Combinación de medidas de diversidad en sistemas multiclasificadores utilizando Lógica Borrosa
106
0
0
Texto completo
(2) DICTAMEN. El que subscribe, Joaquin Artiles Morales, hago constar que el trabajo titulado “Combinación de medidas de diversidad en sistemas multiclasificadores utilizando Lógica Borrosa” fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de los estudios de la especialidad de Ciencia de la Computación, autorizando a que el mismo sea utilizado por la institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos ni publicado sin la autorización de la Universidad.. ____________________ Firma del autor. Los abajo firmantes, certificamos que el presente trabajo ha sido realizado según acuerdos de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. ____________________. ____________________. Firma del tutor. Firma del Jefe de Seminario. ____________________ Fecha. i.
(3) DEDICATORIA. A mi familia que lo es todo en esta vida y aquellos que creen en mí.. ii.
(4) AGRADECIMIENTOS Gracias a la revolución por darnos la oportunidad de estudiar, a mis amigos y familiares por el apoyo incondicional en los distintos momentos de mi carrera, a los excelentes profesores que enseñan y transmiten todo su conocimiento.. iii.
(5) PESAMIENTO. “Sólo tengo por seguro lo que es incierto” François Villon. “Es imposible aprender sobre lo que se cree saber” Epicteto. iv.
(6) RESUMEN Las técnicas de clasificación hoy en día se están utilizando en la solución de diferentes problemas de la sociedad. Existen varios modelos de clasificación reportados en la literatura como las redes neuronales, árboles de clasificación, análisis discriminante, entre otros. En investigaciones recientes muchos autores introducen el término multiclasificador como un “clasificador” que combina las salidas de un conjunto de clasificadores individuales, utilizando algún criterio (ej.; promedio, voto mayoritario, mínimo, etc.). Cuando se combinan clasificadores es importante garantizar la diversidad entre ellos ya que no tendría sentido combinar clasificadores cuya clasificación es la misma. Existen varios modelos para construir un multiclasificador y todos garantizan esta diversidad de diferentes formas. En el caso de aquellos que usan distintos clasificadores bases, existen algunas medidas estadísticas que pueden ser usadas para estimar cuán diversos son, las cuales son llamadas medidas de diversidad. La selección de los distintos clasificadores bases para un sistema multiclasificador es una tarea compleja, precisamente por las grandes cantidades de clasificadores individuales y las múltiples combinaciones que ellos pueden generar, ante este problema combinatorio se propone el uso de las meta heurísticas, con las medidas de diversidad para obtener una combinación de clasificadores diversos y una exactitud en la combinación superior a la mejor individual. El curso pasado se desarrolló la investigación (Hernández, 2014), en la que se usaron específicamente los Algoritmos Genéticos para lograr lo explicado anteriormente, como resultado de la misma se obtuvo la primera versión de un sistema llamado: Splicing v1.2. En dicho software se propuso la combinación de las medidas de diversidad mediantes varios operadores, uno de ellos es un operador borroso (Fuzzy), donde solo se utilizó una función de pertenencia. En este trabajo se realizan las modificaciones necesarias sobre ese sistema para obtener una versión más completa donde se incorporan varias funciones de pertenencia para seleccionar cuál de ellas ofrece los mejores resultados. Además se proponen nuevos criterios de comparación para la combinación de las salidas de estas funciones, se diseñaron experimentos aplicando varias pruebas estadísticas para proponer la mejor función de pertenencia y el mejor v.
(7) criterio. Se realiza una comparación con todos los operadores donde los mejores resultados se obtienen con el operador borroso. Finalmente, se muestra una aplicación en el campo de la Bioinformática.. vi.
(8) ABSTRACT Classification techniques today are being used in solving several problems of society. There are several classification models reported in the literature: neuronal networks, classification trees, discriminant analysis, among others. In recent research many authors introduced the term multi-classifier, as a "classifier" which combines the outputs of a set of individual classifiers, using some criterion (e.g. average, a majority vote, minimum, etc.). When combining classifiers is important to ensure diversity among them, because it would not make sense to combine classifiers whose rating is the same. There are several models to build a multi-classifier and all these guarantee this diversity in different forms. In the case of those using different base classifiers, there are some statistical measures that can be used to estimate how diverse they are, which are called diversity measures. The selection of the different base classifiers for a multiclassifier system is a complex task, precisely because of the large amount of individual classifiers and multiple combinations that they can generate. The use of metaheuristics is proposed in order to deal with this combinatorial problem, with the diversity measures for a combination of different classifiers and an accuracy in the combination superior to the single best. Last year a research was developed (Hernández, 2014), which specifically used Genetic Algorithms to achieve the explained above, and the result was the first version of a system called: Splicing v1.2. In that software was proposed to combine diversity measures through several operators one of which is a fuzzy operator, where only a membership function was used. In this work, the necessary modifications to the system are made to obtain a more complete version, where several membership functions are incorporated to select which one provides the best results. Besides, new criteria for combining the outputs of these functions are proposed, experiments were designed using various statistical tests to propose the best membership function and the best criterion. There is performed a comparison with all operators where the best results are obtained with the fuzzy operator. Finally, an application is shown in the field of Bioinformatics.. vii.
(9) TABLA DE CONTENIDOS. TABLA DE CONTENIDOS RESUMEN .................................................................................................................................. v ABSTRACT ............................................................................................................................. vii INTRODUCCIÓN ....................................................................................................................... 1 CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA .................................................................................................................. 5 1.1. Métodos de Clasificación .............................................................................................. 5. 1.1.1. Algoritmos basados en casos ................................................................................. 6. 1.1.2. Árboles de decisión ............................................................................................... 7. 1.1.3. Redes bayesianas ................................................................................................... 7. 1.1.4. Redes neuronales artificiales ................................................................................. 8. 1.1.5. Análisis Discriminante .......................................................................................... 9. 1.1.6. Regresión logística ................................................................................................ 9. 1.2. Modelos de construcción de multiclasificadores ........................................................ 10. 1.3. Medidas de diversidad como criterio para seleccionar los clasificadores de base ..... 12. 1.3.1. Medidas de diversidad en forma de pares (pairwise) .......................................... 13. 1.3.1.1. Coeficiente de correlación (ρ) ......................................................................... 14 1.3.1.2. El estadístico Q ............................................................................................... 14 1.3.1.3. Medida de diferencias ..................................................................................... 14 1.3.1.4. Medida de doble fallo ..................................................................................... 15 1.3.1.5. Combinación de la medida de diferencia y medida de doble fallo ................. 15 1.3.2. Medidas de diversidad para todo el conjunto (nonpairwise) ............................... 15. 1.3.2.1. Entropía ........................................................................................................... 15 1.3.2.2. Varianza de Kohavi-Wolpert .......................................................................... 16 1.3.2.3. Medida de desacuerdo entre expertos ............................................................. 16 1.3.2.4. Medida de dificultad ....................................................................................... 17 1.3.2.5. Medida de diversidad generalizada ................................................................. 17 1.3.2.6. Medida de diversidad de coincidencia de fallos ............................................. 18.
(10) TABLA DE CONTENIDOS. 1.3.2.7. Medida de diversidad de distintos fallos......................................................... 18 1.3.2.8. Medida de la diversidad global ....................................................................... 19 1.3.2.9. Medida de variabilidad ................................................................................... 20 1.4. Combinación de varias medidas de diversidad ........................................................... 21. 1.4.1. Estandarización de las Medidas de Diversidad ................................................... 21. 1.4.2. Agrupamiento de las medidas en un solo valor ................................................... 21. 1.5. Evaluación de la clasificación ..................................................................................... 22. 1.6. Teoría de la Lógica Difusa.......................................................................................... 23. 1.6.1. Conjunto difuso ................................................................................................... 24. 1.6.1.1 Definiciones básicas sobre conjuntos borrosos ............................................... 26 1.6.2. Intervalos de confianza y números borrosos ....................................................... 29. 1.6.2.1 Intervalos de confianza .................................................................................... 29 1.6.2.2 Números borrosos ............................................................................................ 30 1.6.3. Función de pertenencia ........................................................................................ 32. 1.6.4. Tipos de funciones de pertenencia....................................................................... 33. 1.7. Consideraciones finales del capítulo ........................................................................... 36. CAPITULO 2: DISEÑO E IMPLEMENTACIÓN SOBRE EL SOFTWARE SPLICING V1.3 ................................................................................................................................................... 37 2.1. Diseño e implementación del software Splicing V1.2 ................................................ 37. 2.2. Modificaciones sobre el software ............................................................................... 39. 2.2.1. Diseño e implementación de las nuevas funciones de pertenencia ..................... 41. 2.2.1.1 Función de pertenencia Triangular .................................................................. 41 2.2.1.2 Función de pertenencia Gaussiana ................................................................... 42 2.2.1.3 Función de pertenencia Pseudo_Exponencial.................................................. 43 2.2.1.4 Función de pertenencia Trapezoidal ................................................................ 43 2.2.1.5 Función de pertenencia S ................................................................................. 44 2.2.1.6 Función de pertenencia Gamma ...................................................................... 45 2.2.2 Diseño e implementación de los nuevos criterios para combinar las salidas de las funciones de pertenencia .................................................................................................... 45 2.2.2.1 Mediana ........................................................................................................... 46.
(11) TABLA DE CONTENIDOS. 2.2.2.2 Razón ............................................................................................................... 46 2.2.3. Algoritmo del operador Fuzzy............................................................................. 47. 2.2.4. Diagramas de Casos de Uso y diagrama de clases del paquete DiversityMeasure 48. 2.2.5. Transformaciones en la interfaz visual para incluir nuevas funcionalidades ...... 50. 2.3. Consideraciones finales del capítulo ........................................................................... 51. CAPITULO 3: DISEÑO DE EXPERIMENTOS Y ANÁLISIS DE SUS RESULTADOS. APLICACIÓN EN PROBLEMAS DE BIOINFORMÁTICA. ................................................. 52 3.1. Descripción general de los experimentos ................................................................... 52. 3.2. Análisis Univariado .................................................................................................... 53. 3.2.1. Resultados de las Funciones de Pertenencias ...................................................... 54. 3.2.2. Resultados de los Criterios de Comparación ....................................................... 60. 3.2.3. Resultados de las Medidas de Diversidad ........................................................... 66. 3.2.4. Estudio sobre las Reglas de combinación para las medidas ................................ 69. 3.3. Análisis Multivariado ................................................................................................. 74. 3.4. Comparación entre el operador borroso (Fuzzy) y el Promedio ................................ 78. 3.5. Aplicación real en la Bioinformática .......................................................................... 81. 3.5.1 3.6. Discusión de los resultados ................................................................................. 84. Consideraciones finales del capítulo ........................................................................... 84. CONCLUSIONES ..................................................................................................................... 85 RECOMENDACIONES ........................................................................................................... 86 BIBLIOGRAFÍA ....................................................................................................................... 87 ANEXOS ................................................................................................................................... 90.
(12) LISTA DE FIGURAS. LISTA DE FIGURAS Figura 1: Altura, núcleo, conjunto soporte y α-corte de un conjunto borroso A ...................... 28 Figura 2: Número ordinario A [a1 , a3 ] dado por un intervalo de confianza ......................... 30 Figura 3: Número borroso A. [ a1 , a 2 , a 3 ] ................................................................................. 30. Figura 4: Forma general de un número borroso ........................................................................ 32 Figura 5: Función de pertenencia correspondiente a una medición de temperatura. ................ 32 Figura 6: Representación analítica y gráfica de la función de pertenencia Triangular ............. 33 Figura 7: Representación analítica y gráfica de la función de pertenencia Gamma.................. 33 Figura 8: Representación analítica y gráfica de la función de pertenencia S ............................ 34 Figura 9: Representación analítica y gráfica de la función de pertenencia Gaussiana .............. 34 Figura 10: Representación analítica y gráfica de la función de pertenencia trapezoidal .......... 35 Figura 11: Representación analítica y gráfica de la función de pertenencia Pseudo-Exponencial ................................................................................................................................................... 35 Figura 12: Modelación de la función Triangular ....................................................................... 42 Figura 13: Modelación de la función Gaussiana ....................................................................... 42 Figura 14: Modelación de la función Pseudo_Exponencial ...................................................... 43 Figura 15: Modelación de la función Trapezoidal .................................................................... 44 Figura 16: Modelación de la función S ..................................................................................... 44 Figura 17: Modelación de la función Gamma ........................................................................... 45 Figura 18: Cálculo de la Mediana ............................................................................................. 46 Figura 19: Cálculo de la Razón ................................................................................................. 47 Figura 20: Diagrama de Clases del Paquete DiversityMeasure ................................................ 49 Figura 21: Diagrama de Casos de Uso ...................................................................................... 48 Figura 22: Versión del software Splicing v1.2, sin selección de función de pertenencia y criterios de comparación ........................................................... ¡Error! Marcador no definido. Figura 23: Versión del software Splicing v1.3, con selección de función de pertenencia ........ 50 Figura 24: Versión del software Splicing v1.3, con selección del criterio de comparación ..... 51.
(13) TABLA DE CONTENIDOS. Figura 25: Valores de las funciones de pertenencia según la exactitud .................................... 56 Figura 26: Valor de la función de pertenencia según la diversidad........................................... 56 Figura 27: Valor de la función de pertenencia según la función objetivo ................................. 57 Figura 28: Valores de los criterios de comparación según la exactitud .................................... 62 Figura 29: Valores de los criterios de comparación según la diversidad .................................. 62 Figura 30: Valores de los criterios de comparación según la función objetivo ......................... 63 Figura 31: Valores de las medidas según la exactitud ............................................................... 68 Figura 32: Valores de las medidas según la diversidad ............................................................. 68 Figura 33: Valores de las medidas según la función objetivo ................................................... 69 Figura 34: Valores de las reglas de combinación según la exactitud ........................................ 71 Figura 35: Valores de las reglas de combinación según la diversidad ...................................... 71 Figura 36: Valores de las reglas de combinación según la función objetivo ............................ 72 Figura 37: Árbol que utiliza la variable Medida para predecir diversidad ................................ 75 Figura 38: Árbol que utiliza la variable Medida para predecir función objetivo ...................... 75 Figura 39: Árbol que utiliza las variables Criterio de Comparación y Medida, para predecir función objetivo ......................................................................................................................... 76 Figura 40: Árbol que utiliza las variables Función de Pertenencia y Medida, para predecir función objetivo ......................................................................................................................... 77 Figura 41: Árbol que utiliza las variables Función de Pertenencia, Medida y Criterio de Comparación para predecir función objetivo ........................................................................... 78 Figura 42: Valores de las reglas de combinación Promedio y Fuzzy según la exactitud .......... 80 Figura 43: Valores de las reglas de combinación Promedio y Fuzzy según la diversidad ........ 80 Figura 44: Valores de las reglas de combinación Promedio y Fuzzy según la diversidad ........ 81.
(14) LISTA DE TABLAS. LISTA DE TABLAS Tabla 1. Resultados de los clasificadores Ci y Cj para una instancia ...................................... 13 Tabla 2. Resultados de los clasificadores Ci y Cj para todo el conjunto de instancias ........... 13 Tabla 3. Matriz de incidencia para un sistema con cinco clasificadores ................................... 20 Tabla 4.Características de las bases del Repositorio de la UCIML utilizadas en los experimentos.............................................................................................................................. 52 Tabla 5: Rango de las funciones de pertenencias según resultados del test de Friedman ......... 54 Tabla 6: Estadísticos de Contraste(a,b) de la prueba de Friedman respecto a Tabla 5 ............. 55 Tabla 7: Rango de la función Trapezoidal y función Triangular según los resultados de Wilcoxon utilizando exactitud. .................................................................................................. 58 Tabla 8: Rango de la función Trapezoidal y función Gaussiana según los resultados de Wilcoxon utilizando exactitud ................................................................................................... 58 Tabla 9: Rango de la función Trapezoidal y función S según los resultados de Wilcoxon utilizando exactitud.................................................................................................................... 59 Tabla 10: Rango de la función Gamma y función Pseudo-Exponencial según los resultados de Wilcoxon utilizando diversidad ................................................................................................. 59 Tabla 11: Rango de la función Gamma y función Pseudo-Exponencial según los resultados de Wilcoxon utilizando función objetivo ....................................................................................... 60 Tabla 12: Rango de los criterios de comparación según resultados del test de Friedman ........ 61 Tabla 13: Estadísticos de Contraste(a,b) de la prueba de Friedman respecto a la Tabla 12..... 61 Tabla 14: Rango de los criterios Razón y Promedio según los resultados de Wilcoxon utilizando exactitud.................................................................................................................... 64 Tabla 15: Rango de los criterios Razón y Mediana según los resultados de Wilcoxon utilizando exactitud.................................................................................................................... 64 Tabla 16: Rango de los criterios Razón y Promedio según los resultados de Wilcoxon utilizando diversidad ................................................................................................................. 64 Tabla 17: Rango de los criterios Razón y Promedio según los resultados de Wilcoxon utilizando la función objetivo .................................................................................................... 65 Tabla 18: Rango de los criterios Razón y Mediana según los resultados de Wilcoxon utilizando la función objetivo .................................................................................................... 65.
(15) LISTA DE TABLAS. Tabla 19: Rango de las medidas de diversidad según resultados de Wilcoxon con la exactitud ................................................................................................................................................... 66 Tabla 20: Rango de las medidas de diversidad según resultados de Wilcoxon con diversidad 67 Tabla 21: Rango de las medidas de diversidad según resultados de Wilcoxon con la función objetivo ...................................................................................................................................... 67 Tabla 22: Rango de las reglas de combinación según resultados de Friedman ......................... 70 Tabla 23: Estadísticos de Contraste(a,b) de la prueba Friedman según Tabla 20 .................... 70 Tabla 24: Rango de las reglas Máximo y Promedio según los resultados de Wilcoxon y utilizando exactitud.................................................................................................................... 73 Tabla 25: Rango de las reglas Máximo y Promedio según los resultados de Wilcoxon y utilizando diversidad ................................................................................................................. 73 Tabla 26: Rango de las reglas Máximo y Promedio según los resultados de Wilcoxon utilizando la función objetivo .................................................................................................... 73 Tabla 27: Rango de las reglas de combinación Promedio y Fuzzy según resultados de Wilcoxon con diversidad ........................................................................................................... 79 Tabla 28: Rango de las reglas de combinación Promedio y Fuzzy según resultados de Wilcoxon con función objetivo ................................................................................................. 79 Tabla 29: Estadísticos descriptivos de la base de interacción de proteínas ............................... 83 Tabla 30: Resultados obtenidos al aplicar AG en la base de interacción de proteínas.............. 84 Tabla 31: Conjunto de clasificadores del primer experimento .................................................. 90 Tabla 32: Conjunto de clasificadores del segundo experimento ............................................... 90 Tabla 33: Conjunto de clasificadores del tercer experimento ................................................... 91.
(16) INTRODUCCIÓN. INTRODUCCIÓN Las técnicas de clasificación están cobrando particular importancia en la actualidad debido a la gran cantidad de problemas que ellas resuelven. Estas técnicas se dividen en dos grandes grupos: uno de ellos son los modelos de clasificación individuales como las redes neuronales, redes bayesianas, árboles de decisión, análisis discriminante, regresión logística etc. y el otro grupo está constituido por los sistemas multiclasificadores. Un multiclasificador es un sistema que combina las salidas de un conjunto de clasificadores individuales, utilizando algún criterio (ej. promedio, voto mayoritario, mínimo, máximo, etc.) y obtiene una salida. Se desea combinar de manera efectiva aquellos clasificadores que, integrados en un multiclasificador, superen la exactitud del mejor de ellos. Para ello se deben combinar clasificadores diversos entre sí (KUNCHEVA, 2004). En la actualidad existen numerosas medidas estadísticas reportadas en la literatura por diferentes autores que cuantifican la diversidad entre un conjunto de clasificadores bases, ellas se denominan Medidas de Diversidad. La forma de combinación de estas medidas y su integración en un sistema multiclasificador es un tema actual y relevante. Por otra parte, la Lógica Borrosa es una disciplina relativamente nueva que brinda un tratamiento matemático riguroso a términos permeados de subjetividad, y consecuentemente se obtienen resultados muy precisos. La mayoría de los fenómenos que ocurren a diario son imprecisos en la descripción de su naturaleza. Esta imprecisión puede estar asociada con su forma, posición, momento, color o textura entre otros elementos. En muchos casos el mismo concepto puede tener diferentes grados de imprecisión en diferentes contextos o en el tiempo. La definición exacta de cuando la temperatura pasa de fría a caliente es imprecisa, pues resulta imposible identificar un punto de corte tal que al realizar una variación de sólo un grado, la temperatura del ambiente pase de ser considerada fría a caliente. Este tipo de imprecisión o borrosidad asociado continuamente a los fenómenos, es común en casi todos los campos de estudio: sociología, física, biología, finanzas, ingeniería, y psicología entre muchos otros (Aranguren, 2003). 1.
(17) INTRODUCCIÓN. El software Splicing v1.2 fue creado como resultado de la investigación realizada en (Hernández, 2014) . Este software se usa para encontrar una combinación de clasificadores que asegure simultáneamente una mayor exactitud en los resultados de la clasificación y la diversidad entre los clasificadores seleccionados, esto se logra mediante el uso de una de las meta heurísticas existentes: los Algoritmos Genéticos. Este software consta de cinco áreas fundamentales: Información general, Configuración de la clasificación, Medidas de Diversidad, Configuración del Algoritmo Genético y Resultados de la ejecución del algoritmo. En el área Medidas de Diversidad, como resultado de la misma investigación anterior, se propuso la combinación de medidas mediante un operador que utiliza la lógica borrosa, en el cual solo se encuentra programada la función de pertenencia triangular, se necesita conocer si existen mejores resultados con el uso de otras funciones de pertenencia existentes como son: la trapezoidal, la exponencial, la gaussiana, la triangular, la gamma y la S. Además las salidas de estas funciones solo se logran combinar mediante el promedio por tanto se desea proponer nuevas formas para combinar dichas salidas. Por todo lo anterior, se plantea el siguiente: Objetivo General: Combinar las medidas de diversidad existentes mediante un operador borroso (Fuzzy), utilizando distintas funciones de pertenencia y distintos criterios para la comparación de sus salidas, para proponer la función y el criterio que arroje los mejores resultados. Este objetivo puede ser dividido en los siguientes: Objetivos específicos: 1. Analizar los conceptos principales de la Lógica Borrosa, estableciendo la modelación de cada función de pertenencia para los conjuntos difusos definidos. 2. Proponer diferentes criterios para combinar las salidas de las funciones de pertenencia. 3. Incorporar la implementación de las funciones de pertenencias y nuevos criterios para combinar sus salidas en el software Splicing v1.2. 4. Diseñar un experimento para seleccionar la función de pertenencia que arroja a los mejores resultados, así como, el mejor criterio de combinación para las salidas de las mismas. 2.
(18) INTRODUCCIÓN. 5. Evaluar los resultados alcanzados en una aplicación real de la bioinformática. Preguntas de Investigación: 1. ¿Cuáles son las funciones de pertenencia más relevante existente en la literatura? 2. ¿Cómo es el diseño del software Splicing v1.2, y en particular del operador Fuzzy para incorporar la implementación de las nuevas funciones de pertenencias y nuevos criterios para combinar sus salidas? 3. ¿Cómo diseñar los experimentos para validar los resultados alcanzados? 4. ¿Existe una función de pertenencia que arroje mejores resultados por encima de las demás? 5. ¿Existe algún criterio para combinar las salidas de las funciones que arroje mejores resultados por encima de los demás? 6. ¿Mostrará el operador borroso mejores resultados que otros operadores para combinar las medidas de diversidad? Hipótesis de investigación: El uso del operador borroso (Fuzzy) con otras funciones de pertenencia y nuevos criterios para combinar sus salidas, arroja mejores resultados que otros operadores para combinar las medidas de diversidad. El trabajo que se presenta a continuación se estructura de la siguiente forma: Capítulo 1: Métodos de clasificación, medidas de diversidad y lógica borrosa. El capítulo se encuentra dividido en tres secciones principales. La primera sección recoge los conceptos esenciales de un conjunto de clasificadores que se han utilizado ampliamente en la solución de problemas reales con éxito que van desde los algoritmos basados en casos hasta la regresión logística. Le sigue un estudio de los diversos modelos de combinación de clasificadores reportados en la literatura, entre los que pueden mencionarse: Bagging, Boosting, Stacking y Vote. En la segunda sección se presentan las medidas de diversidad que se reportan en la literatura agrupándolas por pareadas o grupales y se explica el intervalo de valores esperados y su interpretación. Además se especifican las formas en que los valores de distintas medidas pueden ser combinados luego de haberlos estandarizados, esto último según 3.
(19) INTRODUCCIÓN. lo propuesto en (Hernández, 2014) . En la última sección se explica la lógica borrosa que estudia elementos de la lógica tradicional aplicados a valores borrosos, así como las características fundamentales de las funciones de pertenencia. Capítulo 2: Diseño e implementación de las nuevas funciones de pertenencia y los nuevos criterios de comparación sobre el software Splicing v1.2. En este capítulo se presenta un breve resumen del funcionamiento del software Splicing v1.2, el cual constituye un antecedente de este trabajo, para comprender mejor su funcionamiento así como diseño e implementación del mismo. Además se presenta el diseño y la implementación de las nuevas funciones de pertenencia y los nuevos criterios de comparación propuestos. Finalmente, se presenta la herramienta Splicing v1.3 como un sistema integrado que brinda las mismas facilidades de la versión anterior del software y además permite el uso de varias funciones de pertenencia en la combinación de medidas de diversidad mediante un operador borroso (Fuzzy), así como el uso de varios criterios para combinar las salidas de las funciones de pertenencia. Se muestra también el diagrama del caso de uso para combinar varias medidas de diversidad y el diagrama de clase del paquete donde se realizaron las modificaciones principales. Capítulo 3: Diseño de experimentos y análisis de sus resultados. Aplicación en un problema real de la bioinformática. Este capítulo expone los experimentos realizados con la nueva versión del software Splicing v1.3, en los cuales se proponen los resultados para las distintas opciones manejadas en el operador borroso, como son: la mejor función de pertenencia, así como el mejor criterio propuesto para la combinación de sus salidas. Además se muestra el grupo más eficiente de las medidas de diversidad luego se presenta la mejor regla de combinación para las salidas de estas medidas y finalmente se resuelve un problema real de la bioinformática con los resultados obtenidos. El informe culmina con las conclusiones y recomendaciones.. 4.
(20) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA En este capítulo se presentan algunos de los métodos de clasificación existentes así como los modelos clásicos de multiclasificación, además se explican las medidas de diversidad reportadas en la literatura para determinar cuán diverso es un conjunto de clasificadores y por último están algunos elementos esenciales relacionados con la lógica borrosa, los cuales son fundamentales para este trabajo. Actualmente existen varios clasificadores individuales disponibles que se aplican en la solución de problemas de la vida diaria. A pesar de las potencialidades que estos han demostrado, no siempre se obtienen buenos resultados con el uso de uno de ellos, muchos investigadores han comenzado entonces a emplear los sistemas multiclasificadores, los cuales se apoyan en la combinación de varios clasificadores individuales y pueden llegar a obtener resultados mejores que los obtenidos utilizando un solo clasificador. A continuación se explican algunos modelos individuales de clasificación así como algunos modelos multiclasificadores.. 1.1 Métodos de Clasificación Clasificación es la acción o el efecto de ordenar o de disponer por clases (Wikipedia, 2012). Los métodos matemáticos de clasificación están caracterizados fundamentalmente porque se conoce la información acerca de la clase a la que pertenece cada uno de los objetos. Cuando la variable de decisión, función o hipótesis a predecir es continua, a los algoritmos relacionados con los problemas supervisados se les conoce como métodos de regresión. Si por el contrario la variable de decisión, función o hipótesis es discreta, ellos se conocen como métodos de clasificación o simplemente clasificadores. En un problema de clasificación se tienen un conjunto de objetos, elementos, instancias u observaciones divididos en clases o etiquetados. Dado un elemento del conjunto, un especialista le asigna una clase de acuerdo a los rasgos, características o variables que lo describen. Esta relación entre los descriptores y la clase puede estar dada por un conjunto de reglas. La mayoría de las veces este conjunto de reglas no se conoce y la única información. 5.
(21) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. que se tiene es el conjunto de ejemplos etiquetados, de forma tal que las etiquetas representan las clases. De manera general, se puede decir que los métodos de clasificación son un mecanismo de aprendizaje, donde la tarea es tomar cada instancia y asignarla a una clase en particular. La clasificación puede dividirse en tres procesos fundamentales: pre-procesamiento de los datos, selección del modelo de clasificación y, entrenamiento y prueba del clasificador (BONET, 2008). Entre los métodos de clasificación más usados están los algoritmos basados en casos, los árboles de decisión, las redes bayesianas, las redes neuronales artificiales, el análisis discriminante y la regresión logística, pero estos no son los únicos. A continuación se presenta una breve descripción de los mencionados. 1.1.1 Algoritmos basados en casos El razonamiento basado en casos se basa en el principio de usar experiencias viejas para resolver problemas nuevos. Muchos algoritmos usan este razonamiento para resolver los problemas y entre los más comunes están los de clasificación. Aunque todos los métodos de clasificación se basan en casos, existe un conjunto que se conoce como algoritmos basados en casos, o también como métodos de aprendizaje perezoso. Estos algoritmos deben contar con una serie de ejemplos ya conocidos y cuando van a resolver un problema nuevo, lo hacen buscando la semejanza entre éste y los ejemplos almacenados. No necesitan crear reglas, ni árboles, ni ajustar parámetros. A cada ejemplo se le conoce como instancia y a la colección de ejemplos como base de casos. Una nueva instancia se compara con el resto de la base de casos a través de una medida de similitud. La clase de la nueva instancia será la misma que la del caso que más cercano esté a la nueva instancia. A este proceso se le conoce con el nombre de método del “vecino más cercano” (nearest neighbor). Si en lugar de usar el caso más cercano se utilizan los k casos más similares, entonces se habla de los k-vecinos más cercanos1 y la clase asignada a la nueva. 1. kNN por sus siglas en inglés (k Nearest Neighbors). Conocido además como IBk (IB1 cuando el número de vecinos es 1) en la plataforma inteligente para aprendizaje Waikato Environment for Knowledge AnalysisWEKA.. 6.
(22) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. instancia será la más común entre las k instancias más cercanas encontradas en la base de casos (Mitchell, 1997). 1.1.2 Árboles de decisión El aprendizaje usando árboles de decisión es un método para aproximar funciones. Un árbol de decisión clasifica las instancias ordenándolas de la raíz a las hojas. Cada nodo interior del árbol especifica una prueba de algún atributo y las hojas son las clases en las cuales se clasifican las instancias, cada rama descendiente de un nodo interior corresponde a un valor posible del atributo probado en ese nodo. Un árbol de decisión representa una disyunción de conjunciones sobre los valores de los atributos. Así, cada rama, de la raíz a un nodo hoja, corresponde a una conjunción de atributos y el árbol en sí, a una disyunción de estas conjunciones. La familia de algoritmos ID3 (Quinlan, 1986) es el paradigma de los métodos para descubrir reglas usando árboles de decisión; a pesar de esto, tiene algunas limitaciones. Una variante para la solución de estas limitaciones es el algoritmo C4.5 (Quinlan, 1993)2, que usa puntos de corte e introduce varias medidas para evitar el sobre entrenamiento, en particular los criterios de parada de la división y de poda del árbol. Otros árboles de decisión son el CHAID (Chi Square Automatic Interaction Detector) en el que la segmentación ocurre siguiendo criterios chi-cuadrados y el CRT (Classification and Regression Tree) en el que se dividen los casos en segmentos que son lo más homogéneos posibles con respecto a la variable dependiente. Varios de estos árboles se pueden encontrar en WEKA; por ejemplo: J48, Id3, BFTree, NBTree, entre otros. 1.1.3 Redes bayesianas Una red bayesiana es un modelo gráfico probabilístico que representa un conjunto de variables y sus dependencias probabilísticas. Las redes bayesianas permiten declarar supuestos de independencia condicionales que son aplicados a subconjuntos de variables. Son representadas por un gráfico acíclico dirigido, donde cada variable se representa por un nodo de la red, y de ella se especifican dos tipos de información: la estructura de dependencias condicionales que son los arcos de la red 2. Conocido como ADTree en WEKA.. 7.
(23) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. las distribuciones de probabilidad correspondientes. Una red bayesiana puede calcular la distribución de probabilidad para cualquier subconjunto de variables de la red, dado los valores o distribuciones de las variables restantes (Mitchell, 1997). Cuando no se conocen todos los valores de las variables en el conjunto de entrenamiento, el aprendizaje con una red bayesiana puede ser más difícil. Este tipo de clasificador no es muy sensible a los cambios de sus parámetros, ya que se basa en información de toda la base, lo cual hace que pequeños cambios en la base no sean necesariamente significativos (Chavez, 2008). En WEKA hay varias de estas redes implementadas, las más sobresalientes son NaiveBayes y sus variantes. 1.1.4 Redes neuronales artificiales Una red neuronal es un modelo computacional que pretende simular el funcionamiento del cerebro a partir del desarrollo de una arquitectura que toma rasgos del funcionamiento de las neuronas sin llegar a desarrollar una réplica del mismo (Bello et al., 2001). Es una herramienta matemática para la modelación de problemas, que permite obtener las relaciones funcionales subyacentes entre los datos involucrados en problemas de clasificación, reconocimiento de patrones, regresión, etc. Este tipo de método se considera como un excelente aproximador de funciones, esencialmente no lineales, siendo capaces de aprender las características relevantes de un conjunto de datos, para luego reproducirlas en entornos ruidosos o incompletos (Wolpert, 1992). En los últimos años se han producido una amplia variedad de arquitecturas de redes neuronales, encontrándose entre las más utilizadas, las redes multicapa de alimentación hacia adelante (Feed-Forward Neuronal Networks, FFN), las cuales se distinguen porque sus neuronas están conectadas a manera de grafo acíclico dirigido (todos los arcos hacia adelante). Las redes Multi Layer Perceptron (MLP) constituyen un ejemplo genérico de las redes FFN, y se encuentran formadas por un conjunto de capas de neuronas ordenadas secuencialmente. Primero una capa de entrada, luego un conjunto de capas intermedias denominadas capas ocultas y por último una capa de salida. Las MLP usando neuronas ocultas con funciones no lineales, son capaces de aproximar cualquier tipo de función continua y brindar excelentes resultados en las tareas de clasificación (Salazar, 2005).. 8.
(24) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. 1.1.5 Análisis Discriminante El análisis discriminante es una técnica matemática que ayuda a identificar las características que discriminan a dos o más grupos y a crear una función capaz de distinguir con la mayor precisión posible a los miembros de uno u otro grupo. Obviamente, para llegar a conocer en qué se diferencian los grupos se necesita disponer de la información (cuantificada en una serie de variables) en las que se supone que se diferencian. El análisis discriminante es una técnica estadística capaz de determinar cuáles variables permiten diferenciar a los grupos y cuántas de estas variables son necesarias para alcanzar la mejor clasificación posible. La pertenencia a los grupos, conocida de antemano, se utiliza como variable dependiente (una variable categórica con tantos valores discretos como grupos). Las variables en las que suponemos que se diferencian los grupos se utilizan como variables independientes o variables de clasificación (también llamadas variables discriminantes). Ellas deben ser variables cuantitativas continuas o, al menos, admitir un tratamiento numérico ordinal. El objetivo último del análisis discriminante es encontrar la combinación lineal de las variables independientes que mejor permite diferenciar (discriminar) a los grupos. Una vez encontrada esa combinación (la función discriminante) podrá ser utilizada para clasificar nuevos casos. 1.1.6 Regresión logística La regresión logística es un instrumento estadístico de análisis multivariado, de uso tanto explicativo como predictivo. Resulta útil su empleo cuando se tiene una variable dependiente dicotómica (un atributo cuya ausencia o presencia se ha puntuado con los valores cero y uno, respectivamente) y un conjunto de variables predictoras o independientes, que pueden ser cuantitativas o categóricas. En este último caso, se requiere que sean transformadas en variables “dummy”; es decir, variables simuladas. El propósito del análisis consiste en predecir la probabilidad de que a alguien le ocurra cierto “evento”. Puede, además, determinar cuáles variables pesan más para aumentar o disminuir la probabilidad de que a alguien le suceda el evento en cuestión. Esta asignación de probabilidad de ocurrencia del evento a un cierto sujeto, así como la determinación del peso de cada una de. 9.
(25) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. las variables dependientes en esta probabilidad, se basan en las características que presentan los sujetos a los que, efectivamente, les ocurren o no estos sucesos. La regresión logística sólo resuelve problemas de clasificación binarios. Si el problema fuese más general, entonces se puede aplicar un modelo más general basado en los mismos principios, denominado regresión multinomial, precisamente este criterio es el que utiliza la función Logistic, implementada en WEKA. Como se ha visto, se han desarrollado un gran número de clasificadores, pero determinar cuál de ellos logra encontrar una mejor frontera de decisión para separar las clases es el mayor problema. En la búsqueda de mejores métodos de clasificación aparece una tendencia a combinar varios de estos clasificadores. Los algoritmos llamados multiclasificadores se basan en esta idea; utilizar varios clasificadores y combinar sus diferentes salidas (POLIKAR, 2006) con el objetivo de alcanzar un mejor resultado. En (DIETTERICH, 2000) se sugieren tres tipos de razones por las cuales un sistema multiclasificador puede ser mejor que un clasificador simple. La primera es estadística, pues si efectivamente por cada clasificador tenemos una hipótesis, la idea de combinar estas hipótesis, da como resultado una hipótesis que puede no ser la mejor, pero al menos evita seleccionar la peor de ellas. La segunda justificación es computacional, ya que algunos algoritmos ejecutan búsquedas que pueden llevar a diferentes óptimos locales: cada clasificador comienza la búsqueda desde un punto diferente y termina cercano al óptimo. Existe la expectativa de que alguna vía de combinación puede llevar a un multiclasificador a obtener una mejor aproximación. La última justificación es figurativa ya que es posible que el espacio de hipótesis considerado no contenga la hipótesis óptima; pero la aproximación de varias fronteras de decisión puede dar como consecuencia una nueva hipótesis fuera del espacio inicial y que se aproxime más a la óptima.. 1.2 Modelos de construcción de multiclasificadores La combinación de clasificadores es en la actualidad un área activa de investigación en el aprendizaje automatizado y el reconocimiento de patrones. Se han publicado numerosos estudios teórico y empíricos que demuestran las ventajas del paradigma de combinación de clasificadores por encima de los modelos individuales (KUNCHEVA, 2004).. 10.
(26) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. Existen varias formas en las cuales se pueden construir multiclasificadores. Hay una serie de algoritmos desarrollados, algunos para problemas generales como Bagging y Boosting y otros para problemas específicos, pero todos tienen como partes fundamentales: la selección de los clasificadores de base y la elección de la forma de combinar las salidas (BONET, 2008). Entre los modelos más populares que combinan clasificadores están Bagging, Boosting, Stacking, métodos basados en rasgos y Vote. Bagging: Es uno de los primeros algoritmos de multiclasificación. Se basa en crear diferentes conjuntos de entrenamiento, extraídos del conjunto inicial de manera aleatoria y con reemplazo, con lo cual asegura la diversidad. Este modelo necesita la selección de un modelo de clasificador inestable, o sea, un modelo que con pequeños cambios obtenga valores diferentes. Además usa un único modelo de clasificador y la combinación de los clasificadores resultantes se realiza con la técnica de voto mayoritario (Breiman, 1996). Boosting: Es parecido a Bagging porque usa el método de crear bases de entrenamiento aleatorias con reemplazo, a partir de la base original y un único modelo de clasificación para los clasificadores de base, de ahí que la diversidad la garantice de la misma forma. Sin embargo, este algoritmo se realiza de manera secuencial, donde los clasificadores se van entrenando uno detrás del otro porque usan información del anterior. Otra diferencia es que Boosting le da un peso al modelo por su rendimiento, en lugar de dar peso igual a todos los modelos. El reemplazo se realiza estratégicamente de forma que los casos mal clasificados tienen mayor probabilidad, que los bien clasificados, de pertenecer al conjunto de entrenamiento del siguiente clasificador del sistema (Schapire, 1990). Stacking: Es un método diferente a los anteriores pues la diversidad se determina con el empleo de diversos modelos de clasificación. Es menos utilizado que Bagging y Boosting, ya que es difícil de analizar teóricamente. Stacking combina múltiples clasificadores generados por diferentes algoritmos para un mismo conjunto de datos en una primera fase. Para combinar las salidas no utiliza voto mayoritario, sino que introduce un metaclasificador que aprende la relación entre las salidas de los clasificadores de base y la clase original (Wolpert, 1992). 11.
(27) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. Métodos basados en rasgos: En la construcción de un multiclasificador, los clasificadores de base pueden ser obtenidos a partir de subconjuntos de rasgos diferentes, lo cual es otra forma de buscar diversidad. La selección de rasgos tiene como objetivo lograr una mayor eficiencia en los cálculos así como una mayor exactitud del multiclasificador. De esa manera puede que los clasificadores individuales no sean tan precisos o exactos, pero sí sean más diversos. Existen muchos modelos de multiclasificadores que utilizan subconjuntos de rasgos diferentes como los descritos por Kuncheva (KUNCHEVA, 2004). Vote: Al igual que Stacking, establece la diversidad con la utilización de diferentes modelos de clasificación como clasificadores base. Las salidas de estos clasificadores están dadas por vectores con una distribución de probabilidad para cada una de las clases. Vote combina estas probabilidades utilizando diferentes criterios como voto mayoritario, promedio, mínimo, máximo o mediana de las probabilidades. Como se explica anteriormente, en todos estos modelos se garantiza la diversidad, ya sea a través de una selección de rasgos, usando distintos modelos de clasificadores base, usando diferentes conjuntos de bases de entrenamiento o una combinación de ellos. En la construcción de un sistema de este tipo, resulta intuitivo garantizar la diversidad entre los clasificadores individuales que se usen dado que si fuesen idénticos no tendría sentido crear un sistema que los combinara (Shipp and Kuncheva, 2002). En el caso de la utilización de distintos clasificadores base, se han reportado en la literatura un conjunto de medidas que permiten determinar cuán diverso es un grupo de clasificadores.. 1.3 Medidas de diversidad como criterio para seleccionar los clasificadores de base La diversidad en un grupo de clasificadores base es una condición necesaria para la mejora del desempeño de un ensamblado de clasificadores (KUNCHEVA, 2004), ya que de esto dependerá en gran medida el resultado final del multiclasificador. La diversidad de los errores de los clasificadores puede dar una medida del mayor valor posible que se puede aspirar con la combinación de esos modelos. Sin embargo, en algunos casos puede que no se logre una gran. 12.
(28) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. diversidad, de ahí que sea necesario el uso de algunas medidas estadísticas que permiten hacer estimación de cuán diversos son los clasificadores. En (KUNCHEVA and WHITAKER, 2003) se plantea que no hay una medida de diversidad involucrada en forma explícita en los métodos de generación de clasificadores, aunque asumen que la diversidad es el punto clave en cualquiera de los métodos. Las medidas pueden ser clasificadas como medidas en forma de pares (pairwise) y medidas para todo el conjunto (nonpairwise). 1.3.1 Medidas de diversidad en forma de pares (pairwise) Las medidas en forma de pares se calculan por pares de clasificadores usando sus salidas, las cuales son binarias (1,0) que indica si la instancia fue correctamente clasificada o no, por el clasificador. A continuación se indica el resultado de dos clasificadores (Ci, Cj) para una instancia en cuanto si la clasificaron correctamente o no. Cj correcto (1). Cj incorrecto (0). Ci correcto (1). a. b. Ci incorrecto (0). c. d. a+b+c+d=1 Tabla 1. Resultados de los clasificadores Ci y Cj para una instancia. Si se suman para todas las instancias los valores de a, b, c, d entre el par de clasificadores (Ci, Cj) se obtendrá el siguiente resultado, a partir del cual se calculan las medidas en forma de pares: Cj correcto (1). Cj incorrecto (0). Ci correcto (1). A. B. Ci incorrecto (0). C. D. A +B + C + D = N Tabla 2. Resultados de los clasificadores Ci y Cj para todo el conjunto de instancias. Donde A sería igual a la suma total de los valores de a para todas las instancias y así respectivamente con los valores de B, C y D. N es el número total de casos.. 13.
(29) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. Un conjunto de L clasificadores produce en total. pares de valores. Para obtener un. único resultado se promedian estos valores. 1.3.1.1. Coeficiente de correlación (ρ). El coeficiente de correlación entre dos clasificadores Ci y Cj se calcula como: Eq. 1.1. Mientras menor sea el valor de ρ, mayor será la diversidad. (KUNCHEVA, 2004) 1.3.1.2. El estadístico Q. El estadístico Q (Q Statistics) es otra de las medidas para pares de clasificadores. Se calcula de la siguiente forma: Eq. 1.2. Para un par de clasificadores estadísticamente independientes, su valor de. va a ser 0. En. general, el valor de Q va a oscilar entre −1 y 1. Aquellos clasificadores que tienden a reconocer los mismos objetos correctamente tendrán un valor positivo de Q, y aquellos que comentan errores en diferentes objetos poseerán un valor negativo de Q. La mayor diversidad de esta medida se alcanza mientras menor sea su valor. (KUNCHEVA, 2004) Para cualquier par de clasificadores, los valores de ρ y Q tendrán el mismo signo y se puede probar que. Q . (KUNCHEVA and WHITAKER, 2003). 1.3.1.3. Medida de diferencias. La medida de diferencias (The Disagreement Measure) introducida por Skalak (SKALAK, 1996), es la más intuitiva de las medidas entre un par de clasificadores, y es igual a la probabilidad de que los dos clasificadores discrepen en sus predicciones. Mientras mayor sea su valor, mayor será la diversidad. Eq. 1.3. 14.
(30) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. 1.3.1.4. Medida de doble fallo La medida de doble fallo (The Double-Fault Measure) fue introducida por Giacinto y Roli (GIACINTO and ROLI, 2001) y considera el fallo de los dos clasificadores al mismo tiempo (Ruta and Gabrys, 2001) definen a esta medida como una medida no-simétrica. Esto quiere decir que si se intercambian los unos con los ceros en los resultados de los clasificadores, el valor de la medida no va a ser el mismo. Esta medida está basada en el concepto de que es más importante conocer cuando errores simultáneos son cometidos que cuando ambos tienen clasificación correcta. Mientras menor sea el valor, mayor será la diversidad. Eq. 1.4. 1.3.1.5. Combinación de la medida de diferencia y medida de doble fallo. La última de las medidas para pares de clasificadores es una propuesta de una combinación entre la medida de diferencias y la medida de doble fallo (Montero, 2011). Mientras mayor sea el valor de esta medida mayor será la diversidad entre los clasificadores. Eq. 1.5. Como D y DF son medidas que difieren en el extremo hacia el cual se alcanza la mayor diversidad, es necesario llevar una de ellas hacia el extremo contrario. Este proceso se realizó restando a 1 la medida DF, lo cual formó parte del método de estandarización de las medidas de diversidad propuesto en (Hernández, 2014), más adelante se explicará. 1.3.2 Medidas de diversidad para todo el conjunto (nonpairwise) Las medidas de diversidad que se basan en todo el conjunto consideran a todos los clasificadores a la vez y calculan un único valor de diversidad para todo el conjunto. 1.3.2.1. Entropía. La medida de Entropía (The Entropy Measure) enunciada en (KUNCHEVA and WHITAKER, 2003) se basa en la idea intuitiva de que en un conjunto de N casos y L clasificadores la mayor diversidad se obtendrá si L/2 de los clasificadores clasifican una instancia correctamente y los. 15.
(31) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. otros L- L/2 la clasifican incorrectamente. Fue introducida por Cunningham y Carney en (CUNNINGHAM and CARNEY, 2000).. Eq. 1.6. Donde yj,i tendrá valor 1 si el clasificador i clasificó correctamente el caso j y 0 en caso contrario. Si E tiene valor 0 esto indica que no hay diferencia entre los clasificadores y un valor 1 indica la mayor diversidad posible. 1.3.2.2. Varianza de Kohavi-Wolpert. La varianza de Kohavi-Wolpert (Kohavi-Wolpert Variance), fue inicialmente propuesta por Kohavi y Wolpert (KOHAVI and WOLPERT, 1996). Esta medida es originada de la descomposición de la varianza del sesgo del error de un clasificador. Kuncheva y Whitaker presentaron en (KUNCHEVA and WHITAKER, 2003) una modificación para medir la diversidad de un ensamblado compuesto por clasificadores binarios, quedando la medida de diversidad como:. Eq. 1.7. Con esta medida, la diversidad disminuye a medida que el valor de KW aumenta. 1.3.2.3. Medida de desacuerdo entre expertos. La medida de desacuerdo entre expertos (Measurement Interrater Agreement) (Fleiss, 1981)es otra de las medidas de diversidad que se basan en todo el conjunto. Se desarrolla como una medida de fiabilidad entre clasificadores. Puede usarse para medir el nivel de acuerdo dentro de un conjunto de clasificadores, por consiguiente está también basada en el supuesto que un conjunto de clasificadores debe discrepar entre sí para ser diverso. La diversidad disminuye cuando el valor de k aumenta. El k se calcula por: Eq. 1.8. 16.
(32) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. Donde el término de la derecha es la medida de concordancia de Kendall y p es la media de la exactitud de la clasificación individual, y se calcula como:. Eq. 1.9. 1.3.2.4. Medida de dificultad. La medida de dificultad (The Measure of "difficulty" ө) viene del estudio realizado por Hansen y Salamon (Hansen and P., 1990. ). Se calcula a través de la varianza de una variable aleatoria discreta que to HANSEN ma valores en el conjunto. y denota. la probabilidad de que exactamente i clasificadores hayan clasificado bien todas las instancias. Para conveniencia, θ suele ser escalada linealmente en el intervalo [0,1] tomando como el mayor valor posible, donde p es la precisión individual de cada clasificador. La diversidad del ensamblado aumenta con el decremento del valor de la medida de dificultad. La intuición de esta medida puede ser explicada de la siguiente manera: un ensamblado de clasificadores diverso tiene un valor pequeño de medida de dificultad, dado que cada muestra de entrenamiento puede al menos ser clasificada correctamente por una proporción de todos los clasificadores base, lo cual es más probable con una baja varianza de X. Eq. 1.10 1.3.2.5. Medida de diversidad generalizada. La medida de diversidad generalizada (Generalized Diversity) se enunció por Partridge y Krzanowski (PARTRIDGE and KRZANOWSKI, 1997b). Sea Y una variable aleatoria que representa la proporción de clasificadores que clasificaron incorrectamente una muestra x ϵ Rⁿ extraída aleatoriamente del conjunto de datos. Denotemos por pi la probabilidad de que Y=i/L y p(i) la probabilidad de que i clasificadores extraídos de manera aleatoria fallen en clasificar correctamente un objeto X extraído aleatoriamente. Supongamos que dos clasificadores son tomados de forma aleatoria del ensamblado D, Partridge y Krzanowski exponen en su trabajo que la máxima diversidad es lograda cuando uno de los dos clasificadores se equivoca en clasificar un objeto y el otro lo clasifica correctamente. En este caso la probabilidad de equivocarse los dos clasificadores es p(2)=0. 17.
(33) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. Por otra parte argumentan que la mínima diversidad se lograría cuando el fallo de un clasificador es siempre acompañado con el fallo del otro, entonces la probabilidad de que los dos clasificadores fallen es la misma que la probabilidad de que un clasificador escogido de forma aleatoria falle, esto es p(1). Eq. 1.11. Eq. 1.12. El valor de GD varía entre 0 y 1, siendo 0 la menor diversidad cuando p(2)=p(1) y 1 la mayor diversidad cuando p(2)=0 y L la cantidad de clasificadores. 1.3.2.6. Medida de diversidad de coincidencia de fallos. Esta medida (Coincident Failure. Diversity) se enuncia. por Partridge y Krzanowski. (PARTRIDGE and KRZANOWSKI, 1997b), como una mejora a la medida anterior. Esta medida está diseñada de tal forma que tenga un valor mínimo 0 cuando todos los clasificadores siempre clasifiquen correctamente o cuando todos los clasificadores lo mismo clasifiquen correcta o incorrectamente al mismo tiempo. Su máximo valor 1 es alcanzado cuando todos los errores de clasificación son únicos, es decir cuando al menos un clasificador va a clasificar incorrectamente cualquier objeto aleatorio.. Eq. 1.13. p[0]=1 cuando todos los clasificadores siempre son simultáneamente correctos o incorrectos, p[i] es el mismo término de la medida anterior y L es la cantidad de clasificadores. El valor de CFD está entre 0 y 1 y mientras mayor sea, mayor será la diversidad. 1.3.2.7. Medida de diversidad de distintos fallos. Esta medida (Distintic Failure. Diversity) fue igualmente enunciada por Partridge y. Krzanowski (PARTRIDGE and KRZANOWSKI, 1997b), como una mejora a la medida anterior, pues ahora se va a tener en cuenta todas las instancias donde los clasificadores no 18.
(34) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. coinciden en las clases asignadas, es decir, se consideran las distintas posibilidades de fallo teniendo en cuenta las clases.. Eq. 1.14. Aquí t es un vector de probabilidades en el que cada posición se calcula determinando la cantidad de i clasificadores que hayan fallado en asignar la clase correcta dividido por el total de fallos ocurridos y L es la cantidad de clasificadores. El valor de DFD está entre 0 y 1 y mientras mayor sea, mayor será la diversidad. 1.3.2.8. Medida de la diversidad global. La medida de la diversidad global (Overall Diversity) fue enunciada por (PARTRIDGE and KRZANOWSKI, 1997a) como una versión “pesada” de la medida de diversidad de distintos fallos. Dicha medida se calcula como:. Eq. 1.15. Cada posición de w representa el promedio de valores d para cada fila donde i clasificadores fallaron. Los valores d se calculan para cada instancia como;. Eq. 1.16. Donde K es la cantidad de clases o categorías que se asignan a los casos, Ck indica la cantidad de clasificadores que asignaron la clase k a la instancia i, siendo k una clase incorrecta y ni es el total de fallos ocurridos en la instancia i. Por ejemplo, en la ¡Error! No se encuentra el origen de la referencia. se muestra una matriz de incidencias de un sistema constituido por cinco clasificadores que clasifica a dos instancias, a las cuales puede ser asignada una de seis categorías. 19.
(35) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. Cantidad de clasificadores que Número de. asignaron la categoría i. instancia. Categoría. Total de. correcta. fallos. 1. 2. 3. 4. 5. 6. 1. 0. 3. 1. 0. 0. 1. 1. 5. 2. 1. 2. 2. 0. 0. 0. 2. 3. Tabla 3. Matriz de incidencia para un sistema con cinco clasificadores. Los valores de d para estas dos instancias son:. El valor de OD está entre 0 y 1 y mientras mayor sea, mayor será la diversidad. 1.3.2.9. Medida de variabilidad. Esta medida (The Measure of Variability) tiene en cuenta si las clases asignadas por los clasificadores en cada instancia son distintas o no. Mientras mayor sea su valor, mayor será la diversidad. Eq. 1.17. Donde N es el total de instancias y EL(i) es la etiqueta (clase) asignada a la instancia i, por el clasificador i-ésimo. A pesar de la existencia de todas estas medidas, encontrar una combinación de clasificadores que garantice mayor diversidad y exactitud en la clasificación resulta bastante difícil, ya que en ocasiones se cuenta con un número de clasificadores bastante elevado y la cuestión radica en cuáles incluir en el sistema y cuáles no, precisamente esta fue la problemática a la cual el software Splicing v1.2 le dio solución en (Hernández, 2014), en esa investigación se propone además la siguiente combinación de medidas y estandarización de las mismas.. 20.
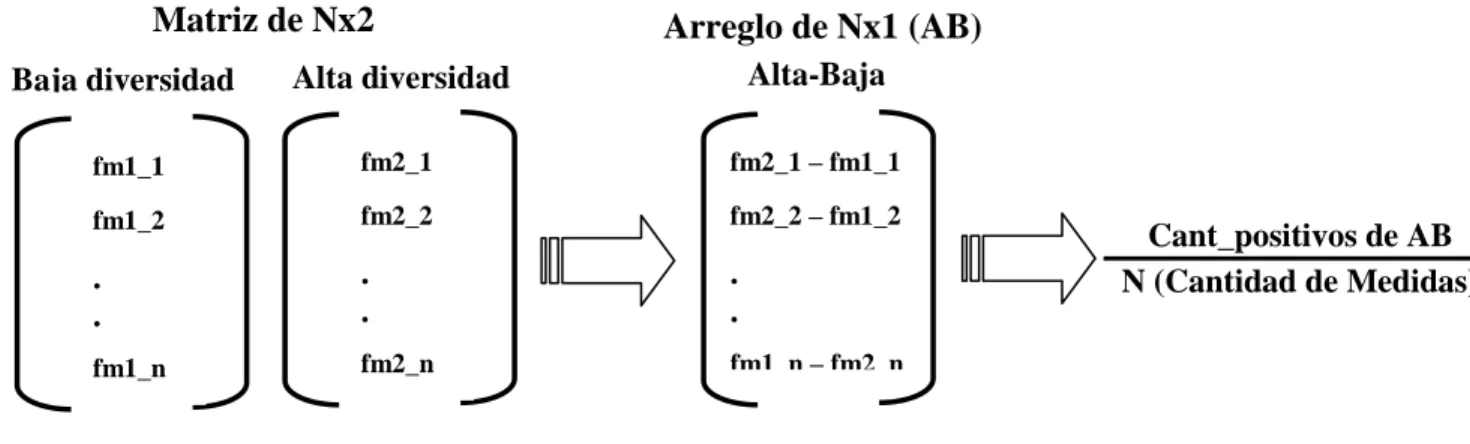
(36) CAPITULO 1: MÉTODOS DE CLASIFICACIÓN, MEDIDAS DE DIVERSIDAD Y LÓGICA BORROSA. 1.4 Combinación de varias medidas de diversidad Para hacer posible el trabajo con más de una medida de diversidad, es necesario garantizar primero su estandarización, de forma que todas se ubiquen en un mismo intervalo y alcancen la mayor diversidad hacia un mismo extremo de dicho intervalo; y segundo utilizar alguna función que agrupe cada uno de estos valores en uno solo. 1.4.1 Estandarización de las Medidas de Diversidad Para llevar cada una de las medidas anteriores a un mismo intervalo, se aplicó la siguiente transformación lineal. Sea el intervalo (a;b) y x un real cualquiera. La representación de x en el intervalo (a;b) está dada por la fórmula: Eq. 1.18. Luego, la transformación del extremo del intervalo en el que alcanzan la diversidad a otro puede hacerse restando la medida estandarizada al extremo más a la derecha. O sea, si fuese en el intervalo (0;1) sería 1- x’. 1.4.2 Agrupamiento de las medidas en un solo valor Para combinar varias medidas de diversidad y obtener un solo valor se propusieron los siguientes operadores: Average: Calcula el promedio de un conjunto de medidas Max: Determina el máximo de un conjunto de medidas Prod: Calcula el producto de un conjunto de medidas Fuzzy operator: Utiliza los conceptos de Inteligencia Artificial referentes a los conjuntos borrosos. Calcula el promedio de pertenencia de cada una de las medidas a los conjuntos borrosos (se usaron solamente funciones triangulares para su construcción) y retorna el máximo estandarizado de esos valores. Los términos lingüísticos manejados por este operador son baja diversidad y alta diversidad. Precisamente en el trabajo con este operador está la contribución de este trabajo.. 21.
Figure



+7





Documento similar