a partir del código fuente de esta versión secuencial:. Fig. 5 Diagrama de colaboración. En rset.h se encuentra todo lo relacionado con los Conjuntos Aproximados, la construcción y operación de las clases de equivalencia; el módulo HillCSec.h contiene todas las funciones relacionadas con el método Quick – Reduct. En aprox.h se ubican los métodos implicados en el cálculo de las aproximaciones y finalmente en xtras.h se encuentran una serie funciones auxiliares que permiten realizar el cálculo en general.. 29.
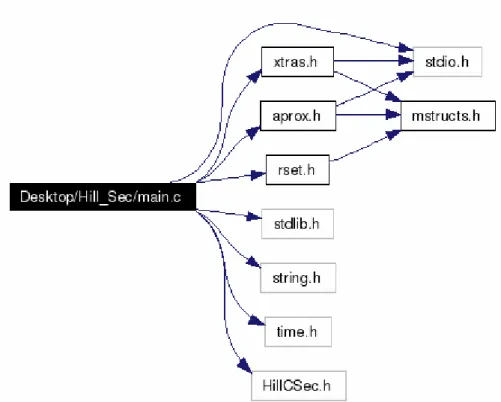
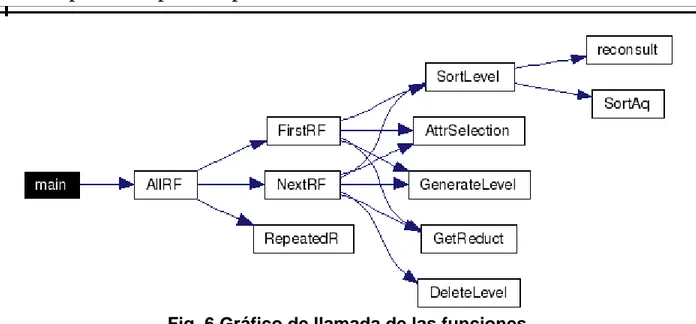
(39) Capítulo 2 Propuesta de paralelización. Fig. 6 Gráfico de llamada de las funciones. El diagrama anteriormente mostrado corresponde con el gráfico de llamadas de las funciones. El algoritmo general consta de los siguientes pasos: 1). Cargar el SD en memoria.. 2). Llamar a AllRF.. 3). Imprimir los reductos a un archivo.. 4). Liberar el SD. 30.
(40) Capítulo 2 Propuesta de paralelización El algoritmo correspondiente a la función ALLRF: Llamar a FirstRF. 1 Si no encontró reductos 1.1) Salir. 2 Mientras (Existan reductos) 2.1 Llamar a NextRF. 2.2 Si Total de Reductos <>0 2.2.1 Incrementar contador. 2.2.2 Si contador = Total de Reductos 2.2.3 Salir 3 Mientras halla reductos repetidos 3.1 Llamar a RepeatedR. 3.2 Desde i=1 hasta rep 3.2.1 Llamar NextRF. Devolver los reductos encontrados.. 2.1.3 La versión paralela En esta parte se tuvieron en cuenta dos modelos principales, el primero sigue la siguiente figura:. Fig. 7 Diseño Paralelo En este primer modelo se pretende minimizar el tiempo de cálculo de la calidad, puesto que el mismo era un punto importante en el desempeño del algoritmo y dejar la generación del árbol de búsqueda en el nodo master y el cálculo de las aproximaciones para los nodos esclavos.. 31.
(41) Capítulo 2 Propuesta de paralelización. La limitación de este esquema como es de notar, es que el mismo no utiliza paralelismo alguno en el caso de la exploración de las soluciones, lo cual puede traer consecuencias en caso que se presenten bases de casos en la cual el espacio de búsqueda sea considerable.. En el capítulo siguiente se muestran las pruebas realizadas sobre el mismo así como las comparaciones realizadas con otro grupo de algoritmos.. En la segunda propuesta se trató de subsanar las limitaciones del primero, por lo que se modificó el modelo inicial descrito en la Fig. 7, para pasar al que se muestra en la Fig. 8.. En este modelo se tomó un conjunto de 7 procesadores, en ellos el nodo 0 es el encargado de repartir el SD a los dos nodos cabezas (1 y 4), posteriormente indica por donde se debe explorar para buscar los reductos y procesar los resultados finales.. El algoritmo que describe este proceso se encuentra descrito en la página que viene a continuación. El algoritmo que describen los nodos cabezas se muestra a continuación: 1) Recibir el SD del nodo 0. 2) Recibir los rasgos iniciales ordenados del nodo 0. 3) Mientras queden reductos por calcular. 3.1) Enviar el id del nodos cabeza. 3.2) Recibir índice por donde explorar. 3.3) Generar Nivel Inicial. 3.4) Llamar a AllRF con la mitad del total de reductos a hallar 3.5) Imprimir los reductos encontrados a un archivo 4) Enviar condición de terminación al 0 (-1). 5) Enviar condición de terminación a los esclavos.. 32.
(42) Capítulo 2 Propuesta de paralelización Señalar aquí que los atributos son ordenados por su calidad con esto se garantiza que la primera exploración de los nodos se haga al igual que el resto, con los más importantes.. Fig. 8 Diseño paralelo para el segundo modelo. El proceso de asignación de los índices por donde deben explorar los nodos para el caso de que se tengan 9 atributos es como sigue: SÅ {1, 2, 3, 4, 5, 6, 7, 8, 9} Conjunto restante de rasgos. L Å 2 Índice donde comienzan las posibles soluciones. AÅ Atributo seleccionado para ser la raíz del árbol Iter. 1. 2. Nodo 0. Nodo (N / 2). L=2. L= 3. AÅS[L-1] SÅ(2,3,4,5,6,7,8,9). AÅS[L-1]. L=4. L=5. AÅS[L-1] SÅ(4,5,6,7,8,9). AÅS[L-1]. SÅ(3,4,5,6,7,8,9). SÅ(5,6,7,8,9). 33.
(43) Capítulo 2 Propuesta de paralelización 3. L=6. L=7. AÅS[L-1] SÅ(6,7,8,9,10). AÅS[L] SÅ(7,8,9,10). … L=8 AÅS[L-1] SÅ(8,9,10). El proceso de asignación finaliza cuando el índice llegue a la cantidad de rasgos o concluyan los dos nodos cabezas.. ACO En este epígrafe se tratan todo los aspectos relacionados con los diseños paralelos propuestos. Características, ventajas, desventajas y funcionamiento interno.. 2.1.4 La versión secuencial El código que se utilizó de este algoritmo inicialmente estaba aplicado al problema del Viajero – Vendedor, posteriormente el Dr. Daniel Gálvez le realizó una serie de modificaciones para adaptarlo al problema del cálculo de reductos aunque el mismo no utilizaba Conjuntos Aproximados (Rough Set) para el cálculo de la calidad, sino que el mismo tomaba de un archivo la lista de conjuntos de atributos con sus calidades y a partir de ahí calculaba. El módulo de cálculo de la calidad usando Conjuntos Aproximados fue adicionado posteriormente.. Fig. 9 Diagrama de relación entre módulos. (pprincipal.c). 34.
(44) Capítulo 2 Propuesta de paralelización. Fig. 10 Diagrama de relación entre módulos. (acomain.c) Teniendo en cuenta que las hormigas en cada iteración todas comienzan por la misma cantidad de atributos se puede dar la situación de que dos hormigas puedan explorar un mismo atributo o conjunto de ellos, por lo que se decidió dejar almacenado los conjuntos de atributos ya explorados con sus calidades para una posterior referencia. El algoritmo que describe la función principal del algoritmo cuenta con lo siguientes pasos: El algoritmo correspondiente a gralAntsCycle(): 1) Mientras (Terminación General==0) 1.1). Distribuir las hormigas.. 1.2). Evaluar la distribución.. 1.3). Mientras (Terminación de las Hormigas==0) 1.3.1) Construir Soluciones.. 1.4). Actualizar la feromona.. 1.5). Actualizar la Colonia.. 35.
(45) Capítulo 2 Propuesta de paralelización El algoritmo correspondiente al cálculo de la calidad: A Å Conjunto de atributos a calcular. Result Å Número real con la calidad de A. 1) Si A existe entonces devolver su calidad sino: 2) Result Å reconsult (A). 3) Retornar Result;. 2.1.5 La versión paralela La primera versión paralela que se utilizó en este algoritmo usa un esquema similar a la utilizada en el epígrafe 2.5.2 Quick – Reduct.. Fig. 11 Diagrama de la distribución de los nodos Básicamente en este modelo (Fig. 11) se realizan las operaciones correspondientes al método en el nodo 0 y las peticiones sobre el cálculo de la calidad se realizan sobre los nodos, el objetivo de utilizar este modelo fue de disminuir el tiempo de cálculo de la calidad y dejar la exploración en un nodo.. Esta propuesta padece de las mismas deficiencias que el primer modelo de Quick Reduct lo que lo convierte en una variante aceptable para los casos en que se quiera aplicar ACO a Sistemas de Información de mediano tamaño y no explota en toda su magnitud el paralelismo que ofrece el hecho de que cada hormiga opere. 36.
(46) Capítulo 2 Propuesta de paralelización independientemente una de otra. En el capítulo 1 se hace referencia a una serie de modelos que lusan con mayor medida el paralelismo que se puede aplicar en el método.. Un segundo modelo propuesto para ACO fue acercar el paralelismo al método de las hormigas como tal y no solo al cálculo de la calidad. Se propuso replicar el modelo inicial en dos grupos de procesadores, aplicar el cálculo sobre el conjunto de atributos y una vez terminado los dos procesos seleccionar las mejores soluciones así como eliminar las que pudieran quedar repetidos.. Fig. 12 Diseño del 2do modelo propuesto para ACO.. Para lograr que se exploren varios espacios de solución se distribuyeron los atributos de tal forma que un grupo explorara una parte de ellos y el otro grupo cogiera la restante esto con el objetivo de garantizar explorar una mayor cantidad de posibles soluciones.. Este diseño tiene la limitación de que la matriz de feromonas se actualiza localmente y no globalmente por lo que las soluciones no se encuentran con la misma rapidez que si se encontrarán compartiendo los resultados de la exploración.. 37.
(47) Capítulo 2 Propuesta de paralelización. Conclusiones parciales Los métodos aplicados en este capítulo son una selección de las revisiones bibliográficas, de los que se pudo obtener las conclusiones siguientes:. -. Son varias las propuestas de paralelización.. -. Cada una de las propuestas de paralelización se apoya en un enfoque diferente a partir de las limitaciones de las implementaciones secuenciales.. -. Existen cuatro modelos paralelos propuestos para el cálculo de reductos.. 38.
(48) Capítulo 3 Evaluación de los resultados y descripción de las funciones Capítulo 3 Evaluación de los resultados y descripción de las funciones Este capítulo se encuentra dividido en dos fases en una primera parte se analizan los resultados obtenidos de aplicar los diferentes algoritmos y en la segunda parte del mismo se detallan las diferentes funciones utilizadas en el cálculo de los reductos en uno y otro método.. Conjuntos Aproximados (Rough Set) En este epígrafe se muestran las diferentes pruebas realizadas al módulo tanto secuencial como paralelo del cálculo de la calidad.. 3.1.1. La versión secuencial. La implementación de la versión secuencial (V.S) fue comparada con una serie de aplicaciones secuenciales (Rosetta, Frank Bossman, ROSE) que realizaban similar cálculo y de ellos se obtuvieron los siguientes resultados: Base de Datos. V. S. Rossetta. Frank Bossman. Rose. [1]. Bw Atributos :*. Calidad: 1 Tiempo: 0.015. Iso5 Atributos : *. Calidad: 1 Tiempo: 0.47. Donors: Atributos: *. Calidad: 1 Tiempo: 3.452. Lrr Atributos : *. Calidad: 1 Tiempo: 6.98. Calidad: 1 Calidad: 1 Tiempo:0.0128 Tiempo: 0.052 Calidad: Calidad: Tiempo: Tiempo: No Respondió No Respondió Calidad: Calidad: Tiempo: Tiempo: No Respondió No Respondió Calidad: Calidad: 1 Tiempo: Tiempo: No Respondió 106.2346. Connect Atributos: *. Calidad: 1 Tiempo: 216.9. Calidad: Tiempo: No Respondió. Calidad: Tiempo: No Respondió. Calidad: 1 Tiempo:0.03157 Calidad: 1 Tiempo: 28.2395 Calidad: 1 Tiempo: 35 Calidad: 1 Tiempo: 3305.2345 Calidad: 1 Tiempo: 3305.2345. Nota: Los tiempos son en segundos y (*) significa que se probó con todos los atributos. Tabla 1.. 39.
(49) Capítulo 3 Evaluación de los resultados y descripción de las funciones [1]. Versión ofrecida por un investigador de Bélgica que visito nuestro centro y dejo una serie de algoritmos implementados entre ellos uno que realizaba este cálculo.. Como se puede observar, el tiempo de V.S para los diferentes Sistemas de Decisión (SD) ofrece mejores resultados en comparación con las otras aplicaciones que realizaban similar cálculo. La razón de la diferencia en los resultados relacionados con el tiempo se debe a que V.S utiliza otra forma de construcción de las Clases de Equivalencia y de cálculo de las aproximaciones, no basado en la Matriz de Diferencia.. En el caso de la calidad, los resultados fueron similares debido a que los (SD) son consistentes con la cantidad de atributos con los que se probó.. 3.1.2. El método paralelo. Los resultados que arrojaron las pruebas realizadas sobre el cluster usando la versión paralela se muestran a continuación:. Nodos 3. 5. 7. SD Bw Atributos :*. Calidad: 1 Tiempo: 0.1. Calidad: 1 Tiempo: 0.36. Calidad: 1 Tiempo: 0.32. Iso5 Atributos : * Donors Atributos: * Lrr Atributos : * Connect Atributos: *. Calidad: 1 Tiempo: 1.54 Calidad: 1 Tiempo: 2.15 Calidad: 1 Tiempo: 10.23 Calidad: 1 Tiempo: 86.78. Calidad: 1 Tiempo: 1.95 Calidad: 1 Tiempo: 4.22 Calidad: 1 Tiempo: 12.99 Calidad: 1 Tiempo: 154.42. Calidad: 1 Tiempo: 2.92 Calidad: 1 Tiempo: 7.19 Calidad: 1 Tiempo: 29.91 Calidad: 1 Tiempo:115.129. Nota: Los tiempos son en segundos y (*) significa que se probó con todos los atributos. Tabla 2. 40.
(50) Capítulo 3 Evaluación de los resultados y descripción de las funciones La calidad se comportó igual por las mismas razones expresadas en las comparaciones de la Tabla1, en cuanto a los tiempos estos empeoran cuando la cantidad de nodos aumenta. En la gráfica que se muestra a continuación se ofrece una comparación entre los resultados obtenidos por el método secuencial y el método paralelo usando tres nodos. 250 200. Tiempo Secuencial. 150. Tiempo Paralelo. 100 50. t co. nn. ec. lrr. rs on o D. t5 ol e is. Bw. 0. Fig. 1 (Tabla comparativa de los tiempos entre el método secuencial y el paralelo). Como se puede apreciar Fig. 1 el método paralelo se comporta de manera estable respecto a la versión secuencial y en algunos casos peores hasta lrr, donde a partir de aquí comienza a verse diferencias significativas de la variante paralela con respecto a su contraparte secuencial. Esto se debe al hecho de que Connect cuenta con una gran cantidad de filas por lo que el proceso secuencial de construcción de las Clase de Equivalencias(CE) y calculo de las aproximaciones se hace muy lento, sin embargo, el procesamiento paralelo permite construir CE en cada nodo por lo que su análisis tiene menos costo computacional.. Quick Reduct En este epígrafe se presentan los resultados obtenidos en corridas paralelas de los algoritmos desarrollados en la investigación y su comparación con respecto a los secuenciales.. 41.
(51) Capítulo 3 Evaluación de los resultados y descripción de las funciones 3.1.3. Versión Secuencial. Los reductos obtenidos por el algoritmo en los casos de Isolet, Lrr y Donors, fueron limitados en dependencia de la cantidad (tabla 3) esto se realizó con el objetivo de poder tener resultados concretos para poder comparar con respecto a los demás software. En el caso de connect, el algoritmo fue detenido cuando llevaba el tiempo de procesamiento + 24 sin haber obtenido resultados. Cantidad Tiempo Long Prom. Cant(Longitud). BW Isolet 5 Lrr Donors Connect 20 50 5 50 -0 23.58 721.7 2054 + 24 hrs 4.4 2 11.8 19.04 -8(4) 10(5) 1(11) 48(19) 50(2) -1(6) 4(12) 2(20) Nota: Los tiempos son en segundos.. Tabla 3 Resultados obtenidos con Quick – Reduct secuencial.. 3.1.4. Versión Paralela. Los resultados de esta de esta versión se muestran ha continuación:. Cantidad Tiempo Long Prom. Cant(Longitud). BW Isolet 5 Lrr Donors 13 50 5 50 40.82 6010.94 747.19 14757 4.38 50 11.8 19 8(4) 5(5) 50(2) 1(11) 4(12) 50(19) Nota: Los tiempos son en segundos. Tabla 4 Quick – Reduct con el 1er Modelo. Connect 2 18 hrs 35 2(35). En este primer modelo (tabla 4) los tiempos obtenidos comparados con la versión secuencial (tabla 3) no son buenos, sin embargo en el caso de connect este modelo pudo obtener resultados en menos de 24 hrs. La versión secuencial en BW, Isolet5 y Lrr, dio mejores resultados que el paralelo debido a que el cálculo de la calidad usado en la versión paralela es más lento.. 42.
(52) Capítulo 3 Evaluación de los resultados y descripción de las funciones Cantidad Tiempo Long Prom.. BW 13 23.47 4.38. Isolet 5 50 5590 50. Lrr 5 835.41 11.8. Donors 50 12532 19. Cant(Longitud). 8(4) 4(5) 1(6). 50(2). 1(11) 4(12). 50(19). Connect 5 14 hrs 34.6 3(35) 2(34). Nota: Los tiempos son en segundos. Tabla 5 Quick – Reduct con el 2do Modelo Con el principio de la división del espacio de búsqueda se obtuvieron resultados significativamente mejores que los obtenidos con el primer modelo, solo en lrr fueron ligeramente superiores. En la Fig. 2 se hace una unión de los tiempos ofrecidos en las Tablas 4 y 5 Grafico de los dos modelos. Tiempo en minutos. 10000 1000 100. Primer Modelo Segundo Modelo. 10 1 0.1 Bw. isolet5 Donors. lrr. connect. (Tiempos de cada propuesta para cada SD en particular). Fig. 2. 43.
Figure

+7

Outline
Documento similar
El contar con el financiamiento institucional a través de las cátedras ha significado para los grupos de profesores, el poder centrarse en estudios sobre áreas de interés
Debido al riesgo de producir malformaciones congénitas graves, en la Unión Europea se han establecido una serie de requisitos para su prescripción y dispensación con un Plan
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
Luis Miguel Utrera Navarrete ha presentado la relación de Bienes y Actividades siguientes para la legislatura de 2015-2019, según constan inscritos en el
En el caso del algoritmo spread spectrum en el dominio frecuencial, los resultados en papel sobre la perceptibilidad de la marca son bajos, ya que el efecto de la marca en la señal
La primera parte de la tesis doctoral está formada por dos capítulos. El capítulo 1 lleva por título “El estudio de la formación de las parejas: teoría, fuentes y métodos”
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
Lo que se pierde en extensión se gana en profundidad, se nos dice. Ello es verdad si se admite que esta profundidad es limitada incluso desde el punto de vista funcional. ¿Por qué se
