Biblioteca de medidas de similitud para textos
91
0
0
Texto completo
(2) Declaración de autoría: Título del documento: Biblioteca de medidas de similitud para textos Dado a los 25 días del mes de junio de 2016 Versión 6.0 publicada en junio del 2016 Copyright © 2016 UCLV, Abel Meneses Abad y Pablo Ulacia Villavicencio Licencia. Esta obra se publica bajo la licencia Creative Commons 3.0 BY-NC-SA que establece las siguientes condiciones: Atribución: Debes reconocer y citar la obra de la forma especificada por el autor y el licenciante.. No Comercial: No se puede utilizar esta obra para fines comerciales.. Licenciar igual: Si se altera o transforma esta obra, o se genera. una obra derivada, sólo se. puede distribuir la obra generada bajo una licencia idéntica a esta.. Para ver una copia de esta licencia visitar la siguiente dirección en internet: http://creativecommons.org/licenses/by-nc-sa/3.0/legalcode. Marcas comerciales y marcas de servicios. Todas las marcas comerciales, marcas de servicios, logotipos y nombres de compañías mencionadas en esta obra son propiedad de sus respectivos dueños. Las mismas están protegidas bajo la ley de marcas comerciales y la ley de competencia desleal. Derechos comerciales. Los derechos comerciales para exportación de esta obra son concedidos a la UCLV y a los autores de forma exclusiva. En territorio cubano la utilización comercial de esta obra no debe interferir con el uso social de la misma. En caso de conflictos.
(3) primará el derecho social sobre el comercial. Autores: Ing. Abel Meneses Abad, Pablo Ulacia Villavicencio En caso de muerte los derechos morales de esta obra, su preservación, ejecución o modificación, quedarán bajo la responsabilidad moral y jurídica de: Yanet Conde González, y Jane Meneses Conde Biblioteca de medidas de similitud para textos.
(4) DEDICATORIA A mis padres Maritza Villavicencio y Pabel Ulacia por ser los mejores padres del mundo, amigos y consejeros que siempre creyeron en mí y me ayudaron a alcanzar mis metas..
(5) AGRADECIMIENTOS A mis padres que siempre me apoyaron en todo. A mi hermano, mis tías, a mis abuelos, a mis primos. A mis amigos por apoyarme a lo largo de la carrera. A mis tutores Abel por prestarme su tiempo y dedicación..
(6) ___________________________________. TABLA DE CONTENIDOS. RESUMEN La detección de paráfrasis en textos es un área de investigación actual en computación. La complejidad de las lenguas naturales y las modificaciones que se pueden hacer a una oración sencilla dando lugar a una nueva de igual significado ha originado clasificaciones diversas para este problema. Los experimentos además utilizan medidas de similitud que aprovechan distintos elementos morfológicos, sintácticos, semánticos, etc. En la actualidad las tecnologías informáticas no integran estos elementos expuestos haciendo difícil la investigación. El problema es peor cuando se experimenta con textos en idioma español. Para facilitar el trabajo de los investigadores cubanos en el área de la detección de similitud de textos en español; se propuso la construcción de una biblioteca de medidas de similitud, diseñada teniendo en cuenta las más populares y recientes reportadas en la literatura y su frecuencia de aparición en proyectos similares que integran pocas medidas. Considerando su uso en sistemas reales se utilizó el lenguaje Python por sus posibilidades de optimización utilizando conversores a C++, su alta productividad y fácil mantenimiento. El resultado es una biblioteca que contiene medidas en cuatro niveles: caracteres, términos, corpus y basadas en conocimiento. Se validaron los resultados utilizando casos reales de paráfrasis. Los experimentos demuestran que varias medidas implementadas influyen positivamente en la detección de paráfrasis. Y se comprueba que la utilización de tecnologías de Python a C++ mejoran los tiempos de corrida hasta en un factor de 13x, sustentando la propuesta para usarse en entornos reales..
(7) ÍNDICE. ABSTRACT The detection of paraphrase in texts is a current research area of computing. The complexity of natural languages and the modifications that can be made to a simple sentence giving rise to a new one having the same meaning, have originated several classifications for this problem. Experiments also use similarity measures that make good use of distinct morphological, syntactic, semantic elements, etc. Nowadays computer technologies do not integrate these elements mentioned above, which makes research difficult. The situation gets worse while experimenting with texts in Spanish. In order to facilitate the work of Cuban researchers in the field of similarity detection in Spanish texts, it was proposed the elaboration of a library of similarity measures. The library was designed taking into account the most popular measures, the most recent ones reported by literature and their frequency of occurrence in similar projects that integrate a few measures. Taking into account its use in real systems, it was utilized the Python language due to its optimization possibilities by using C ++ converters, its high productivity and easy maintenance. After being proved by using real cases of paraphrases, the outcome is a library containing measures at four levels: characters, terms, corpus and based-on-knowledge. Experiments show that several of the implemented measures influence positively in detection. It is also included an example of mixed measures that improves results. And it is confirmed that the use of Python to C ++ technologies improves running times by up to a 13x factor, supporting the proposal for being used in real environments..
(8) ÍNDICE. TABLA DE CONTENIDOS INTRODUCCIÓN ....................................................................................................................... 1 CAPÍTULO 1. LA PARÁFRASIS Y SU DETECCIÓN AUTOMÁTICA .............................. 5 1.1. Análisis de la definición de paráfrasis .......................................................................... 5. 1.2. Aplicaciones de la paráfrasis ........................................................................................ 6. 1.3. Tipologías de la paráfrasis ............................................................................................ 7. 1.3.1.. Morfo-Lexicón (Cambios basados en la morfología).......................................... 10. 1.3.2.. Morfo-Lexicón (Cambios basados en lexicón) ................................................... 10. 1.3.3.. Estructura (Cambios basados en sintaxis) ........................................................... 12. 1.3.4.. Estructura (Cambios basados en discurso) .......................................................... 13. 1.3.5.. Semántico ............................................................................................................ 14. 1.3.6.. Misceláneos ......................................................................................................... 15. 1.4. EL PLN ....................................................................................................................... 15. 1.4.1. 1.5. Niveles del lenguaje............................................................................................. 16. Recursos ...................................................................................................................... 17. 1.5.1.. Lingüística computacional ................................................................................... 18. 1.5.1.1. WordNet.......................................................................................................... 18 1.5.1.2. TF-IDF ............................................................................................................ 20 1.5.1.3. Treebank ......................................................................................................... 21 1.5.1.4. Ngramas .......................................................................................................... 21 1.5.2.. Bibliotecas de Python .......................................................................................... 22. 1.5.2.1. NLTK .............................................................................................................. 22 1.5.2.2. Pattern ............................................................................................................. 23 1.5.2.3. Ixa-pipe-srl ...................................................................................................... 23 1.5.2.4. Gensim ............................................................................................................ 23 1.5.2.5. Jellyfish ........................................................................................................... 24 1.5.3.. Corpus para pruebas y entrenamientos de modelos inteligentes ......................... 24. 1.5.3.1. Corpus METER .............................................................................................. 24.
(9) ÍNDICE. 1.5.3.2. Corpus MSRPC............................................................................................... 26 1.5.3.3. Corpus CPSA .................................................................................................. 28 1.5.3.4. Corpus P4P ..................................................................................................... 28 1.5.3.5. Corpus TNLP .................................................................................................. 29 1.6. Trabajos previos sobre detección de paráfrasis .......................................................... 30. 1.7. Conclusiones del capítulo ........................................................................................... 32. CAPÍTULO 2. DISEÑO E IMPLEMENTACIÓN DE LA BIBLIOTECA DE MEDIDAS DE SIMILITUD 33 2.1. Medidas de similitud ................................................................................................... 33. 2.2. Diseño del módulo de medidas de similitud ............................................................... 36. 2.2.1.. Estructura del módulo .......................................................................................... 36. 2.2.2.. Diagrama de clases .............................................................................................. 37. 2.3. Medidas de similitud basadas en caracteres ............................................................... 40. 2.2.1.. LCS ...................................................................................................................... 41. 2.2.2.. Damerau-Levenshtein .......................................................................................... 42. 2.2.3.. Jaro Winkler ........................................................................................................ 42. 2.2.4.. Jaro Distance........................................................................................................ 42. 2.2.5.. Levenshtein Distance ........................................................................................... 42. 2.4. Medidas de similitud basadas en cadenas implementadas .......................................... 43. 2.4.1.. Matching Coefficient ........................................................................................... 44. 2.4.2.. Jaccard Coefficient .............................................................................................. 44. 2.4.3.. Dice Coefficient ................................................................................................... 44. 2.4.4.. Overlap Coefficient ............................................................................................. 44. 2.4.5.. Similitud Coseno ................................................................................................. 45. 2.4.6.. Euclidean Distance .............................................................................................. 45. 2.4.7.. Manhattan Distance ............................................................................................. 46. 2.4.8.. Binary Distance y Masi Distance ........................................................................ 46. 2.4.9.. Hamming Distance .............................................................................................. 46. 2.5. Medidas de similitud basadas en corpus ..................................................................... 47. 2.6. Medidas WordNet ....................................................................................................... 47.
(10) ÍNDICE. 2.7. Combinaciones de medidas de similitud .................................................................... 50. 2.8. Optimización de la medida jaccard utilizando Cython ............................................... 53. 2.9 Valoraciones de las optimizaciones utilizando compiladores JIT y otros de la familia Py->C++ ................................................................................................................................ 54 2.10 Conclusiones del capítulo ........................................................................................... 57 CÁPITULO 3. VALIDACIÓN DE LA BIBLIOTECA DE MEDIDAS PARA EL ANÁLISIS DE PARÁFRASIS ..................................................................................................................... 58 3.1. Descripción de los experimentos ................................................................................ 58. 3.2. Diseño de las medidas para la detección de paráfrasis ............................................... 59. 3.3. Análisis del comportamiento individual de las medidas............................................. 61. 3.3.1.. Análisis del comportamiento de las medidas basadas en términos ..................... 61. 3.3.2.. Análisis del comportamiento de las medidas basadas en caracteres ................... 62. 3.4. Análisis del comportamiento de las medidas combinadas .......................................... 64. 3.5. Discusión de los resultados ......................................................................................... 66. 3.6. Conclusiones del capítulo ........................................................................................... 68. RECOMENDACIONES ........................................................................................................... 71 REFERNCIA BIBLIOGRÁFICA ............................................................................................. 72 ANEXOS .................................................................................. ¡Error! Marcador no definido..
(11) ___________________________________. LISTA DE FIGURAS. LISTA DE FIGURAS Figura 1. 1: Modelo de detección automática de paráfrasis ...................................................... 17 Figura 1. 2: Extracto de la jerarquía de WordNet...................................................................... 19 Figura 1. 3: Forma general de algoritmo tf-idf .......................................................................... 20 Figura 2. 1: Diagrama de paquetes ............................................................................................ 36 Figura 2. 2: Diagrama de clases ................................................................................................ 37 Figura 2. 3: Diagrama de las clases Stringdists y Chardists ...................................................... 37 Figura 2. 4: Diagrama de las clases Teststringdists y Testchardist ........................................... 38 Figura 2. 5: Test aplicados a los métodos de la clase Stringdists .............................................. 40 Figura 2. 6: Test aplicados a los métodos de la clase Chardists ................................................ 40 Figura 2. 7: Modelación matemática del algoritmo LCS ......................................................... 41 Figura 2. 8: Descripción de la medida Jaro-Winkler (Fierro et al. 2014).................................. 42 Figura 2. 9: Forma general del algoritmo Jaccard ..................................................................... 44 Figura 2. 10: Forma general del algoritmo Dice ....................................................................... 44 Figura 2. 11: Forma general del algoritmo Overlap .................................................................. 45 Figura 2. 12: Forma general de la métrica de similitud coseno ................................................. 45 Figura 2. 13: Medida de similitud propuesta por Mihalcea y otros autores .............................. 51 Figura 2. 14: Método PMI-IR .................................................................................................... 51 Figura 2. 15: Prueba de la clase Chardists utlizando compilador de Python............................. 56 Figura 2. 16: Prueba de la clase Chardists utlizando compilador de PyPy ............................... 57 Figura 3. 2: Visualización del comportamiento de las medidas en Weka para el corpus MSRPC_train ............................................................................................................................ 67.
(12) ___________________________________. _. LISTA DE TABLAS. LISTA DE TABLAS Tabla 1. 1: Visión general de las tipologías de paráfrasis ........................................................... 9 Tabla 1. 2: Estructura general del corpus METER .................................................................... 26 Tabla 2. 1: Medidas de similitud basadas en cadenas ............................................................... 34 Tabla 2. 2: Medidas de similitud basadas en caracteres ............................................................ 35 Tabla 2. 3: Medidas WordNet ................................................................................................... 49 Tabla 3. 1: Estructura del corpus MSRPC................................................................................. 58 Tabla 3. 2: Corrida de las pruebas ............................................................................................. 59 Tabla 3. 3: Resultados de clasificación utilizando el clasificador SVM para medidas basadas en cadenas para corpus MSRPC_test ........................................................................................ 61 Tabla 3. 4: Resultados de clasificación utilizando el clasificador SVM para medidas basadas en cadenas para corpus MSRPC_train ...................................................................................... 61 Tabla 3. 5: Resultados de clasificación utilizando el clasificador J48 para medidas basadas en cadenas para corpus MSRPC_test ............................................................................................. 61 Tabla 3. 6: Resultados de clasificación utilizando el clasificador J48 para medidas basadas en cadenas para corpus MSRPC_train ........................................................................................... 61 Tabla 3. 7: Resultados de clasificación utilizando el clasificador Random Forest para medidas basadas en cadenas para corpus MSRPC_test ........................................................................... 62 Tabla 3. 8: Resultados de clasificación utilizando el clasificador Random Forest para medidas basadas en cadenas para corpus MSRPC_train ......................................................................... 62 Tabla 3. 9: Resultados de clasificación utilizando el clasificador NaiveBayes para medidas basadas en cadenas para corpus MSRPC_test ........................................................................... 62 Tabla 3. 10: Resultados de clasificación utilizando el clasificador NaiveBayes para medidas basadas en cadenas para corpus MSRPC_train ......................................................................... 62.
(13) ÍNDICE. Tabla 3. 11: Resultados de clasificación utilizando el clasificador SVM para medidas basadas en caracteres para corpus MSRPC_test ..................................................................................... 63 Tabla 3. 12: Resultados de clasificación utilizando el clasificador SVM para medidas basadas en caracteres para corpus MSRPC_train ................................................................................... 63 Tabla 3. 13: Resultados de clasificación utilizando el clasificador J48 para medidas basadas en caracteres para corpus MSRPC_test .......................................................................................... 63 Tabla 3. 14: Resultados de clasificación utilizando el clasificador J48 para medidas basadas en caracteres para corpus MSRPC_train ........................................................................................ 63 Tabla 3. 15: Resultados de clasificación utilizando el clasificador Random Forest para medidas basadas en caracteres para corpus MSRPC_test ......................................................... 63 Tabla 3. 16: Resultados de clasificación utilizando el clasificador Random Forest para medidas basadas en caracteres para corpus MSRPC_train ....................................................... 63 Tabla 3. 17: Resultados de clasificación utilizando el clasificador NaiveBayes para medidas basadas en caracteres para corpus MSRPC_test........................................................................ 64 Tabla 3. 18: Resultados de clasificación utilizando el clasificador NaiveBayes para medidas basadas en caracteres para corpus MSRPC_train ...................................................................... 64 Tabla 3. 19: Resultados de clasificación utilizando el clasificador SVM para medidas basadas en combinadas para corpus MSRPC_test .................................................................................. 65 Tabla 3. 20: Resultados de clasificación utilizando el clasificador SVM para medidas basadas en combinadas para corpus MSRPC_train ................................................................................ 65 Tabla 3. 21: Resultados de clasificación utilizando el clasificador J48 para medidas basadas en combinadas para corpus MSRPC_test ....................................................................................... 65 Tabla 3. 22: Resultados de clasificación utilizando el clasificador J48 para medidas basadas en combinadas para corpus MSRPC_train ..................................................................................... 65 Tabla 3. 23: Resultados de clasificación utilizando el clasificador RandomForest para medidas basadas en combinadas para corpus MSRPC_test .................................................................... 65.
(14) ÍNDICE. Tabla 3. 24: Resultados de clasificación utilizando el clasificador RandomForest para medidas basadas en combinadas para corpus MSRPC_train ................................................................... 65 Tabla 3. 25: Resultados de clasificación utilizando el clasificador NaiveBayes para medidas basadas en combinadas para corpus MSRPC_test .................................................................... 66 Tabla 3. 26: Resultados de clasificación utilizando el clasificador NaiveBayes para medidas basadas en combinadas para corpus MSRPC_train ................................................................... 66.
(15) ___________________________________________________________________________________________________INTRODUCCIÓN. INTRODUCCIÓN El lenguaje natural (LN) es la lengua o idioma hablado o escrito por los humanos para propósitos generales de comunicación, son aquellas lenguas que han sido generadas espontáneamente en un grupo de hablantes con propósito de comunicarse, a diferencia de otras lenguas, como puedan ser una lengua construida, los lenguajes de programación o los lenguajes formales usados en el estudio de la lógica formal, especialmente la lógica matemática. Los LN evolucionan y aumentan con el paso de los años, por lo que ha hecho una tarea compleja por su nivel de complejidad lograr una comunicación entre hombre-máquina. Una de las ramas más importantes de la Inteligencia Artificial (IA) es aquella que formula mecanismos computacionalmente efectivos para facilitar la comunicación hombre-máquina por medio del lenguaje natural, logrando que sea esta comunicación mucho más fluida y menos rígida que los lenguajes formales (Abiertos et al. 2008). Dentro de esta área se destaca el procesamiento de lenguajes naturales (PLN) que estudia las interacciones entre las computadoras y el lenguaje humano. Un ejemplo, cuando utilizamos nuestro buscador y escribimos una oración, la máquina no necesita toda esta información, sino, la que de verdad contiene algún valor. El PLN no trata de la comunicación por medio de lenguajes naturales de una forma abstracta, sino de diseñar mecanismos para comunicarse que sean eficaces computacionalmente, que se puedan realizar por medio de programas que ejecuten o simulen la comunicación. En el área de PLN existe una disciplina conocida como Análisis Forense de Textos (Bolshakov & Gelbukh 2010). Dentro de las tareas de esta disciplina está la detección de plagio, que dedica sus esfuerzos a recuperar pares de fragmentos de textos que son similares en textos diferentes (Stein et al. 2007). Aunque en sus inicios la detección de plagio fue aplicado a documentos de código fuente, fue recién en los años 2000 que este problema se extendió a los textos en lenguajes naturales (Clough et al. 2002). El crecimiento exponencial de los documentos en Internet y sus usuarios contribuyó al aumento de la complejidad de este problema, tal es así que en años recientes la detección de plagio debió ser separada en áreas 1.
(16) _______________________________. INTRODUCCIÓN. claves: plagio copy-paste, cros-lingüe, auto-plagio y plagio parafrástico (Potthast et al. 2009), (Stamatatos et al. 2015). La detección del plagio parafrástico conllevó en años recientes al estudio de este fenómeno lingüístico. Debido a la complejidad del mismo, los procesos computacionales – antes: preprocesamiento, análisis detallado y pos procesamiento (Stein et al. 2007) - se han ido dividiendo en partes más pequeñas, ejemplo el “análisis detallado” ahora comprende segmentación, agrupamiento y filtrado (Sanchez-Perez et al. 2015). La necesidad de mejorar los resultados en cada etapa conllevó al desarrollo de nuevos problemas como la denominada “detección de paráfrasis”, que, considerando la segmentación de los textos en oraciones, intenta determinar si dos de ellas son equivalentes semánticamente (Artículo 2015). El proceso de detección de paráfrasis se compone de los siguientes pasos: preprocesamiento, cálculo de medidas de similitud, entrenamiento del modelo de detección y validación del modelo (Bär et al. 2012). En las tecnologías libres las etapas de preprocesamiento, entrenamiento de modelos de aprendizaje automatizado y validación de estos han sido ampliamente trabajados. Dentro de Python encontramos varias bibliotecas que contienen funcionalidades con estos fines: NLTK y Pattern para el preprocesamiento y extracción de estadísticas, Sklearn y Deap para el aprendizaje automático, y Pandas para el procesamiento de datos de grandes dimensiones. Sin embargo el cálculo de medidas de similitud como parte de la extracción de características no tiene una biblioteca avanzada, sino que se encuentran, las que han sido implementadas, dispersas en bibliotecas disímiles (Bär et al. 2015).. Planteamiento del problema En la Universidad Central de Las Villas se desarrolla una investigación sobre detección de plagio parafrástico en idioma español, de conjunto con la Universidad de Camagüey. En esta investigación se desarrollan un conjunto de herramientas y experimentos utilizando el lenguaje Python, con la intención de ser utilizadas en entornos reales como el procesamiento de los bancos de tesis de las universidades cubanas. El equipo de investigadores ha realizado diferentes experimentos para medir la similitud de textos utilizando bibliotecas de Python, y Java, lo que ha provocado dificultades con su integración en la herramienta para los lingüistas y bajos rendimientos en la ejecución de algunas medidas. Al mismo tiempo la experimentación con medidas combinadas, una tendencia actual de investigación se hace.
(17) _______________________________. INTRODUCCIÓN. imposible para los investigadores al tener que integrar fuentes distintas y a su vez incompletas, y en algunos casos es imposible repetir experimentos internacionales. Por lo que se da la necesidad de agrupar en una única biblioteca todas las medidas posibles para ser utilizados posteriormente en un software capaz de determinar los niveles de paráfrasis o reutilización de textos.. Objetivo general Como objetivo general se plantea desarrollar una biblioteca de medidas de similitud para textos utilizando el lenguaje Python, para la detección automática de textos parafraseados.. Objetivos específicos . Caracterizar el estado actual del problema de la detección de paráfrasis y determinar las variantes a implementar.. . Desarrollar una biblioteca de medidas de similitud que permita incorporar los principales elementos técnicos y científicos utilizados en la solución del problema de la paráfrasis.. . Validación de la biblioteca mediante la experimentación de un problema de detección de paráfrasis.. Tareas de investigación . Estudiar y definir las distintas tipologías de paráfrasis.. . Estudiar los distintos recursos con que cuenta la detección automática de paráfrasis.. . Sistematizar sobre los trabajos previos y el estado actual de la detección de paráfrasis.. . Diseñar e implementar una biblioteca de medidas de similitud en el lenguaje Python.. . Investigar técnicas de optimización de código para el lenguaje Python.. . Probar y validar la biblioteca usando Weka con un problema de paráfrasis.. Justificación El principal aporte de este trabajo, está relacionado con las bondades de la biblioteca desarrollada de medidas de similitud para la detección de paráfrasis, contribuye por tanto, a un mejor análisis de semejanza entre textos parafraseados, agrupando estas en una biblioteca común para posteriormente incluirlo en un software con el fin de detectar fraudes o plagios;.
(18) _______________________________. INTRODUCCIÓN. agrupa a otras bibliotecas escritas en Python, que contienen varias medidas útiles para resolver el problema de la detección de paráfrasis. El uso del lenguaje Python y de varias herramientas asociadas al mismo facilita el mantenimiento y optimización mejorando el rendimiento..
(19) CAPÍTULO 1.. LA PARÁFRASIS Y SU DETECCIÓN AUTOMÁTICA. En el presente capítulo se realiza el enmarque teórico que le da sustento a la investigación sobre la detección automática de textos parafraseados. Primeramente se hace un análisis de las principales definiciones de paráfrasis expuestas por diferentes autores. Posteriormente en el epígrafe 2 se abordan los diferentes campos donde el análisis y detección de paráfrasis juega un papel importante y algunas de sus aplicaciones, se realiza un estudio sobre las diferentes tipologías de paráfrasis y en los epígrafes siguientes se describen los recursos utilizados para la detección de paráfrasis y enfoques que han sido propuestos para tratar este problema. 1.1 Análisis de la definición de paráfrasis El tema de la paráfrasis es un tema que ha sido estudiado por diferentes autores los cuales le han dado varias definiciones. Una de estas definiciones es la que da Regina Barzilay donde define la paráfrasis como un conjunto de expresiones intercambiables que son ligeramente diferentes en su matiz, verbosidad, etc.(Barzilay & Mckeown n.d.). Otra definición es la que dan Dekang Lin y Patrick Pantel en (Lin & Pantel n.d.) donde expresan que la paráfrasis constituye un conjunto de patrones para capturar varios tipos de información a partir de documentos, sin embargo, en (Yamamoto n.d.) Kazuhide Yamamoto considera que es el grado de replicabilidad de dos expresiones E1 y E2, las cuales son diferentes entre sí en algunos sentidos. Yusuke Shinyama; Satoshi Sekine y Kiyoshi Sudo exponen una idea mucho más escueta en (Shinyama n.d.), para ellos las paráfrasis son simplemente expresiones similares, definición que varía el primer autor, Yusuke Shinyama en un trabajo posterior (Shinyama & Sekine 2005) donde las considera ocurrencias de pares de caminos extraídos, mientras que Takaaki Hasegawa, Satoshi Sekine y Ralph Grishman piensan en (Hasegawa et al. n.d.) que son un conjunto de frases las cuales expresan la misma cosa o evento. Otras definiciones son la de Yves Lepage y Etienne Denoual en (Lepage & Denoual n.d.): oraciones diferentes que tienen la misma traducción y la de Chris Callison-Burch; Philipp Koehn y Miles Osborne en (Callison-Burch et al. 2006): formas alternativas de expresar la misma información dentro de un lenguaje (Abiertos et al. 2008). Otros autores también han propuesto una definición como 5.
(20) es el caso de Inui, Fujita, Takahash, Iida e Iwakura donde dicen que esta puede considerarse como un paso inicial para la comprensión de textos que puede llevar posteriormente al análisis y a la redacción de nuevos textos tomando como base la información de otros (Inui et al. 2003). Otra manera de verla es como expresa la Dra. Hilda E. Quintana donde aborda el problema de una forma más general, la considerarlo como la explicación o interpretación amplificativa de un texto hecha por el lector del mismo en sus propias palabras(Quintana n.d.). Otra forma más generalizada de apreciar esta definición sería como se expone en (Anon n.d.), donde dice que es también aquella «traducción» que da al texto una visión clara, precisa y didáctica del mismo texto. Por traducción no ha de entenderse aquí el cambio de un idioma a otro necesariamente, sino la reescritura del texto original. Es en sí, una forma de resumir un texto con palabras propias de un individuo con una cultura determinada. Otros de los conceptos tratados en el tema de la paráfrasis es el plagio parafrástico los cuales están estrechamente relacionados entre sí. Algunos autores definen como plagio el acto de tomar escritos de otra persona y adjudicarlos como propios. Este fraude está estrechamente relacionado con la falsificación y la piratería - prácticas generalmente utilizadas en crímenes de violación, como los de las leyes de derecho de autor,(Merriam Webster 2015). Este concepto junto con la paráfrasis nos lleva a otro concepto nuevo, el plagio parafrástico, que consiste en tomar los escritos de otra persona, añadiendo o quitando palabras o letras, agregando errores deliberados de ortografía y gramática, insertando palabras con significados similares o reordenando oraciones y frases (Kakkonen & Mozgovoy 2010). 1.2 Aplicaciones de la paráfrasis Existe diferentes centros investigativos y compañías como es el caso de Google que se dedican al tema de la detección automática de textos parafraseados, algunas, para mejorar sus resultados a la hora obtener una solución, como son el caso con los motores de búsqueda, a la hora de buscar y extraer información sobre el tema que se esté indagando, otros centros para perfeccionar el análisis de textos, etc. Esta es un área con diversas aplicaciones que van a permitir solucionar diferentes problemas como muestra Yaniseth Garcia Vasconcelo y Antonio Fernández Orquín.(Abiertos et al. 2008).
(21) . Extracción de Información: conocer si una información parafrasea a otra que ya fue almacenada, para evitar redundancia en la base de datos, sería de gran importancia. También para extraer información, que esté escrita de alguna forma específica, pudiera ser importante buscarla por sus formas alternativas.. . Generación de Resúmenes: Comparar las frases de aquel o aquellos artículos que se deseen resumir para garantizar que no falte alguna idea importante o se repita una redundante garantiza la calidad y el tamaño óptimo del resumen.. . Traducción Automática: La paráfrasis multilingüe sería capaz de conocer que dos frases dichas o escritas en lenguajes diferentes, con palabras y estilos propios de cada autor, conservan el mismo significado.. . Recuperación de Información: Se puede recuperar la información no en la forma exacta que se solicita, sino también otras palabras en el mismo contexto que son capaces de expresar igual significado.. . Búsqueda de Respuesta: Si la pregunta que se hace, a pesar de contener palabras y estructuras diferentes, posee un significado conocido e igual al de alguna pregunta anterior, no hay necesidad de volver a buscar, la respuesta ya se sabe, la misma.. . Detección de plagios: Con un sistema de detección de paráfrasis se podría facilitar la ardua labor de desenmascarar a los piratas de la propiedad intelectual.. 1.3 Tipologías de la paráfrasis La paráfrasis considerando el enfoque que considera esta como aquella explicación del contenido de un texto para aclarar y facilitar la asimilación de la información en todos sus aspectos (Anon n.d.) o que consiste en recrear con palabras más sencillas y/o con el uso escaso de tecnicismos las ideas propias obtenidas en un texto determinado, para facilitar su comprensión lectora (Anon n.d.), son formas muy simples de ver la complejidad del fenómeno lingüístico de la paráfrasis (Barr & Valencia 2010), la paráfrasis en si es un fenómeno más amplio, el cual posee una variedad de manifestaciones que puede implicar conocimiento de tipo morfológico, léxico, sintáctico, semántico y pragmático (Barr & Valencia 2010). Para.
(22) ilustrar la complejidad de este fenómeno muchos autores ha descrito en el campo de la lingüística y también del Procesamiento de Lenguaje Natural (PLN) varias tipologías de paráfrasis (Barr & Valencia 2010), como el caso de algunos autores que dividen la paráfrasis en dos tipos: paráfrasis mecánica la cual está formada por dos niveles, el sintáctico y el semántico, y la paráfrasis constructiva (Abiertos et al. 2008). . Paráfrasis mecánica: Consiste en sustituir alguna palabra por sinónimos o frases alternas con cambios sintácticos mínimos. o Sintáctica: Está dada básicamente por la relación existente entre lo activo, lo pasivo y lo relativo. Ejemplo: 1. El gato arañó a la niña. 2. A la niña la arañó el gato. 3. La niña fue arañada por el gato. o Semántica: Está dada por la utilización de sinónimos para expresar el mismo significado de palabra sin alterar la estructura de la oración. Ejemplo: utilizando las combinaciones sólo de los sinónimos que a continuación se presentan se obtienen ciento veinte variantes de la oración 1. El gato arañó a la niña. El felino rasguñó a la nena. El miau escarbó a la infanta.. . Paráfrasis constructiva: Esta otra en cambio reelabora el enunciado dando origen a otro con características muy distintas conservando el mismo significado. Ejemplos: 1. Sólo el 30% de los estudiantes aprobó el examen. 2. La mayoría de los estudiantes desaprobaron el examen.. Otros versiones más recientes como es la presentada en (Barrón-Cedeño 2012), dividen las tipologías en 20 tipos agrupadas en 4 clases, (i) cambios basados en la morfología o el lexicón,.
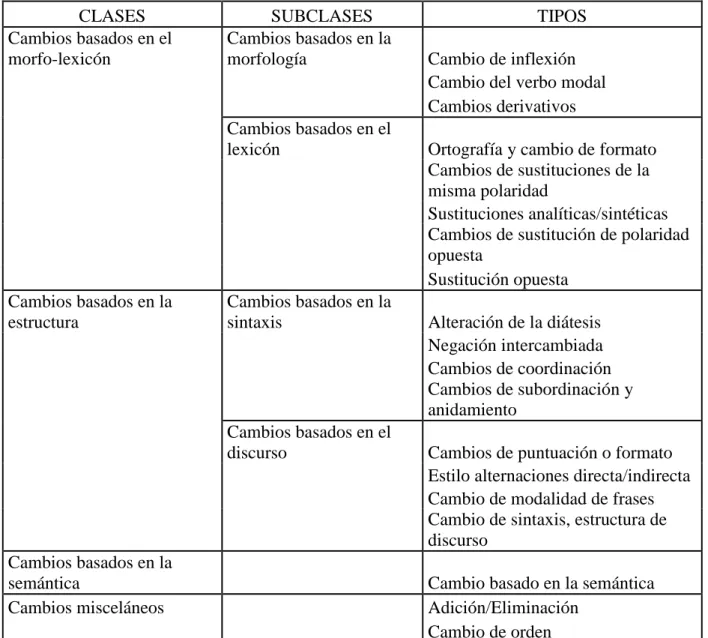
(23) (ii) basados en la estructura, (iii) basados en la semántica, (iv) y los cambios misceláneos y 4 subclases: morfológico, lexicón los cuales están contenidos dentro de la clase (i) y sintaxis, discurso que están presentes en la clase (ii) como se presenta en la Tabla 1.1: Visión general de las tipologías de paráfrasis, incluyendo 4 clases, 4sub-clases y 20 tipos.(Barrón-Cedeño 2012). CLASES Cambios basados en el morfo-lexicón. SUBCLASES Cambios basados en la morfología. Cambios basados en el lexicón. Cambios basados en la estructura. Cambios basados en la sintaxis. Cambios basados en el discurso. Cambios basados en la semántica Cambios misceláneos. TIPOS Cambio de inflexión Cambio del verbo modal Cambios derivativos Ortografía y cambio de formato Cambios de sustituciones de la misma polaridad Sustituciones analíticas/sintéticas Cambios de sustitución de polaridad opuesta Sustitución opuesta Alteración de la diátesis Negación intercambiada Cambios de coordinación Cambios de subordinación y anidamiento Cambios de puntuación o formato Estilo alternaciones directa/indirecta Cambio de modalidad de frases Cambio de sintaxis, estructura de discurso Cambio basado en la semántica Adición/Eliminación Cambio de orden. Tabla 1. 1: Visión general de las tipologías de paráfrasis. Cada uno de estos tipos va a presentar una particularidad en especial que los hacen diferenciarse los unos de los otros, aunque cabe destacar que normalmente es común observar los diferentes tipos entrelazados y no separados como los que vamos a mostrar a continuación,.
(24) los cuales se pueden encontrar más ejemplificados en (Isvani & Blanco 2015),(Barrón-Cedeño 2012; Abiertos et al. 2008; Barr & Valencia 2010; Parafrástico 2015). 1.3.1.. Morfo-Lexicón (Cambios basados en la morfología) Cambios de inflexión. Cuando se hace referencia a cambios de inflexión en el término lingüístico se consideran los cambios o modificaciones que sufre un lexema para expresar su posición en la estructura gramatical (Anon n.d.). Estos pueden ser vistos en el ejemplo siguiente: . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podrían. (inflexión). compilar los códigos. (+morfema del plural). en un pc no. estándar, y obtener el ejecutable.. Cambio del verbo modal Cambio del verbo modal: Son cambios de verbos modales que consumen modalidad. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se debería (verbo modal) compilar el código en un pc no estándar, y obtener el ejecutable. Cambios derivativos. Cambios derivativos: consisten en cambios de categoría con o sin usar afijos derivativos. Estos cambios le dan a entender un cambio sintáctico en la frase en la cual ocurren. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría compilando (derivación) el código en un pc no estándar, y obtener el ejecutable.. 1.3.2.. Morfo-Lexicón (Cambios basados en lexicón) Ortografía y cambios de formato.
(25) Ortografía y cambios de formato: comprenden cambia en la ortografía y formato de unidades léxicas. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría conpilar. (ortografía). el código en un PC. (formato). no estándar, y. obtener el ejecutable. Cambios de sustituciones de la misma polaridad Con cambios de sustituciones de la misma polaridad nos estamos refiriendo al cambio de una unidad léxica por otro con el mismo significado. Entre los mecanismos lingüísticos de este tipo, encontramos sinonimia, sustituciones/específicas generales, o alternaciones/aproximadas. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría compilar el código en un ordenador. (sinónimo)/igual polaridad. no. estándar, y obtener el ejecutable. Sustituciones analíticas/sintéticas. Las sustituciones/analíticas sintéticas consisten en cambiar estructuras sintéticas por estructuras analíticas, y viceversa. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría compilar el código fuente (+frase vacía) en un pc (-frase)/análisis-síntesis. Cambios de sustitución de polaridad opuesta. Cuando nos referimos a este tipo de paráfrasis podemos verla de dos formas: -. Cuando una unidad léxica es cambiada por su antónimo o complementario y otro cambio de polaridad ocurre dentro de la misma frase para mantener el significado de la misma como se muestra a continuación. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable..
(26) . Difícilmente. (antónimo)/polaridad opuesta. no. (+negación). se podría compilar el código en. un pc no estándar, y obtener el ejecutable. -. La otra forma de encontrarle es cuando hay un cambio de polaridad y sentido de los argumentos, ejemplo: . Yoel es el más fuerte de todos.. . Yoel es el menos débil de todos. Sustitución opuesta. Las sustituciones opuestas tienen lugar cuando una unidad léxica es cambiada por su par opuesto. Para mantener el mismo significado, una inversión de argumento tiene que ocurrir. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría desensamblar el ejecutable (inversión) en un pc no estándar, y obtener el código.. 1.3.3.. Estructura (Cambios basados en sintaxis) Alteración de la diátesis. El tipo de alternación de diátesis recoge esas alternaciones de diátesis en las cuales los verbos pueden participar, como la alternación de voz activa /pasivo ejemplo. . El guía atrajo nuestra atención hacia una pequeña mazmorra.. . Nuestra atención fue atraída por nuestro guía hacia una mazmorra. Negación intercambiada. La negación intercambiada consiste en cambiar la posición de la negación dentro de una frase. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría no compilar obtener el ejecutable.. (negación intercambiada). el código en un pc estándar, y.
(27) Cambios de coordinación Los cambios de coordinación consisten en cambios en cual uno de los integrantes de la pareja contienen coordinadas las unidades lingüísticas, y esta coordinación no está presente o cambia su posición y/o formina el otro miembro de la pareja. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría compilar el código en un pc no estándar. (coordinación).. Obteniéndose. el ejecutable. Cambios de subordinación y anidamiento El cambio de subordinación y anidamiento consiste en cambios en el cual los integrantes de la pareja no contienen una subordinación o elemento anidado, que no se presenten, o cambien su posición y/o forma dentro de otro miembro de la pareja. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría obtener el ejecutable. (subordinación),. al compilar el código en un. pc no estándar. 1.3.4.. Estructura (Cambios basados en discurso) Cambios de puntuación o formato. Los cambios de puntuación o formato consisten en cualquier cambio en la puntuación o formato de una frase (no de una unidad léxica). . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Se podría, fácilmente, (puntuación) compilar el código en un pc no estándar, y obtener el ejecutable. Estilo alternaciones directa/indirecta. Los estilos de alternaciones directas e indirectas consisten en cambiar el estilo directo por el indirecto y viceversa. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable..
(28) . “Obtengamos el ejecutable”, dijo al compilar el código en un pc no estándar. (alternar. estilo).. . “Ella es mía”, dijo en Gran Espíritu.. . El Gran Espíritu dijo que ella era suyo. Cambio de modalidad de frases. Cuando se hace referencia a este término se a los casos en los cuales hay un cambio de modalidad los cuales no son provocados por los verbos modales. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . ¿Se podría compilar fácilmente el código en un pc no estándar, y obtener el ejecutable? Cambio de sintaxis, estructura de discurso. Este tipo recoge una amplia variedad de reorganizaciones de sintaxis/discurso encontradas en los tipos en la sintaxis y las subclases analizados anteriormente. . ¡Cómo quedaría mirando él!. . ¡Él quedaría seguro con la mirada fija!. 1.3.5.. Semántico. Los cambios basados en semántica son esos que implican una lexicalización diferente de la misma unidad de contenido. Estos cambios afectan a más de una unidad léxica y una división bien definida de estas unidades en el mapeo entre los dos integrantes de la pareja de paráfrasis no son posibles. . Fácilmente se podría compilar el código en un pc no estándar, y obtener el ejecutable.. . Fácilmente se podría construir un binario en un procesador ejecutando funciones en un ensamblador..
(29) 1.3.6.. Misceláneos. Dentro de la clase misceláneos podemos encontrar varios tipos de paráfrasis como son el caso de la adición, eliminación y el cambio de orden. Adición/Eliminación Estos tipos consisten en eliminar y/o adicionar unidades léxicas y funcionales. Seguidamente se podrán observar diferentes ejemplos para los distintos casos de la eliminación. -. Eliminación de contenido no proporcional: Eliminación una o más piezas del contenido proporcional.. . Juan hizo un intento para dejar de fumar.. . Juan intentó dejar de fumar.. -. Cambio en la estructura argumental: Cambio en el tipo de argumento regido por el verbo. En el ejemplo, el verbo empezar exige una oración subordinada, en la forma parafrástica, se omite el predicado.. . Martí empezó a leer el libro.. . Martí empezó el libro. Cambio de orden. El cambio de orden incluye cualquier tipo de orden desde el nivel de palabra hasta el nivel de frase. Consiste en el cambio de orden de las piezas léxicas. . Antes de irse para su casa María pasó por la librería.. . María pasó por la librería antes de irse para su casa.. 1.4 EL PLN Como se puede observar en (Isvani & Blanco 2015) el PLN es una disciplina que surge para que la comunicación entre el hombre y la máquina resulte más fluida, para que sea la máquina la que se adapte al lenguaje del hombre y no al contrario. Su objetivo es el estudio de los problemas derivados de la generación y comprensión automática del lenguaje natural..
(30) Lo que busca esta disciplina es construir sistemas y mecanismos que permitan la comunicación entre las personas y las máquinas mediante lenguajes naturales, con el fin de lograr que los usuarios se comuniquen con el ordenador de la misma forma que lo harían con otro humano. En los últimos años son cuantiosos los estudios realizados en el campo del PLN y numerosas las ramas de investigación que han surgido, entre las que se destacan: traducción automática, resúmenes automáticos, implicación textual, desambiguación del sentido de las palabras y la detección de autoría. Niveles del lenguaje El uso de técnicas computacionales para el tratamiento de la paráfrasis no aportaría soluciones adecuadas sin una concepción profunda del fenómeno lingüístico (Isvani & Blanco 2015). Para el estudio del mismo es necesario conocer los niveles de la lengua (Castro Rolón et al. n.d.) que han definido diferentes autores como son, el caso del nivel morfológico, el nivel pragmático, sintáctico, semántico y nivel fonético. Estos distintos niveles se encuentran relacionados desde cierto punto con el PLN como se puede apreciar a continuación (Mario Alberich 2007)(Isvani & Blanco 2015): . Nivel fonético: Aplicable en el caso del reconocimiento de voz y de la síntesis de voz.. . Nivel morfológico: Aplicable cuando existen cambios mínimos en las palabras como son los cambios morfológicos.. . Nivel sintáctico: Aplicable en el momento de presenciar cómo se relacionan un conjunto de palabras en los subconjuntos de una frase.. . Nivel semántico: Aplicable a la hora de ver el significado de los términos.. . Nivel pragmático: Aplicable a la hora de interpretar la oración completa dentro de su contexto. Aborda el análisis del texto más allá de los límites de la oración para determinar, por ejemplo, los antecedentes referenciales de los pronombres.. Estos distintos niveles, se trabajan a la hora de elaborar distintas medidas para mejorar el estudio del PLN, como se pueden ver en las métricas de comparación que utiliza WordNet que se exponen en el capítulo siguiente, las cuales se encuentran presentes en los niveles.
(31) morfológicos, sintácticos y semántico; también se puede apreciar otros métodos que trabajan a niveles semánticos como es el caso de la medida de similitud coseno solo por citar un ejemplo. 1.5 Recursos La detección automática de paráfrasis como se puede apreciar en la figura siguiente cuenta con varias fases como son el pre-procesamiento, cálculo de similitud y el modelo de entrenamiento a usar; en cada una de estas fases se cuentan con varios tipos de recursos que nos van a ayudar a completar cada fase como es WordNet, base de datos léxica para el idioma inglés que unido con otras bibliotecas nos pueden ayudar en etapas como el pre-procesamiento y el cálculo de similitud, también tenemos los distintos corpus que trabajan en cálculo de similitud junto con las distintas medidas y por último tendríamos como otro recurso las máquinas de vectores de soporte o VSM que no es más que métodos de aprendizaje supervisado usados para la clasificación y regresión (Isvani & Blanco 2015).. Medidas. Corpus. Pre-procesamiento. Cálculo de similitud. Recursos Lingüística Computacional. Bibliotecas de Python. Figura 1. 1: Modelo de detección automática de paráfrasis. SVM. Modelo de clasificación de textos parafraseados.
(32) 1.5.1.. Lingüística computacional. 1.5.1.1.. WordNet. Otro de los importantes recursos sobre los que tenemos que referirnos es el que se observa en (Artículo 2015), WordNet. Este es una base de datos léxica para idioma inglés (Fellbaum 1998; Miller et al. 1990), que persigue dos objetivos principales: 1) Construir una combinación de diccionario y tesauro que sea intuitivo y fácil de utilizar. 2) Dar soporte a las tareas de análisis textual y PLN. La diferencia fundamental de WordNet respecto a otros sistemas con propósitos similares, radica en la organización del léxico en torno a cinco categorías: sustantivos, verbos, adjetivos, adverbios y elementos funcionales. WordNet utiliza los denominados synonym sets o synsets (conjuntos de elementos léxicos que pueden ser considerados sinónimos entre sí) para la representación de los conceptos, que pueden verse como grupos de elementos de datos semánticamente equivalentes. Un ejemplo de synset es {car, auto, automobile, machine, motorcar}. Al contrario de lo que ocurre con los diccionarios de sinónimos o tesauros tradicionales, un synset no tiene una palabra que actúa como identificador del conjunto. El significado del synset lo aportan pequeñas definiciones (glosas), que en ocasiones pueden ser ejemplos de oraciones que matizan el significado del concepto. Para el synset car, la glosa es “a motor vehicle with four wheels; usually propelled by an internal combustion engine” y el ejemplo de oración corta es “he needs a car to get to work”. Muchas palabras tienen más de un significado (sense) que se refiere a los distintos conceptos o acepciones. Considerando la palabra bridge, el significado más común de esta palabra en el uso general es “a structure that allows people or vehicles to cross an obstacle such as a river, canal, railway, and so on”. Sin embargo, existen otros significados, tales como “the bridge of the nose y the bridge card game”. Los conceptos están contenidos en diferentes synset, lo cual significa que la misma palabra puede aparecer en varios. WordNet::Similarity Como se puede apreciar en (Pedersen et al. 2004) el propósito de las métricas que implementa este paquete es dar una medida cuantitativa de la similitud entre dos palabras. Esto es útil para la tarea de detección de paráfrasis, pues si un par de oraciones comparten muchas palabras.
(33) similares, se podría suponer que sería un buen indicador de que tienen un significado análogo en su conjunto. Es importante hacer algunas aclaraciones con respeto a las métricas de similitud basadas en las relaciones de WordNet. En efecto, tiene en cuenta las similitudes entre los conceptos (significado de las palabras) en lugar de palabras, puesto que una palabra puede tener más de un significado. Las métricas de similitud semántica trabajan sobre pares sustantivo-sustantivo y verbo-verbo, pues estas estructuras sintácticas se pueden organizar en jerarquías es un. Así, las similitudes pueden ser encontradas cuando ambas palabras estén en esta categoría, por ejemplo, los sustantivos perro y gato, y los verbos correr y caminar. Estas medidas cuantifican cuán similar es un concepto (synset) A a otro B. Por ejemplo, una métrica de esta categoría determinaría que un gato es más parecido a un perro que a una silla, puesto que gato y perro comparten el ancestro carnívoro en la jerarquía de sustantivos de WordNet (Figura 1.2). Aunque WordNet incluye adjetivos y adverbios, no están organizados en una jerarquía es un, por lo que las medidas de similitud no pueden ser aplicadas.. Figura 1. 2: Extracto de la jerarquía de WordNet. Los conceptos pueden relacionarse de varias formas, además de la similitud de unos con otros. Incluyen las relaciones parte de (rueda y carro), así como también antítesis (noche y día), y así sucesivamente. Las medidas de relación (relatedness) hacen uso de este adicional, las relaciones no-jerárquicas en WordNet comprenden las glosas y los synset. Como tal, pueden ser aplicados a una amplia gama de pares de conceptos, abarcando palabras de diferentes partes de la oración, como asesino y arma. Las métricas del recurso WordNet::Similarity se ponen a disposición como un conjunto de módulos del lenguaje de programación Perl. De hecho, el nombre del módulo se podría.
(34) considerar impreciso, puesto que contiene tres métricas para medir la relación y seis para la similitud. 1.5.1.2.. TF-IDF. El modelo de representación TF-IDF es un modelo de representación que expresa cuan relevante es una palabra para un documento en una colección. Esta función se utiliza a menudo como un factor de ponderación en la recuperación de la información y la minería de textos (Citizens n.d.). Este es un modelo ampliamente utilizado para el cálculo de similitud, a la hora de dar una representación numérica a las palabras como se puede ver en el capítulo 2 en las distintas medidas que hacen medidas de este modelo. La ponderación tf (term frecuency) consiste en que cada elemento. se define en función de. la frecuencia de la palabra i en el documento d. Trabajos posteriores intentaron incluir una medida de especificidad de la palabra (con palabras más específicas por ser un mejor indicador del contenido del documento que las palabras comunes). “La ponderación idf modela esto en función de la cantidad de documentos donde aparece la palabra y la cantidad total de documentos. Así la combinación de ponderaciones da la ponderación tf-idf” (Spärck Jones 1972):. Figura 1. 3: Forma general de algoritmo tf-idf. donde: . es el número de veces que la palabra i aparece en el documento j. N es la cantidad total de documentos en la colección. es el número de documentos en que la palabra i aparece..
(35) Algunas variaciones del método de la similitud coseno han sido estudiadas para la detección de paráfrasis. El factor variable en estos métodos es la función de ponderación aplicada a cada palabra en el vector: . cosSim: métrica de similitud del coseno no ponderada.. . cosSimTF: métrica de similitud del coseno ponderada tf. . cosSimTFIDF: métrica de similitud del coseno ponderada tf-idf.. 1.5.1.3.. Treebank. Como se puede apreciar en (Frank et al. 2012) Treebanks son recursos lingüísticos que proporcionan las anotaciones en los distintos niveles de la estructura lingüística a partir del nivel de la palabra. Por lo general proporcionan estructuras sintácticas constitutivos o la dependencia de frases, sino que cada vez se extienden más allá de la anotación de la estructura sintáctica, incluyendo la anotación semántica, pragmática y retórica, o van más allá de un solo idioma, como en Treebanks paralelas. La experiencia en la construcción de Treebanks ha demostrado que existe una estrecha relación entre la teoría lingüística formal y el diseño y la práctica de la anotación. Con el aumento de la complejidad de las anotaciones, el diseño de esquemas de anotación se vuelve más y más la teoría dependiente. Al mismo tiempo, las anotaciones Treebanks motivadas lingüísticamente se han convertido de vital importancia para el desarrollo de enfoques basados en datos de procesamiento del lenguaje natural y para la investigación lingüística en general. Por lo tanto, Treebanks constituyen un importante vínculo entre la teoría lingüística y lingüística computacional. 1.5.1.4.. N-gramas. Como bien se expresa en (Anon n.d.) un n-grama es una subsecuencia de n elementos de una secuencia dada. El estudio de los n-gramas es interesante en diversas áreas del conocimiento. Por ejemplo, es usado en el estudio del lenguaje natural, en el estudio de las secuencias de genes y en el estudio de las secuencias de aminoácidos. “La forma en la que extraemos los gramas se tiene que adaptar al ámbito que estamos estudiando y al objetivo que tenemos en mente. Por ejemplo en el estudio del lenguaje natural.
(36) podríamos construir los n-gramas sobre la base de distintos tipos de elementos como por ejemplo fonemas, sílabas, letras, palabras.” “Los n-gramas se emplean en diversas áreas de la informática, lingüística computacional, y matemática aplicada. Son una técnica comúnmente empleada para diseñar núcleos que permiten a algoritmos automáticos de aprendizaje extraer datos a partir de cadenas de texto. También pueden emplearse para realizar eficientemente encajes por aproximación. Convirtiendo una secuencia de elementos en un conjunto de n-gramas, éste puede introducirse en un espacio vectorial (en otras palabras, representarse como un histograma), permitiendo así a la secuencia compararse con otras secuencias de una manera eficiente.” 1.5.2.. Bibliotecas de Python. Las bibliotecas en Python son otros de los fuertes recursos con los que se cuenta para la detección automática de paráfrasis por la gran variedad de herramientas que brindan. A continuación se describen las principales bibliotecas con algoritmos para idioma inglés y español. 1.5.2.1.. NLTK. Como bien se expresa en (Bird et al. 2008) NLTK es una plataforma líder para la creación de programas de Python para trabajar con los datos del lenguaje humano. Proporciona interfaces fáciles de usar para más de 50 corpus y recursos léxicos como WordNet, junto con un conjunto de bibliotecas de procesamiento de texto para la clasificación, tokenización, derivado, etiquetado, análisis y de razonamiento semántico, contenedores para las bibliotecas de PNL de potencia industrial, y un activo foro de discusión . Gracias a una guía práctica en la introducción de fundamentos de programación junto con temas de lingüística computacional, además de una amplia documentación de la API, NLTK es adecuado para los usuarios de los lingüistas, ingenieros, estudiantes, educadores, investigadores y la industria por igual. NLTK está disponible para Windows, Mac OS X y Linux. Lo mejor de todo, NLTK es un código abierto, libre proyecto, impulsado por la comunidad..
(37) Todo esto hace que este kit de herramientas de lenguaje natural esté destinado a apoyar la investigación y la enseñanza en PLN o áreas muy relacionadas, que incluyen la lingüística empírica, las ciencias cognitivas, la inteligencia artificial, la recuperación de información, y el aprendizaje de la máquina.3 NLTK se ha utilizado con éxito como herramienta de enseñanza, como una herramienta de estudio individual, y como plataforma para los sistemas de investigación de prototipos y construcción como se expresó en (Bird et al. 2008). 1.5.2.2.. Pattern. Pattern es un paquete para Python utilizado para la minería de Web, el procesamiento de lenguaje natural, el aprendizaje de máquina y el psicoanálisis de gráfico. Como se puede apreciar en (Smedt 2012) el paquete aspira a ser útil para una audiencia científica y no científica. Entre las herramientas con que cuenta se encuentran: . Minería de datos: servicios web (Google, Twitter, Wikipedia), rastreador web, HTML DOM analizador.. . Procesamiento del Lenguaje Natural: etiquetadores parte-de-voz, n-grama de búsqueda, análisis de sentimientos, WordNet. . Machine Learning: Vector modelo de espacio, el agrupamiento, clasificación (KNN, SVM, Perceptron). . Análisis de Redes: centralidad gráfica y visualización.. 1.5.2.3.. Ixa-pipe-srl. Ixa es una poderosa herramienta de procesamiento del lenguaje natural que proporciona fácil acceso a la tecnología de la PNL para varios idiomas. Ixa-pipe-srl proporciona una envoltura de analizador de dependencias y etiquetadora papel semántico para el idioma español e inglés (Smedt 2012). 1.5.2.4.. Gensim. Gensim es una biblioteca de Python para el tema del modelado, indexación y recuperación de documentos similitud con grandes corpus. Su objetivo es el procesamiento del lenguaje natural.
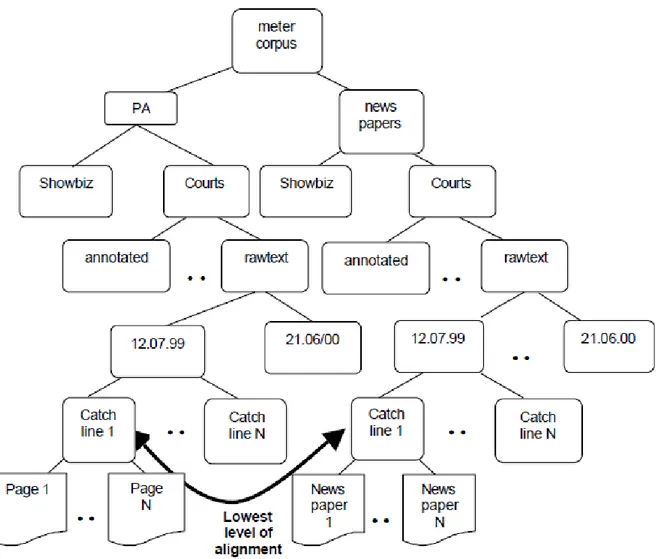
(38) (NLP) y la recuperación de información (IR) (Anon n.d.). Esta biblioteca contiene varias implementaciones de varios núcleos eficientes de algoritmos populares, tales como el análisis semántico latente en línea (LSA / LSI / SVD), la asignación de Dirichlet latente (LDA), proyecciones aleatorias (RP), proceso jerárquico de Dirichlet (HDP) o el aprendizaje profundo word2vec (Řehůřek 2011). 1.5.2.5.. Jellyfish. Jellyfish es una biblioteca de Python para hacer la correspondencia aproximada y fonética de las cadenas (Anon n.d.). Esta cuenta con varios algoritmos de comparación de cadenas como son: . Levenshtein Distance. . Damerau-Levenshtein Distance. . Jaro Distance. . Jaro-Winkler Distance. . Match Rating Approach Comparison. . Hamming Distance. y de codificación fonética como: . American Soundex. . Metaphone. . NYSIIS (New York State Identification and Intelligence System). . Match Rating Codex. 1.5.3.. Corpus para pruebas y entrenamientos de modelos inteligentes. 1.5.3.1.. Corpus METER. El objetivo del corpus METER fue investigar cómo el texto proveniente de agencias de noticias es reutilizado en la producción de artículos de periódicos y determinar si algoritmos pueden detectar y cuantificar automáticamente tal reutilización. Esta reutilización no conforma propiamente un plagio, pues los departamentos de redacción de los periódicos pagan cuotas a.
(39) las agencias de noticias para poder utilizar libremente todos estos materiales. El corpus consiste en una colección de artículos de periódico y textos de agencias de noticias que informaron sobre los mismos temas, en algunos casos los artículos se derivaron de los textos de las agencias y en otros no. Las limitaciones de recursos del proyecto METER influyeron en que los textos se restringieran a dos dominios: eventos judiciales y el mundo del espectáculo. En total existen 1 430 textos judiciales y 287 textos del mundo del espectáculo (Gaizauskas et al. 2001). Los artículos fueron seleccionados de forma manual durante el período de un año a partir de la información publicada por nueve periódicos británicos (The Sun, Daily Mirror, Daily Star, Daily Mail y otros cinco). Los textos de agencias de noticia fueron tomados de la organización Press Association (PA) que entrega noticias a los clientes de los medios de comunicación de todo el Reino Unido. “Una cuestión importante en la construcción del corpus fue la decisión de utilizar una estructura apropiada para almacenar la información, con el propósito de facilitar al humano y la máquina acceso a estos”(Gaizauskas et al. 2001). En el corpus, los textos son organizados en una estructura arbórea, de manera que los textos de la PA se ubican en una subcarpeta en correspondencia con otra donde se encuentran los artículos de periódico con el mismo origen, tema y fecha de publicación. Esta estructura proporciona una identificación única de los textos dentro del corpus. La figura 2 muestra la estructura global de corpus METER (Gaizauskas et al. 2001)..
(40) Tabla 1. 2: Estructura general del corpus METER. 1.5.3.2.. Corpus MSRPC. Microsoft Research Paraphrase Corpus (MSRPC) es un corpus creado a partir de noticias agrupadas de acuerdo a la época y el tema y contiene miles de pares de oraciones que describen hechos similares, tomados de fuentes de noticias de la web (Dolan et al. 2004). Estos pares han sido revisados por jueces humanos para indicar si las oraciones son semánticamente equivalentes o no. Este corpus tuvo como objetivo crear un corpus monolingüe de dominio amplio de pares de oraciones alineadas (Dolan et al. 2004). El MSRPC en un principio reunió más de 100 000 artículos, agrupados aproximadamente en 11000 porciones..
Figure

+7



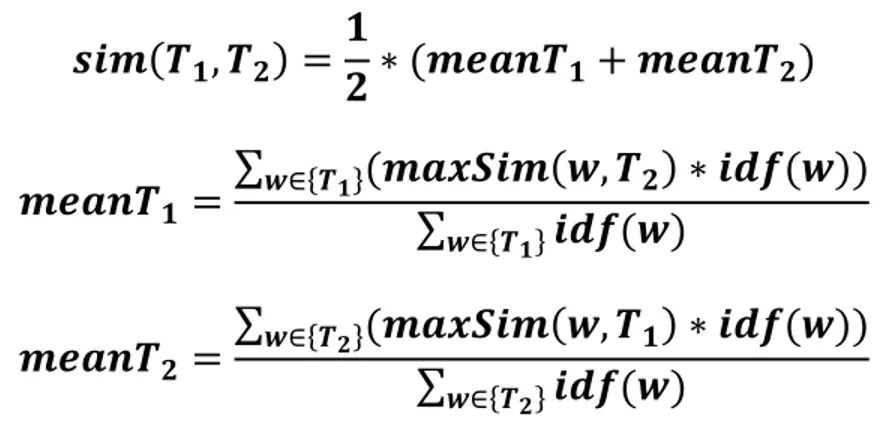

Documento similar