Desarrollo de un control de acceso usando modificación de queries Edición Única
195
0
0
Texto completo
(2) Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey División de Electrónica, Computación, Información y Comunicaciones Programa de Graduados. Los miembros del comité de tesis recomendamos que la presente tesis de Francisco Morales Caro sea aceptada como requisito parcial para obtener el grado académico de Maestro en Ciencias, especialidad en: Tecnologı́a Informática. Comité de tesis:. Dra. Lorena Gómez Martı́nez Asesor de la tesis. MSC. Marı́a Cristina Hernández Rodrı́guez. MTI. Orison Mendoza Domı́nguez. Sinodal. Dr. David Garza Salazar Director del Programa de Graduados. Diciembre de 2005. Sinodal.
(3) Desarrollo de un Control de Acceso usando Modificación de Queries. por. Francisco Morales Caro. Tesis Presentada al Programa de Graduados en Electrónica, Computación, Información y Comunicaciones como requisito parcial para obtener el grado académico de. Maestro en Ciencias especialidad en. Tecnologı́a Informática. Instituto Tecnológico y de Estudios Superiores de Monterrey Campus Monterrey Diciembre de 2005.
(4) a mi hermano.
(5) Agradecimientos En primer lugar agradezco a mi familia, que siempre estuvo conmigo y creyeron en lo que podı́a lograr. Para todos ellos es este trabajo. Gracias a todas las personas que de algún modo estuvieron involucradas en este proceso de investigación. A mis amigos: Raul, Roberto, Lucy, Adrián, Ori, Hiroshi, Mauro, Marco, Carlos, Ely, Cris, la jugada y tantos más que me faltan por mencionar, muchas gracias por su apoyo. A Carmen, por tus consejos, cariño y confianza: Muchas gracias mija.. Francisco Morales Caro Instituto Tecnológico y de Estudios Superiores de Monterrey Diciembre 2005. v.
(6) Resumen En los tiempos modernos, el desarrollo de los manejadores y modeladores de las bases de datos, ha sido demandado por la gran cantidad de información que hoy en dı́a es requerida por miles de necesidades nuevas y de antaño, que los seres humanos hemos creado por la sed de explotar los datos que se manejan de forma cotidiana. Actualmente, las bases de datos están sujetas a un sin número de accesos por aplicaciones y usuarios que necesitan consultar, modificar y manipular la información contenida en ellas; pero el acceso a éstas debe estar sujeto a un control, ya que la confiabilidad y consistencia de los datos determina la veracidad de la información que será utilizada para toma de decisiones, transacciones bancarias y una gama de reportes estadı́sticos que suelen ser crı́ticos para el funcionamiento de una empresa, sin importar su giro. Este trabajo de tesis propone un control de acceso a datos basado en modificación de quieres; también se desarrolló un mecanismo de generación automática de código para implementar la modificación de queries en la base de datos, mismo usa un template que especifica sus parámetros de entrada. Además el control de acceso desarrollado en esta tesis es fácil de administrar, de implementar, de mantener y libera a las aplicaciones de codificar su propio control de acceso ya que éste es implementado en la base de datos..
(7) Índice general. Agradecimientos. V. Resumen. VI. Índice de tablas. XI. Índice de figuras Capı́tulo 1. Introducción 1.1. Antecedentes . . . . . . . . 1.2. Motivación . . . . . . . . . . 1.3. Objetivos . . . . . . . . . . 1.4. Justificación . . . . . . . . . 1.5. Aportaciones . . . . . . . . 1.6. Organización del Documento. XIII. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. . . . . . .. 1 3 4 7 7 8 9. Capı́tulo 2. Marco Teórico 2.1. Técnicas de Control de Acceso . . . . . . . . . . . . . . . . . . . . . . . 2.1.1. Control de Acceso Discrecional (DAC) . . . . . . . . . . . . . . 2.1.2. Control de Acceso tipo Mandatory (MAC) . . . . . . . . . . . . 2.1.3. Control de Acceso por Roles (RBAC) . . . . . . . . . . . . . . . 2.1.4. Control de Acceso basado en Roles de Tareas (T-RBAC) . . . . 2.1.5. Restricciones Clasificadas y por Deducción (Inference Constraints) 2.1.6. Generalized Temporal Role Based Access Control (GTRBAC) . 2.1.7. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2.2. Tecnologı́as de Control de Acceso . . . . . . . . . . . . . . . . . . . . . 2.2.1. Acceso Basado en Vistas . . . . . . . . . . . . . . . . . . . . . . 2.2.2. Bases de Datos Activas . . . . . . . . . . . . . . . . . . . . . . . 2.3. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 10 10 11 12 12 13 14 15 17 17 17 18 25. Capı́tulo 3. Mecanismos para Control de Acceso 3.1. Facilidades de DBMSs para Implementar un Control de Acceso. . . . .. 26 26. vii.
(8) 3.1.1. Informix . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.2. SYBASE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.3. Oracle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.4. SQL Server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.1.5. Caracterı́sticas Especiales y Tabla Comparativa . . . . . . . . . 3.2. Prácticas del Control de Acceso. Casos y Aplicaciones. . . . . . . . . . 3.2.1. Caso 1. Sistema de control de acceso basado en roles (RBAC) de un banco europeo. . . . . . . . . . . . . . . . . . . . . . . . . . 3.2.2. Caso 2. INGRIAN T M Networks. Polı́ticas de seguridad con tarjetas de crédito. . . . . . . . . . . . . . . . . . . . . . . . . . . . 3.2.3. Caso 3. Requerimientos de control de acceso para un sistema de información de salud. . . . . . . . . . . . . . . . . . . . . . . . . 3.2.4. Caso 4. DAFMAT: Dynamic Authorization Framework for Multiple Authorization Types. . . . . . . . . . . . . . . . . . . . . . 3.2.5. Caso 5. Control de Acceso en Empresa Regiomontana. . . . . . 3.3. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Capı́tulo 4. Desarrollo del Control de Acceso 4.1. Problema . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.2. Solución al Problema . . . . . . . . . . . . . . . . . . . . . . . . . 4.3. Funcionamiento y Componentes del Control de Acceso. . . . . . . 4.3.1. Modificación de Queries . . . . . . . . . . . . . . . . . . . 4.3.2. Polı́ticas de Acceso . . . . . . . . . . . . . . . . . . . . . . 4.3.3. Atributo de Clasificación de Información y Usuarios. . . . 4.4. Pasos para Implementar el Control de Acceso . . . . . . . . . . . 4.5. Ejemplos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.5.1. Ejemplo Simple . . . . . . . . . . . . . . . . . . . . . . . . 4.5.2. Resultados: Ejemplo Simple. . . . . . . . . . . . . . . . . . 4.5.3. Ejemplo Complejo . . . . . . . . . . . . . . . . . . . . . . 4.5.4. Resultados: Ejemplo Complejo. . . . . . . . . . . . . . . . 4.5.5. Aclaraciones sobre Polı́ticas y Función de Acceso. . . . . . 4.5.6. Conclusión. . . . . . . . . . . . . . . . . . . . . . . . . . . 4.6. Generación de Código. . . . . . . . . . . . . . . . . . . . . . . . . 4.6.1. Código-Esqueleto para Generar las Funciones de Acceso. . 4.6.2. Algoritmo para la Generación de Código. . . . . . . . . . . 4.6.3. ¿Cómo Genera el Código? . . . . . . . . . . . . . . . . . . 4.6.4. Entradas y Salidas de la Consola de Generación de Código 4.7. Ventajas del Control de Acceso Desarrollado . . . . . . . . . . . . 4.8. Aclaraciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4.9. Limitaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . viii. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. 27 28 29 30 31 34 35 36 37 38 39 39 42 43 43 45 45 46 52 57 58 58 64 66 74 83 84 84 86 89 89 92 98 98 99.
(9) Capı́tulo 5. Caso de Estudio. 100 5.1. Ambiente. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100 5.2. Requerimientos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102 5.3. Operación Básica de la Administración Académica. . . . . . . . . . . . 103 5.3.1. Proceso de Admisiones . . . . . . . . . . . . . . . . . . . . . . . 104 5.3.2. Generación de Información de Alumnos. . . . . . . . . . . . . . 104 5.3.3. Proceso de Inscripción. . . . . . . . . . . . . . . . . . . . . . . . 104 5.3.4. Grupos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105 5.3.5. Profesores. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105 5.3.6. Flujo de la Información. . . . . . . . . . . . . . . . . . . . . . . 105 5.3.7. Resumen. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 105 5.4. Implementación del Control de Acceso. . . . . . . . . . . . . . . . . . . 106 5.4.1. Control de Acceso en el Módulo de Admisiones. . . . . . . . . . 107 5.4.2. Identificación del Atributo de Clasificación. . . . . . . . . . . . . 109 5.4.3. Definición de las Polı́ticas de Acceso. . . . . . . . . . . . . . . . 109 5.4.4. Creación de la Tabla de Clasificación. . . . . . . . . . . . . . . . 112 5.4.5. Función de Acceso. . . . . . . . . . . . . . . . . . . . . . . . . . 113 5.4.6. Protección de las Tablas Involucradas según las Polı́ticas de Acceso.118 5.4.7. Resultados del Control de Acceso Implementado en el Módulo de Admisiones. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 119 5.5. Control de Acceso en el Módulo de Información de Alumnos. . . . . . . 124 5.5.1. Identificación del Atributo de Clasificación. . . . . . . . . . . . . 126 5.5.2. Definición de las Polı́ticas de Acceso. . . . . . . . . . . . . . . . 126 5.5.3. Creación de la Tabla de Clasificación. . . . . . . . . . . . . . . . 128 5.5.4. Función de Acceso . . . . . . . . . . . . . . . . . . . . . . . . . 128 5.5.5. Protección de las tablas Involucradas según las Polı́ticas de Acceso.131 5.5.6. Resultados del Control de Acceso Implementado en el Módulo de Información de Alumnos. . . . . . . . . . . . . . . . . . . . . . . 132 5.6. Control de Acceso en el Módulo de Grupos. . . . . . . . . . . . . . . . 132 5.6.1. Identificación del Atributo de Clasificación. . . . . . . . . . . . . 132 5.6.2. Definición de las Polı́ticas de Acceso. . . . . . . . . . . . . . . . 133 5.6.3. Creación de la Tabla de Clasificación. . . . . . . . . . . . . . . . 134 5.6.4. Función de Acceso . . . . . . . . . . . . . . . . . . . . . . . . . 134 5.6.5. Protección de las tablas Involucradas según las Polı́ticas de Acceso.137 5.6.6. Resultados del Control de Acceso Implementado en el Módulo de Grupos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 138 5.7. Control de Acceso en el Módulo de Profesores. . . . . . . . . . . . . . . 140 5.7.1. Identificación del Atributo de Clasificación. . . . . . . . . . . . . 141 5.7.2. Definición de las Polı́ticas de Acceso. . . . . . . . . . . . . . . . 141 5.7.3. Creación de la Tabla de Clasificación. . . . . . . . . . . . . . . . 142 ix.
(10) 5.7.4. Función de Acceso . . . . . . . . . . . . . . . . . . . . . . . . . 142 5.7.5. Protección de las tablas Involucradas según las Polı́ticas de Acceso.145 5.7.6. Resultados del Control de Acceso Implementado en el Módulo de Profesores. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 146 5.8. Control de Acceso en el Módulo de Inscripción. . . . . . . . . . . . . . 148 5.8.1. Identificación del Atributo de Clasificación. . . . . . . . . . . . . 149 5.8.2. Definición de las Polı́ticas de Acceso. . . . . . . . . . . . . . . . 149 5.8.3. Creación de la Tabla de Clasificación. . . . . . . . . . . . . . . . 150 5.8.4. Función de Acceso . . . . . . . . . . . . . . . . . . . . . . . . . 151 5.8.5. Protección de las tablas Involucradas según las Polı́ticas de Acceso.154 5.9. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154 5.9.1. Eficaz y Eficiente . . . . . . . . . . . . . . . . . . . . . . . . . . 154 5.9.2. Mantenimiento . . . . . . . . . . . . . . . . . . . . . . . . . . . 154 5.9.3. Extensión y Reutilización de Código . . . . . . . . . . . . . . . 154 5.9.4. Confiabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . 155 5.10. Prototipo de Validación del Caso de Estudio. . . . . . . . . . . . . . . . 155 5.10.1. Forma Configuración . . . . . . . . . . . . . . . . . . . . . . . . 158 5.10.2. Forma Alumno . . . . . . . . . . . . . . . . . . . . . . . . . . . 158 5.10.3. Forma Decisión de Admisión. . . . . . . . . . . . . . . . . . . . 161 5.10.4. Forma Grupos . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164 5.10.5. Forma Inscripción . . . . . . . . . . . . . . . . . . . . . . . . . . 167 5.10.6. Resumen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 168 Capı́tulo 6. Conclusiones y Trabajos Futuros 169 6.1. Aportaciones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171 6.2. Trabajos Futuros . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171 Apéndice A. Código A.1. Packages . . . . . . . . . . . . . . . . . A.1.1. ADMISSION ACCESS PKG . . A.1.2. DECISION ACCESS PKG . . . A.1.3. STUDENT ACCESS PKG . . . A.1.4. GROUPS ACCESS PKG . . . A.1.5. PROFESSOR ACCESS PKG . A.1.6. ENROLMENT ACCESS PKG A.2. Tablas . . . . . . . . . . . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 173 173 173 173 174 175 176 176 177. Bibliografı́a. 179. Vita. 182. x.
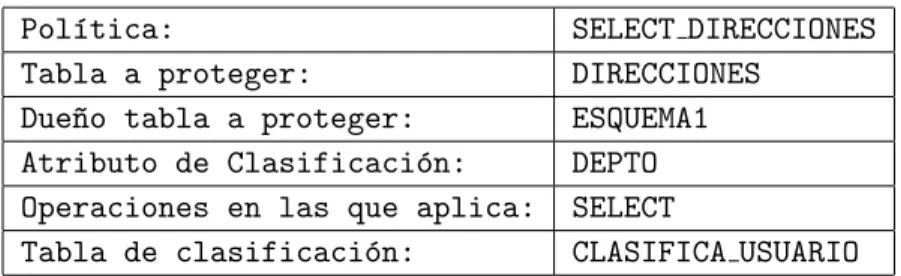
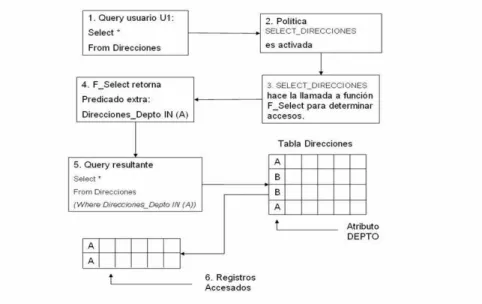
(11) Índice de tablas. 2.1. Técnicas de Control de Acceso . . . . . . . . . . . . . . . . . . . . . . .. 17. 3.1. Tabla Comparativa de los DBMS (Criterios) . . . . . . . . . . . . . . .. 33. 4.1. 4.2. 4.3. 4.4. 4.5. 4.6. 4.7.. Template de Especificación de las Polı́ticas de Acceso . . . . . . Template de Especificación de la Polı́tica de Zona . . . . . . . . Tabla DEPARTAMENTO . . . . . . . . . . . . . . . . . . . . . . . . . Tabla de Clasificación (CLASIFICA USUARIO) . . . . . . . . . . . . Template de Especificación de la Polı́tica SELECT DIRECCIONES . Template de Especificación de la Polı́tica ACCESO PROYECTOS Template de Especificación de la Polı́tica ACCESO PROYECTOS. 5.1. Tabla CAMPUS . . . . . . . . . . . . . . . . . . . . . . . 5.2. Tabla ACCESSUSR . . . . . . . . . . . . . . . . . . . . . . 5.3. Template de Especificación de la Polı́tica de ACCESS ADM 5.4. Template de Especificación de la Polı́tica de ACCESS DCS 5.5. Predicado Extra 1.1 . . . . . . . . . . . . . . . . . . . . 5.6. Query Original(UPDATE) . . . . . . . . . . . . . . . . 5.7. Query Original 1.1(Modificado) . . . . . . . . . . . . . 5.8. Predicado Extra 1.2 . . . . . . . . . . . . . . . . . . . . 5.9. Query Original 1.2 (Modificado) . . . . . . . . . . . . . 5.10. Predicado Extra 2.1 . . . . . . . . . . . . . . . . . . . . 5.11. Query Original 2.1 . . . . . . . . . . . . . . . . . . . . 5.12. Query Original 2.2(Modificado) . . . . . . . . . . . . . 5.13. Predicado Extra 2.2 . . . . . . . . . . . . . . . . . . . . 5.14. Query Original 2.3 (Modificado) . . . . . . . . . . . . . 5.15. Template de Especificación de la Polı́tica de ACCESS STU 5.16. Template de Especificación de la Polı́tica de ACCESS GPS 5.17. Predicado Extra Groups-1.1 . . . . . . . . . . . . . . . 5.18. Query Original (UPDATE-GROUPS) . . . . . . . . . . 5.19. Query Original Modificado Grupos-1.2 . . . . . . . . . 5.20. Query Original Modificado Grupos-1.3 . . . . . . . . . xi. . . . . . . . . . . POLICY . POLICY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . POLICY . POLICY . . . . . . . . . . . . . . . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. . . . . . . .. 55 56 59 60 60 68 68. . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . .. 111 112 112 113 120 120 121 121 121 122 122 123 123 124 128 134 138 139 139 139.
(12) 5.21. Query Original Modificado Grupos-1.4 . . . . . . . . . 5.22. Template de Especificación de la Polı́tica de ACCESS PRF 5.23. Predicado Extra Profesor-1.1 . . . . . . . . . . . . . . . 5.24. Query Original (INSERT-PROFESSOR) . . . . . . . . 5.25. Query Original Modificado Profesores-1.2 . . . . . . . . 5.26. Predicado Extra Profesor 1.3 . . . . . . . . . . . . . . . 5.27. Query Original Modificado Profesores 1.4 . . . . . . . . 5.28. Template de Especificación de la Polı́tica de ACCESS ENR. . . . . . POLICY . . . . . . . . . . . . . . . . . . . . . . . . . . POLICY .. . . . . . . . .. . . . . . . . .. . . . . . . . .. . . . . . . . .. 140 142 147 147 147 148 148 151. 6.1. Principales Caracterı́sticas de Técnicas/Tecnologı́as de Control de Acceso.170. xii.
(13) Índice de figuras. 1.1. Esquema Genérico. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.2. Situación Actual. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1.3. Situación Deseada. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 4 5 6. 4.1. Descripción del Control de Acceso. . . . . . . . . . . . . . . . 4.2. Validaciones Ejecutadas por la Función de Acceso. . . . . . . . 4.3. Función del Paquete DBMS RLS. . . . . . . . . . . . . . . . . 4.4. Modelo de datos - Ejemplo Simple. . . . . . . . . . . . . . . . 4.5. Función de Acceso - Ejemplo Simple. . . . . . . . . . . . . . . 4.6. Protección a la tabla DIRECCIONES contra DML SELECT. . . . . 4.7. Modelo de Datos - Ejemplo Complejo. . . . . . . . . . . . . . 4.8. Función de Acceso PROYECTOS DMLS . . . . . . . . . . . 4.9. Función de Acceso PROYECTO EMPLEADO DMLS . . . . 4.10. Protección tabla PROYECTOS contra DML SELECT. . . . . . . . . 4.11. Protección a la tabla PROYECTOS contra DML UPDATE. . . . . . 4.12. Protección a la tabla PROYECTO EMPLEADO contra DML SELECT. . 4.13. Protección a la tabla PROYECTO EMPLEADO contra DML UPDATE . 4.14. Consola de Generación de Código. . . . . . . . . . . . . . . . . 4.15. Esqueleto para Generar Código. . . . . . . . . . . . . . . . . . 4.16. Esqueleto para Tablas sin Atributo de Clasificación. . . . . . . 4.17. Consola con Parámetros. . . . . . . . . . . . . . . . . . . . . . 4.18. Paquete Generado. . . . . . . . . . . . . . . . . . . . . . . . . 4.19. Conexión a la Base de Datos. . . . . . . . . . . . . . . . . . . 4.20. Proceso de Generación de Código. . . . . . . . . . . . . . . . . 4.21. Archivo Log de la Generación de Código. . . . . . . . . . . . . 4.22. Paquete Generado para Tablas sin Atributo. . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . .. 44 47 50 59 61 64 67 69 71 75 77 79 81 84 87 88 91 92 93 94 95 97. 5.1. 5.2. 5.3. 5.4. 5.5.. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. 101 102 103 107 108. Esquema de Accesos. . . . . . . . . . Situación Actual. . . . . . . . . . . . Situación Deseada. . . . . . . . . . . Admisiones - Recepción de solicitud. Admisiones - Cambios en datos. . . . xiii. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . .. . . . . ..
(14) 5.6. Decisión de Admisión. . . . . . . . . . . . . . . . . . 5.7. Modelo de Datos Módulo Admisiones. . . . . . . . . . 5.8. Paquete ADMISSION ACCESS PKG. . . . . . . . . 5.9. Paquete DECISION ACCESS PKG. . . . . . . . . . 5.10. Alumnos - Captura de Información . . . . . . . . . . 5.11. Alumnos - Modificaciones . . . . . . . . . . . . . . . 5.12. Modelo de Datos Módulo Información de Alumnos. . 5.13. Paquete STUDENT ACCESS PKG. . . . . . . . . . 5.14. Grupos. . . . . . . . . . . . . . . . . . . . . . . . . . 5.15. Modelo de Datos Módulo Grupos. . . . . . . . . . . . 5.16. Paquete GROUPS ACCESS PKG. . . . . . . . . . . 5.17. Profesores. . . . . . . . . . . . . . . . . . . . . . . . . 5.18. Modelo de Datos Módulo Profesores. . . . . . . . . . 5.19. Paquete PROFESSOR ACCESS PKG. . . . . . . . . 5.20. Inscripción. . . . . . . . . . . . . . . . . . . . . . . . 5.21. Modelo de Datos Módulo Inscripción. . . . . . . . . . 5.22. Paquete ENROLMENT ACCESS PKG. . . . . . . . 5.23. Prototipo. . . . . . . . . . . . . . . . . . . . . . . . . 5.24. Configuración. . . . . . . . . . . . . . . . . . . . . . . 5.25. Forma Alumno. . . . . . . . . . . . . . . . . . . . . . 5.26. Forma Alumno - DELETE. . . . . . . . . . . . . . . 5.27. Forma Decisión de Admisión. . . . . . . . . . . . . . 5.28. Forma Decisión de Admisión - INSERT . . . . . . . . 5.29. Forma Decisión de Admisión - Error en DML INSERT. 5.30. Forma Grupos. . . . . . . . . . . . . . . . . . . . . . 5.31. Forma Grupos - UPDATE. . . . . . . . . . . . . . . . 5.32. Asignación de Profesores - INSERT. . . . . . . . . . . 5.33. Asignación de Profesores - Error en DML INSERT. . . 5.34. Forma Inscripción. . . . . . . . . . . . . . . . . . . . 5.35. Forma Inscripción - INSERT. . . . . . . . . . . . . . 5.36. Forma Inscripción - Error en DML INSERT. . . . . . .. xiv. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .. 109 110 114 116 125 126 127 129 132 133 135 140 141 144 149 150 152 157 158 159 160 161 162 163 164 165 166 166 167 168 168.
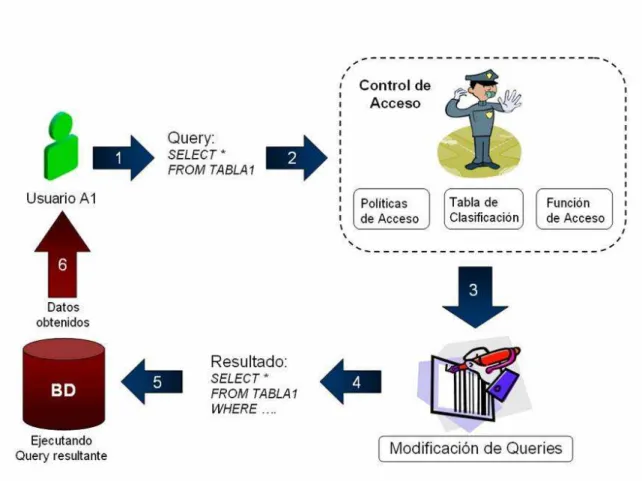
(15) Capı́tulo 1. Introducción El rápido crecimiento y desarrollo de la tecnologı́a ha llevado a que cada vez se requiera almacenar más información y que consecuentemente se explote de manera que ayude a facilitar labores diarias en empresas, escuelas y en hogares. Para ello se utilizan las bases de datos, que son sistemas que sirven para almacenar grandes volúmenes de datos; permiten que varios usuarios puedan accesar a los datos almacenados, modificarlos, borrarlos, insertarlos y explotarlos de la manera en que ellos puedan necesitarlos. De esta manera el uso de una base de datos es indispensable en lugares en donde los datos que se quieren almacenar, sobrepasen la capacidad de almacenamiento y de procesamiento de una simple PC (aunque cada vez éstas sean más poderosas), y además que requieran una organización, sino compleja, distribuida de tal manera que se evite duplicidad, ambigüedad, pérdida de datos, información sin una relación aparente con la demás, accesibilidad y seguridad. Dentro de las bases de datos centralizadas, puede convivir mucha información de diferentes rubros, y ası́ también los usuarios o personas que operan dicha información; éstos últimos pueden tener diferentes funciones y pertenecer a ciertos grupos, los cuáles deben accesar a sólo una parte de los datos. Es importante mencionar que para que los usuarios tengan acceso a su información, dependen directamente de las aplicaciones desarrolladas en algún lenguaje de programación con la facilidad de extracción y manipulación de datos; ası́ que casi al mismo tiempo las necesidades del manejo de información han crecido, también lo ha hecho la forma en cómo almacenarla, accesarla y utilizarla. Por lo tanto, hay algo muy importante que se tiene que tomar en cuenta, que es el cuidado de la información, es decir, la seguridad de los datos. Los datos son uno de los “activos” (por llamarlo de alguna forma) más importantes de una empresa. Es ası́ que la manera en como la información se ha vuelto más importante, en necesario ofrecer alternativas que garanticen la seguridad de los datos, más aún cuando estos se encuentran centralizados y grupos de usuarios tienen la posibilidad de accesar a ellos; de ahı́ que la seguridad en los datos es indiscutiblemente un 1.
(16) aspecto que ha obtenido una alta prioridad e importancia en la actualidad. El concepto de seguridad por sı́ sólo puede variar dependiendo en qué contexto se ponga, pero para efectos de este trabajo, seguridad estará relacionada con el control de acceso hacia los datos. ¿Por qué control de acceso? Dentro de una base de datos centralizada, hay muchos accesos hechos por usuarios, administradores y aplicaciones que buscan y manipulan datos; pero, ¿qué sucede cuando la aplicación o el usuario no deban ver y/o modificar datos que no corresponden a sus funciones dentro de un rol especı́fico? La respuesta es simple, la información se vuelve no confiable, se corrompe, se sobrepasan los lı́mites de privacidad y tiende a utilizarse con intereses y objetivos distintos a los que originalmente se planeó. El control de acceso a la información es importante para mantener, como él lo dice, un control, que permita autorizar o no a usuarios y aplicaciones, a utilizar debidamente los datos que ellos necesiten. Por ellos muchos controles de acceso han sido implementados dentro de las aplicaciones como una solución; pero ello también a la larga se vuelve costoso, porque si en algún momento las polı́ticas de acceso son cambiadas, esto significa que hay que cambiar cada aplicación, implementar las nuevas polı́ticas, evaluar y liberar. Esto se traduce en pérdida de tiempo y en retrabajo que sucederá cada vez que las polı́ticas sean cambiadas. Este trabajo de tesis ha desarrollado un control de acceso a datos para organizaciones con información centralizada, y que a su vez pueda pertenecer a una estructura descentralizada en lo que se refiere a accesos, pues los usuarios pueden estar localizados en diferentes áreas greográficas, por lo tanto, los accesos a los datos son locales y remotos. Además, la información contenida en las bases de datos cumple con la caracterı́stica de poder ser clasificada en base a un atributo(dato), mismo que es usado como caracterı́stica medular para determinar los permisos de acceso. Este control de acceso es implementado a nivel de base de datos, por lo tanto las aplicaciones quedan excentas de codificar un módulo en especial para éste propósito. El control de acceso está implementado usando dos técnicas: Modificación de queries. Generación Automática de Código. Dichas técnicas han sido seleccionadas por su alta confiabilidad y desempeño en el área de las bases de datos y además porque aseguran que el control de acceso es 2.
(17) confiable, robusto y además no impacta de manera crı́tica en el desempeño de la base de datos.. 1.1.. Antecedentes. Desde que las bases de datos aparecieron, se ha tenido la inquietud de tener un control para accesar a los datos. Los primeros diseños e implementaciones de las bases de datos, delegaban este control al sistema operativo [1]; pero consecuentemente, estos diseños iniciales empezaron a crear sus propios mecanismos de seguridad como encriptar los datos, los primeros usos de vistas, métodos llamados query modification y access imprecision [13]. Con el paso del tiempo y la aparición de las bases de datos activas, han llegado nuevos esquemas o métodos para reforzar el control de acceso a los datos(por ejemplo, triggers que monitorean la integridad de la base de datos); existen posturas que han utilizado un control de acceso basado en roles (RBAC) [16]; este tipo de control ha sido muy utilizado y en la actualidad aún se plantea como solución. Otro control de acceso es aquel basado en la separación de tareas (separation of duty). Separación de tareas o de privilegios, básicamente propone que el acceso a los datos no sólo requiera de un rol asignado al usuario o a la aplicación, sino que requiera un segundo rol para asegurar que algo o alguien está avalando el acceso; para ello han tomado como ejemplo del mundo real el cambio de un cheque, el cuál debe de ir firmado por quien lo emite y endosado por quien lo cobra [8]. Otro enfoque propone especificar polı́ticas flexibles de control de acceso con unidades de programación (constraint logic programming). Este cita que los modelos RBAC pueden ser extendidos usando constraint logic programming (CLP) como polı́ticas de acceso permitiendo que las peticiones para accesar a la información y la verificación de reglas (constraints) se validen eficientemente [25]. También existen enfoques que proponen utilizar objetos como para representar constraints, validación de las transacciones y condiciones [4]; otros más proponen predicados fragmentados (fragmentation predicate), reglas y triggers, privilegios de acceso a la base de datos basados en la identidad del usuario y otros mecanismos más para impedir el acceso a los datos de agentes hostiles, usuarios no autorizados o aplicaciones con errores humanos (bugs) [7] [10]. Estas filosofı́as se han complementado también con el método de uso de vistas y sinónimos, que en uno de sus inicios se enfocó a mantener la integridad de los datos como función principal [27]. El uso de vistas y sinónimos resulta ser muy fácil de implementar como mecanismo de seguridad. Con las vistas se pueden hacer varias formas de limitar el acceso a los datos por medio de operaciones simples, por ejemplo, se puede. 3.
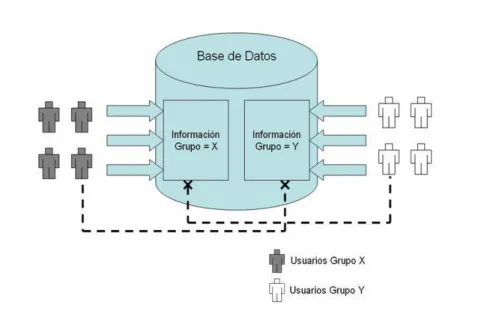
(18) limitar el acceso a usuarios después de una hora determinada (como horario de oficina). Este tipo de control es útil cuando se tiene un modelo que tiene pocas tablas, pero una de sus desventajas es la cantidad de vistas que se tienen que implementar para modelos con una enorme cantidad de tablas, ya que resulta tedioso y laborioso el administrarlo; si por alguna razón el usuario tiene el acceso directamente a las tablas, entonces pasará como inadvertido por el control de acceso [21] [22].. 1.2.. Motivación. El presente trabajo motivó a desarrollar un control de acceso a datos para organizaciones con información centralizada, y a su vez con accesos de usuarios locales o remotos, que pueden manipular información que a ellos no corresponde manejar. El problema a resolver es el acceso no permitido que tienen los usuarios a información que no les corresponde manipular, esto con el fin de proteger la veracidad, confiabilidad e integridad de la información. Con el fin de llevar a la práctica estos principios, el control de acceso desarrollado resuelve los problemas de accesos no autorizados en el esquema de organizaciones antes mencionado, aún cuando los accesos a la información sean tanto locales como remotos.. Figura 1.1: Esquema Genérico. En la figura 1.1, se presenta un esquema general de las necesidades que se cubrieron en este trabajo de investigación. En este esquema se pueden apreciar dos grupos distintos de usuarios, unos que corresponden al X y otros al Y. Nótese cómo cada grupo tiene acceso(indicado con las flechas grandes) a los datos que hacen correspondencia 4.
(19) con su grupo, es decir, los del grupo X pueden tener acceso a la información del grupo X y ası́ aquellos del grupo Y a la información con Y. De manera contraria sucede con aquellos que intentan accesar a información de un grupo distinto al suyo; las lı́neas punteadas y con una “x” en la punta, denotan la negación al acceso a esa información. Para atender esta problemática se tomará un caso de estudio en el cuál se aplicará el trabajo de investigación y que será visto en el capı́tulo 5. Este caso consiste en la administración de la información académica de una universidad, la cuál tiene un número finito de campus situados a lo largo y ancho del paı́s; a su vez cada campus tiene sus propios usuarios y su propia información; la información académica consiste en datos de alumnos, sus calificaciones, historia académica, en profesores, grupos, horarios, etc. todo lo necesario para soportar los procesos comunes de una escuela. Es necesario aclarar que la información es accesada a través de una aplicación, misma que es usada por todos los campus de la universidad y también que dicha información está almacenada en tres diferentes bases de datos, cada una a su vez, aloja los datos y usuarios de varios campus. Se dice que los usuarios que laboran en un campus, pertenecen a él, que pueden tener acceso de consulta a los demás campus pero que sólo deberı́an de manipular la información para el campus al que pertenecen.. Figura 1.2: Situación Actual.. 5.
(20) Tómese como ejemplo una de las tres bases de datos. El problema existente es que los usuarios pueden en este momento actualizar, borrar e insertar datos para cualquier campus, siendo que sólo deberı́an de poder hacerlo para al que pertenecen. Véase la figura 1.2. Dicha figura muestra que aunque les es permitido consultar datos de cualquier campus, los usuarios pueden manipular la información de otros. Administrativamente esto no es correcto, ya que usuarios mal intencionados pueden quebrantar la confiabilidad de la información de otro campus. Por esta razón es necesario implementar un control de acceso. Este control se basará en la necesidad de que sólo los usuarios que pertenezcan, por ejemplo, al campus 1, tengan permisos de manipulación a la información de este campus, pero que puedan hacer consultas a datos de otros. Esta necesidad es ilustrada como sigue:. Figura 1.3: Situación Deseada. La figura 1.3, toma como ejemplo un usuario del campus 1, el cuál está autorizado para hacer consultas a su propio campus, al campus 2 y al 3, pero las modificaciones sólo las puede ejecutar para el cuál pertenece; las flechas punteadas describen que no puede hacer cambio alguno en la información de los campus 2 y 3. De esto se puede deducir que el control de acceso estará en función del atributo CAMPUS. Con estas bases se pretende desarrollar este trabajo de investigación. En resumen, las razones por las cuales el control de acceso fue desarrollado son: Restringir acceso a usuarios no autorizados, dentro del mismo ambiente. Ambiente: • Información centralizada. 6.
(21) • Accesos descentralizados (locales o remotos). • Usuarios manipulan datos que no les corresponde. Proteger la información desde dentro de la organización. Se protege de usuarios no autorizados: • Veracidad • Confiabilidad • Integridad. 1.3.. Objetivos. El objetivo general de este trabajo de tesis es implementar un control de acceso para una organización con datos centralizados, accesos locales y remotos. Este control de acceso a datos utiliza las técnicas de modificación de queries y generación de código en su implementación. Los objetivos especı́ficos son: Diseñar la solución de control de acceso a los datos utilizando los conceptos de modificación de queries y generación de código. Este control se implementa en la base datos, con el fin de dejar a cualquier aplicación libre de incluir en su código, el control de acceso mencionado. Generar automáticamente los procedimientos que modifican queries dados. Desarrollo de una interfaz (consola de generación de código) desde la cuál se genere e implemente de manera automática el control de acceso en la base de datos. Este trabajo alcanzó todos los objetivos antes mencionados llevando a cabo una investigación de un año y efectuando las pruebas y experimentos necesarios para determinar el resultado.. 1.4.. Justificación. La razón primordial por la cuál se decide ha hacer este trabajo de tesis, es por la imperante necesidad de tener un control en las operaciones y transacciones que se llevan a cabo sobre el modelo de base de datos, de organizaciones con las caracterı́sticas antes mencionadas. Debido a que cada vez se integran más usuarios y más información 7.
(22) de diferentes entidades que comparten el modelo y la instancia de la base de datos, es necesario diferenciarlos y que cada quién pueda trabajar sin tener que modificar o accesar a los datos de otros. Los beneficios son obvios, ya que cada quién tendrá protegida su información y no ocasionará que la información deje de ser confiable (esto para operaciones de modificación); ası́ también como la consulta de la misma, que se puede restringir a que sólo los autorizados la consulten.. 1.5.. Aportaciones. Este trabajo de investigación aporta un control de acceso a datos para aquellas organizaciones que tienen información centralizada, pero que a su vez pueden tener accesos desentralizados, es decir desde varios puntos geográficamente separados, y que su información cumpla con la propiedad de poder ser agrupada o clasificada por un atributo(dato) mismo que se usará para determinar los permisos de acceso a los respectivos usuarios. Las técnicas usadas en la implementación de este control de acceso, permiten que el mismo sea: Fácil de mantener. Tiene la caracterı́stica de ser implementado en la base de datos, sólo una vez. Robusto. No importan los privilegios especiales que el usuario posea, en otras palabras, se asegura de que los datos estén bien protegidos modificando dinámicamente los queries que se apliquen sobre ellos(datos). Libera a las aplicaciones de implementar módulos especiales para el control de acceso a los datos. Hace que la implementación de polı́ticas de acceso sea fácil de codificar. El control de acceso actúa directamente sobre las tablas del modelo basándose en el atributo que agrupa o clasifica a la información. El tiempo de desarrollo es prácticamente nulo, pues el código para su implementación es generado. Estos puntos fueron llevados acabo en este trabajo de tesis desarrollando el control de acceso, mismo que es explicado en el capı́tulo 4 de esta tesis. En este capı́tulo se puede ver cómo se desarrolla, los pasos a seguir y la generación de código con la cuál se implementa el control de acceso en la base de datos. Además, en el capı́tulo 5 se muestra que el control de acceso es implementado usando un caso de estudio y que 8.
(23) llevado a la práctica cumple con los objetivos de la tesis y con las aportaciones descritas anteriormente.. 1.6.. Organización del Documento. Este documento es iniciado por un breve resumen que muestra en general el contexto y la problemática que se estudiará. A continuación se presenta el capı́tulo 1 con una introducción que abunda más en la situación actual del problema, un esquema general y en las soluciones propuestas. El capı́tulo 2 muestra el marco teórico con los estudios previos desarrollados; en este capı́tulo se hace una organización de los estudios, de tal manera que sea para un mejor entendimiento. El capı́tulo 3 muestra los mecanismos para el control de acceso basado en facilidades que tienen ciertos DBMSs comerciales, para poder aplicar un control de acceso. Cabe mencionar que este capı́tulo también informa sobre las prácticas de control de acceso que actualmente se llevan a cabo en el plano laboral y profesional. A continuación, se describe en el capı́tulo 4, el desarrollo del control de acceso, el problema, la solución, pasos para implementarlo y ejemplos con resultados del funcionamiento del control de acceso. El capı́tulo 5, está dedicado a el caso de estudio que se tomó para la implementación del control de acceso en ambiente real, incluye el modelo de datos usado, un pequeño bosquejo de evaluación al trabajo y el prototipo de validación usado para la demostración del funcionamiento del control de acceso. Por último, en el capı́tulo 6 se presentan las conclusiones y trabajos futuros que esta investigación dió como resultado, además del anexo, compuesto por el código empleado.. 9.
(24) Capı́tulo 2. Marco Teórico Las bases de datos se han convertido en el núcleo de los sistemas de información, por lo tanto, la seguridad de los datos es altamente necesaria e importante. La mayorı́a de los sistemas de bases de datos relacionales usados actualmente, proveen mecanismos de confidencialidad limitados; estos mecanismos permiten la definición de vistas, conceder y revocar ciertos privilegios (SELECT, INSERT, REFERENCE, etc.) y también la definición de roles. Al mismo tiempo un RDBMS puede implementar mecanismos de control de acceso. A continuación se describe una clasificación de las diferentes corrientes que se han desarrollado para el uso e implementación del control de acceso en las bases de datos.. 2.1.. Técnicas de Control de Acceso. El control de acceso es un mecanismo a través del cuál se asegura o se trata de asegurar que los recursos puedan ser accesados por personas autorizadas y que éstas puedan únicamente ejecutar actividades o funciones que les sean permitidas. Normalmente, el control de acceso aplicado a los recursos, está hecho usando reglas de autorización; a su vez estas reglas se basan en la nomenclatura <s,o,a> (según [16]), o sea, un sujeto s puede actuar(accesar) sobre un objeto o ejecutando una acción a; estos tres conceptos que juegan un papel importante dentro del proceso del control de acceso, es descrito por [16] de la siguiente manera: Sujetos. Son las entidades para las cuales el acceso a los objetos puede ser autorizado. Aunque estas suelen ser usuarios, también pueden considerarse como grupos de usuarios, roles o cada proceso que se esté corriendo por medio de una cuenta de usuario. Objetos. Son los elementos a los cuáles se quieren acceder. En sistemas de bases de datos relacionales, los objetos pueden tener diferente granularidad: vistas y atributos pueden ser accedidos. 10.
(25) Acciones. Son las posibles operaciones que pueden ser ejecutadas, y que usualmente en sistemas de bases de datos relacionales son instrucciones SELECT, INSERT, DELETE y UPDATE. En esta sección se describirán las siguientes técnicas de control de acceso: Control de Acceso Discrecional (DAC). Control de Acceso tipo Mandatory (MAC). Control de Acceso por Roles (RBAC). Control de Acceso basado en Roles de Tareas (T-RBAC). Restricciones Clasificadas y por Deducción (Inference Constraints). Generalized Temporal Role Based Access Control (GTRBAC).. 2.1.1.. Control de Acceso Discrecional (DAC). Según [16], el control de acceso discrecional es la estrategia de control de acceso más antigua, y está basada bajo la idea de que el sujeto accese a los objetos de acuerdo a su identidad y de algunas reglas de autorización, que indican al sujeto, qué acciones puede ejecutar en cada objeto del sistema. Con esta estrategia, si un usuario quiere ejecutar una operación sobre un objeto, una búsqueda es llevada a cabo en el sistema para encontrar un regla de autorización que le otorgue el permiso para ejecutar dicha acción sobre dicho objeto, y si la regla no es encontrada, el acceso es denegado. Esta polı́tica de control de acceso ha sido altamente utilizada, pero la autorización del acceso para cada objeto depende exclusivamente de la existencia (o no) de una regla de autorización, sin importar el nivel de confidencialidad de los datos, ni el nivel que cada sujeto pueda acceder. También existe un mecanismo que otorga la autorización, y permite la posibilidad de acceder ciertos datos a un usuario que no la tenı́a antes, y de esta manera puede llegar a violar la confidencialidad de los datos. Este tipo de control es visto tı́picamente como otorgar o negar privilegios, por ejemplo un usuario U1 puede tener privilegios de SELECT a una tabla T1, pero no de INSERT, UPDATE ni DELETE. La ventaja es que es muy sencillo de operar ya que es una especie de “todo o nada” respecto a los privilegios que se otorgan o revocan, pero la desventaja es que se hace impráctico si se tienen muchos usuarios, y el otorgar o revocar provilegios sobre un número también grande de objetos se hace muy tardado y complejo de administrar.. 11.
(26) Esta técnica ya es usada en el esquema actual de la base de datos del caso de estudio; ayuda a negar el acceso a los objetos (tablas, vistas, etc.) pero no soluciona el problema, ya que la aplicación que se usa, está basada en roles y éstos pueden otorgar privilegios que no se tenı́an.. 2.1.2.. Control de Acceso tipo Mandatory (MAC). Esta polı́tica de control de acceso está basada en el modelo diseñado por Bell y LaPadula para sistemas operativos, y consiste en clasificar a los sujetos y a los datos en diferentes niveles de seguridad. Bell y LaPadula ([16]) proponen los siguientes niveles de seguridad: “sin clasificación(U)”, “confidencial(C)”, “secreto(S)”, “muy secreto(TS)”, donde TS ≥ S ≥ C ≥ U. A su vez esta clasificación aplica para sujetos(usuarios, programas) y objetos(relación, tabla, vista, operación). Por ejemplo un sujeto puede tener la clasificación TS y un objeto la clasificación S. Por nomenclatura, la clasificación de un objeto se determinará como class(S) y la de un objeto como class(O). Este control de acceso utiliza dos reglas básicas: Un sujeto S, tiene acceso para leer un objeto O, si class(S) ≥ class(O). Esta regla es conocida como propiedad simple de seguridad . Un sujeto S, tiene acceso para escribir un objeto O, si class(S) ≤ class(O). Esta es conocida como propiedad estrella (o propiedad-*). La primer regla es intuitiva, ya que muestra que ningún sujeto puede tener acceso de lectura a un objeto que tenga una clasificación mayor que la de él. La segunda regla es menos intuitiva, ésta prohibe a un sujeto escribir un objeto en un nivel de clasificación menor al de él. Por ejemplo, un usuario(sujeto) con clasificación TS puede hacer una copia de un objeto con clasificación TS y entonces reescribirlo como un nuevo objeto pero con clasificación U, dejándolo visible para todo usuario en el sistema, de ahı́ la razón de prohibir este tipo de operación. La principal caracterı́stica de esta polı́tica de control de acceso es que éste es autorizado si existe cierta relación entre el nivel de seguridad del sujeto y el nivel de seguridad del objeto al cuál se desee accesar. También, los datos tienen sus propios niveles de seguridad, sin tomar en cuenta quién desea accesarlos. Para el caso de estudio planteado, esta técnica no aplica ya que la información no está clasificada por niveles de seguridad.. 2.1.3.. Control de Acceso por Roles (RBAC). Este tipo de control de acceso es una alternativa a métodos de acceso tradicionales, como el tipo mandatory y el discrecional. [16] menciona que tradicionalmente el mane12.
(27) jo de la seguridad requiere bajos niveles de control, y normalmente algunas listas de control de acceso que necesitan un esfuerzo considerable para mantenerlas. El RBAC permite ser asociado a un rol, de tal manera que los usuarios se hacen miembros de uno o varios roles; y de esta manera los usuarios obtienen los permisos, simplificando su administración (permisos). Los roles representan cada equipo funcional de organizaciones, agrupando en cada uno a usuarios con funciones y responsabilidades similares; por ejemplo, un usuario de un departamento de ventas tiene asignado el rol que le permita accesar a los objetos necesarios para su función y no tendrá acceso a objetos relacionados al departamento de contabilidad. Bajo este mecanismo es fácil llevar a cabo ciertas acciones, tales como cambiar usuarios de un rol a otro, y agregar o eliminar de ciertos roles, uno o varios permisos. La manera en como se puede asignar un rol es ejecutando la instrucción SET ROLE, que es prácticamente estándar en los DBMS comerciales. En el caso de estudio, es utilizado este tipo de control de acceso, ya que los usuarios son agrupados por departamentos, por ejemplo, el departamento de admisiones, de titulación, de registro, etc. y además la aplicación también hace uso de roles.. 2.1.4.. Control de Acceso basado en Roles de Tareas (T-RBAC). El modelo de control de acceso basado en roles de tareas es una mejora del modelo RBAC (control de acceso basado en roles), que resuelve los problemas comunes de este último, tales como jerarquı́a de rol. En el modelo T-RBAC, los permisos son asignados a tareas y las tareas están asignadas a los roles. Una tarea es la unidad de función de trabajo o una actividad de negocios. Oh y Park [23] proponen al T-RBAC como un modelo de control de acceso, mejor que el modelo tradicional RBAC. T-RBAC es un modelo integrado de control de acceso basado en roles y basado en la actividad de clasificar tareas. Dado que el modelo de control de acceso tiene relación con el mundo real, se ha desarrollado un proceso de derivación de la información de control de acceso desde dentro del ambiente de una empresa. Este proceso está basado en las siguientes observaciones ([23]): En general, los usuarios dentro de la compañı́a pertenecen a la estructura de la organización. Los usuarios ejecutan sus tareas asignadas (funciones de trabajo) de acuerdo a su posición de trabajo. Desde el punto de vista de sistemas de información, esto es un conjunto de objetos de información y operación.. 13.
(28) Los derechos de acceso son requeridos únicamente para ejecutar las tareas asignadas. Si se conocen las tareas asignadas de un usuario, se puede decidir qué derechos de acceso pueden ser asignados a éste. Un rol de negocios o posición de trabajo puede ser definido como un conjunto de tareas. El privilegio más bajo incluye el “Necesito saber” y el “Necesito hacer” como un principio básico de control de acceso dentro del ambiente de la empresa. También se definen tipos de roles en [23] tales como: Rol organizacional. Este es un rol básico para todos los usuarios pertenecientes a la organización. De tal manera los permisos son heredados a los usuarios que pertenecen únicamente a la organización. Ejemplo de estos roles Departamento ventas, Departamento finanzas. Rol de posición de trabajo. Es definido por la posición dentro de la estructura organizacional. Por ejemplo Vice Presidente ventas, Administrador financiero. Rol funcional. Por ejemplo Desarrollador, Programador. Esta técnica no aplica para el trabajo de investigación, ya los roles utilizados no están clasificados como menciona dicha técnica.. 2.1.5.. Restricciones Clasificadas y por Deducción (Inference Constraints). Las polı́ticas tipo mandatory, proveen una simple (en términos de especificación y manejo) forma de control de acceso basado en la clasificación de los datos y de los sujetos; esto parece adecuado, ya que en general los datos necesitan estar disponibles para los usuarios, que tengan los permisos necesarios. El trabajo propuesto por Dawson, De Capitani y Samarati en [6], propone clasificar las restricciones(constraints) con el fin de generar especificaciones que permitan llevar un control de acceso a un nivel de granularidad fino, es decir, aplicar el control de acceso por las operaciones(INSERT, UPDATE, DELETE, SELECT) efectuadas sobre objetos(comunmente tablas). La clasificación de restricciones define requerimientos que los niveles de seguridad asignados a los datos, deben de satisfacerse. Se tienen diferentes tipos de restricciones; según [6]se enumeran como sigue: Restricciones clasificadas básicas. Explı́citamente asignan un nivel de seguridad a cierto atributo, posiblemente dependiendo de algunas condiciones, por ejemplo, “el atributo salario es secreto cuando su valor es mayor a $1000”, y “el atributo nombre es secreto para los empleados los cuáles salario sea mayor a $1000”. 14.
(29) Restricciones asociados. Clasifican la relación (asociación) entre atributos diferentes, posiblemente dependiendo de algunas condiciones, por ejemplo, “la asociación entre nombres y salarios es secreta, cuando salario sea mayor a $1000”. Restricciones por deducción. Ponen condiciones en la clasificación de atributos relacionados por deducción, por ejemplo, el último nivel de seguridad de rango y departamento es requerido para acceder al nivel de salario. Restricciones de integridad. Son aquellos que especifican atributos que son requeridos por un modelo de datos, para definir atributos llaves (primary key), atributos de integridad referencial (referencial key). Este tipo de constraint generalmente es soportado por bases de datos comerciales. Este tipo de clasificación puede ser útil en el momento en que se requiera expander a más atributos de validación para el caso de estudio que esta investigación propone, ya que por el momento el único atributo que se usará para determinar el acceso es el campus.. 2.1.6.. Generalized Temporal Role Based Access Control (GTRBAC). El modelo Generalizado TRBAC [12] incorpora un grupo de constructores de lenguaje para la especificación de varias restricciones temporales en roles, incluyendo restricciones en la activación y en habilitar los roles de usuario y en la asignación de los permisos a roles. En particular, GTRBAC hace una clara distinción entre habilitar roles y activar roles. Un rol está habilitado si un usuario puede adquirir los permisos asignados al rol. Un rol habilitado se convierte en activado cuando un usuario adquiere los permisos asignados al rol en una sesión. Relacionados a estos conceptos de rol habilitado y activado, están las autorizaciones activadas y asignadas presentadas en [26]. Un área de oportunidad dentro del modelo GTRBAC, tanto como el TRBAC [9], es la interacción entre las restricciones temporales y la jerarquı́a de roles. El modelo GTRBAC es una extensión del modelo TRBAC [9]. El modelo GTRBAC introduce la noción por separado de rol habilitado y activación de rol y provee expresiones de eventos y restricciones asociándolas con los anteriores. Un rol habilitado indica que al menos un sujeto ha activado un rol en una sesión. Las restricciones temporales en GTRBAC permiten la especificación de lo siguiente: Restricciones temporales en habilitar/deshabilitar un rol. Estas restricciones permiten especificar la duración de los intervalos de tiempo en los cuáles un rol es habilitado o deshabilitado. Cuando un rol es habilitado, los permisos asignados a él pueden ser adquiridos por un usuario por simple activación del rol. También 15.
(30) es posible especificar la duración del rol. Cuando tal duración es especificada, el evento de habilitar/deshabilitar para un rol es iniciado por una expresión de habilitar restricción que puede ser especificada por separado, en tiempo de ejecución por un administrador, o por un trigger. Restricciones temporales es la asignación de rol a usuario y permisos a rol. Estos son construidos expresando un intervalo especı́fico o una duración en la cual un usuario o permisos son asignados a un rol. Restricciones de activación. Estos permiten especificar cómo un usuario debe ser restringido en la activación de un rol. Esto incluye, por ejemplo, la especificación del total de duración en la que el usuario está permitido a activar un rol, o cuántos usuarios se permiten para activar un rol en particular. Eventos en tiempo de ejecución. Un grupo de eventos en tiempo de ejecución permiten a un administrador iniciar dinámicamente eventos GTRBAC, o habilitar la duración o activación de restricciones. Triggers. Los triggers permiten expresar dependencias entre los eventos del GTRBAC, considerar eventos pasados y definir eventos futuros basados en ellos. Esta técnica no es aplicable al trabajo de investigación, puesto que las conexiones que los usuarios tienen en la aplicación son largas, entonces las activaciones y restricciones de roles serı́an un tanto inadecuadas.. 16.
(31) 2.1.7.. Resumen. En la siguiente tabla se especifican las ventajas y desventajas de las técnicas antes vistas, aplicando al caso de estudio de esta investigación. Técnica Ctrl. de Acceso Discrecional. Ventaja Fácil de usar. Ctrl. de Acceso tipo Mandatory Ctrl. de Acceso por Roles. No aplica Agrupa usuario; es fácil identificar los permisos. Ctrl. de Acceso basado en Roles de Tareas Restricciones Clasificadas y por Deducción. No aplica. GTRBAC. Es útil para hacer una clasificación de reglas de restricciones y para crear un controlde acceso granulado No aplica. Desventaja Impráctico al existir muchos usuarios y objetos No aplica Se puede otorgar permisos extras a usuarios no deseados No aplica Al clasificar mal, no dará los resultados esperados. No aplica. Tabla 2.1: Técnicas de Control de Acceso. 2.2.. Tecnologı́as de Control de Acceso. En esta sección se mencionan unas de las técnicas que se han desarrollado a partir de la tecnologı́a existente para implementar un control de acceso.. 2.2.1.. Acceso Basado en Vistas. Una vista es el área de la base de datos a la que un usuario o grupo de usuarios les es permitido tener acceso [11]. Pernul y Luef [15] conceptualizan a una vista de la siguiente manera: Una vista está definida por un diseñador de base de datos y determinada durante el análisis de los requerimientos del proceso de diseño de una base de datos. Las vistas han sido usadas exitosamente para modelar controles de acceso discrecional para DBMS por algún tiempo, aunque en sus inicios fueron propuestas para controles de acceso tipo mandatory. Aún hoy en dı́a varios proyectos de investigación continúan estudiando el uso de las vistas para ambos tipos de accesos. Una vista es una estructura conceptual[15], la cuál no existe dentro de la base de datos. En un nivel conceptual, cada vista es parte de una extensión de un modelo de datos relacional y definido en un conjunto de esquemas relacionales que forman el nivel conceptual del esquema de la base de datos. Basado en vistas, los esquemas son descompuestos en un grupo de fragmentos. Existen diferentes niveles de granularidad de datos que pueden ser usados para modelar e implementar MAC. Las columnas, renglones, campos, tablas 17.
(32) o vistas son todas las posibilidades existentes para crear un “objeto de seguridad”, pero en [15] se cree que fragmentos de vistas proveen una mejor flexibilidad. El seleccionar fragmentos como objetos de seguridad consiste a un consistente y completo proceso de labeling. El proceso de labeling está basado por el siguiente supuesto: mientras más sea el número de vistas que tengan acceso a un fragmento en particular, menor es la sensibilidad de los datos contenidos en dicho fragmento, y por lo tanto, también será menor el nivel de clasificación que se necesita asignar al fragmento. Las vistas que están accediendo a fragmentos clasificados como de bajo nivel, necesitarán únicamente permisos la clasificación “bajo nivel”; mientras que las vistas que acceden a fragmentos que contengan datos de alta sensibilidad, necesitarán los permisos suficientes que les permitan el acceso a dichos fragmentos. Por esta razón, [15] usa vistas y fragmentos para reforzar seguridad tipo mandatory asociando con cada fragmento y vista una etiqueta de seguridad tipo mandatory. La ventaja de utilizar vistas es que son estructuras que no ocupan espacio en la base de datos, y ayuda a que el usuario no tenga acceso directo a las tablas; la desventaja es que si el query que se utiliza para crear la vista es muy complejo, mal construido, y la tabla es demasiado grande, el acceso a la vista será tardado. Por lo tanto es recomendable usar vistas que requieran consultas sencillas o por lo menos afinar correctamente los queries que se usarán para su construcción.. 2.2.2.. Bases de Datos Activas. Según la definición proporcionada por Abiteboul, Hull y Vianu en[27] y por Widom y Ceri en [3], un sistema manejador de base de datos, es una alternativa para almacenar grandes volúmenes de datos, permitiendo que múltiples usuarios manipulen estos datos dentro de un ambiente eficiente y controlado. Los manejadores de bases de datos convencionales son pasivos, es decir, los datos son creados, consultados, modificados y borrados únicamente en respuesta a las operaciones usadas por los usuarios o por aplicaciones. Las tendencias dentro de las tecnologı́as de las bases de datos, se han enfocado en extender los sistemas convencionales para mejorar su funcionalidad y alojar aplicaciones más avanzadas. En [3] se menciona que una importante y muy usada mejora es transformar los sistemas de bases de datos en activos, esto significa que el sistema por si solo realiza ciertas operaciones automáticamente en respuesta a ciertos eventos que ocurren o, a ciertas condiciones a ser satisfechas. Los sistemas de bases de datos activas (Active Databases) son significantemente 18.
(33) más poderosos que sus contrapartes pasivas: Los sistemas de bases de datos activas pueden eficientemente ejecutar funciones que para los sistemas pasivos deben de ser codificados en aplicaciones. Los sistemas de bases de datos activas sugieren y facilitan aplicaciones más allá del alcance de los sistemas de bases de datos pasivos. Los sistemas de bases de datos activas pueden ejecutar tareas que requiere subsistemas especiales en sistemas pasivos. Dentro de las bases de datos activas, existen funciones que pueden ser ejecutadas eficientemente, pero que en las bases de datos pasivas deben ser codificadas dentro de las aplicaciones[3]; estas funciones son: reglas de integridad (integrity constraints). triggers. Las reglas de integridad son condiciones especı́ficas que rigen sobre los datos en la base de datos, usualmente estipulando que un dato es una representación válida del mundo real. Las bases de datos convencionales (pasivas) soportan limitadas formas de reglas de integridad, tales como una especificación que ciertos datos deben tomar como valores únicos (key constraints), o que ciertos datos deben contener referencias a otros datos (referencial integrity constraints). Pero muchas aplicaciones requieren reglas más allá de estas simples formas, tales como la especificación que todos los valores deben estar dentro de cierto rango, o que una función global en los datos produzca cierto valor. Aunado a esto, en las bases de datos pasivas, la validación de las reglas de integridad, está restricta a inmediatamente después de cada actualización o al final de cada transacción, y la respuesta a una violación de las reglas es deshacer los cambios efectuados por la transacción (roll back). Las bases de datos activas, soportan la especificación y el monitoreo de las integridad de la base de datos en general; ellas permiten la flexibilidad en el momento en que una regla de integridad se verifica y proveen la ejecución de acciones para rectificar una violación de integridad sin necesidad de deshacer lo realizado por la transacción (sin hacer rollback). [28] Los triggers de la base de datos, algunas veces llamados como alertadores o monitores, especifican que ciertas acciones deben ser invocadas siempre que ciertas condiciones son detectadas. Por ejemplo, un trigger de control de inventario debe detectar cuando no hay productos en el almacén y automáticamente reordenar lo necesario. Las bases de datos activas soportan triggers y de hecho están basadas en este concepto.. 19.
(34) Existen dos enfoques que especifican cómo se deberı́an de codificar los triggers y las restricciones de integridad (integrity constraints) en las aplicaciones. En el primero, para cada modificación que se haga sobre los datos mediante una aplicación, se tiene un código que verifica la condición (regla) del trigger y si ésta se cumple, entonces se ejecuta una acción asociada. En caso de que la condición no se cumpla, entonces la acción a seguir es deshacer las modificaciones, es decir, cancelar la transacción. Existen varias desventajas para este enfoque: 1. El agregar, cambiar o remover reglas o triggers requiere encontrar y modificar el código de validación embebido en cada aplicación. 2. El comportamiento de la verificación de las reglas o triggers está garantizado únicamente cuando cada aplicación lo implementa correctamente. El segundo enfoque es agregar un proceso (aplicación) especial que periódicamente monitoree la base de datos para verificar cada regla y trigger. Mientras se resuelven algunos de los problemas con el primer enfoque, el segundo tiene la desventaja de que si el monitorear es muy frecuente, entonces hay una sobrecarga en el desempeño de la base de datos; por otro lado, si el monitoreo es muy esporádico entonces la violación de una regla o la condición de un trigger puede ser no detectada en un momento dado. Las bases de datos activas soportan reglas y triggers sin las desventajas de estos enfoques. Dentro de las bases de datos activas es necesario tomar en cuenta los siguientes puntos: Una base de datos activa debe proveer todas las funcionalidades usuales de una base de datos convencional (pasiva). Mientras tanto, no es deseable que el desempeño deba degradarse por ejecutar tareas que son caracterı́sticas de una base de datos pasiva. Una base de datos activa debe proveer algún mecanismo para que usuarios y aplicaciones especifiquen el comportamiento activo deseado, y esas especificaciones deben convertirse en una persistente parte de la base de datos. Una base de datos activa debe implementar eficientemente algún comportamiento activo que pueda ser especificado; debe monitorear el comportamiento de la base de datos y cuando sea apropiado, iniciar automáticamente las caracterı́sticas activas especificadas. Una base de datos activa debe proveer herramientas de diseño y de depuración, tal y como lo provee una base de datos pasiva, pero extendidas para incorporar el comportamiento activo.. 20.
(35) Reglas en las Bases de Datos Activas Las bases de datos activas están centradas sobre la noción de reglas. Estas reglas dentro de la base de datos activa están definidas por los usuarios, aplicaciones o los administradores de la base de datos (DBA); ellas especifican el comportamiento activo deseado. En una forma general, las reglas de las bases de datos activas consisten de tres partes: Evento. Determina cuando una regla es activada. Condiciones. Son verificadas cuando la regla es activada. Acción. Es ejecutada cuando la regla es activada y su condición se cumple. Una vez que el conjunto de reglas es definido, las bases de datos activas monitorean los eventos relevantes. Para cada regla, si ocurre un evento de la regla, entonces la base de datos activa evalúa la condición (para la misma regla), y si la condición se cumple, entonces se ejecuta la acción de la regla. Los detalles de el monitoreo de la regla y su ejecución, son algo más complejo que esta simple descripción, pero a grandes rasgos este es el paradigma usado por todas las bases de datos activas. Eventos En una regla de base de datos activa, el evento especifica qué causa que la regla sea activada. Los eventos más importantes que activan una regla citados en [3] y [28] son: Modificación de datos. En una base de datos relacional, un evento de modificación de datos debe ser especificado como uno de las tres operaciones de modificación de SQL (inserción, borrado o actualización) en una tabla particular. En una base de datos orientada a objetos, un evento de modificación de datos debe ser especificado como la creación, borrado o actualización de un objeto en particular, o de cualquier objeto de una clase en particular; esto también debe de ser especificado como la invocación de un método particular que modifique objetos. Extracción de datos. En una base de datos relacional, el evento de extracción de datos debe ser especificado como una operación de consulta (select) sobre una tabla en particular; mientras que en una base de datos orientada a objetos debe ser especificado como la obtención (consulta) de un objeto, o como la invocación de un método en particular que consulte objetos. Tiempo. Un evento de tiempo debe especificar que una regla debe ser activada en un tiempo absoluto (por ejemplo, el 1 de Enero de 1995 a las 12:00 hrs.), en una repetición de tiempo (cada dı́a a las 12:00 hrs.) o en intervalos periódicos (cada 10 minutos).. 21.
(36) Definido por la aplicación. Un evento definido por la aplicación debe ser especificado permitiendo a una aplicación declarar un nombre E como un evento (ejemplo, alta temperatura, login de un usuario, dato demasiado largo, etc.) y permitir que reglas de la base de datos activa especifiquen a E como el evento que las activarán. Entonces, cada vez que una aplicación notifique a la base de datos que ocurrió un evento E, alguna regla que especificó a E como su evento, será activada. Usando este enfoque, la aplicación debe ejecutar algún monitoreo o cálculos deseados (teniendo o no acceso a la base de datos) para detectar cuando un evento E debe ocurrir y a su vez, para detectar cuando las reglas asociadas a este evento deban de ser activadas. Condiciones En una regla de base de datos activa, la condición especifica una expresión a ser evaluada una vez que la regla ha sido activada y después de esto la acción es ejecutada. La clasificación de las condiciones según [3] y [28] pueden ser: Predicados de bases de datos. La condición debe especificar que cierto predicado actúa sobre la base de datos, donde el predicado está definido utilizando un lenguaje de consulta en la base de datos (por ejemplo, una base de datos relacional activa debe permitir como condiciones de la regla, cualquier cosa correspondiente a un where de una cláusula SQL). Por ejemplo, una condición expresada como predicada puede establecer que el valor promedio en algún conjunto de valores está por debajo de cierto lı́mite. Predicados restrictos. La condición puede especificar que cierto predicado actúa sobre la base de datos donde el predicado está definido usando una porción restricta de las cláusulas de la condición dentro de un lenguaje de consulta. Por ejemplo, una base de datos relacional activa puede restringir sus condiciones de reglas de tal forma que las operaciones de comparación son permitidas pero joins no lo son. Los predicados restrictos son usados generalmente en vez de usar predicados arbitrarios únicamente por razones de desempeño (la evaluación de una condición puede ser el aspecto más costoso en el procesamiento de una regla). Consultas en la base de datos. La condición puede especificar una consulta usando el lenguaje de consulta del sistema de la base de datos. Por ejemplo, una condición especificada como una consulta, puede regresar todos los datos los cuales están por debajo de algún lı́mite. El resultado puede ser que la condición sea falsa si y sólo si la consulta produce una respuesta vacı́a, o que la condición sea verdadera si y sólo si la consulta produce una respuesta no vacı́a. Como predicados, las condiciones que son consultas pueden usar un lenguaje restricto para garantizar una evaluación eficiente.. 22.
(37) Procedimientos de aplicación. Una condición de una regla puede ser especificada como el llamado a un procedimiento escrito dentro de una aplicación hecha en un lenguaje de programación (ejemplo max-secuencia()), donde el procedimiento puede o no accedes a la base de datos. Si el procedimiento regresa como valor de salida verdadero entonces la condición se efectúa; si el procedimiento regresa falso entonces la condición no se efectúa. Acciones Dentro de una regla de base de datos activa, la acción es ejecutada cuando la regla es activada y su condición es verdadera. Las acciones [3][28] son: Operaciones de modificación de los datos. Una base de datos relacional activa permite acciones de reglas como operaciones SQL (insertar, borrar o actualizar), mientras que en una base de datos activa orientada a objetos puede permitir acciones de reglas como la creación de objetos, borrado de objetos, o llamadas a métodos que modifican objetos. Operaciones de extracción de datos. Una base de datos relacional activa puede permitir acciones de reglas como sentencias select de SQL, mientras que una base de datos activa orientada a objetos puede permitir acciones de reglas como la consulta a objetos, o llamadas a métodos que consulta objetos. Otros comandos de bases de datos. Una acción de una regla puede permitir cualquier operación de base de datos a ser especificada. Agregando a las operaciones de modificación y de consulta de datos, la mayorı́a de los sistemas de bases de datos suportan operaciones para la definición de datos, operaciones de control de transacción (rollback, commit), operaciones para otorgar y revocar privilegios, etc. Procedimientos de aplicación. Una acción de una regla puede ser especificada como una llamada a un procedimiento escrito dentro de una aplicación hecha en un lenguaje de programación, donde el procedimiento puede o no acceder a la base de datos. Triggers Un trigger es un procedimiento que es automáticamente invocado por el DBMS en respuesta a cambios especı́ficos en la base de datos, y es tı́picamente especificado por el DBA [11]. Una base de datos que tiene un conjunto de triggers asociados es llamada Base de Datos Activa. En un sistema de bases de datos activas, cuando el DBMS se encuentra ejecutando una transacción que modifica a la base de datos, este verifica si algún trigger es activado por la transacción(el evento). Si es ası́, el DBMS procesa el trigger evaluando 23.
Figure


+7
Outline
Bases de Datos Activas
Caracter´ısticas Especiales y Tabla Comparativa
Caso 5 Control de Acceso en Empresa Regiomontana
Atributo de Clasificaci´on de Informaci´on y Usuarios
Ejemplo Complejo
Algoritmo para la Generaci´on de C´odigo
Control de Acceso en el M´odulo de Informaci´on de Alumnos
Control de Acceso en el M´odulo de Grupos
Control de Acceso en el M´odulo de Profesores
Control de Acceso en el M´odulo de Inscripci´on
Documento similar
Debido al riesgo de producir malformaciones congénitas graves, en la Unión Europea se han establecido una serie de requisitos para su prescripción y dispensación con un Plan
Como medida de precaución, puesto que talidomida se encuentra en el semen, todos los pacientes varones deben usar preservativos durante el tratamiento, durante la interrupción
No había pasado un día desde mi solemne entrada cuando, para que el recuerdo me sirviera de advertencia, alguien se encargó de decirme que sobre aquellas losas habían rodado
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
Products Management Services (PMS) - Implementation of International Organization for Standardization (ISO) standards for the identification of medicinal products (IDMP) in
This section provides guidance with examples on encoding medicinal product packaging information, together with the relationship between Pack Size, Package Item (container)
Package Item (Container) Type : Vial (100000073563) Quantity Operator: equal to (100000000049) Package Item (Container) Quantity : 1 Material : Glass type I (200000003204)
b) El Tribunal Constitucional se encuadra dentro de una organiza- ción jurídico constitucional que asume la supremacía de los dere- chos fundamentales y que reconoce la separación
