Aplicación de un modelo tonal para la transcripción de prosodia
70
0
0
Texto completo
(2) Universidad Central “Marta Abreu” de Las Villas Facultad de Ingeniería Eléctrica Centro de Estudios de Electrónica y Tecnología de la Información. TRABAJO DE DIPLOMA “Aplicación de un modelo tonal para la transcripción de prosodia”. Autor: Francisco Rivera Olivera Tutor: Ing. Héctor Arturo Kairuz Hernández-Díaz. Santa Clara 2013 "Año del 55 Aniversario del Triunfo de la Revolución".
(3) Hago constar que el presente trabajo de diploma fue realizado en la Universidad Central “Marta Abreu” de Las Villas como parte de la culminación de estudios de la especialidad de Ingeniería en Telecomunicaciones y Electrónica, autorizando a que el mismo sea utilizado por la Institución, para los fines que estime conveniente, tanto de forma parcial como total y que además no podrá ser presentado en eventos, ni publicados sin autorización de la Universidad.. Firma del Autor Los abajo firmantes certificamos que el presente trabajo ha sido realizado según acuerdo de la dirección de nuestro centro y el mismo cumple con los requisitos que debe tener un trabajo de esta envergadura referido a la temática señalada.. Firma del Tutor. Firma del Jefe de Departamento donde se defiende el trabajo. Firma del Responsable de Información Científico-Técnica.
(4) PENSAMIENTO. Mas tú, cuando ores, entra en tu aposento, y cerrada la puerta, ora a tu Padre que está en secreto; y tu Padre que ve en lo secreto te recompensará en público.. Le dijo Tomás: Señor, no sabemos a dónde vas; ¿cómo, pues, podemos saber el camino? Jesús le dijo: Yo soy el camino, y la verdad, y la vida; nadie viene al Padre, sino por mí.. Si me amáis, guardad mis mandamientos. Y yo rogaré al Padre, y os dará otro Consolador, para que esté con vosotros para siempre: el Espíritu de verdad.. Jesús de Nazaret..
(5) DEDICATORIA. Al único Dios Verdadero. A Jesús el Hijo de Dios. A mi fiel amigo el Espíritu Santo. A mi dulce y bella esposa. A mis padres. A mi hermano Addiel. A mis suegros. A mi cuñada Lisett. A mis más íntimos amigos..
(6) AGRADECIMIENTOS. Al Dios y Padre celestial, de quien soy y a quien sirvo, por derramar su amor, sabiduría y poder sobre mí. A mi Señor Jesucristo, a quien deseo con todo mi ser, por su cuidado y fidelidad hacia mi vida. A mi mejor amigo y compañero de trabajo: el Espíritu Santo de Dios, por estar siempre conmigo y ungirme para predicar al rey Jesús y confirmar el mensaje con lo sobrenatural. A mi hermosa y amorosa esposa, por ser quien es, por amarme y ser mi ayuda idónea, por compartir horas de trabajo conmigo y animarme. A mi tutor por su aporte enorme en este trabajo y su ayuda. Por su paciencia y entrega. Por su atención y compañerismo. A mis familiares por empujarme a terminar mis estudios. Especialmente a mi madre y a mi suegra. A los amigos que me ayudaron y se preocuparon por mi desarrollo en la carrera y en la vida en estos años. A todos los profesores que me han impartido clases en la carrera. A todos, sinceramente, muchas gracias..
(7) TAREA TÉCNICA. •. Hacer una revisión bibliográfica para familiarizarse con los conceptos de la prosodia y adquirir conocimientos acerca de los modelos entonativos; donde se logra definir entonces el modelo tonal que se implementa.. •. Dominar el uso y las facilidades que brinda el software MatLab ver. R2009a en el procesamiento digital de señales acústicas.. •. Seleccionar y modificar los algoritmos relacionados a la tarea de transcripción de prosodia.. •. Extraer y transcribir la frecuencia fundamental de una señal de voz a semitonos.. •. Diseñar una interfaz gráfica para el algoritmo programado.. •. Validar el software creado aplicándolo a voces patológicas satisfaciendo la evaluación de los especialistas.. •. Realizar el informe de la investigación.. Firma del Autor. Firma del Tutor.
(8) RESUMEN. En el estudio de la prosodia en pacientes disártricos es de vital importancia el análisis de la entonación del habla. Existe también la necesidad de buscar medidas objetivas, que sean a la vez un complemento a las medidas subjetivas que emplean los expertos en lingüística para diagnosticar las diferentes patologías. En la actualidad se persiguen los más avanzados algoritmos y técnicas que faciliten el análisis de segmentos, con suficiente duración, para el estudio de la entonación en la prosodia. En nuestro país se desarrolla este trabajo con la finalidad de implementar un software que apoye el diagnóstico y la evaluación de pacientes con dificultades en la comunicación oral. En esta investigación se toman oraciones de pacientes con diferentes disartrias y se le extrae la frecuencia fundamental. Se le aplica un modelo tonal con el objetivo de transcribir esta frecuencia a una escala musical. La escala musical seleccionada está en semitonos. Las señales se trabajan a partir de una interfaz gráfica creada para el software diseñado donde el especialista puede observar los diferentes patrones que se analizan. Estos resultados ayudan a determinar las diferentes enfermedades y su nivel de desarrollo en el paciente..
(9) ÍNDICE PENSAMIENTO ............................................................................................................................. 4 DEDICATORIA .............................................................................................................................. 5 AGRADECIMIENTOS ................................................................................................................... 6 TAREA TÉCNICA .......................................................................................................................... 7 RESUMEN ...................................................................................................................................... 8 ÍNDICE ............................................................................................................................................ 9 INTRODUCCIÓN ......................................................................................................................... 11 CAPÍTULO I: MARCO TEÓRICO .............................................................................................. 15 1.1 Afectaciones en el aparato fonador ...................................................................................... 15 1.1.1 La disartria .................................................................................................................... 15 1.1.2 El aparato fonador ........................................................................................................ 16 1.1.3 Daños en el aparato fonador que afectan el fenómeno del habla ................................. 17 1.2 La entonación y sus generalidades dentro de la prosodia .................................................... 19 1.2.1 Unidades de medida de la entonación........................................................................... 20 1.2.2 Afectaciones de la entonación en voces patológicas ..................................................... 23 1.3 Tecnologías en el procesamiento de voz para el análisis de la entonación. ......................... 24 1.3.1 Dificultades en la determinación del período fundamental (T0). ................................. 24 1.3.2 Modelos entonativos y sus características .................................................................... 25 1.4 Tendencias actuales en la transcripción de la F0. ................................................................ 30 Conclusiones parciales ............................................................................................................... 30 CAPÍTULO II: MATERIALES Y MÉTODOS ............................................................................ 32 2.1 Materiales ............................................................................................................................. 32 2.2 Métodos ................................................................................................................................ 33 2.2.1 El Robust Algorithm for Pitch Tracking (RAPT)........................................................... 33 2.2.2 Algoritmo de Wang ........................................................................................................ 36 2.2.3 Algoritmo de Piet Mertens............................................................................................. 39.
(10) 2.3 El Experimento ..................................................................................................................... 41 CAPÍTULO III: RESULTADOS Y DISCUSIÓN ........................................................................ 42 3.1. Transcripción de la curva F0 a semitonos ....................................................................... 42. 3.2. Interfaz gráfica ................................................................................................................ 44. 3.3. Resultados de los algoritmos propuestos sobre la base de datos Aronson ...................... 49. 3.4. Valoración del contorno de entonación ........................................................................... 51. 3.5. Validación de los especialistas ........................................................................................ 51. 3.6. Comparación de algoritmos ............................................................................................ 55. CONCLUSIONES ......................................................................................................................... 59 RECOMENDACIONES ................................................................................................................ 60 REFERENCIAS BIBLIOGRÁFICAS........................................................................................... 61 ANEXOS ....................................................................................................................................... 62 Anexo 1: Contornos de entonación sobre la base de datos Aronson ......................................... 62.
(11) 1. INTRODUCCIÓN Se tienen datos de que desde el siglo XIX en algunos trabajos médicos se emplea la voz como medio de diagnóstico. Ya alrededor de 1950, con la introducción del espectrógrafo se realizaban observaciones de audición por los fonetistas y los lingüistas juntamente con los instrumentos especializados de medición analógica. En la década de 1970 los estudios subjetivos del habla comenzaron a ser más formales y luego aparecen en esta etapa los trabajos de las Clínicas Mayo, donde se localiza la lesión neurológica a partir de las manifestaciones en el habla y se caracterizan los distintos tipos de disartria. En esta segunda mitad del siglo XX se buscaba que la evaluación estuviera menos afectada por quien evaluaba (disminuir la componente subjetiva), por lo que comienza junto con el desarrollo del procesamiento digital de señales, la era de mediciones acústicas. También se introdujo en esta época la estilización del contorno como una manera de simplificar la curva de la frecuencia fundamental (F0) a aquellos aspectos que son relevantes para la comunicación oral. El enfoque se origina en el trabajo por `t J. Hart, Collier, R. y A. Cohen en IPO, Eindhoven, y se ha mejorado aún más por D. Hermes en la década del '80 y '90. Sin embargo, la mayoría de estos enfoques de estilización se basan en las propiedades estadísticas o matemáticas de los datos de la F0 y en su mayoría ignoran los hechos de la percepción del tono. Es bien sabido que la percepción auditiva de las variaciones de paso depende de muchos factores distintos de la variación F0. En 1995, una estilización basada en la simulación de la percepción tonal, fue propuesto por D'Alessandro & P. Mertens. El propósito de esta estilización es proporcionar una curva que se aproxime a la imagen auditiva en la mente del oyente. Este modelo de percepción de tonos ha sido validado en la escucha de experimentos con estímulos resintetizados con el contorno estilizado. Este mismo método puede ser utilizado para obtener una transcripción de la entonación. Esto requiere de una segmentación de la señal de voz en unidades-sílabas, que están motivados por las propiedades fonéticas, acústicas o de percepción. En el libro editado por Kent & Ball en el 2000, aparece un inventario de esta etapa que estaba caracterizada por incontables medidas relacionadas con la calidad vocal pero no por muchos esfuerzos enmarcados en la articulación, la nasalidad y la prosodia, que también se ven afectadas y cuentan para el diagnóstico del habla. En el presente siglo las medidas se concentran en buscar una integración hacia una medida objetiva de la comprensibilidad, lo cual requiere de medidas de articulación, nasalidad y prosodia, que en su mayoría, se han calculado en segmentos cortos debido a la complejidad del análisis del habla.
(12) fluida. El habla fluida es medio de comunicación natural, empleado para realizar las medidas subjetivas y a este se deben acercar las medidas objetivas con el propósito de un mejor análisis del fenómeno del habla en su forma global. Ahora bien, en la actualidad especialmente en nuestro país existe la necesidad de un software que sea capaz de realizar la transcripción, mediante la aplicación de un modelo tonal, de la frecuencia fundamental, en pacientes disártricos, a unidades tonales de manera que se puedan diagnosticar patologías del habla en los mismos. Siendo esta la situación problemática del siguiente trabajo de diploma entonces surgen las siguientes preguntas: ¿Cuál es la situación actual que presenta el diagnóstico de patologías en pacientes con problemas en el habla, específicamente en la entonación? ¿Cómo elaborar un software basado en los principios de la fonética acústica que facilite calcular los esquemas de acentuación. que nos permitan discernir entre las diferentes. patologías del habla? ¿Cómo evaluar la efectividad de este software en la práctica clínica? A fin de dar respuesta a las mismas, y en conocimiento pleno de la situación actual de dichos aspectos en nuestro país, se propone para la investigación, el siguiente objetivo: •. Realizar la transcripción de prosodia basada en la estilización de la frecuencia fundamental a unidades tonales mediante la aplicación de un modelo tonal.. De este objetivo general se derivan los siguientes objetivos específicos: •. Transcribir la frecuencia fundamental de pacientes a unidades tonales.. •. Crear una interfaz gráfica para el software.. •. Validar los resultados con los especialistas (Logopedas).. Ahora bien, cuando los estudios subjetivos del habla comenzaron a ser más formales se comenzaron a localizar lesiones neurológicas a partir de las manifestaciones en el habla y se caracterizaron los distintos tipos de disartria. En la actualidad se buscan algoritmos y técnicas que faciliten el análisis de segmentos con suficiente duración para estudiar la prosodia y en general otras características en el habla fluida. La tarea planteada se desarrolla en medio de una serie de investigaciones enmarcadas en nuestro país con la finalidad de implementar un software que apoye la evaluación de los pacientes con dificultades en la comunicación oral, específicamente en el área de la entonación. Los resultados de este trabajo están encaminados a facilitar una herramienta de diagnóstico de las afectaciones de la entonación en estos.
(13) pacientes. Con este proyecto se pretende desarrollar un software, que contribuya al análisis de las afectaciones en la entonación en pacientes disártricos y que posea soluciones económicamente factibles. La implementación de esta herramienta aporta a los especialistas e investigadores de esta área del conocimiento la posibilidad de realizar estudios y análisis comparativos que logren enriquecer las evaluaciones. Con la ejecución del proyecto se dan soluciones al problema de la adquisición de un software cuyo desarrollo será muy útil en los hospitales y centros médicos de nuestro país. Además, tendrá un gran impacto social ya que su realización permite una mejora considerable en las consultas de logopedia y foniatría, aumentando la calidad de los diagnósticos en las mismas. Los resultados de esta investigación poseen una aplicación práctica y teórica importantes para todos los especialistas e investigadores del procesamiento de voz y también para aquellos fonetistas y lingüistas enfrascados en la investigación sobre disartria y problemas del habla, ya que se adentra en el área de la entonación brindando un algoritmo y un software que simplifica el trabajo de diagnosticar patologías de esta índole. Para la realización de este proyecto, contamos con los recursos necesarios ya que solo se necesita de un micrófono y una computadora con su multimedia para su desarrollo. También contamos con la ayuda de personal capacitado, con experiencia en investigaciones anteriores así como el tiempo y la información necesaria para elaborar un trabajo de tal importancia. Se realizará una investigación de tipo exploratoria, descriptiva y correlacional porque dentro de nuestro objetivo se examinará un problema de investigación poco estudiado en nuestro país, donde se pueden crear y proponer nuevas ideas que enriquezcan el tema. Se esclarecerán las relaciones que puedan existir entre las diferentes variables que se van a analizar durante la investigación. Para esto, se usa fundamentalmente el método empírico para analizar, registrar y transformar la práctica de la investigación en un proceso científico, asimismo se hace necesario trabajar con instrumentos de recopilación de información, como observaciones, análisis de documentos y pruebas de conocimiento. Para la realización de la investigación, hemos trazado una metodología que nos permitirá organizar nuestro tiempo y trabajo en función de lograr mejores resultados, la cual se enumera a continuación: 1. Revisión de la bibliográfica para la construcción del marco teórico de referencia general y realizar la caracterización del proyecto. 2. Selección de las herramientas para el desarrollo del software de la manera más efectiva, dadas las exigencias computacionales de este proyecto..
(14) 3. Elaboración de un algoritmo que permita implementar una interfaz gráfica para el software, que le brinde al logopeda facilidades para el diagnóstico. 4. Validación del resultado por los especialistas en esta área (Logopedas). De esta forma, la investigación queda estructurada en seis partes fundamentales; introducción, capitulario, conclusiones, recomendaciones, referencias bibliográficas y anexos. En el capítulo 1 se ha realizado una caracterización del problema a partir de un análisis de la literatura. Se caracterizan además, los parámetros de la entonación y se realizó una selección de los que serán utilizados posteriormente en el resto del proyecto. En el capítulo 2 se explica el diseño metodológico de la investigación y el algoritmo seleccionado con las modificaciones efectuadas para utilizarlo en voces patológicas. De esta forma se llega al capítulo 3 donde se realiza la validación de la efectividad del algoritmo implementado y del software desarrollado analizando sus resultados con los especialistas en el tema..
(15) CAPÍTULO I: MARCO TEÓRICO Resumen. En este capítulo se introduce el estado del arte sobre el estudio de la entonación en el análisis de voces disártricas y las afectaciones causadas en el aparato fonador. Se revisan las diferentes afectaciones de entonación en voces patológicas y los modelos creados para la transcripción de la frecuencia fundamental (F0). A la hora de la estilización de la F0 se tienen en cuenta las tendencias actuales según las diferentes patologías existentes. Al final del capítulo se propone un algoritmo para el análisis objetivo de estas patologías.. 1.1 Afectaciones en el aparato fonador Existen tres regiones de la corteza cerebral del hemisferio izquierdo (el cual procesa preferentemente la información de naturaleza verbal) relacionadas con el lenguaje: las áreas de Broca, de Wernicke y la circunvolución angular. El área de Broca está situada en la parte posterior de la tercera circunvolución frontal, y anterior a la cisura de Silvio. Corresponde a ella el control del lenguaje articulado. El área de Wernicke ocupa la parte posterior de la cisura de Silvio y se encarga de la decodificación del lenguaje oral. La circunvolución angular ocupa la unión temporo-parieto-occipital, y está implicada en el lenguaje escrito. En la actividad verbal participan también otras estructuras, además de las anteriores, principalmente el área motora suplementaria, situada en la zona pre-motora superior y medial del lóbulo frontal izquierdo. [1]. 1.1.1 La disartria Disartria es cualquier combinación de trastornos de la respiración, fonación, articulación, resonancia o prosodia que puede ser causada por incoordinación muscular, debilidad muscular o alteración del tono muscular. Las disartrias son una familia de trastornos motores del lenguaje caracterizadas por rasgos acústicos distintivos. Cada una se origina en una zona motora distinta del sistema nervioso. [2] Cuando se estudia la propiedad acústica del habla se puede decir que esta es más común en muchas de las muestras de pacientes disártricos y que evidencia la escasez de energía en las altas frecuencias. Esta propiedad ayuda a explicar la reducción en la inteligibilidad porque limita la información para muchas consonantes y reduce la posibilidad de identificar características personales.[3] Casi todos los pacientes disártricos están asociados con algún problema de prosodia en acentuación, contornos de entonación, y/o razón del habla y ritmo. Solo recientemente se ha considerado la prosodia como un problema de primera línea en el tratamiento, dado que históricamente los clínicos.
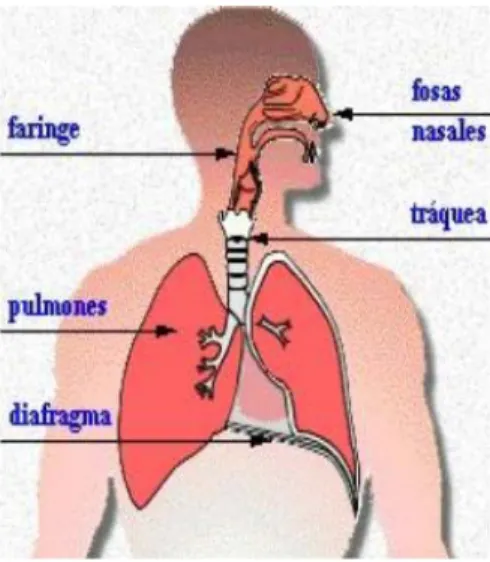
(16) consideraban la prosodia como un asunto a tratar luego de haber remediado otros trastornos en la producción del habla.[4] Ahora, las medidas objetivas para la calidad vocal, articulación y prosodia son componentes esenciales para calcular un índice de inteligibilidad. Existen gran cantidad de trabajos reportados en medidas de calidad vocal, a pesar de las dificultades inherentes al procesamiento digital y la variabilidad de la señal, que se amplifica por los desórdenes del habla; pero por otro lado hay una gran carencia en cuanto a medidas objetivas relacionadas con la articulación y la prosodia debido a la dificultad que acarrea analizar unidades más complejas del lenguaje junto con las dificultades antes mencionadas. [5] 1.1.2 El aparato fonador El aparato fonador es el que permite a las personas poder emitir sonidos al hablar o al cantar. Está formado a su vez por tres partes: el sistema respiratorio, la laringe, y el sistema resonador. El sistema respiratorio, mostrado en la figura 1.1, es el encargado de proporcionar a la voz la corriente de aire necesaria, sin la cual sería imposible emitir los sonidos. Consta de boca, nariz, tráquea, bronquios y pulmones. Además, una serie de músculos, como el diafragma, son los encargados de proporcionar la fuerza para que el aire circule. [6]. Fig. 1.1 Sistema respiratorio..
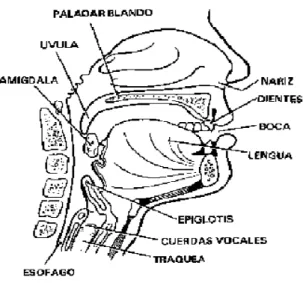
(17) Fig. 1.2 Partes del mecanismo de la producción del habla.. Mediante el movimiento de inspiración, conseguimos introducir aire en los pulmones, que son como esponjas almacenadoras de aire. El movimiento contrario es la espiración, mediante la cual el aire hace el recorrido inverso, de los pulmones a los bronquios, la tráquea, y su salida al exterior por la boca y/o nariz. Donde se produce realmente el sonido en la voz es en las cuerdas vocales, que son unos músculos que forman parte de la laringe. [7] La figura 1.2 muestra varias de las partes que forman el mecanismo de producción del habla. 1.1.3 Daños en el aparato fonador que afectan el fenómeno del habla Producción de la voz La voz es el sonido que se produce por la vibración de las cuerdas vocales de la laringe; [8] la energía vibratoria proviene del aire espirado (presión subglótica) y la amplificación y armonización del sonido se consigue en las cavidades de resonancia del tracto supraglótico (hipofaringe, faringe, nariz y boca). Se denomina F0 o tono al número de veces que en un segundo se cierran y abren las cuerdas vocales para producir el sonido laríngeo; y armónicos a las amplificaciones que éste sufre al pasar por las cavidades de resonancia. La F0 más sus armónicos configuran el timbre, el cual determina que la voz de cada persona sea percibida como diferente y específica. [9] Alteraciones de la voz Existen distintos criterios para clasificar las alteraciones de la voz, en este trabajo se estudian aquellas que tienen en cuenta los mecanismos etiopatogénicos implicados en su producción: • Disfonías orgánicas: cuando existe una clara alteración anatómica o estructural.
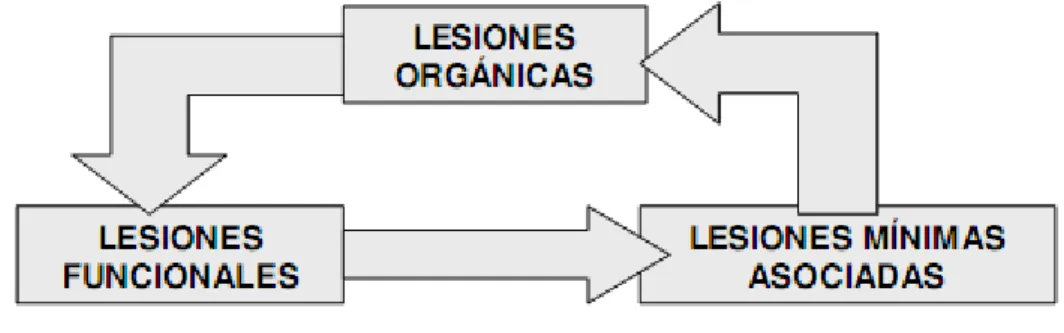
(18) •. Disfonías funcionales: cuando no puede identificarse ninguna alteración anatómica o. estructural. • Disfonías orgánico-funcionales: la alteración inicial es funcional pero, por un mal uso o abuso vocal, acaban convirtiéndose en lesiones orgánicas que no conllevan en su evolución a patología maligna (aunque en su génesis puede participar como elemento favorecedor el tabaco) y que se denominan lesiones mínimas asociadas. Hay que tener en cuenta que entre todos los tipos de disfonía existe una interrelación entre la causa y el efecto de los diferentes mecanismos, siendo muy difícil en ocasiones poder determinar una causa etiológica concreta, como se muestra en la figura 1.3.. Fig. 1.3 Relación entre las diferentes lesiones que pueden afectar el fenómeno del habla.. El concepto de mal uso vocal se refiere a un comportamiento distorsionado e involuntario del aparato fonatorio y que interfiere con la producción vocal efectiva. El concepto de abuso vocal se refiere a un uso incorrecto del tono y de la intensidad en la producción vocal. Este último posee mayor capacidad potencial para ocasionar daño sobre la mucosa laríngea. [7] Nódulos Vocales Son lesiones bien delimitadas, de pequeño tamaño, simétricas y bilaterales. Asientan en el borde libre de las cuerdas vocales, en la zona con mayor capacidad vibratoria: unión del tercio anterior con el tercio medio. Pólipos Vocales Son lesiones generalmente unilaterales, de predominio en el tercio medio de la cuerda vocal y en su borde libre. Pueden aparecer también en la cara superior de la cuerda y en la zona subglótica (no interferencia con la voz). Edema de Reinke Se trata de una acumulación de “líquido” localizado en la capa superficial de la lámina propia o espacio de Reinke. Lesión edematosa y gelatinosa, siendo bilateral en el 60-85% de los casos..
(19) Granuloma de Contacto Lesión sobre-elevada que suele asentar sobre las apófisis vocales de los aritenoides. Quistes Intracordales Son lesiones, generalmente unilaterales, esféricas y de superficie lisa, incluidas en el espesor de la cuerda vocal (producen una sobreelevación del epitelio). Predominan en el tercio medio. Sulcus Vocalis Hay dos tipos de sulcus: en “bolsillo” y en “estría”. La forma en “bolsillo” es una hendidura en la cara superior de la cuerda vocal (2 - 4 mm) con las paredes recubiertas de epitelio escamoso poliestratificado. La forma en “estría” consiste en una atrofia de la cuerda vocal en dónde el epitelio está adherido al ligamento vocal. [7]. 1.2 La entonación y sus generalidades dentro de la prosodia La prosodia es una rama de la lingüística que analiza y representa formalmente aquellos elementos de la expresión oral, tales como el acento, los tonos y la entonación. La prosodia trata la manifestación concreta en la producción de las palabras. Desde el punto de vista fonético-acústico a la variación de la F0, la duración y la intensidad que constituyen los parámetros prosódicos físicos. [9] La prosodia puede dividirse convenientemente en dos aspectos: El análisis de aspectos suprasegmentales, que trata la entonación de la frase en su conjunto y, el control de la melodía, los fenómenos locales de coarticulación, y la acentuación. [10] La entonación se ha definido según el centro de interés de cada investigador, o en función de los objetivos que se perseguían en cada investigación. Unas definiciones se refieren sólo al plano de la sustancia, haciendo incidir la función entonativa en las variaciones de frecuencia del fundamental, como la de D. Jones: “variaciones en el tono de la voz del hablante”. Otras tienen en cuenta distintos parámetros, además de la F0, como la de P. Lieberman: “todo el conjunto de contornos tonales, niveles tonales, y niveles acentuales que ocurren cuando se emite una oración”. Otras giran alrededor de la función lingüística de la entonación, como la de F. Danes: “es uno de los recursos comunicativos elementales de la lenguas, que forma un sistema fonológico especial, y sirve para la organización de enunciados de un modo diferente en diferentes lenguas”. Para Quilis: “la entonación es la función lingüísticamente significativa, socialmente representativa e individualmente expresiva de la F0 en el nivel de la oración’’.[11] Parámetros físicos.
(20) Los parámetros físicos de la entonación son la curva F0, la duración, la intensidad y la estructura armónica. El que tiene mayor relieve en la función entonativa es la variación de F0, cuya base fisiológica está en la vibración de las cuerdas vocales. La F0 depende de varios factores: La corriente de aire espiratorio, la tensión de las cuerdas vocales o ambas simultáneamente. Los músculos de la lengua están unidos a la parte superior del hueso hioides y algunos de los músculos laríngeos están unidos a la parte inferior. Cuando se eleva la lengua para la articulación de una vocal media o alta, la laringe también sube y los músculos laríngeos se tensan. De este modo, aumenta la tensión de las cuerdas vocales y se origina un aumento en el número de sus vibraciones. Además de la F0, la duración y la intensidad también intervienen en la producción y en la percepción de la entonación. A veces, un pequeño descenso de la F0 acompañado de una elevación de intensidad, se percibe como un tono levemente ascendente o en suspensión. En ocasiones, en una enumeración, la percepción de finalidad frente a la no finalidad se produce no por el nivel más bajo alcanzado por la F0 (más bajo al final, menos bajo en los grupos interiores), sino por la diferente duración del segmento final del fundamental en cada uno de los grupos: mayor duración en los grupos interiores (no finalidad), menor en el último (finalidad).[12] Funciones La entonación es la encargada de transformar las palabras de unidades apelativas en unidades comunicativas, esto es, en enunciados. Cada palabra o sucesión de palabras, se convierte automáticamente en un enunciado cuando se pronuncia con una cierta forma de entonación. El enunciado, como un conjunto, y con validez comunicativa, está conformado y señalado doblemente, por un lado, por su forma gramatical; por otro, por la entonación en sí. Su función distintiva reside en los movimientos ascendente o descendente de la F0 al final del enunciado. Un enunciado declarativo termina con la F0 de manera descendente, mientras que un enunciado interrogativo acaba con la F0 de manera ascendente. El mismo movimiento ascendente de la F0 puede servir, en cuanto indicador de sentido no acabado, para formular preguntas o para expresar relaciones entre distintas partes de un enunciado. [11] De lo anteriormente expuesto se concluye que la entonación es un factor importante en el estudio del habla. Es, por lo tanto, el recurso más común y el más elemental del enunciado. Puede haber enunciados con forma gramatical, pero no sin entonación.. 1.2.1 Unidades de medida de la entonación El análisis de la entonación implica la segmentación en unidades que sean lingüísticamente pertinentes y que formen un sistema en el que se conjunten. El problema es establecer esas.
(21) unidades y demostrar que el fenómeno entonativo se estructura en unidades tan discretas como los mismos fonemas. ¿Cuáles y cuántas son estas unidades? No hay acuerdo entre los investigadores. En la descripción del español podemos distinguir, en primer lugar, entre el grupo fónico y el grupo de entonación. Grupo fónico es la porción de discurso comprendida entre dos pausas. Grupo de entonación es la porción de discurso comprendida entre dos pausas, entre pausa e inflexión de la F0, entre inflexión de la F0 y pausa, o entre dos inflexiones de la F0, que configura una unidad sintáctica más o menos larga o compleja (sintagma, cláusula, oración). Es posible distinguir otras unidades menores en la entonación. Existen dos posiciones generales. La posición más general enuncia que la entonación está integrada por un cuerpo melódico, indivisible, y un final; cuerpo y final que constituyen un conjunto orgánico. Es decir, consideran la curva melódica, con todas las variaciones de la F0, como un todo en el que se pueden distinguir, o no, dos partes: el final y el resto. Este es llamado análisis de configuraciones. La posición de la mayoría de los lingüistas norteamericanos es que los contornos entonativos, que son unidades significativas, constituyen morfemas suprasegmentales integrados por fonemas: tonales, acentuales y junturales. Éste es el llamado análisis de niveles. La cuestión de aplicar uno u otro procedimiento no es tan simple como parece. Por ello, F. Dames, propuso que la controversia entre el análisis de niveles y el análisis de configuraciones fuese resuelta partiendo de las configuraciones de niveles, ya que “los niveles de entonación no existen sin contornos y su número sólo puede ser determinado por un análisis de todo el sistema entonativo y no para cada contorno separadamente”. Esta es la postura más aceptada por dos puntos bien importantes: • Mirando una curva de entonación se distinguen claramente una sucesión de ascensos, descensos, deslizamientos a todo lo largo del enunciado; pero para un oído normal, la melodía del lenguaje no reside en estas sucesivas variaciones de F0, sino en una secuencia de niveles tonales, cada uno de los cuales es más alto, más bajo o está a la misma altura que el precedente. • El análisis configurativo incluye también los niveles al describir sus materiales: alto ascendente y descendente, bajo ascendente y descendente; y también incluye las junturas, puesto que los movimientos finales de la frecuencia fundamental, ascendente o descendente, no pueden manejarse si no se perfilan unas unidades más pequeñas. Ambos procedimientos son complementarios. El análisis de niveles tonales y junturales es necesario para describir los puntos pertinentes entre los que se mueve la melodía del lenguaje..
(22) Una notación de configuraciones, por otra parte, es probablemente necesaria para describir las características tonales y determinadas actitudes. En español podemos distinguir tres niveles tonales: /3/ alto; /2/ medio; /1/ bajo. Dos junturas terminales, seguidas o no de pausa: /↓/: descendente, esta se realiza por medio de que la F0 sea descendente. Aparece al final de un enunciado con sentido completo, en los términos de una enumeración, en la frase introductoria de un enunciado en estilo directo. /↑/: ascendente, esta se realiza por medio de que la F0 sea ascendente o en suspensión. Aparece al final de un enunciado con sentido incompleto (sintagma) sujeto, complementos hiperbolizados o parentéticos, enunciados interrumpidos, primer término de una aposición, enunciado interrogativo. Dos acentos: /´/: el fuerte, que es el que se marca, y el débil /˘/, que normalmente no se señala. La distribución de estos fonemas acentuales viene dada por las reglas de acentuación de la lengua. ¿Pueden ser estos elementos que hemos señalado unidades con las que podemos operar en el estudio de la entonación? Si las unidades del lenguaje deben poseer una función combinatoria, o sea, deben tener la capacidad de combinarse mutuamente para formar grupos o complejos capaces de identificar y distinguir palabras y oraciones, los niveles tonales, acentuales y las junturas terminales desempeñan esa función. En efecto, todos los elementos que se han señalado anteriormente tienen una distribución determinada y todos están presentes en el suprasegmento entonativo. Si una unidad debe delimitar y organizar una sustancia, y como tal debe ser localizable, sustituible y el resultado último de la segmentación en su nivel de análisis, los elementos mencionados cumplen esa función. Esto ha sido demostrado para el alemán, sirviéndose de la síntesis del lenguaje: el continuum (conjunto de variedades lingüísticas habladas en territorios colindantes, con diferencias ligeras en las zonas contiguas y con inteligibilidad mutua que decrece a medida que aumenta la distancia, llegando incluso a desaparecer) de un enunciado se segmenta en determinadas unidades discretas, utilizando sólo dos contornos de la F0: ascendente y descendente, situados en diferentes puntos del enunciado. Los resultados han sido satisfactorios. Si las unidades del lenguaje, en virtud de las relaciones sintagmáticas y paradigmáticas, desempeñan una función contrastiva y distintiva, los elementos mencionados también la poseen. Estos elementos que se han podido aislar reúnen, por lo tanto, las características de unidades, unidades prosódicas mínimas que se denominan fonemas prosódicos o fonemas suprasegmentales. Y si, por último, una unidad lingüística no se concibe como tal si no se la puede identificar en una unidad más alta, los fonemas suprasegmentales se insertan en una unidad superior a ellos, que es el morfema de entonación.[10].
(23) 1.2.2 Afectaciones de la entonación en voces patológicas El lenguaje oral en los disártricos, a partir de los trastornos de la entonación, es poco expresivo, monótono y poco modulado. A veces es acelerado y en otras ocasiones retardado. Se observan pausas desiguales e irracionales. Algunos autores señalan que los disártricos hablan como si tuvieran la boca llena. Las alteraciones son resultado de la influencia de múltiples causas. Entre estas se pueden citar las enfermedades de la laringe, faringe, pulmones, bronquios, tráqueas; trastornos auditivos; alteraciones del sistema cardiovascular; alteraciones orgánicas y funcionales del sistema nervioso, diferentes trastornos neuróticos; y las enfermedades del organismo en general.[6] Las afecciones orgánicas de la voz pueden clasificarse en centrales y periférica. Dentro de las afecciones orgánicas centrales se encuentran las disfonías y afonías como síntomas de cuadros disártricos. Es necesario destacar que la afección nerviosa no sólo afecta la respiración; sino también la voz, la entonación y muchas veces la articulación. En disártricos, la voz cambia por la deficiente abducción de las cuerdas vocales; se torna débil, ronca, a veces ni se percibe, conjuntamente, puede presentar síntomas opuestos. Como las afecciones orgánicas periféricas sobresalen aquellas disfonías y afonías que aparecen producto de diferentes procesos patológicos de la laringe como: laringitis, estenosis, o estrechez en la laringe, traumas, parálisis de los pliegues vocálicos, pólipos, nódulos, entre otros. Entre los problemas que se encuentran a la hora de asignar los síntomas vocales a una paresia se encuentran los diferentes grados de gravedad de las lesiones, la característica de distribución, así como, la desigual capacidad de los pacientes para regular, mediante el sistema nervioso central, la función afectada. Esta dificultad en la regulación puede atribuirse a diferentes causas, el resultado final es que crea dificultades en todas las partes del habla. Entre los síntomas relacionados con la paresia laríngea de acuerdo al nervio afectado se encuentra: 1. Nervio laríngeo recurrente: el paciente no es capaz de articular la voz en profundidad en todo su registro. 2. Nervio laríngeo superior: el paciente no es capaz de producir los tonos más altos en todo su registro; tampoco el registro marginal. 3. Nervio hipogloso: la voz se cansa muy rápidamente. 4. Combinaciones: si están lesionados el nervio recurrente y el nervio laríngeo superior, existe una tendencia a la diplofonía. Si la lesión está localizada sobre todo en el nervio recurrente, predomina el registro marginal; si la lesión está localizada sobre todo en el nervio laríngeo superior, predomina el registro profundo completo..
(24) Las cualidades vocales patológicas son, en muchos casos, reversibles mientras que en los casos críticos pueden compensarse con la aplicación adecuada del tratamiento correspondiente. Esto significa que al actuar sobre los órganos vocales afectados o sobre la función deficiente, según sea el caso, es posible desarrollar la sonoridad, la resistencia a la carga vocal y la modulación, entre otros aspectos.[13] 1.3 Tecnologías en el procesamiento de voz para el análisis de la entonación. En la actualidad la entonación es uno de los temas dentro de la prosodia que mayor interés despierta entre los investigadores. La codificación del habla ha sido un área de avanzada en las investigaciones por varias décadas, no obstante, el nivel de actividad e interés en la misma ha aumentado en los últimos tiempos.. 1.3.1 Dificultades en la determinación del período fundamental (T0). La determinación de la sonoridad y el período fundamental (T0) de la voz son dos problemas en el análisis del habla que han sido ampliamente tratados por la importancia que tienen. Sin embargo, no se cuenta con algoritmos que sean suficientemente confiables y de costo computacional adecuado para las diversas aplicaciones por lo que es aún un campo abierto a la investigación. Esto es debido, en gran medida, a las dificultades que se presentan en la detección del T0 de la voz y la variedad de aplicaciones que utilizan estos algoritmos. La precisión y confiabilidad de la medición del T0 de la voz a partir de la onda depresión acústica solamente, es con frecuencia demasiado inexacta por varias razones. La forma de onda de la excitación glotal no es un tren perfecto de pulsos periódicos. La interacción entre el tracto vocal y la excitación glotal, en algunos casos los formantes originados en el primero pueden alterar significativamente la estructura de la forma de onda glotal y esto dificulta detectar su periodicidad. Dificultades en la definición del comienzo y fin exactos de cada período durante los segmentos de voz sonoros. El hacer las mediciones directamente sobre la forma de onda del habla ya sea por distancia entre picos o por cruces por cero, puede conducir a notables diferencias, debido no sólo a la cuasi periodicidad de la forma de onda sino también porque las mediciones de picos son afectadas por la estructura de formantes en el período, mientras que los cruces por cero son sensibles a la estructura de formantes, al ruido y a cualquier nivel de corriente directa en la forma de onda. Dificultades en la distinción entre segmentos sordos y segmentos sonoros de bajo nivel. Si la señal está limitada en banda o distorsionada debido, por ejemplo, al efecto de haber sido transmitida por un canal telefónico, puede tener atenuada significativamente la frecuencia del T0 y muchos de sus armónicos superiores, presentar distorsiones de fase y distorsión de sonidos de alto nivel por recortamiento o modulación de amplitud. Aunque estos efectos no se observan.
(25) simultáneamente, en general obscurecen la estructura periódica de la forma de onda del habla. En dependencia de los parámetros a partir de los cuales se ha de calcular la periodicidad de la señal, pueden hallarse diversas dificultades basadas en la forma no estacionaria de la señal del habla. Si el análisis es hecho sobre la base del contenido espectral, este cambia constantemente dependiendo de la articulación de los diferentes sonidos lo cual reduce el grado de similitud entre segmentos sucesivos y se hace más crítico en los segmentos sordos que carecen de una estructura periódica.[14]. 1.3.2 Modelos entonativos y sus características. Desde los comienzos de la investigación sobre la entonación, la transcripción automática de la entonación ha estado en la lista de deseos de muchos investigadores en fonética, lingüística y análisis del habla en general. La mayoría de los fonetistas usan la F0 para representar los contornos de tono en el habla. La F0 es el parámetro físico de la entonación que mayor información útil proporciona acerca de las propiedades acústicas de la señal de voz En esta área del conocimiento, la estilización del contorno se introdujo como una manera de simplificar la curva de F0 a solo aquellos aspectos que son más relevantes para la comunicación oral. La mayoría de los enfoques de estilización se basan en las propiedades estadísticas o matemáticas de los datos de F0. Estos mismos modelos pueden ser utilizados para obtener una transcripción de la entonación. A continuación se muestran varios de los modelos más usados en la implementación de algoritmos. ToBI (Tone and Break Indices) El Modelo de la Secuencia de Tonos (ToBI, Tone and Break Indices) fue introducido en 1980 por Pierrehumbert para el inglés americano. En el estándar ToBI descrito por Silverman, el contorno entonativo se concibe en su conjunto como una secuencia de fenómenos tonales discretos. A partir de un corpus etiquetado mediante ToBI pueden seguirse diversas estrategias de descodificación y generación de los contornos de F0. Existe la opción de formular un conjunto de reglas que permitan derivar los valores de frecuencia que darán lugar a un contorno melódico a partir de la información anotada, y también la posibilidad de conseguir los valores requeridos empleando únicamente métodos que permitan la automatización de los sistemas. También existen otros trabajos en los que se utiliza una versión modificada de ToBI combinada con modelos estocásticos para la predicción de etiquetas entonativas y para la síntesis de la entonación. INTSINT.
(26) En el Centre National de la Recherche Scientifiquede la Université de Provence, en Aixen-Provence, se ha desarrollado un modelo de entonación que comprende cuatro niveles de representación: acústico, fonético, fonológico superficial y fonológico profundo. El sistema está basado en reglas específicas, y constituido por dos módulos, uno lingüístico y otro fonético. El módulo lingüístico consta, a su vez, de dos submódulos, uno de procesamiento de lenguaje natural y otro fonológico o prosódico. La diferencia entre ambos modelos se basa en el método utilizado para la asignación de los datos acústicos: mientras que el primer modelo usa reglas, el segundo se basa en un método probabilístico que permite generar los contornos entonativos a partir del etiquetado de las categorías gramaticales. El modelo del IPO Uno de los principales objetivos de la llamada escuela holandesa es tener en cuenta aquellos aspectos que son relevantes para la percepción, puesto que no todos los movimientos tonales observables en la curva melódica son perceptivamente significativos. Se ha utilizado el modelo del IPO para generar la entonación en varios idiomas, además del holandés. Para el alemán se ha presentado un modelo en el que los movimientos tonales, que se distribuyen en cinco líneas rectas de declinación, se describen de acuerdo con la posición en la sílaba en la que aparecen, el rango (expresado en semitonos) y la duración. Esta estrategia ha servido a su vez de base para la realización de nuevos modelos. El modelo de H. Fujisaki Fujisaki y sus colaboradores han desarrollado en las últimas décadas un modelo prosódico cuantitativo basado en la fisiología, en el que se concibe la melodía como una respuesta al control neuromotor de la vibración de las cuerdas vocales. Es además, un modelo de superposición en el que diversos componentes actúan e interaccionan, ya que un contorno de F0 se determina mediante la suma de un valor básico de F0 para el hablante, la frecuencia mínima, de unos componentes de frase y de unos componentes de acento (expresados en una escala logarítmica). Cada uno de estos componentes se justifica además por la fisiología propia de los mecanismos de espiración. La generación de un contorno sintetizado con este método requiere además información sobre el tipo de locutor y sobre la lengua a la que se aplica. Para imitar un contorno natural de F0 se modelan separadamente dos tipos de unidades: un contorno entonativo global bajo-alto-bajo que comprende toda la unidad prosódica y una serie de contornos bajo-alto-bajo de ámbito silábico. Se produce así un movimiento global que se inicia con un ascenso y que sigue con un descenso lento hasta el final. Paralelamente, con los contornos locales se generan picos sobre las sílabas.
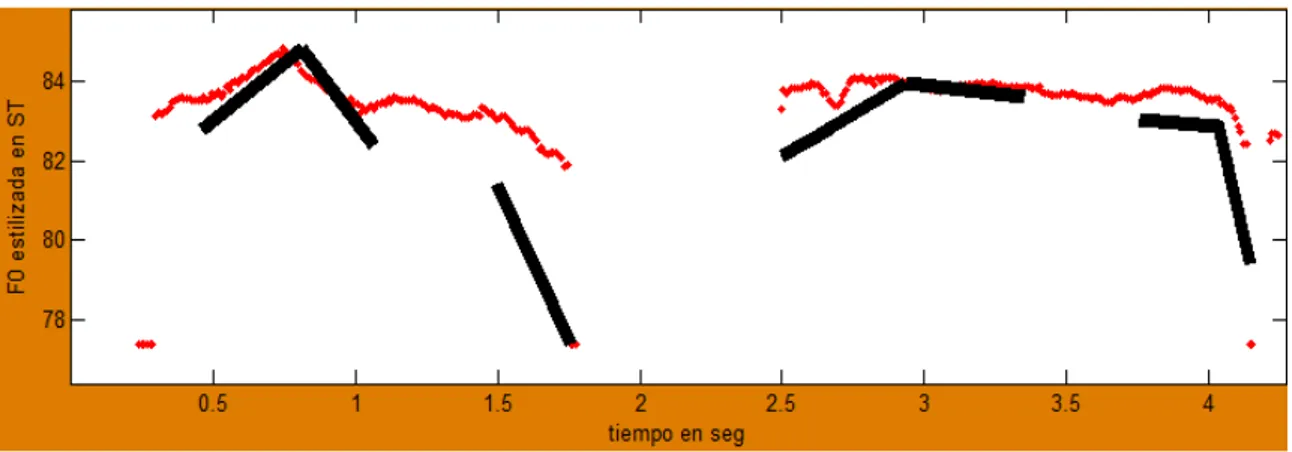
(27) acentuadas, atendiendo a los parámetros de duración y amplitud. El contorno obtenido al fin tras los cálculos es el resultado de la superposición de ambos componentes. Un análisis permite una comparación del contorno natural con el generado, así que la F0 se puede descomponer en los componentes del modelo y decidir qué valores van a tomar los parámetros mediante sucesivas aproximaciones de los contornos simulados a los naturales. El modelo de Piet Mertens El sistema de Mertens, concebido inicialmente para el francés, toma la sílaba como unidad básica de entonación, y describe las curvas melódicas como una secuencia de tonos asociados a las sílabas. En este modelo se distinguen cuatro niveles tonales básicos, dos clases de acentos y tres dominios prosódicos. Los niveles tonales básicos son: High (simbolizado mediante H, h), Low (simbolizado mediante L, l), Extrahigh (simbolizado mediante H+, h+) y Extralow (simbolizado mediante L+, l+), que se asocian a cualquier tipo de sílaba, ya sea acentuada (simbolizada mediante H, L, H+, L+) o inacentuada (simbolizada mediante h, l, h+, l+). Las dos clases de acentos consideradas son el acento final (AF) y el acento inicial (AI); y los tres dominios prosódicos, el grupo acentual, el grupo de entonación y el paquete entonativo. Para que una variación de la frecuencia fundamental sea audible debe tener un tamaño mínimo. Este tamaño varía como una función de la F0 inicial y la duración del estímulo (el cual decrece con la duración). El umbral Glissando se ha utilizado en variaciones lineales de frecuencia en tonos puros, en habla sintetizada o resintetizada (para obtener variaciones lineales). `T Hart [15] formula una definición unificada del umbral Glissando, donde los cambios de entonación sean expresados en semitonos. El valor estándar determinado para experimentos psicoacústicos en vocales aisladas es G = 0.16/T^2 (ST/s), donde T es la duración de la variación (el semitono es una escala musical donde una octava es dividida en 12 intervalos iguales en una escala logarítmica). Las variaciones de frecuencia en el habla natural son lineales en raras ocasiones, lo cual crea la interrogante de cuál variación es perceptible. Esta pregunta se puede reformular como, qué cambios de pendientes son audibles. La respuesta a esto la introduce el umbral Diferencial Glissando (DG). Los cambios de pendiente se comparan con este umbral, de ser subliminales los valores de esta parte se sustituyen por una variación lineal. Hasta este punto solo se han considerado variaciones de F0 en sonidos aislados (en su mayoría vocales). Sin embargo en el habla los sonidos concatenados entre sí implican intensidad y sonoridad, así como cambios espectrales. En la mayoría de los casos la alternancia de vocales y consonantes dan origen a picos de intensidad y sonoridad durante la vocal. Estos se caracterizan por estabilidad espectral relativa. La vocal constituye el núcleo silábico, por otro lado los mínimos de energía.
(28) han de ocurrir en las consonantes. Este contraste es mejor para las oclusivas y fricativas y peor para las líquidas y las nasales. Los mayores cambios acústicos se encuentran en las fronteras de sílaba. En el trabajo de House [16] de percepción de cambios de F0 en el habla, se muestra que las mismas variaciones de F0 se perciben de diferentes formas en dependencia de su localización relativa a la frontera de sílaba. Si aparece dentro de una vocal y excede el umbral de Glissando es perceptible, si parte de este cambio cae en la frontera de sílaba solo será perceptible la parte localizada en la vocal. Esto se debe a que los cambios simultáneos de intensidad, distribución de energía espectral y sonoridad impiden la percepción del cambio de F0. Este fenómeno es más palpable a medida que aumentan las variaciones acústicas. El modelo de N. Thorsen-Grønnum Al igual que Fujisaki, Thorsen-Grønnum propone un modelo de superposición, pensado en principio para el danés estándar, pero aplicable a otras lenguas. Se trata de un modelo creado inicialmente para generar la curva de entonación de frases simples constituidas por un máximo de cuatro grupos acentuales. En él se tiene en cuenta la relación entre los movimientos de F0 y la tonicidad de las sílabas. Cada sílaba, átona o tónica, lleva asociado un movimiento de F0, modificado por propiedades intrínsecas de los sonidos que aparecen en la secuencia. El componente prosódico más importante es el grupo acentual, que consta de una sílaba tónica más todas las sílabas átonas que le siguen dentro del mismo contorno de entonación. El límite del grupo prosódico se coloca antes de la sílaba tónica, independientemente del número y tipo de fronteras sintácticas. Thorsen, basándose en la observación de la curva de F0, describe el grupo acentual del danés mediante un patrón constante: una F0 descendente (Low) asociado a las sílabas tónicas, seguido por un patrón ascendente-descendente (High-falling) asociado a las sílabas átonas.[12] El modelo Métrico-Autosegmental Este modelo parte de un análisis por niveles y de revisión de contornos sin separación interna entre grupo pre-nuclear y nuclear. Existen dos clases básicas de reglas encaminadas a definir la implementación fonética de los contornos. Primero está la regla de asociación entre las unidades tonales y luego la de interpolación fonética. Ellas se ocupan de generar los movimientos melódicos intermedios que conectan los elementos fonológicos entre sí. Uno de los mayores aportes de este método es el reconocimiento de la estructura métrica como eje central entre movimientos melódicos. También plantea que los contornos se pueden representar adecuadamente utilizando solo dos niveles tonales, el alto (H) y el bajo (L), permitiendo asi la minimización del problema de sobregeneración de contornos. Otra de sus características es que toma como punto de partida la existencia de acentos tonales que ayudan a la descripción de los contornos que producen esas unidades.[17].
(29) El modelo AMH (Análisis Melódico del Habla) El modelo AMH, distingue tres tipos de funciones o niveles de la entonación: Entonación lingüística, de identidad fonológica, significativa, definida mediante la oposición de tres rasgos: interrogativo, enfático y suspendido. Ella es la interpretación fonológica de la melodía. Entonación prelingüística: la entonación es un elemento clave tanto en la integración como en la fragmentación y comprensión del discurso, hablaba de la función integradora, delimitadora de la entonación. Entonación paralingüística: expresiva, sirve para indicar actitud, el estado de ánimo del interlocutor. Este modelo está basado en el concepto de jerarquía fónica: cuando hablamos, lo hacemos de forma jerarquizada, no enlazamos sonidos de forma continua sino que a través de los fenómenos suprasegmentales agrupamos los sonidos en diferentes bloques. Esta jerarquía se da en varios niveles: sílabas, palabras fónicas y grupos fónicos. Los tres constituyen bloques de sonido que se agrupan en torno a un acento. Los únicos elementos tonalmente significativos son las vocales, los segmentos que aparecen acústicamente marcados y destacados en el análisis de la línea melódica.[18] Los modelos ocultos de Markov Las cadenas de Markov son modelos estadísticos que proporcionan descripciones de secuencias de eventos. Pueden entrenarse con muchas pronunciaciones y, al decodificar, el costo computacional depende básicamente del número de modelos y no del número de pronunciaciones con que fueron entrenados.[12] Consideraciones Ciertamente existe, para el análisis de la entonación en voces con diferentes patologías, la necesidad de investigar más a fondo e implementar algoritmos que nos brinden mejores resultados en cuanto a la determinación de contornos de entonación y transcripción de la F0. Para esto una de los aportes más innovadores que se han hecho es el reconocimiento del estrecho vínculo que existe entre acentuación y entonación. A lo largo de la historia varios investigadores y escuelas del estudio del habla han creado diversos modelos para hacer más profundo el estudio de la prosodia, y así, relacionando los elementos subjetivos con los objetivos, dar más fuerza y exactitud al diagnóstico de diferentes patologías, haciendo el trabajo menos engorroso a los especialistas. No obstante, es necesario todavía que los aspectos fonéticos y fonológicos se integren aún más en el estudio de la entonación. También se necesita que los modelos creados y los algoritmos implementados, al hacer uso de estos, no se centren solo en el análisis lingüístico y funcional de la entonación sino que también aborden los hechos fonéticos relevantes. Independientemente del desarrollo que se ha.
(30) alcanzado en el desarrollo de los modelos entonativos antes expuestos y de otros que no se incluyeron es un hecho que en la actualidad estos adolecen en parte de una falta de integración histórica entre los aspectos fonéticos y fonológicos de la entonación.. 1.4 Tendencias actuales en la transcripción de la F0. La mayoría de las instituciones y los autores sobre el tema de transcripción de la F0 y el análisis de voces patológicas han señalado con acierto que la falta de un modelo prosódico unificado es una de las razones por las que el conocimiento prosódico no se ha incorporado plenamente a los sistemas comerciales de reconocimiento y análisis del habla. En efecto, una revisión de compilaciones pone claramente de manifiesto la multiplicidad de enfoques en la transcripción prosódica de las lenguas. No obstante, en la actualidad se tienen varios retos muy importantes. Primero, afianzar la relación entre la estructura fonológica de la entonación y el momento fonético. También está la necesidad de profundizar en el estudio de la semántica entonativa ya que el análisis semántico de los contornos ha sido un aspecto bastante desatendido por las distintas escuelas.[18] Lo más importante en cuanto a las tendencias actuales en la transcripción de la F0, enmarcados en las diferentes patologías del habla, es el reconocimiento y uso del modelo ToBI como uno actualmente de gran referencia y uso en un gran número de lenguas. Aunque todavía queden por resolver aspectos controvertidos, como el tratamiento de la declinación o el campo tonal, este modelo se ha estandarizado bastante sin aun solucionar el asunto de tener un modelo único para los investigadores. Propuesta Para el próximo capítulo se propone un algoritmo para la transcripción de la F0. La mayoría de los enfoques de estilización anteriores, incluyendo el modelo ToBI, se basan en las propiedades estadísticas o matemáticas de los datos de la F0 y en su mayoría ignoran los hechos de la percepción del tono. En este trabajo se escoge el modelo de Piet Mertens porque posee esa característica.. Conclusiones parciales En este capítulo se analizan las diferentes afectaciones en el aparato fonador y cómo éstas dañan la producción del habla en los pacientes. Se consideraron los tipos de afectaciones de entonación en las voces patológicas y se muestra lo inexacta que puede llegar a ser la determinación del T0. Son presentados los diferentes modelos entonativos y sus características; y la manera en que estos han ayudado a la transcripción de la F0. Se concluye.
(31) después de toda la investigación realizada que es muy importante el desarrollo e la implementación de un producto que ayude a los especialistas al diagnóstico de patologías presentes en los pacientes con trastornos en la entonación..
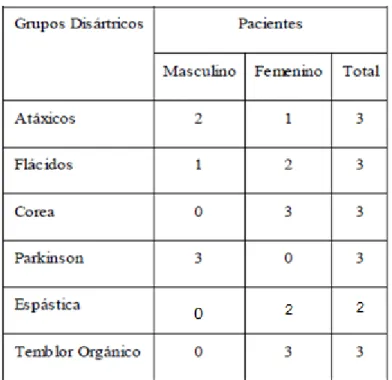
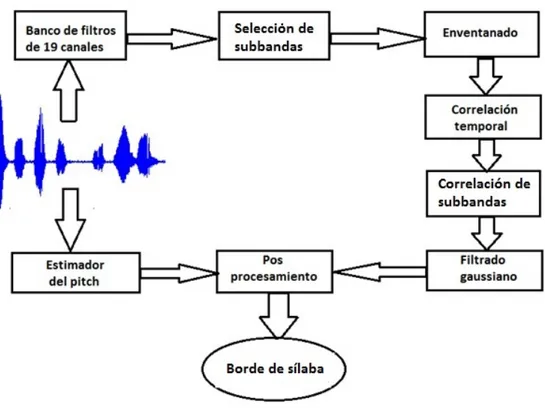
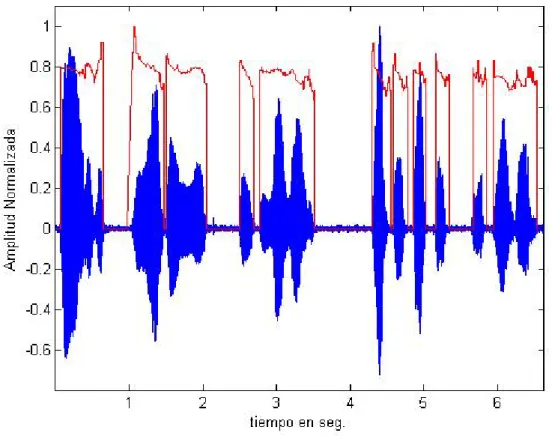
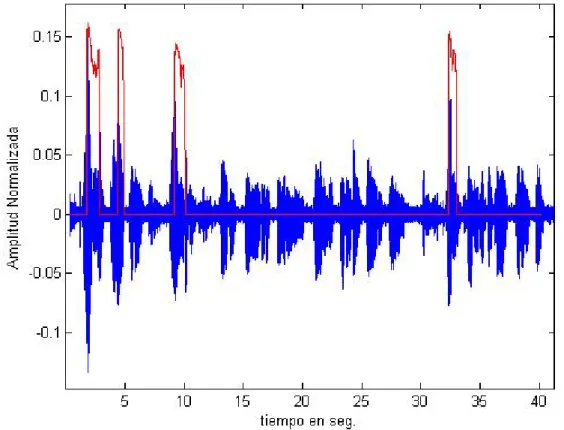
(32) CAPÍTULO II: MATERIALES Y MÉTODOS Resumen. En el transcurso de este capítulo se realiza una descripción del algoritmo implementado, los parámetros a tener en cuenta para la detección de la F0 aplicado a voces patológicas y un análisis de las herramientas utilizadas en el proceso. Se definen los materiales con los que se cuenta y el diseño experimental para la validación de los datos. 2.1 Materiales La Base de Datos Para la detección de los contornos de entonación y l a a p l i c a c i ó n d e l m é t o d o e m p l e a d o se toma una muestra de l a s grabaciones de pacientes de la base de datos de Aronson. [19] Se elige una muestra de personas que presentan diferentes tipos de disartrias. De ella se selecciona un grupo de 17 pacientes que pertenecen a seis grupos disártricos diferentes. Estos se seleccionaron de modo que presenten desviaciones en las dimensiones subjetivas evaluadas por De Bodt, [28] calidad vocal, articulación, nasalidad y prosodia, y como consecuencia en la inteligibilidad. Al mismo tiempo se representan varios grupos disártricos como se aprecia en la Tabla I. Sus edades están entre 20 y 70 años aproximadamente. Tabla I. Distribución de pacientes por sexo y grupos disártricos.. De cada paciente seleccionado se toman dos oraciones en idioma inglés. Las grabaciones de las voces se convierten a un formato PCM, con frecuencia de muestreo de 44.100 kHz y.
(33) con resolución de 16 bits con un canal (mono).. El almacenamiento se efectúa en un. archivo con extensión .WAV. La implementación Los algoritmos detectores de periodicidad seleccionados son implementados con la ayuda del software MatLab versión R2009a, por las bondades que brinda en el cálculo, programación y visualización en pantalla de los datos de interés. Además el ToolBox de procesamiento digital de señales posee una serie de funciones útiles para el análisis de las señales de voz. EL Praat El Praat es una herramienta para la investigación acústica y fonética, escrita por Paul Boersma y David Weenink, del Instituto de Ciencias de la fonética en Amsterdam. Permite grabar voces en varios tipos de archivos de audio y mostrar los espectrogramas. Es útil en el análisis de la entonación, la intensidad o volumen, los formantes, el cocleagrama, etc. También puede ser automatizado para análisis más complejos, lo que ha resultado útil para investigadores de alto nivel. Por lo que se pueden calcular valores de jitter, shimmer, entre otros, y utilizarlos para la clínica de análisis acústico. Es elegido por el hecho de que es poderoso en los cálculos, fácil de usar, programable, de libre acceso y que se ejecuta en muchas plataformas. 2.2 Métodos Aquí se describen los algoritmos que fueron usados para la detección y estilización de la F0 en las voces patológicas analizadas. Se describe el funcionamiento de los mismos y por qué estos se utilizan en este trabajo. 2.2.1 El Robust Algorithm for Pitch Tracking (RAPT) El RAPT es un algoritmo robusto para el estimado de la F0. La principal meta de esta herramienta es obtener, con el menor costo computacional posible, un estimado de la F0 de la manera más robusta y precisa posible. Este detector muestra que varias mejorías en la eficiencia han sido incorporadas reduciendo la complejidad computacional y logrando la precisión buscada. RAPT opera de forma continua. Está diseñado para trabajar a cualquier frecuencia de muestreo (Fs) y también acepta cualquier variación en el tamaño de la ventana, en un rango amplio de la F0. Esto se puede aplicar en condiciones donde, además del segmento del habla que se esté utilizando, pueden haber otras personas hablando y diversas condiciones de ruido. Este algoritmo permite ajustar parámetros para establecer una relación de compromiso entre la velocidad de la detección de la F0 y la precisión para diferentes tipos de voces y condiciones de grabación..
(34) Después del análisis de una voz patológica se pueden observan algunas de las características siguientes: La F0 puede presentar cambios abruptos como sustituciones de F0 por múltiplos y submúltiplos de la misma. El espectro de corta duración presenta marcadas diferencias para las ventanas donde hay sonoridad y para las ventanas donde hay silencios. La amplitud de la señal se incrementa dentro de las ventanas donde hay sonoridad y disminuye donde hay silencios. RAPT usa la NCCF (Función de Correlación-Cruzada Normalizada). Esta función, independientemente de los cambios rápidos que puedan ocurrir en la amplitud de las muestras, ve las formas y los períodos sucesivos como similares. Las propiedades que presenta la NCCF son independientes de las muestras que analiza. Posee, para la parte sonora máxima del segmento, en los intervalos de retraso, una amplitud que se corresponde a los múltiplos enteros del T0. Y para los segmentos silenciosos los máximos aparecen donde no hay retrasos. La estimación precisa de la F0 con esta función se realiza efectivamente aumentando la Fs, y luego realizando un proceso de relocalización de los picos en la tasa de muestreo más alta. Su funcionamiento Este algoritmo posee dos variantes para muestrear los datos. Puede muestrearlos usando la tasa de muestreo original o puede usar también una tasa de muestreo reducida. Usa luego la NCCF para registrar periódicamente una señal con baja tasa de muestreo en el rango de interés de F0, para todos los retrasos de la señal. Después guarda las posiciones de los máximos locales detectados con baja tasa de muestreo. También busca los vecinos de los picos ya encontrados anteriormente pero con una tasa de muestreo alta. Busca los máximos locales de nuevo para obtener una posición más precisa. Los picos obtenidos con la alta tasa de muestreo son los candidatos para detectar la curva de la F0. Es usada la programación dinámica para seleccionar el conjunto de picos de la NCCF o las hipótesis de silencios que mejor equivalencia tengan con las características mencionadas anteriormente. La idea del RAPT está inspirada en el Integrated Pitch Tracker y posee iguales características. Solo se diferencia en algunos puntos importantes. Primero, la NCCF es calculada a partir de la señal de habla en lugar del residuo de los coeficientes de predicción lineal (LPC). Segundo, las dos variantes de la NCCF para muestrear los datos son utilizadas para reducir la carga computacional del proceso. Usa la interpolación de picos a una tasa de muestreo original para incrementar la precisión. El RAPT no requiere ningún preprocesamiento de la señal de entrada y ofrece un buen rendimiento para las muestras de entrada de la señal de voz a cualquier tasa de muestreo típica de audio (6 KHz ≤ Fs ≤ 44 KHz). El costo computacional crece linealmente y a grandes.
Figure
+7
Documento similar
La campaña ha consistido en la revisión del etiquetado e instrucciones de uso de todos los ter- mómetros digitales comunicados, así como de la documentación técnica adicional de
Esta opción permitiría al usuario poder alterar dinámicamente las plantillas para cada sección o incluso crear secciones nuevas desde cero, lo que conlleva la creación de
Otra medida de protección colectiva para evitar la caída de material y como medida higiénica para evitar la salida de polvo al exterior de la obra de demolición es el empleo de
[r]
[r]
[r]
Luis Miguel Utrera Navarrete ha presentado la relación de Bienes y Actividades siguientes para la legislatura de 2015-2019, según constan inscritos en el
If certification of devices under the MDR has not been finalised before expiry of the Directive’s certificate, and where the device does not present an unacceptable risk to health
